 6,且格的维数、陷门尺寸和密文扩展率等参数均有所降低,计算效率明显优化.
6,且格的维数、陷门尺寸和密文扩展率等参数均有所降低,计算效率明显优化. 收稿日期: 2017-06-05;
修回日期: 2017-07-28
基金项目: 国家自然科学基金项目(61300216);河南省科技厅基础与前沿技术研究计划项目(142300410147);河南省教育厅自然科学研究项目(12A520021);河南省教育厅高等学校重点科研项目(16A520013) This work was supported by the National Natural Science Foundation of China (61300216), the Foundation and Advanced Technology Research Plan of Henan Provincial Department of Science and Technology (142300410147), the Natural Science Research Project of Henan Provincial Department of Education (12A520021), and the Key Research Project of Henan Provincial Department of Education (16A520013).
通信作者: 汤永利(yltang@hpu.edu.cn)
叶 青 胡明星 汤永利 刘 琨 闫玺玺
(河南理工大学计算机科学与技术学院 河南焦作 454000)(yeqing@hpu.edu.cn)
摘 要 格上可固定维数陷门派生的身份基分级加密(hierarchical identity-based encryption, HIBE)体制,因其具有在陷门派生前后格的维数保持不变的特性而受到广泛关注,但这种体制普遍存在陷门派生复杂度过高的问题.针对这一问题,分别给出随机预言模型和标准模型下的改进方案.首先利用MP12陷门函数的特性提出一种优化的 ![]() q 可逆矩阵提取算法,再基于该优化算法结合固定维数的陷门派生算法和MP12陷门函数完成方案的建立和陷门派生阶段,然后与对偶Regev算法相结合完成随机预言模型下HIBE方案的构造.并且利用二进制树加密系统将该方案改进为标准模型下的HIBE方案.两方案安全性均可归约至LWE问题的难解性,其中随机预言模型下的方案满足适应性安全,而标准模型下的方案满足选择性安全,并给出严格的安全性证明.对比分析表明:在相同的安全性下,随机预言模型下的方案较同类方案在陷门派生复杂度方面显著降低,而标准模型下的方案是同类最优方案的1 6,且格的维数、陷门尺寸和密文扩展率等参数均有所降低,计算效率明显优化.
q 可逆矩阵提取算法,再基于该优化算法结合固定维数的陷门派生算法和MP12陷门函数完成方案的建立和陷门派生阶段,然后与对偶Regev算法相结合完成随机预言模型下HIBE方案的构造.并且利用二进制树加密系统将该方案改进为标准模型下的HIBE方案.两方案安全性均可归约至LWE问题的难解性,其中随机预言模型下的方案满足适应性安全,而标准模型下的方案满足选择性安全,并给出严格的安全性证明.对比分析表明:在相同的安全性下,随机预言模型下的方案较同类方案在陷门派生复杂度方面显著降低,而标准模型下的方案是同类最优方案的1 6,且格的维数、陷门尺寸和密文扩展率等参数均有所降低,计算效率明显优化.
关键词 格;基于身份的分级加密;陷门派生;容错学习;随机预言模型;标准模型
基于身份加密(identity-based encryption, IBE)是一种高级的公钥加密体制,该体制可使用用户任意的身份标识符(如邮箱地址、手机号码等)作为公钥,相应的私钥由可信第三方私钥生成中心(key generation center, KGC)利用系统主私钥生成.基于身份加密的思想首先于1984年由Shamir [1] 首次提出,但直到2001年,可实际应用的IBE方案才由Boneh等人 [2] 提出并定义了IBE的安全模型.此后IBE的研究引起密码学者的广泛关注,很多IBE的相关方案被相继提出 [3-6] .
基于身份的分级加密(hierarchical identity-based encryption, HIBE)体制是IBE体制的一种推广.在HIBE体制中,多个KGC实体按照有向树的结构分布.HIBE可以更好地应用在大规模网络的应用场景中,有效解决IBE体制在大量的用户请求下无法为每一用户完成身份信息的有效验证并为之安全传送私钥的问题.HIBE体制的特点是体制中每个子KGC陷门均由它的父KGC指定,该过程称为陷门派生.应当注意的是陷门派生是单向的,这意味着每个子KGC均不能利用它的陷门来恢复父KGC或同级KGC的陷门.
近几年,基于格理论构造的新型密码体制因具有较好的渐进效率、运算简单、可并行化、抗量子攻击和存在最坏情况下的随机实例等优点,成为后量子密码时代的研究热点,并取得一系列的研究成果 [7-11] .2008年,Gentry等人 [12] 于STOC’08上利用格的短基作为陷门构造出一种格上原像采样算法,并提出对偶Regev算法;基于这2个算法和Ajtai等人 [13] 提出的陷门生成算法构造出格上IBE方案,并且指出在构造(H)IBE方案时应采用对偶Regev算法来完成方案的加解密阶段,比采用非对偶Regev算法更加合理,随后基于对偶Regev算法的(H)IBE方案 [14-17] 被相继提出.但Gentry等人提出的IBE体制的缺陷是所基于的原像采样算法和陷门生成算法太过复杂,算法的运行时间不满足实际应用;2010年,Cash等人 [18] 基于Gentry等人的原像采样算法构造出一种格上陷门派生算法,并基于此构造出格上首个HIBE方案,但陷门派生算法的派生陷门的维数与系统分级的深度呈2次幂增长关系,这将导致在较高的系统分级中出现格的维数、陷门尺寸等参数过大而导致陷门派生的复杂度过高的问题;2010年,Agrawal等人 [19] 于EUROCRYPT 2010上对Cash等人的方案进行了改进,将按照用户身份向量每1比特分配矩阵的方式改进为按系统分级中每一级分配1个矩阵的方式,从而使格的维数随着系统分级深度的增长而仅呈线性增长,但维数的增长仍然会导致格的维数、陷门尺寸等参数的膨胀而导致陷门派生复杂度过大;2010年,Agrawal等人 [20] 于CRYPTO 2010上提出一种固定维数的格上陷门派生技术,即格的维数在陷门派生前后保持不变,并基于此构造出一种高效的HIBE方案.格的维数是格上密码方案的重要参数与密钥长度、密文尺寸和密文膨胀率等参数密切相关,因此格上固定维数的陷门派生技术引起密码学领域的广泛关注.但该方案和陷门派生算法的构造均依赖一种 ![]() q 可逆矩阵的提取算法(SampleR),而该算法效率取决于原像采样算法,但Agrawal等人所采用的原像采样算法由上述的文献[12]中提出,该算法的输入是高精度的实数且是迭代化运算,这将导致SampleR算法的复杂度过高,进而影响陷门派生的效率.
q 可逆矩阵的提取算法(SampleR),而该算法效率取决于原像采样算法,但Agrawal等人所采用的原像采样算法由上述的文献[12]中提出,该算法的输入是高精度的实数且是迭代化运算,这将导致SampleR算法的复杂度过高,进而影响陷门派生的效率.
2012年,Micciancio等人 [21] (Micciancio和Peikert于2012年发表的文章简称MP12)于EUROCRYPT 2012上提出一种新的格上陷门生成算法和与之对应的原像采样算法,相比文献[17,22]提出的陷门生成算法,该陷门生成过程简单,复杂度仅相当于2个随机矩阵的1次乘运算,且不涉及计算代价高的埃尔米特正规形式(hermite normal form, HNF)和矩阵求逆操作.相比文献[12]的原像采样算法,MP12原像采样算法较简单高效,且算法支持并行运算且输入项为小整数,对离线空间的需求较低.另外,Micciancio等人还提出了一种新的陷门派生算法,该算法相比Cash等人的算法较高效,因为该算法无须进行线性无关检测,且派生陷门的维数与系统分级的深度仅呈线性增长的关系,但维数增长导致陷门派生低效的问题仍然没有解决.
为使基于固定维数派生技术的HIBE方案更具有实际应用可行性,必须解决其陷门派生复杂度过高的问题.因此,本文提出一种高效的格上HIBE方案.主要贡献有:1)利用MP12陷门函数 [21] 的特性构造出一种优化的SampleR算法;2)基于优化的SampleR算法结合固定维数的陷门派生算法和高效MP12陷门生成算法完成HIBE方案的陷门生成和陷门派生阶段,然后与对偶Regev算法有机结合完成随机预言模型下的方案构造;3)利用Cash等人提出的二进制树加密系统消除随机预言机假设,从而改进为标准模型下的HIBE方案.采用与同类方案相同的安全模型进行严格的安全性证明,证明结果表明:本文2个方案的安全性均可归约至容错学习(learning with errors, LWE)问题的难解性,其中随机预言下的HIBE方案满足IND-aID-CPA安全性,标准模型下的HIBE方案满足IND-sID-CPA安全性.在效率对比分析中,为更好地体现对比结果,我们将HIBE陷门派生前的参数和计算效率与派生后的分开进行对比.对比结果表明:与相同安全性的方案相比,本文随机预言模型下的方案在陷门派生复杂度方面显著降低,而标准模型下的方案是同类最优方案的1/6,且格的维数、陷门尺寸和密文扩展率等参数均有所降低,计算效率明显优化.
1 . 1 格的相关定义
定义1 . 格的定义.设 b 1 , b 2 ,…, b m 是 ![]() n 上 m 个线性无关向量,格 Λ 定义为所有这些向量的整系数线性组合,即:
n 上 m 个线性无关向量,格 Λ 定义为所有这些向量的整系数线性组合,即:
其中,向量组 b 1 , b 2 ,…, b m 称为格的一组基.
定义2 . q 元格.设 q , n , m ∈ ![]() , A ∈
, A ∈ ![]() n × m q ,且 u ∈
n × m q ,且 u ∈ ![]() n q ,定义:
n q ,定义:
![]()
即所有与矩阵 A 行向量模 q 内积为 0 的 m 维列向量构成格 Λ ⊥ ( A );格 ![]() 是格 Λ ⊥ ( A )的陪集,满足
是格 Λ ⊥ ( A )的陪集,满足 ![]() 其中
其中 ![]() ).
).
定义3 . 离散高斯分布.对任意 σ >0,定义以向量 c 为中心、 σ 为参数的格 Λ 上的离散高斯分布为
D Λ , σ , c ( y )= ![]() =
= 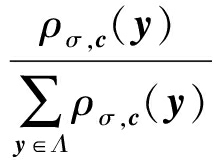 ,
,
其中, y ∈ Λ , ρ σ , c ( y )=exp(- π ‖ y - c ‖  σ 2 ).
σ 2 ).
1 . 2 相关算法和困难问题
本文方案构造所基于的MP12陷门生成算法和与之对应的MP12原像采样算法分别由引理1和引理2给出;SampleR算法由引理3给出;固定维数的陷门派生算法由引理6给出;引理4是引理6的基本算法;对偶Regev算法的具体描述请参阅文献[12];随机预言模型下方案的安全性证明基于引理7、引理8和定义4;标准模型下方案的安全性证明基于引理8和定义4;方案的正确性证明基于引理2和引理9.
定义4 [7] . 容错学习(learning with errors, LWE)问题. 设 n 为正整数, q 为素数,对任意0< α ≤1 ω ( ![]() ),定义 Ψ α 为中心是0、标准差是 α
),定义 Ψ α 为中心是0、标准差是 α ![]() 的[0,1)上的正态分布,对应的
的[0,1)上的正态分布,对应的 ![]() q 上的离散分布为
q 上的离散分布为 ![]() 为
为 ![]() q 上的容错分布,(
q 上的容错分布,( ![]() q , n
q , n ![]() )-LWE问题实例由未指明的挑战预言机 O 构成:预言机 O 是带噪音的伪随机预言机 O s 或者是真随机的预言机 O $ ,2种预言机的输出分别如下:
)-LWE问题实例由未指明的挑战预言机 O 构成:预言机 O 是带噪音的伪随机预言机 O s 或者是真随机的预言机 O $ ,2种预言机的输出分别如下:
O s :输出的采样值形式为 ![]()
![]() n q ×
n q × ![]() q ,其中 s ∈
q ,其中 s ∈ ![]() n q 是随机均匀且不变的秘密向量;
n q 是随机均匀且不变的秘密向量;
O $ :输出 ![]() n q ×
n q × ![]() q 上的真随机且均匀的采样值.
q 上的真随机且均匀的采样值.
( ![]() q , n
q , n ![]() )-LWE问题允许对挑战预言机 O 重复查询.我们称一个攻击算法 A 可以解决(
)-LWE问题允许对挑战预言机 O 重复查询.我们称一个攻击算法 A 可以解决( ![]() q , n
q , n ![]() )-LWE问题如果
)-LWE问题如果
是不可忽略的,其中LWE-adv[ A ]表示 A 解决( ![]() q,n
q,n ![]() )- LWE 问题的优势.
)- LWE 问题的优势.
引理1 [18] . Randbasis算法.设整数 n ≥1, q ≥2和充分大的 ![]()
![]() lb q
lb q ![]() .利用类似引理7的陷门生成算法输出一个均匀随机的矩阵 A 和格 Λ ⊥ ( A )的基 T A ,输入相关高斯参数 σ ,输出一个新的格 Λ ⊥ ( A )的基
.利用类似引理7的陷门生成算法输出一个均匀随机的矩阵 A 和格 Λ ⊥ ( A )的基 T A ,输入相关高斯参数 σ ,输出一个新的格 Λ ⊥ ( A )的基 ![]() ,满足 Pr [‖
,满足 Pr [‖ ![]() ‖> σ
‖> σ ![]() ]≤ negl ( n ),且Randbasis( T A , σ )的输出与输入为格 Λ ⊥ ( A )的任意基 T 的Randbasis( T , σ )输出是统计不可区分的,其中‖
]≤ negl ( n ),且Randbasis( T A , σ )的输出与输入为格 Λ ⊥ ( A )的任意基 T 的Randbasis( T , σ )输出是统计不可区分的,其中‖ ![]() ‖≤ σ ω (
‖≤ σ ω ( ![]() ).
).
引理2 [20] . 陷门派生算法TrapDel.与引理1参数相同,利用SampleR算法(见引理6)抽取一个可逆矩阵 R ,令 B = A 0 R -1 ,计算 ![]() ={ Ra 1 , Ra 2 ,…, Ra m }⊆
={ Ra 1 , Ra 2 ,…, Ra m }⊆ ![]() m ,利用ToBasis算法(见引理9)的算法将
m ,利用ToBasis算法(见引理9)的算法将 ![]() 转换为矩阵 B 的陷门矩阵
转换为矩阵 B 的陷门矩阵 ![]() 运行引理1中的
运行引理1中的 ![]() 算法并输出矩阵 B 的陷门矩阵 T B .
算法并输出矩阵 B 的陷门矩阵 T B .
引理3 [20] . 与引理1参数相同,设可逆矩阵 R 是由SampleR算法(见引理6)抽取且高斯参数 σ 满足 σ >‖ ![]() ‖× σ R
‖× σ R ![]() ω (lb 3 2 m ),令 T B 为调用引理2中陷门派生算法TrapDel输出的矩阵 AR -1 的陷门矩阵,则 T B 的分布与引理1中的Randbasis( T , σ )的输出是统计不区分的,其中 T 是矩阵 AR -1 的任意陷门矩阵,‖
ω (lb 3 2 m ),令 T B 为调用引理2中陷门派生算法TrapDel输出的矩阵 AR -1 的陷门矩阵,则 T B 的分布与引理1中的Randbasis( T , σ )的输出是统计不区分的,其中 T 是矩阵 AR -1 的任意陷门矩阵,‖ ![]() ‖≤ σ ω (
‖≤ σ ω ( ![]() ).若 R 是由
).若 R 是由 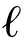 个利用SampleR算法抽取矩阵的积,则高斯参数 σ 的界降至 σ >‖
个利用SampleR算法抽取矩阵的积,则高斯参数 σ 的界降至 σ >‖ ![]() ‖×( σ R
‖×( σ R ![]() ω (lb 1 2 m )) ω (lb m ).
ω (lb 1 2 m )) ω (lb m ).
引理4 [20] . SampleRwithTrap算法.与引理1参数相同.设除了至多 q - n 部分之外所有的 A 0 ∈ ![]() n × m q ,算法SampleRwithTrap输出一个
n × m q ,算法SampleRwithTrap输出一个 ![]() m × m 矩阵 R ,具体是从与 D m × m 统计接近的分布上随机选取矩阵 R 的列向量.且算法SampleRwithTrap输出的 A 0 R -1 的陷门矩阵 T B 满足:
m × m 矩阵 R ,具体是从与 D m × m 统计接近的分布上随机选取矩阵 R 的列向量.且算法SampleRwithTrap输出的 A 0 R -1 的陷门矩阵 T B 满足:
Pr [‖ ![]() ‖> σ R ω (
‖> σ R ω ( ![]() )]≤ negl ( n ).
)]≤ negl ( n ).
引理5 [20] . 与引理1参数相同,设 e 为 ![]() m 中某向量,向量
m 中某向量,向量 ![]()
![]() m q ,则| e T y |可看作[0, q -1]中的整数,满足| e T y |≤‖ e ‖ qαω (
m q ,则| e T y |可看作[0, q -1]中的整数,满足| e T y |≤‖ e ‖ qαω ( ![]() )+‖ e ‖
)+‖ e ‖ ![]() 2.
2.
引理6 [20] . SampleR算法.与引理1参数相同,设 T 是格 ![]() m 的格基,利用与引理8类似的原像采样算法随机抽取 m 个向量 r i ←Sample(
m 的格基,利用与引理8类似的原像采样算法随机抽取 m 个向量 r i ←Sample( ![]() m , T , σ R , 0 ),其中 i =1,2,…, m ,将 r i 作为矩阵 R 的列向量.如果矩阵 R 是
m , T , σ R , 0 ),其中 i =1,2,…, m ,将 r i 作为矩阵 R 的列向量.如果矩阵 R 是 ![]() q 可逆(矩阵 R 是
q 可逆(矩阵 R 是 ![]() q 可逆指矩阵 R mod q 仍是
q 可逆指矩阵 R mod q 仍是 ![]() m × m 上的可逆矩阵)的,则输出 R ,否则重新抽取 r i .
m × m 上的可逆矩阵)的,则输出 R ,否则重新抽取 r i .
引理7 [21] . MP12陷门生成算法.与引理1参数相同,令 H ∈ ![]() n × n q 为可逆矩阵, G ∈
n × n q 为可逆矩阵, G ∈ ![]() n × w q 是构造公开的矩阵.选取一个均匀随机矩阵
n × w q 是构造公开的矩阵.选取一个均匀随机矩阵 ![]()
![]()
![]() q ,存在概率多项式时间(probabilistic polynomial time, PPT)算法
q ,存在概率多项式时间(probabilistic polynomial time, PPT)算法 ![]() 输出矩阵
输出矩阵 ![]() ‖ HG -
‖ HG - ![]()
![]() n × m q 和陷门矩阵 T A 0 =[ a 1 ‖ a 2 ‖…‖ a w ]∈
n × m q 和陷门矩阵 T A 0 =[ a 1 ‖ a 2 ‖…‖ a w ]∈ ![]()
![]() ,陷门尺寸 s 1 ( T A 0 )≤
,陷门尺寸 s 1 ( T A 0 )≤ ![]() × ω (
× ω ( ![]() ),其中 A 0 在
),其中 A 0 在 ![]() n × m q 上是统计均匀的, T A 0 是矩阵 A 0 的陷门.
n × m q 上是统计均匀的, T A 0 是矩阵 A 0 的陷门.
引理8 [21] . MP12原像采样算法.与引理1参数相同,设 u ∈ ![]() n q 为均匀随机向量,充分大的高斯参数 σ = O (
n q 为均匀随机向量,充分大的高斯参数 σ = O ( ![]() ), ω (
), ω ( ![]() )表示渐进性高于
)表示渐进性高于 ![]() ,则存在概率多项式时间算法MP12Sample( A 0 , M , T A 0 , u , σ ),其中, M ∈
,则存在概率多项式时间算法MP12Sample( A 0 , M , T A 0 , u , σ ),其中, M ∈ ![]() n × w q ,输出向量 e ∈
n × w q ,输出向量 e ∈ ![]()
![]() ,且 e 的分布与
,且 e 的分布与 ![]() 统计不可区分
统计不可区分 ![]() ‖ e ‖> σ
‖ e ‖> σ ![]() ]≤ negl ( n ),其中
]≤ negl ( n ),其中 ![]() ).
).
引理9 [23] . ToBasis算法.与引理1参数相同,设 Λ 是一个 m 维格,存在一个确定性多项式算法:输入格 Λ 的任意一组基和格 Λ 中的一个满秩集合 S ={ s 1 , s 2 ,…, s m },输出格 Λ 的一组基 T ,满足‖ ![]() ‖≤‖
‖≤‖ ![]() ‖,且‖ T ‖≤‖ S ‖
‖,且‖ T ‖≤‖ S ‖ ![]() 2.
2.
2 . 1 符号说明
为表述方便,对文中符号进行说明,如表1所示:
Table 1 Notations Description
表1 符号说明

2 . 2 优化的SampleR算法
本节给出一种优化的SampleR算法,算法输出是 ![]() q 可逆矩阵 R ∈
q 可逆矩阵 R ∈ ![]() m × m .SampleR算法是基于固定维数陷门派生技术的HIBE方案的重要组成部分.其重要性主要体现在:SampleR算法的时间复杂度不仅支配着陷门派生算法的效率,而且支配着在标准模型下的HIBE方案构造中系统建立阶段(Setup)和陷门派生阶段(Derive)的性能.此外,SampleR算法还是我们2个方案安全性证明中SampleRwithTrap算法(见引理4)的基本算法.
m × m .SampleR算法是基于固定维数陷门派生技术的HIBE方案的重要组成部分.其重要性主要体现在:SampleR算法的时间复杂度不仅支配着陷门派生算法的效率,而且支配着在标准模型下的HIBE方案构造中系统建立阶段(Setup)和陷门派生阶段(Derive)的性能.此外,SampleR算法还是我们2个方案安全性证明中SampleRwithTrap算法(见引理4)的基本算法.
本节构造的优化SampleR算法的功能与Agrawal等人提出的陷门派生算法中的(见引理6)相同.由于SampleR算法输出的 R 矩阵是公开的,且算法的时间复杂度主要来自于算法中循环调用的原像采样算法.所以我们考虑采用较高效的MP12原像采样算法MP12Sample(见引理8).具体方法是利用MP12陷门函数中构造公开的特殊矩阵 G 和其公开陷门矩阵 T G 来进行SampleR算法中的原像采样操作.具体优化算法如下:
算法 ![]() ).
).
输入:整数 m = O ( n lb q )、用来在陪集 Λ ⊥ ( G )高斯采样的预言机 O G 、其高斯参数为 σ G ;
输出: ![]() q 可逆矩阵 R ∈
q 可逆矩阵 R ∈ ![]() m × m .
m × m .
1) 与引理1的参数相同 ![]() 是随机均匀选取的
是随机均匀选取的 ![]() 矩阵, G 为一个构造公开的矩阵, G = I n ⊗ g T ∈
矩阵, G 为一个构造公开的矩阵, G = I n ⊗ g T ∈ ![]() n × nk q ,其中 I n 是 n × n 单位矩阵, g T =(1,2,2 2 ,…,2 k -1 )∈
n × nk q ,其中 I n 是 n × n 单位矩阵, g T =(1,2,2 2 ,…,2 k -1 )∈ ![]() k q , k =
k q , k = ![]() lb q
lb q ![]() , T G 是矩阵 G 的公开陷门;
, T G 是矩阵 G 的公开陷门;
2) For i =1,2,…, m do:
① 调用预言机 ![]()
![]() w ,判断
w ,判断 ![]() 与 D
与 D ![]() w , σ G 是否统计接近,如不是,则再次生成;
w , σ G 是否统计接近,如不是,则再次生成;
② 计算 ![]()
![]()
![]() q ;
q ;
③ 计算 ![]()
④ 令 ![]() ‖
‖ ![]() 并输出 r i ∈
并输出 r i ∈ ![]() m ;
m ;
3) 将 r i 作为矩阵 R 的列向量,检测 R 是否是 ![]() q 可逆,是则输出 R ,否则重新进行步骤2.
q 可逆,是则输出 R ,否则重新进行步骤2.
分析:因为 O G 的输出是随机均匀的,由非齐次小整数解问题(inhomogeneous small integer solution problem, ISIS)可知 u 是统计均匀的,再由引理8可知原像采样算法MP12Sample的输出向量 ![]() 是统计均匀的,因此由
是统计均匀的,因此由 ![]() 和
和 ![]() 的拼接向量 r i 也是统计均匀的.
的拼接向量 r i 也是统计均匀的.
相比Agrawal等人 [20] 提出的SampleR算法:首先,在效率上,MP12Sample算法的输入项是小整数可支持并行化运算而不是输入项是高精度实数的正交化迭代运算,且原像采样过程中利用 G 矩阵和 G 矩阵陷门的特殊构造,时间复杂度相比通常的原像采样算法的 Ω ( n 2 lb 2 n )可降至 O ( n lb c n ),其中 c 是常数.因此,相比Agrawal等人提出复杂度是 Ω ( n 3 lb 3 nn )的SampleR算法,我们的算法复杂度是 O ( n 2 lb c n ).其次,在输出质量(原像采样算法的输出质量为所采样向量的范数)上,质量好坏与原像采样大小限制参数 β 负相关.Agrawal等人的HIBE方案采用的是文献[21]的陷门生成算法和文献[12]的原像采样算法,则 β Agrawal >45 n lg q ,而本文 β our ≈2.3 n lg q ,相比之下本文有近19倍的提升.
我们的优化算法存在的不足是相比Agrawal等人的SampleR算法多了第2步中的②操作,该操作采用高效正向计算的方式输出,复杂度仅等同于执行1次Hash算法.
2 . 3 随机预言模型下的HIBE方案
方案具体构造如下,其基本参数包括:均匀随机矩阵 A 0 ∈ ![]() n × m q 和其陷门 R 0 ∈
n × m q 和其陷门 R 0 ∈ ![]()
![]() ,其中 n 是安全参数, d 是系统支持的最大分级深度,用户身份 id =( id 1 ‖ id 2 ‖…‖ id )∈({0,1} * ) ,其中 ∈[ d ], i ∈[1, ].令
,其中 n 是安全参数, d 是系统支持的最大分级深度,用户身份 id =( id 1 ‖ id 2 ‖…‖ id )∈({0,1} * ) ,其中 ∈[ d ], i ∈[1, ].令 ![]() 其中
其中 ![]() .一个构造公开的矩阵 G = I n ⊗ g T ∈
.一个构造公开的矩阵 G = I n ⊗ g T ∈ ![]() n × nk q ,其中 I n 是 n × n 单位矩阵, g T =(1,2,2 2 ,…,2 k -1 )∈
n × nk q ,其中 I n 是 n × n 单位矩阵, g T =(1,2,2 2 ,…,2 k -1 )∈ ![]() k q ;随机预言机 H :({0,1} * ) ≤ d →
k q ;随机预言机 H :({0,1} * ) ≤ d → ![]() m × m q : id |→ H ( id )~ D m × m .
m × m q : id |→ H ( id )~ D m × m .
HIBE-Setup(1 n ,1 d ):输入安全参数 n 和系统最大分级深度 d ,运行引理7的算法 ![]() 输出均匀随机矩阵
输出均匀随机矩阵 ![]() ‖
‖ ![]() 的陷门矩阵 T A 0 =[ a 1 ‖ a 2 ‖…‖ a w ]∈
的陷门矩阵 T A 0 =[ a 1 ‖ a 2 ‖…‖ a w ]∈ ![]()
![]() ,选取 n 维均匀随机向量 u ∈
,选取 n 维均匀随机向量 u ∈ ![]() n q ,输出主公钥 MPK =( A 0 , u 0 )和主私钥 MSK =( T A 0 ).
n q ,输出主公钥 MPK =( A 0 , u 0 )和主私钥 MSK =( T A 0 ).
HIBE-Derive(MPK, SK i d | , id ):输入主公钥MPK;输入 SK i d | 表示系统分级深度为 时用户公钥矩阵 A i d | 所对应的陷门矩阵,其中 ![]()
![]() n × m q ,父用户身份 id | =( id 1 ‖ id 2 ‖…‖ id ),可逆矩阵 R i d | = H ( id |1 ) H ( id |2 )… H ( id | )∈
n × m q ,父用户身份 id | =( id 1 ‖ id 2 ‖…‖ id ),可逆矩阵 R i d | = H ( id |1 ) H ( id |2 )… H ( id | )∈ ![]() m × m ;输入子用户身份 id =( id 1 ‖ id 2 ‖…‖ id ‖ id +1 ‖…,‖
m × m ;输入子用户身份 id =( id 1 ‖ id 2 ‖…‖ id ‖ id +1 ‖…,‖ ![]() 其中
其中 ![]() d .计算 R = H ( id | +1 ) H ( id | +2 )… H ( id | k )∈
d .计算 R = H ( id | +1 ) H ( id | +2 )… H ( id | k )∈ ![]() m × m 并令 A i d = A i d R -1 .调用引理2的陷门派生算法
m × m 并令 A i d = A i d R -1 .调用引理2的陷门派生算法 ![]() 输出陷门矩阵 SK i d = S ′.另外,将参数 A i d 0 设为 A 0 , SK i d |0 设为 T A 0 ,HIBE-Derive算法相当于IBE方案中的用户密钥提取算法IBE-Extract.
输出陷门矩阵 SK i d = S ′.另外,将参数 A i d 0 设为 A 0 , SK i d |0 设为 T A 0 ,HIBE-Derive算法相当于IBE方案中的用户密钥提取算法IBE-Extract.
HIBE-Encrypt(MPK, id , b ):输入主公钥 MPK 、分级深度为 ![]() 的接收方用户身份 id 和待加密消息 b ∈{0,1}.计算可逆矩阵
的接收方用户身份 id 和待加密消息 b ∈{0,1}.计算可逆矩阵 ![]()
![]() m × m .计算用户公钥矩阵
m × m .计算用户公钥矩阵 ![]()
![]() n × m q .利用对偶Regev算法来加密消息 b :首先选取均匀随机向量 s ←
n × m q .利用对偶Regev算法来加密消息 b :首先选取均匀随机向量 s ← ![]() n q ;然后选取容错值
n q ;然后选取容错值 ![]()
![]() q 和容错向量
q 和容错向量 ![]()
![]() m q ;计算并输出密文
m q ;计算并输出密文 ![]()
![]() q /
q / ![]()
![]() q ×
q × ![]() m q .
m q .
HIBE-Decrypt( MPK , SK i d , CT ):输入主公钥 MPK ;输入陷门矩阵 SK i d ,其中用户身份 id 的分级深度为 ![]() ;输入密文 CT .令高斯参数
;输入密文 CT .令高斯参数 ![]() 计算如HIBE-Encrypt中的矩阵 A i d ∈
计算如HIBE-Encrypt中的矩阵 A i d ∈ ![]() n × m q ,运行引理8中的原像采样算法
n × m q ,运行引理8中的原像采样算法 ![]() 满足
满足 ![]()
![]() q ,将 b ′与
q ,将 b ′与 ![]() q /2
q /2 ![]() 视为
视为 ![]() 中的整数并比较,如果
中的整数并比较,如果 ![]()
![]() q /4
q /4 ![]() ,输出1,否则输出0.
,输出1,否则输出0.
2 . 4 标准模型下的HIBE方案
与2.3节随机预言模型下的HIBE方案不同的是,在标准模型下我们采用Cash等人 [18] 提出的二进制树加密(binary tree encryption, BTE)系统来构造方案.具体是将系统分级中每一级的用户身份看作长度是 ![]() 的二进制向量.因加解密算法与随机预言模型下的HIBE加解密算法相同,因此本节只给出系统建立算法和陷门派生算法的构造.
的二进制向量.因加解密算法与随机预言模型下的HIBE加解密算法相同,因此本节只给出系统建立算法和陷门派生算法的构造.
HIBE-Setup(1 n ,1 d ):输入安全参数 n 和BTE可支持的最大分级深度 d ,运行引理7的算法 ![]() 输出均匀随机矩阵
输出均匀随机矩阵 ![]() ‖ HG -
‖ HG - ![]()
![]() n × m q 和 A 0的陷门矩阵 T A 0 =[ a 1 ‖ a 2 ‖…‖ a w ]∈
n × m q 和 A 0的陷门矩阵 T A 0 =[ a 1 ‖ a 2 ‖…‖ a w ]∈ ![]()
![]() ,选取 n 维均匀随机向量 u ∈
,选取 n 维均匀随机向量 u ∈ ![]() n q .运行2.2节优化的SampleR(1 m )算法,输出2 d 个矩阵 R 1,0 , R 1,1 , R 2,0 , R 2,1 ,…, R d ,0 , R d ,1 ∈
n q .运行2.2节优化的SampleR(1 m )算法,输出2 d 个矩阵 R 1,0 , R 1,1 , R 2,0 , R 2,1 ,…, R d ,0 , R d ,1 ∈ ![]() m × m .输出主公钥 MPK =( A 0 , u 0 , R 1,0 , R 1,1 , R 2,0 , R 2,1 ,…, R d ,0 , R d ,1 )和主私钥 MSK =( T A 0 ).
m × m .输出主公钥 MPK =( A 0 , u 0 , R 1,0 , R 1,1 , R 2,0 , R 2,1 ,…, R d ,0 , R d ,1 )和主私钥 MSK =( T A 0 ).
HIBE-Derive( MPK , SK i d | , id ):输入主公钥 MPK ;输入 SK i d | 表示系统分级深度为 时用户公钥矩阵 A i d | 所对应的陷门矩阵,其中 A i d = A 0 ( R 1, id 1 ) -1 ( R 2, id 2 ) -1 …( R , id ) -1 ∈ ![]() n × m q ,父用户身份 id | ={0,1} ≤ d ;输入子用户身份 id =( id 1 ‖ id 2 ‖…‖ id ‖ id +1 ‖…,‖
n × m q ,父用户身份 id | ={0,1} ≤ d ;输入子用户身份 id =( id 1 ‖ id 2 ‖…‖ id ‖ id +1 ‖…,‖ ![]() 其中
其中 ![]() d .令
d .令 ![]()
![]() m × m , A i d = A i d R ∈
m × m , A i d = A i d R ∈ ![]() n × m q .调用2.3节的陷门派生算法
n × m q .调用2.3节的陷门派生算法 ![]() 输出陷门矩阵 SK i d = S ′.
输出陷门矩阵 SK i d = S ′.
通常,一个HIBE方案的安全性需满足选择身份攻击和选择明文攻击下的密文不可区分性(IND-ID-CPA),根据安全强度不同,分为适应性选择身份选择明文攻击(IND-aID-CPA)和选择性选择身份选择明文攻击(IND-sID-CPA).本文方案在随机预言模型下满足IND-aID-CPA安全,在标准模型下满足IND-sID-CPA安全.
本方案采用Agrawal等人 [19] 在EEUROCRYPT 2010上提出的格上HIBE方案的INDr-s/aID-CPA安全模型进行安全性证明,该安全模型不仅可证明IND-s/aID-CPA安全,还可以保护接收方的匿名性,且主公钥的私密性可被其创建的密文保护.基于该安全模型进行安全证明的还有2010年Agrawal等人 [20] 于CRYPTO 2010和2016年Wang等人 [24] 于FITEE提出的HIBE方案.
正确性. 本文HIBE方案的解密正确性由定理1刻画.
定理1 . 本文HIBE方案的解密是正确的,对任意的 id ∈ ID ,( MPK , MSK )←HIBE-Setup(1 n , d ), sk i d ←HIBE-Extract( MPK , R -1 ,( id 1 ‖ id 2 ‖…‖ id -1 )‖ id )和消息 b ∈{0,1},其中 ID 为身份空间,有
Pr [Decrypt( MPK , sk i d ,Encrypt( MPK , id , b ))= b ]=1- negl ( n )成立.
证明. HIBE方案解密算法的输出为
![]()
![]() q /
q / ![]()
![]() q /
q / ![]() 由引理8可知,‖ e i d ‖≤ τ
由引理8可知,‖ e i d ‖≤ τ ![]() = σ mω (
= σ mω ( ![]() ),再由引理5可知, error - term 被约束为
),再由引理5可知, error - term 被约束为 ![]() ).为保证解密的正确性,我们需要确保在1≤ ≤ d 中 error - term 小于 q 5,则 α <[ σ mω (lb m )] -1 , q = σ m 3 2 ω (
).为保证解密的正确性,我们需要确保在1≤ ≤ d 中 error - term 小于 q 5,则 α <[ σ mω (lb m )] -1 , q = σ m 3 2 ω ( ![]() ),且 q >2
),且 q >2 ![]() α ,引理7中TrapGen算法要求 m ≥2 n lb q ,引理2中TrapDel算法要求高斯参数 σ > σ -1 m 3 2 ω (lb 2 m ).方案的参数(随机预言模型)设定如表2所示:
α ,引理7中TrapGen算法要求 m ≥2 n lb q ,引理2中TrapDel算法要求高斯参数 σ > σ -1 m 3 2 ω (lb 2 m ).方案的参数(随机预言模型)设定如表2所示:
Table 2 Parameters Setting of HIBE Scheme Under Random Oracle Model
表2 随机预言模型下HIBE方案的参数设置

标准模型下方案的参数计算方式与随机预言模型下的相同,不同在于标准模型下的系统分级中的身份向量为二进制形式.设每级用户身份的二进制向量长度为 ![]() 方案的参数(标准模型)设定如表3所示:
方案的参数(标准模型)设定如表3所示:
Table 3 Parameters Setting of HIBE Scheme Under Standard Model
表3 标准模型下HIBE方案的参数设置

表2和表3所示的参数设定下,本文2.3节和2.4节的HIBE方案中的 error - term 均小于 q 5,则方案正确性得以保证.
证毕.
安全性. 本文随机预言模型下的HIBE方案的安全性由定理2刻画.
定理2 . 设 A 为攻击2.3节随机预言模型下HIBE方案的PPT攻击者, H 为随机预言机 H :({0,1} * ) ≤ d → ![]() m × m q .令 Q H 为敌手 A 对可对 H 询问的最大次数, d 为系统可支持的最大分级深度,则存在一个PPT算法 B 满足:如果 A 是一个具有优势 ε 的适应性攻击者(INDr-aID-CPA),那么
m × m q .令 Q H 为敌手 A 对可对 H 询问的最大次数, d 为系统可支持的最大分级深度,则存在一个PPT算法 B 满足:如果 A 是一个具有优势 ε 的适应性攻击者(INDr-aID-CPA),那么 ![]() ).
).
证明. 已知LWE问题是区分定义4中预言机 O 的输出是来自伪随机预言机 O s 还是真随机预言机 O $ .基于 A 的能力,构造一个优势是 ε ![]() 的DLWE算法 B .
的DLWE算法 B .
B 对预言机 O 进行询问并获取一组实例( u i , v i )∈ ![]() n q ×
n q × ![]() q ,其中 i =1,2,…, m ,要求 B 通过模拟游戏并基于 A 的能力区分出实例来自预言机 O s 或 O $ .模拟过程如下:
q ,其中 i =1,2,…, m ,要求 B 通过模拟游戏并基于 A 的能力区分出实例来自预言机 O s 或 O $ .模拟过程如下:
系统建立. B 选取 d 个均匀随机整数 ![]()
![]() ;运行2.3节的
;运行2.3节的 ![]() 算法来抽取 d 个随机矩阵
算法来抽取 d 个随机矩阵 ![]() 其中 i =1,2,…, d ; B 利用实例( u i , v i )∈
其中 i =1,2,…, d ; B 利用实例( u i , v i )∈ ![]() n q ×
n q × ![]() q 生成随机矩阵 A ∈
q 生成随机矩阵 A ∈ ![]() n × m q ,矩阵 A 的第 i 列是向量 u i , i =1,2,…, m ,将向量 u 0 作为公共随机向量
n × m q ,矩阵 A 的第 i 列是向量 u i , i =1,2,…, m ,将向量 u 0 作为公共随机向量
u 0 ∈ ![]() n q ;选取一个随机整数 φ ∈[ d ]并令
n q ;选取一个随机整数 φ ∈[ d ]并令 ![]() 因 A 在
因 A 在 ![]() n × m q 上是均匀的,且
n × m q 上是均匀的,且 ![]() 是模 q 可逆的,则 A 0 在
是模 q 可逆的,则 A 0 在 ![]() n × m q 上是均匀的.输出主公钥 MPK =( A 0 , u 0 ).
n × m q 上是均匀的.输出主公钥 MPK =( A 0 , u 0 ).
模拟随机预言机. 对于适应性的攻击者 A , A 能够在任意时间适应性地选择任意用户身份 id = id 1 , id 2 ,…, id i 提交给随机预言机 H 进行询问.假设 A 的询问是唯一的,否则 B 对相同的输入返回相同的内容且不增加询问计数器 Q 的值.令 i =| id |为用户身份的深度,对于 A 的询问 B 的回应分2种情况:
如果 ![]() 定义
定义 ![]() 并返回 H ( id );
并返回 H ( id );
如果 ![]() 计算
计算 ![]()
![]() n × m q ,运行引理4中的SampleRwithTrap( A i )算法输出一个随机矩阵 R ~ D m × m 和矩阵 B = A i R -1 mod q 的一个陷门 T B .保存五元组( i , id , R , B , T B )并返回 H ( id )← R .
n × m q ,运行引理4中的SampleRwithTrap( A i )算法输出一个随机矩阵 R ~ D m × m 和矩阵 B = A i R -1 mod q 的一个陷门 T B .保存五元组( i , id , R , B , T B )并返回 H ( id )← R .
模拟私钥派生.对于适应性的攻击者 A , A 能够在任意时间适应性地选择任意用户身份进行私钥询问. B 对某用户身份 ![]() 询问的回应如下:
询问的回应如下:
1) 令 ![]() 作为
作为 ![]() 的最低系统分级深度.对于不可能事件
的最低系统分级深度.对于不可能事件 ![]() 将终止模拟.
将终止模拟.
2) 查询本地存储的五元组( i , id | j , R , B , T B ),该五元组在模拟者 B 回应攻击者 A 的询问 H ( id | j )时创建.不失一般性地认为当某用户身份 id 被询问时,此 id 的所有前缀已被询问.构造矩阵 ![]() 且 T B 是矩阵 B 的陷门矩阵.不难看出,矩阵 B 与2.3节随机预言模型下HIBE方案加密算法中父身份 id | j =( id 1 , id 2 ,…, id j )的用户公钥矩阵 A i d | j 相同,则 T B 是 A i d | j 的陷门矩阵.
且 T B 是矩阵 B 的陷门矩阵.不难看出,矩阵 B 与2.3节随机预言模型下HIBE方案加密算法中父身份 id | j =( id 1 , id 2 ,…, id j )的用户公钥矩阵 A i d | j 相同,则 T B 是 A i d | j 的陷门矩阵.
3) 运行2.3节HIBE方案中的Derive( MPK , T B , id )算法,利用父身份 id | j 的陷门矩阵 T B 派生出子身份 id 的陷门矩阵.如果 j = k ,直接运行引理5中的RandBasis( T B , σ k )算法.输出并发送 id 的陷门矩阵至攻击者 A .
挑战阶段.攻击者 A 向模拟者 B 宣布待攻击的用户身份 id * 并输出一个消息比特 b * ∈{0,1}.要求 id * 不能是攻击者 A 已经询问或即将询问的用户身份的父身份.令 =| id * |,如果存在 i ∈[ ]满足 ![]() 模拟终止.已知
模拟终止.已知 ![]() 如果 φ ≠ ,模拟终止.
如果 φ ≠ ,模拟终止.
假设 φ = 且对任意的 i ∈[ ]有 ![]() 定义
定义 ![]() 将从预言机 O 获取到的一组实例中的 v 1 , v 2 ,…, v m ∈
将从预言机 O 获取到的一组实例中的 v 1 , v 2 ,…, v m ∈ ![]() q 设为
q 设为 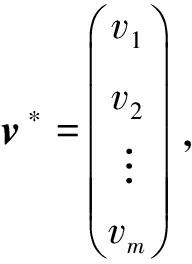 并令
并令 ![]()
![]() m q ;利用 v 0 盲化消息位得
m q ;利用 v 0 盲化消息位得 ![]()
![]() q /2
q /2 ![]() ∈
∈ ![]() q ;发送挑战密文
q ;发送挑战密文 ![]() 至攻击者 A .若 O 是伪随机LWE预言机,则
至攻击者 A .若 O 是伪随机LWE预言机,则 ![]()
![]() q /
q / ![]() 其中 s ←
其中 s ← ![]() n q 为均匀随机选取的向量,
n q 为均匀随机选取的向量, ![]()
![]() q 和
q 和 ![]()
![]() m q 分别为噪音值和噪音向量,则 CT * 是利用挑战身份 id * 对消息位 b * 的有效加密密文;若 O 是真随机预言机,则( v 0 , v * )在
m q 分别为噪音值和噪音向量,则 CT * 是利用挑战身份 id * 对消息位 b * 的有效加密密文;若 O 是真随机预言机,则( v 0 , v * )在 ![]() q ×
q × ![]() m q 上是均匀的,那么挑战密文
m q 上是均匀的,那么挑战密文 ![]() 在
在 ![]() q ×
q × ![]() m q 上也是均匀的.
m q 上也是均匀的.
模拟私钥派生.该阶段与挑战前阶段的前的模拟私钥派生阶段相同,攻击者 A 可以继续选择用户身份进行私钥询问,模拟者 B 以同样的方式进行回应.最后,攻击者 A 猜测挑战密文 CT * 是否是利用挑战身份 id * 对消息位 b * 的有效加密密文,模拟者 B 输出 A 的猜测并结束模拟.
由以上可知,主公钥中参数的分布与实际系统中陷门派生算法所需的参数的分布是相同的.且由引理3可知,对随机预言机 H 询问的回应与实际系统是相同的.如果模拟者 B 不终止模拟,则挑战密文 CT * 的分布在( ![]() q ×
q × ![]() m q )上是独立随机的或与实际系统相同.因此,如果模拟者 B 不终止模拟,则 B 在区分DLWE问题上的优势与攻击者 A 成功攻击方案的优势相同.对于PPT攻击者 A 来说, A 在随机预言机上发现碰撞的概率是可忽略的,则模拟者 B 可进行而不终止的概率是 Pr [
m q )上是独立随机的或与实际系统相同.因此,如果模拟者 B 不终止模拟,则 B 在区分DLWE问题上的优势与攻击者 A 成功攻击方案的优势相同.对于PPT攻击者 A 来说, A 在随机预言机上发现碰撞的概率是可忽略的,则模拟者 B 可进行而不终止的概率是 Pr [ 
![]()
![]() d - negl ( n ).因此,如果攻击者 A 的优势是 ε ,则模拟者 B 解决LWE问题实例的优势至少是[ ε
d - negl ( n ).因此,如果攻击者 A 的优势是 ε ,则模拟者 B 解决LWE问题实例的优势至少是[ ε ![]() ).
).
证毕.
安全性.本文标准模型下的HIBE方案的安全性由定理3刻画.
定理3 . 若 ![]() 的难解性成立,则本文在标准模型下HIBE方案是INDr-sID-CPA安全的.
的难解性成立,则本文在标准模型下HIBE方案是INDr-sID-CPA安全的.
证明. 假设攻击者 A 在区分定义4中预言机 O 的输出的具有不可忽略的优势,我们基于 A 的能力构造一个LWE算法 B .
B 对预言机 O 进行询问并获取一组实例( u i , v i )∈ ![]() n q ×
n q × ![]() q ,其中 i =1,2,…, m ,要求 B 通过模拟游戏并基于 A 的能力区分出实例来自预言机 O s 或 O $ .模拟过程如下:
q ,其中 i =1,2,…, m ,要求 B 通过模拟游戏并基于 A 的能力区分出实例来自预言机 O s 或 O $ .模拟过程如下:
目标确定:攻击者 A 向模拟者 B 确定并宣布待攻击的目标身份 ![]() 当 < d 时,模拟过程相对简单,为此,我们直接假设攻击者 A 宣布的待攻击目标身份的深度| id * |是系统可支持的最大分级深度,即
当 < d 时,模拟过程相对简单,为此,我们直接假设攻击者 A 宣布的待攻击目标身份的深度| id * |是系统可支持的最大分级深度,即 ![]()
系统建立:模拟者 B 首先利用实例( u i , v i )∈ ![]() n q ×
n q × ![]() q 生成随机矩阵 A ∈
q 生成随机矩阵 A ∈ ![]() n × m q ,矩阵 A 的第 i 列是向量 u i , i =1,2,…, m ,将向量 u 0 作为公共随机向量 u 0 ∈
n × m q ,矩阵 A 的第 i 列是向量 u i , i =1,2,…, m ,将向量 u 0 作为公共随机向量 u 0 ∈ ![]() n q ;然后利用2.2节优化的SampleR算法抽取 个随机矩阵
n q ;然后利用2.2节优化的SampleR算法抽取 个随机矩阵 ![]()
![]() m × m ,令
m × m ,令 ![]() 考虑如下 d 个矩阵
考虑如下 d 个矩阵
其中 i =0,1,…, d -1.模拟者 B 为每一个矩阵 A i 调用引理4中的SampleRwithTrap算法来生成随机矩阵 ![]()
![]() m × m 和矩阵
m × m 和矩阵 ![]() 的陷门矩阵 T A i .最后,模拟者 将主公钥 MPK =( A 0 , u 0 , R 1,0 , R 1,1 , R 2,0 , R 2,1 ,…, R d ,0 , R d ,1 )发送给攻击者 A .
的陷门矩阵 T A i .最后,模拟者 将主公钥 MPK =( A 0 , u 0 , R 1,0 , R 1,1 , R 2,0 , R 2,1 ,…, R d ,0 , R d ,1 )发送给攻击者 A .
模拟私钥派生:模拟者 B 利用系统建立阶段调用引理4中的SampleRwithTrap生成的陷门矩阵 T A i 来回应攻击者 A 的私钥询问.要求攻击者 A 询问的用户身份不能是目标身份 id * 的父身份.模拟者调用2.4节HIBE方案中的Derive( MPK , T A i , id )算法,利用攻击者所查询身份的父身份的陷门矩阵 T A i 派生出所查询身份的陷门矩阵.如果 i = d ,直接运行引理1中的RandBasis( T A i , σ d )算法.输出并发送 id 的陷门矩阵至攻击者 A .
挑战阶段.攻击者 A 向模拟者 B 发送一个消息比特 b * ∈{0,1}, B 将从预言机 O 获取到的一组实例中的 v 1 ,…, v m ∈ ![]() q 设为
q 设为 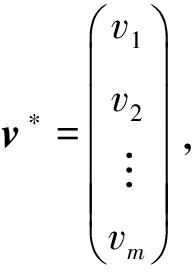 并令
并令 ![]() v * ∈
v * ∈ ![]() m q ;利用 v 0 盲化消息位得
m q ;利用 v 0 盲化消息位得 ![]()
![]() q /2
q /2 ![]() ∈
∈ ![]() q ;选取一个随机位 r ←{0,1},如果 r =0,发送挑战密文
q ;选取一个随机位 r ←{0,1},如果 r =0,发送挑战密文 ![]() 至攻击者 A ,如果 r =1,选取一个随机的 CT * =( c 0 , c 1 )∈
至攻击者 A ,如果 r =1,选取一个随机的 CT * =( c 0 , c 1 )∈ ![]() q ×
q × ![]() m q 发送给攻击者.
m q 发送给攻击者.
容易看出,当定义4中的预言机 O 输出是伪随机的(即 O = O s 时 ![]() 与挑战密文中的
与挑战密文中的 ![]() 部分是相同的,且
部分是相同的,且 ![]() 与挑战密文中的
与挑战密文中的 ![]() 是相同的, x 和 y 分别是选自
是相同的, x 和 y 分别是选自 ![]() 和
和 ![]() 分布的容错值和容错向量.因此,挑战密文
分布的容错值和容错向量.因此,挑战密文 ![]() 的分布与预言机 O s 的输出是统计不可区分的;当 O = O $ 时, v 0 在
的分布与预言机 O s 的输出是统计不可区分的;当 O = O $ 时, v 0 在 ![]() q 上和 v * 在
q 上和 v * 在 ![]() m q 上都是均匀的,则挑战密文 CT * =( c 0 , c 1 )在
m q 上都是均匀的,则挑战密文 CT * =( c 0 , c 1 )在 ![]() q ×
q × ![]() m q 总是均匀的.
m q 总是均匀的.
猜测阶段.在攻击者 A 完成又一轮的私钥询问后,攻击者 A 猜测收到的挑战密文 CT * 是来自伪随机预言机 O s 还是是真随机的预言机 O $ .模拟者 B 输出 A 的猜测结果作为对LWE问题的求解.
综上,模拟者 B 解决LWE实例的优势和攻击者 A 猜测与之交互的是 O s 还是 O $ 的优势相同.因此不存在PPT算法有效求解 ![]() 问题,本方案是INDr-sID-CPA安全的.模拟完成.
问题,本方案是INDr-sID-CPA安全的.模拟完成.
证毕.
本节对随机预言模型下和标准模型下的HIBE方案分别进行效率分析.为更好地体现本文HIBE方案的优越性,我们将HIBE陷门派生前的参数和计算效率与派生后的分开进行对比.为简单直观,我们将派生前和派生后的分级深度设为 =1和 =2.
4 . 1 随机预言模型下的HIBE方案效率分析
我们选择2个随机预言模型下的HIBE方案作为参照对象:Cash等人 [18] 于EUROCRYPT 2010提出的随机预言模型下适应性安全的首个格上HIBE方案(简称CHKP方案);Agrawal等人 [19] 于CRYPTO 2010上提出的一种具有较短密文尺寸且可固定维数派生的随机预言模型下适应性安全的HIBE方案(简称ABBa方案).设安全参数 n =284, q =2的24次方.对比结果如表4和表5所示,其中RO-adaptive表示该方案满足随机预言模型下INDr-aID-CPA安全性.
Table 4 Efficiency Comparison of HIBE Schemes Before Trapdoor Delegation Under Random Oracle Model
表4 随机预言模型下的HIBE方案陷门派生前效率对比
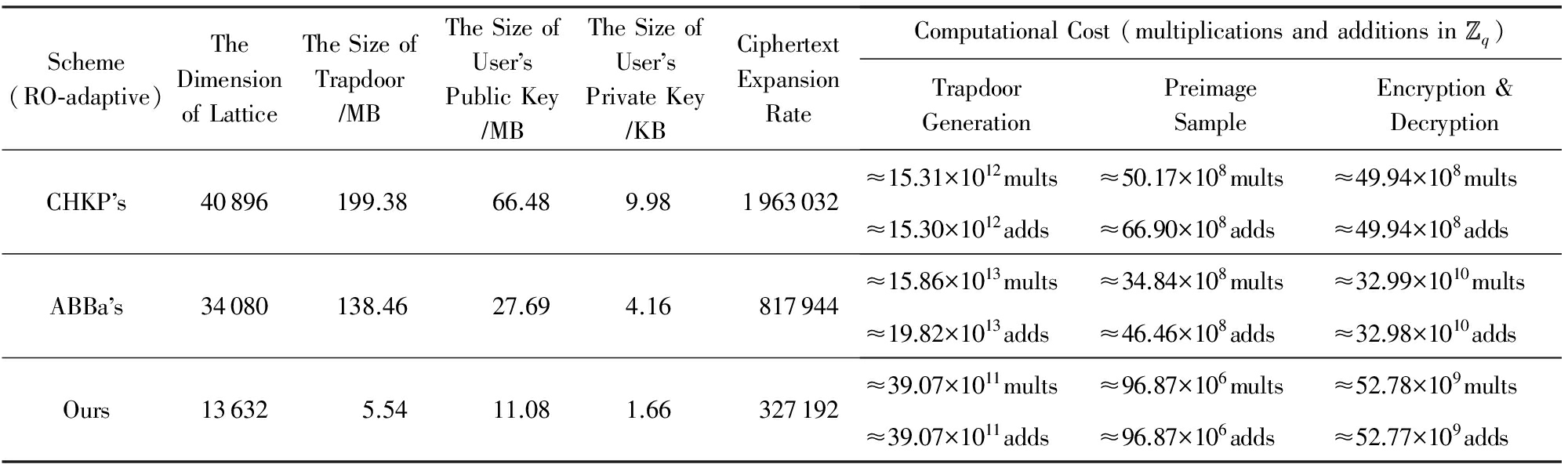
Table 5 Efficiency Comparison of HIBE Schemes After Trapdoor Delegation Under Random Oracle Model
表5 随机预言模型下的HIBE方案派生后效率对比
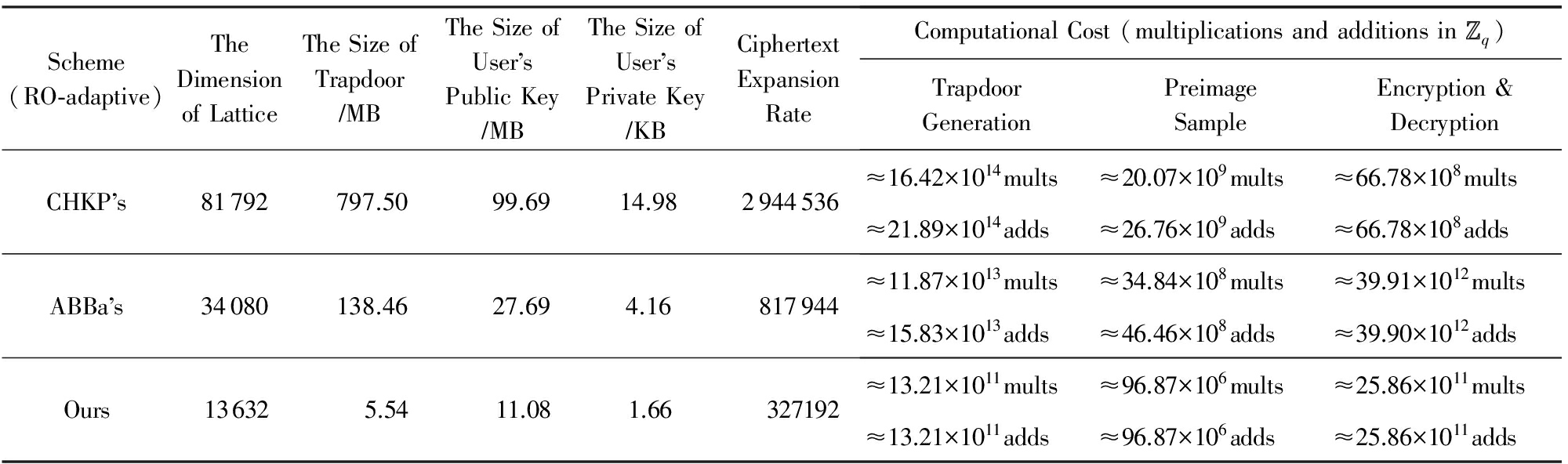
由表4和表5对比可以看出,相比CHKP方案,ABBa方案和本文方案的主要优势在于陷门派生前后格的维数保持不变,因此效率参数如陷门尺寸、用户公私钥尺寸、明文-密文扩展率以及计算效率上的原像采样算法的复杂度均保持不变.但是,基于固定维数陷门派生技术的HIBE方案存在的主要缺点是加密复杂度较大,原因是:当加密者向分级深度为 的用户发送消息时,需要计算 个 m × m 矩阵的连续乘积.但优点是该运算对于每个用户身份只需进行1次,且与发送的消息是无关的.
相比同是固定维数陷门派生的ABBa方案,本文方案的优势在于具有较低的格的维数.原因在于所采用的MP12陷门生成算法(见引理7)输出的矩阵 A ∈ ![]() n × m q 的维数仅为2 n lb q 时,矩阵 A 的分布与均匀分布的统计距离即可满足是安全参数 n 的可忽略函数.且陷门生成算法所输出陷门不再是格 Λ ⊥ ( A )的格基,而是从特定概率分布随机抽取的短向量组成的陷门矩阵,因此陷门矩阵的尺寸相比表中其他方案较小.此外,低维数和小的陷门尺寸也是用户公钥和私钥尺寸较短的主要原因.
n × m q 的维数仅为2 n lb q 时,矩阵 A 的分布与均匀分布的统计距离即可满足是安全参数 n 的可忽略函数.且陷门生成算法所输出陷门不再是格 Λ ⊥ ( A )的格基,而是从特定概率分布随机抽取的短向量组成的陷门矩阵,因此陷门矩阵的尺寸相比表中其他方案较小.此外,低维数和小的陷门尺寸也是用户公钥和私钥尺寸较短的主要原因.
在陷门生成复杂度上,相比ABBa方案,本文方案具有明显的优势.原因在于本文方案在陷门生成过程中不存在计算代价高的HNF和矩阵求逆操作,陷门生成的复杂度仅相当于2个随机矩阵的1次乘运算;在原像采样复杂度上,本文方案是ABBa方案的5 13倍,原因在于原像采样算法使用小整数作为输入项且支持并行化运算,而不是使用输入项是高精度实数的正交化迭代运算;在陷门派生上,本文方案比其他方案高效的原因在于,陷门派生算法复杂度主要取决于所调用的SampleR算法(见引理6)和RandBasis算法(见引理1),而它们效率的根本都取决于所调用的原像采样算法.在2.2节我们分析所调用的原像采样算法的时间复杂度相比通常原像采样算法的 Ω ( n 2 lb 2 n )可降至 O ( n lb c n ),且基于固定维数派生陷门算法的HIBE方案的陷门派生复杂度不会随系统分级深度的增长而变高.
4 . 2 标准模型下的HIBE方案效率分析
我们选择3个标准模型下的HIBE方案作为参照对象:Agrawal等人 [19] 在EUROCRYPT 2010上提出的一种高效的标准模型下选择性安全的HIBE方案(简称ABBb方案);Agrawal等人 [20] 在CRYPTO 2010上提出的可固定维数派生的标准模型下选择性安全的HIBE方案(简称ABBa方案); 2016年Wang等人 [24] 提出的一种标准模型下高效的选择性安全的HIBE方案(简称WWL方案).与4.1节相同,设安全参数 n =284, q =2的24次方.此外,在ABBa,WWL和本文方案中,设 ![]() 是每个分级中用户身份的二进制长度.对比结果如表6和表7所示,表中SM-selective表示该方案满足标准模型下INDr-sID-CPA安全性.
是每个分级中用户身份的二进制长度.对比结果如表6和表7所示,表中SM-selective表示该方案满足标准模型下INDr-sID-CPA安全性.
由表4和表5对比可以看出,与4.1节随机预言模型下的对比结果相似,相比非固定维数派生的ABBb方案,其他方案的主要优势在于陷门派生前后格的维数保持不变,因此效率参数如陷门尺寸、用户公私钥尺寸、明文-密文扩展率以及计算效率上的原像采样算法的复杂度均保持不变.但是,基于固定维数陷门派生技术的HIBE方案存在的主要缺陷仍然是加密的复杂度,且该复杂度比4.1节随机预言模型下的要高,原因是在无随机预言模型的情况下,标准模型下的HIBE方案将每一级的用户身份设置为长度为 ![]() 的二进制向量的形式,在加密者向分级深度为 的用户发送消息时,需要计算
的二进制向量的形式,在加密者向分级深度为 的用户发送消息时,需要计算 ![]() 个 m × m 矩阵的连续乘积,且不排除 =1的情况.但优点是该运算对于每个用户身份只需进行1次,且与发送的消息是无关的.
个 m × m 矩阵的连续乘积,且不排除 =1的情况.但优点是该运算对于每个用户身份只需进行1次,且与发送的消息是无关的.
Table 6 Efficiency Comparison of HIBE Schemes Before Trapdoor Delegation Under Standard Model
表6 标准模型下的HIBE方案派生前效率对比
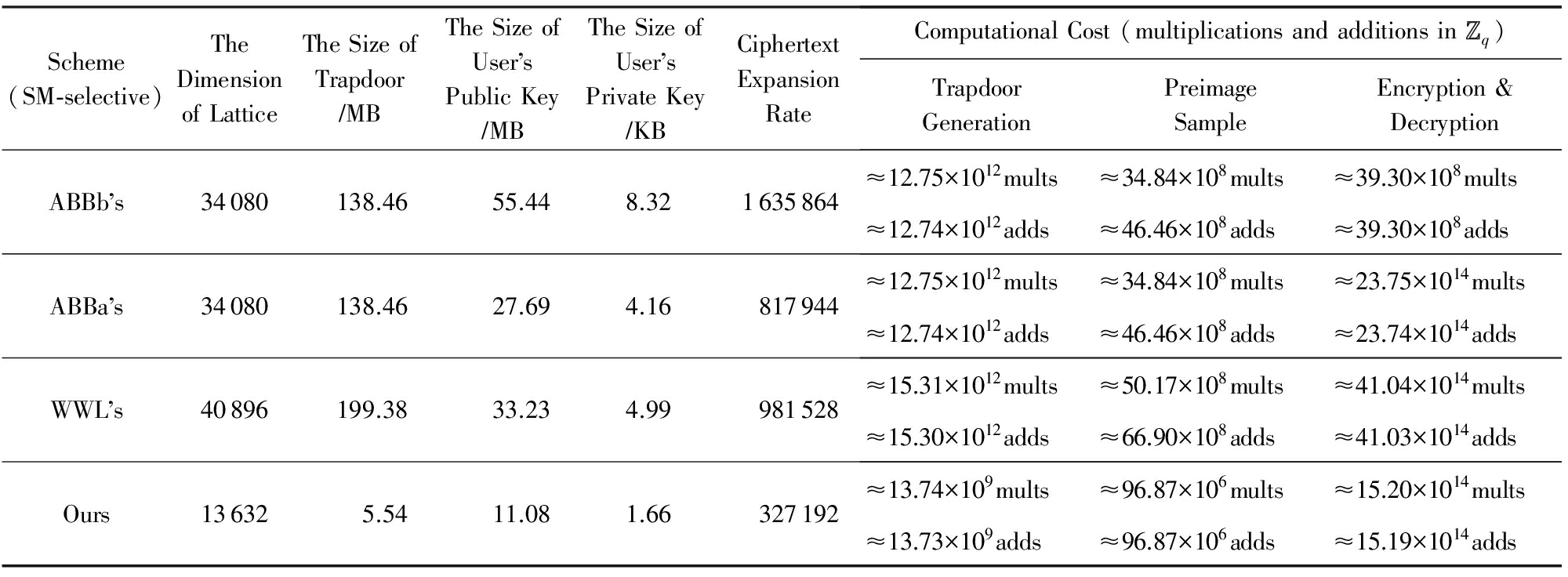
Table 7 Efficiency Comparison of HIBE Schemes After Trapdoor Delegation Under Standard Model
表7 标准模型下的HIBE方案派生后效率对比
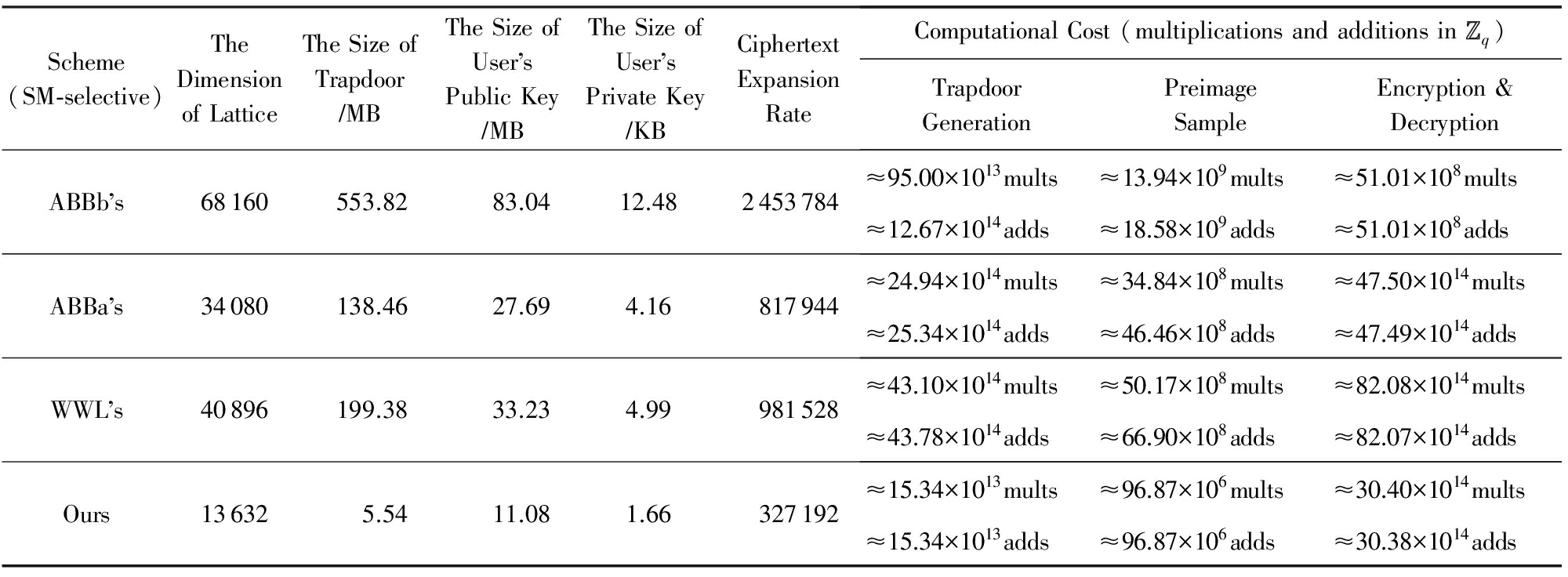
在陷门派生上,对于固定维数派生的HIBE方案,由于ABBa和WWL方案均基于ABBa中提出的时间复杂度是 Ω ( n 3 lb 3 n )的SampleR算法,本文方案采用2.2节优化后的SampleR算法可将算法时间复杂度降至 O ( n 2 lb c n ), c 为常数;对于非固定维数派生的HIBE方案,其时间复杂度与格的维数紧密相关.由表7可以看出,在系统分级深度仅为2时,本文方案相比ABBb方案已有6倍的提升,且基于固定维数派生的HIBE方案因为格的维数在陷门派生前后不变,因此陷门派生的时间复杂度不受系统分级深度的影响.
综上所述,相比同类方案,本文方案在随机预言模型和标准模型下的陷门派生复杂度有效降低,且方案的效率参数和计算效率整体有所提高.因此,本文方案总体上是较高效的.
为解决格上基于固定维数陷门派生技术的HIBE方案中陷门派生复杂度过高的问题,本文提出一种高效的 ![]() q 可逆矩阵提取算法,并基于该算法结合固定维数的陷门派生算法和MP12陷门函数分别在随机预言模型和标准模型下给出2种改进方案.方案安全性均归约至LWE问题的难解性,其中基于随机预言模型的HIBE方案的安全性满足IND-aID-CPA安全,基于标准模型的HIBE方案安全性满足IND-sID-CPA安全.对比分析表明,格上基于固定维数派生技术HIBE方案中陷门派生复杂度过高的问题得到有效解决,且在其他效率参数和计算效率上整体提升.
q 可逆矩阵提取算法,并基于该算法结合固定维数的陷门派生算法和MP12陷门函数分别在随机预言模型和标准模型下给出2种改进方案.方案安全性均归约至LWE问题的难解性,其中基于随机预言模型的HIBE方案的安全性满足IND-aID-CPA安全,基于标准模型的HIBE方案安全性满足IND-sID-CPA安全.对比分析表明,格上基于固定维数派生技术HIBE方案中陷门派生复杂度过高的问题得到有效解决,且在其他效率参数和计算效率上整体提升.
本文方案的不足在于标准模型下方案安全性仅满足IND-sID-CPA安全,如何构造标准模型下IND-aID-CPA安全的格上HIBE方案是值得进一步研究的问题.
参考文献
[1] Shamir A. Identity-based crypto systems and signature schemes[C] //Proc of CRYPTO 1984. Berlin: Springer, 1984: 47-53
[2] Boneh D, Franklin M. Identity-based encryption from the weil pairing[C] //Proc of CRYPTO 2001. Berlin: Springer, 2001: 213-229
[3] Waters B. Efficient identity-based encryption without random oracles[C] //Proc of EUROCRYPT 2005. Berlin: Springer, 2005: 114-127
[4] Lai Junzuo, Deng R H, Liu Shengli, et al. Identity-based encryption secure against selective opening chosen-ciphertext attack[C] //Proc of EUROCRYPT 2012. Berlin: Springer, 2012: 77-92
[5] Yamada S. Adaptively secure identity-based encryption from lattices with asymptotically shorter public parameters[C] //Proc of EUROCRYPT 2016. Berlin: Springer, 2016: 32-62
[6] Wang Fenghe, Liu Zhenhua, Wang Chunxiao. Full secure identity-based encryption scheme with short public key size over lattices in the standard model[J]. International Journal of Computer Mathematics, 2016, 93(6): 854-863
[7] Regev O. On lattices, learning with errors, random linear codes, and cryptography[J]. Journal of the ACM, 2009, 56(6): 84-93
[8] Nguyen P, Zhang Jiang, Zhang Zhenfeng. Simpler efficient group signatures from lattices[C] //Proc of Public-Key Cryptography. Berlin: Springer, 2015: 401-426
[9] Libert B, Ling San, Nguyen K, et al. Zero-knowledge arguments for lattice-based accumulators: Logarithmic-size ring signatures and group signatures without trapdoors[C] //Proc of EUROCRYPT 2016. Berlin: Springer, 2016: 1-31
[10] Brakerski Z, Perlman R. Lattice-based fully dynamic multi-key FHE with short ciphertexts[C] //Proc of CRYPTO 2016. Berlin: Springer, 2016: 190-213
[11] Zhang Yanhua, Hu Yupu. A new verifiable encrypted signature from lattices[J]. Journal of Computer Research and Development, 2017, 54(2): 305-312 (in Chinese)
(张彦华, 胡予濮. 新的基于格的可验证加密签名方案[J]. 计算机研究与发展, 2017, 54 (2): 305-312
[12] Gentry C, Peikert C, Vaikuntanathan V. Trapdoors for hard lattices and new cryptographic constructions[C] //Proc of the 40th ACM Symp on Theory of Computing. New York: ACM, 2008: 197-206
[13] Ajtai M. Generating hard instances of the short basis problem[C] //Proc of Int Colloquium on Automata, Languages and Programming. Berlin: Springer, 1999: 1-9
[14] Agrawal S, Boyen X, Vaikuntanathan V, et al. Functional encryption for threshold functions (or fuzzy IBE) from lattices[C] //Proc of Public Key Cryptography. Berlin: Springer, 2012: 280-297
[15] Ducas L, Lyubashevsky V, Prest T. Efficient identity-based encryption over NTRU lattices[C] //Proc of ASIACRYPT 2014. Berlin: Springer, 2014: 22-41
[16] Katsumata S, Yamada S. Partitioning via non-linear polynomial functions: More compact IBEs from ideal lattices and bilinear maps[C] //Proc of ASIACRYPT 2016, Berlin: Springer, 2016: 682-712
[17] Zhang Jiang, Chen Yu, Zhang Zhenfeng. Programmable hash functions from lattices: Short signatures and IBEs with small key sizes[C] //Proc of CRYPTO 2016. Berlin: Springer, 2016: 302-332
[18] Cash D, Hofheinz D, Kiltz E, et al. Bonsai trees, or how to delegate a lattice basis[C] //Proc of EUROCRYPT 2010. Berlin: Springer, 2010: 523-552
[19] Agrawal S, Boneh D, Boyen X. Efficient lattice (H) IBE in the standard model[C] //Proc of EUROCRYPT 2010. Berlin: Springer, 2010: 553-572
[20] Agrawal S, Boneh D, Boyen X. Lattice basis delegation in fixed dimension and shorter-ciphertext hierarchical IBE[C] //Proc of CRYPTO 2010. Berlin: Springer, 2010: 98-115
[21] Micciancio D, Peikert C. Trapdoors for lattices: Simpler, tighter, faster, smaller[C] //Proc of EUROCRYPT 2012. Berlin: Springer, 2012: 700-718
[22] Alwen J, Peikert C. Generating shorter bases for hard random lattices[C] //Proc of the 26th Int Symp on Theoretical Aspects of Computer Science. Berlin: Springer, 2009: 535-553
[23] Micciancio D, Goldwasser S. Complexity of Lattice Problems: A Cryptographic Perspective [G] //The International Series in Engineering and Computer Science: 671. Berlin: Springer, 2002
[24] Wang Fenghe, Wang Chunxiao, Liu Zhenhua. Efficient hierarchical identity based encryption scheme in the standard model over lattices[J]. Frontiers of Information Technology & Electronic Engineering, 2016, 17(8): 781-791
Ye Qing, Hu Mingxing, Tang Yongli, Liu Kun, and Yan Xixi
( School of Computer Science and Technology , Henan Polytechnic University , Jiaozuo , Henan 454000)
Abstract Hierarchical identity-based encryption (HIBE) in fixed dimension has drawn wide attention because its lattice dimension keeps unchanged upon delegation, but there is a common defect of high complexity in trapdoor delegation stage of these schemes. Aiming at this problem, we propose two improved HIBE schemes under random oracle model and standard model respectively. We first use the MP12 trapdoor function to construct an optimized ![]() q -invertible matrix sample algorithm. Based on this optimized algorithm, combined with trapdoor delegation algorithm in fixed dimension and MP12 trapdoor function, we design system setup and trapdoor delegation stages. And we complete the HIBE scheme under random oracle model in conjunction with Dual-Regev algorithm. And then, we remove the random oracle by employing binary tree encryption system. The security of both proposed schemes strictly reduce to the hardness of learning with errors (LWE) problem, in which the scheme under random oracle model satisfies the adaptive security while the scheme under standard model satisfies selective security. Comparative analysis shows that, under the same security level, the overhead of trapdoor delegation in our scheme under random oracle model is reduced significantly compared with the relevant schemes, while the overhead of our scheme under standard model is reduced nearly 6 times compared with the relevant optimal schemes. Furthermore, the parameters such as lattice dimension, trapdoor size and ciphertext expansion rate etc., all decrease in some degree, and the computational cost is reduced obviously.
q -invertible matrix sample algorithm. Based on this optimized algorithm, combined with trapdoor delegation algorithm in fixed dimension and MP12 trapdoor function, we design system setup and trapdoor delegation stages. And we complete the HIBE scheme under random oracle model in conjunction with Dual-Regev algorithm. And then, we remove the random oracle by employing binary tree encryption system. The security of both proposed schemes strictly reduce to the hardness of learning with errors (LWE) problem, in which the scheme under random oracle model satisfies the adaptive security while the scheme under standard model satisfies selective security. Comparative analysis shows that, under the same security level, the overhead of trapdoor delegation in our scheme under random oracle model is reduced significantly compared with the relevant schemes, while the overhead of our scheme under standard model is reduced nearly 6 times compared with the relevant optimal schemes. Furthermore, the parameters such as lattice dimension, trapdoor size and ciphertext expansion rate etc., all decrease in some degree, and the computational cost is reduced obviously.
Key words lattice; hierarchical identity-based encryption (HIBE); trapdoor delegation; learning with errors (LWE); random oracle model; standard model
中图法分类号 TP309

Ye Qing , born in 1981. Associate professor at Henan Polytechnic University. Received her PhD degree from Beijing University of Posts and Telecommunications. Her main research interests include lattice cryptography and algebra.

Hu Mingxing , born in 1994. Master candidate in School of Computer Science and Technology, Henan Polytechnic University. His main research interests include information security and lattice cryptography.

Tang Yongli , born in 1972. Professor at Henan Polytechnic University. Senior member of CCF. Received her PhD degree from Beijing University of Posts and Telecommunications. His main research interests include information security and cryptography.

Liu Kun , born in 1978. Associate professor at Henan Polytechnic University. Received her MSc degree from Chongqing University of Posts and Telecommunications. Her main research interests include cryptography and number theory.

Yan Xixi , born in 1985. Associate professor at Henan Polytechnic University. Received her PhD degree from Beijing University of Posts and Telecommunications. Her main research interests include lattice cryptography and algebra.