 N; e 是N维的单位列向量;矩阵 U ∈
N; e 是N维的单位列向量;矩阵 U ∈ 谈 超 吉根林 赵 斌
(南京师范大学计算机科学与技术学院 南京 210023)
(tutu_tanchao@163.com)
摘 要 流形学习是为了寻找高维空间中观测数据的低维嵌入.作为一种有效的非线性维数约减方法,流形学习被广泛应用于数据挖掘、模式识别等机器学习领域.然而,对于样本外点学习、增量学习和在线学习等流形学习方法,面对流式大数据的学习算法时间效率较低.为此提出了一种新的基于增量切空间的自适应流式大数据学习算法(self-adaptive streaming big data learning algorithm based on incremental tangent space alignment, SLITSA),该算法采用增量PCA的思想,增量地构造子空间,能在线或增量地检测数据流中的内在低维流形结构,在迭代过程中构建新的切空间进行调准,保证了算法的收敛性并降低了重构误差.通过人工数据集以及真实数据集上的实验表明:该算法分类精度和时间效率优于其他学习算法,可推广到在线或流式大数据的应用当中.
关键词 流形学习;非线性维数约减;流式大数据;增量切空间;自适应
云计算、物联网、移动互联、社交网络等新兴信息技术和应用模式的快速发展,促使全球数据总量急剧增加,推动人类社会迈入大数据时代 [1] .流式大数据作为大数据的一种重要形态,在商务智能、市场营销和公共服务等诸多领域有着广泛的应用前景,并已在金融银行业、互联网、物联网等场景的应用中取得了显著的成效.但流式大数据呈现出的动态到达以及样本数量规模大、类别多等显著特征,使得其与传统批量大数据在数据处理的要求、方式等方面有着明显的不同,也使得当前诸多模式识别和机器学习等相关算法无法直接应用到流式大数据处理中.而在实际的数据挖掘、模式识别和机器学习中,降维是许多任务的先决条件.因此,开发有效的降维方法是大数据时代的一个研究热点.
流形学习作为一种有效的非线性降维算法,主要是为了发现高维观测数据的低维光滑流形结构.近几年来,大多数流形学习算法都属于“批量”模式,以批处理的方式执行,即在运行算法之前必须收集好所有的数据,不能有效地处理数据连续到达的大数据流问题.这些流形方法包括等距映射算法(isometric mapping, Isomap) [2] 、Laplacian特征映射算法(Laplacian eigenmaps, LE) [3] 、局部线性嵌入算法(locally linear embedding, LLE) [4] 、局部切空间校准算法(local tangent space alignment, LTSA) [5] 等.然而,在实际中很多应用都需要处理实时数据流,图像或数据是依次收集的,例如新闻文本分析、网络数据挖掘、视频监控及地震信号监测等.这些应用要求增量形式的流形学习算法能够持续有效地更新在新来的以及已有的数据基础上构建的流形,而无需在整个数据集上进行重复计算.另外,增量学习算法能够可视化数据流形的变化过程,这对理解流式大数据的结构特征提供了极大的帮助.
有学者提出了增量流形学习算法.其中典型的增量流形学习算法包括增量Isomap算法(incremental Isomap, IIsomap) [6] 、增量Laplacian映射算法(incremental LE, ILE) [7] 、增量LLE算法(incremental LLE, ILLE) [8] 、增量LTSA算法(incremental LTSA, ILTSA) [9] 及增量HLLE算法(incremental HLLE, IHLLE) [10] 等.现有增量流形学习算法的思想总体可以归结为2类:第1类是在假设现有结果完全正确的前提下处理新来的样本.这类算法能够高效地处理新来的数据.但是,当前的数据流常常不能够准确地反映其本征的流形结构,特别是在非均匀采样的情形下,这类算法无法正确地给出高维数据的低维嵌入.第2类方法在嵌入训练数据集以外样本的同时,更新训练数据集的嵌入坐标,使其能够更好地反映数据的特征.相比之下,这类方法能够给出更加可靠的结果.
经过调研发现,现有增量流形学习算法有着一定的局限性.例如,对于一些增量学习方法,新点可能会改变当前邻域以及流形的局部分布情况.典型的如IIsomap算法就无法保证邻域矩阵的连续性,新点的加入可能删除邻域图中的临界边,显著地改变相应的测地距离,因此将会产生短回路、空洞现象或者过度卷曲等问题.此外,计算成本过高是另一个问题.例如ILE算法通过引入局部线性重构机制来加入新点的邻接信息,更新已有数据集的内在结构.该算法需要解决( k +1)×( k +1)的特征问题,总的时间复杂度为 O (( k +1) 3 ).虽然保证了邻域矩阵的连续性,但更新节点仍需要巨大的计算代价.ILLE算法是对新增数据点进行逐个更新,计算代价高,新的观测区域数据的出现会破坏原有的几何结构.ILTSA算法主要是采用迭代算法计算整个过程,而迭代优化问题的哪个部分需要计算则是未知的,故计算量很大.文献[11]中算法的问题类似于上述的ILTSA算法,必须重新构建校准矩阵来容纳新加入的点,对于大规模流式数据集来说不是很实用.
现有增量学习算法的局限还表现在:近似误差方面没有保证.例如,在增量PCA算法 [12] 中,新样本点是逐个加入的,更新后的特征空间是通过使用原始图像的低维系数向量获得,所以这些方法受到不可预测近似误差的影响.其他增量算法也存在类似的问题 [13-14] ,例如ILLE算法的误差在降维过程中会越来越大,这是因为该算法中新代价矩阵 M new 的特征值没有得到更新.随着新增样本数目的增加, M new 与原代价矩阵 M 的前d个最小的特征值之间的差值会增大,从而误差也会越来越大.
最近,有许多semi-supervised特征提取算法 [15-17] 被提出,结合了半监督技术与局部判别分析方法.然而这些方法没有充分考虑在动态流形方面的增量学习,这在如今的流式大数据领域已成为一个研究热点.
针对上述问题,本文提出了一种新的基于增量切空间校准的自适应流式大数据学习算法(self-adaptive streaming big data learning algorithm based on incremental tangent space alignment, SLITSA).SLITSA不受限于样本协方差矩阵的大小,可解决LTSA中对大规模矩阵的特征分解问题.受文献[18-20]的思想启发,SLITSA首先通过增量主成分分析方法找到样本点的局部主成分;然后增量地构造高维空间中数据样本的切空间来刻画局部邻域,避免重复构造特征空间,获得新点的局部坐标;最后通过最小平方差最小化原点和映射点之间的误差,得到新点的全局坐标.在合成和真实世界数据集上的实验结果表明本文所提SLITSA算法可以更加精确有效地获得原始数据的低维近似表达.
本节内容由3个部分组成:1)在加入新样本点以后更新协方差矩阵;2)构造增量形式的局部切空间;3)根据得到的局部几何信息获取低维全局坐标.
1 . 1 协方差矩阵的更新
Min等人 [21] 证明了一个样本的局部切空间可以由其邻域中样本点组成的协方差矩阵的特征向量来表示.而该矩阵的特征向量可以通过局部主成分分析的方法来求解,因此,计算样本点在低维空间中映射坐标的问题可以转化为求解局部主成分分析的问题.
1) 构造新的局部切空间.给定采样自非线性流形的一组数据点 X =( x 1 , x 2 ,…, x N ),将它们从m维空间映射到d维空间.传统主成分分析方法 PCA 搜索向量 c , T 和矩阵 U ,将 X 从高维流形映射到低维流形 ![]() d 中: X = ce T + UT + E .为了得到最优解,我们对重构误差 E 进行最小化: min ‖ E ‖
d 中: X = ce T + UT + E .为了得到最优解,我们对重构误差 E 进行最小化: min ‖ E ‖ ![]() ‖X-( ce T + UT )‖ F .其中,‖·‖ F 为矩阵的 Frobenius 形式; c 为 X 的平均值, c = Xe N; e 是N维的单位列向量;矩阵 U ∈
‖X-( ce T + UT )‖ F .其中,‖·‖ F 为矩阵的 Frobenius 形式; c 为 X 的平均值, c = Xe N; e 是N维的单位列向量;矩阵 U ∈ ![]() m×d 是仿射子空间的一组标准正交基;而 T 则是 X 在空间
m×d 是仿射子空间的一组标准正交基;而 T 则是 X 在空间 ![]() d的低维特征向量.线性条件下的奇异值分解可以用于解决这个问题,而当在非线性条件下,特别是在实时环境中,情况要复杂得多.为了求解增量非线性映射问题,需要通过局部线性排列来实现.
d的低维特征向量.线性条件下的奇异值分解可以用于解决这个问题,而当在非线性条件下,特别是在实时环境中,情况要复杂得多.为了求解增量非线性映射问题,需要通过局部线性排列来实现.
当加入一个新样本点时,用 x new 表示.我们准备基于现有点的特征向量来更新新点的局部信息.假设现有N个样本点的特征空间中,每个点以k个点作为邻域.设 X i =( x i 1 , x i 2 ,…, x i k )为包含 x i 的k个近邻点(欧氏距离意义)的矩阵.新点的坐标 X new 以如下形式映射到已有的特征空间中: X new =w i u i + ![]() ,i=1,2,…,N.其中,w i 是新点在特征空间中第i个系数, u i 是包含N个样本点的特征空间中第i个特征向量,
,i=1,2,…,N.其中,w i 是新点在特征空间中第i个系数, u i 是包含N个样本点的特征空间中第i个特征向量, ![]() 是N个样本点的平均向量.
是N个样本点的平均向量.
2) 重构新增点的坐标.为了解决增量非线性映射问题,第1步是要估计平均值并构造样本点的协方差矩阵,从而确定特征空间中样本点的特征向量.设 M N 为m维空间中现有的N个样本点的平均向量.该平均值可以估计为: M N = ![]() e T ,i=1,2,…,N.在本节中我们提出了一个新的表达式 M new 来表示已有样本点协方差矩阵当新点插入以后的几何信息.
e T ,i=1,2,…,N.在本节中我们提出了一个新的表达式 M new 来表示已有样本点协方差矩阵当新点插入以后的几何信息.
M new =α M N +(1-α) x new e T ,
其中,α是自适应因子,控制已有样本如何影响 M new 的估计值.如何选择α基于增量环境的情况:当前环境下样本更新快,α取得就小;若更新慢,则α取较大的值.我们设1-α为依赖于数据集实时性质的学习率,依赖于观测数据样本 X new 的估计.在文献[20]中被设为 ![]() 与其他常数的乘积,可以实现统计有效性.对于在线学习来说,对学习率进行手动调节是不实际的,在这里我们使用遗忘因子p对学习率进行改进.当使用遗忘因子让α改进时,出现在早期估计阶段的一些“噪音”可被规避,故可加速对 M new 的估计.令α=
与其他常数的乘积,可以实现统计有效性.对于在线学习来说,对学习率进行手动调节是不实际的,在这里我们使用遗忘因子p对学习率进行改进.当使用遗忘因子让α改进时,出现在早期估计阶段的一些“噪音”可被规避,故可加速对 M new 的估计.令α= ![]() ,为了便于描述,我们在后文中首先设置p=0,α=
,为了便于描述,我们在后文中首先设置p=0,α= ![]() .
.
3) 得到迭代形式的协方差矩阵.传统 PCA 通过对协方差矩阵求奇异值分解( SVD )来计算其特征解 ![]() 为N个样本点的均值向量.相应矩阵形式的表达式可以写为: C =( X i -
为N个样本点的均值向量.相应矩阵形式的表达式可以写为: C =( X i - ![]() e T )( X i -
e T )( X i - ![]() e T ) T =( X N -
e T ) T =( X N - ![]() )( X N -
)( X N - ![]() ) T .求解矩阵 C 对应d个最大特征值的特征向量,张成一个d维的子空间.在递归更新过程中,只需要保存 M new 及现有协方差矩阵 C N ,故在一定程度上可降低算法的复杂度.类似地,我们可以得到如下迭代形式的协方差矩阵:
) T .求解矩阵 C 对应d个最大特征值的特征向量,张成一个d维的子空间.在递归更新过程中,只需要保存 M new 及现有协方差矩阵 C N ,故在一定程度上可降低算法的复杂度.类似地,我们可以得到如下迭代形式的协方差矩阵:
C N =α C N-1 +(1-α)( X N - ![]() )( X N -
)( X N - ![]() ) T .
) T .
式(2)的迭代过程是算法 SLITSA 的一个重要部分.其收敛性可由下述理论证明.在文献[20-21]中可见一个类似的理论.
定理1 . 设{a n }是一组实数,若 ![]() 则
则 ![]() .推广到矩阵序列{ A n },‖ A n ‖lt;∞,收敛于矩阵
.推广到矩阵序列{ A n },‖ A n ‖lt;∞,收敛于矩阵 ![]() 则
则 ![]() 其中 A 是非负正定矩阵, A ∈
其中 A 是非负正定矩阵, A ∈ ![]() d×d ,并且‖ A ‖lt;∞, A 的特征值满足λ 1 ≥λ 2 ≥…gt;0,那么如下迭代过程收敛:
d×d ,并且‖ A ‖lt;∞, A 的特征值满足λ 1 ≥λ 2 ≥…gt;0,那么如下迭代过程收敛:
v(n)= ![]() v(n-1)+
v(n-1)+ ![]() A n
A n ![]() .
.
现在,我们将证明式(2)中计算 C N 的迭代过程收敛.
证明. 因为 ![]() 若
若 ![]() 则根据定理1,
则根据定理1,
![]()
C =( X N - ![]() )( X N -
)( X N - ![]() ) T ,
) T ,
同理,
则有:
其中,‖·‖表示l 2 范式,‖ x ‖= ![]() .
.
而
![]()
![]()
![]() ( x i -
( x i - ![]() )( x i -
)( x i - ![]() ) T =
) T = ![]() C N-1 +
C N-1 + ![]() ( x i -
( x i - ![]() )( x i -
)( x i - ![]() ) T ,
) T ,
故:
![]()
![]()
根据定理1,‖ C N ‖lt;∞并收敛于一个矩阵 ![]() 该矩阵非负,并且
该矩阵非负,并且 ![]() 的特征值满足λ 1 ≥λ 2 ≥…gt;0.故计算 C N 的迭代过程收敛.
的特征值满足λ 1 ≥λ 2 ≥…gt;0.故计算 C N 的迭代过程收敛.
证毕.
用 ![]() 代替α,并插入新样本 x new 以后,我们得到 C 的更新形式 C new :
代替α,并插入新样本 x new 以后,我们得到 C 的更新形式 C new :
这里 X new 是 x new e T 的矩阵形式.
根据 PCA , C =( X i - ![]() e T )( X i -
e T )( X i - ![]() e T ) T 的最优解由 X i -
e T ) T 的最优解由 X i - ![]() e T 的奇异值分解给出.令λ i (i=1,2,…,d)为 C 的前d个最大的特征值, v i 是对应的特征向量,故可得
e T 的奇异值分解给出.令λ i (i=1,2,…,d)为 C 的前d个最大的特征值, v i 是对应的特征向量,故可得 ![]() 其中矩阵 C 的特征向量 v i 组成了列向量 V Nd ,而对角矩阵 Λ dd 由 C 的特征值组成.
其中矩阵 C 的特征向量 v i 组成了列向量 V Nd ,而对角矩阵 Λ dd 由 C 的特征值组成.
得到 C new 的增量矩阵形式表达式为
C new = ![]() VΛV T +
VΛV T + ![]() ( X new - M new )( X new - M new ) T .
( X new - M new )( X new - M new ) T .
为便于计算,式(4)可以具体化为
![]()
![]() ( X new - M new )( X new - M new ) T ,
( X new - M new )( X new - M new ) T ,
其中 X new - M new 可具体化为
X new - M new = x new e T - ![]()
![]() e T -
e T - ![]() x new e T =
x new e T = ![]() ( x new -
( x new - ![]() ) e T .
) e T .
1 . 2 构造增量形式的局部切空间
为了在低维空间增量地更新所有点的嵌入坐标,我们以下述步骤来进行矩阵的更新.
1) 对 C new 进行特征分解.获得 C new 前d个最大的特征值λ i 和特征向量 v i ,i=1,2,…,d.然后我们基于λ i 和 v i 构造d+1个向量: A =( y 1 , y 2 ,…, y d+1 ),大小为k×(d+1),其中: y i = v i ![]() ,i=1,2,…,d, y d+1 =
,i=1,2,…,d, y d+1 = ![]() ( X new - M new ).
( X new - M new ).
因为
C new = ![]() C +
C + ![]() ( X new - M new )( X new - M new ) T =
( X new - M new )( X new - M new ) T = ![]() VΛV T +
VΛV T + ![]() ( X new - M new )( X new - M new ) T =
( X new - M new )( X new - M new ) T = ![]()
将 A =( y 1 , y 2 ,…, y d+1 )代入式(7)可知: C new = AA T ,表示新样本的邻域点以及它自身的局部切空间矩阵.
2) 构造一个内积矩阵 B . B = AA T , B 的大小为k×k,远远小于 C .这样可以增量地构造局部切空间矩阵,而不是重复计算新的协方差矩阵 C .矩阵 B 是在矩阵 A 的列向量张成的子空间上的正交投影.故在增量子空间上的新点 x new 的局部坐标可以通过计算 A 的前d个奇异向量得到 [22-23] ,相当于 B 的前d个最小的特征值对应的特征向量 u 1 , u 2 ,…, u d .
设 B 的特征向量和特征值分别为 ![]() 和
和 ![]() 有
有 ![]() k.则
k.则 ![]() 等式两边同乘以 A ,得
等式两边同乘以 A ,得 ![]() 令
令 ![]() 则
则 ![]() 即
即 ![]() 故 C new 的特征向量为
故 C new 的特征向量为 ![]()
3) 计算新加入样本点 x new 的局部坐标.得到增量协方差矩阵的特征向量以后,新加入的样本点 x new 的局部坐标可计算为
1 . 3 获得最优低维全局坐标
在本节中,我们根据局部切空间中的信息构造全局坐标.受Zhang等人 [5] 的LTSA算法启发,基于 B 的特征向量 u i ,我们可以导出最优低维坐标 t i 的构造.
令ε i 代表重构误差,最优低维坐标 t i 由 t i = ![]() + Y i u i +ε i .其中
+ Y i u i +ε i .其中 ![]() 表示 t i 的k个近邻均值,即k表示 t i 的k近邻数量; Y i 为正交基,形成由特征向量 u i 张成的特征空间.
表示 t i 的k个近邻均值,即k表示 t i 的k近邻数量; Y i 为正交基,形成由特征向量 u i 张成的特征空间.
将 t i 写成矩阵形式:
T i = ![]() T i ee T + Y i U i + E i .
T i ee T + Y i U i + E i .
T i =( t i 1 , t i 2 ,…, t i k )是由最优嵌入坐标组成的矩阵.为了尽可能多地保存特征空间中的低维几何信息,我们将重构误差 E i 最小化,如式(10)所示,
E i = T i ( I - ![]() ee T )- Y i U i .
ee T )- Y i U i .
优化函数可以写为
![]() ‖ E i
‖ E i ![]() =
= ![]() ‖ T i ( I -
‖ T i ( I - ![]() ee T )- Y i U i
ee T )- Y i U i ![]() ,
, ![]() (11)
(11)
用 ![]() 来代替 Y i ,优化函数可表示为
来代替 Y i ,优化函数可表示为
![]() ‖
‖ ![]() ‖
‖ ![]()
设 ![]() 则:
则:
![]() ‖E i
‖E i ![]() =
= ![]() ‖ T i R i
‖ T i R i ![]() =Tr( T i R i
=Tr( T i R i ![]() ).
). ![]() (13)
(13)
为了最小化‖ ![]() 我们应当选择
我们应当选择 ![]() 的前d个最小特征值对应的特征向量,也就是 T i =( t i 1 , t i 2 ,…, t i d ).因此算法的最优解由
的前d个最小特征值对应的特征向量,也就是 T i =( t i 1 , t i 2 ,…, t i d ).因此算法的最优解由 ![]() 前d个最小特征值对应的特征向量给出,以上方法我们命名为基于增量切空间校准的自适应流形学习算法.
前d个最小特征值对应的特征向量给出,以上方法我们命名为基于增量切空间校准的自适应流形学习算法.
2 . 1 算法描述
给定N个m维样本向量构成的矩阵 X =( x 1 , x 2 ,…, x N ),取样自流形 ![]() m,新增样本点 x new 插入到 X 中.本文提出的 SLITSA 算法将这些点映射到低维的空间,以增量的方式给出d维坐标 y 1 , y 2 ,…, y N (dlt;m),以及新点的低维映射坐标y n .
m,新增样本点 x new 插入到 X 中.本文提出的 SLITSA 算法将这些点映射到低维的空间,以增量的方式给出d维坐标 y 1 , y 2 ,…, y N (dlt;m),以及新点的低维映射坐标y n .
根据第1节的分析,基于增量切空间校准的自适应流形学习 SLITSA 的算法描述见算法1.
算法1 . 基于增量切空间的自适应流式大数据学习算法.
输入:高维样本集 X i =( x i 1 , x i 2 ,…, x i N )、新增样本点 x new ,其中i=1,2,…,N;
输出:低维嵌入坐标 T i =( t i 1 , t i 2 ,…, t i N )与 t new .
步骤1. 更新协方差矩阵.
① 为每个点 x i 确定k个近邻点(欧氏距离),组成矩阵 x i ,i=1,2,…,N;
② 迭代地构造式(2)中的协方差矩阵 C N ,表示每个数据点的增量切空间,这里α= ![]() ;
;
③ 根据式(3)计算 C new .
步骤2. 构造增量形式的局部切空间.
① 对 C new 进行特征分解;基于 C new 的前d个最大的特征值λ i 和特征向量 v i 构造矩阵 A 和矩阵 B : A =( y 1 , y 2 ,…, y d+1 ), B = AA T ;
② 计算矩阵 B 的前d个最小的特征值对应的特征向量 u 1 , u 2 ,…, u d ;
③ 根据式(8)计算新加入样本点 x new 的局部坐标.
步骤3. 获得最优低维全局坐标.
基于 B 的前d个最小的特征值对应的特征向量构成 W i =( e ![]() , u i 1 , u i 2 ,…, u i d ),令
, u i 1 , u i 2 ,…, u i d ),令 ![]() 计算
计算 ![]() 前d个最小特征值对应的特征向量 T i =( t i 1 , t i 2 ,…, t i d ),即算法 SLITSA 针对每个数据点的最优低维坐标,其中i=1,2,…,N.同理,根据 x new 的局部坐标可计算出其低维嵌入坐标 t new .
前d个最小特征值对应的特征向量 T i =( t i 1 , t i 2 ,…, t i d ),即算法 SLITSA 针对每个数据点的最优低维坐标,其中i=1,2,…,N.同理,根据 x new 的局部坐标可计算出其低维嵌入坐标 t new .
2 . 2 算法分析
算法1的计算复杂性首先是估计 M new ,在式(2)中,对于自适应因子α来说,当使用遗忘因子p让α变小时,可以规避出现在早期估计阶段的一些“噪音”,加速对 M new 的估计,故α= ![]() .通过第3节的实验部分我们知道 M new 的表达式具有相当低的误差方差和较高的统计效率,同时对于算法的时间复杂度也有一定的提高.
.通过第3节的实验部分我们知道 M new 的表达式具有相当低的误差方差和较高的统计效率,同时对于算法的时间复杂度也有一定的提高.
算法的复杂性体现在矩阵 A 和 B 的构造, A 的大小为k×(d+1),而 B = AA T ,大小为k×k,远远小于 C .接着基于 B 的特征向量构造切空间,并在矩阵 ![]() 上做特征分解.依照1.3节的定义
上做特征分解.依照1.3节的定义 ![]() 令
令 ![]() 由 B 的前d个最小的特征值对应的特征向量 u i 1 , u i 2 ,…, u i d 组成.最终算法的最优解由
由 B 的前d个最小的特征值对应的特征向量 u i 1 , u i 2 ,…, u i d 组成.最终算法的最优解由 ![]() 前d个最小特征值对应的特征向量 T i =( t i 1 , t i 2 ,…, t i d )给出.
前d个最小特征值对应的特征向量 T i =( t i 1 , t i 2 ,…, t i d )给出.
与 LTSA 相比, A 和 B 这2个矩阵在我们算法中的作用十分重要. LTSA 与本文算法的时间效率近似,首先它们都是基于大小为协方差矩阵来构造切空间,然后这2个算法均是按相近的方式在d+1阶的矩阵上进行特征分解或奇异值分解.然而,矩阵 A 和 B 的使用使得本文算法具有了增量学习的能力.另一方面,与其他增量算法相比,对基于矩阵 B 的特征解构建的切空间进行调准,可以提高降维结果的精度,这一点可以在第3节的实验中得到证实.
本文用一系列实验结果来展示所提算法的性能和优势,算法用Matlab实现,实验环境为Core-2 2.2 GHz CPU的PC,具有2 GB内存.实验所用数据取自一些典型的非线性流形学习数据集,包括来自真实世界的图像,可以推广到在线或流式大数据的应用当中.其中第1个数据集Swiss Roll是仿真数据,代表基本的非线性流形,常用于流形学习算法的直观降维实验中;后3个数据集都是真实世界中采样的数字和人脸图像数据集,具有多种特征维数,常用于流形学习算法在模式识别和图像处理实验中,能够从识别精度和重构误差等角度来深入考察算法对高维流形的学习效果.为了清楚地展示不同算法对这些数据集高维样本点的降维效果,一般采用染色的办法,相同颜色的点代表在高维空间中的位置关系.
3 . 1 Swiss Roll数据集增量降维实验
第1组实验是在Swiss Roll数据集 [2] 上测试增量学习能力,与增量Isomap算法进行比较.该数据集有500个初始样本点,将从3维空间映射到2维空间中.设 k 为近邻点数,数据点以随机顺序递增.
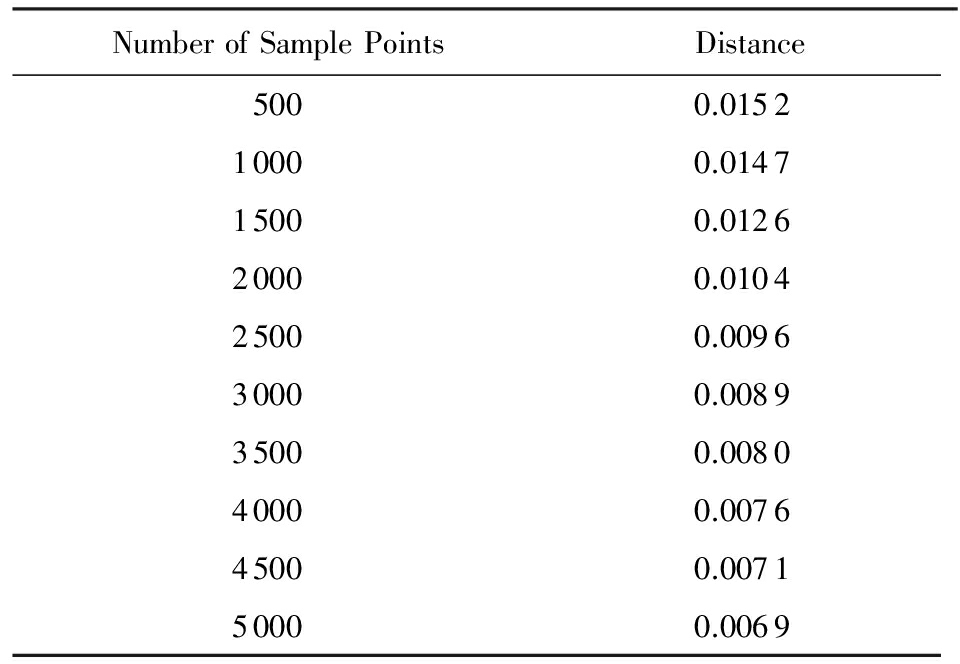
首先,为了展示算法增量更新新点的精确度,我们在原来3维流形中加入一个坐标为[2,2,3]的新点,用本文提出的算法SLITSA和LTSA进行降维以后,计算该点在降维后新空间中的位置距离,如表1所示,可见当点数从开始的500个递增至5 000个时(每次增加500个点),该点在2种算法降维后的新空间中位置距离逐渐缩小.
Table 1 Comparison of Distance in New Space Between
SLITSA and LTSA
表1 SLITSA和LTSA算法降维后新空间中位置距离
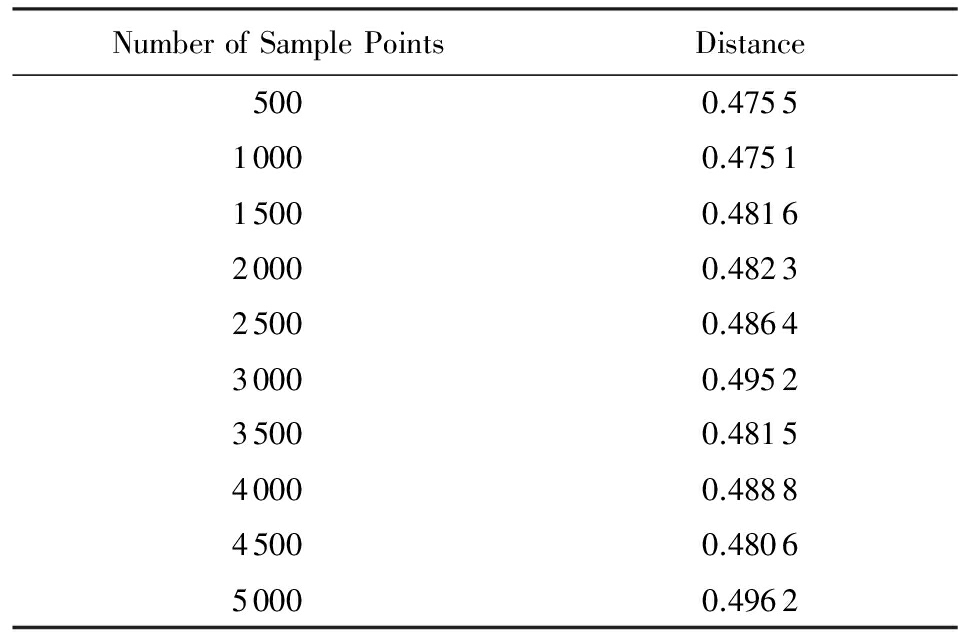
为了进行对比,我们又对增量Isomap算法(IIsomap)和Isomap算法进行了同样实验,结果如表2所示.可以看出,该点在增量Isomap算法(IIsomap)和Isomap算法降维以后的新空间中位置变化较大,并且随着点数增大而逐渐拉大.说明本文提出的算法在降维后能够较好地保持原始空间中点的位置,并检测高维空间中流形的结构关系.
Table 2 Comparison of Distance in New Space Between
IIsomap and Isomap
表2 IIsomap和Isomap算法降维后新空间中位置距离
3 . 2 MNIST数据集分类精度实验
本节中所用的数据集是MNIST手写数字数据集 [24] .我们选取该数据集中的5类手写数字图像,其中包括数字0,1,3,4,6的图像,每张手写图像大小为28×28,部分图像如图1所示.我们取每个数字的600张图片作为测试集,4 000张作为训练集,降到 d 维以后进行分类( d =11,12,…,20).当遗忘因子 p 取不同值时( p =0,1,…,8),分类的结果如表3所示.

Fig. 1 Some images of MNIST dataset
图1 手写数字数据集中的部分图像
Table 3 Classification Accuracy After Dimensional Reduction of SLITSA on MINIST Dataset
表3 SLITSA算法在MNIST数据集上降维后的分类精度
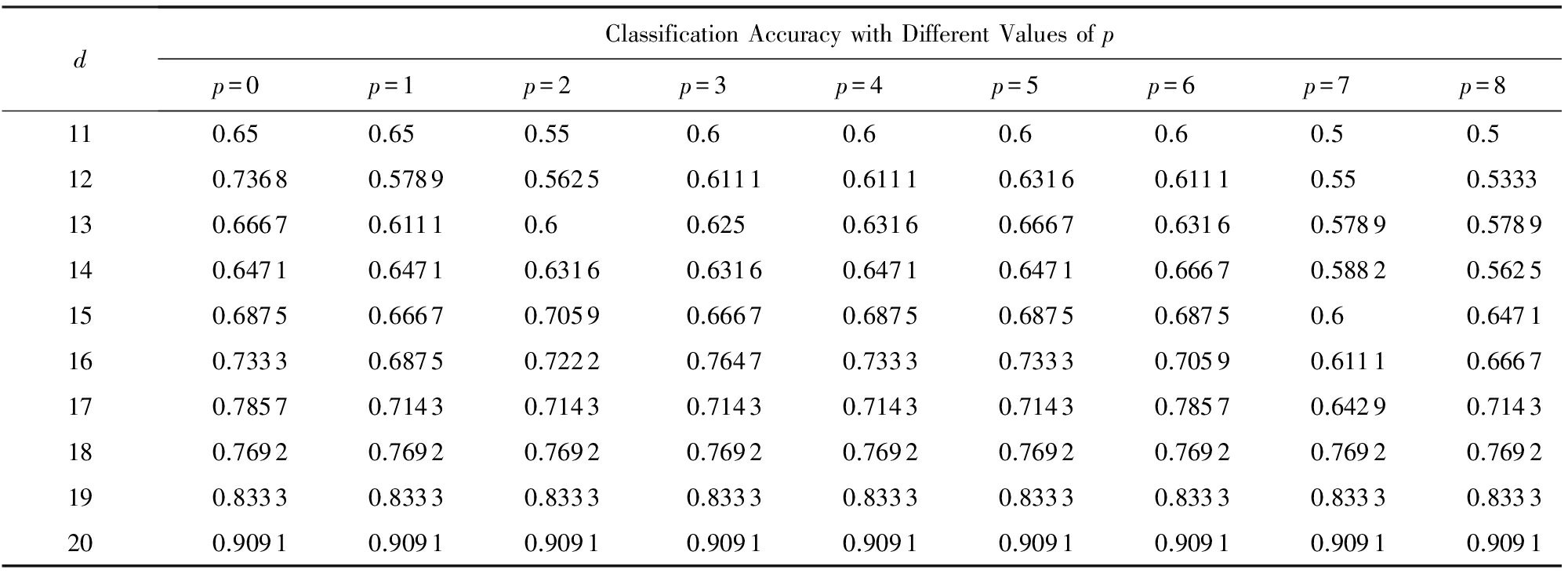
可以看出,当原数据集降维到较低维数时( d =11,12,…,15),随着 p 的增加,分类精度有下降的趋势.根据文献[20]我们知道,样本均值是均值分布的一种有效估计,虽然当 N 较大时 M N 前面的系数 α = ![]() 接近于1,但是对于早期样本来说快速收敛是很重要的,如果在开始时式(2)不能很好收敛,当 N 较大时就难以收敛了.故本文中我们将设置 p =0, α =
接近于1,但是对于早期样本来说快速收敛是很重要的,如果在开始时式(2)不能很好收敛,当 N 较大时就难以收敛了.故本文中我们将设置 p =0, α = ![]() .通过3.3节和3.5节的实验部分可以看出,式(2)具有相当低的误差方差和较高的统计效率.
.通过3.3节和3.5节的实验部分可以看出,式(2)具有相当低的误差方差和较高的统计效率.
3 . 3 面部图像分类精度实验
维数约减通常作为很多机器学习中分类任务的预处理步骤,所以降维在这些分类任务中起到重要作用.本节中我们首先在Olivetti Faces数据集 [24] 上展示采用不同算法降维以后的分类效果.
我们选择此数据集中共8个人的人脸图像,每人各选10张不同表情的图像,每张图像的大小为64×64,部分图像如图2所示:

Fig. 2 Some images of Olivetti Faces dataset
图2 人脸图像数据集中部分图像
将选取的人脸图像数据集分为训练集和测试集这2组.我们使用训练集来学习1个投影矩阵,并将人脸图像从高维空间映射到1个低维子空间.将数据集降到不同维数后,我们用 k 近邻算法( k NN)作为分类器,在子空间估计测试样本的分类精确度,设近邻点数 k =5.
实验重复了10次,最后取平均值作为最终识别率.在本实验中,将设置SLITSA的参数 p =0, α = ![]() .在其他用于对比的增量算法中,确定近邻样本权重矩阵时,近邻点个数的参数值设为8.
.在其他用于对比的增量算法中,确定近邻样本权重矩阵时,近邻点个数的参数值设为8.
从图3所示的分类精确度可以看出,本文算法SLITSA能够很好地发现输入流形的内在结构信息,分类精度优于增量LE [7] 、增量LTSA [9] 、增量Isomap [6] 、增量LLE [8] 及增量HLLE [10] 等比较算法.对于增量Isomap算法来说,新点的加入会导致短路边问题,引起噪音现象,由于算法本身的原因,无法克服新点对邻域图中临界边的影响,导致了算法受到邻域大小限制,对新点的学习能力大大削弱,不利于进行增量学习.而其他增量算法如增量LE、增量LTSA、增量LLE及增量HLLE等把数据点邻域的样本协方差矩阵的主元当作数据点切空间的标准正交基,在一些非均匀采样的流形学习中,样本邻域的均值点与样本自身有可能偏离程度较大,这时算法就会造成较大误差,算法对于新来的样本点不能进行有效的处理.而我们的算法SLITSA可以精确地映射样本点到低维空间中,原因可以总结为SLITSA在特征空间的学习过程中使用了 A 和 B 这2个矩阵,保证了收敛并降低了重构误差.
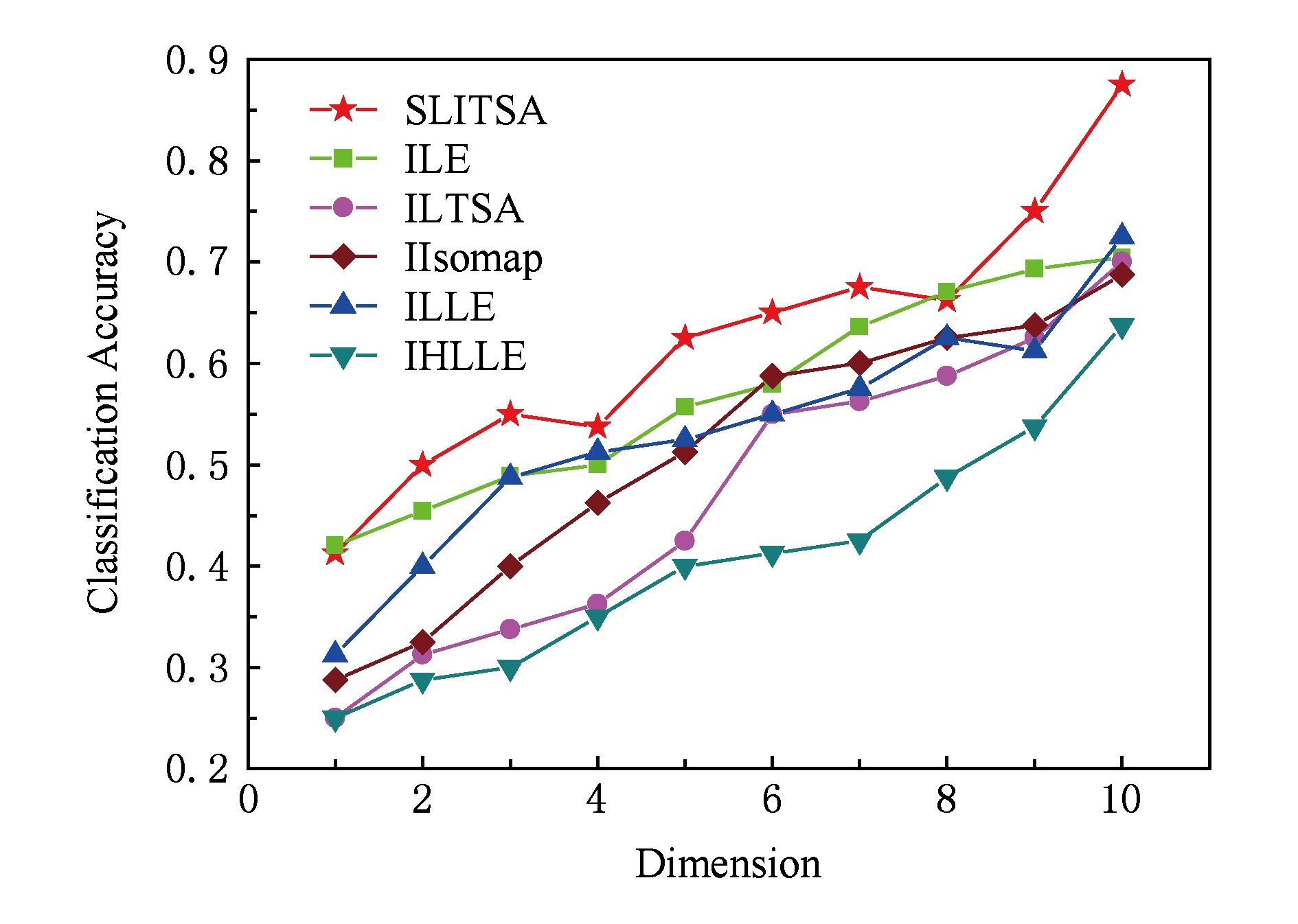
Fig. 3 Accuracy results of kNN classification after dimensional reduction on Olivetti Faces dataset
图3 Olivetti Faces数据集降到不同维数后kNN分类的精确度
为了进一步说明本文提出的算法在其他较大规模数据集上的效果,我们选择Frey Face人脸图像数据集 [24] ,将本文算法SLITSA与其他增量算法(增量LE、增量LTSA、增量LLE及增量HLLE等)在该数据集上降到10~100维并进行精确度对比,如图4所示.Frey Face表情数据库由1965幅维像素的面部表情图像组成,包含不同姿态和表情的图像数据.我们将其中600个图像作为测试样本,并在剩下的部分中随机选择10个图像作为测试集.将数据集降到不同维数后,用 k 近邻算法( k NN)作为分类器,估计测试样本的分类精确度,设近邻点数 k =5.在本实验中,SLITSA算法及其他增量算法的参数设置与Olivetti Faces数据集上的实验相同.

Fig. 4 Accuracy results of kNN classification after dimensional reduction on Frey Face dataset
图4 Frey Face数据集降到不同维数后kNN分类的精确度
从图4所示的分类精确度可以看出,算法SLITSA能够很好地发现输入流形的内在结构信息,在同样条件下降维以后和增量LE、增量LTSA、增量LLE及增量HLLE等算法相比,具有不错的学习效果,主要是归功于流形学习过程中2个矩阵的使用,取得了更精确的降维结果,保证了收敛并降低了重构误差,可知算法SLITSA具有更好的稳定性及更可靠的准确性.
3 . 4 Rendered Face数据集上的降维结果
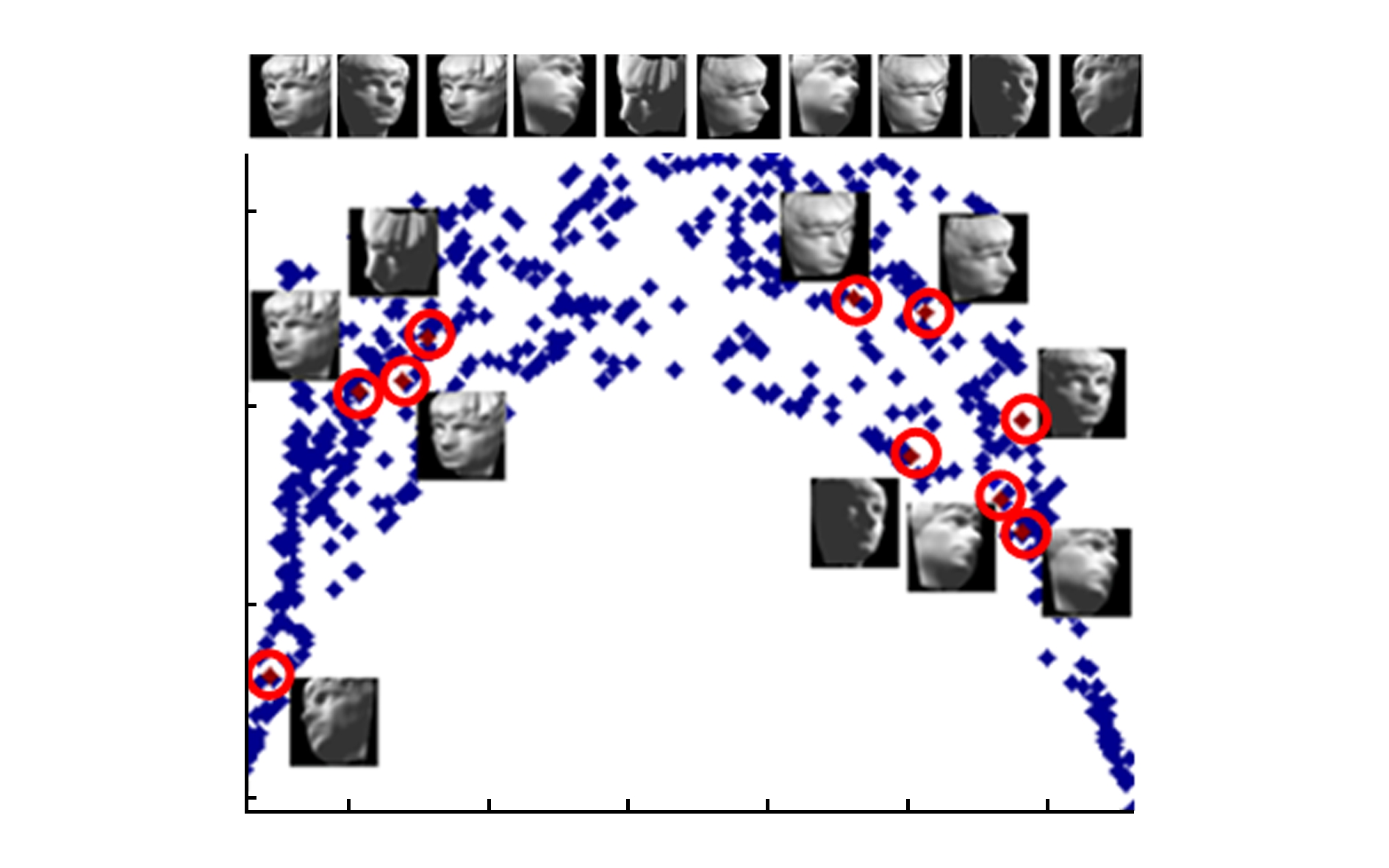
Fig. 5 Dimensionality reduction results on Rendered Face dataset
图5 Rendered Face数据集上的降维结果
本节中考虑Rendered Face数据集 [2] 上的实验结果,如图5所示.该数据集包含698个人脸雕塑图像,具有64×64像素.人脸图像具有2组姿态参数,从上到下和从左到右.我们用SLITSA算法将这698个高维图像数据集降到2维,并在2维的坐标图中展示其结果,每个点代表一个人脸图像.随机选取10个图像作为样本,并用圆圈进行标记.我们可以直观地看出,人脸沿着横坐标从朝向左边转到朝向右边,沿着纵坐标从仰视变为俯视.故通过我们的算法,低维的映射结果能够很好地保持原始数据集的内在结构.
3 . 5 算法时间性能比较
为了展示本算法SLITSA与其他增量算法(增量LE、增量LTSA、增量LLE及增量HLLE等)的计算效率,我们在3.1节中的Swiss Roll数据集和3.4节的Rendered Face数据集上进行降维实验,将原数据集降到2维以后进行了时间复杂度的比较.
如图6所示,增量HLLE算法(IHLLE)的时间复杂度远远高出其他算法,在图7中我们列出了其中4种算法的时间复杂度.一开始本算法SLITSA的复杂度高于增量LE算法,但随着样本点数 n 的增加,本算法SLITSA的复杂度渐趋平稳,并且比增量LE算法以外的其他已有增量流形学习算法都快,故在目前已有的增量流形学习算法中能够达到良好的效果.图8所展示的是Rendered Face数据集上的实验,可见在100~600个高维图像数据集降维实验中,本算法始终保持较低的时间复杂度,结合前面3.1~3.4节的分类精度和重构误差实验,可知本算法SLITSA的综合性能非常优秀,具有重要的研究价值.
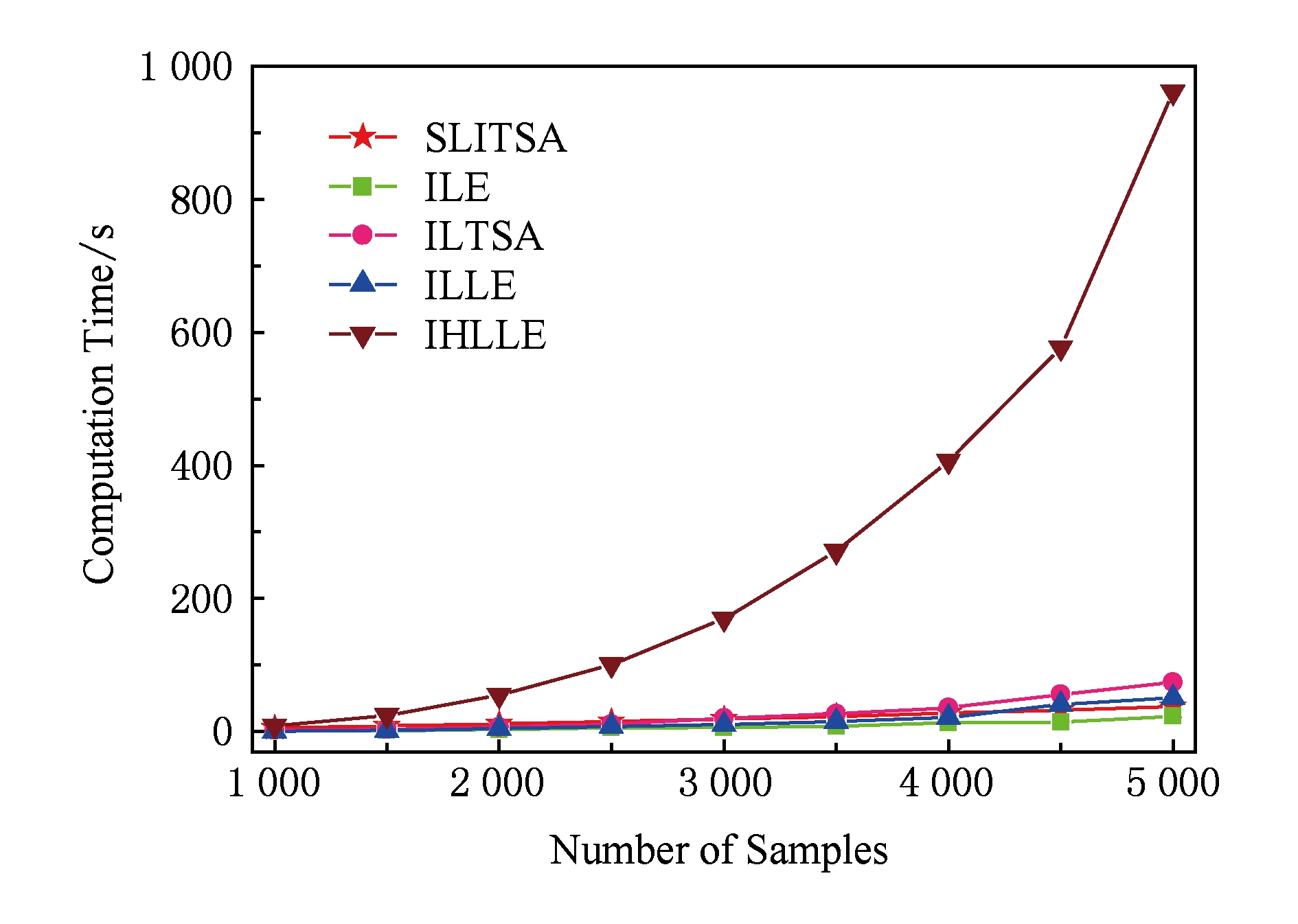
Fig. 6 Computation complexity on Swiss Roll dataset
图6 Swiss Roll数据集上的时间复杂度比较
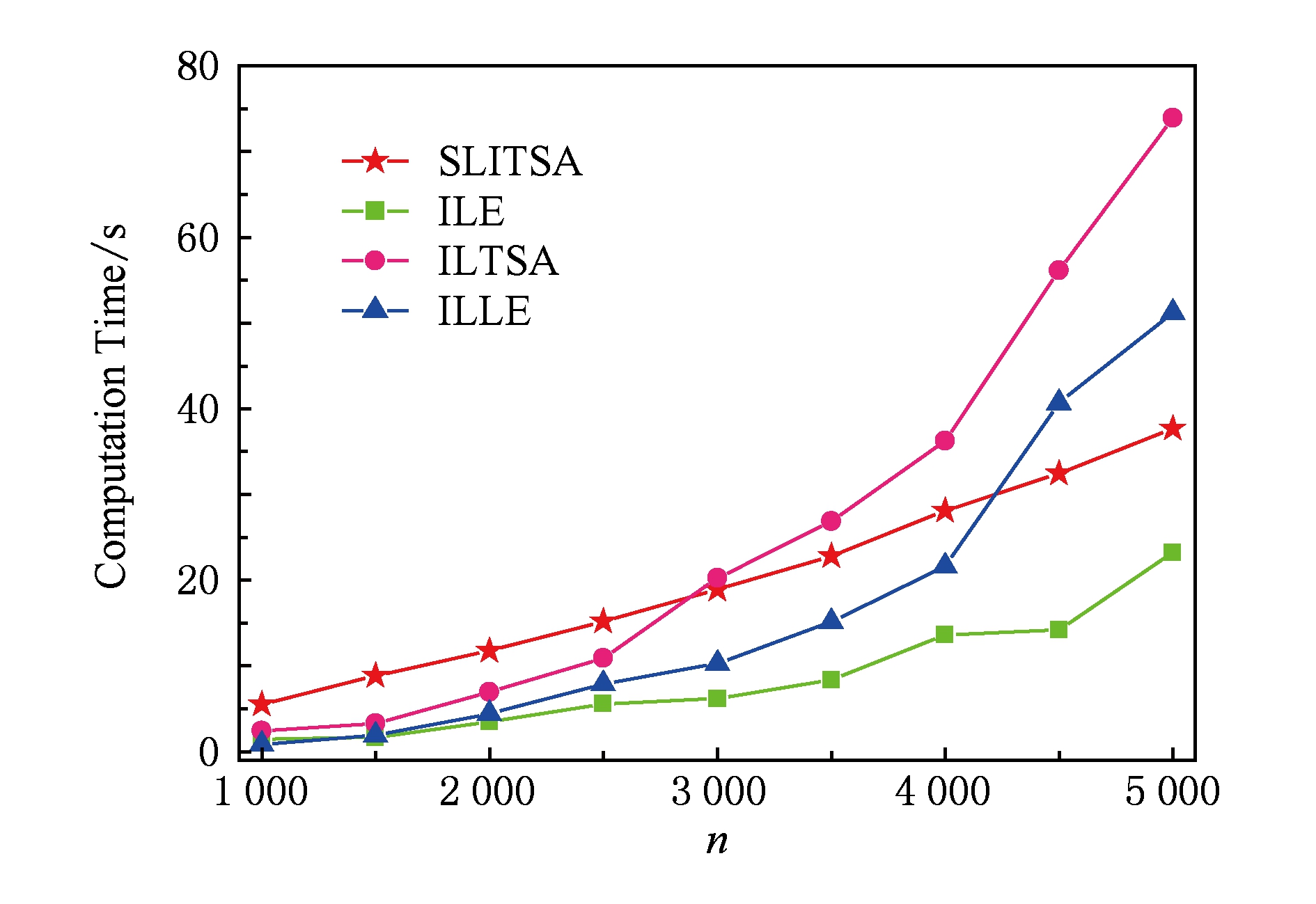
Fig. 7 Computation complexity of four incremental methods
图7 4种增量算法的时间复杂度比较
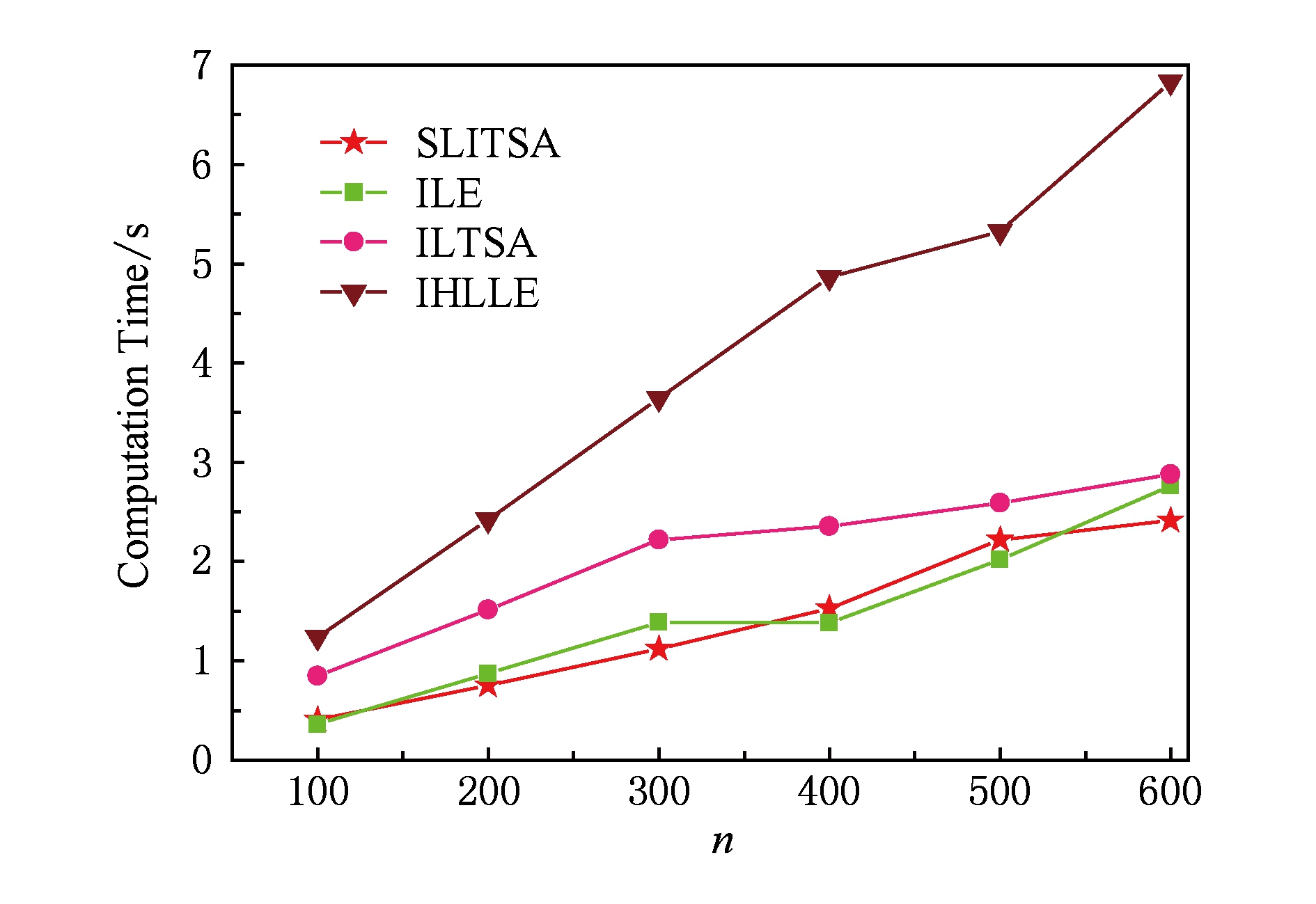
Fig. 8 Computation complexity on Rendered Face dataset
图8 Rendered Face数据集上的时间复杂度比较
本文基于增量切空间提出了一种新的增量流形学习算法SLITSA.该算法采用增量PCA的思想,增量地构造子空间,样本点局部信息的更新是从已有点和新点的特征向量得到的,故在更新局部切空间时无需重复计算整个协方差矩阵,与传统的批量模式算法相比,实时效果有了一定提高;受已有样本影响的自适应因子控制,新点的高维坐标局部线性重构以后保存了其到低维空间的映射,并反映了增量的性质;算法SLITSA可以精确地映射样本点到低维空间中,原因是SLITSA在特征空间的学习过程中使用了 A 和 B 这2个矩阵,在迭代过程中我们基于矩阵 B 的特征解构建的切空间进行了调准,保证了收敛并降低了重构误差.可以提高降维结果的精度,使得本文算法具有了增量学习的能力.
大量针对实际数据集的实验表明本文算法与其他算法相比,具有较好的降维效果及识别能力,可以很好地应用于大规模数据流分析中.其中,手写数字数据集是机器学习和模式识别领域被广泛使用的标准测试样本集,这里我们使用该数据集对本文提出的算法和相关算法进行实验验证和比较,具有一定的客观性和说服力.尽管人工智能在现实世界中的应用环境发生了变化,特别是在流式大数据的分析和识别中,数据集从静态变为了动态数据,而我们的实验表明,本文提出的方法采用增量PCA的思想,增量地构造子空间,实时效果有了一定提高,并反映了增量的性质,使得该文算法具有了增量学习的能力.故这里虽然使用的手写数字数据集属于静态数据集,但在近期将我们的方法应用于其他类型的符号识别可能特别有前途,包括动态环境下的流式数据集.在这些环境下,应用本文算法不但可以识别新的样本,与传统的批量模式算法相比,本文算法SLITSA可以精确地映射样本点到低维空间中,保证了收敛并降低了重构误差,可以提高降维结果的精度.
参考文献
[1]Li Zhijie, Li Yuanxiang, Wang Feng, et al. Online learning algorithms for big data analytics: A survey[J]. Journal of Computer Research and Development, 2015, 52(8): 1707-1721 (in Chinese)(李志杰, 李元香, 王峰, 等. 面向大数据分析的在线学习算法综述[J].计算机研究与发展, 2015, 52(8): 1707-1721)
[2]Tenenbaum J, Silva V, Langford J. A global geometric framework for nonlinear dimensionality reduction[J]. Science, 2000, 290(5500): 2319-2323
[3]Belkin M, Niyogi P. Laplacian eigenmaps for dimensionality reduction and data representation [J]. Neural Computation, 2003, 15(6): 1373-1396
[4]Roweis S T, Saul L K. Nonlinear dimensionality reduction by locally linear embedding[J]. Science, 2000, 290 (5500): 2323-2326
[5]Zhang Zhenyue, Zha Hongyuan. Principal manifolds and nonlinear dimensionality reduction via tangent space alignment[J]. SIAM Journal of Scientific Computing, 2004, 26(1): 313-338
[6]Law M H C, Jain A K. Incremental nonlinear dimensionality reduction by manifold learning[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2006, 28(3): 377-391
[7]Jia Peng, Yin Junsong, Huang Xinsheng, et al. Incremental Laplacian eigenmaps by preserving adjacent information between data points[J]. Pattern Recognition Letters, 2009, 30(16): 1457-1463
[8]Kouropteva O, Okun O, Pietikäinen M. Incremental locally linear embedding[J]. Pattern Recognition, 2005, 38(10): 1764-1767
[9]Abdel-Mannan O, Hamza A B, Youssef A. Incremental line tangent space alignment algorithm[C] //Proc of the Canadian Conf on Electrical and Computer Engineering. Piscataway, NJ: IEEE, 2007: 1329-1332
[10]Li Housen, Jiang Hao, Barrio R, et al. Incremental manifold learning by spectral embedding methods[J]. Pattern Recognition Letters, 2011, 32(10): 1447-1455
[11]Zhang Peng, Qiao Hong, Zhang Bo. An improved local tangent space alignment method for manifold learning[J]. Pattern Recognition Letters, 2011, 32(2): 181-189
[12]Zhao Haitao, Yuen Pongchi, Kwok J T. A novel incremental principal component analysis and its application for face recognition[J]. IEEE Trans on Systems, 2006, 36(4): 873-886
[13]Han Zhi, Meng Deyu, Xu Zongben, et al. Incremental alignment manifold learning[J]. Journal of Computer Science and Technology, 2011, 26(1): 153-165
[14]Li Bo, Du Jing, Zhang Xiaoping. Feature extraction using maximum nonparametric margin projection[J]. Neurocomputing, 2016, 188(5): 225-232
[15]Ling Gohfan, Han Pangying, Yee K E, et al. Face recognition via semi-supervised discriminant local analysis[C] //Proc of the 3rd Int Conf on Signal and Image Processing Applications(ICSIPA). Piscataway, NJ: IEEE, 2015: 292-297
[16]Han Pangying, Yin O S, Ling Gohfan. Semi-supervised generic descriptor in face recognition[C] //Proc of the 11th Int Colloquium on Signal Processing and Its Applications(CSPA). Piscataway, NJ: IEEE, 2015: 21-25[
17]Xu Yunfei, Huang Houjun, Yang Lin, et al. Semi-supervised local fisher discriminant analysis for speaker verification[J]. Advances in Information Sciences and Service Sciences, 2014, 6(6): 1-11
[18]Cheng Miao, Fang Bin, Tang Yuanyan, et al. Incremental embedding and learning in the local discriminant subspace with application to face recognition[J]. IEEE Trans on Systems, Man, and Cybernetics-PART C: Applications and Reviews, 2010, 40(5): 580-591
[19]Mantziou E, Papadopoulos S, Kompatsiaris Y. Scalable training with approximate incremental laplacian eigenmaps and PCA[C] //Proc of the 21st ACM Int Conf on Multimedia. New York: ACM, 2013: 381-384
[20]Weng Juyang, Zhang Yilu, Hwang W S. Candid covariance-free incremental principal component analysis[J].IEEE Trans on Pattern Analysis and Machine Intelligence, 2003, 25(8): 1034-1040
[21]Min Wanli, Lu Ke, He Xiaofei. Locality pursuit embedding[J]. Pattern Recognition, 2004, 37(4): 781-788
[22]Li Yongmin. On incremental and robust subspace learning[J]. Pattern Recognition, 2004, 37(7): 1509-1518
[23]Golub G H, Van Loan C F. Matrix Computations[M]. Baltimore, MD: Johns Hopkins University Press, 2012[24]Roweis S. Research: Data for MATLAB[OL].[2016-03-20]. http://www.cs.nyu.edu/~roweis/data.html

Tan Chao , born in 1983. PhD. Lecturer. Member of CCF. Her main research interests include machine learning and data mining.

Ji Genlin , born in 1964. PhD. Professor, PhD supervisor. Member of CCF. His main research interests include data mining and its application.

Zhao Bin , born in 1978. PhD. Associate professor, MSc supervisor. Member of CCF. His main research interests include data mining and its application (zhaobin@njnu.edu.cn).
Tan Chao, Ji Genlin, and Zhao Bin
(School of Computer Science and Technology, Nanjing Normal University, Nanjing 210023)
Abstract Manifold learning is developed to find the observed data’s low-dimension embeddings in high dimensional data space. As a type of effective nonlinear dimension reduction method, it has been widely applied to the machine learning field, such as data mining and pattern recognition, etc. However, when processing a large scale data stream, the complexity of time is too high for many traditional manifold learning algorithms, including out of sample learning algorithm, incremental learning algorithm, online learning algorithm, and so on. This paper presents a novel self-adaptive learning algorithm based on incremental tangent space alignment (named SLITSA) for big data stream processing. SLITSA adopts the incremental PCA to construct the subspace incrementally, and can detect the intrinsic low dimensional manifold structure of data streams online or incrementally. In order to ensure the convergence of SLITSA and reduce the reconstruction error, it can also construct a new tangent space for adjustment during the iterative process. Experiments on artificial data sets and real data sets show that the classification accuracy and time efficiency of the proposed algorithm are better than other manifold learning algorithms, which can be extended to the application of streaming data and real-time big data analytics.
Key words manifold learning; nonlinear dimension reduction; big data streams; incremental tangent space; self-adaptive
收稿日期: 2016-09-20;
修回日期: 2017-02-21
基金项目: 国家自然科学基金项目(41471371,61702270);江苏省高校自然科学基金项目(15KJB520022)
This work was supported by the National Natural Science Foundation of China (41471371, 61702270) and the Natural Science Foundation of Jiangsu Provincial Education Department (15KJB520022).
通信作者: 吉根林(glji@njnu.edu.cn)
中图法分类号 TP181