朱真峰 翟艳祥 叶阳东
(郑州大学信息工程学院 郑州 450052)
摘要AUC(area under the ROC curve)优化问题的损失函数由来自不同类别的样本对构成,这使得依赖于损失函数之和的目标函数与训练样本数二次相关,不能直接使用传统在线学习方法求解.当前的在线AUC优化算法聚焦于在求解过程中避免直接计算所有的损失函数,以减小问题的规模,实现在线AUC优化.针对以上问题提出了一种AUC优化的新目标函数,该目标函数仅与训练样本数线性相关;理论分析表明:最小化该目标函数等价于最小化由L2正则化项和最小二乘损失函数组成的AUC优化的目标函数.基于新的目标函数,提出了在线AUC优化的线性方法(linear online AUC maximization, LOAM);根据不同的分类器更新策略,给出2种算法LOAMILSC和LOAMAda.实验表明:与原有方法相比,LOAMILSC算法获得了更优的AUC性能,而对于实时或高维学习任务,LOAMAda算法更加高效.
关键词分类;AUC优化;在线学习;线性方法;最小二乘损失
AUC(area under the ROC curve)[1]是衡量分类算法性能的重要指标之一,被广泛应用于不平衡类的学习、代价敏感学习、排序学习和异常检测等[2-5].AUC值难以精确计算,通常采用参数假定、半参数假定或非参数假定方法进行估计.机器学习领域常用非参数假定方法,其估计在数值上等价于排序的WMW(Wilcoxon-Mann-Whitney)统计[6].设计分类算法通常需要将评价指标作为优化目标,使算法的优化目标与性能评价指标一致,以期获得理想的性能.基于AUC评价指标,研究者提出诸多直接优化AUC的批处理算法[7-11],这类算法假设学习之前已经得到全部训练数据.
在线学习凭借其处理大规模数据和流数据的高效性,在机器学习领域受到广泛关注[12-18].传统在线学习方法的目标函数仅需考虑由单个训练样本构成的损失函数之和;而AUC优化的目标函数来自不同类别的样本对构成的损失函数之和,与训练样本数呈二次增长关系.直接将传统在线学习方法应用于AUC优化问题,需要存储所有历史(旧)样本,这对于大数据分析是不可行的.
为了实现在线AUC优化,研究者提出了多种以AUC为优化目标的在线学习方法[19-23].这些方法可以分为2类:缓冲方法和统计方法.缓冲方法基于缓冲采样思想,构建2个固定大小的缓冲,分别存储采样的正负旧样本[19-21],把接收的新样本存储在相应的缓冲中;如果缓冲满,采用蓄水池抽样(reservoir sampling)或先进先出(fist-in-first-out)策略,以新样本替换相应缓冲中的旧样本,并用新样本与另一个缓冲中的所有样本构成的损失函数代表新样本与另一类的所有旧样本构成的损失函数进行计算,更新模型.统计方法通过存储和更新一阶统计量(平均值)和二阶统计量(协方差矩阵),利用随机梯度下降方法[22]或者AdaGrad方法[23]实现在线AUC优化;每次迭代的梯度由新样本与另一类的所有旧样本的平均值和协方差矩阵计算得到.
上述2类方法都是通过在求解过程中避免直接计算所有的损失函数,以减小问题的规模.不同之处在于,缓冲方法需要存储并不断地扫描缓冲中的样本,算法的空间复杂度和每次迭代的时间复杂度与缓冲大小呈正比关系.统计方法不需要存储任何旧样本,只需要扫描一遍训练集,其存储规模独立于训练样本个数;统计方法涉及协方差矩阵的存储和计算,相应算法的空间复杂度和每次迭代的时间复杂度与样本维数平方呈正比关系,高于传统在线梯度下降算法[12]、与ONS(online Newton step)[16]相同.
如何使AUC优化的目标函数不再和训练样本数二次相关、仅与训练样本数线性相关是一个值得研究的问题.本文在深入研究现有AUC优化算法的基础上,提出了一种与训练样本数线性相关的目标函数;理论推导证明了最小化该目标函数等价于最小化由L2正则化项和最小二乘损失函数组成的AUC优化的目标函数.基于该目标函数,本文提出了线性的在线AUC优化(linear online AUC maximization, LOAM)方法,并根据不同的分类器更新策略,给出2种算法:1)采用增量式最小二乘法(incremental least squares classifier, ILSC)[24-25]更新分类器的LOAMILSC算法;2)采用AdaGrad方法[17,23]更新分类器的LOAMAda算法.其中,LOAMILSC算法的空间复杂度和每次迭代的时间复杂度与ILSC算法相同,LOAMAda算法的空间复杂度和每次迭代的时间复杂度与传统在线梯度下降算法相同;这2种算法都仅需扫描一遍训练集,不需要存储任何旧样本.本文通过大量的实验验证了所提算法的有效性.
给定一个独立同分布的二分类训练样本集X={(xi,yi)∈![]() d×1×{-1,+1},1≤i≤m},其中d是样本维数,m是样本个数.样本集X可以划分为2个子集:1)所有正样本构成的子集
d×1×{-1,+1},1≤i≤m},其中d是样本维数,m是样本个数.样本集X可以划分为2个子集:1)所有正样本构成的子集![]() 所有负样本构成的子集
所有负样本构成的子集![]() -1),1≤j≤m-},其中m+和m-分别表示正样本和负样本的个数,m++m-=m.对于给定的决策函数f(x),采用非参数假定的估计,AUC计算为
-1),1≤j≤m-},其中m+和m-分别表示正样本和负样本的个数,m++m-=m.对于给定的决策函数f(x),采用非参数假定的估计,AUC计算为
![]()
 (m+m-),
(m+m-),
其中,Γ(k)为指示函数(indicator function),如果k为真,则结果为1,否则结果为0.AUC反映了随机抽取一个正样本的决策值大于随机抽取一个负样本的决策值的概率.AUC优化的目标是在二分类训练样本集上获得决策函数f(x).AUC越大,代表决策函数f(x)的性能越好.由于Γ(k)非凸,也不连续,因而无法直接实现AUC优化.实用的方法一般采用损失替代函数把AUC优化问题转化为凸优化问题.AUC优化等价于最小化经验风险(empirical risk)函数:
其中,l(θ)是凸函数,![]() 的类型有最小二乘损失函数l(θ)=(1-θ)2,指数损失函数l(θ)=e-θ和对数损失函数l(θ)=ln(1+e-θ)等[26].文献[26]研究了损失函数与AUC优化之间的一致性问题,最终证明:最小二乘损失函数、指数损失函数和对数损失函数等对AUC优化具有一致性.
的类型有最小二乘损失函数l(θ)=(1-θ)2,指数损失函数l(θ)=e-θ和对数损失函数l(θ)=ln(1+e-θ)等[26].文献[26]研究了损失函数与AUC优化之间的一致性问题,最终证明:最小二乘损失函数、指数损失函数和对数损失函数等对AUC优化具有一致性.
本文针对二分类问题,构建一个线性分类模型.对于线性分类器w,即决策函数f(x)=wTx,AUC计算为
![]() (m+m-).
(m+m-).
为了避免过拟合,AUC优化通常使用结构风险最小化(structural risk minimization, SRM)策略.本文考虑由L2正则化项和最小二乘损失函数组成的结构风险函数作为目标函数[22-23],即:
(1)
其中,λ>0是L2正则化参数,用来控制学习模型的复杂度,常数12用于在求导时抵消常数项.式(1)有2个优点:1)最小二乘损失函数对AUC优化具有一致性;2)可以求得解析解.
由于传统分类算法的经验风险函数是m个单个样本构成的损失函数之和的均值,为了减少AUC优化问题的规模,本文把式(1)调整为分母为m的形式:
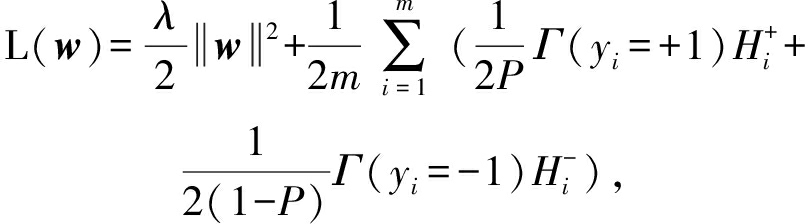
(2)
其中,![]() m-表示xi为正样本时,与所有负样本构成的损失函数之和的平均值;
m-表示xi为正样本时,与所有负样本构成的损失函数之和的平均值;![]() m+表示xi为负样本时,与所有正样本构成的损失函数之和的平均值;P=m+m表示正样本在所有训练样本中所占的比例.既然
m+表示xi为负样本时,与所有正样本构成的损失函数之和的平均值;P=m+m表示正样本在所有训练样本中所占的比例.既然![]() 由m-个损失函数组成,
由m-个损失函数组成,![]() 由m+个损失函数组成,如果
由m+个损失函数组成,如果![]() 和
和![]() 能分别用一个函数替代,就能产生与训练样本数线性相关的新目标函数.
能分别用一个函数替代,就能产生与训练样本数线性相关的新目标函数.
假设![]() m+表示正样本的平均值,
m+表示正样本的平均值,![]() m-表示负样本的平均值.xi为正样本时,采用
m-表示负样本的平均值.xi为正样本时,采用![]() 替代
替代![]() 为负样本时,采用
为负样本时,采用![]() 替代
替代![]() 最终可得到新的目标函数:
最终可得到新的目标函数:

(3)
为了分析式(1)和式(3)之间的关系,本文采用
![]()
![]()
![]()
![]()
分别表示正样本的协方差矩阵和负样本的协方差矩阵,I为单位矩阵,方阵A=λI+Cov++Cov-,列向量C=c+-c-,式(1)和式(3)的解析解分别为![]()
定理1. 当式(3)的正则化参数是式(1)的正则化参数的12时,![]() 即最小化式(3)等价于最小化式(1).
即最小化式(3)等价于最小化式(1).
证明. 为了区分式(1)和式(3),记:
![]()
(4)

(5)
对式(4)求偏导,其梯度为
![]() L1(w)=λw+
L1(w)=λw+![]()
(λI+Cov++Cov-+(c+-c-)(c+-c-)T)w-
(c+-c-)=(A+CCT)w-C.
由协方差矩阵的性质可知Cov+,Cov-都是半正定矩阵,又因λI为正定矩阵,CCT为半正定矩阵,所以A和A+CCT为正定矩阵,即A和A+CCT可逆.
令![]() L1(w)=0,则解析解
L1(w)=0,则解析解![]()
对式(5),同样求偏导,其梯度:
![]()
![]()
![]()
![]()
其中:
![]()
![]()
![]()
![]()
所以:
![]()
![]()
(c+-c-)(c+-c-)T)w-(c+-c-),
解析解:
由于C是列向量,采用Sherman-Morrison公式[27]化简![]() 则:
则:
![]()
A-1C![]() =α1A-1C,
=α1A-1C,
同理:
其中,
α1=1(1+CTA-1C),
α2=2(1+2CTA-1C).
因为A是正定矩阵,所以A-1也是正定矩阵.由正定矩阵的性质可知,对于任意非0向量C,有CTA-1C>0,因此,α1>0,α2>0.
对于线性分类器w,w乘以一个正数AUC不变,所以![]()
如果C是0向量,则![]() 同样有
同样有![]()
证毕.
由第2节的分析可知,最小化式(3)与最小化式(1)等价,且式(3)与训练样本数线性相关.令:
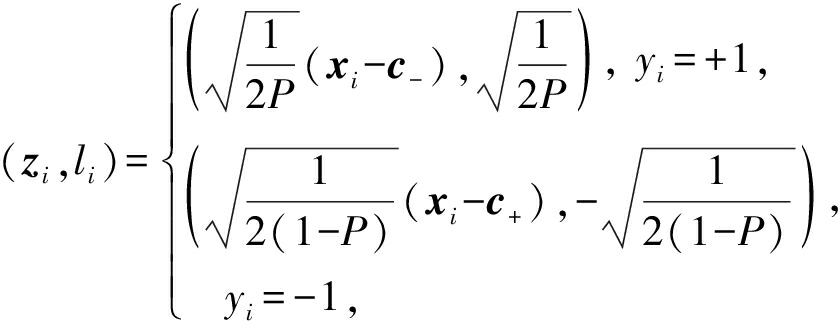
则式(3)可以转化为
(6)
式(6)与线性回归问题的目标函数形式相同,可以使用回归分析方法进行优化.对于批处理任务,我们容易求得参数P,c+,c-,再利用最小二乘法、梯度下降等方法求解式(6).对于在线学习任务,无法得到全部训练样本,因此参数P,c+,c-未知.为了解决这个问题,假设训练样本序列Xt={(xi,yi),1≤i≤t}服从独立同分布,![]() 为Xt中的正样本集合,
为Xt中的正样本集合,![]() 为Xt中负样本集合,
为Xt中负样本集合,![]() 和
和![]() 分别表示Xt中正样本的个数和负样本的个数,采用Xt中正样本所占的比例
分别表示Xt中正样本的个数和负样本的个数,采用Xt中正样本所占的比例![]() t估计P,采用Xt中正样本的平均值
t估计P,采用Xt中正样本的平均值![]()
![]() 负样本的平均值
负样本的平均值![]()
![]() 分别估计c+和c-的值.另外,当
分别估计c+和c-的值.另外,当![]() 时,记
时,记![]() 综上所述,在线学习训练过程中,接收第i个训练样本(xi,yi)后,
综上所述,在线学习训练过程中,接收第i个训练样本(xi,yi)后,![]() 的表达式为
的表达式为
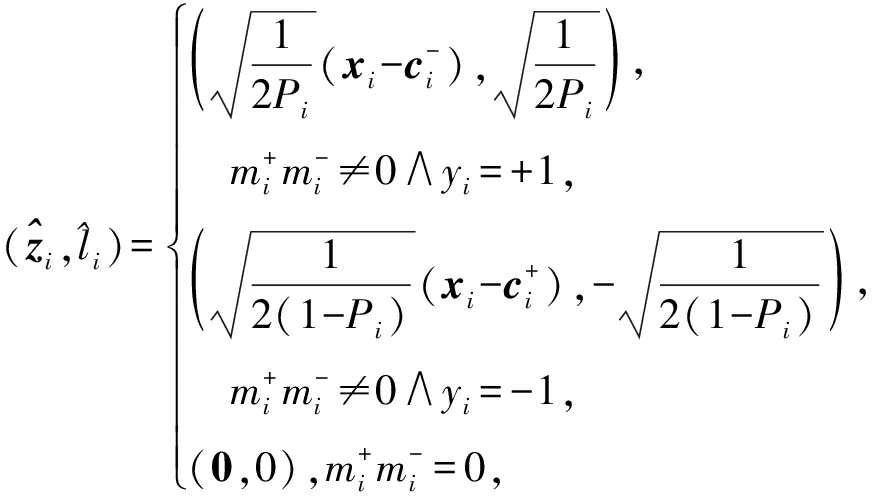
(7)
在上述分析基础上,LOAM算法描述见算法1.
算法1. LOAM算法.
输入:训练样本序列{(xi,yi)![]() ;
;
输出:wmt.
① 初始化:![]()
② fori=1,2,…,mt
③ 接收新样本(xi,yi);
④ ifyi=+1
⑤![]()
![]()
⑥ else
⑦![]()
![]()
⑧ end if
⑨ 通过式(7)计算![]()
⑩ 采用ILSC或AdaGrad策略更新分类器wi;
 end for
end for
在LOAM算法中,我们分别使用2种策略处理![]() 更新分类器wi.
更新分类器wi.
第1种分类器更新策略为增量式最小二乘法(ILSC).ILSC是正则化最小二乘法的增量式版本,与批处理正则化最小二乘法同解.使用ILSC策略每次迭代得到的wi是函数![]() 的解析解,即:
的解析解,即:
其中,![]()
该策略的基本思想是利用Sherman-Morrison公式对![]() 进行更新:
进行更新:
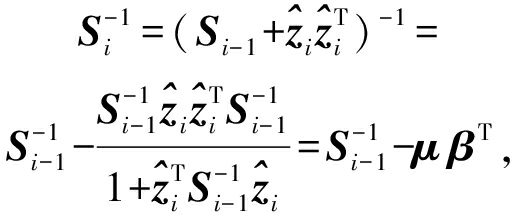
其中,![]()
![]() 进而可以推导出wi的更新规则,
进而可以推导出wi的更新规则,
其中,![]()
另外第1次迭代时,对于![]() 和
和![]() 其更新规则:
其更新规则:
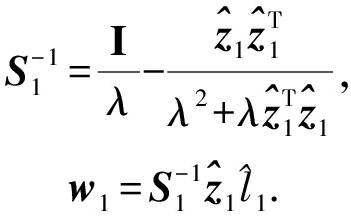
算法2详细描述了ILSC更新策略.
算法2. ILSC更新策略.
输入:正则化参数λ;
输出:wmt.
① 初始化:![]()
② fori=1,2,…,mt
③ 接收![]()
④ ifi=1
⑤![]()
![]()
⑥ else
⑦β=![]()
![]()
⑧ end if
⑨ end for
第2种分类器更新策略为AdaGrad方法.记gi为第i次迭代时的梯度,gi,j为gi的第j维,η为学习率.与在线梯度下降方法对每个特征设置相同的学习率不同,AdaGrad方法使得出现频率较低的特征具有较高的学习率,出现频率较高的特征具有较低的学习率,每一维的迭代更新规则为
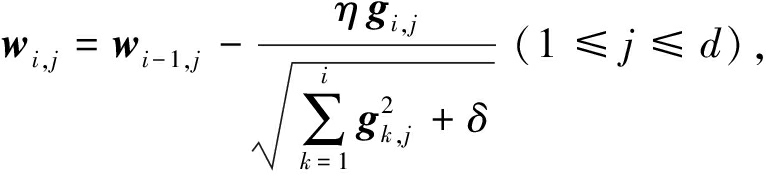
其中,δ>0是平滑参数,用于避免分母为0,通常设置一个非常小的值.算法3详述了AdaGrad更新策略.
算法3. AdaGrad更新策略.
输入:正则化参数λ、步长参数{ηi![]() 、平滑参数δ≥0;
、平滑参数δ≥0;
输出:wmt.
① 初始化:w0=g0=0.
② fori=1,2,…,mt
③ 接收![]()
④ 计算梯度![]()
⑤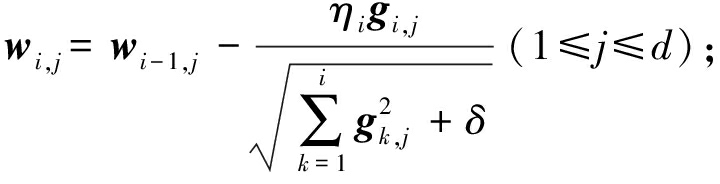
⑥wi![]()
⑦ end for
① https: www.csie.ntu.edu.tw~cjlinlibsvmtoolsdatasets
www.csie.ntu.edu.tw~cjlinlibsvmtoolsdatasets
② http:archive.ics.uci.edumldatasets.html
③ http:vikas.sindhwani.orgsvmlin.html
本文通过基准数据集和高维稀疏数据集上的大量实验验证新算法的有效性,数据集来自LIBSVM①,UCI②,SVMLin③.由第2节分析知,最小化式(3)等价于最小化式(1),因此本文对比了新算法LOAM和优化式(1)的多个在线算法.实验对比了5个算法:
1) AdaOAM算法.利用AdaGrad方法对式(1)进行优化求解[23].
2) OPAUC算法.利用随机梯度下降方法对式(1)进行优化求解[22].
3) OPAUCs算法.OPAUC算法的变体,用来处理高维稀疏数据任务[28].
4) LOAMILSC算法.采用增量式最小二乘法更新分类器.
5) LOAMAda算法.采用AdaGrad方法更新分类器.
16个基准数据集如表1所示包含二类数据集和多类数据集.AUC是衡量二分类算法性能的评价指标,实验中将多类数据集转化为二类数据集,表1中的不平衡率(imbalance ratio)统计出了多样本类与少样本类的样本数之比.
Table1TheDetailedInformationofBenchmarkDatasets
表1基准数据集详细信息

DatasetsExampleNumberDimensionNumberImbalanceRatioglass21491.8158svmguide4300105.8182hill6061001.0542vehicle846182.9906diabetic1151191.1315svmguide31243223.1993semeion15932659.0823faults1941271.8841satimage4435369.6867wilt4839517.5402EEG14980141.2282sensorless585094810.0000mnist600007809.2547connect4675571261.9266acoustic78823503.3165combined788231003.3153
实验中使用1次5折交叉验证选择最优参数.对比算法的参数选择范围参照文献[22-23],AdaOAM和OPAUC算法的步长参数选择范围为{2-12,2-11,…,210}(简记为2[-12:10],下同),正则化参数选择范围为2[-10:2];LOAMAda算法的步长参数选择范围为2[-12:10],考虑到定理1:当式(3)的正则化参数是式(1)的正则化参数的1/2时,![]() 算法的正则化参数选择范围为2[-11:1];LOAMILSC算法的正则化参数选择范围为2[-10:10].
算法的正则化参数选择范围为2[-11:1];LOAMILSC算法的正则化参数选择范围为2[-10:10].
为了减少随机分组对实验结果的影响,对每个数据集使用5次5折交叉验证,总共实验25次,实验结果是测试集上25次AUC的平均值,记录方式为“平均值±标准差”.
表2为4种算法在基准数据集上的AUC结果.由表2知:1)LOAMILSC算法在多数数据集上显著优于LOAMAda,AdaOAM,OPAUC算法.由标准差知,与后者相比,LOAMILSC算法更加稳定.2)LOAMAda算法与AdaOAM和OPAUC算法的性能基本相当.
图1显示了4种算法在基准数据集上的运行时间(单位ms).其中,横轴为各个基准数据集,纵轴为对数坐标(log-scale),4条柱状图从左至右依次表示LOAMAda,LOAMILSC,AdaOAM,OPAUC算法的运行时间.由图1知:LOAMAda算法的运行效率最高,其次为LOAMILSC算法;AdaOAM和OPAUC算法的运行效率最低,且基本相当.
随着数据集维数的增加,LOAMILSC,AdaOAM,OPAUC算法的运行时间与LOAMAda算法运行时间之间的差距变大.例如在数据集mnist上,LOAMILSC,AdaOAM,OPAUC算法的运行时间是LOAMAda算法的几十倍甚至上百倍.这是由于LOAMILSC算法涉及逆矩阵的存储和计算,AdaOAM和OPAUC算法涉及协方差矩阵的存储和计算;这3个算法的空间复杂度和每次迭代的时间复杂度均为O(d2).对比而言,LOAMAda算法只需要存储平均值,其空间复杂度和每次迭代的时间复杂度仅为O(d).总之,LOAMAda算法的空间复杂度和每次迭代的时间复杂度比LOAMILSC,AdaOAM,OPAUC算法低一个量级.
Table2TheAUCResultsofFourAlgorithmsonBenchmarkDatasets
表24种算法在基准数据集上的AUC结果
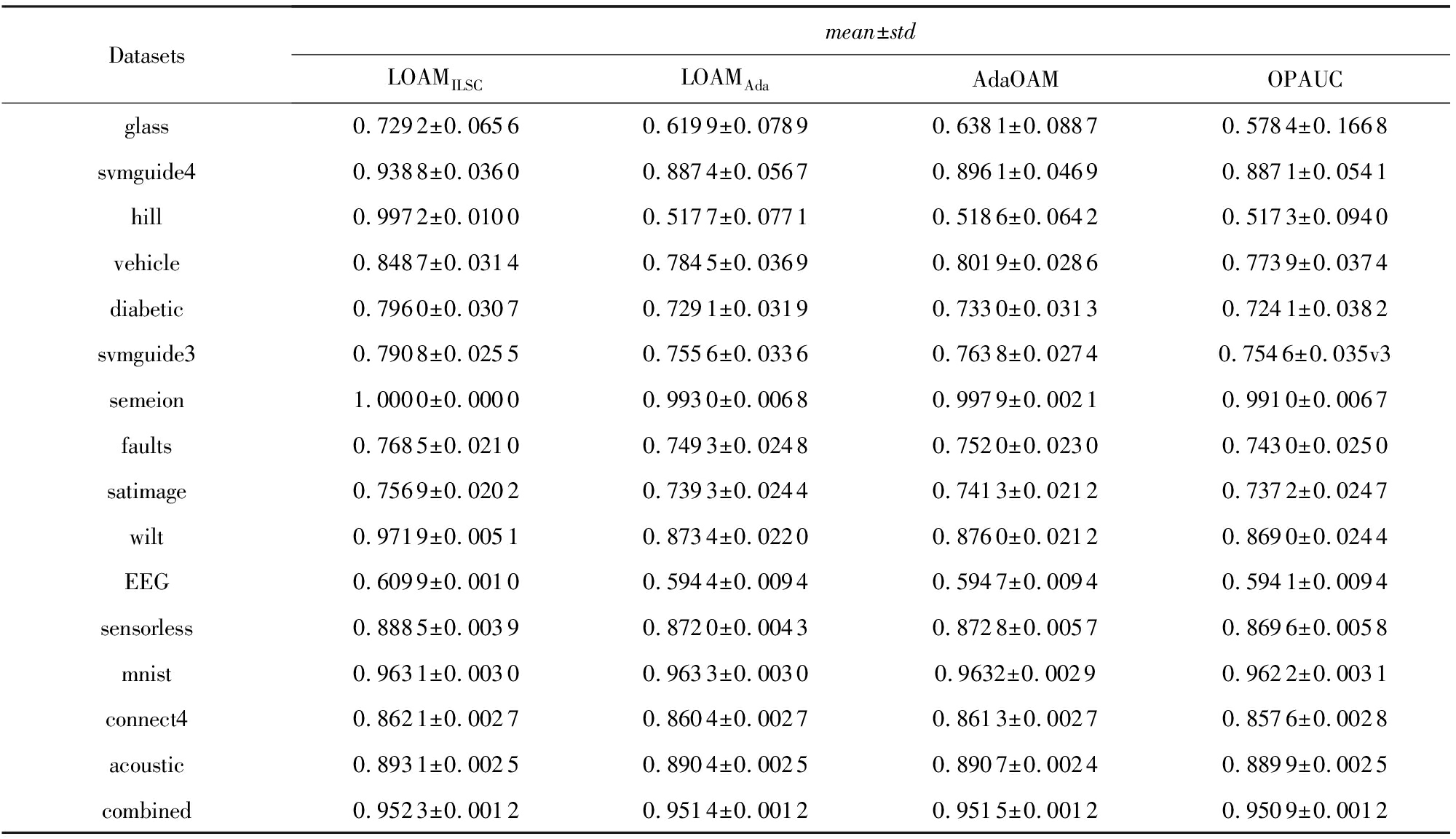
Datasetsmean±stdLOAMILSCLOAMAdaAdaOAMOPAUCglass0.7292±0.06560.6199±0.07890.6381±0.08870.5784±0.1668svmguide40.9388±0.03600.8874±0.05670.8961±0.04690.8871±0.0541hill0.9972±0.01000.5177±0.07710.5186±0.06420.5173±0.0940vehicle0.8487±0.03140.7845±0.03690.8019±0.02860.7739±0.0374diabetic0.7960±0.03070.7291±0.03190.7330±0.03130.7241±0.0382svmguide30.7908±0.02550.7556±0.03360.7638±0.02740.7546±0.035v3semeion1.0000±0.00000.9930±0.00680.9979±0.00210.9910±0.0067faults0.7685±0.02100.7493±0.02480.7520±0.02300.7430±0.0250satimage0.7569±0.02020.7393±0.02440.7413±0.02120.7372±0.0247wilt0.9719±0.00510.8734±0.02200.8760±0.02120.8690±0.0244EEG0.6099±0.00100.5944±0.00940.5947±0.00940.5941±0.0094sensorless0.8885±0.00390.8720±0.00430.8728±0.00570.8696±0.0058mnist0.9631±0.00300.9633±0.00300.9632±0.00290.9622±0.0031connect40.8621±0.00270.8604±0.00270.8613±0.00270.8576±0.0028acoustic0.8931±0.00250.8904±0.00250.8907±0.00240.8899±0.0025combined0.9523±0.00120.9514±0.00120.9515±0.00120.9509±0.0012
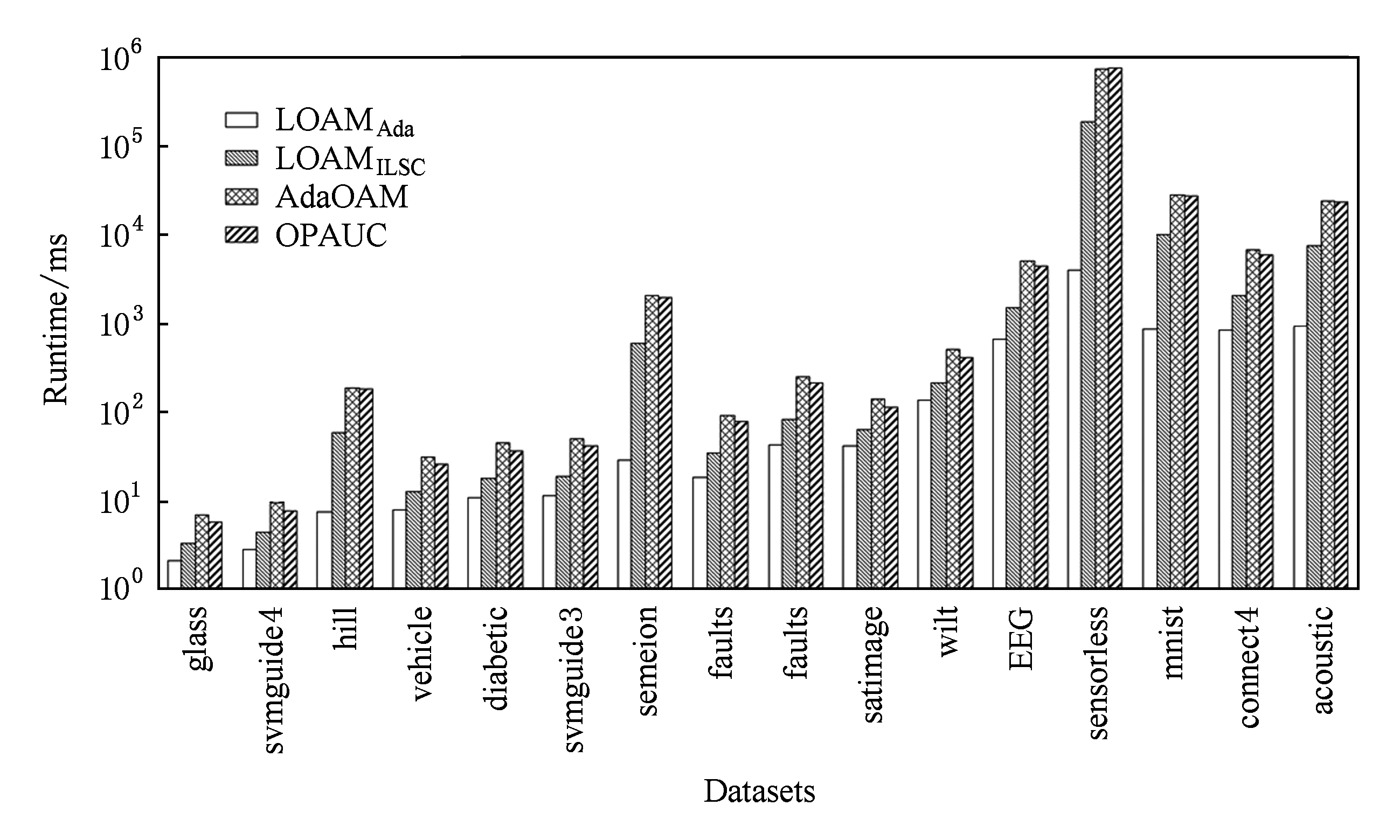
Fig. 1 The runtime of four algorithms on benchmark datasets
图1 4种算法在基准数据集上的运行时间
图1和表2所示的实验结果对比表明:LOAMILSC算法的AUC性能最优最稳定;LOAMAda算法的运行效率最高,更适合处理实时或者高维学习任务.
本节进一步在6个高维稀疏数据集(如表3所示)上验证了LOAMAda算法在处理高维学习任务时的高效性.对于其中的多类数据集,将其转为二类不平衡数据集.
由于LOAMILSC,AdaOAM,OPAUC算法的空间复杂度和每次迭代的时间复杂度均为O(d2),而6个高维稀疏数据集的维数均超过20 000维,考虑到时间和存储开销,本节只对比了LOAMAda和OPAUCs算法.
与4.1节相同,本节采用1次5折交叉验证选择最优参数,OPAUCs算法的参数选择范围参照文献[28],步长参数选择范围为2[-12:10],正则化参数选择范围为2[-10:2],参数τ=50.LOAMAda算法的步长参数选择范围为2[-12:10],正则化参数选择范围为2[-11:1].同样对每个数据集使用5次5折交叉验证,实验结果为测试集上25次AUC的平均值.
Table3TheDetailedInformationofHighDimensionalSparseDatasets
表3高维稀疏数据集详细信息
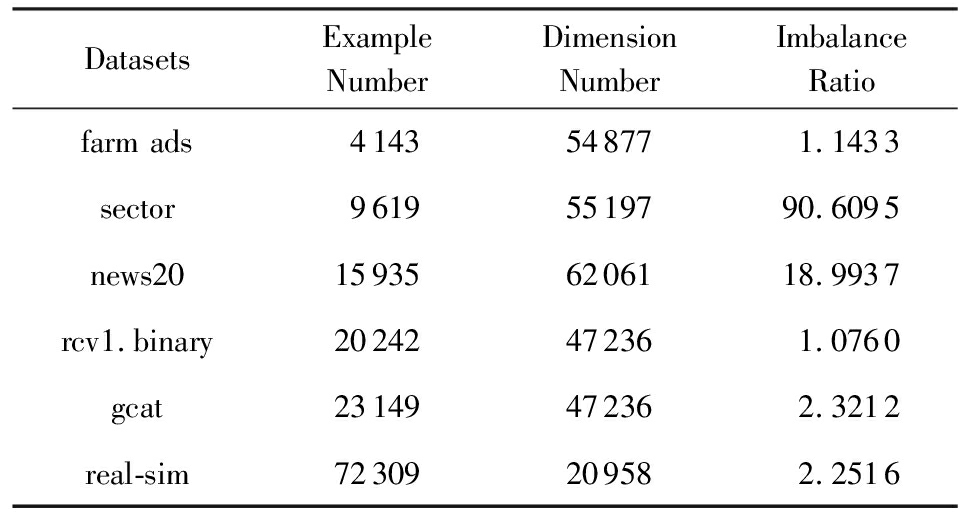
DatasetsExampleNumberDimensionNumberImbalanceRatiofarm ads4143548771.1433sector96195519790.6095news20159356206118.9937rcv1.binary20242472361.0760gcat23149472362.3212real-sim72309209582.2516
表4为LOAMAda和OPAUCs算法在高维稀疏数据集上的AUC结果.由表4所示,LOAMAda算法的平均值高于OPAUCs算法、标准差小于OPAUCs算法.这表明LOAMAda算法的AUC性能优于OPAUCs算法且更加稳定.
Table4TheAUCResultsofLOAMAdaandOPAUCsonHighDimensionalSparseDatasets
表4LOAMAda和OPAUCs在高维稀疏数据上的AUC结果

Datasetsmean±stdLOAMAdaOPAUCsfarm ads0.9556±0.00790.9456±0.0136sector0.9885±0.01430.9881±0.0188news200.9741±0.00660.9655±0.0087rcv1.binary0.9922±0.00090.9883±0.0011gcat0.9893±0.00130.9831±0.0017real-sim0.9926±0.00050.9854±0.0006
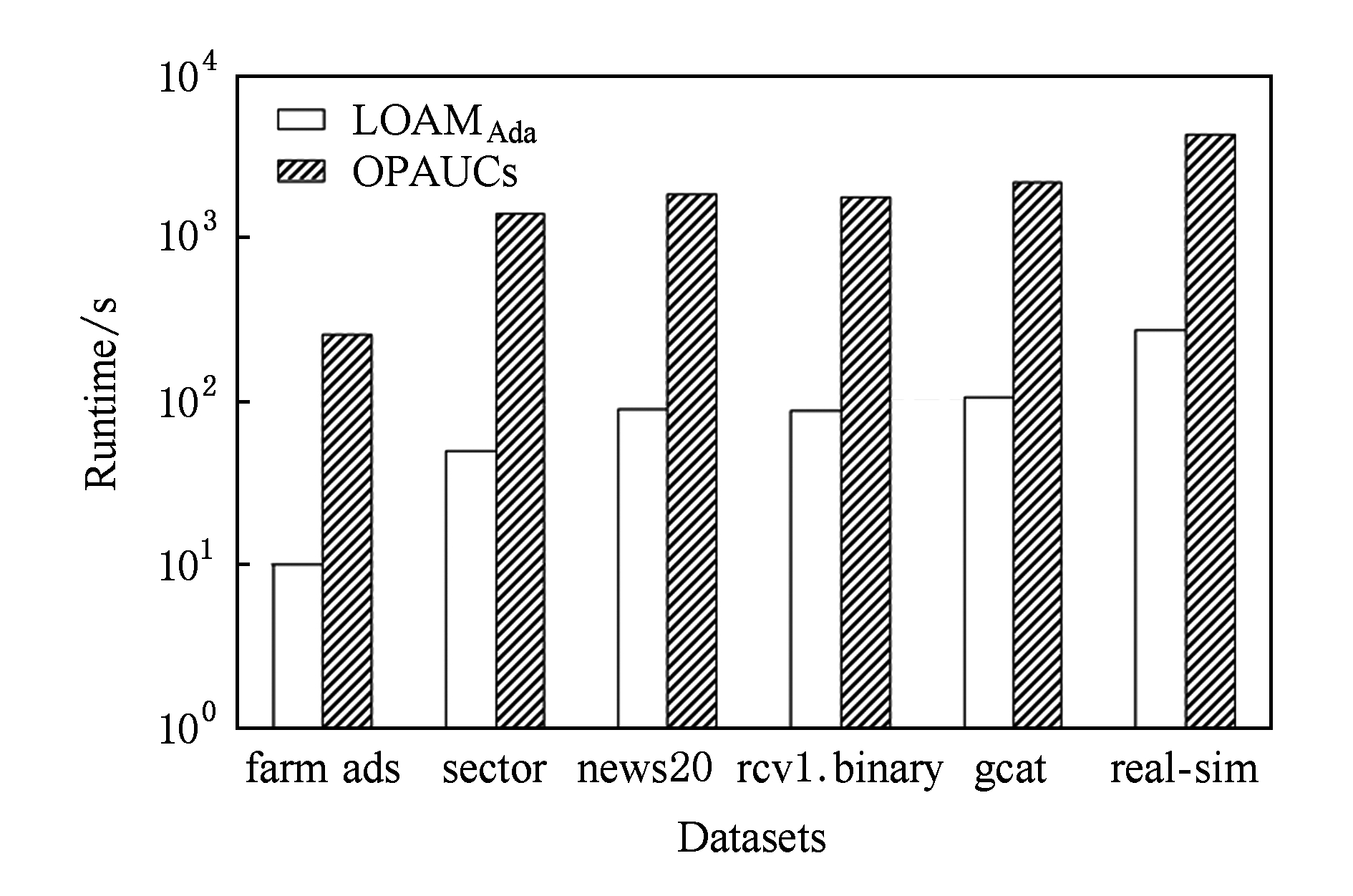
Fig. 2 The runtime of LOAMAdaand OPAUCs on high dimensional sparse datasets
图2 算法LOAMAda和OPAUCs在高维稀疏数据集上运行时间
图2为LOAMAda和OPAUCs算法在高维稀疏数据集上的运行时间(单位s),其中横轴为各个高维稀疏数据集,纵轴为对数坐标,2条柱状图从左至右依次表示LOAMAda,OPAUCs算法的运行时间.图2说明:LOAMAda算法的运行时间远低于OPAUCs算法的运行时间.对比结果表明LOAMAda算法更为高效,更适合处理高维数据.
本文提出一种AUC优化的目标函数,最小化该目标函数等价于最小化由L2正则化项和最小二乘损失函数组成的AUC优化的目标函数,但该目标函数仅与训练样本数线性相关.基于该目标函数,提出了在线AUC优化的线性方法LOAM,并分化出2种LOAM算法:采用增量式最小二乘法更新分类器的LOAMILSC算法和采用AdaGrad方法更新分类器的LOAMAda算法.LOAMILSC算法和LOAMAda算法仅需扫描一遍训练集,不需要存储任何旧样本;它们的空间和时间复杂度分别与ILSC和传统在线梯度下降算法相同.实验对比表明,LOAMILSC算法的AUC性能最优也最稳定,而对于实时或高维学习任务,LOAMAda算法则更加高效.
参考文献
[1]Fawcett T. An introduction to ROC analysis[J]. Pattern Recognition Letters, 2006, 27(8): 861-874
[2]Ferri C, Hernández-Orallo J, Flach P A. A coherent interpretation of AUC as a measure of aggregated classification performance[C] //Proc of the 28th Int Conf on Machine Learning. New York: ACM, 2011: 657-664
[3]Cortes C. AUC optimization vs. error rate minimization[C] //Proc of the 17th Neural Information Processing Systems. Cambridge, MA: MIT Press, 2003: 313-320
[4]Vayatis N, Depecker M, Clémençcon S J. AUC optimization and the two-sample problem[C] //Proc of the 23rd Neural Information Processing Systems. Cambridge, MA: MIT Press, 2009: 360-368
[5]Clémençcon S J, Vayatis N. Overlaying classifiers: A practical approach for optimal ranking[C] //Proc of the 22nd Neural Information Processing Systems. Cambridge, MA: MIT Press, 2008: 313-320
[6]Hanley J A, McNeil B J. The meaning and use of the area under a receiver operating characteristic (ROC) curve[J]. Radiology, 1982, 143(1): 29-36
[7]Freund Y, Iyer R, Schapire R E, et al. An efficient boosting algorithm for combining preferences[J]. Journal of Machine Learning Research, 2003, 4(11): 933-969
[8]Brefeld U, Scheffer T. AUC maximizing support vector learning[C] //Proc of the 22nd Int Conf on Machine Learning Workshop on ROC Analysis. New York: ACM, 2005: 377-380
[9]Herschtal A, Raskutti B. Optimising area under the ROC curve using gradient descent[C] //Proc of the 21st Int Conf on Machine Learning (ICML 2004). New York: ACM, 2004: 385-392
[10]Rudin C, Schapire R E. Margin-based ranking and an equivalence between AdaBoost and RankBoost[J]. Journal of Machine Learning Research, 2009, 10(3): 2193-2232
[11]Joachims T. Training linear SVMs in linear time[C] //Proc of the 12th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2006: 217-226
[12]Zinkevich M. Online convex programming and generalized infinitesimal gradient ascent[C] //Proc of the 20th Int Conf on Machine Learning. New York: ACM, 2003: 928-936
[13]Bottou L E, Cun Y L. Large scale online learning[C] //Proc of the 17th Neural Information Processing Systems. Cambridge, MA: MIT Press, 2003: 217-224
[14]Crammer K, Dekel O, Keshet J, et al. Online passive-aggressive algorithms[J]. Journal of Machine Learning Research, 2006, 7(3): 551-585
[15]Orabona F, Crammer K. New adaptive algorithms for online classification[C] //Proc of the 24th Neural Information Processing Systems. Cambridge, MA: MIT Press, 2010: 1840-1848
[16]Hazan E, Agarwal A, Kale S. Logarithmic regret algorithms for online convex optimization[J]. Machine Learning, 2007, 69(2): 169-192
[17]Duchi J, Hazan E, Singer Y. Adaptive subgradient methods for online learning and stochastic optimization[J]. Journal of Machine Learning Research, 2011, 12(7): 2121-2159
[18]Li Zhijie, Li Yuanxiang, Wang Feng, et al. Online learning algorithms for big data analytics: A survey[J]. Journal of Computer Research and Development, 2015, 52(8): 1707-1721 (in Chinese)(李志杰, 李元香, 王峰, 等. 面向大数据分析的在线学习算法综述[J]. 计算机研究与发展, 2015, 52(8): 1707-1721)
[19]Zhao Peilin, Hoi S C H, Jin Rong, et al. Online AUC maximization[C] //Proc of the 28th Int Conf on Machine Learning. New York: ACM, 2011: 233-240
[20]Kar P, Sriperumbudur B, Jain P, et al. On the generalization ability of online learning algorithms for pairwise loss functions[C] //Proc of the 30th Int Conf on Machine Learning. New York: ACM, 2013: 441-449
[21]Hu Junjie, Yang Haiqin, King I, et al. Kernelized online imbalanced learning with fixed budgets[C] //Proc of the 29th AAAI Conf on Artificial Intelligence. Menlo Park, CA: AAAI, 2015: 2666-2672
[22]Gao Wei, Jin Rong, Zhu Shenghuo, et al. One-pass AUC optimization[C] //Proc of the 30th Int Conf on Machine Learning. New York: ACM, 2013: 906-914
[23]Ding Yi, Zhao Peilin, Hoi S C H, et al. An adaptive gradient method for online AUC maximization[C] //Proc of the 29th AAAI Conf on Artificial Intelligence. Menlo Park, CA: AAAI, 2015: 2568-2574
[24]Zhu Zhenfeng, Zhu Xingquan, Guo Yuefei, et al. Inverse matrix-free incremental proximal support vector machine[J]. Decision Support Systems, 2012, 53(3): 395-405
[25]Zhu Zhenfeng, Guo Yuefei, Xue Xiangyang. Incremental least squares classifier vs. incremental proximal support vector machine[J]. Journal of Chinese Computer Systems, 2011, 32(3): 493-498 (in Chinese)(朱真峰, 郭跃飞, 薛向阳. 增量式最小二乘法分类器与增量式支持向量机的对比[J]. 小型微型计算机系统, 2011, 32(3): 493-498)
[26]Gao Wei, Zhou Zhihua. On the consistency of AUC pairwise optimization[C] //Proc of the 24th Int Joint Conf on Artificial Intelligence. San Francisco: Morgan Kaufmann, 2015: 939-945
[27]Hager W W. Updating the inverse of a matrix[J]. SIAM Review, 1989, 31(2): 221-239
[28]Gao Wei, Wang Lu, Jin Rong, et al. One-pass AUC optimization[J]. Artificial Intelligence, 2016, 236: 1-29
Zhu Zhenfeng, Zhai Yanxiang, and Ye Yangdong
(SchoolofInformationEngineering,ZhengzhouUniversity,Zhengzhou450052)
AbstractThe loss function of AUC optimization involves pair-wise instances coming from different classes, so the objective functions of AUC methods, depending on the sum of pair-wise losses, are quadratic in the number of training examples. As a result, the objective functions of this type can not be directly solved through conventional online learning methods. The existing online AUC maximization methods focus on avoiding the direct calculation of all pair-wise loss functions, in order to reduce the problem sizes and achieve the online AUC optimization. To further solve the AUC optimization problems described above, we propose a novel AUC objective function that is only linear in the number of training examples. Theoretical analysis shows the minimization of the proposed objective function is equivalent to that of the objective function for AUC optimization by the combination of L2 regularization and least square surrogate loss. Based on this new objective function, we obtain the method named linear online AUC maximization (LOAM). According to different updating strategies for classifiers, we develop two algorithms for LOAM method: LOAMILSCand LOAMAda. Experimental results show that, compared with the rival methods, LOAMILSCcan achieve better AUC performance, and LOAMAdais more effective and efficient to handle real-time or high dimensional learning tasks.
Keywordsclassification; AUC optimization; online learning; linear method; least square loss
This work was supported by the Talent Cultivation Joint Funds of National Natural Science Foundation of China and Henan Provincial Government (U1204610), the National Natural Science Foundation of China (61772475, 61502434), the National Key Research and Development Program of China (2018YFB1201403), the Science and Technology Key Project of Henan Province (172102210011), and the Training Project for Young Backbone Teachers of Henan Colleges and Universities.
通信作者:叶阳东(ieydye@zzu.edu.cn)
基金项目:国家自然科学基金委员会-河南省人民政府人才培养联合基金项目(U1204610);国家自然科学基金项目(61772475,61502434);国家重点研发计划基金项目(2018YFB1201403);河南省科技攻关项目(172102210011);河南省高等学校青年骨干教师培养计划基金项目
修回日期:2018-03-16
收稿日期:2017-05-31;
中图法分类号TP18; TP301.6
(iezfzhu@zzu.edu.cn)

ZhuZhenfeng, born in 1980. PhD, associate professor, master supervisor. Member of CCF. His main research interests include machine learning, pattern recognition, and computer vision.

ZhaiYanxiang, born in 1989. Master. His main research interests include machine learning and data mining.

YeYangdong, born in 1962. PhD, professor, PhD supervisor. Senior member of CCF. His main research interests include intelligent system, machine learning, and database system.