赛道存储器移动操作的温度模型及控制策略
张 超 1 孙广宇 1 张学莹 2 赵巍胜 2
1 (北京大学高能效计算与应用中心 北京 100871) 2 (北京航空航天大学电子信息工程学院 北京 100191)(gsun@pku.edu.cn)
摘 要: 赛道存储器(racetrack memory, RM)作为一种新型的非易失存储器件,对于未来存储结构设计具备很高的竞争力.RM通过将多个位信息存储在一个条带状的磁材料纳米线上,从而达到很高的存储密度.同时,又能够提供很快的读  写访问速度.为了能够访问RM条带上不同位置的位信息,需要引入一种特有的“移动”操作.然而,研究人员观察到移动操作需要较高驱动电流并产生大量热量,从而引起性能和稳定性的下降,甚至由于温度过高引起存储单元的损坏.现在仍缺乏一个关于RM移动的热力模型来估算运行中的温度.更重要的是,RM急需一个体系结构级的管理策略来避免温度过高带来的稳定性问题.针对这些问题,首先提出了一个热力模型来研究RM使用时温度与设计参数的关系.同时,为了提高RM的稳定性,一种基于“配额制度”的移动操作管理策略被讨论,以保证单位时间内的移动强度被限定在特定阈值下.实验结果表明,该方法能够以3.5%的性能代价将温度升高控制在20℃之内.
写访问速度.为了能够访问RM条带上不同位置的位信息,需要引入一种特有的“移动”操作.然而,研究人员观察到移动操作需要较高驱动电流并产生大量热量,从而引起性能和稳定性的下降,甚至由于温度过高引起存储单元的损坏.现在仍缺乏一个关于RM移动的热力模型来估算运行中的温度.更重要的是,RM急需一个体系结构级的管理策略来避免温度过高带来的稳定性问题.针对这些问题,首先提出了一个热力模型来研究RM使用时温度与设计参数的关系.同时,为了提高RM的稳定性,一种基于“配额制度”的移动操作管理策略被讨论,以保证单位时间内的移动强度被限定在特定阈值下.实验结果表明,该方法能够以3.5%的性能代价将温度升高控制在20℃之内.
关键词: 赛道存储器;热力模型;移动操作;稳定性;温度管理
赛道存储器(racetrack memory, RM)通常也被称作磁畴壁存储器(domain wall memory).最近,关于RM的研究已经成为一个热门方向,在器件级、电路级和体系结构级都受到了存储研究人员的广泛关注.RM是一种新型的非易失存储器,它具有超高的存储密度(可以与NAND Flash密度媲美)和很快的读写访存速度(可以与SRAM访存速度媲美) [1] .由于RM同时具备这两大优势,存储研究人员对它在未来存储结构设计中替代传统存储器件工艺寄予厚望.
RM的基础,即磁畴壁移动的物理机制,已经被科研人员研究了几十年.在物理层面,研究人员主要关注如何减少RM的驱动电流密度,以及如何提高磁畴壁的移动速度.直到2008年,Parkin教授等人 [1] 利用CoFeB材料在硅片上制造出了纳米线,首次正式提出了RM的概念.此后,对于RM器件级和电路级的研究飞速发展.鉴于RM原型器件和电路已经被不同研究组进行制造和验证,自2010年以来,对于RM的体系结构级也受到了广泛关注.
例如,Venkatesan教授等人 [2] 最早提出使用RM作为高速缓存,并针对性能、功耗等进行了优化.随后,他又提出了一种基于移动操作的RM写入方式;美国匹兹堡大学的李教授等人 [3] 在多个层次详细讨论了RM的体系结构优化问题.2014年,美国普渡大学Venkatesan教授 [4] 首次提出在GPU中使用RM,并设计数据预测方式来降低RM的访存代价.上述研究主要探讨如何减少RM“移动操作”(将在1.1节中详细介绍)所带来的延时和功耗的开销.
然而,现有的体系结构层次研究工作,对于RM的稳定性问题,尤其是热稳定性问题仍旧缺少足够的重视.实际上,研究人员已经指出:移动操作所需的电流远高于读写电流,因此在移动操作过程中产生大量的热量,导致RM器件温度迅速升高 [5-7] .温度升高不仅会引起磁畴壁移动操作的性能扰动,而且会降低RM工作的稳定性.更有甚者,器件材料在温度过高的情况下会被破坏,导致RM无法工作.
需要指出的是,这种由于移动操作引起的高温问题在现阶段并没有很好地得到解决.首先,缺乏一个关于RM移动的热力模型来估算运行中的温度;其次,急需一个体系结构级的管理策略来避免温度过高带来的稳定性问题.针对这些问题,我们首先提出了一个热力模型来研究RM使用时温度与设计参数的关系.同时,为了提高RM的稳定性,我们提出了一种基于“配额制度”的移动操作管理策略,从而保证单位时间内的移动强度被限定在特定阈值下.实验结果表明,该方法能够有效地避免温度过高,并且将性能损失控制在合理的范围内.
1 背景介绍
1.1 Racetrack Memory基本知识
RM是一种基于“自旋电子(spintronic)”工艺的新型非易失存储器件存储器.RM将多比特数据存储在一个条状的磁性材料结构上(下文简称“磁条”),其存储单元由磁条和若干访问晶体管构成,如图1所示.磁条上均匀分布的磁畴壁将磁条分割出多个“磁畴”(domain),并通过磁畴的磁场方向用来存储比特‘0’和‘1’.

Fig. 1 Cell structure of the spintronic-bused racetrackmemory
图1 基于自旋电子工艺的新型赛道存储器件示意图
RM读操作的原理和单阶自旋矩传输磁存储器(SLC STT-RAM)类似 [8] ,磁条中部的晶体管构成了用于读写的“读写端口”.通过阻值的测量能够确定与端口垂直对齐的磁畴中磁场方向,从而读出数据.磁条两端的晶体管组成所谓的“磁畴移动端口”,磁畴移动是基于驱动电流引起的自旋动量转移现象,是RM特有的操作.其目的是将需要进行(读写)访问的磁畴沿磁条移动到与读写端口垂直对齐的位置.
写操作利用了与移动操作相同的原理.在磁条两侧制作2个固定的磁畴,将其与某一磁畴连通.这样就构成了图1中的一个写端口.通过控制垂直磁条的电流方向,将选定的磁场方向移入对应的磁畴,从而改变存储在RM中的数值.值得注意的是,读、写端口可以分离或者组合在一起构成读-写端口.
由于RM单个磁条上的磁畴数量可以高达128个 [5] ,因此可以提供很高的存储密度.RM与其他存储器典型设计对比如表1所示:
Table 1 Typical Design Comparison between Racetrack Memory with Others
表1 赛道存储与其他存储器典型设计对比
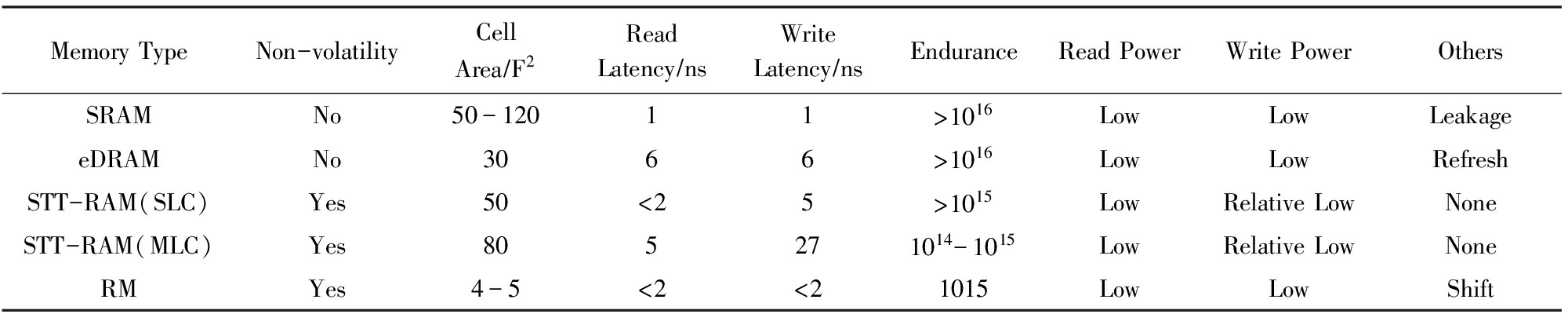
MemoryTypeNon-volatilityCellArea∕F2ReadLatency∕nsWriteLatency∕nsEnduranceReadPowerWritePowerOthersSRAMNo50-12011>1016LowLowLeakageeDRAMNo3066>1016LowLowRefreshSTT-RAM(SLC)Yes50<25>1015LowRelativeLowNoneSTT-RAM(MLC)Yes805271014-1015LowRelativeLowNoneRMYes4-5<2<21015LowLowShift
由对比可见,RM的存储密度远远超过包括嵌入式动态随机存储器(eDRAM)、多阶自旋矩传输磁存储器(MLC STT-RAM)在内的其他4种存储工艺;同时,读写访问的速度能够和SRAM器件媲美;并且具备低静态功耗和非易失的优良特性.因此,RM在片上存储设计方面具备非常强的竞争力.最近的研究工作已经表明,使用RM器件能够有效提高片上存储的容量和性能并降低功耗 [3-5] .
1.2 相关研究工作介绍
2013年,Venkatesan等人 [9] 提出使用RM作为高速缓存,并且进行了一系列面积、性能、功耗的优化.随后,他又提出了一种基于移动操作的RM写入方式.同年,李等人 [3] 在多个层次详细讨论了RM的协同优化问题.2014年,Venkatesan等人 [4] 发表将RM作为高速缓存的论文,并设计数据预测方式来降低RM的访存代价.与之前SRAM和STT-RAM相比,他们的设计能分别降低能耗69.7%和61.5%,同时分别提升性能12.1%和5.8%.
同年,刘等人 [10] 提出利用RM进行包括缓存、寄存器在内的数据备份架构,能够解决异常断电的情况下数据丢失的问题.张等人 [5-6] 提出RM电路级的仿真模型,以及针对磁畴移动操作引起的错误进行分析和体系结构优化.2013年,余等人 [11] 根据RM高密度以及移动操作的特点,提出了利用RM来作为主存以及加法比较运算的ALU.2014年,Mao等人 [12] 提出利用RM替代现行的SRAM或者STT-RAM来实现.Ghosh等人 [7] 根据物理模型研究了RM作为主存时的发热问题.但是在电路级和体系结构级仍旧缺乏相应的建模以及温度控制管理策略.
2 热力模型
为研究工作状态下RM存储单元的温度变化,我们根据Racetrack Memory的结构特性和工作特点,建立了其热扩散热力模型.为尽量符合实际的场景,我们采用LGA封装设计.RM封装后芯片的剖视图如图2所示.
芯片衬底是单晶硅,单晶硅的上一层是晶态二氧化硅,由硅衬底自然氧化(native oxidation)生成.二氧化硅的上层为赛道存储纳米线,由若干根Co 20 Fe 60 B 20 赛道存储纳米线平行排列,纳米线的间隙及上层由无定形态的二氧化硅(amorphous silica)填充,而在无定形态的二氧化硅上面则是散热装置.
工作状态时RM的热量主要是由纳米线内部推动磁畴壁移动的电流脉冲在焦耳热效应下而产生的,热量在使得纳米线升温的同时,经过上层的二氧化硅填充层及下层的衬底进行扩散,进而由芯片外层与散热片之间的热交换作用,最终把热量导出到外界.因此,我们建立如下的模型来描述racetrack memory的热扩散过程:
 ,
,
(1)
其中, P 代表存储器芯片焦耳热的产生功率, C 代表芯片内所有纳米线的总热容, T 代表纳米线的温度, Q 2和 Q 3分别代表单位时间内芯片由下表面晶体硅衬底层和上表面无定形态的二氧化硅层传导出去的热量.因为纯粹由赛道纳米线所在层侧面散失到封装外的热量很小,此处忽略不计.

Fig. 2 Sectional view of the racetrack memory chip package
图2 赛道存储器芯片封装剖视图
纳米线的热容我们可以由Dulong-Petit模型 [13] 估计出,即固体物质的总热容与其所包含的原子数目成正比,故热容表示如式(2)所示.其中 e 是纳米线的厚度, n 是原子数量, w 1是每根纳米线宽度, l 是纳米线的长度, k B 为玻尔兹曼常数, N 代表纳米线(即磁条)的总数量.
C =3 new 1 lk B N .
(2)
芯片的发热功率 P 可以由式(3)计算获得.其中 α 表示驱动电流脉冲的总占空比,即RM阵列中磁条在时间上的激活百分比; β 表示整个RM阵列中被激活的磁条在数量上的激活百分比; j 代表移动操作的驱动电流密度; ρ 代表的是热阻率; V 代表的是RM磁条的体积(可通过上文纳米线的尺寸计算).
P = α βNj 2 ρV .
(3)
单位时间内芯片由上下表面传导出去的热量 Q 2和 Q 3可由式(4)(5)计算.其中, A 代表RM阵列的上下表面积, λ 2和 λ 3代表相应的热容量, T 2 和 T 3 分别代表相应表面外界温度.表面积 A 可由式(6)简单计算,其中 w 2代表磁条之间的间距.
Q 2= Aλ 2( T - T 2 ),
(4)
Q 3= Aλ 3( T - T 3 ),
(5)
A = N ( w 1+ w 2) l .
(6)
由于下表面衬底的厚度远高于芯片上表面的各层厚度之和,因此可以忽略下表面散热量 Q 2,只需关注上表面散热量 Q 3.其中 λ 3与其他参数的关系可表示为
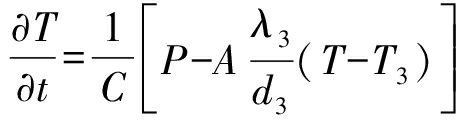 .
.
(7)
将上述公式组合,我们得到RM阵列的瞬时温度函数,在式(8)(9)中进行表示.这2个公式表明,时间足够长以后温度会逐渐趋于稳定.如果采用表2中的各种参数典型值,我们计算得到:经过7 ns左右,摄氏温度达到稳定值的90%以上,之后上升趋势变缓.可见RM的温度变化非常迅速.
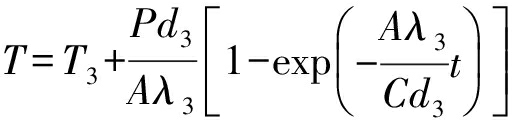 , (8)
, (8)
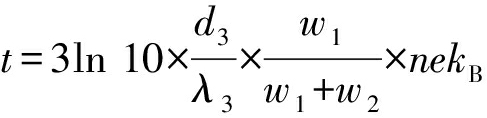 . (9)
. (9)
Table 2 Parameters Configurations for Thermal Model
表2 温度模型参数说明和典型值

ParameterDefinitionValueλ1∕(W·m-1·K-1)Thermalconductivityofsingle-crystalsilicon[14]145λ2∕(W·m-1·K-1)Thermalconductivityofcrystallinesilica12λ3∕(W·m-1·K-1)Silicathermalconductivityofamorphous1.5j∕(A·m-2)Criticalshiftcurrentdensity[15]1012ρ∕ΩmResistivityofCo20Fe60B2010-6
考虑到实际情况中,RM的散热情况和移动操作的强度有关,因此我们通过前文定义的参数 α 和 β 来估算实际的温度变化情况,其计算如式(10)所示.可以简单理解为,在一定时间内的移动强度可以由 α 和 β 表示:
 .
.
(10)
基于表2中的参数,当 α × β =1时(即RM工作在最高移动强度时),RM的稳定温度能够达到800 K,已经远超过材料的接受范围.图3对比了不同移动强度下的稳定温度.由此可见,需要进行合理的移动强度管理来控制温度.
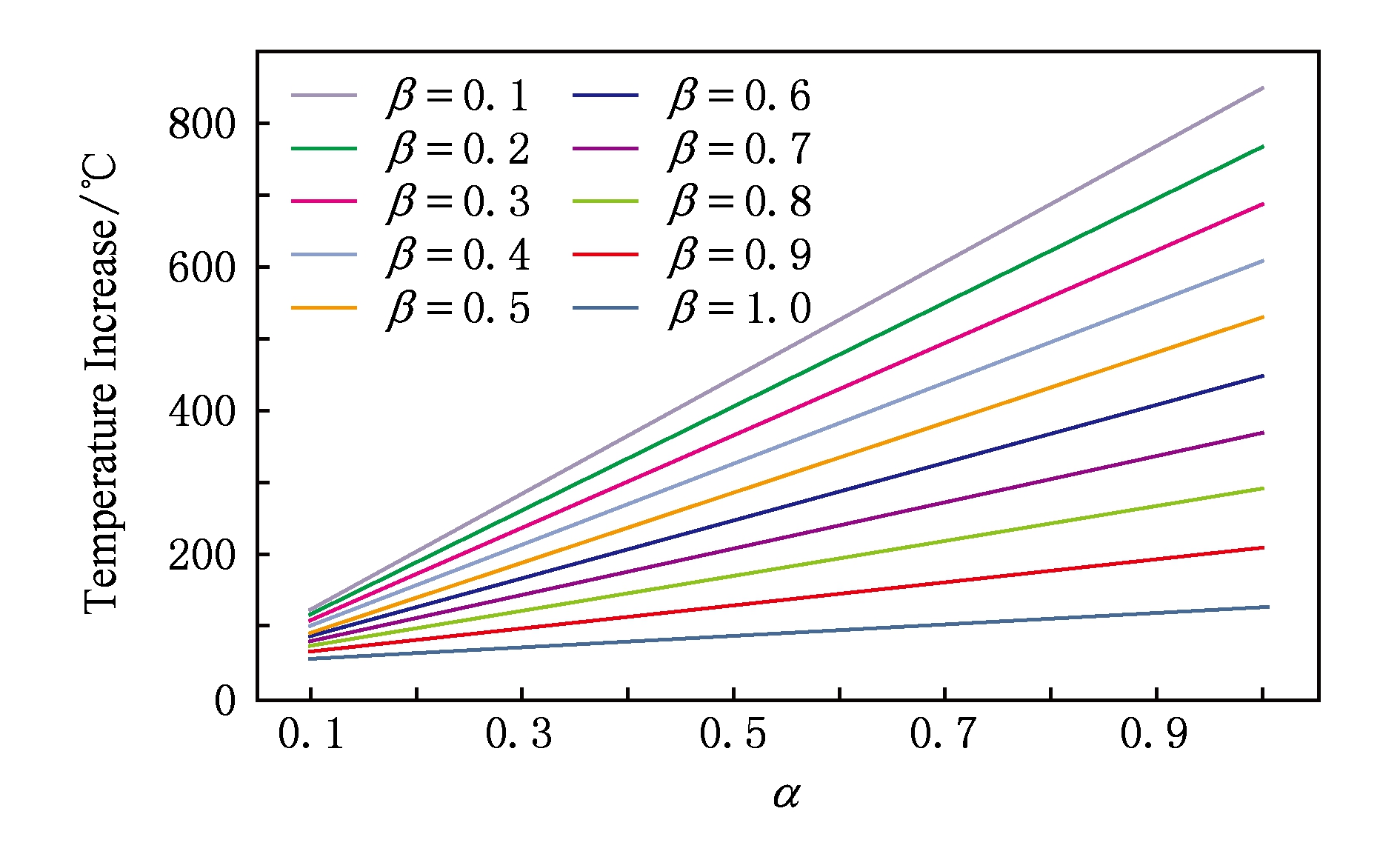
Fig. 3 Comparison of stable temperature under variant
α and β
图3 RM最终温度随时间α、数量β激活比的变化
3 体系结构温度控制及优化
移动操作的强度随着程序的运行,在不同的时刻有很强烈的波动,因此移动操作所贡献的能量也会有很大波动.直接减慢移动的速度或者限制单次移动的强度可能会对性能造成比较大的影响.本节,我们详细地探索基于时间的温度控制方法,首先介绍基本控制方法,然后对其进行优化.
3.1 存储阵列激活磁条摆放
通过将发热的磁条和不发热的磁条间隔放置可以均摊热量,减少单位面积的发热量,从而控制温度.现有的工作只考虑了将不同的请求分发到不同的bank中,以减少单独一个bank的使用量,从而减少热点.本工作通过分析存储整列内激活磁条的分布,考虑了赛道存储阵列内的情况.我们先讨论数据块比特到磁条的映射,再分析激活磁条的摆放问题.
赛道存储的磁条上可以存储多个位,但是将同一个数据块的所有位存储在一个磁条上并不高效,因为这将导致磁条多次移动和访问.一种比较常见的高效数据映射方式是将一个数据块分散在多个磁条(group)上,多个磁条同时移动,从而并行读取数据.然而,将这些磁条相邻放置会导致局部热点.由温度模型中的公式可知,单位面积内发热的磁条越少,则纳米线层温度上升越少.因此,将映射了同一个数据块的磁条在存储阵列中分别放置,可以增大散热面积,减少温度升高.我们将单位面积内同一个数据块所占的磁条数和区域内总磁条数的比作为 β .根据芯片的导热系数,能够视作同一个散热区域的面积仅能容纳有限个磁条.不失一般性,我们将设置 β =18.
3.2 配额制度
配额制度的基本思路是在一个程序运行区间(period)内,为移动的步数设定“配额”(quota),并根据受限数据的特点选择等待或向下发起请求.
配额定义为一段时间(运行区间)内可以移动的总步数.当配额用尽,除非进入下一个区间,不能再有更多的移动操作被执行.由于不能移动,一些数据将无法被访问到.这些数据由于所在位置没有正对读写端口,因而没有移动的配额时不能被访问;而在有足够配额时,这些数据仍然可以被访问到.所以,这些块被暂时称为“冻结块”.如果冻结块的数据是干净(clean)的,当我们需要读写它时只需要从下一级存储中访问即可;而如果冻结块的数据是脏(dirty)的,我们只能将该请求挂起,等待下一个区间有足够的配额来进行移动和访问操作.
3.3 设计实现
为实现这一控制方法,我们选择CPU中的末级高速缓存作为设计基础.该级存储通常为组相连(set-associative),每个数据块包含标签和数据2部分.一个组(set)中的所有数据共享组地址,而以标签加以区分.通常,末级缓存的访问是先比较标签,命中后再访问数据.当一个请求到达缓存时,请求根据它访问的地址进行解码,从而被送到对应的组.组内多个标签进行比较判定是否发生命中.同时,被命中的数据需要检查有效性(validity)和一致性(coherence)状态.先前的赛道存储设计 [5] 保证标签的访问并不需要移动操作.因此,比较标签不涉及移动操作.如果访问命中在一个有效信息上,存储数据的赛道存储条将被移动到指定位置,继而相应数据被执行相应的读写操作.此时,如果移动和读写操作能够顺利完成,缓存执行这一条请求结束,并能够为下一条请求服务.如果结果是未命中(miss)或者是数据无效(invalid),请求将被发向下一级存储(此处为主存),缓存有可能会阻塞后续的请求,直到这条请求在下一级存储完成.
对于基于赛道存储的数据阵列,每个group都有一个端口位置寄存器用来指示访问端口与组中的域序列的相对位置.通过比较端口位置寄存器的数值和请求访问地址解码的域坐标,可以得出需要移动的距离.因而,group在移动过相应的距离后,则可以将所需的域对准访问端口,并进行读写.
当我们考虑采用基于配额的控制方法后,上述缓存操作流程将发生变化.特别是当请求命中了“冻结块”后,请求将暂时得不到数据.变化后的缓存操作流程如图4所示:
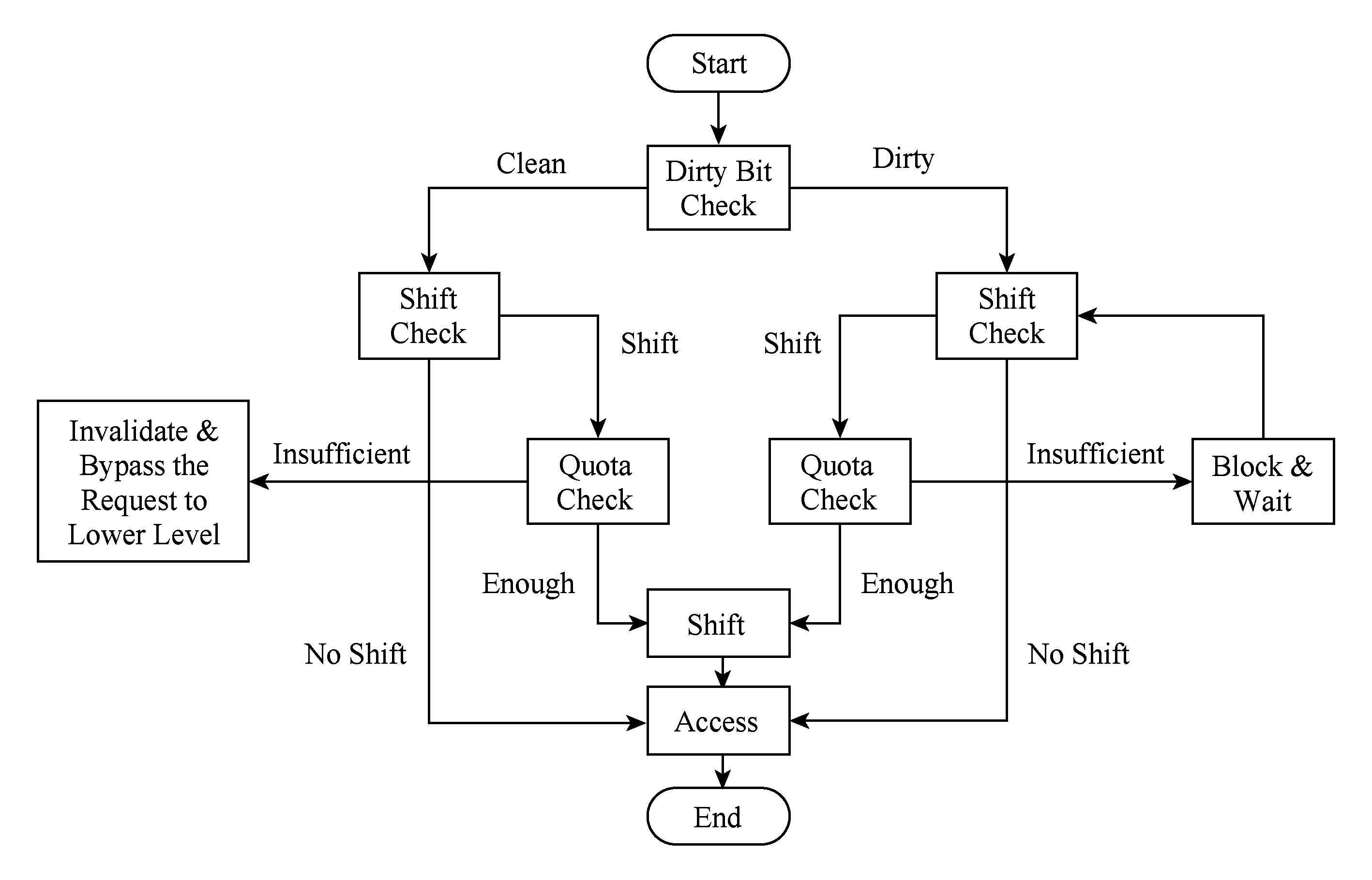
Fig. 4 Data access flow based on quota mechanism
图4 基于配额制度的缓存数据访问逻辑
1) 访问.一旦计算出移动距离,缓存试图从剩余的配额中减去移动的配额开销.如果配额足够,移动可以执行;如果不够,被访问的那个数据块将被当作冻结块,它标签中的cleandirty标记位将被检查.如果它是clean的,缓存将冻结块的标签中valid位设为无效,并且返回缓存控制器一个miss,使请求可以继续向下一级存储发起数据请求;如果是dirty的,缓存将会被阻塞,以等待下一个区间的开始.
2) 配额.配额在每个区间的开始由缓存控制器自动添加,并在区间中被移动操作消耗.区间的长度取决于芯片的热特性,而配额和区间的比值则表示 α ,是决定赛道存储温度的重要指标.
根据温度模型, α 和 β 的乘积应不大于140,以保证热稳定性(温度变化小于20℃).一个区间内可以移动的最大步数(配额)可以表示为 α 乘以区间长度与移动一步的时间开销的比值.
3.4 性能优化
3.3节提出的基本配额制度可以有效地控制温度,但是其性能损失较大,详见第5节.因此,我们提出一种优化方法来减小这种温度控制方式的性能开销.
我们将配额分成2种:clean配额和dirty配额.一个访问clean数据的请求只能使用clean配额;而访问dirty数据的请求优先使用dirty配额,在dirty配额不够时可以使用clean配额.改进方法与之前基本设计的相同点是:clean配额和dirty配额的总和与之前的移动配额相同,保证了对温度控制的一致性.为表述简单,我们定义dirty配额和总配额的比值为 γ . γ =1时,clean配额为0,因此所有访问clean数据的请求都不能执行移动操作;而当 γ =0时,dirty配额为0,优化方法退化为简单方法.因此,也可以把前面介绍的基本配额制度看作优化方法在 γ =0的一个特例.
4 实 验
本节中,我们评估提出的控制方法对温度控制的有效性及其对系统性能的影响.与第3节相同,我们将RM作为末级缓存.详细的实验配置如4.1节所示.我们用赛道存储的温度来衡量其稳定性,用末级缓存的访存时间来衡量性能.
4.1 实验设置
我们使用gem5模拟器获取末级缓存的访问踪迹.设计和实现了基于赛道存储的末级缓存仿真平台.利用仿真平台,我们计算了缓存的运行时间.测试程序我们选择能够提供多线程支持的PARSEC测试程序集.系统的配置如表3所示:
Table 3 Experiment Setup
表3 实验系统配置

ComponentConfigurationCPU4cores,2GHzL1PrivateI∕D,32KB∕32KB,2-way,64B,LRUL2Sharedby2cores,1MBintotal,4-way,64B,LRULLCShared,4MB,16-way,64B,LRU64-domain,4-portcells
4.2 温度影响
基于配额的温度控制系统有效地控制了程序的峰值移动强度,从而控制了移动引起的温度升高.图5展示了测试程序blackscholes在200个程序运行区间内的移动数量,4条曲线分别表示 α 取值为0.1,0.2,0.4,0.8时的结果.我们可以明显地看到,程序的移动强度随着程序的运行不断波动,有周期性变化,也有非周期变化.与 α =0.8的情况相比, α 取值为0.4,0.2,0.1分别将一个运行区间内最高移动步数从1 000左右减到800,400,200.配额方式对所有测试程序展现出相同的温度控制效果,因此我们省略其他程序的移动步数变化图.使用配额方法之后明显降低了最高的移动步数.通过降低一个区间内的移动步数,可以降低该区间内移动产生的热量,从而使平衡温度处在可接受的范围内.
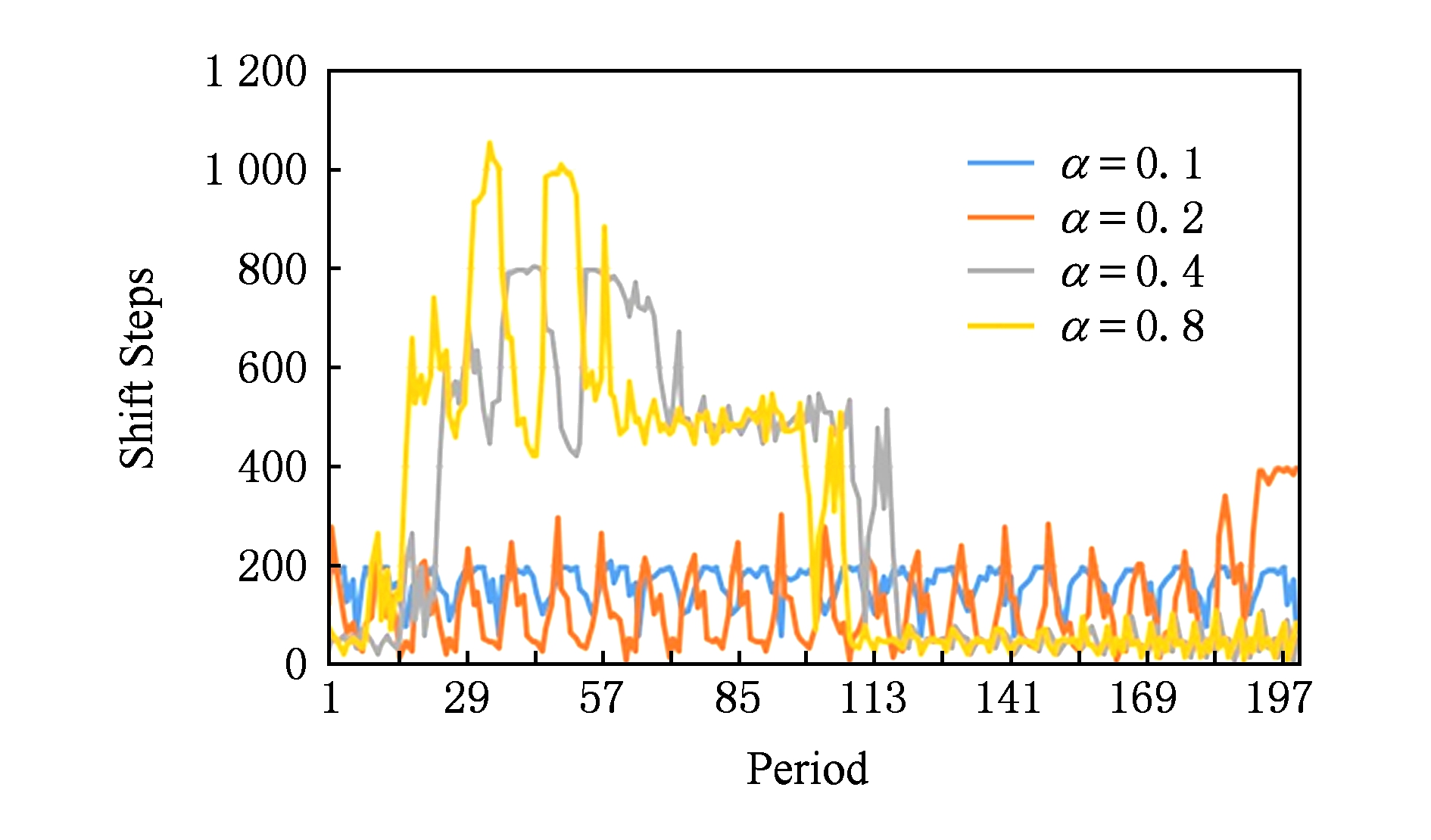
Fig. 5 Variation of shift steps along execution period
图5 移动步数随程序运行区间的变化
4.3 性能影响
由于配额限制了移动操作,很多访存操作被延迟,因而导致缓存访问时间增加.图6展示了测试程序的存储访问开销.该图纵轴为缓存总运行时间,数值和未使用配额方法的缓存进行相对比较.可以明显地看到,在 α =0.1时,部分程序(blackscholes,ferret等)缓存访问时间变长了将近1倍,部分程序(dedup,streamcluster等)访存时间变化了约50%,部分程序(x264,rtview等)访存时间变化了约20%;但是,在 α =0.2时,大部分程序的访存时间延长都不超过10%; α =0.4和 α =0.8则对性能没有影响.平均情况下, α =0.1将访存延迟增加了60%, α =0.2将访存延时增加了5%.
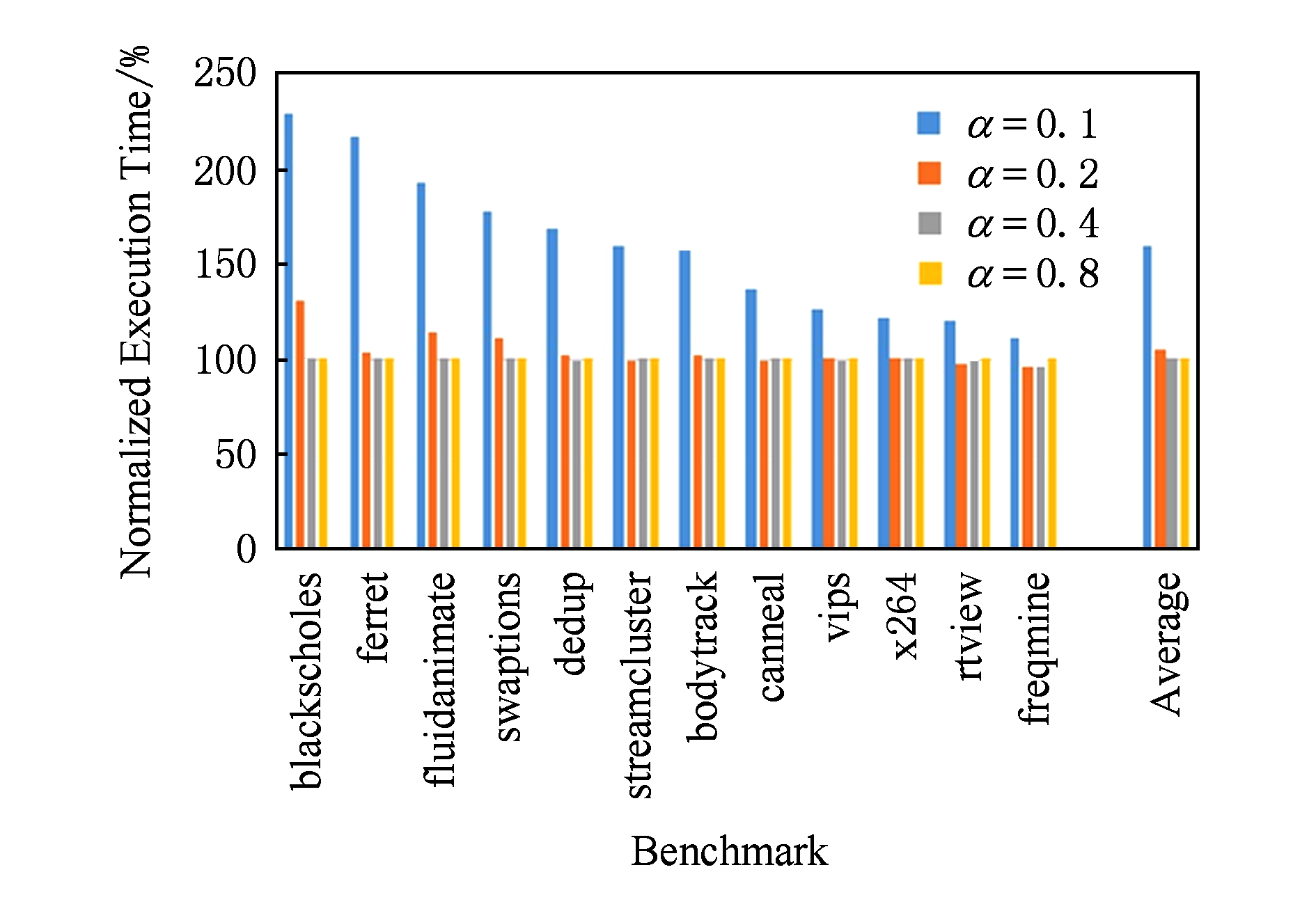
Fig. 6 Comparison of cache access time among variant α
图6 不同α时程序访存延时的比较

Fig. 7 Comparison of cache access time among variant γ when α= 0.1
图7 α=0.1时不同γ对程序访存延时的影响
为进一步减少性能损失,我们提出了对配额方法的优化,该方法在 α =0.1时的效果如图7所示.图7纵轴为缓存总运行时间,数值和未使用优化方法( γ =0)的缓存进行相对比较.可以看到,对于大部分程序,随着 γ 从0变化到1,缓存访问时间经历了下降再上升的过程.平均情况下, γ =0.1缩短了0.1%的访存时间, γ =0.5缩短了2.4%的访存时间, γ =1.0增加了79.5%的访问时间.这说明大部分程序都存在访问dirty数据块的情况,因此优先保障一部分访问dirty数据块的请求执行移动操作,有利于缩短总访问时间.也有个别程序(streamcluster)的访问时间表现出随γ增大而一致增大的情况,其原因是程序主要以串行的读请求为主,较少dirty数据,因而减少了访问clean数据的配额,势必使得更多的请求访存不命中,从而增大访问延迟.同时,当 γ =1.0时,缓存访问延迟明显上升,因此, γ 不应当过大或者过小.本工作中, γ =0.5已经表现出比较好的性能优化.
该优化方法在 α =0.2时,效果有所不同,如图8所示.缓存访问时间在 γ 较小时均无明显变化.平均情况下, γ =0.1时,访存延时增加1.3%; γ =0.5时,访存延时减少1.4%,相比未使用配额机制的缓存访问延迟只增加了3.5%.这是因为当 α =0.2时,程序中被配额机制限制访问的运行区间相比 α =0.1时少很多,运行时间受到配额机制影响较小,所以对优化技术不敏感.

Fig. 8 Comparison of cache access time among variant
γ when α= 0.2
图8 α=0.2时不同γ对程序访存延时的影响
总之,将α取做110和15都能有效地将温度控制在合理范围内,而配合使用等比例区分配额的优化方式,在α=15时配额制度只带来3.5%的性能损失.
5 结 论
赛道存储器(RM)具有高存储密度、低访问延时、非易失性等优点,很有潜力替代传统的存储器件实现未来高容量、高性能、低功耗的存储结构设计.然而,其特有的移动操作也对其实际应用提出了新的挑战.其中,由于移动操作释放的热量引起温度过高的问题,一直没有得到重视.通过本文中提出的赛道存储器热力模型,可以有效地估算其运行过程中所达到的实际温度.研究发现,如果没有合适的工作强度管理策略,移动操作引起的高温将会破坏存储材料,致使赛道存储器损坏无法工作.因此,我们提出一种基于配额的工作强度控制策略,将赛道存储器的工作温度控制在合理的范围内.并且,我们发现可以根据不同操作对性能的影响,进一步优化配额的分配制度,尽量减少温度控制引起的性能下降.
参考文献:
[1]Parkin S, Hayashi M, Thomas L. Magnetic domain-wall racetrack memory[J]. Science, 2008, 320(5873): 190-194
[2]Venkatesan R, Kozhikkottu V, Augustine C, et al. TapeCache: A high density, energy efficient cache based on domain wall memory[C]  Proc of ISLPED’12. New York: ACM, 2012: 185-190
Proc of ISLPED’12. New York: ACM, 2012: 185-190
[3]Sun Zhenyu, Wu Wenqing, Li Hai. Cross-layer racetrack memory design for ultra-high density and low power consumption[C] Proc of DAC’13. New York: ACM, 2013: 1-6
[4]Venkatesan R, Ramasubramanian S, Venkataramani S, et al. STAG: Spintronic -Tape architecture for GPGPU cache hierarchies[C] Proc of ISCA’14. New York: ACM, 2014: 253-264
[5]Zhang Chao, Sun Guangyu, Zhang Weiqi, et al. Quantitative modeling of racetrack memory, a tradeoff among area, performance, and power[C] Proc of ASP-DAC’15. Piscataway, NJ: IEEE, 2015: 100-105
[6]Zhang Chao, Sun Guangyu, Zhang Xian, et al. Hi-fi playback: Tolerating position errors in shift operations of racetrack memory [C] Proc of ISCA’15. New York: ACM, 2015: 694-706
[7]Motaman S, Iyengar A, Ghosh S. Domain wall memory-layout, circuit and synergistic systems[J]. IEEE Trans on and Synergistic Nanotechnology, 2015, 14(2): 282-291
[8]Zhang Yue, Zhao Weisheng, Lakys Y. Compact modeling of perpendicular-anisotropy cofeb mgo magnetic tunnel junctions[J]. Transactions on Electron Devices, 2012, 59(3): 819-826
[9]Venkatesan R, Sharad M, Roy K, et al. DWM-TAPESTRI: An energy efficient all-spin cache using domain wall shift based writes[C] Proc of DATE’13. Piscataway, NJ: IEEE, 2013: 1825-1830
[10]Li Hehe, Liu Yongpan, Zhao Qinghang, et al. An energy efficient backup scheme with low inrush current for nonvolatile sram in energy harvesting sensor nodes[C] Proc of DATE’15. Piscataway, NJ: IEEE, 2015: 7-12
[11]Wang Yuhao, Yu Hao. An ultralow-power memory-based big-data computing platform by nonvolatile domain-wall nanowire devices[C] Proc of ISLPED’13. New York: ACM, 2013: 329-334
[12]Mao Mengjie, Wen Wujie, Zhang Yaojun, et al. Exploration of GPGPU register file architecture using domain-wall-shift-write based racetrack memory[C] Proc of DAC’14. New York: ACM, 2014: 1-6
[13]Landau L D, Lifshitz E M. Statistical Physics[M]. 3rd ed. Oxford, UK: Pergamon Press, 1980: 193-196
[14]Leturcq P, Dorkel J, Napieralski A, et al. A new approach to thermal analysis of power devices[J]. IEEE Trans on Electron Devices, 1987, 34(5): 1147-1156
[15]Parkin S, Yang S. Memory on the racetrack[J]. Nature Nanotechnology, 2015, 10(3): 195-198
Zhang Chao, born in 1988. PhD candidate at Peking University. Student member of CCF and Institute of Electrical and Electronics Engineers. His main research interests include energy-efficient memory architecture and non-volatile memory.
Sun Guangyu, born in 1981. Assistant professor and PhD supervisor at Peking University. Member of CCF and Institute of Electrical and Electronics Engineers. His main research interests include energy-efficient memory architectures, storage system optimization for new devices, and acceleration systems for deep learning applications.
Zhang Xueying, born in 1987. PhD candidate at Beihang University. His main research interests include spintronics, racetrack memory, magneto dynamic in nanowire.
Zhao Weisheng, born in 1980. Professor and PhD supervisor at Beihang University. His main research interests include hybrid integration of emerging nanodevices with CMOS circuits towards logic and memory applications, architecture design, and radiation hardness IC design techniques.
Thermal Modeling and Management for Shift Operations of Racetrack Memory
Zhang Chao 1 , Sun Guangyu 1 , Zhang Xueying 2 , and Zhao Weisheng 2
1 ( Center for Energy - Efficient Computing and Applications , Peking University , Beijing 100871) 2 ( School of Electronic and Information Engineering , Beihang University , Beijing 100191)
Abstract: Racetrack memory (RM) is a competitive emerging non-volatile memory technology for future memory designs. It achieves ultra-high storage density by integrating multiple bits into a tape-like nanowire (called racetrack) and provides fast access speed. In order to access required bits in RM, a unique shift operation is introduced. However, it has been observed that the shift operation requires higher current than read and write operations and causes significant amount of energy dissipation, which degrades reliability and performance or even destroys RM cells. However, there still lacks an analytical thermal model to estimate run-time temperature of RM. More important, corresponding architecture level management schemes are needed to avoid thermal emergency that violates the constraint of peak temperature. In this work, we first propose a thermal model to explore relationship between temperature and design parameters. At the same time, in order to improve thermal reliability, we propose a quota-based shift management scheme to ensure the intensity of shift operations which is constrained under a specific threshold. Experiments show that the temperature increase is limited in 20℃ with only 3.5% performance degradation.
Key words: racetrack memory (RM); thermal model; shift operation; reliability; temperature management
收稿日期: 2015-10-12;
修回日期: 2016-02-26
基金项目: 国家“八六三”高技术研究发展计划基金项目(2013AA013201);国家自然科学基金项目(61572045);科技部国际科技合作专项项目(2015DFE12880);中组部“青年千人”项目 This work was supported by the National High Technology Research and Development Program of China (863 Program) (2013AA013201), the National Natural Science Foundation of China (61572045), Ministry of Science and Technology of China (2015DFE12880), and the Thousand Talents Plan of Organization Department of the Communist Party of China.
中图法分类号: TP333



