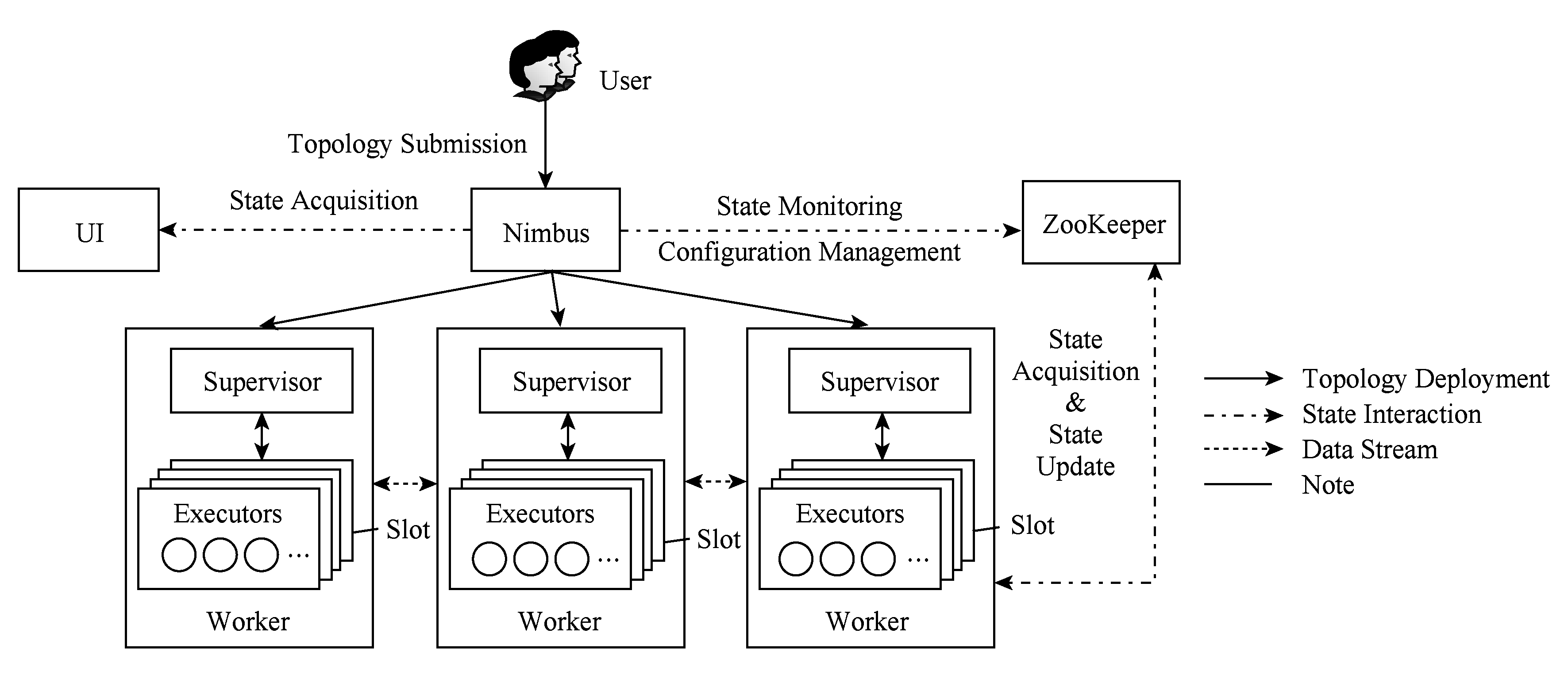
Fig. 1 Architecture of Storm
图1 Storm系统架构
鲁 亮 1 于 炯 1 卞 琛 1 刘月超 1 廖 彬 2 李慧娟 3
1 (新疆大学信息科学与工程学院 乌鲁木齐 830046)
2 (新疆财经大学统计与信息学院 乌鲁木齐 830012)
3 (国网乌鲁木齐供电公司 乌鲁木齐 830011)
(luliang19891108@gmail.com)
近些年来,大数据相关研究及应用已成为学术界和企业界关注的热点,其计算模式包括批量计算、流式计算、交互计算、图计算等 [1-5] ,并以前两者应用居多.批量计算为先存储后计算(如Hadoop生态系统),适合实时性不高且需覆盖全局数据的应用场景;流式计算打破了Hadoop中MapReduce [6] 框架一统天下的局面,它无需存储,只要数据源处于活动状态,数据就会持续生成,并以流(由时间上无穷的元组序列组成)的形式在各工作节点的内存中进行计算,适合实时性要求严格且仅需针对窗口内的局部数据进行处理的应用场景.流式大数据处理平台大大提高了在线数据密集型(on line data intensive, OLDI)应用 [7] 的用户体验,可广泛应用于金融银行业、互联网和物联网等诸多领域,涵盖股市实时分析、搜索引擎与社交网站、交通流量实时预警等各类典型应用 [8] .现有的流式大数据处理框架以Twitter公司的Storm系统为代表 [9] .Storm是一个采用主从式架构的开源分布式实时计算平台,其编程模型简单,支持包括Java在内的多种编程语言,横向可扩展性良好.相较于目前同样主流的Flink [10] 和Spark Streaming [11] ,Storm在大数据流式处理方面的实时性更佳;相较于不开源的Puma [12] 和社区冷淡的S4 [13] ,Storm的商用前景更为广阔.加之新版本特性的加入、更多库的支持以及与其他开源项目的无缝融合,Storm逐渐成为学术界和工业界的研究热点,被称为“实时处理领域的Hadoop”.
一个流式计算作业及其包含的一系列任务可用有向无环图(directed acyclic graph, DAG)表示,Storm中称之为拓扑(topology).从拓扑实例模型的角度来看,拓扑的1个顶点代表某一特定任务,1条有向边代表任务之间的依赖关系.Storm在进行任务分配时采用轮询调度策略(round-robin scheduling),即先将拓扑中包含的每个任务均匀地分布到各个工作进程中,再将各工作进程均匀地分布到各工作节点上,并未考虑到不同工作节点的性能和负载差异,以及工作节点之间的网络传输开销和节点内部的进程与线程通信开销,无法最大限度地发挥Storm集群的实时计算能力.本文针对Storm轮询调度策略存在的不足,主要作了4个方面研究工作:
1) 分析已有流式计算框架调度策略的优缺点,阐述本文的优化方向和实施思路.
2) 从拓扑的逻辑模型、实例模型和任务分配模型出发,比较Storm集群中3种不同的通信方式.由此建立资源约束模型和最优通信开销模型,提出并证明了最优通信开销原则.
3) 为解决异构Storm系统中工作节点任务过载和节点间通信开销大的问题,建立任务迁移模型,提出并证明了迁移优化原则和节点间数据流最优性原理,并由此推出最优迁移原则,为任务迁移策略的设计提供理论依据.
4) 从源节点选择、阻尼线程选择和目的节点选择3个方面出发,提出异构Storm环境下的任务迁移策略(task migration strategy for heterogeneous Storm cluster, TMSH-Storm),包括源节点选择算法和任务迁移算法,使系统在拓扑执行过程中根据各工作节点和各任务的实时负载情况以及任务间的数据流大小,实现任务的优化迁移.实验通过4个基准测试从不同角度证明了算法的有效性.
针对实时大规模数据的处理,现有解决方案可大致归纳为3类:高性能批量计算模式、流式计算模式和两者混合的模式.其中,高性能批量计算模式的核心思想是修改以Hadoop为代表的批处理框架,通过减少中间结果的磁盘读写次数以及增加作业间的流水化程度来提高吞吐量 [14-19] .混合模式的主要思想是基于MapReduce模型增加或修改其中的某些处理步骤,以实现流式处理 [20-25] .这2种方案在一定程度上解决了大数据处理的实时性问题,但其性能仍逊色于流式计算模式,且其研究成果无法直接移植于现有流式计算平台中.针对这一问题,已有国内外学者提出了流式计算框架下的各种性能优化方向和实施策略.文献[8,26]在大数据流式计算综述中总结了流式大数据在典型应用领域中呈现出的实时性、易失性、突发性、无序性和无限性等特征,给出了理想的大数据流式计算系统在系统结构、数据传输、应用接口和高可用性等方面应该具备的关键技术特征,阐述了已有各类流式计算系统在可伸缩性、容错机制、状态一致性、负载均衡和吞吐量等方面所面临的技术挑战.此外,为获得更好的服务质量,已有学者提出各类性能感知的数据流调度算法,例如混合启发式遗传调度算法 [27] 、竞争感知的任务复制调度算法 [28] 、基于支持向量域描述和支持向量聚类算法 [29] 以及基于双分子结构的化学反应优化算法 [30] 等.
以上研究工作的侧重点各异,但大多只适用于任务和节点信息变化不够迅速的场景.如果数据流大小和速率经常变化,以上调度策略的部署可能引起较大的系统波动.针对大数据流式计算环境下数据量大、变化迅速且无法追踪的特点,有学者提出各类流式计算环境下的虚拟机监测和可扩展平台,从监测对象 [31-33] (CPU等硬件负载、工作节点和线程的数量、作业的执行情况等)、虚拟机部署和调整方式 [33-35] (人工干预、半自动和全自动)、优化范围 [36] (基于当前状态的局部优化、基于预测的全局优化)等方面弹性调整虚拟机的数量和任务的部署,以达到性能优化和负载均衡的效果.为更好地处理复杂作业中的大规模流式数据,文献[37]针对高可扩展的分布式中间件System S [38] 提出一种分布式应用调度优化算法.该算法分为4个阶段:前2个阶段计算作业运行的备选节点,后2个阶段决定各处理单元在各节点上的分配.该算法在满足系统高可扩展性的同时,提高了调度的实时性.文献[39]从有向无环图优化的角度出发,提出弹性自适应数据流图模型,并使用该策略进行资源分配,以寻求最大化吞吐量和最小化响应时间.文献[40]从虚拟化网络数据中心(virtualized networked data centers, VNetDCs)的角度,提出云计算SaaS计算模型下针对实时流式应用的最小化能耗调度策略.该研究充分考虑到大数据实时流数据量大、数据到达速率不可控和不稳定等特性,在响应时间约束的前提下,最小化计算和网络传输总能耗.文献[41]提出大数据流式计算环境下实时且节能的资源调度模型Re-Stream.作者建立了能耗、响应时间和CPU利用率之间的数学关系,定义了有向无环图的关键路径,并综合运用关键路径上性能感知的任务调度策略和非关键路径上能耗感知的任务整合策略,达到了响应时间和能耗双目标优化的效果.以上研究均在兼顾了流式大数据特征的前提下提出了各类流式计算平台下的优化策略,但针对Storm这一具体框架,在资源感知和通信开销的优化方面仍存在很大的探索空间.
针对Storm框架下的调度优化策略,已有少量学者开展了部分研究.针对地理位置分散的Storm集群而言,文献[42]提出并实现了一种服务质量感知的Storm分布式调度器,其在网络时延和可靠性等方面均优于Storm默认调度策略的执行结果,但这与本文集中式数据中心的研究背景不符.文献[43]提出Storm环境下的自适应调度策略,分为离线调度和在线调度2种.离线调度是在拓扑运行前分析其结构,将相互关联的1对任务尽量调度到同一个工作进程中,然后将所有工作进程轮询调度到各个工作节点上;在线调度则是通过插件实时监测拓扑运行过程中系统的CPU负载和任务间数据流大小,当某节点上的任务持续过载时触发重分配机制,依次将通信开销较大的1对任务分配在CPU负载较轻的工作进程中,同理将通信开销较大的1对工作进程分配在CPU负载较轻的工作节点上.这种自适应调度策略很好地解决了Storm环境中的通信开销问题,但仍有4点有待优化:1)算法复杂度很高,在线调度策略执行时将导致延迟极大,对性能造成了一定的冲击;2)算法有效降低了工作节点间通信开销,但对于同一节点内的进程间开销仍比较大;3)Storm的拓扑结构错综复杂,而实验中采用的线性拓扑缺乏代表性;4)该策略仅考虑CPU这一资源负载,度量角度较为单一.
文献[44]提出Storm框架下流量感知的在线调度策略T-Storm.T-Storm通过监控各任务的CPU负载、数据流传输(流量)负载以及各工作节点的CPU负载,实现任务的在线动态重部署,在保证没有工作节点过载的情况下最小化网络传输开销;同时,针对运行于同一个工作节点且属于同一个拓扑的所有任务,T-Storm只为其分配1个工作进程(槽),从而消除了进程间通信开销.此外,T-Storm能通过参数调整增加或减少启动的工作节点数量.然而该文献仍存在2方面不足:1)与文献[43]类似,T-Storm仍存在调度执行开销大和资源负载度量角度单一的问题;2)T-Storm将各任务发送和接收的数据流大小孤立考虑,忽略了直接通信的1对任务之间的数据流情况,对于通信复杂的拓扑而言可能无法达到近似最优.
Fig. 1 Architecture of Storm
图1 Storm系统架构
文献[45]提出Storm框架下资源感知的调度策略R-Storm.R-Storm将资源约束分为针对内存的硬约束以及针对CPU和网络带宽的软约束,其中硬约束条件必须满足,而软约束条件则尽量满足.与文献[44]提出的T-Storm相同,R-Storm不考虑任务与工作进程的映射关系,而直接考虑拓扑中各任务在工作节点上的分配,在最小化网络时延的同时最大化资源利用率,最终达到提高整个集群吞吐量的效果.R-Storm充分考虑了资源池中各类资源的有效利用,但仍存在2点不足:1)虽然R-Storm为编程人员提供了丰富的应用程序接口(application programming interface, API),但对于拓扑中各任务的CPU、内存和网络带宽需求需要通过API人为设置而非实时监测获得,无法用于数据流快速变化场景下的在线调度.与此同时,Storm编程人员往往专注于业务功能的开发,对任务运行时的资源评估缺乏经验,可能对资源的有效利用造成一定影响.2)R-Storm只适合于同构环境下,不能通用于异构环境.
本文与上述研究成果的不同之处在于:
1) 本文提出的任务迁移策略针对以上不足进行了改进,能够实时监测并统筹兼顾拓扑中各线程的CPU、内存和网络带宽负载,在各类资源约束的前提下最小化通信开销,保证集群的低延迟.
2) 现有研究 [43-45] 均是在拓扑的运行过程中,发现资源溢出后针对所有任务进行重新部署.这种做法虽然能够带来较为明显的优化效果,但算法的执行过程将引起极大的延迟,进而影响Storm系统的运行效率.本文提出的任务迁移策略开销较小,能够保证任意时刻系统的实时性处理需求.
3) 实验基于Intel公司Zhang等人 [46] 发布在GitHub上的storm-benchmark-master基准测试,而非已有文献中作者定义的拓扑结构,更具代表性.
4) 该策略可适用于异构集群环境中,应用范围更为广阔.
本节针对Storm架构和部分概念做简要介绍.
如图1所示,一个完整的Storm分布式系统由4类节点组成:
1) 主控节点(master node).它是运行Storm Nimbus后台服务的节点.Nimbus是Storm系统的中心,负责接收用户提交的拓扑作业,向工作节点分配任务(进程级和线程级)并传输作业副本,依赖协调节点的服务监控集群运行状态,提供状态获取接口,在Storm中的地位类似于Hadoop中的JobTracker.
2) 工作节点(work node).它是运行Storm Supervisor后台服务的节点.Supervisor负责监听Nimbus分配的任务并下载作业副本,启动、暂停或撤销任务的工作进程(Worker)及工作线程(Executor).Supervisor是分布式部署的,在Storm中的地位类似于Hadoop中的TaskTracker.
3) 控制台节点(Web console node).它是运行Storm 用户界面(user interface, UI)后台服务的节点.它实际上是一个Web服务器,在指定端口提供网页服务.用户可以使用浏览器访问控制台节点的Web页面,提交、暂停和撤销作业,也可以以只读的形式获取系统配置、作业及各个组件的运行时状态.
4) 协调节点(coordinate node).它是运行Zoo-Keeper进程的节点.Nimbus和Supervisor之间所有的协调,包括分布式状态维护和分布式配置管理,都是通过该协调节点实现的.在协调节点的帮助下,Nimbus和Supervisor的无状态服务可以快速失败,这也是Storm系统的稳定性和可用性较高的原因之一.
为便于后文理解,现对工作节点内部结构以及拓扑相关概念做简要说明:
1) 拓扑(topology).即流式作业本身,可用一个有向无环图表示,由Spout、Bolt和数据流组成.
2) 元组(tuple).Storm数据处理的基本单元,是包含了1个或者多个键值对的列表.
3) 数据流(stream).由无限的元组组成的序列,是Storm中对传递的数据进行的抽象.
4) Spout.Storm中的数据源编程单元,用于为拓扑生产数据.一般地,Spout从消息队列、关系型数据库、非关系型数据库(NoSQL)、实时日志、Hadoop分布式文件系统(Hadoop distributed file system, HDFS)等外部数据源不间断地读取数据,并以元组的形式传递给拓扑进行处理.
5) Bolt.Storm中的数据处理编程单元,实现拓扑中的处理逻辑.一般地,编程人员可在Bolt中实现数据过滤、聚合和查询数据库等操作,处理的结果以元组形式流式传递至其下游组件进行处理.
6) 组件(component).Spout和Bolt的统称.
7) 流组模式(stream grouping).Storm各组件之间的数据传递模式,目前共有8种,分别是随机分组(shuffle grouping)、按域分组(field grouping)、副本分组(all grouping)、全局分组(global grouping)、直接分组(direct grouping)、本地分组(local or shuffle grouping)、不区分分组(non grouping)和自定义流组.
8) 工作进程(Worker).实际上是一个Java虚拟机(Java virtual machine, JVM),由它执行指定的子拓扑.同一个拓扑可以由多个工作进程共同完成,但1个工作进程只能执行1个子拓扑.
9) 槽(Slot).配置在工作节点上用于接收数据的端口,1个工作进程占用1个槽,槽的数量表明该工作节点最多可容纳的工作进程的数量.一般为了拓扑的进程级并行,槽的个数配置为工作节点CPU的核心数.
10) 任务(task).每个任务为其对应组件的1个实例,是拓扑执行的代码单元.
11) 工作线程(Executor).每个工作进程由多个工作线程组成,并且运行1个组件中包含的1个或多个任务,因此系统中工作线程的数量总是小于或等于任务的数量.一般地,为了实现任务的线程级并行,1个工作线程只包含1个任务.在这种情况下,Storm任务的调度即相当于该任务所对应的工作线程的调度.本文即在此场景下研究Storm的任务迁移策略,下文简称为线程.
为简便起见,除第5节之外,下文出现“节点”之处均指工作节点,出现“进程”之处均指工作进程;第5节实验部分为避免混淆,均对具体意义上的“节点”和“进程”做了说明.
本节从Storm拓扑的逻辑模型、实例模型和任务分配模型出发,比较Storm集群中3种不同的通信方式.由此建立资源约束模型和最优通信开销模型,为任务迁移策略的设计与实现提供了理论依据.
定义1 . 拓扑逻辑模型.任意拓扑可使用二元组( C , S )表示,其中 C ={ c 1 , c 2 ,…, c | C | }为拓扑的顶点集合,每个元素表示1个组件,即Spout或Bolt; S ={ s 1,2 , s 1,3 ,…, s | C |- i ,| C | }为拓扑的有向边集合,每个元素表示2个组件间传递的数据流.如果存在 s i , j ∈ S 且 i ≠ j ,则 c i , c j ∈ C ,表示数据由组件 c i 发出并由 c j 接收.这样的有向无环图表示的拓扑称为拓扑逻辑模型.如图2所示,其中{ c a , c b ,…, c g }为组件集,{ s a , c , s a , d ,…, s e , g }为数据流集. c a 和 c b 为数据源编程单元Spout,负责读取外部数据源并发送至流式计算集群进行处理;其余的组件为数据处理编程单元Bolt,负责处理上游组件发送的数据并以某种流组模式将结果发送至其下游组件;特别地,组件 c f 和 c g 为数据终点,通常用于将最终结果展示至终端或持久化至数据库.
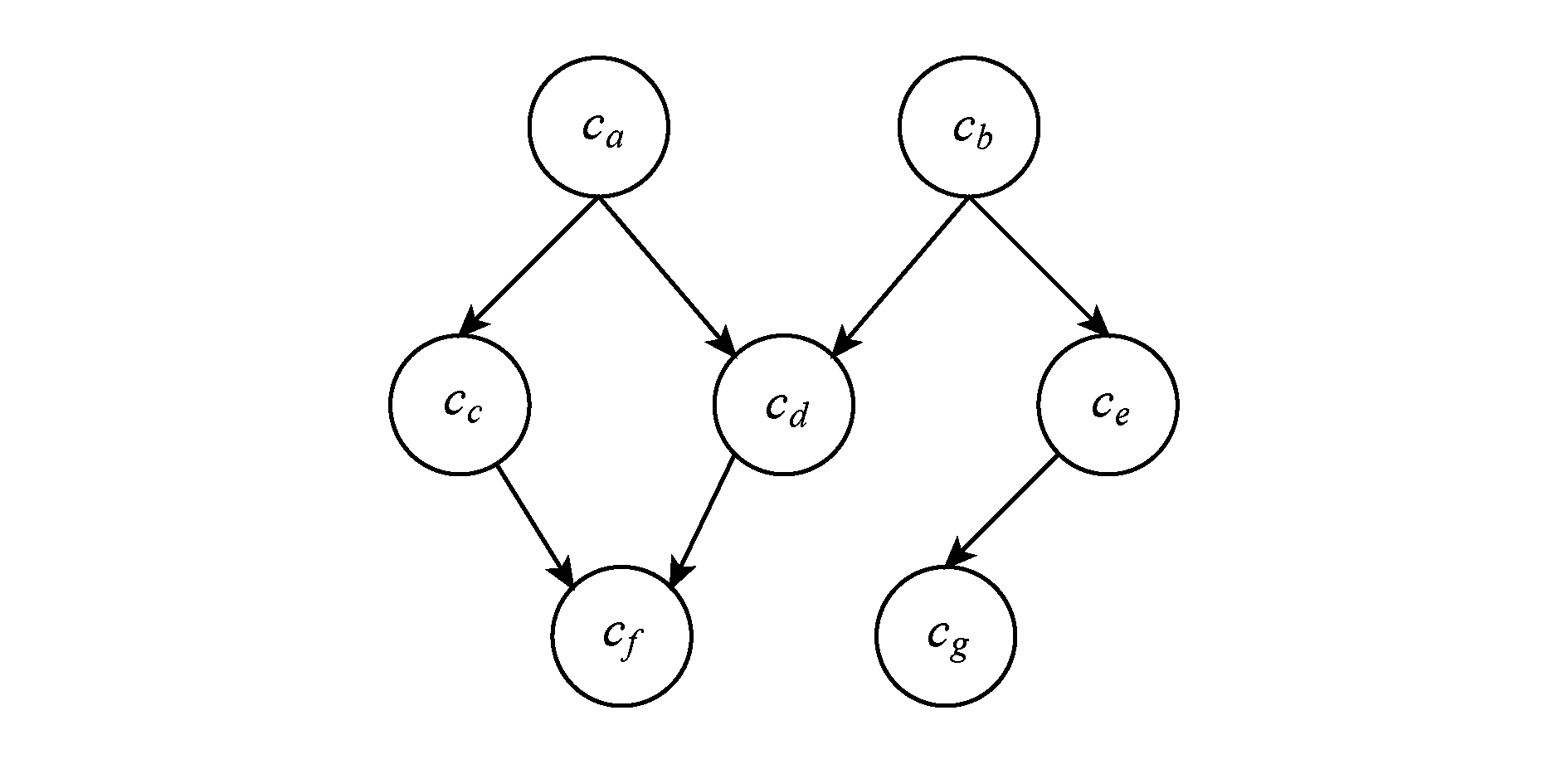
Fig. 2 Logical model of a topology
图2 拓扑逻辑模型
定义2 . 拓扑实例模型.在定义1中,为提高拓扑执行的并行度,每个组件均可同时运行多个实例,每个实例由1个线程执行.即对于任意 c i ∈ C ,存在 E i ={ e i 1 , e i 2 ,…, e i | E i | },其中 e i j 表示组件 c i 运行的第 j 个实例(线程).特别地,当组件 c i 的线程数量为1时,定义 E i ={ e i 1 }= e i .若在拓扑逻辑模型中存在 s k , i ∈ S ( k < i )且 s i , l ∈ S ( i < l ),则对于 E i 中的所有线程,存在 ![]() 和
和 ![]() 其中
其中 ![]() 表示组件 c i 的所有线程接收的数据流集合
表示组件 c i 的所有线程接收的数据流集合 ![]() 表示组件 c i 的所有线程发出的数据流集合.这样的有向无环图表示的拓扑称为拓扑实例模型.如图3为图2的一种实例模型
表示组件 c i 的所有线程发出的数据流集合.这样的有向无环图表示的拓扑称为拓扑实例模型.如图3为图2的一种实例模型 ![]() }.
}.

Fig. 3 Instance model of a topology
图3 拓扑实例模型
定义3 . 子拓扑.由拓扑实例模型中原拓扑的线程的子集以及这些线程之间的数据流构成.设原拓扑的线程集合为 E ,拓扑的线程的子集为 E ′,对于 e mn ∈ E 和 e i j , e k l ∈ E ′,若在原拓扑中存在 s i j , mn 和 s mn , k l ,则必然有 e mn ∈ E ′.例如在图3中, e b , e d 2 , e f 2 以及它们之间的数据流可构成子拓扑,而仅由 e b 和 e f 2 则无法构成子拓扑.
定义4 . 任务分配模型.在Storm集群中,资源池由一系列节点构成,定义该集合为 N ={ n 1 , n 2 ,…, n | N | }.每个节点内配置有若干个槽,对于任意 n i ∈ N ,有 Slot i ={ slot i 1 , slot i 2 ,…, slot i | Slot i | },其中 slot i j 表示第 i 个节点的第 j 个槽.对于任意1个拓扑,用户将在代码中设置其运行所需的进程数量和每个组件的线程数量.设某拓扑的进程集合为 W i ={ w i 1 , w i 2 ,…, w i | W i | },其中 w i j 表示第 i 个节点上运行的第 j 个进程.由槽和工作进程的定义可知,有 W i ⊆ Slot i .若组件 c i 运行的第 j 个线程 e i j 分配到了第 k 个节点上,则记 f ( e i j )= n k ;若组件 c i 运行的第 j 个线程 e i j 分配到了第 k 个节点的第 l 个槽上,则记 g ( e i j )= slot k l .其中 f 和 g 均为分配函数.如图4为图3的拓扑运行于Storm集群中的真实场景,其中椭圆形虚线表示进程,矩形实线表示节点,图4的含义为拓扑的10个线程分布在2个节点的3个进程中,以 e d 2 和 e e 为例可表示为: f ( e d 2 )= n 1 , g ( e d 2 )= slot 12 , f ( e e )= n 2 , g ( e e )= slot 21 .
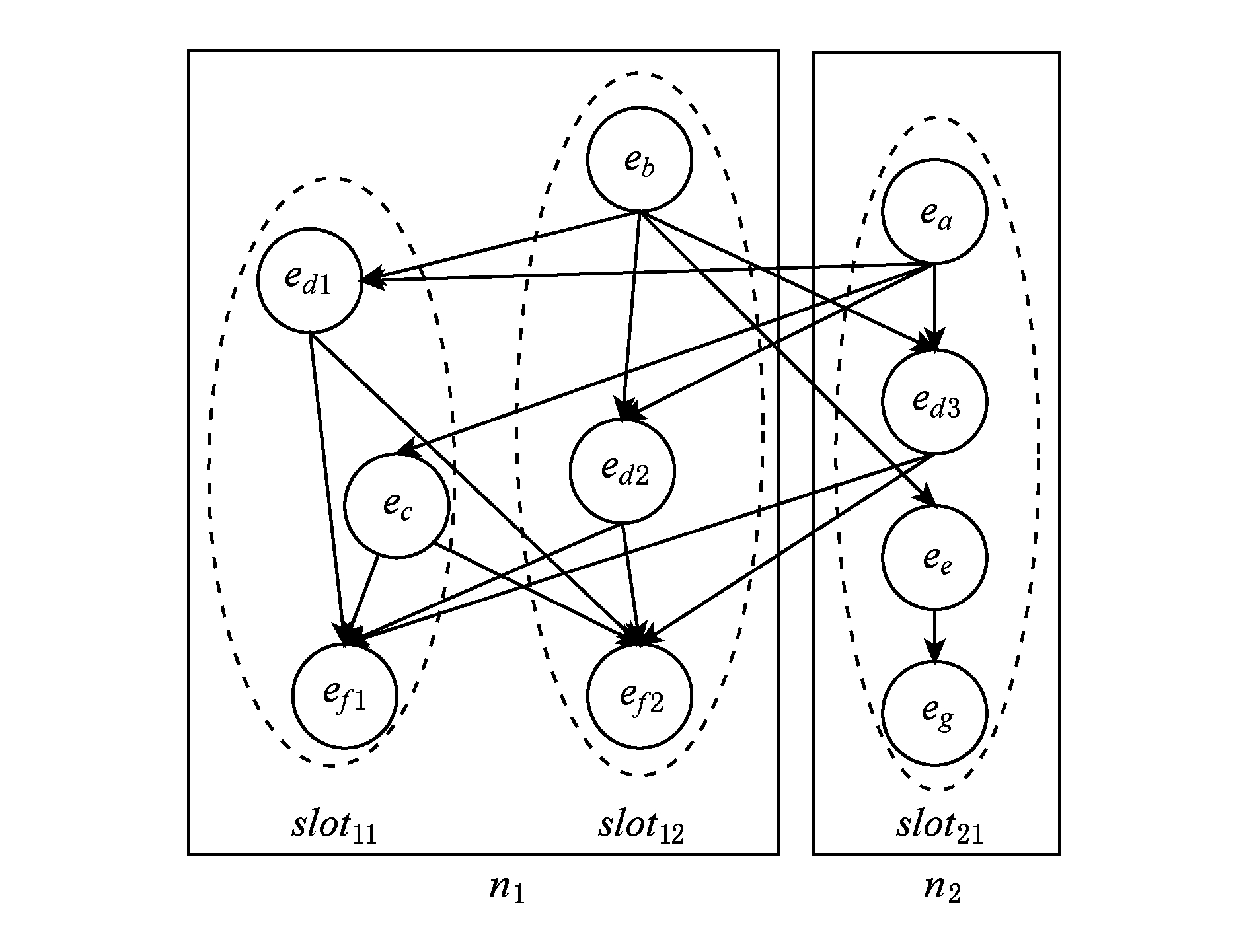
Fig. 4 Model for task assignment
图4 任务分配模型
由此可见,在Storm系统中存在3种通信方式:
1) 节点间通信,即节点间的直接通信.这种通信开销最大,需要占用大量的网络资源.如果网络负载过高或带宽过小,将对数据处理的实时性产生很大影响.如图4所示,线程 e b 和 e d 3 之间的通信即属于节点间通信,数据流 s b , d 3 为节点间数据流.
2) 进程间通信,即同一个节点内的进程间直接通信.这种通信开销介于节点间通信开销和线程间通信开销之间.如图4所示,线程 e d 1 和 e f 2 之间的通信即属于进程间通信,数据流 s d 1, f 2 为进程间数据流.
3) 线程间通信,即同一个节点且同一进程内的线程间直接通信.这种通信开销最小且不可避免.如图4所示,线程 e d 1 和 e f 1 之间的通信即属于线程间通信,数据流 s d 1, f 1 为线程间数据流.
Storm默认调度器EvenScheduler采用轮询策略进行任务分配.EvenScheduler首先遍历拓扑中的所有实例并为每个实例分配1个线程;然后将其均匀分配到各个进程中;接着根据各个节点上槽的空闲情况,将进程均匀分配到各个节点上.这样的调度策略并未考虑到节点间和进程间较大的通信开销以及异构节点间的性能差异.针对这一问题,本文从以下3个方面提出优化构思:
1) 文献[44]通过Storm吞吐量测试 [47] 表明,针对运行在1个节点上的子拓扑而言,若为其分配多个进程(即占用多个槽),将会增加进程间通信开销进而影响性能.因此,在节点数量不变的情况下,仅为位于每个节点的子拓扑各分配1个进程,能够达到性能最优的效果,这为解决最小化进程间通信开销问题提供了思路.
2) 对于节点间通信问题,需在充分利用有限资源的基础上,尽量将彼此间数据流较大的1对任务部署到同一节点,即将节点间通信转化为节点内的线程间通信,从而达到最小化节点间通信开销的目的.
3) 针对异构节点间的性能差异问题,需实时监测不同节点上各线程的负载,并预测某线程迁移到目的节点上各资源的变化情况,为线程的迁移提供决策.
根据Storm计算模式的特点,本文将集群各节点 N ={ n 1 , n 2 ,…, n | N | }的硬件资源分为CPU、内存和网络带宽3类,即 R ={ R C , R M , R B }.其中CPU资源为 ![]() 内存资源为
内存资源为 ![]() 网络带宽资源为
网络带宽资源为 ![]() }.若线程 e i j 运行在节点 n k 上,设其占用的CPU资源为
}.若线程 e i j 运行在节点 n k 上,设其占用的CPU资源为 ![]() 单位Hz),占用的内存资源为
单位Hz),占用的内存资源为 ![]() 单位B),占用的网络带宽资源为
单位B),占用的网络带宽资源为 ![]() 单位bps).由于流式计算环境中数据源源不断产生,拓扑一旦提交则将持续运行下去.因此为保证集群的高效运行,当且仅当每个节点的各项资源都不会溢出,即对于任意 n k ∈ N ,有
单位bps).由于流式计算环境中数据源源不断产生,拓扑一旦提交则将持续运行下去.因此为保证集群的高效运行,当且仅当每个节点的各项资源都不会溢出,即对于任意 n k ∈ N ,有
(1)
(2)
![]()
在Storm应用环境中,为保证集群的可靠性目标,各节点不能满负荷运行,一般需由运维人员设定相应阈值以预留少量的计算资源,当超出阈值后则发出警告.设CPU占用率阈值为 α ,内存占用率阈值为 β ,网络带宽占用率阈值为 γ ,则式(1)~(3)可进一步完善为
(4)
(5)
![]()
在Storm集群中,各节点的资源占用由运行在该节点上的子拓扑所包含的所有线程占用的各类资源共同构成,则剩余资源为各资源总量与资源占用的差值,有:
(7)
(8)
![]()
其中 ![]() 分别代表节点 n k 的剩余CPU、内存和网络带宽资源.将式(7)~(9)带入式(4)~(6)通过简单变形可得:
分别代表节点 n k 的剩余CPU、内存和网络带宽资源.将式(7)~(9)带入式(4)~(6)通过简单变形可得:
(10)
(11)
(12)
转化后的资源约束模型将为后文线程迁移的决策过程提供理论依据.
由3.1节可知,拓扑中包含3种通信开销,节点间通信开销最大,进程间通信开销次之,线程间通信开销最小.因此需要在满足资源约束模型的同时最小化这3类开销.然而拓扑一旦提交,线程数量和数据流数量即固定下来,且为保证元组的流式传递,各线程之间的通信开销不可避免.若要达到最小化通信开销的效果,需最小化节点间通信开销和进程间通信开销;换言之,即需尽可能地将节点间通信开销和进程间通信开销转化为线程间通信开销.同一类型的通信开销可由数据流大小体现,数据流越大,则传输时间越长,即通信开销越大,反之亦然.设拓扑中线程 e i j 与 e k l 之间的数据流大小为 v i j , k l 或 v k l , i j ( v 的下标与数据流向无关),则可建立优化模型:
(13)
![]()
约束条件为式(10)~(12).
定理1 . 最优通信开销原则.最小化节点间通信开销和进程间通信开销等价于最大化线程间通信开销,即上述目标函数等价于
(15)
证明. 根据Storm流式计算模型,拓扑一旦提交到集群,其包含的线程数量和数据流数量即不可改变.因此在不发生拥塞的情况下,总数据流大小为一定值 C ,即
![]()
![]() C .
C .
(16)
因此,当节点间数据流 ![]() 和进程间数据流
和进程间数据流 ![]() 取得最小值时,线程间数据流
取得最小值时,线程间数据流 ![]() 取得最大值.
取得最大值.
证毕.
为了消除进程间通信开销,本文仅为调度到各节点上的子拓扑各分配1个进程,可看作是将节点上原有的多个进程合并,这样就将原来存在的进程间通信开销转化为线程间通信开销,在节点数量不变的前提下优化了通信效率.因此下面将着重解决节点间通信开销问题.
为满足最优通信开销模型的要求,需修改Storm默认调度策略,将已提交拓扑的各个线程重新分配至各个节点.若将各节点理解成不同容量的背包,拓扑中的线程理解为不同的物品,可使用0-1背包问题的思想分析和解决此类NP问题.然而为同时满足3.2节资源约束模型的要求,各背包应同时存在CPU、内存和网络带宽3类不同的资源约束,且为保证最小化节点间开销,需成对考虑线程的放置,这便构成了一个二次型三维约束条件的多背包问题.已有学者提出多种方法解决背包问题的变形,例如动态规划 [48] 、搜索树(如A * 算法) [49] 、近似算法 [50-51] 等.然而,在分布式流式计算框架中,此类算法时间复杂度较高,拓扑的部署过程开销很大,将对集群的运行效率带来较大的负面影响;此外,在拓扑各线程的调度过程中,数据源仍在源源不断地产生数据,若无法及时得到处理,可能导致元组积压甚至因超时而处理失败,无法满足Storm用户的实时性业务需求.可见调度策略的优化设计应尽可能减少受影响的线程数量,由此提出Storm框架下的任务迁移模型.
定理2 . 迁移优化原则1.若存在这样1个节点,使得某线程与该节点的节点间数据流大于该线程与其所在节点内的线程间数据流,则该线程迁移后将获得更优的通信开销.
证明. 设待迁移线程为节点 n s 上的线程 e i j ,与 e i j 存在节点间数据流且剩余资源充裕的节点集合为 N d ,其中 n d 为 N d 中任意节点.则线程 e i j 与其所在节点 n s 内的线程形成的数据流大小为
(17)
线程 e i j 与其他节点之间形成的数据流大小总和为
(18)
线程 e i j 与 n d 之间的数据流大小为
(19)
因此,对于线程 e i j ,与其相关的数据流总量为
v i j = v interExecutor+ v interNode=
v interExecutor+ v inter _n d +( v interNode- v inter _n d ).
(20)
若将线程 e i j 迁移至节点 n d ,则原来的 v interExecutor必然由节点 n s 内的线程间数据流变为 n d 与 n s 之间的节点间数据流,即:
(21)
而原来的 v inter _n d 变为了节点 n d 内部的线程间数据流,即:
(22)
此时迁移至节点 n d 上的线程 e i j 形成的节点间数据流总和为
(23)
因此对于迁移后的线程 e i j ,与其相关的数据流总量为
![]() =
= ![]() +
+ ![]() =
= ![]() + v inter _n s +(
+ v inter _n s +( ![]() - v inter _n s ).
- v inter _n s ).
(24)
线程迁移前后拓扑实例模型并未改变,因此有:
v i j = ![]() .
.
(25)
要使得迁移后的拓扑具有更优的通信开销,则根据定理1需获得更大的线程间数据流,即令:
![]() - v interExecutor >0,
- v interExecutor >0,
(26)
由式(22)可知, ![]() 由 v inter _n d 转化而来,即有:
由 v inter _n d 转化而来,即有:
![]() = v inter _n d ,
= v inter _n d ,
(27)
故式(26)等价于
v inter _n d - v interExecutor >0.
(28)
因此,若存在这样的节点 n d ,使得线程 e i j 与 n d 的节点间数据流大于 e i j 与其所在节点 n s 内的线程间数据流,则该线程迁移至节点 n d 后将获得更优的通信开销.
证毕.
定理2阐述了为满足最优通信开销模型的要求,选择迁移目的节点时的理论依据.实际上,定理2还可以从选择待迁移线程的角度出发进行如下描述:
定理2 ′. 迁移优化原则2.若存在这样1个线程,使得该线程与某节点的节点间数据流大于该线程与其所在节点内的线程间数据流,则该线程迁移后将获得更优的通信开销.
定理2′的证明过程与定理2类似,在此不再赘述.
引理1 . 节点间数据流最优性原理.若某线程迁移前与某一节点之间的数据流最大,则迁移到该节点后将转化为最大的线程间数据流,且与其他节点之间的数据流达到最小.
证明. 若存在某节点 n d ( f ( e i j )≠ n d )使得线程 e i j 与 n d 之间的数据流 v inter _n d 最大,则由式(27)可知, e i j 迁移后新形成的线程间数据流 ![]() 最大;又由式(24)和式(25)可知,当
最大;又由式(24)和式(25)可知,当 ![]() 取得最大时,必然使得 e i j 与其他节点之间的数据流
取得最大时,必然使得 e i j 与其他节点之间的数据流 ![]() 达到最小.
达到最小.
证毕.
由定理2和引理1可以得出以下结论:
结论1 . 最优迁移原则.为了通过线程迁移达到最优通信开销原则的要求,需在存在若干节点与待迁移线程之间的数据流大于该线程与其所在节点内的线程形成的数据流的基础上,将线程迁移至具有最大节点间数据流的节点,即
(29)
s.t.
(30)
其中, e i j 为位于节点 n s 上的待迁移线程 ![]() 为迁入的目的节点.值得注意的是:目的节点的选择不能违背资源约束模型的要求.
为迁入的目的节点.值得注意的是:目的节点的选择不能违背资源约束模型的要求.
为保证Storm的性能需求,任务迁移策略需满足3个原则:1)为减少线程的迁移对Storm运行效率的冲击,需最小化迁移开销;2)迁移后各节点的各类资源占用不超过阈值;3)迁移后集群的运行效率得以提高,即令通信开销达到最优.为同时满足以上3个原则的要求,需要实时监测各节点的各类资源剩余情况,当可用资源不足时,选择对该节点运行效率影响最大的线程执行迁移,且同时兼顾降低节点之间的通信开销.本节将围绕任务迁移策略的具体设计过程展开讨论.
当某节点的某类资源占用率持续一段时间超出阈值后,则将该节点标记为源节点,意味着运行在该节点上的某些线程将被迁出.这里需要考虑2种特殊情况:
1) 多个节点的资源占用率同时超出阈值.当这种情况发生时,不便于同时将各节点均标记为源节点.这是因为源节点上的线程在迁移之前需要预测迁移后目的节点的资源剩余情况,而为了寻求最优迁移目标,符合本节提出的3个原则的节点均可作为各源节点上待迁出线程的目的节点,不具有排他性.若多个源节点同时选择了相同的目的节点且并发地将部分线程迁移至此,则迁移后目的节点的资源剩余情况将远小于线程迁移前预测的结果,并可能发生资源溢出.因此就本文研究背景来看,需在时间开销可接受范围内将资源占用率超出阈值的节点分别处理.
2) 同一节点上不同类资源(CPU、内存和网络带宽)的占用率均超出阈值.当某2类资源或者这3类资源的占用率同时超过阈值时,需根据流式计算的特点为各类资源分配不同的优先级.在Storm系统中,内存作为数据临时性存储的唯一介质,一旦溢出将会造成灾难性后果,所以解决内存资源的紧缺性问题最为迫切,优先级应设为最高.其次,CPU执行具体任务,并不可避免地产生序列化、反序列化和保证消息可靠传输等额外开销,网络则负责将CPU计算后的结果在节点之间进行传输,这2类资源均会对拓扑的执行效率产生直接影响,其优先级需针对不同应用中资源占用的倾向不同而人为设定.
综合以上2种情况,我们在主控节点中采用了LinkedHashMap这一数据结构.与HashMap不同的是,LinkedHashMap保存了记录的插入顺序,读取时可按序输出,保证最先发生任务过载的节点被最先处理.当某个节点的某类资源占用率超出阈值后,将  节点ID,资源类型
节点ID,资源类型  这一键值对发送并插入到位于主控节点的LinkedHashMap中;当同一节点上不同类型的资源占用率超出阈值后,执行插入操作时则需根据资源优先级类型进行判断:若当前资源的优先级高于LinkedHashMap中已存有的资源类型,则自动执行替换;否则保持原状.由此设计算法1.
这一键值对发送并插入到位于主控节点的LinkedHashMap中;当同一节点上不同类型的资源占用率超出阈值后,执行插入操作时则需根据资源优先级类型进行判断:若当前资源的优先级高于LinkedHashMap中已存有的资源类型,则自动执行替换;否则保持原状.由此设计算法1.
算法1 . 源节点选择算法.
输入:节点 n 1 , n 2 ,…, n i ,…;CPU占用率阈值 α ,内存占用率阈值 β ,网络带宽占用率阈值 γ ;CPU优先级 pr_cpu ,内存优先级 pr_ram ,网络带宽优先级 pr_bandwidth ;
输出:源节点集 N s ;
初始化: N s ←new LinkedHashMap Node , Resource . /*源节点集*/
① if节点 n i 的内存占用率在时间间隔 T 内持续大于 β then
② N s . put ( n i , “RAM”);
③ end if
④ if节点 n i 的CPU占用率在时间间隔 T 内持续大于 α then
⑤ if N s . containsKey ( n i )=false then
/* n i 为新加入源节点集的节点*/
⑥ N s . put ( n i , “CPU”);
⑦ else
⑧ pr ← getPriority ( N s . get ( n i ));
/*获取 n i 已超出阈值资源的优先级*/
⑨ if pr_cpu > pr then
/*CPU优先级更高*/
⑩ N s . put ( n i , “CPU”);
 end if
end if
 end if
end if
 end if
end if
 return N s .
return N s .
出于篇幅原因,算法1仅以CPU和内存资源为例说明了不同优先级的资源占用率超出阈值时源节点的选择情况.若某一节点的网络带宽资源占用率超出阈值时,其算法逻辑与行④~ 相同,只需把CPU资源替换为网络带宽资源即可.可见,当同一节点上不同类资源占用率均超出阈值时,算法1能够保证优先级高的资源被优先考虑,而优先级低的资源则暂被取代.其可行的原因是后文采用了线程迁移策略,随着线程的迁出,源节点上优先级高的资源问题解决之后,其余类型的资源问题可能随之解决;若没有解决,该节点将由于某类资源占用率超出阈值而继续触发行①和行④的判定条件,进而重新加入源节点集等候处理.各源节点的处理时间很短,不会因某源节点未及时处理而导致资源溢出等严重后果,这将在4.3节的算法评估中详细介绍.
任务迁移分为迁移决策和迁移执行2个过程,其中执行仅作为决策结果的实施,因此本节的重点在于论述任务迁移的决策过程,分为阻尼线程的选择和迁移目的节点的选择2个步骤.
1) 阻尼线程的选择
源节点资源占用率超出阈值后,应迁出运行在该节点上的部分线程以降低负载.为选择合适的待迁移线程,首先引入阻尼线程的概念.
定义5 . 阻尼线程.即决定从源节点迁移出的线程.由于这样的线程对源节点运行效率起到了一定的阻碍作用,故称之为“阻尼”.为使得Storm集群的性能达到最优,需选择阻尼线程进行迁移.
从表面上看,资源占用越大的线程则阻尼越大,为使得某节点的资源占用率迅速降至阈值以下,应采用贪心策略依次将该节点上资源占用最大的线程迁出,直到满足资源约束模型为止.这种做法虽然可以减少迁移次数从而最小化迁移开销,但未将线程之间的通信类型考虑在内,可能导致迁移后节点间通信开销的增加.因此,为同时满足最优通信开销模型的要求,应在尽可能减少迁移次数的前提下,选择那些能够使得节点间通信开销转化为更多节点内线程间通信开销的线程.这样的线程才满足阻尼线程的标准.
2) 目的节点的选择
阻尼线程选定之后,另一个关键问题是目的节点的选择,由结论1可知,选择的目的节点需与阻尼线程之间存在最大节点间数据流,且需满足这样的节点间数据流大于与阻尼线程相关的源节点内线程间数据流.这种做法虽然优化了通信开销,但需在满足资源约束模型的前提下进行迁移,否则可能导致迁移后目的节点负载过重形成新的瓶颈.为了保证容纳阻尼线程迁入的节点资源占用不超出阈值,在阻尼线程迁出源节点之前务必完成剩余资源的估算,下面将以CPU资源为例展开讨论.
为使得Storm任务迁移策略适用于异构环境中,首先对CPU资源进行归一化处理.由于CPU性能的差异,同一线程在不同CPU上的占用率不同.但若将占用率这一百分比数值转化为具体的资源度量单位Hz,即可获取某一特定线程的资源占用数量,与CPU个体差异无关.设与阻尼线程存在直接节点间通信且当前剩余资源充裕的节点集合为备选目的节点集 N d ,令 ![]() 和
和 ![]() 分别为源节点 n s 和备选目的节点 n d ( n d ∈ N d )上线程 e i j 的CPU占用率, f n s 和 f n d 分别为源节点 n s 和备选目的节点 n d 的CPU时钟频率, δ n s 和 δ n d 分别为源节点 n s 和备选目的节点 n d 的CPU核心数,则有:
分别为源节点 n s 和备选目的节点 n d ( n d ∈ N d )上线程 e i j 的CPU占用率, f n s 和 f n d 分别为源节点 n s 和备选目的节点 n d 的CPU时钟频率, δ n s 和 δ n d 分别为源节点 n s 和备选目的节点 n d 的CPU核心数,则有:
(31)
其中 ![]() 均可通过实验获得,故线程 e i j 占用的CPU资源
均可通过实验获得,故线程 e i j 占用的CPU资源 ![]() 容易定量描述.若欲在迁移决策时计算线程 e i j 在备选目的节点上的CPU占用率,则由式(31)变形可得:
容易定量描述.若欲在迁移决策时计算线程 e i j 在备选目的节点上的CPU占用率,则由式(31)变形可得:
![]() /( f n d δ n d ).
/( f n d δ n d ).
(32)
例如,若源节点采用2.5 GHz的双核CPU,备选目的节点采用2.0 GHz的4核CPU,某线程在源节点上的CPU占用率为10%,则根据式(32),得该线程在备选目的节点上的CPU占用率为6.25%.
在迁移的决策过程中,可通过式(33)(34)预测线程迁移后源节点和备选目的节点的资源剩余情况:
(33)
(34)
其中 ![]() 和
和 ![]() 分别表示线程 e i j 迁出前和迁出后源节点的剩余CPU资源
分别表示线程 e i j 迁出前和迁出后源节点的剩余CPU资源 ![]() 和
和 ![]() 分别表示线程 e i j 迁入前和迁入后备选目的节点的剩余CPU资源.由此可得线程迁移决策的一般性原则如下:令
分别表示线程 e i j 迁入前和迁入后备选目的节点的剩余CPU资源.由此可得线程迁移决策的一般性原则如下:令 ![]() 和
和 ![]() 分别表示源节点和备选目的节点的CPU资源总量.在阻尼线程 e i j 迁移的决策过程中,如果预测迁移后有
分别表示源节点和备选目的节点的CPU资源总量.在阻尼线程 e i j 迁移的决策过程中,如果预测迁移后有 ![]() 则只需将该线程迁出即可,迁移结束;否则需要继续迁出其他线程,直到源节点资源占用低于阈值为止.如果预测迁移后有
则只需将该线程迁出即可,迁移结束;否则需要继续迁出其他线程,直到源节点资源占用低于阈值为止.如果预测迁移后有 ![]() 且剩余内存和网络带宽资源充裕,表示线程 e i j 可被允许迁入至该备选目的节点;否则该节点剩余资源不足,拒绝该线程的放置.在确保所有节点均满足资源约束模型的要求后,接下来即可遵循最优迁移模型中的思想实现线程的最优迁移,具体过程如算法2所示:
且剩余内存和网络带宽资源充裕,表示线程 e i j 可被允许迁入至该备选目的节点;否则该节点剩余资源不足,拒绝该线程的放置.在确保所有节点均满足资源约束模型的要求后,接下来即可遵循最优迁移模型中的思想实现线程的最优迁移,具体过程如算法2所示:
算法2 . 任务迁移算法.
输入:节点 n 1 , n 2 ,…, n i ,…;源节点集 N s ;
初始化: n s ←new Node ; /*源节点*/
![]() Executor ;
Executor ;
/*分配在源节点上的有序线程集合*/
v interExecutor ←0; /*当前线程与源节点内的前驱和后继线程构成的线程间数据流大小*/
N d ←new Array Node ; /*备选目的节点集*/
![]() ; /*目的节点*/
; /*目的节点*/
v inter _n d ←0; /*当前线程与某备选目的节点上的前驱和后继线程构成的节点间数据流大小*/
v max ←0. /*最大节点间数据流*/
① n s ←获取 N s 中的第1个元素;
② ![]() ←将节点 n s 中包含的所有线程按其对应资源的占用率大小递减排序;
←将节点 n s 中包含的所有线程按其对应资源的占用率大小递减排序;
③ ![]()
④ 若源节点剩余资源充裕则跳出该循环,不再迁移下一个线程,否则执行下述语句;
⑤ 根据式(17)计算 v interExecutor ;
⑥ N d ←与线程 i 存在直接节点间通信且当前剩余资源充裕的节点;
⑦ for n d = N d [0] to N d .Length-1 do
⑧ if预测节点 n d 容纳线程 i 后依然满足
资源约束模型then
⑨ 根据式(19)计算 v inter _n d ;
⑩ if v inter _n d > v max then
v max ← v inter _n d ;
![]()
end if
end if
 end for
end for
 if v interExecutor < v max then
if v interExecutor < v max then
/*当前线程与目的节点的节点间数据流大于该线程与所在源节点内的线程间数据流*/
 将线程 i 异步迁移至节点
将线程 i 异步迁移至节点 ![]() 并更新节点 n s 和
并更新节点 n s 和 ![]() 上的剩余资源情况;
上的剩余资源情况;
 end if
end if
 end for
end for
 N s . remove ( n s ).
N s . remove ( n s ).
/*该源节点上所有阻尼线程及其迁出的目的节点决策完成,从源节点集中删去该节点*/
算法2中行③~ 为源节点线程迁移的决策过程,行 表示线程迁移的异步执行.迁移执行时源节点内的阻尼线程将被分配至目的节点内运行,进程Nimbus将随之更新进程ZooKeeper所在节点上与该线程相关的任务分配信息,新生成的数据流将被重定向至新的节点.需要说明的是,由于Storm自定义调度器异步执行任务迁移,算法2的运行效率不会受到迁移执行效率的影响,且源节点和目的节点上的剩余资源情况可根据式(33)和式(34)进行预先估计并更新,待迁移执行完毕后再通过实时监测结果进行刷新.这种做法可在本次迁移执行的同时进入下一次迁移决策,大幅缩短了各源节点的处理时间,实现了线程的高效迁移.
4.3.1 算法复杂度分析
算法1实质上为LinkedHashMap的插入和替换算法,时间复杂度为 O (1).下面将针对算法2中迁移决策的计算开销和迁移执行开销进行分析.
本文在资源约束模型中设定了相关阈值以保证各节点不会过载.设在满足这些约束条件的情况下,各异构节点 N ={ n 1 , n 2 ,…, n | N | }最大能够承载的线程数量分别为 h n 1 , h n 2 ,…, h n | N | ,而实际上由Storm默认调度策略分配于各节点的线程数量分别为 ![]() ,
, ![]() ,…,
,…, ![]() ,则对于∀ n s ∈ N ,迁移次数最多
,则对于∀ n s ∈ N ,迁移次数最多
为Δ h n s = ![]() - h n s .设与阻尼线程 e i j ∈ f -1 ( n s )存在直接通信的线程总数为 y e i j ,则算法2执行的最坏时间复杂度为 O ( y e i j ×Δ h n s ),即在常数时间内即可完成1个源节点上阻尼线程和迁移目的节点的计算,因此不会因下一个源节点未及时处理而导致资源溢出等严重后果.
- h n s .设与阻尼线程 e i j ∈ f -1 ( n s )存在直接通信的线程总数为 y e i j ,则算法2执行的最坏时间复杂度为 O ( y e i j ×Δ h n s ),即在常数时间内即可完成1个源节点上阻尼线程和迁移目的节点的计算,因此不会因下一个源节点未及时处理而导致资源溢出等严重后果.
对异步迁移的执行开销进行分析.由上一段文字可知,对于Storm集群的迁移过程而言,总迁移次数最多为 ![]() 仅对少量线程产生影响,远小于将各线程完全重部署的代价.特别是在数据流变化迅速的业务需求下,迁移策略更能在较短时间内快速响应变化.
仅对少量线程产生影响,远小于将各线程完全重部署的代价.特别是在数据流变化迅速的业务需求下,迁移策略更能在较短时间内快速响应变化.
4.3.2 算法执行效果分析
如3.3节所述,Storm拓扑在各节点上的分配是一个二次型三维约束条件的多背包问题,无法在多项式时间内找到全局最优解,但可以采用已有研究的方法将拓扑重部署以寻求近似全局最优 [43-45] .而本文提出的线程迁移仅针对阻尼线程重新调度,可看作是任务分配模型的局部优化.本节将通过对比分析,针对局部优化后的效果展开讨论.
流式计算的性能可使用各任务计算的时间开销和任务间传输的时间开销进行衡量.为了实现任务的线程级并行,通常1个线程只包含1个任务,因此文中线程与任务的含义一致.根据文献[41]中流式计算模式下计算和通信开销的评估方法可知,对于运行在源节点 n s 上的任意1个线程 e i j ,其计算开销可表示为
(35)
其中, p n s 为源节点 n s 的计算能力,可使用其剩余计算资源的多少进行衡量,通常包括CPU资源和内存资源2个方面.在其他条件不变的前提下,线程的计算开销与其所在节点的计算能力成反比,即剩余的计算资源越多则计算能力越强,计算开销越小,反之则计算能力越弱,计算开销越大.此外,式(35)中 τ e i j 为线程 e i j 中任务的时间复杂度 ![]() 为线程 e i j 接收到的数据流大小, F e 为以上3个变量与线程 e i j 的计算开销 t e i j 之间的函数关系.
为线程 e i j 接收到的数据流大小, F e 为以上3个变量与线程 e i j 的计算开销 t e i j 之间的函数关系.
以CPU资源为例,设算法2中行②排序后的线程集合表示为 ![]() 若依次将
若依次将 ![]() 中的线程从源节点 n s 迁移至目的节点,则对于任意
中的线程从源节点 n s 迁移至目的节点,则对于任意 ![]() 其迁移后的计算开销可表示为
其迁移后的计算开销可表示为
(36)
其中 ![]() 为当前线程 e i j 决策后迁入的目的节点,则
为当前线程 e i j 决策后迁入的目的节点,则 ![]() 为当前目的节点
为当前目的节点 ![]() 的计算能力,由算法2可知,为提高线程的运行效率,目的节点的剩余资源需大于源节点的剩余资源,因此有
的计算能力,由算法2可知,为提高线程的运行效率,目的节点的剩余资源需大于源节点的剩余资源,因此有 ![]() ;而拓扑一旦提交则其包含的具体任务和数据流数量固定,线程的迁移仅能带来节点间以及节点内线程间通信方式的相互转化,并不会带来任务时间复杂度和接收数据流大小的改变,因此 τ e i j 和
;而拓扑一旦提交则其包含的具体任务和数据流数量固定,线程的迁移仅能带来节点间以及节点内线程间通信方式的相互转化,并不会带来任务时间复杂度和接收数据流大小的改变,因此 τ e i j 和 ![]() 保持原状,可将式(35)和式(36)中的 τ e i j 和
保持原状,可将式(35)和式(36)中的 τ e i j 和 ![]() 看作常量,有关系:
看作常量,有关系:
![]() ).
).
(37)
式(37)为线程 e i j 迁移前在源节点 n s 上的计算开销与迁移后在目的节点 ![]() 上的计算开销的差值,表明了线程因迁移而降低的计算开销,可见Δ t e i j 仅与源节点和目的节点的计算能力有关.当迁移第1个线程时,由于线程占用计算资源最大且源节点 n s 上资源紧缺,那么 n s 的计算能力 p n s 必然很小, F e ( p n s )必然很大,此时 e i j 的迁移将能够获得最大的性能提升.若在此基础上继续优化迁移
上的计算开销的差值,表明了线程因迁移而降低的计算开销,可见Δ t e i j 仅与源节点和目的节点的计算能力有关.当迁移第1个线程时,由于线程占用计算资源最大且源节点 n s 上资源紧缺,那么 n s 的计算能力 p n s 必然很小, F e ( p n s )必然很大,此时 e i j 的迁移将能够获得最大的性能提升.若在此基础上继续优化迁移 ![]() 中的其他线程,设
中的其他线程,设 ![]() 为第 k -1次迁移完成后源节点 n s 的计算能力
为第 k -1次迁移完成后源节点 n s 的计算能力 ![]() 为第 k 次迁移获得的计算能力,则第 k 次迁移完成后源节点 n s 的计算能力为
为第 k 次迁移获得的计算能力,则第 k 次迁移完成后源节点 n s 的计算能力为
(38)
随着迁移次数 k 的增加,每次迁移后源节点 n s 可获得的计算能力提升将愈加有限,即:
且
故 n s 上各线程的计算开销 F e ( p n s )下降的速率将逐渐变缓.而对于剩余资源充裕的各目的节点而言,每次迁移过程相对独立,当前线程迁移选择的目的节点的计算能力 ![]() 可看作是与上次迁移无关的量.因此,随着源节点 n s 上线程的迁出,其计算能力与当前选择的目的节点
可看作是与上次迁移无关的量.因此,随着源节点 n s 上线程的迁出,其计算能力与当前选择的目的节点 ![]() 的计算能力的差距将越来越小.若在第 m 次迁移完成后线程的计算开销不再降低,则此时已达到拓扑近似全局最优的线程分配,可表示为
的计算能力的差距将越来越小.若在第 m 次迁移完成后线程的计算开销不再降低,则此时已达到拓扑近似全局最优的线程分配,可表示为
(39)
其中 ![]() 分别表示第 m 次迁移前源节点 n s 的计算能力、迁移后目的节点
分别表示第 m 次迁移前源节点 n s 的计算能力、迁移后目的节点 ![]() 的计算能力以及迁移后降低的计算开销.结合式(37)和式(38)可知,在共计 m 次的线程迁移过程中,计算开销逐渐降低且下降的速率逐渐变缓.
的计算能力以及迁移后降低的计算开销.结合式(37)和式(38)可知,在共计 m 次的线程迁移过程中,计算开销逐渐降低且下降的速率逐渐变缓.
同理可分析各对线程之间的通信开销,其函数关系为
(40)
其中 ![]() 为存在直接通信的1对线程 e i j 与 e k l 之间剩余的网络带宽资源,若 e i j 与 e k l 运行于不同的节点,那么在其他条件不变的前提下,线程的通信开销与链路上剩余的网络带宽资源成反比,即剩余的网络带宽资源越多则通信开销越小,反之则通信开销越大;若 e i j 与 e k l 运行于相同的节点,则其通信方式为节点内线程间通信,相当于此时拥有无穷多的网络带宽资源,开销可忽略不计.式(40)中, l i j , k l 为线程 e i j 所在节点与 e k l 所在节点间的物理距离,由于本文的研究背景为集中式数据中心,各节点间的网络传输距离基本相同,因此当 e i j 与 e k l 运行于不同的节点时 l i j , k l 为一定值,当 e i j 与 e k l 运行于同一节点时该值为0.此外, v i j , k l 表示 e i j 与 e k l 之间的数据流大小; F s 表示以上3个变量与通信开销 t i j , k l 之间的函数关系.
为存在直接通信的1对线程 e i j 与 e k l 之间剩余的网络带宽资源,若 e i j 与 e k l 运行于不同的节点,那么在其他条件不变的前提下,线程的通信开销与链路上剩余的网络带宽资源成反比,即剩余的网络带宽资源越多则通信开销越小,反之则通信开销越大;若 e i j 与 e k l 运行于相同的节点,则其通信方式为节点内线程间通信,相当于此时拥有无穷多的网络带宽资源,开销可忽略不计.式(40)中, l i j , k l 为线程 e i j 所在节点与 e k l 所在节点间的物理距离,由于本文的研究背景为集中式数据中心,各节点间的网络传输距离基本相同,因此当 e i j 与 e k l 运行于不同的节点时 l i j , k l 为一定值,当 e i j 与 e k l 运行于同一节点时该值为0.此外, v i j , k l 表示 e i j 与 e k l 之间的数据流大小; F s 表示以上3个变量与通信开销 t i j , k l 之间的函数关系.
设 ![]() 为源节点 n s 上的所有线程按网络带宽占用率大小递减排列后的有序线程集合,若依次将
为源节点 n s 上的所有线程按网络带宽占用率大小递减排列后的有序线程集合,若依次将 ![]() 中的线程从源节点 n s 迁移至目的节点,则对于任意
中的线程从源节点 n s 迁移至目的节点,则对于任意 ![]() 其迁移后的通信开销可表示为
其迁移后的通信开销可表示为
(41)
其中 ![]() 为迁移后线程 e i j 与 e k 之间剩余的网络带宽资源,
为迁移后线程 e i j 与 e k 之间剩余的网络带宽资源, ![]() 为迁移后线程 e i j 与 e k l 之间的距离,数据流大小 v i j , k l 不发生变化.由之前的分析可知,迁移后距离虽然可能改变,但其值仅与相互通信的1对线程所处的节点位置相关且具有二值性,可看作是因带宽资源
为迁移后线程 e i j 与 e k l 之间的距离,数据流大小 v i j , k l 不发生变化.由之前的分析可知,迁移后距离虽然可能改变,但其值仅与相互通信的1对线程所处的节点位置相关且具有二值性,可看作是因带宽资源 ![]() 变化而变化的1个中间变量.因此有:
变化而变化的1个中间变量.因此有:
![]() ).
).
(42)
式(42)为迁移前线程 e i j 与 e k l 之间的通信开销与迁移后线程 e i j 与 e k l 之间的通信开销的差值,表明了线程因迁移而降低的通信开销,可见Δ t i j , k l 仅与线程 e i j 与 e k l 之间剩余的网络带宽资源有关.接下来即可采用与上述评估计算开销相同的方法进行各次迁移过程中通信开销的评估.结果表明,若在第 m 次迁移完成后,各对线程之间的通信开销已达最优,则在共计 m 次的线程迁移过程中,通信开销逐渐降低且下降的速率逐渐变缓,能够由节点间通信转化为节点内线程间通信的数据流将越来越少.
设采用Storm默认调度策略的线程分配结果为 G ,采用本文策略进行局部迁移后的线程分配结果为 G ′,拓扑重部署后达到的近似全局最优的线程分配结果为 G ″.如4.3.1节所述,在 G 向 G ′演变的过程中,对于∀ n s ∈ N ,线程的迁移次数最多为Δ h n s ;若要使得 G ′与 G ″相等,则需在 G ′的基础上继续迁移位于 n s 上的 m -Δ h n s 个线程.设第 i 次线程迁移可降低的计算和通信开销共为Δ t i ,则由 G 演变到 G ′的Δ h n s 次迁移过程中可降低的开销总和为
(43)
平均每次迁移可降低的开销为
![]() /Δ h n s .
/Δ h n s .
(44)
在此基础上若再进行 m -Δ h n s 次迁移,即由 G ′演变到 G ″的过程中可降低的开销总和为
(45)
平均每次迁移可降低的开销为
![]() /( m -Δ h n s ).
/( m -Δ h n s ).
(46)
由 G 到 G ″的 m 次迁移过程中可降低的开销总和为
(47)
平均每次迁移可降低的开销为
![]() / m .
/ m .
(48)
由本节分析可知,随着线程的迁移,各线程计算开销和线程之间通信开销的下降速率均变缓,降低计算开销和通信开销的过程将变得愈加困难,因此存在 ![]() 可见线程的局部迁移为集群性能的提升作出了主要贡献.若一味地追求近似全局最优,其后续迁移开销将远大于迁移后带来的价值,对于Storm这一高实时性系统而言并非适用.因此本文提出的线程迁移策略能运用较少的迁移次数获得较大的性能提升,达到了预期效果.
可见线程的局部迁移为集群性能的提升作出了主要贡献.若一味地追求近似全局最优,其后续迁移开销将远大于迁移后带来的价值,对于Storm这一高实时性系统而言并非适用.因此本文提出的线程迁移策略能运用较少的迁移次数获得较大的性能提升,达到了预期效果.
Storm为编程人员提供了可插拔的自定义调度器.为部署本文提出的任务迁移策略,需实现backtype.storm.scheduler.IScheduler接口中的 schedule 方法,其原型为public void schedule (Topologies topologies , Cluster cluster ).其中对象 topologies 包含当前集群运行的所有拓扑信息,包括各类参数的配置信息以及线程到组件ID的映射关系等;对象 cluster 包含当前集群的所有状态信息,包括拓扑中各线程在节点和进程上的映射信息、节点和槽的使用与空闲信息等.以上信息均可通过各对象的API获得.对于拓扑中各线程的CPU资源占用信息,可通过Java API中ThreadMXBean类的 getThreadCpuTime (long id )方法获取,其中 id 为线程ID;对于各线程的网络带宽资源占用信息,可通过Storm UI提供的REST API获取节点间各线程的元组传输速率,并结合实验中设置的元组大小,通过累加简单估算求得;而由于各线程存在共享内存,则对于各线程的内存资源占用情况,仅能结合storm.yaml文件中配置的 worker . childopts 参数和jstack等JVM性能监控工具进行粗略估计;此外,操作系统中硬件相关参数和负载信息可通过/proc目录下相关文件获取.代码编写完毕后,将其打jar包至${ STORM_HOME }/lib目录下,并在主控节点的storm.yaml文件中配置参数 storm . scheduler 即可运行.
改进的Storm架构如图5所示.需要说明的是,运行进程UI的控制台节点和运行进程ZooKeeper的协调节点仍保持原状,故图5中将其相关部分省去.改进的Storm系统架构中新增4个模块:
1) 负载监视器(load monitor).在一定时间窗口内,收集各线程占用的CPU、内存和网络带宽负载信息及各线程之间的数据流大小.部署时需在各Spout的 open ()和 nextTuple ()方法以及各Bolt的 prepare ()和 execute ()方法中调用该模块.
2) MySQL数据库(MySQL Database).存储任务分配信息和负载监视器传来的负载信息,并实时更新.
3) 迁移发生器(migration generator).部署算法1和算法2.负责读取数据库中的负载信息,并作出任务迁移决策.
4) 自定义调度器(custom scheduler).覆盖主控节点的默认调度策略,读取迁移发生器的调度决策并执行迁移.

Fig. 5 Improved architecture of Storm
图5 改进的Storm系统架构
为验证任务迁移策略的有效性,本节将通过下述实验进行比较和评价.
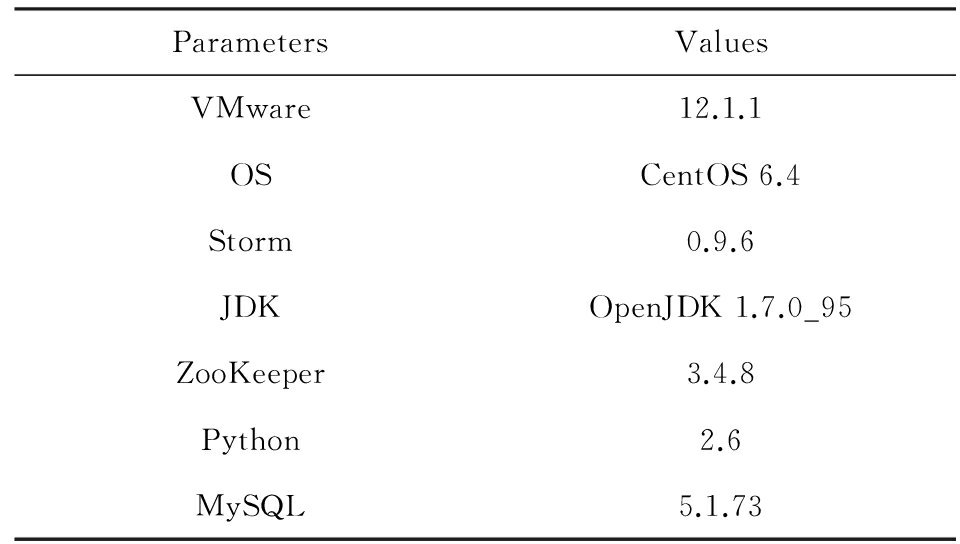
为更好地观测资源有限且节点异构的情况下任务迁移策略的执行过程,实验环境采用不同硬件配置的PC机搭建1个包含有20个节点的Storm集群,其中运行进程Nimbus、进程UI和数据库服务MySQL的主控节点1个,运行进程ZooKeeper的协调节点3个,其余16个为运行进程Supervisor的工作节点.表1列出了各节点具体的硬件配置,其中各工作节点的CPU仅使用其单核的处理能力,硬盘容量为250 GB,转速为7 200 r/min,接口为SATA3.0.在表1中,根据运行进程Supervisor的16个工作节点的硬件配置的高低,可大体将工作节点分为低端、中端和高端3类,为简便起见,下文将运行进程Supervisor 1~3的工作节点简称为低配节点,将运行进程Supervisor 4~13的工作节点简称为中配节点,将运行进程Supervisor 14~16的工作节点简称为高配节点.除硬件配置之外,各节点软件方面配置相同,如表2所示.
Table 1 Hardware Configuration of Storm Cluster
表1 Storm集群硬件配置
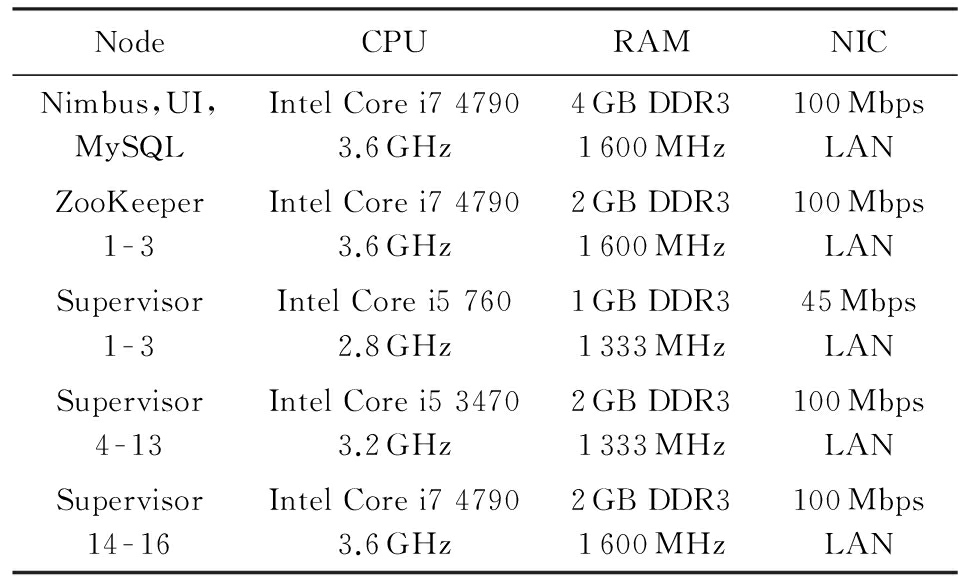
Table 2 Software Configuration of Storm Cluster
表2 Storm集群软件配置
为全面测试任务迁移策略在各类不同资源开销下的有效性,实验数据选取GitHub上storm-benchmark-master提供的4组基准测试用例,分别是CPU敏感型(CPU-sensitive)的WordCount、内存敏感型(memory-sensitive)的RollingSort、网络带宽敏感型(network-sensitive)的SOL以及Storm真实场景下的应用RollingCount [46] .各基准测试均采用其自带的文本文档作为输入数据.表3列出了各项参数配置,需要进一步解释的参数如下:1) component . xxx_num 为该基准测试中设置的组件并行度,即1个Spout或Bolt运行的实例(线程)数量.2) topology . pr_xxx 为运行该项基准测试时设置的资源优先级,其值越大表示该类资源的优先级越高,在源节点选择算法运行时将被优先考虑.3)SOL中的 topology . level 表示拓扑的层次,即其包含的组件数量,需设置为大于或等于2的整数;本文设置该值为3,结合 component . xxx_num 参数配置来看,该拓扑应包含有1个运行着64个实例的
Table 3 Configuration of Benchmarks
表3 基准测试参数配置

Spout和2个运行着128个实例的Bolt,其包含的线程总数与WordCount和RollingCount一致,但与RollingSort不同.除表3所示配置之外还需进行一些通用配置:1)为消除进程间通信开销,各基准测试运行时仅在1个工作节点内分配1个工作进程,即设置 topology . workers 为16;2)为保证数据流的可靠传输,各工作进程除了运行分配给它的线程之外,还额外运行1个Acker Bolt实例,即设置 topology . acker . executors 为16;3)为方便实验观测而有意提高工作节点负载,但需保证在表3的配置下防止元组传输因超时而重传,通过多次实验结果设置 topology . max . spout . pending 的合适值为100;4)为结合以上配置而适时触发任务迁移,设定CPU占用率阈值 α 、内存占用率阈值 β 和网络带宽占用率阈值 γ 均为70%,设定任务迁移策略的触发周期 T 为30 s,表示系统在趋于稳定后,若某类资源占用率在30 s内持续超过70%,则触发任务迁移策略.
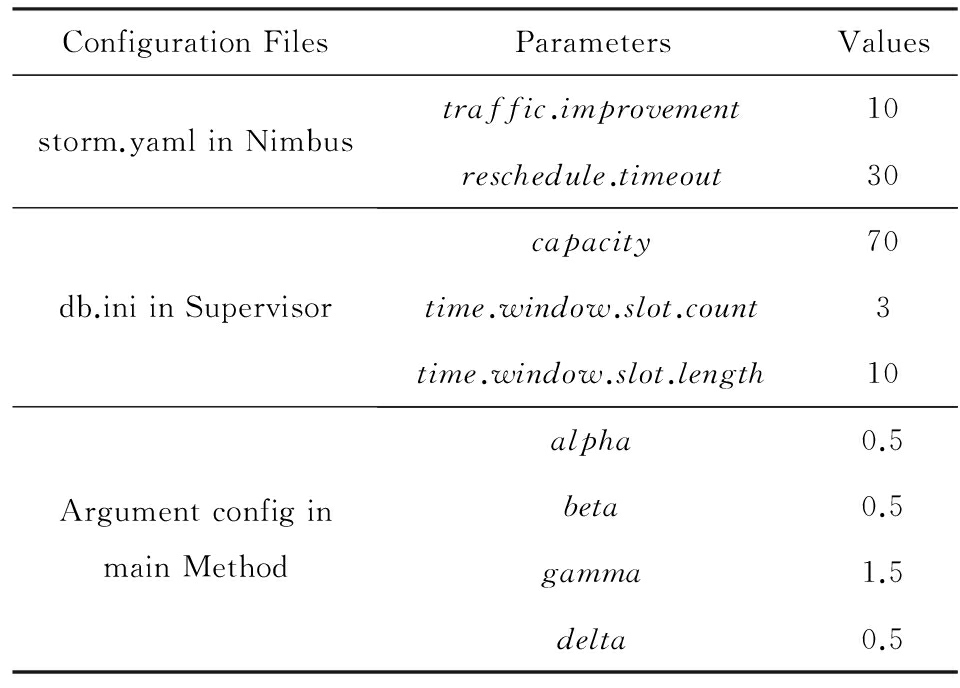
为验证本文迁移策略的有效性,文中除了与Storm默认轮询策略进行对比之外,还部署了文献[43]的Storm自适应在线调度策略.其核心思想是实时监测CPU负载情况和各对线程之间的数据流大小,当CPU负载持续超出阈值时触发任务重部署机制,即首先按照大小递减的顺序排列拓扑中各对线程之间的数据流,然后将线程逐对调度至那些能够令其部署后产生最低CPU负载的工作进程和工作节点中.该策略可看作是任务重部署策略的代表,下文简称为在线策略.表4列出了采用在线策略时的各项参数配置.需要说明的是,表4中的 reschedule . timeout 为在线策略的触发周期, capacity 为在线策略中CPU的使用率上限,这2个值分别与本文算法中的 T 和 α 值设置一致,目的是在同等CPU负载条件下触发任务调度;此外,最后4项为在线策略中为优化拓扑执行效率而人为设定的值,与本文提到的资源占用率阈值 α , β , γ 无关.
Table 4 Configuration of Online Scheduler
表4 在线策略参数设置
本节首先使用WordCount,RollingSort,SOL这3组资源敏感型的基准测试在延迟、资源占用和工作节点间通信开销这3个方面进行任务迁移策略的评估,最后使用RollingCount这一Storm环境下的真实场景在延迟方面进行测试.为便于数据统计,以下测试均设置 metrics . poll =5 s, metrics . time =300 s,即每组实验每5 s进行1次采样,时长为5 min.
5.2.1 延迟测试
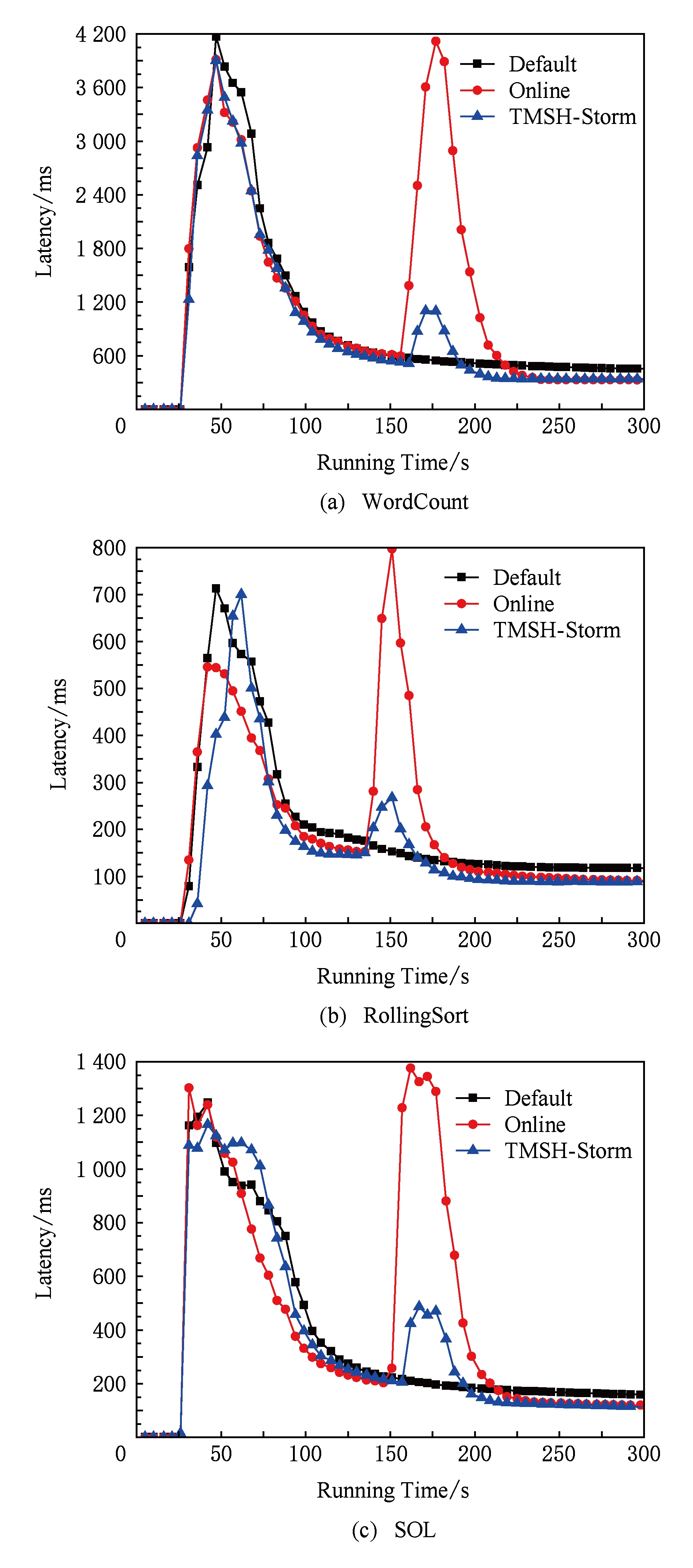
Fig. 6 Comparison of latency among different task scheduling strategies
图6 不同任务调度策略下的系统延迟对比
延迟表明了1个元组从Spout发射到最终被成功处理的时间消耗,反应了拓扑执行1次的响应时间,刻画了系统的运行效率.图6统计了基准测试WordCount,RollingSort,SOL在Storm默认策略(Default)、在线策略(Online)和任务迁移策略(TMSH-Storm)下的系统延迟.
如图6所示,从0开始到第1个峰值结束时间段表明各拓扑提交时的部署过程,此时的调度均遵循Storm默认策略,故在同一个基准测试中,各策略均需在这一阶段耗费几乎相同的时间,元组的处理延迟也大体相同.第1个峰值过后,系统延迟逐渐趋于收敛,在线策略与任务迁移策略开始收集集群中各工作节点以及工作节点上各线程占用的CPU、内存和网络带宽负载信息及各线程之间的数据流大小,为各线程的优化配置提供决策依据.
图6(a)展示了各策略执行1次WordCount过程中的系统延迟.可见在第160 s时在线策略触发,延迟出现极高峰值.这是由于在线策略需根据各线程的CPU负载和各对线程之间数据流的大小情况,将拓扑中包含的所有线程在各工作节点上重新分配,整个过程相当于拓扑提交时的初始化任务分配,执行开销较大,此时数据流因无法及时处理而导致延迟出现极高峰值.由图6(a)可知,该策略执行对系统延迟的影响时长约在第160~205 s范围内,共耗时约45 s,平均延迟约2.369 s,这将影响Storm系统处理数据的实时性并易导致数据流处理失败.而任务迁移策略因只影响超出阈值的一小部分线程,执行开销较小.迁移发生在第165~185 s之间,共耗时约20 s,平均延迟约920.1 ms,有效降低了算法执行过程对集群性能的冲击.
接下来对内存敏感型的RollingSort和网络带宽敏感型的SOL进行测试.需要说明的是,仅当CPU负载在30 s内持续超过70%时在线策略才会被触发生效,对于其他资源占用率超出阈值的情况并不作任何处理.本文为了更全面地开展对比实验,特经过反复调参设定各值(如表3所示),以保证在RollingSort和SOL的运行过程中,存在1个以上的工作节点在超出内存和网络带宽阈值但不发生资源溢出的同时,令其CPU占用率也超出阈值,这样即满足了在线策略触发的条件.由图6(b)和图6(c)可以看出,RollingSort和SOL的执行过程与Word-Count类似,分别约在第140~170 s和第155~195 s期间执行在线策略,平均延迟分别约为471.4 ms和983.6 ms;在第140~160 s和160~185 s期间执行任务迁移策略,平均延迟分别约为217.4 ms和408.1 ms,分别仅为在线策略的46.1%和41.5%.其中Rolling-Sort的初次部署和重部署消耗的时间都略小于其他基准测试,这是因为它的组件中仅存在1个包含有64个线程的Spout和1个包含有128个线程的Bolt,相对于WordCount和SOL,其包含的线程数更少,因此具有更低的部署开销;而SOL的迁移时间略大于其他的基准测试,这是因为它需要迁移的线程数量更多,具体原因将在5.2.2节中进行阐述.
在线策略和任务迁移策略执行完毕后,系统延迟再次趋于收敛,且表现明显低于默认策略.在WordCount中,2种策略的系统延迟分别稳定在332.4 ms和340.8 ms,相对于默认策略分别降低约28.7%和26.9%;在RollingSort中,延迟分别稳定在93.3 ms和88.4 ms,相比默认策略降低约21.1%和25.3%;在SOL中,延迟分别稳定在123.1 ms和118.6 ms,相比默认策略降低约24.6%和27.4%.可以看到,在WordCount基准测试中,任务迁移策略稳定后的表现稍逊色于在线策略;而在RollingSort和SOL基准测试中,任务迁移策略稳定后的表现甚至略优于在线策略.这是因为在线策略在进行拓扑中各线程重部署时仅考虑到CPU资源剩余情况,对于集群中各工作节点而言,这样的分配策略仅可在一定程度上满足CPU这一资源层面上的负载均衡,适合于WordCount这类CPU敏感型的应用;而就本实验中各工作节点的硬件配置来看,10个中配节点和3个高配节点均具有相同的内存大小和网络带宽,若仅从CPU资源方面考虑,3个高配节点必将承载更多的线程放置,进而导致内存和网络带宽剩余资源紧缺形成性能瓶颈.而任务迁移策略充分考虑到各工作节点中各类资源的剩余情况,优化迁移负载超出阈值的线程,保证各类资源的剩余情况均在阈值设定范围之内,因此在RollingSort和SOL测试中表现更佳.
综上所述,相对于Storm默认调度机制,在线策略和任务迁移策略均能有效降低系统延迟.而由于任务迁移策略能够统筹兼顾工作节点中各类资源的剩余情况,且只针对负载超出阈值的少量线程进行迁移,因此更加适用于不同种类的应用场景,且执行过程不会对集群运行效率造成较大影响,保证了大数据流式处理的实时性.
5.2.2 资源占用测试
本节讨论在Storm默认调度策略、在线策略和任务迁移策略下,CPU敏感型的WordCount、内存敏感型的RollingSort和网络带宽敏感型的SOL分别运行时的资源占用情况.由于这3组基准测试具有明显不同的资源占用倾向,因此只需分别测试其倾向于占用的资源类型即可.图7展示了各基准测试在3类调度策略下运行稳定后各工作节点的资源占用情况.
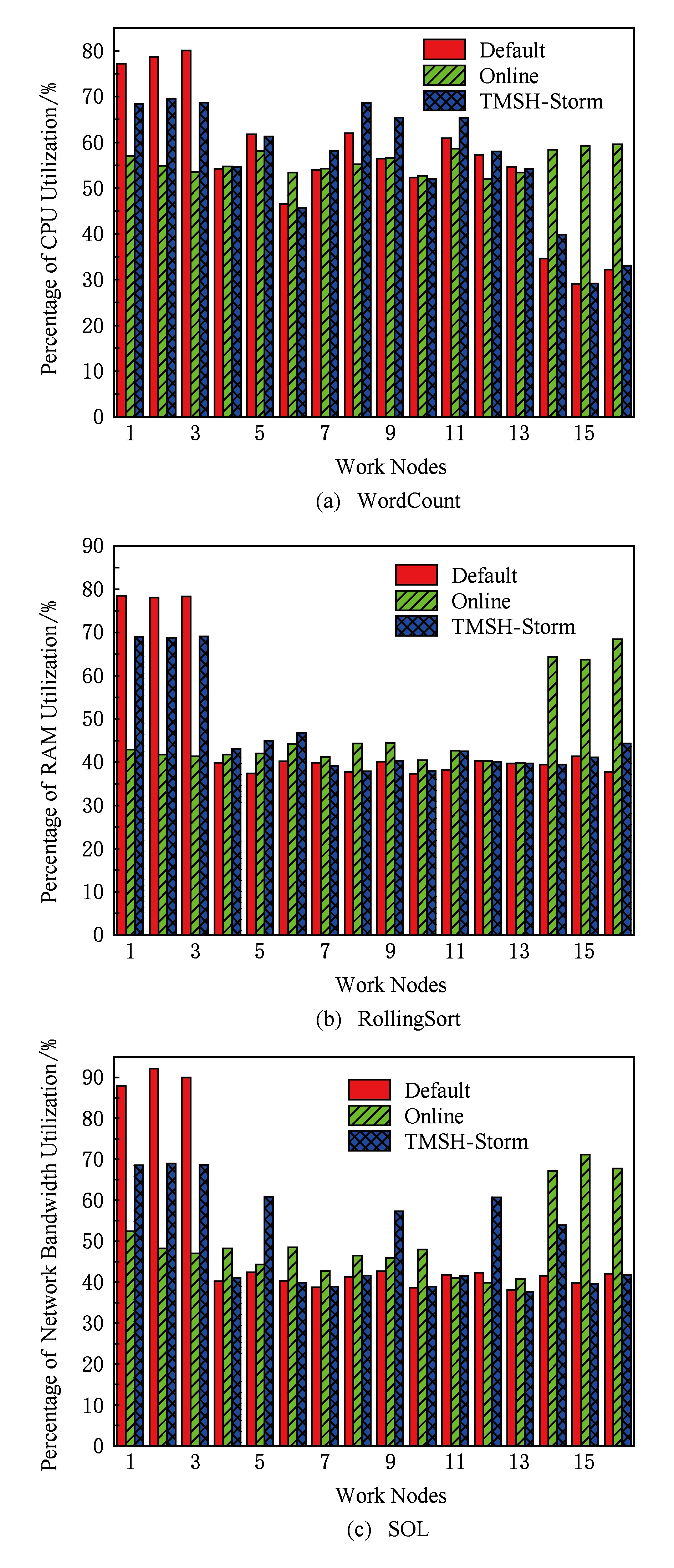
Fig. 7 Comparison of resource occupancy rate among different task scheduling strategies
图7 不同任务调度策略下的资源占用率对比
由图7可知,由于Storm轮询的调度机制为各工作节点分配相同的线程个数,忽略了彼此之间的性能差异,因此各工作节点上的负载分配并不均匀,3个低配节点上的各类资源占用均已超出阈值.图7(a)表示WordCount运行时各工作节点的CPU占用率.由于低配、中配和高配3类节点具有明显的CPU性能差异,因此在默认策略中显示出了明显的阶梯特征,性能越低的工作节点CPU占用率越高,而同等配置的若干工作节点之间CPU占用率差距不大.图7(b)(c)分别表示RollingSort运行时各工作节点的内存占用率和SOL运行时各工作节点的网络带宽占用率.由于在表1的硬件配置中,中高配节点的内存和网络带宽性能相同,仅与3个低配节点存在性能差异,因此中高配节点上这2类资源的占用率相差不大,而低配节点的占用率明显更高,且资源占用与其拥有的资源总量基本呈现反比关系.以图7(b)为例,对于配置了1 GB内存的3个低配节点,其内存占用率平均值为78.3%;而对于配置了2 GB内存的其他13个工作节点,其内存占用平均值仅为39.2%,约为低配节点的一半左右.可见默认策略仅适用于Storm同构环境,异构环境中则极易造成严重的资源占用倾斜甚至溢出.
在线策略根据CPU负载和各对线程之间的数据流大小情况实现在线任务重部署.这种做法执行开销较大,但针对CPU敏感型的拓扑而言,能够达到异构环境下CPU层面上负载均衡的效果.图7(a)充分说明了这一点,可以看出在线策略运行稳定后各工作节点的CPU占用率基本均衡.但在图7(b)和(c)中,高配节点的内存和网络带宽占用率明显更高,甚至在图7(c)的Supervisor 15中,网络带宽占用率已超出设定的阈值.这是由于在线策略仅孤立地考虑CPU负载,而忽略了其他资源的剩余情况.在本实验的硬件配置环境下,10个中配节点和3个高配节点的CPU配置不同,而内存和网络带宽配置一致,当在线策略执行后,势必导致更多的线程分配至高配节点,内存和网络带宽占用率必将大幅上升.特别地,当高配节点CPU性能更高,而其他类型的硬件配置与中配节点持平甚至更低的情况下,内存与网络带宽资源可能发生溢出并导致拓扑无法执行.这是在线策略的另一个缺陷.
探讨本文提出的任务迁移策略.当某工作节点上某类资源的占用率持续30 s超出阈值时,迁移发生器根据本文提出的源节点选择算法和任务迁移算法,选择少量线程执行迁移,直到集群中不存在任何工作节点的任意类型资源负载超出阈值为止.由于任务迁移策略触发前采用的依旧是Storm默认轮询的调度机制,因此可将图中的Default策略看成是迁移策略执行前各工作节点的资源占用情况.由图7可知,WordCount,RollingSort,SOL在默认策略下运行时,3个低配节点的CPU、内存和网络带宽占用已分别超出阈值.当任务迁移策略执行完毕并趋于稳定后,低配节点上的若干线程迁移到了其他节点,任务过载问题均得以解决.此时通过Storm UI观测发现,在图7(a)所示的WordCount运行过程中,原分布在3个低配节点上的11个线程分别迁移到了节点Supervisor 7,8,9,11,14上,其中节点Supervisor 9容纳3个线程,其余节点各容纳2个线程;同理,在图7(b)所示的RollingSort运行过程中,原分布在3个低配节点上的8个线程分别迁移到了节点Supervisor 4,5,6,11,16上,其中节点Supervisor 4和11分别容纳1个线程,其余节点各容纳2个线程.在图7(c)所示的SOL运行过程中,3个低配节点的网络带宽占用率分别为87.9%,92.1%,90%,已较大程度超出阈值,因此迁移的线程数量较多.据统计,低配节点中共计27个线程分别迁移到了节点Supervisor 5,9,12,14上,各节点分别容纳8个、6个、8个和5个线程.由此可见,任务迁移策略能够统筹兼顾Storm异构环境下各类资源的剩余情况,有效解决任务过载问题,但出于最小迁移开销考虑,尚无法实现集群中各工作节点的负载均衡.为更好地解决这一问题,需在拓扑运行前充分分析其内部结构,使用改进的任务分配方式取代轮询方式的初次部署,未来将继续开展研究.
5.2.3 节点间通信开销测试
本节讨论在Storm默认策略、在线策略和任务迁移策略下,WordCount,RollingSort,SOL运行时的工作节点间通信开销.图8展示了10次实验中各基准测试运行稳定后工作节点间单位时间通信总量的均值.

Fig. 8 Comparison of inter-node communication overhead among different task scheduling strategies
图8 不同任务调度策略下的节点间通信开销对比
由图8可知,使用在线策略和任务迁移策略执行3组基准测试之后,工作节点间传输的数据流大小均有所下降.在线策略执行后,工作节点间数据流大小的平均值分别为61 743 tuple/s,27 504 tuple/s,33 046 tuple/s,相对于默认策略分别降低了13.8%,19.6%,23.8%;任务迁移策略执行后,工作节点间数据流大小的平均值分别为64 130 tuple/s,29 665 tuple/s,35 213 tuple/s,相比默认策略的运行结果分别降低了10.4%,13.3%,18.8%,效果稍落后于在线策略.这是因为在线策略是以降低工作节点间通信开销为目的进行拓扑中各线程的重新部署,虽然执行开销大且易导致资源占用不均,但优化的范围更广.然而从优化效率的角度来看,当任务迁移策略执行结束之后,各基准测试中迁移的线程数量分别为11个、8个和27个,平均迁移1个线程可降低的工作节点间通信开销约为0.9%,1.6%,0.7%;而对于在线策略而言,所需重部署的线程数量即为该拓扑中包含的线程总数,分别为336个、208个和336个,平均迁移1个线程可降低的工作节点间通信开销微乎其微,远小于任务迁移策略的优化效率,这与4.3.2节中算法执行效果分析的结果是一致的.
5.2.4 真实应用场景下的测试
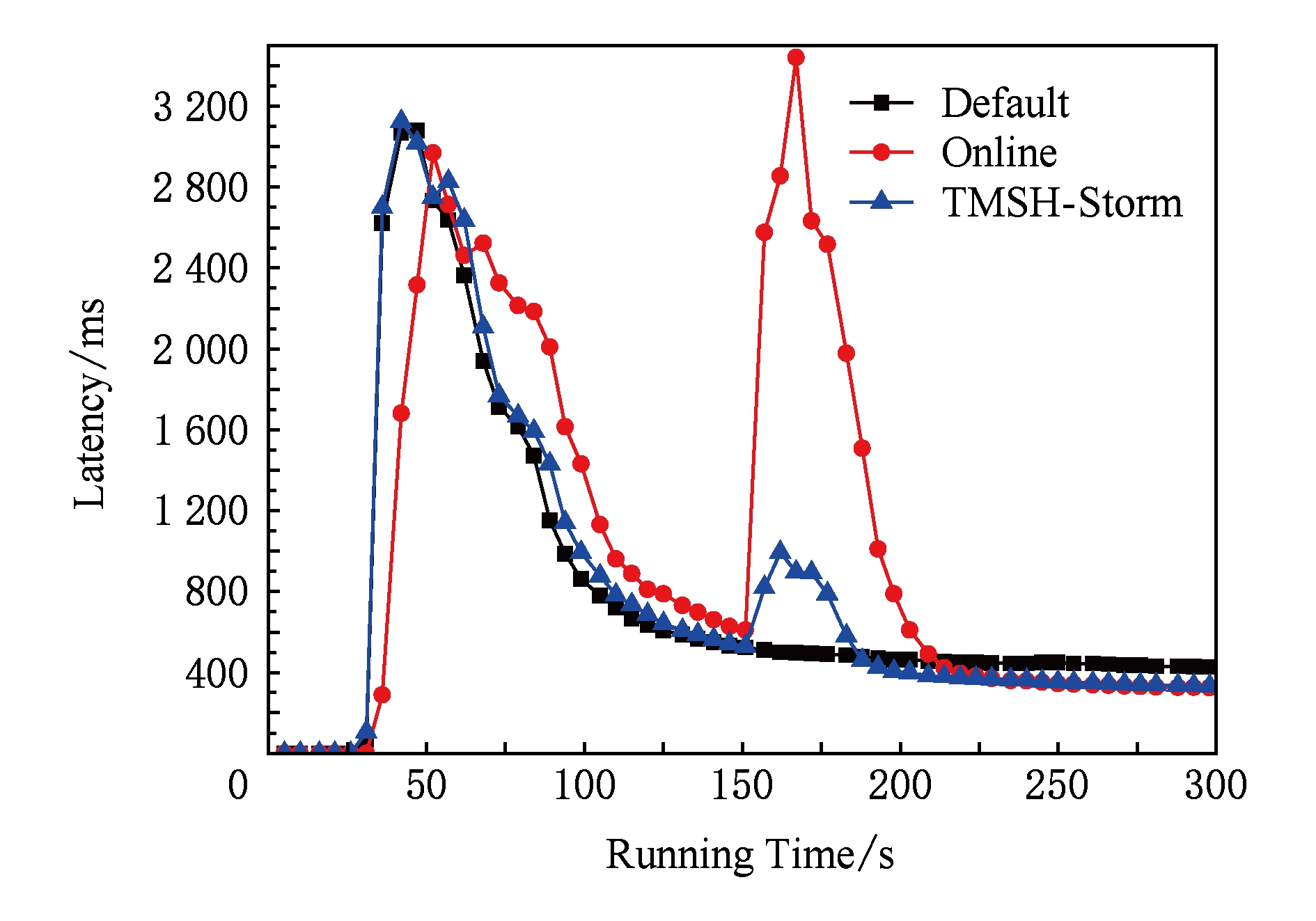
Fig. 9 Comparison of latency on RollingCount among different task scheduling strategies
图9 RollingCount在不同任务调度策略下的系统延迟对比
RollingCount是Storm环境下的一个典型大数据应用程序,它用于在内存中持续按照某个统计指标(如出现次数)计算窗口内的Top N ,然后每隔一段时间输出实时计算后的Top N 结果,能够广泛应用于各类大数据实时排序需求的场景,例如实时热门微博、广告和商品等的统计.表3中的参数 window . length 和 emit . frequency 即为设定的窗口长度和统计频率,单位为s.本组实验采用与5.2.1节中描述相同的方法统计RollingCount分别在Storm默认策略、在线策略和任务迁移策略下运行的系统延迟,结果如图9所示:
由图9可知,与之前3个基准测试结果类似,RollingCount的部署需要一个过程.第1个峰值过后,系统延迟趋于平稳,在线策略和任务迁移策略开始统计集群中各工作节点以及工作节点上各线程占用的CPU、内存和网络带宽负载信息及各线程之间的数据流大小.第155 s时在线策略触发,拓扑中各任务在各工作节点上重新部署,约耗时40 s,平均延迟约2.145 s;任务迁移策略触发于第155 s,约耗时20 s,平均延迟约877.8 ms,仅为在线策略的40.9%左右,执行过程中共有17个线程发生迁移.由此可见,任务迁移策略有效降低了调度的执行过程对系统实时性造成的负面影响.2种策略执行完毕后,系统延迟再次趋于收敛并分别稳定在约331.1 ms和339.9 ms,相对于默认策略分别降低约23.7%和21.7%,两者差距很小,实验结果较为理想.可见,在数据流大小变化迅速且任务过载时有发生的Storm商业应用领域中,使用任务迁移策略平滑调整将更有利于保证Storm处理的实时性.
Storm作为大数据流式计算的主流框架,已逐渐引起学术界和工业界的广泛关注.然而其默认的轮询调度机制并未考虑到不同工作节点的自身性能和负载差异,以及工作节点之间的网络传输开销和节点内部的进程与线程通信开销,无法最大化发挥Storm集群的性能.近年来已有研究改进了Storm默认调度机制存在的不足,但仍存在应用场景单一和算法开销过大等问题.本文通过分析Storm基本模型和3种不同的通信方式,建立了Storm异构环境下的资源约束模型、最优通信开销模型和任务迁移模型,并在此基础上提出了包含源节点选择算法和任务迁移算法的任务迁移策略,使系统能够根据各工作节点和各任务的实时负载情况和任务间的数据流大小,决策并实施任务的优化迁移.最后通过4个基准测试从延迟、资源占用、通信开销角度证明了算法的有效性.
下一步研究工作主要集中在3个方面:
1) 将本文提出的任务迁移策略进一步推广至更为复杂的Storm商业应用领域,使其适用于多租户且种类更多的业务场景.
2) 目前拓扑执行需要的进程和线程数量完全由用户(程序员)设置,研究拓扑中各组件的自适应并行度调节机制将能在提高节点资源利用率的同时,有效提高拓扑的执行效率.
3) 从拓扑自身的结构特征出发优化算法,在保证异构Storm集群高效运行的同时达到负载均衡的效果.
参考文献
[1] Meng Xiaofeng, Ci Xiang. Big data management: Concepts, techniques and challenges[J]. Journal of Computer Research and Development, 2013, 50(1): 146-169 (in Chinese)
(孟小峰, 慈祥. 大数据管理: 概念、技术与挑战[J]. 计算机研究与发展, 2013, 50(1): 146-169)
[2] Chen C L P, Zhang Chunyang. Data-intensive applications, challenges, techniques and technologies: A survey on big data[J]. Information Sciences, 2014, 275(11): 314-347
[3] Kambatla K, Kollias G, Kumar V, et al. Trends in big data analytics[J]. Journal of Parallel and Distributed Computing, 2014, 74(7): 2561-2573
[4] Sun Dawei. Big data stream comuting: Features and challenges[J]. Big Data Research, 2015,1(3): 99-105 (in Chinese)
(孙大为. 大数据流式计算: 应用特征和技术挑战[J]. 大数据, 2015,1(3): 99-105)
[5] Ranjan R. Streaming big data processing in datacenter clouds[J]. IEEE Cloud Computing, 2014, 1(1): 78-83
[6] Apache. Apache Hadoop[EB/OL]. [2016-08-05]. http://hadoop.apache.org
[7] Vamanan B, Sohail H B, Hasan J, et al. Timetrader: Exploiting latency tail to save datacenter energy for online search[C] //Proc of the 48th Int Symp on Microarchitecture. New York: ACM, 2015: 585-597
[8] Sun Dawei, Zhang Guangyan, Zheng Weimin. Big data stream computing: Technologies and instances[J]. Journal of Software, 2014, 25(4): 839-862 (in Chinese)
(孙大为, 张广艳, 郑纬民. 大数据流式计算: 关键技术及系统实例[J]. 软件学报, 2014, 25(4): 839-862)
[9] Toshniwal A, Taneja S, Shukla A, et al. Storm@Twitter[C] //Proc of the 2014 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2014: 147-156
[10] Alexandrov A, Bergmann R, Ewen S, et al. The stratosphere platform for big data analytics[J]. The VLDB Journal, 2014, 23(6): 939-964
[11] Zaharia M, Das T, Li Haoyuan, et al. Discretized streams: An efficient and fault-tolerant model for stream processing on large clusters[C] //Proc of the 4th USENIX Conf on Hot Topics in Cloud Computing. Berkeley, CA: USENIX Association, 2012: 1-6
[12] Borthakur D, Gray J, Sarma J S, et al. Apache Hadoop goes realtime at Facebook[C] //Proc of the 2011 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2011: 1071-1080
[13] Neumeyer L, Robbins B, Nair A, et al. S4: Distributed stream computing platform[C] //Proc of the 10th IEEE Int Conf on Data Mining Workshops (ICDMW 2010). Piscataway, NJ: IEEE, 2010: 170-177
[14] Fischer M J, Su Xueyuan, Yin Yitong. Assigning tasks for efficiency in Hadoop[C] //Proc of the 22nd Annual ACM Symp on Parallelism in Algorithms and Architectures. New York: ACM, 2010: 30-39
[15] Bhatotia P, Wieder A, Rodrigues R, et al. Incoop: MapReduce for incremental computations[C] //Proc of the 2nd ACM Symp on Cloud Computing. New York: ACM, 2011: 1-14
[16] Borkar V, Carey M, Grover R, et al. Hyracks: A flexible and extensible foundation for data-intensive computing[C] //Proc of the 27th Int Conf on Data Engineering. Piscataway, NJ: IEEE, 2011: 1151-1162
[17] Chen Fangfei, Kodialam M, Lakshman T V. Joint scheduling of processing and shuffle phases in MapReduce systems[C] //Proc of the 2012 IEEE INFOCOM. Piscataway, NJ: IEEE, 2012: 1143-1151
[18] Chen Gang, Chen Ke, Jiang Dawei, et al. E3: An elastic execution engine for scalable data processing[J]. Journal of Information Processing, 2012, 20(1): 65-76
[19] Jin Hui, Yang Xi, Sun Xianhe, et al. ADAPT: Availability-aware MapReduce data placement for non-dedicated distributed computing[C] //Proc of the 32nd Int Conf on Distributed Computing Systems (ICDCS). Piscataway, NJ: IEEE, 2012: 516-525
[20] Kumar V, Andrade H, Gedik B, et al. DEDUCE: At the intersection of MapReduce and stream processing[C] //Proc of the 13th Int Conf on Extending Database Technology. New York: ACM, 2010: 657-662
[21] Condie T, Conway N, Alvaro P, et al. Online aggregation and continuous query support in MapReduce[C] //Proc of the 2010 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2010: 1115-1118
[22] Karve R, Dahiphale D, Chhajer A. Optimizing cloud MapReduce for processing stream data using pipelining[C] //Proc of the 5th UKSim European Symp on Computer Modeling and Simulation (EMS). Piscataway, NJ: IEEE, 2011: 344-349
[23] Backman N, Pattabiraman K, Fonseca R, et al. C-MR: Continuously executing MapReduce workflows on multi-core processors[C] //Proc of the 3rd Int Workshop on MapReduce and Its Applications Date. New York: ACM, 2012: 1-8
[24] Lam W, Liu Lu, Prasad S T S, et al. Muppet: MapReduce-style processing of fast data[J]. Proceedings of the VLDB Endowment, 2012, 5(12): 1814-1825
[25] Aly A M, Sallam A, Gnanasekaran B M, et al. M3: Stream processing on main-memory MapReduce[C] //Proc of the 28th Int Conf on Data Engineering. Piscataway, NJ: IEEE, 2012: 1253-1256
[26] Li K C, Jiang Hai, Yang L T, et al. Big Data: Algorithms, Analytics, and Applications[M]. Boca Raton, FL: CRC Press, 2015: 193-214
[27] Daoud M I, Kharma N. A hybrid heuristic-genetic algorithm for task scheduling in heterogeneous processor networks[J]. Journal of Parallel & Distributed Computing, 2011, 71(11): 1518-1531
[28] Sinnen O, To A, Kaur M. Contention-aware scheduling with task duplication[J]. Journal of Parallel and Distributed Computing, 2011, 71(1): 77-86
[29] Wang Changdong, Lai Jianhuang, Huang Dong, et al. SVStream: A support vector-based algorithm for clustering data streams[J]. IEEE Trans on Knowledge & Data Engineering, 2013, 25(6): 1410-1424
[30] Xu Yuming, Li Kenli, He Ligang, et al. A DAG scheduling scheme on heterogeneous computing systems using double molecular structure-based chemical reaction optimization[J]. Journal of Parallel & Distributed Computing, 2013, 73(9): 1306-1322
[31] Saikrishna P S, Pasumarthy R. Automated control of webserver performance in a cloud environment[C] //Proc of the 2013 IEEE Recent Advances in Intelligent Computational Systems (RAICS). Piscataway, NJ: IEEE, 2013: 239-244
[32] Al-Haidari F, Sqalli M, Salah K. Impact of CPU utilization thresholds and scaling size on autoscaling cloud resources[C] //Proc of the 5th IEEE Int Conf on Cloud Computing Technology and Science (CloudCom). Piscataway, NJ: IEEE, 2013: 256-261
[33] Van d V J S, Van D W B, Lazovik E, et al. Dynamically scaling Apache Storm for the analysis of streaming data[C] //Proc of the 1st IEEE Int Conf on Big Data Computing Service and Applications. Piscataway, NJ: IEEE, 2015: 154-161
[34] Lorido-Botran T, Miguel-Alonso J, Lozano J A. A review of auto-scaling techniques for elastic applications in cloud environments[J]. Journal of Grid Computing, 2014, 12(4): 559-592
[35] Trihinas D, Pallis G, Dikaiakos M D. JCatascopia: Monitoring elastically adaptive applications in the cloud[C] //Proc of the 14th IEEE/ACM Int Symp on Cluster, Cloud and Grid Computing (CCGrid). Piscataway, NJ: IEEE, 2014: 226-235
[36] Nikravesh A Y, Ajila S A, Lung C H. Cloud resource auto-scaling system based on hidden Markov model (HMM)[C] //Proc of the 2014 IEEE Int Conf on Semantic Computing (ICSC). Piscataway, NJ: IEEE, 2014: 124-127
[37] Wolf J, Bansal N, Hildrum K, et al. SODA: An optimizing scheduler for large-scale stream-based distributed computer systems[C] //Proc of the 9th ACM/IFIP/USENIX Int Conf on Middleware. Berlin: Springer, 2008: 306-325
[38] Amini L, Andrade H, Bhagwan R, et al. SPC: A distributed, scalable platform for data mining[C] //Proc of the 4th Int Workshop on Data Mining Standards, Services and Platforms. New York: ACM, 2006: 27-37
[39] Sun Dawei, Fu Ge, Liu Xinran, et al. Optimizing data stream graph for big data stream computing in cloud datacenter environments[J]. International Journal of Advancements in Computing Technology, 2014, 6(5): 53-65
[40] Cordeschi N, Shojafar M, Amendola D, et al. Energy-efficient adaptive networked datacenters for the QoS support of real-time applications[J]. The Journal of Supercomputing, 2014, 71(2): 448-478
[41] Sun Dawei, Zhang Guangyan, Yang Songlin, et al. Re-Stream: Real-time and energy-efficient resource scheduling in big data stream computing environments[J]. Information Sciences, 2015, 319: 92-112
[42] Cardellini V, Grassi V, Lo Presti F, et al. Distributed QoS-aware scheduling in Storm[C] //Proc of the 9th ACM Int Conf on Distributed Event-Based Systems. New York: ACM, 2015: 344-347
[43] Aniello L, Baldoni R, Querzoni L. Adaptive online scheduling in Storm[C] //Proc of the 7th ACM Int Conf on Distributed Event-Based Systems. New York: ACM, 2013: 207-218
[44] Xu Jielong, Chen Zhenhua, Tang Jian, et al. T-Storm: Traffic-aware online scheduling in Storm[C] //Proc of the 34th IEEE Int Conf on Distributed Computing Systems. Piscataway, NJ: IEEE, 2014: 535-544
[45] Peng Boyang, Hosseini M, Hong Zhihao, et al. R-Storm: Resource-aware scheduling in Storm[C] //Proc of the 16th Annual Middleware Conf. New York: ACM, 2015: 149-161
[46] Zhang Manu. Intel-hadoop/storm-benchmark forked from manuzhang/storm-benchmark[EB/OL]. (2015-11-02) [2016-08-05]. https://github.com/intel-hadoop/storm-benchmark
[47] Marz N. Public stormprocessor/storm-benchmark[EB/OL]. (2012-08-20) [2016-08-05]. https://github.com/stormprocessor/storm-benchmark
[48] Martello S, Toth P. Dynamic programming and strong bounds for the 0-1 knapsack problem[J]. Management Science, 1999, 45(3): 414-424
[49] Sarkar U K, Chakrabarti P P, Ghose S, et al. Reducing reexpansions in iterative-deepening search by controlling cutoff bounds[J]. Artificial Intelligence, 1991, 50(2): 207-221
[50] Chekuri C, Khanna S. A polynomial time approximation scheme for the multiple knapsack problem[J]. SIAM Journal on Computing, 2005, 35(3): 713-728
[51] Fayard D, Zissimopoulos V. An approximation algorithm for solving unconstrained two-dimensional knapsack problems[J]. European Journal of Operational Research, 1995, 84(3): 618-632
Lu Liang 1 , Yu Jiong 1 , Bian Chen 1 , Liu Yuechao 1 , Liao Bin 2 , and Li Huijuan 3
1 ( School of Information Science and Engineering , Xinjiang University , Urumqi 830046) 2 ( School of Statistics and Information , Xinjiang University of Finance and Economics , Urumqi 830012) 3 ( Wulumuqi Electric Power Supply Company , State Grid Corporation of China , Urumqi 830011)
Abstract As one of the most representative platforms in stream computing, Apache Storm has become the first choice for the scenarios of real-time big data processing due to its advantages in open source, simplicity and excellent performance. A round-robin scheduling strategy is used as the Storm default scheduler, without considering the differences of performance and workload among distinct work nodes, and the different overhead of inter-node, inter-process and inter-executor communication under heterogeneous environment, which cannot fully exploit the high performance of Storm cluster in itself. In order to minimize the communication overhead on the premise of all kinds of resource constraints, a task migration strategy for heterogeneous Storm cluster (TMSH-Storm) is proposed on the basis of resource-constrained model, optimal communication overhead model and task migration model, which comprises two algorithms: source node selection algorithm and task migration algorithm. Source node selection algorithm adds work nodes which exceed the threshold to a set of source nodes according to the workload and priority of CPU, memory and network bandwidth in each work node; Task migration algorithm takes into account various factors such as the migration overhead, communication overhead, resource constraint as well as load of each node and each task, migrating the tasks that from source nodes to proper destination nodes successively and asynchronously. Experimental results show that the proposed strategy can reduce latency and overhead of inter-node communication, moreover, the implementation cost is lower compared with the existing research.
Key words big data; stream computing; Storm; communication overhead; task migration
摘 要 Storm作为流式计算模式下最具代表性的平台之一,其默认轮询的调度机制未考虑到异构环境下不同工作节点的自身性能和负载差异,以及工作节点之间的网络传输开销和节点内部的进程与线程通信开销,无法充分发挥集群的性能.为了在各类资源约束的前提下最小化通信开销,在建立并论证Storm资源约束模型、最优通信开销模型和任务迁移模型的基础上,提出一种异构Storm环境下的任务迁移策略(task migration strategy for heterogeneous Storm cluster, TMSH-Storm),包括源节点选择算法和任务迁移算法.其中,源节点选择算法根据集群中各工作节点CPU、内存和网络带宽的负载情况以及各类资源的优先级顺序,将超出阈值的节点加入源节点集;任务迁移算法综合迁移开销、通信开销、节点资源约束以及节点和任务负载等因素,依次将源节点中的待迁移任务异步迁移至目的节点上.实验表明:相对于现有研究而言,TMSH-Storm能有效降低延迟和节点间通信开销,且执行开销较小.
关键词 大数据;流式计算;Storm;通信开销;任务迁移
中图法分类号 TP311
收稿日期: 2016-11-10;
修回日期: 2017-07-17
基金项目: 国家自然科学基金项目(61462079,61262088,61562086,61363083,61562078);新疆维吾尔自治区自然科学基金项目(2017D01A20);新疆维吾尔自治区高校科研计划基金项目(XJEDU2016S106)
This work was supported by the National Natural Science Foundation of China (61462079, 61262088, 61562086, 61363083, 61562078), the Natural Science Foundation of Xinjiang Uygur Autonomous Region of China (2017D01A20), and the Educational Research Program of Xinjiang Uygur Autonomous Region (XJEDU2016S106).

Lu Liang , born in 1990. PhD candidate. Student member of CCF. His main research interests include distributed computing, green computing and in-memory computing.

Yu Jiong , born in 1964. PhD, professor and PhD supervisor. Senior member of CCF. His main research interests include grid computing, parallel computing, etc. (yujiong@xju.edu.cn).

Bian Chen , born in 1981. PhD and associate professor. Member of CCF. His main research interests include parallel computing, distributed system, etc. (bianchen0720@126.com).

Liu Yuechao , born in 1989. Master. Her main research interests include stream computing, big data and machine learning (weewee975@163.com).

Liao Bin , born in 1986. PhD and associate professor. Member of CCF. His main research interests include database theory and technology, big data and green computing (liaobin665@163.com).

Li Huijuan , born in 1989. Master. Her main research interests include opportunistic network and ubiquitous computing (865129239@qq.com).