吕亚丽 1,2 武佳杰 2 梁吉业 1 钱宇华 1
1 (计算智能与中文信息处理教育部重点实验室(山西大学) 太原 030006) 2 (山西财经大学信息管理学院 太原 030006)
(sxlvyali@163.com)
摘 要 近年来,贝叶斯网络(Bayesian network, BN)在不确定性知识表示与概率推理方面发挥着越来越重要的作用.其中,BN结构学习是BN推理中的重要问题.然而,在当前BN结构的2阶段混合学习算法中,大多存在一些问题:第1阶段无向超结构学习中存在容易丢失弱关系的边的问题;第2阶段的爬山搜索算法存在易陷入局部最优的问题.针对这2个问题,首先采用Opt01ss算法学习超结构,尽可能地避免出现丢边现象;然后给出基于超结构的搜索算子,分析初始网络的随机选择规则和对初始网络随机优化策略,重点提出基于超结构的随机搜索的SSRandom结构学习算法,该算法一定程度上可以很好地跳出局部最优极值;最后在标准Survey, Asia,Sachs网络上,通过灵敏性、特效性、欧几里德距离和整体准确率4个评价指标,并与已有3种混合学习算法的实验对比分析,验证了该学习算法的良好性能.
关键词 贝叶斯网络;结构学习;随机搜索;超结构;混合算法
贝叶斯网络(Bayesian network, BN)模型 [1] 是人工智能学科表示并处理概率知识的一种重要方法.该模型已被广泛应用于基因调控、医疗诊断、故障检测、金融预测分析等方面.其中,BN学习 [2-10] 是目前BN研究的主要热点之一,也是该模型推向应用的前提基础.
BN学习主要包括结构学习 [2-7] 和参数学习 [8-10] 2部分.本文主要集中于对其结构学习的研究.目前,对于BN结构学习算法大致可分为3类:
1) 基于约束(constraint based, CB)或者依赖分析的算法 [3] ,即利用统计学或者信息论中的知识,对变量之间的依赖性进行测试,分析出各变量之间的关系,然后利用这些依赖性关系构建BN模型.该类算法过程比较复杂,但在一些假设下可以得到最优的BN结构,并且算法可具有多项式时间复杂度,该类算法比较适合于建立变量多、网络稀疏的BN结构学习.
2) 基于评分搜索的算法,即对所有可能的BN结构利用某种优化算法进行搜索,然后对搜索到的BN进行评分 [4-5] ,以期待找出得分较高的BN结构.该类算法过程简单规范,但打分函数的运算复杂程度和结构搜索空间大小都随变量增加呈指数增加,通常以解决时间复杂性高的算法有:①给定节点顺序,进行局部打分,如经典的K2算法 [6] ;②选择启发式搜索策略进行整体打分等.该类算法比较适合于变量较少、网络较稠密的BN结构学习.
3) 目前较为流行的混合学习算法 [7,11-12] ,该类算法结合上述2类算法的优点,首先基于约束的方法系统检查条件独立性关系,得出网络的基本无向图框架(skeleton) [7,13] ,然后基于此无向图框架采用评分搜索算法来学习整个BN结构.其中较典型的混合学习算法有MMHC(max-min hill-climbing) [7] .在MMHC算法中,首先利用MMPC(max-min parents and children)算法得到网络的无向图框架,然后利用爬山算法得到BN结构.但由于MMPC得到的无向图框架中会丢失应有的一些边,即存在丢边问题.另外,对于经典的爬山算法众所周知的缺点是易陷入局部最优.
2014年,Villanueva和Maciel [14] 提出一种有效学习BN超结构(super-structure, SS)的Opt01ss算法,该算法在有限数据情况下,一定程度上可以避免条件独立性(conditional independence, CI)测试不一致性和近似确定关系(approximate deterministic relationships, ADRs)等问题,尽可能减少了弱关系下边的丢失问题.因此,本文借鉴文献[14]中的超结构学习算法,重点研究随机搜索算法,并考虑解决陷入局部极值问题,提出一种基于超结构的随机搜索BN结构的混合学习算法.
本节主要介绍BN模型与其评价准则、超结构框架及其Opt01ss学习算法.
1 . 1 BN模型与其评价准则
BN模型是图论和概率论的“结合体”,主要由有向无环图(directed acyclic graph, DAG)结构和每个节点相对应的条件概率分布表(conditional probability table, CPT)组成.该模型可形式化表示成M=(G,P),其中G=(V,E)表示 BN 的 DAG 结构.V表示节点变量;E表示边集,反映变量间的相互依赖关系;P表示每个节点相对应的 CPT 集合,反映父子节点变量之间的依赖程度.
给定数据集D, BN 结构学习指从数据中获得与数据集D拟合程度较好的 DAG 结构.评价网络结构与样本数据拟合程度的函数称为评分函数.常见的评分函数有多种,如贝叶斯信息评分准则( BIC ) [15] 、 CH 评分 [6] 、最小描述长度( MDL ) [5] 等,这里简单介绍本文所采用的 BIC 评分函数,该函数的评分越高,说明从数据中获得的 DAG 网络结构越好.其具体形式为
其中 ![]() 表示给定数据D对模型M的最大似然参数
表示给定数据D对模型M的最大似然参数 ![]() 表示模型的参数个数,q i 是节点变量V i 的父节点组合数,r i 是节点变量V i 的取值个数;N是样本量的大小.
表示模型的参数个数,q i 是节点变量V i 的父节点组合数,r i 是节点变量V i 的取值个数;N是样本量的大小.
1 . 2 超结构
对BN结构的混合学习算法,一般来说,首先基于约束关系构建出其无向框架图,即其超结构SS;然后在SS的基础上运用搜索评分方法优化BN结构,得到评分较高的网络.
定义1 . 超结构 SS [13-14] .对于一个 DAG G, 若一个无向图包含G去掉方向之后的所有边,即完全包含该 DAG 的基本架构,则称该无向图是G的一个完全超结构,否则称为不完全超结构.若无特别说明,本文均指完全超结构.
近年来,许多学者研究了BN超结构的学习算法 [13-14,16] .其中,Villanueva和Maciel [14] 提出的Opt01ss算法取得了较好的效果.该算法解决了在样本量有限的情况下,其他超结构学习算法容易出现的2个问题:1)CI测试不一致的问题;2)如图1所示的ADRs问题,即避免了存在较弱关系的边的丢失问题,保留了尽可能多的边.
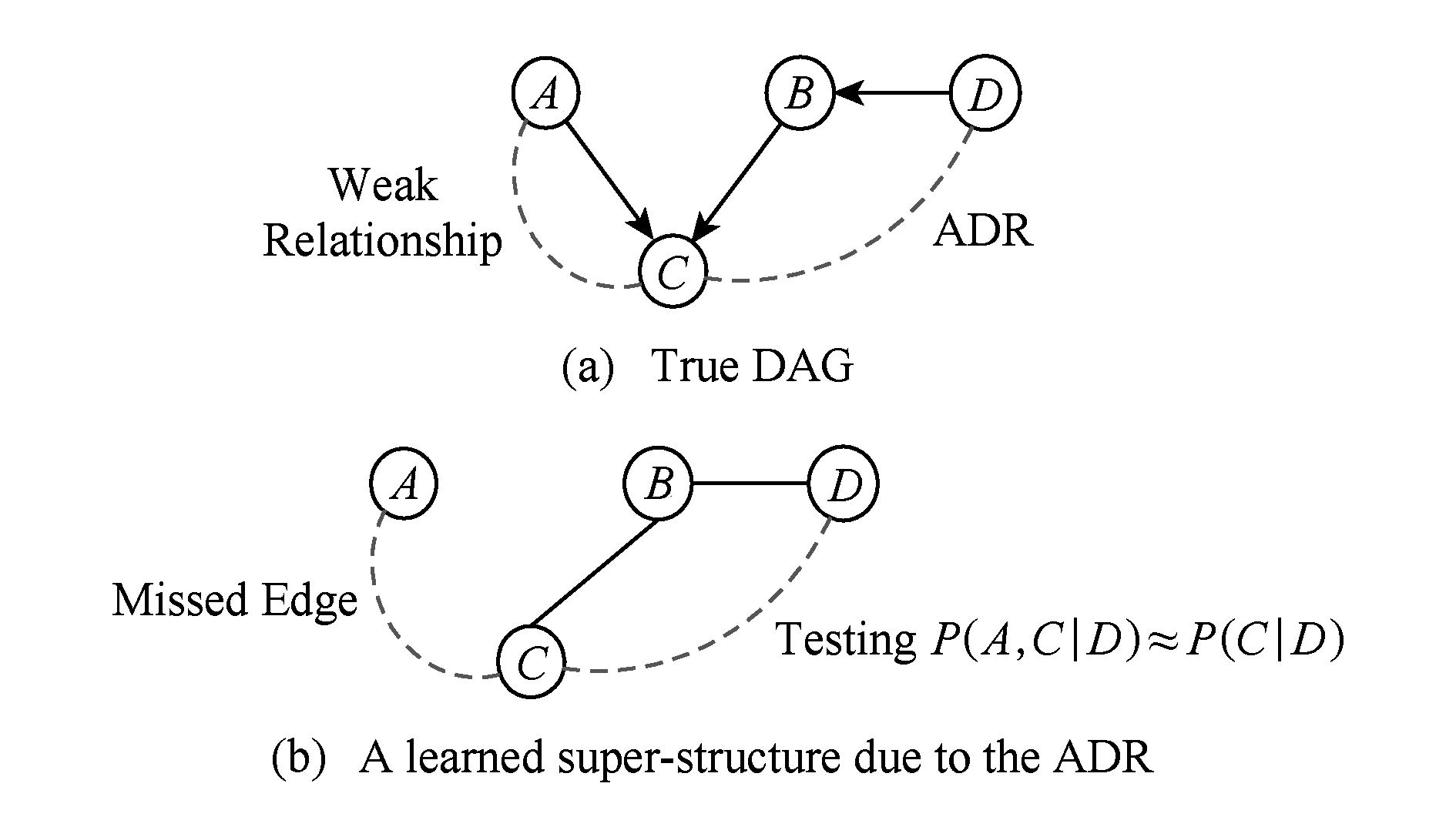
Fig. 1 An example to illustrate ADR problem
图1 ADR问题解释示例
由此,本文采用该Opt01ss算法思想获得BN超结构,然后重点进行随机搜索找出较优的BN结构.
在基于Opt01ss算法获得SS的基础上,本节主要针对爬山算法中网络最终结果对初始结构的依赖度大,导致易陷入局部极值的问题,研究基于SS的随机搜索算法.具体地,首先介绍基于SS的3种搜索算子,然后分析基于SS的初始网络的随机选取规则,接着讨论使得初始网络避免陷入局部极值的随机优化策略,进一步提出基于SS的随机搜索(random search based on SS, SSRandom)的学习算法.
2 . 1 基于SS的搜索算子
由于本文第1阶段得出的SS已包含最优BN去掉方向后的所有边,因此,候选DAG的3个搜索算子主要指:
1) 添方向算子,记作 O Add .该算子不同于爬山法中的加边算子,它指将超结构中的边加一个方向后添加到当前DAG中.
2) 减边算子,记作 O Sub .即在当前DAG中减去一条边.
3) 转方向算子,记作 O Rev .即将当前DAG中的一条边的方向进行翻转.
需要注意的是:与爬山法相同,加边和转边的前提是保证该图仍保持无环,即保持候选网络仍是DAG结构.
2 . 2 基于SS的初始网络的随机选取规则
定义2 . 基于SS的随机DAG——SSRDAG.通过基于SS的3种搜索算子,对某DAG随机进行一步或多步 O Add , O Sub , O Rev 操作后得到的DAG,即称为该DAG基于SS的随机DAG,记作SSRDAG.
在爬山法中,其初始网络是一个无边图,在无边图的基础上进行一步搜索选择得分较高的候选网络作为当前网络,并在此基础上继续优化.可知,初始无边网络相对距离最优网络较远.本文探讨的初始网络是距离最优网络要较近的网络.为了加快搜索,我们初始网络的选择是保留SS的所有边,只是在不形成环路的前提下,给每条无向边通过 O Add 算子随机添加一个方向,并随机搜索 m 次,得出 m 个SSRDAGs,并将BIC得分最高的SSRDAG作为初始模型G0.可知,该初始网络的选择较爬山法来说有2个好处:1)离最优网络更近了一步;2)初始网络是 m 个中根据得分函数选出的,自然这时选择的初始网络相对较优.
2 . 3 对初始网络的随机优化策略
由于初始网络G0中已包含 SS 中的所有无向边,因而对其优化时只需要考虑减边O Sub 和转方向O Rev 操作,不需要添方向O Add 操作.初始优化时,首先将初始G0作为当前需优化的模型G*,然后随机选择O Sub 和O Rev 操作m次,得到m个 SSRDAGs ,即得出m个候选的G* j (1≤j≤m),并对当前G*和候选的G* j (1≤j≤m)共m+1个 SSRDAGs 按 BIC 得分进行非升序排列,将得分最高网络记为当前网络模型G*.
为了继续优化当前网络G*,并考虑避免结果陷入局部最优,文中引入2个 SSRDAGs 随机交叉的概念.
定义3 . 2个SSRDAGs的随机交叉.对于2个SSRDAGs模型,其随机交叉指随机选择1对节点或多对节点,并互相交叉选定的边后得到2个新SSRDAGs的操作.
例1 . 对于常见的一个关于年龄A、性别G、抽烟S和肺癌LC的 BN 实例,已知其 DAG 结构包括的有向边有  A,S
A,S 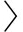 , G,S , S,LC ,下面以该网络的一个包含无向边(A,S),(A,G),(G,S),(S,LC),(G,LC)的 SS 为例来详细说明其2个 SSRDAGs 的随机交叉操作.
, G,S , S,LC ,下面以该网络的一个包含无向边(A,S),(A,G),(G,S),(S,LC),(G,LC)的 SS 为例来详细说明其2个 SSRDAGs 的随机交叉操作.
Fig. 2 Two SSRDAGs and their random cross results
图2 两个SSRDAGs与其随机交叉结果
对于图2(a)(b)中的2个SSRDAGs,假设我们随机选择了节点对( A , G )和( S , LC ),并互相交叉它们边的情况,得出如图2(c)(d)所示的2个新SSRDAGs.
进一步在 m +1个排好序的模型中,随机选取排序的前2个模型中的一个,记为G*,并与后面m-1个中的一个模型随机交叉.这样与得分较低网络的随机交叉的目的是以一定的概率接受低分网络,跳出对当前网络的过度依赖,避免陷入局部极值.并且每次交叉后保留2个 SSRDAGs 中得分较高的那个模型,这样的随机循环搜索共进行m次,并将每次搜索结果记为G* k (1≤k≤m).接着,对m个G* k (1≤k≤m)模型中最高得分与G*的得分相比较,用高分网络替代当前网络G*.一直循环,直至达到循环结束条件,最后得出优化的 BN 模型的 DAG 结构.
2 . 4 SSRandom学习算法
BN结构学习的SSRandom算法的目标是基于SS随机搜索出BIC得分较高的BN模型的DAG.大致分为3个步骤:
Step1. 基于Opt01ss算法获得BN的SS;
Step2. 在SS基础上,对所有无向边随机使用 O Add 算子添加方向,获得得分最高的初始模型G0作为当前模型G*;
Step 3. 通过减边算子O Sub 和转方向算子O Rev 对G*随机进行m次优化,并将高分网络与低分网络进行随机交叉,允许以一定的概率接受低分网络,避免结果陷入局部最优,循环得出优化的BN结构.
其伪代码描述如算法1所示:
算法1 . SSRandom 算法.
输入:数据集D、循环次数n、随机搜索次数m;
输出:优化后 BN 的 DAG G结构.
通过 Opt 01 ss 算法从数据集D中获得超结构 SS ;
while 循环次数n或循环条件满足 do
for i=1 to m do
通过O Add 算子,随机获得m个 SSRDAGs 模型(G 1 ,G 2 ,…,G m ),这些模型去掉边后均包含 SS 中的所有边;
end for
初始模型 ![]() ;
;
当前模型G*←G0;
for j=1 to m do
随机通过O Sub 和O Rev 算子,优化G*,获得 SSRDAGs G* j ;
end for
Sort (G*,G* 1 ,G* 2 ,…,G* m ),即按 BIC 得分,对m+1个 SSRDAGs 非升序排列;
G*← Sort 中最高得分的网络;
for k=1 to m do
G*←从G*和 Sort 中次高得分的网络中随机选一个网络;
G*与剩余m-1个中的任意一个进行随机交叉,得2个 SSRDAGs 网络G1* k 和G2* k ;
G* k ← arg max (f BIC (G1* k ),f BIC (G2* k ));
end for
if ![]()
end if
end while
return G ←G*.
2 . 5 时间复杂性分析
在SSRandom算法中,在SS基础上的随机搜索部分,第1个for循环是随机选择初始网络,其时间复杂度为O(m),m表示随机搜索次数. Sort 排序算法用快速排序时,其时间复杂性为O(m log m),其中m表示m次随机搜索后获得的m个网络.第2个和第3个 for 循环是随机优化初始网络,其时间复杂度均为O(m).因而,整个随机搜索算法部分时间复杂度为O(m log m).
而在 SS 的基础上,若考虑用其他算法优化 BN 结构,如蛮力法( brute force )和爬山法( hill climbing )等,那么需要对照分析其时间复杂性情况.首先假设 SS 得出的无向边数为e,最坏情况下e= ![]() ,其中|V|表示网络节点变量个数.下面分别对其具体情况进行分析:
,其中|V|表示网络节点变量个数.下面分别对其具体情况进行分析:
1) 蛮力法.由于要对无向图中的e条边定向,而每条边的定向情况有2种,因而最终的网络搜索空间为2 e ,故其时间复杂度为O(2 e ).
2) 爬山法.由于其搜索网络空间为搜索算子对当前网络的一次加边、或减边、或转边后得到的网络集合,易知,在 SS 的基础上,有i(0≤i≤e)条有向边的当前网络的候选网络个数为
2e=2(e-i)+i+i,
其中,(e-i)表示一次加边产生的网络个数,2个i分别表示一次减边和一次转边后产生的网络个数,因而i取e种情况下共有2e 2 个候选网络,故其时间复杂度为O(e 2 ).
由此,在 SS 基础上3种算法的时间复杂度分别如表1所示:
Table 1 The Time Complexity Comparison
表1 时间复杂性对比

Notes: m is the number of random search, and e is the number of undirected edge in SS.
通常,大多情况下 BN 的有向边数均会大于节点数|V|,因而一般混合学习算法第1阶段得出的 SS 的无向边数egt;|V|,或至少也会接近|V|.随着网络变量数增加,蛮力法和爬山法的搜索空间会较随机搜索算法的搜索空间快速增加,从本文第3节实验也可得到,当|V|分别为6,8,11且本文的随机搜索次数m=10时,大多情况下已比其他 BN 结构算法学到的结果要好.可见,该随机搜索策略要比通常基于评分搜索的算法高效.
本节在标准数据集上,通过将本文所提算法以及已有的3种BN结构学习算法,分别与标准结果在4方面评估指标上的对比分析,验证本文所提算法的学习性能.
3 . 1 实验环境与数据集
实验运行环境为:操作系统Windows 7、处理器Intel ® Core TM i7-4510U CPU@2.00 GHz、内存4.00 GB.
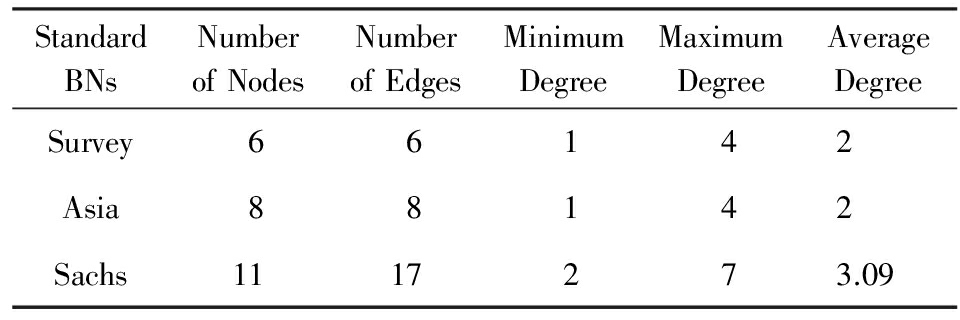
所有实验在R语言环境中借助于R语言自带的bnlearn工具包 [17] 实现.实验选用标准的Survey,Asia,Sachs三个网络 [17] ,其网络结构情况如表2所示.实验中具体所用数据均是通过这些基准网络经过逻辑抽样后得出的模拟数据.
Table 2 Three Standard Structures of BNs Used in the Experiments
表2 实验所采用的3个标准BN结构
3 . 2 评价指标
BN结构的学习结果通过灵敏性 Sn (sensitivity)、特效性 Sp (specificity)、欧几里德距离 Ed (Euclidean distance) [14] 以及本文定义的整体准确率 Pa (percentage of overall accuracy)四个指标进行评价.各指标具体描述如下:
1) 灵敏性Sn.反映正确学到的边占实际边的比率,该指标值越大越好.其格式化表示为
Sn= ![]() ,
,
其中,TP表示基准网络中有边而且也学出的边的个数,即正确学出的边的个数;FN表示基准网络中有边但没有学出的边的个数,即丢失边的个数.
2) 特效性Sp.反映正确学出的无边占实际无边的比率,该指标值越大越好.其格式化表示为
Sp= ![]() ,
,
其中,FP表示基准网络中无边但学出有边的个数,即冗余边的个数;TN表示基准网络中无边而且学出无边的个数,即正确学出无边的个数.
3) 欧几里德距离Ed.反映学出网络与真实网络之间在欧氏空间的差距,该指标值越小越好.其格式化表示为
Ed= ![]() .
.
4) 整体准确率Pa.主要通过正确学出的有向边和正确学习的无边的比率来度量学习所得的网络结构的整体准确度,该指标值越大越好.其格式化表示为
Pa= ![]() .
.
3 . 3 结果对比与分析
实验主要对比本文所提的SSRandom算法和已有的MMHC,Hiton+HC (bnlearn工具包自带的Hiton和HC搜索策略的混合)、GS+HC (bnlearn自带的Grow-Shrink和HC的混合)三种结构学习算法在Survey,Asia,Sachs网络上的实验结果,对比指标主要有 Sn , Sp , Ed , Pa 四个.
由于本文所提方法还涉及到算法的循环次数n和随机搜索次数m的设置.因而实验中,对于n的取值,考虑n=100和n=300这2种情况;对于m的取值,考虑m=10和m=30这2种情况.
对于 SSRandom 算法,每种情况下学习5次进行平均;对于其他3种算法,并不涉及这些参数,所以不需要分情况讨论.因而在每种情况下,在每次运行 SSRandom 算法的相同数据集上,同时运行其他3种算法学习 BN 结构,即它们是20(即4×5)次或5次的平均.具体实验结果如表3~5,粗体数字表示每个指标下最好的实验结果.
Table 3 Comparison Between SSRandom and Other Three Algorithms on the Dataset of Size 5 000
表3 样本容量为5 000时SSRandom与其他3种算法的实验结果对比
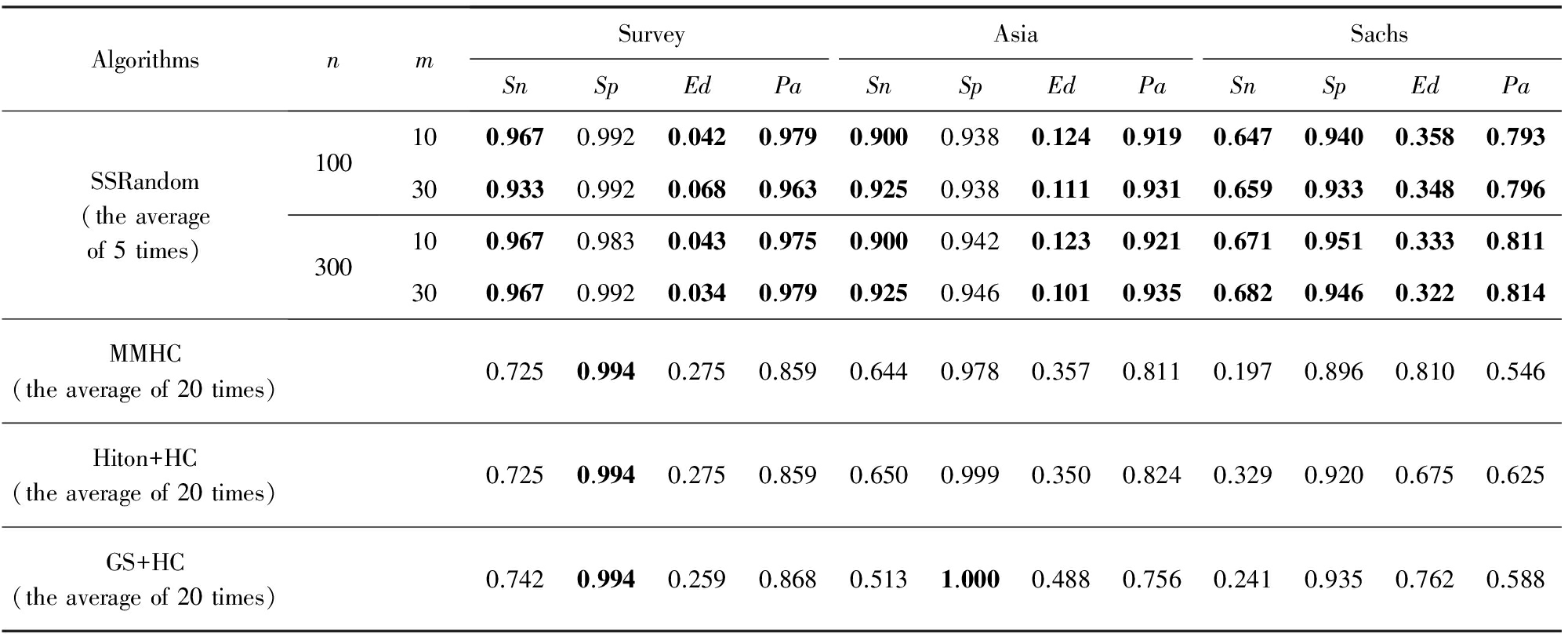
Table 4 Comparison Between SSRandom and Other Three Algorithms on the Dataset of Size 2 000
表4 样本容量为2 000时SSRandom与其他3种算法的实验结果对比
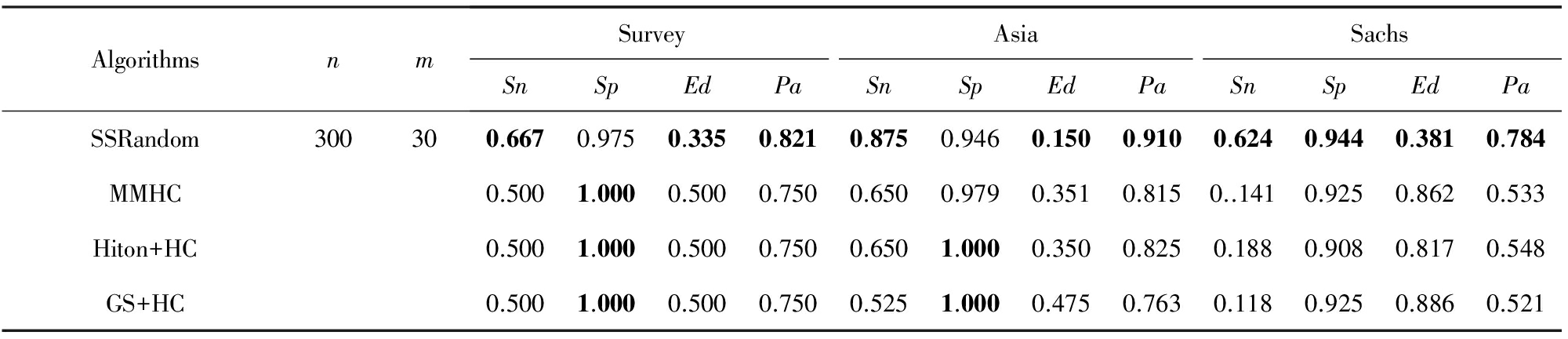
Notes: The results of each algorithm are the average of 5 times.
Table 5 Comparison Between SSRandom and Other Three Algorithms on the Dataset of Size 10 000
表5 样本容量为10 000时SSRandom与其他3种算法的实验结果对比
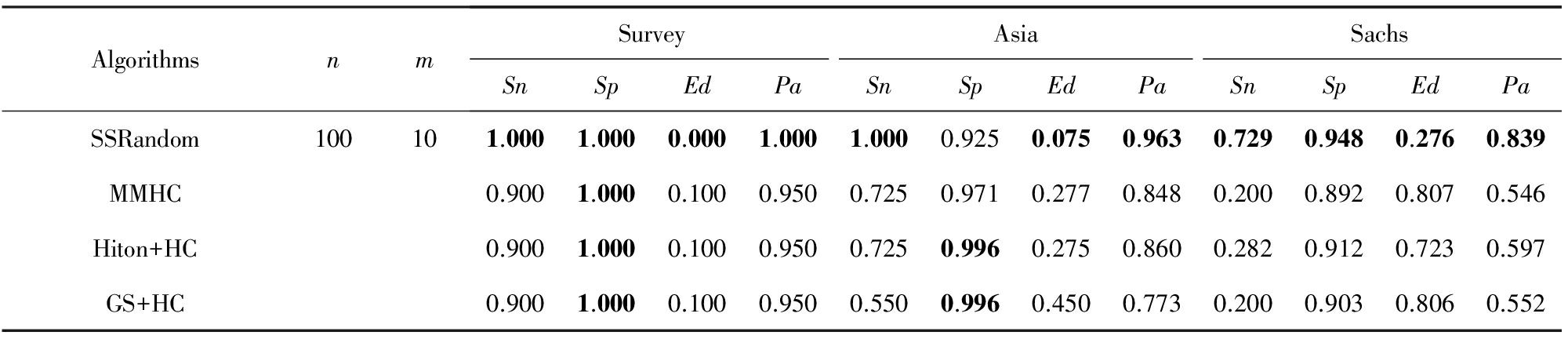
Note: The results of each algorithm are the average of 5 times.
从表3可看出,样本量达5 000时,分别在( n =100, m =10),( n =100, m =30),( n =300, m =10),( n =300, m =30)四种情况下,除Survey网络上的 Sp 和Asia网络上GS+HC方法的 Sp 外,SSRandom算法在4种指标下均比其他3种算法效果好,其 Pa 结果在Survey和Asia网络上可达90%以上,在Sachs网络上可达近80%,但其他3种算法在Sachs网络上的 Pa 效果却在63%及其以下.而且可统计出SSRandom算法循环次数 n =300时的结果中有83.3%(10  12)的要比 n =100时好,具体可通过每个网络上 n =300与 n =100在 m =10和 m =30 共4种组合下的比较统计得出.同理得出 m =30时中有75%(9 12)的结果要比 m =10时的好.
12)的要比 n =100时好,具体可通过每个网络上 n =300与 n =100在 m =10和 m =30 共4种组合下的比较统计得出.同理得出 m =30时中有75%(9 12)的结果要比 m =10时的好.
下面进一步对样本量减少和增加时,4种学习算法的性能进行对比分析.首先看样本量减少的情况,由于样本量为5 000时,SSRandom算法在4种指标下的学习结果大多好于其他3种算法,而且在 n =300时的整体效果要比 n =100时的好,在 m =30时的整体效果要比 m =10时的好.因而,当样本量减少为2 000时,考虑SSRandom算法在( n =300, m =30)情况时与其他3种算法的实验结果进行对比分析,同样,每次在样本量为2 000的相同数据集上运行,共实验5次后求平均.具体如表4所示.
从表4可知,除部分 Sp 外,本文SSRandom算法性能在其他指标下均比样本量为5 000时有所下降,但仍比其他3种算法要好.而且从实验数据上看,所有 Pa 均可达78%以上,但其他3种算法,尤其在Sachs网络上的 Pa 效果却在55%以下.因此,本文算法与其他算法相比,仍较适合样本量2 000时进行BN结构的学习.接着,看样本量增加的情况.同理,由于样本量为5 000时,SSRandom算法的学习效果较好,所以当样本量增加为10 000时,我们只考虑SSRandom算法在( n =100, m =10)情况时与其他3种算法5次平均的实验结果进行对比分析,具体如表5所示.
从表5可知,除Asia网络上的 Sp 外,SSRandom算法在其他情况下的学习结果比其他3种算法的结果要好或一样好.而且从实验数据整体上来看,4种算法的学习结果较之前样本量为2 000和5 000时均有所提高.但对于其他3种算法,在Sachs网络上的 Pa 效果仍在60%以下,而本文SSRandom算法可提高到83%以上.
进一步,从表3~5中,分析3个样本量情况下Sachs网络的学习结果.由表2可知,Sachs网络最大度为7,较Survey和Asia网络来说,该网络更易产生ADRs问题,丢失较多弱关系边;而本文算法在有限样本情况下,可以较好处理这一问题,而且在后续学习阶段该算法可以一定概率较好地避免使学习结果陷入局部最优等不足,从而使得学习结果相对理想,提高了实验结果的 Pa .另外,从表3~5可得出,4种算法在不同网络上的各指标效果与不同样本量的关系,具体如图3所示.
从图3(a)~(l)明显可知,随着样本量的增加,除特效性 Sp 外,3个网络在各评价指标下4种算法的性能均在增加.虽然反映正确学出的无边的特效性 Sp 的性能有所下降,但关联到 Sp 的整体准确率的 Pa 和欧几里德距离 Ed 指标下的性能仍是增加的.并且可看出本文的SSRandom算法在每个样本量下与其他方法相比,整体上效果较好.更重要的是,当样本量为2 000时,较其他网络而言,就可学出很好的网络结构,尤其对于Survey网络;当样本量从2 000增加至5 000时,SSRandom算法的其各项性能增加得较为明显,很快就可增加至近似最好结果;当样本量从5 000增加至10 000时,其增长趋势相对平缓一些,这说明了本文SSRandom算法与其他3种算法相比,在较少样本量的情况下,可以较好地学得网络结构.
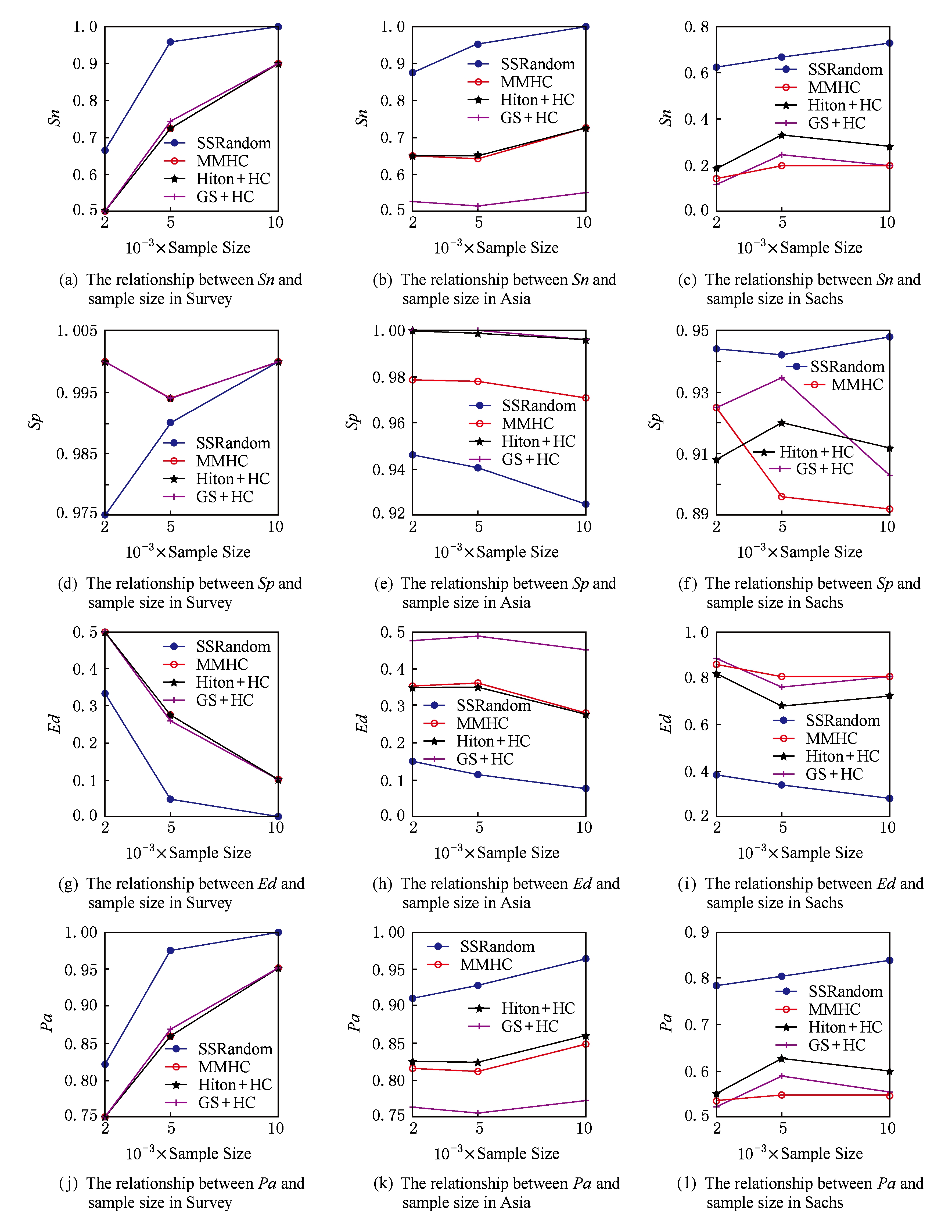
Fig. 3 The relationship between each evaluation index and sample size in Survey, Aisa and Sachs networks, respectively
图3 各评价指标与样本量分别在Survey, Aisa, Sachs网络上的关系
本文针对BN结构混合学习算法中超结构构建时容易丢失边和空间搜索时爬山法易陷入局部最优等问题,通过采用Opt01ss算法学习超结构,以尽可能地避免了出现丢失边的问题;接着重点研究了基于超结构随机搜索的SSRandom学习算法,该随机算法可以一定的概率跳出局部最优.通过在标准网络上多种样本量情况下4种评价指标上的实验,验证了该算法的良好学习性能.进一步的研究工作将面向高维小样本数据探讨BN结构的随机学习方法.
参考文献
[1]Pearl J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference[M]. San Mateo, CA: Morgan Kaufmann, 1988
[2]Bouhamed H, Masmoudi A, Lecroq T, et al. Structure space of Bayesian networks is dramatically reduced by subdividing it in sub-networks[J]. Journal of Computational and Applied Mathematics, 2015, 287: 48-62
[3]Cheng J, Greiner R, Kelly J. Learning Bayesian networks from data: An information-theory based approach[J]. Artificial Intelligence, 2002, 137(1  2): 43-90
2): 43-90
[4]De Campos L M. A scoring function for learning Bayesian networks based on mutual information and conditional independence tests[J]. Journal of Machine Learning Research, 2006, 7(2): 2149-2187
[5]Lam W, Bacchus F. Learning Bayesian belief networks: An approach based on the MDL principle[J]. Computational Intelligence, 1994, 10(3): 269-293
[6]Cooper G F, Herskovits E. A Bayesian method for the induction of probabilistic networks from data[J]. Machine Learning, 1992, 9(4): 309-347
[7]Tsamardinos I, Brown L E, Aliferis C F. The max-min hill-climbing Bayesian network structure learning algorithm[J]. Machine Learning, 2006, 65(1): 31-78
[8]Masegosa A R, Feelders A J, Gaag L C. Learning from incomplete data in Bayesian networks with qualitative influences[J]. International Journal of Approximate Reasoning, 2015, 69: 18-34
[9]Yao Tiansheng, Choi A, Darwiche A. Learning Bayesian network parameters under equivalence constraints[J]. Artificial Intelligence, 2015, 29(9): 1349-1354
[10]Liao Wenhui, Ji Qiang. Learning Bayesian network parameters under incomplete data with domain knowledge[J]. Pattern Recognition, 2009, 42(11): 3046-3056
[11]Masegosa A R, Moral S. New skeleton-based approaches for Bayesian structure learning of Bayesian networks[J]. Applied Soft Computing, 2013, 13(2): 1110-1120
[12]GaSSe M, AuSSem A, Elghazel H. A hybrid algorithm for Bayesian network structure learning with application to multi-label learning[J]. Expert Systems with Applications 2014, 41(15): 6755-6772
[13]Perrier E, Imoto S, Miyano S. Finding optimal Bayesian network given a super-structure[J]. Journal of Machine Learning Research, 2008, 9(4): 2251-2286
[14]Villanueva E, Maciel C. Efficient methods for learning Bayesian network super-structures[J]. Neurocomputing, 2014, 123: 3-12
[15]Lähdesmäki H, Shmulevich I. Learning the structure of dynamic Bayesian networks from time series and steady state measurements[J]. Machine Learning, 2008, 71(2): 185-217
[16]Villanueva E, Maciel C. Optimized algorithm for learning Bayesian network super-structures[C OL] Proc of the ICPRAM’12. 2012 [2016-07-01]. https: www.researchgate.net publication 289765566_Optimized_algorithm_for_learning_Bayesian_network_super-structures?ev=auth_pub
[17] Scutari M. Learning Bayesian networks with the bnlearn R package[J]. Journal of Statistical Software, 2010, 35(3): 1-22

L ü Yali , born in 1975. PhD. Associate professor. Member of CCF. Her main research interests include probabilistic reasoning, data mining and machine learning.

Wu Jiajie , born in 1989. Master candidate. Student member of CCF. His main research interests include machine learning and probabilistic reasoning(sxcjdxjsjw@163.com).

Liang Jiye , born in 1962. Professor and PhD supervisor. Distinguished member of CCF. His main research interests include granular computing, data mining and machine learning(ljy@sxu.edu.cn).

Qian Yuhua , born in 1976. Professor and PhD supervisor. Member of CCF. His main research interests include granular computing, social computing and machine learning for big data(jinchengqyh@126.com).
Lü Yali 1,2 , Wu Jiajie 2 , Liang Jiye 1 , and Qian Yuhua 1
1 (Key Laboratory of Computational Intelligence and Chinese Information Processing (Shanxi University), Ministry of Education, Taiyuan 030006) 2 (School of Information Management, Shanxi University of Finance amp; Economics, Taiyuan 030006)
Abstract Recently, Bayesian network(BN) plays a vital role in knowledge representation and probabilistic inference. BN structure learning is crucial to research on BN inference. However, there are some disadvantages in the most two-stage hybrid learning method of BN structure: it is easy to lose edges with weak relationship in the first stage, when we learn the super-structure; hill climbing search method is easily plunged into local optimum in the second stage. To avoid the two disadvantages, the super-structure of BN is firstly learned by Opt01ss algorithm, which makes the result miss few edges as much as possible. Secondly, based on super-structure, three search operators are given to analyze the random selection rule of the initial network and address the random optimization strategy for the initial network. Further, SSRandom learning algorithm of BN structure is proposed. The algorithm is a good way to jump out of local optimum extremum to a certain extent. Finally, the learning performance of the proposed SSRandom algorithm is verified by the experiments on the standard Survey, Asia and Sachs networks, by comparing with other three hybrid algorithms according to four evaluation indexs, such as the sensitivity, specificity, Euclidean distance and the percentage of overall accuracy.
Key words Bayesian network (BN); structure learning; random search; super-structure; hybrid algorithm
收稿日期: 2016-09-20;
修回日期: 2017-02-21
基金项目: 国家自然科学基金重点项目(61432011);军民共用重大研究计划联合基金重点项目(U1435212);国家自然科学基金优秀青年科学基金项目(61322211);国家自然科学基金项目(61672332);中国博士后科学基金项目(2016M591409);山西省自然科学基金项目(2013011016-4,2014011022-2)
This work was supported by the Key Program of the National Natural Science Foundation of China (61432011), the Key Program of Plan Joint Foundation for Military and Civilian Sharing Major Research (U1435212), the National Natural Science Foundation of China for Excellent Young Scientists (61322211), the National Natural Science Foundation of China (61672332), the China Postdoctoral Science Foundation (2016M591409), and the Natural Science Foundation of Shanxi Province (2013011016-4, 2014011022-2).
中图法分类号 TP18