
Fig. 1 Numbers of selected publications arranged by year
图1 本文所选大数据背景下的集群调度论文按年份分布
郝春亮 1,2 沈 捷 3 张 珩 1,2 武延军 1 王 青 1 李明树 1
1 (中国科学院软件研究所基础软件中心 北京 100190)
2 (中国科学院大学 北京 100049)
3 (帝国理工大学计算学院 伦敦 SW72AZ)
(chunliang@nfs.iscas.ac.cn)
20世纪70年代之前,计算任务所依赖的物理设备多为昂贵且专用的计算设备,罕有将多台设备互联的实际案例 [1] .至20世纪80年代初期,随着微电脑的出现,单台计算设备的体积和成本急剧下降,多台电脑协同工作于同一区域之中的情况时有发生.因此,出现了比单台电脑更为复杂的、利用局域网络互联多台电脑资源的研究工作 [2-4] .这些早期对于多台计算设备协作的研究开启了对集群以及相关技术的探索,其中包括解决资源使用与任务分配的集群调度问题研究.
自20世纪80年代至今,集群自身以及其相关调度研究都经历了持续的发展.例如服务于高性能计算的集群调度研究以及与集群调度紧密关联的网格调度研究都取得了长足的进展,并且诞生了大量的研究工作 [5-6] .这些调度研究工作是目前集群调度研究的基础.
在大数据背景下,集群调度面临全新挑战.集群经历了规模由小到大、计算模型和计算需求由单一到复杂、计算设备由同构到异构等快速变化 [7] .正因为这些变化,集群调度研究的目标和最终实现方式都出现了显著差异,以至于目前出现了集中调度结构、双层调度结构、分布式调度结构、混合调度结构多种调度结构的分支,由此衍生了不同的研究方向.本文通过对目前大数据背景下不同集群调度结构研究现状与进展的介绍与综合分析,对各结构中代表性工作涉及的主要研究内容以及技术方法进行梳理;继而对其各自的适用场景、优劣、典型研究工作方向进行归纳、总结.在此基础上,对未来集群调度的发展方向提出粗浅的看法.
为了全面准确地收集大数据背景下集群调度的典型调度方法、热点研究方向以及代表性的研究工作,本文对下列数据来源进行了详细筛选:
1) 在IEEE,ACM,Springer,CNKI等搜索引擎中进行文献检索.检索使用的关键字包括“scheduling”,“cluster computing”,“decentralized”,“locality”,“fairness”,“task parallism”等.
2) 通过人工筛选的方式.剔除与研究问题无关的论文,保留问题相关、有代表性的高水平学术会议以及期刊论文(保留CCF推荐列表 [8] A类、B类、Core列表 [9] A*以及同水平的中文论文).
3) 参考所选论文中的引文,识别遗漏.通过以上筛选,获得直接相关调度研究论文44篇(连同其他相关论文,如集群负载分析、计算模型研究等共78篇,连同其他引用合计96条).按照年份对直接相关论文进行统计分析,获得了年份与论文篇数的关系分布图和年份与4种调度结构发展的趋势图,如图1所示:
Fig. 1 Numbers of selected publications arranged by year
图1 本文所选大数据背景下的集群调度论文按年份分布
从图1可以发现,所选论文代表的总体趋势是:集中调度结构是最传统的调度结构,从2007年至今每年都有高水平的文章发表;双层结构以及分布式结构是为了应对集群以及计算环境变化产生的分支,最近几年各有部分研究成果发表;混合结构则是目前集群调度研究的新方向,是对调度结构研究的前沿探索.
集群是通过冗余局域网络互联的计算资源,因此集群调度的研究重点是单一冗余局域网络内的资源使用和作业执行;有别于基于广域网络的网格调度研究和云调度研究,可参考Mishra等人 [10] 和Qureshi等人 [11] 进行的网格调度的综述以及Bala等人 [12] 和陈康等人 [13] 对云调度的综述.其中,部分云调度和集群调度的研究文献多有交叉,难以精确分割,故本文的选文中也包括少量以云调度为主要方向的论文.
此外,本文关注大数据背景下的集群调度而非大数据技术本身.目前大数据计算有众多计算模型,包括:面向批处理的MapReduce [14] ,RDD [15] ;面向数据库的Tenzing [16] ,SparkSQL [17] ,Hive [18] ;面向图处理的Pregel [19] ,Unicorn [20] 等.他们各自有相关的研究文献和实现原型,有些也包含了模型内的任务调度设计.目前集群调度关注的更多是对各模型的统一抽象以及整体决策,故本文有别于对大数据计算技术的综述性文章 [7] .
目前与本文研究目标类似的综述文章例如Hussain等人 [21] 对集群、网格以及云计算中的作业执行、运维管理等多方面的调度研究进行综述;Schwarzkopf等人 [22] 包含了对2013年前集群调度结构的综述.上述论文都没有深入讨论在大数据背景下引发的集群调度结构变化以及各结构的具体设计内容、特点和局限.与集群调度有关的集群能耗研究问题,由于主要解决的是成本和可靠性问题 [23] ,与集群调度结构的关联度较低,本文亦不做讨论.
近年来,互联网中的数据量在持续迅速地增长.据统计,2013年度全球范围内新增和被复制的数据总量约为4.4 ZB,2020年预期将增长至44 ZB [24] .数据的大量累积和增长归功于各个企业和个人的数据相关实践.以Facebook为例,每日用户上传图片总数最多时可达3亿张,每日内容传递最多时可达25亿条,每日可新增多达500 TB的数据总量 [25] .与之类似,Google的月搜索量多时可达1 000亿次 [26] .针对持续积累的大数据,集群计算利用冗余局域网络内的大规模计算设备进行感知、获取、管理、处理和服务.
在这种背景下,集群调度包括了对集群内计算资源进行统一抽象、同步计算资源使用情况、管理工作负载中的计算作业、分配各计算作业的计算任务、跟踪任务执行情况等工作.随着数据量持续快速增长,集群调度研究主要面临2方面的挑战:
1) 因集群自身向着更大、更复杂的方向发展带来的调度挑战.主流大数据集群在十数年间从几十台服务器发展到数千台,业内少数集群内已经容纳了数万服务器 [27] .对这些节点上的资源进行统一抽象、管理和同步的系统开销逐渐增大.同时,集群计算设备的差异化也导致集群资源难以得到有效利用.
2) 数据处理方式和需求日益多样、复杂,为工作负载的妥善管理和计算作业的合理分配带来挑战.一方面集群任务吞吐量的上升扩大了调度时需要面对的问题空间,同时增长了需要进行的决策计算和通信频率,使整体负载管理变得困难;另一方面同一集群内并存的大数据计算作业种类增多,不同作业之间的需求冲突以及执行冲突为集群调度带来多方面的难题.
为了应对上述2个挑战,研究者从不同的角度、不同的研究问题入手,改进调度方法,由此也导致了集群调度结构的变化.我们从现有文献中分析得出,与集群调度结构变化有关的主要研究问题如下.
与第1个挑战,即集群硬件环境持续变化相关的主要研究问题包括4个:
1) 可扩展性问题.为了应对快速增长的集群规模和数据规模,避免调度器本身成为瓶颈,并行可扩展性(即去除调度逻辑中的关键路径)成为当前的重要研究问题.该问题又因为集群调度的本身特点区分为2个子问题,即将资源调度过程进行并行可扩展设计以及将任务管理过程进行并行可扩展设计(本文中弱可扩展性指仅具备部分可扩展设计的调度方法).
2) 资源异构性问题.由于集群中计算设备的持续更新、扩容,不同设备处理能力之间的区别在集群中可能存在显著差异.例如CPU主频及缓存差异、内存主频差异等.早期的大数据调度方法中将集群中所有同类型资源都进行统一抽象,并不区分不同的CPU、内存之间的可能区别.随着新旧硬件之间的能力差别增加,集群调度需要识别并考虑资源异构性.
3) 面向多线程的放置优化问题.目前集群的常见服务器配置通常支持至少16并发线程 [28] .虽然单机内各线程可以并行使用CPU资源,但不同线程普遍存在竞争其他资源如硬盘、公用锁等情况.因此提高单机并发度时通常会观测到显著的执行时间变化.解决该问题不仅需要数据计算模型的改进,同时也需要高效的调度方法.
4) 本地性问题.由于网络带宽和存储设备吞吐速率之间的显著差异,不同节点获取集群内同一数据分块或其备份的时间代价显著不同,因此产生了本地性问题.常见的3级网络拓扑的集群逻辑结构中将产生对应的3级本地性,即同机器、同机架或不同机架.不同本地性级别的任务放置选择将导致不同的任务执行时间.
与第2个挑战,即工作负载持续变化相关的主要研究问题包括6个:
1) 作业内任务关联问题.目前的大数据集群中通常运行着大量不同的计算模型.例如 MapReduce [14] ,RDD [15] ,Tenzing [16] ,SparkSQL [17] ,Pregel [19] 等.每一种计算模型中,作业的完成都依赖于作业内部全部计算任务的完成.各计算任务因计算模型差异会存在不同的依赖关系,这种依赖关系需要在调度时进行抽象表达以精确理解作业执行逻辑,因此产生了作业内任务关联问题.
2) 延迟敏感任务问题.在诸多数据处理方式中,交互类作业处理是比较特殊的一类.由于用户持续等待交互类作业处理的结果,因此需要调度器提供对此类延迟敏感作业的支持保证.调度延迟敏感作业有别于调度常见的批处理作业,需要调度器保证其完成时间最短而不是在限定时间或服务等级内完成.
3) 放置约束问题.由于计算模型的不同,大数据集群中的不同计算任务对集群资源的依赖是不一致的.因此部分作业类型可以通过调度获得“更适合”的节点,例如CPU密集型任务和I/O密集型任务分别适合执行与更快速CPU与使用固态硬盘的服务器节点.这类并不必须但推荐被调度于某类节点的需求被称为软约束;与之相对的,硬约束描述部分数据处理作业必须运行于特定类型的计算节点(如作业对GPU计算的需求).由于二者的相似性,本文将其统称为放置约束.
4) 多资源调度问题.正是由于不同计算任务对资源的需求日趋复杂,大数据集群早期对资源进行的单资源类型统一抽象可能降低集群的资源使用效率,因此需要考虑多资源调度优化.
5) 主动资源调整问题.在任务的执行过程中,不仅是不同计算任务之间存在资源需求差异,即使是同一个计算任务,在其自身的完整执行周期中对资源的需求也会发生变化.因此可以考虑主动调整资源分配的方式提高集群资源的整体使用效率.
6) 公平性问题.由于不同的计算任务的提交者可能是来自于不同的人或组织,调度方法需要涉及公平性问题,保证不同提交者对集群的公平使用.
上述10个研究问题涵盖了集群调度研究工作的主要调度考虑.通过分析上述问题可以对调度结构的变化进行描述和解释.当然,调度研究工作还涉及除以上所述研究问题之外的内容,例如定价问题、设备可用性问题、硬件的故障预测等.这些问题由于与调度结构变化的关联较小,不在本文的叙述范围内.
如图1所示,在大数据背景下,集群调度方法已逐渐分为4种结构,即集中、双层、分布式以及混合结构.4类调度结构代表性论文与上述10个重要调度问题如表1所示.具体到每一种结构中的论文与研究问题的对应情况将在各小节分别列出(集中结构、双层结构、分布式结构、混合结构分别见表2~5.所涉研究问题的多寡与论文的学术价值没有严格的对等关系).从表1还可以获得关于4种调度结构的宏观认知:集中结构与双层结构考虑更多的本地性、公平性等全局问题;分布式结构研究考虑了更多的可扩展性以及延迟敏感任务;混合结构研究仍处于结构探索阶段.
Table1 Scheduling Research Concerns Status in Each Scheduling Structure
表1 不同调度结构研究中所针对的调度问题统计

In this table, each integer indicate the amount of publications that consider specific scheduling concern. TP(total number of publication), SC(scalability), LO(locality), FA(fairness), PC(placement constraint), TD(task dependency), LJ(latency-sensitive job), RH(resource heterogeneity), MS(multi-resource scheduling), AA(allocation adjustment), MO(multi-thread optimization).
1) 大数据背景下集中调度结构的产生
在大数据集群发展的初期,由于大数据计算自身处于发展探索阶段,如HoD(Hadoop on demand)环境,使用当时成熟的泛用集群调度方法是最直接且方便的方式.一种典型的方案是组合使用Torque资源管理工具以及Maui或Maob [29] 调度器进行调度.使用这种解决方案的主要目的是以最低的开发代价解决当时的集群资源不足和多用户共享问题.然而,它们的基本工作方式和特点并不符合以MapReduce为主的大数据计算逻辑,产生的问题例如无法处理数据本地性以及过高的调度开销等.
在以上背景下,大数据计算平台开始内置集中结构调度器.最具有代表性的是Hadoop1.X版本使用的集中结构调度器:全部客户的所有作业使用唯一提交入口,未获得执行的作业和任务暂存在队列中;调度器统一收集作业执行、计算节点状态等信息并进行作业状态管理;集群资源的管理和决策也都在同一节点上进行.在该调度结构中,作业决策和资源管理2个部分都不具备并行的可扩展性,只能通过在模块内部增加或修改代码的方式进行调度逻辑的扩展或调整.在集中结构的调度研究中,计算节点的资源通常被统一抽象成固定大小的资源槽(slot).相比HoD环境使用虚拟子集群的方式,资源槽更加细粒度、易操控.大数据环境的另一个主要计算平台,Spark也内置了完全类似Hadoop1.X的集中结构调度器.Hadoop1.X以及Spark都可以根据不同调度侧重地切换可插拔调度策略,例如FIFO,Capacity Schedule [30] ,Fair Scheduler [31] 等.
在当前的大数据计算环境下,Borg调度方法代表了集中调度结构的前沿.谷歌公司目前使用Borg管理大部分核心集群,其覆盖集群规模已经达到10万节点级.Borg改变了许多集中调度结构的基本特性,例如使用资源配给(alloc)取代了普通集中调度结构中的资源槽,使其支持多资源按需分配;采用了集群范围的调度策略管控与评分机制;此外,虽然在单集群上使用集中调度结构,但是Borg可以以集群为单位通过cells并行扩展,从而进行数据中心级的调度.
2) 集中调度结构的相关研究
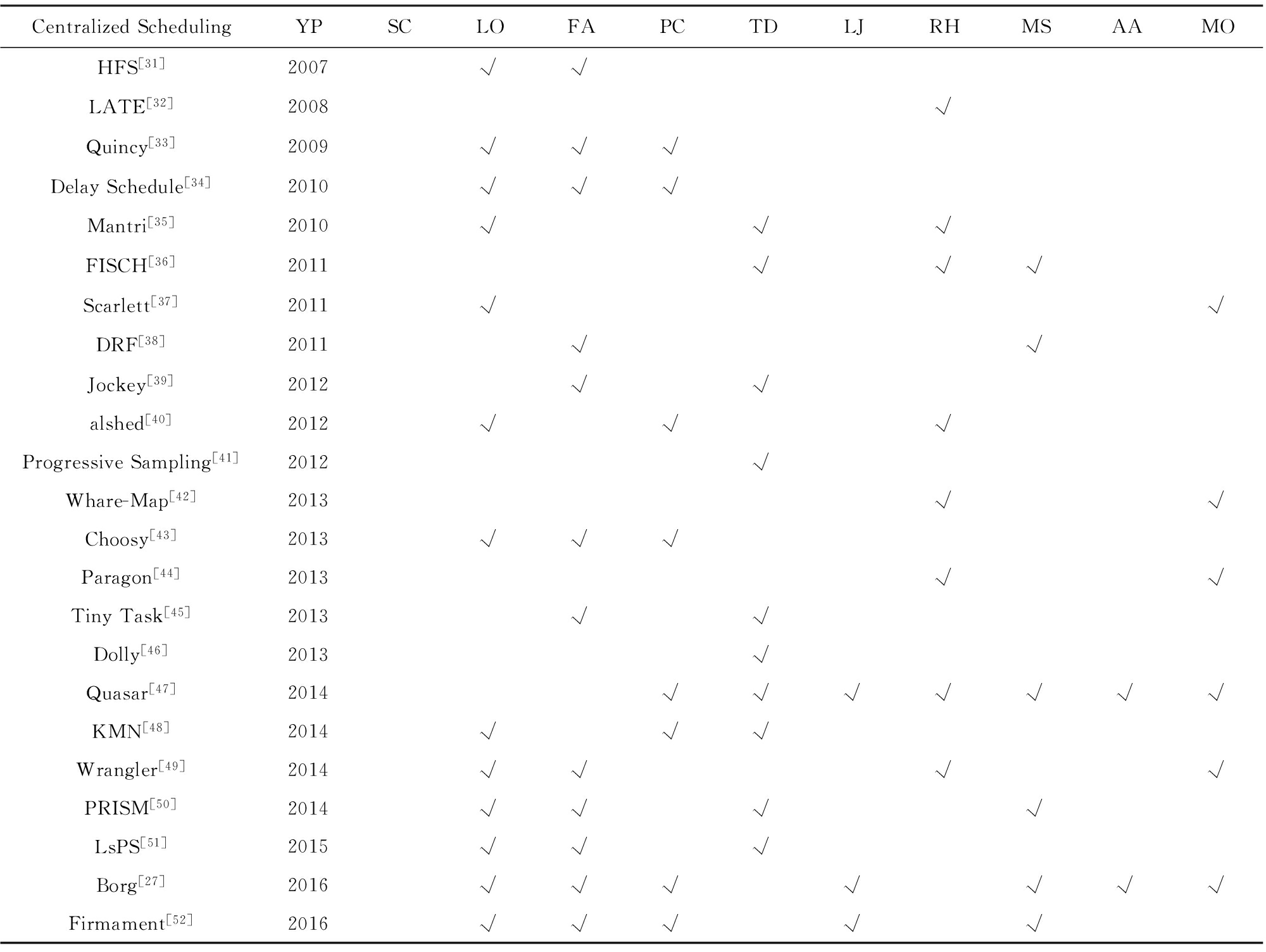
本文将所选的集中调度的代表性研究——对10个研究问题的涉及情况——进行了整理.如表2所示,集中调度适合进行性全局性的调度考量,例如考虑公平性、本地性、任务并行性等.具备完备集群信息的集中调度器可以对集群执行状态进行有效推测,从而提供高精确度的调度方案.
集中调度结构有利于公平性保证.在集中调度结构中,最常见的公平性解决方法是使用传统的Max-Min公平性模型 [53] .它约定了针对某种可以获取的资源类型,不同的用户或作业之间按照各自权重分配资源的方式.Max-Min公平性模型可以很好地用于及中调度结构使用的资源槽.Max-Min公平性模型可以快速有效地工作,但是其自身也有很多局限性.例如,该公平性原则并不考虑各作业的执行目标,如结束时间限制,存在降低集群服务等级的风险.因此,Ghodsi等人 [43] 将Max-Min公平性方法扩展,形式化定义放置约束下的公平性问题并继而给出了近似调度策略以及Choosy调度模块.
集中调度结构中本地性问题的难点在于,本地性需求常常与公平性发生冲突.按照心跳同步分发计算任务的严格公平性策略经常会使计算本地性无法得到保证.使用Max-Min等严格公平策略保证公平性的情况下,集中调度模块每次必须选出低资源占用的作业进行策源分配.而该作业中未必包含了可以获得较好数据本地性的计算任务.因此,强行将资源分配给该用户不仅会导致单个任务执行的延迟,同时也会降低集群资源利用率.针对以上问题,在集中调度结构下产生了多种解决思路.Isard等人 [33] 使用工作流抽象和最优化求解方法解决本地性与公平性冲突,并依此设计了Quincy调度模块.Zaharia等人 [34] 通过略微放松公平性的方法获得本地性该进.其策略被称为“延迟调度”,即如果对某一作业的资源分配过程中可以达到高本地性,则进行资源分配;如果无法达到高本地性,那么就暂时放弃严格公平性.在集中调度结构中,存储策略与调度结合的研究方向也被证明是解决本地性问题的可行思路.Ananthanarayanan等人 [35] 认为大数据集群中本地性问题的关键在于热点数据,因而提出了主动预测数据并发访问量、识别热点文件以及主动备份热点文件的方法.王强等人 [54] 在此基础上提出了以访问频率和文件大小共同作为动态调整备份数量依据的数据放置与任务调度方法,进一步减少作业内的数据传输时间.不同于一般的本地性研究,Ananthanarayanan等人 [55] 对集群计算中的本地性问题提出了前瞻性思考,认为本地性的2个前置条件(磁盘带宽高于网络带宽,磁盘读写时间在任务执行总时长里占据较大比重)的有效性逐渐减弱或消失.
Table 2 Scheduling Research Concerns Status in Centralised Scheduling Structure
表2 调度问题统计 - 所选集中调度研究方法
In this table, check mark “√” indicate the specific concern is discussed in corresponding publication. YP(year of publishment),SC(scalability), LO(locality), FA(fairness), PC(placement constraint), TD(task dependency), LJ(latency-sensitive job), RH(resource heterogeneity), MS(multi-resource scheduling), AA(allocation adjustment), MO(multi-thread optimization).
集中调度结构适合考虑非交互数据处理作业内各任务的依赖关系.作业内各任务之间最基本的一种依赖关系是任务并行性,即单个数据计算作业完成当且仅当其中的所有计算任务全部完成 [35] .任务并行性限制导致任何缓慢任务都会为作业带来延迟.在集中调度结构中缓解该问题的一种方法是主动缩小任务粒度.Ousterhout等人 [45] 提出按照输入数据大小切分任务的方法,通过缩小数据块粒度形成大量同构的子任务.该方法不仅可以缓解因任务并行性引起的额外作业延时,也可以缓解异构负载中长任务阻塞资源队列的问题.Ramakrishnan等人 [41] 则针对MapReduce模型中Reduce关键词计算量不一致导致的并发延迟问题,提出了Reducer关键词切分技术.
在集中调度结构中,通过主动终止并重新调度缓慢任务也可以优化作业内的并发性延迟.这种主动调整方法不可避免地导致任务的重复执行和资源浪费.该类方法通常基于对作业中缓慢任务的精确识别.Hadoop平台 [56] 的调度模块内置了推测任务执行百分比、识别并重启缓慢任务的特性.然而,由于不同类型任务之间可能存在的显著差异 [57] ,基于执行百分比的推测并不精确.Zaharia等人 [32] 认为,面向任务执行剩余时间的推测方式可以有效改进缓慢任务的识别准确度.他们继而提出基于剩余时长的主动识别、终止并重启缓慢任务的方法.Yadwadkar等人 [49] 提出可以通过静态学习的方法在任务决策阶段提前避免缓慢任务.避免缓慢任务的另一个可行研究思路是任务克隆,通过在适当位置启动完全一致的任务备份提高任务按期完成的概率.Ananthanarayanan等人 [46] 提出了针对交互作业的主动任务克隆方法,并指出由于在主流工业负载中交互作业的总资源占用率相对较低,因此该方法的资源占用开销相应对整体系统的影响并不显著.
单个作业内的各个任务除了并行关系之外,还可能包含串行关系,抑或同时存在.Ahmad等人 [58] 针对Shuffle阶段的任务依赖关系进行分析,优化其网络使用、计算位置等调度选择从而减少作业执行总时长.在多种依赖条件同时作用的情况下,估算各个任务的执行情况可以提高作业调度.集中调度结构下最常见的估算方法是建立基于待处理数据大小的线性模型 [59] .李千目等人 [60] 基于这种线性估算模型提出了Max-D调度方法,并根据MapReduce作业中的任务关系对方法进行了进一步优化.Coppa等人 [61] 提出了基于近邻算法和统计曲线拟合的细粒度过程估算方法,改进了线性分析模型的准确度.
由于集中结构可以获取已经到达的所有计算任务信息,因此对工作负载规划的全局规划成为可能.Ferguson等人 [39] 提出静态推测方法帮助调度模块保证作业需求的完成.结合推测正在执行任务状态以及到达作业状态,该方法模拟未来一段时间的集群使用情况进行调度规划.Henzinger等人 [36] 提出了基于抽象精化技术的调度方法,该方法对各个计算作业内部逻辑进行梳理并对系统状态进行抽象、提炼,以此作为调度规划的依据.变动频繁、异构的工作负载中,由于任务类型复杂多样,现有任务的执行状态和即将到来的作业情况都更难预料.然而由于大数据环境的发展,集群中作业保持着复杂和差异化的趋势.Delimitrou等人 [47] 通过侧写分类对不同分类的计算任务进行逻辑隔离,从而减少因为异构性带来的相互影响.Yao等人 [51] 则通过对既往集群运行痕迹的累计和学习攫取可用的模式和调度依据,从而使Hadoop适应不同类型的工作负载.对不同来源作业类型之间的相互影响,Leverich等人 [62] 则提出了不同种类作业之间冲突分析以及混合放置技术.
3) 集中调度结构目前的局限性
2013年Schwarzkopf等人 [22] 认为集中调度结构存在性能瓶颈和软件工程复杂度过高问题,并以此为依据提出了基于共享状态表的调度方法.同年Ousterhout等人 [63] 也描述了集中调度的针对低延迟任务的调度问题.表2印证了集中调度研究对可扩展问题、低延迟调度任务以及早期研究对多资源调度的不足,在本节中分别分析如下:
① 不可扩展问题.集中结构的核心问题是不可扩展,随着集群计算以及集群自身的持续发展,容易导致性能问题以及软件工程问题.在性能方面,由于集中调度器是工作负载和集群资源之间的唯一通路,因此其调度工作量与通信量会随着集群中节点数量增加、单节点能力提升以及工作负载规模增长而变化.调度器本身也部署于集群中的一个节点,其计算能力的提升仅仅依靠单节点计算能力提升.调度器自身处理能力的提升速度与其调度工作量的增长之间不匹配,使调度器本身成为系统的潜在瓶颈,因此集中调度结构能够管理的集群规模一直受到质疑.在软件工程方面,在多个研究工作中,如Schwarzkopf等人 [22] 以及Vavilapalli等人 [64] 都详述了集中调度的软件工程困境,即在同一代码模块中不断整合大量不同作业逻辑导致的高维护、更新开销.直到2016年,在Verma等人 [27] 的研究中验证了通过合理的设计,集中调度结构可以有效管理万规模的集群.这类前沿研究并未消除集中结构造成系统性能和软件工程问题的隐患.由于这些前沿工作大部分闭源,集中结构在此方面的能力和发展还有待检验.
② 缺乏对延迟敏感作业的支持问题.任务敏感作业通常有2个需求,首先需要简单快速地调度逻辑以保证作业可以在最短时间内完成,其次由于当前的工业负载中任务敏感作业通常占负载中的多数,因此造成高吞吐需求 [63] .集中结构由于自身限制难以满足以上2种需求,因而多数集中结构下的研究工作不考虑任务敏感作业,如表2所示.Delimitrou等人 [47] 虽然对延迟敏感任务的调度有所考虑,但是该研究所获得的效果相较Sparrow等分布式调度器而言还有距离.2016年Gog等人 [52] 证明了在中等规模集群内(几百节点)通过集中调度可以获得与Sparrow类似甚至更低的作业延迟.集中结构对任务敏感作业的支持能力有待未来进一步研究.
除上述2个主要问题之外,早期的集中结构调度研究罕有对多资源进行支持.这种问题本身并不是集中调度自身的局限性,而更多的是历史原因.早期的数据处理模型都使用了单类型资源抽象的方法,因此在2013年之前的调度研究普遍继承了这种方式.之后随着双层结构研究的流行,多资源调度成为主流,因此在集中结构研究中也开始考虑多资源调度并引入相关设计.
1) 大数据背景下双层调度结构的产生
以Hadoop1.X为例,集中调度结构中包含的仅仅是对MapReduce模型的支持,而不能支持其他同样有广泛需求的计算方式如BSP,RDD,MPI等.随着大数据计算的不断演化,在同一集群中使用多数据计算模型是必须且急迫的需求.另一方面,集中调度结构中使用的资源槽抽象方法存在使用不灵活的情况.这些问题促生了双层结构的集群调度方法.
Hindman等人 [65] 率先提出了基于双层调度结构的Mesos调度平台.Mesos清楚地将调度结构分为2层,Mesos资源管理层负责集群资源的决策和抽象,并以资源配给为单位分配给各平台;之后由各个平台独立在资源配给范围内进行任务的分配.各平台内原本的调度器实际保留了作业管理职责,可以在获得的配给资源范围内调整任务执行.因为Hadoop,Spark,MPI等计算平台的良好支持,Mesos在一段时间内是多平台环境资源调度的最好选择.Hadoop继而也在其2.0以及以后版本内置了双层调度方法Yarn [64] .虽然Mesos和Yarn的论文都发表于2013年,但是在业界的应用分别始于2011—2012年.2011年前者的项目从闭源变为开源,而后者则开始出现于2012年Hadoop的2.0.0-alpha版本中.
目前双层调度结构因Mesos,Yarn的广泛使用成为了最常见的大数据集群调度结构.与二者相似的,Facebook出于对自身负载规模的考虑以及不满足于Mesos与Yarn的执行效率,提出了双层结构的调度方法Corona [66] .Corona为了改进作业调度延迟,以推送请求的通讯方式替代了常用的心跳汇总方式;因而降低了作业调度的必要延迟但是同时降低了结构自身的可扩展性.
2) 双层调度结构的相关研究
以Yarn和Mesos为代表,双层调度结构的良好兼容性首先体现在持续对更多计算模型的兼容以及对集中调度结构中研究工作的兼容,Mesos目前可以支持的计算模型已经多达几十种,其中大数据处理计算模型包括Dpark,Hadoop,Hama,MPI,Spark,Storm等.
如表3所示,双层结构中的相关研究工作仍然延续了集中结构下对本地型、公平性、放置约束和作业内任务关联这些全局调度考量的关注.集中调度结构中的研究工作基本都可以在双层调度环境下适用.本地性研究的发展如孙瑞琦等人 [74] 提出的基于以及虚拟机在线迁移技术 [75] 以及任务提交时虚拟机能力调整的高数据本地性调度方法.工作负载规划研究的发展如Curino等人 [69] 提出了基于预约的、混合整数线性规划的调度方法,该方法可以根据实际任务执行状态实时调整规划方案.
Table 3 Scheduling Research Concerns Status in Two - layer Scheduling Structure
表3 调度问题统计 - 所选双层调度研究方法

In this table, check mark “√” indicate the specific concern is discussed in corresponding publication. YP(year of publishment),SC(scalability), LO(locality), FA(fairness), PC(placement constraint), TD(task dependency), LJ(latency-sensitive job), RH(resource heterogeneity), MS(multi-resource scheduling), AA(allocation adjustment), MO(multi-thread optimization).
双层结构相关研究工作的最大特点是对多资源调度的考虑.Mesos与Yarn为代表的双层调度结构将资源抽象单位由固定的资源槽改为了灵活的资源组合,因此产生了全新的多资源使用考量.Ghodsi等人 [38] 在Max-Min公平性模型的基础上,提出了保障多资源公平性的DRF(dominant resource fairness)调度模型(该工作的基础是在集中调度结构中完成,继而在双层结构调度器中获得广泛使用).DRF模型引入了占优资源这个概念,并以各任务的占优资源为公平性判断的主要标准,从而在多资源考量的前提下保证公平性.在DRF调度模型的基础上,Bhattacharya等人 [76] 完成了针对分层调度框架的多资源公平性方法.Wang等人 [67] 扩展了DRF模型对异构集群的支持,提出DRF-H模型.DRF-H模型展开了DRF模型中关于计算集群环境的讨论,将多资源公平性模型由同构集群假设扩展到了异构集群假设.由于资源分配时只考虑占有资源这单一维度,因此DRF模型和DRF-H模型都很容易因资源碎块化导致整体集群资源利用率较低.针对这一问题,王金海等人 [77] 定义并使用占优熵以及占优资源权重,进而提出了基于占优资源的多资源联合公平分配算法,有效提升了集群整体资源利用率.
3) 双层调度结构目前的局限性
由于双层调度结构的核心资源调度逻辑仍然依赖不可扩展的调度模块完成,在保留了集中调度结构一些缺点的同时,也引入了新的局限性,其主要的问题如下:
①弱可扩展性问题.双层调度的资源分配模块本身仍然是可能的系统瓶颈.尤其是在近几年随着小规模、高吞吐的交互作业(例如交互查询)的发展,负责进行资源分配的线程容易被超载.同时,集群内资源状态同步仍然可能成为调度瓶颈.由于采用了可并行扩展的任务管理方式,双层结构的可扩展性要好于集中结构.随着近期集中结构对大规模集群万量级集群的调度成果 [27] ,双层调度在大规模集群下的潜在性能问题可能会进一步得到改善.
②任务敏感作业处理问题.与集中结构的局限性类似,虽然分散的作业管理逻辑简化了调度流程,但是集中的资源管理仍然不利于任务敏感作业的处理.
③资源异构性问题.相对于集中结构,双层结构中对资源异构性问题(同种资源之间的差异)的考虑显著减少,如表3所示.根据Ousterhout等人 [78] 的研究,考虑多资源时不同资源的利用率和分配对集群调度的影响是不同的,而CPU是影响最大的因素.因而多资源的异构与单资源不同不能仅考虑能力差异,还需考虑其对不同作业的影响程度等因素.相比而言,在集中结构中考虑单资源调度的资源异构性更容易,只需要考虑单一种类的资源执行能力差异.
1) 大数据背景下分布式调度结构的产生
由于集中调度结构和双层调度结构都使用了不可扩展的集群资源分配模块,因此二者公有了相关设计局限,如3.2节所述.主要体现在作业延迟和可扩展性2个方面.
具体来说,随着大数据环境的发展,交互作业类型日趋繁杂,来自Dremel,Spark,Impala等模型的交互作业已经成为了数据计算集群的重要组成部分,并开始在部分大数据集群中占据过半的作业总数 [79] .同时,交互作业的执行时长开始降至百微秒级或更小,因而需要相应的远低于普通批处理作业所需的调度延迟 [63] .由于这些作业的交互属性,提供更低延迟会直接提升集群使用者的满意度,并且可以衍生全新的数据使用模式.然而,集中调度结构以及双层结构的作业响应时间难以满足这种需求:由于使用了不可扩展的集群资源分配模块,调度决策的依次处理和计算资源信息的统一同步都为作业调度延迟设定了较高下限.此外,随着集群规模的扩大以及运行任务的增加,在集中的资源分配模块中可能出现调度线程自身满载的情况.
以资源同步过程为例,集中调度结构和双层结构中最常见的心跳同步机制会为作业增加基本延迟时间,因此为了降低延迟,必须增加各节点心跳频率.然而增加心跳频率会提高资源分配模块的同步开销,造成系统瓶颈,尤其是在当前的千数量级节点的大规模集群环境下.同理,不采用心跳同步而主动获取资源状态的方式 [66] 则会引发更严重的调度瓶颈问题.在以上背景下,研究者开始探寻使用可并行扩展的集群资源分配模块的可能性.
Schwarzkopf等人 [22] 实现了使用共享状态表方法的分布式集群调度器Omega.共享状态表方法的核心是使用多个独立的调度器,其中每个都拥完整的作业管理、资源分配模块以及对整个集群所有资源的使用权限.虽然调度器相互独立,但是调度决策时使用的集群资源信息由统一的共享状态表获取.状态表模块负责同步集群计算资源信息并向各个调度器进行定期推送,因此调度器决策过程中使用的集群状态信息是不完全实时的.
Ousterhout [63] 等人依据“The Power of Two”原则 [80] 设计了取样集群调度器Sparrow,并验证了取样方法在面对次秒级交互任务的有效性.与共享状态表相同,取样调度同样可以使用多个同构且独立运行的调度器.不同的是,取样方法将资源状态收集也交由各个调度器分别进行,意味着取样调度方法中不再有任何的逻辑关键路径.如图2所示.每次决策过程中,调度器都要先从集群中取样选取固定数量的工作节者点.该次调度分配的资源必须从所选节点中获取;若所选节点中可用资源不足,则需要将任务安排至工作者队列中.为负载均衡考虑,每次决策时都要重新取样获得新的工作节点.Sparrow面向以Spark为主的快速数据计算环境,并已经在Spark上衍生出可用的Sparrow分支版本.
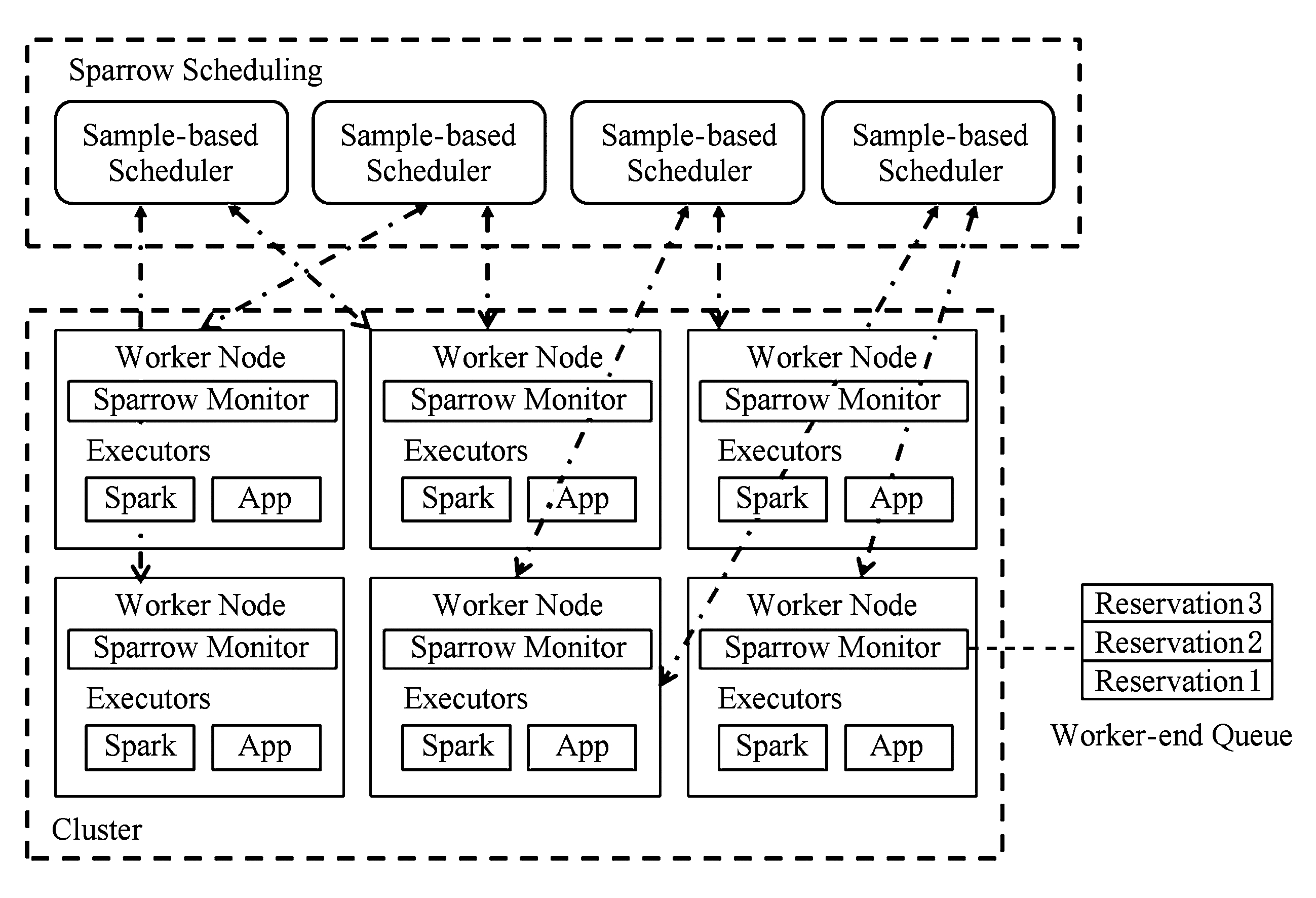
Fig. 2 Demonstration of Sparrow scheduling process
图2 Sparrow调度方法示意
2) 分布式调度结构的研究特点
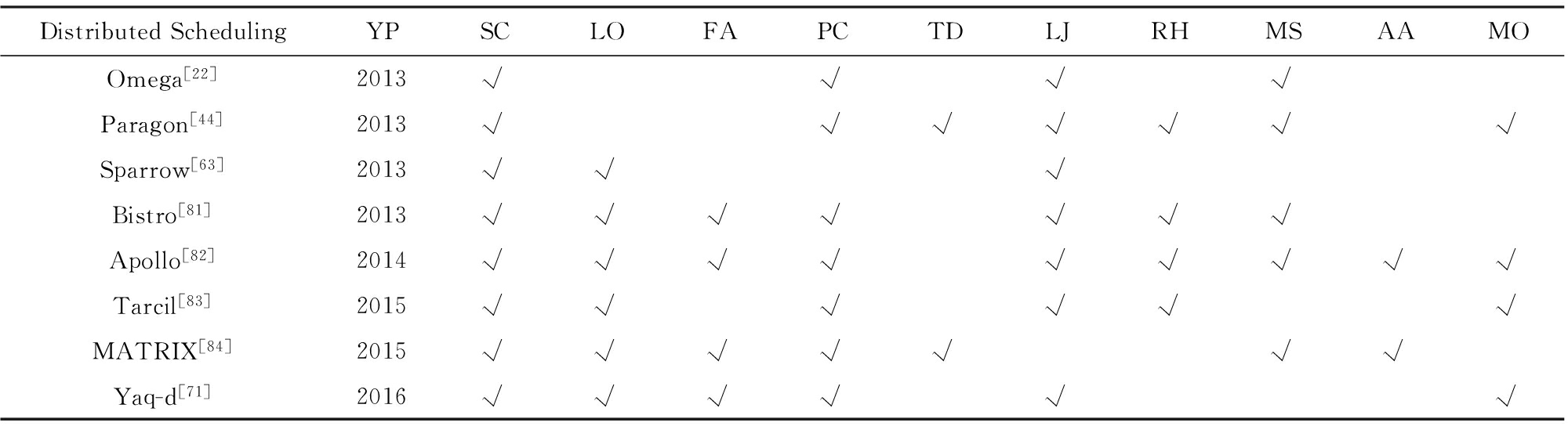
如表4所示,分布式调度研究的基本特点之一就是其普遍的可扩展性.比较特殊的是,共享状态表方法(表4中Omega以及Apollo)由于唯一状态表模块的存在限制了该方法的可扩展性,因此严格意义上来说是介于分布式调度方法和混合调度方法之间的调度结构.采样方法则是充分体现了分布式调度结构的高可扩展性特点.在采样方法的基础上也可以添加额外的全局控制模块 [81] ,从而以可扩展性为代价改进调度准确性.由于高可扩展性,当多个分布式调度器同时运行于系统中时,其中任意一个调度器的失效并不会影响系统整体的可用性.集群不需要如集中调度结构或双层调度结构一样启用备用节点,而是仅需将失效节点的负载在其它调度器接入即可.因此分布式调度结构在具有高可扩展性同时也带来了良好的可用性收益.
Table 4 Scheduling Research Concerns Status in Distributed Scheduling Structure
表4 调度问题统计 - 所选分布式调度研究方法
In this table, check mark “√” indicate the specific concern is discussed in corresponding publication. YP(year of publishment),SC(scalability), LO(locality), FA(fairness), PC(placement constraint), TD(task dependency), LJ(latency-sensitive job), RH(resource heterogeneity), MS(multi-resource scheduling), AA(allocation adjustment), MO(multi-thread optimization).
分布式调度结构具有低调度延迟的特点.取样方法和状态表方法都可以为次秒级作业提供低至十毫秒级的调度延迟.在共享状态表方法中,各个调度器随时具有全部集群资源的状态表,因此调度决策时并不需要进行单独的资源状态同步.这种方法有效地降低了调度延迟.在高负载集群中,资源状态表的非实时性可能引发决策冲突,带来额外的调度延迟.Schwarzkopf等人 [22] 指出在谷歌生产环境中,这种冲突的处理代价在可接受的范围内.而Boutin等人 [82] 则通过调度器间的同步协调算法以及工作者端任务队列的使用减少冲突发生,进一步改善作业延迟.取样方法中,由于每次调度仅需要取样几个节点,且调度决策也只考虑这几个节点的资源状态,因此具备低通信开销和本地计算开销.Sparrow方法中作业延迟受次优决策问题 [85] 影响.Delimitrou等人 [83] 通过2个技术减少取样过程的次优决策的产生:1)通过动态调整取样大小,主动保证每次取样中包含所需资源的概率;2)在难以获得理想取样结果时对任务采取准入控制.
相较于集中和双层调度结构,分布式结构中部分设计元素发生了显著改变.最有代表性的是队列变化,集中和双层调度的队列设计是在调度器端,而分布式调度设计中开始使用工作者端队列.这种变化的原因是,当使用调度器端队列时,无法立即在工作者节点获得资源的任务必须退回到调度器进行队列或重新调度,造成额外的延迟和通讯开销.Rasley等人 [71] 指出工作节点队列的使用有准确度不高的局限性,且会将任务置入相对难以预测的执行状态.他们针对工作者队列进行详细分析、讨论,提出了工作者端队列的优先级设计以及工作者与调度器队列的平衡算法.
3) 分布式调度结构目前的局限性
在目前的集群调度研究领域,分布式调度结构仍然处于探索和发展的状态.伴随着这种结构突出的优点,其自身的局限性也非常明显,主要包括但不限于:
① 适用性问题.由于缺少集中调度模块,分布式方法缺乏对作业和资源的全局控制.因此,不同的分布式调度方法或多或少地对调度问题进行了简化折中.例如在共享状态表方法中的乐观冲突控制 [22] ,即是以默认接受冲突和无效调度为基础的折中.取样方法则更为明显,在目前的取样方法中,仍只能采用单资源调度以保证取样的准确性 [83] .
② 全局调度考量问题.各自独立的调度器设计使全局调度考量变得困难.例如取样方法处理本地性必须直接选取高本地性节点进行调度,因而严重破坏了由取样随机性带来的负载均衡;而公平性、优先级等调度考量则需要在工作者队列中以局部调整的方式进行.类似地,共享状态表方法虽然表面上可以通过抢占配合状态表进行全局考量,但因此也会进一步加剧任务的失败和重调度概率.
③ 兼容性问题.除以上局限性问题之外,兼容性是分布式调度目前不能得到广泛推广而主要适用于特定集群的重要原因之一.分布式调度结构不能直接继承或者迁移使用集中结构或双层结构的大多数研究成果,其原因是后者通常假设全局资源信息是天然具备的、且并不考虑不同调度器之间的资源分配冲突.更为重要的是,分布式调度结构的部署意味着整体大数据集群系统的改变,包括数据处理代码的重写.而它不擅于进行全局考量的天然缺点又限制了大数据集群对该调度结构的需求,因此目前仅见于部分特别需求的大数据集群环境中.
1) 大数据背景下混合调度结构的产生
混合调度结构代表了在同一个集群调度方法中部署不同类型的集群资源分配模块;使用不可扩展的集中资源分配模块进行高准确度全局调度的同时,使用可扩展的资源分配模块进行低延迟调度.混合调度结构是目前集群调度的前沿探索,旨在寻找最适合未来复杂集群环境的调度结构.相关工作主要出现在2014年之后,目前在实际集群中部署运行较罕见,对该结构的研究探索仍处于起步阶段.混合结构的诞生基于研究者对未来大数据集群工作负载的预期,即一定是交互与非交互作业混杂的.交互作业需要最小化调度延迟而非交互作业需要精确资源放置,这种场景通过其他调度结构不易处理.如3.3节所述,分布式调度结构具备不可替代的低延迟以及高可扩展优势.然而分布式调度由于缺乏全局控制机制也难以应对需要特殊调度需求以及高调度准确度的场景.分布式调度结构的低延迟特性主要归功于其各自独立工作且可并行扩展的资源分配模块.虽然在这些模块之间建立协同机制可以帮助提高分布式调度结构的准确度,但同时也会增加其决策成本.
目前研究者认为集中调度结构或双层调度结构中的统一资源分配模块与分布式调度结构中的可扩展资源分配模块可以互补,通过二者的混合工作同时满足不同类型作业执行的需求,即可以同时提供高准确度和低延迟调度.
Karanasos等人 [86] 组合了Yarn的双层调度结构以及通过协调器关联的分布式调度结构,提出混合结构调度器Mercury.如图3所示,Mercury通过对计算任务的再封装以及调度逻辑区分,为系统提供了相互独立的二元调度策略.使用者可以通过开发接口切换调度逻辑路径,从而侧重任务调度的实时性或精确性.在该方法中,分布式调度的协调器辅助集中调度模块工作,确保实现全局调度考量.实际工作时,使用Mercury分布式调度模块可以根据协调器提供的弱化集群负载信息进行快速决策;使用集中调度模块则需要与Yarn相同进行资源需求审批以及分配的过程.
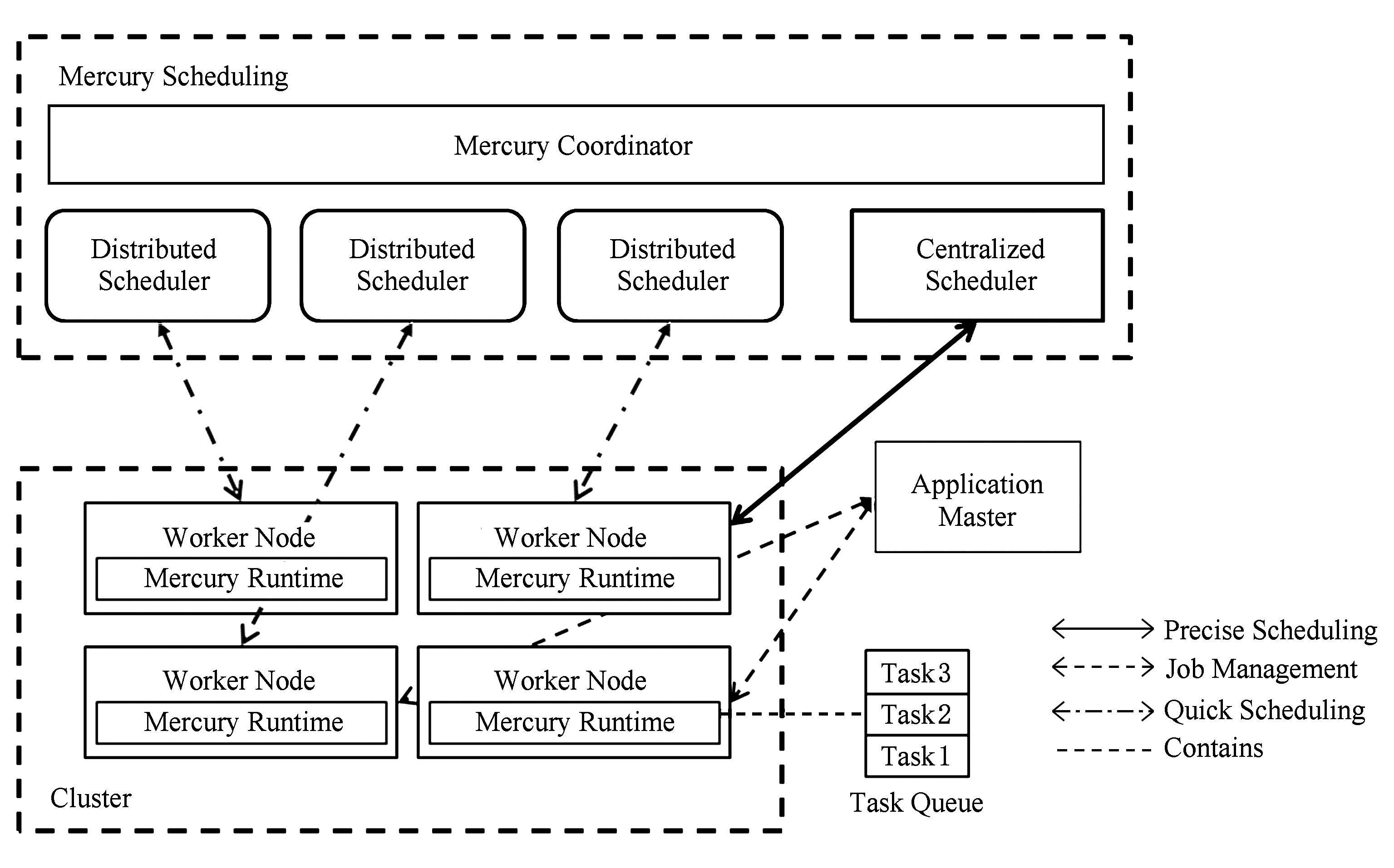
Fig. 3 Demonstration of Mercury scheduling process
图3 Mercury调度方法示意
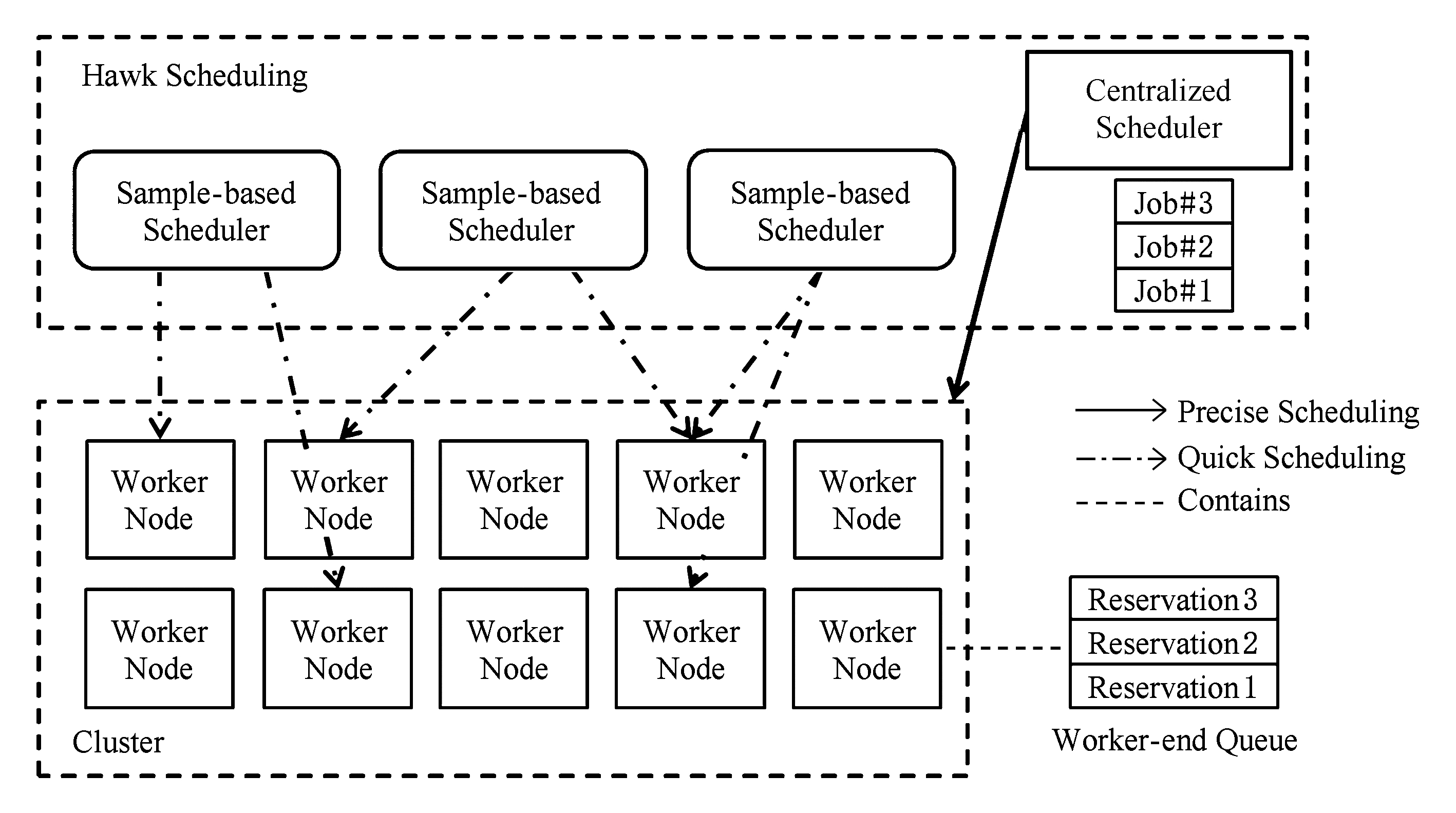
Fig. 4 Demonstration of Hawk scheduling process
图4 Hawk调度方法示意
Delgado等人 [87] 通过整合集中调度和取样调度形成混合结构调度方法Hawk,如图4所示.与Mercury不同的是,Hawk方法中并没有协同控制器的存在,该调度方法中分成了独立运行的多个取样调度器以及唯一的集中调度器,每个调度器都包含了作业管理以及资源分配模块的职能.集中调度器与Spark的集中调度方法一致,使用心跳同步触发调度过程并维护调度器端优先级队列.而取样调取器则与Sparrow一致,调度过程由作业到达触发并维持工作者端队列.在该研究中同时提出了取样偷取技术改进取样调度的次优决策问题.
混合结构目前的代表性工作较少,如表5所示.混合调度为延迟敏感任务提供的执行支持不仅仅是通过优先级以及抢占获得的,而是通过2种不同调度器协作达到的执行效率提升.混合结构的调度仍处于前瞻性研究阶段,因此目前的研究工作主要考虑延迟敏感任务与传统任务并存的问题.
Table 5 Scheduling Research Concerns Status in Hybrid Scheduling Structure
表5 调度问题统计 - 所选混合调度研究方法

In this table, check mark indicate the specific concern is discussed in corresponding publication. YP(year of publishment),SC(scalability), LO(locality), FA(fairness), PC(placement constraint), TD(task dependency), LJ(latency-sensitive job), RH(resource heterogeneity), MS(multi-resource scheduling), AA(allocation adjustment), MO(multi-thread optimization).
混合调度结构理论上可以兼具集中结构和分布式结构的优点.该结构的可扩展性取决于集中调度器的使用频率和使用方式.2种调度器协同工作时,混合结构的可扩展性介于集中结构和分布式结构之间,受限于集中调度器的使用频率和决策逻辑;完全运行交互作业时,所有作业都通过分布式调度器提交,混合调度结构的调度方法等同于分布式结构,具备良好的可扩展性;当所有作业都不通过分布式调度器提交时,混合调去结构等同于集中(或双层)调度结构.同时以集中调度器作为中心,全局资源信息可以向分布式调度器进行广播,以便于提高调度精确度.Delgado等人 [88] 提出了通过集中调度器向分布式调度器主动推送延迟任务信息以改进分布式调度延迟的方法.
混合结构使用了不可扩展的资源分配模块,在集中调度结构或双层调度结构下的研究成果和代码大多可以被很好地兼容并方便地迁移.同时,分布式调度研究中产生的研究结果和代码也可以直接套用到相应的混合结构中.例如Hawk中的资源分配模块由于使用了取样方法,可以方便地继承Sparrow中的所有优化机制.
2) 混合调度结构目前的局限性
作为目前对于调度结构的前沿探索,混合结构调度的研究工作仍然处于初期的阶段.它在理论上能够带来对于工业负载中复杂任务的支持,也兼具了分布式结构的可扩展特点.但是,仅从目前的研究来看该结构仍有比较强的局限性.
① 结构复杂度问题.复杂的结构带来了更高的维持成本,混合调度结构需要支付两套调度系统的正常运行开销.同时,充分使用混合调度结构必须有效使用其2个资源调度部分,因此使用者必须经历新的学习过程以及相关的代码重写.
② 资源分配冲突问题.使用分布式的资源分配逻辑本身会引起冲突,在此基础上引入集中资源分配逻辑将会使冲突加剧.在现有的设计中集中模块都负责调度优先级较低的批处理任务,该部分任务在调度冲突时会被终止 [86] .引入集中资源分配模块的目标是高准确性,因此需要实时获知正确的集群计算资源状态.然而分布式调度模块面向高吞吐的交互作业,其更为频繁的资源分配很容易抢占集中资源分配的目标计算资源.而提高集中调度的资源状态同步频率虽然可以缓解上述冲突,但会严重增加调度的必要开销.因此混合调度结构目前可能在某些实验条件下会有很好的执行结果,但是其实际生产过程中的适用性仍有待后续发展和检验.
当前集群调度结构研究仍然处于起步阶段,新思路、新方法、新技术不断涌现,各类调度结构的研究内容、特性以及局限性都在变化之中.因此,哪种调度结构最能应对未来集群中大数据挑战远无定论.
本文尝试从3方面对集群调度结构未来的研究发展方向进行阐述:1)从文献统计分析的角度总结各种调度结构关注的热点问题;2)通过著名研究团队的前沿研究工作分析各种调度结构的发展趋势;3)根据我们研究团队对集群调度的理解,对未来发展方向提出粗浅看法.
从文献统计的角度看:在有关集中调度结构的研究成果中,讨论本地性和公平性文献超过50%,从2014年,关注延迟敏感任务和多资源调度的文献从无到有,分别达到43%和50%,如表2所示.因此,公平性、本地性、多资源调度和延迟敏感任务是其优先考虑的研究问题.在双层调度结构研究成果中,本地性、公平性、放置约束、作业内任务关联以及多资源调度5个问题的文章都超过了50%,如表3所示.因此,上述5个问题是双层结构调度研究优先考虑的问题.在分布式调度研究成果中,除作业内任务关联与主动资源调整问题之外,其余研究问题的文献都超过了50%,如表4所示.因此,未来的分布式调度研究需要考虑全面,讨论尽量多的研究问题.目前,有关混合结构现有文献较少,如表5所示,且对除延迟敏感作业与可扩展性之外的问题讨论不多.由此可知该方向尚处于起步阶段,短期内的研究仍会以结构性探索为主.
从著名研究团队的前沿研究工作看:对于集中调度结构,谷歌和剑桥前沿研究工作 [27,52] 打破了研究者对集中调度的固有认知,展示出集中结构对当前以及未来大规模集群的调度能力和对延迟敏感作业的初步支撑能力.这2个方向可能是未来的研究热点.同时考虑到这2部分研究目前是闭源状态,将它们进行开源实现也具有重要意义.对于双层调度结构,近几年开源项目Mesos开始选择与Yarn差异化设计,逐渐支持跨平台资源整合.此类双层结构未来可以很好地适用于集群衍生的一些计算场景,例如最近兴起的雾计算 [89] 研究.对于分布式调度结构,来自微软和斯坦福的最新研究成果表明 [82-83] ,共享状态表方法的并发冲突问题和取样方法的精确度问题具有较大的应用潜力与研究价值.除上述2方向外,本文认为研究者可以尝试将其他研究方向中已经得到验证的协作机制,例如耳语机制 [90] 引入分布式调度研究,从而使各独立调度器更高效地协同工作.最后,由于混合结构的研究较少,尚处于起步阶段,已在前文进行了分析,在此不再赘述.
从我们研究团队的理解看:集群计算环境的整体改变(包括集群自身变化与新型工作负载出现)通常是引起集群调度结构不断演化的主要原因.我们认为机架级计算(rack-scale computing)在未来将取代现有的集群计算结构(这同时也是微软、英特尔等企业对集群计算共有的愿景),即机架逐渐变成集群拓扑结构中的最下层 [91] .整合单机架内资源,从软、硬件角度抛弃传统的服务器单位.从目前诞生的具备机架级计算特质的原型 [92-93] 中可以预见,机架计算对集群调度的影响将是颠覆性的,新的方法甚至新的调度结构也许会在该场景中产生.对当前的普通集群调度研究者而言,机架级大数据集群的调度方法是相对空白但前景光明的研究领域;英特尔公司也已经提供了开源的机架级资源整合工具 [94] ,使用者可以通过该工具在传统集群上模拟机架计算,提前实现和验证在该场景下的调度方法与结构设想.
大数据背景下的调度问题一直是集群计算中的热点研究问题.目前国际上有多个在持续进行相关研究工作的高水平研究机构,不仅包括谷歌、微软、Hotonworks,Facebook等大数据领域的领军企业,还包括例如加州大学伯克利分校的NetSys实验室 [95] 、剑桥大学计算机系的系统研究组 [96] 等高校研究小组.他们各自有出色且成体系的调度研究工作,保证了该研究方向持续的业界发展和学术活力.也正因如此,在集群环境快速变化的今天,产生出了优劣各异的调度结构以及多样的调度方法.相较于美国、欧洲而言,我国在该方向的调度研究处于相对较弱的阶段.虽然不乏杰出的研究者从事相关工作,但是相对于我国大数据行业的整体体量来说研究成果仍然较少.希望本文能为从事该方向研究的人员提供有益的参考.
参考文献
[1] Fuchel K, Heller S. Consideration in the design of a multiple computer system with extended core storage[C] //Proc of the 1st ACM Symp on Operating System Principles. New York: ACM, 1967: 17.11-17.13
[2] Wulf W, Cohen E, Corwin W, et al. Hydra: The kernel of a multiprocessor operating system[J]. Communications of the ACM, 1974, 17(6): 337-345
[3] Ousterhout J K, Scelza D A, Sindhu P S. Medusa: An experiment in distributed operating system structure[J]. Communications of the ACM, 1980, 23(2): 92-105
[4] Rashid R F, Robertson G G. Accent: A communication oriented network operating system kernel[J]. ACM Sigops Operating Systems Review, 1981, 15(5): 64-75
[5] Dong Fangpeng, Gong Yili, Li Wei, et al. Research on resource discovery mechanisms in grids[J]. Journal of Computer Research and Development, 2003, 40(12): 1749-1755 (in Chinese)
(董方鹏, 龚奕利, 李伟, 等. 网格环境中资源发现机制的研究[J]. 计算机研究与发展, 2003, 40(12): 1749-1755)
[6] Hovestadt M, Kao O, Keller A, et al. Scheduling in HPC resource management systems: Queuing vs Planning[J]. Genetica, 2003, 112-113(1): 445-461
[7] Wang Yuanzhuo, Jin Xiaolong, Cheng Xueqi. Network big data: Present and future[J]. Chinese Journal of Computers, 2013, 36(6): 1125-1138 (in Chinese)
(王元卓, 靳小龙, 程学旗. 网络大数据: 现状与展望[J]. 计算机学报, 2013, 36(6): 1125-1138)
[8] China Computer Federation. CCF Publication Ranking[OL]. [2016-07-20]. http://www.ccf.org.cn/sites/ccf/biaodan.jsp?contentId=2567518742937
[9] Computing Research and Education. Core Conf Ranking[OL]. [2016-07-20]. http://portal.core.edu.au/conf-ranks/
[10] Mishra M K, Patel Y S, Rout Y, et al. A survey on scheduling heuristics in grid computing environment[J]. International Journal of Modern Education and Computer Science, 2014, 6(10): 57-77
[11] Qureshi M B, Dehnavi M M, Min-Allah N, et al. Survey on grid resource allocation mechanisms[J]. Journal of Grid Computing, 2014, 12(2): 399-441
[12] Bala A, Chana I. A survey of various workflow scheduling algorithms in cloud environment[C] //Proc of the 2nd National Conf on Information and Communication Technology. Piscataway, NJ: IEEE, 2011: 26-30
[13] Chen Kang, Zheng Weimin. Cloud computing: System instances and current research[J]. Journal of Software, 2009, 20(5): 1337-1348 (in Chinese)
(陈康, 郑纬民. 云计算: 系统实例与研究现状[J]. 软件学报, 2009, 20(5): 1337-1348)
[14] Dean J, Ghemawat S. MapReduce: Simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107-113
[15] Zaharia M, Chowdhury M, Das T, et al. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing[C] //Proc of the 9th USENIX Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2012: 2-14
[16] Chattopadhyay B, Lin L, Liu W, et al. Tenzing a SQL implementation on the MapReduce framework[C] //Proc of the 37th Int Conf on Very Large Data Base. Berlin: Springer, 2011: 23-33
[17] Armbrust M, Xin R S, Lian C, et al. SparkSQL: Relational data processing in Spark[C] //Proc of the 2015 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2015: 1383-1394
[18] Thusoo A, Sarma J S, Jain N, et al. Hive: A warehousing solution over a Map-Reduce framework[J]. The VLDB Endowment, 2009, 2(2): 1626-1629
[19] Malewicz G, Austern M H, Bik A J, et al. Pregel: A system for large-scale graph processing[C] //Proc of the 2010 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2010: 135-146
[20] Curtiss M, Becker I, Bosman T, et al. Unicorn: A system for searching the social graph[J]. Proceedings of the VLDB Endowment, 2013, 6(11): 1150-1161
[21] Hussain H, Malik S U R, Hameed A, et al. A survey on resource allocation in high performance distributed computing systems[J]. Parallel Computing, 2013, 39(11): 709-736
[22] Schwarzkopf M, Konwinski A, Abd-El-Malek M, et al. Omega: Flexible, scalable schedulers for large compute clusters[C] //Proc of the 8th ACM European Conf on Computer Systems. New York: ACM, 2013: 351-364
[23] Valentini G L, Lassonde W, Khan S U, et al. An overview of energy efficiency techniques in cluster computing systems[J]. Cluster Computing, 2013, 16(1): 3-15
[24] EMC Corporation. The digital universe of opportunities: Rich data and the increasing value of the Internet of things[OL]. [2016-12-02]. https://www.emc.com/leadership/digital-universe/2014iview/executive-summary.htm
[25] Facebook Corporation. The top 20 valuable Facebook statistics[OL]. [2016-12-21]. https://zephoria.com/top-15-valuable-facebook-statistics/
[26] Google Corporation. 2013 Founders’ Letter[OL]. [2016-09-18]. http://investor.google.com/corporate/2013/founders-letter.html
[27] Verma A, Pedrosa L, Korupolu M, et al. Large-scale cluster management at Google with Borg[C] //Proc of the 10th ACM European Conf on Computer Systems. New York: ACM, 2015: 18-34
[28] Amazon Corperation. EC2 Service[OL]. [2017-01-20]. https://aws.amazon.com/ec2/
[29] Maob. HPC Suite[OL]. [2016-08-12]. http://www.adaptive computing.com/products/hpc-products/moab-hpc-basic-edition/
[30] Hadoop Project. Capacity Scheduler[OL]. [2017-01-19]. https://hadoop.apache.org/docs/r1.2.1/capacity_scheduler.html
[31] Hadoop Project. Fair Scheduler[OL]. [2017-01-19]. https://hadoop.apache.org/docs/r1.2.1/fair_scheduler.html
[32] Zaharia M, Konwinski A, Joseph A D, et al. Improving MapReduce performance in heterogeneous environments[C] //Proc of the 8th USENIX Symp on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2008: 29-42
[33] Isard M, Prabhakaran V, Currey J, et al. Quincy: Fair scheduling for distributed computing clusters[C] //Proc of the 22nd ACM Symp on Operating Systems Principles. New York: ACM, 2009: 261-276
[34] Zaharia M, Borthakur D, Sen Sarma J, et al. Delay scheduling: A simple technique for achieving locality and fairness in cluster scheduling[C] //Proc of the 5th ACM European Conf on Computer Systems. New York: ACM, 2010: 265-278
[35] Ananthanarayanan G, Kandula S, Greenberg A G, et al. Reining in the outliers in Map-Reduce custers using Mantri[C] //Proc of the 9th USENIX Symp on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2010: 24-35
[36] Henzinger T A, Singh V, Wies T, et al. Scheduling large jobs by abstraction refinement[C] //Proc of the 6th ACM European Conf on Computer Systems. New York: ACM, 2011: 329-342
[37] Ananthanarayanan G, Agarwal S, Kandula S, et al. Scarlett: Coping with skewed content popularity in MapReduce clusters[C] //Proc of the 6th ACM European Conf on Computer Systems. New York: ACM, 2011: 287-300
[38] Ghodsi A, Zaharia M, Hindman B, et al. Dominant resource fairness: Fair allocation of multiple resource types[C] //Proc of the 8th USENIX Symp on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2011: 24-34
[39] Ferguson A D, Bodik P, Kandula S, et al. Jockey: Guaranteed job latency in data parallel clusters[C] //Proc of the 7th ACM European Conf on Computer Systems. New York: ACM, 2012: 99-112
[40] Tumanov A, Cipar J, Ganger G R, et al. Alsched: Algebraic scheduling of mixed workloads in heterogeneous clouds[C] //Proc of the 3rd ACM Symp on Cloud Computing. New York: ACM, 2012: 1-7
[41] Ramakrishnan S R, Swart G, Urmanov A. Balancing reducer skew in MapReduce workloads using progressive sampling[C] //Proc of the 3rd ACM Symp on Cloud Computing. New York: ACM, 2012: 16-29
[42] Mars J, Tang Liu. Whare-map: Heterogeneity in homogeneous warehouse-scale computers[C] //Proc of ACM SIGARCH Computer Architecture News. New York: ACM, 2013: 619-630
[43] Ghodsi A, Zaharia M, Shenker S, et al. Choosy: Max-min fair sharing for datacenter jobs with constraints[C] //Proc of the 8th ACM European Conf on Computer Systems. New York: ACM, 2013: 365-378
[44] Delimitrou C. Kozyrakis C. Qos-aware scheduling in heterogeneous datacenters with paragon[J]. ACM Trans on Computer Systems, 2013, 31(4): 12-25
[45] Ousterhout K, Panda A, Rosen J, et al. The case for tiny tasks in compute clusters[C] //Proc of the 14th Workshop on Hot Topics in Operating Systems. Berkeley, CA: USENIX Association, 2013: 12-18
[46] Ananthanarayanan G, Ghodsi A, Shenker S, et al. Effective straggler mitigation: Attack of the clones[C] //Proc of the 10th USENIX Symp on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2013: 185-198
[47] Delimitrou C, Kozyrakis C. Quasar: Resource-efficient and QoS-aware cluster management[C] //Proc of the 19th ACM Int Conf on Architectural Support for Programming Languages and Operating Systems. New York: ACM, 2014: 127-144
[48] Venkataraman S, Panda A, Ananthanarayanan G, et al. The power of choice in data-aware cluster scheduling[C] //Proc of the 11th USENIX Symp on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2014: 301-316
[49] Yadwadkar N J, Ananthanarayanan G, Katz R. Wrangler: Predictable and faster jobs using fewer resources[C] //Proc of the 5th ACM Symp on Cloud Computing. New York: ACM, 2014: 1-14
[50] Zhang Qi, Zhani M F, Yang Yuke, et al. PRISM: Fine-grained resource-aware scheduling for MapReduce[J]. IEEE Trans on Cloud Computing, 2015, 3(2): 182-194
[51] Yao Yi, Tai Jianzhe, Sheng Bo, et al. LsPS: A job size-based scheduler for efficient task assignments in Hadoop[J]. IEEE Trans on Cloud Computing, 2015, 3(4): 411-424
[52] Gog I, Schwarzkopf M, Gleave A, et al. Firmament: Fast, centralized cluster scheduling at scale[C] //Proc of the 12th USENIX Symp on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2016: 99-115
[53] Hahne E L. Round-robin scheduling for max-min fairness in data networks[J]. IEEE Journal on Selected Areas in Communications, 1991, 9(7): 1024-1039
[54] Wang Qiang, Li Xiongfei, Wang Jing. A data placement and task scheduling algorithm in cloud computing[J]. Journal of Computer Research and Development, 2014, 51(11): 2416-2426 (in Chinese)
(王强, 李雄飞, 王婧. 云计算中的数据放置与任务调度算法[J]. 计算机研究与发展, 2014, 51(11): 2416-2426)
[55] Ananthanarayanan G, Ghodsi A, Shenker S, et al. Disk-locality in datacenter computing considered irrelevant[C] //Proc of the 13th Workshop on Hot Topics in Operating Systems. Berkeley, CA: USENIX Association, 2011: 12-15
[56] Apache. Hadoop Project[OL]. [2017-01-20]. http://hadoop.apache.org/
[57] Reiss C, Tumanov A, Ganger G R, et al. Heterogeneity and dynamicity of clouds at scale: Google trace analysis[C] //Proc of the 3rd ACM Symp on Cloud Computing. New York: ACM, 2012: 7-19
[58] Ahmad F, Chakradhar S T, Raghunathan A, et al. Shufflewatcher: Shuffle-aware scheduling in multi-tenant Mapeduce clusters[C] //Proc of the 2014 USENIX Annual Technical Conf. Berkeley, CA: USENIX Association, 2014: 1-13
[59] Morton K, Balazinska M, Grossman D. ParaTimer: A progress indicator for MapReduce DAGs[C] //Proc of the 29th ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2010: 507-518
[60] Li Qianmu, Zhang Shengxiao, Lu Lu, et al. A job scheduling algorithm and hybrid scheduling method on Hadoop platform[J]. Journal of Computer Research and Development, 2013, 50(Suppl1): 361-368 (in Chinese)
(李千目, 张晟骁, 陆路, 等. 一种Hadoop平台下的调度算法及混合调度策略[J]. 计算机研究与发展, 2013, 50(增刊1): 361-368)
[61] Coppa E, Finocchi I. On data skewness, stragglers, and MapReduce progress indicators[C] //Proc of the 6th ACM Symp on Cloud Computing. New York: ACM, 2015: 139-152
[62] Leverich J, Kozyrakis C. Reconciling high server utilization and sub-millisecond quality-of-service[C] //Proc of the 9th European Conf on Computer Systems. Berkeley, CA: USENIX Association, 2014: 4-19
[63] Ousterhout K, Wendell P, Zaharia M, et al. Sparrow: Distributed, low latency scheduling[C] //Proc of the 24th ACM Symp on Operating Systems Principles. New York: ACM, 2013: 69-84
[64] Vavilapalli V K, Murthy A C, Douglas C, et al. Apache Hadoop YARN: Yet another resource negotiator[C] //Proc of the 4th ACM Symp on Cloud Computing. New York: ACM, 2013: 5-20
[65] Hindman B, Konwinski A, Zaharia M, et al. Mesos: A platform for fine-grained resource sharing in the data center[C] //Proc of the 8th USENIX Symp on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2011: 22-35
[66] Facebook Corperation. Under the hood: Scheduling MapReduce jobs more efficiently with Corona[OL]. [2017-01-10]. https://www.facebook.com/notes/facebook-engineering/under-the-hood-scheduling-mapreduce-jobs-more-efficiently-with-corona/10151142560538920
[67] Wang Wei, Li Baochun, Liang Ben. Dominant resource fairness in cloud computing systems with heterogeneous servers[C] //Proc of the 33rd IEEE Int Conf on Computer Communications. Piscataway, NJ: IEEE, 2014: 583-591
[68] Cho B, Rahman M, Chajed T, et al. Natjam: Design and evaluation of eviction policies for supporting priorities and deadlines in MapReduce clusters[C] //Proc of the 4th ACM Symp on Cloud Computing. New York: ACM, 2013: 6-17
[69] Curino C, Difallah D E, Douglas C, et al. Reservation-based scheduling: If you’re late don’t blame us![C] //Proc of the 5th ACM Symp on Cloud Computing. New York: ACM, 2014: 1-14
[70] Grandl R, Ananthanarayanan G, Kandula S, et al. Multi-resource packing for cluster schedulers[J]. ACM SIGCOMM Computer Communication Review, 2014, 44(4): 455-466
[71] Rasley J, Karanasos K, Kandula S, et al. Efficient queue management for cluster scheduling[C] //Proc of the 11th European Conf on Computer Systems. Berkeley, CA: USENIX Association, 2016: 36-48
[72] Grandl R, Kandula S, Rao S, et al. Graphene: Packing and dependency-aware scheduling for data-parallel clusters[C] //Proc of the 12th USENIX Symp on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2016: 81-97
[73] Grandl R, Chowdhury M, Akella A, et al. Altruistic scheduling in multi-resource clusters[C] //Proc of the 12th USENIX Symp on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2016: 65-70
[74] Sun Ruiqi, Yang Jie, Gao Zhan, et al. A resource scheduling approach to improving data locality for virtualized Hadoop cluster[J]. Journal of Computer Research and Development, 2014(Suppl2): 189-198 (in Chinese)
(孙瑞琦, 杨杰, 高瞻, 等. 一种提高虚拟化Hadoop系统数据本地性的资源调度方法[J]. 计算机研究与发展, 2014(增刊2): 189-198)
[75] Clark C G, Fraser K, Hand S, et al. Live migration of virtual machines[C] //Proc of the 2nd Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2005: 273-286
[76] Bhattacharya A A, Culler D, Friedman E, et al. Hierarchical scheduling for diverse datacenter workloads[C] //Proc of the 4th ACM Symp on Cloud Computing. New York: ACM, 2013: 1-15
[77] Wang Jinhai, Huang Chuanhe, Wang Jing, et al. A heterogeneous cloud computing architecture and multi-resource-joint fairness allocation strategy[J]. Journal of Computer Research and Development, 2015, 52(6): 1288-1302 (in Chinese)
(王金海, 黄传河, 王晶, 等. 异构云计算体系结构及其多资源联合公平分配策略[J]. 计算机研究与发展, 2015, 52(6): 1288-1302)
[78] Ousterhout K, Rasti R, Ratnasamy S, et al. Making sense of performance in data analytics frameworks[C] //Proc of the 10th USENIX Symp on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2015: 293-307
[79] Chen Yanpei, Alspaugh S, Borthakur D, et al. Energy efficiency for large-scale MapReduce workloads with significant interactive analysis[C] //Proc of the 6th ACM European Conf on Computer Systems. Berkeley, CA: USENIX Association, 2012: 43-56
[80] Mitzenmacher M. The power of two choices in randomized load balancing[J]. IEEE Trans on Parallel & Distributed Systems, 2001, 12(10): 1094-1104
[81] Goder A, Spiridonov A, Wang Yin. Bistro: Scheduling data-parallel jobs against live production systems[C] //Proc of the 2015 USENIX Annual Technical Conf. Berkeley, CA: USENIX Association, 2015: 459-471
[82] Boutin E, Ekanayake J, Lin Wei, et al. Apollo: Scalable and coordinated scheduling for cloud-scale computing[C] //Proc of the 11th USENIX Symp on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2014: 285-300
[83] Delimitrou C, Sanchez D, Kozyrakis C. Tarcil: Reconciling scheduling speed and quality in large shared clusters[C] //Proc of the 6th ACM Symp on Cloud Computing. New York: ACM, 2015: 97-110
[84] Wang Ke, Liu Ning, Sadooghi I, et al. Overcoming Hadoop scaling limitations through distributed task execution[C] //Proc of 2015 IEEE Int Conf on Cluster Computing. Piscataway, NJ: IEEE, 2015: 236-245
[85] Hao Chunliang, Shen Jie, Zhang Heng, et al. Sparkle: Adaptive sample based scheduling for cluster computing[C] //Proc of the 5th Int Workshop on Cloud Data and Platforms. Berkeley, CA: USENIX Association, 2015: 1-6
[86] Karanasos K, Rao S, Curino C, et al. Mercury: Hybrid centralized and distributed scheduling in large shared clusters[C] //Proc of the 2015 USENIX Annual Technical Conf. Berkeley, CA: USENIX Association, 2015: 485-497
[87] Delgado P, Dinu F, Kermarrec A M, et al. Hawk: Hybrid datacenter scheduling[C] //Proc of the 2015 USENIX Annual Technical Conf. Berkeley, CA: USENIX Association, 2015: 499-510
[88] Delgado P, Didona D, Dinu F, et al. Job-aware scheduling in Eagle: Divide and stick to your probes[C] // Proc of the 7th ACM Symp on Cloud Computing. New York: ACM, 2016: 497-509
[89] Bonomi F, Milito R, Zhu Jiang, et al. Fog computing and its role in the Internet of things[C] //Proc of the 1st MCC Workshop on Mobile Cloud Computing. New York: ACM, 2012: 13-16
[90] Wuhib F, Stadler R, Spreitzer M. Gossip-based resource management for cloud environments[C] //Proc of the 2010 Int Conf on Network and Service Management. New York: ACM, 2010: 1-8
[91] Microsoft Corperation. Rack-scale Computing[OL]. [2017-01-20]. https://www.microsoft.com/en-us/research/project/rack-scale-computing/
[92] AMD Corperation. SeaMicro[OL]. [2017-01-20]. http://www.seamicro.com/
[93] HP Corperation. Moonshot system: The world’s first software define server[OL]. [2017-01-20]. http://h10032.www1.hp.com/ctg/Manual/c03728406.pdf
[94] Intel Corperation. Intel®Rack Scale Design[OL]. [2017-01-20]. http://www.intel.com/content/www/us/en/architecture-and-technology/rack-scale-design-overview.html
[95] University of California, Berkeley. NetSys Projects[OL]. [2017-01-20]. http://netsys.cs.berkeley.edu/projects/
[96] University of Cambridge. Opera Projects[OL]. [2017-01-21]. https://www.cl.cam.ac.uk/research/srg/opera/projects/
Hao Chunliang 1,2 , Shen Jie 3 , Zhang Heng 1,2 , Wu Yanjun 1 , Wang Qing 1 , and Li Mingshu 1
1 ( National Engineering Research Center for Fundamental Software , Institute of Software , Chinese Academy of Sciences , Beijing 100190) 2 ( University of Chinese Academy of Sciences , Beijing 100049) 3 ( Department of Computing , Imperial College , London SW72AZ)
Abstract Cluster scheduling is one of the most investigated topics in big data environment. The main problem it aims to solve is to efficiently fulfill the requirements of data analytic workload using finite amount of cluster resources. Along with the rapid development in big data applications within the past decade, the context and goals of cluster scheduling also rose significantly in complexity. As the drawbacks of traditional centralized scheduling methods have becoming increasingly apparent in modern clusters, many alternative scheduling structures, including two-level scheduling, distributed scheduling, and hybrid scheduling, have been proposed in recent years. Unfortunately, as each of these methods embodies a distinct set of advantages and limitations, there is yet to appear a simple one-fits-all answer that can overcome all scheduling challenges simultaneously in big data environment. Therefore, this work aims at providing a comprehensive survey on various families of mainstream scheduling methods, focusing on their motivation, strengths and weaknesses, and suitability to different application scenarios. Seminal works of each scheduling structure are analyzed in-depth in this paper to bring insights on the current state of development. Last but not least, we try to extrapolate the current trend in cluster scheduling and highlight the challenges to be tackled in future works.
Key words cluster scheduling; resource abstraction; cluster computing; big data; data analytic job
摘 要 集群调度一直以来是集群计算方向的热点研究问题.集群调度研究主要关注在固定的集群资源条件下,数据处理作业如何快速、精确地获得所需运行资源,从而达到预先设定的执行目标.随着大数据计算的发展,集群环境在过去10年内持续且快速地发展变化,集群调度场景和目标也日趋复杂.尤其是在大数据背景下,传统集中调度结构的性能瓶颈被放大,研究者开始向全新的调度结构进行探索,应运而生了众多新思路、新结构.从大数据背景下集群调度研究的主要研究问题出发,分别介绍了大数据背景下的4种集群调度结构:集中结构、双层结构、分布式结构以及混合结构,并对各结构的产生原因、适用场景、优劣、典型研究工作、研究进展进行分析,并尝试对各结构的未来发展进行展望.
关键词 集群调度;资源抽象;集群计算;大数据;数据处理作业
中图法分类号 TP316.4
收稿日期: 2017-01-24;
修回日期: 2017-05-31
基金项目: 中国科学院战略性先导科技专项(XDA06010600)
This work was supported by the Strategic Priority Research Program of the Chinese Academy of Sciences (XDA06010600).
通信作者: 王青(wq@iscas.ac.cn)

Hao Chunliang , born in 1986. PhD, assistant researcher. His main research interests include cluster scheduling, especially cooperation mechanism among distribute schedulers and the support of interactive jobs in oversized cluster.

Shen Jie , born in 1987. PhD, assistant professor. His main research interests include facial recognition, human-robot interaction and heterogeneous scheduling.

Zhang Heng , born in 1990. PhD candidate. His main research interests include graph computing and cluster scheduling.

Wu Yanjun , born in 1977. PhD, professor, PhD advisor. His main research interests include big data, cluster computing and database.

Wang Qing , born in 1964. PhD, professor, PhD advisor. Her main research interests include software testing, crowdsourcing, empirical software study, etc.

Li Mingshu , born in 1966. PhD, professor, PhD advisor. His main research interests include operating system, software engineering and distributed system.