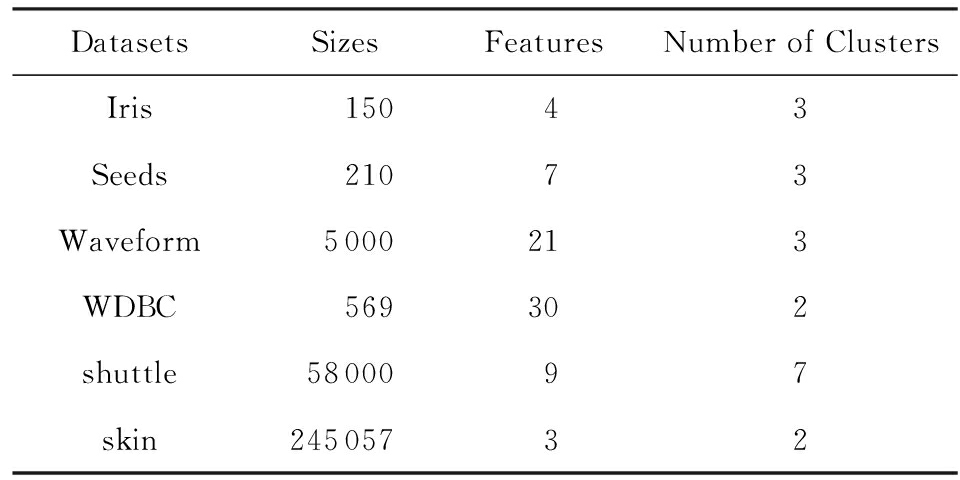
张远鹏 1,2 邓赵红 1 钟富礼 3 杭文龙 1 王士同 1,3
1 (江南大学数字媒体学院 江苏无锡 214122)
2 (南通大学医学信息学系 江苏南通 226019)
3 (香港理工大学计算学系 香港 999077)
(155297131@qq.com)
摘 要 在基于代表点的聚类算法中,为了解决算法自适应性和聚类速度问题,在快速压缩集密度估计的基础上,提出了一种基于代表点评分策略的快速自适应聚类算法.该算法的提出基于3个非常重要的假设:1)每个簇有一个代表点,且代表点来自簇内高密度样本;2)代表点或在压缩集中,或在压缩集附近且与压缩集中样本具有高度相似性;3)各簇中样本围绕代表点并沿着压缩集扩散.基于第1个和第2个假设,提出用代表点分值来评估样本成为代表点的可能性,并分析了其合理性.基于第3个假设和代表点分值,构建了一种快速的自适应聚类算法,该算法将所有样本按照其代表点分值从大到小排序,形成代表点候选集;然后从代表点候选集中逐个选择代表点,利用其邻域不断传递标签至整个压缩集;最后采用同样的方法将压缩集中样本的标签扩散至整个数据集,在此过程中引入抽样,提高标签传播速度.在人工数据集和真实数据集上的实验表明:所提出的算法能够处理任意形状的数据集和大规模数据集,且不需要指定类别数.
关键词 代表点分值;快速压缩集密度估计器;压缩集;标签传播;抽样
聚类分析是一种无监督的学习方法,在模式识别领域占有非常重要的地位,成熟的聚类算法目前在图像分割、数据挖掘、生物信息学以及计算机视觉等领域得到了广泛的应用 [1-3] .聚类的目标是找到数据集中样本的“自然分组”,即相似样本的集合,称之为“簇”.目前聚类的方法有很多种,其中基于代表点的聚类算法近年来受到了广泛的关注.
代表点(exemplar)是数据集中实际存在的样本,代表簇中心.目前,基于代表的聚类算法可大体分为3类:
1) 以AP(affinity propagation) [4] 和EEM (enhanced α -expansion move) [5] 等为代表的聚类算法.该类算法可以通过优化Markov随机场(Markov random field, MRF)进行求解.优化MRF的方法有2种:①AP所采用的基于信息传递的LBP(loop belief propagation)算法 [6] ;②EEM所采用基于Graph Cuts的方法 [7] .在该类算法中,将数据集中所有的样本都当成潜在的类中心,然后通过迭代不断更新每个样本的吸引度值和归属度值,直到产生高质量的代表点 [5] .
2) 以 K -medoid [8] 及其模糊版本FCMdd(fuzzy c -medoids) [9] 等为代表的聚类算法.该类算法首先以随机的方式选择代表点,然后通过不断迭代调整,使得距离平方误差之和达到最小 [4] .
3) 以CDP(clustering by fast search and find of density peaks) [10] 及其相关改进算法为代表的基于密度的聚类算法 [11] ,该类算法通过密度估计,可以发现任意形状数据集的密度峰值点(代表点).
上述不同类型的基于代表点聚类算法,有着各自的优缺点.例如,AP算法突破了类中心及类中心个数需要预设的限制,同时算法的鲁棒性较好.但是,AP算法在进行样本分配时,将其分配给离自己最近的代表点,因此,算法很难发现非凸形状的簇,同时,AP算法的时间复杂度为 O ( N 2 log N ),无法处理大规模数据. K -medoid算法由于是随机选择初始代表点,故对初始簇代表点的选择非常敏感,若初始簇代表点选择不当,会造成聚类的结果和数据的实际分布相差很大.另外和AP一样,该算法同样不能很好地发现非凸形状的簇.CDP算法认为簇代表点的局部密度应该大于其邻居的局部密度,且不同簇代表点之间的距离相对较远.通过这2种特征,CDP算法很容易发现簇代表点.该算法所采用的“一步”样本分配策略(将样本分配到距离自己最近且局部密度比自己大的样本所在簇)可以发现任意形状的簇,但是,容易出现一步错、步步错的局面.
受CDP算法的启发,通过概率密度估计来寻找代表点也是一种有效的方法,因为代表点往往出自概率密度高的样本.Parzen窗(Parzen window, PW)是一种有效的非参数概率密度估计模型,但该模型在进行概率密度估计时需要所有的样本都参与计算,因此,在样本规模较大时概率密度估计的效率低下,不适合大规模数据集 [12] .解决这个问题的方法通常是用一个能够代表原数据集样本分布的子集来参与概率密度估计,即对原样本进行数据压缩.目前用于执行数据压缩的方法很多,如Catlett [13] 提出的随机抽样(random sampling)、分层抽样(stratified sampling)和窥孔法(peepholing),Lewis等人 [14] 提出的不确定抽样(uncertainty sampling)以及主动学习(active learning)算法等.Girolami等人 [15] 提出的压缩集密度估计器(reduced set density estimator,RSDE)就是其中具有代表性的一种方法,通过该方法获得的压缩集能够以较高的精确逼近原数据集.RSDE的求解过程可等价于二次规划问题,因此,时间复杂度在 O ( N 2 )以上,同样不适合大规模数据集.随后,Deng等人 [16] 提出了一种快速压缩集密度估计器(fast reduced set density estimator, FRSDE),认为RSDE等价于中心约束的最小包含球问题,并利用近似最小包含球的快速核心集技术求解,使得FRSDE的时间复杂度和样本规模呈近似线性关系,空间复杂度与样本规模无关,与近似最小包含球的逼近参数有关,且所形成的压缩集亦能够以较高的精度逼近原数据集.
基于FRSDE,我们提出3点假设:1)每个簇有一个代表点,且代表点来自簇内高密度样本;2)代表点或在压缩集中,或在压缩集附近且与压缩集中样本具有高度相似性;3)各簇中样本围绕代表点并沿着压缩集扩散.基于以上3个假设,我们提出一个基于代表点评分策略的快速自适应聚类算法(fast self-adaptive clustering algorithm based on exemplar score, ESFSAC),该算法过程可以分为3部分:1)快速确定簇内代表点;2)压缩集聚类;3)压缩集标签传播.本文的贡献主要体现在3个方面:
1) 在已有工作的基础上,提出了一种基于压缩集的快速密度估计方法计算每个样本的代表点分值(exemplar score, ES),用于评估样本成为簇内代表点的可能性,且从理论上证明了所提方法的合理性.借助ES,可以发现具有不同形状数据集的簇内代表点;
2) FRSDE“清理”了簇与簇之间的稀疏样本,使得压缩集中簇与簇之间的边界更加清晰,因此,在压缩集聚类时,摒弃了基于划分的方法(将样本分配给离自己最近的代表点),利用代表点的邻域不断传播标签,使得算法适用于不同形状的数据集;
3) 根据第3个假设和ES,提出了一种快速的压缩集标签传播方法.该方法以压缩集中获得类别标签的样本作为“种子”,不断通过其邻域传播标签,当已经标记的样本达到一定规模后,利用抽样方法,加速标签传播速度.
RSDE通过雇用样本空间的高密度区域的样本来实现对原始样本空间分布的逼近,其优化过程可等价于求解一个二次规划问题,优化所得到的结果为一个与样本对应的稀疏向量,向量中的元素表示样本的权重系数.对于给定的数据集 D ={ x 1 , x 2 ,…, x N }∈ ![]() d ,该问题可以描述为
d ,该问题可以描述为
![]()
(1)
其中, 1 表示一个 N ×1的单位向量; C 表示一个大小为 N × N 的矩阵,其元素可表示为
C ( x i , x j )= ![]() K h ( x , x i ) K h ( x , x j )d x ,
K h ( x , x i ) K h ( x , x j )d x ,
K h 表示一个核函数,向量 p 中元素为所有样本的PW密度估计值,可表示为
![]()

![]()
对于核函数 K h 的选择,Kollios等人 [17] 指出,核函数的形状不会影响逼近精度,所以,为了简化计算,我们采用高斯型核函数,这样便可将 ![]() 简化为 G 2 h ( x i , x j ).通过优化式(1)所描述的问题,可以得到稀疏向量 γ ,向量中不为0的元素对应的样本所构成的集合即为所求压缩集.但是,此优化过程需要消耗 O ( N 3 )的时间复杂度以及至少 O ( N 2 )的空间复杂度,不能满足实际的需求.为了解决算法复杂度问题,通过证明RSDE与最小包含球(minimum enclosing ball, MEB)之间的等价关系,从而可以利用MEB的核心集算法快速求解RSDE问题,即FRSDE算法.
简化为 G 2 h ( x i , x j ).通过优化式(1)所描述的问题,可以得到稀疏向量 γ ,向量中不为0的元素对应的样本所构成的集合即为所求压缩集.但是,此优化过程需要消耗 O ( N 3 )的时间复杂度以及至少 O ( N 2 )的空间复杂度,不能满足实际的需求.为了解决算法复杂度问题,通过证明RSDE与最小包含球(minimum enclosing ball, MEB)之间的等价关系,从而可以利用MEB的核心集算法快速求解RSDE问题,即FRSDE算法.
为了使得更多的机器学习中的核化方法等价于MEB问题,Tsang等人 [18] 将MEB问题扩展为中心约束的最小包含球问题(center constrained minimal enclosing ball, CCMEB).
在CCMEB中,通过引入特征 δ i ,将MEB的核空间 Γ 进行扩维,形成新的核空间 Γ ′, Γ ′中样本的特征可表示为 ![]() 球中心点特征为
球中心点特征为 ![]() 其中 c 表示 Γ 空间的球心向量.故扩维后新特征空间的MEB问题,即CCMEB可以表示为
其中 c 表示 Γ 空间的球心向量.故扩维后新特征空间的MEB问题,即CCMEB可以表示为
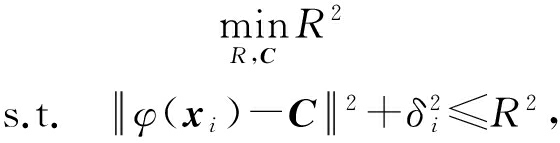
(2)
式(2)的对偶形式可以表示为
![]()
(3)
在式(3)中,
(4)
K 表示 N × N 的矩阵,其元素为 K ( x i , x j )= φ ( x i ) T φ ( x j ).由于式(3)中的约束条件 α T 1 =1,故式(5)与式(3)同解.
![]()
(5)
其中 η 为一常数.对于满足式(5)且约束条件满足式(4)的问题,可视为CCMEB问题.在式(1)中,令:
Δ =- diag ( C )+2 p + η 1 ,
(6)
其中, η 取值需要使得 Δ ≥ 0 ,则式(1)可重新表示为
![]()
(7)
比较式(7)和式(5),在 K = C , α = γ 的情况下,显然等价.因此,RSDE与CCMEB之间存在等价关系,可以利用近似MEB的快速核心集技术求解,具体求解过程请参见文献[16].
为了寻找簇内代表点,我们定义一个度量,即代表点分值ES来评价数据集中每个样本成为簇内代表点的可能性.对于给定的数据集 D ={ x 1 , x 2 ,…, x N }∈ ![]() d , x i 的代表点分值定义如下:
d , x i 的代表点分值定义如下:
(8)
其中, j ∈{ i | β i >0, i =1,2,…, N }, β j 表示样本 x j 在压缩集中的权重系数,样本 x i 的概率密度 p ( x i )可以通过压缩集进行估计,即:
(9)
其中, K σ ( x i , x j )表示核函数,由于核函数的形状对样本密度估计的精度影响不大 [17] ,因此这里选择比较常用的高斯核函数.从式(9)可以看出,我们仅选择了压缩集中的样本对原数据集中的样本进行密度估计,在数据集规模较大时这种方式可以显著提高效率.
从式(8)中可以看出,ES的提出同时考虑了前文所述的第1个和第2个假设,即认为簇内代表点来自密度高的样本,且代表点或在压缩集中,或在压缩集附近且与压缩集中样本具有高度相似性.接下来,通过2个定理来论证ES提出的合理性.
定理1 . 密度高的样本是潜在的簇内代表点.
证明. 对于给定的数据集 D ={ x 1 , x 2 ,…, x N }∈ ![]() d ,从中选择 M 个样本来估计 D 中样本的概率密度,按照PW密度估计理论 [19] , D 中样本的概率密度可以表示为 p ( x )=(1/
d ,从中选择 M 个样本来估计 D 中样本的概率密度,按照PW密度估计理论 [19] , D 中样本的概率密度可以表示为 p ( x )=(1/ ![]() ).若用
).若用 ![]() 表示 D 中样本真实概率密度,则
表示 D 中样本真实概率密度,则 ![]() 与 p ( x )的积分累计误差
与 p ( x )的积分累计误差 ![]() 为
为
ISE ( ![]() ( x ), p ( x ))=
( x ), p ( x ))= ![]() (
( ![]() ( x )- p ( x )) 2 d x =
( x )- p ( x )) 2 d x = ![]()
![]()
![]()
(10)
其中等式右边第1项可以表示为数学期望的形式,即:
![]()
![]() ].
].
(11)
由于所有样本的概率密度之和为1,因此,对于所选的 M 个样本,在没有任何先验知识的情况下,我们粗略认为这 M 个样本的概率密度之和为1,故 E M [ p ( x )]= ![]() ;等式右边第2项可以表示为
;等式右边第2项可以表示为
![]()
![]() ;
;
式(10)等号右边第3项 ![]() 为一常数 C .综合这3项的等价(或近似等价)表达,式(10)亦可以表示为
为一常数 C .综合这3项的等价(或近似等价)表达,式(10)亦可以表示为
ISE ( ![]() ( x ), p ( x ))≈
( x ), p ( x ))≈ ![]() -
- ![]() p ( x i )+ C .
p ( x i )+ C . ![]() (12)
(12)
显然,从式(12)中可以看出 ![]() 仅与所选的样本数量 M 以及所选样本的密度有关,换言之,若使
仅与所选的样本数量 M 以及所选样本的密度有关,换言之,若使 ![]() 越小,所选的 M 个样本的密度需要越高,故定理1成立.因此,在聚类过程中,簇内代表点应该优先选择概率密度高的样本.
越小,所选的 M 个样本的密度需要越高,故定理1成立.因此,在聚类过程中,簇内代表点应该优先选择概率密度高的样本.
证毕.
定理2 . 聚类的泛化性能仅仅依赖于样本的概率密度分布.
证明. 首先我们来观察数据集 D 的真实概率密度函数 ![]() 和在 D 上进行聚类的泛化性能之间的关系.假设某一测试数据集 D 由一随机变量 X 生成,整个测试误差可以定义为
和在 D 上进行聚类的泛化性能之间的关系.假设某一测试数据集 D 由一随机变量 X 生成,整个测试误差可以定义为
![]()
![]()
(13)
其中, p ( C x | x )为对真实概率密度函数 ![]() 的估计,其含义表示样本 x 的类别标签是 C x 的可能性.
的估计,其含义表示样本 x 的类别标签是 C x 的可能性. ![]() 表示关于样本 x 密度估计的绝对误差.我们定义 η ( x )=e - ε ( x ) 来评估对样本 x 进行密度估计的精度,显然, η ( x )与 ε ( x )之间呈反比关系.另外,我们还假设
表示关于样本 x 密度估计的绝对误差.我们定义 η ( x )=e - ε ( x ) 来评估对样本 x 进行密度估计的精度,显然, η ( x )与 ε ( x )之间呈反比关系.另外,我们还假设 ![]() 是有界的且 η ( x )通过
是有界的且 η ( x )通过 ![]() 正则化,这样 η ( x )为一个近似概率密度函数且满足
正则化,这样 η ( x )为一个近似概率密度函数且满足 ![]() 由于 ε ( x )=-ln η ( x ),故:
由于 ε ( x )=-ln η ( x ),故:
![]()
![]()
H ( X )+ KL ( X ‖ Z ),
(14)
其中, Z 表示关于 η ( x )的随机变量.对于给定的 X ,由于香农熵 H ( X )是一个常量,所以, e test 仅依赖于分布 Z 、 X 的真实概率密度函数 ![]() 和 η ( x )之间的KL距离.由此可见,最小化 e test 等价于最小化 KL ( X ‖ Z ),根据Jensen不等式 [20] ,可以得到:
和 η ( x )之间的KL距离.由此可见,最小化 e test 等价于最小化 KL ( X ‖ Z ),根据Jensen不等式 [20] ,可以得到:
KL ( X ‖ ![]()
![]()
(15)
在式(15)中,当且仅当 ![]() 时,等号成立.换言之,为了获得最小的 e test ,期望聚类数据集对应的概率密度函数 η ( x )与其真实的概率密度函数
时,等号成立.换言之,为了获得最小的 e test ,期望聚类数据集对应的概率密度函数 η ( x )与其真实的概率密度函数 ![]() 相等.因此,在进行数据压缩时,我们需要使得压缩集的样本密度分布尽量接近原始的数据集的样本密度分布,也就是说,定理2成立.
相等.因此,在进行数据压缩时,我们需要使得压缩集的样本密度分布尽量接近原始的数据集的样本密度分布,也就是说,定理2成立.
证毕.
ES的提出,继承了上述2个定理的本质,因此具有一定的理论依据.
ESFSAC聚类算法过程可以分为3个部分:1)在压缩集的基础上,利用代表点评分策略评估所有样本的ES值;2)根据每个样本的ES值,完成压缩集的类别标定,即压缩集聚类;3)将压缩集的标签传递至整个数据集,即剩余集聚类(剩余集指原数据集中去除压缩集剩下的样本集合).为了易于理解,首先给出算法中所涉及的3个相关定义.
定义1 . 代表点候选集(exemplar candidate set).数据集中的样本按照其ES值进行从大到小进行排序后所形成的样本集合,该集合中,排在前面的样本成为簇内代表点的可能性越大.
定义2 . 样本 x 在数据集 D 中的 ξ 邻域 Nb ξ ( x , D ). D 是所有样本到 x 的距离小于等于 ξ 的样本的集合.
定义3 . 冗余代表点(superfluous exemplar).某一簇中,除去ES值最大的样本以外,还存在1个或1个以上的样本 x i , x i +1 ,…的ES值大于其他簇中最大的ES值,则称 x i , x i +1 ,…为冗余类代表点.
本节通过ES值来评估数据集中每个样本成为簇内代表点的可能性,并根据ES值形成代表点候选集.另外,值得注意的是,在评估样本的ES值时,参与计算的是由FRSDE得到的原数据集的子集,由于其规模远小于原数据集,故相对于PW来说,其评估速度有较大的提升.本节的算法描述如算法 1所示:
算法1 . 估算代表点分值(evaluate exemplar score, EES).
输入:压缩集 ![]() ⊆ D 、核宽 σ 、权重系数向量 β =( β 1 , β 2 ,…, β N r );
⊆ D 、核宽 σ 、权重系数向量 β =( β 1 , β 2 ,…, β N r );
输出:代表点候选集 D c .
过程:
① 初始化ES集 E =∅,初始化代表点候选集 D c =∅;
② For i =1 to N
For k =1 to N r
End For
E = E ∪{ es i };
End For
③ D c = sort ( E , D ,‘descending’).
在算法 1中, D r 为数据集 D 对应的压缩集, β i 为 D r 中样本 ![]() 的权重系数, N r 表示压缩集 D r 的大小, D r 和 β i 可由FRSDE得到. E ={ es 1 , es 2 ,…, es N }表示 D 中所有样本ES值的集合, D c 表示代表点候选集.算法 1主体可以分为3个步骤,在步骤①中,完成集合 E 和 D c 的初始化;在步骤②中,按照式(8)计算数据集 D 中每个样本的ES值;在步骤③中,按照每个样本的ES值从大到小的顺序重新排列样本得到代表点候选集.
的权重系数, N r 表示压缩集 D r 的大小, D r 和 β i 可由FRSDE得到. E ={ es 1 , es 2 ,…, es N }表示 D 中所有样本ES值的集合, D c 表示代表点候选集.算法 1主体可以分为3个步骤,在步骤①中,完成集合 E 和 D c 的初始化;在步骤②中,按照式(8)计算数据集 D 中每个样本的ES值;在步骤③中,按照每个样本的ES值从大到小的顺序重新排列样本得到代表点候选集.
在此阶段,我们需要考虑3个问题:1)如何使得聚类过程具有自适应性?即无需事先由用户指定聚类类别数.2)如何使得聚类算法能够适应不同形状的数据集?3)针对出现的冗余代表点,如何处理?关于何时会出现冗余代表点,这里作一点简要说明.当数据集中各个簇的样本密度分布较为平衡时(如4.2节中DS1,DS2,DS3),一般不会出现冗余代表点.但是,在有些情况下,数据集中各个类别之间样本大小不平衡或者样本密度分布不均匀,容易出现冗余代表点.如DS4,样本最多的簇中出现2个冗余代表点.
针对上述问题,我们设计了压缩集聚类算法2.算法2的基本思想是从代表点候选集中逐个选择代表点,并将其类别标签利用 ξ 邻域传递的方式扩散至整个压缩集,直到所有压缩集中的样本都获得类别标签.显然,算法2具有自适应性,且类别标签是沿着数据流的分布进行 ξ 邻域传递,故适合不同形状的数据集.另外,对于某一个簇中的冗余代表点而言,其具有非常明显的识别特征,因为冗余代表点一般在真实代表点(该簇中ES最大的样本)附近,真实代表点会先于冗余代表点被选中,故在该簇的真实代表点执行类别标签扩散时,冗余代表点已经获取到真实代表点的类别信息.因此,在代表点候选集中选择代表点时,对于已经获取了类别标签的代表点,则过滤.详细的算法描述见算法2.
算法2 . 压缩集聚类(reduced set clustering,RSC).
输入:压缩集 ![]() ⊆ D 、代表点候选集 D c 、距离阈值 ξ ;
⊆ D 、代表点候选集 D c 、距离阈值 ξ ;
输出:压缩集标签向量 Label r .
过程:
① 初始化标签向量 Label r = 0 ;
For i =1 to N
② ![]() 已经标定
已经标定
Continue;
End If
③ 计算 ![]() 且在 Label r 中将对应的标签设置为 i ;
且在 Label r 中将对应的标签设置为 i ;
④ While D nb ≠∅
For each y in D nb
计算 Nb ξ ( y , D r )在 Label r 中将对应的标签设置为 i ;
D r = D r \Nb ξ ( y , D r );
D nb = D nb \ y ;
D nb = D nb ∪( Nb ξ ( y , D r ) \ y );
End For
End While
If D r ==empty
Break;
End If
End For
在算法2中, Label r 为1× N r 的向量,表示压缩集样本的类别标签; D nb 为一个临时集合,储存中间结果.整个算法过程可以分为4个步骤,在步骤①中,初始化标签向量 Label r ;在步骤②中,判断当前的代表点 ![]() 是否为冗余代表点,如果是,则过滤
是否为冗余代表点,如果是,则过滤 ![]() 继续选择
继续选择 ![]() 否则执行步骤③;在步骤③中,将当前代表点的类别标签信息传递至其 ξ 邻域,并将获取类别标签信息的样本存储至临时集合 D nb 中,且从 D r 中删除;在步骤④中,对于 D nb 中的样本 y ,将 y 的类别标签信息传递至其 ξ 邻域,并将 Nb ξ ( y , D r )从 D r 中删除,将 y 从 D nb 中删除,最后合并至 D nb .重复这一过程直至 D nb =∅,整个算法当 D r =∅时终止.
否则执行步骤③;在步骤③中,将当前代表点的类别标签信息传递至其 ξ 邻域,并将获取类别标签信息的样本存储至临时集合 D nb 中,且从 D r 中删除;在步骤④中,对于 D nb 中的样本 y ,将 y 的类别标签信息传递至其 ξ 邻域,并将 Nb ξ ( y , D r )从 D r 中删除,将 y 从 D nb 中删除,最后合并至 D nb .重复这一过程直至 D nb =∅,整个算法当 D r =∅时终止.
第3个假设认为,剩余集中的样本围绕着代表点和已经获得类别标签的压缩集分布,故仍然可以采用 ξ 邻域类别标签传递的方法将压缩集样本的类别传递至剩余集样本.但是,随着已获得标签的样本逐渐增多,尤其当数据集规模较大时,这种传递策略效率低下.因此,为了提高剩余集样本类别分配的效率,采用Smola等人在文献[21]中提出的抽样方法,当已经获得类别标签的样本数量达到一定的阈值时(本文设定为1 000),从已获得标签的样本中不断进行抽样,传递抽样样本的标签.这种方法能够提高剩余集样本的聚类速度.剩余集聚类算法的详细描述见算法3.
算法3 . 剩余集聚类(remaining set clustering, RMSC).
输入:数据集 D 、压缩集 D r 、压缩集标签向量 Label r 、距离阈值 ξ ;
输出:剩余集标签向量 Label rm .
过程:
① 初始化剩余集标签向量 Label rm = 0 ,
D rm = D\D r ;
② While D rm ≠∅
If N r ≤1 000
D s = D r ;
Else
D s = SmolaRandom ( D r ,1 000);
End If
For i =1 to N s
计算 ![]() 且在 Label rm 中将对应的标签设置为
且在 Label rm 中将对应的标签设置为 ![]()
End For
End While
在算法3中, SmolaRandom 表示一个抽样过程; Label rm 是一个标签向量,代表剩余集中样本的类别标签; D rm 表示剩余集样本集合.整个算法过程可以分为2个步骤:在步骤①中,初始化标签向量 Label rm 以及获取剩余集样本集合;在步骤②中, D s 是一个临时集合,存储标签传播的“种子”样本,在已标记样本数目小于等于1 000时“种子”即为所有标记样本,当已标记样本数目大于1 000时启动抽样过程,然后不断将“种子”标签传播至未标记样本,直到所有样本均获得标签.
从算法1~3可以看出,ESFSAC算法的时间复杂度主要由4个部分构成:FRSDE,EES,RSC,RMSC.根据Badoiu等人 [22] 提出的核心集理论可知,FRSDE的算法复杂度和样本规模呈近似线性关系,即 O ( N );对于EES,从算法1的描述可知,其复杂度为 O ( NN r + N log N ),其中 N r 表示压缩集规模;对于RSC,从算法2的描述可知,其复杂度为 ![]() ,其中 N e 表示压缩集聚类结束时从代表点候选集中选择的代表点的个数;一般来说 N e 略大于或等于真实类别数;对于RMSC,从算法3的描述可知,其复杂度为 O ( N s SN ),其中, N s 表示算法3中 D s 的规模即“种子”数, S 表示剩余集聚类结束时一共抽样的次数.因此,鉴于以上分析,ESFSAC算法的时间复杂度可以表示为 O ( N (1+ N r +log N +
,其中 N e 表示压缩集聚类结束时从代表点候选集中选择的代表点的个数;一般来说 N e 略大于或等于真实类别数;对于RMSC,从算法3的描述可知,其复杂度为 O ( N s SN ),其中, N s 表示算法3中 D s 的规模即“种子”数, S 表示剩余集聚类结束时一共抽样的次数.因此,鉴于以上分析,ESFSAC算法的时间复杂度可以表示为 O ( N (1+ N r +log N + ![]() 其中, N r , N e , S 以及 N s 均远小于 N .
其中, N r , N e , S 以及 N s 均远小于 N .
为了验证所提出的聚类算法的性能,本节将采用不同类型的数据集进行实验,包括:1)不同形状和不同规模的人造数据集;2)真实数据集.同时,选择基于代表点的聚类算法 K -medoid,AP以及基于密度的聚类算法DBSCAN [23] ,OPTICS [24] ,KNNCLUST [25] 作为对比算法,并利用指标 NMI (normalized mutual information) [26] 和 ARI (adjusted rand index) [27] 进行聚类效果评价,其中 NMI 基于信息论, ARI 基于样本对计数,二者的定义如下.
假设某一数据集包含 N 个样本, N i j 表示由聚类算法产生的第 i 个簇与真实的第 j 个簇的契合程度, N i 和 N j 分别表示所述第 i 个簇与第 j 个簇的样本数,则:
NMI =  ,
,
(16)
![]()
![]() }/
}/ ![]()
![]()
![]() },
},
其中 ![]() 的取值区间为[0,1],值越大,表示聚类效果越好; ARI 的取值区间为[-1,1],同样是值越大,表示聚类效果越好.
的取值区间为[0,1],值越大,表示聚类效果越好; ARI 的取值区间为[-1,1],同样是值越大,表示聚类效果越好.
在实验部分,ESFSAC算法与对比算法的可调参数设置均采用网格搜索法进行确定,具体网格设置如表1所示,所显示的评价指标均为最优参数下运行50次所获取的均值与标准差.实验所采用的硬件环境为:Intel I5-4950 3.3 GHz×2,8 GB RAM;软件环境为:Windows 7 64 bit,MATLAB R2012 b.
Table 1 Parameter Setup
表1 实验参数设置
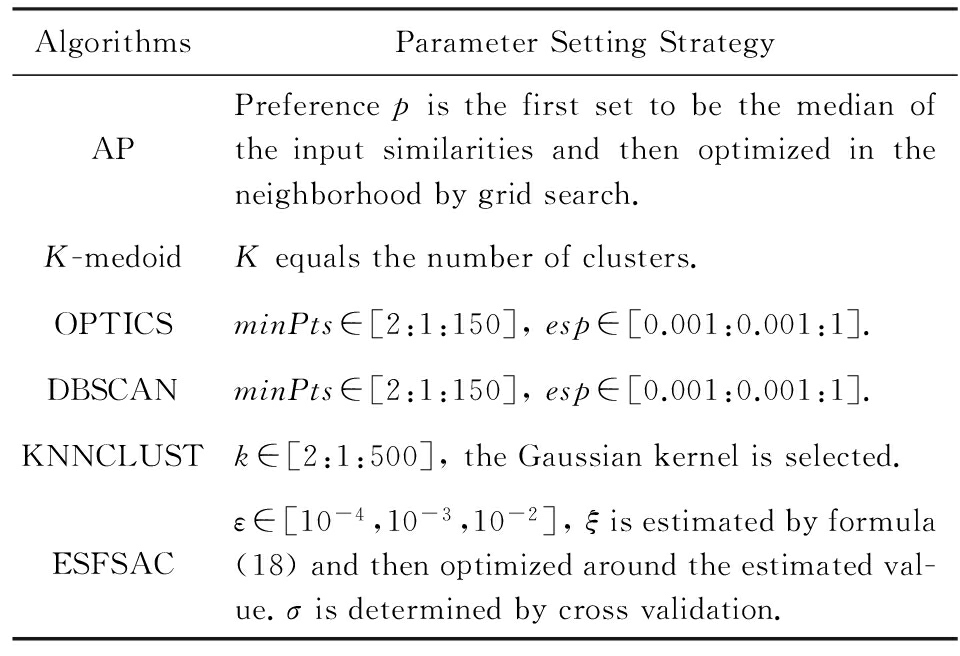
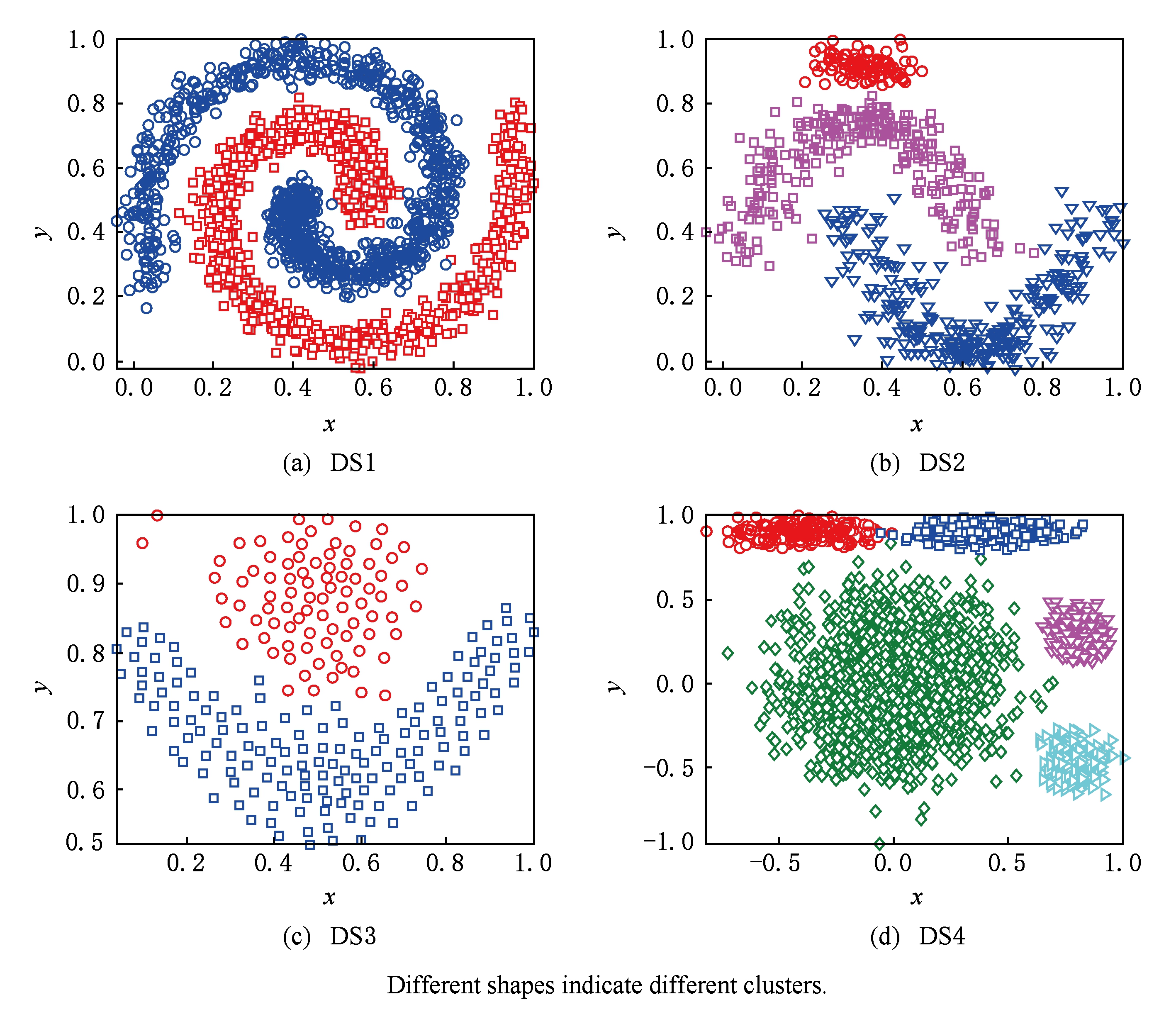
Fig. 1 Distributions of synthetic datasets with different shapes
图1 不同形状人工数据集的分布
为了验证ESFSAC算法对具有不同形状人造数据集的处理能力,选择4个不同形状的数据集进行实验,为了方便描述,将这4个数据集分别命名为DS1,DS2,DS3,DS4,数据集的相关属性和分布如表2和图1所示,数据集在进行实验时,全部进行归一化处理.图2给出了4个人造数据集的压缩集聚类结果以及在聚类过程中代表点从其候选集中的选择情况,每个子图右侧矩形框中的实心圆表示聚类结束时从代表点候选集中所选择的代表点,箭头表示代表点的ES值沿箭头方向逐渐增大.
Table 2 Synthetic Datasets with Different Shapes
表2 不同形状人造数据集的相关属性
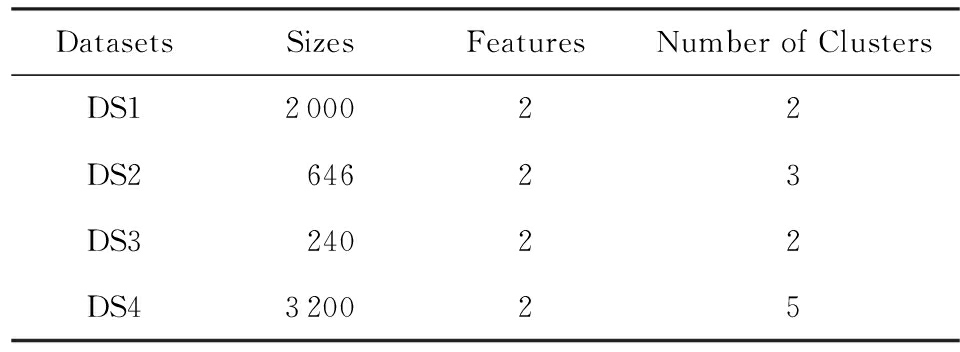
从图2可以看出,由FRSDE所获得的压缩集能够反映出原数据集的骨架结构,结合图1可知,剩余集中的样本沿着其骨架结构呈扩散状分布.这一现象符合所提出的第3个假设,也为剩余集的样本类别标定奠定基础.另外,从压缩集聚类结果可以看出,在事先未指定类别数的前提下,所选的4种不同形状的数据集的压缩集从视觉角度来看均达到了几乎完美的划分.具体来说,在图2(a)~(c)中,当压缩集聚类结束时,从代表点候选集中选择的代表点的个数恰好与各个数据集真实类别数相同,且所选代表点均来自原数据集中密度较高的区域.这说明:1)在数据集各个簇不存在显著密度不平衡的情况下,一般不会出现冗余代表点;2)通过所提出的ES值来选择代表点是有效的,能够在较低的系统开销情况下找出各个簇内的代表点.在图1(d)所示的DS4中,菱形(◇)所标记的簇与其他簇之间存在显著密度不平衡关系,这使得密度较大簇中可能有多个样本的ES值高于密度较小簇,即存在冗余代表点.例如在图2(d)中,按照冗余代表点的定义,可以判断△和▷标记的样本(即椭圆内的样本)属于冗余代表点.冗余代表点的出现,会增加我们从代表点候选集中选择代表点的个数(大于真实类别数),但是并不会影响压缩集聚类结果,因为由算法2可知,冗余代表点在被选中时,已经通过其所在簇的真实代表点获取类别标签,即使在后续过程中被选中,可以通过其标签状态进行过滤.另外,对比图2和图1亦可看出,压缩集中簇之间的间隔比原数据集明显,更易于划分.图3给出了 K -medoid,AP,DBSCAN,KNNCLUST,OPTICS以及本文算法在DS1~DS4上的视觉划分,同时,表3给出了 NMI 和 ARI 的评价结果.另外,由于AP,DBSCAN,KNNCLUST,OPTICS以及本文算法均为自适应算法.因此,在表3中,用“ NC ”表示算法识别出的类别数,对于 K -medoid而言, NC 表示指定的类别数;“Par”表示算法通过网格搜索得到的最优参数设置.
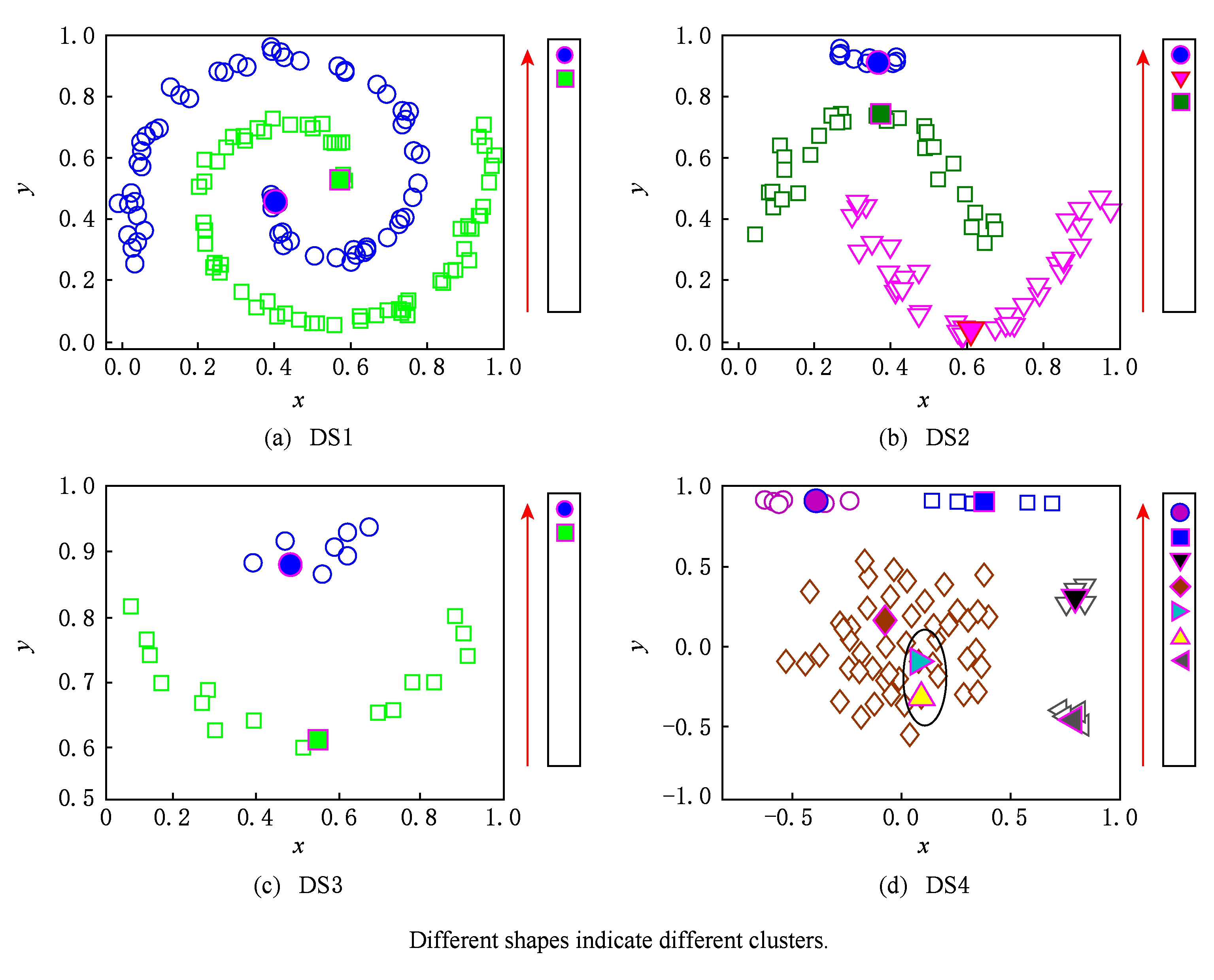
Fig. 2 Exemplars selecting and clustering results of reduced set for DS1-DS4
图2 DS1~DS4代表点选择情况以及压缩集的聚类结果
从图3和表3中可以看出,对于非球形数据集或不平衡数据集, K -medoid和AP算法显得无能为力,其原因是这2种算法的划分策略均是将样本分配给离自己最近的代表点,对于非球形数据集或不平衡数据集,显然无法达到理想的划分结果.DBSCAN是一种基于密度的聚类算法,它被认为是基于图的连通性(直接密度可达)进行样本分配,因此能够发现任意形状的簇.但是,对于簇类边缘稀疏的样本,由于无法满足直接密度可达的条件,故被当成噪声样本处理,单独划分成一类,如图3(c)的DS1,DS3,DS4.另外,若2个簇之间存在边界重合的情况,易使得二者达到连通条件,被划分成同一类别,如图3(c)的DS2所示.KNNCLUST算法与使用密度函数寻找簇之间的“密度低谷”的密度算法不同,它通过最大化分类密度效应和函数来确定数据点归属,无法较好地识别不同形状的簇,例如图3(d)的DS1,DS3.OPTICS算法并非对目标数据集进行直接划分,而是生成一个样本的扩展序列,该序列反映了数据集基于密度的聚类结构,并使用陡变量阈值来划分序列,自动识别类结构.该算法的聚类结果可被认为是一个类的结构树,其节点表示一个簇,节点的子节点表示为簇的子类.但是这种结构无法确定一个簇是否需要继续划分成子类还是与其他簇进行合并,故无法向用户提供有价值的簇归属信息.

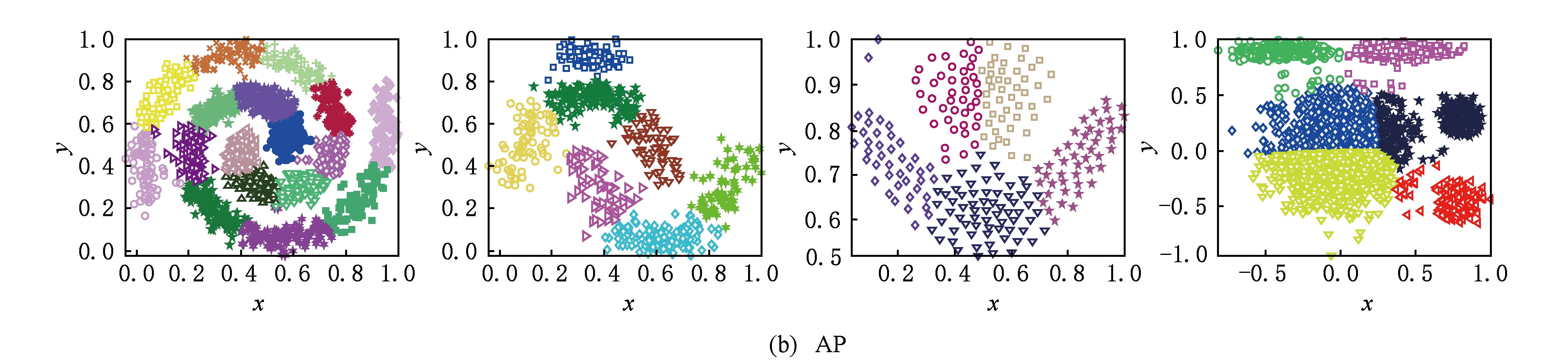
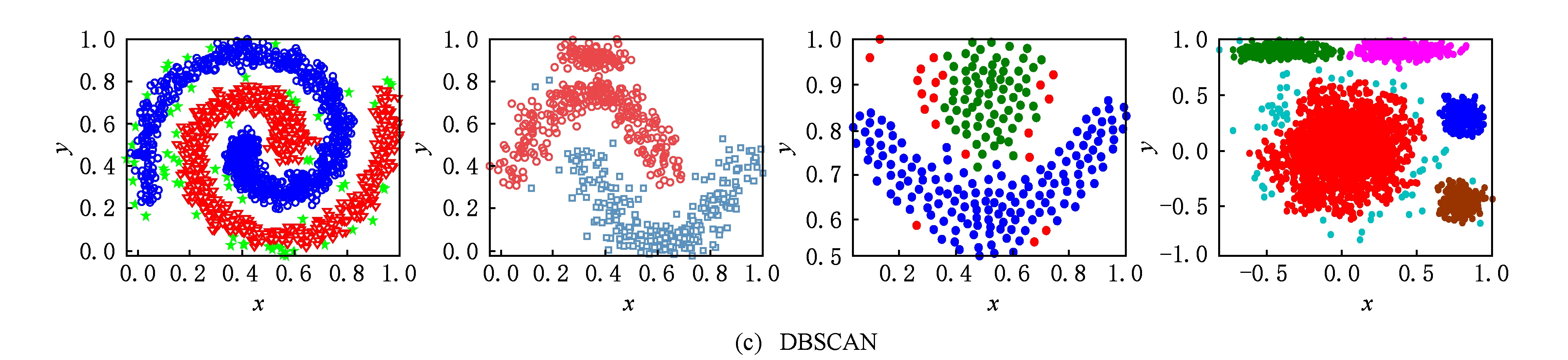

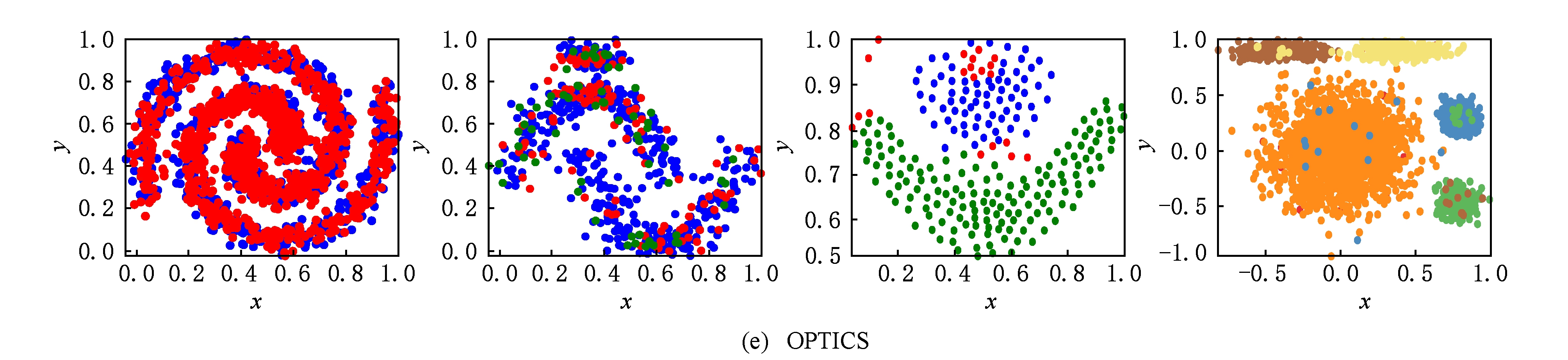
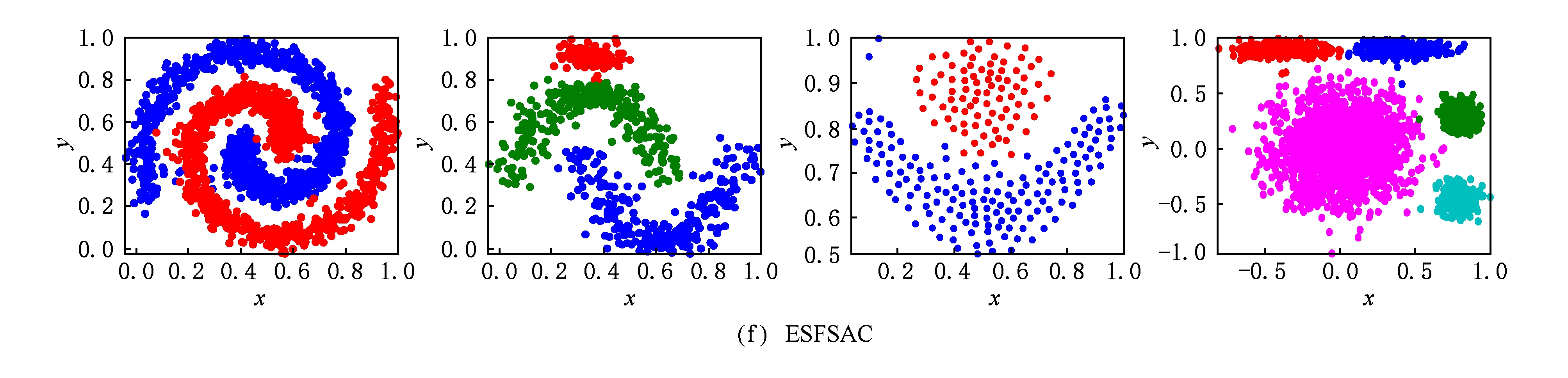
Fig. 3 Visual partitions of different algorithms for DS1-DS4
图3 不同算法在DS1~DS4上的视觉划分
Table 3 Clustering Results of Different Algorithms for DS1 ![]() DS4
DS4
表3 不同算法在DS1 ~ DS4上的聚类结果

Notes:“ (+) ” represents that the improvement of the proposed ESFSAC is significant at 5% significance level, i.e.; p -value is less than 0.05 compared with the comparison algorithms; data in parenthesis represent standard deviation.
本文所提出的聚类算法对DS1~DS4达到了近乎完美的划分,并且能够正确地识别出簇的个数,其原因可以归结为4个方面:
1) 所提出的用于评价样本成为簇内代表点可能性的ES值,能够较为准确地发现簇内代表点,同时结合自适应的聚类策略,这成为本文算法成功的关键所在;
2) 原始数据集经过FRSDE压缩之后,获取了反映原始样本骨干结构的压缩集,这使得原始数据集中簇之间的间隔在压缩集中变得更加明显,也更容易划分,这亦为本文所提算法能够正确发现簇个数的主要原因,这一点通过图1和图2的对比,更加形象地体现出来;
3) 在压缩集类别标定策略上,摒弃了传统的划分方法(将样本分配给离其最近的代表点),利用邻域传播的策略,沿着数据流方向进行样本标签传播,这使得所提算法能够适应不同形状的数据集;
4) 由于剩余集中的样本沿着其骨架结构(压缩集)呈扩散状分布,故在剩余集类别标定策略上,仍然利用邻域传播将压缩集中样本类别标签传递至剩余集,这种标定策略不会破坏在压缩集聚类过程中所形成的簇结构.
利用压缩集来估计样本的ES值以及在剩余集样本标定过程中抽样加速策略的使用,对于提高本文所提算法的效率有着非常大的帮助,接下来,通过不同规模的数据集来验证二者所带来的加速效果.按照图4中的概率分布图 [10] 生成10个不同规模大小的数据集DS5.1~DS5.10,样本的规模 S 分别为1 500,3 000,8 000,12 000,22 000,44 000,88 000,180 000,260 000,340 000.对于DS5.1~DS5.4,直接选择所有的样本参与ES值的计算;而对于DS5.5~DS5.10,利用FRSDE对原始数据集进行压缩,选择压缩集参与ES值的计算.

Fig. 4 The probability distribution of DS5.1-DS5.10
图4 DS5.1~DS5.10样本概率分布图
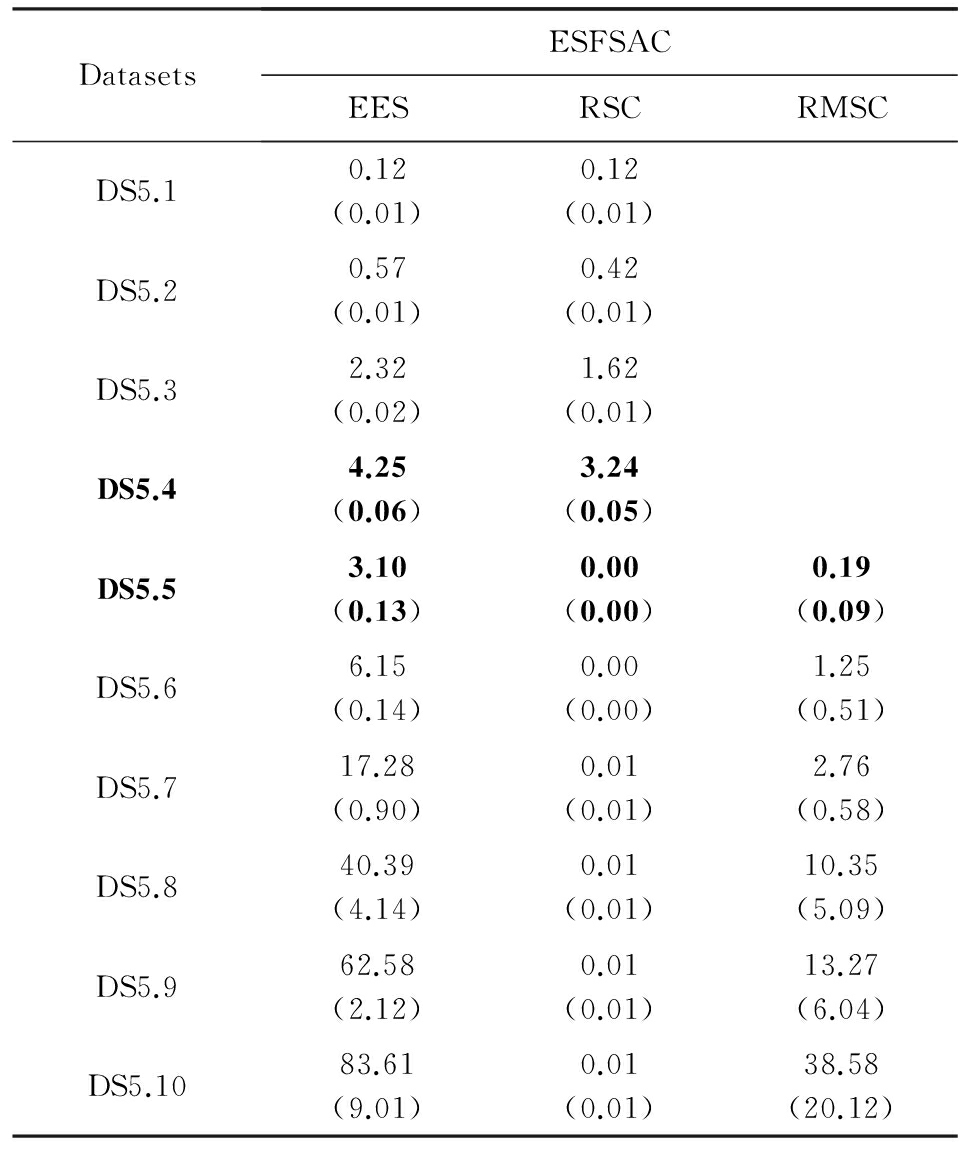
为了验证既定的目标,分别统计EES,RSC,RMSC的运行时间,结果如表4所示:
Table 4 CPU Seconds of Three Components of the Proposed ESFSAC
表4 不同规模数据集算法各个模块的运行时间 s
Note: Data in parenthesis represent standard deviation.
在表4中,由于DS5.1~DS5.4是所有样本参与ES值的计算,故在RSC模块,所有样本已全部标定完成,无RMSC过程,在表4中以“空白”表示,另外,表4中的“0.00”表示大于0的一个非常小的数.从表4中加粗的两行可以看出,对于DS5.5,由于是其压缩集参与ES值计算,在数据集规模显著高于DS5.4的情况下,EES过程的执行时间仍然低于DS5.4,这充分说明通过压缩集来进行ES值计算能显著提高代表点寻找速度.另外,由于通过FRSDE获取的压缩集在规模上已经远小于原数据集,故在样本分配阶段,其时间主要消耗在RMSC模块,而在RMSC模块,采用了抽样加速策略,能保证以较快的速度完成剩余集样本的分配.为了进一步突出ESFSAC算法的聚类速度优势,图5给出了ESFSAC与其他对比算法在DS5.1~DS5.10上的运行时间.由于AP算法的算法复杂度较高,当样本数超过20 000时,其寻参时间超出了可接受范围,故仅给出DS5.1~DS5.4的运行结果.从图5中可以看出,相比所选的对比算法而言,本文所提的聚类算法在运行时间上具有一定的优势,正如前面所述,这得益于规模较小的压缩集代替整个样本参与ES值计算以及剩余集样本标定时的抽样加速.
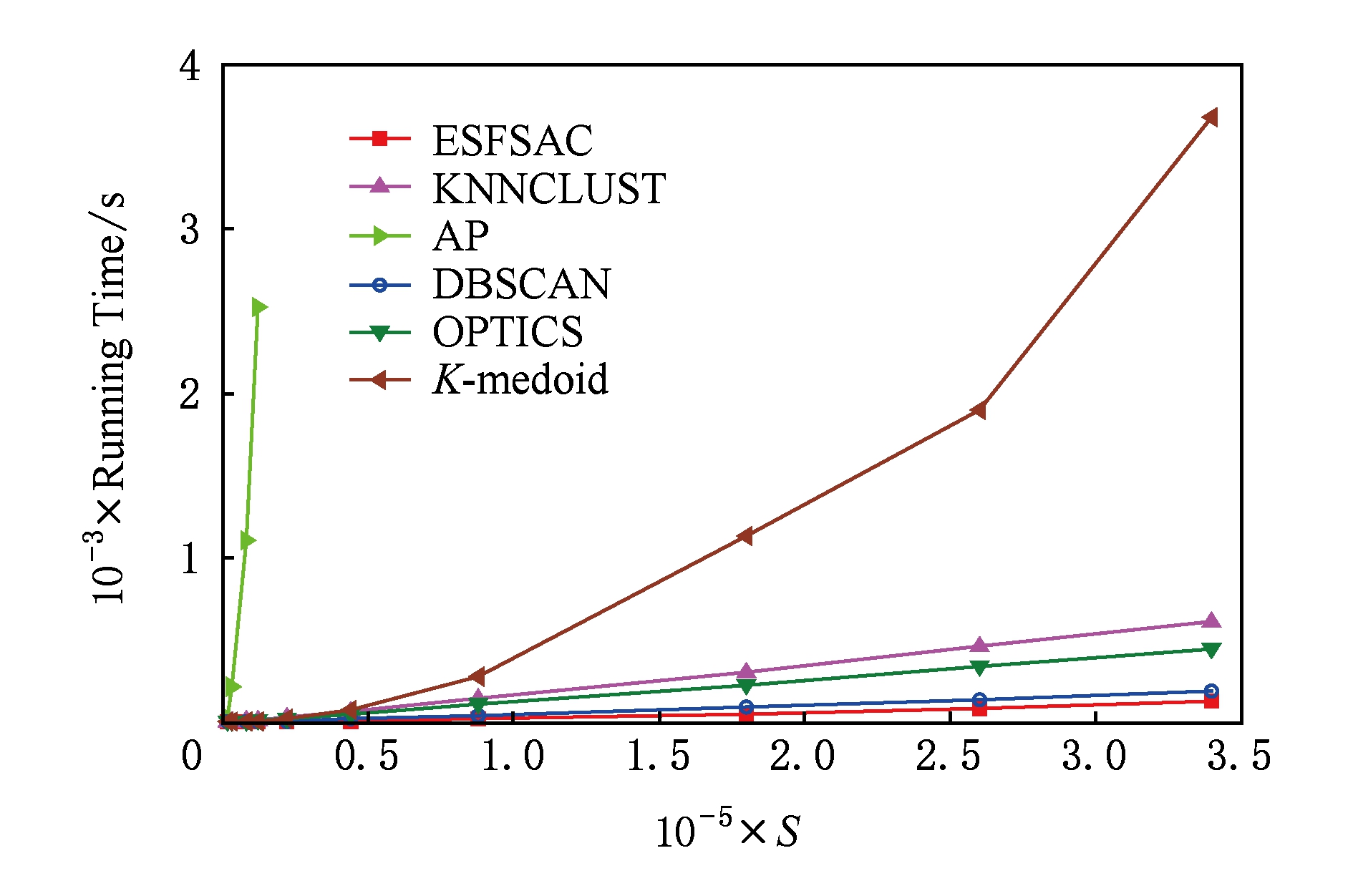
Fig. 5 Clustering performance in terms of CPU seconds for ten datasets with different sizes
图5 不同算法在DS5.1~DS5.10上运行时间比较
为了验证本文所提算法在真实数据集上的表现,选择6个来自UCI * http://archive.ics.uci.edu/ml/index.html 的数据集进行实验,所选数据集的相关属性如表5所示,数据集在进行实验时全部进行归一化处理.
Table 5 UCI Datasets
表5 UCI数据集的相关属性
ESFSAC算法与5个对比算法在UCI数据集上运行的结果如表6所示,由于AP算法在shuttle和skin上以及DBSCAN和OPTICS在skin上无法在可容忍的时间范围内进行参数寻优,故在表6中以“空白”表示.图6以可视化的方式突出各个算法在评价指标 NMI 和 ARI 上的差异.
Table 6 Clustering Results of Different Algorithms for UCI Datasets
表6 不同算法在UCI数据集上的聚类结果
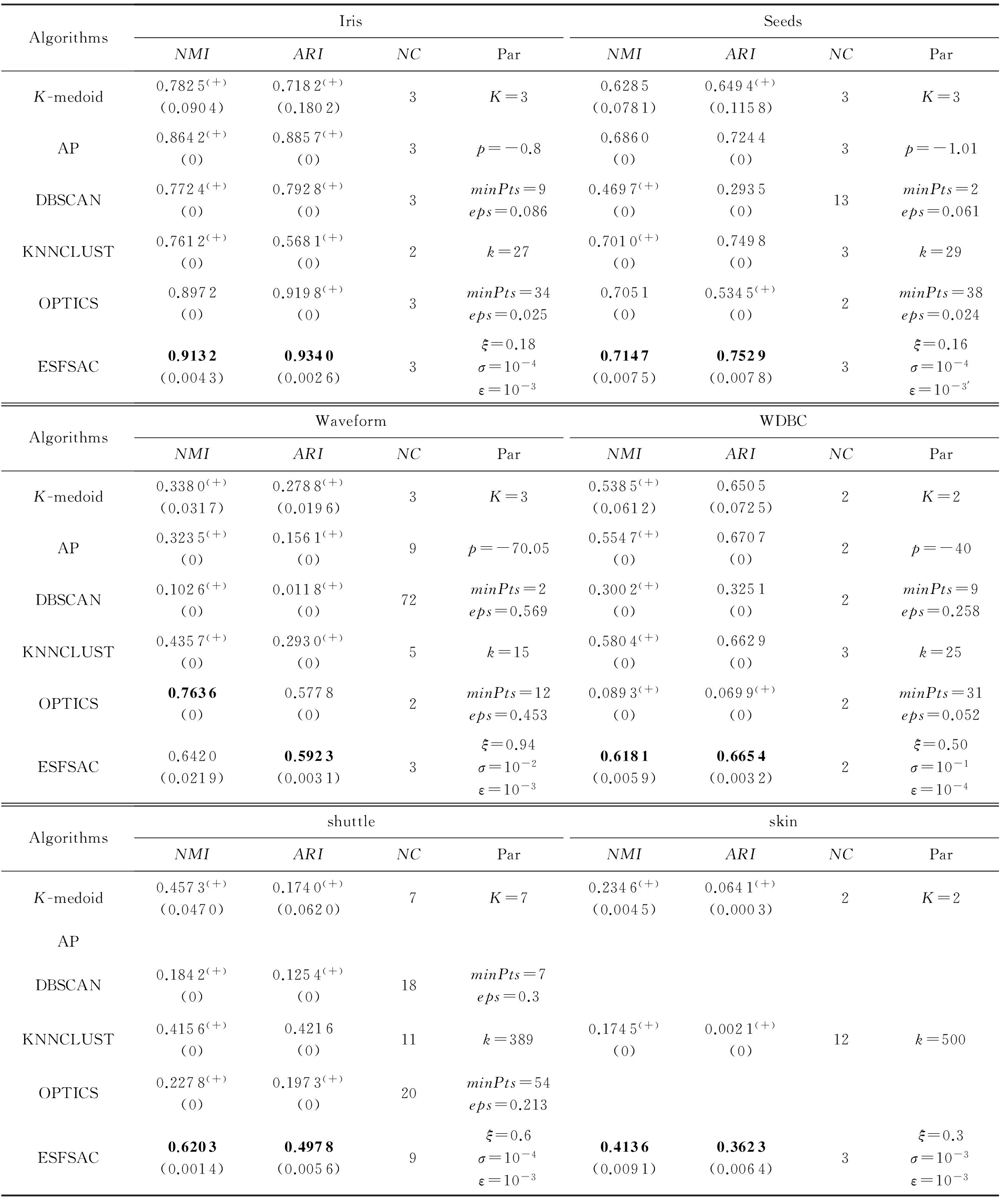
Notes: “ (+) ” represents that the improvement of the proposed ESFSAC is significant at 5% significance level, i.e.; p -value is less than 0.05 compared with the comparison algorithms; data in parenthesis represent standard deviation.
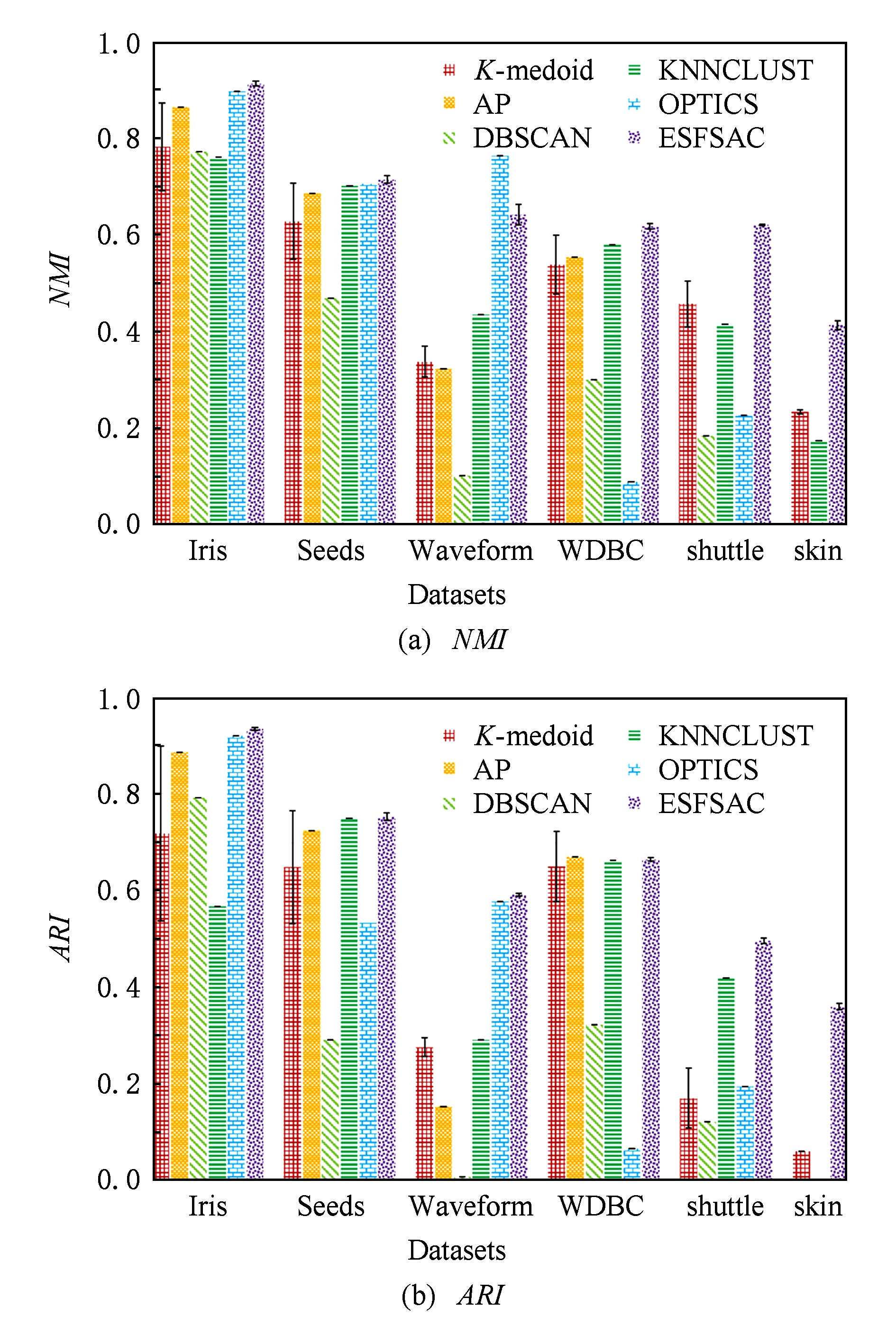
Fig. 6 Comparison of clustering results on UCI dataset for different algorithms
图6 不同算法在UCI数据集上聚类精度比较
除了在Waveform数据集上,ESFSAC算法的 NMI 指标低于OPTICS外,其他均优于比较算法,故总体来说具有一定的优势.另外,AP,DBSCAN,KNNCLUST,OPTICS算法由于不包含任何随机过程,故这些算法每次运行的 NMI 和 ARI 均相同,因此标准差为0; K -medoid算法和ESFSAC算法均包含随机过程,但从实验结果来看,本文算法的标准差总体来说小于 K -medoid算法,这说明本文算法较 K -medoid算法稳定.
本文所提算法的重要参数包括3个,分别为FRSDE中的逼近参数 ε 、压缩集和剩余集类别标定时使用的距离阈值 ξ 以及高斯核参数 σ .对于高斯核参数,可以通过交叉验证策略得到,这里就不做过多的阐述,重点分析逼近参数和距离阈值参数.
Deng等人 [16] 指出,FRSDE的逼近速度和逼近精度均受 ε 影响,较大的 ε 可以取得较好的逼近速度,但却以牺牲逼近精度为代价.如何在逼近速度和逼近精度之间寻找折中的参数显得非常重要.图7给出了在不同逼近参数 ε 下本文所提算法在DS4,Iris数据集上的聚类结果(仅给出 NMI 指标, ARI 类似).这里需要注意的是,由于距离阈值 ξ 的设定与逼近参数 ε 之间存在相关性,较大 ε 往往需要较大的 ξ ,这是因为较大 ε 会导致较为粗放的逼近和较高的压缩率(压缩集规模和原数据集规模的比值),换言之,较大的 ε 会使得压缩集变得更加稀疏,样本间距更大,因此需要更大的距离阈值.故为了突出 ε 的影响,对于不同的 ε ,设定最优的距离阈值.如对于DS4数据集, ξ 的最优值分别为0.22,0.22,0.22,0.22,0.22,0.22,0.22,0.27,0.27,0.3,0.34;对于Iris数据集, ξ 的最优值分别为0.17,0.17,0.17,0.17,0.18,0.18,0.18,0.18,0.20,0.3,0.34.对这2个数据集,最优高斯核参数均为10 -3 .
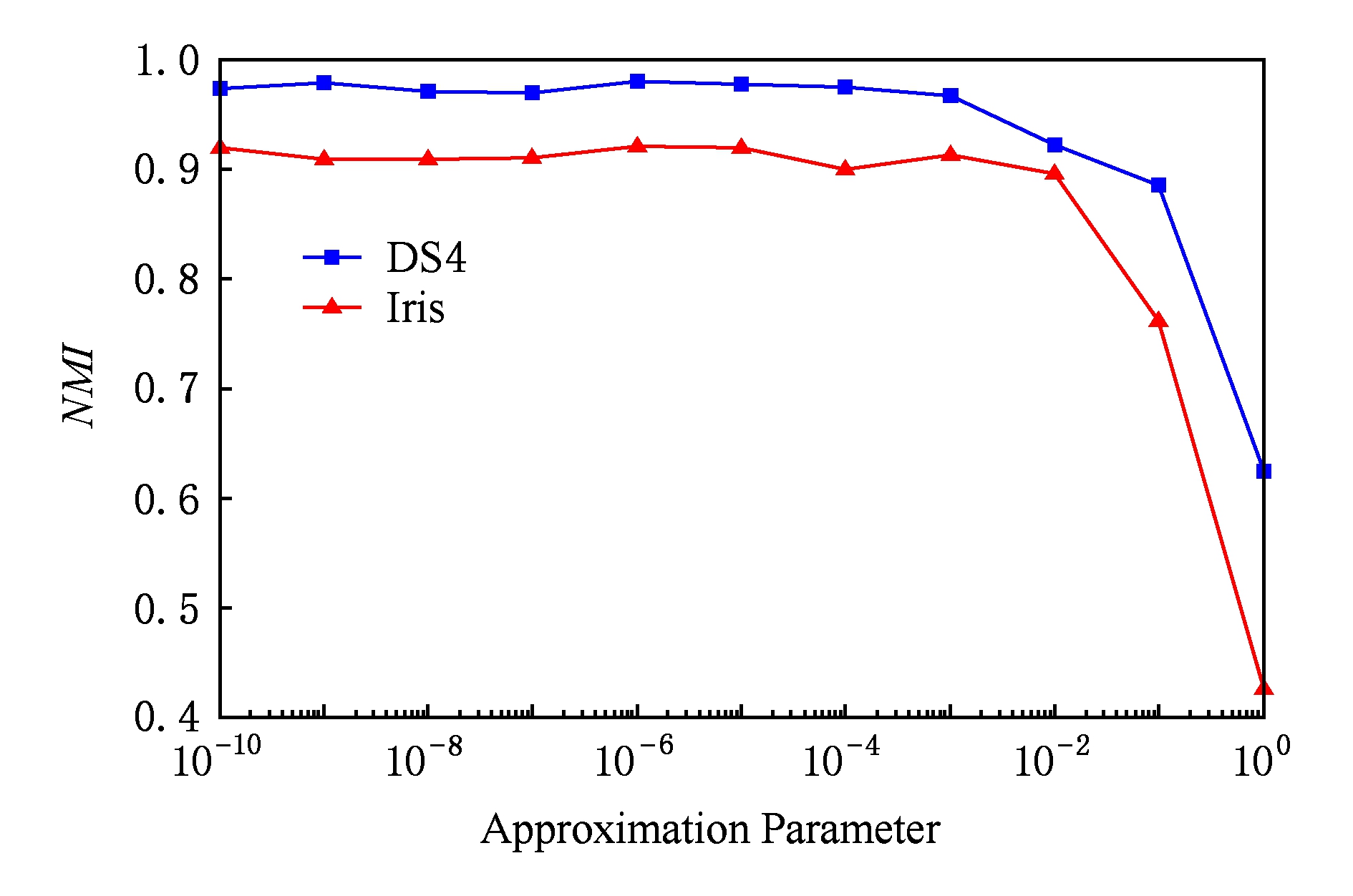
Fig. 7 The NMI values on two datasets with different approximation parameters
图7 逼近参数对聚类指标NMI的影响

Fig. 8 The reduced set of DS4 with ε=1
图8 DS4在逼近参数ε=1时的压缩集
根据Deng等人 [16] 的建议, ε =10 -6 对于FRSDE来说是最佳选择,但是从图7中可以看出,10 -5 ,10 -4 ,10 -3 甚至10 -2 均能保证较好的聚类精度,这是因为本文算法所需要的压缩集无需精确逼近原数据集,只需反映原数据集的骨架即可.随着 ε 的进一步增大,压缩集分布已经“失真”,例如图8给出了DS4在 ε =1时的压缩集,已经无法反映原数据集的骨干结构.
对于距离阈值 ξ 的设定,与数据集样本分布的疏密程度有关,通过大量实验,我们给出该参数的估计原则:
(18)
其中, N r 表示压缩集的规模, NC 表示期望划分的类别数, Dis ( x i , x j )表示样本 x i 和 x j 之间的距离,通过该原则可以计算出 ξ 的估计值,在寻优过程中在该估计值的附近进行搜索寻优.图9给出了不同的距离阈值对聚类精度的影响(DS4: ε =10 -3 , σ =10 -3 ;Iirs: ε =10 -4 , σ =10 -3 ),可以看出,本文算法的最优结果对该参数比较敏感.
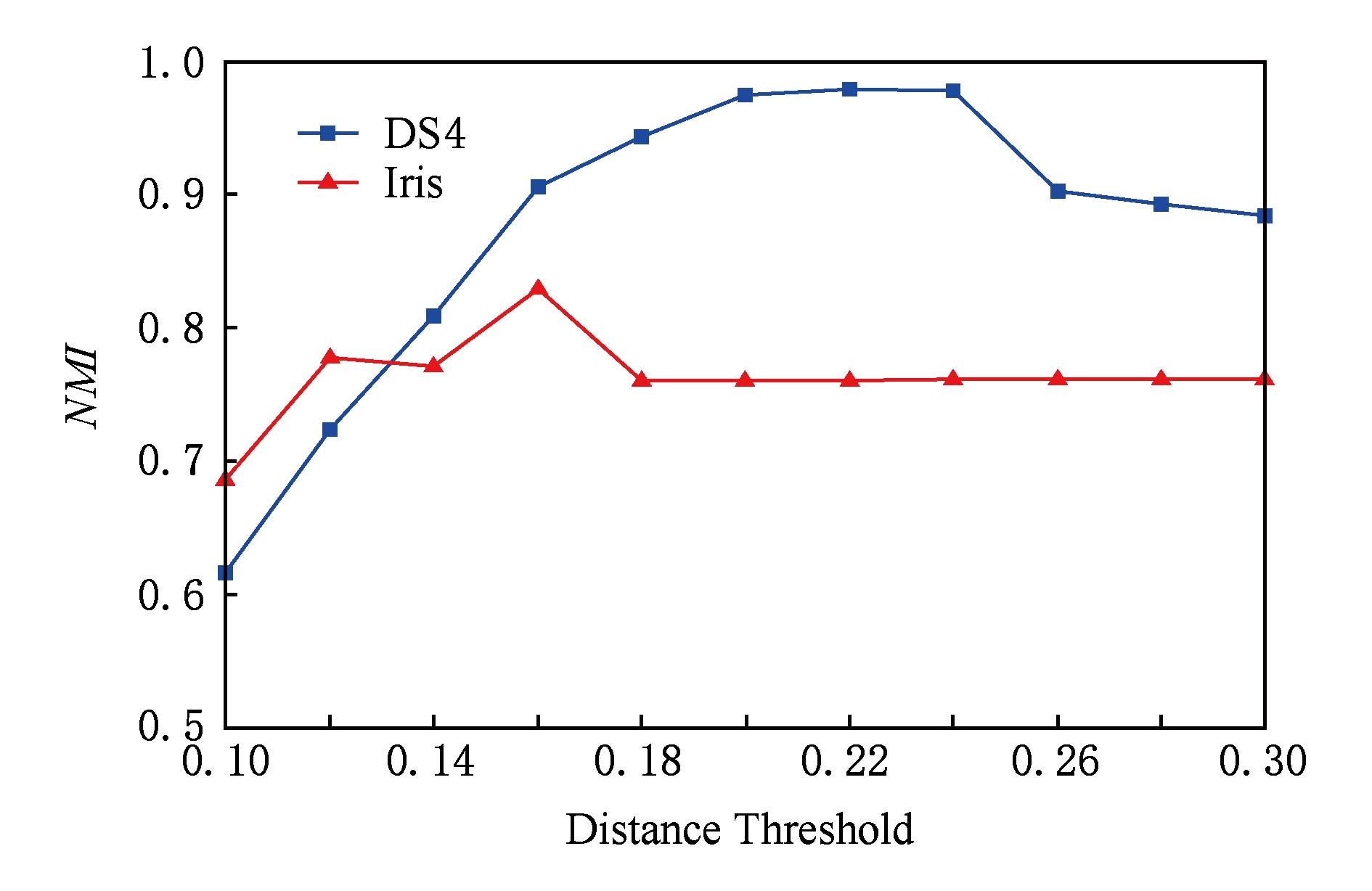
Fig. 9 The NMI values on two datasets with different distance thresholds
图9 距离阈值对聚类指标NMI的影响
本文在已有的工作基础上,提出了一种基于代表点评分策略的快速自适应聚类算法,该算法的提出基于3个重要假设.根据前2个假设,提出了簇代表点的评分策略来评价样本成为代表点的可能性,并从理论上论证了该策略的合理性;根据第3个假设,构建了一种剩余集样本标定策略,同时,为了提高效率,引入抽样方法.通过在人工数据集上的实验,证实了该算法对于不同形状数据集的有效性,同时能够处理大规模数据集,另外,通过真实数据集证实了该算法的实际应用能力.
所提的算法仍然存在一定的后续研究的空间,例如对于少量离群点,经过FRSDE后,无法保留在压缩集中,在剩余集聚类时,无法在有效的距离阈值范围内进行标定.
参考文献
[1] Ying Wenhao, Xu Min, Wang Shitong, et al. Fast adaptive clustering by synchronization on large scale datasets[J]. Journal of Computer Research and Development, 2014, 51(4): 707-720 (in Chinese)
(应文豪, 许敏, 王士同, 等. 在大规模数据集上进行快速自适应同步聚类[J]. 计算机研究与发展, 2014, 51(4): 707-720)
[2] Bi Anqi, Dong Aimei, Wang Shitong. A dynamic data stream clustering algorithm based on probability and exemplar[J]. Journal of Computer Research and Development, 2016, 53(5): 1029-1042 (in Chinese)
(毕安琪, 董爱美, 王士同. 基于概率和代表点的数据流动态聚类算法[J]. 计算机研究与发展, 2016, 53(5): 1029-1042)
[3] Wang Jie, Liang Jiye, Zheng Wenping. A graph clustering method for detecting protein complexes[J]. Journal of Computer Research and Development, 2015, 52(8): 1784-1793 (in Chinese)
(王杰, 梁吉业, 郑文萍. 一种面向蛋白质复合体检测的图聚类方法[J]. 计算机研究与发展, 2015, 52(8): 1784-1793)
[4] Frey B J, Dueck D. Clustering by passing messages between data points[J]. Science, 2007, 315(5814): 972-976
[5] Zheng Yun, Chen Pei. Clustering based on enhanced α -expansion move[J]. IEEE Trans on Knowledge and Data Engineering, 2013, 25(10): 2206-2216
[6] Murphy K P, Weiss Y, Jordan M I. Loopy belief propagation for approximate inference: An empirical study[C] //Proc of the 15th Conf on Uncertainty in Artificial Intelligence. San Francisco: Morgan Kaufmann, 1999: 467-475
[7] Tappen M F, Freeman W T. Comparison of graph cuts with belief propagation for stereo, using identical MRF parameters[C] //Proc of the 9th IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2003: 900-906
[8] Zhou Jin, Pan Yuqi, Chen C L P, et al. K -medoids method based on divergence for uncertain data clustering[C] //Proc of IEEE Int Conf on Systems, Man, Cybernetics. Piscataway, NJ: IEEE, 2016: 2671-2674
[9] Krishnapuram R, Joshi A, Nasraoui O, et al. Low-complexity fuzzy relational clustering algorithms for Web mining[J]. IEEE Trans on Fuzzy Systems, 2001, 9(4): 595-607
[10] Rodriguez A, Laio A. Clustering by fast search and find of density peaks[J]. Science, 2014, 344(6191): 1492-1496
[11] Xie Juanying, Gao Hongchao, Xie Weixing. K -nearest neighbors optimized clustering algorithm by fast search and finding the density peaks of a dataset[J]. Scientia Sinica: Informationis, 2016, 46(2): 258-280 (in Chinese)
(谢娟英, 高红超, 谢维信. K 近邻优化的密度峰值快速搜索聚类算法[J]. 中国科学: 信息科学, 2016, 46(2): 258-280)
[12] Hoti F. On estimation of a probability density function and mode[J]. Annals of Mathematical Statistics, 2003, 33(3): 1065-1076
[13] Catlett J. Megainduction: Machine learning on very large databases[C]//Proc of the 31st Int Conf on VLDB’05. New York: ACM, 1991: 23-45
[14] Lewis D D, Catlett J. Heterogeneous uncertainty sampling for supervised learning[C]//Proc of the 8th Int Conf on Machine Learning. San Francisco: Morgan Kaufmann 1994: 148-156
[15] Girolami M, He Chao. Probability density estimation from optimally condensed data samples[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2003, 25(10): 1253-1264
[16] Deng Zhaohong, Chung Fu-lai, Wang Shitong. FRSDE: Fast reduced set density estimator using minimal enclosing ball approximation[J]. Pattern Recognition, 2008, 41(4): 1363-1372
[17] Kollios G, Gunopulos D, Koudas N, et al. Efficient biased sampling for approximate clustering and outlier detection in large data sets[J]. IEEE Trans on Knowledge and Data Engineering, 2003, 15(5): 1170-1187
[18] Tsang I W, Kwok J T, Cheung P M, et al. Core vector machines: Fast SVM training on very large data sets[J]. Journal of Machine Learning Research, 2005, 6(1): 363-392
[19] Parzen E. On estimation of probability density function and mode[J]. Annals of Mathematical Statistics, 1961, 33(3): 1065-1076
[20] Goldberger J, Gordon S, Greenspan H. An efficient image similarity measure based on approximations of KL-divergence between two Gaussian mixtures[C] //Proc of IEEE Int Conf on Computer Vision. Los Alamitos, CA: IEEE Computer Society, 2003: 487-493
[21] Smola A J, Schökopf B. Sparse greedy matrix approximation for machine learning[C]//Proc of the 17th Int Conf on Machine Learning. San Francisco: Morgan Kaufmann, 2000: 911-918
[22] Bādoiu M, Har-Peled S, Indyk P. Approximate clustering via core-sets[C] //Proc of the 3rd-4th Annual ACM Symp on Theory of Computing. New York: ACM, 2002: 250-257
[23] Ester M, Kriegel H P, Sander J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise[C] //Proc of the 2nd Int Conf on Knowledge Discovery and Data Mining. Menlo Park, CA: AAAI, 1996: 226-231
[24] Ankerst M, Breunig M M, Kriegel H P, et al. OPTICS: Ordering points to identify the clustering structure[C] //Proc of the 1999 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 1999: 49-60
[25] Tran T N, Wehrens R, Buydens L M C. KNN-kernel density-based clustering for high-dimensional multivariate data[J]. Computational Statistics and Data Analysis, 2006, 51(2): 513-525
[26] Jiang Yizhang, Chung Fu-lai, Wang Shitong, et al. Collaborative fuzzy clustering from multiple weighted views[J]. IEEE Trans on Cybernetics, 2014, 45(4): 688-701
[27] Qian Pengjiang, Chung Fu-lai, Wang Shitong, et al. Fast Graph-based relaxed clustering for large data sets using minimal enclosing ball[J]. IEEE Trans on Cybernetics, 2012, 42(3): 672-87
Zhang Yuanpeng 1,2 , Deng Zhaohong 1 , Chung Fu-lai 3 , Hang Wenlong 1 , and Wang Shitong 1,3
1 ( School of Digital Media , Jiangnan University , Wuxi , Jiangsu 214122) 2 ( Department of Medical Informatics , Nantong University , Nantong , Jiangsu 226019) 3 ( Department of Computing , Hong Kong Polytechnic University , Hong Kong 999077)
Abstract Among the exemplar-based clustering algorithms, in order to improve their efficiencies and make them self-adaptive, a fast self-adaptive clustering algorithm based on exemplar score (ESFSAC) is proposed based on our previous work, a fast reduced set density estimator (FRSDE). The proposed ESFSAC is based on three significant assumptions that are stated as: 1) exemplars should come from high-density samples; 2) exemplars should be either the components of the reduced set or their neighbors with high similarities; 3) clusters can be diffused by surrounding both exemplars and its labeled reduced set. Based on the first two assumptions, a quantity called exemplar score is proposed to estimate the possibility of a sample as an exemplar and its rationale is theoretically analyzed. With exemplar score and the third assumption, a fast self-adaptive clustering algorithm is proposed. In this novel algorithm, firstly, all samples are ranked ordered by their exemplar scores descendingly, and stored in a set called exemplar candidate set. Secondly, exemplars in the candidate set are selected one by one and their labels are propagated to their neighbors in the reduced set. Thirdly, with the same strategy, the unlabeled samples gain their labels from the samples in the reduced set. To speed up this process, a sampling algorithm is introduced. The power of the proposed algorithm is demonstrated on several synthetic and real world datasets. The experimental results show that the proposed algorithm can deal with datasets with different shapes and large scale datasets without presetting the number of clusters.
Key words exemplar score; fast reduced set density estimator (FRSDE); reduced set; label propagation; sampling
Received his BS degree from the University of Manitoba, Winnipeg, MB, Canada, in 1987 and his PhM and PhD degrees from the Chinese University of Hong Kong, Hong Kong, in 1991 and 1995, respectively. In 1994, he joined the Department of Computing, Hong Kong Polytechnic University, where he is currently an associate professor. His main research interests include transfer learning, social network analysis and mining, kernel learning, dimensionality reduction, and big data learning (korris.chung@polyu.edu.hk).
收稿日期: 2016-12-07;
修回日期: 2017-03-14
基金项目: 国家自然科学基金项目(81701793,61170122,61272210,61572236);江苏省自然科学基金项目(BK20114172);江苏省自然科学基金杰出青年基金项目(BK20140001)
This work was supported by the National Natural Science Foundation of China (81701793, 61170122, 61272210, 61572236), the Natural Science Foundation of Jiangsu Province of China (BK20114172), and the Excellent Youth Foundation of Jiangsu Province (BK20140001).
中图法分类号 TP391

Zhang Yuanpeng , born in 1984. PhD candidate. Lecturer in Nantong University. His main research interests include pattern recognition and data mining.

Deng Zhaohong , born in 1981, PhD. Professor with the School of Digital Media, Jiangnan University, and a visiting associate researcher with the University of California,Davis, CA, USA in 2014. His main research interests include computa-tional intelligence and pattern recognition (dzh666828@yahoo.com.cn).


Hang Wenlong , born in 1988. PhD candidate. He visited Hong Kong Polytechnic University, Hong Kong, as a research assistant. His main research interests include pattern recognition, data mining and their applications (hwl881018@163.com).

Wang Shitong , born in 1964. Professor and PhD supervisor. Senior member of CCF. Received his MS degree in computer science from Nanjing University of Aeronautics and Astronautics, China, in 1987. His main research interests include artificial intelligence, pattern recognition, fuzzy system, medical image processing, data mining, and intelligent computation and their applications (wxwangst@aliyun.com).