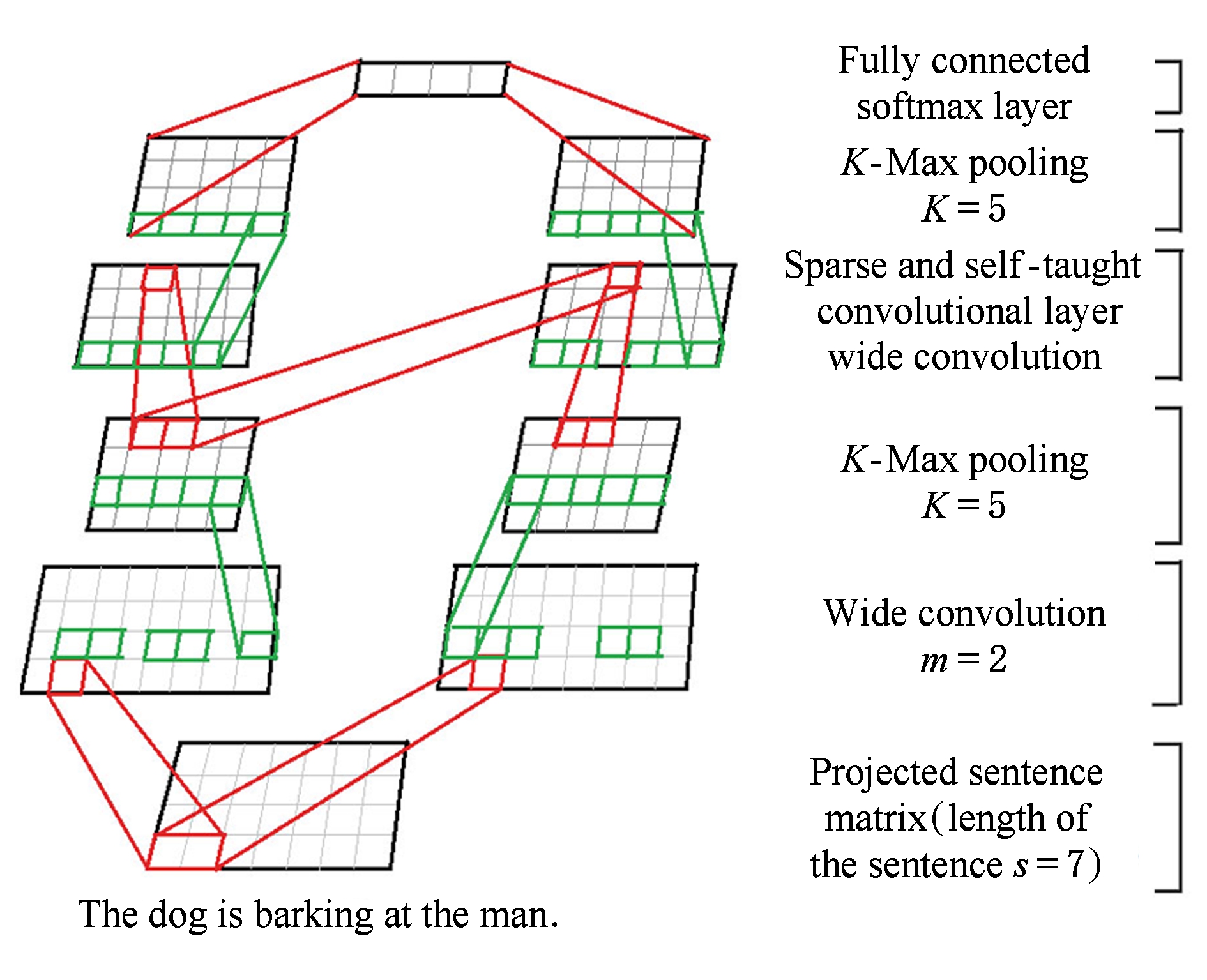
Fig. 1 Structure of the SCNN model
图1 SCNN模型结构图
高云龙 1,2 左万利 1,2 王 英 1,2 王 鑫 2,3
1 (吉林大学计算机科学与技术学院 长春 130012)
2 (符号计算与知识工程教育部重点实验室(吉林大学) 长春 130012)
3 (长春工程学院计算机技术与工程学院 长春 130012)
(1458299660@qq.com)
句子是传递人类意见、情感等语义的一种基本的语言表示形式.在自然语言处理中,句子模型 [1] 是句子语义、情感分析以及句子分类的有效工具.传统句子模型的构建往往基于语言的文法(产生句子的规则),即句法驱动的句子模型构建:根据文法,构建句子对应的分析树,从而理解句子的层次化结构.由于不同语言的句法通常并不一致,且一个句子的语义并非是句子各个部分语义的简单组合 [2] ,因此句法驱动的句子模型的构建往往有很大的局限性.基于深度学习网络构建的句子模型,不依赖于特定语言的句法,其输入往往为句子中每个词的词向量,神经网络根据其学习的特征函数从词向量中提取特征,所提取的特征作为原始句子的高层次的抽象,可以用于句子语义分析或者句子分类.
深度学习网络在计算机视觉、语音识别等领域中已经取得了巨大的成功 [3] ;在自然语言处理领域,深度学习网络虽然没有取得系统性的突破,但也得到很多研究人员的广泛关注 [4] .目前,在句子分类领域的大多数卷积神经网络模型(convolutional neural networks, CNNs)中,卷积层的输入特征map是通过人工选择的,虽然取得了较好的效果,但往往偏离最优值.基于以上研究,本文提出一个基于稀疏自学习卷积神经网络(sparse and self-taught CNN, SCNN)的句子分类模型,实现了卷积层自动学习输入组合的功能,并首次应用于句子分类问题中.主要贡献包括2个方面:
1) 在模型训练过程中,通过自学习策略,让卷积层自己学习特征map的输入组合,在一定程度上排除了人为因素的干扰;
2) 在卷积层,利用L1范数为模型增加稀疏性约束,使得神经元节点在大部分的时间内都是处于被抑制的状态,进而使得模型在复杂度和泛化误差之间达到平衡.
通过与4种基本的句子分类模型进行对比,实验结果表明:在所使用的4组英文数据集中,SCNN模型可以有效地用于提取数据特征,在句子分类方面均取得较优的效果.
通常来讲,句子模型是人类理解自然语言的重要基础,是计算机处理句子语义和情感分析以及句子分类等自然语言处理工作的有效工具.句子分类模型的构建本质上是学习语句数据所包含的特征 [5] ,按照所提取特征的不同,本文将句子分类模型分为2种:基于语言学特征的句子分类模型和基于神经网络的句子分类模型.
基于语言学特征的句子分类模型往往提取与语言相关的特征.大量的相关研究证明模型所学习的语言学特征对于自然语言处理能够提供十分重要的价值 [6] .多年来,研究学者提出了许多类型的语言学特征. Pang等人 [7] 提出使用 N -grams特征可以有效地识别影评的极性,其中,Unigram特征的效果最佳;Turney [8] 提出5种无监督的基于句法的句子模型,可以有效地用于提取句子的情感信息,进而处理句子情感分类问题;Yang等人 [9] 提出基于语句上下文语境的模型CRF-PR,可以有效地整合局部以及全局的语句上下文信息,并利用带有语言学特征的正则化因子训练CRF模型,在情感分类问题上取得较好的效果;Wang等人 [10] 利用词语bigram特征训练NB和SVM模型,在句子或文本主题分类问题中取得一致的较好的效果;Silva等人 [11] 使用多组基于语言学的特征(uni-bi-trigram, wh word, head word, POS, parse, hypernyms)训练SVM模型,可以有效地用于问题分类.基于语言学特征的句子分类模型也存在着许多不足 [12] :1)提取特征是十分费时的,其消耗往往随着数据集规模的变大而呈现指数型增加;2)模型所提取的语言学特征具有局限性,缺乏实质性的实验数据表明它们对于不同类型的数据集均显示出良好的有效性.
近年来,一些基于数据驱动的模型相继被提出.其中,基于神经网络的句子分类模型将神经网络模型与分类模型进行有效的组合,在句子分类问题上往往较传统的机器学习算法或者基于语言学的句子分类模型都表现出良好的效果.Kim [13] 首次将卷积神经网络CNN应用到句子模型的构建中,并提出了几种变形;Kalchbrenner等人 [14] 提出一种动态卷积神经网络(dynamic convolutional neural network, DCNN)的网络模型,由一维的卷积层以及动态的 K -Max池化层构成,卷积层采用的是广义卷积,可以处理变长的句子;Hu等人 [15] 利用CNN网络研究句子匹配的问题,提出多个卷积层实现的是提取句子中不同组合的语义信息,而池化层则过滤掉置信度较低的特征;He等人 [16] 采用多种不同类型的卷积和池化来实现对句子的特征表示,并利用所学习到的特征表示构建句子相似度模型.基于神经网络的句子分类模型由于使用词向量数据,并且不依赖于特定语言的句法,因此在不同类型的数据集或者不同的语言中都显示出良好的扩展性和有效性.
Fig. 1 Structure of the SCNN model
图1 SCNN模型结构图
本文提出的基于稀疏自学习卷积神经网络句子分类模型SCNN共有5层(不含输入层),如图1所示.利用Word2vec工具,将语料库中的句子转换为词向量矩阵,并作为模型SCNN的输入,卷积层在词向量矩阵的每一行上进行一维卷积,并采用广义卷积,池化层采用 K -Max Pooling,选择每一行中较大的 K 个特征,并同时维护特征相对位置不变;第3层(卷积层)自学习前一层特征map的输入组合,排除人为因素,同时在训练过程中增加稀疏性约束;第4层(池化层)输出全连接到softmax层,利用提取的特征训练分类器.
与现有处理句子分类的卷积神经网络模型相比,SCNN模型的第3层(卷积层)充分基于自学习和稀疏性思想,即不人为约定卷积层节点的输入,通过训练使得节点可以动态学习前一层输入的有效组合,从而可以动态捕获句子范围内各个特征的关联.如图1所示的SCNN模型中,训练结果显示第2层的第1个特征矩阵对于第3层的2个特征map均产生作用,而第2个特征矩阵只对第3层的第2个特征map产生作用,从而使得卷积层学习到不同的特征表示.
在图1所示的模型中,输入句子长度 s =7,其对应的词向量矩阵维度为4×7;第1层广义卷积操作(卷积核维度 m =2)得到该层的feature map,维度为4×8;池化层选取对应卷积层feature map每一维的最大的 K 个特征,得到池化层的特征矩阵,维度为4×5;第3层(卷积层)采用稀疏自学习前一层特征矩阵的输入组合,特征矩阵的维度为4×6;第4层(池化层)同样选取前一层每一维度最大的 K 个特征,得到的特征矩阵将作为一个输入向量输入到softmax分类器中,从而实现对句子分类.
卷积是卷积神经网络CNN重要的特征之一.卷积层以特征map为组织结构,其中的每一个单元与前一层的局部感受野相连,利用共享的卷积核与局部感受野作卷积运算,再经过非线性函数(如 Sigmoid , ReLU )作用,得到特征值 [17] . 通常来说,卷积指的是狭义上的卷积,即对于某一句子输入 c ∈ ![]() s ,一维卷积核 k ∈
s ,一维卷积核 k ∈ ![]() m ,且满足 s ≥ m ,我们得到式(1),卷积结果 c ′∈
m ,且满足 s ≥ m ,我们得到式(1),卷积结果 c ′∈ ![]() s - m +1:
s - m +1:
c j ′= k T c j : j + m , 0≤ j ≤ s - m +1.
(1)
为了使得卷积核可以作用到整个输入句子向量上,包括句子边缘上的词,Kalchbrenner等人 [14] 提出一种广义卷积运算,也称宽卷积.广义卷积不要求 s 与 m 的大小关系,同时保证卷积输出 c ′不为空向量.如表达式(2)所示, c ′∈ ![]() s + m -1,当 j <0或者 j > s 时, c j =0:
s + m -1,当 j <0或者 j > s 时, c j =0:
c j ′= k T c j : j + m , - m +1≤ j ≤ s .
(2)
由式(1)(2)可知,狭义卷积结果为广义卷积结果的一个子集,广义卷积是狭义卷积的一种扩展,它充分考虑了各种可能存在的特征,从而最大程度上保证所提取特征的多样性.
一个长度为 s 的句子对应一个词向量矩阵 X n × s ,其中 n 为句子中每个词的词向量长度.词向量是通过语料库训练Word2vec模型得到的,设置维度 n =200,对于未出现在语料中的词,其词向量采用随机取值进行初始化.将词向量矩阵输入SCNN,广义卷积后卷积层的每一个节点都可以生成一个大小为 n ×( s + m -1)的特征map.
3.2.1 自学习特征组合
一般而言,卷积层 l 的每一个节点与 l -1层的若干节点相关联,通过卷积核与相关联的节点的输出特征map相卷积,再对卷积结果求和,得到其特征map,相关联的节点通常是人为约定的.这样, l 层第 j 个输出特征map可以表示为
(3)
其中 ![]() 和
和 ![]() 分别表示 l 层的第 j 个节点的输出map和偏置
分别表示 l 层的第 j 个节点的输出map和偏置 ![]() 表示 l 层第 j 个节点与 l -1层第 i 个节点相关联时的卷积核, f 则表示非线性函数.
表示 l 层第 j 个节点与 l -1层第 i 个节点相关联时的卷积核, f 则表示非线性函数.
为了排除人为因素对于最优结果产生的偏移,我们尝试让模型在训练过程中自己学习最佳的输入特征组合.参数 α i j 表示在得到第 j 个节点的输出map时 l -1层的第 i 个节点的贡献值,得到:
(4)
其中,对于每个 i , α i j 满足 ![]()
进一步地,我们可以将 α i j 表示为一组无约束的隐含参数 β i j ,通过使用软最大函数,我们得到:
α i j = 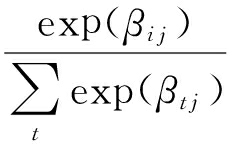 .
.
(5)
在迭代优化模型参数时,需要计算参数变量的梯度.SCNN模型总误差 E 对于参数 α i j 的导数为
(6)
其中, θ l 为第 l 层的灵敏度矩阵.
基于链式规则,我们进一步可以得到误差对于隐含参数变量 β i j 的导数为
3.2.2 稀疏性约束
由式(4)可知,对于 l -1层的所有输入特征map,都会在l层节点的输出map中产生一定的贡献值.为了限定只有某几个输入特征map是有效的,我们可以通过使用L1范数增加稀疏性限制,使得对于大部分 i ,有 α i j =0.
重写误差函数为
(8)
L1范数 ![]() 对于 α i j 的导数为
对于 α i j 的导数为
![]() = q sgn( α i j ).
= q sgn( α i j ).
(9)
进一步对于 β i j 的导数为
![]() ).
).
(10)
所以,最终误差函数对于 β i j 的梯度计算为
![]() =
= ![]() +
+ ![]() .
.
(11)
3.2.3 稀疏自学习算法描述
基于以上分析,本文给出SCNN模型稀疏自学习算法的抽象描述:
算法1 . 稀疏自学习算法.
输入:特征矩阵 X ;
输出:卷积层参数,包括卷积核 K 、偏置 b 、标识矩阵 β ;
初始化:随机设置矩阵 K , b , β 和 theta 的值.
步骤1. 设置迭代次数 iter =0;
步骤2. 将矩阵 K , b , β 和 theta 分别转换成一维向量,并将其连接成一个长向量 W ;
步骤3. 根据函数1计算卷积层误差 E ′和梯度向量 grad ;
步骤4. 使用拟牛顿法优化向量 W ;
步骤5. iter = iter +1;
步骤6. 如果 iter <1 000,转到步骤3;
步骤7. 由向量 W 构造矩阵 K , b , β ,得到该卷积层参数.
进一步地,本文给出函数 calculate_cost_grad 形式化描述:
函数1. calculate_cost_grad .
输入:一维向量 W ;
输出:模型误差 E ′和梯度向量 grad .
步骤1. 根据式(5)计算 α i j ;
步骤2. 根据式(4)计算卷积层特征矩阵 X c ;
步骤3. 计算池化层特征矩阵 X p ;
步骤4. X out = theta T · X p ;
步骤 ![]()
步骤6. 根据式(8)计算误差 E ′;
步骤7. 根据式(11)计算 ![]() ;
;
步骤8. 根据神经网络模型反向传播算法计算误差 E ′对于 K , b , theta 的导数,并将其连接成一个长梯度向量 grad ;
步骤9. 返回模型误差 E ′和梯度向量 grad .
为了验证模型的有效性,本文采用如下4种标准的数据集进行实验,语料库均可通过开源网站获得:
1) MRD(movie review data * http://www.cs.cornell.edu/people/pabo/movie-review-data ).电影评论语料库,每个句子作为1条影评,共有正面、反面2种类别标签.
2) SST(stanford sentiment treebank * http://nlp.stanford.edu/sentiment/ ).情感分类语料库是MRD语料库的扩展,共有5种类别标签,分别为:very positive, positive, neutral, negative, very negative.
3) TREC(trec question dataset * http://cogcomp.cs.illinois.edu/Data/QA/QC/ ).问题分类语料库,问题标签共有6种(about person, location, numeric information, etc),用于将问题指定某一具体的类型.
4) CR(customer reviews * http://www.cs.uic.edu/~liub/FBS/sentiment-analysis.html ).顾客评论语料库,关于产品的正面和反面的二元分类语料库.
语料库相关说明和具体参数如表1所示.
Word2vec是一款高效的用于将词表示为词向量的工具 [18] ,实验通过使用Python爬虫程序抓取的包含有10亿数量级的英文词语的语料库训练Word2vec模型,得到词汇的数量特征表示;卷积层非线性函数为 Sigmoid ;池化层 K 值通过10-fold交叉验证实验,在按照经验给出的范围内选择使得泛化误差最低的取值;优化算法选择拟牛顿法.
Table 1 Specific Parameters of the Corpus
表1 语料库具体参数
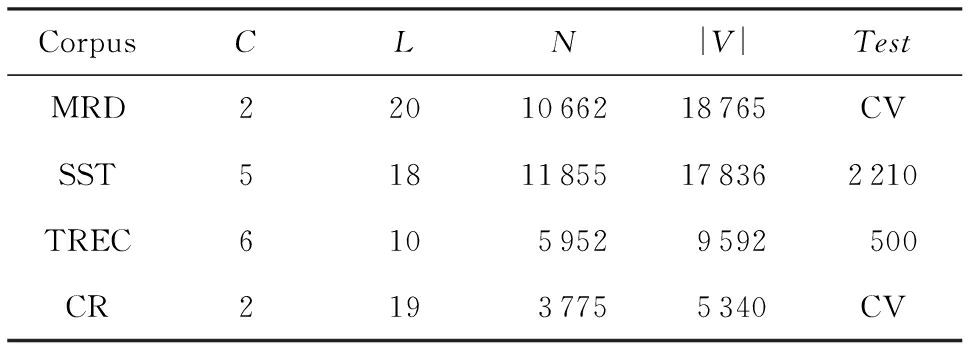
Notes: C is number of target classes; L is average sentence length; N is dataset size; | V | is vocabulary size; Test is test set size (CV means there was no standard train/test split and thus 10-fold CV was used).
4.2.1 池化层 K 值选取对模型的影响
K -Max Pooling是Max Pooling的扩展,用于选取特征map上最大的 K 个数值特征. K 值选取的合适与否在一定程度上影响着实验的效果,通过10-fold交叉验证试验我们得到如图2所示的实验结果.
通过图2可知,对于不同的数据集, K 值对于实验的泛化误差的影响并不一致:对于平均句子长度为10的数据集TREC, K =8时交叉验证实验得到的泛化误差最低;而对于平均句子长度分别为18,19,20的数据集SST,CR,MRD, K =13时泛化误差分别达到最低值.实验结果表明:模型所提取的特征的个数往往要受限于数据集中句子的平均长度,特征个数设置过低,模型容易欠拟合,导致模型不能准确学习数据集合中的真实规律;特征个数设置过高,则模型容易过拟合,从而造成模型的泛化能力过低.
4.2.2 稀疏自学习与非稀疏策略对模型的影响
本文提出的基于稀疏自学习卷积神经网络的句子模型SCNN,旨在卷积层可以在训练时自己学习最佳的输入特征map的组合,代替将前一层全部的特征map作为下一层的输入,采用“软”概率参数 α i j 作为输入的贡献值,并使用L1范数增加稀疏性限制,从而降低模型的复杂度.
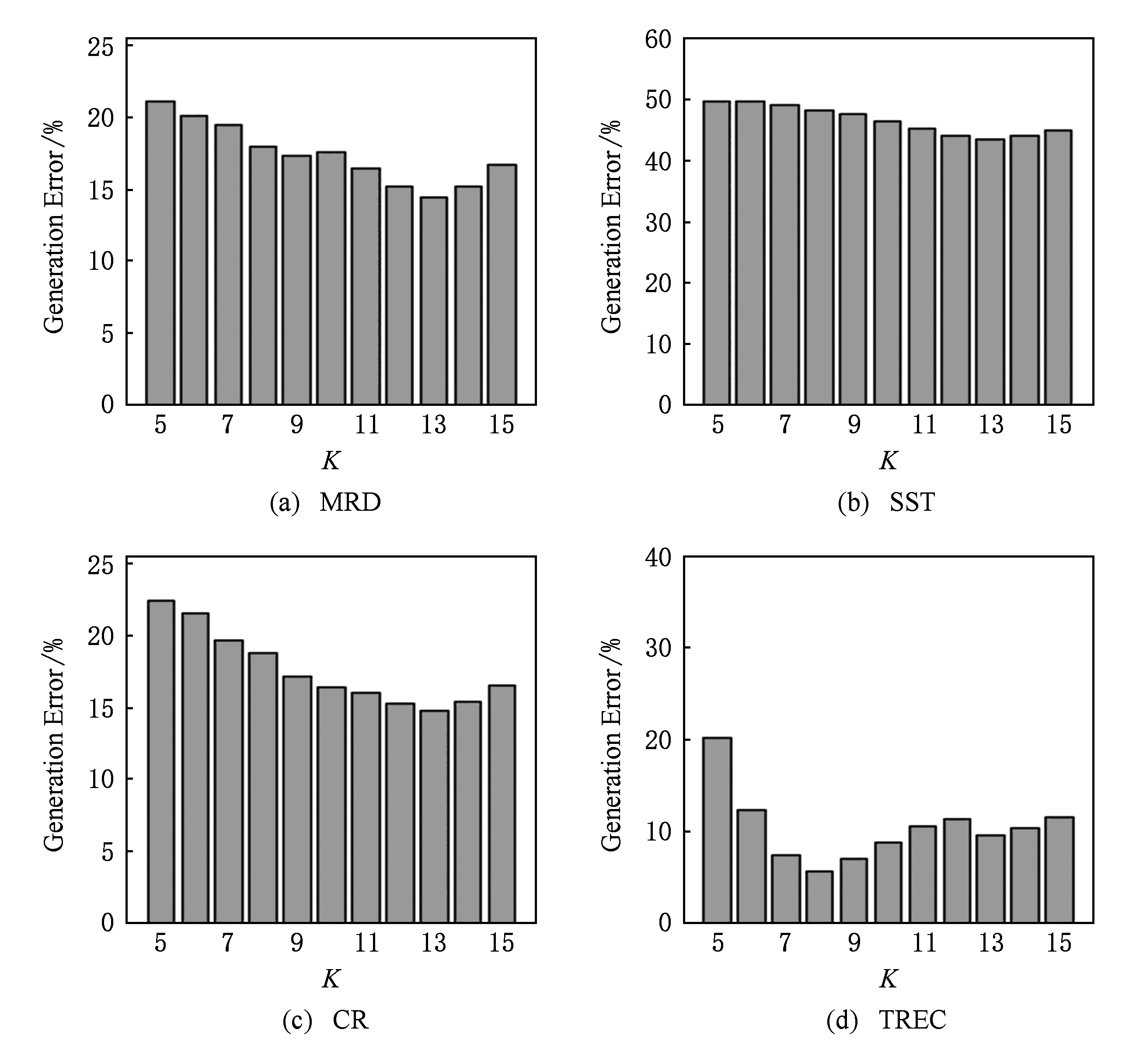
Fig. 2 Influence of K on generation error
图2 K值对于泛化误差的影响
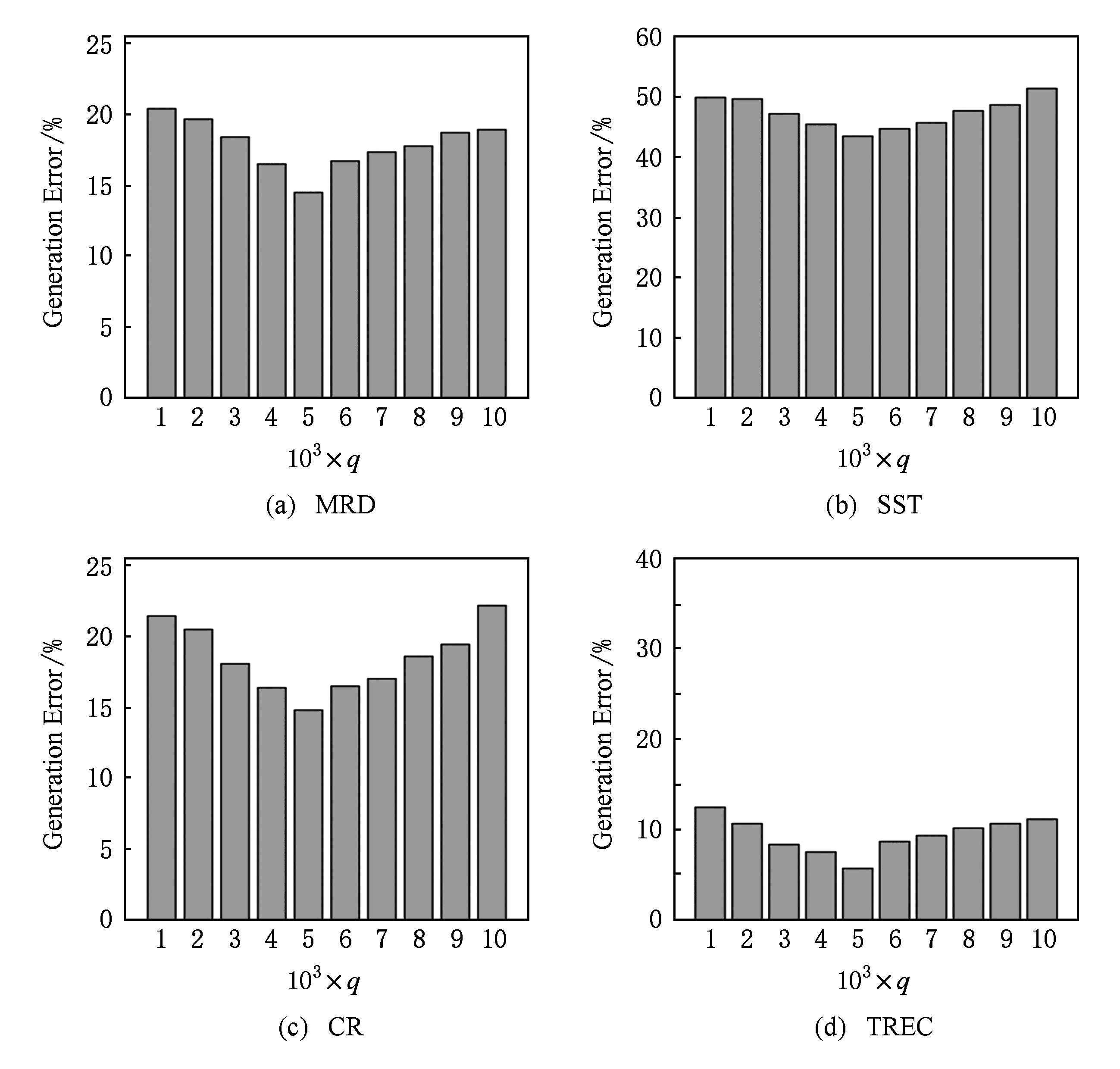
Fig. 3 Influence of q on generation error
图3 q值对于泛化误差的影响
模型选择的典型方法是正则化.正则化是结构风险最小化策略的实现,是在经验风险上加一个正则化项或者罚项.SCNN模型通过使用L1范数调节模型的复杂度.其中正则化参数 q 可以用于选择经验风险与模型复杂度同时较小的模型.图3显示了 q 值选取的不同对于SCNN模型泛化误差的影响.通过实验结果可知:当 q 值较小时,表现为SCNN模型的复杂度较低,此时SCNN模型呈现出欠拟合状态,所学习到的特征无法作为模型输入的抽象表示;当 q 值较大时,通常表现为SCNN模型的复杂度较高,此时SCNN模型呈现出过拟合的状态,泛化能力较低,从而导致泛化误差较高.
将SCNN模型与非稀疏模型卷积网络句子模型进行对比,我们得到如图4所示的实验结果:
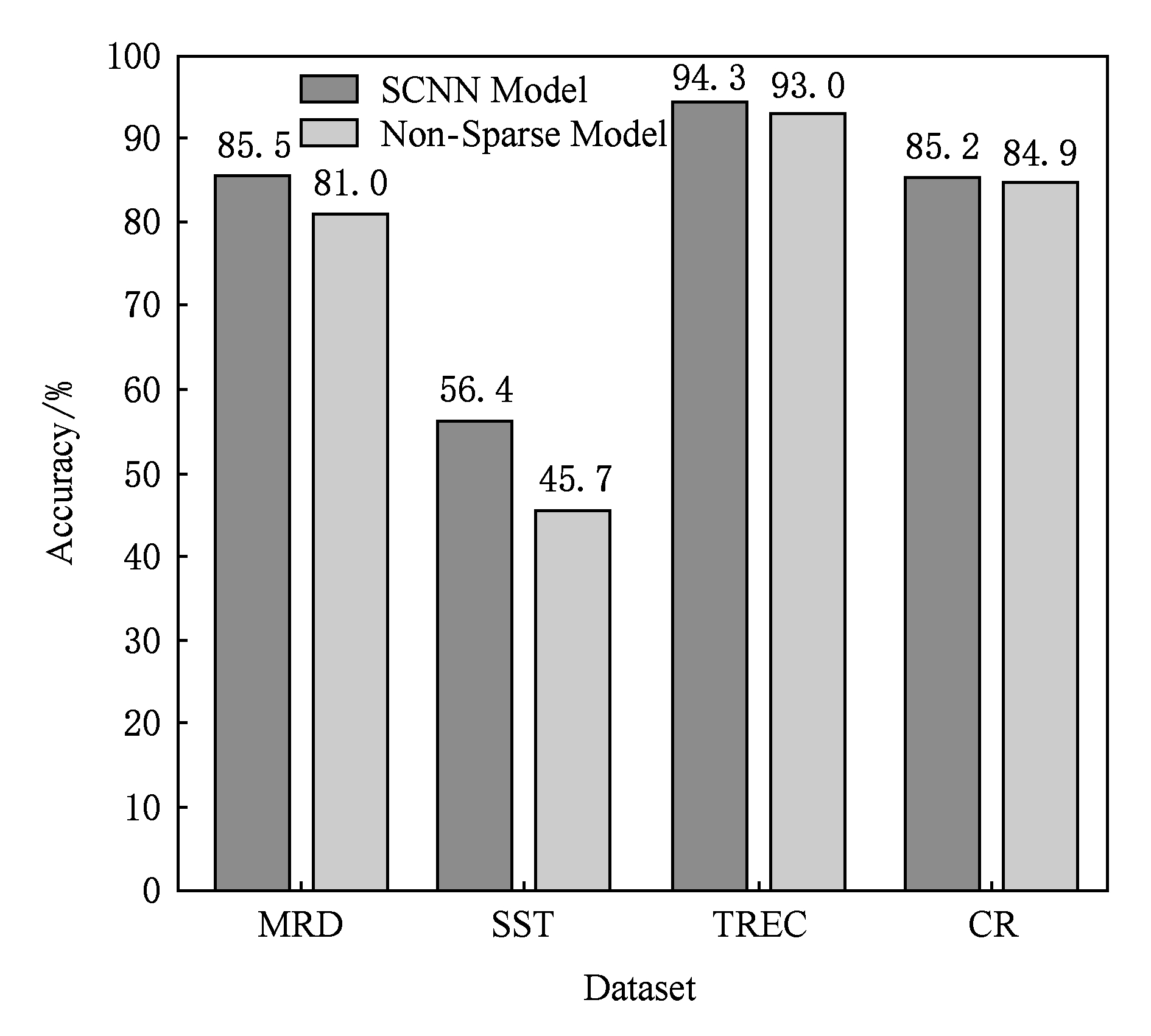
Fig. 4 Accuracy comparison between the models
图4 SCNN与非稀疏模型准确率对比
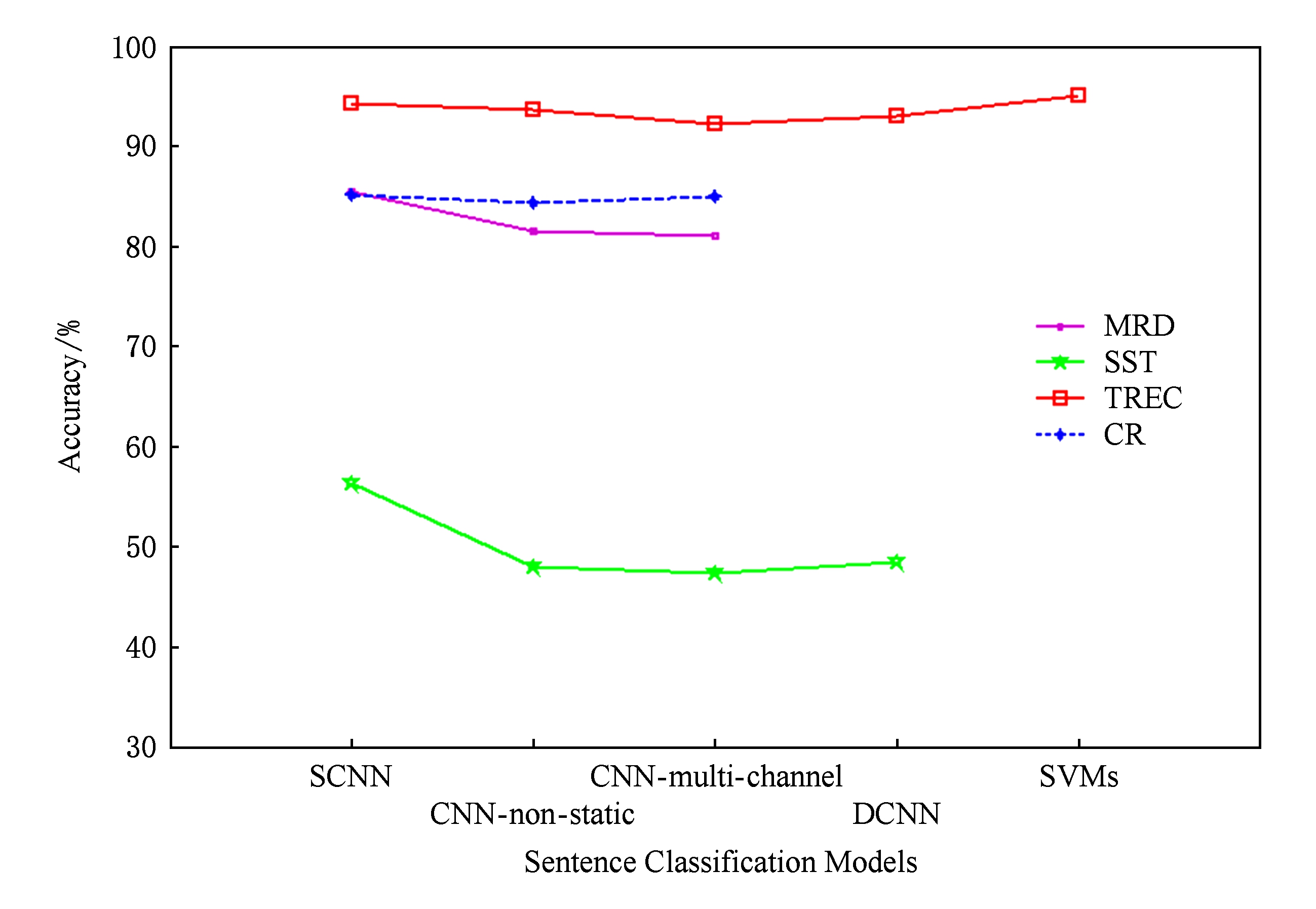
Fig. 5 Experimental results comparison on sentence classification of the models
图5 SCNN模型与其他句子分类模型实验对比
好的特征具有不变性和可区分性 [19] ,而人工约定卷积层输入组合往往并不能让模型学习到好的特征,从而偏离最优值;SCNN在训练模型时(池化层 K 值对应4.2.1节最优值,正则化参数 q =0.005)自学习较好的输入特征map组合,从而更加接近最优值,因此能在测试集上显示出更好的泛化能力;此外,和人脑神经网络类似,稀疏性的表达往往比其他表达方式更为有效 [20] ,SCNN通过加入稀疏性约束,可以使得在同一时刻网络中大部分神经元都处于被抑制的状态,而只有少数几个神经元处于被激活的状态.由图4可知,在4组语料库中,SCNN模型在准确率方面均优于非稀疏模型.
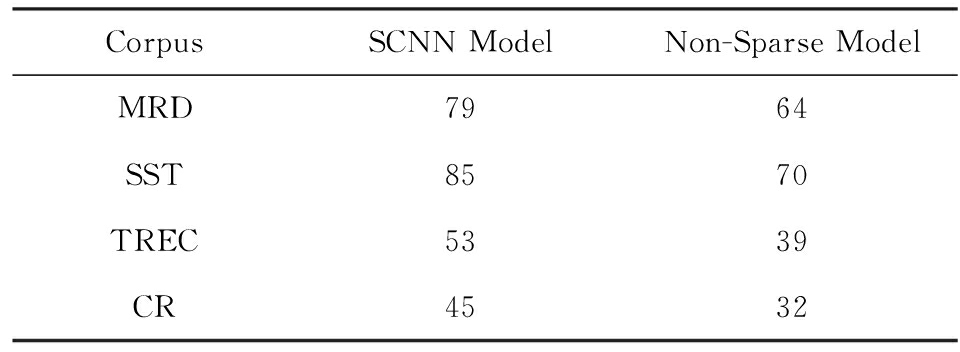
在时间使用方面,实验结果显示:由于非稀疏模型训练较少的参数,时间消耗普遍低于SCNN模型,具体时间消耗情况如表2所示:
Table 2 Time Comparison Between the Models
表2 模型时间使用对比 min
4.2.3 SCNN与其他模型比较
本文最后将SCNN模型与其他句子分类模型进行对比,实验对比折线图如图5所示.由实验结果可知,SCNN模型具有较好的泛化能力,实验结果优于大部分模型.CNN-non-static [13] 在模型训练过程中把输入句子的词向量矩阵作为可调参数;CNN-multi-channel [13] 将不可调参的输入句子词向量矩阵与可动态调参的输入句子词向量矩阵共同作为模型的2个输入;DCNN [14] 在池化层引入动态的 K -Max pooling策略选择 K 个最大的特征值.但以上3个基于神经网络的句子分类模型均是人为设置卷积层的输入组合,SCNN模型通过稀疏自学习输入特征map的有效组合,可以改善卷积层所提取的数值特征,从而提高了分类器的准确率.SVMs [11] 通过使用 uni-bi-trigrams, wh word, POS, parser 等基于语言学的特征,利用SVM模型在TREC数据集上取得较基于神经网络的句子分类模型更好的分类效果.
本文基于卷积神经网络模型之上,提出稀疏自学习卷积神经网络的句子分类模型SCNN,可以有效地在训练过程中学习输入特征map的组合,排除人为约定因素,更好地提取数据特征,提高分类精准度;此外,利用L1范数可以有效地限制模型的复杂度,从而避免欠拟合问题所带来的负面影响.通过与其他模型进行实验对比,在多组数据集上取得了较好的分类效果,验证了SCNN模型的有效性.
将来,我们将进一步考虑把从语料库中提取的语言学特征作为先验知识加入到本文所提出的模型中,以充分利用两者的优点达到增强分类效果的目的.总的来说,本文的工作为句子分类问题提供了一个可行的解决方案,为今后的自然语言处理研究提供了新的思想和方向.
参考文献
[1] Zhang Rui, Lee H, Radev D. Dependency sensitive convolutional neural networks for modeling sentences and documents[C] //Proc of the 15th Conf of the North American Chapter of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2016: 1512-1521
[2] Galitsky B A, De La Rosa J L, Dobrocsi G. Inferring the semantic properties of sentences by mining syntactic parse trees[J]. Data and Knowledge Engineering, 2012, 81: 21-45
[3] Guo Yanming, Liu Yu, Oerlemans A, et al. Deep learning for visual understanding: A review[J]. Neurocomputing, 2016, 187: 27-48
[4] Chen Xinchi, Qiu Xipeng, Zhu Chenxi, et al. Sentence modeling with gated recursive neural network[C] //Proc of Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2015: 793-798
[5] Zhao Jingling, Zhang Huiyun, Cui Baojiang. Sentence similarity based on semantic vector model[C] //Proc of the 9th Int Conf on P2P, Parallel, Grid, Cloud and Internet Computing (3PGCIC). Piscataway, NJ: IEEE, 2014: 499-503
[6] Chenlo J M, Losada D E. An empirical study of sentence features for subjectivity and polarity classification[J]. Information Sciences, 2014, 280: 275-288
[7] Pang B, Lee L, Vaithyanathan S. Thumbs up?: Sentiment classification using machine learning techniques[C] //Proc of the 2nd Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2002: 79-86
[8] Turney P D. Thumbs up or thumbs down?: Semantic orientation applied to unsupervised classification of reviews[C] //Proc of the 40th Annual Meeting on Association for Computational Linguistics. Stroudsburg, PA: ACL, 2002: 417-424
[9] Yang Bishan, Cardie C. Context-aware learning for sentence-level sentiment analysis with posterior regularization[C] //Proc of the 52nd Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2014: 325-335
[10] Wang Sida, Manning C D. Baselines and bigrams: Simple, good sentiment and topic classification[C] //Proc of the 50th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2012: 90-94
[11] Silva J, Coheur L, Mendes A C, et al. From symbolic to sub-symbolic information in question classification[J]. Artificial Intelligence Review, 2011, 35(2): 137-154
[12] Qin Pengda, Xu Weiran, Guo Jun. An empirical convolutional neural network approach for semantic relation classification[J]. Neurocomputing, 2016, 190: 1-9
[13] Kim Y. Convolutional neural networks for sentence classification[C] //Proc of Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2014: 1746-1751
[14] Kalchbrenner N, Grefenstette E, Blunsom P. A convolutional neural network for modelling sentences[C] //Proc of the 52nd Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2014: 655-665
[15] Hu Baotian, Lu Zhengdong, Li Hang, et al. Convolutional neural network architectures for matching natural language sentences[C/OL] //Proc of Annual Conf on Neural Infor-mation Processing Systems. 2014 [2016-09-20]. http://papers.nips.cc/paper/5550-convolutional-neural-network-architectures-for-matching-natural-language-sentences.pdf
[16] He Hua, Gimpel K, Lin J. Multi-perspective sentence similarity modeling with convolutional neural networks[C] //Proc of Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2015: 1576-1586
[17] Zhou Kailong, Zhuo Li, Geng Zhen, et al. Convolutional neural networks based pornographic image classification[C] //Proc of the 2nd IEEE Int Conf on Multimedia Big Data. Piscataway, NJ: IEEE, 2016: 206-209
[18] Ma Long, Zhang Yanqing. Using word2vec to process big text data[C] //Proc of IEEE Int Conf on Big Data. Piscataway, NJ: IEEE, 2015: 2895-2897
[19] LeCun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015, 512(7553): 436-444
[20] Liu Baoyuan, Wang Min, Foroosh H, et al. Sparse convolutional neural networks[C] //Proc of IEEE Conf on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ: IEEE, 2015: 806-814
Gao Yunlong 1,2 , Zuo Wanli 1,2 , Wang Ying 1,2 , and Wang Xin 2,3
1 ( College of Computer Science and Technology , Jilin University , Changchun 130012) 2 ( Key Laboratory of Symbolic Computation and Knowledge Engineering ( Jilin University ), Ministry of Education , Changchun 130012) 3 ( College of Computer Technology and Engineering , Changchun Institute of Technology , Changchun 130012)
Abstract The study and establishment of sentence classification model have an important impact on the study of nature language processing and understanding. In this paper, we propose a sentence classification model named SCNN based on sparse and self-taught convolutional neural networks in extracting characteristics of the features from data in the CNN model. Firstly, in this method, the convolutional layer itself studies the effective combinations from the feature matrices of the previous layers in order to dynamically learn the relationships of data features in the scope of the sentence, eliminating the user-defined feature-map input of the convolutional layers. Secondly, during the unsupervised training process, using L1-norm to increase sparse constraints, the complexity of the proposed model can be effectively decreased, on the contrary, the accuracy of SCNN model can be effectively increased. Finally, by employing K -Max Pooling in the feature extraction layer, the maximal feature sequence can be selected, and relative orders among features can be effectively preserved. SCNN can cope with sentence with variant length, and furthermore, the model can apply to any language due to its independence to any linguistic features like syntax and parse trees. Experiments on the standard corpus dataset show that the proposed model is effective for the task of the sentence classification.
Key words convolutional neural networks (CNN); sparse; self-taught; classification; L1-norm
摘 要 句子分类模型的建立对于自然语言理解的研究有着十分重要的意义.基于卷积神经网络(convolutional neural networks, CNN)提取数据特征的特点,提出基于稀疏自学习卷积神经网络(sparse and self-taught CNN, SCNN)的句子分类模型.首先,在卷积层排除人为约定的特征map输入,自学习前一层输入的特征矩阵的有效组合,动态捕获句子范围内各个特征的有效关联;然后,在训练过程中利用L1范数增加稀疏性约束,降低模型复杂度;最后,在采样层利用 K -Max Pooling选择句子中最大特征的序列,并保留特征之间的相对次序.SCNN可以处理变长的句子输入,模型的建立不依赖于句法、分析树等语言学特征,从而适用于任何一种语言.通过对语料库进行句子分类实验,验证了所提出模型有较好的分类效果.
关键词 CNN;稀疏;自学习;分类;L1范数
中图法分类号 TP181
收稿日期: 2016-11-01;
修回日期: 2017-05-23
基金项目: 国家自然科学基金项目(60903098,60973040,61602057);国家自然科学基金青年科学基金项目(61300148);吉林省科技厅优秀青年人才基金项目(20170520059JH);吉林省教育厅青年基金项目(2016311);吉林大学研究生创新基金项目(2016184)
This work was supported by the National Natural Science Foundation of China (60903098, 60973040, 61602057), the National Natural Science Foundation of China for Young Scientists (61300148), the Foundation of Science and Technology Department of Jilin Province (20170520059JH), the Youth Fund of Jilin Provincial Department of Education (2016311), and the Graduate Innovation Fund of Jilin University (2016184).
通信作者: 左万利(zuowl@jlu.edu.cn)

Gao Yunlong , born in 1993. Master candidate. His main research interests include data mining, machine learning, deep learning.

Zuo Wanli , born in 1957. PhD, professor, PhD supervisor. Senior member of CCF. His main research interests include database theory, data mining, Web mining, machine learning, and Web search engines.

Wang Ying , born in 1981. PhD, associate professor. Senior member of CCF. Her main research interests include data mining, machine learning, social computing and search engine (wangying2010@jlu.edu.cn).

Wang Xin , born in 1981. PhD, lecturer. Member of CCF. His main research interests include data mining, social computing and search engine (wangxccs@126.com).