一种基于大规模知识库的语义相似性计算方法
张立波 1 孙一涵 2 罗铁坚 2
1 (中国科学院软件研究所 北京 100190) 2 (中国科学院大学 北京 101408)
(zsmj@hotmail.com)
摘 要 人类知识总量不断增加,依靠人类产生的结构化大数据进行语义分析在推荐系统和信息检索等领域都有着重要的应用.在这些领域中,首要解决的问题是语义相似性计算,之前的研究通过运用以维基百科为代表的大规模知识库取得了一定突破,但是其中的路径并没有被充分利用.研究基于人类思考方式的双向最短路径算法进行单词和文本的相似性评估,以充分利用知识库中的路径信息.提出的算法通过在维基百科中抽取出颗粒度比词条更细密的节点之间的超链接关系,并首次验证了维基百科之间的普遍连通性,并对2个词条之间的平均最短路径长度进行评估.最后,在公开数据集上进行的实验结果显示,算法在单词相似度得分上明显优于现有算法,在文本相似度的得分上趋于先进水平.
关键词 大规模知识库;语义相似性;维基百科;最短距离;连通性
利用计算机进行语义相似度评估是人工智能领域的一个瓶颈问题,这个问题的核心是如何让计算机模拟人类的思考方式.然而人类思维模式复杂,难以模仿,但一个基本事实是,人类的思考模式是基于自身的经历和经验所形成的知识来进行推理、分析和决断.因此,利用大规模的知识库赋予计算机一种类似人类的知识结构模型,是一个根本的解决途径.人类根据自身掌握的知识进行联想,对2个单词、段落或文本之间的相似性进行判断,本文通过提取维基百科中的双向最短路径来模拟人类的联想机制进行相似性评估.
语义相似度在自然语言处理和信息检索领域中一直都有着重要的应用,例如问答系统、拼写检查、文本翻译等领域 [1] .传统方法主要基于单词重叠度来评估语义相关性,这在论文查重系统中有着广泛应用,但如果使用不同的单词表示同样的含义时,这类方法明显无法适用,它的缺陷在于简单地将单词作为评估对象,而没有考虑单词之间的内在联系 [2] .概率潜在语义分析等方法利用了文章中的单词和主题的关系,但是没有考虑到单词在知识结构中的关系 [3] .近些年来,一些新的算法考虑到可以利用包含人类知识结构的大规模知识库,例如百科全书和语料库进行语义相似性评估 [4] ,具体来说,它们利用百科中2个词条页面中包含的文本和链接捕获真实世界的知识结构,进而评估语义相似度.
在人类编撰形成的知识库中,大英百科全书和维基百科全书最具有代表性,它们经过人工的梳理和编辑,构成以词条为单位的人类知识宝库.相比大英百科,维基百科在保证了同等正确率的同时,包含了更多的词条量.我们将维基百科词条中含有链接的单词称为节点,节点之间的最短路径能够反映出人类联想机制,为了验证这一点,我们提出了一种基于最短路径对语义相关性进行评估的算法.与之前的算法不同,本文第1次对维基百科中词条之间的连通性进行验证,证明了维基百科中的词条具有普遍联系,2个节点之间一定存在一条通路,即从一个概念出发,经过有限次数的跳转链接可以到达另一个任意节点.在相关的研究论文中,研究者假设任意2个词条之间都可以建立路径关系,但是缺乏证明;最新的一些论文使用随机游走算法寻找路径,而我们使用了最短路径.传统的有关最短路径的算法是基于词条所属分类间的最短路径,而我们使用了更细密的节点;大部分对维基进行的研究都将其限定在100万节点左右,而我们使用了1 200万节点进行更加细致的探究.本文提出了一种基于维基百科节点的最短路径进行语义相似性分析的算法,并验证了通过最短路径能够模拟人类的联想机制对语义相似性进行评估.
1 相关工作
传统语义关系的分析需要依靠人类自身知识和经验的背景进行推理和联想,而这对计算机一直是难以克服的障碍.为了探索2个词条之间的关系,计算机必须获取大量相关领域的背景知识,而之前的相关工作更多地依靠统计而忽略了背景知识;另外一些基于背景知识进行语义相关的研究由于知识总量的限制无法取得很好的效果;一些论文基于网页链接对语义进行分析,取得了一定的突破,但是由于网页中的知识颗粒度较粗,并且知识含量较为稀疏,因此不能够反映出某个知识点的全貌.2005年,Giles [5] 指出,维基百科的广度和深度都值得信任,从此之后,开启了基于维基百科进行语义分析的热潮.
本文系统地收集了在维基百科的基础上提出的利用人类知识库进行语义分析的方法,如表1所示.传统的方法主要有2类:1)基于内容的方法;2)基于链接的方法.Gabrilovich等人 [6] 提出一种名为显示语言分析的方法,这种方法通过维基百科收集概念,将文本中的内容与收集的概念建立矩阵关系,但缺乏对人类知识体系的使用.Zesch等人 [7] 证明了使用维基百科能够提高之前方法的效果,但性能的提升受到制约.Hassan等人 [8] 衡量2个概念之间的跨越关系,并通过显示语言分析来建立概念的矢量表述.Syed等人 [9] 将维基百科词条作为本体,使用3种方式将关键词、主题与文本结合,但是缺乏对词条路径关系的考虑.Coursey等人 [10] 建立了概念和分类关系图,提出了一个自动化的主题分类方法,但是无法解决分类数量有限和概念从属多种分类的问题.Gabrilovich等人 [11] 通过建立一个语义转换器对概念建立权重矢量,并通过矢量之间的比较进行语义相关性评估,这种方法仅基于文本内容,在概念之间的关系上只考虑了所属分类之间的关系,而忽视了超链接形成的路径.
Table 1 Comparison of Our Method with Previous Work
表1 相关工作的总结与比较
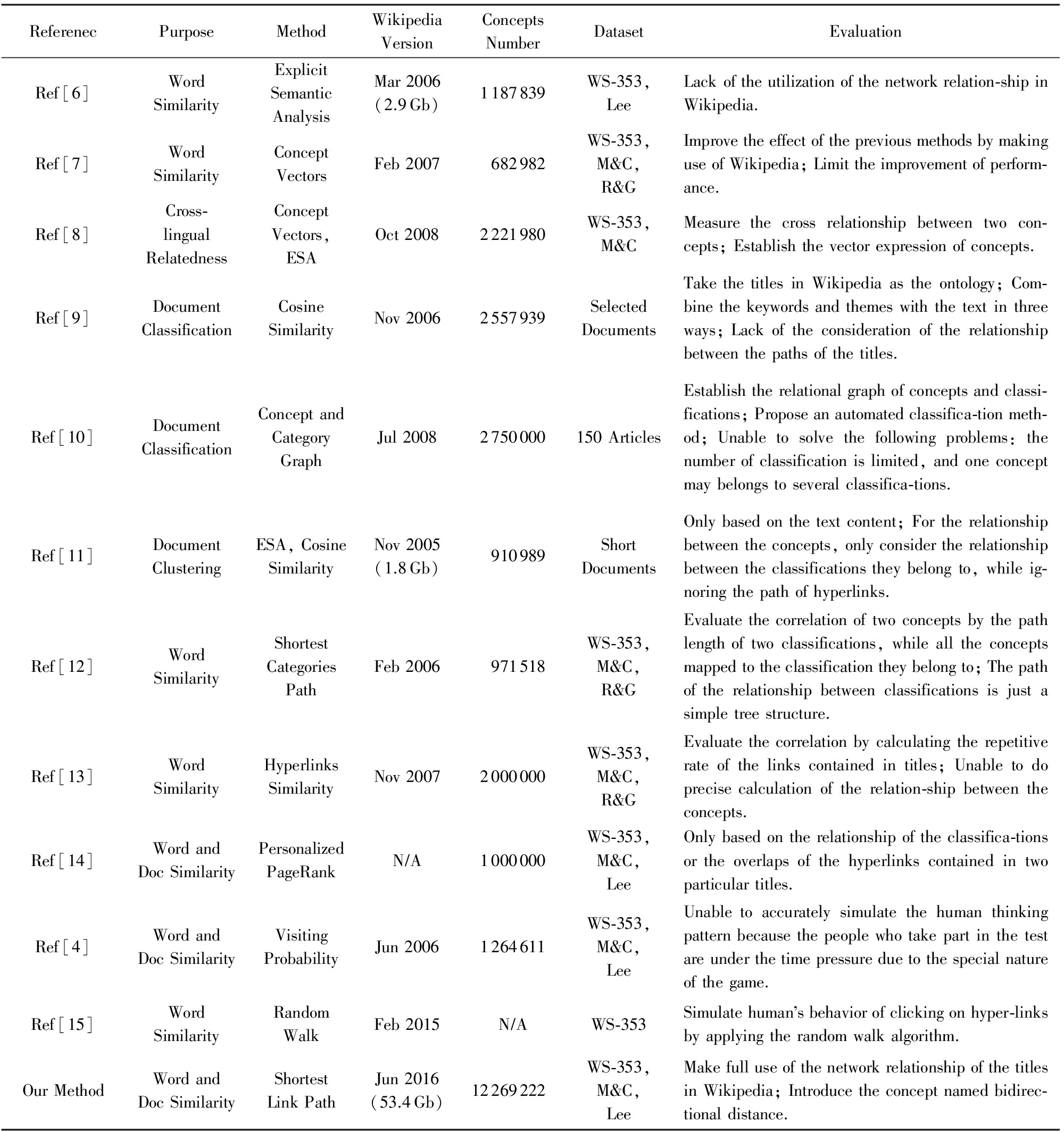
ReferenecPurposeMethodWikipediaVersionConceptsNumberDatasetEvaluationRef[6]WordSimilarityExplicitSemanticAnalysisMar2006(2.9Gb)1187839WS⁃353,LeeLackoftheutilizationofthenetworkrelation⁃shipinWikipedia.Ref[7]WordSimilarityConceptVectorsFeb2007682982WS⁃353,Mamp;C,Ramp;GImprovetheeffectofthepreviousmethodsbymakinguseofWikipedia;Limittheimprovementofperform⁃ance.Ref[8]Cross⁃lingualRelatednessConceptVectors,ESAOct20082221980WS⁃353,Mamp;CMeasurethecrossrelationshipbetweentwocon⁃cepts;Establishthevectorexpressionofconcepts.Ref[9]DocumentClassificationCosineSimilarityNov20062557939SelectedDocumentsTakethetitlesinWikipediaastheontology;Com⁃binethekeywordsandthemeswiththetextinthreeways;Lackoftheconsiderationoftherelationshipbetweenthepathsofthetitles.Ref[10]DocumentClassificationConceptandCategoryGraphJul20082750000150ArticlesEstablishtherelationalgraphofconceptsandclassi⁃fications;Proposeanautomatedclassifica⁃tionmeth⁃od;Unabletosolvethefollowingproblems:thenumberofclassificationislimited,andoneconceptmaybelongstoseveralclassifica⁃tions.Ref[11]DocumentClusteringESA,CosineSimilarityNov2005(1.8Gb)910989ShortDocumentsOnlybasedonthetextcontent;Fortherelationshipbetweentheconcepts,onlyconsidertherelationshipbetweentheclassificationstheybelongto,whileig⁃noringthepathofhyperlinks.Ref[12]WordSimilarityShortestCategoriesPathFeb2006971518WS⁃353,Mamp;C,Ramp;GEvaluatethecorrelationoftwoconceptsbythepathlengthoftwoclassifications,whilealltheconceptsmappedtotheclassificationtheybelongto;Thepathoftherelationshipbetweenclassificationsisjustasimpletreestructure.Ref[13]WordSimilarityHyperlinksSimilarityNov20072000000WS⁃353,Mamp;C,Ramp;GEvaluatethecorrelationbycalculatingtherepetitiverateofthelinkscontainedintitles;Unabletodoprecisecalculationoftherelation⁃shipbetweentheconcepts.Ref[14]WordandDocSimilarityPersonalizedPageRankN∕A1000000WS⁃353,Mamp;C,LeeOnlybasedontherelationshipoftheclassifica⁃tionsortheoverlapsofthehyperlinkscontainedintwoparticulartitles.Ref[4]WordandDocSimilarityVisitingProbabilityJun20061264611WS⁃353,Mamp;C,LeeUnabletoaccuratelysimulatethehumanthinkingpatternbecausethepeoplewhotakepartinthetestareunderthetimepressureduetothespecialnatureofthegame.Ref[15]WordSimilarityRandomWalkFeb2015N∕AWS⁃353Simulatehumansbehaviorofclickingonhyper⁃linksbyapplyingtherandomwalkalgorithm.OurMethodWordandDocSimilarityShortestLinkPathJun2016(53.4Gb)12269222WS⁃353,Mamp;C,LeeMakefulluseofthenetworkrelationshipofthetitlesinWikipedia;Introducetheconceptnamedbidirec⁃tionaldistance.
另外一些研究,利用路径信息进行语义相似度评估,例如Ponzetto等人 [12] 将概念映射到所属的分类中,通过2个分类之间的路径长度对2个概念的相关性进行评估,但是分类之间的路径关系仅仅是简单的树形结构.Milne等人 [13-16] 通过计算词条所包含链接的重复率进行相关性评估,这种方法无法对概念之间的关系进行精确计算.与Yeh等人 [14] 的方法类似,有研究者提出了一种基于维基漫步方法, Yazdani等人 [4] 提出一种访问概率的方法来计算节点之间的距离,这种方法仅仅基于概念所属分类的路径关系,或者是特定2个词条包含超链接的重叠性.刘均等人 [17] 设计了一种利用维基百科链接关系的13维特征适量来进行关系抽取,但是缺乏对节点之间通路的考虑.Singer等人 [18] 使用了一种维基游戏,通过人们的点击来寻找2个词条之间的路径关系,然而由于游戏的特殊性质,会对参与测试的人们造成时间压力,因此无法准确模拟人类的思考模式.Niebler等人 [19] 注意到了无约束航行数据,维基百科点击流数据 [20] 记录了人们在一个维基词条中如何进行下一次链接点击.Dallmann等人 [15] 基于这个数据集,使用随机游走的算法模拟了人类的超链接点击行为,但是随机游走往往无法获取最佳路径,而最短路径才对人类的决策最有意义.
与传统方法中利用词条中的链接关系不同,我们通过寻找2个节点之间的链接通路,来描述它们之间的关系.本文提出一种新的方法,通过结构化的维基百科节点中的最短路径关系,对2个词条之间的关系进行刻画.
2 主要工作
2 . 1 预处理
互联网百科全书是当前能够随意查阅的最大的、最完整的人类知识库,其中维基百科是人类共同参与编撰的规模最大的互联网多语言百科全书,其与专业人士编撰的大英百科全书具有相近的正确率,但由于编撰自由,发展更加迅速.截至2016年7月25日,英文维基百科总计拥有5 201 640篇文章、39 827 021个页面,覆盖了人类的大部分知识领域,词条为最小知识单元,以链接跳转表现知识之间的联系.维基百科本身的链接结构是人类经过时间积累的智慧结晶,编撰结构和人类的思考方式高度吻合,因此本文选取维基百科作为基本数据集.我们使用原始数据集是完整的维基百科版本(2016-06-01),解压后得到一个53.4 GB的XML文件.这个XML文件包含了所有的词条,而每个词条中都包含了指向其他词条的超链接.传统的算法主要关注词条之间的关系,而我们希望能从更小的维度进行观察,本文将每个词条中的超链接对应的单词作为研究对象,称之为节点, 该数据集包含了所有节点之间的链接关系.我们处理后所使用的节点数量为1 200万,这是传统算法中研究对象数量的5~10倍.
本文的预处理工作主要包括5个步骤:
1) 在原始XML文件中,先抽取词条本身和其文本中超链接对应的单词.这个数量远大于词条, 我们称之为节点.
2) 规整词条格式,在节点中去除不合法的链接和词条,例如词条包含的锚链接等.
3) 删除空指向的词条.
4) 因为文件中有些节点首字母为小写,而在维基百科网页中,全部词条的首字母均为大写,因此将文档中节点的小写首字母转化为大写.
5) 在节点构成的网络中,用Hadoop集群将单项链接转化为双向链接,即把链接构成的有向图转化为无向图.
2 . 2 节点普遍联系的验证
在基于路径的语义分析的研究中,利用超链接寻找从一个词条到另一个词条的通路,都是建立在存在通路的假设前提下.虽然根据经验可以基本判断维基百科的词条间应该是普遍连通的,但是缺乏有力验证.我们在预处理的基础上对维基百科中节点的普遍联系进行验证,利用广度优先搜索算法在节点构成的无向图中生成连通分量.
我们获得了节点中连通分量的分布,如表2所示,维基百科中节点构成的网络中,一共包含10 441个连通分量,这些连通分量一共含有12 280 497个节点.其中最大联通分量中含有12 269 222个节点,可以清楚地看出,99.91%的节点都包含在最大联通分量中.经过观察,其他联通分量包含的节点是一些特殊字符,因此我们将最大联通分量视为研究对象.这就意味着,如果我们将整个维基百科网络视为无向图,任意2个节点之间都存在着通路.
Table 2 Connected Component Number and the
Corresponding Node Number
表2 连通分量及对应节点数量
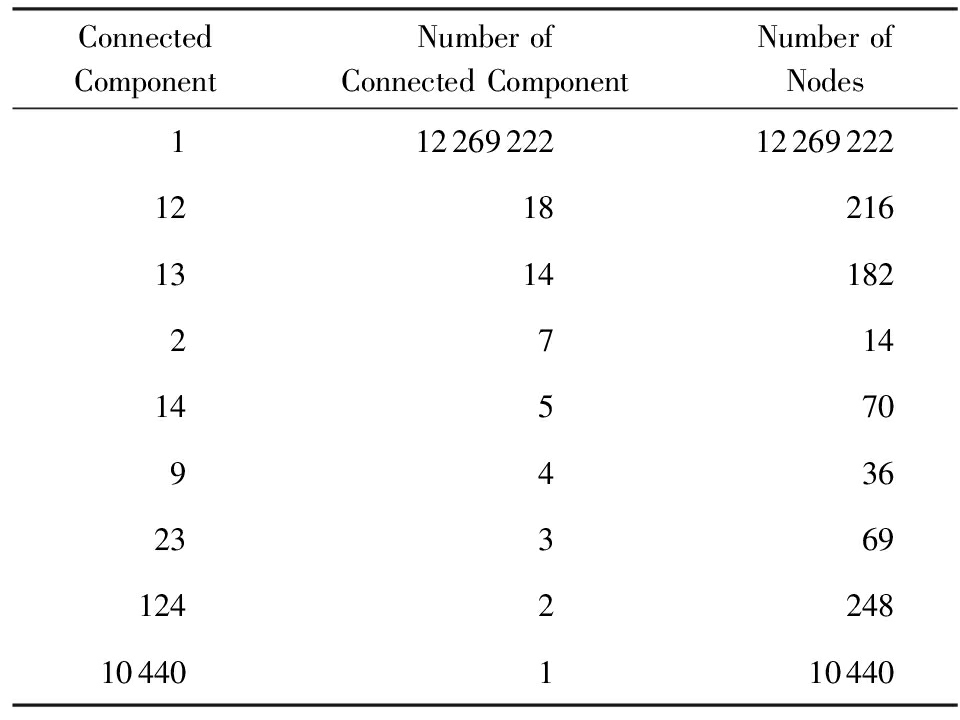
ConnectedComponentNumberofConnectedComponentNumberofNodes1122692221226922212182161314182271414570943623369124224810440110440
2 . 3 维基百科节点间的最短路径
维基百科是由词条构成,词条文本中含有节点间的链接关系.每一个维基百科词条的页面中,都包含了与之相关的其他词条,通过这些词条对其进行解释,因此我们可以直接使用维基百科而无需对文本做深层次的语义理解.图1显示了维基百科词条间的链接关系,圆点代表词条,颜色代表词条距离选定词条的不同层级,虚线圆代表处于同一层级的词条,红色箭头代表词条间通过超链接的跳转.具体来说,红色圆圈代表选定的初始节点;绿色圆圈代表与初始节点存在直接链接关系的词条,也就是从初始节点出发,可以通过一次链接到达绿色节点,我们把这些绿色节点定义为第1层节点.

Fig. 1 The hyperlink relationship in Wikipedia nodes
图1 维基百科中节点的链接关系
类似地,从绿色节点词条经过一次跳转,可以到达紫色节点,我们把紫色节点定义为初始节点的第2层节点.以此类推,我们把蓝色节点定义为初始节点的第3层节点.需要额外说明的是,在计算第 n 层节点的词条时,先排除处于 n 层中但与 n 层之前重复的部分词条.我们认为2个节点之间的最短路径越短,表明他们之间的关系越密切;2个节点之间的路径越长,则表明他们之间的关系越遥远.这个观点也与人类的思维模式相同,面对一个具体问题,人类首先会联想到与这个问题最相关的因素,之后再深入到每个因素之中.举个例子,当提到“Milk”时,人们首先会想到有关的产品,例如“Cheese”等;通过“Cheese”会深入联想到制作所需的材料,例如“Pepper”等.而这和维基百科的构建方式刚好吻合,在维基百科中,词条“Cheese”和“Pepper”,分别是词条“Milk”的第1层和第2层上的节点.
2 . 4 基于双向最短路径的语义相似性算法
在使用维基百科评估语义相似度的方法中,大多都利用了2个单词之间超链接所构建的路径 [18] .传统算法将单词 A 到单词 B 的路径长度和单词 B 到单词 A 的路径长度看作是等同的,并随机地从单词 A 和单词 B 中选取一个单词作为起始点,然后在这种模式下探寻到达另一个单词的超链接路径.但是这种路径方式有很大的局限性,因为大部分情况下,2种方向的路径长度并不相同,可以通过一个显而易见的例子进行说明:当提到单词“成都”时,人们会自然地想到“中国”;但是当提到“中国”时,却很难想到成都.从这个例子可以明显看出,从“成都”到“中国”和从“中国”到“成都”的距离(联想难度)明显不同.我们进一步通过维基百科的链接结构进行解释,如图2所示为传统算法考虑路径时链接路径的模式,给定的2个单词“Night”和“System”,可以通过一个“Energy”页面进行中转,于是这2个单词的最短距离是2.传统算法的思考模式将整个维基的链接网络看成一个无向图,任选一个单词作为起点并不会影响最短路径的长度.本文算法的灵感来自于对人类思维模式的思考:当人类考虑单词 A 和单词 B 相似性时,不会采用单方向的思考方式,而是采用双向的思考模式,正向距离和反向距离都会影响思考过程.我们将整个维基链接结构视为有向图,在有向图中寻找最短路径.
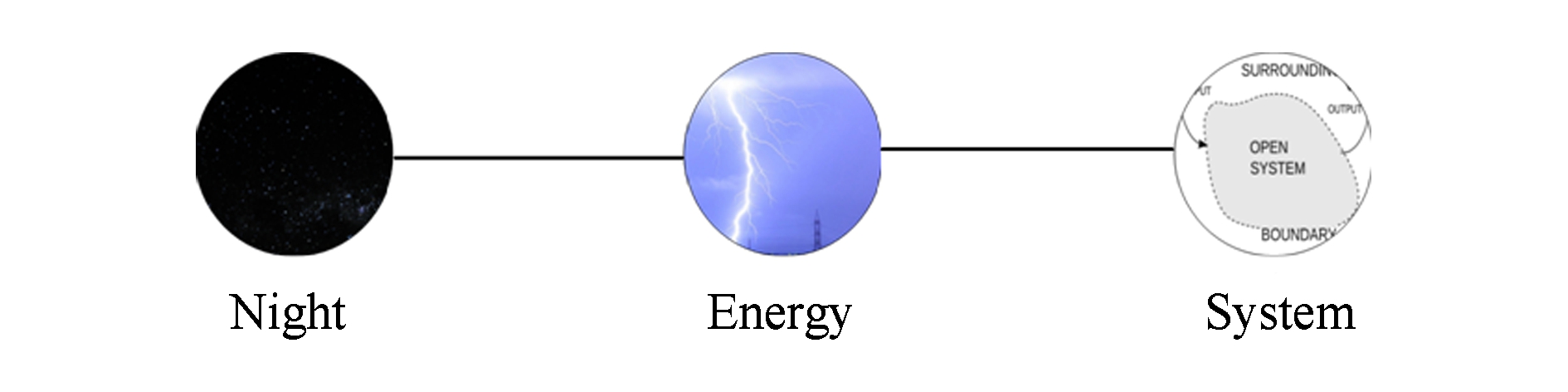
Fig. 2 The representation of traditional shortest link path
图2 传统链接最短路径表示
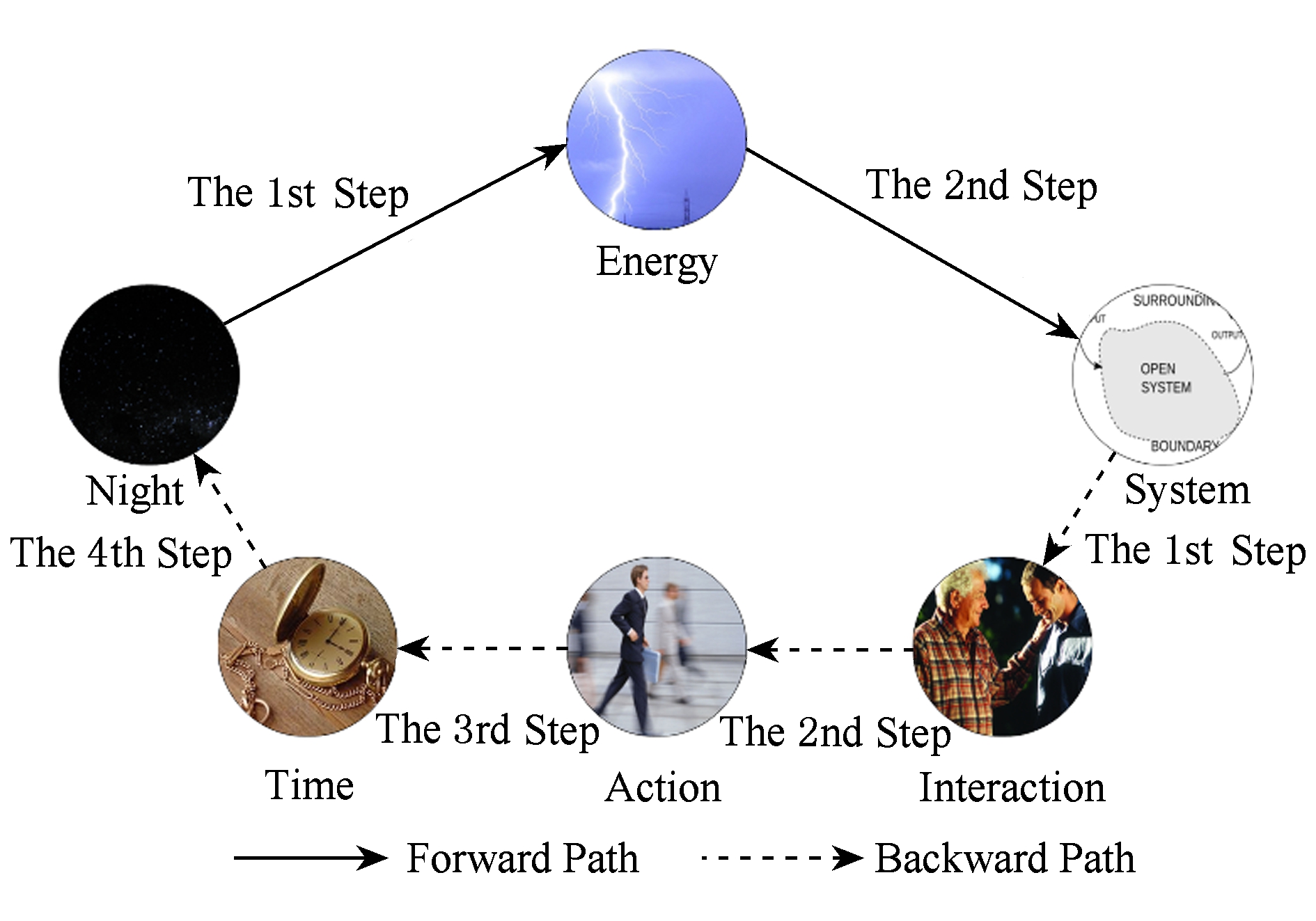
Fig. 3 The representation of bidirectional shortest link path
图3 双向链接最短路径表示
如图3所示,人类联想2个单词相关性的最优解法是通过双向最短路径(我们称之为前向路径和反向路径),这是因为维基百科中2个单词会因为起点和终点的转换引起最短路径的长度不同.具体来说,前向路径中从“Night”出发,经过“Energy”1次跳转后到达“System”;反向路径中从“System”出发,依次经过“Interaction”,“Action”,“Time”3次跳转后到达“Night”.由此看出,“Night”和“System”中的前向最短路径长度为2,反向最短距离为4.
我们使用维基百科有2个原因:
1) 维基百科包含多种语言,其中英文版本约有500万的词条和1 000万的标题,是现今人类在网络中最大的知识仓库,它由人类经过结构化编撰而成,正确率和权威性已经得到了普遍认可;
2) 维基百科具有良好的成长性,在每个知识的宽度和深度上,随着时间稳步增长.
我们定义2个单词之间的最短路径长度:
L= 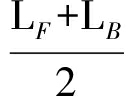 ,
,
其中,L F 为前向最短路径长度,L B 为反向最短路径长度.在通过双向最短路径进行语义相似性评估时,有一个需要解决的核心问题:如何设定最短路径的步长上限.因为尽管在我们验证了节点的普遍联通性,但是寻找2个节点间的最短路径时,仍会遇到路径过长的问题.为了解决这个问题,我们设计了一个实验:随机选取300 000个单词对,用广度优先搜索算法找到每对单词的前向最短路径长度,最后求得2个节点间的平均最短路径长度值E(L)=3.84,标准偏差σ=1.73.根据切比雪夫不等式:
P{|L-E(L)|≥k×σ}≤ 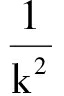 ,
,
令k=3可得平均路径长度L≥9.03的概率小于1 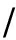 9,因此我们将最短路径的步长上限设置为8,即超过8步就认为2个单词不存在相似性.
9,因此我们将最短路径的步长上限设置为8,即超过8步就认为2个单词不存在相似性.
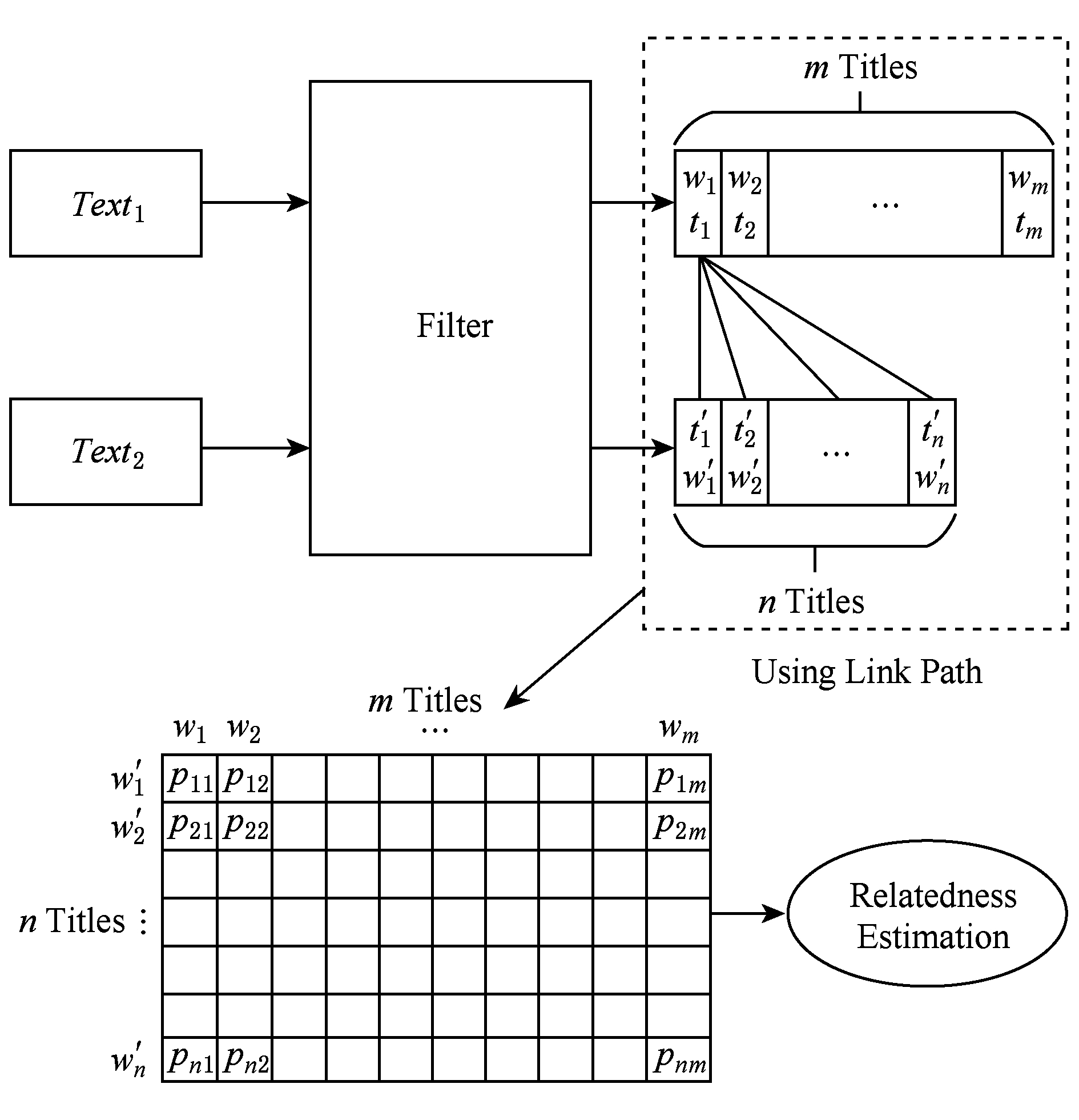
Fig. 4 The similarity evaluation of texts based on bidirectional shortest path
图4 基于双向最短路径的文本相似性算法
在运用双向最短路径衡量2个单词相似性的基础上,我们提出了一个新的评测文本相似性的方法.具体算法图4所示,Text 1 和Text 2 为需要进行相似性评估的文本,我们将其输入一个滤波器,这个滤波器会对文本进行预处理工作,包括去除停用词、词形归并等;之后通过将文本中的单词与维基词条比对后进行分词.将Text 1 划分成由m个词条构成的集合 T 1 ={w 1 ,w 2 ,…,w n },其中w代表每个词条,t代表对应词条在Text 1 中出现的次数.同样地,将Text 2 划分成由n个词条构成的集合T 2 ={ 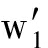 ,
, 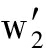 ,…,
,…, 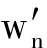 },其中w′代表每个词条,t′代表对应词条在Text 2 中出现的次数.通过Text 1 中m个词条和Text 2 中的n个词条构成一个m×n的矩阵(假设mgt;n),矩阵第i行第j列的值m ij 为单词w i 与单词
},其中w′代表每个词条,t′代表对应词条在Text 2 中出现的次数.通过Text 1 中m个词条和Text 2 中的n个词条构成一个m×n的矩阵(假设mgt;n),矩阵第i行第j列的值m ij 为单词w i 与单词
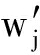 的平均最短路径长度,即代表了2个单词的相似性;m行分别包含Text 1 文本中可用单词的元组A=(w 1 ,w 2 ,…,w m );n列分别包含Text 2 文本中可用单词的元组B=(
的平均最短路径长度,即代表了2个单词的相似性;m行分别包含Text 1 文本中可用单词的元组A=(w 1 ,w 2 ,…,w m );n列分别包含Text 2 文本中可用单词的元组B=( 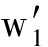 ,
, 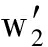 ,…,
,…, 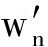 ).
).
下面我们通过矩阵分块来计算Text 1 文本和Text 2 文本的相关性:
1) 我们对矩阵进行重排,假设|A∩B|=p,重排元组A和B使得:
∀1≤k≤p, w k = 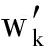 ,
,
这是将A和B中共有的单词排列于各自元组的前端,并保证下标相同.

Fig. 5 Matrix partitioning
图5 矩阵分块
2) 从A和B中删除共有的元素得到 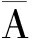 和
和 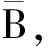 即令:
即令:
其中,w p+1 ,w p+2 ,…,w m , 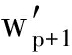 ,
, 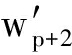 ,…, 两两不同,这样我们得到了一个(m-p)×(n-p)的子矩阵.
,…, 两两不同,这样我们得到了一个(m-p)×(n-p)的子矩阵.
3) 对子矩阵进行重排,使得:
∀(p+1)≤r≤s≤m,t r ≥t s ,
∀(p+1)≤r′≤s′≤n, 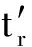 ≥
≥ 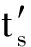 ,
,
其中t r ,t s 分别为w r ,w s 在Text 1 文本中的权重; , 分别为 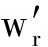 ,
, 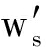 在Text 2 文本中的权重.即行和列都按照各单词的权重降序排列.
在Text 2 文本中的权重.即行和列都按照各单词的权重降序排列.
4) 令q= min (m,n),取:
我们进一步得到一个q×q的方阵.
由于对于任意 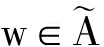 和
和 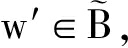 相关性与w和w′的顺序无关,正向和反向应用 Gale - Shapley 算法的结果相同,因此在q×q的方阵中应用 Gale - Shapley 算法.
相关性与w和w′的顺序无关,正向和反向应用 Gale - Shapley 算法的结果相同,因此在q×q的方阵中应用 Gale - Shapley 算法.
5) 对q×q方阵进行重排,重排元组 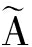 和
和 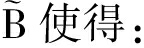
∀(p+1)≤k≤q,w k 与 匹配,
即相互匹配的元素下标相同.
6) 将最终获得的矩阵记为 M ′,其中第i行第j列的元素记为 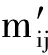 .计算文本A和文本B的相关性:
.计算文本A和文本B的相关性:
corr ( A , B )= 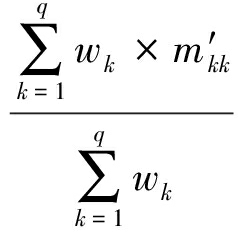 ,
,
w k = 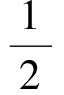 (t k +
(t k + 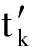 ).
).
3 实验评估
3 . 1 WS - 353Ex数据集
在语义相关性评估中,研究者通常会使用标准的黄金数据集WS-353 [21] (WordSimilarity-353).WS-353中包含了353对英语单词,每一对都用一个范围在0~10的分数来表示它们的相关程度.每个分数都是由16个人分别打出,最后取平均值而得到.WS-353是根据人类的联想和判断,确定对语义相似度的评估标准.因此,我们可以通过与其结果的对比,判断本文提出的算法能否与人类的联想机制契合.
我们对WS-353进行了改进,称之为WS-353Ex(WS-353 extend version),这是因为其中一些单词无法映射到维基百科的词条中.之前的研究中一些研究者也发现了这一问题,但是一直没有得到有效的解决.Milne等人 [13] 选择直接删除60个不合适的单词.Singer 等人 [18] 也发现了这个问题,并给出了改进版的数据集WikipediaSimilarity-353,将单词对删减到308个,但是Singer等人忽视了引起这个问题的真正原因.我们发现,自从2002年WS-353提出之后,维基百科经过14年的发展和变化,在数量级上发生了数十倍的增长,导致部分单词无法映射到维基百科中进行路径探索的原因是WS-353中的一些单词出现在重定向页面和消歧义页面.为了解决这个问题,我们做了2项工作:
1) 将重定向的单词进行替换,例如 “Diego Maradona”更换为“Maradona”,“theater”更换为“theatre”;
2) 将维基百科中无法查到的单词删除,例如“defeating”.
我们对2002年的数据集WS-353进行了改进和修正,形成WS-353Ex,最后保留了344对单词.如表3所示,WS-353在最初的3个维度(Word1,Word2,human mean)的基础上,增加了3个新的维度:前向最短路径长度 f 、反向最短路径长度 b 和平均最短路径长度 a .以“tiger”和“cat”举例,人类对2个单词相似性的打分是7.35,从“tiger”出发经过2步能够链接到“cat”,从“cat”出发经过3步能够链接到“tiger”, “tiger” 与“cat”的平均最短路径为2.5.
Table 3 Demonstration of WS - 353Ex Dataset
表3 WS - 353Ex数据集样例
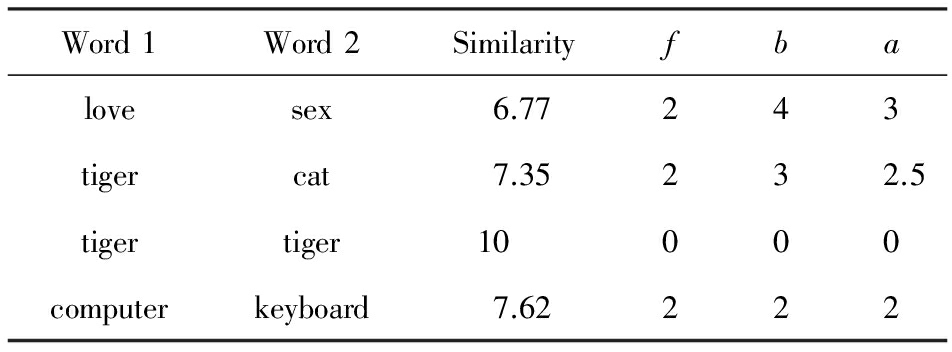
Word1Word2Similarityfbalovesex6.77243tigercat7.35232.5tigertiger10000computerkeyboard7.62222
3 . 2 语义相似性评估
在本节中,我们分别使用WS-353Ex和Lee [22] 数据集来验证算法在单词和文本相似度评估的有效性.首先使用WS-353Ex数据集进行单词相似度评估,具体步骤如下:
1) 基于在3.1节中相关方法所计算出的WS-353Ex中每对单词之间的f和b,求出:
a= 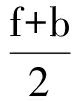 .
.
2) 采用岭回归方法,分别使用单词对的f,b,a与对应的人类打分进行拟合:
其中,h代表人类的打分,w=(w 1 ,w 2 ,…, w p ) 代表系数,w 0 代表截断我们使用岭回求解:
 ‖
‖ 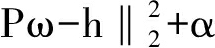 ‖
‖ 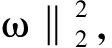
其中,α是复杂性系数,α的值越大, 收缩性越好,也就使得系数拥有更强的鲁棒性.
3) 我们采用斯皮尔曼等级相关系数、皮尔逊相关系数和谷本系数 [1,4] 来评价预测拟合模型的正确性,评估的分数区间为0~1,越趋近于1说明该方法的准确度越高.实验结果验证了通过最短路径算法进行相似性评估的准确性.
本文设计了3组实验,分别使用f,b,a与人类打分值进行组合预测:实验随机选取了测试集和验证集(分别采用3:7,5:5,7:3的比例),重复500次取平均值.实验结果如表4所示,单独使用f和b最高只能达到0.51和0.53的分数,而使用a能够将分数稳定在0.84.为了进一步的评估,我们将本文的算法与之前的一些重要相关研究结果作了比较,如表5显示,Milne等人 [13] 所提出的一种基于超链接相似度的方法可以将分数提高到0.78.在本文基本方法的基础上,我们观察到在WS-353Ex数据集中有一些明显错误样本数据,人工删除这些误差样本后重新进行评估,能够将准确率提高到0.90.从表5中可以看出,通过本文提出的算法与8种传统算法的比较,验证了所述算法在单词相似度计算的有效性上明显超越现有算法.
Table 4 Comparison of Word Similarity Using Three Kinds of Shortest Path
表4 基于3种最短路径评估单词相似性的分数对比
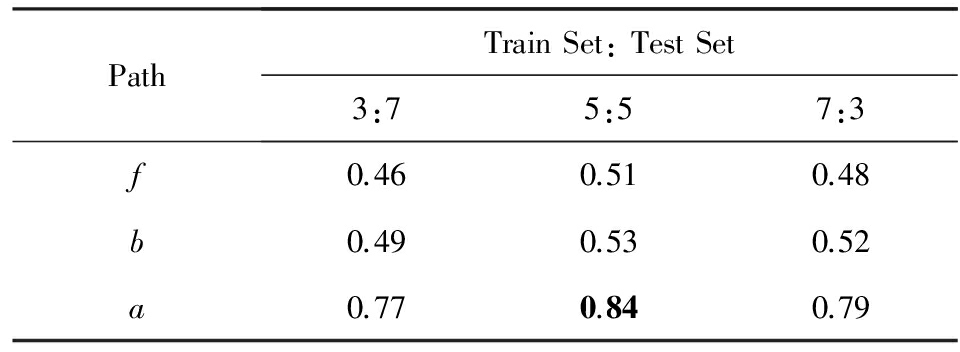
PathTrainSet:TestSet3:75:57:3f0.460.510.48b0.490.530.52a0.770.840.79
为了探究在评估文本相似度的效果,我们基于双向最短路径算法在Lee数据集 [26] 上进行了验证,这个数据集包含了50个文本,以及每一对文本对应的人类打出的相似性分数.实验中随机抽取1 000对文本进行实验,得到分数的平均值.如表6所示,Hassan等人 [8] 提出基于小规模语料库进行训练的LSA算法,能够得到0.69的分数.Gabrilovich等人 [11] 提出了ESA算法,并得到0.75的分数.本文通过双向最短路径算法进行文本相似性分析,能够得到0.77的分数.基于双向最短路径的算法在单词相似性的评估上取得了很好的效果,但是在文本相似度上效果与之前的算法效果相当,我们认为这主要因为训练集较小,仅基于数据集WS-353Ex,只包含344对单词;另一个影响因素是我们仅通过文本在维基百科网络中的链接关系进行评估,没有结合其他更多的属性.
Table 5 Comparison of Word Similarity Scores with
8 Methods
表5 本文算法与8种算法基于单词相似度分数的比较

MethodScoresSpearmanCorrelationPearsonCorrelationTanimotoCoefficientRef[21]0.560.530.52Ref[23]0.550.610.49Ref[12]0.480.440.50Ref[24]0.550.470.57Ref[11]0.750.670.76Ref[25]0.780.850.86Ref[4]0.700.760.71Ref[13]0.790.740.77OurBasicMethod0.840.830.82OurAdvanceMethod0.890.900.89
Table 6 Comparison of Text Similarity Scores with
3 Methods
表6 本文算法与2种算法基于文本相似度分数的比较
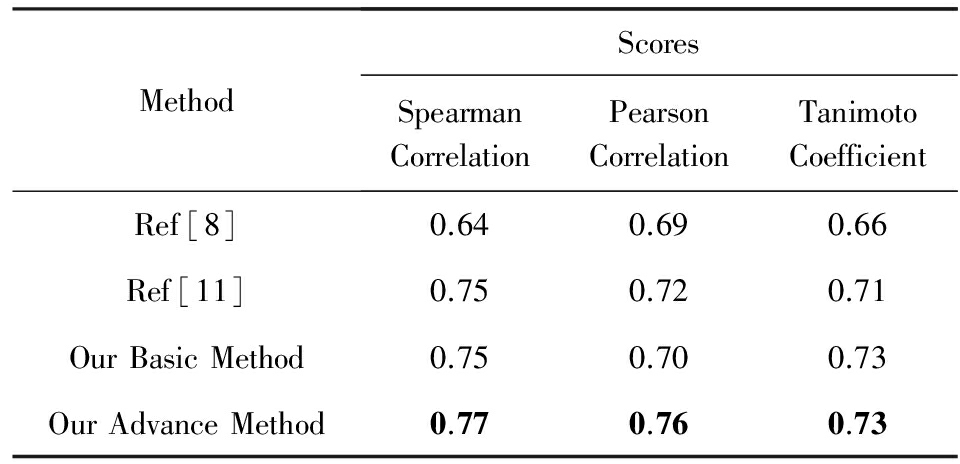
MethodScoresSpearmanCorrelationPearsonCorrelationTanimotoCoefficientRef[8]0.640.690.66Ref[11]0.750.720.71OurBasicMethod0.750.700.73OurAdvanceMethod0.770.760.73
4 总 结
本文提出了一种基于维基百科中超链接结构进行语义相似性评估的方法.这是首次在论文中考虑到2个单词之间双向路径的不同,并证明了维基百科中词条的普遍连通性,发现了它们之间的平均最短路径长度约为3.84.考虑到人类双向思维的方式,我们应用双向最短路径长度设计了一种新的算法,该算法能够充分利用维基百科结构中的潜在人类特性.本文使用提出的算法分析单词相似性,取得了很好的效果,在此基础上提出一种使用矩阵分解进行文本相似性分析的方法,取得了良好的效果.另外,我们对传统的WS-353进行了修正和升级.本文最大的贡献在于:在仅使用维基百科中链接关系和数量较少的训练数据的情况下,取得了出色的评估效果.在未来的工作中,我们希望能够结合其他文本特征,并增加更多训练数据来改进评估模型.
参考文献
[1]Zhang Libo, Zhang Fei, Luo Tiejian. Knowledge structure evolution and evaluation method in computer science[J]. Journal of University of Chinese Academy of Sciences, 2016, 33(6): 844-850 (in Chinese) (张立波, 张飞, 罗铁坚. 计算机科学知识体系演化与评估方法[J]. 中国科学院大学学报, 2016, 33(6): 844-850)
[2]Xin Yu, Yang Jing, Tang Chuheng, et al. An overlapping semantic community detection algorithm based on local semantic cluster[J]. Journal of Computer Research and Development, 2015, 52(7): 1510-1521 (in Chinese) (辛宇, 杨静, 汤楚蘅, 等. 基于局部语义聚类的语义重叠社区发现算法[J]. 计算机研究与发展, 2015, 52(7): 1510-1521)
[3]Wang Junhua, Zuo Wanli, Yan Zhao. Word semantic similarity measurement based on Naive Bayes model[J]. Journal of Computer Research and Development, 2015, 52(7): 1499-1509 (in Chinese) (王俊华, 左万利, 闫昭. 基于朴素贝叶斯模型的单词语义相似度度量[J]. 计算机研究与发展, 2015, 52(7): 1499-1509)
[4]Yazdani M, Popescu-Belis A. Computing text semantic relatedness using the contents and links of a hypertext encyclopedia: Extended abstract[J]. Artificial Intelligence, 2013, 194: 176-202
[5]Giles J. Internet encyclopaedias go head to head[J]. Nature, 2005, 438: 900-901
[6]Gabrilovich E, Markovitch S. Computing semantic relatedness using Wikipedia-based explicit semantic analysis[C]  Proc of the 20th Int Joint Conf on Artificial Intelligence. San Francisco, CA: Morgan Kaufmann, 2007: 1606-1611
Proc of the 20th Int Joint Conf on Artificial Intelligence. San Francisco, CA: Morgan Kaufmann, 2007: 1606-1611
[7]Zesch T, Müller C, Gurevych I. Using Wiktionary for computing semantic relatedness[C] Proc of AAAI Conf on Artificial Intelligence. Menlo Park, CA: AAAI, 2008: 861-866
[8]Hassan S, Mihalcea R. Cross-lingual semantic relatedness using encyclopedic knowledge[C] Proc of Conf on Empirical Methods in Natural Language Processing. New York: ACM, 2009: 1192-1201
[9]Syed Z S, Finin T, Joshi A. Wikipedia as an ontology for describing documents[C] Proc of Int Conf on Weblogs and Social Media. Menlo Park, CA: AAAI, 2008
[10]Coursey K, Mihalcea R. Topic identification using Wikipedia graph centrality[C] Proc of Conf on the North American Chapter of the Association of Computational Linguistics. New York: ACM, 2009: 117-120
[11]Gabrilovich E, Markovitch S. Wikipedia-based semantic interpretation for natural language processing[J]. Journal of Artificial Intelligence Research, 2014, 34(4): 443-498
[12]Strube M, Ponzetto S P. WikiRelate! computing semantic relatedness using Wikipedia[C] Proc of the 19th National Conf on Artificial Intelligence. Menlo Park, CA: AAAI, 2006: 1419-1424
[13]Milne D, Witten I H. An open-source toolkit for mining Wikipedia[J]. Artificial Intelligence, 2013, 194: 222-239
[14]Yeh E, Ramage D, Manning C D, et al. WikiWalk: Random walks on Wikipedia for semantic relatedness[C] Proc of Workshop on Graph-Based Methods for Natural Language Processing. New York: ACM, 2009: 41-49
[15]Dallmann A, Niebler T, Lemmerich F, et al. Extracting semantics from random walks on Wikipedia: Comparing learning and counting methods[C] Proc of the 10th Int AAAI Conf on Web and Social Media. Menlo Park, CA: AAAI, 2016: 33-40
[16]Witten I, Milne D. An effective, low-cost measure of semantic relatedness obtained from Wikipedia links[C] Proc of AAAI Workshop on Wikipedia and Artificial Intelligence: An Evolving Synergy. Menlo Park, CA: AAAI, 2008: 25-30
[17]Wei Bifan, Liu Jun, Ma Jian, et al. Motif-based hyponym relation extraction from Wikipedia hyperlinks[J]. IEEE Trans on Knowledge and Data Engineering, 2014, 26(10): 2507-2519
[18]Singer P, Niebler T, Strohmaier M, et al. Computing semantic relatedness from human navigational paths: A case study on Wikipedia[J]. International Journal on Semantic Web amp; Information Systems, 2013, 9(4): 171-172
[19]Niebler T, Schlör D, Becker M, et al. Extracting semantics from unconstrained navigation on Wikipedia[J]. Künstliche Intelligenz, 2016, 30(2): 1-6
[20]Ellery W, Dario T. Wikipedia Clickstream, v21.0[OL]. [2016-09-24]. https: meta.wikimedia.org wiki Research:Wikipedia_clickstream
[21]Finkelstein L, Gabrilovich E, Matias Y, et al. Placing search in context: The concept revisited[C] Proc of the 10th Int Conf on World Wide Web. New York: ACM, 2001: 406-414
[22]Lee M D. An empirical evaluation of models of text document similarity[J OL]. Cognitive Science, 2005 [2016-09-24]. https: core.ac.uk download pdf 22875578.pdf
[23]Jarmasz M. Roget’s thesaurus as a lexical resource for natural language processing[D]. Ottowa, Canada: University of Ottowa, 2012
[24]Hughes T, Ramage D. Lexical semantic relatedness with random graph walks[C] Proc of the 45th Conf on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Stroudsburg, PA: ACL, 2007: 581-589
[25]Agirre E, Alfonseca E, Hall K, et al. A study on similarity and relatedness using distributional and WordNet-based approaches[C] Proc of Conf on the North Americ Human Language Technologies. New York: ACM, 2013: 19-27
[26]Hoerl A E, Kennard R W. Ridge regression: Biased estimation for nonorthogonal problems[J]. Technometrics, 1970, 12(1): 55-67
Sun Yihan , born in 1994. PhD candidate. Her main research interests include recommendation system, information retrieval, machine learning and distributed storage system.
Luo Tiejian , born in 1962. PhD, professor. Director of the Information Dynamic and Engineering Applications Laboratory. His main research interests include Web mining, large scale Web performance optimization and distributed storage systems.
Calculate Semantic Similarity Based on Large Scale Knowledge Repository
Zhang Libo 1 , Sun Yihan 2 , and Luo Tiejian 2
1 (Institute of Software, Chinese Academy of Sciences, Beijing 100190) 2 (University of Chinese Academy of Sciences, Beijing 101408)
Abstract With the continuous growth of the total of human knowledge, semantic analysis on the basis of the structured big data generated by human is becoming more and more important in the application of the fields such as recommended system and information retrieval. It is a key problem to calculate semantic similarity in these fields. Previous studies acquired certain breakthrough by applying large scale knowledge repository, which was represented by Wikipedia, but the path in Wikipedia didn’t be fully utilized. In this paper, we summarize and analyze the previous algorithms for evaluating semantic similarity based on Wikipedia. On this foundation, a bilateral shortest paths algorithm is provided, which can evaluate the similarity between words and texts on the basis of the way human beings think, so that it can take full advantage of the path information in the knowledge repository. We extract the hyperlink structure among nodes, whose granularity is finer than that of articles form Wikipedia, then verify the universal connectivity among Wikipedia and evaluate the average shortest path between any two articles. Besides, the presented algorithm evaluates word similarity and text similarity based on the public dataset respectively, and the result indicates the great effect obtained from our algorithm. In the end of the paper, the advantages and disadvantages of proposed algorithm are summed up, and the way to improve follow-up study is proposed.
Key words large scale knowledge repository; semantic similarity; Wikipedia; shortest path; connectivity
Received his PhD degree in computer software and theory from the University of Chinese Academy of Sciences. Assistant research professor in the Institute of Software, Chinese Academy of Sciences. His main research interests include image processing, pattern recognition, knowledge graph and deep learning.
收稿日期: 2016-08-10;
修回日期: 2017-02-20
基金项目: 中国科学院系统优化基金项目(Y42901VED2,Y42901VEB1,Y42901VEB2)
This work was supported by the Foundation of System Optimization in Chinese Academy of Sciences (Y42901VED2, Y42901VEB1, Y42901VEB2).
中图法分类号 TP391


