Fig. 1 Graphical model of Labeled LDA
图1 Labeled LDA的图模型
杜雨萌 张伟男 刘 挺
(哈尔滨工业大学社会计算与信息检索研究中心 哈尔滨 150001)
(ymdu@ir.hit.edu.cn)
随着移动互联网技术的发展及移动终端的普及,Twitter、微博等社交类应用上聚集了大量的用户,每个用户每天可以接收到成百上千条微博,从而导致信息过载,严重影响用户的信息及知识获取.自动识别微博用户的兴趣,进而根据用户兴趣来协助用户组织及过滤信息,能够有效解决信息过载的问题.同时,用户兴趣识别对于商品推荐、广告定向投放等业务也有很大帮助.
已有研究中,Ramage等人 [1] 使用Labeled LDA主题模型对Twitter用户进行了兴趣挖掘,这种方法将用户的所有Tweets集合作为一个文档,使用主题模型预测出文档的主题分布,以此表示用户的兴趣主题分布.该方法的问题在于,没有区分用户发布的Tweets中词的权重,而现实中对一条Tweet或微博进行分类时,其中的每个词起到的作用是不一样的,往往是少数几个词起到决定用户兴趣的作用.这就导致尽管一个用户发表了很多自身兴趣相关的微博,但由于表达兴趣的词周围存在大量噪声词,使得Labeled LDA主题模型对用户兴趣词的主题分配随上下文而发生严重偏移,从而导致用户兴趣识别发生错误.
针对上述问题,本文首先通过对用户的微博进行逐条兴趣分类,从而缓解噪声词对用户兴趣词的影响;然后通过用户微博的兴趣类别分布进而识别用户兴趣.具体地,本文提出一种主题增强卷积神经网络(convolutional neural network, CNN)的兴趣识别方法,结合了词向量提供的连续语义特征和Labeled LDA模型提供的离散主题特征.在进行用户兴趣识别时,首先使用主题增强CNN对用户的微博进行逐条分类,之后根据用户微博的兴趣类别分布,通过极大似然估计得到微博用户的兴趣.
1.1.1 Labeled LDA主题模型
1) 主题生成过程
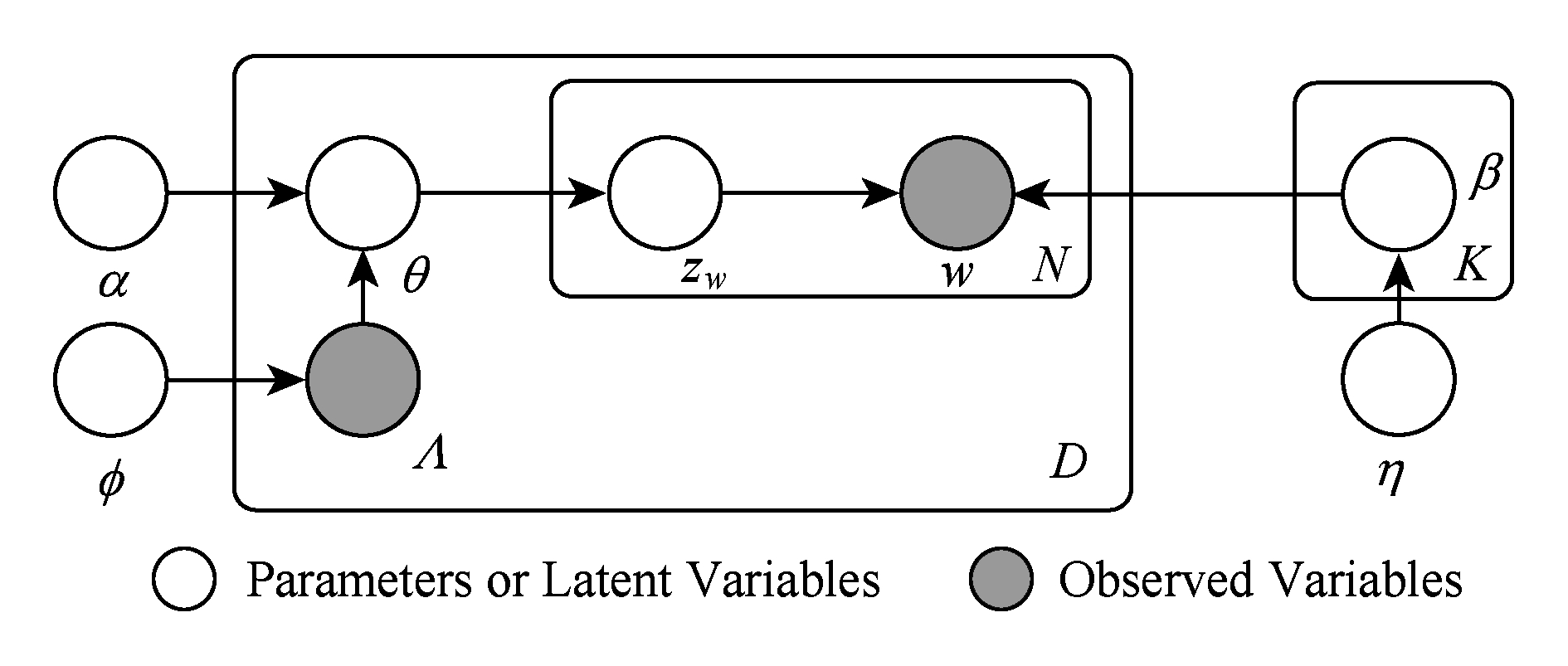
Labeled LDA是一种描述带标签的文档的生成过程的概率图模型 [2] .与传统LDA模型 [3] 一样,Labeled LDA认为每篇文档是一组主题的混合,文档里的每个词都由一个主题生成.与传统LDA模型不同的是,Labeled LDA通过把主题模型中的主题限制在了与每篇文档关联的一个标签集合上,从而在模型中融入了监督信息.Labeled LDA的图模型如图1所示:
Fig. 1 Graphical model of Labeled LDA
图1 Labeled LDA的图模型
设每篇文档 d 被表示为一个元组,该元组由一个词索引列表 w ( d ) =( w 1 , w 2 ,…, w N d )和一个二元的标签出现/缺失指示器 Λ ( d ) =( l 1 , l 2 ,…, l K )构成,其中每个 w i ∈{1,2,…, V },每个 l k ∈{0,1}.这里 N d 表示文档的长度, V 表示词表的长度, K 表示语料库中标签的数目.
令Labeled LDA模型中的主题数目等于语料库中标签的数目,则生成过程如算法1所示:
算法1 . Labeled LDA主题模型算法.
① For each topic k ∈{1,2,…, K }
② Generate β k =( β k ,1 , β k ,2 ,…, β k , V ) T ~
Dir (·| η );
③ End for
④ For each document d
⑤ For each topic k ∈{1,2,…, K }
⑥ Ge ![]()
Bernoutlli (·| φ k );
⑦ End for
⑧ End for
⑨ Generate α ( d ) = L ( d ) × α ;
⑩ Ge ![]()
Dir (·| α ( d ) |);
 For each i in {1,2,…, N d }
For each i in {1,2,…, N d }
 Ge
Ge ![]()
Mult (·| θ ( d ) |);
 Generate w i ∈{1,2,…, V }~
Generate w i ∈{1,2,…, V }~
Mult (·| β z i |);
 End for
End for
在步骤①和步骤②中,从一个参数为 η 的Dirichlet先验分布抽取出每个主题 k 在词表上的多项分布 β k ,即主题-词分布.传统的LDA模型中,接下来将为每一篇文档,从一个参数为 α 的Dirichlet先验分布中抽取一个多项分布 Λ ( d ) ,作为该文档在 K 个主题上的主题分布,但在Labeled LDA中,把 θ ( d ) 限制在标签指示器 Λ ( d ) 显示出现的那些标签所对应的主题中.因为在分配文档中每个位置的主题时要参考 θ ( d ) ,所以上述限制确保了分配的主题都来自于文档的标签集合.
在步骤⑥中,对每个主题 k 我们通过参数为 φ k 的伯努利分布,生成其在标签指示器 Λ ( d ) 中对应的元素.进而我们就得到了该文档的标签向量 ![]() }.这使得我们可以为每篇文档定义一个大小为 M d × K 的标签映射矩阵 L ( d ) ,其中 M d =| λ ( d ) |,矩阵 L ( d ) 中第 i 行第 j 列的元素
}.这使得我们可以为每篇文档定义一个大小为 M d × K 的标签映射矩阵 L ( d ) ,其中 M d =| λ ( d ) |,矩阵 L ( d ) 中第 i 行第 j 列的元素 ![]() 的值为
的值为
(1)
也就是说,在矩阵 L ( d ) 的第 i 行中第 j 列的元素为1而其他列元素为0,当且仅当文档的第 i 个标签 ![]() 是主题 j .
是主题 j .
步骤⑨中使用标签映射矩阵 L ( d ) 与Dirichlet先验分布的参数向量 α =( α 1 , α 2 ,…, α K ) T 相乘,这一步运算将参数向量 α 映射到更低的维度,得到了针对于每篇文档 d 的Dirichlet分布的参数向量 ![]() 这个结果满足了我们将文档的主题限制在文档标签的条件.步骤⑩~ 与传统LDA模型的文档生成过程相同.
这个结果满足了我们将文档的主题限制在文档标签的条件.步骤⑩~ 与传统LDA模型的文档生成过程相同.
2) 学习和预测
Labeled LDA对用户打好标签的文档进行学习和预测的过程与传统的LDA模型的学习和预测过程是相似的.区别只在于:Labeled LDA将每篇文档用以获取主题分布的先验Dirichlet分布的参数 α ( d ) 限制在了文档的标签集合 λ ( d ) 上.因此在训练时,像LDA模型一样使用Gibbs采样,文档 d 里位置 i 的主题为 j 的概率为
P ( z i = j | z 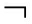 i |)∝
i |)∝ ![]() ×
× ![]() ,
,
(2)
其中 ![]() 表示除当前位置 i 外,词 w i 出现在主题 j 下的次数;缺失的上标或者下标表示在对应维度上的求和,例如
表示除当前位置 i 外,词 w i 出现在主题 j 下的次数;缺失的上标或者下标表示在对应维度上的求和,例如 ![]() 表示除当前位置 i 外,主题 j 被分配的次数.
表示除当前位置 i 外,主题 j 被分配的次数.
在从训练集中学习出多项分布 β ,即主题-词分布后,就可以使用Gibbs采样对打好标签的新文档进行主题预测.
3) 基于Labeled LDA主题模型的用户兴趣识别
Ramage等人 [1] 使用Labeled LDA主题模型对Twitter用户进行了兴趣识别,方法是:将兴趣主题设置为Labeled LDA模型中使用的主题,将用户的Tweets集合作为一篇文档,之后使用Labeled LDA主题模型计算用户的Tweets文档的主题分布,获得的主题分布即为用户的兴趣主题分布.
1.1.2 基于卷积神经网络的句子分类器
CNN是计算机图像领域发明的一种前馈神经网络,在图像识别、影像分析等应用中表现出色 [4-6] .随后,CNN在自然语言处理领域的句法分析 [7] 、查询检索 [8] 、句子建模 [9] 等工作上都取得了良好的效果.Kim [10] 使用单层卷积层的CNN实现了一个句子分类器,该模型结构如图2所示:
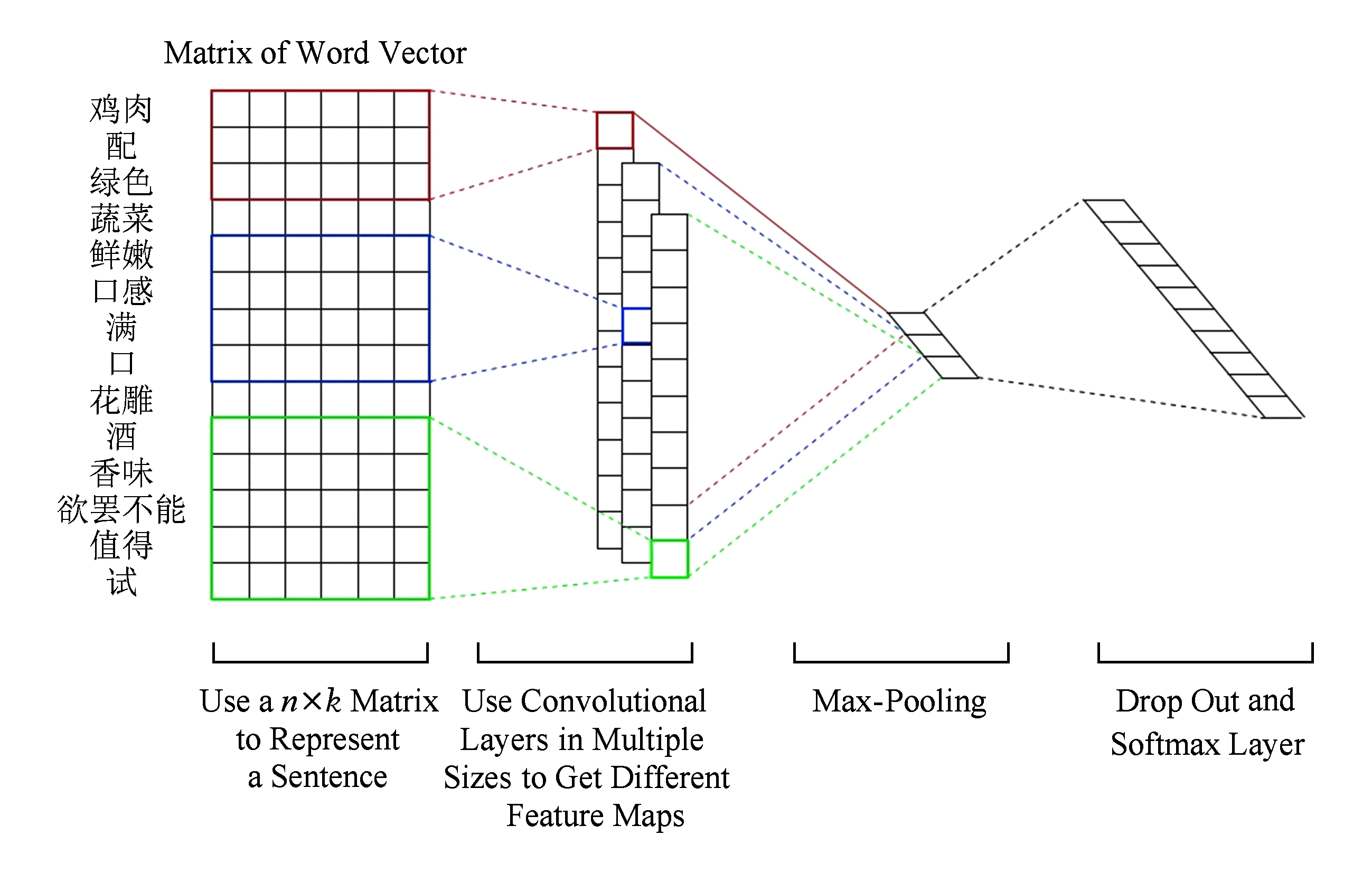
Fig. 2 Model architecture of CNN sentence classifier
图2 卷积神经网络句子分类器的模型结构
模型的输入是一个 n × k 的词向量矩阵,设 x i ∈ ![]() k 是句子里第 i 个词对应的词向量.一个长度为 n 的句子,可以表示为
k 是句子里第 i 个词对应的词向量.一个长度为 n 的句子,可以表示为
x 1: n = x 1 ⊕ x 2 ⊕…⊕ x n ,
(3)
令 x i : i + j 表示 x i , x i +1 ,…, x i + j 词的连接,一个卷积操作是指使用过滤器(filter) w ∈ ![]() h k ,从一个包含 h 个词的窗口生成一个新的特征.设 c i 是从窗口 x i : i + h -1 生成的特征:
h k ,从一个包含 h 个词的窗口生成一个新的特征.设 c i 是从窗口 x i : i + h -1 生成的特征:
c i = f ( w · x i : i + h -1 + b ),
(4)
其中, b 是偏置, f 是一个非线性函数.这个过滤器在句子的所有词窗口 x 1: h , x 2: h +1 ,…, x n - h +1: n 上都生成新的特征,就得到了一个特征映射(feature map)
c =( c 1 , c 2 ,…, c n - h +1 ),
(5)
之后使用max pooling操作,选择出feature map中的最大值 ![]() 的思想是,每个feature map里的最大值代表了每个feature map里最重要的特征.
的思想是,每个feature map里的最大值代表了每个feature map里最重要的特征.
模型中会使用多个filter,所以会产生多个feature map以及多次max pooling操作.之后将max pooling操作后的结果作为特征向量输入到softmax层,最终softmax层输出句子在不同类别上的概率分布.
本文提出一种基于主题增强卷积神经网络的用户兴趣识别方法,是一种结合了连续的语义特征和离散的主题特征的方法, 模型框架如图3所示:
Fig. 3 Model architecture of topic augmented CNN
图3 主题增强CNN的模型结构
模型的2个输入分别是一条微博对应的词向量矩阵和主题信息矩阵.词向量由预先训练好的word2vec模型获得,对微博进行填充(padding)后,将微博里的每个词都转换为对应的词向量,便得到该微博对应的词向量矩阵.我们设定了 K 个兴趣主题,主题信息矩阵中的每一行的 K 维向量对应微博中每个词分配到各个兴趣主题的概率.如果计算微博中第 i 个位置上的词 w i 被分配为主题 k 的概率,首先是根据由主题模型获得的第 i 个位置以外的位置的主题分配情况,可以估算出当前位置 i 被分配为主题 k 的概率:

(6)
其中 ![]() 表示概率估计值; i 表示位置 i 以外的位置;
表示概率估计值; i 表示位置 i 以外的位置; ![]() 表示位置以外的位置分配为主题 k 的个数.因为在训练好的Labeled LDA模型中,我们可以获取到主题 k 下的主题-词分布 β k ,所以主题 k 下出现词 w i 的概率 P ( w i | z i = k )是已知的.结合式(6)得到的对主题先验的估计,由贝叶斯公式我们可以计算出第 i 个位置上的词 w i 被分配为主题 k 的概率:
表示位置以外的位置分配为主题 k 的个数.因为在训练好的Labeled LDA模型中,我们可以获取到主题 k 下的主题-词分布 β k ,所以主题 k 下出现词 w i 的概率 P ( w i | z i = k )是已知的.结合式(6)得到的对主题先验的估计,由贝叶斯公式我们可以计算出第 i 个位置上的词 w i 被分配为主题 k 的概率:
![]() ( z i = k | w i |)=
( z i = k | w i |)= ![]() ( z i = k )× P ( w i | z i = k ),
( z i = k )× P ( w i | z i = k ),
(7)
由于 ![]() 是估算值,所以会出现
是估算值,所以会出现 ![]() k | w i )≠1的情况,因此,还需要进行归一化,归一化后的结果就是微博第 i 个位置上的词 w i 被分配为主题 k 的概率:
k | w i )≠1的情况,因此,还需要进行归一化,归一化后的结果就是微博第 i 个位置上的词 w i 被分配为主题 k 的概率:
P ( z i = k | w i )= 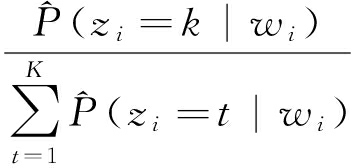 .
.
(8)
本文的模型是一个双通道的CNN,2个通道的结构相似.在每个通道的输入矩阵上都添加了一个单层卷积层,对卷积后获得的feature map执行max pooling操作,然后将2个通道的池化操作后的结果合并输入到一个全连接层,全连接层的输出作为特征向量输入到softmax层,最终softmax层输出微博在不同兴趣类别上的概率分布.
本文的用户兴趣识别方法如下:设主题类别体系为 C ={ c 1 , c 2 ,…, c M },给定某个用户 u ,抽取其发布的微博文本集合 W ={ w 1 , w 2 ,…, w n },文本数目为 n ,使用本文提出的主题增强CNN作为分类器进行预测,得到 n 条微博文本对应的类别列表 L ={ l 1 , l 2 ,…, l n },其中 l i ∈ C .在类别列表上定义一个计数函数 count ( x , L )表示类别 x 在 L 中出现的次数,其中, x ∈ C .按照 count ( x , L )由高到低排序,选择排序靠前的类别表示用户兴趣.
以类别体系覆盖面大、类别间区分度大为原则,并参考相关文献 [11] ,本文设定了10个微博兴趣类别,分别为:体育、娱乐、汽车、财经、时事/军事、科技、健康/养生、旅游/摄影/美食、星座/时尚/语录、校园/教育/职场.
由于普通用户所发的微博涵盖的种类比较多,包含较多的噪声,因此我们在获取训练数据时选取的是各个类别下的微博认证用户,且尽量选择企业认证用户.比如体育类,我们选取了“新浪体育”、“虎扑体育”等用户,从这些用户的微博中抽取训练语料.
爬取各个类别的认证用户的微博,在对原始微博语料进行必要的过滤后抽取出训练语料、验证语料和测试语料.训练集、验证集和测试集的微博文本数目如表1所示:
Table 1 Number of Microblog Text in Training Set , Validation Set and Test Set
表1 训练集 、 验证集和测试语料微博文本数目
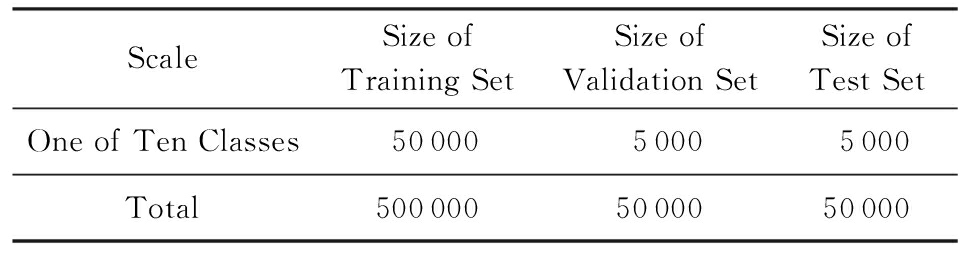
此外,还需要训练一个Labeled LDA模型,以构造微博的主题信息矩阵.训练集是每个兴趣类别为100 000条微博,将每个类别下的微博合并为一个文档,并打上相应的类别标签.比如体育类,将从“新浪体育”、“虎扑体育”等体育类的用户的微博中抽取出的微博合并为一个文档,并且将该文档的标签设为体育.
本文模型中的词向量长度为100,padding的最大长度参考微博的最大长度设置为140,卷积层的激活函数选用 RLU ,在词向量的通道里卷积层选择了长度为3,4,5的过滤器各100个,在主题信息的通道里卷基层选择了长度为2,3,4的过滤器各100个,在模型的倒数第2层全连接层的隐含神经元数量为300个,全连接层的激活函数为 RLU ,输出设定为300维,在倒数第2层与最后1层的softmax层之间设定 dropOutRate =0.5,在最后一层softmax层里使用了值为1的 l 2 正则化项.
2.4.1 评价微博分类效果
本文对微博分类效果的评价标准采用准确率(accuracy)、精确率 P (precision)、召回率 R (recall)以及 F 值.
2.4.2 评价用户兴趣识别效果
对用户的微博逐条兴趣分类后,通过极大似然估计得到微博用户的兴趣,选择数量最多的兴趣类别作为兴趣识别结果.采集了400位微博测试用户的数据,根据用户的标签、简介和微博内容对用户的兴趣类别进行标注.评价标准采用准确率.
2.5.1 微博文本分类效果
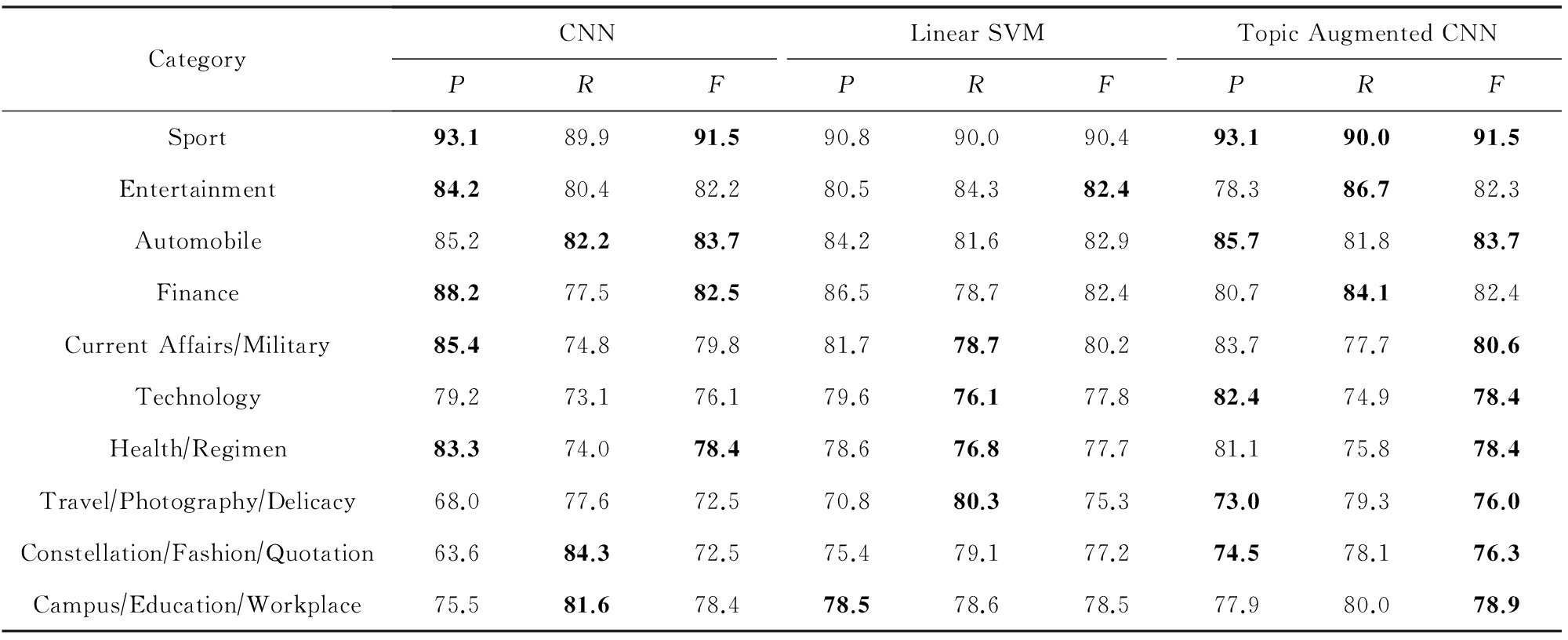
使用本文提出的主题增强CNN模型进行微博文本分类,作为对比实验,选择了CNN句子分类器 [10] 和在大规模中文语料分类任务上表现出色的以bigram为特征的线性SVM [12] .主题增强CNN、CNN和线性SVM在微博文本分类上的准确率分别为:80.8%,79.6%,80.4%.表2对比了3种方法在微博文本分类上的精确率 P 、召回率 R 以及 F 值.
Table 2 Precision , Recall and F value Comparison of Microblog Text Classification
表2 微博文本分类精确率 、 召回率 、 F 值对比 %
2.5.2 实例分析
从实验结果可以看出,主题增强CNN在微博文本分类上取得了最好的效果.与 CNN相比,主题增强CNN加入了微博里每个词被分配到各个主题的概率,在CNN分类效果较差的旅游  摄影 美食和星座 时尚 语录类别上取得了较大提升,整体上获得了更高的准确率.
摄影 美食和星座 时尚 语录类别上取得了较大提升,整体上获得了更高的准确率.
实例1 . 图4中显示的是1条旅游/摄影/美食类微博.
预处理后,这条微博为“日本 料理 惊闻 原 绿川 老师 著 更 自立 便 友人 前 拜访 品尝 客人 大部 份 客人 喜欢 坐 寿司 台前 海鲜 想 吃 口 吃 出 照料 功力”.CNN将其误分类为校园/教育/职场类,原因是预处理后的文本中包含了“老师”、“自立”、“友人”、“功力”,这些和教育/校园相关的词在只使用词向量的情况下出现了误分类.

Fig. 4 A travel/photography/delicacy microblog
图4 一条旅游/摄影/美食类微博
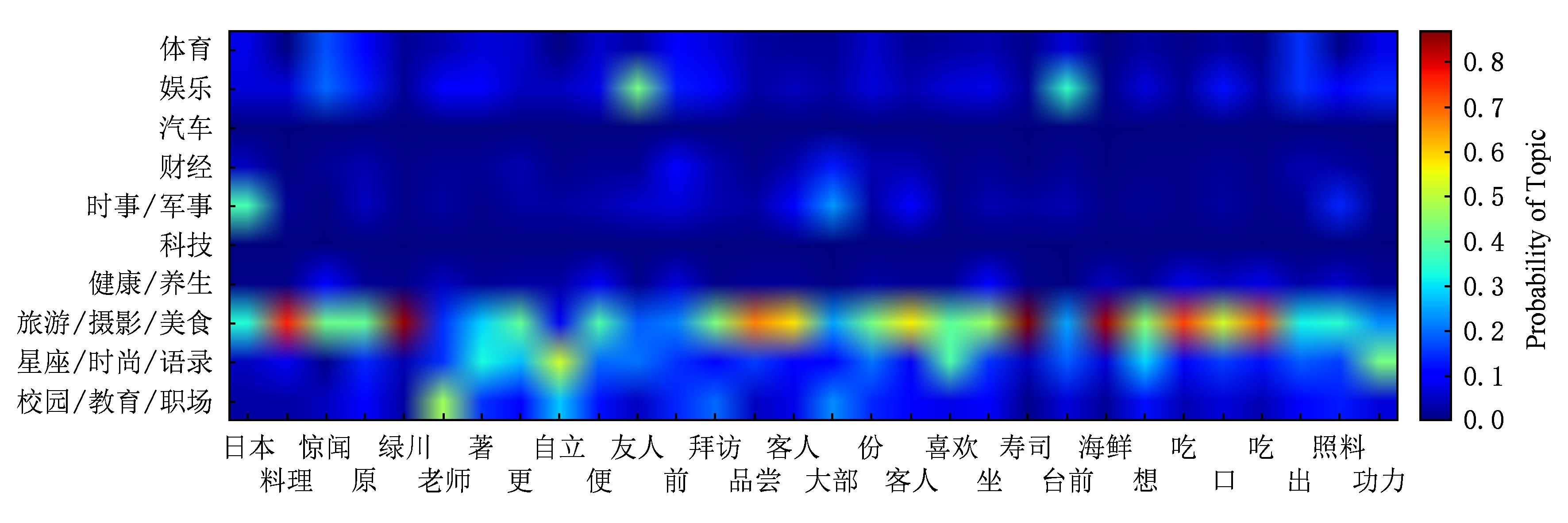
Fig. 5 Image of topic information matrix of microblog used in example 1
图5 实例1中使用的微波的主题信息矩阵的图像
将这条微博的主题信息矩阵图像化,其中横坐标是该微博预处理后包含的词,纵坐标是主题类别,图5中颜色的冷暖程度表示一个词被分配为一个主题的概率,概率与颜色的对应关系如图5中右侧的图例所示,概率由小至大对应于颜色由冷色变为暖色.
图5纵坐标是旅游/摄影/美食的行明显亮于其他行,经统计,该微博的30个词中被分配为旅游/摄影/美食类上的概率超过30%的词有22个,而被分配为校园/教育/职场主题上的概率大于30%的词只有2个.由此可见,这条微博的主题信息对其被正确分类起到了重要作用.
实例2 . 图6中显示的是一条星座/时尚/语录类微博.
预处理后,这条微博为“熟知 米兰 伦敦 爱 玩 爱闹 巴黎 处心积虑 玩 段位 米兰 精致 手工艺 阳刚 男性 魅力 招牌”,其中“米兰”、“巴黎”、“玩”等与旅游相关的词,使用词向量的CNN将其误分类为旅游/摄影/美食类.而该微博的主题信息矩阵的图像如图7所示:

Fig. 6 A constellation/fashion/quotations microblog
图6 一条星座/时尚/语录类微博
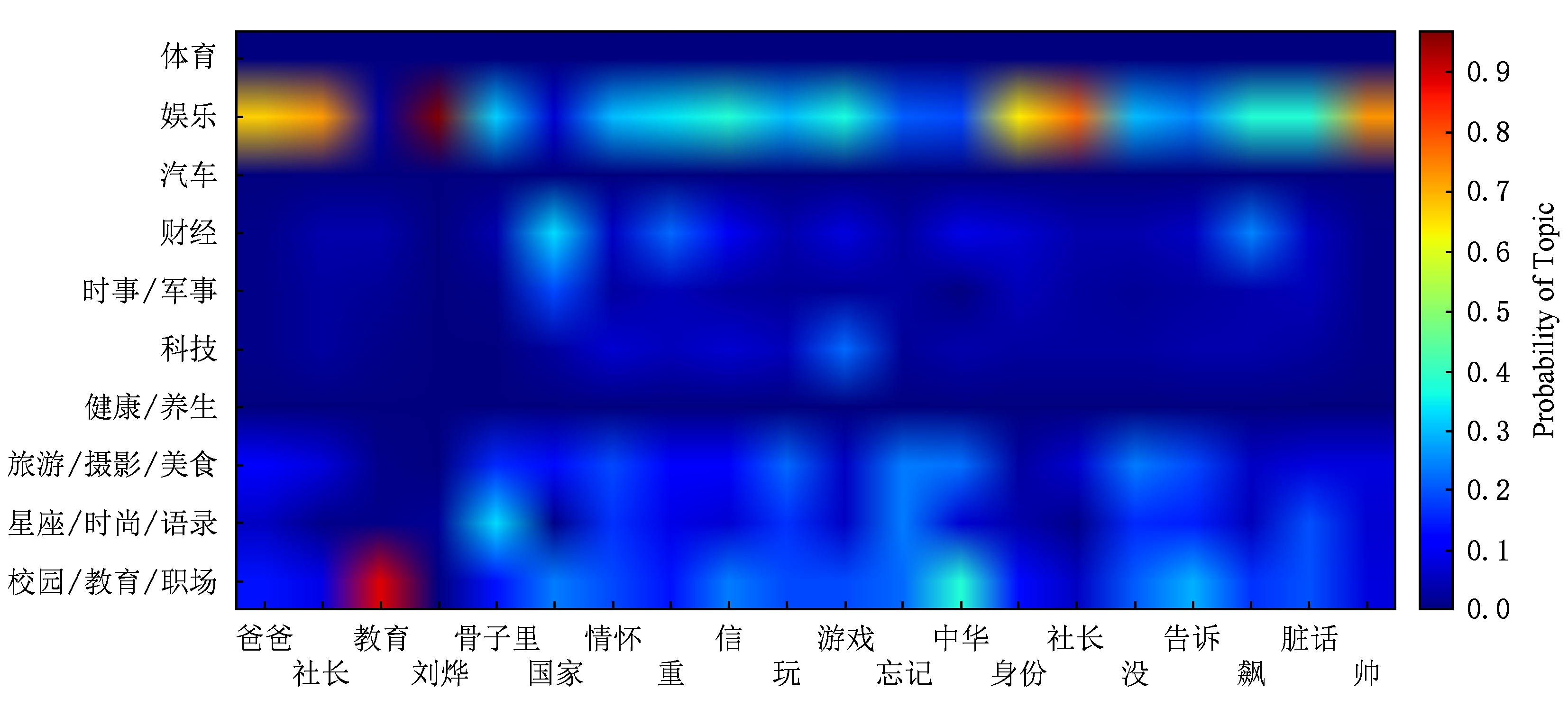
Fig. 7 Image of topic information matrix of microblog used in example 2
图7 实例2中使用的微波的主题信息矩阵的图像

Fig. 8 An entertainment microblog
图8 一条娱乐类微博
图7中纵坐标是星座/时尚/语录的行颜色明显亮于其他行,经统计,该微博中每个词被分配为星座/时尚/语录主题主题的概率都超过30%,但没有一个词被分配为旅游/摄影/美食主题的概率超过30%.可以看出主题信息对我们的模型正确分类这条微博起到了重要作用.
与使用bigram特征的线性SVM相比,主题增强CNN利用主题信息,对于包含噪声词比较多的微博,可以分类得更准确.
实例3 . 图8中显示的是一条娱乐类微博.
预处理后,这条微博为“爸爸 社长 教育 刘烨 骨子里 国家 情怀 重 信 玩 游戏 忘记 中华 身份 社长 没 告诉 飙 脏话 帅”,使用线性SVM将该微博误分类为校园/教育/职场类,因为“爸爸 社长”、“社长 教育”、“玩 游戏”、“身份 社长”这些bigram与校园/教育/职场类体现出很强的相关性,所以使用bigram作为特征的线性SVM将其误分类到校园/教育/职场类.而该微博的主题信息矩阵图像如图9所示:
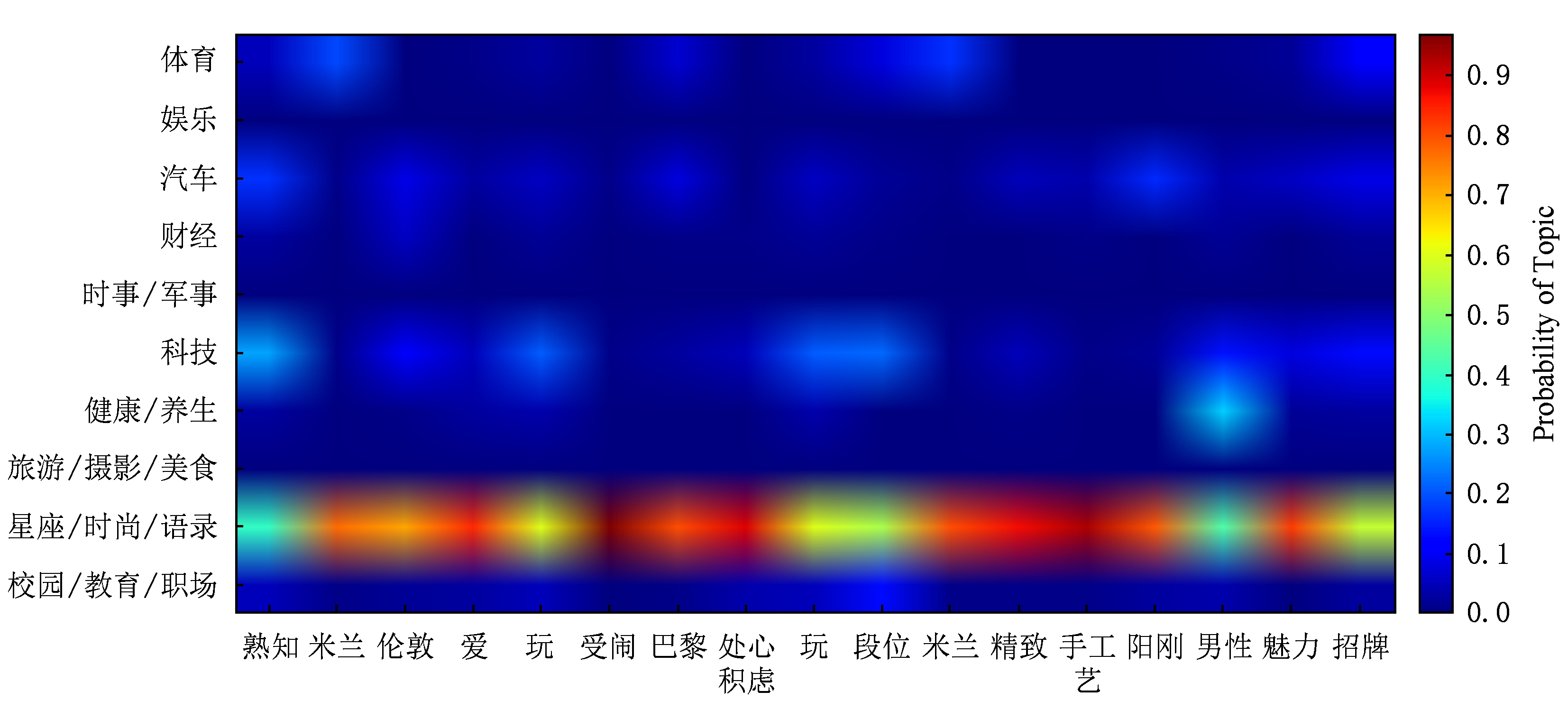
Fig. 9 Image of topic information matrix of microblog used in example 3
图9 实例3使用的微波 的主题信息矩阵的图像
图9中纵坐标为娱乐的行明显要亮于其他行,经统计,该微博20个词中被分配为娱乐主题的概率超过30%的词有15个,而被分配为校园/教育/职场类的概率超过30%的词只有1个.因此,主题信息对正确分类这条微博起到重要作用.
2.5.3 用户兴趣识别效果

Fig. 11 A sport microblog
图11 一条体育类微博
使用上述3个微博文本分类器,对用户的微博进行逐条分类,之后根据用户微博的兴趣类别分布,通过极大似然估计得到微博用户的兴趣.此外还增加了基于Labeled LDA主题模型的用户兴趣识别方法作为对比.使用Labeled LDA模型进行兴趣识别时,把一个用户的微博集合作为一篇文档,之后使用Labeled LDA模型预测每个用户的微博文档的主题分布,选择占据最高比例的主题作为兴趣识别的结果.图10显示了上述4种方法对400名测试用户的兴趣识别效果.
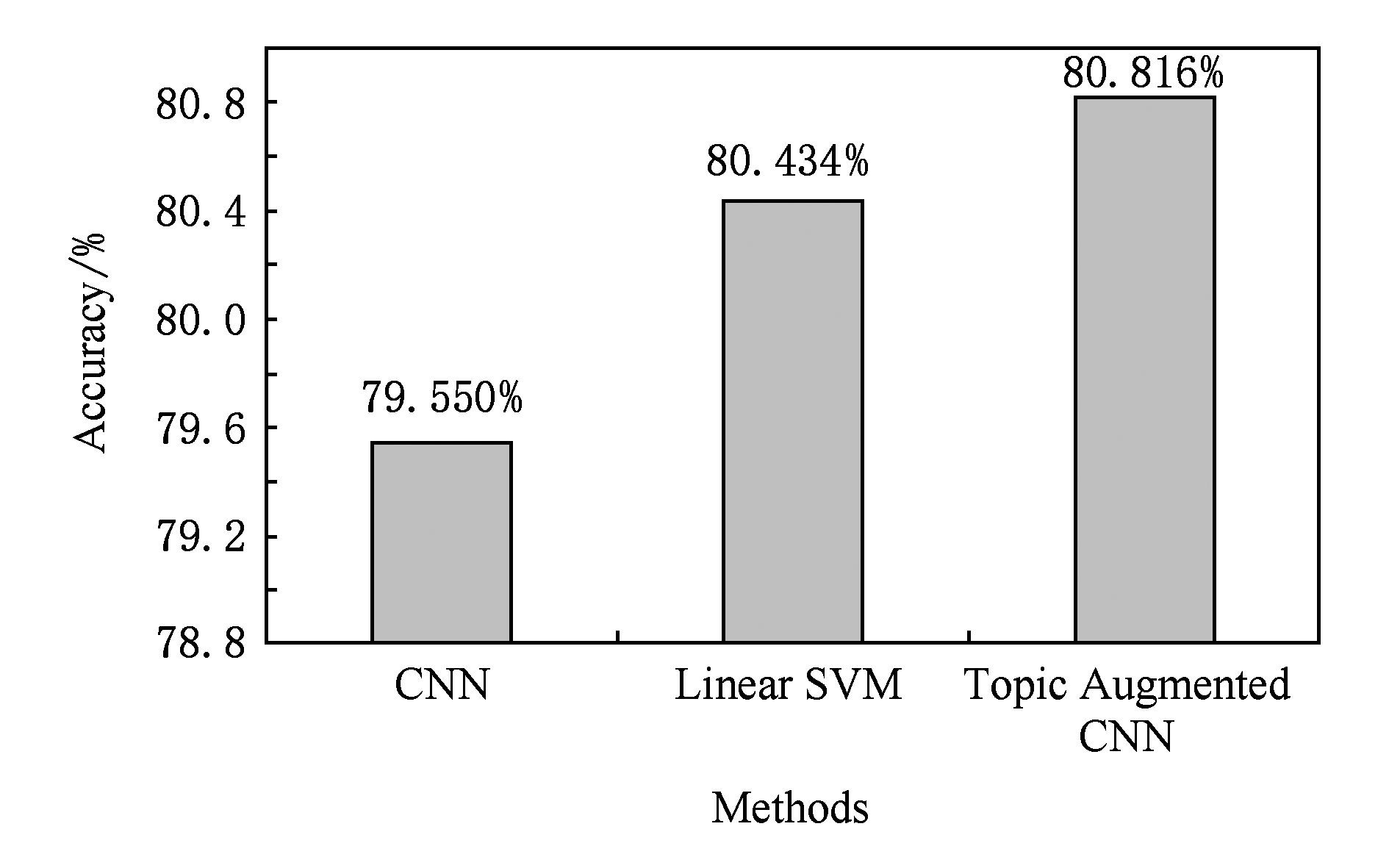
Fig. 10 Accuracy comparison of user interest recognition
图10 用户兴趣识别准确率对比
可以看出在这4种方法中,主题增强CNN+MLE取得了最好的效果.主题增强CNN+MLE、线性SVM和CNN这3种方法的兴趣识别效果和它们在微博文本分类上的效果正相关.Labeled LDA模型对文档中的一个词分配主题时,是结合当前位置以外的位置上的主题分配情况,以及训练好的Labeled LDA模型所提供的主题-词分布来确定的,Labeled认为每个词的权重都是一样的.然而在判断一条微博的类别时,微博中每个词的作用大小是不一样的,往往是少数几个词起决定类别的作用.
图11所示是一条体育类微博,虽然微博中多次出现“大学”和“理工”、“学院”这些教育相关的词语,但是“男篮”、“CUBA”这2个体育相关的词起到了决定微博类别的作用,所以分类为体育类微博.所以当一个用户发布很多自身兴趣相关的微博,但表达兴趣的词周围存在大量噪声词时,Labeled LDA主题模型在对用户兴趣词的主题分配会随上下文而发生严重偏移,从而导致用户兴趣识别发生错误.我们的方法通过对用户的微博进行逐条兴趣分类进而获得用户的兴趣,缓解了噪声词对用户兴趣词的影响,取得了更好的效果.
目前社会媒体上用户兴趣识别的方法主要有以下2类:
1) 基于用户微博内容的兴趣识别.Michelson等人 [13] 通过检测用户在他们的Tweets中提到的实体来挖掘他们的兴趣主题.Ramage 等人 [1] 将用户的所有Tweets集合看作一篇文档,然后使用Labeled LDA模型推断用户微博文档上的兴趣主题分布,在Twitter排序和推荐任务行取得很好的效果.Zhao等人 [14] 提出了一个Twitter-LDA模型,假设一条Tweet只包含一个主题,用来挖掘每条Tweet的主题;Xu等人 [15] 提出一种改进的作者-主题(author-topic)模型——Twitter-user模型,对每一条Twitter,该模型使用一个隐变量(latent variable)去预测它是否同用户的兴趣相关;Sasaki等人 [16] 提出了一个基于Twitter-LDA的改进模型,可以估计每个用户的所有Tweets中背景词与主题词之间的比例,并提出了一个新的概率主题模型主题追踪模型(topic tracking model, TTM),可以获取用户兴趣主题趋势的动态性进行在线推理;Guo等人 [17] 提出一个面向时间戳的动态主题模型,作者将每个主题下概率最高的词看作是用户的兴趣,并且作者提出了一个基于密度的算法来选择主题的数目.
2) 基于用户的行为(关注、转发等)的兴趣识别.Abel 等人 [18] 对基于用户在Twitter上的活动推导出的用户兴趣信息的时间动态性进行了分析,并且把时间特性引入到用户模型,定义了时间敏感的用户模型;Jin等人 [19] 在Facebook上通过用户的点赞(like)信息,挖掘用户的兴趣;Orlandi等人 [20] 提出一种通过分析社会网络用户发布的消息和诸如发表的评论、签到的地点、喜欢的链接等,可以自动抽取、聚合、表示用户兴趣的算法;Wang等人 [21] 提出一种基于连接关系二元图的正则化框架(regularization framework)来提高用户兴趣主题挖掘的效果;Vosecky等人 [22] 提出一个协同的用户主题模型,通过用户的社会连接来全面地获得用户的偏好,也提出了一种双层的用户模型结构以解决Twitter上主题多样性的问题,可以解决语义感知的查询消岐,完成个性化的Twitter搜索;Bhattacharya 等人 [23] 使用一种基于社会标注(social annotations )的方法,首先推断出popular user擅长的主题,进而推测关注这些popular user的用户的兴趣主题;Zhao 等人 [24] 在不同行为(如发布、评论、点赞等)下用户的兴趣是不同的,作者首先构建各个行为的user-topic矩阵,之后对每个user-topic矩阵进行矩阵分解学习latent embedding,最后构建用户信息(user profile),对用户在各个主题上的兴趣进行预测.
本文提出了一种基于主题增强卷积神经网络的用户兴趣识别方法,通过构建一个结合连续的语义特征和离散的主题特征的CNN作为微博文本分类器,对用户的微博进行兴趣分类,通过极大似然估计得到微博用户的兴趣.在400个微博用户的测试集上,与Labeled LDA、使用词向量的CNN和线性SVM这3种兴趣识别方法进行了比较,取得了最佳效果,准确率到达了91.25%.实验结果将连续的语义特征和离散的主题特征结合将显著提高用户兴趣识别的效果.
参考文献
[1] Ramage D, Dumais S T, Liebling D J. Characterizing microblogs with topic models[C] //Proc of Int Conf on Weblogs & Social Media. Menlo Park, CA: AAAI, 2010: 130-137
[2] Ramage D, Hall D, Nallapati R, et al. Labeled LDA: A supervised topic model for credit attribution in multi-labeled corpora[C] //Proc of Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2009: 248-256
[3] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3: 993-1022
[4] Schmidhuber J, Meier U, Ciresan D. Multi-column deep neural networks for image classification[C] //Proc of IEEE Conf on Computer Vision & Pattern Recognition. Piscataway, NJ: IEEE, 2012: 3642-3649
[5] An D, Meier U, Masci J. Flexible, high performance convolutional neural networks for image classification[C] //Proc of the Int Joint Conf on Artificial Intelligence. San Francisco, CA: Morgan Kaufmann, 2011: 1237-1242
[6] Ji Shuiwang, Xu Wei, Yang Ming. 3D convolutional neural networks for human action recognition[J]. IEEE Trans on Pattern Analysis & Machine Intelligence, 2013, 35(1): 221-231
[7] Yih W T, He Xiaodong, Meek C. Semantic parsing for single-relation question answering[C] //Proc of Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2014: 643-648
[8] Shen Yelong, He Xiaodong, Gao Jianfeng, et al. Learning semantic representations using convolutional neural networks for Web search[C] //Proc of Int Conf on World Wide Web Companion. New York: ACM, 2014: 373-374
[9] Kalchbrenner N, Grefenstette E, Blunsom P. A convolu-tional neural network for modelling sentences[OL]. 2014[2016-04-10]. https://arxiv.org/abs/1404.2188
[10] Kim Y. Convolutional neural networks for sentence classification[J/OL]. 2014 [2016-04-10]. https://arxiv.org/abs/1408.5882
[11] Xu Wei, Zhang Yu, Xie Yubin, et al. User interest recognition based on microblog classification[J]. Intelligent Computer and Applications, 2013, 3(4): 80-83 (in Chinese)
(宋巍, 张宇, 谢毓彬, 等. 基于微博分类的用户兴趣识别[J]. 智能计算机与应用, 2013, 3(4): 80-83)
[12] Li Jingyang, Sun Maosong, Zhang Xian. A comparison and semi-quantitative analysis of words and character-bigrams as features in Chinese text categorization [C] //Proc of the 21st Int Conf on Computational Linguistics and the 44th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2006: 545-552
[13] Michelson M, Macskassy S A. Discovering users’ topics of interest on Twitter: A first look[C] //Proc of the Workshop on Analytics for Noisy Unstructured Text Data. New York: ACM, 2010: 73-80
[14] Zhao Xin, Jiang Jing, Weng Jianshu, et al. Comparing Twitter and traditional media using topic models[G] //LNCS 6611: Advances in Information Retrieval. Berlin: Springer, 2011: 338-349
[15] Xu Zhiheng, Ru Long, Xiang Liang, et al. Discovering user interest on Twitter with a modified author-topic model[C] //Proc of IEEE/WIC/ACM Int Conf on Web Intelligence. New York: ACM, 2011: 422-429
[16] Sasaki K, Yoshikawa T, Furuhashi T. Twitter-TTM: An efficient online topic modeling for Twitter considering dynamics of user interests and topic trends[C] //Proc of Int Symp on Soft Computing and Intelligent Systems. Piscataway, NJ: IEEE, 2014: 440-445
[17] Guo Hongjian, Chen Yifei. User interest detecting by text mining technology for microblog platform[J]. Arabian Journal for Science & Engineering, 2016, 41(8): 3177-3186
[18] Abel F, Gao Qi, Houben G J, et al. Analyzing temporal dynamics in Twitter profiles for personalized recommenda-tions in the social Web[C] //Proc of Int Web Science Conf. New York: ACM, 2011: 1-8
[19] Jin Xin, Wang Chi, Luo Jiebo, et al. LikeMiner: A system for mining the power of ‘like’ in social media networks[C] //Proc of ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2012: 753-756
[20] Orlandi F, Breslin J, Passant A. Aggregated, interoperable and multi-domain user profiles for the social Web[C] //Proc of Int Conf on Semantic Systems. New York: ACM, 2012: 41-48
[21] Wang J, Zhao W X, He Y, et al. Infer user interests via link structure regularization[J]. ACM Trans on Intelligent Systems & Technology, 2014, 5(2): 1-22
[22] Vosecky J, Leung W T, Ng W. Collaborative personalized Twitter search with topic-language models[C] //Proc of Special Interest Group on Information Retrieval. New York: ACM, 2014: 53-62
[23] Bhattacharya P, Zafar M B, Ganguly N, et al. Inferring user interests in the Twitter social network[C] //Proc of the 8th ACM Conf on Recommender Systems.New York: ACM, 2014: 357-360
[24] Zhao Zhe, Cheng Zhiyuan, Hong Lichan, et al. Improving user topic interest profiles by behavior factorization[C] //Proc of Int Conf on World Wide Web. New York: ACM, 2015: 1406-1416
Du Yumeng, Zhang Weinan, and Liu Ting
( Research Center for Social Computing and Information Retrieval , Harbin Institute of Technology , Harbin 150001)
Abstract With the development of mobile Internet technology and the popularity of mobile terminals, there have been many social websites and applications on the Internet. As a social application, microblog has attracted a large number of users, with its convenience of operation and rapid propagation. A user receiving hundreds of microblogs every day, which leads to the situation of information overload, increases the difficulty of the user’s information and knowledge acquisition. On the other hand, more and more merchants treat microblog as a marketing platform, which makes the advertisements directed delivery become a problem with highly commercial value. Microblog user interest recognition can contribute to solve the problems discussed above. This paper proposes a topic augmented convolutional neural network approach to recognize user interest. By integrating the continuous semantic information and the discrete topic information, the proposed approach first obtains the category distribution of users’ microblogs. It then recognizes users’ interest through the maximum likelihood estimation over the category distribution of users’ microblogs. Experimental results show that the proposed topic augmented convolutional neural network approach outperforms the labeled LDA based approach and the traditional convolutional neural network approach significantly on the microblog classification and user interest recognition.
Key words topic model; convolutional neural network (CNN); microblog classification; user interest recognition; microblog
摘 要 提出了一种基于主题增强卷积神经网络的用户兴趣识别的方法,通过构造一个双通道CNN模型,融合连续语义信息和离散主题信息,获取用户微博类别分布,在此基础上,通过极大似然估计识别用户的兴趣.实验结果表明,相较于基于Labeled LDA主题模型的方法和传统卷积神经网络的方法,提出的主题增强卷积神经网络缓解了噪声词对用户兴趣词的影响,并且通过融入主题信息提高了对于包含噪声词较多的微博的分类效果,在微博分类及用户兴趣识别上的效果获得了显著的提升.
关键词 主题模型;卷积神经网络;微博分类;用户兴趣识别;微博
中图法分类号 TP391
收稿日期: 2016-11-24;
修回日期: 2017-02-23
基金项目: 国家“九七三”重点基础研究发展计划基金项目(2014CB340503);国家自然科学基金项目(61472107,61502120)
This work was supported by the National Basic Research Program of China (973 Program) (2014CB340503) and the National Natural Science Foundation of China (61472107, 61502120).

Du Yumeng , born in 1991. Master. His main research interests include data mining on social networks and natural language processing.

Zhang Weinan , born in 1985. PhD, lecturer. Member of CCF. His main research interests include chat robot, natural language processing and information retrieval.

Liu Ting , born in 1972. PhD, professor, PhD supervisor. Director of Research Center for Social Computing and Information Retrieval, Harbin Institute of Technology. Senior member of CCF. His main research interests include natural language processing, and information retrieval.