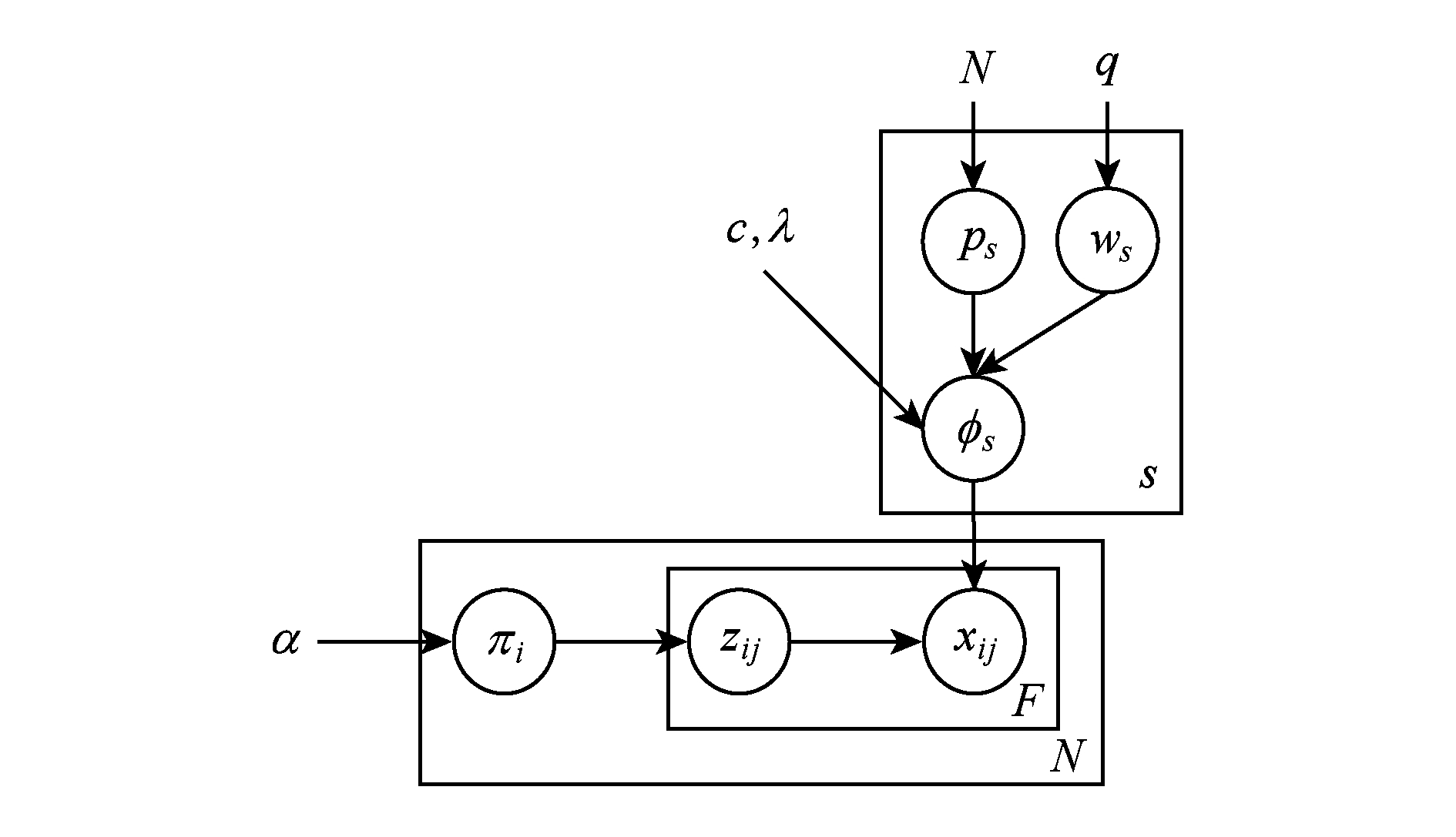
Fig. 1 Bayesian case model
图1 贝叶斯案例模型
潘笑颜 娄铮铮 姬 波 叶阳东
(郑州大学信息工程学院 郑州 450001) (panxiaoyan@gs.zzu.edu.cn)
摘 要: 针对聚类中的多视角和可解释的问题,提出多视角生成模型的可解释性聚类算法(interpretable clustering with multi-view generative model, ICMG).ICMG能够产生多个视角的聚类划分,并通过视角的语义信息对聚类结果进行定性和定量地解释.首先,构建一种多视角生成模型(multi-view generative model, MGM),该模型使用贝叶斯程序学习(Bayesian program learning, BPL)和嵌入多视角因素的贝叶斯案例模型(multi-view Bayesian case model, MBCM)生成多个视角.其次,基于视角的匹配度进行聚类得到多种聚类方案.最后使用视角的原型和子空间所附带的语义信息定性和定量地解释聚类结果.实验结果表明:ICMG能够得到多种可解释的聚类结果,相比于传统多视角聚类算法具有较明显的优势.
关键词: 贝叶斯程序学习;贝叶斯案例模型;可解释;多视角;聚类
聚类将相似数据划分为同一簇,不相似数据划分为不同簇,进而捕捉到数据之间的模式结构 [1-2] .传统的聚类算法仅仅从单一视角对数据进行分析,并且由于聚类分析缺乏带有语义的类标签,因此得到的聚类结果单一化和不可解释.单一的和不可解释的聚类结果给决策者提供的信息非常匮乏,然而决策者需要参考丰富的信息来支撑自己的决策.例如针对一个主要地震带的地震数据,如果仅仅基于传统聚类对地震数据做一个划分,从这个划分中我们能了解到的地震信息极少;如果将地震数据分别按发生位置、震动性质以及震源深度等进行划分,这样的划分将使我们对这个地震带所发生的地震的了解比较全面和透彻,有助于帮助人们做好周到的预防减少损失.因此,聚类结果的多视角性和可解释性非常重要.聚类结果的多视角性指基于多个视角进行聚类得到多种聚类结果.聚类结果的可解释性即聚类结果由决策规则推理得到,并且聚类结果可以被定性和定量地解释.多视角的和可解释的聚类结果将给决策者提供更多的选择空间,并且可以使决策者批判性、改善性和探索性地相信和使用聚类结果.
针对聚类结果的多视角性问题,比较直接的方法是通过简单地连接不同的视角将谱聚类从单视角扩展到多视角,然后基于相似图表或相似矩阵进行聚类 [3-7] .但是这种方法的视角之间缺少协调和互补,所以不能得到令人满意的聚类效果.Kumar等人 [8-9] 提出使用多视角的协同训练进行谱聚类的方法,但是这个方法需要构建每个视角的相似图表,这个过程对于高维多视角数据非常复杂,所以谱聚类方法不能有效地处理高维多视角数据.Cai等人 [10] 提出了一种不需要构建每个视角的相似图表的方法,即MVKM算法.该方法使用 l 2,1 准则学习每个视角的权值并且使用 K -Means进行聚类.然而,MVKM基于没有任何可区别子空间学习机制的原始特征进行聚类,所以容易导致维灾难.为了避免维灾难,一些研究者提出一种含有可区别子空间学习机制的多视角聚类方法 [11-13] .这种方法首先学习视角的子空间,然后基于视角的子空间进行多视角聚类.但是这种方法的聚类结果仅仅列出了每一个数据在每个视角下的类标签,这对于数据的探索性分析来说是远远不够的 [14] ,数据的探索性分析需要解释数据被这样划分的原因,即需要简明地解释聚类结果.
针对聚类结果的可解释性问题,Fraiman等人 [15] 提出基于无监督二叉树的可解释聚类.该方法将聚类结果的可解释总结在一个结构简单的二叉树里,具体有3步:1)使用一个递归分裂算法构建一个二叉树;2)使用极小相异原则修建树;3)聚合不需要分享相同的祖先的叶子.该方法虽然可以得到可解释的聚类规则,但是对于高维数据则需要构造的树相对较大,得到的可解释规则较复杂.Kim等人 [14] 提出了一种不需要构造树的可解释的特征选择和提取方法.该方法将可解释标准直接加入特征选择和提取的模型中,然后得到可解释的特征.由于此方法没有得到可解释的聚类规则,所以Chen等人提出了基于判别矩阵混合模型的可解释聚类(DReaM) [16] .DReaM是一个学习每个簇的矩形决策规则的概率判别模型.由于矩形判别规则可以明确地解释一个簇的定义过程和不同簇之间的区别,所以DReaM可以得到可解释的聚类结果.但是DReaM需要先有基于规则的领域知识即是半监督方法,并且不能定性和定量地解释聚类结果.
本文提出多视角生成模型的可解释性聚类算法(interpretable clustering with multi-view genera-tive model, ICMG),该算法构建了多视角生成模型(multi-view generative model, MGM),该模型通过使用贝叶斯程序学习(Bayesian program learning, BPL)的组合思想和嵌入多视角因素的贝叶斯案例模型(multi-view Bayesian case model, MBCM)生成多个视角.ICMG基于每个视角的匹配度进行聚类得到多种聚类方案,并且使用视角的原型和子空间所附带的语义信息定性和定量地解释聚类结果.
本文的主要贡献有3方面:
1) 构建MBCM.MBCM是将多视角因素引入到贝叶斯案例模型上的一种生成模型,MBCM生成的数据包含多视角因素.
2) 构建MGM.MGM基于有效原则和无冗余原则使用BPL的组合思想和逆过程使用MBCM生成多个有效的无冗余视角,并使用原型和子空间描述视角.
3) 提出ICMG算法.ICMG首先使用MGM得到多个使用原型和子空间描述的视角;然后利用原型和子空间构建规则集,基于规则集进行聚类;最后使用原型和子空间所附带的语义信息定性和定量地解释聚类划分,进而得到有语义的类标签.
1 . 1 贝叶斯案例模型
贝叶斯案例模型(Bayesian case model, BCM) [17] 定义了一个数据的生成过程,贝叶斯案例模型的图形式如图1所示,其中а, c , q 和 λ 是超参数, N 表示数据的数目, S 表示类的数目.过程如下:
1) 生成数据 x i 的混合权值 π i , π i ~ Dirichlet ( α ).
2) 生成类 s 的原型 p s ,子空间特征指示器 w s 和特征取值分布 Φ s , p s ~ Uniform (1, N ), w sj ~ Bernoulli ( q ), Φ sj ~ Dirichlet ( g ( p sj , w sj , λ )).
3) 从混合权值 π i 中选择第 i 个数据第 j 个特征的类 z ij , z ij ~ Multinomial ( π i ),从特征取值分布 Φ s 中选择类 z ij 的第 j 个特征的取值即为第 i 个数据第 j 个特征的取值.
Fig. 1 Bayesian case model
图1 贝叶斯案例模型
贝叶斯案例模型使用吉布斯采样算法执行推理,吉布斯采样算法能很快地收敛,特别是在混合模型中 [18] .贝叶斯案例模型经过推理得到式(1)和式(2).其中,如果 z ij = s 和 x ij = v 1,则 n ( s , i , j , v 1)=1,表示如果第 i 个数据第 j 个特征的取值为 v 1且属于类 s ,则 n ( s , i , j , v 1)为1,否则为0. n ( s ,·, j , v 1)表示第 j 个特征取值为 v 1且属于类 s 的所有数据的总和. n ( s ,·,  j ,·)表示第 i 个数据除了第 j 个特征的所有特征取值为 v 1且属于类 s 的特征个数之和, B 为Beta函数.
j ,·)表示第 i 个数据除了第 j 个特征的所有特征取值为 v 1且属于类 s 的特征个数之和, B 为Beta函数.
p ( z j = s | z i j , x , p , w , α , λ )∝ ![]() ×
× 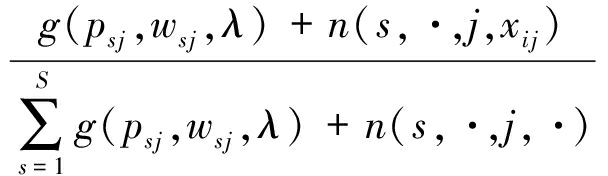 .
.
(1)
p ( w sj = b | q , p sj , λ , φ , x , z , α )∝ 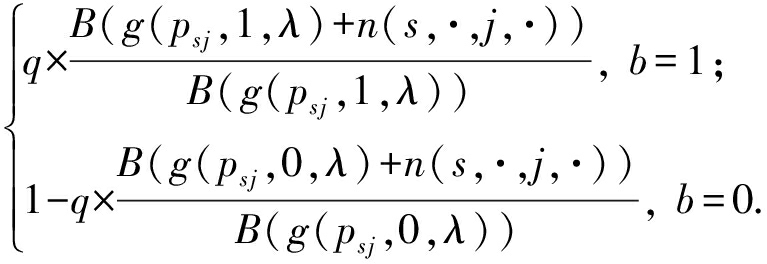
(2)
贝叶斯案例模型是一个基于案例的可解释模型,并且使用无监督生成机制解释聚类而不是使用监督的方法 [19] 或仅仅关注邻居点的方法 [20] .贝叶斯案例模型利用案例推理和原型分类模拟生成过程,能够自动地提供生成解释性的框架.贝叶斯案例模型由一个代表观察者潜在结构的标准离散混合模型 [21-22] 构成,并且在标准混合模型上增加了代表聚类的原型和子空间特征指示器,原型和子空间特征指示器比标准混合模型更适宜人类理解.
1 . 2 贝叶斯程序学习
贝叶斯程序学习(BPL) [23] 是通过部分、子部分和空间关系的组合来学习可以代表概念的随机程序的方法.BPL定义了一个生成模型,这个生成模型的过程如下(以生成一个字符为例):
1) 从原始的笔画中抽样 n 1个笔画作为子部分集,然后抽样子部分的顺序;
2) 基于子部分和子部分数据构造部分集;
3) 抽样部分之间的联系,基于部分和部分之间的联系构造代表概念的程序;
4) 增加子部分的变动因素,抽样部分开始的位置,组成一个部分的轨道;
5) 抽样发散性变化,基于发散性变化抽样图像;
6) 得到字符图像.
BPL捕获了从仅仅几个例子中学习类的可视化概念和以人类最相似的方式生成事物的能力 [23-25] .BPL使用简单的概率程序代表概念.BPL通过重用已经存在的部分构造新的程序,具有现实世界中生成过程的因果和组合的特性.
本文针对聚类的多视角性和可解释性问题,提出ICMG算法.ICMG构建了多视角生成模型,该模型逆过程使用MBCM生成多个视角.ICMG基于每个视角的匹配度进行聚类,并且使用视角的原型和子空间所附带的语义信息定性和定量地解释聚类结果.
2 . 1 嵌入多视角因素的贝叶斯案例模型
嵌入多视角因素的贝叶斯案例模型(MBCM)将多视角因素引入贝叶斯案例模型,如图2所示.图2中的变量的意义参照贝叶斯案例模型,推理公式参照贝叶斯案例模型.嵌入多视角因素的贝叶斯案例模型定义数据的生成过程如下:
1) 选择第 i 个数据的第 j 个特征的一个视角 v ,再选择视角 v 的类 s ;
2) 然后根据 ![]() 的取值得到视角 v 下的第 i 个数据的第 j 个特征的取值
的取值得到视角 v 下的第 i 个数据的第 j 个特征的取值 ![]()
3) 循环步骤1)和2) F v 次, F v 为视角 v 的特征的个数,得到第 i 个数据基于视角 v 的取值 ![]()
4) 循环步骤3) V 次,得到由多个视角生成的第 i 个数据 x i ;
5) 循环步骤4) N 次,得到数据集 X .
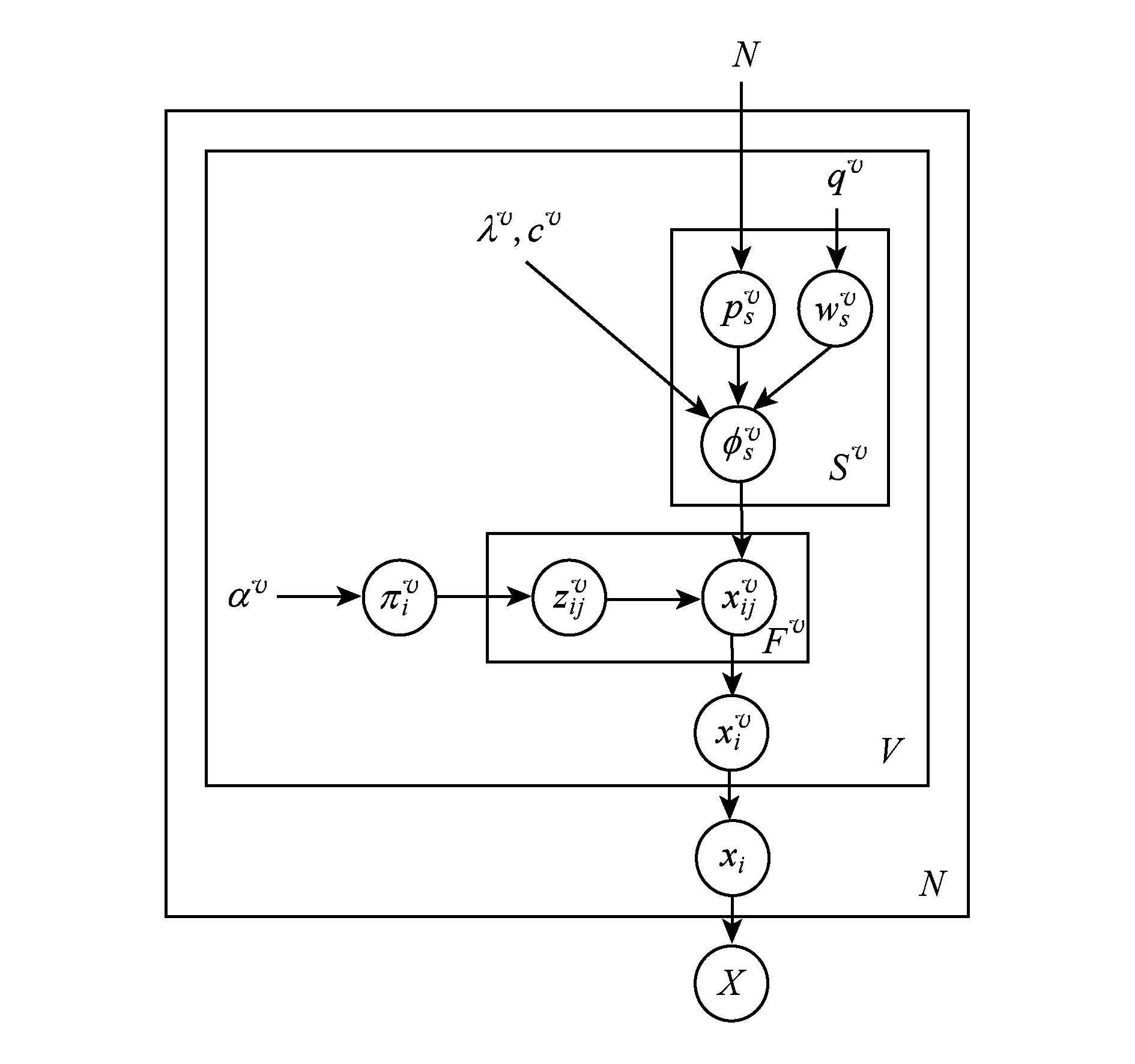
Fig. 2 Multi-view bayesian case model
图2 嵌入多视角因素的贝叶斯案例模型
MBCM利用案例推理模拟多视角数据的生成过程,能够自动地提供生成解释性的框架.MBCM的主要任务是通过类标签、原型和重要特征进行联合推理学习每个视角的每个类的原型和重要特征指示器.MBCM从基于案例推理上形式化概念,并利用原型和重要特征指示器对聚类进行本质的解释,利用原型和重要特征指示器在解释性上提供了定量的和可测量的好处.
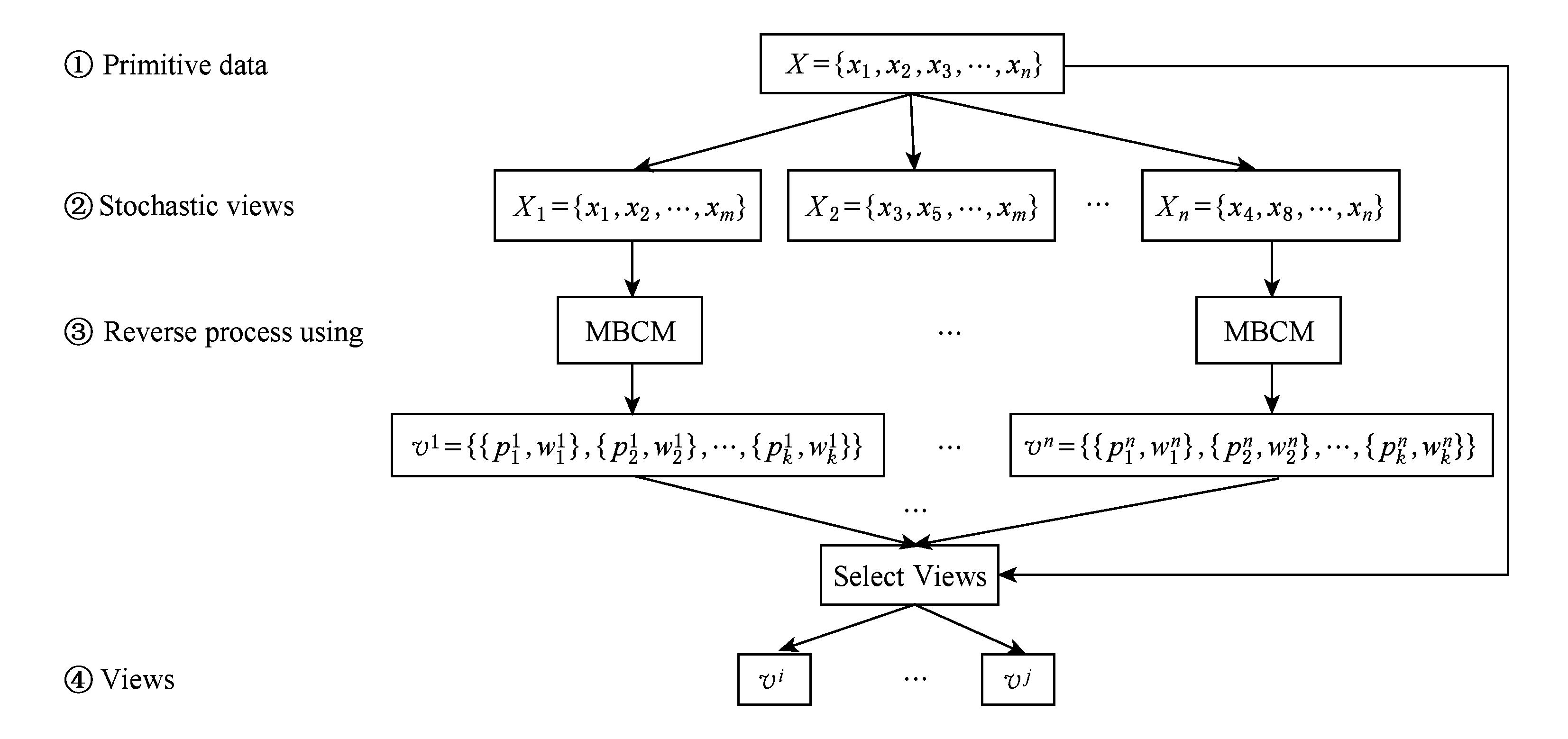
Fig. 3 Multi-view generating model
图3 多视角生成模型
MBCM和BCM的区别如下:
1) MBCM将多视角因素引入生成模型,BCM没有多视角因素.
2) MBCM生成的数据包含多个视角,BCM生成的数据只有一个视角.
3) MBCM包含由多个视角构造数据的过程,BCM没有该过程.
2 . 2 多视角生成模型
多视角生成模型(MGM)基于有效原则和无冗余原则使用BPL的组合思想和MBCM生成多个有效的无冗余视角.MGM随机组合数据构成随机类,然后随机组合随机类构成随机视角,最后逆过程使用MBCM得到描述视角的原型和子空间,并且使用视角评价标准从全部数据的角度选择有效的和无冗余的视角.MGM的图形式如图3所示.图3中的 x i 代表第 i 条数据, N 表示数据的数目, m 的取值范围为[1, N ], k 代表一个视角的类的个数. V i 代表第 i 个视角 ![]() 和
和 ![]() 分别代表第 i 个视角的第 j 个类的原型和重要特征.
分别代表第 i 个视角的第 j 个类的原型和重要特征.
MGM根据视角的有效原则和无冗余原则制定了2个评价视角的标准:
标准1 . 基于视角 V i 能够聚为唯一一个类的数据的个数越多,视角 V i 被选择的可能性就越大.
标准2 . 选择的较好视角中,各视角的关注点越不同越好.
标准1的计算如式(3)和式(4),标准2的计算如式(5).式(3)和式(4)统计了基于各视角能够聚为唯一一个类的数据的个数,式(5)统计了各视角之间的子集关系,通过删除有子集的较好视角进而实现视角的无冗余.式(3)中的 ct ij 表示第 i 个数据是否只能完全匹配第 j 类,式(5)中的 h ij 表示第 i 个视角中是否存在类的重要特征是第 j 个视角类的重要特征的子集.选择 ct i 值最大并且 h i * =0的视角作为有效的无冗余视角.
![]() ;
;
(3)
(4)
(5)
MGM基于组合和因果原则生成多个视角;MGM逆过程使用MBCM得到描述视角的原型和子空间,原型和子空间本身的语义可以解释视角;MGM基于有效性原则和无冗余原则筛选出多个有效的无冗余视角.
2 . 3 多视角生成模型的可解释性聚类算法
多视角生成模型的可解释性聚类算法(ICMG)基于MGM生成的多视角进行聚类,并使用多视角的原型和子空间本身的语义解释聚类结果.聚类结果和视角一一对应,所以可以得到多种可解释的聚类方案.过程如下:1)MGM生成多视角,并且得到对视角具有描述意义的原型和子空间;2)基于视角的原型,子空间和匹配度公式(见式(6))进行聚类,并使用原型和子空间本身的语义对聚类结果进行定性和定量地解释.
d ij = ![]() ,
,
(6)
其中, d ij 表示数据 i 和类 j 的重要特征的匹配度, nt ij 表示数据 i 和类 j 的重要特征的取值相同的个数, nt j 表示类 j 的重要特征的个数.
算法1使用MGM生成多个视角,根据视角的匹配度进行聚类并且使用原型和子空间本身的语义对聚类结果进行定性和定量地解释,聚类结果和视角一一对应,所以可以得到多种可解释的聚类方案.
算法1 . ICMG算法
输入: 数据集 X ( N 行, u 列)、聚类的个数 S 、抽样次数 N 1 、每次抽样的个数 n 1 ;
输出: 数据的较好视角的类标号 L 、较好视角的类的原型和重要特征 T .
① for i =1: N 1
D 为从 X 中随机抽样的 n 1条数据;
逆过程使用MBCM得到 ![]() ;
;
end for
② for i =1: N
利用式(3)和式(4)计算 ct i ;
end for
③ for i =1: n 1
for j =1: n 1
利用式(5)计算 h ij ;
end for
end for
④ 利用标准1和标准2得到视角 T ={ t 1, t 2,…, t y }, y 为 T 中元素的个数.
⑤ for f =1: y
for i =1: N
for j =1: S
利用式(6)计算 ![]()
end for
![]() ; /
; / ![]() 为数据 i 的 较好视角 t f 的类标号*/
为数据 i 的 较好视角 t f 的类标号*/
end for
end for
⑥ ![]() 为较好视角下所有数据的类标号;
为较好视角下所有数据的类标号;
⑦ return L , T .
2 . 4 算法分析
在ICMG算法里,首先要生成多个视角,多视角生成的步骤可在 O ( N 2)的时间内完成, N 为数据的数目;其次基于视角计算匹配度,计算匹配度的步骤可以在 O ( m 1× N )的时间内完成,其中 m 1为视角的数目和类的数目的乘积;最后基于视角对所有数据进行聚类,这一步骤可在 O ( t × N )的时间内完成,其中 t 为视角的数目.所以,ICMG算法的时间复杂度与数据的数目的平方相关.
3 . 1 实验数据集
实验数据集是Attribute Datasets [26] 中的Apascal_train数据集和Ayahoo_test数据集.Apascal_train数据集共6 340张图片,人工把这些图片分成2类:有人的图片为类1,没有人的图片为类2;Ayahoo_test数据集共2 644张图片,人工把这些图片分成2类:有动物的图片为类1,没有动物的图片为类2.多视角算法CTSC [27] 和CRSC [28] 作为对比算法.
3 . 2 实验结果及分析
3.2.1 Apascal_train数据集实验结果
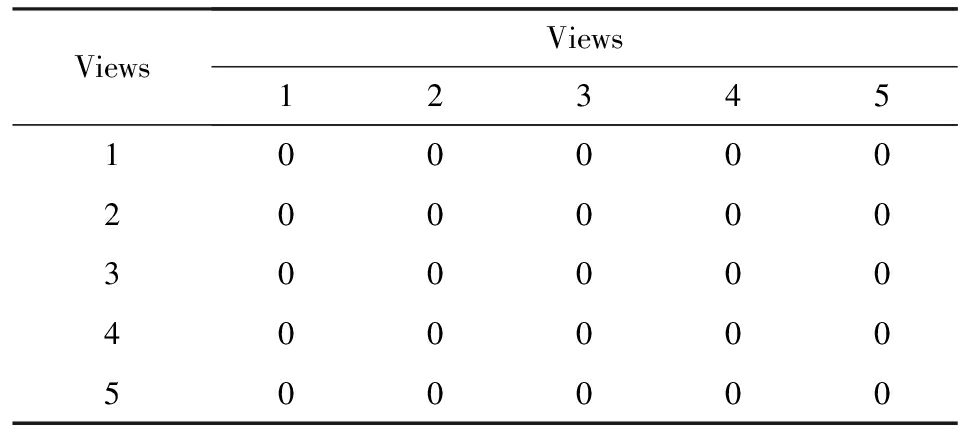
ICMG算法对Apascal_train数据集聚类得到表1和表2.其中表1根据评价标准1统计了各视角能够唯一确定类的数据的数目,从表1中得到能够唯一确定类的数据的个数最多的是视角2、视角3和视角4.表2根据评价标准2统计了各视角之间的子集关系,表2中的所有0表示所有视角的关注点都不一样.根据表1和表2得到Apascal_train数据集较好的视角为视角2、视角3和视角4.
Table 1 The Results of Criterion 1 ( Apascal_train )
表1 标准1的计算结果 ( Apascal_train数据集 )
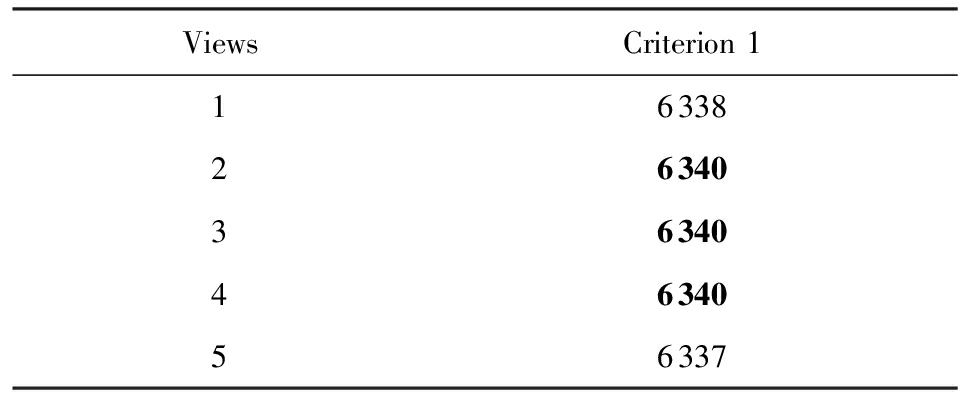
Table 2 The Results of Criterion 2 ( Apascal_train )
表2 标准2的计算结果 ( Apascal_train数据集 )
Apascal_train数据集基于ICMG的聚类结果的定性解释如下:
1) 基于视角2的聚类关注的是图中是否有圆形物、头发、手、喷气发动机、排气管、踏板、发动机、桅杆、马鞍、茎杆、皮肤、嘴、皮肤和羊毛.
2) 基于视角3的聚类关注的是图中是否有卧式气缸、耳朵、嘴、腿、脚/鞋、炉子、花、茎杆、罐、羽毛、排气、踏板、发动机、帆、桅杆、叶、羊毛、明亮的和草木.
3) 基于视角4的聚类关注的是图中是否有头、脸、螺旋桨、桅杆、炉子、炉子座、缰绳、马鞍和羊毛.
Apascal_train数据集基于ICMG的聚类结果的定量解释如下(如图4~6所示):
1) 基于视角2的聚类结果的类1中66.48%是没有圆形物、没有头发、没有手、没有喷气发动机、没有排气、没有踏板、没有发动机、没有桅杆、没有马鞍、没有茎杆、没有皮肤和不明亮的图片.基于视角2的聚类结果的类2中都是有嘴、有头发、有皮肤和没有羊毛的图片.
2) 基于视角3的聚类结果的类1中23.62%是没有卧式气缸、没有耳朵、没有嘴、没有腿、没有脚/鞋、没有炉子、没有羽毛但是有花、茎杆和罐的图片.基于视角3的聚类结果的类2中77.68%是没有排气管、没有踏板、没有发动机、没有帆、没有桅杆、没有叶子、没有茎杆、没有罐、没有羊毛、没有草木和不明亮的图片.

Fig. 4 Clustering based on view 2 for Apascal_train
图4 Apascal_train数据集基于视角2的聚类
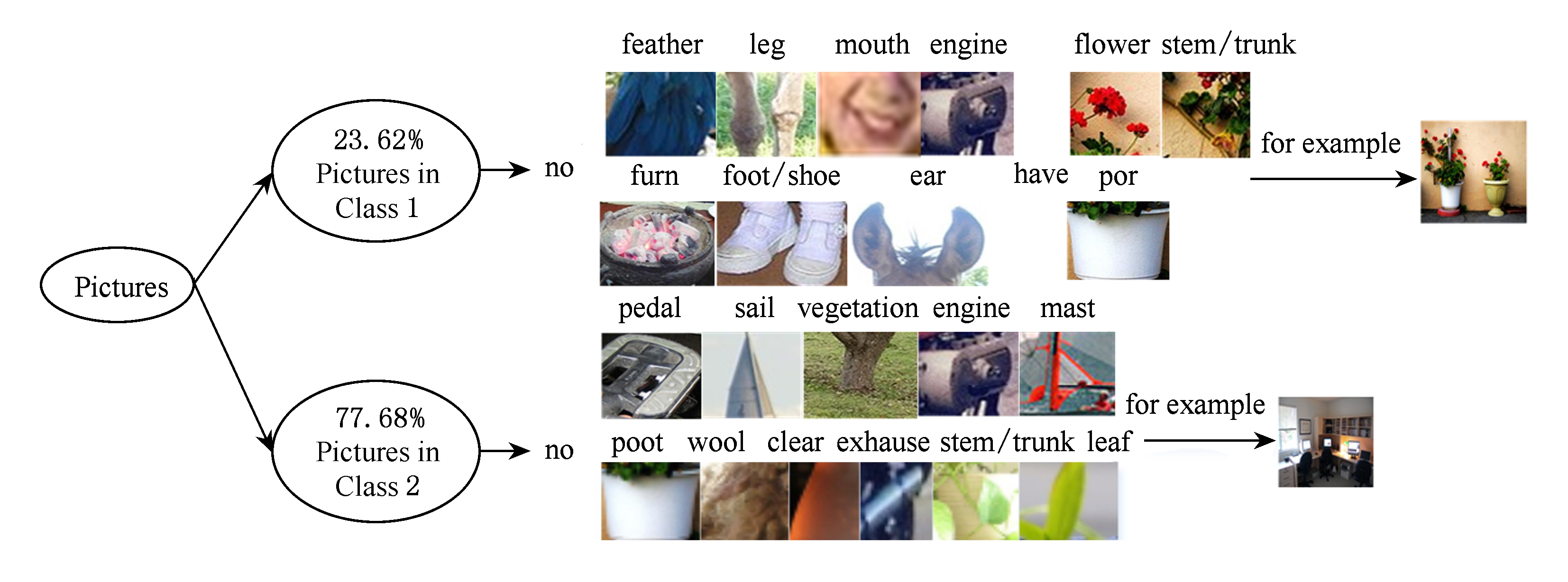
Fig. 5 Clustering based on view 3 for Apascal_train
图5 Apascal_train数据集基于视角3的聚类

Fig. 6 Clustering based on view 4 for Apascal_train
图6 Apascal_train数据集基于视角4的聚类
3) 基于视角4的聚类结果的类1中82.02%是没有头、没有脸、没有螺旋桨、没有桅杆、没有炉子和没有炉子座的图片.基于视角4的聚类结果的类2中90.5%是有头、没有缰绳、没有马鞍和没有羊毛的图片.
3.2.2 Ayahoo_test数据集实验结果
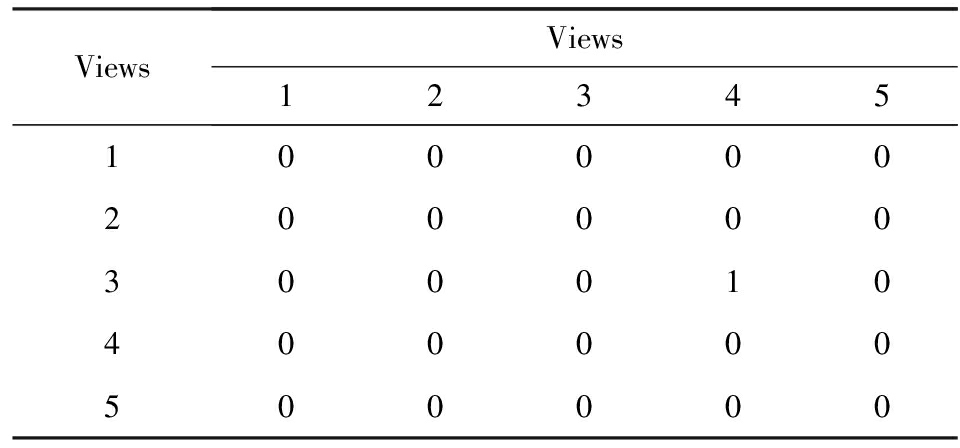
ICMG算法对Ayahoo_test数据集进行聚类得到表3和表4.表3根据评价标准1统计了各视角能够唯一确定类的数据的个数,从表3中得到能够唯一确定类的数据的个数最多的是视角1、视角2、视角3、视角4和视角5.表4根据评价标准2统计了各视角之间的子集关系,表4中的1表示视角3的关注点是视角4的关注点的子集.根据表3和表4得到Ayahoo_test数据集的较好的视角为视角1、视角2、视角3和视角5.
Table 3 The Results of Criterion 1 ( Ayahoo_test )
表3 标准1的计算结果 ( Ayahoo_test数据集 )
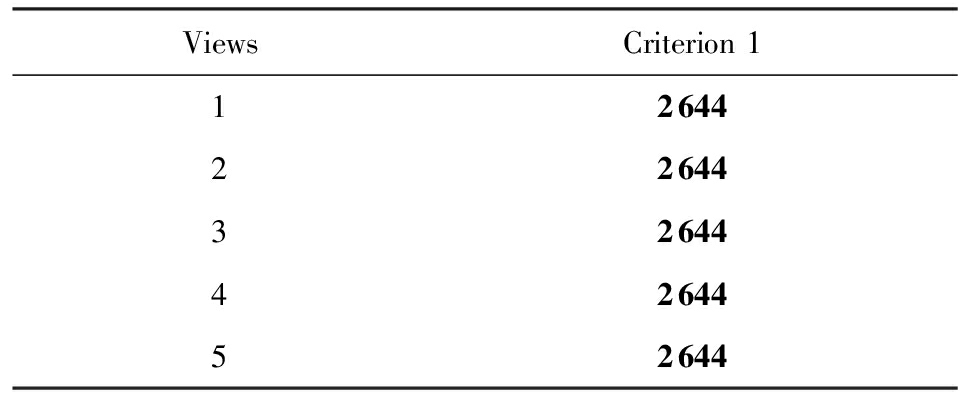
Table 4 The Results of Criterion 2 ( Ayahoo_test )
表4 标准2的计算结果 ( Ayahoo_test数据集 )
Ayahoo_test数据集基于ICMG的聚类结果的定性解释如下:
1) 基于视角1的聚类关注的是图中是否有腿、脚/鞋、缰绳、马鞍、塑料、闪光、头、鼻子、手、轮子、门、前灯、发动机、木制品、布、毛茸茸、羊毛、明亮和皮革制品.
2) 基于视角2的聚类关注的是图中是否有躯干、大灯、排气、发动机、缰绳、布、羊毛、明亮、耳、眼、腿、翅膀、马鞍、金属和毛茸茸.
3) 基于视角3的聚类关注的是图中是否有躯干、角、缰绳、马鞍、金属、圆形物、头、耳朵、鼻子、脸、眼、轮子、门、排气管、发动机、布、毛茸茸、明亮和皮革制品.
4) 基于视角5的聚类关注的是图中是否有阻塞、耳、眼、躯干、腿、翅膀、缰绳、马鞍、方方正正、圆形物、轮子、前灯、排气管、发动机、布、毛茸茸的、明亮和皮革制品.
Ayahoo_test数据集基于ICMG的聚类结果的定量解释如下:
1) 基于视角1的聚类结果的类1中59.39%的图片中没有缰绳、没有马鞍、没有塑料和不发光,但是有腿、有脚/鞋和有毛茸茸的东西.基于视角1的聚类结果的类2中51.27%的图片中没有头、没有鼻子、没有手、没有轮子、没有门、没有前灯、没有发动机、没有木制品、没有布、没有毛茸茸的东西、没有羊毛、不明亮和没有皮革制品.如图7所示.
2) 基于视角2的聚类结果的类1中69.85%的图片是没有躯干、没有大灯、没有排气、没有发动机、没有缰绳、没有布、没有羊毛和不明亮.基于视角2的聚类结果的类2中64.70%的图片中没有翅膀、没有缰绳、没有马鞍和没有金属,但是有耳朵、有眼睛、有躯干、有腿和有毛茸茸的东西.如图8所示.
3) 基于视角3的聚类结果的类1中56.00%的图片中没有角、没有缰绳、没有马鞍和没有金属,但是有耳朵、有躯干和有毛茸茸的东西.基于视角3的聚类结果的类2中60.07%的图片是没有圆形物、没有头、没有耳朵、没有鼻子、没有脸、没有眼睛、没有轮子、没有门、没有排气管、没有发动机、没有角、没有缰绳、没有马鞍、没有布、没有毛茸茸的东西、不明亮和没有皮革制品.如图9所示.
4) 基于视角5的聚类结果的类1中所有图片中没有阻塞、没有翅膀、没有缰绳和没有马鞍,但是有耳朵、有眼睛、有躯干、有腿和有毛茸茸的东西.基于视角5的聚类结果的类2中48.89%的图片中没有方方正正的东西、没有圆形物、没有轮子、没有前灯、没有排气、没有发动机、没有布、没有毛茸茸的东西、不明亮和没有皮革制品.如图10所示.

Fig. 7 Clustering based on view 1 for Ayahoo_test
图7 Ayahoo_test数据集基于视角1的聚类

Fig. 8 Clustering based on view 2 for Ayahoo_test
图8 Ayahoo_test数据集基于视角2的聚类

Fig. 9 Clustering based on view 3 for Ayahoo_test
图9 Ayahoo_test数据集基于视角3的聚类

Fig. 10 Clustering based on view 5 for Ayahoo_test
图10 Ayahoo_test数据集基于视角5的聚类
3.2.3 ICMG算法与其他多视角算法的对比分析
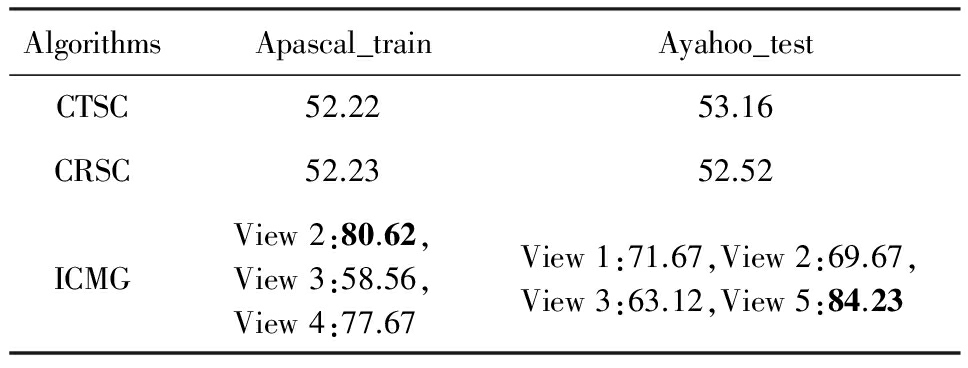
ICMG算法对Apascal_train数据集和Ayahoo_test数据集的聚类结果如表5所示,表5展示的是准确率(AC),从表5中可以看出:
1) 针对数据集Apascal_train和Ayahoo_test,ICMG得到了多种聚类方案,而且每个聚类方案的准确率都比CRSC和CTSC高.
2) 不同的视角的准确率不同.
Table 5 Clustering Results
表5 聚类准确率 %
本文从3个方面对比验证算法的可解释性,分别是:聚类过程是否黑盒化,算法是否产生决策规则,聚类结果是否有定性和定量地解释.如表6所示.聚类过程黑盒化是指不表明一个数据被划分为一个簇的原因,如图11所示.
Table 6 Algorithmic Interpretation
表6 算法的可解释性
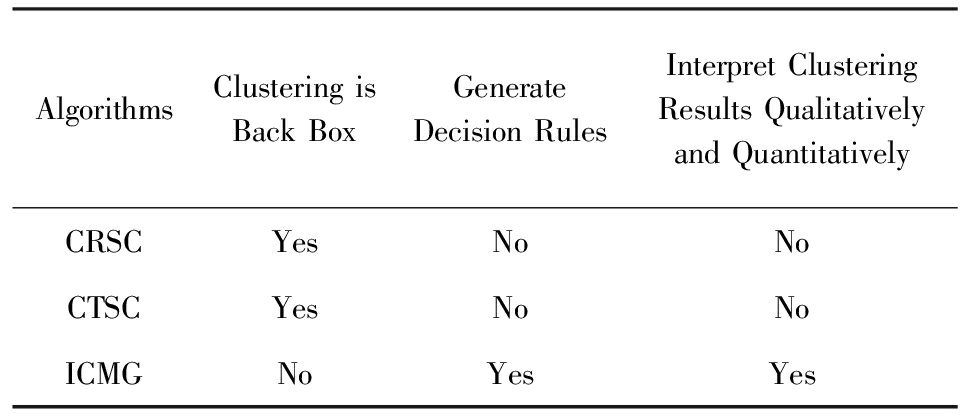
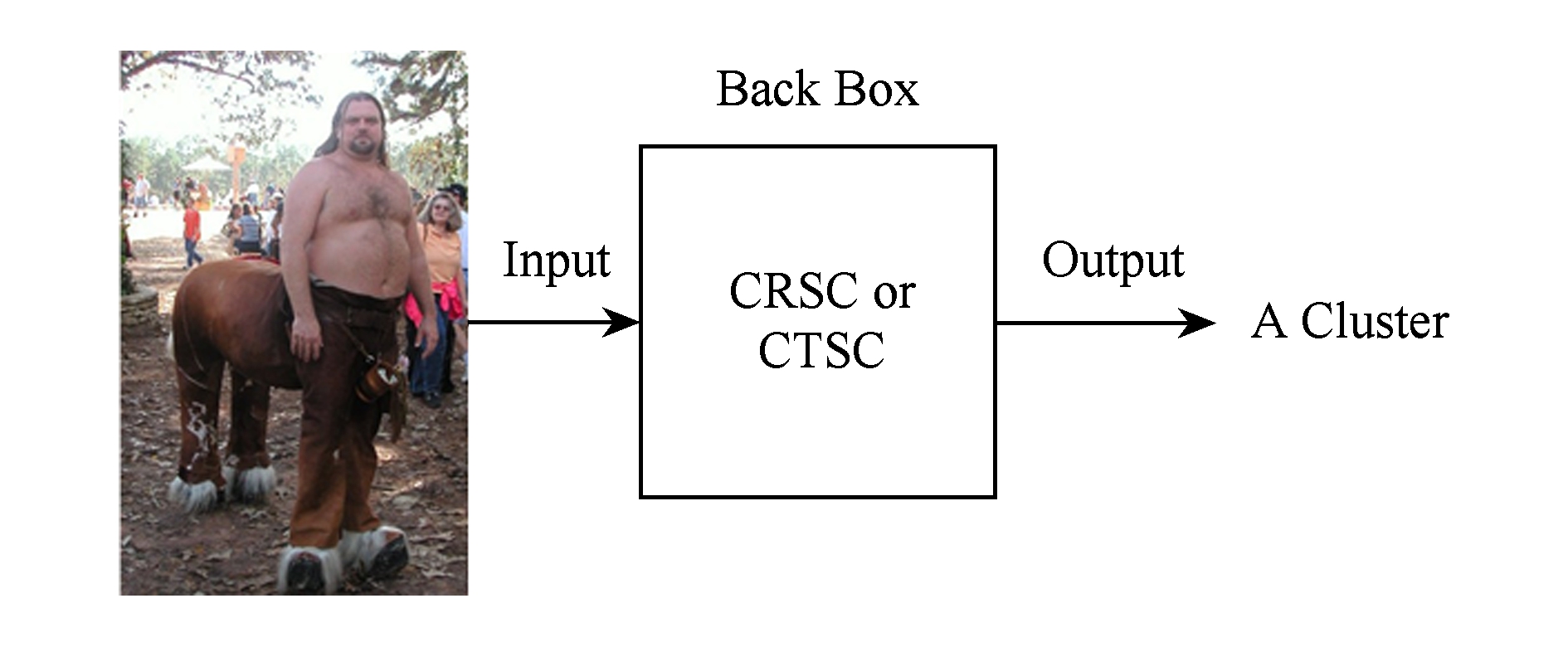
Fig. 11 Clustering in back box
图11 聚类过程黑盒化
从表6可以得到:
1) CRSC和CTSC是聚类过程黑盒化的算法,如图11所示.ICMG不是黑盒化的算法,因为ICMG基于决策规则进行聚类,如图12所示:

Fig. 12 Clustering based on decision rules
图12 基于决策规则的聚类
2) ICMG比CRSC和CTSC具有更好的解释性.因为ICMG是基于决策规则进行聚类并且可以定性和定量地解释聚类结果.
ICMG算法利用视角的重要特征构成规则集,基于规则集进行聚类可以得到每一个数据被划分为一个簇的原因.ICMG算法利用视角的语义定性和定量地解释聚类结果进而得到每一个簇的详细的组成成分.因此,ICMG聚类性能优于其他多视角聚类.ICMG算法对聚类结果的解释可以使使用者基于自己的专业知识批判性、改善性和探索性地相信和使用聚类结果.
3 . 3 聚类结果可解释的验证
为了验证ICMG的可解释性的效果,我们做了一个社会调查的实验.实验过程如下:1 000个人,平均年龄24岁,给这些人分别展示Ayahoo_test数据集的CRSC算法的聚类结果和ICMG算法的聚类结果,每人给两分种时间观察这些聚类结果,然后总结每个类的成分或聚成一类的图片的共同点.实验结果是60%的人认为CRSC算法的聚类结果看不出每个类的成分,也找不到聚成一类的图片的共同点,40%的人是集中观察部分CRSC算法聚类结果进而理解每个类的成分,这样得到的理解往往是片面的和不自信的,80%的人认为ICMG算法的聚类结果由于有类的原型和子空间做指引能很快地了解每个类的成分,而且能很自信地说出聚成一类的图片的共同点,20%的人对ICMG算法的聚类结果表示怀疑,认为存在个别图片与此图片所在的类的原型和子空间不完全符合,但承认大部分图片还是符合的和能让人理解的.因此,ICMG得到的聚类结果具有可解释性.
针对聚类的多视角和可解释问题,本文提出ICMG算法.为了得到多个有语义的视角,ICMG构建MGM模型.MGM基于有效原则和无冗余原则使用BPL的组合思想和MBCM生成多个有效的无冗余视角,并使用原型和子空间描述视角.ICMG基于每个视角的匹配度进行聚类,并且使用视角的原型和子空间所附带的语义信息定性和定量地解释聚类结果,所以ICMG可以得到多种可解释的聚类方案.
参考文献:
[1] Rodriguez A, Laio A. Clustering by fast search and find of density peaks[J]. Science, 2014, 344(6191): 1492-1496
[2] Lou Zhengzheng, Ye Yangdong, Liu Ruina. Non-redundant multi-view clustering based on information bottleneck[J]. Journal of Computer Research and Development, 2013, 50(9): 1865-1875(娄铮铮, 叶阳东, 刘瑞娜. 基于IB方法的无冗余多视角聚类[J]. 计算机研究与发展, 2013, 50(9): 1865-1875
[3] Wang Yang, Zhang Wenjie, Wu Lin, et al. Iterative views agreement: An iterative low-rank based structured optimization method to multi-view spectral clustering[C] //Proc of the 25th Int Joint Conf on Artificial Intelligence. San Francisco, CA: Morgan Kaufmann, 2016: 2153-2159
[4] Li Yeqing, Nie Feiping, Huang Heng, et al. Large-scale multi-view spectral clustering via bipartite graph[C] //Proc of the 29th AAAI Conf on Artificial Intelligence. Menlo Park: AAAI, 2015: 2750-2756
[5] Cai Xiao, Nie Feiping, Huang Heng, et al. Heterogeneous image feature integration via multi-modal spectral clustering[C] //Proc of the 24th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2011: 1977-1984
[6] Guo Dongyan, Zhang Jian, Liu Xinwang, et al. Multiple kernel learning based multi-view spectral clustering[C] //Proc of the 22nd Int Conf on Pattern Recognition. Piscataway, NJ: IEEE, 2014: 3774-3779
[7] Wang Hongxing, Weng Chaoqun, Yuan Junsong, et al. Multi-feature spectral clustering with minimax optimization[C] //Proc of the 2014 IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2014: 4106-4113
[8] Kumar A, Daume H. A co-training approach for multi-view spectral clustering[C] //Proc of the 28th Int Conf on Machine Learning. New York: ACM, 2011: 393-400
[9] Kumar A, Rai P, Daume H. Co-regularized multi-view spectral clustering[C] //Proc of the 25th Annual Conf on Neural Information Processing Systems. Cambridge: MIT Press, 2011: 1413-1421
[10] Cai Xiao, Nie Feiping, Huang Heng. Multi-view k -means clustering on big data[C] //Proc of the 23rd Int Joint Conf on Artificial Intelligence. San Francisco, CA: Morgan Kaufmann, 2013: 2598-2604
[11] Xu Jinglin, Han Junwei, Nie Feiping. Discriminatively embedded K -means for multi-view clustering[C] //Proc of the 29th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 5356-5364
[12] Xu Yumeng, Wang Changdong, Lai Jianhuang. Weighted multi-view clustering with feature selection[J]. Pattern Recognition, 2016, 53: 25-35
[13] Cao Xiaochun, Zhang Changqing, Fu Huazhu, et al. Diversity-induced multi-view subspace clustering[C] //Proc of the 28th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015: 586-594
[14] Kim B, Shah J, Doshi-Velez F. Mind the gap: A generative approach to interpretable feature selection and extraction[C] //Proc of the 29th Annual Conf on Neural Information Processing Systems. Cambridge: MIT Press, 2015: 2260-2268
[15] Fraiman R, Ghattas B, Svarc M. Interpretable clustering using unsupervised binary trees[J]. Data Analysis and Classification, 2013, 7(2): 125-145
[16] Chen Junxiang, Chang Yale, Hobbs B. Interpretable clustering via discriminative rectangle mixture model[C] //Proc of the 16th IEEE Int Conf on Data Mining. Piscataway, NJ: IEEE, 2016: 823-828
[17] Kim B, Rudin C, Shah J. The bayesian case model: A generative approach for case-based reasoning and prototype classification[C] //Proc of the 28th Annual Conf on Neural Information Processing Systems. Cambridge: MIT Press, 2014: 1952-1960
[18] Attias H. Inferring parameters and structure of latent variable models by variational bayes[C] //Proc of the 15th Conf on Uncertainty in Artificial Intelligence. Paris: AUAI, 1999: 21-30
[19] Graf A B A, Bousquet O, Ratsch G, et al. Prototype classification: Insights from machine learning[J]. Neural Computation, 2009, 21(1): 272-300
[20] Baehrens D, Schroeter T, Harmeling S, at al. How to explain individual classification decisions[J]. Journal of Machine Learning Research, 2010, 11(2010): 1803-1831
[21] Hofmann T. Probabilistic latent semantic indexing[C] //Proc of the 22nd Annual Int ACM SIGIR Conf on Research and Development in Information Retrieval. New York: ACM, 1999: 50-57
[22] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3(2003): 993-1022
[23] Lake B M, Salakhutdinov R, Tenenbaum J B. Human-level comcept learning through probabilistic program induction[J]. Science, 2015, 350(6266): 1332-1338
[24] Lake B M, Salakhutdinov R, Tenenbaum J B. One-shot learning by inverting a compositional causal process[C] //Proc of the 27th Annual Conf on Neural Information Processing Systems. Cambridge: MIT Press, 2013: 2526-2534
[25] Lake B M, Salakhutdinov R, Gross J. One shot learning of simple visual concepts[C] //Proc of the 33rd Annual Meeting of the Cognitive Science Society. United Kindom: Psychology, 2011: 2568-2573
[26] Farhadi A, Endres I, Hoiem D. Describing objects by their attributes[C] //Proc of IEEE Computer Society Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2009: 1778-1785
[27] Kumar A, Daumé H. A co-training approach for multi-view spectral clustering[C] //Proc of the 28th Int Conf on Machine Learning. New York: ACM, 2011: 393-400
[28] Kumar A, Rai P, Daumé H. Co-regularized multi-view spectral clustering[C] //Proc of the 25th Annual Conf on Neural Information Processing Systems. Cambridge: MIT Press, 2011: 1413-1421
Pan Xiaoyan, Lou Zhengzheng, Ji Bo, and Ye Yangdong
( School of Information Engineering Zhengzhou University , Zhengzhou 450001)
Abstract: Clustering has two problems: multi-view and interpretation. In this paper, we propose an interpretable clustering with multi-view generative model (ICMG). ICMG can get multiple clustering based multi-view meanwhile qualitatively and quantitatively interpret clustering results by using semantic information in views. Firstly, we construct a multi-view generative model (MGM). It generates multiple views by using Bayesian program learning (BPL) and multi-view Bayesian case model (MBCM). Then we get multiple clustering by clustering based on views’ matching degree. Finally, ICMG qualitatively and quantitatively interprets clustering results by using semantic information in views’ prototypes and important features. Experimental results show ICMG can get multiple interpretable clustering and the performance of ICMG is superior to traditional multi-view clustering.
Key words: Bayesian program learning (BPL); Bayesian case model (BCM); interpretable; multi-view; clustering

Pan Xiaoyan , born in 1990. Master at Zhengzhou University. Her main research interests include machine learning and data mining.

Lou Zhengzheng , born in 1984. PhD. His main research interests include machine learning, pattern recognition and computer vision.

Ji Bo , born in 1973. PhD. Associate professor. His main research interests include artificial intelligence, pattern recognition and information theory.

Ye Yangdong , born in 1962. Professor. PhD supervisor at Zhengzhou University. Senior member of CCF. His main research interests include intellectual system, database system, machine learning.
收稿日期: 2017-03-19;
修回日期: :2017-05-22
基金项目: 国家自然科学基金项目(61502434,61170223);河南省科技攻关项目(172102210011) This work was supported by the National Natural Science Foundation of China (61502434,61170223) and the Henan Provincial Key Technology Research and Development Program (172102210011).
通信作者: 叶阳东(ieydye@zzu.edu.cn)
中图法分类号: TP181