
Fig. 1 Clustered superscalar processor microarchitecture
图1 分簇超标量处理器微结构
刘炳涛1,2,3王 达1叶笑春1范东睿1,2张志敏1唐志敏1
1(计算机体系结构国家重点实验室(中国科学院计算技术研究所) 北京 100190)
2(中国科学院大学计算机与控制学院 北京 100049)
3(杭州电子科技大学信息与控制研究所 310018)
(liubingtao@ict.ac.cn)
摘要分簇超标量处理器将硬件资源分区来避免大的单体部件导致的功耗与周期惩罚,动态多核处理器融合多个物理核的硬件资源提供适应程序需求的计算能力,这些结构合理使用空间分布的硬件资源实现高能效的计算.空间分区结构中指令负载不均衡和跨区操作数传递延迟等问题可导致性能惩罚,需要有效的指令调度方法将计算在分区间进行分布.提出了基于数据流块(data-flow block, DFB)的空间指令调度方法.DFB是动态构建、缓存并重用的一个或数个顺序执行的指令基本块的调度模式.DFB调度算法建模动态指令流中的数据流约束和硬件资源定义的调度空间,然后根据指令量化的相对关键性完成调度决策.介绍了DFB调度的微结构框架和算法.通过对分区数、分区间延迟和调度窗口容量等与调度方法密切相关的微结构参数的实验,证明了DFB调度的性能和稳定性优于负载均衡调度和基于依赖的调度.最后举例证明结合一种数据流块缓存实现的DFB调度达到的调度效果接近理想化的DFB调度.
关键词处理器微结构;负载均衡;指令调度;数据流;关键路径
超标量处理器发掘指令级并行性(instruction level parallelism, ILP)的能力随着发射宽度和调度窗口的增大而提升,然而发射队列和操作数传递网络等关键部件的复杂度随着发射宽度和调度窗口的增大呈平方增长的趋势[1].分簇超标量处理器[2]将硬件资源分区来避开大的单体部件带来的功耗与周期惩罚.如图1所示,分簇超标量处理器负责完成指令执行的流水线后端划分为多个区,各分区有独立的发射队列、物理寄存器文件和功能单元,跨分区传递操作数需要额外的周期,我们称之为分区间延迟(inter-partition latency,IPL).
Fig. 1 Clustered superscalar processor microarchitecture
图1 分簇超标量处理器微结构
处理器单核的性能和频率提升受限于结构复杂度和功耗墙[3]等问题,为了提升计算能效,善于发掘线程级并行性(thread level parallelism, TLP)的多核处理器逐渐成为主流[4].但处理器的单线程处理能力仍然重要,Hill与Marty[5]指出,依据阿姆达法则,随着并行部分的加速,串行部分逐渐成为继续降低程序运行时间的瓶颈.动态多核处理器(dynamic multi-core, DMC)[5]融合数个物理核的资源来提供适应需求的计算能力.如图2所示,含8个物理核的DMC处理器可以提供相当于2个或4个物理核计算能力的虚拟核.物理核有独立的硬件资源,虚拟核内跨越物理核边界传递操作数也存在IPL.
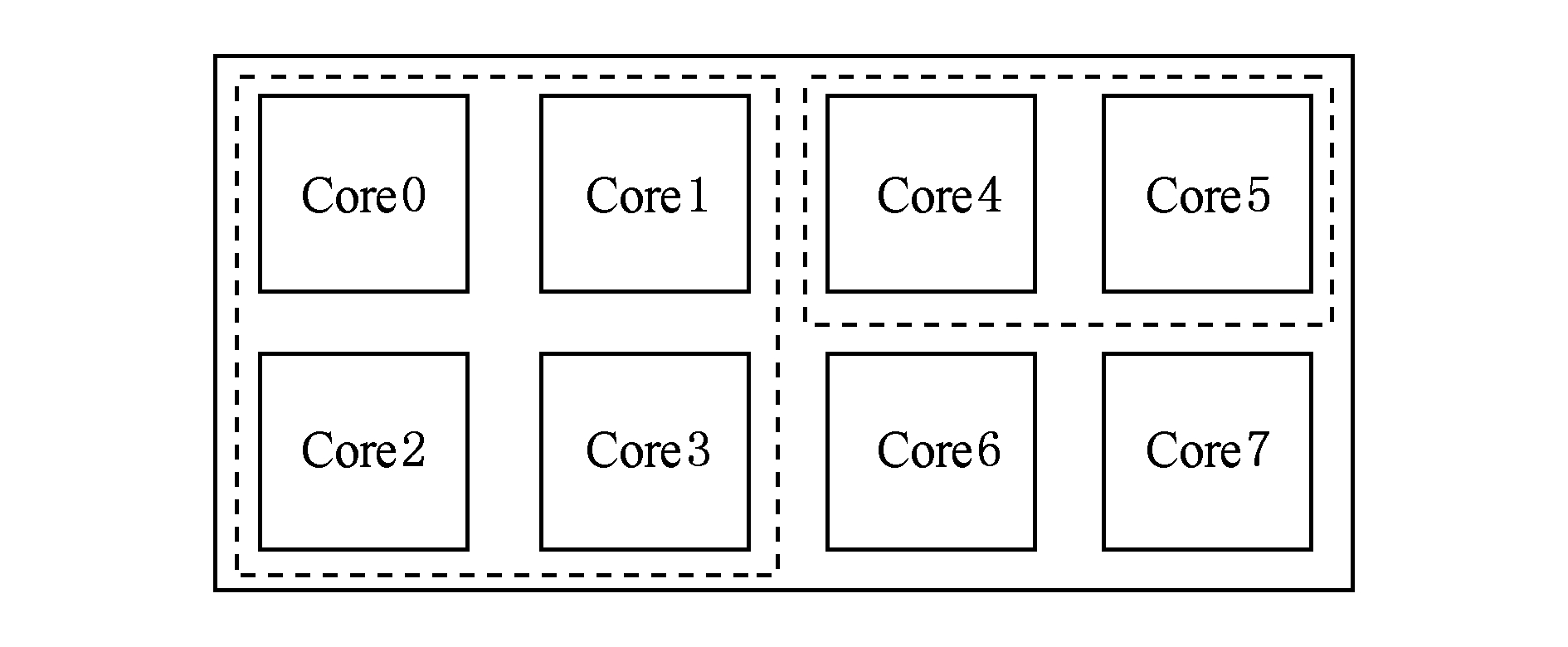
Fig. 2 Dynamic multi-core processor microarchitecture
图2 动态多核处理器微结构
超标量处理器采用同时多线程技术(simultaneous multithreading, SMT)[6]可以发掘TLP.SMT技术在单核中发掘TLP,DMC技术在多核中发掘ILP.殊途同归,它们都是通过合理使用在空间分布的硬件资源实现高能效计算.分区结构能以较低功耗与周期开销提供可扩展的计算能力,但负载不均衡和IPL可能导致性能惩罚,分区结构需要有效的指令调度方法分布指令到各分区.负载均衡倾向于将指令分布到不同分区,而减少IPL惩罚则倾向于将指令根据依赖关系分布到同一分区,存在冲突的策略需要根据指令的关键性进行权衡决策,这就是空间指令调度问题.
为解决空间指令调度问题,我们提出了基于数据流块(data-flow block,DFB)的空间指令调度方法,简称DFB调度.DFB是动态构建、缓存并重用的一个或数个顺序执行的指令基本块的调度模式.DFB调度算法用数据流约束模型描述动态指令序列中的依赖关系,用调度空间模型描述硬件资源约束,量化分析每条指令的调度裕量,根据指令间的相对关键性完成调度决策,生成周期跨度尽量小的调度模式,DFB调度缓存重用这种调度模式.我们介绍了DFB调度的微结构框架和算法.通过对分区数、IPL和调度窗口容量等与调度方法密切相关的微结构参数的实验,我们证明了DFB调度的性能和稳定性优于负载均衡调度和基于指令绝对关键性的依赖调度.最后举例证明结合一种数据流块缓存实现的DFB调度达到的调度效果接近理想化的DFB调度.
本文贡献主要存在于3方面:
1) 我们构造了描述指令依赖关系的数据流约束模型并提出了基于量化指标的指令相对关键性的概念;
2) 我们构造了描述分区结构资源限制的调度空间模型并分析了空间指令调度问题;
3) 我们提出了DFB调度并进行了评估.
Palacharla等人[1]研究了发射队列的复杂度与时钟周期的关系,指出随着发射宽度和调度窗口增大,唤醒和选择逻辑成为关键路径.该文提出了多体发射队列,利用分区结构解决超标量处理器可扩展性问题.
指令预调度[7-9]从时间维度调度指令,提升发射队列效率.根据生产者指令执行延迟,指令在预调度窗口内重新排列,然后逐行进入发射队列,这样减少了指令在发射队列内的等待周期数.WIB[10]和Cyclone[11]将阻塞指令从发射队列中暂时取出,也属于时间指令调度.
较多研究[12-15]关注分簇超标量处理器中指令空间调度问题.已有方法首先判断指令是否是关键路径指令,然后做出调度决策,研究重点在于指令关键性的判定.Fields等人[16]通过指令依赖链的长度做出指令关键性预测.Salverda等人[17]通过指令的历史执行信息做出关键性预测.本文提出的DFB调度量化指令的调度裕量并参照硬件资源约束做出调度决策.
动态多核处理器[18-22]通过重构虚拟核的硬件资源来适应计算需求.Core Fusion[18]融合片上多核处理器(chip multi-core processor, CMP)中多个物理核提供发射宽度可变的虚拟核.TFlex[19]采用EDGE指令集,借助编译器进行指令调度.DCM(dynamic core morphing)[20]可以根据应用的阶段性特征,提供合适的后端完成计算.Voltron[21]实现宽发射的VLIW虚拟核和能进行细粒度通信的多VLIW核双模式计算.WiDGET[22]根据需求分配合适数量的功能单元来实现与功耗成比例的计算.部分动态多核结构借助编译器完成静态指令调度,部分动态多核结构采用基于依赖的动态指令调度.除了动态多核处理器外,其他类型的空间结构[23-26]多借助编译器完成指令调度.
DFB调度缓存、优化并重用指令调度策略.DIF[27]结构将调度完成的指令组缓存.再次遇到时,指令组由VLIW后端加速执行.Fill unit[28]将执行的指令压缩并缓存,提高发射带宽.基于Trace Cache[29],处理器可以对缓存的指令进行动态优化以提升其执行性能[30].rePLay[31]提出了支持动态优化的框架.
分簇超标量处理器与动态多核处理器中负责执行指令的流水线后端都可抽象为分区结构.硬件资源由单体实现变为分区实现带来的变化主要有3点:1)单个分区分得的功能单元减少;2)跨分区传递操作数有额外的延迟;3)单个分区的发射队列变小.分区结构的指令调度可以看作优化问题,尝试减弱或消除上述3要素导致的性能惩罚,使分区实现接近单体实现的执行效率.
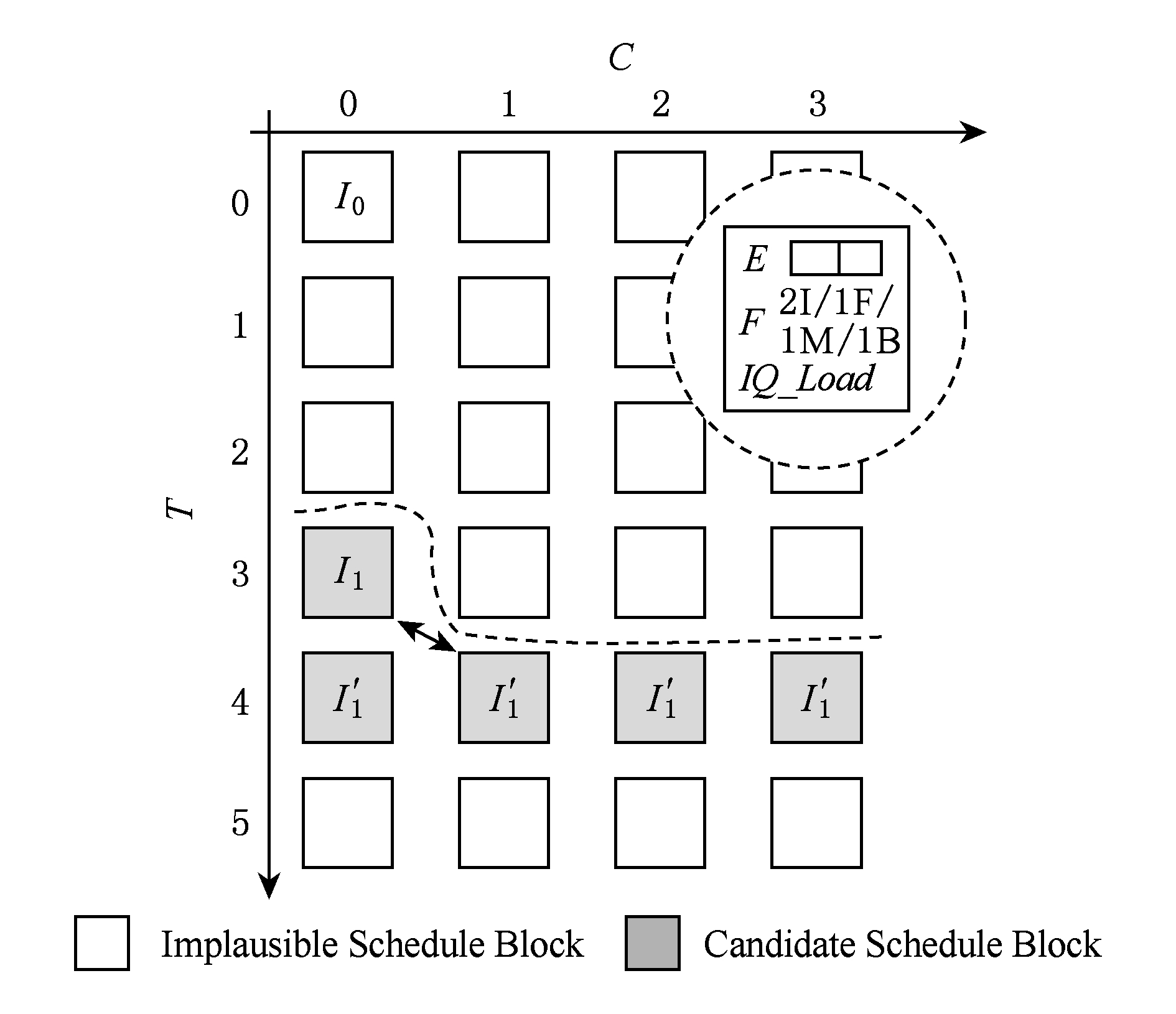
Fig. 3 Scheduling space model for spatial architecture
图3 分区结构的调度空间模型
单个分区的指令发射带宽、功能单元组成和发射队列容量等限制指令调度,我们用调度块(schedule block,ScB)描述这些资源约束.随着周期的增长,所有分区的ScB构成了矩阵形式的调度空间约束模型,矩阵行坐标T表示指令的预期发射周期,列坐标C表示指令的分区指派,矩阵的第i行第j列的元素ScBij描述了第j个分区在第i个周期的资源约束.空间指令调度为动态指令片段中的指令确定分区指派C,在不违反调度空间约束模型的情况下,尽量减小指令片段调度模式的周期跨度.图3展示了4分区结构的调度空间约束模型,单个分区每周期可发射2条指令,有2个整型、1个浮点、1个访存和1个分支功能单元.调度空间约束模型的术语定义如表1所示.
Table1TerminologyofScheduleSpaceConstraintsModel
表1调度空间约束模型术语

指令I调度到ScBij意味着IssT(I)=i,C(I)=j.指令执行完成周期等于发射周期加上指令的执行延迟ExedT(I)=IssT(I)+Lat(I).举例说明在调度空间约束模型下如何完成指令调度.如图3所示,I1依赖I0,假设I1调度到ScBij,则需要满足4项约束:
E(ScBij)>0,
(1)
F(ScBij)[type(I1)]>0,
(2)
IQ_Load(ScBij)<IQ_Size,
(3)
(4)
其中,type(I)表示取执行指令I的功能单元类型,IQ_Size是单个分区的发射队列容量,IPL为分区间延迟.式(1)~(3)为资源约束,式(4)为生产者指令对消费者指令的调度约束.IPL设定为1周期,假设I0调度到ScB00,且Lat(I0)=3,则I1在I0的约束下的调度备选ScB如图3所示.
如何完成调度使指令序列在调度空间约束模型的T方向上分布尽量窄,即指令调度问题.指令空间调度通过改变指令的C(I)来权衡负载均衡与IPL.已有调度方法考察指令位于关键路径的可能性,然后依照其关键性预测做负载均衡和依赖调度2选1的即时决策,我们称这种定性的决策标准为指令的绝对关键性.我们认为依据绝对关键性进行调度存在不足,原因有2个:1)实时关键性难以准确预测,指令位于不同执行路径时,其关键性存在差异;2)调度决策会反馈影响指令关键性,根据依赖进行调度会加重负载的不均衡,根据负载进行调度会使得路径的延迟增长,非关键路径可转化为关键路径.
DFB调度根据指令上下文分析其调度裕量,不违反调度空间约束模型生成合理的调度模式并缓存复用.关注指令调度需求与资源约束的互动,通过对比竞争资源的多个指令的调度裕量做出调度决策,我们称这种定量的决策标准为指令的相对关键性.第3节介绍定量描述程序调度需求的数据流约束模型.
“操作数准备好,指令开始执行.”是数据流计算的基本思想,也为指令调度提供依据.我们在数据流概念的基础上做出扩展,定义指令的数据流约束为与指令有依赖关系的生产者与消费者指令对指令调度附加的周期约束.数据流约束有2个特点:1)量化约束关系,计算指令的调度裕量;2)参考指令的消费者依赖关系,即反向数据流依赖.传统指令调度方法逐条完成指令调度,无法参考反向数据流依赖关系,DFB调度缓存并重用指令调度模式,能够参考指令的消费者对其附加的数据流约束.数据流约束模型的术语的定义如表2所示.
数据流约束的计算举例如图4所示.动态指令序列可表示为无环的有向数据流图,如图4中①所示,边表示指令间的依赖关系,边的权值表示估计的指令执行延迟Lat(I),虚线框表示指令是Terminal.数据流约束的计算有3步:
1) 按指令序遍历所有指令,计算得到指令的调度上限sched_ub.如图4中②所示,I0,I1等没有生产者指令约束的指令sched_ub为周期0,ExedT(I0)=1且ExedT(I1)=3,则sched_ub(I2)=3.
2) 设置Terminal的sched_lb为其sched_ub,如图4中③所示,然后逐个遍历D-Tree追踪反向数据流依赖关系,更新lb_mat,如图4中④⑤所示.
3)lb_mat中指令约束最紧值即为指令的sched_lb,(sched_ub,sched_lb)定义指令的调度区间,差值为调度裕量,如图4中⑥所示.
Table2TerminologyofData-FlowConstraintsModel
表2数据流约束模型术语

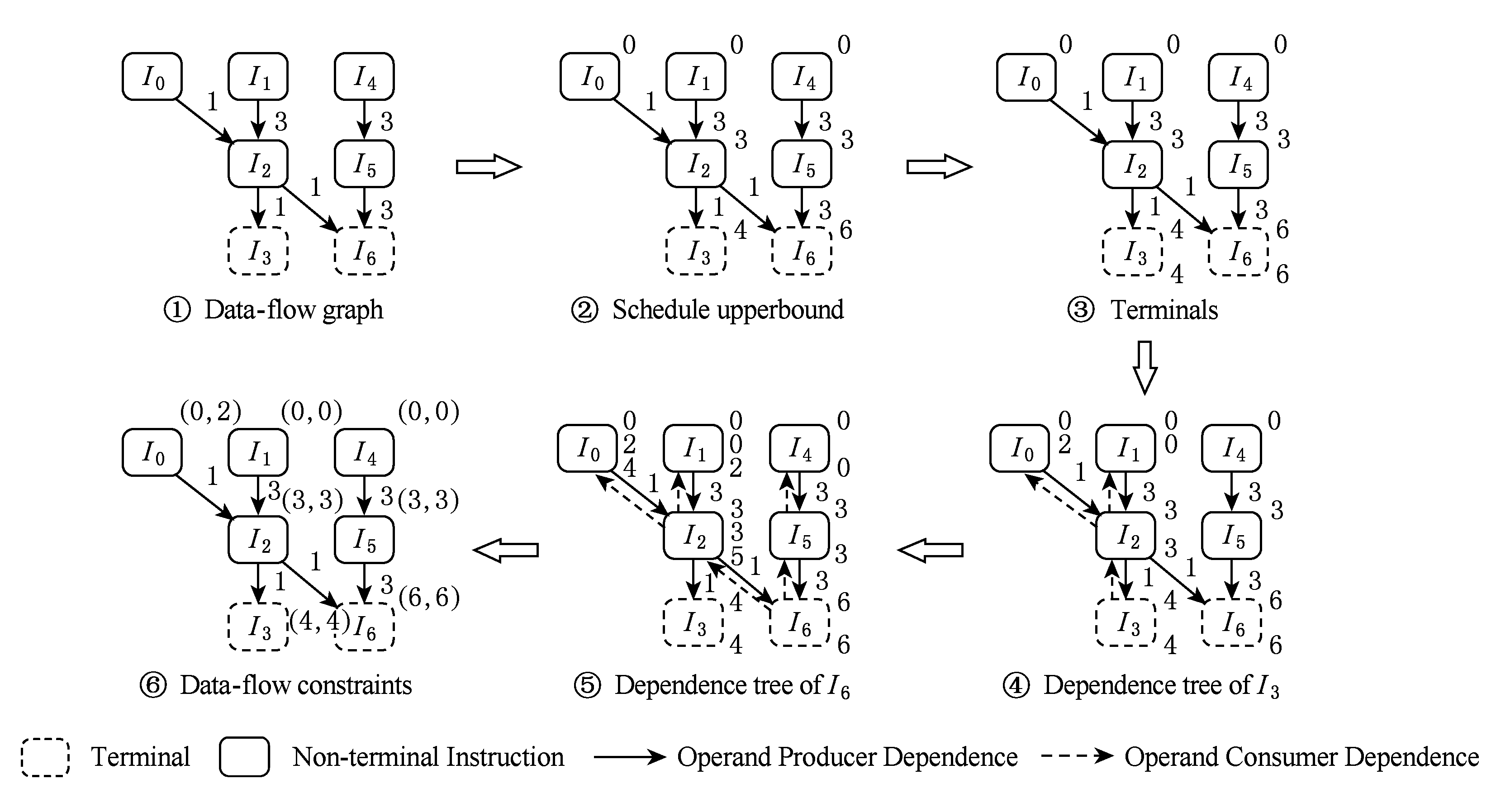
Fig. 4 Data-flow constraints computation
图4 数据流约束的计算
数据流约束描述了程序的细粒度计算需求,调度上下限差值为指令的调度裕量:1)调度裕量量化表示了指令的相对关键性强弱,调度裕量越大其相对关键性越弱,当多条指令竞争调度资源时,优先满足相对关键性强的指令;2)调度裕量是考虑了调度策略影响的动态指标,当指令跨分区传递操作数时,IPL消耗指令的调度裕量,其相对关键性得到提升.调度裕量表示的相对关键性是与上下文相关的、量化的、动态的指令关键性指标.
DFB是动态构建、缓存并重用的调度模式.扩展支持DFB调度的处理器微结构框图如图5所示.在传统分区结构的基础上,添加了DFB构建、缓存和重用的逻辑.DFB调度的实现基于集成数据流缓存的处理器前端设计[32],该设计解耦合指令转换与分支预测,DFB Cache利用程序的计算局部性覆盖大部分的动态指令流,从而降低DFB构建的执行频率,减少DFB Trainer的功耗开销.DFB Trainer可以被芯片上多个物理核复用,降低其平均面积开销.
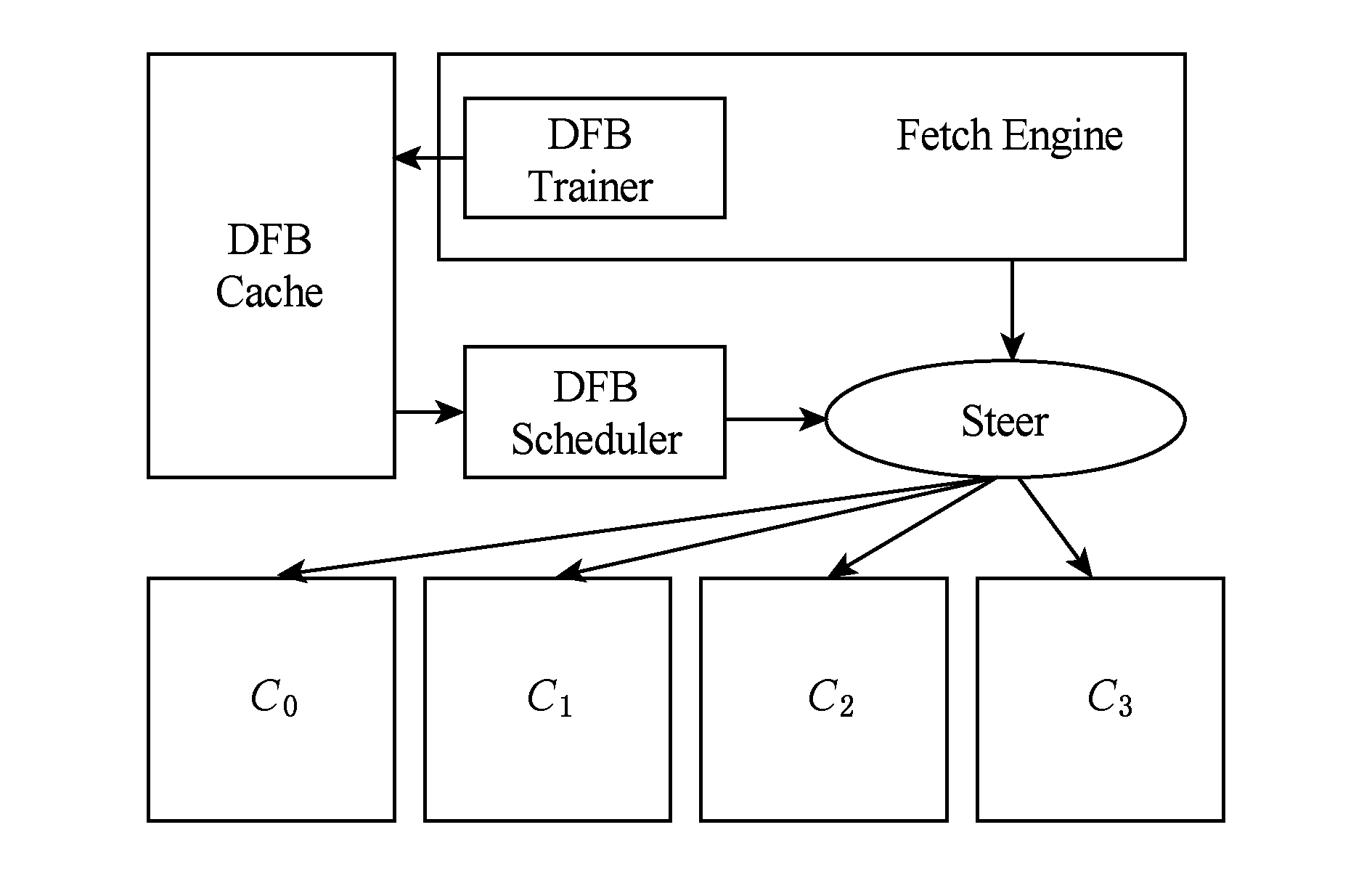
Fig. 5 Microarchitecture augmented with DFB scheduling
图5 扩展支持DFB调度后的微结构
分支预测器给出取指地址来查询DFB Cache:1)命中,DFB Scheduler取出缓存的DFB,指导指令的空间调度;2)未命中,DFB Trainer采样指令,并执行DFB调度算法,将调度模式存入DFB Cache.在程序的计算局部性支持下,经过一段时间的训练,DFB Cache可以覆盖大部分的动态指令.
DFB内指令依赖的表示采用前向数据流指针[32],操作数由生产者指令主动传递给消费者指令,DFB Trainer在DFB内插入额外的copy指令完成操作数的跨分区传递.指令不需要跨分区广播操作数或访问物理寄存器文件.主分区维护ROB(reorder buffer)信息,每个DFB占用ROB的1个空位,当DFB的最后1条指令达到提交阶段时,整个DFB一起提交.物理寄存器和ROB的实现不会限制结构的可扩展性.
DFB Trainer使用DFB调度算法,输入动态指令序列,参照数据流约束模型和调度空间约束模型完成指令调度,输出指令序列的调度模式.DFB调度算法的目标是在不违反资源限制的前提下,尽量满足程序的计算需求,生成时间跨度尽量小的调度模式.
在数据流约束表示的指令相对关键性的指导下,DFB调度算法对每条指令做依赖调度和负载均衡调度的权衡,为其指派分区.当指令的数据流约束无法满足时,放宽约束所在D-Tree上指令的sched_lb,继续尝试调度当前指令,直到所有指令调度完成.
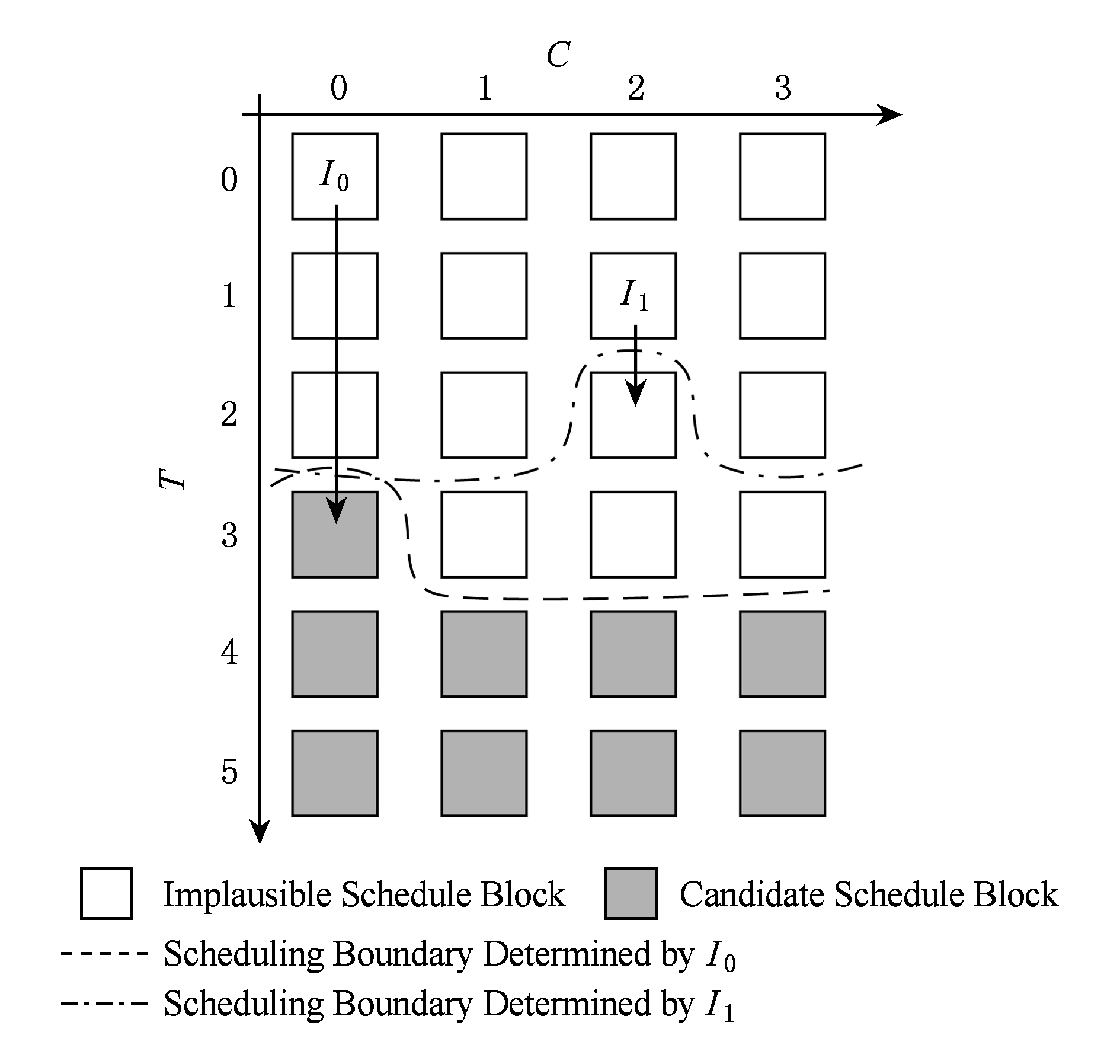
Fig. 6 Dependence based scheduling constraints
图6 基于依赖的调度约束
调度依指令序逐条进行,当某指令开始调度时,其生产者指令已经调度完成,对其调度上限构成约束.图6展示指令I2开始调度的周期,其依赖的指令I0调度在ScB00,I1调度在ScB12.假设Lat(I0)=3,Lat(I1)=1,IPL=1,则I0与I1附加的调度上限约束分别如图6中虚线和点划线所示.基于依赖的调度要求IssT(I2)同时满足2个约束,灰色ScB为备选位置.
考虑I2的相对关键性.当I2的调度下限大于周期3时,可以将I2调度到分区0以外,此时I0附加的调度约束如图7中虚线所示.将I2调度到分区0之外,让出了分区0的执行机会或者使负载更均衡.
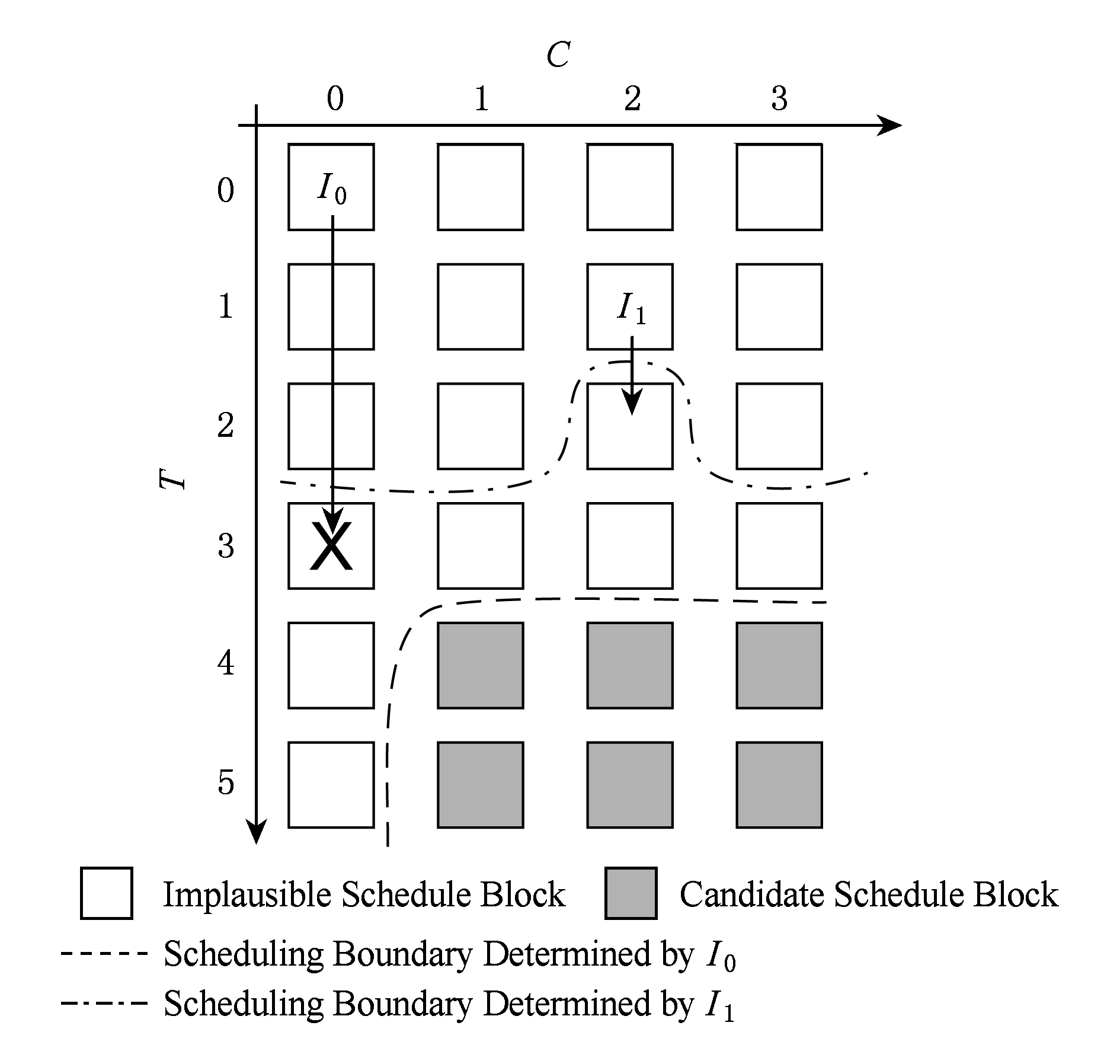
Fig. 7 Scheduling according to relative criticality
图7 依据相对关键性进行调度
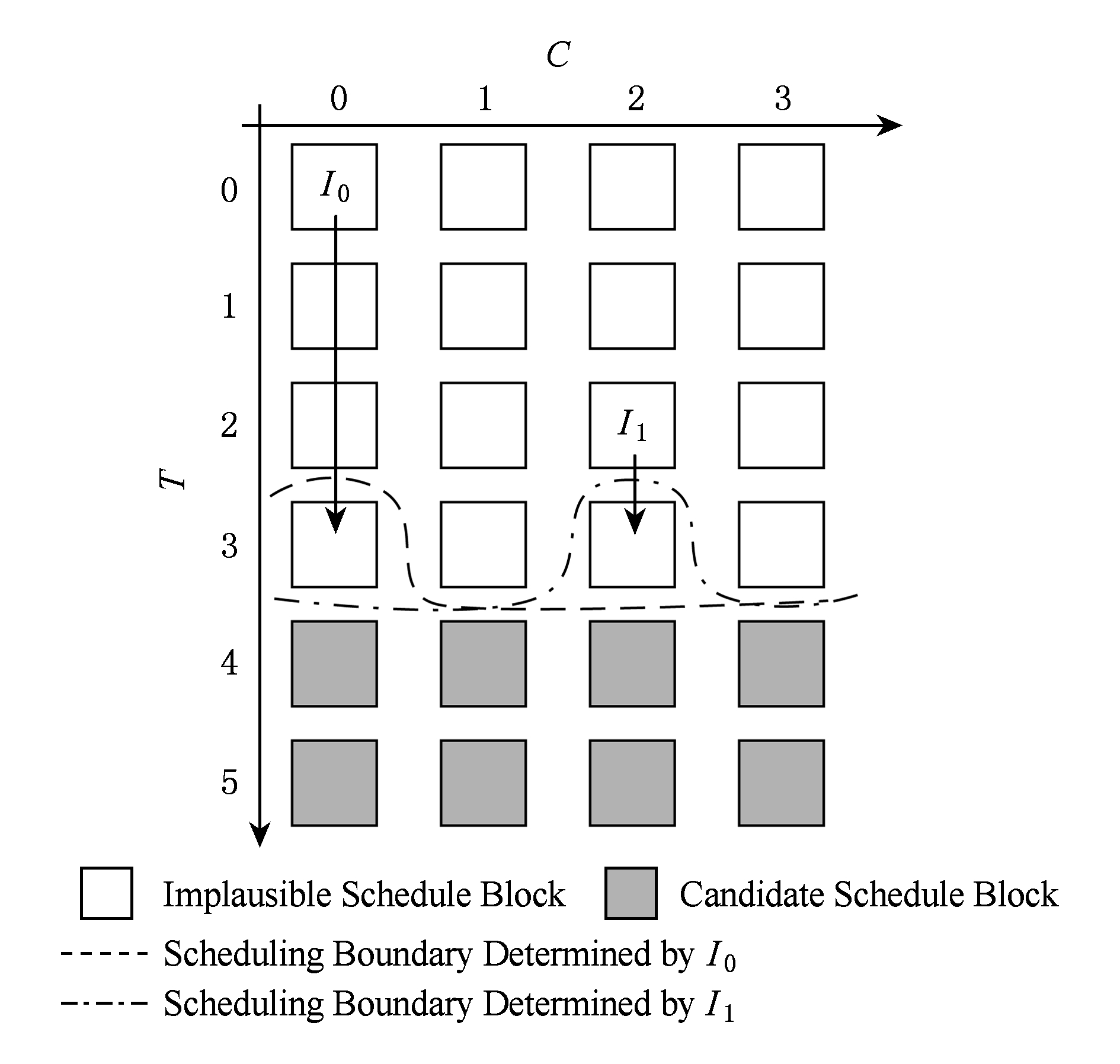
Fig. 8 Loosen data-flow constraints when needed
图8 适时放松数据流约束
根据依赖关系和相对关键性确定了备选ScB后,按照IssT从小到大的顺序考察ScB,若找到不违反资源限制约束的且IssT满足sched_lb要求的ScB开始下条指令的调度;否则,放松数据流约束,继续尝试调度当前指令.如图8所示,I1调度在了ScB22,则sched_lb(I2)=3的数据流约束无法满足.追踪约束来源的D-Tree,将对应的Terminal的sched_lb增1,更新lb_mat,计算sched_lb约束,重新尝试调度I2,重复该过程直到调度成功.
DFB空间调度算法使用调度空间约束模型对功能单元计算能力建模,而采用计数排序的方法应对发射队列负载均衡的问题,优先考虑指令数少的分区,对于指令数相等的分区,优先调度到最久没有被使用的分区.根据分区负载确定调度优先级的电路示意图如图9所示:
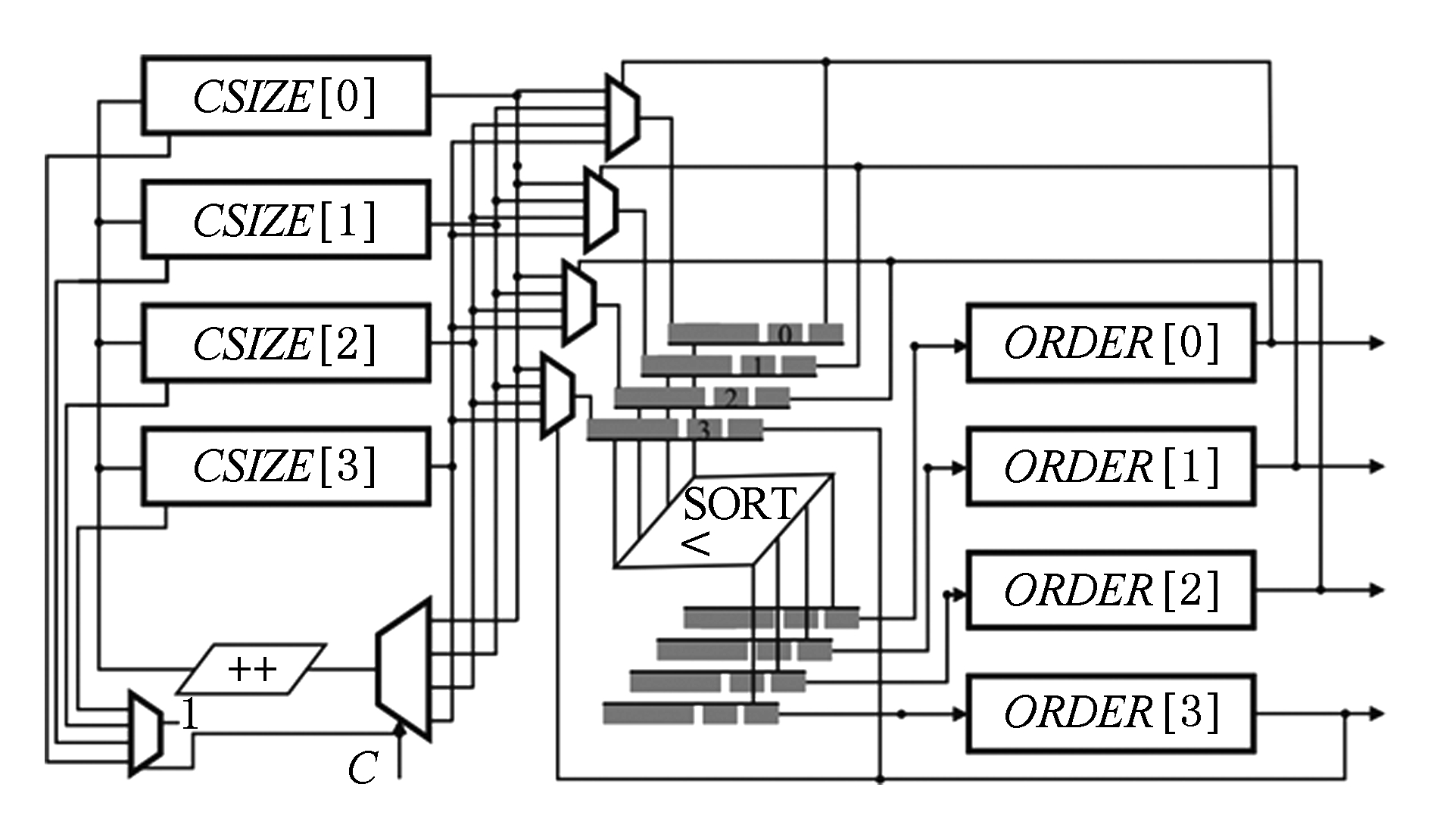
Fig. 9 Priority updating circuit for load balancing
图9 负载均衡优先级更新电路
电路主要维护2组寄存器,CSIZE寄存器组存储各分区已经指派的指令数量,ORDER寄存器组按负载均衡优先级输出调度分区编号.DFB开始构建时CSIZE寄存器清0,每调度1条指令,CSIZE寄存器和ORDER寄存器依次变化,更新优先级:1)指令调度的分区号C控制对应的CSIZE寄存器加1;2)更新ORDER寄存器,CSIZE越大的分区优先级越低,CSIZE相等的分区,维持优先级顺序.
DFB调度算法依指令序逐条调度指令.调度单条指令分为3步:
1) 根据依赖关系和数据流约束表示的相对关键性确定备选ScB;
2) 按照IssT递增的顺序在备选的ScB中尝试调度指令,相同IssT的ScB依负载均衡优先级调度,若成功则完成当前指令调度;
3) 放松当前指令sched_lb所在D-Tree的约束,并返回步骤1继续尝试进行调度.DFB的所有指令调度完成时算法结束.
伪代码中,n为指令数,nC为分区数,IPL为跨分区操作数传递延迟.inst是输入指令序列,ScB是调度空间模型矩阵,sched_con记录指令的关键消费者;输出是分区指派C和预期发射周期IssT.算法如下:
算法1. DFB空间指令调度.
输入:inst[],ScB[][],sched_ub[],sched_lb[],sched_con[];
输出:C[0:n-1],IssT[0:n-1].
伪代码:
函数SCHED_MAIN()
 *初始化负载均衡优先级电路*
*初始化负载均衡优先级电路*
① for all:ORDER[i]=(rr_token+i)%nC;
② for all:CSIZE[i]=0;
③rr_token=(rr_token+P)%nC;
*按指令序依次调度*
④ for eachiin[0:n-1]
⑤ while (SCHED_INST(i)≠true)
*调度失败则放松数据流约束,直到调度成功*
*term为指令约束所在D-Tree的根*
⑥sched_lb[term]++;
⑦recalc_lb();
⑧ end while
*更新负载均衡优先级*
⑨ for eachjin[0:nC-1]
⑩vec.add(CSIZE[ORDER[j]]≪4|j≪2|ORDER[j]);
 end for
end for
 vec.sort(‘<’);
vec.sort(‘<’);
 for eachjin[0:nC-1]
for eachjin[0:nC-1]
 ORDER[j]=vec[j]%nC;
ORDER[j]=vec[j]%nC;
 end for
end for
 end for
end for
函数SCHED_INST(idx)
 if (inst[idx]’ssrc1 is valid):*操作数1有依赖*
if (inst[idx]’ssrc1 is valid):*操作数1有依赖*
 ExedT[src1]=IssT[src1]+Lat[src1];
ExedT[src1]=IssT[src1]+Lat[src1];
 if(sched_con[src1]≠idx&&
if(sched_con[src1]≠idx&&
(ScB[ExedT[src1]][C[src1]] is nearly full‖sched_lb[idx]>ExedT[src1]))yield=true;
 end if
end if
 for eachiin[0:nC-1]
for eachiin[0:nC-1]
 if (i==C[src1])
if (i==C[src1])
 if(yield)Y1[i]=maxINT;*最大整数*
if(yield)Y1[i]=maxINT;*最大整数*
 elseY1[i]=ExedT[src1];
elseY1[i]=ExedT[src1];
 end if
end if
 elseY1[i]=ExedT[src1]+IPL;
elseY1[i]=ExedT[src1]+IPL;
 end if
end if
 end for
end for
 end if
end if
 if (inst[idx]’ssrc2 is valid)*操作数2有依赖*
if (inst[idx]’ssrc2 is valid)*操作数2有依赖*
 Y[:]=max(Y1[:],Y2[:]);
Y[:]=max(Y1[:],Y2[:]);
 minY=min(Y[:]);
minY=min(Y[:]);
 end if
end if
 if(minY>sched_lb[idx]) return false;
if(minY>sched_lb[idx]) return false;
 end for
end for
 for eachiin (minY:sched_lb[idx])
for eachiin (minY:sched_lb[idx])
 for eachjin [0:nC-1]
for eachjin [0:nC-1]
 if (Y[ORDER[j]]≤i)
if (Y[ORDER[j]]≤i)
 if(ScB[i][ORDER[j]] satisfies
if(ScB[i][ORDER[j]] satisfies
inst[idx])
 C[idx]=ORDER[j];
C[idx]=ORDER[j];
 IssT[idx]=i;
IssT[idx]=i;
 CSIZE[ORDER[j]]++;
CSIZE[ORDER[j]]++;
 return true;
return true;
 end if
end if
 end if
end if
 end for
end for
 end for
end for
 return false.
return false.
时间复杂度简要分析如下:函数SCHED_INST调度单条指令,Y1和Y2分别表示2条生产者指令对当前指令的调度上限约束,Y由Y1和Y2共同确定,Y的最小值minY表示当前指令最早的IssT,行~计算的时间复杂度为O(1).Y与sched_lb确定了IssT的取指范围,各分区最顶部的ScB作为调度目标,算法在硬件实现时可以维护各分区各功能单元的发射机会向量,其与调度范围求交集后,顶部的ScB即是各分区的候选,对最多nC个备选的ScB,按照小的IssT第1优先,ORDER寄存器第2优先的顺序确定调度到的ScB,行~计算的时间复杂度为O(1).所以,SCHED_INST的时间复杂度为O(1).SCHED_MAIN负责指令序列的调度.行⑨~更新负载均衡优先级电路,其时间复杂度为O(n).行④~⑤确定2层循环,行⑤~⑦为最内层循环体,每进行1次约束放松,至少有1条指令的sched_lb增1.任何1条指令的sched_lb不会超过n×(max(Lat)+IPL),行⑥~⑦进行约束放松为O(n2)次,行⑤调用SCHED_INST的次数等于约束放松的次数加n.因此算法总的时间复杂度为O(n2).
我们为ESESC模拟器[33]添加了DFB调度后运行SPECINT CPU2006测试程序集,使用ref输入数据.我们略过初始的1亿条指令后,模拟1亿条指令的连续执行.因为DFB Cache依赖程序的计算局部性,关闭模拟器的采样执行模式使模拟的动态指令流的计算局部性尽量接近程序实际执行情况.
支持乱序执行的流水线的指令执行性能受到多个结构参数的影响,取指带宽、指令窗口容量、调度窗口容量、功能单元配置等都会影响程序的执行.为了评估指令空间调度方法,使指令执行性能体现调度方法的差异,我们对结构参数进行了差异化的设置,重点关注3个与指令空间调度方法密切相关的结构参数:分区数、IPL和调度窗口容量.部分结构参数配置如表3所示.ROB、寄存器文件等后端部件使用多端口RAM实现,可扩展性强于调度器,它们的设置根据调度窗口容量和功能单元配置合理设定,尽量减少对性能的影响.
Table3ProcessorModelConfiguration
表3处理器模型配置
已有的指令调度方法对指令关键性的判定存在差异,但调度策略可以归为负载均衡和依赖调度2类.我们设置2个参照的调度方法:RR调度轮转分配指令到各分区,维持负载均衡;DEP调度基于生产者依赖关系调度指令,没有依赖时按照LRU(least recently used)策略选择分区;DFB调度即本文提出的依据指令的相对关键性构建调度模式并缓存重用的调度方法.
算法评估基于理想DFB调度,假设所有动态指令都被DFB Cache覆盖.对分区数量、IPL和调度窗口容量3个结构参数,每次变化其中1个,观察不同调度方法的性能差异.调度效果评价有2个指标:1)每指令周期数(cycle per instruction, CPI),CPI越低调度效果越好,我们以CPI最低的配置为基准对CPI进行归一化处理,方便比较;2)调度阻塞率(schedule blocking rate, SBR),如果调度方法为指令选择的分区发射队列已满,则阻塞流水线,直至调度成功,SBR表示阻塞周期数占总周期数的比率,SBR越小通常调度效果越好.
6.2.1 分区数与调度效果
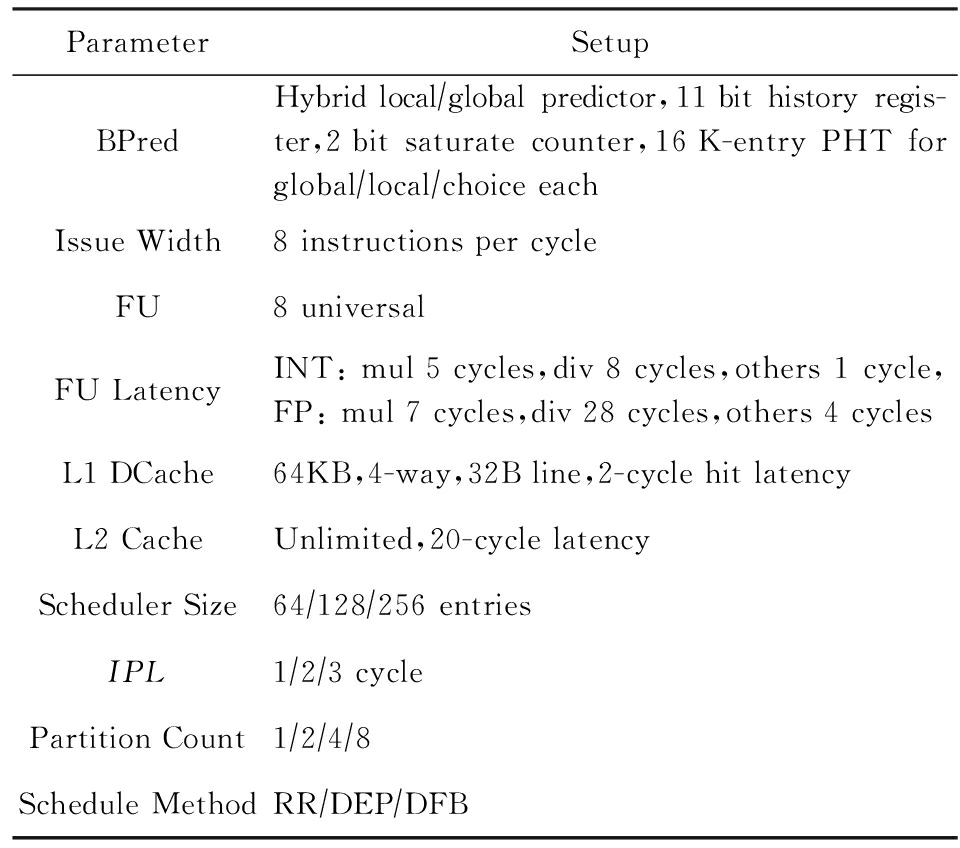
不考虑分区结构在功耗、时序以及可扩展性等方面存在的优势.分区越多,单个分区的资源越少,负载不均衡和IPL对性能产生负面影响的可能性越大.我们设置IPL为1个周期,总调度窗口容量为128条指令.分区数为2,4,8的配置下,各调度方法的测试结果分别如图10~12所示.折线表示程序的CPI,绘制在主纵轴上;柱状图表示程序的SBR,绘制在辅纵轴,用百分比表示.

Fig. 10 Experimental result for 2 partitions
图10 分区数为2的实验结果
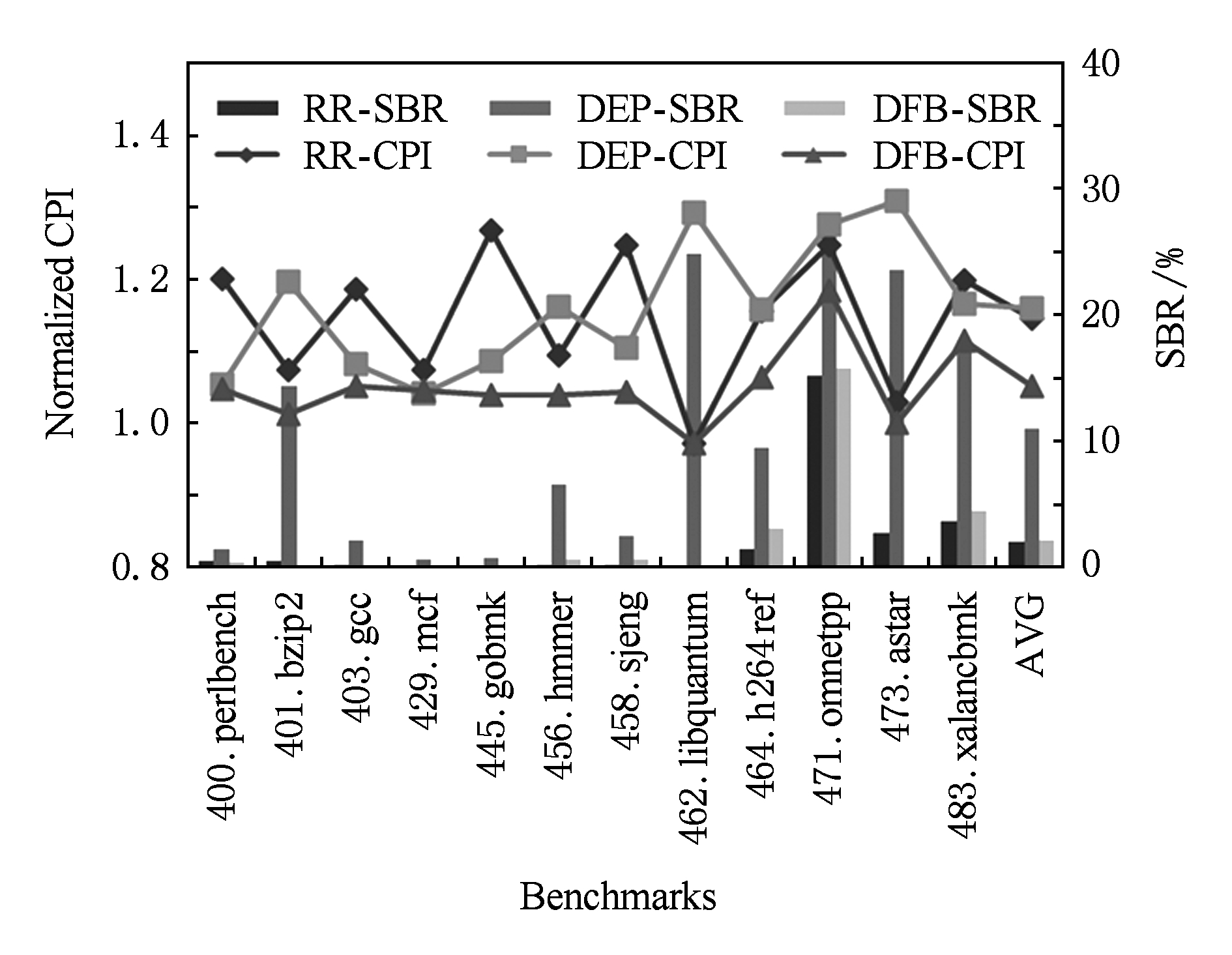
Fig. 11 Experimental result for 4 partitions
图11 分区数为4的实验结果
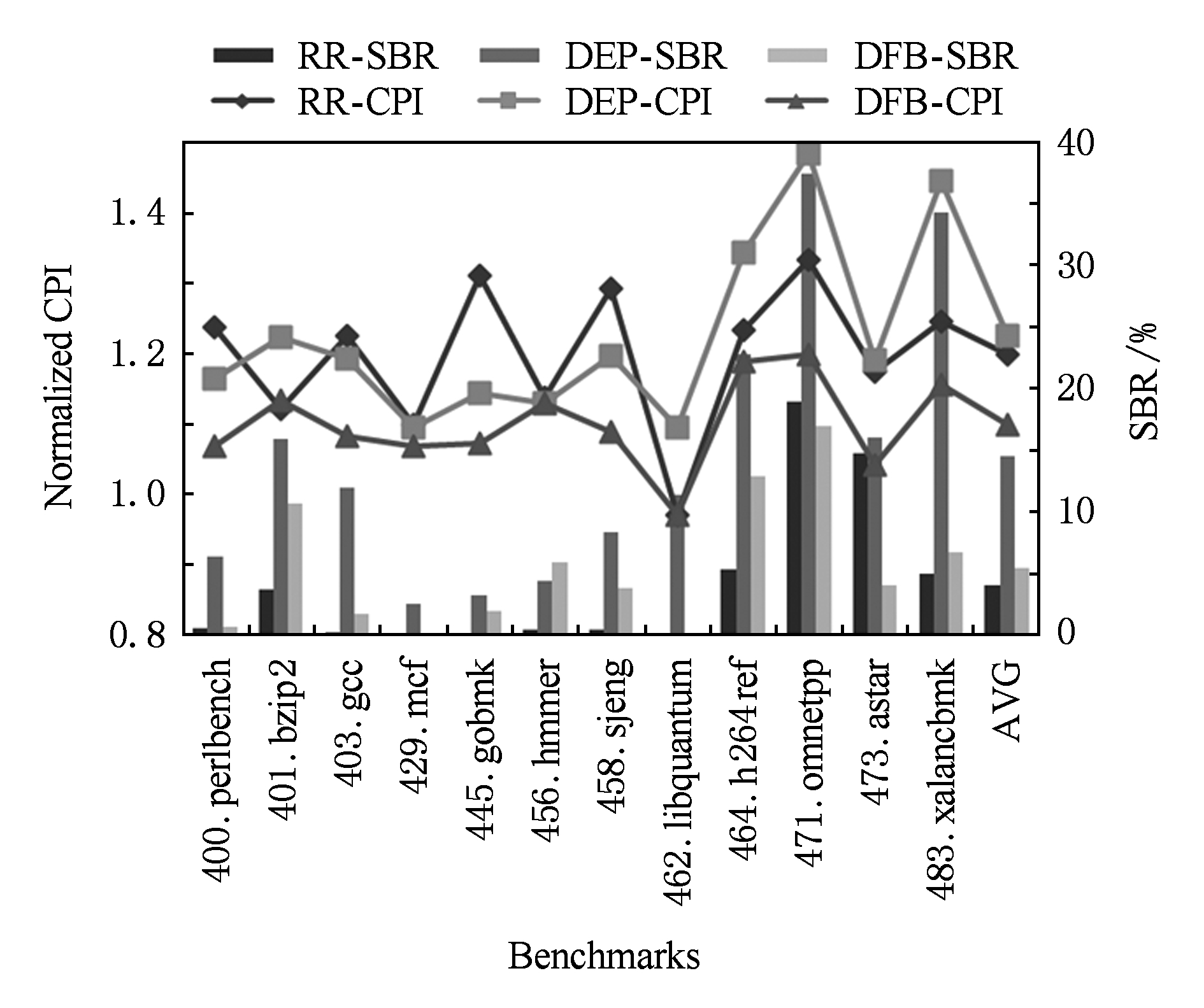
Fig. 12 Experimental result for 8 partitions
图12 分区数为8的实验结果
程序的并行性特征不同导致其对调度方法存在偏好.perlbench的ILP有限,指令依赖较多,偏好DEP调度;bzip2的ILP较高,负载均衡压力大,调度窗口易阻塞,偏好RR调度;omnetpp和xalancbmk在分区数较小时偏好DEP调度,随着分区数增大逐渐偏好RR调度.不同程序对调度方法的偏好不同,同一个程序对调度方法的偏好也随分区数改变,所以RR调度和DEP调度之间不存在绝对的性能优劣,适应程序并行性特征的调度方法的调度效果较好.DFB调度量化程序的数据流约束,参照硬件资源约束生成调度模式并缓存重用,可以DFB调度的质量和稳定性优于RR和DEP调度.
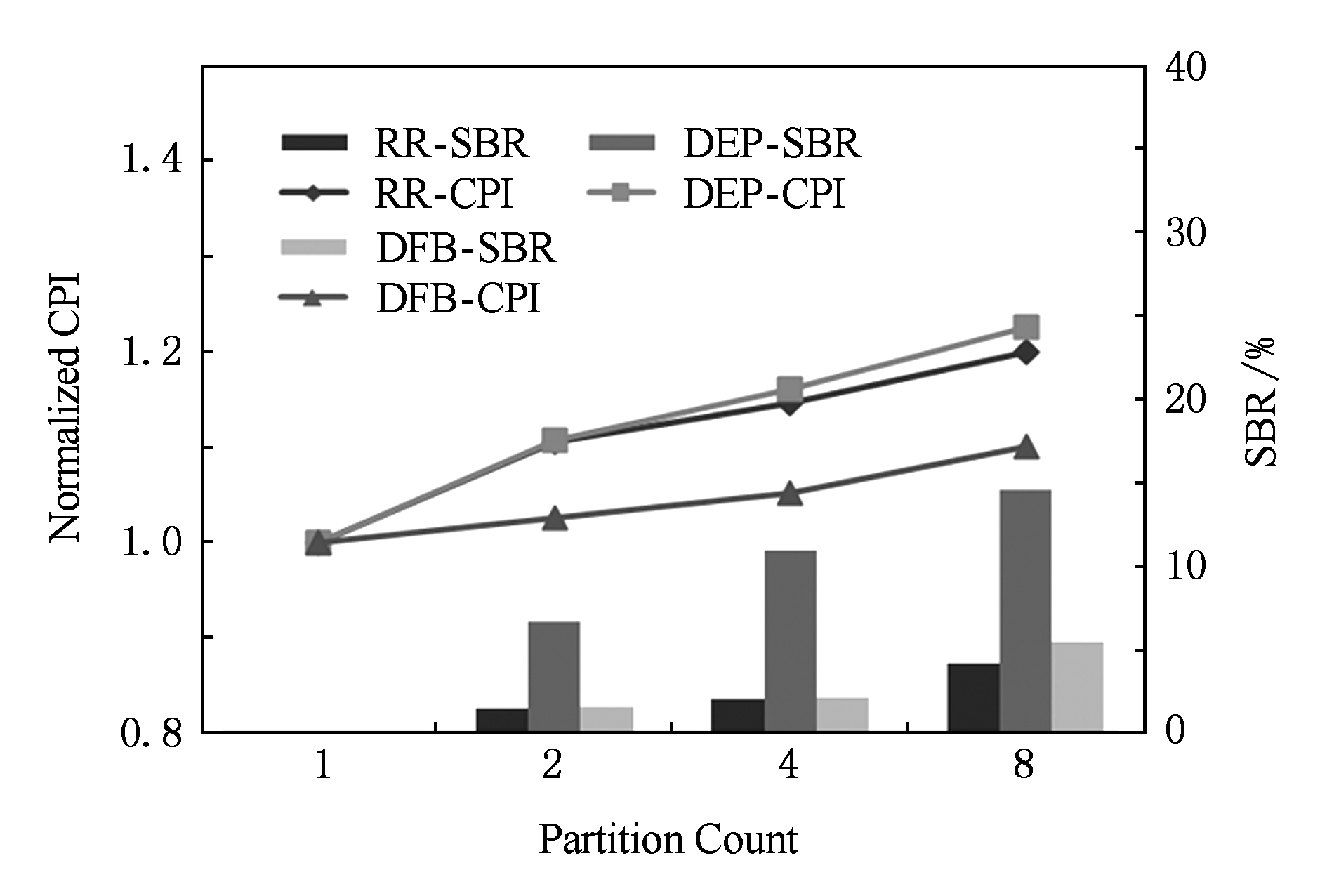
Fig. 13 Performance trend with increasing partition count
图13 随着分区数增加性能的变化趋势
程序平均性能随分区数变化的趋势如图13所示.随着分区数增加,CPI和SBR逐渐上升,负载均衡和IPL对性能影响逐渐增大.RR调度有最低的SBR;DEP调度容易导致调度窗口阻塞,SBR较高;DFB调度维持负载均衡的效果弱于RR,但其性能强于RR,说明DFB调度对指令关键性把握较好,照顾负载均衡的同时并没有使得关键路径过多受到IPL的惩罚.
6.2.2 跨区操作数传递延迟与调度效果
芯片上的功能单元互相传递操作数需要通信网络.单体实现时,操作数的传递延迟为1个周期,但周期较长.分区实现时,邻近功能单元操作数的传递延迟为1个周期,而距离越远延迟周期数越多,但周期较短.IPL定量描述了功能单元间通信延迟不均匀的程度,比如,分簇超标量处理器中调度到同簇的指令可以背靠背执行,延迟为0周期,跨越簇的边界广播操作数,需要1周期.动态多核处理器中虚拟核的物理分区之间传递操作数需要配对的复制或同步指令,需要2或3周期.基于片上网络在更多的核间传递操作数的延迟与核间的曼哈顿距离成比例.我们设置总调度窗口容量为128条指令,分区数为8.IPL为1,2,3周期时,各调度方法的测试结果分别如图14~16所示.
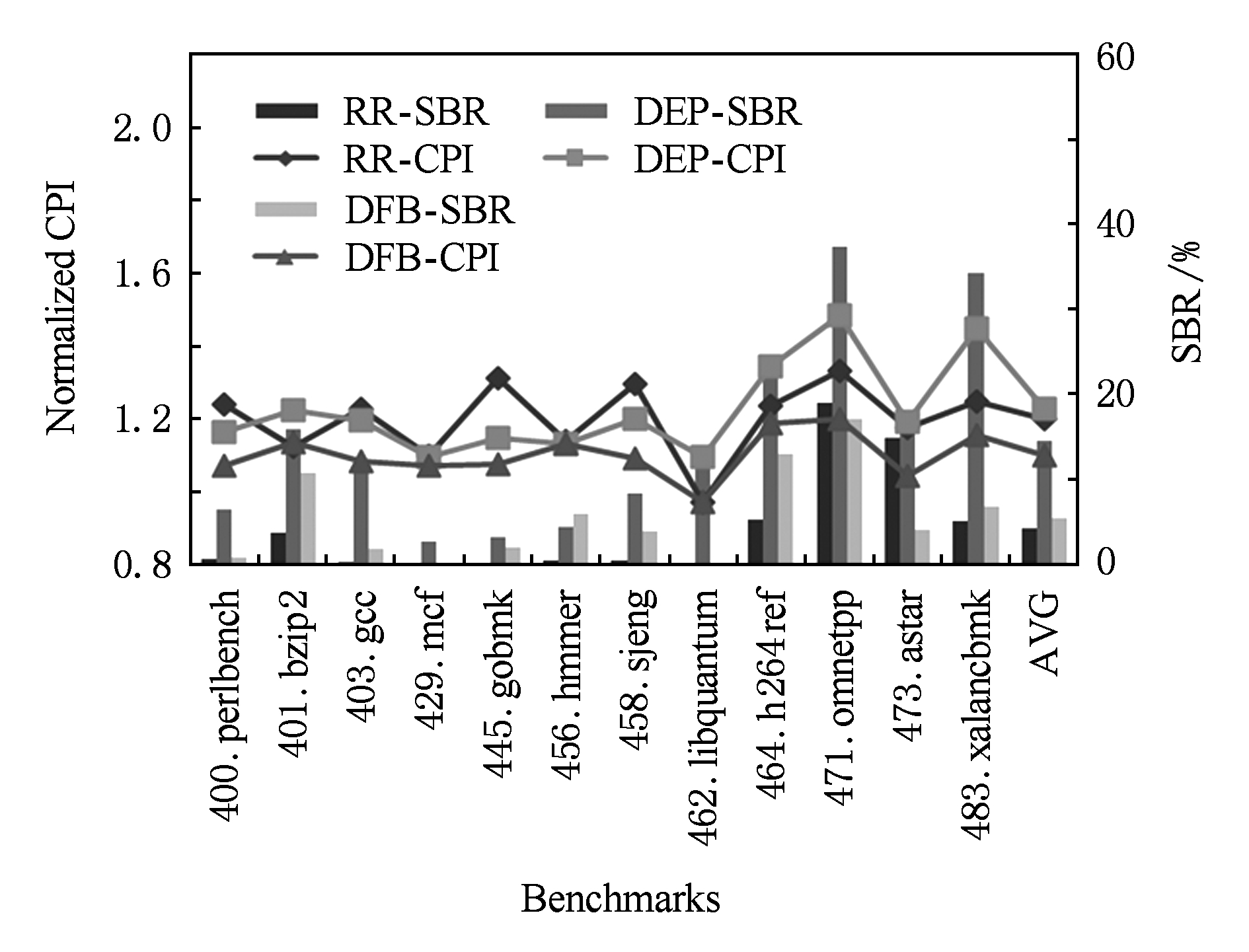
Fig. 14 Experimental result for 1-cycle IPL
图14 IPL为1周期的实验结果
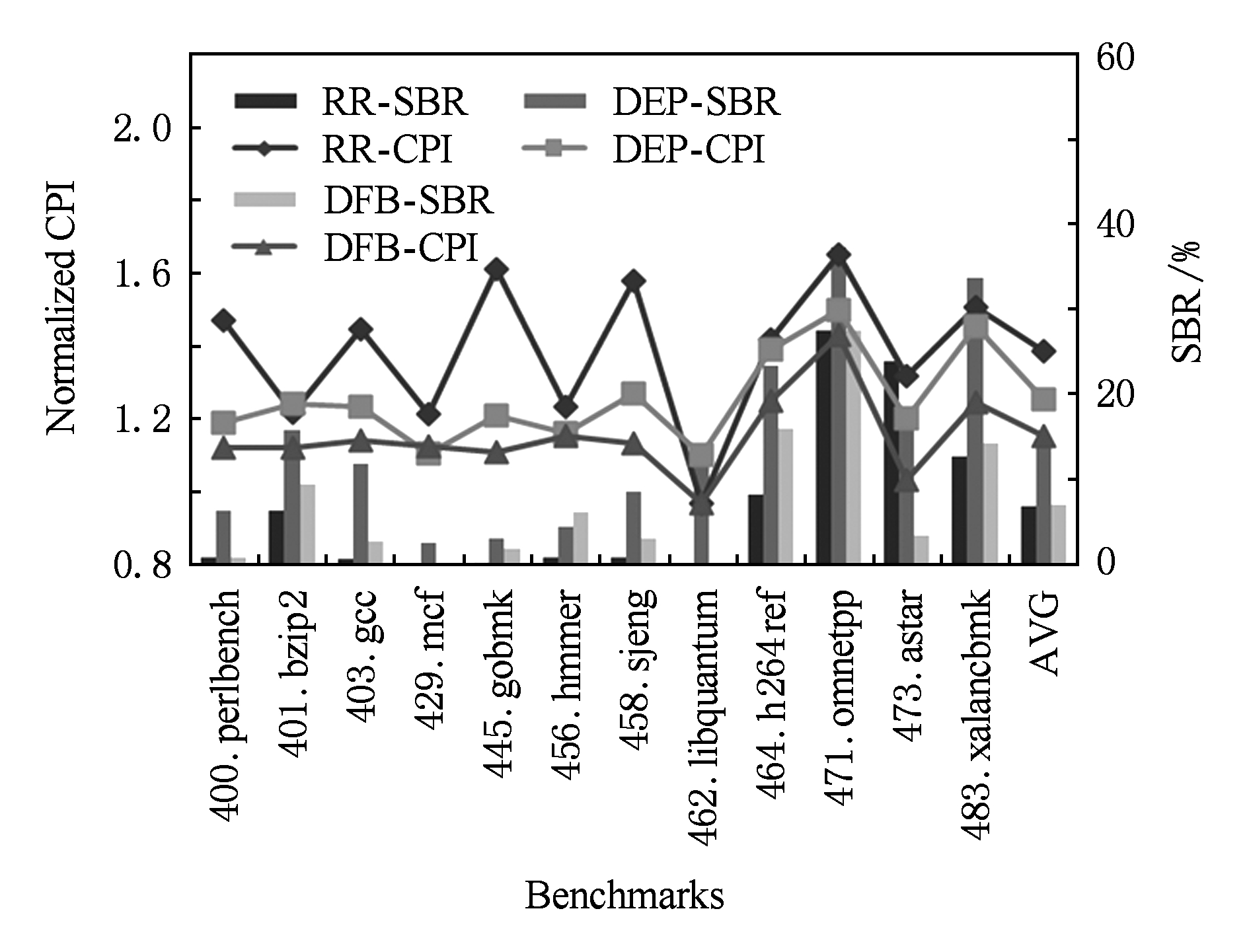
Fig. 15 Experimental result for 2-cycle IPL
图15 IPL为2周期的实验结果

Fig. 16 Experimental result for 3-cycle IPL
图16 IPL为3周期的实验结果
IPL增加会增大跨分区传递操作数导致的性能惩罚.RR调度不考虑指令的依赖关系,随IPL增加性能下降最明显;DEP调度的SBR随着IPL增加基本没有变化,因为存在依赖关系的指令被分到同一分区的概率较高,性能变化较小.
程序的平均性能随IPL变化的趋势如图17所示.DFB调度具有最佳调度效果.随着IPL增长,调度裕量消耗加快,负载均衡调度的机会减少,调度结果逐渐趋近于DEP调度.
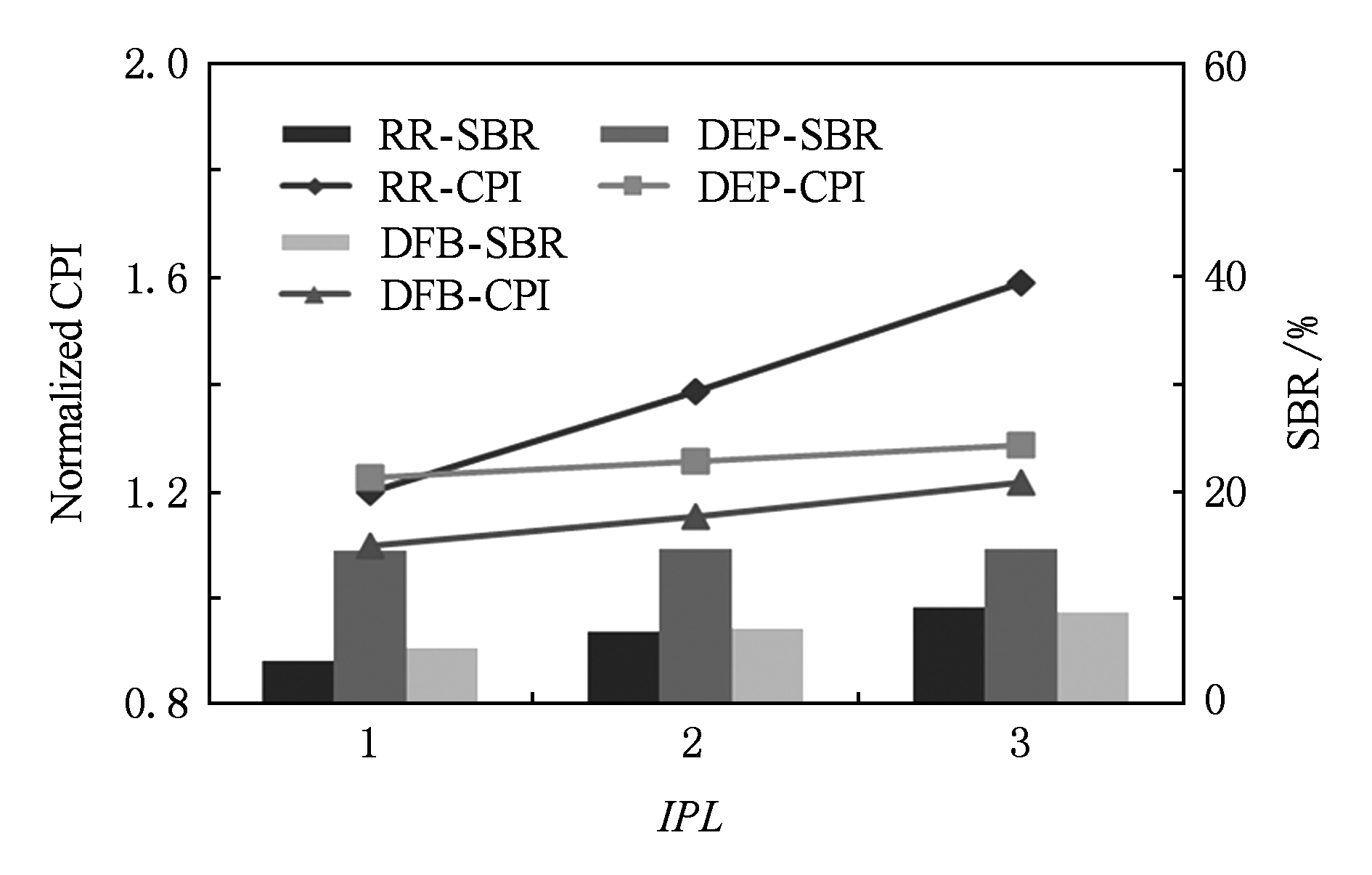
Fig. 17 Performance trend with increasing IPL
图17 随着IPL增加性能的变化趋势
6.2.3 调度窗口容量与调度效果
发射队列影响周期长度.小的发射队列容易被阻塞导致性能损失.我们设置分区数为8,IPL为1个周期.总调度窗口容量为64,128,256条指令时,各调度方法的测试结果见图18~20所示.
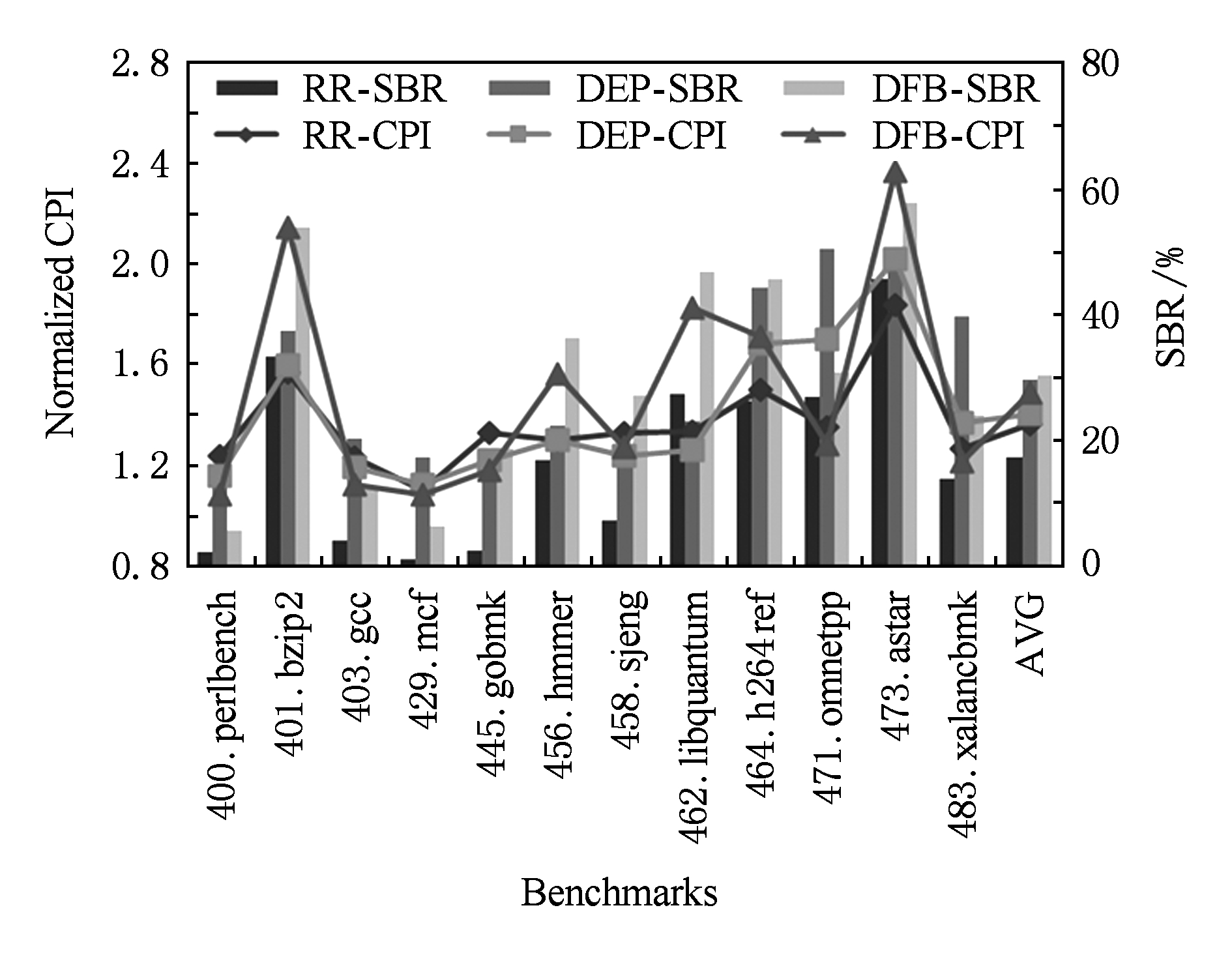
Fig. 18 Experimental result for 64-entry schedule window
图18 调度窗口大小为64的实验结果
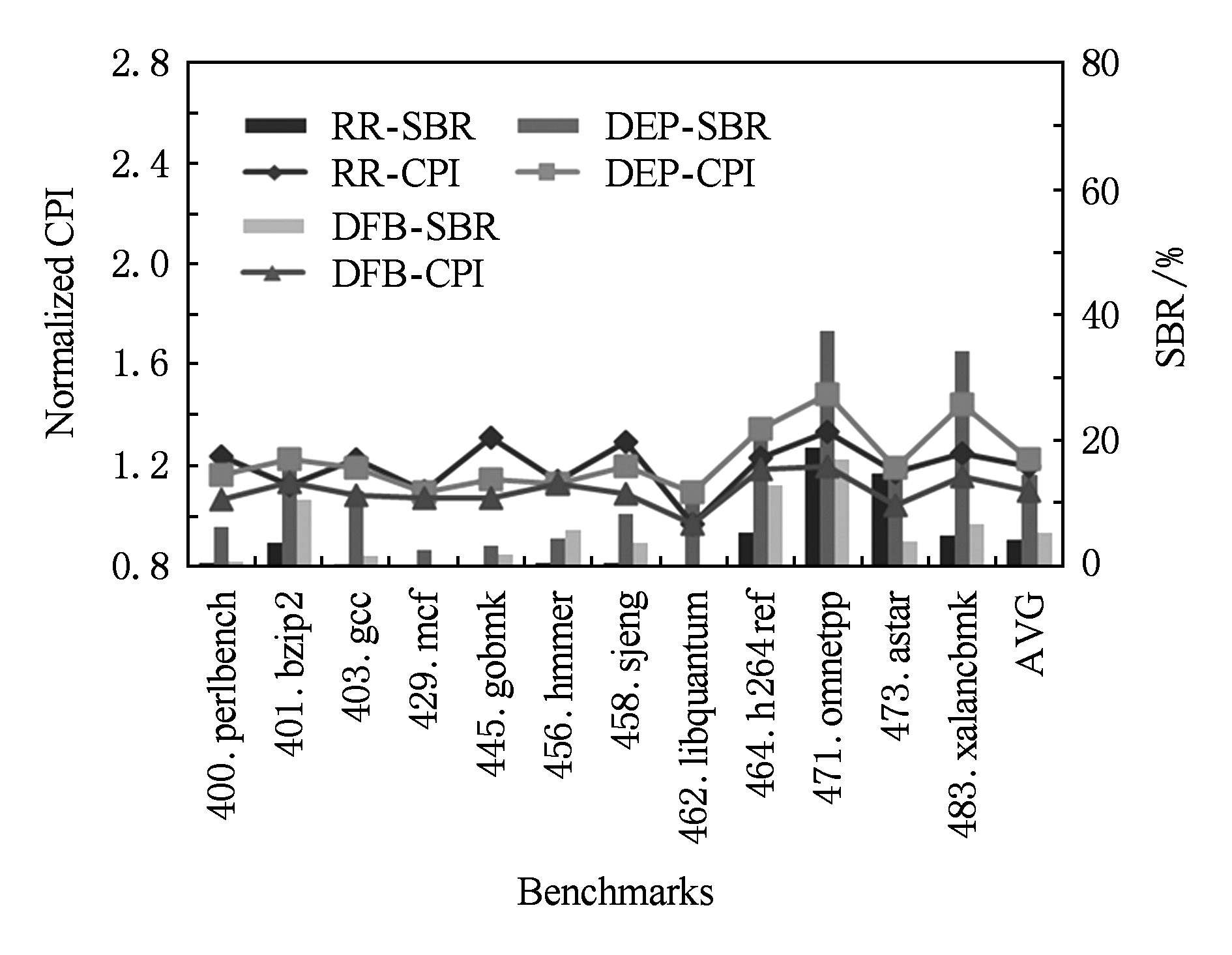
Fig. 19 Experimental result for 128-entry schedule window
图19 调度窗口大小为128的实验结果

Fig. 20 Experimental result for 256-entry schedule window
图20 调度窗口大小为256的实验结果
总调度窗口容量为64时,程序的SBR大幅增加,各调度方法性能损失严重.总调度窗口容量从128变为256时:增大的调度窗口为RR调度带来较小的性能改进;DEP调度效果变差,因为大的调度窗口使指令在做调度决策时有更大几率分布到其生产者所在分区,这使得负载均衡变差;DFB调度受益于调度窗口容量增长,实际指令发射与执行情况接近DFB缓存的调度模式,从而有较好的调度效果.
随着调度窗口增大,测试程序平均调度效果的变化趋势如图21所示.过小的调度窗口阻塞非常严重,RR调度均衡使用所有的分区,其SBR最小,平均性能最好.随着调度窗口增大,DFB调度的SBR快速下降,性能变化曲线陡峭,受益于调度窗口容量增大最明显.

Fig. 21 Performance trend with increasing schedule window size
图21 随着调度窗口大小增加性能的变化趋势
6.2.4 DFB空间指令调度算法分析小结
通过对分区数、IPL和调度窗口容量的实验,我们总结出5条规律:
1) 随着分区数的增加或发射队列的变小,RR调度逐渐强于DEP调度.
2) 随着IPL的增加,DEP调度性能稳定,而RR调度性能损失严重.
3) 具有不同并行性特征的程序对调度方法存在偏好.同一程序在不同资源配置下对调度方法存在偏好.
4) DFB调度同时参考相对关键性这种量化的程序并行性特征与资源约束进行调度决策,其调度效果、适应性和稳定性同时优于RR调度和DEP调度.
5) DFB调度对发射队列容量敏感,调度效果与调度阻塞率有明显相关性,采用合理的发射队列大小或者引入指令预调度技术可以改善DFB调度效果.
DFB Trainer构建DFB有延迟,DFB Cache也不可能覆盖所有的动态指令.DFB Cache未命中时,DFB Scheduler使用DEP调度.假设DFB Cache最多缓存256个DFB,采用LRU替换策略,DFB Trainer构建DFB的延迟平均为100个周期.图22展示了该DFB Cache对动态指令的覆盖率.设置调度窗口容量为128条指令,分区数为8,IPL为1周期,程序执行结果与RR调度、DEP调度以及理想DFB调度的对比如图23所示.
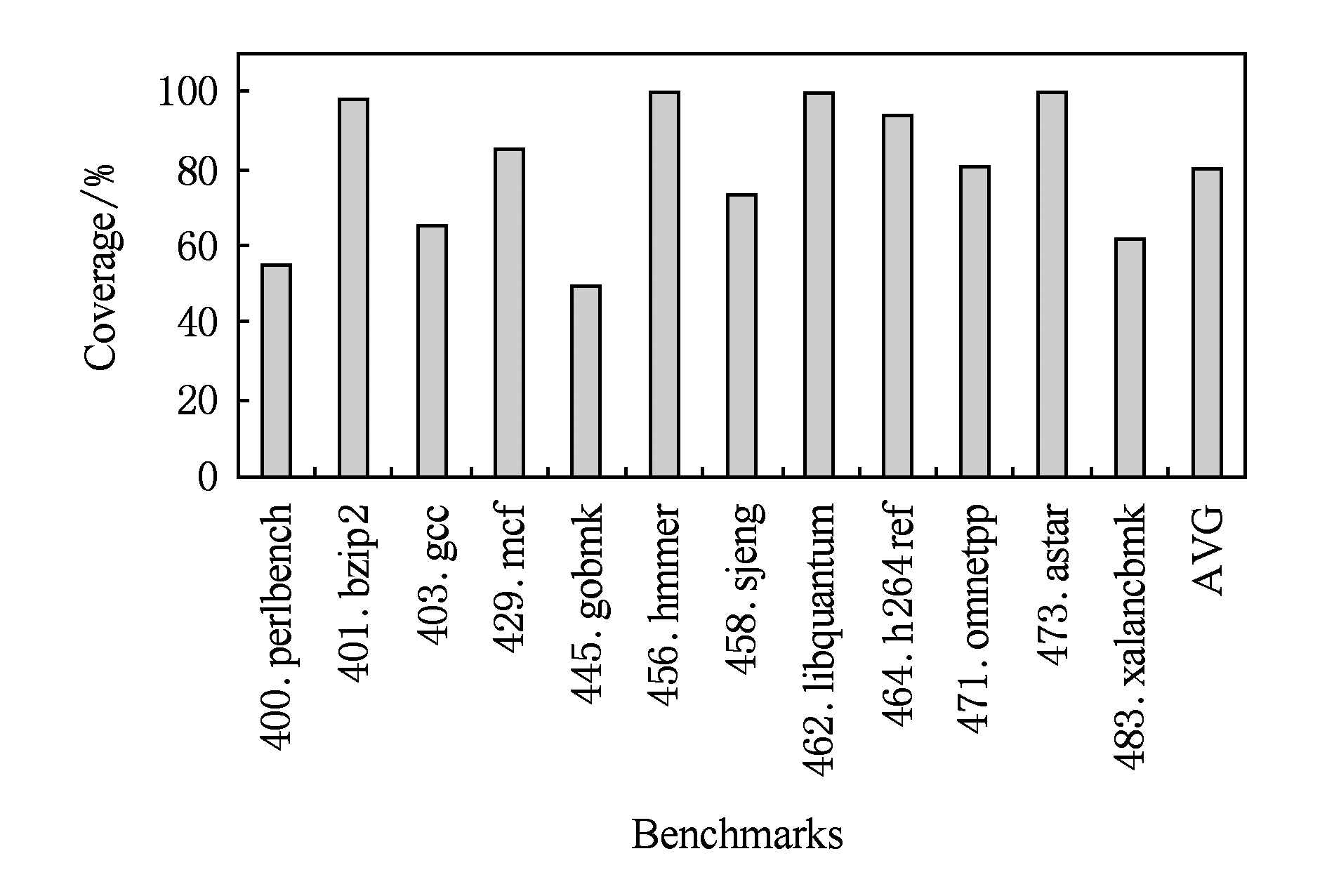
Fig. 22 Dynamic instruction coverage with the implementation example
图22 示例实现对动态指令的覆盖率
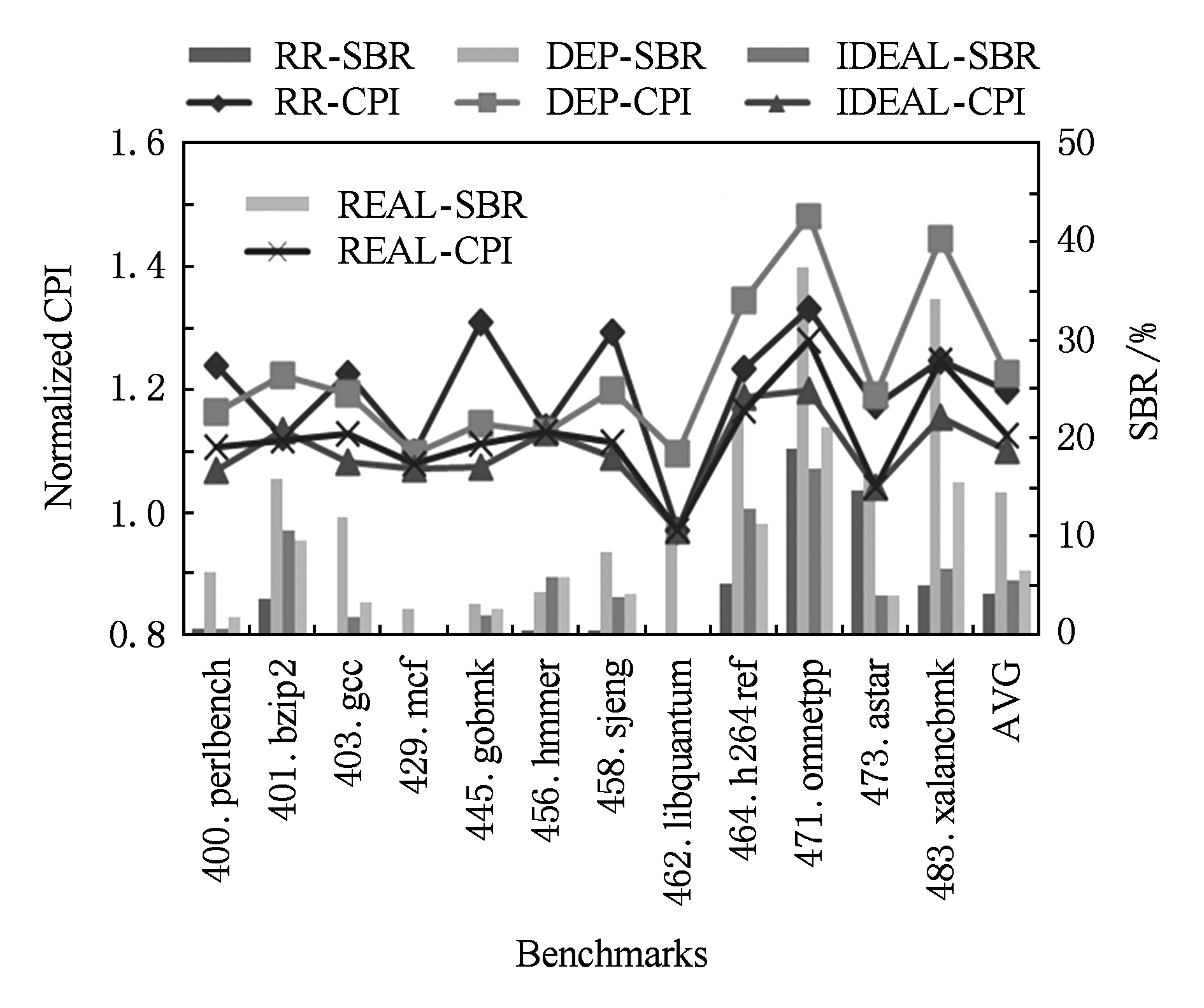
Fig. 23 Experimental result of the implementation example
图23 示例实现的实验结果
DFB Cache平均动态指令覆盖率达到了80%.不同程序的覆盖率由其计算局部性决定,覆盖率越高,调度结果越接近理想DFB调度.缓存32 KB指令的DFB Cache的面积开销约为同等容量的4路组相连ICache的40%,功耗仅为ICache的一半[32].
DFB Cache覆盖率较低且DEP调度的SBR较大时,示例DFB调度实现的CPI和SBR比理想调度稍差.bzip2和h264ref的调度效果略强于理想调度,SBR稍有降低,这是因为计算局部性较差的指令基本块被过滤掉,负载均衡优先电路的平衡作用更好.从平均调度结果可以看出,示例DFB调度实现的调度效果强于RR调度和DEP调度,比较接近理想DFB调度.
为了解决周期、功耗或可扩展性等方面的问题,分簇超标量处理器与动态多核处理器等微结构使用空间分布的多个硬件分区.分区结构可能受到负载不均衡与跨区操作数传递延迟导致的性能惩罚,空间指令调度通过合理分布指令降低这些性能惩罚.已有方法基于指令是否位于关键路径的判断,在依赖调度和负载均衡调度之间做出权衡.
本文提出了基于数据流块的空间指令调度.数据流块是动态构建、缓存并重用的一个或数个顺序执行的指令基本块的调度模式.与已有方法不同,基于数据流块的调度用调度裕量量化描述程序的并行性特征,根据指令的相对关键性进行调度.我们介绍了基于数据流块的空间指令调度的微结构框架和算法.通过对分区数、跨区操作数传递延迟和调度窗口容量等与调度方法密切相关的结构参数的实验,我们证明了基于数据流块的空间调度方法的调度效果和稳定性优于负载均衡调度和参考绝对关键性的依赖调度.最后举例证明,与基于数据流缓存的前端设计[32]相结合,以有限的面积与功耗开销,基于数据流块的空间调度的调度效果接近理想化调度.
当发射队列较小导致调度阻塞率上升时,基于数据流块的空间指令调度的调度效果受到较大影响.指令预调度等时间指令调度方法可以提升发射队列的使用效率,将来我们考虑综合使用时间和空间指令调度,进一步提升基于数据流块的调度方法的适应性.
参考文献
[1]Palacharla S, Jouppi N P, Smith J E. Complexity-effective superscalar processors[C] Proc of the 24th Int Symp on Computer Architecture. New York: ACM, 1997: 206-218
Proc of the 24th Int Symp on Computer Architecture. New York: ACM, 1997: 206-218
[2]Parcerisa J M. Desigen of clustered superscalar microarchitectures[D]. Barcelona, Spain: Universitat Politècnica de Catalunya, 2004
[3]Agarwal V, Hrishikesh M S, Keckler S W, et al. Clock rate versus IPC: The end of the road for conventional microarchitectures[C]Proc of the 27th Int Symp on Computer Architecture. New York: ACM, 2000: 248-259
[4]Borkar S, Dubey P, Kahn K, et al. Platform 2015: Intel processor and platform evolution for the next decade[JOL]. [2015-07-04]. http:www.researchgate.netpublication247190040
[5]Hill M D, Marty M R. Amdahl's law in the multicore era[J]. Computer, 2008, 41(7): 33-38
[6]Levy H M, Eggers S J, Tullsen D M. Simultaneous multithreading: Maximizing on-chip parallelism[J]. ACM Sigarch Computer Architecture News, 1995, 23(2): 392-403
[7]Seznec A, Michaud P. Data-flow prescheduling for large instruction windows in out-of-order processors[C]Proc of Int Symp on High Performance Computer Architecture. Piscataway, NJ: IEEE, 2001: 27-36
[8]Canal R, Gonzalez A. Reducing the complexity of the issue logic[C]Proc of Int Conf on Supercomputing. New York: ACM, 2001: 312-320
[9]Raasch S E, Binkert N L, Reinhardt S K. A scalable instruction queue design using dependence chains[J]. ACM Sigarch Computer Architecture News, 2002, 30(2): 318-329
[10]Lebeck A R, Koppanalil J, Li T, et al. A large, fast instruction window for tolerating cache misses[C]Proc of Int Symp on Computer Architecture. Piscataway, NJ: IEEE, 2002: 59-70
[11]Ernst D, Hamel A, Austin T. Cyclone: A broadcast-free dynamic instruction scheduler with selective replay[C]Proc of Int Symp on Computer Architecture. Piscataway, NJ: IEEE, 2003: 253-262
[12]Canal R, Parcerisa J M, Gonzalez A. Dynamic cluster assignment mechanisms[C]Proc of the 6th Int Symp on High-Performance Computer Architecture. Piscataway, NJ: IEEE, 2000: 133-142
[13]Baniasadi A, Moshovos A. Instruction distribution heuristics for quad-cluster, dynamically-scheduled, superscalar processors[C]Proc of Int Symp on Microarchitecture. Piscataway, NJ: IEEE, 2000: 337-347
[14]Balasubramonian R, Dwarkadas S, Albonesi D H. Dynamically managing the communication-parallelism trade-off in future clustered processors[C]Proc of the 30th Int Symp on Computer Architecture. Piscataway, NJ: IEEE, 2003: 275-286
[15]Bhargava R, John L K. Improving dynamic cluster assignment for clustered trace cache processors[C]Proc of Int Symp on Computer Architecture. Piscataway, NJ: IEEE, 2003: 264-274
[16]Fields B, Rubin S, Bodik R. Focusing processor policies via critical-path prediction[C]Proc of Int Symp on Computer Architecture. Piscataway, NJ: IEEE, 2001: 74-85
[17]Salverda P, Zilles C. A criticality analysis of clustering in superscalar processors[C]Proc of the 38th Int Symp on Microarchitecture. Piscataway, NJ: IEEE, 2005: 66-77
[18]Ipek E, Kirman M, Kirman N, et al. Core fusion: Accommodating software diversity in chip multiprocessors[C]Proc of the 34th Int Symp on Computer Architecture. New York: ACM, 2007: 186-197
[19]Kim C, Sethumadhavan S, Govindan M S, et al. Composable lightweight processors[C]Proc of the 40th Int Symp on Microarchitecture. Piscataway, NJ: IEEE, 2007: 381-394
[20]Rodrigues R, Annamalai A, Koren I, et al. Performance per watt benefits of dynamic core morphing in asymmetric multicores[C]Proc of Int Conf on Parallel Architectures and Compilation Techniques. Los Alamitos, CA: IEEE Computer Society, 2011: 121-130
[21]Zhong H, Lieberman S A, Mahlke S A. Extending multicore architectures to exploit hybrid parallelism in single-thread applications[C]Proc of the 13th Int Symp on High Performance Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2007: 25-36
[22]Watanabe Y, Davis J D, Wood D A. WiDGET: Wisconsin decoupled grid execution tiles[C]Proc of the 37th Int Symp on Computer Architecture. New York: ACM, 2010: 2-13
[23]Sankaralingam K, Nagarajan R, Liu H, et al. Exploiting ILP, TLP, and DLP with the polymorphous TRIPS architecture[C]Proc of Int Symp on Computer Architecture. Piscataway, NJ: IEEE, 2003: 422-433
[24]Taylor M B, Psota J, Saraf A, et al. Evaluation of the raw microprocessor[J]. ACM Sigarch Computer Architecture News, 2004, 32(2): 2-13
[25]Govindaraju V, Ho C H, Sankaralingam K. Dynamically specialized datapaths for energy efficient computing[C]Proc of Int Symp on High Performance Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2011: 503-514
[26]Gupta S, Feng S, Ansari A, et al. Bundled execution of recurring traces for energy-efficient general purpose processing[C]Proc of Int Symp on Microarchitecture. Piscataway, NJ: IEEE, 2011: 12-23
[27]Hopkins M E, Nair R. Exploiting instruction level parallelism in processors by caching scheduled groups[C]Proc of Int Symp on Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 1997: 13-25
[28]Franklin M, Smotherman M. A fill-unit approach to multiple instruction issue[C]Proc of Int Symp on Microarchitec-ture. Piscataway, NJ: IEEE, 1994: 162-171
[29]Rotenberg E, Bennett S, Smith J E. Trace cache: A low latency approach to high bandwidth instruction fetching[C]Proc of Int Symp on Microarchitecture. Los Alamitos, CA: IEEE Computer Society, 1996: 24-34
[30]Friendly D H, Patel S J, Patt Y N. Putting the fill unit to work: Dynamic optimizations for trace cache microprocessors[C]Proc of the 31st Int Symp on Microarchitecture. Piscataway, NJ: IEEE, 1998: 173-181
[31]Patel S J, Lumetta S S. rePLay: A hardware framework for dynamic optimization[J]. IEEE Trans on Computers, 2001, 50(6): 590-608
[32]Liu Bingtao, Wang Da, Ye Xiaochun, et al. A dataflow cache processor frontend design[J]. Journal of Computer Research and Development, 2016, 53(6): 1221-1237 (in Chinese)(刘炳涛, 王达, 叶笑春, 等. 一种缓存数据流信息的处理器前端设计[J]. 计算机研究与发展, 2016, 53(6): 1221-1237)
[33]Ardestani E K, Renau J. ESESC: A fast multicore simulator using time-based sampling[C]Proc of the 19th IEEE Int Symp on High Performance Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2013: 448-459
Liu Bingtao1,2,3, Wang Da1, Ye Xiaochun1, Fan Dongrui1,2, Zhang Zhimin1, and Tang Zhimin1
1(StateKeyLaboratoryofComputerArchitecture(InstituteofComputingTechnology,ChineseAcademyofSciences),Beijing100190)
2(SchoolofComputerandControlEngineering,UniversityofChineseAcademyofSciences,Beijing100049)
3(InstituteofInformationandControl,HangzhouDianziUniversity,Hangzhou310018)
AbstractClustered superscalar processors partition hardware resources to circumvent the energy and cycle time penalties incurred by large, monolithic structures. Dynamic multi-core processors fuse hardware resources of several physical cores to provide the computation capability adapting to applications. Energy-efficient computation is achieved in these architectures with a carefully orchestrated utilization of spatially distributed hardware resources. Problems such as instruction load imbalance and operand forwarding latency between partitions may cause performance penalties, so an effective spatial instruction scheduling method is needed to distribute the computation among the partitions of spatial architectures. We present the data-flow block(DFB) based spatial instruction scheduling method. DFBs are dynamically constructed, cached and reused schedule patterns for one or more sequentially executed instruction basic blocks. DFB scheduling algorithm models the data-flow constraints of dynamic instruction stream and the scheduling space defined by hardware resources, then makes the scheduling decision according to the relative criticality, which is the quantitative scheduling slack of instructions. We present the framework and algorithm related to DFB scheduling. Through experimenting with various microarchitecture parameters closely related to scheduling method such as partition count, inter-partition latency and schedule window capacity, we prove that ideal DFB scheduling performs better and stabler than round-robin and dependence-based scheduling. At last, we show that the scheduling performance with a DFB cache implementation example closes to ideal DFB scheduling.
Keywordsprocessor microarchitecture; load balancing; instruction scheduling; data-flow; critical path
This work was supported by the National Key Research and Development Program of China (2016YFB0200501), the National Natural Science Foundation of China (61332009, 61521092, 61671196, 61327902), the Open Program of the State Key Laboratory of Mathematical Engineering and Advanced Computing (2016A04), and Beijing Municipal Science and Technology Commission Program (Z15010101009).
基金项目:国家重点研发计划项目(2016YFB0200501);国家自然科学基金项目(61332009,61521092,61671196,61327902);数学工程与先进计算国家重点实验室开放基金项目(2016A04);北京市科委科技计划专项项目(Z15010101009)
修回日期:2016![]() 06
06![]() 07
07
收稿日期:2016![]() 03
03![]() 10;
10;
中图法分类号TP303

LiuBingtao, born in 1983. PhD candidate. Student member of CCF. His main research interests include processor microarchitecture, reconfigurable computing and heterogeneous computing.

WangDa, born in 1981. PhD, associate professor. Member of CCF. Her main research interests include IC testing, analysis and micro-architecture design.

YeXiaochun, born in 1981. PhD, associate professor. Member of CCF. His main research interests include high-performance computer architecture and software simulation.

FanDongrui, born in 1979. PhD, professor and PhD supervisor. Member of CCF. His main research interests include low-power design and processor microar-chitecture.

ZhangZhimin, born in 1963. Professor and PhD supervisor of the Institute of Computing Technology, the Chinese Academic of Sciences. His main research interests include SoC design and computer architecture.

TangZhimin, born in 1966. Received his PhD degree from the Institute of Computing Technology, Chinese Academy of Sciences in 1990. Professor and PhD supervisor. Senior Member of CCF. His main research interests include high performance computer architecture design, MPP system and digital signal processing.