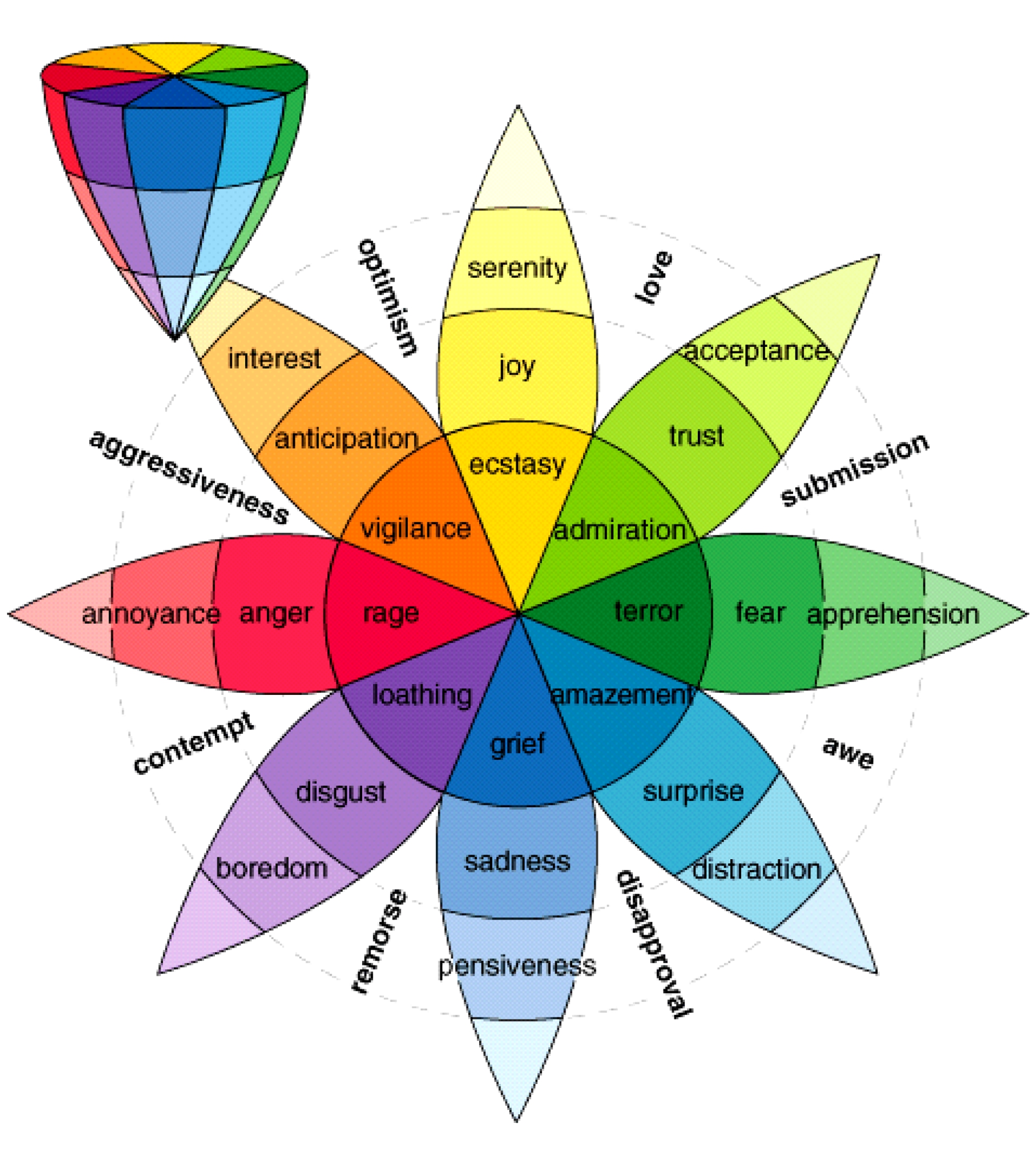
Fig. 1 Plutchik’s wheel of emotions
图1 Plutchik提出的情绪轮
李 然 1,2 林 政 1 林海伦 1 王伟平 1 孟 丹 1,2
1 (信息内容安全技术国家工程实验室(中国科学院信息工程研究所) 北京 100093)
2 (中国科学院大学网络空间安全学院 北京 100049)
(liran@iie.ac.cn)
随着社交媒体的迅猛发展,Twitter、微博、MSN、微信等社交网络正逐渐地改变着人们的生活.越来越多的人愿意在社交网络上表达自己的态度和情感,而不仅仅是被动地浏览和接收信息.对微博等文字中的情绪进行分析可以使人们获得更多关于内心世界的知识.因此,文本情绪分析技术可帮助研究机构、信息咨询组织和政府决策部门掌握社会情绪动态,这种需求极大地促进了情绪分析技术的发展.
近年来,文本情绪分析也渐渐引起了工业界和学术界的研究兴趣.在早期的工作中,研究重点主要集中在基于正负类的情感分析和对情感文本进行正面、负面、中性方面的分析.然而,基于二分类的情感分析难以充分表达人类复杂的内心世界,不仅忽视了用户所表达的细微情绪变化,同时也难以较全面地涵盖用户的心理状态,这都加速了对基于多分类的细粒度情绪分析的需求.
情绪分析又称细粒度类别的情感分析,反之,情感分析也可以看作是二分类的情绪分析.情绪分析是在现有粗粒度的二分类分析工作的基础上,从人类的心理学角度出发,多维度地描述人的情绪态度.比如“卑劣”是个负面的词语,而它更精确的注释是憎恨和厌恶.由于情绪分析对于快速掌握大众情绪的走向、预测热点事件甚至是民众的需求都有很重要的作用.研究者们的研究重点也逐渐从单一的文本正负情感分析转变为更加细粒度的情绪分析.
情绪,是多种感觉、思想、行为综合产生的生理和心理状态,是对外界刺激所产生的生理反应,如喜爱、悲伤、气愤等.“情绪”在《辞海》中的定义为:从人对事物的态度中产生的体验.与“情感”一词常通用,但有区别.情绪与人的自然性需要相联系,具有情景性、暂时性和明显的外部表现;情感与人的社会性需要相联系,具有稳定性、持久性,不一定有明显的外部表现.情感的产生伴随着情绪反应,而情绪的变化也受情感的控制.通常能满足人某种需要的对象,会引起正向的情绪体验,如满意、喜悦、愉快等;反之则引起负向的情绪体验,如不满、忧愁、恐惧等.因此也可以看出情感是多种情绪的综合表现,而情绪是情感的具体组成.因为情绪是人天性中的一个重要元素,所以它在心理学和行为科学中一直有着广泛的研究.由于自然语言的复杂性和人类情绪的多变性、敏感性,不同领域的研究对情绪类别的划分也有不小的差异.虽然目前学术界对情绪的分类还没有达成共识,但国内外学者已经对情绪分类做了较为深入的研究,并提出了不同的情绪集理论.
我国很早就开始对情绪分类开展研究,据《礼记》记载,人的情绪有“七情”的分法,即为喜怒哀惧爱恶欲;《白虎通》中情绪可以分为“六情”,即喜怒哀乐爱恶;在此基础上,现代心理学家林传鼎 [1] 根据《说文》将情绪分为18类,即安静、喜悦、抚爱、恨怒、惊骇、哀怜、恐惧、悲痛、惭愧、忧愁、忿急、烦闷、恭敬、憎恶、骄慢、贪欲、嫉妒、耻辱.
在现代心理学起源和繁盛的西方,研究者们对情绪集理论也有着丰富的成果.法国的哲学家笛卡儿(Descartes)在其著作《论情绪》中认为,人的原始情绪分为诧异(surprise)、爱悦(happy)、憎恶(hate)、欲望(desire)、欢乐(joy)和悲哀(sorrow),其他的情绪都是这6种原始情绪的分支或者组合.此后,美国心理学家Ekman [2] 提出一个基础情绪理论,其认为基本情绪包括高兴(joy)、悲伤(sadness)、愤怒(anger)、恐惧(fear)、厌恶(disgust)和诧异(surprise),因为这6种情绪可以依靠面部表情和生理过程(如增加心率和流汗)辨别,所以这些情绪被认为比其他的更基本.
在此基础上,美国心理学家Plutchik [3] 基于进化规则的综合理论,提出了一种多维度的情绪模型,模型定义了8种基本双向情绪,包括Ekman的6种情绪以及信任(trust)、期望(anticipation).可以分为4对双向组合:高兴与悲伤(joy vs. sadness)、愤怒与恐惧(anger vs. fear)、信任与厌恶(trust vs. disgust)、诧异与期望(surprise vs. anticipation).图1显示了Plutchik模型的情绪类别在“情绪轮”上的排序,其中颜色的深浅代表这种情绪的饱和度,离圆心的远近代表情绪的强度.每种情绪都可以进一步分为3度.例如满足是较小程度的高兴,是一种不饱和状态;狂喜是强烈的高兴,是饱和状态.此外,Plutchik还提出一种假设,2种相邻近的基本情绪组合会产生一种复合的情绪.例如乐观是由高兴和期望的组合;此外,一些外在的刺激也可以产生复合情绪,若同时触发了高兴和信任,人们会表现出爱的情绪.
Fig. 1 Plutchik’s wheel of emotions
图1 Plutchik提出的情绪轮
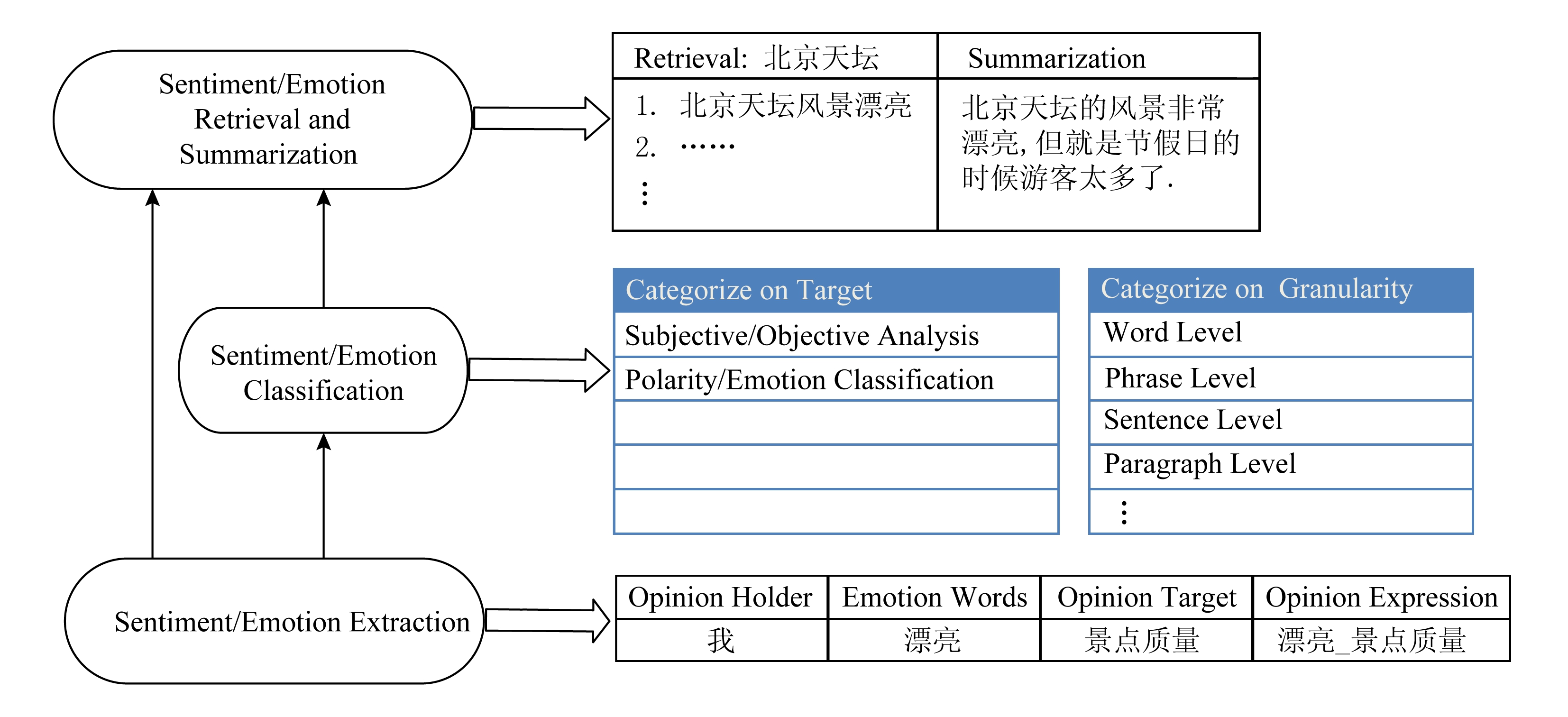
Fig.2 Research framework of sentiment/emotion analysis
图2 情感/情绪分析的研究框架
另一种在多项研究 [4-5] 中被采用的人类情绪识别模型是美国心理学家Ortony等人 [6] 提出的OCC (Ortony Clore Collins)情绪模型,该模型基于人对各种情况的情绪反应制定了22种情绪类别,主要用于模拟一般情况下的情绪.
此外,从分层的角度出发,英国心理学家Parrott [7] 提出了一种基于树结构的情绪分类模型,该模型由6种基本情绪组成,分别为:爱(love)、高兴(joy)、诧异(surprise)、愤怒(anger)、悲伤(sadness)和恐惧(fear),并根据基本情绪构建了一个3层的树结构.分类模型的第1层由6种基本情绪构成,第2层、第3层都改善了上一层的粒度.Parrot模型可以识别出100多种情绪,并在树结构化列表中将抽象的情绪概念化,被认为是最微妙的情绪分类.
随着社交网络的发展,微博等社交媒介已成为人们的主流联络工具.人们乐于在微博等社交网络上抒发自己的感情、表达自己的观点.这些包含喜、怒、哀、乐等个人情绪的网络文本成为了情绪分析的重要资源,研究机构、信息咨询组织和政府决策部门可以根据情绪分析来构建用户的个人肖像,分析用户的性格特点;利用人们对公共事件、社会现象的态度,掌握事态的演变,从而更好地监测和控制事件进展.
由于研究者们早期的工作主要集中在二分类的情感分析上,其成果较为成熟,形成了体系化的研究框架.情绪与情感的分析任务相似,可以借鉴并归纳出一个适用于情感/情绪的通用研究框架,其自底向上包含抽取、分类、检索与归纳等多项研究任务 [8] .如图2所示,情感/情绪信息抽取主要包括观点持有者识别、情感和情绪词抽取、评价对象抽取等,这些方法是整个研究框架的基石;情感/情绪分类则建立在情感/情绪信息抽取的基础上,对带有情感/情绪的文本进行正负类极性判定,或进行细粒度的情绪分类.此外,情感/情绪分类还可按照不同的层级粒度细分为词级、短语级、句子级和篇章级.情感/情绪分类的上层研究综合利用前2层的分析结果,为不同领域的应用提供服务,主要包括情感/情绪的归纳与检索等.文本情绪分析已经在各个领域得到应用并具有良好的应用前景.
1.2.1 舆情监控
舆情分析,就是通过收集和整理民众态度,发现相关的意见倾向,从而客观反映出舆情状态.从古代的“防民之口甚于防川”,到现在的网络时代,“每个人都有了自己的麦克风”.互联网为社情民意的表达提供了平台,体现用户意愿、评论和态度的网络舆情也愈发受到重视.所谓网络舆情 [9] ,就是对社会热门问题持有不同看法的网络舆论,是社会舆论的一种表现形式,也是公众通过互联网对现实生活中某些热点、焦点问题发表具有较强影响力、倾向性的言论和观点.网络舆情的2个重要特点就是网络非理性情绪和群体极化.
许多非理性的情绪,如仇富、仇官、反权力、反市场等,借助暴力性和娱乐化的网络表达强化,使人们变得更加情绪化和极端化.网民的非理性情绪,对社会存在潜在威胁,值得警醒.另一种特征“群体极化”是由美国教授Cass Robert Sunstein提出的,就是“起初团队成员拥有某种方面的潜在倾向,在讨论之后,人们朝着所倾向的方向继续移动,最后形成极端的观点”.例如最初群体中成员的意见都比较保守,在经过了群体的商议后,决策就会更加保守;相反,若个体成员意见倾向于冒险化,则经商议后的群体决策就可能会更趋向于冒险.
社会的安全管理需要不断关注网络舆情动向,并及时正确引导网络舆论方向,保证社会的长治久安.然而,各种渠道得到的信息庞杂,只靠人工方法进行甄别无法应对海量信息.因此,研发精确有效的情绪分析系统,实现对舆情信息的自动处理,对维持社会稳定有着非常重要的意义.
1.2.2 商业决策
随着互联网的发展,网购在生活中愈发普及,人们通过C2C(如淘宝网、易趣网等)和B2C(如京东网、亚马逊等)形式的电子商务购买商品后,写下对商品的评论.其他消费者通过这些评论可以了解商品质量、售前售后服务,并且直接影响他们的购买决定.同时,生产商通过分析在线评论信息和情绪特征,可以获得消费者的行为特点,预测消费者偏好的变化趋势.此外,销售商还可以通过分析消费者的对商品或售前售后服务的心理状态,获得促销对消费者情绪的影响,为改善营销行为提供决策基础,从而获得竞争优势.
1.2.3 观点搜索
随着信息时代的到来,网络数据呈现出爆炸式的增长,激发了用户从互联网海量信息中搜索有效信息的需求.在搜索过程中同时考虑搜索关键字和用户的情感诉求,可以使搜索变得更加便捷、准确和智能.情绪检索技术是解决该问题的重要方法之一,其任务是从海量文本信息中查询文本所蕴含的观点,并根据主题相关度和观点倾向性对结果进行排序.情绪检索返回的结果需要同时满足主题相关性和情感倾向性,情感倾向性既可以是文本带有的情感倾向,也可以是指定情感倾向的文本.因此,情绪信息检索是比情绪分类更加复杂的任务.
为满足互联网用户日益增长的搜索需求,2006年国际文本检索会议(Text Retrieval Evaluation Conference,TREC)首次引入博客检索(blog track)任务.Mishne [10] 在LiveJournal blogs上标注了37种情绪类别,并利用频率统计、博客长度、语义特征等方法实现了对博客的情绪分类,为情绪检索提供了基础.此外,在图书、随笔等长文本观点搜索任务中,Mohammad [11] 提出一种基于情绪词密度的观点搜索方法.该方法利用谷歌书库定义的情绪实体与共现词之间的关联,发现了童话和小说之间情绪词密度的区别,并可按照情绪类别组织文本集,提高了长文本的搜索性能.此外,该方法还支持对文本中所含情绪的可视化展示与追踪.
1.2.4 信息预测
随着越来越多的人热衷于参与到微博等网络互动中,微博对人们的生活也带来了巨大的影响.情绪分析技术可以通过对微博上的新闻、评论等信息进行分析,预测事件的发展趋势,其主要的应用方向包括3个方面:
1) 金融预测
情绪分析在金融中的巨大应用潜力引起了研究者们的兴趣.美国印第安纳大学和英国曼彻斯特大学的学者发现了一个有趣的现象 [12] :Twitter可以从一定程度上预测3~4天后的股市变化.他们通过OpinionFinder方法将人的情绪分为正面和负面2种模式,再利用GPOMS(Google profile of mood)将情绪分为更加细致的类别,包括:冷静(calm)、警惕(alert)、确信(sure)、活力(vital)、友善(kind)和幸福(happy)6类.若将其中的“冷静”情绪指数后移3天,竟与道琼斯工业平均指数(DJIA)惊人的相似.研究者们推测:在股票市场中,微博上对某支股票的议论可以影响投资者的行为,从而进一步影响股市变化的趋势.Devitt等人 [13] 通过对金融文本所表达的情感极性判断,也实现了在一定程度上预测市场交易、股票价格和公司收益波动性的未来走势.
2) 选情预测
情绪分析在选情预测中也扮演着重要的角色.在美国大选期间,Tumasjan等人 [14] 通过挖掘和分析民众在Twitter上对各竞选团队的评论,制定针对摇摆州(美国大选中的一个专有名词,指竞选双方势均力敌,都无明显优势的州)的特定宣传政策,从而提高己方的民意支持率.此后,Kim等人 [15] 通过对网络新闻的分析,以81.68%的准确率成功预测出美国大选花落谁家.此外,在2011年意大利议会选举和2012年法国总统大选过程中,Ceron等人 [16] 用情绪分析计算出政治领导候选人的Twitter支持率.
3) 其他预测
情绪分析还可用于对政策性事件的民意预测,如延迟退休的年龄等,为国家相关政策的制定提供辅助支撑.此外,情绪分析还可以应用到疫情、地震等自然灾害的判断和预测.
随着信息预测的应用内容越来越丰富,情绪分析技术愈发受到重视.情绪分析技术通过分析互联网新闻、博客等信息源,可以较为准确地预测某一事件的未来走势,无论是政治经济领域还是日常生活中都具有重大意义.
1.2.5 情绪管理
用户在微博、社区和论坛中的社交活动都是现实生活对网络社会的映射,这些社交网站中储存了大量的用户个人言论.由于用户的情绪与其所关注的话题通常具有较强的连续性,分析用户发布的言论可以较为准确地获得人们的生活状态和性格特点.Golder等人 [17] 通过研究Twitter用户在昼夜和不同季节所展现的情绪节奏,包括用户在工作、睡觉等不同时间段内表现的情绪,绘制出心情曲线,从而了解人们的精神状态.此后,Kim等人 [18] 通过研究也发现人们的情绪在6点、11点、16点和20点达到了高峰,并总结了用户一天中的情绪总体走向.利用这些研究成果,公司可以了解员工的工作状态,从而更有效地制定工作计划.此外,Zhou等人 [19] 对不同行业名人的微博进行分析,统计名人发布微博中各类情绪的比例,可以分析出不同名人的性格、关注点和个人喜好.随着时代的进步和社会的发展,人们对自我关注的需求不断提高.通过对用户进行情绪分析可以让用户更加了解自我,从而找到更加适合自己的方式去学习、工作和生活,情绪管理领域也将拥有更广阔的应用市场.
随着应用的发展与需求的变化,文本情感/情绪分析研究任务更加繁重,基于正负二分类的情感分析作为多分类情绪分析的前期准备和一种特例,其成熟的研究框架和流程值得研究与借鉴.
文本情感分析不同于文本挖掘和文本分类,文本中所蕴含的情感本身具有抽象性,难以根据字面信息直接进行处理.情感分析的主要任务 [8] 包括:情感信息抽取、情感分类、情感检索与归纳.
情感信息抽取的目标是抽取文本中有价值的情感信息,找出文本中倾向性单元的要素 [20] ,包括识别情感表达者、评价对象以及情感观点等有价值的任务.
2.1.1 情感表达者的识别
情感表达者就是抽取观点的持有者,即观点、评论的隶属者.Kim等人 [21] 提出了一种基于语义角色的观点持有者识别方法.该方法通过目标词、短语类型、解析树路径等特征和最大熵分类器识别出情感表达者.在FrameNet数据集的实验中,该方法的效果优于贝叶斯分类器,其 F 值可达78.7%.
此后,为解决不同领域观点持有者抽取的适应性问题,Carstens等人 [22] 提出了一种基于多模型的观点持有者识别系统.该系统通过提取交叉领域不同方法的共同点,从而提高了系统的通用性.在实验中,该方法相较于支持向量机(support vector machine, SVM),准确率提高了5.6%.
2.1.2 评价对象的抽取
评价对象是指文本所描述的对象,同时也是承载情感表达者所抒发情感的载体.Eirinaki等人 [23] 提出了一种基于形容词评分的抽取方法,该方法从被形容词描述的名词中提取评价对象.在吸尘器、相机和DVD播放器3类评价对象的样本中,该方法的识别准确率可达87%.
Yu等人 [24] 提出了一种基于统计学和句法规则的抽取方法,该方法通过评价对象出现的相对频率找出候选评价对象,并将大于预设阈值的对象作为最终的结果.在淘宝和腾讯拍拍的评论数据集上,该方法的 F 值可达84.02%.
此后,戴敏等人 [25] 提出了一种基于条件随机场的抽取模型,通过加入句法特征来提高评价对象抽取的性能.在德国城市服务评论数据集(Darmstadt service review corpus, DSRC)语料库的实验中,其 F 值达到62.57%.为提高评价对象的识别效果,宋晖等人 [26] 提出一种基于模糊匹配和半监督的抽取评价对象方法.该方法通过手工标记样本获取种子词规则集,利用句法结构和词性等特征提取评价对象.在京东商品评论数据集中,该方法 F 值可达79.34%.此外,还有一些研究者利用依存句法分析来抽取评价对象 [27-28] .
2.1.3 情感词的抽取
情感词是带有情感倾向性的词语,目前情感词的抽取主要分为基于情感词典和基于规则的方法.
基于词典的评价词语抽取方法是通过分析词语间的词义联系以获取评价词语.Li等人 [29] 通过抽取语料中的形容词和副词,并与WordNet词表比对选出情感词.在电影评论数据集的实验中,该方法准确率可达77.17%.
基于规则的方法主要由用户事先制定分类规则,方法主要包括专家标注、专业词典、统计方法等.王昌厚等人 [30] 提出一种基于模式的种子式自扩张(bootstrapping)方法,利用种子词与汉语副词的搭配方式,通过多次迭代来进行情感词抽取.实验表明,当该方法迭代约100次时准确率最高,约90%.
情感信息抽取是情感分析的基础任务,可对情感文本中有价值的情感信息进行抽取,为上层的情感分类和情感检索与归纳任务提供了支撑.
情感分类又称情感倾向性分析,其任务是识别指定文本的主观性观点,并判断文本情感的正负倾向性,主要包括基于词典和规则的方法和基于机器学习的方法.
2.2.1 基于词典和规则的情感分类方法
情感词典作为一种重要的情感分类方法,能够体现文本的非结构化特征.Paltoglou等人 [31] 采用基于情感词典的情绪分类方法.该方法利用否定词、大写字母、情感增强减弱、情感极性等多种语言学预测函数,对微博进行情感分类.在Twitter,MySpace,Digg等社交媒体的实验中,该方法准确率可达86.5%.此后,Qiu等人 [32] 提出一种基于句法分析和情感词典相结合的情感分类方法,该方法利用情感词典从广告上下文中识别情感句,根据主题和关键字提取消费者的态度.在automotiveforums.com论坛语料库实验中,该方法准确率为55%.在此基础上,Jiang等人 [33] 扩充了情感词典特征和主题相关特征,在Twitter语料分类实验中,准确率可达85.6%.
在中文情感分类的研究中,Wan [34] 利用机器翻译技术将中文商品评论翻译成英文评论,再利用英文情感分析资源对翻译后的评论进行情感极性分类.在中文it168.com网站语料库实验中,该方法准确率可达81.3%.此后,Wei等人 [35] 通过引入多语言模型,利用结构一致学习算法(structural corres-pondence learning, SCL)减少机器翻译的噪声,充分利用了已有的中英文情感语料.在使用文献[34]的语料库时,该方法准确率可达85.4%.
为应对海量无标记数据情感分类的挑战,研究者们开展基于规则的情感分类的研究.Turney [36] 提出一种基于互信息(pointwise mutual information, PMI)的情感分类方法,该方法在提取文本词性的基础上,根据预定义的规则选取形容词、副词的搭配,对文本所有搭配的互信息差求和,判断情感类别.对情感分类的平均准确率可达74.39%.
针对文献[36]受限于较依赖种子褒/贬义词集合的问题,Zagibalov等人 [37] 通过分析文本中的否定词和状语信息并引入迭代机制,使无监督学习情感分类的准确率达到了82.72%.
由于某些情感词在不同的领域或语境中有不同的情感极性,Jo等人 [38] 提出一种基于“主题-句子”关系的情感分类方法.该方法在情感词上同时标记主题和情感2种标签,并利用句子的主题标签采样代替词的主题标签采样,缩小词与词之间的主题联系.由于基于主题的模型有着其他方法难以替代的优点,受到了广大研究者们的关注 [39-41] .
随着互联网中新词的不断涌现,基于词典和规则的分类方法在分类时灵活度不高,难以应对不断变化的词形词意,为提高情感分类的准确率,研究者们开展了基于机器学习的情感分析方法.
2.2.2 基于机器学习的情感分类方法
随着机器学习技术不断创新,开拓的新领域无处不在,文本情感分析一直是机器学习研究的活跃领域之一.
1) 有监督学习的情感分类方法
有监督学习方法认为情感分类是一个针对标记训练文档的标准模式分类问题.Pang等人 [42] 首次将有监督学习方法应用到情感分类中.通过对比一元特征、二元特征、形容词打分、位置等多种特征和特征权值选择策略,并着重比较了SVM、朴素贝叶斯和最大熵等算法的分类效果.在电影评论领域,一元特征与SVM组合效果最好,准确率可达82.9%.
此后,Dong等人 [43] 提出一种基于自适应递归神经网络的情感分类方法,该方法通过上下文和句法规则对词的情感标记进行自适应传播,实现了目标依赖的情感分类.在Twitter样本集的实验中,该方法的准确率比SVM高,可达66.3%.
Tang等人 [44] 设计了一种基于消息级微博情感分析的深度学习系统.该系统通过将特定情感词向量(sentiment-specific word embedding)与手工选择的表情符号、语义词典等特征相结合,并利用SVM进行情感分类.该系统在Twitter情感语料库上的准确率可达87.61%.
随着大数据时代的到来,通过各种途径采集到的数据大多是无标记的,这成为了研究的瓶颈.为了在基于词典和规则方法的省力省时和有监督学习方法的高准确率优势之间取得平衡,研究者们开展了半监督学习情感分类方法的研究.
2) 半监督学习的情感分类方法
半监督学习分类方法可以利用少量已标注的样本和对大量未标注样本进行训练和分类.Tan等人 [45] 提出了一种基于半监督特征提取的情感分类系统,该系统融合谱聚类、主动学习、迁移学习等不同方法提取情绪特征,应用迁移学习的方法完成整个情感分析系统的构建.在搜狐学习评论、搜狐股票评论和中关村电脑评论语料库的实验中,该方法的最小 F 值可达82.62%.
此后,Ortigosa等人 [46] 将态度分析应用到半监督学习情感分类方法中,将文本发布者的态度主观性、情感极性和影响力等指标进行优化与合并,对语料中的情感进行分类.该方法在人造数据集的实验中,情感分类准确率为54%.
在递归自编码的基础上加入了情感类别的标记信息,Socher等人 [47] 提出了一种递归自编码半监督学习情感分析模型.该模型在构建短语向量表示时,可以更大程度地保留情感信息,提高了预测情感的准确率,可达86.4%.
通过将先验知识嵌入到学习结构中,Zhou等人 [48] 提出一种基于模糊深度置信网络的半监督学习情感分类方法.该方法不仅继承了深度置信网络强大的抽象能力,还具备对情感数据的模糊分类能力.在影评、DVD评论等5类语料库的实验中,其准确率可达到79.4%.
在跨语言分类的任务中,传统的情感分析方法很难直接应用.He等人 [49] 提出有监督学习与空间转移相结合的方法,该方法主要思想是利用目标语言的内在情绪知识,补充转移过程中丢失的信息.在图书、DVD、音乐等不同商品评论的语料库实验中,该方法的准确率可达82%.
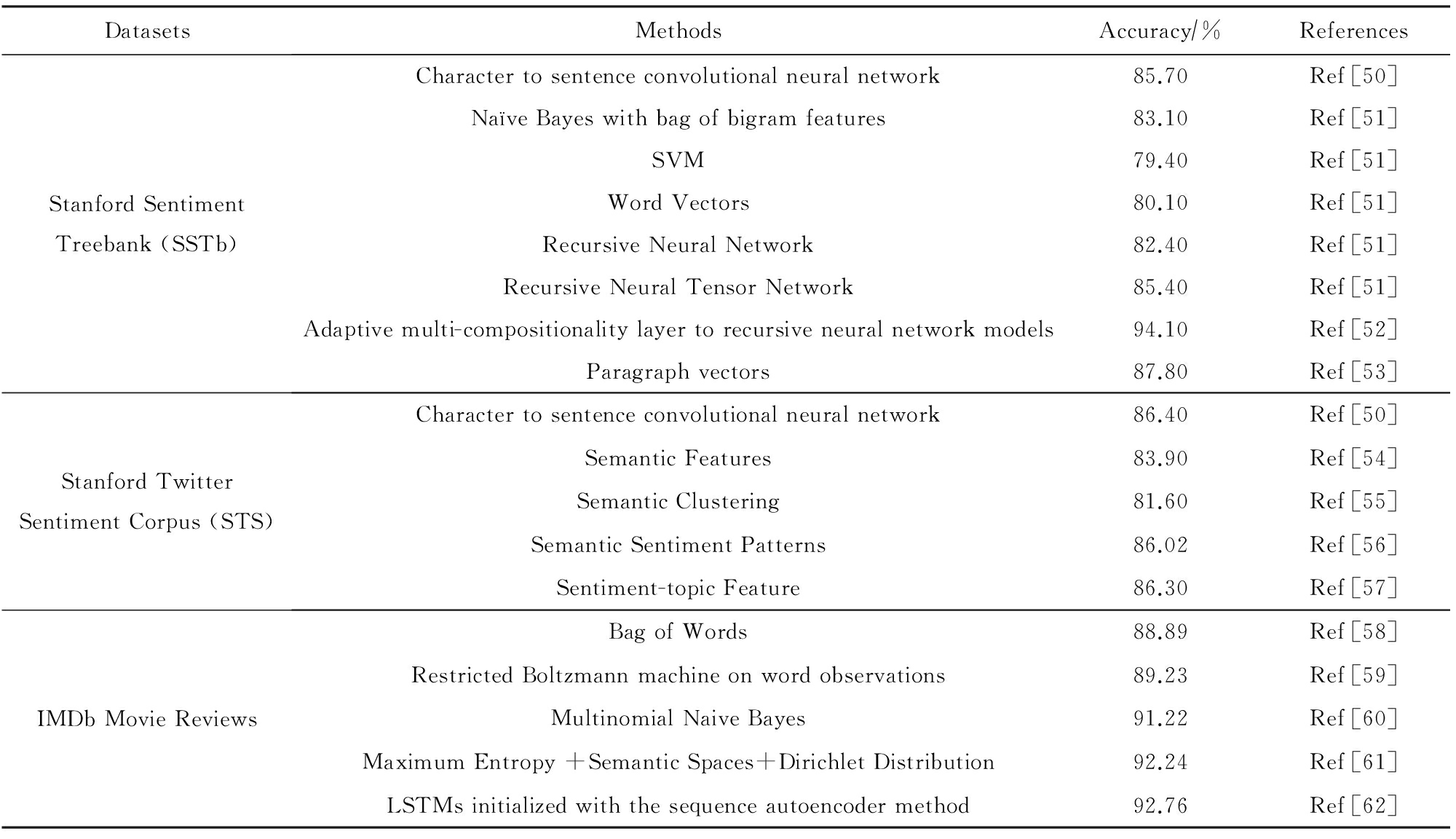
为方便对不同情感分析方法的效果进行比较,本文将使用相同公开数据集的方法及其准确率进行了汇总,包括斯坦福情感树库(Stanford sentiment treebank, SSTb) [50-53] 、斯坦福Twitter情感语料库(Stanford Twitter sentiment corpus, STS) [50,54-57] 、IMDb影评 [58-62] 等,具体性能对比如表1所示:
Table 1 The Performance Comparison of Sentiment Analysis
表1 情感分析方法性能对比
情感摘要任务是对带有情感的文本数据进行浓缩、提炼,从而产生文本所表达的关于情感意见的摘要.Stoyanov等人 [63] 提出了一种基于细粒度观点信息情感摘要的生成方法.通过将描述同一个实体的评论关联起来,收集现实世界中所有识别到的观点属性,并最终合成一个完整的情感摘要.Ku等人 [64] 提出一种基于文本的观点提取、摘要和跟踪方法.该方法通过对词语、句子、篇章级别的观点抽取,将主题与观点信息总结为情感摘要.在新闻和博客语料库的实验中,该情感摘要提取方法的 F 值分别可达到47.97%和32.58%.
情感检索任务最早由Hurst等人 [65] 提出,他们归纳了情感检索2个主要任务:①检索和查询相关观点的文档或者句子;②根据主题相关性和观点倾向性对检索出的文档或句子进行排序.在此基础上,Zhang等人 [66] 提出了一种基于词典的观点检索方法.该方法利用一个二次方程将主题相关性和观点抽取结合起来.该方法在TREC博客数据集的实验中,检索结果提升了40.3%.
情感检索将传统的信息检索技术和情感分析技术相融合,而如何更好地融合二者以获得理想的情感检索结果是近期和未来要关注的.
多分类情绪分析作为正负二分类情感分析的延伸,也遵循情感/情绪研究框架.相比情感分析,情绪分析现有的工作还比较少.由于现有的文本情绪分析任务中的情绪抽取任务基本与情感抽取相同,不少方法可以直接应用到情绪分析中来.此外,现有情绪分析工作主要集中在情绪分类的研究上,目前尚无针对情绪摘要和检索的研究.
文本情绪分类任务主要指通过提取文本内容中的情绪要素,将文本划分到一个或多个预定义的情绪类别中,通过判定文本中所表达的情绪类别,实现对文本发布者情绪的监控、预测和管理.目前,情绪分类方法主要包括:基于词典和规则的方法、基于机器学习的方法、复合方法以及其他方法.
基于词典和规则的方法能体现文本的非结构化特征,易于理解和解释.此外,该方法处理速度快且精度较高,在相对短的时间内能够对大型数据源做出可行且效果良好的结果.
3.1.1 基于词典的情绪分类方法
基于词典的方法主要利用情绪词典资源,将语料库中的情绪表达关键字提取出来,并藉此对语料进行情绪分类.在早期的研究中,Ma等人 [67] 提出了一种基于词典的情绪分类方法,并将其应用到即时通讯系统上.该方法首先利用关键字识别出文本中情绪相关的内容,再利用句法特征检测其中的情绪意义,并通过文本消息中的情绪对系统中的语音合成、手势等功能进行调整,帮助用户更好地与远距离用户沟通.在此基础上,Aman等人 [68] 提出一种基于情绪强度知识的分类方法,该方法除使用情绪词典之外,还增加了情绪强度知识库.该方法在博客语料的情绪分类任务中,其准确率可达66%以上.
由于情绪词典中的情感词有较大程度的领域依赖性、时间依赖性和语言依赖性,同一词汇在不同的领域、时间和语言环境中可能会表达完全不同的情绪,然而传统方法在构建情绪词典时并未考虑词典的应用环境因素,甚至无法应用到其他语种.因此,在跨领域、跨时间、跨语言的文本情绪分类任务中效果并不理想.
为解决领域依赖性的问题,Yang等人 [69] 提出一种基于特定领域情绪词典分类的方法.该方法利用情绪感知LDA(emotion-aware LDA,EaLDA)模型,为预定义的情绪构建特定领域的情绪词典.EaLDA模型使用一组领域无关的最小种子词作为先验知识,来发现特定领域的词典.在SemEval-2007数据集的综合实验中,该方法可以有效辅助文本情绪分类任务,其中对最难辨别的Disgust类别,其 F 1值可达10.52%,其他分类如Sadness可达36.85%.
为挖掘时间依赖性对情绪分类的影响,Golder等人 [17] 利用情绪词典对全球不同地域、不同文化背景博主所发表的Twitter进行统计,分析了数百万篇公开Twitter中所表达的情绪,并明确地识别出人们的情绪会随着季节、星期、昼夜呈现出周期性变化的模式.
解决情绪词典语言依赖性问题最常用的方法是构建本语言的情绪词典,因此,很多研究者们开展了构建中文情绪词典的研究工作.
对于中文及其他语料资源匮乏的语言,难以获得用于构建本语言情绪词典的语料素材.为解决该问题,Xu等人 [70] 提出一种基于英文情绪词典WordNet-Affect自动构建中文情绪词典的方法.该方法首先将英文情绪词典中所有的英文单词都翻译成中文;再借助中文同义词词典《同义词词林》将每个情绪类别构建一个双语无向图,并提出一个图算法用以过滤翻译过程中引入的非情绪词,以获得种子情绪词集;最终通过同义词扩大表示类似情绪的词汇量,从而获得数量大、质量高的中文情绪词典.图3展示了Anger情绪的部分双语图,图3中将多个同义词作为边添加到Anger情绪节点上.例如n#05588321的字母部分是该词条的词性(part of speech,POS),数字部分是同义词集的ID.该方法在中文语料的6种情绪anger,disgust,fear,joy,sadness,surprise分类实验中,准确率可达77.08%以上.
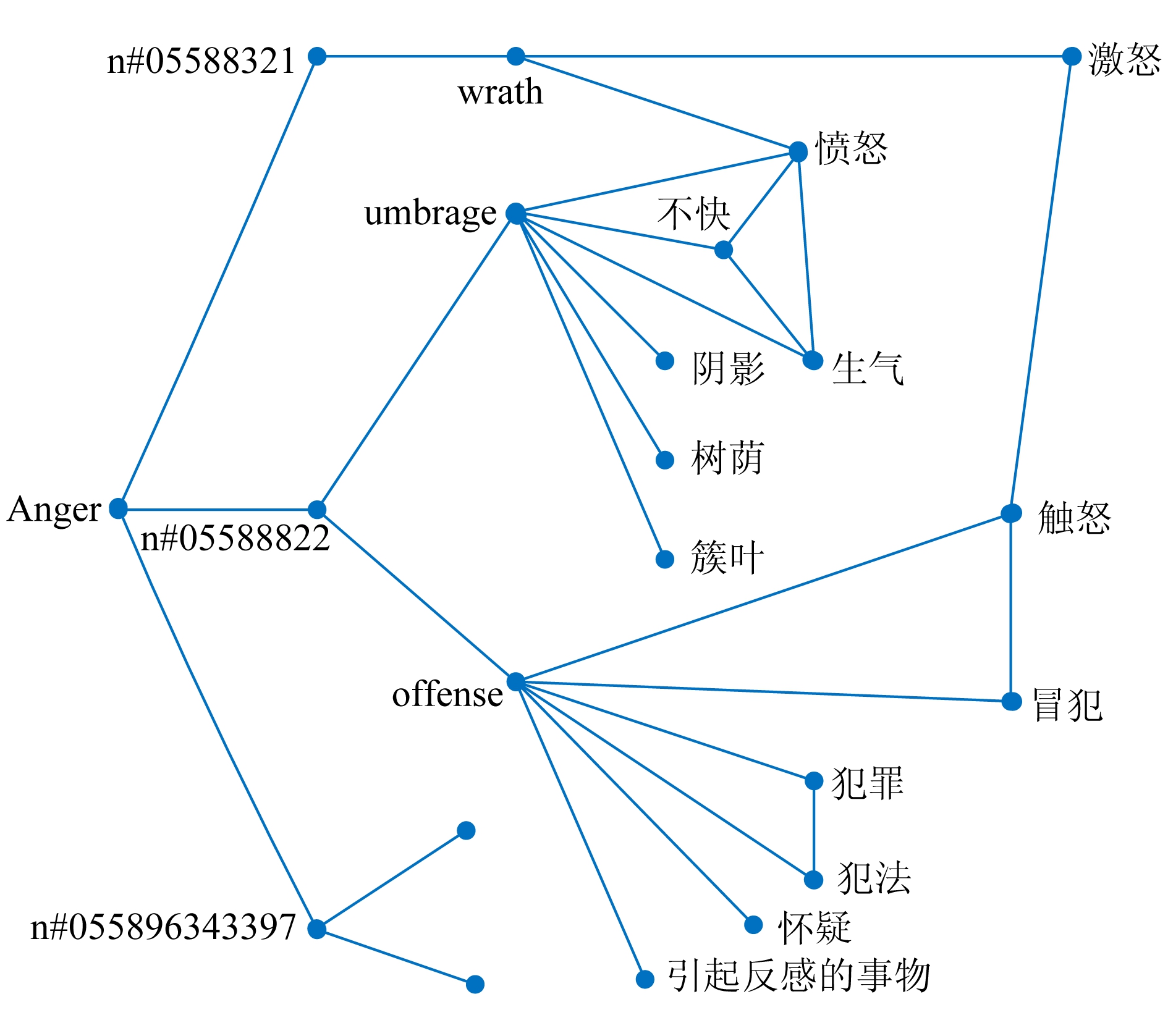
Fig. 3 A partial bilingual graph of “Anger”
图3 Anger的部分双语图
文献[70]主要解决语料库资源严重不足条件下构建情绪词典的问题,但由于不同语言不同文化中词汇所表达的情绪存在差异,对情绪分类的准确率存在影响,为此一些研究者开始研究利用少量种子词构建情绪词典的方法.Song等人 [71] 提出一种基于异构图的情绪词典分类方法,该方法利用种子词和表情符号构建情绪词典,并使用随机游走算法强化对情绪分布的评估效果.在新浪微博真实数据的实验中,利用该方法构建的情绪词典对7种情绪anger,disgust,fear,happiness,like,sadness,surprise分类的准确率可达54.1%.
此外,传统的情绪词典方法还存在词典中情绪词固定,难以及时捕捉新词、变形词的缺陷.为此,Wu等人 [72] 提出一种基于数据驱动的微博专用情绪词典分类方法.该方法设计了一个包含3种词典的情绪知识统一框架.为了提高情绪词的覆盖率,该方法还支持将检测到的情绪新词加入到词典中,不断扩展情绪词典的样本集.在新浪微博数据集的实验中,该方法准确率可达58.04%.
影响情绪词典方法分类准确率的主要因素包括情绪词典的覆盖率和标注的准确率,目前的情绪词典在这2个方面仍有不足,一些研究者利用互联网的便利,通过网民的帮助构建了一个高质量情绪词典.Staiano等人 [73] 提出一种基于“众包”的情绪分类方法,该方法利用大规模“众包”方式建立情绪注释与新闻文章之间的联系.使用分布语义自动构建高质量、高精度的情绪词典.在rappler.com新闻消息数据集的实验中,该方法较好地完成了fear,anger,surprise,joy,sadness 这5类情绪的分类任务,其中对fear的分类效果最好,准确率可达56%,surprise效果最差,准确率为25%.
总体上,基于情绪词典的分类方法能体现出文本的非结构化特征,在词典中情感词覆盖率和标注准确率较高的情况下,分类效果比较理想.然而,该类方法依赖领域、时间、语言等方面的背景知识,且难以及时捕捉新词、变形词,使如何构造高质量的情绪词典成为其难点.
3.1.2 基于规则的情绪分类方法
除了情绪词典,还有一类基于规则的情绪分类方法,可以快速实现对情绪语料的分类.在早期的工作中,Strapparava等人 [74] 提出了一种基于语义规则的情绪分类方法,该方法利用隐形语义算法(latent semantic analysis, LSA)计算通用语义词和情绪词的语义相似度,再根据语义相似度对新闻标题进行分类.该方法在Times,BBC,CNN等新闻语料的情绪分类任务中,准确率可达38.28%.
由于网络中的非正式文本比较多,文献[74]在对不规范文本的情绪分类任务中表现并不理想.为解决该问题,Neviarouskaya等人 [75] 首先对网络文本中非正式缩写、情绪图标以及语法错误等不规范文本进行了预处理,再利用基于语义规则的方法分阶段处理每个句子,最终将目标语料中的情绪分为9类interest,joy,surprise,anger,sadness,fear,disgust,guilt,shame,其架构如图4所示.在包括日记博客、童话和新闻标题等不同领域的数据集中,该方法情绪分类的准确率可达72.6%.此外,该方法在具有复杂句子的环境中也具有较好的分类效果.
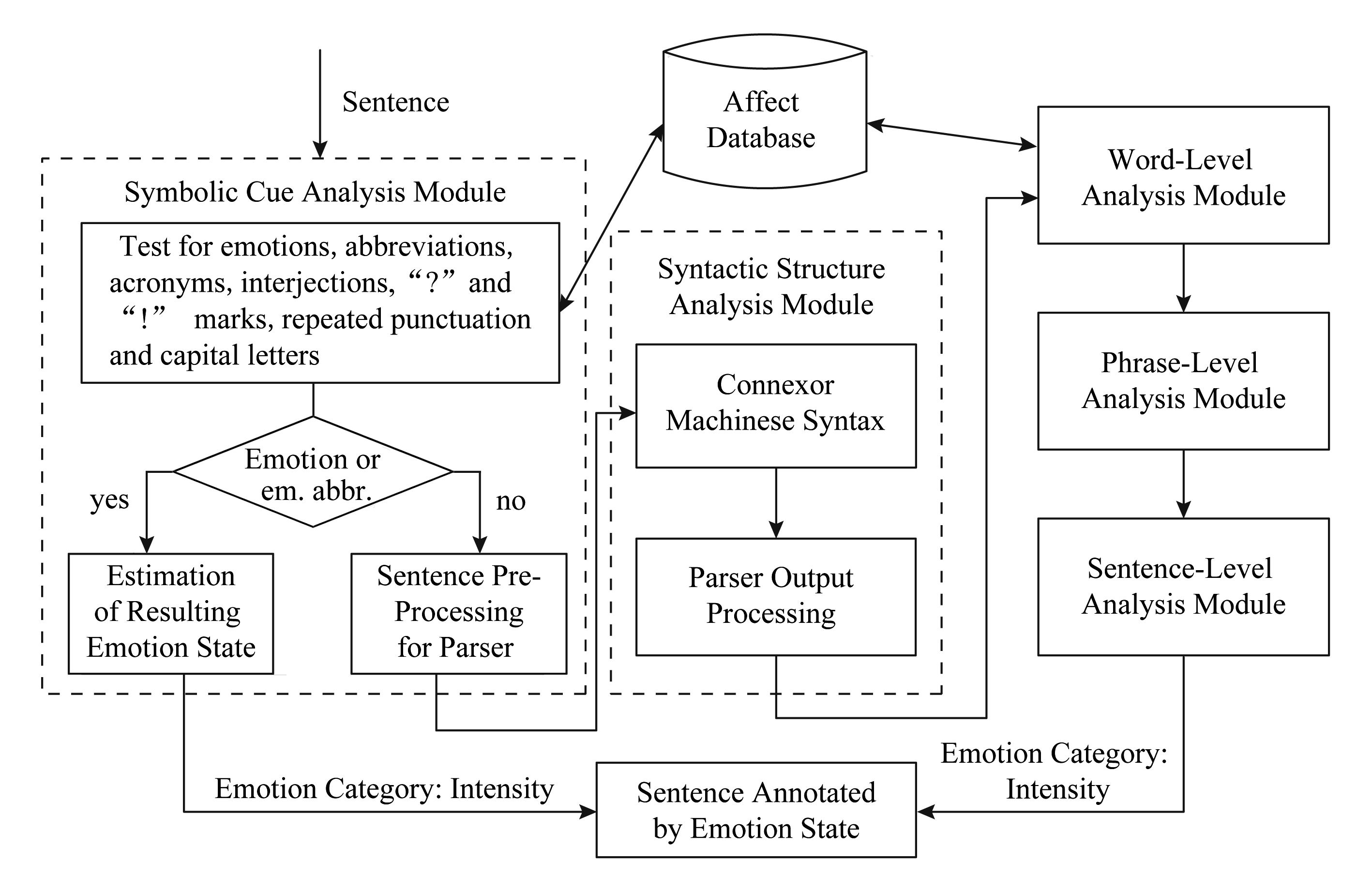
Fig. 4 The emotion analysis architecture based on semantic
图4 基于语义规则的情绪分析架构
对于句子级情绪分析,现有的基于情绪词典的方法表现并不理想,因为其并未考虑文本顺序和篇章结构.Wen等人 [76] 提出一种利用类序列规则情绪分类的方法,将指定文本中的情绪分为7类anger,disgust,fear,happiness,like,sadness,surprise.该方法首先分别利用情绪词典和机器学习方法获得句子的2个潜在情绪标签,并将每个微博文本看作一个数据序列,再从数据集中挖掘文本的类规则序列,最后根据规则的特性对微博进行情绪分类.在2013年新浪微博的情绪分析评测任务中,该方法对7种情绪的分类准确率均达到41.33%以上.
通过分析社会媒体中公众情绪的成因,可以利用情绪与起因事件的关联关系来提高情绪分类的准确率.传统的情绪分类方法主要基于统计手段,没有考虑到引起情绪的触发事件.Lee等人 [77] 提出一种基于文本驱动的情绪成因检测方法.该方法通过对中文语料库数据的分析,确定了7种语言线索,包括原因事件的位置、体验者情绪关键词的位置、使役动词、动作词、认知标记、连接词和介词,并据此归纳出语言规则来检测情绪的成因.
在此基础上,部分研究者将基于规则的方法与事件成因相结合,从而实现对媒体文本的情绪分类.Li等人 [78] 提出一种结合语义规则和事件触发理论的情绪分类方法.该方法根据社会学以及其他领域的知识和理论,从推断和提取情感的原因入手进行分析.通过构造一个基于语义规则的系统,自动检测并抽取每个博客语料中情绪的起因事件.再利用起因事件训练分类器对语料库进行情绪分类.在新浪微博的实验中,该方法在加入了原因事件后,对6个情绪类别anger,disgust,fear,happiness,sadness,surprise的分类准确率均有所提高.例如,Happiness从85.41%提升至87.36%,Surprise从71.71%提升至72.52%等.
此后,Gao等人 [79] 结合情绪起因事件,提出一种基于规则的情绪分析系统.该系统从事件的结果、代理的行为和对象的性质中分析产生情绪的原因事件,并根据这些事件挖掘其中的基本情绪、复合情绪(满意、感激、悔恨和愤怒)和扩展情绪(信任、失望、怜悯等)的关联规则,通过抽取的情绪规则对中文微博进行分类.在对新浪微博语料中实验,分类准确率可达82.50%.
综上,虽然基于规则的情绪方法可以在较短时间内获得分类结果,且可以加入事前起因等其他规则来提高情绪分类的准确率,但在数据量较大时,规则的维护比较复杂,且不易扩展.
在大数据时代的背景下,捕获文本数据并从中萃取有价值的情绪信息是基于机器学习情绪分类方法的主要任务,该方法主要包括有监督和半监督方法.
3.2.1 有监督学习情绪分类方法
在有监督学习的过程中,只需要给定输入情绪样本集,即可推演出目标情绪分类的可能结果.有监督学习相对比较简单,针对不同的情绪分类任务可分为单标签和多标签情绪分类方法.
特征选取是否合适是影响有监督学习分类效果的一个主要因素,现有方法中用于情绪分类的特征主要包括词级、句子级和篇章级特征.其中,词级特征主要包括词频(例如词袋特征)、词性(例如名词、动词、连接词)、语义(例如词向量的相似度)、表情符号及其组合等.
在早期的研究中,为了使得语音合成技术TTS(text-to-speech)朗读时语调更自然,研究者们需要挖掘出童话故事中所蕴含的情绪.Alm等人 [80] 提出一种将SVM与SNoW (sparse network of winnows)架构结合的文本情绪预测方法.该方法通过选取故事首句、特定的连接词等30种特征将22篇格林童话划分为happy,sad,fearful,angry,disgusted,surprised,non-emotion这7类,其中surprised又细化为正向Su+和负向Su-.实验通过对比SVM、朴素贝叶斯等基准分类器,结果显示将SVM与SNoW架构结合的方法效果最好,其准确率可达到69.37%.
相较于童话故事、博客等长文本语料,社交网络信息通常是简短的,如微博、即时消息、新闻标题等.短文本受字数的限制,呈现出特征稀疏、内容简短、表述直接等特点,这使得以往的情绪分类方法在面向短文本语料时,难以保证其分类效果.面向短文本的情绪分析 [81] 是近几年最热门的研究方向之一.
在微博环境中,表情符号被广泛用来表达不同的情绪,社交网络运营商也为用户提供了丰富的情绪图标,方便用户表达对事物的情绪.因此,表情符号也被视为情绪分类的重要信号.此外,表情符号具有其他词语所不具备的独立性,在大多数话题、领域、时间段中,表情符号所代表的情绪基本保持不变,因此,很多研究者都将表情符号作为其特征中的一个重要组成部分.
Read [82] 提出一种基于表情符号的情绪分类方法.该方法从语料库中抽取指定情绪符号的文本集合,把所得的样本集作为训练数据来实现情绪分类.该方法在包含金融主题、并购主题以及2个主题混合的数据集上进行测试,证明了表情符号特征的主题独立性,其分类准确率可达70%.
在此基础上,Zhao等人 [83] 建立一个基于表情符号与词袋相结合的情绪分类系统Moodlens,该系统避免了使用传统关键字的方法,在1 000多个表情符号中手工选取95个记作 E ,并将这95个表情符号映射到愤怒、厌恶、开心和悲伤(angry,disgusting,joyful,sadness)4个类别.实验将收集到的7 000多万条微博数据中所包含 E 中表情符号的350万微博作为测试集,记作 T .对 T 中每一条微博,Moodlens将其转化为一个词序列{ w i }, w i 是一个词, i 是该词在 T 中的位置.
在Moodlens系统中,用简单的朴素贝叶斯法构建分类器,仅需少量的训练时间即可得到分类结果.从标记的微博中可以获得单词 w i 属于情绪类别 c j 的先验概率:
P ( w i | c j )= 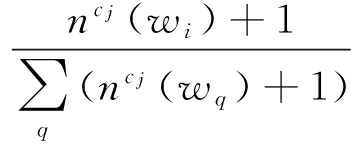 ,
,
(1)
其中 ![]() 是词 w i 在类别 c j 中所有微博里出现的次数,采用Laplace平滑来避免零概率的问题.构建贝叶斯分类器时,对于一个词序列为 w i 的未标记微博 t ,它的类别可以按照式(2)获得:
是词 w i 在类别 c j 中所有微博里出现的次数,采用Laplace平滑来避免零概率的问题.构建贝叶斯分类器时,对于一个词序列为 w i 的未标记微博 t ,它的类别可以按照式(2)获得:
c * ( t )= ![]() P ( c j )
P ( c j ) ![]() P ( w i ‖ c j ),
P ( w i ‖ c j ),
(2)
其中, P ( c j )是 c j 的先验概率.文献[83]中使用标准词袋作为特征,设置训练集与总微博数据集的比例 f t =0.9, P ( c j )=0.25,从而得到一个朴素贝叶斯分类器.Moodlens还实现了增量学习的方法,可以解决情绪转变以及新词的问题.应用该系统可以有效地检测异常事件.最后,通过使用高效的贝叶斯分类器,Moodlens可以实现在线实时情绪监控.使用该系统对实时新浪微博数据进行测试,其准确率可达64.3%.
此后,Ouyang等人 [84] 提出了一种基于卷积神经网络的情绪分类架构.该架构使用Google word2vec方法从文本中提取词向量,并将其作为卷积神经网络的输入.通过一个基于3对卷积层和池化层的卷积神经网络架构对影评语料进行情绪分类.在电影评论语料库(rottentomatoes.com)的实验中,将该架构与递归神经网络和矩阵向量递归神经网络等其他的神经网络模型对比,该方案在5类情绪分类任务中表现良好,准确率达到45.4%.
词级特征可以将大多数信息表示成词向量形式,并且可以较方便地衡量2个词之间的相似度,在情绪分类任务中具有难以替代的作用.然而,句子中的词语并非词汇的堆砌,不同的句法会带来完全不同的情绪表达,词级特征缺乏对文本语料整体上的考虑,在复杂句式中对情绪的分类并不理想.
随着深度学习方法的兴起,许多研究者开始将其应用于文本情绪分析工作中.通过构建多隐层的模型,深度学习可以提取更深层的句子级特征,从而提高文本分类的准确率.Santos等人 [85] 提出一种基于字符到句子的卷积神经网络情绪分类方法(character to sentence convolutional neural network, CharSCNN),该方法利用一个含有双卷积层的神经网络,从字符、词和句子级别的信息中分别抽取特征.该方法在斯坦福影评情感树库(SSTb)的5种情绪分类任务中,平均准确率可达48.3%.
此外,部分研究者将递归神经网络也引入到情绪分类的工作中.由于普通的递归神经网络缺乏层级表示能力,Irsoy等人 [86] 提出了一种基于深度递归神经网络的情绪分类方法.该方法将3个递归层叠加,利用非线性递归信息构成一个树型结构,递归计算每个节点的贡献值.该方法在斯坦福情感树库(SSTb)上的5种情绪分类任务中,分类效果略优于文献[85],平均准确率可达49.8%.
句子级特征在表达整体情绪时的优秀表现,引发了研究者们向更高级情绪特征的思考,一些研究者们开始着手研究篇章级的情绪特征.Kang等人 [87] 从情绪空间的角度对情绪表达的作用进行了分析.该方法利用在中文情绪语料(Ren-CECPs)中抽取的8种情绪标记:exception,joy,love,surprise,anxiety,sorrow,anger,hate构成8维情绪空间.根据这8种情绪所构成的矩阵空间描述情感成分(词,词汇),将这些情绪成分通过内积的形式构成更高级(句子,篇章)的情绪矩阵,利用SVM对中文语料(Ren-CECPs)进行情绪分类.在中文博客9类情绪分类的实验中,该方法的 F 值可达39.24%.
此后,Rao等人 [88] 提出一种基于主题的篇章级情绪分析方法.该方法通过潜在主题建模、多种情绪标签和众多读者共同标记来生成主题的特征.其中最大熵的过度拟合问题也通过将特征映射到概念空间得到缓解.在实际数据集(包括BBC论坛博客、顶客网的博客、MySpace评论、Runners World论坛的博客、Twitter微博以及YouTube的评论)的实验中,验证了该方法在长文本和短文本情绪分类上同样有效,准确率可达86.06%.
另一种情绪分析问题是因为文本语料往往会涉及多个属性,文本情绪分类可以仅仅看作是多标签分类任务中的一个属性,结合情绪属性和其他相关属性,可以有效提高情绪分类的准确率.Huang等人 [89] 提出了一个基于多任务的情绪分类方法.该方法在按照情绪分类的同时也进行基于主题的分类,对于每个任务用多个标签进行训练,有助于解决类歧义的问题.对真实的Twitter数据试验中,该方法准确率要高于朴素贝叶斯、SVM和最大熵模型,可达到74.4%.
此后,Zhang等人 [90] 结合了情绪与社会领域知识2个重要指标,提出了一种基于因子图算法(factor graph)的情绪分类模型.该方法通过观察带注释的Twitter数据集,归纳出影响用户情绪的2个主要因素:情绪相关性和社会相关性.并将这2个因素作为特征,相较于决策树、SVM和逻辑回归等基准方法,该方法使用因子图算法取得了较好的分类效果,准确率可达72%.
总体上,基于有监督学习的方法在准确率上优于基于词典和规则的方法,但对样本数据的质量要求较高,需要花费巨大的时间成本和人力成本对语料进行标注,影响了该方法的推广.
3.2.2 半监督学习分类方法
随着大数据时代的到来,数据的采集变得比以往任何时候都容易,标记数据却成为了有监督学习方法的瓶颈,半监督学习方法可以充分利用大量的未标记样本改善分类器性能,在情绪分类任务中扮演着重要的角色,研究者们对此开展了大量研究.
半监督学习方法主要利用少量标记数据对训练样本进行初始化,Sun等人 [91] 将表情符号与一元特征、二元特征结合起来,提出了一种面向中文微博的半监督情绪分类方法.该方法利用表情符号对未标记数据进行初始化,将语句中所含表情符号最多的一类标记为该语句的情绪标签;再通过提取语句中词语的一元特征与二元特征,用SVM与朴素贝叶斯分类器将微博中表达的情绪分为7种类别:乐、喜、悲、怒、恐、恶、惊.实验表明情绪自动标记的准确率可达到88.7%,情绪分类中朴素贝叶斯分类器要优于SVM,其精准率和召回率都超过71%.
此后,Sintsova等人 [92] 提出一种基于多项贝叶斯的半监督情绪分类方法.该方法首先将根据情绪词典将未标记的数据分为36个情绪类别,并根据每个文本中选出的最突出标签对标注进行改进;然后从文本中抽取 n -grams特征并过滤无关信息;最后利用重新平衡的伪标记数据和多项贝叶斯分类器对微博语料进行分类.该方法在Twitter语料库的实验中 F 1值可达到20.2%.
另一部分研究者将半监督学习与Ekman,Plutchik等情绪分类体系相结合,利用心理学情绪分类知识对训练样本进行初始化.Purver等人 [93] 提出一种半监督学习与Ekman分类体系相结合的情绪分类方法.该方法采用少量人工选取的标签(hashtag)和情感符(emoticon)来自动标注微博情绪,以省去大量手工标注语料的过程.在Twitter语料的实验中,利用hashtag分类的准确率可达67.4%以上,利用emoticon分类的准确率可达75.2%以上.然而,该方法对恐惧、惊讶和憎恶(fear,surprise,disgust)3类情绪的区分度不高,因为训练语料中标签和情感符的意思含糊,对区分情绪起到了干扰.
在此基础上,Suttles等人 [94] 也提出了一种基于离散二进制半监督学习的情绪分类方法.与文献[93]的研究不同,该方法根据Plutchik的情绪轮进行情绪分类,把固有的多层次情绪分类问题转换成一个含有4组对立情感的二进制问题,选取情感符号(emoticon)、标签以及表情符(emoji)作为参考进行人工标记.该方法首先提取不同类型的特定标签,并将表示相同情绪类别的标签进行归类,然后对比每个独立的二元分类器的准确性.在Twitter微博数据测试中,该方法的分类准确率最高可达91%.
此后,Jiang等人 [95] 提出一种基于表情符号空间模型(emoticon space model)的半监督情绪分类方法,该方法利用表情符号从未标记的数据中构建词向量,通过将词和微博映射到表情符号空间来确定微博的主观性、极性和情绪.在中文微博基准语料库(NLP&&CC 2013)实验中,该方法的情绪分类准确率优于SVM及朴素贝叶斯,可达61.7%.
在文本情绪分类任务中,有很多情况下需要对读者评论中的情绪进行分析,而读者评论又与源文本之间存在紧密的联系.针对该现象,Li等人 [96] 提出一种基于双视图标签传播的半监督方法,对读者评论中的情绪进行分类.该方法先通过词袋、二元特征提取文本中的情绪信息,再通过双视图提取文本之间的对应关系.双视图依赖于2个图关系:包括源文本之间的关系以及评论文本之间的关系.此外还将源文本与相应评论文本之间的依赖关系集成到这2个图中.最后在源文本和评论文本之间配置一个权重以处理评论文本中信息的不足.该方法在Yahoo Kimo News语料的情绪分类实验中,准确率可达74.5%.
该类方法的优点在于可以较方便地获得大量的标记数据用以训练样本集,解决了有标记数据集稀缺的问题.然而,该类在第1次分类过程中分错的样本,会影响到第2次分类的准确率.
由于前2种分类方法的优缺点都很明显,一些研究者开始考虑综合2种方法,吸取各自方法的优点.这些复合分类方法主要分为2类,其中一类是将情绪分类任务分解成有无情绪、正负情感、细粒度情绪等子任务,再分别针对不同子任务设计不同算法的层次情绪分类方法.
情绪分类中,类别之间不是互相独立的,它们之间有一定层次关系.基于层次结构的复合方法就是利用这种层次关系,提高情绪分类的准确率.Ghazi等人 [97] 提出一种基于层次情绪分类的方法,该方法包含3层结构:1)第1层定义文本是否包含情感;2)第2层对第1层中有情感的文本进行正负划分;3)第3层将第2层的正类划为happiness,负类细化为sadness,fear,anger,disgust,surprise.该方法有助于粗粒度到细粒度的分类,在格林童话上分类的准确率可达60%以上.
在此基础上,Esmin等人 [98] 提出一种面向短文本的层次情绪分类方法.该方法仍将第1层用来确定文本是否含有情绪;第2层对上一层有情绪的文本做极性分类,其中仅happiness是正类;第3层将负类分为sadness,fear,surprise,disgust,anger,最终利用Multiclass SVM分类器对微博语料进行分析.在Twitter语料库的情绪分类实验中,该方法的平均准确率达63.2%.
此后,Xu等人 [99] 也用层级分类法对中文微博进行了情绪分类,同时还将主成分分析法引入到情绪分类中,计算微博中主要情绪的比例.该方法采用4层结构,将情绪细分为19种类别.在新浪微博数据上进行了4层实验,其中第1层只采用平面型文本分类;第2层与第1层不同,采取了层级分类;第3层在第2层的基础上加入了词性特征;第4层在第3层的基础上还加入了心理学情绪词典.通过第1层对文本是否有情感信息的分类和第2层正、负情感的分类,将无关的文本剔除,使后续分类工作更加容易.在层级分类的实验中,第3层的分类准确率可以达到90%左右,其4层层级结构如图5所示:
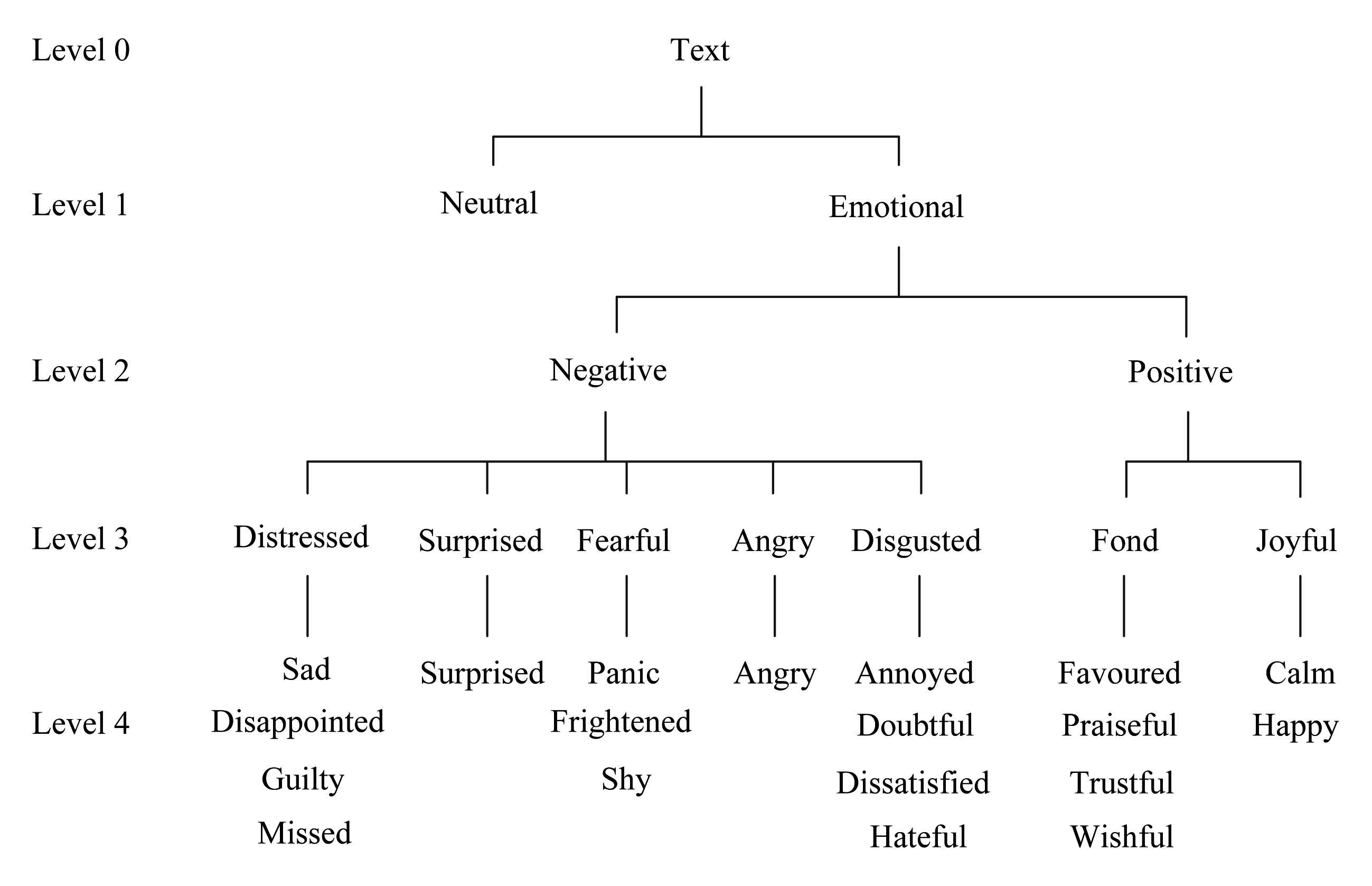
Fig. 5 Four-level hierarchy
图5 4层层级结构
由于微博语料通常是隐式的、不平衡的,为解决该问题,Zhang等人 [100] 提出了一种基于主题模型的层级情绪分类法.该方法先对微博语料进行去除无关信息的预处理;然后根据主题模型进行特征选择,用选出的特征词和情绪词典构成(情绪,情绪指示)关联,识别隐含的情绪;最后构造一个树结构的层级分类器对微博进行分类.该方法在新浪微博语料库的情绪分类实验中, F 值可达70%.
该类通过将情绪分类任务分解成较为有无情感检测、情感分类、细粒度情绪等子任务,利用更为成熟的主客观检测、情感分类的技术对样本进行预分类,从而降低情绪分类的难度.
另一类基于子类的复合方法是将语料库先分为更细致的子类,再利用分好的子类对样本进行分析,从而获得最终的情绪分类.Keshtkar等人 [101] 也提出了一种基于层次的心情分类方法.该方法对博客的心情进行分类,总共分为132类,但是情绪与心情有所区别,情绪持续的时间比心情的要短,二者之间的层次结构和分类任务并不相同.此后,刘宝芹等人 [102] 在文献[101]的基础上,根据Ekman的6类情绪理论中情感极性与情绪间的相互关系,为6类情绪建立了3层树状结构,并利用该结构对不同话题微博的情绪进行自动分析.在新浪微博的情绪分类实验中,该方法比传统的贝叶斯方法情绪识别精度更高,同时还降低了情绪数据分布不均衡对结果的影响,该方法在6种情绪分类任务中,平均精准率可达70.6%.
此后,欧阳纯萍等人 [103] 提出一种基于情绪词汇本体的多种有监督学习复合方法.该方法使用朴素贝叶斯算法对微博是否有情绪进行预分类,并根据分类结果对情绪进行精确分析.该方法首先将情感词汇本体库的7种类别细分为21小类(快乐、安心、尊敬等),并把这21小类作为每条微博的最终特征,分别采用SVM和 k NN( k -nearest neighbors)算法对预分类后的新浪微博数据集进行细粒度情绪分类.在2013年CCF自然语言处理与中文计算机会议的中文微博情绪分析评测任务中,该方法相较于单纯使用SVM和 k NN分类器,其 F 值提高近11%,其对情绪判别的准确率可达72.71%,表现优于单一分类算法.
归纳上述3类方法,主要是针对极性或单一情绪标签分类,忽略了情绪标签在实例中多情绪共存的情况.因此,情绪分析与传统的情感分析相比,从另一个维度还可以看作是一个多标签情绪分类问题.
传统的情绪分析方法很少认为一个文本可以同时表达多种情绪,而事实中一条语料可能出现有多种情绪共存的情况.为了更准确地把握文本中所表达的情绪信息,研究者们从另一个新的维度出发,开展了基于多标签情绪分类的研究.
Yang等人 [104] 提出了一种多标签情绪分类方法.该方法利用表情符号、标点符号和小型词典对数据进行标记,再用多标签情绪分类(multi-label emotion classification, MEC)算法对微博进行分类.MEC算法同时考虑文本级和词级信息,先用 k NN收集特定微博的情绪信息,再利用朴素贝叶斯计算微博在词语层面属于任何一个情绪类别的概率,最后设置一个阈值抽取微博的情绪标签.准确率最高83.6%.
此后,Buitinck等人 [105] 提出了一种面向影评的多标签情绪检测系统.该方法先通过词袋和篇章特征将句子标记为预设情绪标签集的一个子集,然后分别用one-vs.-rest SVM和RAKEL方法对文本进行分类.在IMDB影评数据集的实验中,RAKEL分类器的表现最好,因为多标签分类相较于单标签分类器,分类规则更加复杂,评价标准除准确率外,常用的指标还有汉明损失(hamming loss, HL )、平均精度(average precision, AP )、1-错误率(one error, OE )等,其平均准确率可达84.1%, HL 为11.2%, AP 为89.8%, OE 为24.6%.
在此基础上,Liu等人 [106] 提出了一种基于多标签的情绪分类方法.该方法利用DUTSD,NTUSD,Hownet这3个情绪词典提取微博语料中的情绪特征和原始分割词特征,通过与ML k NN (multi-label k -nearest neighbors),BR k NN (binary relevance k -nearest neighbors)等使用 k NN算法的基准方法做对比,发现CLR (calibrated label ranking)分类效果最好,其平均准确率可达65.5%, HL 为16.7%, AP 为76.6%, OE 为37.3%.
因为一个句子可能包含多种不同强度的情绪,有些情绪可以共存,而有些则不会同时出现.根据这一特性,一些研究者在多标签情绪分析工作中加入了情绪强度分布的要素.Wang等人 [107] 提出了一种多标签情绪分类方法.该方法利用skip-gram语言模型训练词汇情绪的分布式表达,将微博语句降维成词向量,并将二者作为卷积神经网络的输入,最终使用基于CLR的多标签学习方法获得每条微博的最终情绪标签排序,其流程如图6所示:
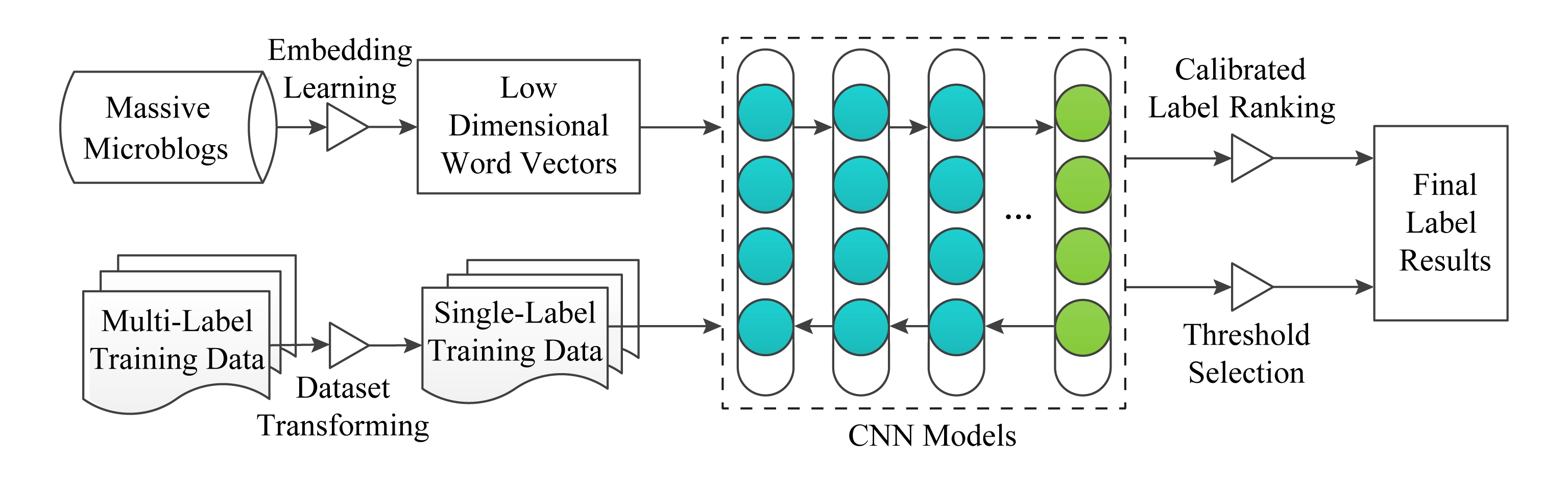
Fig. 6 Multi-label emotion classification based on CLR
图6 基于CLR的多标签情绪分类方法
该方法在NLPCC 2014情绪分析语料EACWT和Ren-CECPs语料的实验中,平均准确率分别为75.56%和63.20%, HL 分别为19.58%和31.64%, AP 分别为75.56%和63.2%, OE 为26.28%和43.52%.
针对现有语料库中情绪类别不平衡的特征,Li等人 [108] 提出了一种基于最大熵(multi-label maxi-mum entropy, MME)短文本情绪分布检测方法.该方法利用最大熵原理估计词与社会情绪之间的关系,为了提高在新闻、微博等多种规模语料库中的预测能力,引入了L-BFGS算法来缓解约束.该方法在Semeval,SSTweet,ISEAR这3个语料库上的 F 1值分别为36.96%,90.30%,54.86%.
在此基础上,Zhou等人 [109] 提出一种基于情绪分布学习的分类方法.该方法设计了一个从句子到情绪分布的映射函数,用以描述多重情绪和它们各自的强度,并引入Plutchik情绪轮理论以提高情绪检测的准确率.该方法在中文博客Ren-CECPs语料库的实验中,其平均准确率可达66.54%, HL 为17.72%, AP 为64.10%, OE 为52.39%.
由于篇章级语料上下文信息对情绪分布有着很大的影响,Xu等人 [110] 提出一种迭代多标记的情绪分布检测方法,该方法利用句子内部特征(intra-sentence features)对句子进行初始分类,结合上下文信息,根据初始分类结果与整篇微博情绪类别的转移概率,综合考虑转移概率、ML- k NN和随机多标签RAKEL(random k -labelsets)这3种多标签分类器的分类结果,最终获得该微博的情绪分布.在中文微博情绪分类数据集(包含14 000条微博、45 431个句子)的实验中,对7种情绪happiness,like,anger,sadness,fear,disgust,surprise分类的平均准确率可达83.26%.
虽然基于多情绪标签的分类方法的复杂性和难度都比较高,且该研究方向才刚刚起步,但其应用前景较好,将会成为一个新的研究热点.表2对4种主流的情绪分类方法进行了概括和对比分析.
Table 2 Comparison of Emotion Analysis Methods
表2 情绪分析方法对比

Table 2 ( Continued )

目前针对文本情绪分析的研究已经取得了一定的成果,但该研究领域还处于一个相对年轻的阶段.文本情绪分析技术在理论和应用上都还存在一些挑战以及新的方向需要进一步研究探讨.
当前文本情绪分析研究面临来自多方面的挑战,主要包括:数据稀缺性,无论是情绪训练语料还是情绪词典资源,都处于比较匮乏的阶段;类别不平衡,收集到的样本中情绪各类别的数量明显存在差异;领域依赖性,情绪词在不同领域的表达存在差异;语言不平衡,当前大多数工作都基于英文语料,语言迁移存在困难.
1) 数据稀缺性
文本情绪分析主要包括基于情绪词典和规则的方法、基于机器学习的方法.然而,无论是哪种方法,数据都很稀缺.在基于词典的方法中,情绪词典很难获取资源,目前尚无公开的情绪词典可用.此外,即使有开源的情绪词典,由于网络新词层出不穷,需要不断对情绪词典进行扩充和更新;在基于机器学习的方法中,需要借助有情绪标注的语料库来提取特征并训练情绪分类器.然而情绪标注语料本身也是稀缺资源,由于不同领域的情绪表达有不同特点,通用的情绪训练语料无法满足不同领域研究的需求.
2) 类别不平衡
情感分析的工作已经开展很多年,目前大多数工作都假设正负样本是均衡的.情绪分析是在情感分析的基础上进行更细粒度的分类.然而,不同情绪的数据集规模往往不均衡,在实际收集的微博语料中,一些情绪类别的语料数量明显多于另一些类别,例如表达喜欢的语料明显多于表达害怕的.所以,适用于均衡分类的方法在面对不均衡数据时效果往往并不理想.样本数据的不平衡分布会使机器学习方法在进行分类时严重偏向于样本多的类别,从而影响到分类的性能.
3) 领域依赖性
同一个词在不同的领域背景下表达着不同的情绪,例如“不可预测”在电影评论领域是褒义的,在汽车评论领域则是贬义的.因此,在进行情绪分析时,应该充分考虑情绪词的领域依赖性.跨领域情绪分析是文本情绪分析的一个重要研究课题,跨领域情绪分析有很多问题需要解决.例如,在一个领域的意见表达,在另一个领域可能反转.此外,还应该考虑不同领域情绪词汇的差异.
4) 语言不平衡
现有情绪分析工作大多基于英文 [111] ,虽然近些年对中文的情绪分析也有了一定的研究成果 [83] ,但是基于情绪词典或语义知识库的工作都需依赖特定语种的外部资源,基于英文的情绪分析研究很难迁移到其他语言.此外,由于非英语的情绪分析训练集和测试集也相对匮乏,极大限制了非英语语种的情绪分析研究.
当不同媒体、不同形态的情绪信息“融合”在一起,会随之产生“质变”.与此同时,领域自适应、社交网络分析和深度学习等技术的发展,也给文本情绪分析研究指出了新的研究方向.从技术的发展趋势分析看,未来文本情绪分析的研究还需要关注如下4个方面.
1) 基于多媒体融合的情绪分析
传统的情绪分析主要关注文本,然而图片等多媒体通常可以比文本表达更明显的情绪效果,即所谓的“一图胜千言”.此外,另一种情绪信息表达的主要载体——语音,也可以很好地反映用户的当前情绪状态.因此,随着图像、音频等不同类型社交网络数据的不断增长,各种类型的用户数据相结合的研究将具有更好的应用前景.
2) 基于领域自适应的情绪分析
领域自适应技术可以利用信息丰富的源域资源提升目标或模型的性能.传统情绪分析方法为了克服情绪词本身具有的领域依赖性,刻意选择领域无关的特征,如表情符号.而领域自适应的方法可以充分利用情绪词在不同领域所表达的不同情绪,准确、快速地识别文本情绪.因此,随着不同领域情绪语料资源的积累,基于领域自适应的情绪分析将逐渐成为一个新的研究热点.
3) 基于社交网络分析的情绪分析
社交网络的迅猛发展,产生了大量的用户交互数据,这些数据反应了用户的思想、情绪及社交关系.通过结合社交网络的关系分析技术,可以了解不同的社会群体是如何表达情绪以及情绪倾向.因此,研究基于社交网络分析的情绪分析技术可以更好地掌握大众情绪走向,为舆情分析、情绪管理等应用提供支撑.
4) 基于深层语义的情绪分析
深度学习作为机器学习研究中的一个新领域,取得了很大的进展.在自然语言处理的各项任务中,深度学习也有着许多可喜的成果.随着计算能力不断提高、数据量不断增加,可以预测未来将涌现出更多优秀的神经网络模型.该类方法将在自动抽取情绪特征、减少人工标记工作等方面做出巨大贡献.另外,在深度学习算法中加入一定的策略,可以更好地学习词汇和句子的语义表达,从而实现理解句子以及整个文档的任务.
在此基础上,随着互联网+时代的到来,涌现出大数据分析、特定主题挖掘、用户画像构建和多语言协同等众多新的应用需求,也给文本情绪分析带来了新的机遇.
1) 面向大数据的文本情绪分析
大数据技术的发展使数据的收集变得非常容易且成本低廉,对海量的信息数据进行挖掘,可以获得巨大的产品或服务价值.然而收集的数据大多以非结构化文本形式存储,在对文本数据进行情绪分析时,传统的概率潜在语义分析方法的时间复杂度和空间复杂度较高,难以满足训练大规模数据的需求,需要提出面向大数据的文本情绪分析方法.
2) 面向特定主题的情绪分析
由于情绪表达在不同主题下有所不同,无论是采用有监督还是无监督的学习方法,情绪分析的准确率在一定程度上受主题的影响.同样的短语在不同的主题下,其语言规则、词库判断标准都存在不同.现有针对主题差异的研究工作,在实际应用中仍存在不少问题.例如,当主题差别过大时,分析性能会明显下降,需要对跨主题情绪分析的算法和相关问题开展进一步研究.
3) 面向个性化的情绪分析
随着互联网+时代的到来,用户对各类应用都提出了个性化的需求,而情绪是一种高度主观的用户行为特征,同样的情绪词汇根据不同的用户历史情绪变化也会产生不同的情绪含义及强度.因此,通过观察用户情绪变化曲线,为不同的用户构建情绪画像,从而实现利用有限的信息对用户情绪进行个性化精准分析.
4) 面向多语言的情绪分析
随着文化交流的增加,多种语言的网络信息相互影响与融合.现有工作主要针对单一语言,而在单一语言情绪分析中所收集到的语料资源与成果,无法在多语言的环境中直接使用;此外,不同语言情绪分析的语料资源也存在不均衡性,难以在跨语言的环境中直接使用.在解决情绪分析任务的基本问题外,还需要考虑机器翻译、多语言文本处理等工作,这都对多语言情绪分析提出了新的需求.
本文对文本情绪分析研究进行了综述,概括了情绪分类的心理学模型和情绪分析的应用场景,重点对主流的情感/情绪分析方法进行了介绍和对比,最后总结了现有工作主要存在的问题,并对将来的研究工作进行了展望.
文本情绪分析作为自然语言处理和文本挖掘中一个新兴的研究方向,有着很广泛的应用前景.情感分析的研究已经比较成熟,而情绪分析的研究尚处于起步阶段,且国内研究较少.
可以预见,在未来的文本挖掘研究中,将会涌现大量情绪分析的相关工作.
参考文献
[1] Lin Chuanding. Emotional problems in socialist psychology[J]. Science of Social Psychology, 2006, 21(83): 37-62 (in Chinese)
(林传鼎. 社会主义心理学中的情绪问题[J]. 社会心理科学, 2006, 21(83): 37-62)
[2] Ekman P. An argument for basic emotions[J]. Cognition and Emotion, 1992, 6(3/4): 169-200
[3] Plutchik R. The nature of emotions[J]. Philosophical Studies, 2001, 89(4): 393-409
[4] Egges A, Kshirsagar S, Magnenat-Thalmann N. A model for personality and emotion simulation[C] //Proc of the 7th Int Conf on Knowledge-Based and Intelligent Information and Engineering Systems. Berlin: Springer, 2003: 453-461
[5] Zhao Jichun, Wang Zhiliang, Wang Chao. Study on emotion model building and virtual feeling robot[J]. Computer Engineering, 2007, 33(1): 212-215 (in Chinese)
(赵积春, 王志良, 王超. 情绪建模与情感虚拟人研究[J]. 计算机工程, 2007, 33(1): 212-215)
[6] Ortony A, Clore G, Collins A. The cognitive structure of emotions[J]. The Quarterly Review of Biology, 1990, 18(65): 2147-2153
[7] Parrott W G. Emotions in Social Psychology: Essential Readings[M]. Oxford, UK: Psychology Press, 2001
[8] Zhao Yanyan, Qin Bing, Liu Ting. Sentiment analysis[J]. Journal of Software, 2010, 21(8): 1834-1848 (in Chinese)
(赵妍妍, 秦兵, 刘挺. 文本情感分析[J]. 软件学报, 2010, 21(8): 1834-1848)
[9] Hao Yazhou, Zheng Qinghua, Chen Yanping, et al. Recognition of abnormal behavior based on data of public opinion on the Web[J]. Journal of Computer Research and Development, 2016, 53(3): 611-620 (in Chinese)
(郝亚洲, 郑庆华, 陈艳平, 等. 面向网络舆情数据的异常行为识别[J]. 计算机研究与发展, 2016, 53(3): 611-620)
[10] Mishne G. Experiments with mood classification in blog posts[C] //Proc of the 28th ACM SIGIR Workshop on Stylistic Analysis of Text for Information Access. New York: ACM, 2005: 321-327
[11] Mohammad S. From once upon a time to happily ever after: Tracking emotions in novels and fairy tales[C] //Proc of the 5th Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities. Stroudsburg, PA: ACL, 2011: 105-114
[12] Bollen J, Mao H, Zeng X. Twitter mood predicts the stock market[J]. Journal of Computational Science, 2011, 2(1): 1-8
[13] Devitt A, Ahmad K. Sentiment polarity identification in financial news: A cohesion-based approach[C] //Proc of the 45th Association of Computational Linguistics. Stroudsburg, PA: ACL, 2007: 25-27
[14] Tumasjan A, Sprenger T O, Sandner P G, et al. Predicting elections with Twitter: What 140 characters reveal about political sentiment[C] //Proc of the 4th Int AAAI Conf on Weblogs and Social Media. Menlo Park, CA: AAAI, 2010: 178-185
[15] Kim S M, Hovy E H. Crystal: Analyzing predictive opinions on the Web[C] //Proc of the 4th Joint Conf on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Stroudsburg, PA: ACL, 2007: 1056-1064
[16] Ceron A, Curini L, Iacus S M, et al. Every tweet counts? How sentiment analysis of social media can improve our knowledge of citizens’ political preferences with an application to Italy and France[J]. New Media and Society, 2014, 16(2): 340-358
[17] Golder S A, Macy M W. Diurnal and seasonal mood vary with work, sleep, and daylength across diverse cultures[J]. Science, 2011, 333(6051): 1878-1881
[18] Kim S, Lee J, Lebanon G, et al. Estimating temporal dynamics of human emotions[C] //Proc of the 29th Int AAAI Conf on Artificial Intelligence. Menlo Park, CA: AAAI, 2015: 168-174
[19] Zhou Xinjie, Wan Xiaojun, Xiao Jianguo. Collective opinion target extraction in Chinese microblogs[C] //Proc of the 10th Conf on Empirical Methods on Natural Language Processing. Stroudsburg, PA: ACL, 2013: 1840-1850
[20] Huang Xuanjing, Zhang Qi, Wu Yuanbin. A survey on sentiment analysis[J]. Journal of Chinese Information Processing, 2011, 25(6): 118-127 (in Chinese)
(黄萱菁, 张奇, 吴苑斌. 文本情感倾向分析[J]. 中文信息学报, 2011, 25(6): 118-127)
[21] Kim S M, Hovy E. Extracting opinions, opinion holders, and topics expressed in online news media text[C] //Proc of the 44th Workshop on Sentiment and Subjectivity in Text. Stroudsburg, PA: ACL, 2006: 1-8
[22] Carstens L, Toni F. Enhancing sentiment extraction from text by means of arguments[C] //Proc of the 2nd Int Workshop on Issues of Sentiment Discovery and Opinion Mining. New York: ACM, 2013: 1-9
[23] Eirinaki M, Pisal S, Singh J. Feature-based opinion mining and ranking[J]. Journal of Computer and System Sciences, 2012, 78(4): 1175-1184
[24] Yu Long, Duan Xiangchao, Tian Shengwei, et al. Topic extraction based on product reviews[J]. Journal of Computational Information Systems, 2013, 9(2): 773-780
[25] Dai Min, Wang Rongyang, Li Shoushan, et al. Opinion target extraction with syntactic features[J]. Journal of Chinese Information Processing , 2014, 28(4): 92-97 (in Chinese)
(戴敏, 王荣洋, 李寿山, 等. 基于句法特征的评价对象抽取方法研究[J]. 中文信息学报, 2014, 28(4): 92-97)
[26] Song Hui, Shi Nansheng. Comment object extraction based on pattern matching and semi-supervised learning[J]. Computer Engineering, 2013, 39(10): 221-226 (in Chinese)
(宋晖, 史南胜. 基于模式匹配与半监督学习的评价对象抽取[J]. 计算机工程, 2013, 39(10): 221-226)
[27] Ren Bin, Che Wanxiang, Liu Ting. Dependency parsing-based social media text mining—A case study in analysis of weibo users’ eating habits[J]. Journal of Chinese Information Processing, 2014, 28(6): 208-215 (in Chinese)
(任彬, 车万翔, 刘挺. 基于依存句法分析的社会媒体文本挖掘方法——以饮食习惯特色分析为例[J]. 中文信息学报, 2014, 28(6): 208-215)
[28] Tao Xinzhu, Zhao Peng, Liu Tao. Extraction of evaluation collection of merging kernel sentence and dependency relation[J]. Computer Technology and Development, 2014, 24(1): 118-121 (in Chinese)
(陶新竹, 赵鹏, 刘涛. 融合核心句与依存关系的评价搭配抽取[J]. 计算机技术与发展, 2014, 24(1): 118-121)
[29] Li Gang, Liu Fei. Application of a clustering method on sentiment analysis[J]. Journal of Information Science, 2012, 38(2): 127-139
[30] Wang Changhou, Wang Fei. Extracting sentiment words using pattern based Bootstrapping method[J]. Computer Engineering and Applications, 2014, 50(1): 127-129 (in Chinese)
(王昌厚, 王菲. 使用基于模式的Bootstrapping方法抽取情感词[J]. 计算机工程与应用, 2014, 50(1): 127-129)
[31] Paltoglou G, Thelwall M. Twitter, MySpace, Digg: Unsupervised sentiment analysis in social media[J]. ACM Trans on Intelligent Systems and Technology, 2012, 3(4): 67-83
[32] Qiu Guang, He Xiaofei, Zhang Feng, et al. DASA: Dissatisfaction-oriented advertising based on sentiment analysis[J]. Expert Systems with Applications, 2010, 37(9): 6182-6191
[33] Jiang Long, Yu Mo, Zhou Ming, et al. Target-dependent Twitter sentiment classification[C] //Proc of the 49th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2011: 151-160
[34] Wan Xiaojun. Using bilingual knowledge and ensemble techniques for unsupervised Chinese sentiment analysis[C] //Proc of the 4th Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2008: 553-561
[35] Wei Bin, Pal C. Cross Lingual adaptation: An experiment on sentiment classifications[C] //Proc of the 48th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2010: 258-262
[36] Turney P. Thumbs up or thumbs down?: Semantic orientation applied to unsupervised classification of reviews[C] //Proc of the 40th Annual Meeting on Association for Computational Linguistics. New York: ACM, 2002: 417-424
[37] Zagibalov T, Carroll J. Automatic seed word selection for unsupervised sentiment classification of Chinese text[C] //Proc of the 22nd Int Conf on Computational Linguistics, Vol 1. New York: ACM, 2008: 1073-1080
[38] Jo Y, Oh A. Aspect and sentiment unification model for online review analysis[C] //Proc of the 4th Int Conf on Web Search and Web Data Mining. New York: ACM, 2011: 815-824
[39] Thomas H. Probabilistic latent semantic analysis[J]. Computer Science, 2015, 25(4): 289-296
[40] Blei D, Ng A, Jordan M. Latent Dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3: 993-1022
[41] Hoffman M, Bach F, Blei D. Online learning for latent Dirichlet allocation[C] //Proc of the 24th Conf on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2010: 856-864
[42] Pang Bo, Lee L, Vaithyanathan S. Thumbs up?: Sentiment classification using machine learning techniques[C] //Proc of the 40th Association for Computational Linguistics Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2002: 79-86
[43] Dong Li, Wei Furu, Tan Chuanqi, et al. Adaptive recursive neural network for target-dependent Twitter sentiment classification[C] //Proc of the 52nd Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2014: 49-54
[44] Tang Duyu, Wei Furu, Qin Bing, et al. Coooolll: A deep learning system for Twitter sentiment classification[C] //Proc of the 8th Int Workshop on Semantic Evaluation. Stroudsburg, PA: ACL, 2014: 208-212
[45] Tan Songbo, Cheng Xueqi, Wang Yuefen, et al. Adapting Naive Bayes to domain adaptation for sentiment analysis[C] //Proc of the 31st European Conf on IR Research. Berlin: Springer, 2009: 337-349
[46] Ortigosa H, Rodríguez J, Alzate L, et al. Approaching sentiment analysis by using semi-supervised learning of multi-dimensional classifiers[J]. Neurocomputing, 2012, 92(3): 98-115
[47] Socher R, Pennington J, Huang E H, et al. Semi-supervised recursive autoencoders for predicting sentiment distributions[C] //Proc of the 8th Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2011: 151-161
[48] Zhou Shusen, Chen Qingcai, Wang Xiaolong. Fuzzy deep belief networks for semi-supervised sentiment classification[J]. Neurocomputing, 2014, 131(9): 312-322
[49] He Xiaonan, Zhang Hui, Chao Wenhan, et al. Semi-supervised learning on cross-lingual sentiment analysis with space transfer[C] //Proc of the 2nd Big Data Computing Service and Applications. Piscataway, NJ: IEEE, 2015: 371-377
[50] Santos C, Gattit M. Deep convolutional neural networks for sentiment analysis of short texts[C] //Proc of the 25th Int Conf on Computational Linguistics. New York: ACM, 2014: 69-78
[51] Socher R, Perelygin A, Wu J, et al Recursive deep models for semantic compositionality over a sentiment treebank[C] //Proc of the 10th Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2013: 1631-1642
[52] Dong Li, Wei Furu, Zhou Ming, et al. Adaptive multi-compositionality for recursive neural models with applications to sentiment analysis[C] //Proc of the 28th AAAI Conf on Artificial Intelligence. Menlo Park, CA: AAAI, 2014: 1537-1543
[53] Le Quoc V, Mikolov T. Distributed representations of sentences and documents[J]. Computer Science, 2014, 4: 1188-1196
[54] Saif H, He Yulan, Alani H. Semantic sentiment analysis of Twitter[C] //Proc of the 11th Int Semantic Web Conf. Berlin: Springer, 2012: 508-524
[55] He Yunchao, Yang Chinsheng, Yu Liangchih, et al. Sentiment classification of short texts based on semantic clustering[C] //Proc of the 2nd Int Conf on Orange Technologies. Piscataway, NJ: IEEE, 2015: 54-57
[56] Saif H, He Yulan, Fernandez M, et al. Semantic patterns for sentiment analysis of Twitter[C] //Proc of the 13th Int Semantic Web Conf. Berlin: Springer, 2014: 324-340
[57] Hassan S , He Y, Alani H. Alleviating data sparsity for Twitter sentiment analysis[C] //Proc of the 2nd Workshop on Making Sense of Microposts. New York: ACM, 2012: 2-9
[58] Mass A L, Daly R E, Pham P T, et al. Learning word vectors for sentiment analysis[C] //Proc of the 49th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2011: 142-150
[59] Dahl G, Adams R, Larochelle H. Training restricted boltzmann machines on word observations[C] //Proc of the 29th Int Conf on Machine Learning. New York: ACM, 2012: 679-686
[60] Wang Sida, Manning C. Baselines and bigrams: Simple, good sentiment and text classification[C] //Proc of the 50th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2012: 90-94
[61] Brychcin T, Habernal I. Unsupervised improving of sentiment analysis using global target context[C] //Proc of the 11th Int Conf Recent Advances in Natural Language Processing. Stroudsburg, PA: ACL, 2013: 122-128
[62] Dai A M, Le Q V. Semi-supervised sequence learning[C] //Proc of the 25th Conf on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2015: 3079-3087
[63] Stoyanov V, Cardie C. Partially supervised coreference resolution for opinion summarization through structured rule learning[C] //Proc of the 3rd Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2006: 336-344
[64] Ku Lunwei, Liang Yuting, Chen Hsin Hsi. Opinion extraction, summarization and tracking in news and blog corpora[C] //Proc of the 21st AAAI Conf Spring Symp: Computational Approaches to Analyzing Weblogs. Menlo Park, CA: AAAI, 2006: 100-107
[65] Hurst M, Nigam K. Retrieving topical sentiments from online document collections[C] //Proc of the 5th Electronic Imaging Conf. Bellingham, WA: SPIE Press, 2004: 27-34
[66] Zhang Min, Ye Xingyao. A generation model to unify topic relevance and lexicon-based sentiment for opinion retrieval[C] //Proc of the 31st Annual Int ACM SIGIR Conf on Research and Development in Information Retrieval. New York: ACM, 2008: 411-418
[67] Ma Chunling, Osherenko A, Prendinger H, et al. A chat system based on emotion estimation from text and embodied conversational messengers[C] //Proc of the 4th Int Conf on Active Media Technology. Piscataway, NJ: IEEE, 2005: 546-548
[68] Aman S, Szpakowicz S. Identifying expressions of emotion in text[C] //Proc of the 10th Int Conf on Text, Speech and Dialogue. Berlin: Springer, 2007: 196-205
[69] Yang Min, Peng Baolin, Chen Zheng, et al. A topic model for building fine-grained domain-specific emotion lexicon[C] // Proc of the 52nd Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2014: 421-426
[70] Xu Jun, Xu Ruifeng, Zheng Yanzhen, et al. Chinese emotion lexicon developing via multi-lingual lexical resources integration[C] //Proc of the 14th Int Conf on Computational Linguistics and Intelligent Text Processing. Berlin: Springer, 2013: 174-182
[71] Song Kaisong, Feng Shi, Gao Wei, et al. Build emotion lexicon from microblogs by combining effects of seed words and emoticons in a heterogeneous graph[C] //Proc of the 26th ACM Conf on Hypertext and Social Media. New York: ACM, 2015: 283-292
[72] Wu Fangzhao, Huang Yongfeng, Song Yangqiu, et al. Towards building a high-quality microblog-specific Chinese sentiment lexicon[J]. Decision Support Systems, 2016, 87: 39-49
[73] Staiano J, Guerini M. DepecheMood: A lexicon for emotion analysis from crowd-annotated news[C] //Proc of the 52nd Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2014: 427-433
[74] Strapparava C, Mihalcea R. Learning to identify emotions in text[C] //Proc of the 23rd ACM Symp on Applied Computing. New York: ACM, 2008: 1556-1560
[75] Neviarouskaya A, Prendinger H, Ishizuka M. Affect analysis model: Novel rule-based approach to affect sensing from text[J]. Natural Language Engineering, 2011, 17(1): 95-135
[76] Wen Shiyang, Wan Xiaojun. Emotion classification in microblog texts using class sequential rules[C] //Proc of the 28th AAAI Conf on Artificial Intelligence. Menlo Park, CA: AAAI, 2014: 187-193
[77] Lee S Y M, Chen Ying, Huang Churen. A text-driven rule-based system for emotion cause detection[C] //Proc of the 10th NAACL HLT Workshop on Computational Approaches to Analysis and Generation of Emotion in Text. Stroudsburg, PA: ACL, 2010: 45-53
[78] Li Weiyuan, Xu Hua. Text-based emotion classification using emotion cause extraction[J]. Expert Systems with Applications, 2014, 41(4): 1742-1749
[79] Gao Kai, Xu Hua, Wang Jiushuo. A rule-based approach to emotion cause detection for Chinese micro-blogs[J]. Expert Systems with Applications, 2015, 42(9): 4517-4528
[80] Alm C, Roth D, Sproat R. Emotions from text: Machine learning for text-based emotion prediction[C] //Proc of the 2nd Conf on Human Language Technology and on Empirical Methods in Natural Language Processing. New York: ACM, 2005: 579-586
[81] Cheng Xueqi, Yan Xiaohui, Lan Yanyan, et al. BTM: Topic modeling over short texts[J]. IEEE Trans on Knowledge and Data Engineering, 2014, 26(12): 2928-2941
[82] Read J. Using Emoticons to reduce dependency in machine learning techniques for sentiment classification[C] //Proc of the 43rd ACL Student Research Workshop. Stroudsburg, PA: ACL, 2005: 43-48
[83] Zhao Jichang, Dong Li, Wu Junjie, et al. Moodlens: An emoticon-based sentiment analysis system for Chinese tweets[C] //Proc of the 18th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2012: 1528-1531
[84] Ouyang Xi, Zhou Pan, Li Chenghua, et al. Sentiment analysis using convolutional neural network[C] //Proc of the 15th Int Conf on Computer and Information Technology; the 14th Int Conf on Ubiquitous Computing and Communications; the 13th Int Conf on Dependable, Autonomic and Secure Computing; the 13th Int Conf on Pervasive Intelligence and Computing. Piscataway, NJ: IEEE, 2015: 2359-2364
[85] Santos C, Gatti M. Deep Convolutional neural networks for sentiment analysis of short texts[C] //Proc of the 25th Int Conf on Computational Linguistics. New York: ACM, 2014: 69-78
[86] Irsoy O, Cardie C. Deep recursive neural networks for compositionality in language[C] //Proc of the 28th Conf on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2014: 2096-2104
[87] Kang Xin, Ren Fuji, Wu Yunong. Bottom up: Exploring word emotions for Chinese sentence chief sentiment classification[C] //Proc of the 6th Natural Language Processing and Knowledge Engineering. Piscataway, NJ: IEEE, 2010: 1-5
[88] Rao Yanghui, Xie Haoran, Li Jun, et al. Social emotion classification of short text via topic-level maximum entropy model[J]. Information and Management, 2016, 53(8): 978-986
[89] Huang Shu, Peng Wei, Li Jingxuan, et al. Sentiment and topic analysis on social media: A multi-task multi-label classification approach[C] //Proc of the 5th Annual ACM Web Science Conf. New York: ACM, 2013: 172-181
[90] Zhang Xiao, Li Wenzhong, Lu Sanglu. Emotion detection in online social network based on multi-label learning[C] //Proc of the 22nd Int Conf on Database Systems for Advanced Applications. Berlin: Springer, 2017: 659-674
[91] Sun Xiao, Li Chengcheng, Ye Jiaqi. Chinese microblogging emotion classification based on support vector machine[C] //Proc of the 5th Int Conf on Computing, Communication and Networking Technologies. Piscataway, NJ: IEEE, 2014: 1-5
[92] Sintsova V, Musat C, Pu Pearl. Semi-supervised method for multi-category emotion recognition in tweets[C] //Proc of the 17th Int Conf on Data Mining Workshop. Piscataway, NJ: IEEE, 2014: 393-402
[93] Purver M, Battersby S. Experimenting with distant supervision for emotion classification[C] //Proc of the 13th Conf of the European Chapter of the Association for Computational Linguistics. New York: ACM, 2012: 482-491
[94] Suttles J, Ide N. Distant supervision for emotion classification with discrete binary values[C] //Proc of the 14th Int Conf on Intelligent Text Processing and Computational Linguistics. Berlin: Springer, 2013: 121-136
[95] Jiang Fei, Liu Yiqun, Luan Huanbo, et al. Microblog sentiment analysis with emoticon space model[J]. Journal of Computer Science and Technology, 2015, 30(5): 1120-1129
[96] Li Shoushan, Xu Jian, Zhang Dong, et al. Two-view label propagation to semi-supervised reader emotion classification[C] //Proc of the 26th Int Conf on Computational Linguistics. New York: ACM, 2016: 2647-2655
[97] Ghazi D, Inkpen D, Szpakowicz S. Hierarchical versus flat classification of emotions in text[C] //Proc of the 9th NAACL HLT Workshop on Computational Approaches to Analysis and Generation of Emotion in Text. Stroudsburg, PA: ACL, 2010: 140-146
[98] Esmin A A A, De Oliveira R L, Matwin S. Hierarchical classification approach to emotion recognition in Twitter[C] //Proc of the 11th Int Conf on Machine Learning and Applications. Piscataway, NJ: IEEE, 2012: 381-385
[99] Xu Hua, Yang Weiwei, Wang Jiushuo. Hierarchical emotion classification and emotion component analysis on Chinese micro-blog posts[J]. Expert Systems with Applications, 2015, 42(22): 8745-8752
[100] Zhang Fan, Xu Hua, Wang Jiushuo, et al. Grasp the implicit features: Hierarchical emotion classification based on topic model and SVM[C] //Proc of the 29th Int Joint Conf on Neural Networks. Piscataway, NJ: IEEE, 2016: 3592-3599
[101] Keshtkar F, Inkpen D. A hierarchical approach to mood classification in blogs[J]. Natural Language Engineering, 2011, 18(18): 61-81
[102] Liu Baoqin, Niu Yun. Multi-hierarchy emotion analysis of Chinese microblog[J]. Computer Technology and Development, 2015, 25(11): 23-26 (in Chinese)
(刘宝芹, 牛耘. 多层次中文微博情绪分析[J]. 计算机技术与发展, 2015, 25(11): 23-26)
[103] Ouyang Chunping, Yang Xiaohua, Lei Longyan, et al. Multi-strategy approach for fine-grained sentiment analysis of Chinese microblog[J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2014, 50(1): 67-72 (in Chinese)
(欧阳纯萍, 阳小华, 雷龙艳, 等. 多策略中文微博细粒度情绪分析研究[J]. 北京大学学报: 自然科学版, 2014, 50(1): 67-72)
[104] Yang Jun, Jiang Lan, Wang Chongjun, et al. Multi-label emotion classification for tweets in weibo: Method and application[C] //Proc of the 26th Int Conf on Tools with Artificial Intelligence. Piscataway, NJ: IEEE, 2014: 424-428
[105] Buitinck L, Van Amerongen J, Tan E, et al. Multi-emotion detection in user-generated reviews[C] //Proc of the 37th European Conf on Information Retrieval. Berlin: Springer, 2015: 43-48
[106] Liu Shuhua, Chen Jiunhung. A multi-label classification based approach for sentiment classification[J]. Expert Systems with Applications, 2015, 42(3): 1083-1093
[107] Wang Yaqi, Feng Shi, Wang Daling, et al. Multi-label Chinese microblog emotion classification via convolutional neural network[C] //Proc of the 18th Asia-Pacific Web Conf. Berlin: Springer, 2016: 567-580
[108] Li Jun, Rao Yanghui, Jin Fengmei, et al. Multi-label maximum entropy model for social emotion classification over short text[J]. Neurocomputing, 2016, 210: 247-256
[109] Zhou Deyu, Zhang Xuan, Zhou Yin, et al. Emotion distribution learning from texts[C] //Proc of the 21st Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2016: 638-647
[110] Xu Ruifeng, Wang Zhaoyu, Xu Jun, et al. An iterative emotion classification approach for microblogs[C] //Proc of the 16th Int Conf on Intelligent Text Processing and Computational Linguistics. Berlin: Springer, 2015: 104-113
[111] Janssens O, Slembrouck M, Verstockt S, et al. Real-time emotion classification of tweets[C] // Proc of the 5th IEEE/ACM Int Conf on Advances in Social Networks Analysis and Mining. New York: ACM, 2013: 1430-1431
Li Ran 1,2 , Lin Zheng 1 , Lin Hailun 1 , Wang Weiping 1 , and Meng Dan 1,2
1 ( National Engineering Laboratory for Information Security Technologies ( Institute of Information Engineering , Chinese Academy of Sciences ), Beijing 100093) 2 ( School of Cyber Security , University of Chinese Academy of Sciences , Beijing 100049)
Abstract With the rapid development of social networks, electronic commerce, mobile Internet and other technologies, all kinds of Web data expand rapidly. There are a large number of emotional texts on the Internet, and they are very helpful to understand the netizen’s opinion and viewpoint if fully explored. The aim of emotion classification is to predict the emotion categories of emotive texts,which is the core of emotion analysis. In this paper, we first introduce the background knowledge of emotion analysis including different emotion classification systems and its application scenarios on public opinion management and control, business decisions, opinion search, information prediction, emotion management. Then we summarize the mainstream approaches of emotion classification, and make a detailed description and analysis on these approaches. Finally, we expound the problems of data sparsity, class imbalance learning, dependence for the strong domain knowledge and language imbalance existing in the emotion analysis work. The research progress of text emotion analysis is summarized and prospect combined with large data processing, the mixing of multiple media, deep learning development, mining on a specific topic and multilingual synergy.
Key words emotion analysis; opinion mining; sentiment analysis; machine learning; emotion lexicon
摘 要 随着社交网络、电子商务、移动互联网等技术的发展,各种网络数据迅速膨胀.互联网上蕴含着大量带有情绪色彩的文本数据,对其充分挖掘可以更好地理解网民的观点和立场.首先介绍了情绪分析的相关背景知识,包括不同情绪分类体系和文本情绪分析在舆情管控、商业决策、观点搜索、信息预测、情绪管理等场景的应用;然后从情绪分类的角度整理归纳了文本情绪分析的主流方法,并对其进行了细致的介绍和分析对比;最后,阐述了文本情绪分析存在的数据稀缺性、类别不平衡、领域依赖性、语言不平衡等问题,并结合大数据处理、多媒体融合、深度学习发展、特定主题挖掘和多语言协同等研究热点对文本情绪分析的前沿进展进行了概括和展望.
关键词 情绪分析;观点挖掘;情感分析;机器学习;情绪词典
中图法分类号 TP391
收稿日期: 2017-02-06;
修回日期: 2017-08-07
基金项目: 国家自然科学基金项目(61502478,61602467);国家“八六三”高技术研究发展计划基金项目(2013AA013204)
This work was supported by the National Natural Science Foundation of China (61502478, 61602467) and the National High Technology Research and Development Program of China (863 Program) (2013AA013204).
通信作者: 林政(linzheng@iie.ac.cn)

Li Ran , born in 1987. PhD candidate. Her main research interests include data mining, sentiment analysis etc.

Lin Zheng , born in 1984. PhD, assistant researcher. Her main research interests include nature language processing, sentiment analysis etc.

Lin Hailun , born in 1987. PhD, assistant researcher. Her main research interests include data mining, knowledge processing etc.

Wang Weiping , born in 1975. Professor and PhD supervisor. His main research interests include data stream, high perfor-mance database and parallel processing etc.

Meng Dan , born in 1965. Professor and PhD supervisor. His main research interests include high performance computer archi-tecture, distributed file system and system security etc.