基于未来锁集的死锁规避
禹 振 苏小红 齐 鹏 马培军
(哈尔滨工业大学计算机科学与技术学院 哈尔滨 150001) (yuzhen_3301@aliyun.com)
摘 要: 针对现有动态死锁规避方法存在能力有限、被动盲目、开销较大和影响目标程序正确性等问题,提出一种基于未来锁集的动静结合死锁规避方案Flider.基本思想是,对于一个加锁操作,若其未来锁集中的所有锁都是空闲的,则执行该加锁操作不会导致死锁.一个加锁操作的未来锁集包括当前要加锁的锁和从该加锁操作到与之相对应的解锁操作过程中遇到的所有加锁操作所要加的锁.通过静态分析,计算锁效应信息并插桩到相应的加锁操作和函数调用操作前后.通过动态分析,劫持加锁操作,根据其锁效应信息为之计算未来锁集,只有当未来锁集中的所有锁都未被锁定才执行该加锁操作,否则等待.测评实验和对比实验表明Flider能智能主动地规避多种类型死锁,开销较小,扩展性好,不影响程序正确性.
关键词: 并发缺陷;并发测试;死锁;死锁检测;死锁规避;未来锁集
多线程程序中,如果某线程集合中的每一个线程都在等待另一个线程占据的互斥性资源,或者等待一个不可能发生的信号,则由此导致的循环等待或者无限等待即为死锁.死锁一般由互斥锁、读写锁、条件变量、信号量甚至线程栅栏造成 [1-2] .互斥锁和读写锁通常导致有环死锁,而条件变量、信号量和线程栅栏则能够导致无环死锁 [3] .本文只研究有环死锁.
多方统计调查显示 [3-5] ,死锁缺陷占所有并发缺陷的30%以上,严重威胁并发程序的可用性和可靠性.与其他并发缺陷一样,死锁具有难以检测、难以调试和难以修复的特点 [6] ,且其经常在多个线程按照相反的顺序请求某些资源或者等待某个信号的罕见执行交错下发生.死锁难以检测、调试和修复而又仅在罕见的执行交错下才暴露出来,因此如果合理安排线程请求资源或者等待信号的顺序,避开那些包含死锁的执行交错,则即使多线程程序中存在死锁,也不会被触发进而影响程序执行正确性,此即死锁规避.通常使用执行控制方法在目标程序运行时动态规避死锁.
目前研究者们已提出多种方法规避死锁,较为著名和代表较新水平的有Dimmunix [7] ,Glock [8] ,Sammati [9] ,Grace [10] ,Flock [11] 和Scrider [12] 等.Dimmunix先检测死锁,并记录导致死锁的线程的栈帧作为死锁的签名,然后在并发程序下次运行时,有意识地控制线程调度,阻止相关线程再次进入相应的栈帧,避免已遇到的死锁再次发生.Dimmunix离线规避死锁,而Glock在线规避死锁.Glock检测潜在的死锁环并在该死锁环对应的代码段前添加门锁,使这些代码段互斥执行以规避死锁.Sammati和Grace都使用基于软件事务内存的回滚  重新执行技术规避死锁,但:1)事务粒度不同,Sammati以关键区为粒度,而Grace以2个线程交互操作(如线程开始 线程创建、线程开始 线程结束和线程开始 信号发送等)之间的代码段为粒度;2)规避方式不同,Sammati保持互斥锁语义,在对互斥锁加锁时检测是否有死锁环存在,如果存在,则在死锁环中寻找导致当前加锁操作死锁的锁,将当前线程的执行回退到对该锁的最早加锁操作前,并丢弃所有与该最早加锁操作相关的内存更新,重新执行;Grace则置所有加锁解锁操作为空操作,纯粹以事务内存机制来解决内存冲突,当一个事务执行完毕将要提交时,检查它是否与已经提交的事务存在冲突(即检查它是否读取过时内存),当存在冲突时丢弃该事务从开始到目前为止的所有内存更新,回滚到开始点并重新执行.Flock动静结合地计算一个即将执行的加锁操作的未来锁集,仅当其中的所有锁都未被占据的情况下才允许该加锁操作执行.Scrider动态地将多线程程序的指令序列划分为关键区和非关键区2类区域,并保证在任何时刻只有一个线程执行关键区中的指令.
重新执行技术规避死锁,但:1)事务粒度不同,Sammati以关键区为粒度,而Grace以2个线程交互操作(如线程开始 线程创建、线程开始 线程结束和线程开始 信号发送等)之间的代码段为粒度;2)规避方式不同,Sammati保持互斥锁语义,在对互斥锁加锁时检测是否有死锁环存在,如果存在,则在死锁环中寻找导致当前加锁操作死锁的锁,将当前线程的执行回退到对该锁的最早加锁操作前,并丢弃所有与该最早加锁操作相关的内存更新,重新执行;Grace则置所有加锁解锁操作为空操作,纯粹以事务内存机制来解决内存冲突,当一个事务执行完毕将要提交时,检查它是否与已经提交的事务存在冲突(即检查它是否读取过时内存),当存在冲突时丢弃该事务从开始到目前为止的所有内存更新,回滚到开始点并重新执行.Flock动静结合地计算一个即将执行的加锁操作的未来锁集,仅当其中的所有锁都未被占据的情况下才允许该加锁操作执行.Scrider动态地将多线程程序的指令序列划分为关键区和非关键区2类区域,并保证在任何时刻只有一个线程执行关键区中的指令.
现有死锁规避方法存在4个缺点:1)能力有限,大部分方法(除Grace和Scrider外)只能规避由互斥锁造成的死锁;2)被动盲目,Dimmunix,Sammati,Glock需要检测到死锁环后才能规避死锁,而Scrider使所有关键区,包括没有可能造成死锁的关键区,串行执行;3)开销较大,在线规避方法如Glock,Grace,Scrider等的时间开销都超过10%,Scrider更超过30%,离线规避死锁方法Dimmunix,需要重新执行目标程序;4)影响目标程序执行正确性,Grace和Sammati不能回滚IO操作,因此可能在规避死锁时导致程序输入输出错误,Scrider不能处理条件变量,可能导致没有死锁的程序发生死锁或者活锁.
本文的研究目标是“智能、主动、高效地规避多种类型死锁,不影响程序正确性”,而Flock基于未来锁集技术,通过动静结合分析能在“不影响程序正确性”的前提下,“智能、主动、高效地规避互斥锁死锁”.受Flock基本思想启发,本文提出一种动静分析结合的基于未来锁集的死锁规避方案Flider (future lockset based deadlock avoider),如图1所示,使之从死锁规避能力方面改进Flock,不仅能处理互斥锁还能处理读写锁,以规避由互斥锁和读写锁造成的多种类型死锁,而不仅仅是互斥锁死锁.在图1中,Flider首先使用Clang对源码进行词法语法分析,生成语法树并建立过程内控制流图.然后在过程内控制流图上进行路径敏感分析,计算和插桩锁效应信息,使得加锁操作和函数调用能够“提前知道”将来要进行哪些加锁解锁操作,为动态分析阶段的“智能、主动、高效”规避提供基础.最后通过动态分析,劫持加锁操作,根据静态插桩的锁效应信息计算未来锁集,并根据未来锁集执行规避逻辑动态规避死锁.
在Flider中,动态阶段的死锁规避由于有静态阶段的信息辅助,只会使可能存在死锁的2个关键区串行执行,而不影响非关键区和不可能产生死锁的关键区的并行执行.Flider主动规避死锁,死锁不可能发生,故无需遇到死锁时回滚目标程序并重新执行,从而不会导致程序输入输出错误.
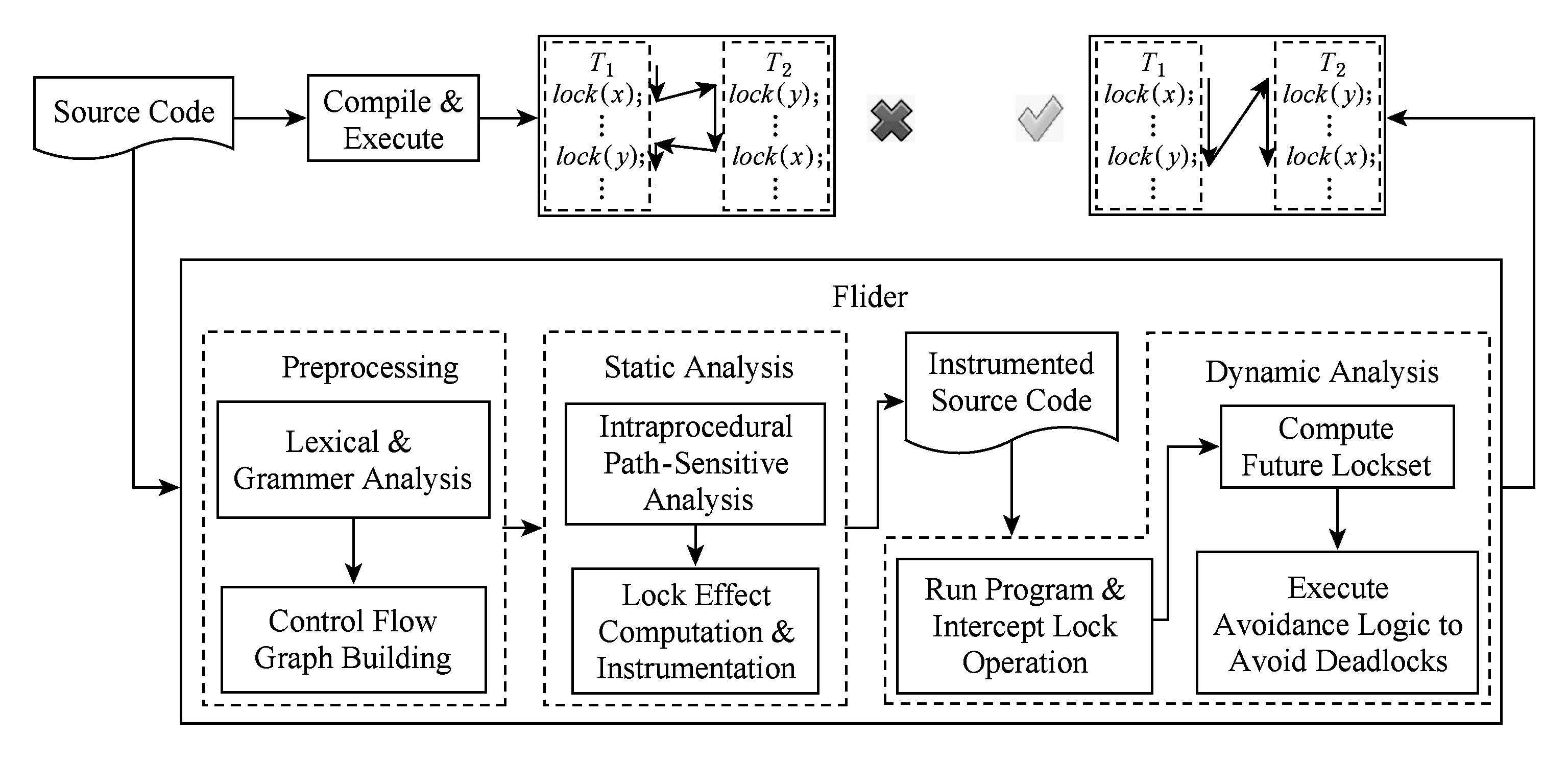
Fig. 1 Scheme of deadlock avoiding based on future lockset
图1 基于未来锁集的死锁规避方案
1 规避对象
Flider与Flock的死锁规避能力不同,Flock只能规避由互斥锁导致的死锁,而Flider则试图规避由pthread库中2种同步设施,即互斥锁和读写锁,造成的5类死锁:互斥锁造成的死锁、读写锁造成的死锁、互斥锁与读写锁造成的混合死锁、互斥锁自锁和读写锁自锁,如图2所示:
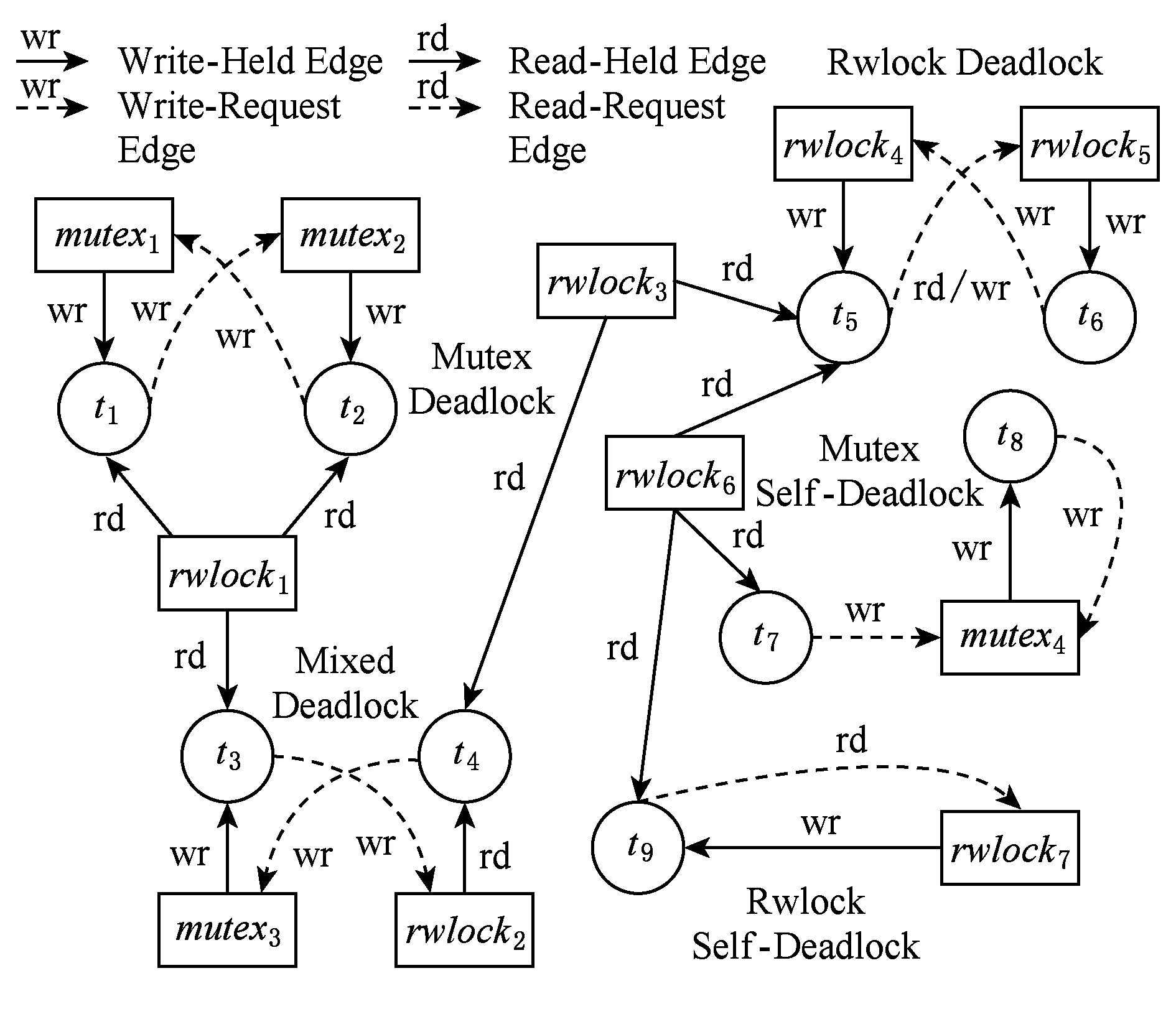
Fig. 2 Five deadlock scenarios caused by mutex and rwlock
图2 互斥锁和读写锁造成的5种死锁场景
实际多线程程序中,互斥锁和读写锁的使用频率都很高.程序员通常使用互斥锁来保护只允许读写操作互斥执行的共享变量,而对于允许多个读操作同时执行而写操作互斥执行的同步场景,程序员为提高性能往往使用读写锁而不是互斥锁来保护共享变量.Flock不能规避由读写锁造成的死锁,以及读写锁和互斥锁造成的混合死锁,因此Flider在死锁规避能力上对Flock的扩展具有重要意义和实际应用价值.
互斥锁与读写锁的区别是:互斥锁在任何时刻只能被至多一个线程占据,因此任何线程对互斥锁的占据和请求都是互斥占据和互斥请求;读写锁在任何时刻可被多个线程同时读占据,但只能被至多一个线程写占据,因此对读写锁的占据和请求各自分为2类,即共享占据与互斥占据和共享请求与互斥请求.本文将对锁(不论互斥锁还是读写锁)的互斥占据和互斥请求称为写占据和写请求,将对锁的共享占据和共享请求称为读占据与读请求.图2中用不同的线型和标签表示这4种操作.
本节定义混合锁分配图(multiple-type lock allocation graph, MLAG)以表征多线程程序相对于互斥锁和读写锁的同步状态,并在此基础上给出5类死锁的严格定义.
定义1. 混合锁分配图.混合锁分配图 G 是一个动态的简单图( V ( t ), E ( t )),其中:
1) V ( t )和 E ( t )分别表示在时刻 t 的顶点和边的集合.
2) V ( t )中的顶点分成3类:代表线程的顶点集合 T ( t )、代表互斥锁的顶点的集合 M ( t )和代表读写锁的顶点集合 RW ( t ),显然3个顶点集合中任2个交集为空.
3) E ( t )中的每一条边 e 是一个3元组( v , thd , tp 1 )或者( thd , v , tp 2 ),其中 v ∈ M ( t )∪ RW ( t ), thd ∈ T ( t ), tp 1 ∈{wr_held,rd_held}, tp 2 ∈{wr_request,rd_request}.( v , thd , tp 1 )表示同步设施 v 正被线程 thd 以 tp 1 方式占据,( thd , v , tp 2 )表示线程 thd 正以 tp 2 方式请求同步设施 v . tp 1 和 tp 2 的取值依下列规则而定:①若 v ∈ M ( t ),则 tp 1 =wr_held, tp 2 =wr_request.②若 v ∈ RW ( t ),则 tp 1 =wr_held当且仅当不存在( v , thr ,rd_held)和( v , thr ,wr_held), tp 1 =rd_held当且仅当不存在( v , thr ,wr_held),其中 thr ∈ T ( t ); tp 2 取值wr_request或者rd_request.
混合锁分配图根据多线程程序执行的加锁解锁操作而实时更新,当图上出现环时,可以根据环中顶点的类型和边的类型判断其是否代表死锁以及是哪种死锁.假设 G 中存在一个环 p = v 1 e 1 v 2 e 2 v 3 … v k e k v 1 ,其中1≤ k ≤min(| V ( t )|,| E ( t )|), v 1 ∈( M ( t )∪ RW ( t )),记 tp ( e )为边 e 的到其类型值的映射.根据 G 的定义, k 必定是偶数.
定义2. 互斥锁死锁.环 p 代表一个互斥锁死锁当且仅当同时满足下列条件:1) k ≥4;2)如果 i 是奇数,则 v i ∈ M ( t ), tp ( e i )=wr_held;3)如果 i 是偶数,则 v i ∈ T ( t ), tp ( e i )=wr_request.其中1≤ i ≤ k .
定义3. 读写锁死锁.环 p 代表一个读写锁死锁当且仅当同时满足下列条件:1) k ≥4;2)如果 i 是奇数,令 e 0 = e k ,则 v i ∈ RW ( t ),且( tp ( e i -1 )≠rd_request‖ tp ( e i )≠rd_held)成立;3)如果 i 是偶数,则 v i ∈ T ( t ).其中1≤ i ≤ k .条件2要求读写锁顶点的入边和出边不能同时是读类型的边.
定义4. 混合死锁.环 p 代表一个混合死锁当且仅当同时满足下列条件:1) k ≥4;2)存在奇数 i 和 j ,使得 v i ∈ M ( t ), v j ∈ RW ( t );3)如果 i 是奇数,令 e 0 = e k ,则( tp ( e i -1 )≠rd_request‖ tp ( e i )≠rd_held)成立;4)如果 i 是偶数,则 v i ∈ T ( t ).其中1≤ i ≤ k ,1≤ j ≤ k .
定义5. 互斥锁自锁.环 p 代表一个互斥锁自锁当且仅当同时满足下列条件:1) k =2;2) v 1 ∈ M ( t ), v 2 ∈ T ( t );3) e 1 =wr_held且 e 2 =wr_request.
定义6. 读写锁自锁.环 p 代表一个读写锁自锁当且仅当同时满足下列条件:1) k =2;2) v 1 ∈ RW ( t ), v 2 ∈ T ( t );3)( tp ( e 2 )≠rd_request‖ tp ( e 1 )≠rd_held)成立.
2 锁效应与未来锁集
Flider与Flock的基本思想相同,即若一个加锁操作的未来锁集中的所有锁都未被锁定,则执行该加锁操作是安全的,不会导致死锁.一个加锁操作的未来锁集可能分布在多个函数内,因此Flider似乎需要进行过程间分析以计算未来锁集.但利用锁效应概念和函数调用机制,Flider只需在静态阶段进行过程内分析以为加锁操作和函数调用操作计算锁效应信息,而为加锁操作计算跨过程分布的未来锁集则推迟到动态阶段.
Flock最早针对互斥锁提出锁效应和未来锁集的概念,但未给出形式化定义.本节针对互斥锁和读写锁给出这些概念的严格定义与实例,第3节给出死锁规避逻辑并展示基于未来锁集的死锁规避过程.
假设一条非空路径 path 由 n 个指令按顺序构成,即 path = ins 1 , ins 2 ,…, ins n ,其中 n ≥2, ins n 表示结束指令.令 x 表示一个互斥锁或读写锁, lock ( x )表示对互斥锁或读写锁 x 的(任意)加锁操作, unlock ( x )表示对 x 的解锁操作.记 type ( x )表示锁 x 的类型,取值MTX或RWLOCK.
定义7. 关键区.指令序列 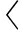 ins u , ins u +1 , ins u +2 ,…, ins v -1 , ins v
ins u , ins u +1 , ins u +2 ,…, ins v -1 , ins v 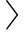 (1≤ u < v ≤ n )称为一个关键区,当且仅当:1) ins u = lock ( x )且 ins v = unlock ( x );2)若存在 u < q < v 使得 ins q = lock ( x ),则存在 q < w < v 使得 ins w = unlock ( x ),且指令序列 ins q , ins q +1 , ins q +2 ,…, ins w -1 , ins w 也是一个关键区.
(1≤ u < v ≤ n )称为一个关键区,当且仅当:1) ins u = lock ( x )且 ins v = unlock ( x );2)若存在 u < q < v 使得 ins q = lock ( x ),则存在 q < w < v 使得 ins w = unlock ( x ),且指令序列 ins q , ins q +1 , ins q +2 ,…, ins w -1 , ins w 也是一个关键区.
关键区既可局限在一个函数内,也可跨越函数而存在.对关键区的定义考虑到了可递归互斥锁的语义.图3给出了一个线程可能执行的5条路径,其中 x 和 z 是互斥锁, y 是读写锁.在 path 1 中, ins 2 , ins 3 , ins 4 , ins 5 , ins 1 , ins 2 , ins 3 , ins 4 , ins 5 , ins 6 都是关键区,而 ins 1 , ins 2 , ins 3 , ins 2 , ins 3 , ins 4 , ins 5 , ins 1 , ins 2 , ins 3 , ins 4 , ins 5 都不是关键区,因为 ins 2 , ins 3 , ins 4 , ins 2 , ins 3 , ins 4 都不是关键区.在 path 2 中, ins 1 , ins 2 , ins 3 , ins 4 , ins 5 和 ins 2 , ins 3 , ins 4 , ins 5 , ins 6 都是关键区.
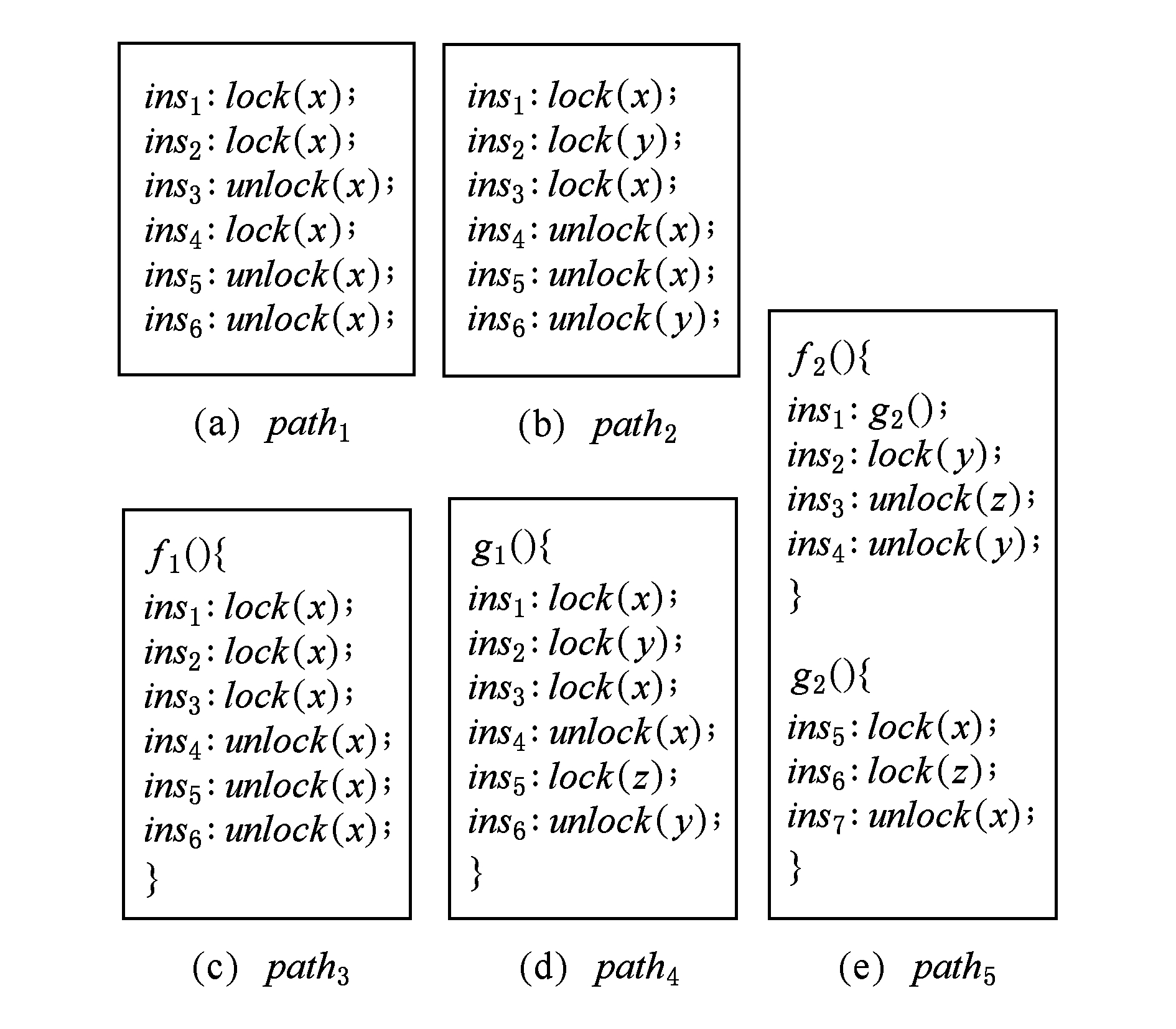
Fig. 3 Five paths possibly taken by a single thread
图3 单个线程可能执行的5条路径
定义8. 锁效应.假设 path 是非空函数 f ()的一条路径, ins n 表示函数结束指令.记 effect ( ins )为指令 ins 的锁效应信息.如果 ins 不是加锁操作或函数调用操作,则 effect ( ins )为空.
1) 若存在指令序列 ins u , ins u +1 , ins u +2 ,…, ins v -1 , ins v (1≤ u < v ≤ n )构成一个关键区,则对于 ins u = lock ( x ),其锁效应 effect ( ins u )按如下步骤计算:①检查所有 ins i , u +1≤ i ≤ v -1,若 ins i = lock ( y )且 y ≠ x ,则将( y ,+, type ( y ))从尾部插入 effect ( ins u ),若 ins i = unlock ( y )且 y ≠ x ,则将( y ,-, type ( y ))从尾部插入 effect ( ins u );②从尾部向 effect ( ins u )插入( x ,-, type ( x ));③逆向遍历 effect ( ins u ),对于元素 ef ,删除后续遍历过程中遇到的所有与之相等的元素.
2) 若存在指令 ins u = lock ( x ),1≤ u ≤ n ,但不存在 ins v = unlock ( x ), u < v ≤ n ,使得 ins u , ins u +1 , ins u +2 ,…, ins v -1 , ins v 构成一个关键区,则锁效应 effect ( ins u )按如下步骤计算:①检查所有 ins i , u +1≤ i ≤ n -1,若 ins i = lock ( y )且 y ≠ x ,则将( y ,+, type ( y ))从尾部插入 effect ( ins u ),若 ins i = unlock ( y )且 y ≠ x ,则将( y ,-, type ( y ))从尾部插入 effect ( ins u );②逆向遍历 effect ( ins u ),对于元素 ef ,删除后续遍历过程中遇到的所有与之相等的元素;
3) 若存在指令 ins u 为自定义函数调用操作,1≤ u ≤ n ,则 effect ( ins u )的计算过程与2)相同(除判断任意锁 y 是否等于 x 外,因为这里没有特定锁 x ).
锁效应的概念和定义只局限在单个函数范围内.只为加锁操作和自定义函数调用操作计算锁效应信息.对于某函数内一条路径上的加锁操作,其锁效应是从该加锁操作到与之相对应的解锁操作或者函数结束点的过程中遇到的所有非冗余加锁解锁信息.函数调用操作的锁效应信息与之类似.在图3的 path 3 中, effect ( ins 1 ), effect ( ins 2 ), effect ( ins 3 )都为{( x ,-,MTX)}; path 4 中, effect ( ins 2 )为{( x ,+,MTX),( x ,-,MTX),( z ,+,MTX),( y ,-,RWLOCK)}, effect ( ins 1 )为{( y ,+,RWLOCK),( z ,+,MTX),( y ,-,RWLOCK)}; path 5 中, effect ( ins 5 )为{( z ,+,MTX),( x ,-,MTX)}, effect ( ins 1 )为{( y ,+,RWLOCK),( z ,-,MTX),( y ,-,RWLOCK)}.
定义9. 未来锁集.假设 path 为非空线程 thd 的一条路径, ins n 表示当前 thd 将要执行的指令.记 flset ( ins )为指令 ins 的未来锁集.如果 ins 不是加锁操作,则 flset ( ins )为空.记 stack 为线程 thd 专用的一个栈,在 thd 被创建时为空.
1) 若指令 ins n 是自定义函数调用操作call f (),将锁效应 effect ( ins n )中的元素逆序入栈 stack .
2) 若指令 ins n 是自定义函数返回操作ret f (),假设与之相对应的自定义函数调用操作是 ins u =call f (),1≤ u ≤ n ,则从栈 stack 中正序弹出锁效应 effect ( ins u ).
3) 若指令 ins n 是加锁操作 lock ( x ),则首先将 x 从尾部插入 flset ( ins n ),并将 effect ( ins n )逆序入栈 stack ,然后从栈顶向栈底查找( x ,-, type ( x )),在查找过程中一旦遇到 ( y ,+, type ( y ))且 y ≠ x ,就将( y , type ( y ))从尾部插入 flset ( ins n ).不论成功找到或者直到栈底都没有找到( x ,-, type ( x )),都从栈 stack 中逆序弹出 effect ( ins n ).
未来锁集的概念与定义只局限在单个线程范围内.只为加锁操作计算未来锁集.对于某线程内一个路径上的加锁操作,其未来锁集包括该加锁操作所要加的锁和从该加锁操作到与之相对应的解锁操作或线程结束点的过程中遇到的所有非冗余加锁操作所要加的锁.在图3的 path 3 中, flset ( ins 1 ), flset ( ins 2 ), flset ( ins 3 )都为{( x ,MTX)}; path 4 中, flset ( ins 2 )为{( y ,RWLOCK),( x ,MTX),( z ,MTX)}; path 5 中, flset ( ins 6 )为{( z ,MTX),( y ,RWLOCK)}.
3 规避逻辑
假设一个多线程程序有 thd 1 , thd 2 ,…, thd m 共 m 个线程, m ≥1,线程 thd i 到目前为止的执行路径是 path i ,1≤ i ≤ m . path i 由指令 ins i ,1 , ins i ,2 ,…, ins i , len ( i ) 构成,其中 len ( i )表示当前路径 path i 的长度.
定理1. 对于线程 thd i ,若当前路径 path i 的当前指令 ins i , len ( i ) = lock ( x ),且其未来锁集 flset ( ins i , len ( i ) )={ l 1 , l 2 ,…, l s },其中 x 是一个互斥锁或者读写锁, l 1 = x , s ≥1,那么下列命题成立:若任意 l j 都没有被占据,1≤ j ≤ s ,则 thd i 执行 ins i , len ( i ) 会成功获取锁 x 且不会导致死锁.
证明. 1)因为任意锁 l j (包括 x )都没有被锁定,1≤ j ≤ s ,所以执行 ins i , len ( i ) 必定能成功获取锁 x ;2)若成功获取锁 x 导致线程 thd i 在将来执行与 ins i , len ( i ) 对应的释放锁 x 操作之前的某个时刻参与到某个死锁环,则说明当 thd i 执行 ins i , len ( i ) 时,某个线程 thd h 已占据{ l 1 , l 2 ,…, l s }中的某个锁,1≤ h ≤ m ,否则根据混合锁分配图(定义1)的定义, thd i 不可能参与构成死锁环,但根据命题前提可知,这不可能发生,因此 thd i 不会陷入死锁.
证毕.
定理1指出,只有在加锁操作的未来锁集中所有锁都未被占据的情况下,线程执行加锁操作才不会导致死锁,但没有说明若未来锁集中存在某些锁被占据的情况下,线程应执行何种动作.实际上,在这种情况下,Flider让线程延迟执行加锁操作直到该加锁操作的未来锁集中所有锁都空闲.定理1也没有考虑到加锁操作的未来锁集中的锁已被当前线程所占据的情况.在实现时,当线程 thd 执行加锁操作 lock ( x ),若发现 x 已被自身占据,则将该加锁操作和相应的解锁操作视为空操作而执行,若发现该加锁操作的未来锁集中某个非 x 的其他锁已被自身占据,则仍然执行该加锁操作而不等待(当然需要检查 x 是否已被自身占据).这样Flider就能够规避互斥锁自锁与读写锁自锁(4.5节).
定理2. 对于线程 thd i ,若当前路径 path i 的当前指令 ins i , len ( i ) = lock ( x ),且其未来锁集 flset ( ins i , len ( i ) )={ l 1 , l 2 ,…, l s },其中 x 是一个互斥锁或者读写锁, l 1 = x , s ≥1,那么下列命题不成立:若 ins i , len ( i ) 是写请求加锁,则若任意 l j ,1≤ j ≤ s ,都没有被(写或读)占据,则 thd i 执行 ins i , len ( i ) 不会导致死锁;若 ins i , len ( i ) 是读请求加锁,则若任意 l j 都没有被写占据,则 thd i 执行 ins i , len ( i ) 不会导致死锁.
证明. 若要证明定理2成立,只需构造一个例子使得其中的命题不成立.假设图4中多线程代码的执行顺序是 ins 1,1 , ins 2,1 , ins 1,2 , ins 2,2 , x 和 y 是读写锁.

Fig. 4 A deadlock example caused by rwlocks
图4 一个读写锁死锁例子
图4中的指令根据定理2中命题的规则执行.当线程 thd 1 执行 ins 1,1 时,由于 ins 1,1 是读请求加锁且 flset ( ins 1,1 )={( x ,RWLOCK),( y ,RWLOCK)}中的所有锁都未被写占据,则 thd 1 执行 ins 1,1 成功地读占据 x .然后当 thd 2 执行 ins 2,1 时,由于 ins 2,1 也是读请求加锁且 flset ( ins 1,1 )={( y ,RWLOCK),( x ,RWLOCK)}中的所有锁都未被写占据,则 thd 2 执行 ins 2,1 成功地读占据 y .当 thd 1 执行 ins 1,2 时,由于 ins 1,2 是写请求加锁且 flset ( ins 1,2 )={( y ,RWLOCK)}中的 y 已被线程 thd 2 读占据,所以 thd 1 不执行 ins 1,2 而等待 thd 2 释放 y .当 thd 2 执行 ins 2,2 时,由于 ins 2,2 是写请求加锁且 flset ( ins 2,2 )={( x ,RWLOCK)}中的 x 已被线程 thd 1 读占据,所以 thd 2 不执行 ins 2,2 而等待 thd 1 释放 x .这样就造成了 thd 1 和 thd 2 之间的相互循环等待,也即死锁,因此定理2成立.
证毕.
定理2指出比定理1更细粒度的规避逻辑是不可行的.即对于一个读请求加锁操作,即使其未来锁集中的锁都被读占据,Flider也不会允许其执行,因为根据定理2,允许此读请求加锁操作执行可能导致程序在将来遭遇死锁.在定理1和定理2中,检查未来锁集中的锁是否已被占据是通过搜索混合锁分配图来完成的.在目标程序运行时,Flider通过劫持加锁解锁操作以建立和更新混合锁分配图.
Flider进行过程内分析,为每条执行路径上的加锁操作和自定义函数调用操作计算锁效应信息(定义8)并插桩到相应操作执行前后.而在动态分析时利用插桩的锁效应信息为加锁操作计算未来锁集(定义9).最后根据未来锁集中的锁是否空闲(定义1)执行规避逻辑(定理1)以控制线程调度规避死锁.基于定理1,Flider只使可能发生死锁的关键区串行,而不会影响不可能发生死锁的关键区和非关键区的并行执行,从而达到“智能、高效”的规避目标.我们用图5展示整个基于未来锁集的死锁规避过程.
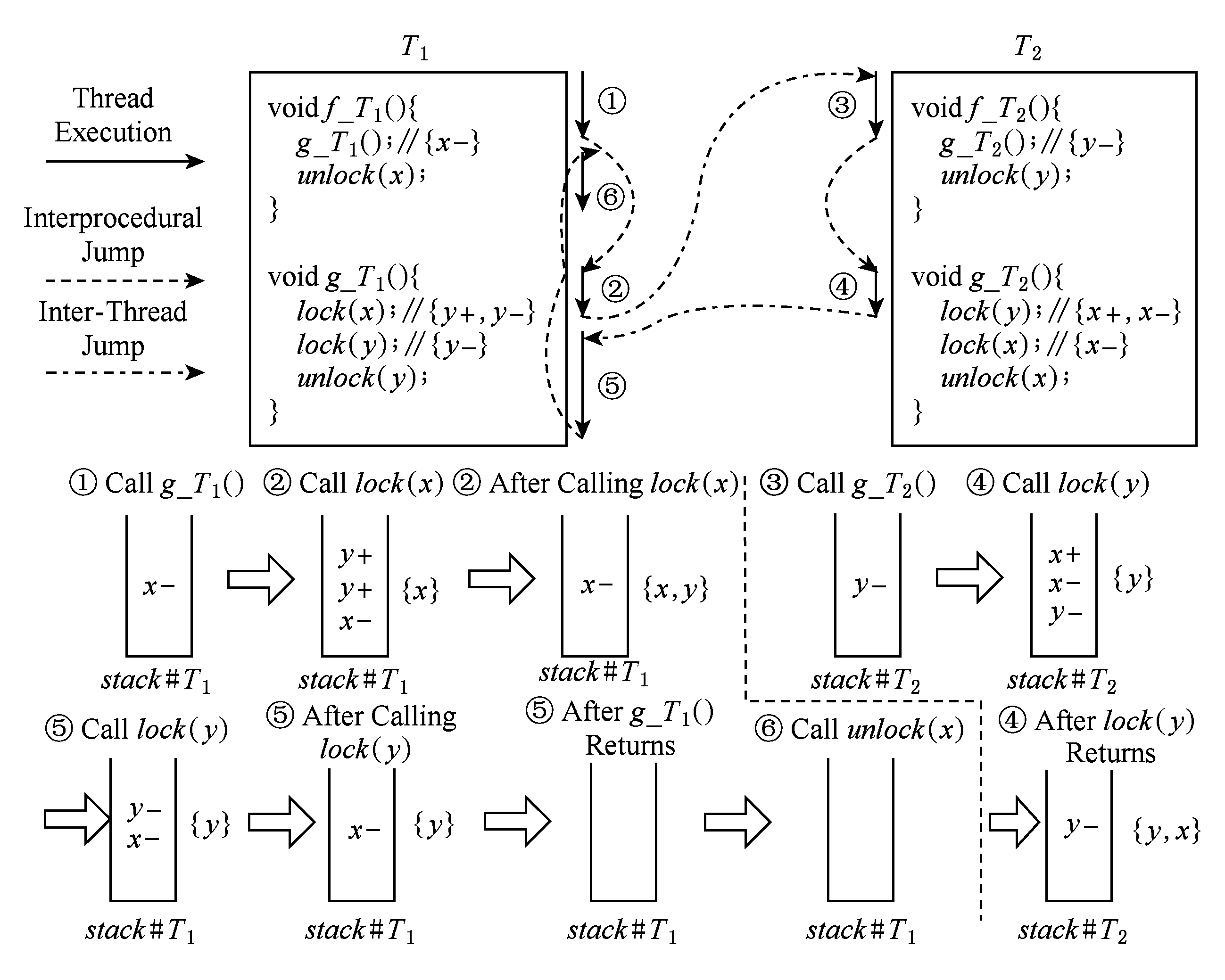
Fig. 5 Demonstration of deadlock avoiding mechanism based on future lockset
图5 基于未来锁集的死锁规避示例
在图5中,首先静态分析源码,针对过程内的单个路径为加锁操作和自定义函数调用操作计算锁效应信息,这里我们省略锁效应信息中的锁类型信息,例如 g_T 1 ()内 lock ( x )的锁效应信息为{ y +, y -}, f_T 2 ()内 g_T 2 ()的锁效应信息是{ y -};然后按照图中标示的顺序执行代码.在 T 1 调用 g_T 1 ()时,将锁效应信息 effect ( f_T 1 : g_T 1 ())入栈 stack # T 1 ,在执行 g_T 1 ()内 lock ( x )时,先将锁 x 加入未来锁集 flset ( g_T 1 : lock ( x )),并将锁效应 effect ( g_T 1 : lock ( x ))入栈,然后在栈中查找 x -,将查找过程中遇到的 y +中的 y 从尾部插入 flset ( g_T 1 : lock ( x )),于是得到 g_T 1 内 lock ( x )的未来锁集是{ x , y }.由于这2个锁都没有被锁定,因此Flider允许 T 1 执行 lock ( x )以成功占据锁 x .线程 T 1 占据锁 x 后,操作系统调度 T 2 执行.在 T 2 调用 g_T 2 ()时,将锁效应信息 effect ( f_T 2 : g_T 2 ())入栈 stack # T 2 ,在执行 g_T 2 ()内 lock ( y )时,先将锁 y 加入未来锁集 flset ( g_T 2 : lock ( y )),并将锁效应 effect ( g_T 2 : lock ( y ))入栈,然后在栈中查找 y -,将查找过程中遇到的 x +中的 x 从尾部插入 flset ( g_T 2 : lock ( y )),于是得到 g_T 2 内 lock ( y )的未来锁集是{ y , x }.由于{ y , x }中的一个锁 x 已被 T 1 占据,因此Flider不允许 T 2 执行 lock ( y )而是等待直到 y 和 x 都变得空闲.此时操作系统挂起 T 2 而去重新执行 T 1 .在 T 1 执行 g_T 1 ()内 lock ( y ),先计算出 flset ( g_T 1 : lock ( y ))为{ y }.由于 y 未被占据,则Flider允许 T 2 执行 lock ( y )以成功获取锁 y .在 g_T 1 ()返回时,将 effect ( f_T 1 : g_T 1 ())从栈中弹出. T 1 执行 unlock ( x )和 unlock ( y )时,Flider会更新混合锁分配图,从而 T 2 能够通过搜索混合锁分配图知道 x 和 y 已被释放,进而执行 g_T 2 ()内 lock ( y ).至此,Flider成功规避了图5中多线程代码在执行时可能发生的死锁.
4 Flider实现
我们在Ubuntu 14.04(内核:Linux-3.13.0)上实现了Flider.如图1所示,Flider主要包括预处理、静态分析和动态分析三大模块,分别负责完成过程内控制流图建立、锁效应计算与插桩以及未来锁集计算与规避逻辑执行等功能.与Flock不同,Flider使用Clang而不是CIL [13] 进行预处理和锁效应插桩;另外Flider使用路径敏感分析技术而不是类型推理计算锁效应.前者使得Flider更通用,能处理比Flock更多类型的源程序;而后者使得Flider的锁效应计算更简洁和易于理解.
4.1 过程内控制流图建立
使用Clang对多线程程序源码进行词法语法分析,建立抽象语法树并在此基础上建立过程内控制流图.Clang建立的控制流图是一个由基本块组成的有向图,利用该图可以方便地判断程序结构,了解程序中各语句之间的先后执行顺序,获得程序的执行路径.基本块代表一个可顺序执行的语句序列,其中包括块号、语句体、分支条件和前驱后继.如图6(a)是函数 foo ()的源码,图6(b)是Clang为之生成的控制流图.
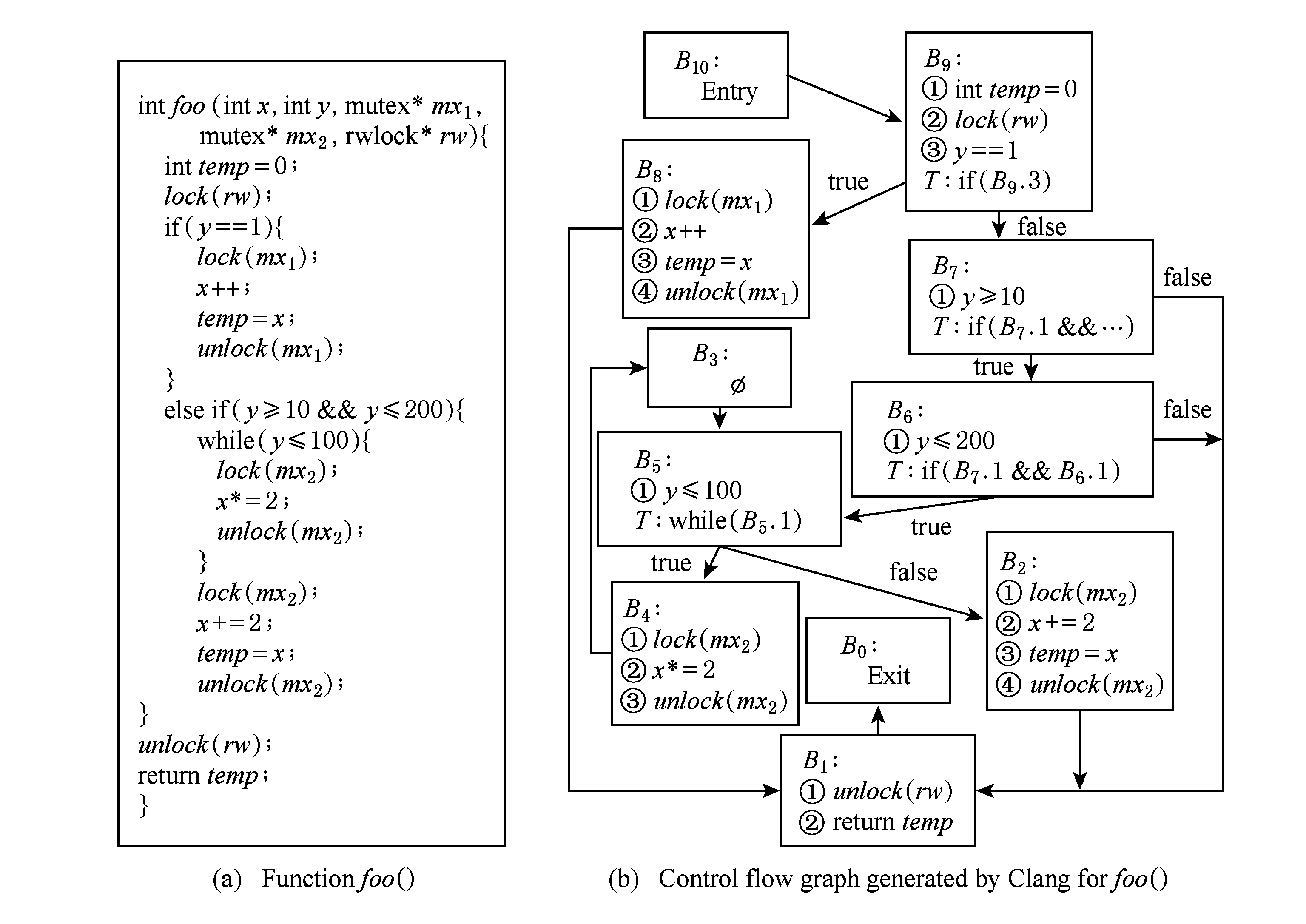
Fig. 6 Function foo() and its CFG generated by Clang
图6 函数foo()及其控制流图
图6(b)中的每个节点都代表一个基本块,从 B 0 到 B 10 共11个基本块,其中 B 10 和 B 0 分别是 f ()的入口块和出口块,这2个块对每个函数都有且只有一个; B 5 , B 4 , B 3 构成了一个环,对应图6(a)中的while循环; B 3 是只有前驱和后继信息的空块,用于清晰地表示循环结构,每个while循环都至少有一个空块;非空块中的带标号文本为块中语句或表达式,与源码中的语句或表达式相对应;带有 T 的块表示分支块,表示源码中的分支结构, T 后的文本表示分支块的分支条件;有向边表示块之间的前驱后继关系,分支块的出边带有标签true或false,分别指向条件为真或为假时的后继块.
4.2 过程内控制流图路径分析
Flider针对过程内每条路径为加锁操作和自定义函数调用操作计算锁效应(定义8),因此在计算锁效应之前需要在过程内控制流图上进行路径分析,获取从入口块到出口块的所有可能路径.
简单的深度或者广度优先遍历,只能分析有向图中2个节点的可达性,但不能计算出这2个节点之间的所有互异可达路径,因此我们提出算法1所示的路径分析算法求取从入口块到出口块的所有可能路径.路径分析算法不适用于带环的有向图,故在进行路径分析之前,需要先对过程内控制流图进行去环处理,即将循环结构改为循环体只执行一次的分支结构.图7展示了图6中控制流图的去环过程,其中控制流图的基本块节点以块号表示.可以看到图7(a)中基本块 B 5 , B 4 , B 3 构成一个环,去环过程中,我们将链接 B 4 和 B 5 的空块 B 3 去除,将 B 4 的后继指向 B 5 的后继 B 2 ,从而得到图7(b)所示的无环控制流图.
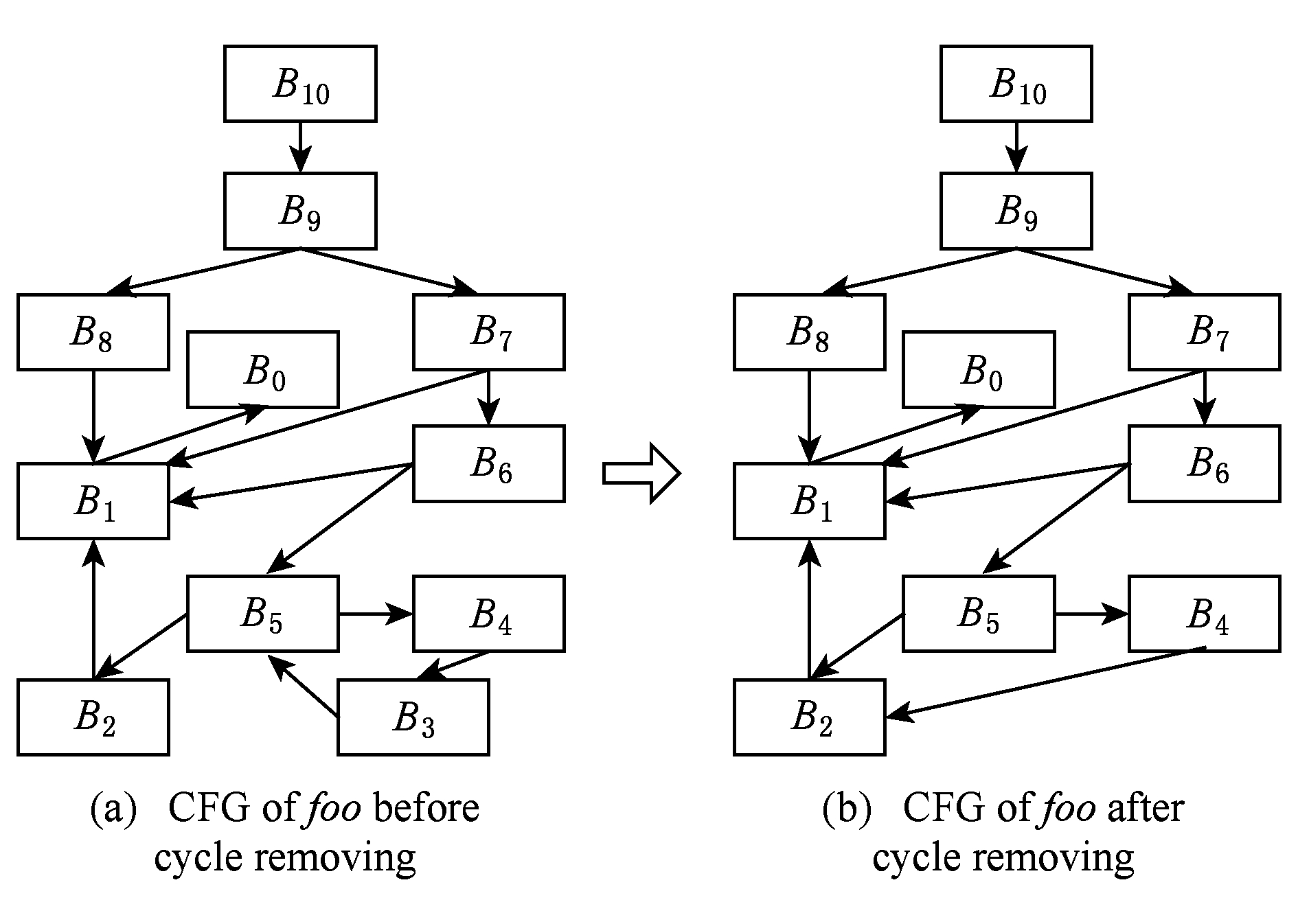
Fig. 7 Cycle removing on CFG of function foo()
图7 对函数foo()的控制流图进行去环处理
算法1以邻接矩阵 Arcs [ N ][ N ]为输入,它表示经过去环处理的控制流图, N 是所有节点的个数.算法1深度优先遍历控制流图,每个节点可能被多次遍历,使用栈 nstack 存储遍历过程中找到的可能构成路径的节点,使用 VertexStatus [ N ]和 ArcStatus [ N ][ N ]这2个数据结构控制节点的入栈和出栈.对于0≤ i ≤ N , VertexStatus [ i ]=0表示 i 号节点未进栈或者已出栈,否则 VertexStatus [ i ]为1.对于0≤ i , j ≤ N , ArcStatus [ i ][ j ]=0当且仅当节点 i 和节点 j 都在栈外,否则 ArcStatus [ i ][ j ]=1.算法1中, Traverse ( nstack )遍历栈 nstack ,将从栈底到栈顶的块号按序排列组成一条所求路径. UpdateArcStatus ( VertexStatus , ArcStatus )根据 VertexStatus 更新 ArcStatus ,使得所有2个顶点都不在栈内的边的状态为0.
算法1. 过程内控制流图上路径分析算法.
输入:过程内控制流图邻接矩阵形式 Arcs [ N ][ N ];
输出:过程内控制流图上从基本块 N 到基本块0的所有路径集合 paths .
算法1首先将起始块 N 入栈 nstack ,并置 VertexStatus [ N ]为1表示块 N 已入栈(行④~⑤),然后检查栈是否为空,当栈不为空且栈顶元素是块0时,则栈中从栈底到栈顶的块号序列构成一条所求路径,生成路径并加入到路径集合中,将块0从栈顶弹出,并相应更新 VertexStatus 和 ArcStatus ,使得块0的入栈状态为0和以块0为其中一个顶点的2个顶点都不在栈中的边的入栈状态为0(行⑦~  ),如果栈不为空且栈顶元素不是块0时,则寻找序号最大的的块 i ,该块不在栈中(条件 C 1 )且栈顶块 elem 与块 i 形成的边(如果有边的话,条件 C 3 )也不在栈中(条件 C 2 ),将块 i 入栈,置边( elem , i )的入栈状态为1(行
),如果栈不为空且栈顶元素不是块0时,则寻找序号最大的的块 i ,该块不在栈中(条件 C 1 )且栈顶块 elem 与块 i 形成的边(如果有边的话,条件 C 3 )也不在栈中(条件 C 2 ),将块 i 入栈,置边( elem , i )的入栈状态为1(行  ~
~  ),如果不存在这样的块 i ,则说明在当前情况下,块 elem 的所有出边已被访问过,此时向上回溯,将块 elem 弹出并相应地更新 VertexStatus 和 ArcStatus (行
),如果不存在这样的块 i ,则说明在当前情况下,块 elem 的所有出边已被访问过,此时向上回溯,将块 elem 弹出并相应地更新 VertexStatus 和 ArcStatus (行  ~
~  ).最后,算法返回所有合法路径(行
).最后,算法返回所有合法路径(行  ).
).
需要注意的一点是,为保证正确性和深度优先遍历特性,算法1仅在弹出栈顶元素时调用 UpdateArcStatus ( VertexStatus , ArcStatus ).在图7(b)上运行算法1,得到所有可能执行路径:
path 1 : B 10 → B 9 → B 7 → B 6 → B 5 → B 2 → B 1 → B 0 ,
path 2 : B 10 → B 9 → B 7 → B 6 → B 5 → B 4 → B 2 → B 1 → B 0 ,
path 3 : B 10 → B 9 → B 7 → B 6 → B 1 → B 0 ,
path 4 : B 10 → B 9 → B 7 → B 1 → B 0 ,
path 5 : B 10 → B 9 → B 8 → B 1 → B 0 ,
其中→表示直接可达.
4.3 锁效应计算与插桩
针对函数 f ()的控制流图中的一条路径 path ,Flider按照定义8为其上加锁操作或者自定义函数调用操作计算锁效应.计算出锁效应后,根据 path 是否含有分支块,按照不同的插桩规则将锁效应信息插桩到相应操作前后,以便传递到动态分析模块供计算未来锁集之用.假设函数 f ()在线程 thd 中,针对锁效应中的一个元素( x ,+,MTX),则在相应操作之前和之后的插桩语句分别是 stack # thd . push ( x ,1)和 stack # thd . pop ( x ,1),针对元素( y ,-,RWLOCK),在相应操作之前和之后的插桩语句是 stack # thd . push ( y ,0)和 stack # thd . pop ( y ,0).这里有2点需要注意:1)由于锁的类型信息在未来锁集计算和规避逻辑执行时无用(定理1和定理2),我们省略对其的插桩,不将其传递到动态分析模块;2)由于静态分析阶段无法确定线程的标识,线程专用的栈 stack # thd 是动态阶段通过映射动态创建和查找的,我们静态插桩能够自动完成这种映射的代码.
如果 path 不含有任何分支块,则 f ()是不包含任何分支语句的顺序结构函数,将锁效应信息直接插桩到相应操作的前后.图8展示了对图5中线程 T 1 执行的2个顺序结构函数 f_T 1 ()和 g_T 1 ()的插桩结果.函数 g_T 1 ()中需要插桩的语句有 lock ( x )和 lock ( y ),根据它们的锁效应信息,在 lock ( x )前后插桩语句 stub 3 , stub 4 和 stub 5 , stub 6 ,在 lock ( y )前后插桩语句 stub 7 和 stub 8 .函数 f_T 1 ()中需要插桩的语句是自定义函数调用 g_T 1 (),在其前后插桩语句 stub 1 和 stub 2 .
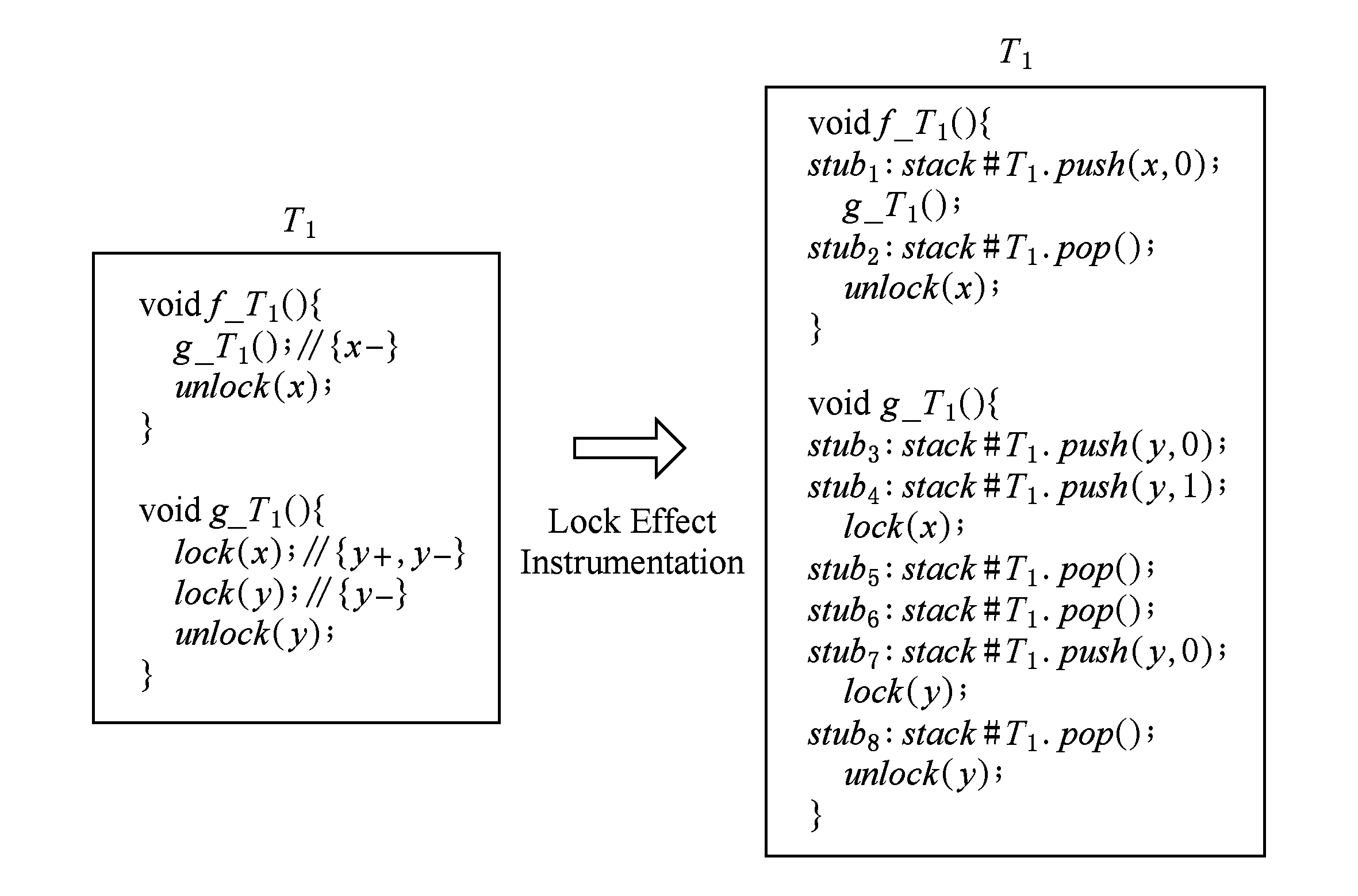
Fig. 8 Lock effect instrumentation for functions with sequential structures
图8 顺序结构函数的锁效应插桩
顺序结构函数只含有一条路径,对其锁效应插桩较简单.但若函数 f ()含有条件分支语句(循环控制语句是条件分支语句的一种),则其控制流图必定具有多条路径,且每条路径都至少包含一个分支块.对分支结构函数的锁效应插桩较复杂.
对于路径 path = B N → B b 1 → B b 2 →…→ B b n → B 0 ,若 B b i 是分支块,则令 C b i 表示 B b i 的分支条件,其中 b 1 , b 2 ,…, b n ∈{0,1,2,…, N }, n ≥0, N ≥1.令 B p → + B q 表示 B p 经过至少一个块可达 B q ,0≤ p , q ≤ N .假设 path 内的所有分支块 B v 1 , B v 2 ,…, B vr 构成 B v 1 → + B v 2 …→ + B vr , C v 1 , C v 2 ,…, C vr 分别是各自块的分支条件,其中 v 1 , v 2 ,…, v r ∈{ b 1 , b 2 ,…, b n }, r ≥0.Flider按下列规则为路径 path 上的加锁操作和自定义函数调用操作计算和插桩锁效应信息:
1) 按照定义8计算锁效应.
2) 若某个加锁操作与相应的解锁操作(这2个指令与它们之间的指令构成一个关键区)都在一个块内,则直接在该加锁操作前后插入相应的 push 和 pop 语句.
3) 设存在 u ∈{ b 1 , b 2 ,…, b n },使得 B u 不是分支块且 B u → + B v 1 → + B v 2 …→ + B vr .若加锁操作指令 ins l 在 B u 内,且其相应的解锁指令不在 B u 而在 B v 1 或者 B u 与 B v 1 之间的非分支块中,则直接在 ins l 前后插入相应插桩语句.若 ins l 的相应解锁指令不在 B u 而在 B vs ,2≤ s ≤ r ,则插桩在 ins l 前后的 push 和 pop 语句集各自位于条件语句if( C v 1 && C v 2 &&…&& C vs -1 )中.若 ins l 的相应解锁指令不在 B u 而在 B vs 与 B vs +1 (规定 B vr +1 为出口块)之间的某个非分支块中,2≤ s ≤ r ,则插桩在 ins l 前后的 push 和 pop 语句集各自位于条件语句if( C v 1 && C v 2 &&…&& C vs )中.若自定义函数调用指令 ins f 在 B u 内,则插桩在 ins f 前后的 push 和 pop 语句集各自位于条件语句if( C v 1 && C v 2 &&…&& C vr )中.
4) 设存在 u ∈{ b 1 , b 2 ,…, b n },使得 B u 不是分支块且 B v 1 → + B v 2 …→ + B vr → + B u .若 ins l 和 ins f 分别是 B u 中的加锁指令和自定义函数调用指令,则直接将锁效应信息插桩到相应指令前后.
5) 对于分支块 B vw 或位于 B vw -1 (规定 B v 0 为入口块)与 B vw 之间的非分支块 B u , u ∈{ b 1 , b 2 ,…, b n },1≤ w ≤ r ,若 ins l 是 B vw 或 B u 中的加锁指令,且其相应解锁指令在 B vs +1 或者 B vs 与 B vs +1 之间的非分支块中,则插桩在 ins l 前后的 push 和 pop 语句集各自位于条件语句if( C vw && C vw +1 &&…&& C vs )中.若 ins f 是 B vw 或 B u 中的自定义函数调用指令,则插桩在 ins f 前后的 push 和 pop 语句集各自位于条件语句if( C vw && C vw +1 &&…&& C vr )中.
图9展示了使用上述规则对分支结构函数的锁效应插桩结果.图9控制流图上存在2条路径 path 1 : B 5 → B 4 → B 3 → B 1 → B 0 和 path 2 : B 5 → B 4 → B 2 → B 1 → B 0 , B 4 是分支块.对 path 1 和 path 2 中 B 4 的加锁指令 lock ( mtx 1 )运用规则5插桩锁效应,对 B 3 和 B 2 运用规则2插桩锁效应,得到插桩后基本块.
插桩规则3~5对于在分支块或者在位于分支块之前的非分支块中的加锁操作和自定义函数调用操作进行锁效应插桩时,会将相应分支条件提前计算,以保证插桩的锁效应是针对当前路径的.但是有时分支条件不能提前计算,如分支条件中包含加锁操作,分支条件中使用的变量在加锁操作或自定义函数调用操作之后被定义或修改(图10).在这种情况下,Flider使用路径不敏感分析方法插桩锁效应,即将从加锁操作或自定义函数调用操作到函数结束的所有语句视为一条路径上的语句,使用针对不含有分支块的路径的锁效应插桩方法插桩.这种方法可能会串行化一些不必要串行的关键区,也可能会引入活锁.
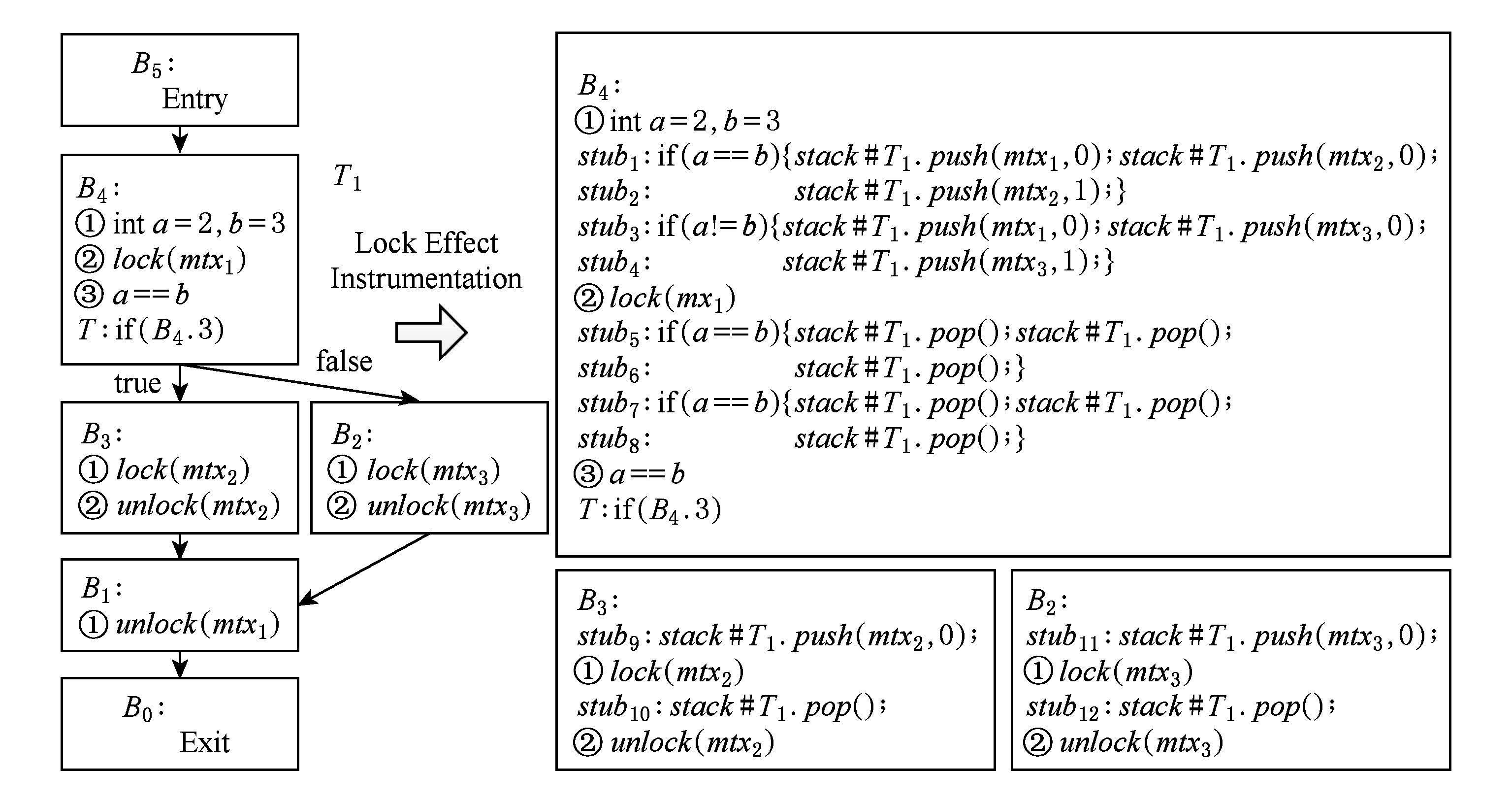
Fig. 9 Lock effect instrumentation for functions with conditional structures
图9 分支结构函数的锁效应插桩

Fig. 10 Examples of buggy instrumentation
图10 错误插桩的例子
对于循环结构,由于其已在控制流上转化成分支结构,因此对循环结构的锁效应插桩自动按照对分支结构的插桩方法处理.
插桩完成后,Flider利用Clang的代码重写器读取已插桩的控制流图,生成插桩过锁效应的源码.
4.4 加锁解锁操作劫持
我们将Flider的动态分析模块实现为一个动态链接库.在插桩过锁效应信息的目标程序执行时,该动态库以预加载机制作为第一个被加载的动态库加载到目标程序的进程空间内.通过使用Linux提供的预加载机制LD_PRELOAD,Flider劫持表1中所有作用于互斥锁和读写锁的加锁解锁操作,以便构建和更新全局混合锁分配图 G (定义1)、为加锁操作计算未来锁集(定义9)、根据未来锁集执行规避逻辑(定理1).
混合锁分配图根据加锁解锁操作的执行效果而实时更新.若线程 T 执行加锁操作 lock ( x )请求加锁 x 但目前还没有成功占据 x ,则建立从 T 到 x 的(读 写)请求关系;若线程 T 执行加锁操作 lock ( x )成功,则删除从 T 到 x 的(读 写)请求关系并建立从 x 到 T 的(读 写)占据关系;若线程 T 执行解锁操作 unlock ( x )成功,则删除从 x 到 T 的(读 写)占据关系.在Flider中,混合锁分配图以映射数组的形式实现.
4.5 规避逻辑的原子执行
由于有锁效应信息的辅助,加锁操作的未来锁集计算直接按照定义9进行即可.而规避逻辑检查未来锁集中的锁的状态,只有当所有锁都未被占据时,才允许当前加锁操作执行.其中2个动作,即检查锁状态和决定加锁操作是否执行,必须原子性执行,否则规避逻辑不能正确运行.假设线程 T 1 在执行加锁操作 lock ( x )前,Flider计算出该加锁操作的未来锁集是{ x , y },然后Flider检查发现 x 和 y 都未被占据,在它进一步决定允许 T 1 执行 lock ( x )时,操作系统调度 T 2 执行 lock ( y ),假设 lock ( y )的未来锁集也是{ x , y },则 T 2 会被运行执行 lock ( y )并成功获取锁 y .当 T 1 再次执行时,它仍然认为 x 和 y 都是空闲的,从而执行 lock ( x )以获取 x .这种规避逻辑可能不能规避死锁.因此为保证正确性,规避逻辑必须原子性执行.为此,我们为所有的规避逻辑加上全局同一锁保护,使得所有的规避逻辑串行执行.具体地,锁状态检查在全局锁的保护下进行,如果发现未来锁集中的锁不是全都空闲,则释放全局锁,等待一段时间,然后重新获取全局锁,检查锁状态.若在全局锁的保护下,发现未来锁集中的锁都未被占据,则执行加锁操作,然后释放全局锁.这样就保证了规避逻辑的正确性.此外,为规避互斥锁自锁和读写锁自锁,当Flider检查发现未来锁集中的锁已被当前线程占据时,就将当前加锁操作和后续执行中的相应解锁操作视为空操作.
Table 1 Lock  Unlock Operations on Mutual Exclusive Locks and Read Write Locks
Unlock Operations on Mutual Exclusive Locks and Read Write Locks
表1 读写锁和互斥锁加锁解锁操作

LockTypeLock∕UnlockOperationspthread_mutex_tintpthread_mutex_lock(pthread_mutex_t*);intpthread_mutex_trylock(pthread_mutex_t*);intpthread_mutex_timedlock(pthread_mutex_t*,conststructtimespec*);intpthread_mutex_unlock(pthread_mutex_t*).pthread_rwlock_tintpthread_rwlock_rdlock(pthread_rwlock_t*);intpthread_rwlock_tryrdlock(pthread_rwlock_t*);intpthread_rwlock_wrlock(pthread_rwlock_t*)intpthread_rwlock_trywrlock(pthread_rwlock_t*);intpthread_rwlock_timedrdlock(pthread_rwlock_t*,conststructtimespec*);intpthread_rwlock_timedwrlock(pthread_rwlock_t*,conststructtimespec*);intpthread_rwlock_unlock(pthread_rwlock_t*).
5 实验与分析
本节使用表2和表3列出的2个基准程序集和引言部分介绍的Dimmunix [7] ,Grace [10] ,Flock [11] ,Scrider [12] 这4个具有代表性的死锁规避工具,实验回答以下问题.
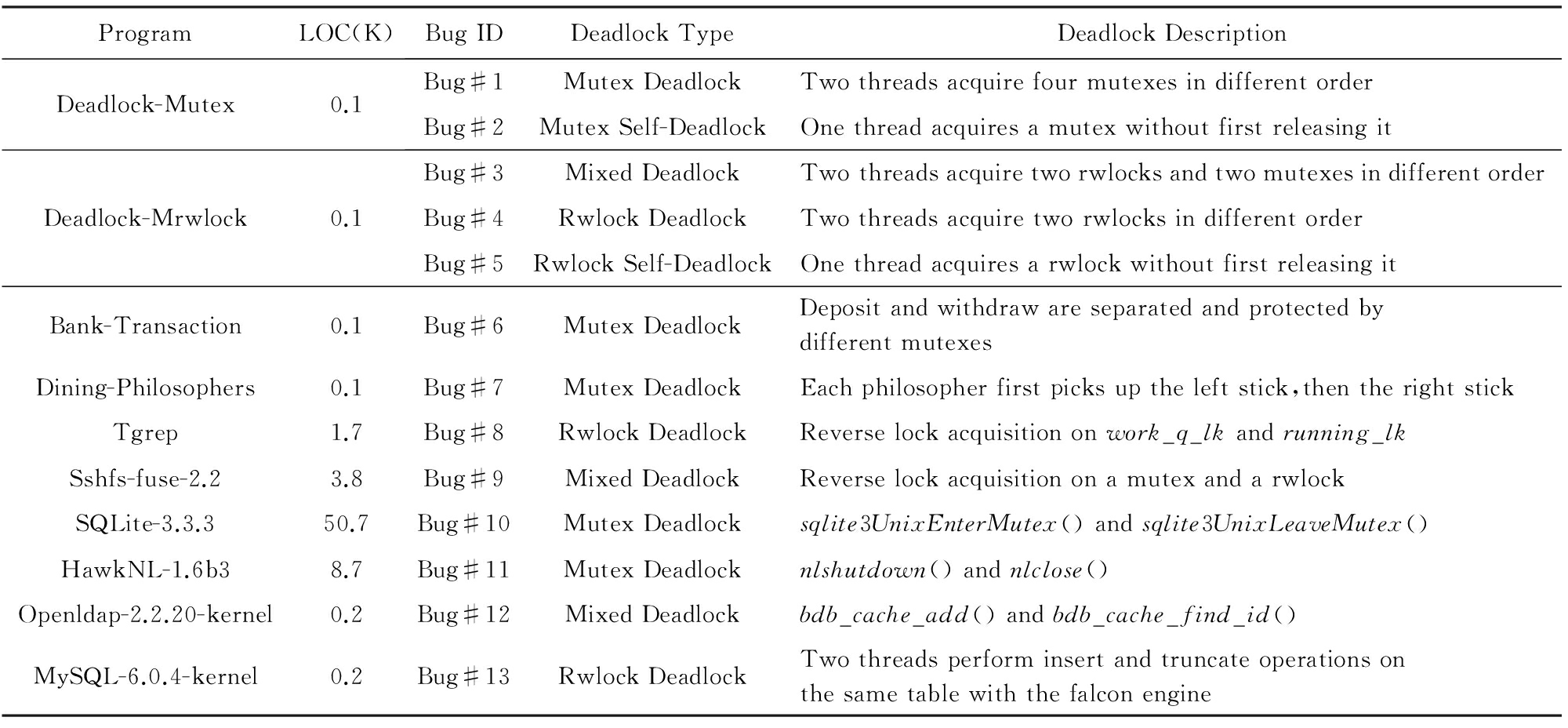
Table 2 The Deadlock Benchmark Composed of Ten May-Deadlock Programs
表2 由10个死锁程序构成的死锁基准程序集
ProgramLOC(K)BugIDDeadlockTypeDeadlockDescriptionDeadlock-Mutex0.1Bug#1MutexDeadlockTwothreadsacquirefourmutexesindifferentorderBug#2MutexSelf-DeadlockOnethreadacquiresamutexwithoutfirstreleasingitBug#3MixedDeadlockTwothreadsacquiretworwlocksandtwomutexesindifferentorderDeadlock-Mrwlock0.1Bug#4RwlockDeadlockTwothreadsacquiretworwlocksindifferentorderBug#5RwlockSelf-DeadlockOnethreadacquiresarwlockwithoutfirstreleasingitBank-Transaction0.1Bug#6MutexDeadlockDepositandwithdrawareseparatedandprotectedbydifferentmutexesDining-Philosophers0.1Bug#7MutexDeadlockEachphilosopherfirstpicksuptheleftstick,thentherightstickTgrep1.7Bug#8RwlockDeadlockReverselockacquisitiononwork_q_lkandrunning_lkSshfs-fuse-2.23.8Bug#9MixedDeadlockReverselockacquisitiononamutexandarwlockSQLite-3.3.350.7Bug#10MutexDeadlocksqlite3UnixEnterMutex()andsqlite3UnixLeaveMutex()HawkNL-1.6b38.7Bug#11MutexDeadlocknlshutdown()andnlclose()Openldap-2.2.20-kernel0.2Bug#12MixedDeadlockbdb_cache_add()andbdb_cache_find_id()MySQL-6.0.4-kernel0.2Bug#13RwlockDeadlockTwothreadsperforminsertandtruncateoperationsonthesametablewiththefalconengine
Table 3 The Deadlock-Free Benchmark Composed of Four Kernel Programs from SPLASH-2
表3 由4个SPLASH-2核心程序组成的基准非死锁程序集

ProgramParameterSetupProgramDescriptionLU(contiguous)-n6144-p1∕2∕4∕8∕16∕32-b16MatrixdecompositionusingDoolittlealgorithmFFT-p1∕2∕4∕8∕16∕32-m24-n65536-14FastFouriertransformationRADIX-p1∕2∕4∕8∕16∕32-n67108864-r8-m524288RadixsortforintegernumbersCHOLESKY-p1∕2∕4∕8∕16∕32-b32-c16384.∕inputs∕tk17.OMatrixdecompositionusingCholeskyalgorithm
问题1. Flider的规避能力如何,即能否主动地规避多种类型的死锁.
问题2. Flider的规避效率如何,即能否高效智能地规避死锁.
问题3. Flider的可扩展性如何,即能否在线程数目指数级增长情况下,其规避开销保持平稳增长.
5.1 死锁基准程序集和非死锁基准程序集
为回答问题1和2,本节使用的死锁基准程序集由作者编写的2个含有多个不同类型死锁的程序与在死锁检测和死锁规避领域 [7,11,14] 广泛使用的8个死锁程序构成,如表2所示.由于死锁缺陷在正常情况下难以暴露,我们在这10个程序的关键代码点插入 sleep ()语句,以影响程序的线程调度和执行路径,使得死锁以几乎100%的概率被触发.
表2列出死锁程序的规模、死锁程序中包含的死锁缺陷、死锁缺陷的具体类型和死锁缺陷的发生原因或触发场景.Deadlock-Mutex和Deadlock-Mrwlock是作者自己编写的死锁程序,分别包含2个和3个不同种类的死锁缺陷;Bank-Transaction,SQLite-3.3.3,Dining-Philosophers,HawkNL-1.6b3各自包含一个互斥锁死锁缺陷;Tgrep和MySQL-6.0.4-kernel则各自包含一个读写锁死锁缺陷;Openldap-2.2.20-kernel和Sshfs-fuse-2.2各自包含一个混合死锁缺陷.我们使用Bug#12和Bug#13模拟真实死锁缺陷MySQL#37080 ① http://bugs.mysql.com/bug.php?id=37080 和OpenLDAP#3494 ② http://www.openldap.org/lists/openldap-bugs/200501/msg00101.html ,故包含这2个缺陷的程序MySQL-6.0.4-kernel和Openldap-2.2.20-kernel程序规模较小.
为回答问题2和3,本节使用的非死锁基准程序集由4个SPLASH-2 ③ http://www.capsl.udel.edu/splash/,http://kbarr.net/splash2 核心程序构成.表3给出各个程序的简要描述和在实验中使用的参数设置.
5.2 实验环境与死锁规避工具
所有评测和对比实验在下列实验环境下进行:Intel Core i5 M430 2.27 GHz CPU,6 GB内存,Ubuntu 14.04 32位操作系统,Clang-3.6和Gcc-4.9.1编译器.
为评价Flider的死锁规避能力、死锁规避效率和可扩展性,使用表4中死锁规避工具监视表2和表3中程序运行.之所以选用Dimmunix,Grace,Flock,Slider这4个死锁规避工具,是因为它们代表了死锁规避领域的最新水平,且源码开放,能在我们的实验环境下编译运行.Sammati [9] 源码开放,但只能在64位操作系统下编译运行,我们的实验环境不支持.虽然没有使用Sammati做对比实验,但根据文献[9]可知,Sammati只能规避互斥锁死锁.
Table 4 Deadlock Avoidance Tools Used in Our Experiments
表4 实验中使用的死锁规避工具
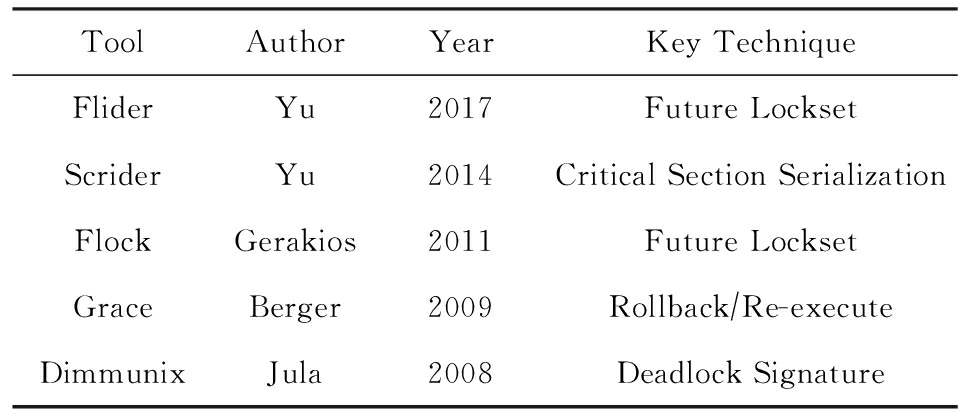
ToolAuthorYearKeyTechniqueFliderYu2017FutureLocksetScriderYu2014CriticalSectionSerializationFlockGerakios2011FutureLocksetGraceBerger2009Rollback∕Re-executeDimmunixJula2008DeadlockSignature
5.3 问题1:Flider死锁规避能力
为评价Flider的死锁规避能力,按如下步骤进行实验:1)分别在Flider,Scrider,Dimmunix,Grace,Flock下运行表2中的各个死锁程序,每个死锁程序在每个规避工具下运行30次;2)针对一个死锁缺陷,如果某个工具在30次运行中只要有一次没有成功规避该缺陷,则认为该工具不能规避该缺陷;3)统计每个工具对每个死锁缺陷的规避结果.
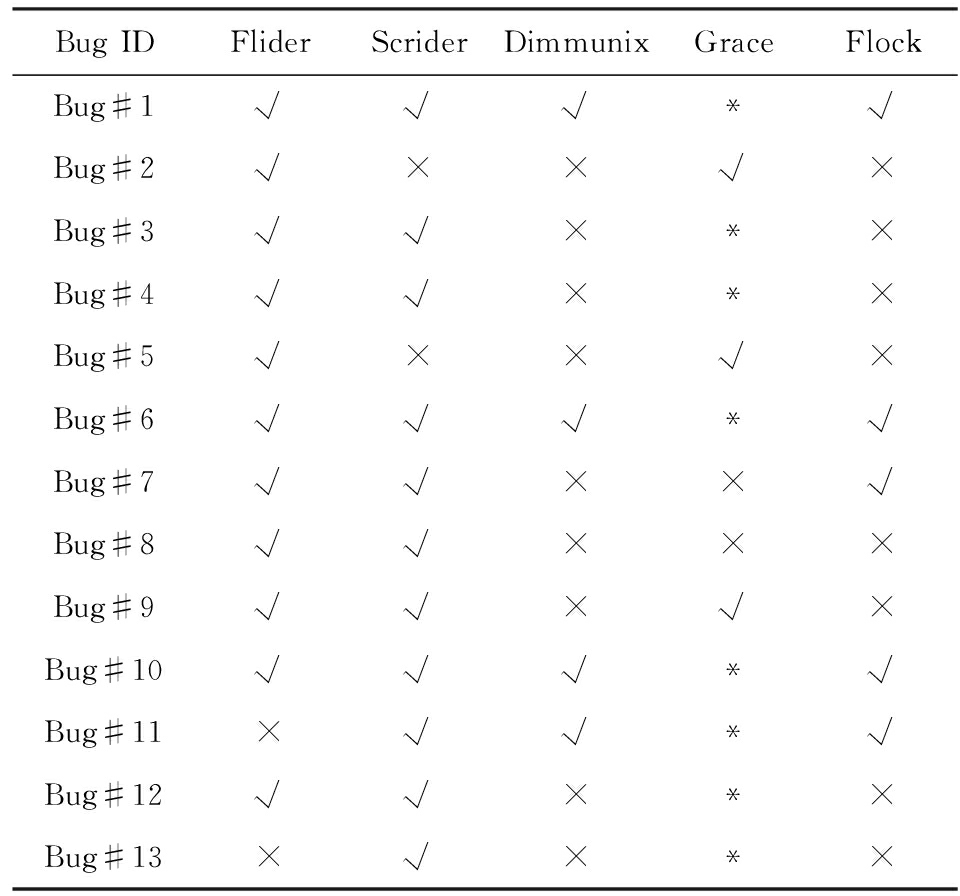
实验结果如表5所示,其中√表示规避成功,×表示规避失败,*表示规避成功但输出错误.针对所有13个不同类型的死锁缺陷,Flider,Scrider,Grace各自成功规避其中11个,Flock成功规避5个,Dimmunix只成功规避了4个.
Table 5 Deadlock Avoiding Results of Five Avoidance Tools
on The Deadlock Benchmark
表5 5个死锁规避工具在死锁基准程序集上的规避结果
BugIDFliderScriderDimmunixGraceFlockBug#1√√√*√Bug#2√××√×Bug#3√√×*×Bug#4√√×*×Bug#5√××√×Bug#6√√√*√Bug#7√√××√Bug#8√√×××Bug#9√√×√×Bug#10√√√*√Bug#11×√√*√Bug#12√√×*×Bug#13×√×*×
Note: √,Succeed;×,Fail;*,Wrongly Output
各个死锁规避工具的规避结果基本符合预期.Scrider成功规避了除互斥锁自锁(Bug#2)和读写锁自锁(Bug#5)的所有类型死锁.Dimmunix和Flock只能规避互斥锁死锁(Bug#1,Bug#6,Bug#7,Bug#10,Bug#11),其他类型死锁都不能规避.但令人惊奇的是,与文献[7]相悖,Dimmunix没有能够规避互斥锁死锁缺陷Bug#7.Bug#7是程序Dining-Philosophers中的一个简单互斥锁死锁,当5个哲学家不停地进餐 思考,并在进餐时每个哲学家(用线程模拟)都先拿到左手边筷子(用互斥锁模拟)再去拿右手边筷子时,Bug#7就会发生.Bug#7涉及5个线程和5个互斥锁,每个线程都占据一个互斥锁并请求另一个线程占据的互斥锁.我们仔细检查了Dimmunix的源码,发现其用于存储加锁解锁事件的无锁队列实现错误,这一错误可能导致某些加锁解锁事件丢失,从而Dimmunix不能察觉到构成死锁的条件正在一个个发生,更不能控制线程调度以规避将要发生的死锁.
Grace使用回滚 重新执行技术虽能成功规避11个死锁缺陷,但在规避其中8个死锁时,由于不能回滚IO操作,导致包含死锁的程序输出发生错误,影响了程序正确性.此外,Grace不能规避Bug#7和Bug#8.对于Bug#7,原因可能是由于参与到Bug#7中的5个线程频繁读写共享变量,Grace未能成功隔离对共享变量的修改而导致回滚时使程序进入到一个非法状态;对于Bug#8,原因是由于参与到Bug#8中的线程使用条件变量进行同步,而Grace不能处理条件变量操作.
Flider成功规避了除Bug#11和Bug#13外的所有死锁,其规避能力与Scrider相当.Flider不能规避这2个缺陷是因为不精确的过程内锁效应计算和插桩会导致Flider“看不到”某些本来应该属于未来锁集中的锁.例如,Bug#11和Bug#13可以抽象为如图11所示的代码,由于静态阶段没有进行过程间分析,Flider为 f 1 ()的 lock ( x )计算出的锁效应是{ x -},实际上,线程 T 1 在执行 lock ( x )后还会调用 g 1 ()进而执行 lock ( y ).对于 f 2 ()中的 lock ( y )也存在这样的情况.由于锁效应信息不准确,Flider为加锁操作计算出的未来锁集也不准确.当 T 1 执行 lock ( x )时,Flider为其计算的未来锁集是{ x }, x 此时未被占用,故Flider允许 T 1 执行 lock ( x )并占据 x .当 T 2 执行 lock ( y )时,Flider也允许其执行并占据 y .这样当程序继续执行时,死锁必定会发生,而且不能被Flider规避掉.

Fig. 11 A deadlock example that Flider fails to avoid
图11 一个Flider不能规避的死锁例子
虽然存在以上不足,但从死锁规避数量、死锁规避类型方面评价,Flider的死锁规避能力在5个规避工具中是最高的.Flider能规避所有5种类型的死锁缺陷,而Scrider和Flock分别只能规避3种和1种类型的死锁缺陷.Flider主动规避死锁,在Flider的规避逻辑下,死锁不可能发生,而Dimmunix则只有在死锁发生后才能规避死锁.Flider允许执行的每个加锁操作都是安全的,因此无需回滚程序执行,也就不会造成输出错误.只要目标程序不包含如图11所示的死锁缺陷,则Flider不会对目标程序正确性造成影响.
5.4 问题2:Flider死锁规避效率
为评价Flider的死锁规避效率,对比分析多个规避工具在死锁程序集和非死锁程序集上的规避开销.
1) Flider和Flock在死锁程序集上的静态分析效率对比
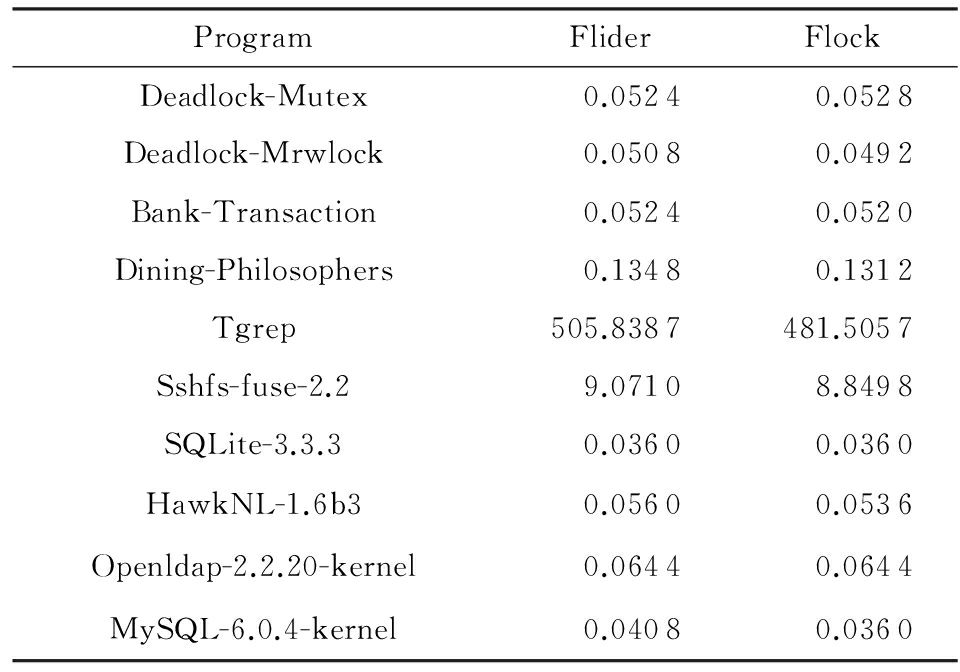
由于Flider和Flock在进行动态规避之前,需要先进行源码分析以计算锁效应信息和插桩代码将锁效应信息传递给动态规避逻辑,因此在对比分析规避工具的动态规避开销之前,使用Flider和Flock对死锁程序集中的每个程序分别进行10次静态分析(即锁效应计算和代码插桩),统计得到平均分析时间,如表6所示:
Table 6 Comparison in Static Analysis Efficiency of Flider and Flock on Ten Deadlock Programs
表6 Flider和Flock在死锁程序集上静态分析效率 s
ProgramFliderFlockDeadlock-Mutex0.05240.0528Deadlock-Mrwlock0.05080.0492Bank-Transaction0.05240.0520Dining-Philosophers0.13480.1312Tgrep505.8387481.5057Sshfs-fuse-2.29.07108.8498SQLite-3.3.30.03600.0360HawkNL-1.6b30.05600.0536Openldap-2.2.20-kernel0.06440.0644MySQL-6.0.4-kernel0.04080.0360
在表6中,由于只对SQLite-3.3.3和HawkNL-1.6b3中涉及到死锁的文件进行静态分析,因此Flider和Flock对这2个程序很快完成了锁效应计算和插桩.Flider和Flock对Tgrep和Sshfs-fuse-2.2的静态分析耗费时间较长,是由于其中存在具有大量条件分支语句的函数,而路径敏感的算法1在这种情况下会逐条遍历每条路径,导致静态分析速度变慢.另外,从表6中还可以看出,对于只含有互斥锁死锁的程序,如SQLite-3.3.3等,Flider和Flock的静态分析时间相同,而对于含有读写锁死锁或者混合死锁的程序,如Tgrep,Flider的分析时间一般较Flock长,因为针对这些程序,Flider不仅要为互斥锁加锁操作计算锁效应和插桩,也要为读写锁加锁操作进行锁效应分析.根据表6,只要并发程序中的函数不具有过分巨大的条件分支,如一个函数中含有50个以上的分支条件,则Flider会在合理时间内完成静态分析.
2) 多个规避工具在死锁程序集上的规避效率
统计Flider,Scrider,Grace在规避Bug#1,Bug#3,Bug#4,Bug#6,Bug#9,Bug#10,Bug#12时,包含这些死锁缺陷的程序Deadlock-Mutex,Deadlock-Mrwlock,Bank-Transaction,Sshfs-fuse-2.2,SQLite-3.3.3,Openldap-2.2.20-kernel的运行时间.我们没有选用Dimmunix和Flock是因为Dimmunix不能在线规避死锁,规避效率较差,且Dimmunix和Flock规避死锁数量和类型都较少.另外,我们修改Deadlock-Mutex以保证其执行时Bug#2不会发生,对Deadlock-Mrwlock也做了类似修改.
用箱式图统计分析各个工具在各个程序上的规避时间,如图12所示.对所有6个程序中的4个,即Deadlock-Mrwlock,Deadlock-Mutex,SQLite-3.3.3,Openldap-2.2.20-kernel,Flider的规避时间都比Scrider小,其中对Deadlock-Mrwlock,Scrider的平均规避时间甚至达到了Flider的53倍.Grace的规避开销较小,对所有6个程序中的3个,即SQLite-3.3.3,Deadlock-Mutex,Openldap-2.2.20-kernel,Grace的规避时间是3个工具中最小的,但Grace在规避过程中造成6个程序中的5个,即Deadlock-Mutex,Deadlock-Mrwlock,SQLite-3.3.3,Bank-Transaction,Openldap-2.2.20-kernel,输出错误.
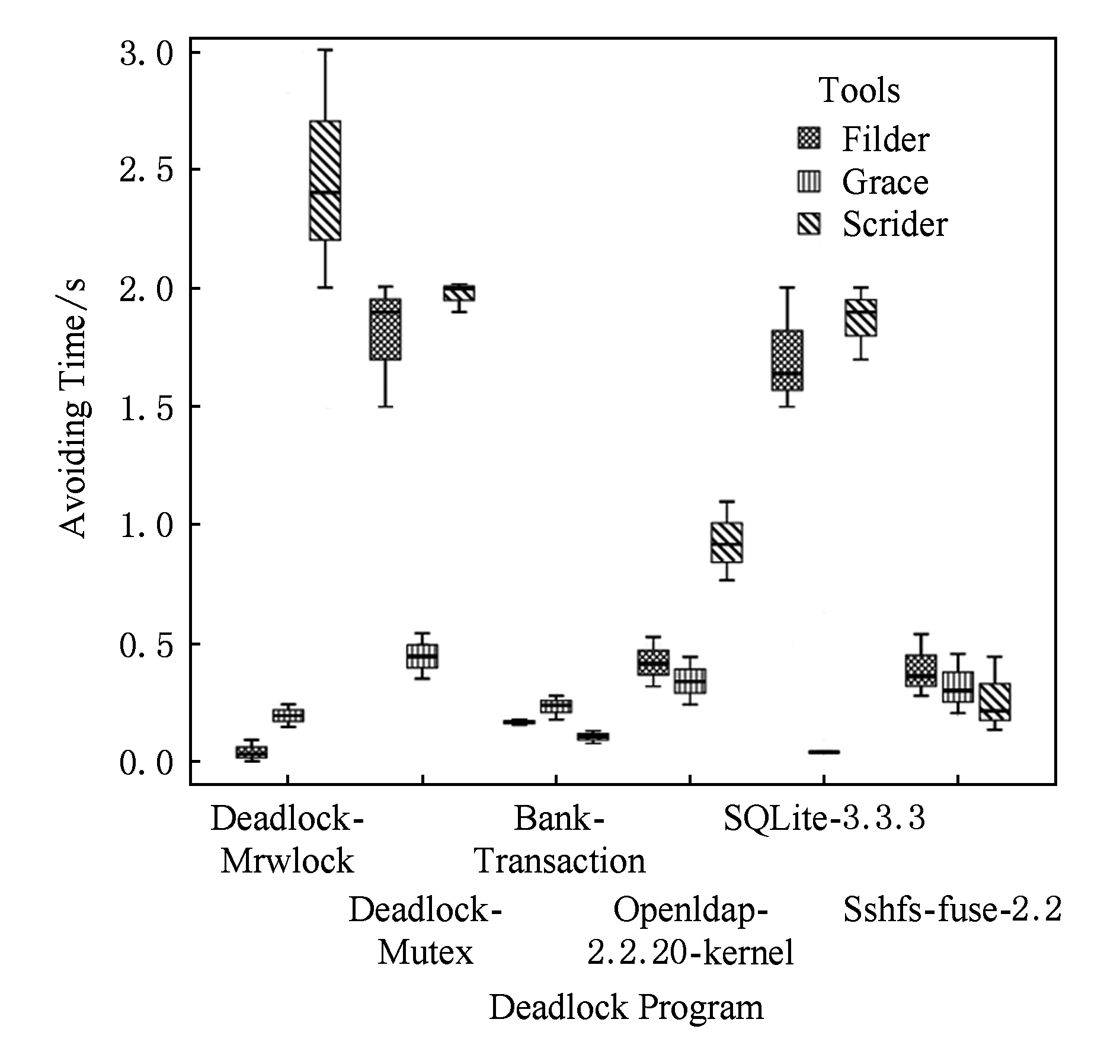
Fig. 12 Comparison in avoiding efficiency of three toolson six deadlock programs
图12 3个规避工具在6个死锁程序上的规避效率对比
另外,对所有6个程序中的4个,即Deadlock-Mrwlock,Bank-Transaction,Sshfs-fuse-2.2,Openldap-2.2.20-kernel,Flider的规避开销与Grace相近,平均约是Grace的0.85倍.图12还直观地反映出3个工具的稳定性:Grace的稳定性较好,Flider稳定性一般,Scrider稳定性较差.
根据表5可知,Flider和Flock都能规避的死锁缺陷是Bug#1,Bug#6,Bug#7,Bug#10.我们对比Flider和Flock对包含这些死锁缺陷的并发程序的规避开销,如表7所示.从表7中可以看出,Flider和Flock对这4个死锁缺陷的平均、最大和最小规避开销在数值上几乎相同,而在百分比上平均规避开销差异在-9.1%~6%之间,最大规避开销差异在0~12.5%之间,最小规避开销在0.2%~14.3%之间.Flider和Flock对这4个死锁缺陷的规避开销相差很小,是因为这4个死锁都是互斥锁死锁,而且包含这4个死锁缺陷的并发程序只调用互斥锁函数进行加锁解锁操作,这就使得Flider和Flock进行的静态分析(包括锁效应计算和代码插桩)完全一样,进而导致并发程序执行的规避逻辑完全一样.这样,Flider和Flock对每个死锁缺陷的规避开销就几乎相同.
Table 7 Comparison in Avoiding Efficiency of Flider and Flock on Four Deadlock Programs
表7 Flider和Flock在4个死锁程序上规避效率对比 s
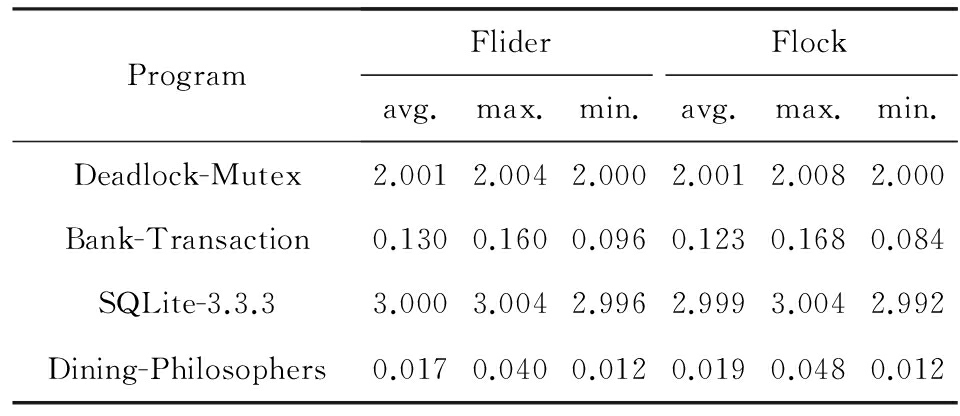
ProgramFliderFlockavg.max.min.avg.max.min.Deadlock-Mutex2.0012.0042.0002.0012.0082.000Bank-Transaction0.1300.1600.0960.1230.1680.084SQLite-3.3.33.0003.0042.9962.9993.0042.992Dining-Philosophers0.0170.0400.0120.0190.0480.012
3) 多个规避工具在非死锁程序集上的规避效率
实验方法:①分别在Flider和Scrider下运行表3中的4个非死锁程序各30次,每个程序的线程数目参数设置为2;②记录每个程序的运行时间并求平均值.由于4个非死锁程序存在使用共享变量进行线程间通信的情况,用Grace对它们进行规避可能导致活锁,因此本实验不选用Grace.实验结果如图13所示.
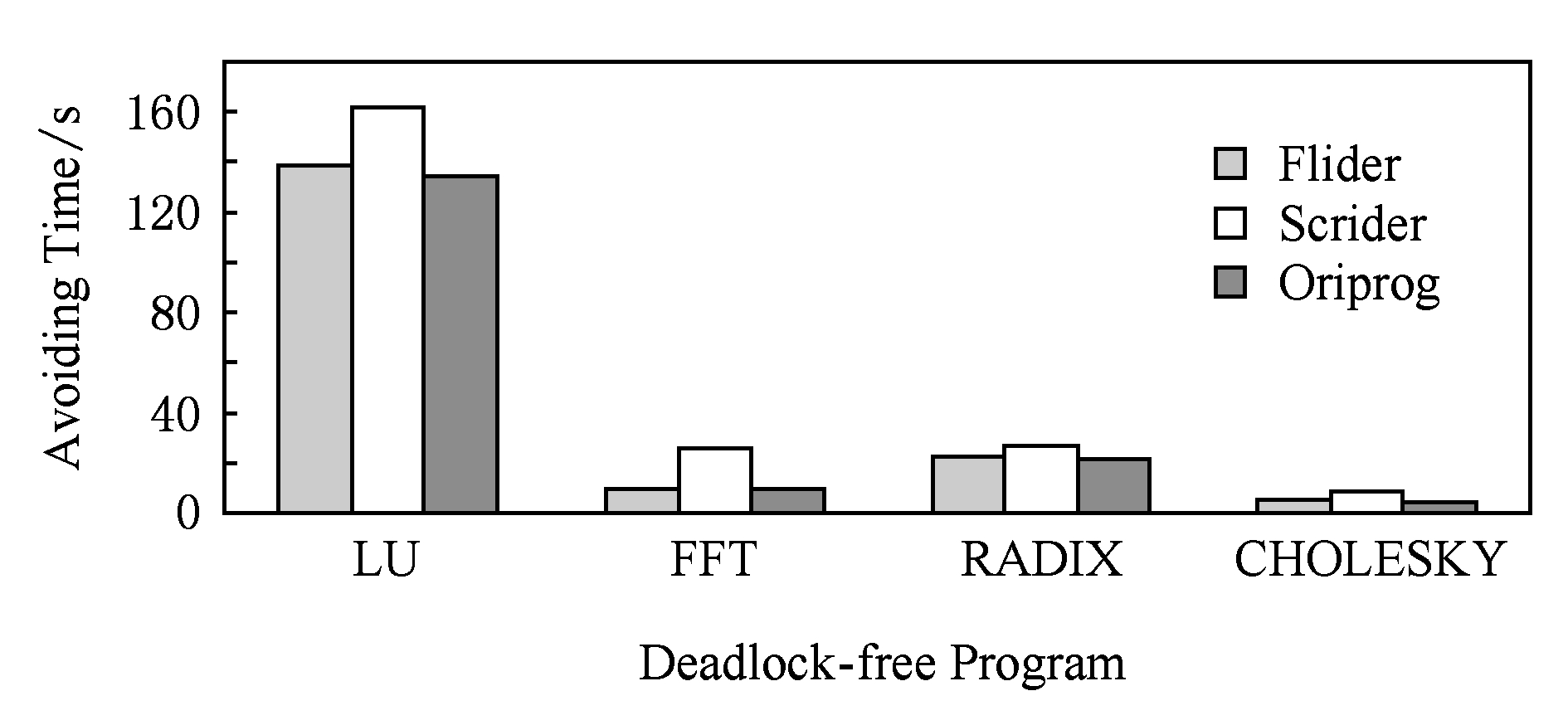
Fig. 13 Comparison in avoiding efficiency of two tools on four deadlock-free programs
图13 2个规避工具在4个非死锁程序上的规避效率对比
Flider分别对LU,FFT,RADIX,CHOLESKY造成3.6%,-0.1%,3.0%,21%的性能下降,平均规避开销是6.9%;而Scrider分别对上述4个程序造成20.5%,178.7%,25.7%,100.5%的性能下降,平均规避开销是81.4%.相比来说,Flider对目标程序的性能影响较微小,而Scrider几乎使目标程序的运行速度变慢为原来的1 2.这2个工具都采用串行关键区的方法来规避死锁,但与Flider不同,由于没有锁效应信息的辅助,Scrider串行所有的关键区,不论关键区之间是否可能造成死锁,这种盲目的方法使得Scrider的规避开销急剧上升.Flider只串行可能导致死锁的关键区,而不影响绝大部分关键区的并行执行,这种智能的方法大大降低了其规避开销.
综上,Flider对死锁程序集和非死锁程序集的规避开销都较低,且能高效智能地规避死锁程序集中的死锁缺陷.
5.5 问题3:Flider死锁规避可扩展性
为评价Flider的死锁规避可扩展性,按如下步骤进行实验:1)在线程数目参数设置为1,2,4,8,16,32的情况下,分别在Flider和Scrider下运行表3中的各个非死锁程序30次;2)记录并计算每个程序在每个工具下对每个线程数目参数设置的平均运行时间.
实验结果如图14所示.对LU,当线程数目从1增加到32时,Flider的开销在4.6%~9.7%之间,而Scrider的开销则在13.0%~38.4%之间.对FFT,当线程数目从2增加到16时,Flider的开销从1.2%增加到4.8%,而Scrider的开销从50%迅速增加到195%.对CHOLESKY,当线程数目从1增加到32时,Flider的开销在16%~85.3%之间,而Scrider的开销在100.5%~802.0%之间,虽然两者的开销变化都较大,但在特定的线程数目时,Flider对目标程序的开销相对Scrider很小.对RADIX,Flider和Scrider的规避开销与对其他3个程序的开销类似.
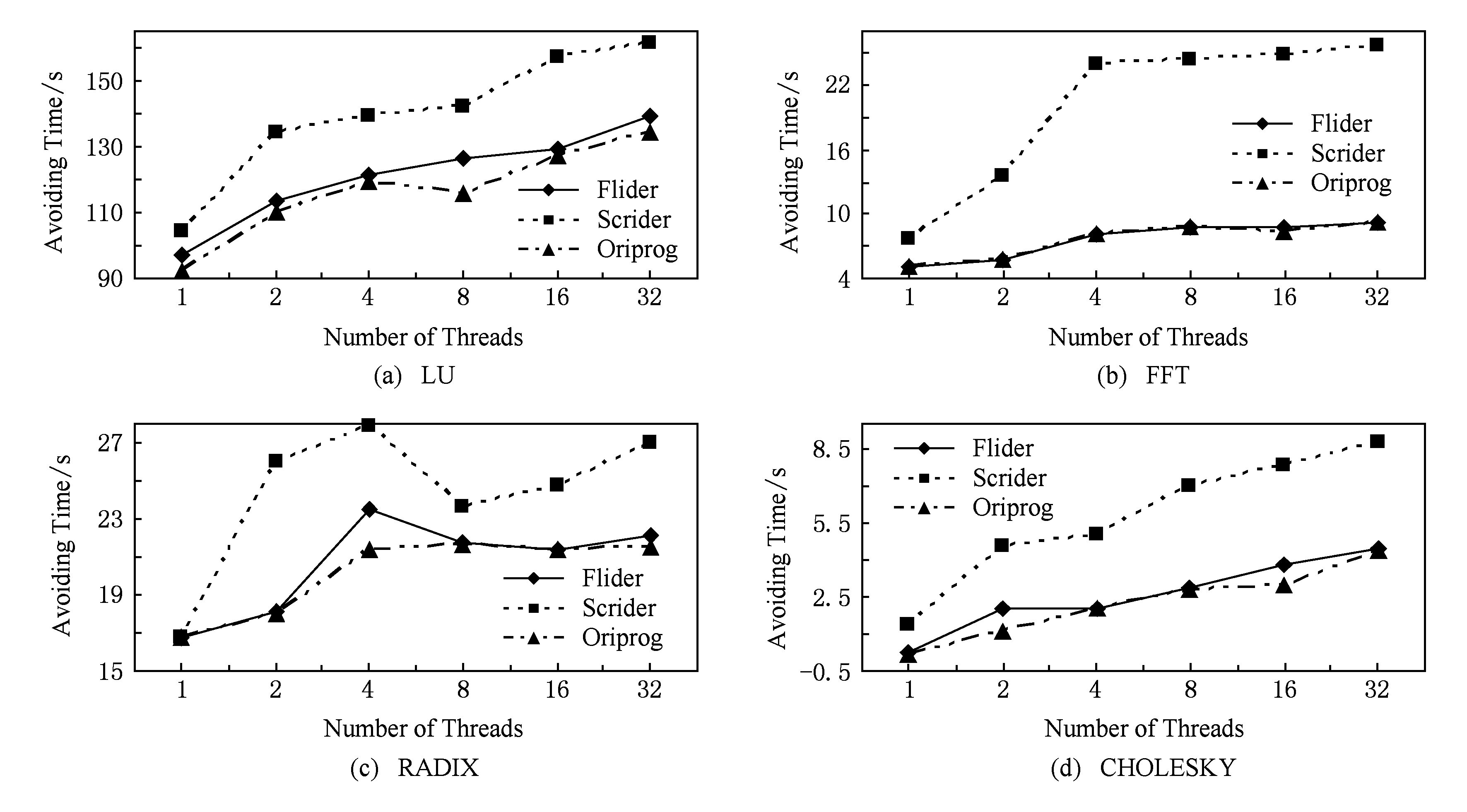
Fig. 14 Comparison in avoiding efficiency of two tools on four deadlock-free programs
图14 2个规避工具在4个非死锁程序上的规避效率对比
因此,从图14中4个折线图可以看出,总体上,随着线程数目指数增长,Flider的规避开销总体保持平稳增长;而Scrider对线程数目的变化较敏感,其规避开销随线程数目的增多而迅速增加.
6 结 论
现有动态规避方法存在能力有限、被动盲目、开销较大和影响目标程序正确性等问题,为解决这些问题,本文提出一种动静结合的基于未来锁集的死锁规避方案Flider.首先形式化描述该方案并在理论上证明该方案的正确性;然后从3个方面,即过程内控制流图建立、路径敏感的锁效应计算与插桩和未来锁集计算与规避逻辑执行,来具体介绍该方案的实现细节;最后进行测评和对比实验,回答以下3个研究问题:
1) 与问题1相关的实验中,Flider主动规避了所有13个死锁缺陷中的11个(这11个死锁缺陷分别属于5种不同类型的死锁),且在规避所有11个死锁缺陷时,没有对目标程序的正确性造成影响.实验结果表明Flider能主动规避多种类型的死锁,且不会影响目标程序的正确性.
2) 与问题2相关的实验中,Flider借助于静态时插桩的锁效应信息,智能地只串行化可能发生死锁的关键区,在执行规避逻辑时对目标程序造成的影响小.实验结果表明Flider能智能高效地规避死锁.
3) 与问题3相关的实验中,Flider在目标程序线程数目从1指数级增长到32时,规避开销的增长相对于线程数目的增长较平稳.实验结果表明Flider的可扩展性良好.
综上所述,本文提出的死锁规避方案达到了 “智能、主动、高效地规避多种类型死锁,不影响程序正确性”的研究目标.
参考文献:
[1]Agarwal R, Stoller S D. Runtime detection of potential deadlocks for programs with locks, semaphores and conditional variables[C] //Proc of the 2006 Workshop on Parallel and Distributed Systems: Testing and Debugging. New York: ACM, 2006: 51-60
[2]Wang Zhaofei, Huang Chun. Static detection of deadlocks in OpenMP Fortran programs[J]. Journal of Computer Research and Development, 2007, 44(3): 536-543 (in Chinese)(王昭飞,黄春. OpenMP Fortran程序中死锁的静态检测[J]. 计算机研究与发展, 2007, 44(3): 536-543)
[3]Shimomura T, Ikeda K. Two types of deadlock detection: Cyclic and acyclic[J]. Intelligent Systems for Science and Information, 2014, 54(2): 233-259
[4]Fonseca P, Li C, Singhal V, et al. A study of the internal and external effects of concurrency bugs[C] //Proc of the 2010 IEEE/IFIP Int Conf on Dependable Systems and Networks (DSN). Piscataway, NJ: IEEE, 2010: 221-230
[5]Lu S, Park S, Seo E, et al. Learning from mistakes: A comprehensive study on real world concurrency bug characteristics[J]. ACM SIGARCH Computer Architecture News, 2008, 36(1): 329-339
[6]Su Xiaohong, Yu Zhen, Wang Tiantian, et al. A survey on exposing, detecting and avoiding concurrency bugs[J]. Chinese Journal of Computers, 2015, 38(11): 2215-2233 (in Chinese)(苏小红, 禹振, 王甜甜, 等. 并发缺陷暴露、检测与规避研究综述[J]. 计算机学报, 2015, 38(11): 2215-2233)
[7]Jula H, Tralamazza D M, Zamfir C, et al. Deadlock immunity: Enabling systems to defend against deadlocks[C] //Proc of the 8th USENIX Symp on Operating Systems Design and Implementation. Berkeley, CA: USENIX, 2008: 295-308
[8]Nir-Buchbinder Y, Tzoref R, Ur S. Deadlocks: From exhibiting to healing[C] //Proc of the 8th Int Conf on Runtime Verification. Berlin: Springer, 2008: 104-118
[9]Pyla H K, Varadarajan S. Avoiding deadlock avoidance[C] //Proc of the 19th Int Conf on Parallel Architectures and Compilation Techniques. New York: ACM, 2010: 75-86
[10]Berger E D, Yang T, Liu T, et al. Grace: Safe multithreaded programming for C/C++[J]. ACM SIGPLAN Notices, 2009, 44(10): 81-96
[11]Gerakios P, Papaspyrou N, Sagonas K. A type and effect system for deadlock avoidance in low-level languages[C] //Proc of the 7th ACM SIGPLAN Workshop on Types in Language Design and Implementation. New York: ACM, 2011: 15-28
[12]Yu Zhen, Su Xiaohong, Ma Peijun. Scrider: Using single critical sections to avoid deadlocks[C] //Proc of the 4th IEEE Int Conf on Instrumentation and Measurement, Computer, Communication and Control. Piscataway, NJ: IEEE, 2014: 1000-1005
[13]Necula G C, McPeak S, Rahul S P, et al. CIL: Intermediate language and tools for analysis and transformation of C programs[C] //Proc of the 11th Int Conf on Compiler Construction. Berlin: Springer, 2002: 213-228
[14]Wang Y, Kelly T, Kudlur M, et al. Gadara: Dynamic deadlock avoidance for multithreaded programs[C] //Proc of the 8th USENIX Symp on Operating Systems Design and Implementation. Berkeley, CA: USENIX, 2008: 281-294
Yu Zhen, born in 1987. PhD candidate in the School of Computer Sience and Technology at Harbin Institute of Technology (HIT). Student member of CCF. His main research interests include software static or dynamic analysis, implicit rules mining from large-scale software and concurrency bug (including deadlock, data race and atomicity violation) detection and avoidance.
Su Xiaohong, born in 1966. Professor and PhD supervisor in the School of Computer Science and Technology at HIT. Senior member of CCF. Her main research interests include software engineering, information fusion, image processing and computer graphics.
Qi Peng, born in 1990. Master in the School of Computer Science and Technology at HIT. His main research interests include software engineering and deadlock bug detection  avoidance (qipengsemail@163.com).
avoidance (qipengsemail@163.com).
Ma Peijun, born in 1963. Professor and PhD supervisor in the School of Computer Science and Technology at HIT. His main research interests include software engineering, information fusion, image processing, embedded system simulation, and so on (ma@hit.edu.cn).
Deadlock Avoiding Based on Future Lockset
Yu Zhen, Su Xiaohong, Qi Peng, and Ma Peijun
( School of Computer Science and Technology , Harbin Institute of Technology , Harbin 150001)
Abstract: Existing dynamic methods for deadlock avoidance have four main drawbacks: limited capability, passive or blind avoiding algorithm, large performance overhead and no guarantee of correctness of target programs. In order to solve these problems, a combined static and dynamic avoiding method based on future lockset is proposed and named as Flider. The key idea is that, for a lock operation, if none of its future locks are occupied, then it makes sure that executing this lock operation won’t lead the current thread to trap into a deadlock state. The future lockset for a lock operation is a set of locks that will be requested by the current thread before the corresponding unlock operation is reached. Firstly, Flider statically computes lock effects for lock operations and function call operations, and inserts them before and after the corresponding operations. Secondly, Flider dynamically intercepts lock operations and computes its future lockset using lock effects inserted by static analysis. Flider permits a lock operation to be executed if and only if all locks of its lockset are not held by any other threads. Otherwise, the lock operation waits until the condition is satisfied. Evaluation and comparison experiments verify that this method can efficiently avoid multi-type deadlocks in an active, intelligent, scalable and correctness-guaranteed way.
Key words: concurrency bugs; concurrent testing; deadlock bugs; deadlock detection; deadlock avoidance; future lockset
收稿日期: 2015-07-29
修回日期: 2016-12-22
基金项目: 国家自然科学基金项目(61173021) This work was supported by the National Natural Science Foundation of China (61173021).
通信作者: 苏小红(sxh@hit.edu.cn)
中图法分类号: TP311




