 card ( I ),运行时剩余能力 C r R 为 card ( I )),数值按式(1)计算.
card ( I ),运行时剩余能力 C r R 为 card ( I )),数值按式(1)计算. 周墨颂 董小社 陈 衡 张兴军
(西安交通大学电子与信息工程学院 西安 710049)
(zhoumosong@stu.xjtu.edu.cn)
摘 要 云平台资源管理中存在资源供给与需求不匹配的问题,导致平台性能受到严重影响.针对此问题,基于相似任务建立运行时计算资源剩余能力评估模型,该模型利用云计算负载中相似任务执行逻辑相同的特点,使用相似任务代替测试程序量化资源剩余能力,避免了执行测试程序的计算资源代价;依据该模型提出了一种运行时云计算资源剩余能力分类评估方法RCE(resource capacity evaluation),该方法综合各方面因素评估运行时资源剩余能力,具有运行时代价低、评估结果准确且有时效性的特点.将RCE评估结果应用在若干算法中,以提高云平台资源供给与需求的匹配程度并优化云平台各方面性能;在独享环境和真实云环境中验证了RCE方法和基于RCE的算法,实验结果表明:RCE评估结果及时反映了计算资源能力变化,为算法和平台的优化提供了有力支持,基于RCE优化的算法解决了云计算资源管理中资源供给与需求不匹配问题并大幅提高云计算平台性能.
关键词 云计算;资源能力评估;相似任务;资源管理;平台优化
目前,云平台普遍采用的资源管理算法只考虑资源量而忽略资源的品质.例如,Hadoop [1] 使用槽作为资源划分单位,代表定量的CPU和内存资源.Yarn [2] 使用容器封装一定虚拟核和内存资源.Hadoop和Yarn均不保证所分配计算资源品质.资源品质因素在资源管理中十分重要:资源的品质可能直接影响任务的资源需求量,比如相同任务在不同品质的CPU上可呈现出不同的资源需求量;资源品质也可能影响资源总量,比如品质好的网络资源具有更高的传输带宽;负载的资源使用行为可能造成资源品质持续波动,比如负载的多少可以影响CPU的切换频率,从而影响CPU资源品质.在资源管理时忽略计算资源的品质导致资源分配与任务资源需求不匹配:1)如果资源供给过剩,则任务执行过程中易出现资源碎片,造成资源浪费 [3] ;2)如果资源供给不足,则任务执行过程中易出现资源瓶颈,造成性能下降 [4] .另外,云计算服务器间普遍存在的异构性加剧了计算资源品质的差异,从而增加了资源供给与需求不匹配的频率和程度,严重影响云平台性能 [3,5-7] .
资源供给与需求不匹配的原因在于资源管理中没有精确量化资源的剩余能力,即资源品质和资源量.为了解决上述问题,云平台资源管理中需要一种评估计算资源剩余能力的方法.现存的性能评估方法 [8-10] 均因时效性、准确性以及代价等问题而不宜应用在云平台的资源管理决策中.本文提出计算资源剩余能力评估方法RCE(resource capacity evaluation),该方法使用云负载中普遍存在的相似任务 [11-12] 代替传统的测试程序,通过相似任务保证评估结果准确性的同时避免了执行测试程序的资源代价;通过比较相似任务在不同计算资源上的执行情况,在运行时获得具有时效性的计算资源剩余能力评估结果;克服了传统评估方法的缺点,可为云平台和算法的优化提供支持.本文的主要贡献有3个方面:
1) 基于相似任务建立运行时云计算资源剩余能力评估模型,依据相似任务在不同计算资源上的执行情况量化计算资源运行时剩余能力.
2) 基于评估模型针对CPU、内存、磁盘、网络4种资源提出了分类评估方法RCE,并实现了与平台无关的评估服务.
3) 设计了基于RCE的任务资源需求推测、资源分配、负载均衡、异常识别等算法,并在Yarn平台中实现算法以解决云资源管理平台中的问题,优化云平台性能.
测试结果显示,RCE的评估结果有效且及时反映出计算资源能力变化,基于RCE评估结果的算法有效解决了资源供给与需求的匹配问题,提高了云平台资源利用率,降低了负载完成时间.RCE为平台及算法的优化提供了良好的支持.
近年来很多研究 [3,5-7] 分析了国内外公司的日志文件,指出现代云计算中心及负载普遍存在规模及异构性的挑战.异构性加剧了资源品质的差异性,从而使云计算中心资源供给与需求间的不匹配问题更加突出.资源供给与需求的不匹配可能造成计算资源被浪费,也可能造成负载争抢资源出现局部资源瓶颈,导致云计算中心性能大幅下降.
Hadoop [1] 分布式平台实现了MapReduce计算框架,可以在商用集群上提供分布式并行计算.Yarn [2] 资源管理平台从Hadoop延续而来,它采用双层调度模型解耦了资源管理与任务调度,以支持多样性负载.Mesos [13] 采用与Yarn类似的双层调度模型并支持多种计算模型.国内外众多公司均使用Hadoop,Yarn,Mesos等构建云计算平台 [14-15] ,但是上述开源云资源管理平台均存在资源供给与需求的匹配问题.
Corona [16] 平台使用消息推送机制提高了平台可扩展性同时降低了MapReduce作业延迟.Fuxi [17] 具有很强的可扩展性和容错性,被用于管理Alibaba公司并发任务数以万计的大型云平台.Borg [18] 是一个在Google公司使用超过10年的资源管理系统,可以管理上万节点组成的大型云平台.Omega [19] 是Google公司的新一代资源管理系统,通过共享状态和乐观锁极大地提高了资源分配并发度,实现了对大规模云平台的管理.上述工业界云计算资源管理平台中同样存在着资源供给与需求的匹配问题,该问题存在的根本原因是目前的资源管理平台不了解运行时计算资源剩余能力和负载的资源需求.
资源供给与需求的不匹配直接导致个别任务执行缓慢,最终拖慢整个作业的完成时间 [20] .LATE [21] 通过计算任务剩余执行时间判断识别落后任务并启动冗余执行,防止个别任务拖慢作业完成.Mantri [4] 分析实时进度报告找出落后任务,并采用重新启动任务、网络感知放置等措施减轻落后任务的影响.LATE和Mantri等算法可以缓解由资源供给与需求不匹配造成的影响,但是不能预防执行缓慢任务的出现,更不能解决资源供给与需求的匹配问题.
在云平台执行负载期间实时评估负载的资源需求和计算资源剩余能力是解决上述问题的一种有效方法.针对云计算资源能力评估研究的主要思路分为2种:
1) 文献[8],它基于CloudSuite,HiBench,BenchClouds,TPC-W等基准测试结果建立性能评估模型,对云计算平台效率、弹性、QoS等进行评估.这种方式并不能应用在运行时资源能力评估中,原因在于在运行时引入额外测试程序的性能代价太大,且通过分析测试程序运行结果得出的评估结果不具有时效性.
2) 文献[9-10],它们针对云计算平台的性能指标建立基于随机回报Petri网、连续时间马尔可夫链等的评估模型.由于这种方式无法全面考虑所有影响因素、不使用测试程序,因此其评估结果并不准确.
已有评估研究的问题在于不使用测试程序得不到准确结果,而使用测试程序会消耗资源,影响负载执行.本文评估解决了这个问题,它利用云计算负载中相似任务的特性,采用相似任务代替传统评估方法中使用的测试程序,并综合相似任务运行时信息、计算资源理论性能及基准测试信息等建立了运行时计算资源剩余能力评估模型.因此本文的评估具有的优势包括:运行时不引入负载无关的测试程序,性能代价小;使用负载中相似任务代替测试程序,保证结果准确性;运行时实时评估,结果时效性高.
Apollo [11] 是一个分布式协作的调度框架,它通过整合、共享集群的资源可用性信息实现多调度器分布式调度,解决了调度的扩展性问题.Apollo中的资源可用性信息通过预测、整合各任务的完成时间得出,而其对任务完成时间的预测是通过分析相似任务实现的,因此本文在资源剩余能力评估模型以及基于RCE的任务资源需求推测算法中均利用了与Apollo相似的原理.但是本文在评估中进一步定义了相似任务,同时在评估中引入了其他因素,而本文的需求推测算法在推测过程中考虑了任务使用资源的差异性,这是Apollo中没有考虑到的.Google公司提出的CPI2 [12] 将相似原理应用到异常任务识别中,但并未涉及到计算资源评估方面.
RCE评估方法可以应用到Hadoop,Yarn,Mesos等开源云计算平台中,为平台及算法优化提供有力支持.例如,文献[22]提出一种适用于异构集群的调度算法和基于负载的混合调度策略,基于RCE评估、分析异构集群可以更好地获取负载状态,取得更好的平均完成时间;文献[23]根据节点性能、任务特征等信息进行负载均衡,但是在判断节点性能时只依据硬件配置信息且在任务特征方面只考虑CPU和IO这2种类型,使用RCE评估节点性能、判断任务特征有利于提升方法效率.
云计算负载中普遍存在的执行逻辑相同的任务具有相同的资源使用行为.本文在执行逻辑相同任务上进一步定义了相似任务,并采用相似任务代替测试程序量化计算资源剩余量以及品质.在此基础上,综合其他信息建立计算资源剩余能力的评估模型.
定义1 . 计算资源剩余能力C r R .假设计算资源R在运行时的空闲资源量为μ、资源品质(单位计算资源拥有的计算性能)为θ,则R剩余能力可由二元组(μ,θ)表示,且其数值可以按C r R =μ×θ计算.
定义2 . 相似任务.假设任务执行逻辑为L,任务所处阶段为S,处理数据量为D,如果对于任务i和j存在关系L i =L j ∧S i =S j ∧D i =D j ,则任务i和j互为相似任务.
定义2约束了相似任务的3个方面:执行逻辑、所处阶段以及处理数据量.只有在3个方面均相同的任务才互为相似任务.这样约束的原因在于,任务的执行逻辑以及所处的阶段均能影响资源的使用行为,而处理数据量可能影响某些资源的使用量以及任务阶段的划分.
定理1 . 计算资源运行时品质可通过占用该资源的任务与其相似任务性能指标的比值衡量,假设总量为R a 的计算资源上有任务集合I,集合中任务i占用资源量为R i 且有与资源品质成正比的性能指标P i ,任务i的相似任务性能指标中位值为 ![]() 为集合I中的任务数量,则计算资源品质为
为集合I中的任务数量,则计算资源品质为 ![]() card ( I ),运行时剩余能力 C r R 为
card ( I ),运行时剩余能力 C r R 为 ![]() card ( I )),数值按式(1)计算.
card ( I )),数值按式(1)计算.
![]() card ( I ).
card ( I ).
(1)
定理1推导如下:
任务的性能指标P与任务逻辑L和计算资源品质θ间存在映射关系:
f:L,θ→P,ρ P,θ gt;0,ρ P,L lt;0.
(2)
对于相似任务i和j而言,执行逻辑相同,即L i =L j ,因此有:
θ ∝P⟹∀P i lt;P j ,∃θ i lt;θ j .
(3)
因此任务与其相似任务性能指标的比较关系可以反映出任务占用资源的品质,云负载相似任务可以代替测试程序用于评估计算资源剩余能力.
评估模型依据定理1评估资源剩余能力C r R ,并综合计算资源的理论能力C s R 以及实测峰值S j ,使评估结果C R 更加准确.评估模型如式(4),其计算结果数值越大表示被评估的计算资源剩余能力越大.
其中,C r R 为计算资源剩余能力;M r R 为同类计算资源运行时剩余能力的中位数;TEST为计算资源测试项集合;S j 为测试项j的实测峰值;E j 为测试项j的期望结果;W j 为测试项j的权重;M s R 为同类计算资源理论能力的中位数;α,β,η为权重参数,满足α+β+η=1.
基于相似任务的评估模型的创新在于使用云计算负载代替了传统测试程序,它在3个方面具有优点:
1) 准确度.该模型考虑计算资源上任务执行情况、理论能力、测试结果等方面,评估结果准确度高.
2) 代价低.该模型在运行时只需要执行负载,评估运行时代价很低.
3) 时效性.评估过程与负载执行同时进行,评估结果时效性高.
3 . 1 RCE概述
同一任务对不同计算资源的使用行为不同,各种计算资源信息间不具有比较性.因此,RCE方法按资源类型分类评估,目前分CPU、内存、磁盘、网络4类进行.图1所示为RCE方法示意图.
图1中Master为云平台管理节点;Worker为云平台工作节点,其内小矩形表示计算资源;阴影代表被占用.工作节点上运行着资源特性各异的各种任务,任务 A 与 A ′互为相似任务.RCE执行流程如下:
1) 当服务器作为工作节点首次加入云平台时,RCE收集服务器计算资源理论能力并执行各种基准测试采集测试结果.
2) 云平台工作节点执行云负载时,RCE采集任务及资源的运行时信息.
3) RCE分类存储各种运行时信息,识别负载中相似任务,并按资源类型分类评估计算资源.
4) 云平台管理服务Master通过RCE接口获取评估结果并应用在各种算法中,优化云平台性能.
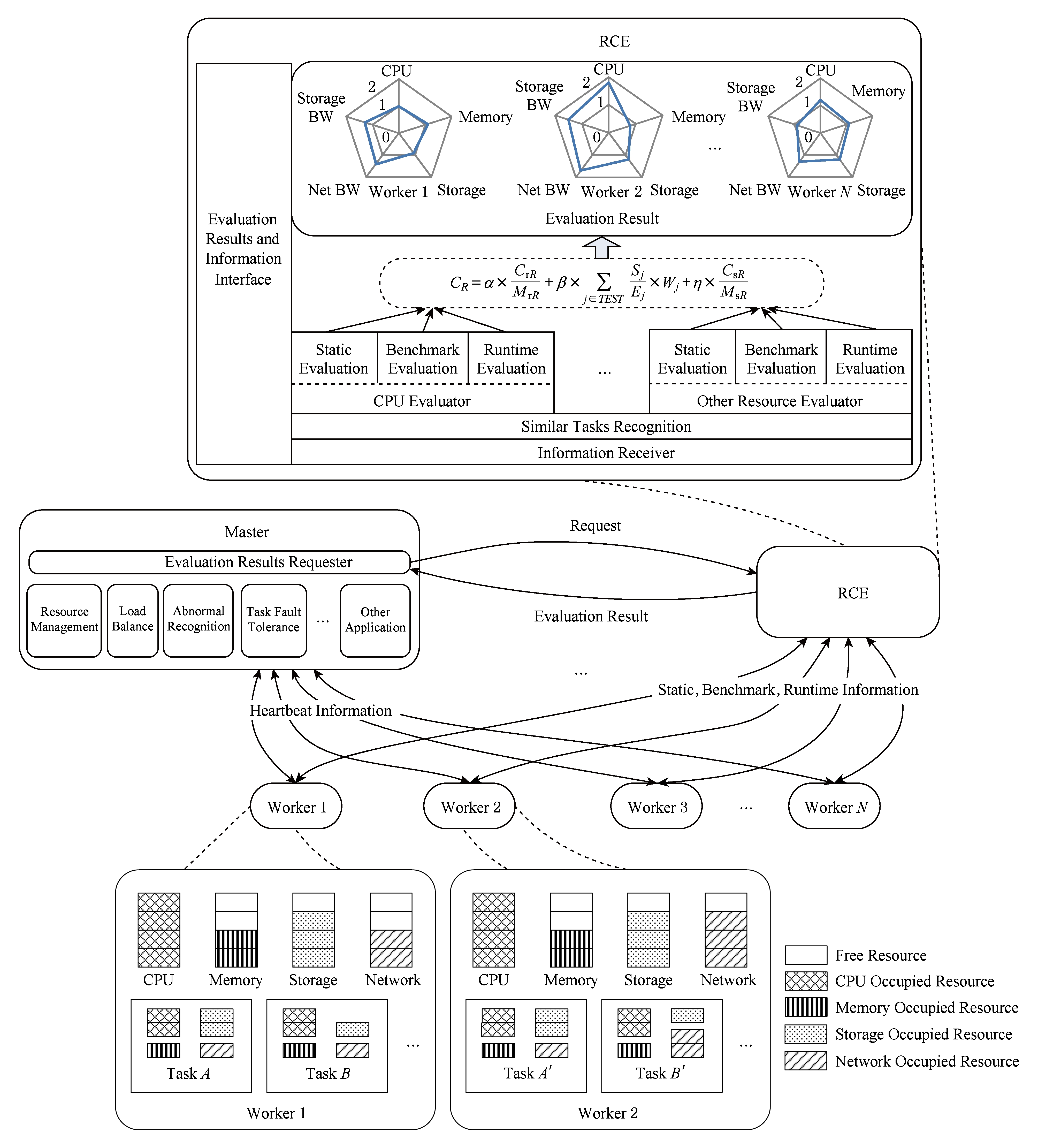
Fig. 1 Schematic diagram of RCE
图1 RCE示意图
3 . 2 相似任务识别
识别云计算负载中的相似任务是资源剩余能力评估的基础,RCE依照任务执行逻辑、处理数据大小、所处执行阶段识别相似任务,具体步骤如下:
1) 将执行逻辑相同且处理数据大小相等的任务作为相似任务的备选集合;
2) 根据运行时信息分别迭代计算任务各种资源每个进度的资源使用情况;
3) 根据任务资源使用信息划分任务执行阶段;
4) 按照任务执行阶段将备选集合划分成多个子集,执行阶段相同的任务在相同子集中,子集内的任务互为相似任务.
λ= e -5  60 ×λ′+(1- e -5 60 )×γ.
60 ×λ′+(1- e -5 60 )×γ.
(5)
式(5)为任务资源使用情况的迭代计算公式.其中,λ为任务在某进度时的资源使用量,λ′为更新前任务资源使用量,γ为更新的任务资源使用信息.当λ′=0时,采用前3次信息的平均值作为λ的初始值.
利用任务资源使用信息划分执行阶段时,依据不同资源划分出的任务阶段可能不同. RCE 依据 CPU 、内存、磁盘、网络资源得出4种执行阶段划分,依据某种资源划分任务执行阶段的流程图如图2所示.
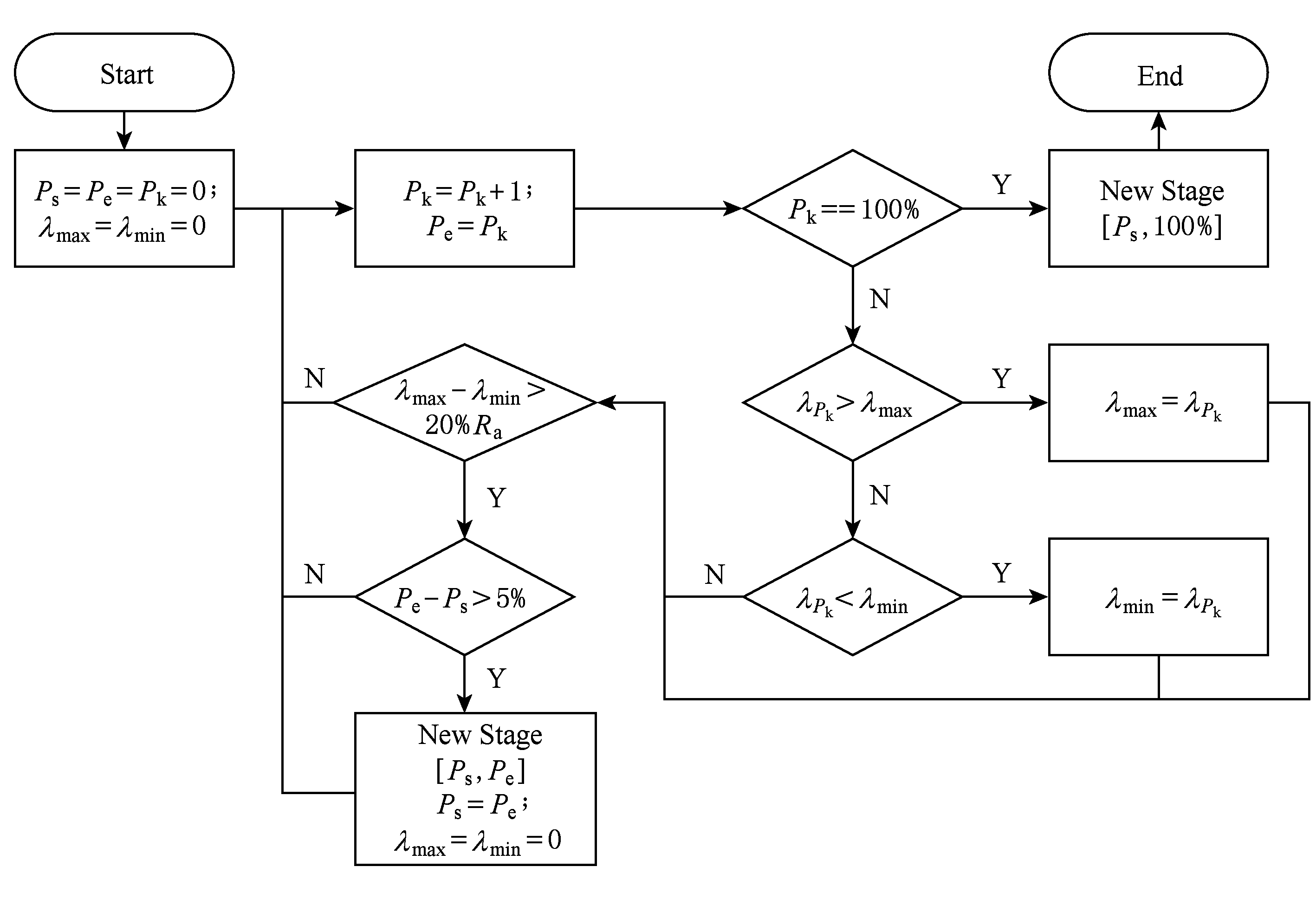
Fig. 2 Flow chart of task stage recognition
图2 任务阶段划分流程图
图2中P k ,P s ,P e 分别表示任务进度、阶段起始进度、阶段终止进度;λ max ,λ min 分别表示任务在阶段内最大、最小资源使用量.初始时,各种变量均为0;然后P e 随P k 增加,并更新[P s ,P e ]区间内的最大、最小资源使用量;当[P s ,P e ]区间大于5%并且区间内最大最小资源使用量之差大于总资源量R a %时,将[P s ,P e ]划分为1个任务阶段,直至任务划分完成.
3 . 3 计算资源分类评估
3.3.1 CPU资源评估
由于CPU架构设计的差异,相同任务使用不同架构CPU得到的性能指标可能大不相同.因此,RCE按照CPU型号系列分类评估CPU剩余能力.CPU资源运行时剩余能力 C rc 计算具体如式(6)所示,其中 C idle 为CPU空闲时间百分比, C load 为平均队列长度, TASK 为CPU上执行中任务集合,I t 为任务t平均每个时钟周期完成的指令数,M t 为任务t的 cache 失效率,S t 为任务t的上下文切换频率,M IPC t ,M m t ,M s t 分别为任务t的相似任务在同型号系列 CPU 上平均每个时钟周期完成的指令数、 cache 失效率、上下文切换频率的中位数,C t 为任务t的 CPU 时间占用率,card(TASK)为TASK集合内任务数量.
C rc = ![]() ×
× 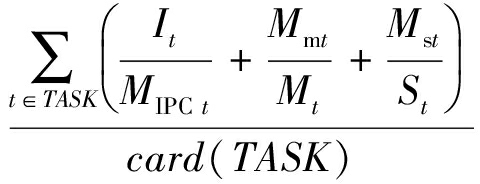 .
.
(6)
在分析 CPU 理论性能时, RCE 主要考虑计算核心数、主频、缓存等指标.由于层次越小的缓存对 CPU 性能影响越大,因此分析时赋予层次低的缓存更大的权重.
(7)
其中,C h 为计算核心数,S p 为主频,L i 为i层的缓存大小,W为小于1的权值,设置t=3.
RCE采用Whetstone [24] 作为CPU的基准测试,Fortran版的Whetstone是第1个工业标准上的通用CPU综合测试.相比常用于超级计算机科学计算的LINPACK [25] 测试,Whetstone含有浮点计算、过程调用、条件跳转、数学函数等多个测试项,更加适合测试云计算服务器CPU的综合能力.
3.3.2 内存资源评估
在内存资源评估中,RCE以缺页频率的倒数作为衡量内存资源品质的指标,并按照式(8)计算内存资源运行时剩余能力值 C rm .
C rm =(M-M u +M c ×W c +M b ×W b )×  ,
,
(8)
其中,M为内存总容量,M u 为被占用内存大小,M c 和M b 分别是 cache 和 buffer 占用内存大小,W c 和W b 分别是 cache 和 buffer 占用内存可回收百分比,M-M u +M c ×W c +M b ×W b 即内存空闲资源量.TASK为使用内存的任务集合,P t 为任务t的平均缺页频率,M p t 为任务t的相似任务平均缺页频率的中位数,M t 为任务t占用的内存百分比 ![]() card(TASK)即计算内存资源品质.
card(TASK)即计算内存资源品质.
RCE使用内存资源的理论带宽值作为内存理论性能分析结果,并采用STREAM [26] 作为内存资源基准测试,测试中启动与CPU计算核心相等的线程并行操作内存以衡量其可持续的带宽.
3.3.3 磁盘资源评估
在磁盘资源评估中,RCE以磁盘上IO请求排队及执行时间等指标衡量磁盘资源品质,而以未利用的磁盘带宽和传输次数等指标考察可用资源量,磁盘资源剩余能力C rs 计算为
![]()
(P tps -C tps ),
(9)
其中,P io ,P tps 分别为磁盘读写带宽和每秒完成传输次数的峰值;C io ,C tps 分别为磁盘当前被占用带宽和传输次数;(P io -C io )(P tps -C tps )为磁盘空闲资源量;AVG()表示求均值;Q,W,S分别为 IO 请求的平均队列长度、等待时间、执行时间;M Q ,M W ,M S 分别为各服务器上指标Q,W,S的中位数; AVG ( ![]() ,
, ![]() ,
, ![]() )即为磁盘资源品质的指标.
)即为磁盘资源品质的指标.
RCE使用磁盘转速、磁头数、缓存大小的乘积作为磁盘理论性能的分析结果.磁盘基准测试中分别读写不同大小的文件及磁盘缓存,并记录磁盘峰值带宽及传输次数作为结果,测试数据范围为16 KB~8 GB,单个测试项的读写次数从5~500次不等.
3.3.4 网络资源评估
网络资源评估针对带宽资源进行,带宽品质均相等,评估时只需考虑空闲资源量.RCE使用未利用的网络带宽作为网络空闲资源量,网络资源运行时剩余能力C rn 在数值上等于实测带宽峰值P nio 与当前被占用带宽C nio 的差,即:
C rn =P nio -C nio .
(10)
RCE使用网络设备标识的理论带宽作为理论性能.在网络资源基准测试中,RCE使用多台服务器协同测试,模拟实际网络使用并记录峰值带宽.测试中传输数据按大小分为3类,范围涵盖16 KB~2 GB.
3.3.5 评估值计算
RCE将各计算资源评估因素代入评估模型分别计算最终评估结果.由于不同计算资源的特性具有差异,RCE针对CPU、内存、磁盘、网络资源的特性分别调整评估模型参数使最终评估结果准确.评估模型中的 α , β , η 参数分别代表计算资源运行时剩余能力、基准测试性能峰值、理论性能在计算资源剩余能力评估结果中所占的权重.对于CPU资源,RCE使用默认参数0.8,0.1,0.1分别作为 α , β , η 的值;对于内存资源,RCE在默认参数的基础上提高了 α 而降低了 β , η 的值;对于磁盘和网络资源,RCE在默认参数的基础上提高了 β 而降低了 η ,这是由于资源的理论性能达不到,参考意义不大.
3 . 4 RCE实现
RCE在实现时设计为1个评估服务和若干信息采集服务组成的主从式架构,其中采集服务负责采集评估所需的各种信息并汇报给评估服务,评估服务负责分类存储各种信息、识别相似任务并使用评估模型量化运行时计算资源剩余能力评估值.评估服务可以与云平台管理服务分离部署,这使得服务不互相干扰,不影响云平台可扩展性.RCE的实现与具体云平台无关,其评估服务中设计有获取各种评估因素以及结果的接口,可供其他服务获取使用.因此,RCE可以灵活接入各种云平台提供评估服务.
RCE在评估过程中多次用到了数据的中位数.在具体实现中,我们以平衡二叉树存储信息,并使用二叉树根节点数据作为近似中位数在计算中使用,以提高中位数的获取效率.
在负载运行时得到具有时效性的计算资源剩余能力结果为匹配资源供给与需求打下基础,同时为优化云平台各种算法提供了新思路和支持.本节基于RCE设计、优化了任务需求推测、资源分配、负载均衡等算法并在Yarn平台中实现了这些算法:1)解决云平台中资源供给与需求的问题、提高云平台性能;2)演示计算资源剩余能力评估结果的应用,证明评估结果对算法优化的支持效果.
4 . 1 任务资源需求推测算法
本文依据相似任务的资源使用情况,考虑计算资源的品质因素,推测任务对CPU、内存、磁盘、网络等资源的需求,具体如算法1所示:
算法1 . 任务资源需求推测算法.
输入:任务T、相似任务集合S T ;
输出:任务T的资源需求.
① for T中每个阶段 do
② R c ,R m ,R s ,R n ,N,T time ,N time ←0;
③ M←Median(θ,S T );
④ for S in S T do
*叠加资源使用量并计数*
⑤ R c ←R c +S c × max (θ M ,1);
⑥ R m ←R m +S m ;
⑦ N←N+1;
⑧ R s ←R s +S s ;
⑨ T t ←T t +S t ;
⑩ S nr ≪S sr ? continue :(R n ←R n +S n ,
N t ←N t +S t );
 end for
end for
 T c ← min (R c N,100%);
T c ← min (R c N,100%);
*推测资源需求*
 T m ←R m N;
T m ←R m N;
 T s ←R s T t ;
T s ←R s T t ;
 T n ←R n N t ;
T n ←R n N t ;
 end for
end for
资源需求推测算法推测任务每个阶段的资源需求,首先初始化变量并取得与任务 T 使用相同型号系列CPU的相似任务集合 S T 中任务使用的CPU资源品质的中位数 M .在资源总量叠加过程中,算法使用任务CPU资源品质 θ 与 M 的商衡量当前CPU资源的品质,任务S占用的 CPU 时间S c 与 max (θ M,1)的乘积被叠加进 CPU 的总量R c 中.当θ Mlt;1时,即任务 CPU 资源品质较差时, max (θ M,1)按1计算,以防止 CPU 资源品质突然变差造成需求推测变小.之后算法叠加相似任务内存使用量R m 并记录任务数.由于磁盘和网络资源只叠加传输量,因此并不考虑资源能力因素.磁盘传输量R s 分读和写分别统计,并记录任务执行的总时间T t .在计算相似任务网络传输量及传输时间时,算法会根据网络接收数据量S nr 和磁盘读取数据量S sr 过滤掉具有数据本地性的任务,以保证推测准确性.最后算法计算相似任务各种资源的平均使用量或平均传输速度作为任务资源需求的推测值.
4 . 2 资源分配算法
基于RCE的资源分配算法依据计算资源剩余能力评估结果和需求推测值提高资源供给与需求的匹配程度,一方面充分满足任务的资源需求,另一方面减少资源碎片、提高计算资源利用率.资源分配算法如算法2所示:
算法2 . 资源分配算法.
输入:服务器集合S e 、任务资源需求T x .
① for s∈S e do
② if C idle × min (θ M,1)gt;T c then
*检查 CPU 资源*
③ if C m -M× min ( max (1-C rm ,0)+Th 0 , Th 1 )gt;T m then *检查内存资源*
④ if C s gt;T s and C b - Th s × B s C st gt;T b and T e T w gt;Th w then *检查磁盘 IO 资源*
⑤ if C n -Th n ×B n C nt gt;T n then
*检查网络资源*
⑥ AllocResoucre(s, T x );
*分配资源*
⑦ R as ←R as \{T x }; *更新资源量*
⑧ end if
⑨ end if
⑩ end if
end if
end for
算法2遍历云平台服务器集合S e 查找合适任务执行的资源.算法首先检查服务器 CPU 资源是否满足任务需求,C idle 为 CPU 空闲百分比,θ为服务器 CPU 资源品质,M为相同型号系列 CPU 资源品质的中位数,T c 为任务对 CPU 资源的需求量.由于任务对内存带宽的使用不受控制,因此在内存方面只考虑内存可用空间C m 在保留一定比例后是否满足任务的使用需求T m ,M为总内存大小,C rm 为内存资源当前剩余能力. min ( max (1-C rm ,0)+Th 0 ,Th 1 )为保留比例,该数值根据内存资源剩余能力在Th 0 和Th 1 之间调节,剩余能力升高则预留减少,反之则预留增加.之后算法2检查磁盘容量、带宽等资源,当磁盘可用空间C s 满足任务磁盘空间需求T s 、磁盘可用带宽C b 在预留一定比例之后满足任务磁盘带宽需求T b 并且磁盘当前状态良好时,则通过磁盘资源检查.B s 为磁盘实测带宽峰值,C st 为磁盘资源剩余能力评估结果,T e 为磁盘 IO 请求的平均执行时间,T w 为磁盘 IO 请求平均等待时间.最后,算法检查可用网络带宽C n 在保留网络实测带宽B n 的一定比例之后是否满足任务的网络带宽需求T n ,其中Th n 为预留阈值,C nt 为网络资源评估值.Th n C nt 为保留带宽比例,该比例与网络资源评估值成反比,即性能越好的网络资源的保留带宽越小,反之保留带宽增加以避免网络拥塞.通过所有资源检查之后,分配算法向任务分配计算资源,并更新服务器可用计算资源量R as .
4 . 3 负载均衡算法
云计算平台负载是否均匀分布是衡量平台可用性的重要指标之一,基于RCE的负载均衡算法依据RCE评估结果和任务资源特性筛选被分配服务器,使负载在各服务器上均匀分布,实现有效的负载均衡.
R jR = 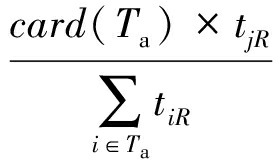 .
.
(11)
定义3 . 任务资源需求度. 假设任务i对资源R的需求量为t iR ,则任务j对资源R的需求度R jR 如式(11)计算,T a 为所有任务集合,card(T a )为T a 中元素个数.
定义4 . 任务主资源.任务资源需求度最大的资源称为任务的主资源,任务主资源在一定程度上可以刻画任务的资源特性.
负载均衡算法如算法3所示:
算法3 . 负载均衡算法.
输入:任务资源需求T x 、任务平均资源需求A x 、资源类型X.
① M←0;
② for x∈X do
③ R x ←T x A x ;
*计算任务每种资源需求度*
④ R m ←Mlt;R x ?(M←R x ,x): R m ;
*确定主资源*
⑤ end for
⑥ T 0 ← system time ;
⑦ for s∈S e do
⑧ T c ← system time ;
⑨ if T c -T 0 lt;Th T then *检查时延*
⑩ Check(C rm )?Alloc(T x ,s):;
*以任务主资源筛选服务器,并检查、分配资源*
else
Alloc(T x ,s); *检查、分配资源*
end if
end for
算法3首先计算任务T对各种资源的需求度,并找出任务的主资源R m .之后算法遍历当前服务器集合S e ,在时延阈值Th T 之内依据资源的评估值 ![]() 筛选出符合任务资源特性的服务器,如果超出时延阈值,则放弃对主资源质量的要求.Alloc()检查任务的所有资源需求是否能够在服务器上得到满足并分配资源,具体的资源检查、分配过程与算法2中一致.
筛选出符合任务资源特性的服务器,如果超出时延阈值,则放弃对主资源质量的要求.Alloc()检查任务的所有资源需求是否能够在服务器上得到满足并分配资源,具体的资源检查、分配过程与算法2中一致.
4 . 4 异常识别算法
云平台中服务器资源异常轻则影响任务执行,重则影响整个平台运转.基于RCE的异常识别算法是通过分析RCE的评估指标来识别异常,并采取报告异常原因、停止分配等相关措施避免异常造成严重影响.异常识别算法如算法4所示:
算法4 . 异常识别算法.
输入:服务器集合S e 、疑似集合G、异常集合H;
输出:异常集合H.
① for C∈S e do
② if C p gt;Th p then
③ ClearTimestamp(C); *清除时间戳*
④ G←G\{C}; *更新疑似集合*
⑤ H←H\{C}; *更新异常集合*
⑥ continue ;
⑦ end if
⑧ T 0 ←(C IPC lt;Th IPC and C idle lt;Th idle )? system time :0;
*更新 CPU 资源异常时间戳*
⑨ T 1 ←(C pf gt;Th pf and C free lt;Th free )? system time :0;
*更新内存资源异常时间戳*
⑩ T 2 ←(C w gt;Th w or C l gt;Th l )? system
time :0;
*更新 IO 资源异常时间戳*
if T 0 +T 1 +T 2 ≠0 then
G←G∪{C}; *将C加入疑似集合*
else
G←G\{C};
H←H\{C};
continue ;
 end if
end if
 T← system time ;
T← system time ;
 if (T-T 0 )×T 0 gt;Th time ×T 0 or (T-T 1 )×T 1 gt;Th t ×T 1 or (T-T 2 )×T 2 gt;Th t ×T 2 then
if (T-T 0 )×T 0 gt;Th time ×T 0 or (T-T 1 )×T 1 gt;Th t ×T 1 or (T-T 2 )×T 2 gt;Th t ×T 2 then
*检查异常持续时间*
 RecordInformation(C);
RecordInformation(C);
*记录异常信息*
 H←H∪{C}; *将C加入异常集合*
H←H∪{C}; *将C加入异常集合*
 end if
end if
 if C∈G or C∈H then
if C∈G or C∈H then
 StopAllocation(C);
StopAllocation(C);
*停止分配C的资源*
 end if
end if
 end for
end for
算法4使用任务进度指标C p 进行初筛,C p 由服务器上任务与其相似任务的每秒进度值计算,当C p 大于集合S中各服务器该指标的10分位值Th p 时,则认为服务器C不存在异常;如果服务器上可能存在异常,则开始分析服务器计算资源.C IPC 由服务器上各任务与其相似任务平均每个时钟周期完成的指令数的比值,再与其资源占用百分比相乘求和后再除以总资源占用率计算.当服务器任务指标C IPC 小于集合S中相同型号系列 CPU 相应指标的10分位值Th IPC 并且 CPU 空闲百分比C idle 小于Th idle 时,即 CPU 大部分时间被占用但是性能很差,则加盖时间戳T 0 .C pf 与C IPC 计算过程相似,其指示服务内存平均缺页频率情况.当服务器C pf 指标大于各服务器相应指标的10分位值Th pf 并且内存空闲百分比C free lt;Th free 时,则加盖时间戳T 1 .当磁盘 IO 请求平均等待时间C w 大于各服务器 IO 请求平均等待时间的95分位值Th w 或者磁盘 IO 队列长度C l 大于各服务器 IO 队列长度的95分位值Th l 时,则加盖时间戳T 2 .如果3个时间戳均为0,则将服务器C从疑似异常集合G以及异常集合H中除去并进入下一次循环,否则将C加入疑似异常集合G中.当服务器由于某种原因在疑似异常集合中持续存在超过Th t 时,则将服务器加入异常集合并记录异常信息.当服务器处于异常或疑似异常集合中时,云平台将暂停分配该服务器资源,避免异常造成影响.
当没有足够数据可供分析时,阈值不准确会造成算法判断失误率大幅升高,此时算法会暂停识别工作等待足够数据出现.相比传统的异常识别方法,基于RCE的异常识别算法在识别速度和精度上均有提升,它不仅可以精确报告出现异常的计算资源,而且可以在异常出现时停止分配服务器资源,防止异常造成的影响扩大,更加适合应用在实际环境中.
4 . 5 缓慢任务发现算法
在云计算中,作业中全部任务完成才标志作业完成,因此避免个别任务拖慢整个作业十分重要.基于RCE的缓慢任务发现算法依据RCE评估结果及运行时信息精确识别缓慢任务并在必要时启动冗余任务,从预防到补救全方位避免作业完成时间被拖长.缓慢任务发现算法如算法5所示:
算法5 . 缓慢任务发现算法.
输入:任务集合S ta 、疑似集合G、缓慢集合H;
输出:
① for T∈S ta do
② T 0 ←(T s lt;Th s and T IPC lt;Th IPC )?
系统时间:0;
③ G←(T 0 ==0)?(H←H\{T},G\{T}):G∪{T};
④ T 1 ←系统时间;
⑤ if (T 1 -T 0 )×T 0 gt;T t ×T 0 then
⑥ H←H∪{T};
⑦ if (100%-T p ) T s gt;(100%+Th t )×A T then
⑧ ApplyAndRestart(T);
*申请资源重启任务*
⑨ end if
⑩ end if
end for
算法5监测任务平均每秒钟取得的进度T s 以及平均每个时钟周期完成的指令数T IPC ,如果T s 和T IPC 均小于相似任务相应指标的阈值,则记录时间戳T 0 并将任务加入观察集合G中.当1个任务在观察集合G中持续存在超过阈值T t 时,将任务加入执行缓慢任务集合H并判断是否需要启动冗余任务.假设启动的冗余任务取得相似任务平均完成时间A T ,如果该完成时间相对当前已取得进度T p 且继续以当前速度T s 执行的任务有Th t 的提升,则算法为任务申请资源并重新启动任务.算法在申请冗余任务所需资源时会标识只接受任务主资源评估值大于一定值的服务器,以保证冗余执行快速完成.
调节算法中的阈值T t 可以在发现缓慢任务的耗时和准确性之间做出取舍.当阈值T t 较小时,算法5对执行缓慢的任务十分敏感,这一方面大幅缩短了发现缓慢任务的耗时,另一方面将执行稍微缓慢的任务识别为缓慢任务,在发现准确度方面做出了一定的妥协.在任务被确认执行缓慢之后,算法5权衡利弊决定是否启动冗余任务,因此并不是所有执行缓慢任务都被冗余执行,这很大程度上弥补了准确度下降带来的影响.调节阈值Th t 可以决定冗余任务的启动条件,冗余任务占用的总资源以及任务数也可以配置,以避免过度启动冗余任务浪费计算资源.
算法5发现缓慢任务的精确度依赖于各种阈值的准确性,当阈值不准确时算法会暂停发现以避免发现效率大幅下降.当阈值随平台运行时间及负载信息的增加而趋于准确之后,算法会继续工作.
本节首先介绍各种测试的环境以及负载;之后测试验证RCE和基于RCE的各种算法,证明RCE评估的有效性、时效性、扩展性以及RCE评估结果对算法和平台的优化支持.
5 . 1 测试环境及负载介绍
本文使用国家高性能计算中心(西安)中的一个集群测试验证,该集群由30台服务器组成,具体配置如表1所示.RCE方法有效性和时效性测试使用集群中3台 A 类型和2台 B 类型服务器,在1台 A 类型服务器上部署RCE评估服务,其余4台服务器作为计算节点.在方法扩展性测试中,使用集群所有服务器模拟各种规模的集群.该部分测试使用CPU、内存、磁盘等资源特性突出的测试程序作为负载.
Table 1 Hardware Information of Cluster
表1 集群硬件配置

在基于RCE的算法测试及平台优化测试中均使用集群所有服务器,Yarn平台管理服务和RCE评估服务被部署在 A 类型服务器上,其余节点作为云平台计算节点.集群上部署Yarn 平台并在平台上配置MapReduce,Spark,Storm等多种计算框架.该部分测试负载由多个处理不同大小数据的作业混合组成.测试中以负载规模表示测试数据大小,负载规模1定义为使集群内所有服务器计算核心同时执行任务所处理的数据大小.测试负载单次处理数据最高达到300 GB,数据来源于Wikipedia、集群日志以及随机生成等.各作业数据大小服从Facebook作业大小分布 [27] ,提交时间服从泊松分布.
本文分别在独享和云2种环境下测试验证:在独享环境中,整个集群只执行测试负载;在云环境中,集群资源由Yarn平台和科学计算等应用共享,集群处于日常真实使用状态.
5 . 2 RCE方法测试
5.2.1 有效性测试
由于空闲资源量从系统直接采集,而资源理论性能和基准测试等信息不变,因此评估值的有效性主要由资源品质值决定.测试从2方面证明RCE结果的有效性:1)检验RCE评估出资源品质值能否体现出真实资源品质的变化;2)以任务平均完成时间验证评估出资源品质值的有效性.如果评估出各服务器上计算资源品质随负载变化,且与任务完成时间比较关系一致,则说明RCE评估结果有效地反映出了资源能力.资源品质变化测试和有效性测试均使用资源特性单一负载按计算资源类型分别进行.由于网络评估中只考虑了空闲资源量,而该值由系统中采集的资源使用量决定,因此无需证明有效性.
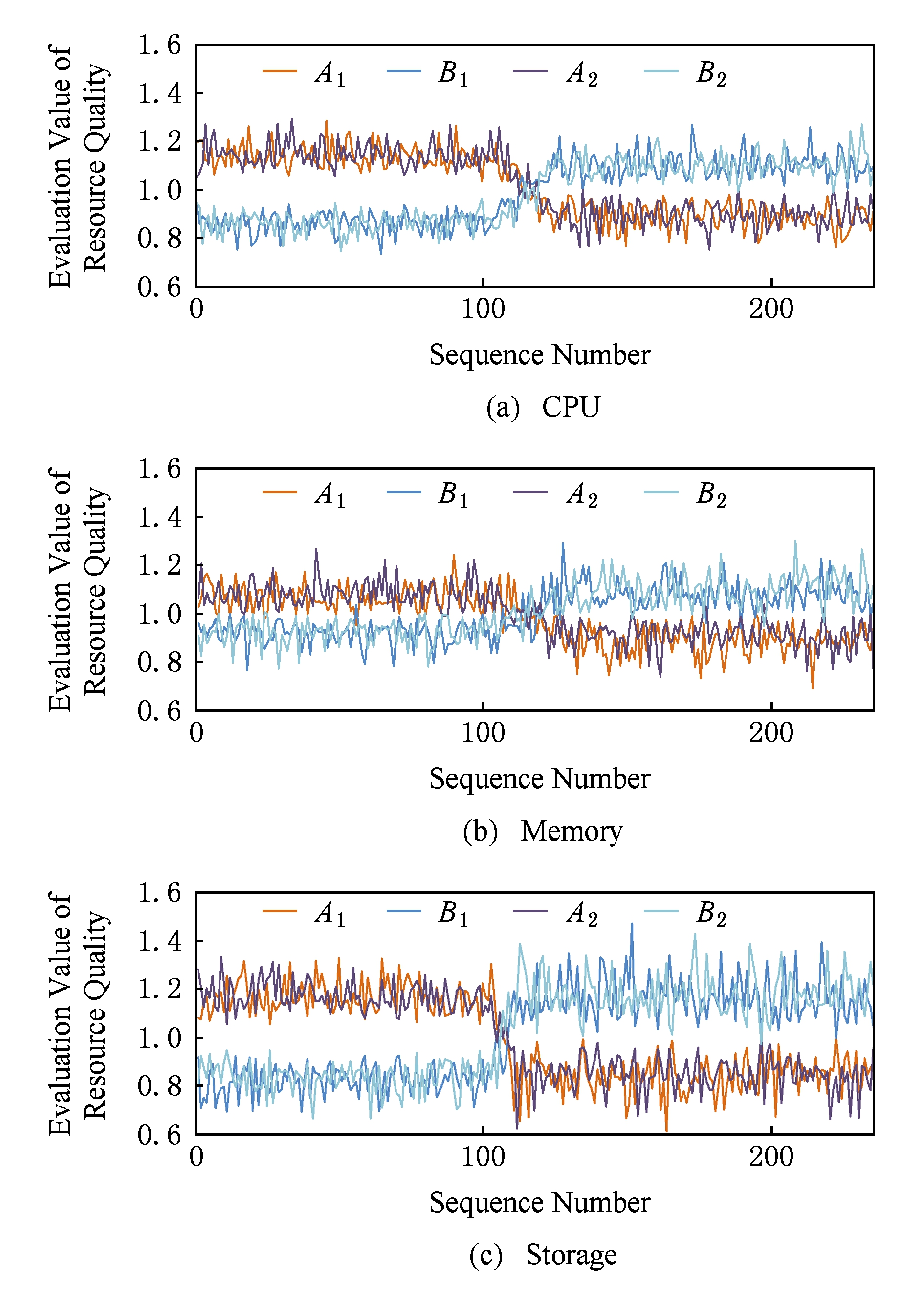
Fig. 3 The influence of workload on resource quality
图3 负载变化对资源品质的影响
资源品质变化测试初始时在每个服务器上提交相同数量的负载,随后逐渐增加配置较好的 A 类型服务器上的负载数量,观察资源品质评估值的变化.资源品质变化情况如图3所示,图3中曲线A 1 ,A 2 和B 1 ,B 2 分别为A类型和B类型服务器资源品质值变化.从图3中可以看出,开始时曲线A 1 ,A 2 的值大于曲线B 1 ,B 2 的值,即A类型服务器资源品质值在初始时优于B类型;随着A类服务器负载加重,A 1 ,A 2 开始下降而B 1 ,B 2 逐渐上升,这是由于A类型服务器负载过重导致资源品质指标下降,品质指标中位数发生变化,从而影响B类型服务器资源品质值反方向变化;负载持续加重时,2种类型服务器上计算资源品质的比较关系发生逆转,B类型服务器资源品质值优于A类型;当负载数量不再变化,资源品质值也随之稳定.综上所述, RCE 对资源品质的评估值随资源运行情况而变化,可以反映出真实资源品质.
资源品质有效性测试中在每个服务器上提交相同数量的测试负载.图4所示为各资源的品质情况及任务平均完成时间,曲线A 1 ,A 2 和B 1 ,B 2 意义与图3中一致, ![]() ,
, ![]() 和
和 ![]() ,
, ![]() 分别为各A类和B类服务器归一化后的任务平均完成时间.图4中同类服务器同种计算资源品质值整体稳定,这是因为测试中服务器上负载单一且数量稳定.资源品质持续小幅度波动可能由相似任务集合变动等因素引起.图4( a )( b )( c )三幅图中 CPU 、内存、磁盘的品质值波动幅度逐渐变大,这可能与评估中考虑的因素数量有关,考虑因素越全面则波动幅度越小.从图4可以看出:A类服务器的资源品质值始终高于B类服务器,A类服务器上测试任务平均完成时间也始终优于B类服务器;同类型服务器资源品质基本一致,而任务平均完成时间也基本一致.这证明了 RCE 对计算资源品质评估正确,评估结果有效.
分别为各A类和B类服务器归一化后的任务平均完成时间.图4中同类服务器同种计算资源品质值整体稳定,这是因为测试中服务器上负载单一且数量稳定.资源品质持续小幅度波动可能由相似任务集合变动等因素引起.图4( a )( b )( c )三幅图中 CPU 、内存、磁盘的品质值波动幅度逐渐变大,这可能与评估中考虑的因素数量有关,考虑因素越全面则波动幅度越小.从图4可以看出:A类服务器的资源品质值始终高于B类服务器,A类服务器上测试任务平均完成时间也始终优于B类服务器;同类型服务器资源品质基本一致,而任务平均完成时间也基本一致.这证明了 RCE 对计算资源品质评估正确,评估结果有效.
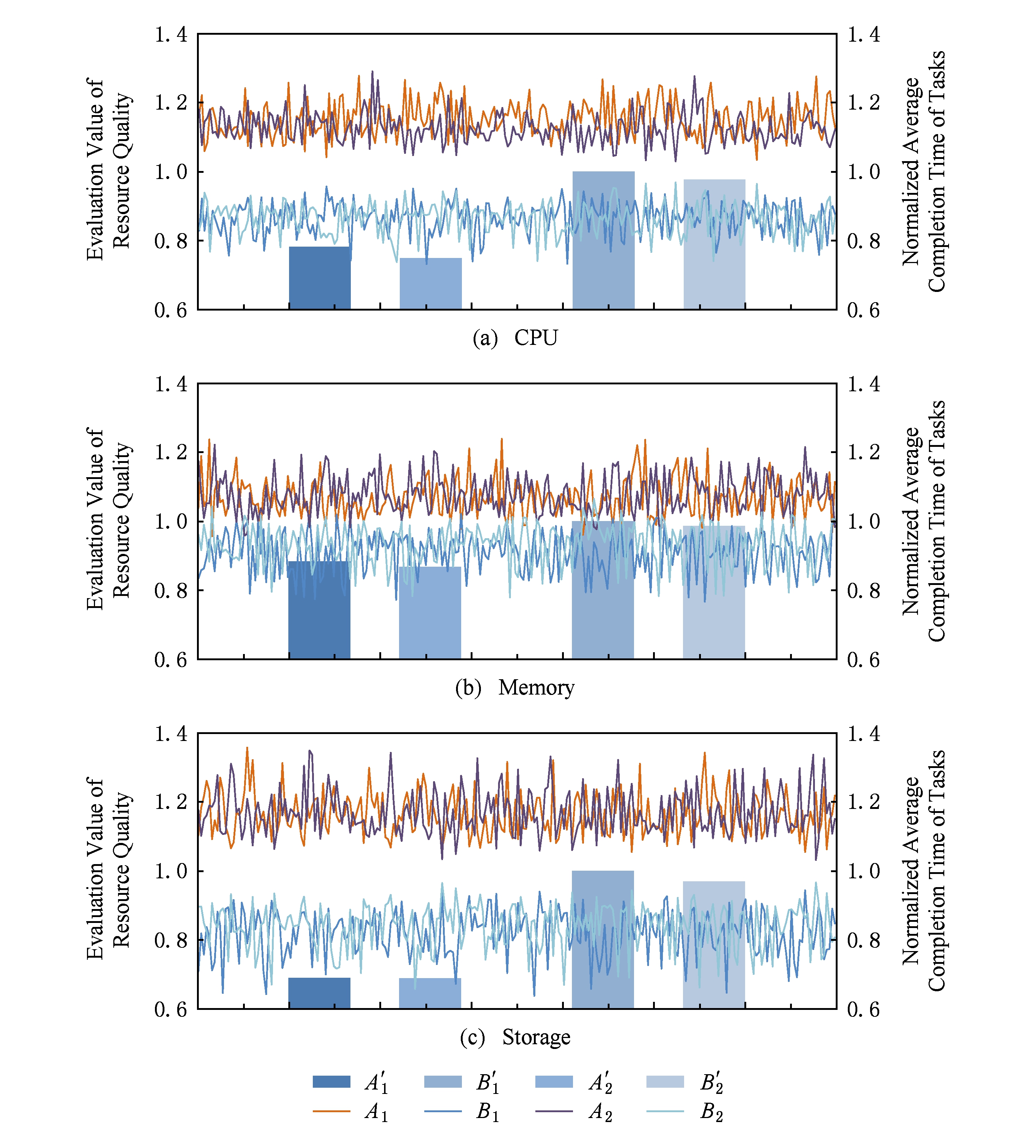
Fig. 4 Resource quality and average completion time of tasks
图4 计算资源品质与任务平均完成时间
5.2.2 时效性测试
RCE时效性测试在之前测试程序的基础上增加了网络测试程序.测试在50 ms,100 ms,200 ms,400 ms,800 ms的采集周期下分别进行,图5为不同采集周期下RCE评估各种资源剩余能力的评估耗时变化.从图5中可以看出,采集周期变小时,各种资源的评估耗时略有增加.因为周期越小,RCE接收信息越频繁,对数据的处理、维护代价越大.在同一采集周期下,磁盘与网络的评估耗时基本相同,而内存、CPU的评估耗时及波动幅度均明显大于磁盘与网络,因为CPU和内存在评估过程中需要更新、处理多种数据.
当采集周期为50 ms时,CPU评估平均耗时14.06 ms,内存评估平均耗时10.58 ms,磁盘与网络的评估平均耗时分别不足6 ms和5 ms.因此RCE方法在运行时评估的资源年剩余能力评估结果具有时效性.
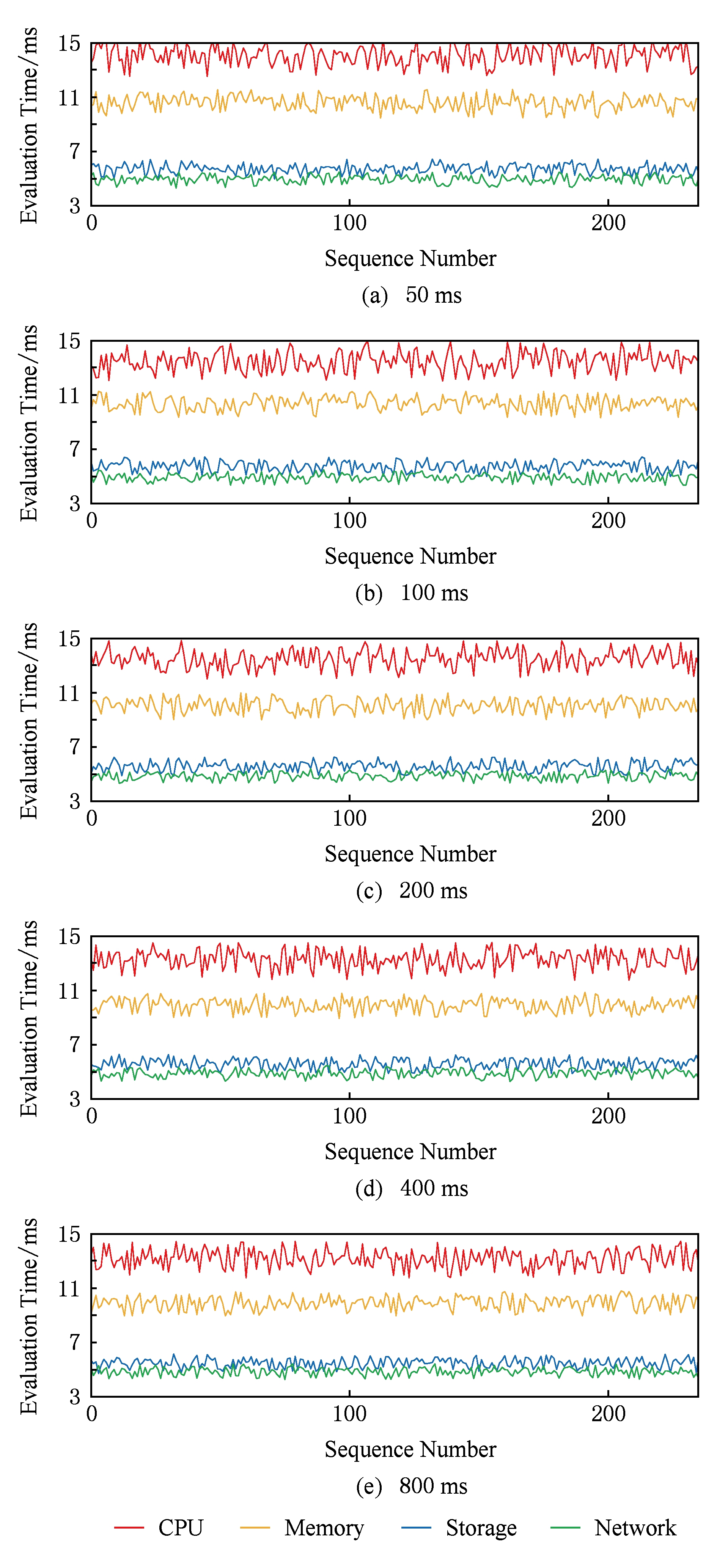
Fig. 5 Evaluation time of RCE in different acquisition cycles
图5 不同采集周期下RCE评估耗时
5.2.3 扩展性测试
扩展性测试中,各计算节点将每次的采集信息在6 000 ms的周期内向RCE评估服务发送多次,分别模拟600,1 200,1 800,2 400,3 000节点的集群规模.
RCE在不同集群规模下的评估耗时如图6所示.从图6中可以看出,扩展性测试评估耗时及其波动幅度大于之前的测试,且随着模拟规模增大而增大.原因是集群规模的增大导致网络传输、数据处理、数据结构维护、相似任务识别等代价增加.CPU和内存的资源评估耗时增加大于磁盘和网络资源的资源评估耗时,因为CPU和内存资源在评估中需要处理的数据更多,使用平衡树数据结构更频繁,相似任务集合维护代价会更大.
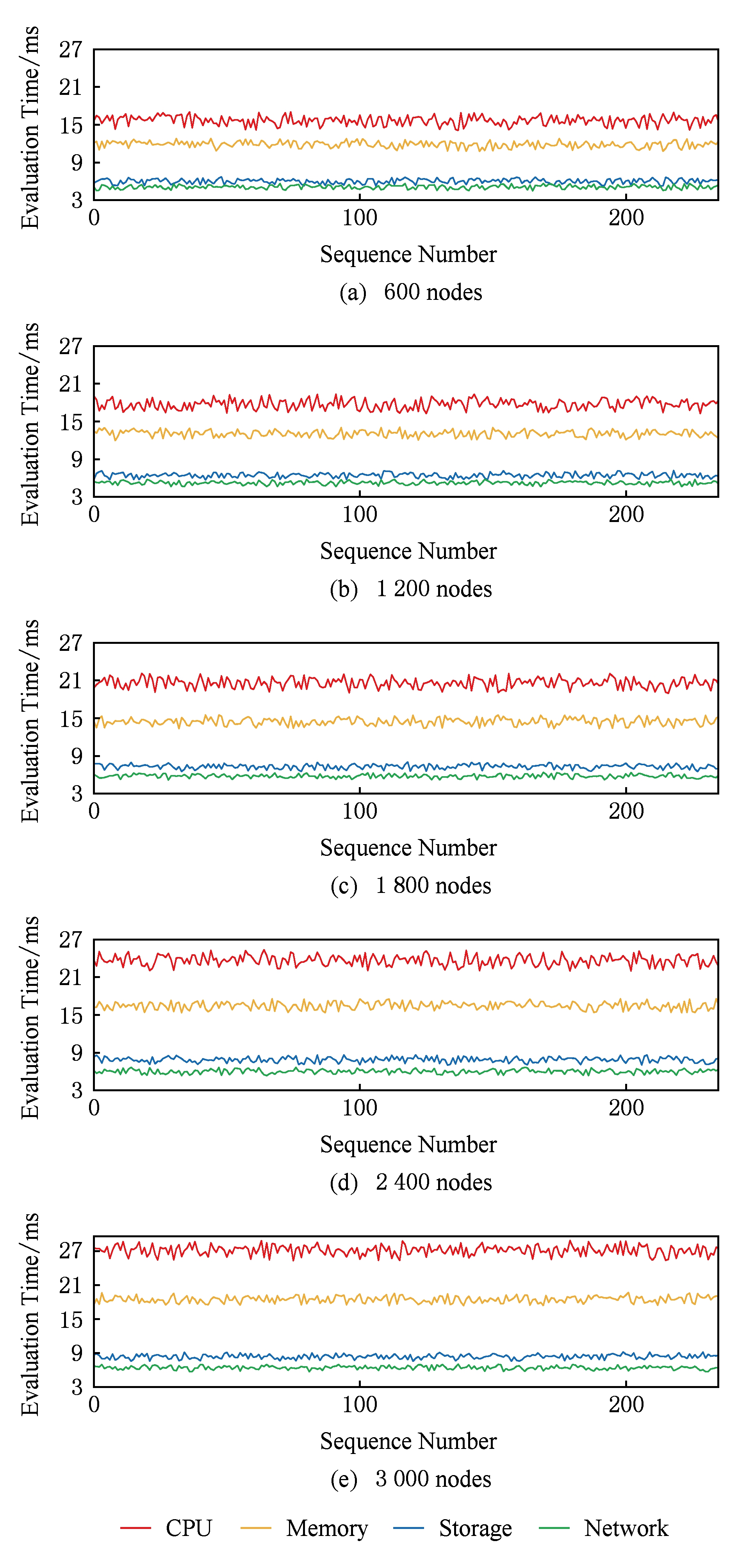
Fig. 6 Evaluation time of RCE in different cluster scale
图6 RCE在不同集群规模下的评估耗时
当模拟集群规模达到3 000节点时,CPU、内存、磁盘、网络评估的平均耗时分别为27.16 ms,18.49 ms,8.41 ms,6.45 ms.RCE方法在节点规模达到3 000时仍能得出具有时效性的结果,说明该方法扩展性良好,可以应用在大规模云平台上.
5 . 3 基于RCE的算法测试
5.3.1 资源分配算法测试
资源分配算法测试的负载规模从2开始,每次递增0.5,当规模达到16时,单次负载处理数据总计达到240 GB.资源分配测试分别在独享和云环境下进行,相同负载规模下完成时间越小表示性能越好.资源分配测试2种环境下测试结果如图7和图8所示.
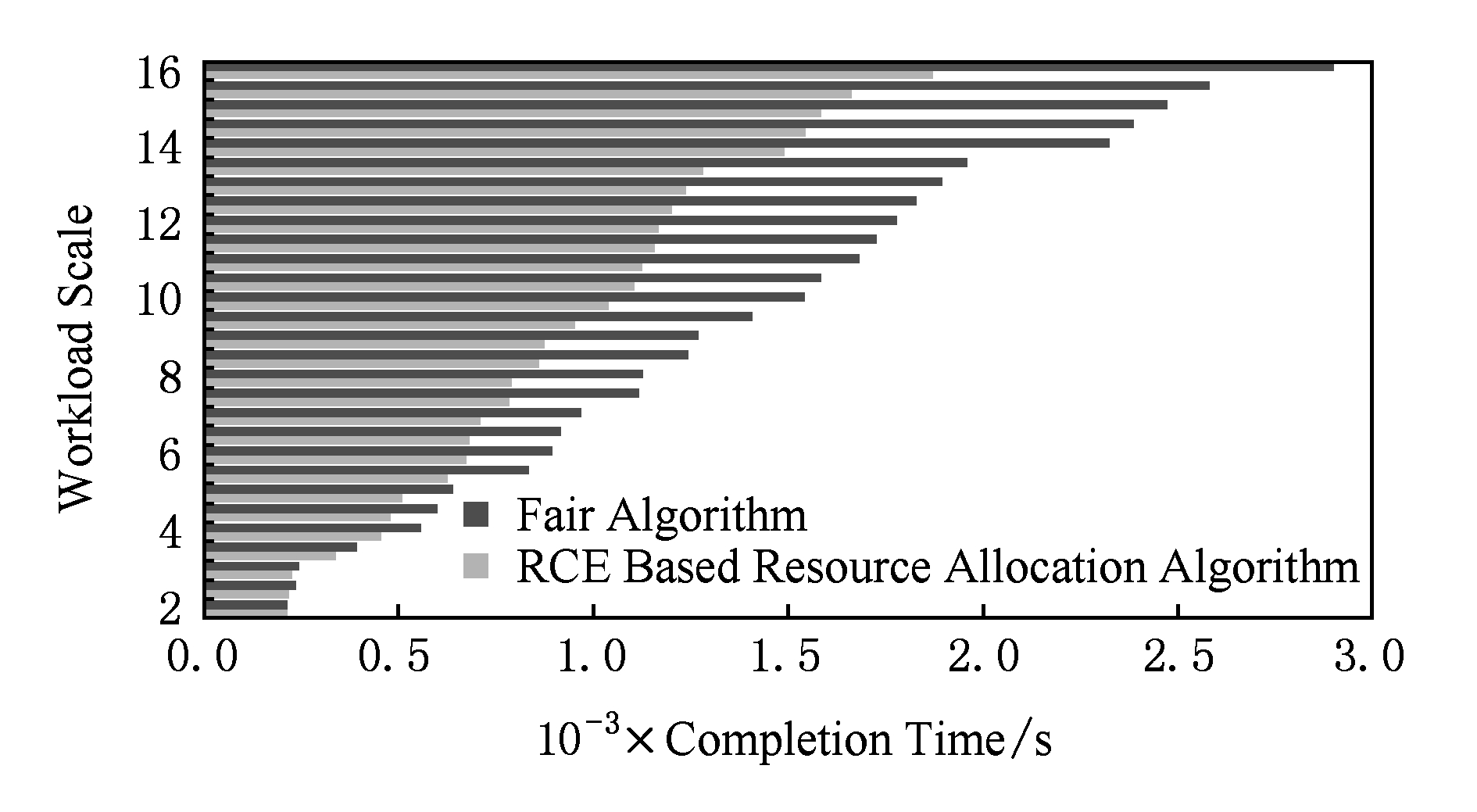
Fig. 7 Resource allocation test in dedicated environment
图7 独享环境下资源分配测试
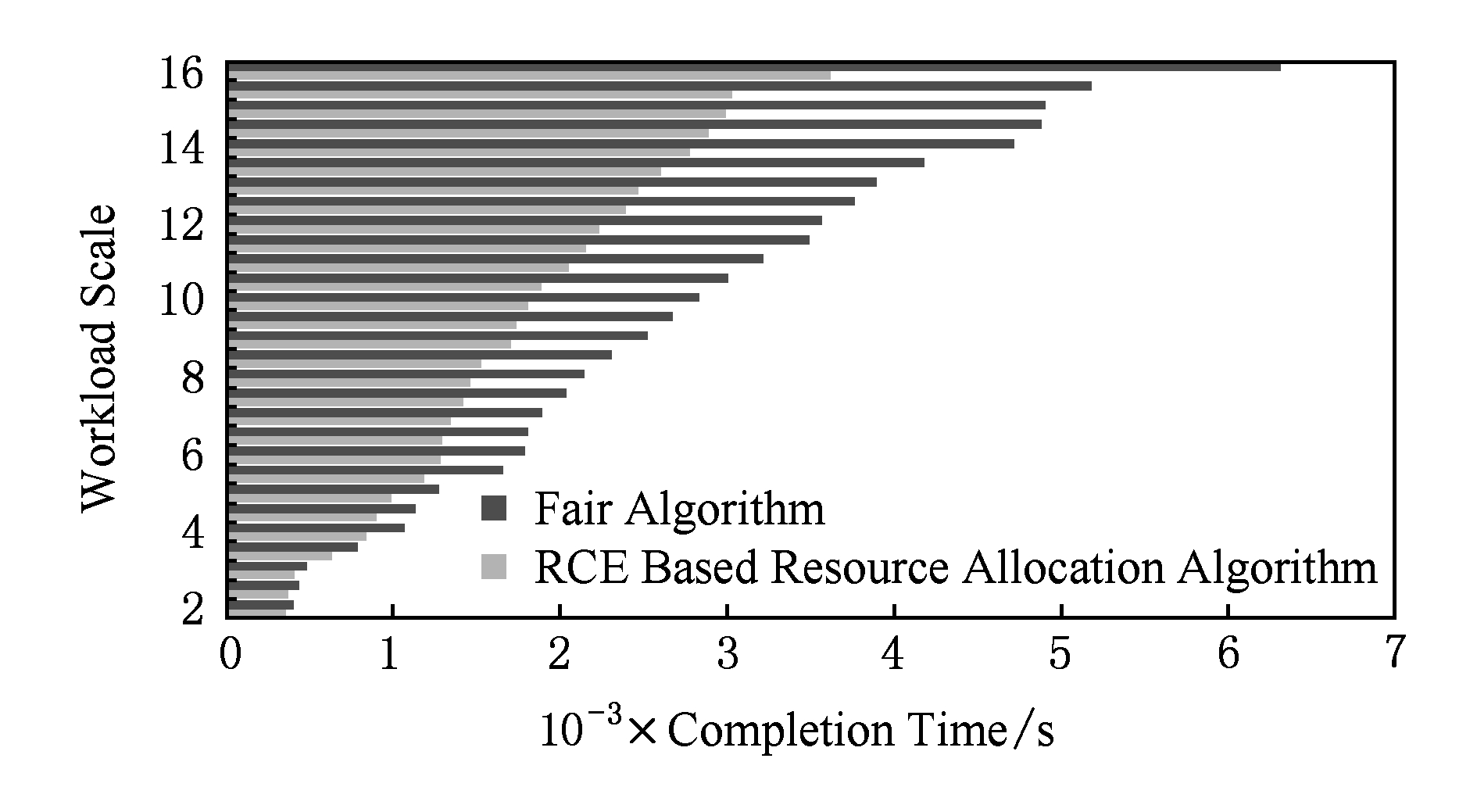
Fig. 8 Resource allocation test in cloud environment
图8 云环境下资源分配测试
从图7中可以看出,基于RCE的资源分配算法在相同规模负载下总是取得比Fair [27] 算法更小的完成时间,并且随着负载规模的增大,两者负载完成时间差距越来越显著.负载规模超过14时,基于RCE的资源分配算法的性能提升稳定在35.5%左右.独享环境下带来的性能提升源于对任务资源需求和计算资源剩余能力的准确量化.
相比在独享环境中的测试结果,云环境测试在相同规模负载下的完成时间普遍大幅增加,这是环境中其他应用占用及争抢计算资源所造成的.与独享环境资源分配测试结果一致的是,云环境中资源分配算法的优化效果随着负载规模的增大而增大.不同的是资源分配算法在云环境中取得了更好的效果,在规模超过14后负载完成时间降低稳定在41%左右.原因是Fair算法不感知其他应用造成的计算资源剩余能力变化,也不在分配资源时对计算资源剩余能力的变化做出调整,造成了计算资源被过多的任务争抢使用,最终导致负载完成时间大幅增加.基于RCE的资源分配算法依据时刻变化的计算资源剩余能力评估值调整资源分配,避免了计算资源承载过多的任务.
对比图7和图8,当测试的负载规模较小时,2图中柱状图均十分接近.原因有:1)基于RCE的资源分配算法的阈值由于负载执行信息过少未达到精准,效果不佳;2)负载规模较小时,负载中处理数据量大的作业往往决定着整个负载的完成时间,优化效果不明显.
5.3.2 负载均衡算法测试
负载均衡测试分别在独享和云2种环境下进行,每次均提交规模为20的负载.负载执行中对各服务器上CPU、内存、磁盘、网络等资源的使用情况随机采样并计算资源利用率均值和标准差.测试结果以CPU被利用的时间百分比作为CPU资源利用率;以内存空间被任务占用的百分比作为内存资源利用率;以磁盘和网络当前传输速度占实测峰值传输速度的百分比作为磁盘和网络资源利用率.
独享环境下测试结果如图9所示,基于RCE的负载均衡算法明显提高了各种资源的平均利用率,并且降低了各服务器上资源利用率的差异,具体变化如表2所示,表2显示云平台中各个服务器上资源使用情况趋于均匀,负载均衡取得了良好的效果.云环境下测试结果如图10所示,基于RCE的负载均衡算法在云环境中同样取得了良好的效果,各种资源平均利用率提高,且各服务器间资源利用率差异降低,负载均匀分散在各个服务器上,具体变化如表3所示.
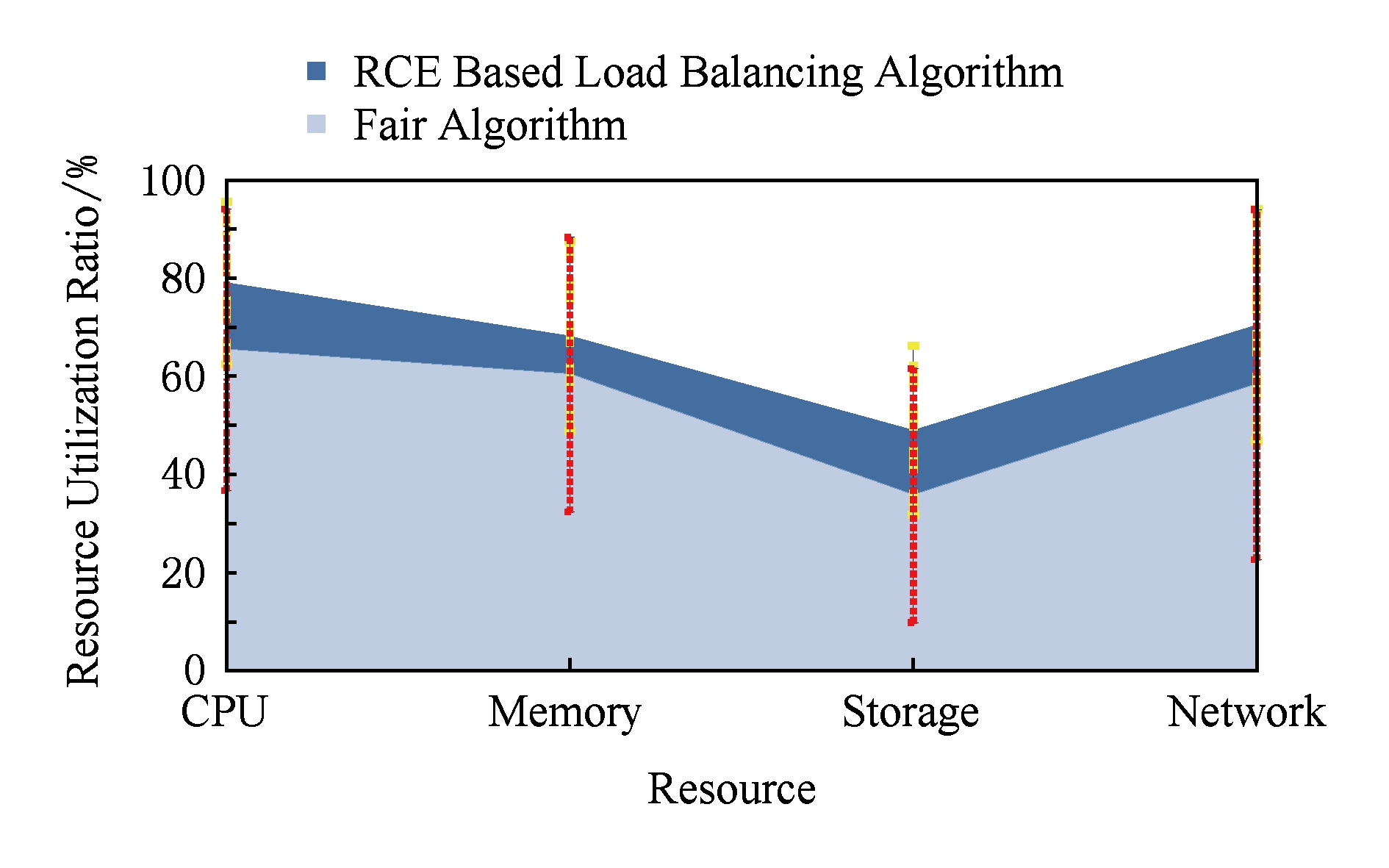
Fig. 9 Resource utilization in dedicated environment
图9 独享环境下负载资源利用情况
Table 2 Changes of Resource Utilization in Dedicated Environment
表2 独享环境中资源使用情况变化 %
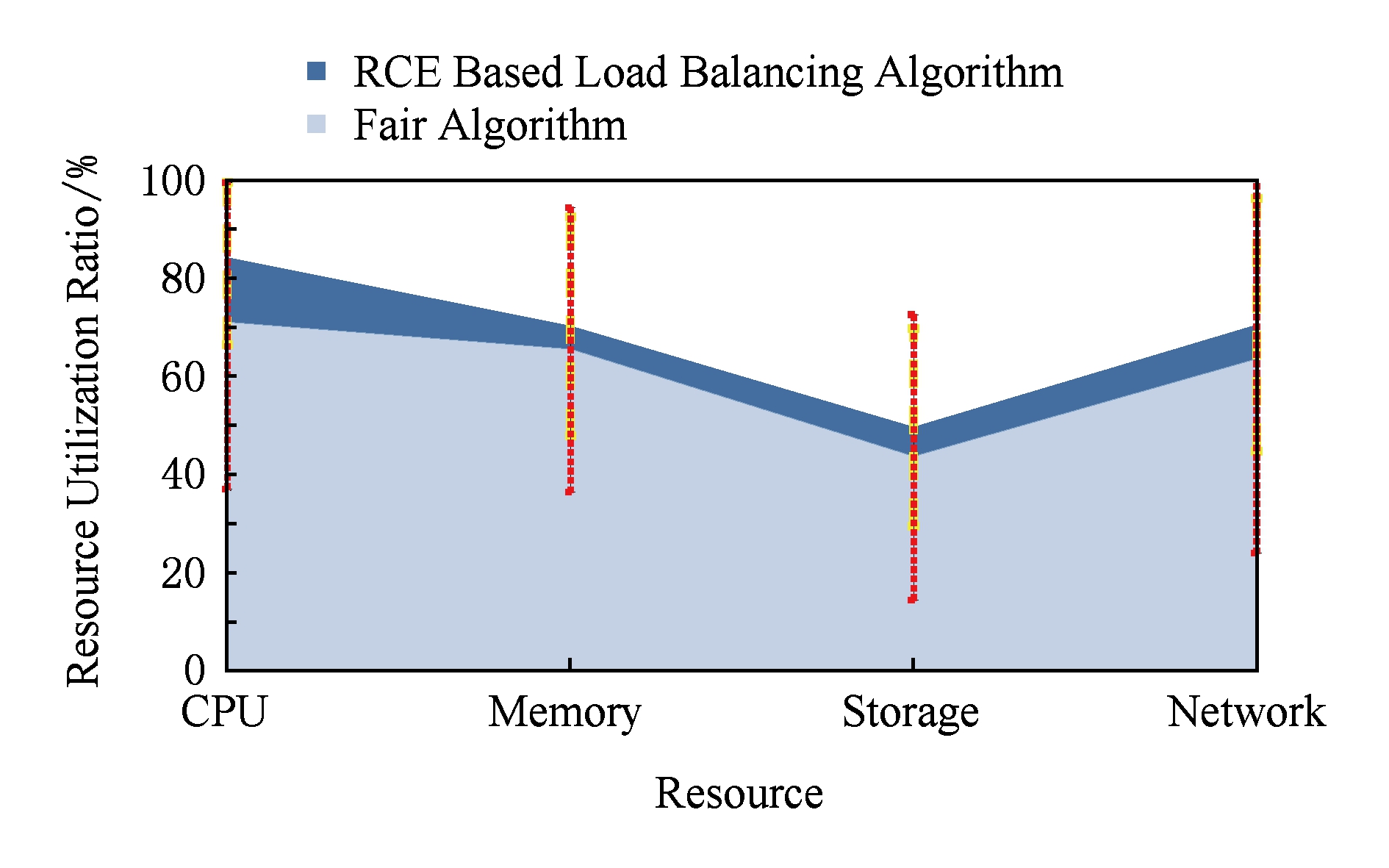
Fig. 10 Resource utilization in cloud environment
图10 云环境下负载资源利用情况
Table 3 Changes of Resource Rtilization in Cloud Environment
表3 云环境中资源使用情况变化 %
对比图9和图10中Yarn平台资源使用情况,不难发现相同负载下云环境中的资源利用率比在独享环境中的更高,且各服务器资源利用率的差异更大.这是由于云环境中存在的其他应用与Yarn应用同时使用计算资源,造成个别服务器出现资源争抢导致利用率升高,而在个别服务器上资源利用不变导致资源利用率的标准差变大.但是这种资源利用率的升高并不意味着性能的提升,严重的资源争抢会导致局部的资源瓶颈,最终引起性能大幅下降.对比图9和图10中基于RCE的负载均衡算法取得的结果,可以看出该算法在云环境中相比在独享环境中的平均资源利用率基本不变,而资源利用率标准差略有升高,这说明该算法适应了环境中其他应用的资源使用行为,并有效地调节了负载对计算资源的选择.
对比表2和表3可知:1)基于RCE的负载均衡算法在云环境中对于资源平均利用率的提升相较独享环境有所下降,其原因在于云环境中存在的科学计算应用的资源使用行为提高了资源利用率,压缩了提升空间;2)基于RCE的负载均衡算法在2种环境中取得的各服务器资源利用率标准差变化基本持平,这再次说明了该算法根据可用计算资源调节负载的资源选择,并且取得了良好的效果.
5.3.3 异常识别算法测试
异常识别算法测试在独享环境中进行,测试中提交规模为20的负载,随机制造多次计算资源异常并在异常被发现时解除.测试结果如图11所示,有意制造的资源异常识别率达94.58%,且准确记录下异常原因,算法取得了很好的效果.从图11中曲线可以看出,识别异常所需时间随着系统运行时间增长而逐渐减少,最终稳定在52 s左右.原因是算法的识别耗时与阈值准确性直接相关,随着系统的运行各种评估结果趋于准确,依据该结果确定的各种识别阈值也一同趋于准确,最终表现为识别耗时逐渐减少.
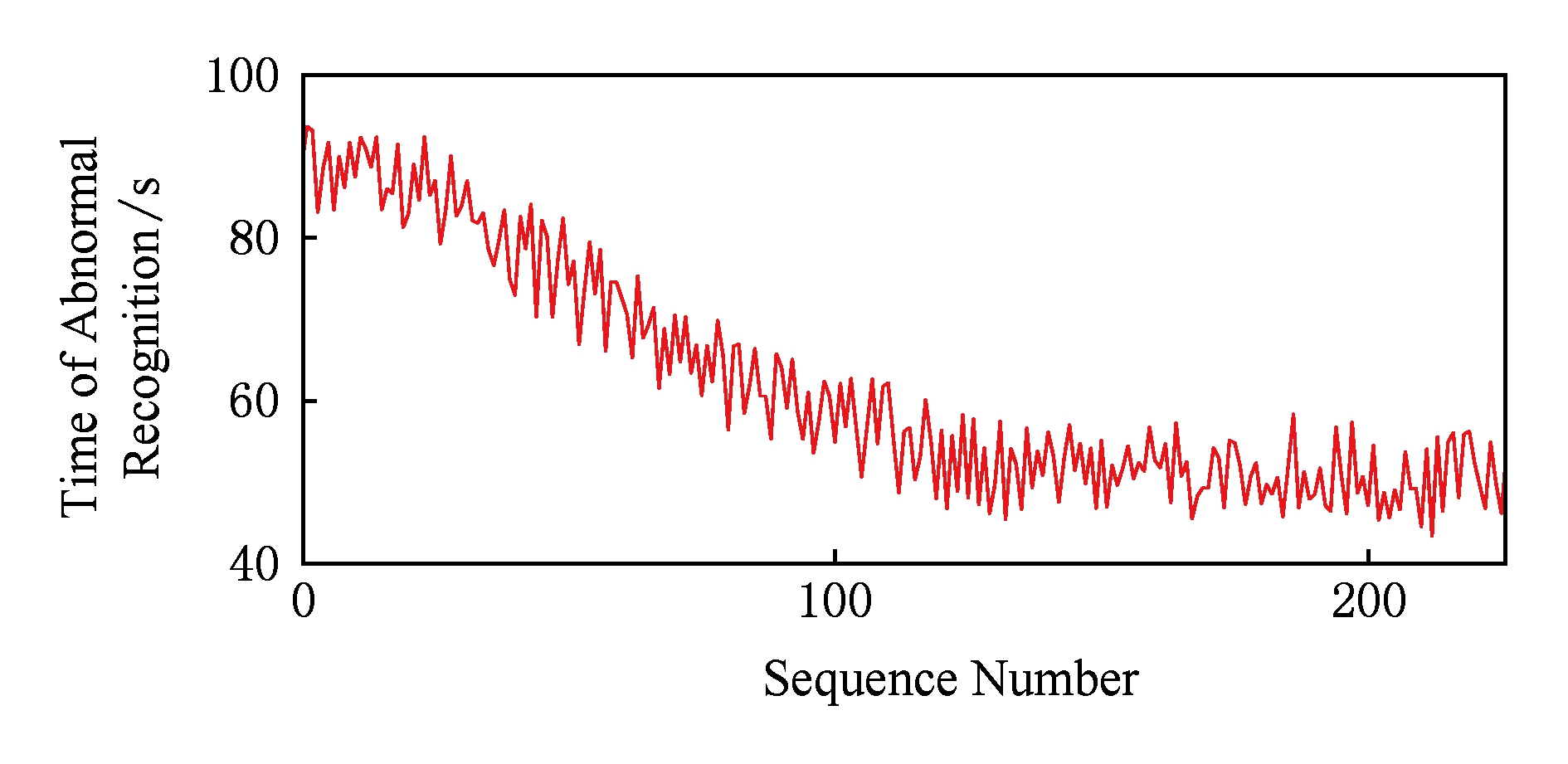
Fig. 11 Time of abnormal recognition
图11 异常识别耗时
由此测试可以得出结论,基于RCE的异常识别算法可以准确且迅速地识别出服务器资源异常,并及时停止分配相应服务器上的计算资源,避免服务器资源异常造成平台整体性能下降,提高了云平台稳定性.
5.3.4 缓慢任务发现算法测试
缓慢任务发现测试在独享环境下进行,测试中提交规模为20的负载,并在负载中随机挑选5%的任务进行干扰使其执行缓慢,当任务被发现时停止干扰.
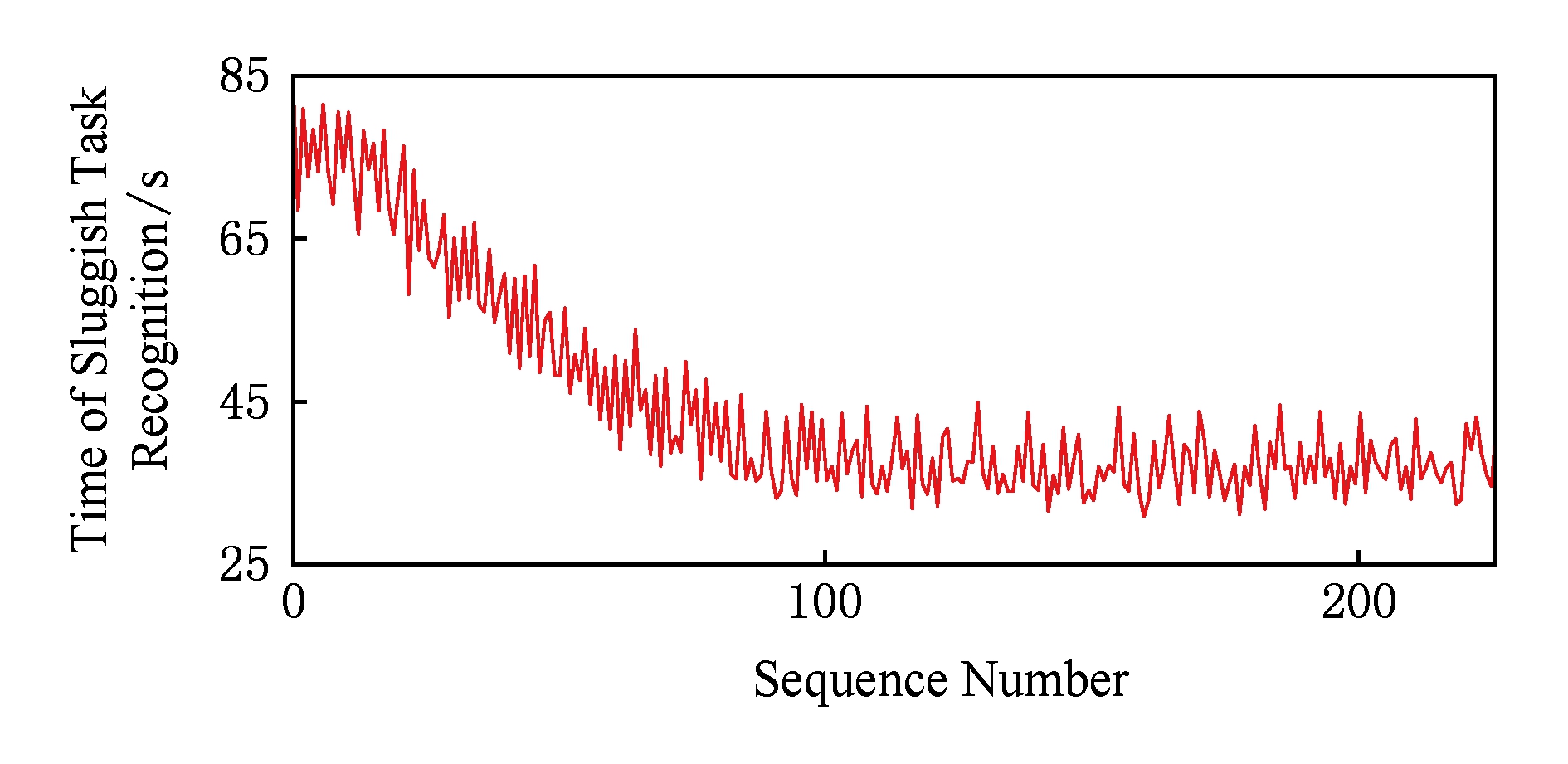
Fig. 12 Time of sluggish task recognition
图12 缓慢任务发现耗时
缓慢任务发现耗时如图12所示,被干扰产生的缓慢任务全部被发现,且发现所需时间逐渐减少,最终稳定在36 s左右.算法耗时与其使用的阈值有关,随着负载的执行信息越来越多,算法阈值变得准确,发现耗时逐渐减少.
图13所示为制造缓慢任务并分别采用基于RCE的缓慢发现算法及LATE算法 [21] 时相对不制造缓慢任务Yarn平台的负载完成时间.从图13中可以发现,采用基于RCE的缓慢任务发现算法时,负载完成时间相比无缓慢任务时仅增加了16.26%;而使用LATE算法时完成时间增加了35.04%,基于RCE的缓慢任务发现算法相比LATE算法有18.78%的性能提升.
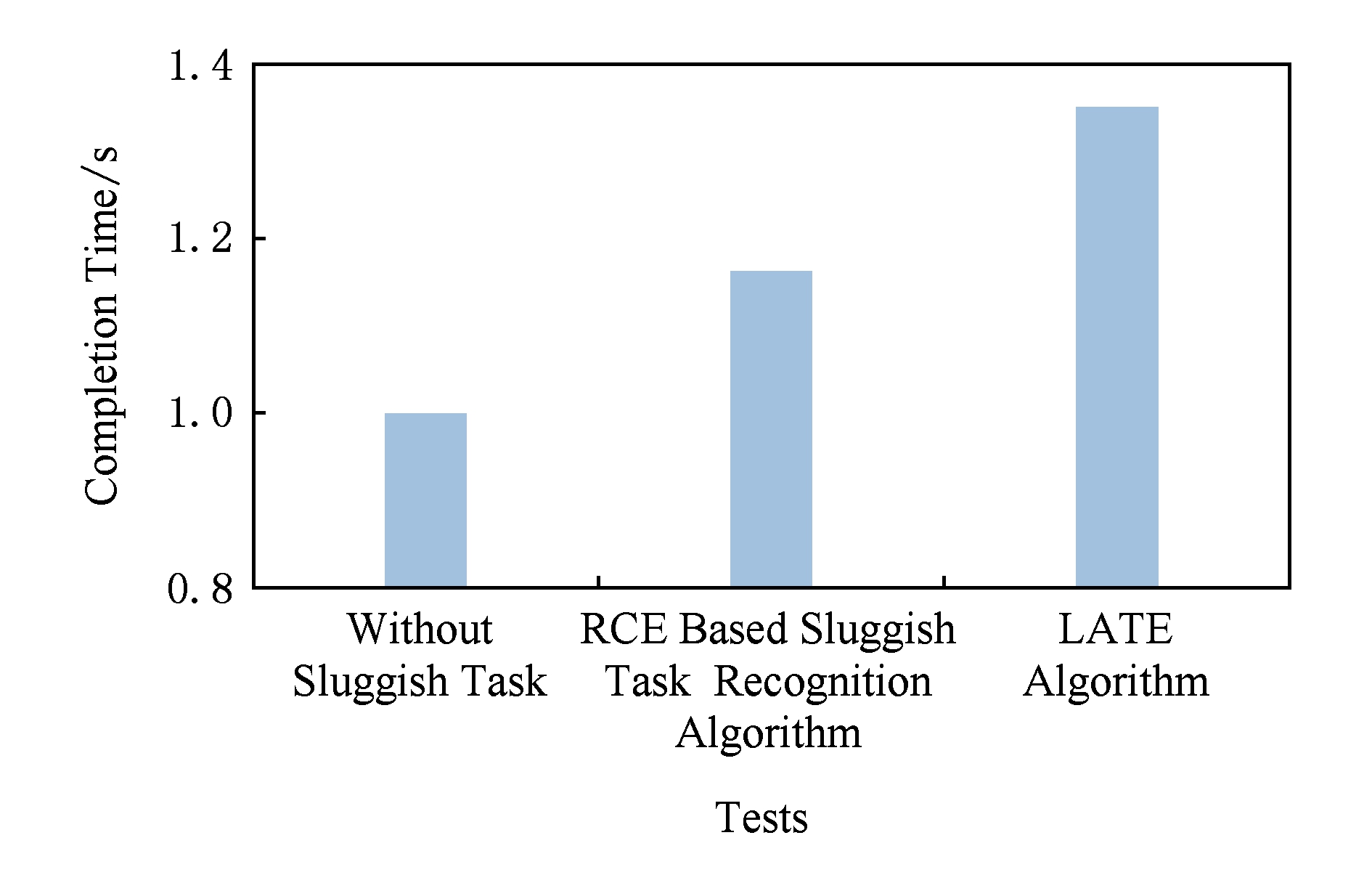
Fig. 13 The influence of sluggish task on completion time
图13 缓慢任务对负载完成时间的影响
5 . 4 云平台优化测试
本节测试中,在Yarn平台中整合上述算法,验证基于RCE的算法对Yarn平台的整体优化效果.原Yarn平台使用LATE算法作为缓慢任务发现算法.测试中分别在独享和云2种环境中提交不同规模的负载并记录负载完成时间.
图14所示为独享环境测试的负载完成时间.从图14中曲线可以看出,基于RCE优化后的Yarn平台在各规模负载测试中均取得了优于原始Yarn平台的完成时间,并且优化效果随着负载规模的增大而增大.这是由于随负载规模增大,RCE方法评估结果越准确,算法的效果越明显.当负载规模超过14.5时,基于RCE的算法降低负载完成时间稳定在57%左右.
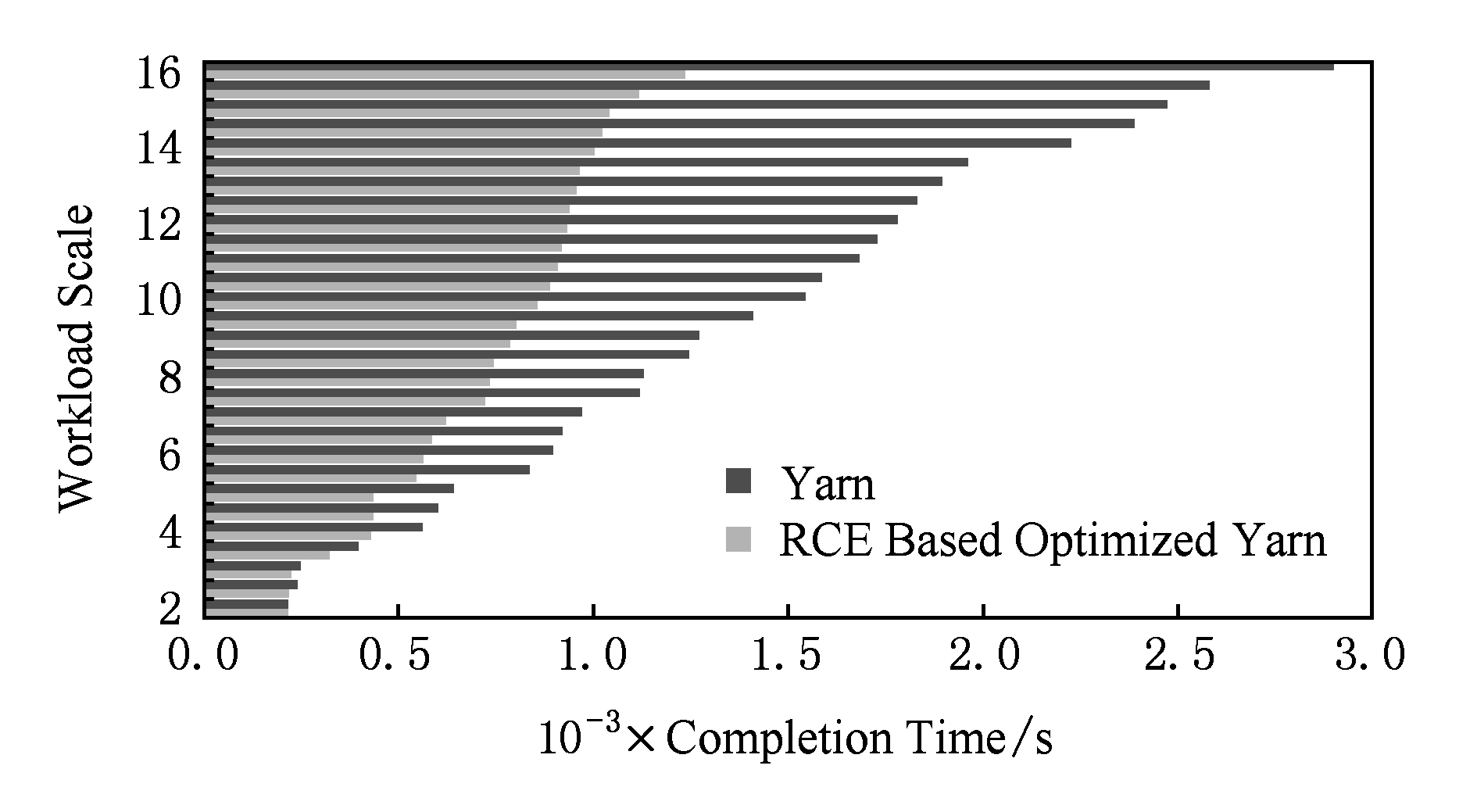
Fig. 14 Workload completion time in dedicated environment
图14 独享环境中负载完成时间
图15为云环境测试的负载完成时间.优化效果随着负载规模的增大而显著,当测试负载规模超过14时,优化后平台相比原平台的负载完成时间降低效果稳定在59%左右.另外,在云环境中优化后的平台降低了规模为2的负载12.09%的完成时间,这远远优于独享环境测试中0.4%的优化效果.这可能由2方面原因共同导致:1)规模较小的负载所需完成时间较少;2)云环境中的其他应用影响了Yarn应用的资源使用.本身较小的负载完成时间受到影响之后大幅增加,也增加了其可被优化的空间.
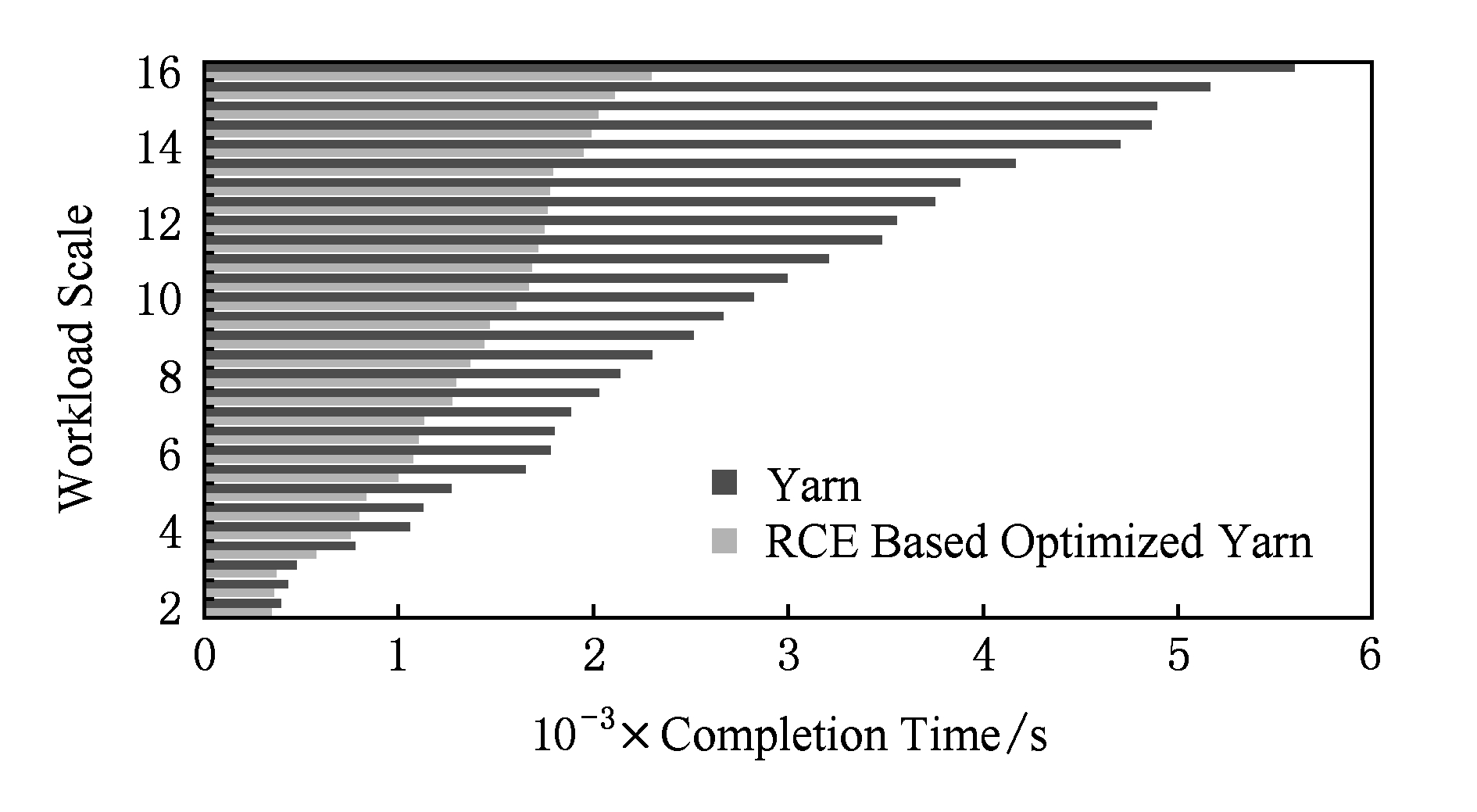
Fig. 15 Workload completion time in cloud environment
图15 云环境中负载完成时间
从图14和图15中的测试结果可以得出结论,基于RCE的算法在独享和云环境中均能给云计算平台带来性能的大幅提升.
针对云平台中存在的资源供给与需求的匹配问题,本文提出了一种新的解决思路:首先,利用相似任务特性,采用相似任务代替传统的测试程序,并综合其他因素建立了运行时计算资源剩余能力评估模型;其次,提出依据该模型的计算资源分类评估方法RCE,得出运行时评估结果;最后,将计算资源剩余能力应用在算法设计和优化中,解决资源供给与需求的匹配问题,并对Yarn平台进行多方面优化.在独享和云环境中对本文工作进行验证,测试结果显示RCE的评估结果有效、具有时效性且扩展性良好,并为平台及算法优化提供了有力支持,基于RCE的算法可以提高资源分配与任务资源需求的匹配程度,大幅提高云计算平台性能.
在未来研究中,我们计划将RCE应用到更多种类资源的剩余能力评估中,并进一步提高其效率.
参考文献

[1]Apache. Hadoop[OL]. [2016-07-05]. http:  hadoop.apache.org
hadoop.apache.org
[2]Vavilapalli V K, Murthy A C, Douglas C, et al. Apache Hadoop Yarn: Yet another resource negotiator[C] Proc of the 4th Annual Symp on Cloud Computing. New York: ACM, 2013: 5-20
[3]Reiss C, Tumanov A, Ganger G R, et al. Heterogeneity and dynamicity of clouds at scale: Google trace analysis[C] Proc of the 3rd ACM Symp on Cloud Computing. New York: ACM, 2012: 7-20
[4]Ananthanarayanan G, Kandula S, Greenberg A G, et al. Reining in the outliers in Map-Reduce clusters using Mantri[C] Proc of the 9th USENIX Symp on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2010: 24-37
[5]Mishra A K, Hellerstein J L, Cirne W, et al. Towards characterizing cloud backend workloads: Insights from Google compute clusters[J]. ACM SIGMETRICS Performance Evaluation Review, 2010, 37(4): 34-41
[6]Sharma B, Chudnovsky V, Hellerstein J L, et al. Modeling and synthesizing task placement constraints in Google compute clusters[C] Proc of the 2nd ACM Symp on Cloud Computing. New York: ACM, 2011: 3-16
[7]Chen Yanpei, Alspaugh S, Katz R H. Design insights for MapReduce from diverse production workloads, UCB EECS-2012-17[R]. Berkeley, CA: California University Department of Electrical Engineering and Computer Science, 2012
[8]Hwang Kai, Bai Xiaoying, Shi Yue, et al. Cloud performance modeling with benchmark evaluation of elastic scaling strategies[J]. IEEE Trans on Parallel and Distributed Systems, 2016, 27(1): 130-143
[9]Bruneo D. A stochastic model to investigate data center performance and QoS in IaaS cloud computing systems[J]. IEEE Trans on Parallel and Distributed Systems, 2014, 25(3): 560-569
[10]Wang Bin, Chang Xiaolin, Liu Jiqiang. Modeling heterogeneous virtual machines on IaaS data centers[J]. IEEE Communications Letters, 2015, 19(4): 537-540
[11]Boutin E, Ekanayake J, Lin Wei, et al. Apollo: Scalable and coordinated scheduling for cloud-scale computing[C] Proc of the 11th USENIX Symp on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2014: 285-300
[12]Zhang Xiao, Tune E, Hagmann R, et al. CPI2: CPU performance isolation for shared compute clusters[C] Proc of the 8th ACM European Conf on Computer Systems. New York: ACM, 2013: 379-391
[13]Hindman B, Konwinski A, Zaharia M, et al. Mesos: A platform for fine-grained resource sharing in the data center[C] Proc of the 11th USENIX Symp on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2011: 22-35
[14]Wikipedia. Powered by Apache Hadoop[OL]. [2016-07-05]. https: wiki.apache.org hadoop PoweredBy
[15]Apache. Organizations using Mesos[OL]. [2016-07-05]. http: mesos.apache.org documentation latest powered-by-mesos
[16]Facebook. Under the Hood: Scheduling MapReduce jobs more efficiently with Corona[OL]. [2016-07-05]. https: www.facebook.com notes face book-engineering under-the-hood-scheduling-mapreduce-jobs-more-efficiently-with-corona 10151142560538920
[17]Zhang Zhuo, Li Chao, Tao Yangyu, et al. Fuxi: A fault-tolerant resource management and job scheduling system at Internet scale[J]. Proceedings of the VLDB Endowment, 2014, 7(13): 1393-1404
[18]Verma A, Pedrosa L, Korupolu M, et al. Large-scale cluster management at Google with Borg[C] Proc of the 10th European Conf on Computer Systems. New York: ACM, 2015: 18-34
[19]Schwarzkopf M, Konwinski A, Abd-El-Malek M, et al. Omega: Flexible, scalable schedulers for large compute clusters[C] Proc of the 8th ACM European Conf on Computer Systems. New York: ACM, 2013: 351-364
[20]Dean J, Barroso L A. The tail at scale[J]. Communications of the ACM, 2013, 56(2): 74-80
[21]Zaharia M, Konwinski A, Joseph A D, et al. Improving MapReduce performance in heterogeneous environments[C] Proc of the 8th USENIX Symp on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2008: 7-20
[22]Li Qianmu, Zhang Shengxiao, Lu Lu, et al. A job scheduling algorithm and hybrid scheduling method on Hadoop platform[J]. Journal of Computer Research and Development, 2013, 50(Suppl.): 361-368 (in Chinese)(李千目, 张晟骁, 陆路, 等. 一种 Hadoop 平台下的调度算法及混合调度策略[J]. 计算机研究与发展, 2013, 50(增刊): 361-368)
[23]Zheng Xiaowei, Xiang Ming, Zhang Dawei, et al. An adaptive tasks scheduling method based on the ability of node in Hadoop cluster[J]. Journal of Computer Research and Development, 2014, 51(3): 618-626 (in Chinese)(郑晓薇, 项明, 张大为, 等. 基于节点能力的 Hadoop 集群任务自适应调度方法[J]. 计算机研究与发展, 2014, 51(3): 618-626)
[24]Curnow H J, Wichmann B A. A synthetic benchmark[J]. The Computer Journal, 1976, 19(1): 43-49
[25]Dongarra J J. Performance of various computers using standard linear equations software in a Fortran environment[J]. Simulation, 1987, 49(2): 51-62
[26]McCalpin J D. A survey of memory bandwidth and machine balance in current high performance computers[J OL]. IEEE TCCA Newsletter, 1995 [2017-02-06]. http: www.cs.virginia.edu ~mccalpin papers balance
[27]Zaharia M, Borthakur D, Sarma J S, et al. Job scheduling for multi-user mapreduce clusters, UCB EECS-2009-55[R]. Berkeley, CA: Department of Electrical Engineering and Computer Science, California University, 2009 Zhou Mosong , born in 1988. PhD candidate. His main research interests include cloud computing and distributed computing.

Dong Xiaoshe , born in 1963. PhD, professor, PhD supervisor. Member of CCF. His main research interests include high performance computer architecture, grid computing, cloud computing and storage.

Chen Heng , born in 1979. PhD, lecturer. His main research interests include cloud computing.

Zhang Xingjun , born in 1969. PhD, professor, PhD supervisor. Member of CCF. His main research interests include high performance computer architecture, the new technologies of computer networks and high performance computing.
Zhou Mosong, Dong Xiaoshe, Chen Heng, and Zhang Xingjun
(School of Electronic and Information Engineering, Xi’an Jiaotong University, Xi’an 710049)
Abstract There is a mismatch between computing resource supply and demand in cloud computing platform resource management, which leads to the performance degradation. This paper establishes a runtime computing resource available capacity evaluation model base on similar tasks. The model uses the characteristic of cloud computing workload in which similar tasks have the same execution logic, evaluates computing resource available capacity according to similar tasks avoiding computing resource consumption in executing benchmark. This paper applies the model to propose a computing resource capacity evaluation method called RCE, which considers many factors and evaluates runtime computing resource available capacity classified by resource type. This method gets accurate evaluation results timely with little cost. We apply RCE results in some algorithms to match computing resource supply and demand, and improve cloud computing platform performance. We test RCE method and algorithms base on RCE in dedicated and real cloud computing environments. The test results show that the RCE method gets runtime evaluation results timely and the evaluation results reflect computing resource available capacity accurately. Moreover, the RCE method supports the optimization of algorithm and platform effectively. And algorithms base on RCE resolve the mismatch problem between resource supply and demand, and significantly improve the performance of cloud computing platform.
Key words cloud computing; resource capacity evaluation (RCE); similar task; resource management; platform optimization
收稿日期: 2016-09-14;
修回日期: 2017-02-21
基金项目: 国家重点研发计划项目(2016YFB0200902);国家自然科学基金项目(61572394)
This work was supported by the National Key Research and Development Program of China (2016YFB0200902) and the National Natural Science Foundation of China (61572394).
通信作者: 陈衡(hengchen@mail.xjtu.edu.cn)
中图法分类号 TP391