李宇溪 周福才 徐 剑 徐紫枫
(东北大学软件学院 沈阳 110819)
摘要围绕当前云存储环境中用户数据机密性以及可用性的问题,对多关键字密文搜索方案展开研究,提出双服务器模型下支持相关度排序的多关键字密文搜索方案(multi-keyword encrypted search with relevance ranking, MES-RR),在能够保证高效地实现多关键字密文搜索的同时,实现对于搜索结果的排序.方案基于TF-IDF加权技术并融合Paillier同态加密体制,构建关键字相关度安全索引,优化计算代价并降低了存储复杂度;设计双服务器模型架构,引入安全可信的协同处理机制来构造安全排序协议,实现对于搜索结果的高效排序.在安全性方面,在诚实与好奇的威胁场景下构建方案的安全模型,并对安全性进行严格分析,结果表明方案能够在随机预言模型下抵抗自适应性选择关键字攻击,具有IND-CKA2安全性.性能分析表明:该方案用户生成q个关键字搜索令牌仅需要常数级时间O(q),而且仅需和服务器进行1次交互即可得到搜索结果,与以往的支持排序的多关键字密文搜索方案相比,该方案大大降低了计算代价和访问交互次数,适用于实际的云存储环境.
关键词密文搜索;相关度排序;双服务器;同态加密;自适应性选择关键字攻击
密文搜索是指当数据以加密形式存储在设备中时,在确保数据安全的前提下检索数据的技术.因为数据加密后会严重影响用户数据的可用性,因此如何在保证用户隐私和数据安全性的前提下,确保密文数据的可用性,就成为了密文搜索领域的重要研究内容.总体来说,密文搜索主要包括两大实体:用户和服务器.以及2个步骤:初始化阶段和搜索阶段.在初始化阶段,用户在客户端加密文件集合与索引数据结构,并上传给服务器加密后的文件集合和一个加密索引;在搜索阶段,用户想要服务器返回包括某关键字的所有文件.为了执行这一请求,用户发送一个令牌,这一令牌能够封装这一搜索请求,并且不会泄露任何关于关键字的信息.服务器收到用户发送的令牌后,用这个令牌以及加密索引,通过某种方式返回符合搜索条件的加密文件.
当前,密文搜索方案大都基于单服务器模型,用户将密文数据存储在单个云服务提供商中.受限于预计算量较大、交互轮数较多等实际缺陷,云服务器只能进行简单的搜索请求,大大影响了密文搜索方案的可用性.这种情况下云服务器不能在完全在保证用户数据隐私的前提下,对密文搜索功能进行丰富完善,使其真正投入企业级大规模应用收到了限制.实际情况下,云服务提供商并不仅限于单个实体,可能协同服务提供商同时提供服务.多服务器模型在近几年很多相关工作已被广泛使用[1-3].由于云服务提供商之间存在一定的竞争关系,因而不会为了短期利益而勾结在一起攻击用户隐私数据.在现实的应用场景中,协同云服务通常由大公司来提供,例如亚马逊、微软和谷歌等这些公司不会因为商业利益来与云存储服务器工商进行合谋,这不仅会破坏他们的声誉,从长远角度来看也会影响其商业利润和公司发展.
然而,很多情况下,粗粒度的返回全部搜索结果并不能满足用户的需求.在数据量较大的情况下,用户在进行多关键字搜索时,不仅需要获得匹配到的文件,与此同时希望服务器根据其与搜索关键字的相关度,对搜索的文件进行排序,从而更有效地得到想要的结果.然而,多数密文搜索方案都是将匹配到关键字搜索条件的全部搜索结果返回给用户,并没有搜索结果进行筛选或排序,尤其是在多关键字搜索场景下.虽然现在已有相关工作试图解决支持排序的密文搜索问题,但其基于较高的系统模型假设(例如,引入可信第三方)或较低的安全目标(例如,允许服务器获得关键词信息)或由于通过服务器重加密或其他复杂运算而导致效率较低.因此,完善现有的支持结果排序的密文搜索机制,是未来需要研究的一个重要方向.
针对上述问题,并结合实际应用场景中对多关键字密文搜索的可用性需求及安全性需求,面向双服务器模型,提出了支持相关度排序的多关键字密文搜索方案,在能够保证安全高效地实现密文搜索的同时,满足对于搜索结果的排序.
1) 方案基于TF-IDF加权技术并融合同态加密体制,构建包含相关度权值的关键字安全索引,优化搜索过程中服务器计算代价并降低了存储复杂度.方案利用TF-IDF加权规则来计算关键字与文件之间的相关度权值,并利用Paillier同态加密算法将其加密,使得服务器在搜索过程中,无需对令牌及密文进行解密的前提下能够对权值密文进行相加,从而获得多关键字权值密文之和,满足多关键字搜索请求下对结果的排序.
2) 构建安全可信的协同处理机制实现对于搜索结果安全排序.方案构建2个不可共谋的服务器S和coS来共同扮演服务提供者的角色.其中S负责存储密文和索引信息,coS负责协助S来进行搜索结果排序工作.方案引入两方安全密文比较协议,在不向协同服务器泄露搜索模式与访问模式的前提下,实现对于搜索结果的高效排序.与单服务器模型相比,降低了用户与服务器之间通信代价的同时,减少了向服务器泄露的消息.
3) 在安全性方面,在诚实并好奇的半可信场景下给出MES-RR方案的安全模型,并依据所提出的安全模型对该方案的安全性进行严格证明,证明方案在随机语言模型下能够抵抗敌手自适应选择关键字攻击,满足IND-CKA2安全性.性能分析表明,与以往的支持搜索结果排序的多关键字密文搜索方案相比,本方案大大降低了用户存储代价和访问交互次数,适用于实际的云存储环境.
密文搜索由Song等人在2000年首次提出[4],作者使用了一个特殊的2层的加密构造,将明文文件划分为“单词”并对其分别加密,通过对整个密文文件扫描和密文单词进行比对,就可确认关键词是否存在,甚至统计其出现的次数,然而这导致了搜索复杂度较高,与文件集合的大小呈线性关系.之后,密文搜索方案按照实体不同分为对称和非对称2种应用场景.在对称场景中,数据拥有者加密自己的数据.加密的数据和对应的数据结构被存储在服务器中,只有数据拥有者以及被数据拥有者认证的用户才能够对其进行搜索.Curtmola等人在2006年对对称场景的密文搜索模型进行了形式化定义,并基于倒排索引提出了一个高效的构建方案[5],方案只需常数级时间即可完成搜索操作,然而,执行文件的添加或删除操作需要重新构建索引,时间开销较大.除此之外,他们提出了基于广播加密技术的多用户密文搜索构造思想,即使只有单一数据拥有者,仍然可以允许任意被授权的用户,通过向数据拥有者请求搜索令牌,来向服务器发送搜索请求.另一个对称场景的经典方案是Kamara等人在2012年提出的支持搜索结果完整性验证的密文搜索方案[6],方案利用基于双线性映射累加器和扩展欧几里德算法的集合证明理论,实现对于搜索结果的离线验证.Boneh等人在2004年首次提出非对称场景的密文搜索方案[7],并且他们的创新性思想为后来很对研究成果提供了启发.在非对称场景中,数据拥有者将数据加密并上传至服务器,任何拥有解密密钥的用户可以执行搜索请求(例如邮件服务器场景).
在很多情况下,用户想要搜索包含多个关键字信息的文件,基于此需求,Golle等人首先提出了多关键字密文搜索机制并给出了具体构造方案[8],但是方案中搜索令牌的大小与加密文件数呈线性关系,用户计算代价过高.Cash等人在2013年提出了第一个面向任意结构化数据的支持交集的密文搜索方案[9],并证明方案满足IND-CKA2安全性.2014年,Cash等人提出了一个支持连接词查询的高效密文搜索方案[10],方案针对数据集中关键字的出现频率设计3层安全索引结构,使搜索过程更具有灵活性,更适合大数据场景.2017年,Wang等人提出了面相多关键字的模糊密文搜索方案[11],方案不需要提前设置索引存储空间,从而大大降低了方案的搜索复杂度.
在通用密文搜索方案中,用户必须解密所有返回的搜索结果,才能得到所需文件.然而,在数据量较大的情况下,查询结果中可能仅仅有极少部分为用户所需文件.支持排序的密文搜索方案可以按照关键词与文件的相关度对搜索结果进行排序,并返回最相关的文件来优化搜索结果,用户只需根据排序结果解密少量加密文件即可获得所需文件,这能在一定程度上降低网络负载并且增强系统可用性.
早期支持排序的密文搜索方案[12-14]大多利用保序加密方法(order-preserving encryption, OPE)实现了针对单关键字密文搜索结果的排序.用户在上传文件之前,使用OPE对关键字相关性分数加密,搜索过程中服务器根据每个文件对搜索关键字相关性分数的密文结果进行排序,并将经过排序后的前k个文件返回给用户.这种方法的优点是,在每次搜索的过程中,用户可以得到在特定相关度权衡模型下对该关键字最为相关的文件,节省了带宽和因为解密带来的计算开销,但是服务器也掌握了每个文件对于某个关键字相关性程度的信息.
Cao等人在2014年首次提出支持搜索结果排序的多关键字密文搜索方案[15],方案中基于内积相似性(inner product similarity, IPS)来计算每个文件中匹配到的关键字的数量,以此来计算文件权值并对文件进行排序.内积相似性中文件的权值与每个文件中匹配的关键字的个数相关.但是仅仅依赖IPS技术,使得方案没有考虑关键字对于整个文件集合的重要性等信息.TF-IDF加权技术为信息检索领域常用来评估某个关键词对于一个文件集或一个语料库中的其中一份文件的重要程度的方法.许多支持排序的密文搜索方案基于TF-IDF加权技术来实现:Strizhov等人在2014年融合TF-IDF加权技术和IPS设计了新型密文搜索排序方案[16],为了防止服务器获取相关度信息,方案中假设服务器仅仅执行搜索功能,并不能对结果进行排序,服务器将搜索到的全部文件返回给用户,用户在本地基于相关度权值对搜索结果进行排序.方案的不足之处在于,为了实现排序,相关度由全同态加密方案进行加密,使得构建索引阶段时间复杂度较高,而且方案不支持文件动态更新.同年,Sun等人利用余弦度量技术设计一个支持排序的可验证密文搜索方案[17].他们的方案能够在稍稍牺牲搜索准确度的前提下,提高搜索效率.Zhang等人提出了一个多数据拥有者模型下的支持排序的密文搜索方案[18].不同的数据拥有者利用不同的私钥来加密文件和关键字,经过认证的用户能够在不知道拥有者私钥的前提下发起查询.2015年,Fu等人提出了支持并行搜索的可排序密文搜索方案[19],方案利用向量空间模型构造索引,模型中将每一个TF-IDF权值转化成2个随机向量搜索过程中将搜索向量转化成矩阵乘积形式,并且计算搜索向量与数据库中所有密文文件向量的点相似度来判定相关性.
Orencik等人在2016年提出了支持排序的多关键字密文搜索方案[20],他们利用位置敏感Hash函数(location sensetive Hash, LSH)来聚类相似文件.然而,LSH适用于相似性搜索但是不能提供精确排序.同文献[15]类似,他们的排序机制仅仅依赖文件中关键字的出现频率,导致搜索准确性较差,具有一定误差.同年,Xia等人提出了基于树结构的动态多关键字密文搜索方案[21],论文利用向量空间模型构建树型索引结构,并利用深度优先搜索方案进行关键字搜索.2017年,Song等人提出支持全文检索的密文搜索方案[22],他们使用布隆过滤器(bloom filter)作为加密索引,并且提出了索引关键字熵的概念来计算搜索令牌中关键字和文件的相关度.同年,Shen等人提出了一个基于RSA和ElGamal加密算法的相关度排序方案[23].方案利用高阶聚类索引(hierarchical clustering index)构造索引结构来提高搜索效率.为了提高安全性,方案中权值的计算由服务器执行,结果的排序由用户执行,大大提高了搜索效率.在上述方案中,当文件集合的大小呈指数增长时,搜索时间也成线性增长.
本方案的构建基于同态密码体制,主要应用Paillier[24]以及Goldwasser-Micali(GM)加密方法[25].上述2个方法均支持加法同态性,即给定2个密文Enc(m1)和Enc(m2),应用加同态操作可以得到2个明文相加之后的密文Enc(m1+m2).
详细来讲,Paillier同态加密算法由3个函数组成:
1)P.Gen(1k).输入安全参数1k,随机选择2个k位素数P和Q,并置N=PQ.随机选择一个数g,满足gcd(L(gλ(N)modN2),N)=1,其中函数L(u)=(u-1)/N,λ(N)=lcm(P-1,Q-1),选择一个随机数a∈R![]()
![]() 令h=aNmodN2,可知h在模N2下的阶为λ(N).加密系统公钥PKP为(N,g,h),私钥SKP为(P,Q).
令h=aNmodN2,可知h在模N2下的阶为λ(N).加密系统公钥PKP为(N,g,h),私钥SKP为(P,Q).
2)P.EncPKP(m).输入消息m∈![]() N,选择随机数r∈
N,选择随机数r∈![]() N,计算密文[m]=gmhrmodN2.
N,计算密文[m]=gmhrmodN2.
3)P.DecSKP([m]).输入密文c∈![]()
![]() 计算明文m=(L([m]λ(N)modN2)/L(gλ(N)modN2)) modN.
计算明文m=(L([m]λ(N)modN2)/L(gλ(N)modN2)) modN.
除此之外,Lipmaa等人在2005年提出Paillier双重加密的方法[26],设‖m‖为双重加密之后的密文,其中明文m1满足m∈![]() N2,则Paillier双重加密系统满足如下性质:‖[m1]‖[m2]=‖[m1][m2]‖=‖[m1+m2]‖.
N2,则Paillier双重加密系统满足如下性质:‖[m1]‖[m2]=‖[m1][m2]‖=‖[m1+m2]‖.
同样,GM加密算法包含3个函数:
1)GM.Gen(1k).输入安全参数1k,选择2个随机k-bit素数P和Q,并置N=PQ.选取模n的一个二次非剩余δ∈![]()
![]() 满足雅可比符号
满足雅可比符号![]() 公钥PKGM=(δ,n),私钥是SKGM=(P,Q).
公钥PKGM=(δ,n),私钥是SKGM=(P,Q).
2)GM.EncPKGM(m).输入消息m∈(0,1),选择随机数r∈![]() N,计算密文‖m‖=r2δmmodn.
N,计算密文‖m‖=r2δmmodn.
3)GM.DecSKGM(‖m‖).输入密文‖m‖∈![]()
![]() 计算明文
计算明文
GM算法的明文空间为1位,并且[m]指的是一位比特值m利用GM方法加密之后的密文.GM的密钥对表示为KGM=(PKGM,SKGM).GM方法的同态性表示为‖m1‖‖m2‖=‖m1⊕m2‖.
为了能够实现搜索结果的相关度排序,本文使用TF-IDF加权技术[27]来计算某次搜索请求中匹配文件的相关度权值.TF-IDF加权技术是一种用于信息检索与数据挖掘的常用加权技术,用以评估某个关键词对于一个文件集或一个语料库中的其中一份文件的重要程度.TF-IDF加权技术主要基于2个独立的参数:词频(term frequency, TF)以及逆向文件频率(inverse document frequency, IDF).
定义1. 词频.词频指的是某一个给定的关键字ti在某个文件d中出现的频率,可表示为
(1)
其中,![]() 表示关键字ti在文件d中出现的次数,
表示关键字ti在文件d中出现的次数,![]() 表示文件d中所有关键字出现的次数之和.
表示文件d中所有关键字出现的次数之和.
定义2. 逆向文件频率.逆向文件频率是一个词语在整个文件集中的普遍重要性的度量,可表示为
![]()
(2)
其中|D|表示总文件数目,j表示含有关键字ti的文件数目.本文采用式(3)来权衡关键字ti在文件d中的相关度:
![]()
(3)
本文利用文献[28]中的两方安全密文比较协议来作为方案排序协议构建模块.协议的交互双方中一方持有2个利用Paillier加密方案加密的密文,其需要在不解密的情况下比较2个密文对应的明文值的大小.协议要求在比较过程中不泄露任何关于明文的信息.现如今的方法中不存在有效的方案使其能够在上述调前的情况下比较2个密文的大小.因此,需要另一方与其配合进行比较协议.
详细来说,假设A和B为交互双方,其中A拥有密文[a]←P.EncPKP(a)和[b]←P.EncPKP(b),B拥有私钥SKP.比较协议的目标是在不向任意一方揭示a,b明文的情况下,判定2个长度为l位的数值a,b的大小.协议主要思想是计算2l+b-a(l+1)并验证第l+1位比特值来判定a,b的大小.如果等于1,则a≤b,否则a>b.协议结束之后,A得到比较结果的密文,而B不会得到任何有用信息.方案在诚实并好奇敌手模型下被证明满足语义安全.
Batcher排序网络[29]能够将一个包含N个元素的数组进行高效排序,可看作是一个具有O((logN)2)个连贯层级的排序算法,每个层级要比较O(N)对元素.具体来说,如图1所示,设Ai是第i层的序列,其中Ai{j}为序列Ai的第j个元素.每一个层级i输入Ai,输出Ai+1,其中i层被指定需要排序的元素对在Ai+1中的是有序的.例如A2{1}和A2{2}包含有序的A1{1}和A1{2},A2{3}和A2{4}包含有序的A1{3}和A1{4}.pairi表示层级i中需要排序的元素对集合,pairi.next表示下一个需要排序的元素对集合.
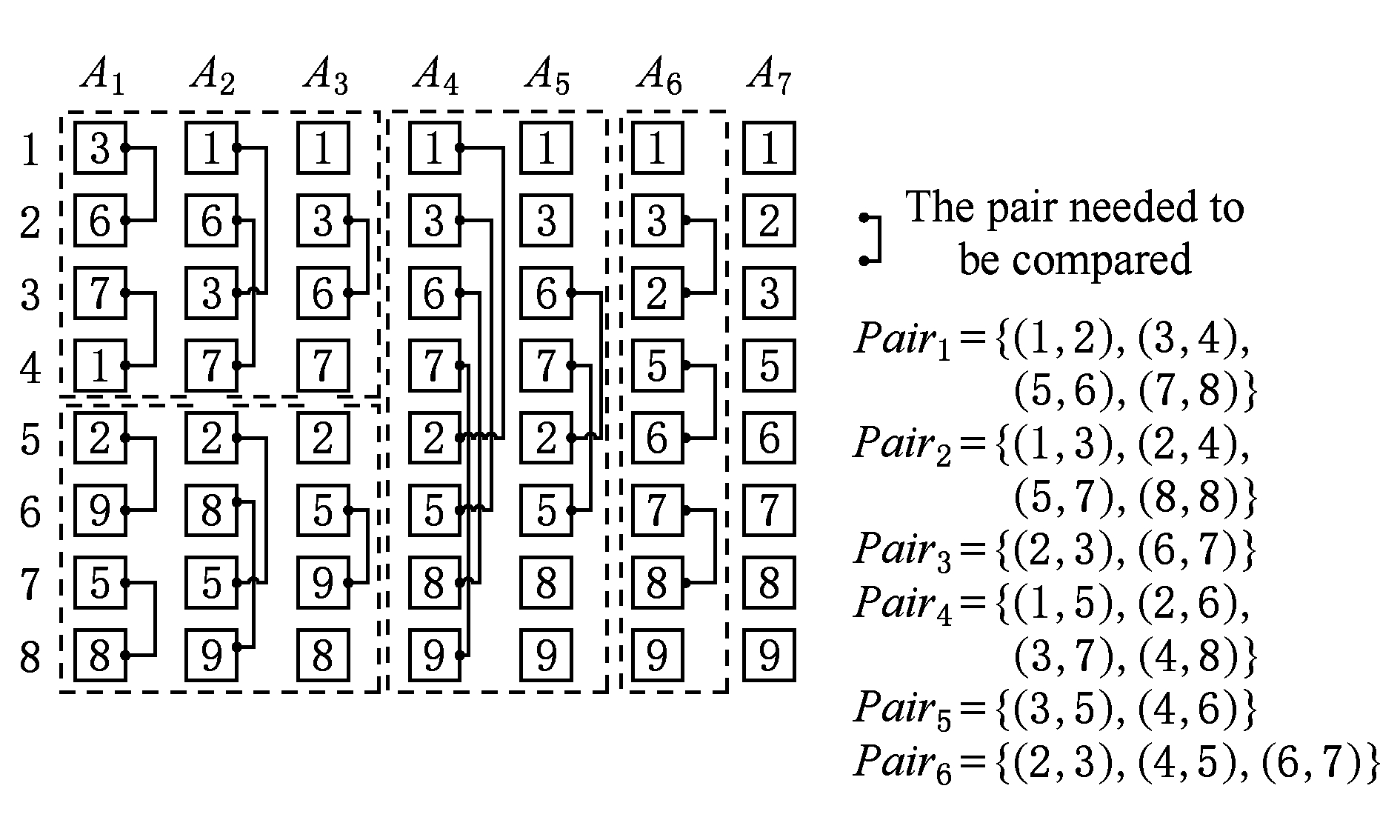
Fig. 1 An illustration of Batcher sort procession
图1 Batcher排序实例
图1为Batcher排序网络实例,输入序列A1={3,6,7,1,2,9,5,8},首先将序列分为前半部分和后半部分,2个子序列同时进行奇偶排序,最终得到A4={1,3,6,7,2,5,9,8}.随后,对整个序列进行奇偶归并,得到A6={1,3,2,5,6,7,8,9},最后将相邻元素进行邻近排序,得到最终的排序之后的序列A7={1,2,3,5,6,7,8,9}.本文利用Batcher排序网络来实现搜索结果排序.
MES-RR由3类实体构成:用户U、云存储服务器S以及协同服务器coS.其中,用户U为数据拥有者,云存储服务器S为向用户提供数据存储服务,根据用户特搜索定请求完成对应的搜索操作,协同服务器coS为辅助服务器,协助云存储服务器S完成多关键字搜索结果的排序.
在本场景中,数据以文件的形式进行组织,每个文件都带有若干个对应的关键字.使用“令牌”来描述用户的请求.例如,在进行搜索时,用户U首先生成一个搜索令牌,并发送给服务器S.服务器S使用该令牌作为输入来执行搜索算法.随后服务器S在协同服务器coS的协助下完成搜索结果的排序.由于方案只关注文件的标识和关键字索引,因此文件的类型与大小不会对性能产生影响.
由图2可以看出,方案主要包含4个阶段:文件预处理阶段、搜索令牌生成阶段、搜索排序阶段以及搜索结果返回阶段.用户U将文件和索引加密后,外包至服务器S端进行存储,用户U选择若干关键字进行集合搜索时,根据关键字集合生成对应的搜索令牌发送给服务器S,服务器S在加密索引上执行搜索操作,得到每个关键字对应的密文集合,对密文集合进行对应的集合操作,并与协同服务器coS共同进行搜索结果排序.随后服务器S将排序后的搜索结果返回给用户,用户可以根据该搜索结果来选择相应的文件.
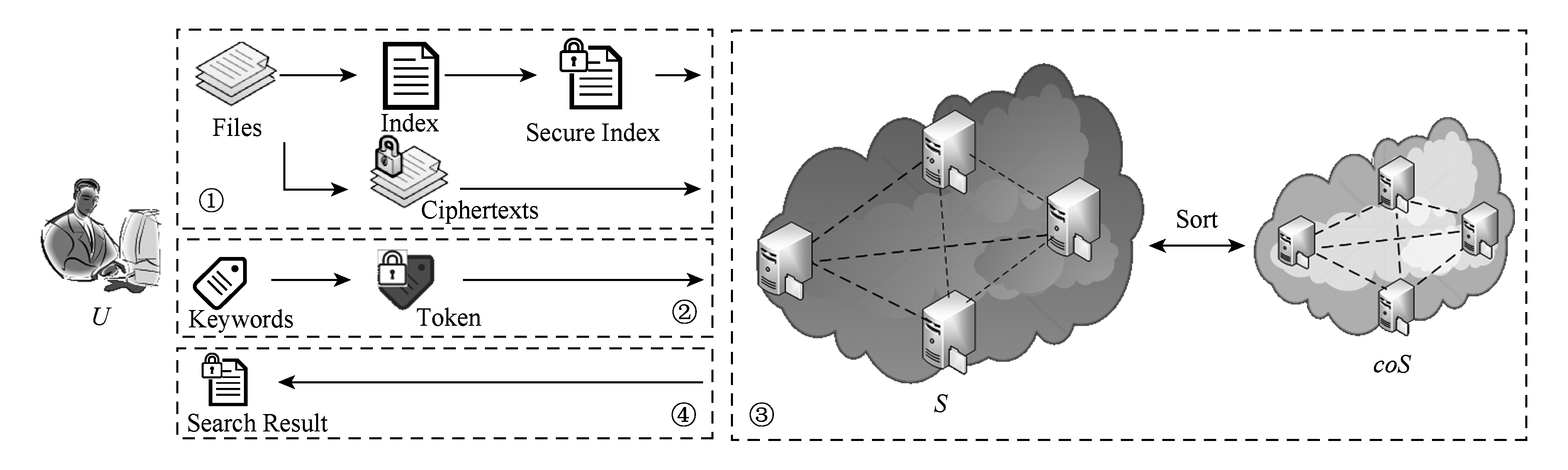
Fig. 2 Scheme architecture
图2 方案架构
3.1.1 形式化定义
MES -RR由6个多项式时间算法或协议组成,即MES-RR=(KeyGen,Setup,SrchToken,Search,Sort,Dec),具体描述如下:
1) 密钥生成算法(K,SK,PK)←KeyGen(1k).由用户U执行,生成用户对称密钥K以及公私钥PK,SK.
2) 初始化算法(γ,c)←Setup(K,PK,F).由用户U执行,用于初始化安全索引结构并对要上传的数据进行加密.算法输入密钥K,PK和数据文件集合F,输出加密索引γ和密文文件集合C.
3) 搜索令牌生成算法τ←SrchToken(K,W).由用户U执行,用于生成搜索令牌τ.算法输入密钥K和关键字集合W,输出搜索令牌τ.
4) 搜索算法IW←Search(γ,T).服务器S执行,用于实现搜索.算法输入加密索引γ和搜索令牌τ,输出文件标识集合IW.
5) 排序协议![]() 由服务器S和协同服务器coS之间交互运行,用于对搜索结果进行排序.在协议中,服务器S输入公钥PK、搜索结果IW;协同服务器输入私钥SK.协议结束后,服务器得到将IW按相关度排序的重加密序列
由服务器S和协同服务器coS之间交互运行,用于对搜索结果进行排序.在协议中,服务器S输入公钥PK、搜索结果IW;协同服务器输入私钥SK.协议结束后,服务器得到将IW按相关度排序的重加密序列![]()
6) 解密算法![]() 由用户U执行,用于对接收到的搜索结果进行解密.算法输入密钥K和搜索结果
由用户U执行,用于对接收到的搜索结果进行解密.算法输入密钥K和搜索结果![]() 输出按相关度排序的文件标示符序列id1,id2,…,idm.
输出按相关度排序的文件标示符序列id1,id2,…,idm.
方案的正确性意味着,对于所有的安全参数k、所有由KeyGen(1k)生成的K,SK,PK、所有的F和δ、所有由Setup(K,F)输出的(γ,C),对于所有由τ←SrchToken(K,W)生成的搜索令牌τ,搜索算法IW←Search(γ,C,τ)都会得出正确的搜索结果IW,并且经过排序协议Sort(S:IW,PK;coS:SK)总会得到有序的搜索结果![]() 意味着用户可以通过解密算法
意味着用户可以通过解密算法![]() 对序列解密成功,得到按搜索关键字相关度排序的文件标识符序列id1,id2,…,idm.
对序列解密成功,得到按搜索关键字相关度排序的文件标识符序列id1,id2,…,idm.
3.1.2 安全模型
与经典的密文搜索方案的安全模型不同,MES-RR的安全模型中包括2个不合谋的服务器:服务器S以及协同服务器coS,均为满足“诚实但好奇”模型的半可信实体,即具有可以分析用户的搜索过程的能力,但是不会试图共谋来获取用户数据.服务器S会诚实地为用户提供文件存储服务,并且不会主动更改或损坏用户的数据,但可能试图查看、分析或使用用户的数据、索引和令牌信息;协同服务器coS配备了用于保存密钥的密码处理器,仅仅进行辅助工作,不会获得任何有用数据,并且2个服务器之间不会共谋.具体来说,在MES-RR安全模型中,S得到加密的文件集合以及安全索引的情况下,响应用户发送的搜索请求,并通过的coS的协助,对搜索结果按照相关度进行排序,并返回给用户.在上述过程中,S能够学习到文件的个数以及在倒排索引中关键词的个数,以及在多项式次搜索过程中用户的每一次搜索令牌信息.coS只能学习到文件的个数以及用户进行搜索请求的时间.然而,coS不会得到任何有关搜索内容的信息.
文献[5]曾提到,目前已知的大多数高效的密文搜索方案均或多或少泄露了用户的私有信息,诸如用户的搜索模式访问模式等.因此在本方案中,将方案在执行的过程中用户向服务器所泄露的信息抽象成一组泄露函数L1,L2和L3来描述在方案执行期间向服务器S和协同服务器coS泄露的信息,分别代表初始化过程,搜索过程以及排序协议中泄漏的信息.并在这些泄露函数存在的条件下给出安全性的定义.其主要目标是证明,所有具有多项式时间计算能力(probabilistic polynomial-time, PPT)的敌手都无法从数据和查询中获取到任何信息,除了在泄露函数中所刻画的之外.以下为方案的安全性定义.
定义3. IND-CKA2安全性.设AS和AcoS为2个自适应敌手,分别代表方案中的服务器S与协同服务器coS,自适应表示敌手可以根据之前的质询结果来发起新的质询.view为敌手在实验过程中所能够收集到的所有信息.Sim1和Sim2为2个具有多项式时间计算能力的模拟器,L1,L2和L3为方案向AS和AcoS泄露的信息构成的泄漏函数.
设RealA(k)为敌手AS和AcoS和用户之间的交互式实验,使用真实的方案算法.在该实验中,用户U随机选择b∈(0,1),AS向用户发送2个拥有相同的文件数目和相同的关键字数的文件集合F0,F1,用户U随机选择b∈(0,1),生成Fb的安全索引γb并发送给AS.随后,AS向用户发起至多nq次的质询,其中nq为多项式级:每次质询i中,AS选择2个长度相等的多关键字搜索请求![]() 发送给用户,满足
发送给用户,满足![]() 用户生成
用户生成![]() 的搜索令牌
的搜索令牌![]() 并返回给敌手AS,AS执行搜索算法
并返回给敌手AS,AS执行搜索算法![]() 得到搜索结果
得到搜索结果![]() 随后,AS与AcoS执行排序协议
随后,AS与AcoS执行排序协议![]() 将结果进行排序,生成
将结果进行排序,生成![]() 由于AS是自适应敌手,所以其每次质询的结果都可以作为输入来产生下一次质询.在所有nq次质询结束后,将AS得到的信息记做
由于AS是自适应敌手,所以其每次质询的结果都可以作为输入来产生下一次质询.在所有nq次质询结束后,将AS得到的信息记做![]() 仅参与与AS的交互环节,并从中得到的viewAcoS.实验结束后,AS输出
仅参与与AS的交互环节,并从中得到的viewAcoS.实验结束后,AS输出![]() 输出OutputAcoS.
输出OutputAcoS.
设IdealSim(k)为模拟器Sim1,Sim2和用户U之间的交互式实验,该实验与RealA(k)实验的区别是,在IdealSim(k)中,模拟器不运行真实方案中的算法,而是利用泄漏函数L1,L2和L3来作为唯一输入,来生成随机化的数据来回应用户搜索请求.每次质询i中,Sim1选择2个长度相等的多关键字搜索请求![]() 发送给用户,满足
发送给用户,满足![]() 用户生成
用户生成![]() 的搜索令牌
的搜索令牌![]() 并返回给Sim1,Sim1执行搜索算法
并返回给Sim1,Sim1执行搜索算法![]() 得到搜索结果
得到搜索结果![]() 随后,Sim1,Sim2利用泄漏函数执行排序协议将结果进行排序,生成
随后,Sim1,Sim2利用泄漏函数执行排序协议将结果进行排序,生成![]() 在所有nq次质询结束后,将Sim1得到的信息记做
在所有nq次质询结束后,将Sim1得到的信息记做![]() 仅参与与Sim1的交互环节,将Sim2得到的信息记做
仅参与与Sim1的交互环节,将Sim2得到的信息记做![]() 实验结束后,Sim1输出
实验结束后,Sim1输出![]() 输出
输出![]()
我们称MES-RR方案满足IND-CKA2安全性,当且仅当用户不能区分与其交互的为真实的敌手还是模拟器,即当且仅当以下2个条件成立:
1) 对于敌手AS,存在一个多项式时间的模拟器Sim1满足2个分布式计算不可区分性:![]()
![]()
2) 对于敌手AcoS,存在一个多项式时间的模拟器Sim2满足2个分布式计算不可区分性:Outpu![]() ≈
≈![]()
本节给出了MES-RR的具体构建方案.在MES-RR中,文件集合F和倒排索引δ为初始输入.与文件索引不同的是,倒排索引是一种以关键字为起始的索引结构.每个关键字后面都存在一组包含该关键字的文件集合.方案中用到了多种数据结构,如链表L、数组A和查找表T.值得说明的是,方案中所用到的查找表T是一种以key/value对为基本元素的数据结构,其元素的形式为(σ,v),其中σ表示键,v表示对应于键σ的值.记号T[σ]表示在查找表T中键σ所对应的元素值,T[σ]=v表示将键σ的元素值置为v.记号#T表示查找表T中的元素个数.
初始化阶段用户生成用于加密文件以及生成安全索引结构使用的密钥K,以及Paillier同态加密算法的公私钥(PKP,SKP)和GM加密算法的公私钥(PKGM,SKGM).随后将用户的批量文件加密并生成加密索引,随后将密文文件C,加密索引γ以及公钥(PKP,PKGM)一同上传至服务器S,并将密钥对(PKP,SKP)和(PKGM,SKGM)利用密钥分发算法分享给协同服务器coS.
随后用户构建文件索引结构,首先从他的文件集F中提取到所有的关键字集合W,计算每个关键字w在文件集F中针对所有文件的tf-idf相关度权值,并生成倒排索引δ,δ中每个关键字对应一个长度为N的数组Fw,数组Fw中的位置d中的元素代表了关键字w在文件d中相关度权值,如果权值为0则表示关键字w不存在文件d中.
δ中列的个数为M(w中关键字的个数)行数为N(F中文件的个数).为了满足后续密码学运算,用户将每一个相关度权值映射到一个空间为Zn的整数值score之中,并将其用Paillier进行加密(明文空间为Zn).因为Paillier密文具有不可区分性,所以倒排索引δ不泄露任何关于关键字的文件个数的信息.随后,用户根据倒排索引δ构造安全索引γ,安全索引γ包含2个数据结构:查找表T以及搜索数组A.查找表T包含了系统中的所有关键字,同时表中的每个关键字都指向搜索数组中的一个链表.而在搜索数组A中,元素是以“文件/关键字”对的形式出现的,每个元素都是一个唯一的“文件/关键字”对,并通过以关键字为引导的链表进行组织具体来说,令F,G和P为3个伪随机函数,H为Hash函数.K=(K1,K2,K3)为用户生成的对称密钥.针对用户的文件集合F和倒排索引δ,对其中的每个关键字w构建一个链表Lw.每个链表都由#Fw个节点(N1,N2,…,N#fw)构成,并且存储在搜索数组A中的随机位置.定义节点Ni的结构为Ni=( idi,[scorei],addr(Ni+1)
idi,[scorei],addr(Ni+1) ⊕H(PK3(w),ri),ri),其中idi为文件fi的唯一标识,文件中包含对应的关键字,[scorei]是关键字w在文件fi中的相关度权值的Paillier密文:[scorei]←P.EncPKp(scorei).addr(N)表示节点N在数组A中的位置.链表Lw中的所有节点都使用H(PK3(w),ri)进行异或加密,其中ri为储存在节点中的随机值,K3为伪随机函数P的密钥.数组A中未使用的节点都随机利用0或1进行填充.
⊕H(PK3(w),ri),ri),其中idi为文件fi的唯一标识,文件中包含对应的关键字,[scorei]是关键字w在文件fi中的相关度权值的Paillier密文:[scorei]←P.EncPKp(scorei).addr(N)表示节点N在数组A中的位置.链表Lw中的所有节点都使用H(PK3(w),ri)进行异或加密,其中ri为储存在节点中的随机值,K3为伪随机函数P的密钥.数组A中未使用的节点都随机利用0或1进行填充.
对于每个关键字w,查找表T中的对应元素以FK1(w)为键,以指向链表Lw头节点的指针为值,其中K1为伪随机函数的密钥.指针使用GK2(w)进行异或加密,其中K2是伪随机函数G的密钥.即:T[FK1(w)]=addr(N1)⊕GK2(w).值得说明的是,数组A和查找表T共同作为安全索引存储至服务器S端.文件利用标准加密算法进行加密,生成文件密文集合C={c1,c2,…,c#F},同样上传至服务器S.
为了搜索某个关键字集合W={w1,w2,…,wn},用户需要首先生成一个搜索令牌τ并发送给服务器S.搜索令牌τ中包含了针对每个关键字wi的FK1(wi),GK2(wi)和PK3(wi),即ti=(FK1(wi),GK2(wi),PK3(wi)),输出搜索令牌τ=(t1,t2,…,tn).
对于每个关键字wi∈W,服务器S使用FK1(wi)作为键来在查找表T中找到加密的指针,然后使用GK2(w)来解密得到Lw的明文指针并定位到数组A中的节点,即α=T[t1]⊕t2=T[FK1(w)]⊕GK2(w),其中α代表N1在A中的坐标,最后使用PK3(w)和储存在各自节点中的随机值r来解密整个链表节点,即[idi,[scorei],addr(Ni+1)]=li⊕H(PK3(w),ri),进而得到针对关键字w的文件标识符集合S={id1,[score1],id2,[score2],…,idm,[scorem]}.为了不在后续排序协议中泄露信息,服务器处理每个关键字wi对应的搜索结果集合Si,最终得到所有关键字的集合{S1,S2,…,Sn}.对于集合中每个文件标示符idj,对其对应的全部关键字的权值密文[scorej]进行累积相加,得到最终的权值ej,即![]() 因此交集为IW={id1,e1,id2,e2,…,idm,em}=S1∩S2∩…∩Sn,并集为IW={id1,eid1,id2,eid2,…,idm,eidm}=S1∪S2∪…∪Sn.
因此交集为IW={id1,e1,id2,e2,…,idm,em}=S1∩S2∩…∩Sn,并集为IW={id1,eid1,id2,eid2,…,idm,eidm}=S1∪S2∪…∪Sn.
图3为搜索过程的示例.用户想要搜索文件集中包含w1以及w3的文件,生成w1∪w3的搜索令牌τ=(t1,t2),其中t1=(FK1(w1),GK2(w1),PK3(w1)),t2=(FK1(w3),GK2(w3),PK3(w3)).用户将令牌发送给服务器S,服务器S以FK1(w1)为键,对应到查找表T中加密的指针0⊕GK2(w1),再利用GK2(w1)解密,得到搜索数组中链表的头节点位置0的值l1,使用PK3(w1)和储存在节点0中的随机值r1来解密,得到(id2‖[score2]‖4)=l1⊕H(PK3(w1),r1),即得到指向位置4的指针,继续解密位置4,得到的指针指向了位置0,然后结束遍历.对于w3服务器进行相同的操作,最终所有包含关键字w1和w3的文件都可以被找到,提取出文件标识符合和对应权值密文,组成Sw1={id2,[score2]w1,id4,[score4]w1},Sw3={id1,[score1]w3,id2,[score2]w3}然后服务器对于相同标识符id2的权值密文进行同态相加得到e2=[score2]w1⊕[score2]w3,从而得到最终搜索结果Iw1∩w3={id1,e1,id2,e2,id4,e4}.
搜索阶段结束之后,服务器S得到搜索结果IW={id1,e1,id2,e2,…,idm,em},即文件标示符与对应的相关度权值密文组成的二元组的集合.然而,由于权值由Paillier同态加密进行加密,其随机性导致密文并不会表达明文的顺序,所以服务器S并不能通过权值的密文来得到排序之后的结果.为了实现结果排序,服务器S通过协同服务器coS的协助得到最终有序的搜索结果.然而,本文的安全模型定义不允许协同服务器coS获得和文件有关的任何信息,因此为了不向其泄漏消息,在进行协议之前服务器对IW进行变换,将文件标示符利用Paillier加密方法进行加密,得到标示符密文[idi]←P.EncPKp(idi),并将[idi]替代集合中的idi,生成IW,1={[id1],e1,[id2],e2,…,[idm],em}.随后服务器S与协同服务器coS对IW,1中的[idi],ei进行两两比较并排序,排序以ei为主键.具体来说,对于Batcher排序网络中每个层级i中pairsi对应的每对元素([idx],ex,[idy],ey),服务器S计算[z] [2l]×[ex]×[ey]-1modn2(l>k)并对其进行盲化处理:选择r∈(0,1)l+k,计算[d][z]×[r] modn2,并发送[d]给coS.同样,S与coS分别计算r′rmod 2l与d′←P.DecSKP[d] mod 2l,随后双方执行DGK两方安全比较协议[29]比较d′和r′的大小,DGK协议结束后,云存储服务器得到比较结果的GM密文‖λ‖,满足λ=1⟺d′≤r′.随后,coS提取出d′的第l位比特值,记做dl,发送给S,同时,S提取出AcoS的第l位比特值,记做
[2l]×[ex]×[ey]-1modn2(l>k)并对其进行盲化处理:选择r∈(0,1)l+k,计算[d][z]×[r] modn2,并发送[d]给coS.同样,S与coS分别计算r′rmod 2l与d′←P.DecSKP[d] mod 2l,随后双方执行DGK两方安全比较协议[29]比较d′和r′的大小,DGK协议结束后,云存储服务器得到比较结果的GM密文‖λ‖,满足λ=1⟺d′≤r′.随后,coS提取出d′的第l位比特值,记做dl,发送给S,同时,S提取出AcoS的第l位比特值,记做![]() 计算‖v‖=‖dl‖×‖rl‖×‖λ‖,并与coS运行比特重加密协议以及密文选择协议[30],得到重加密之后的排序好的
计算‖v‖=‖dl‖×‖rl‖×‖λ‖,并与coS运行比特重加密协议以及密文选择协议[30],得到重加密之后的排序好的![]() 图4为协同排序过程示例.
图4为协同排序过程示例.
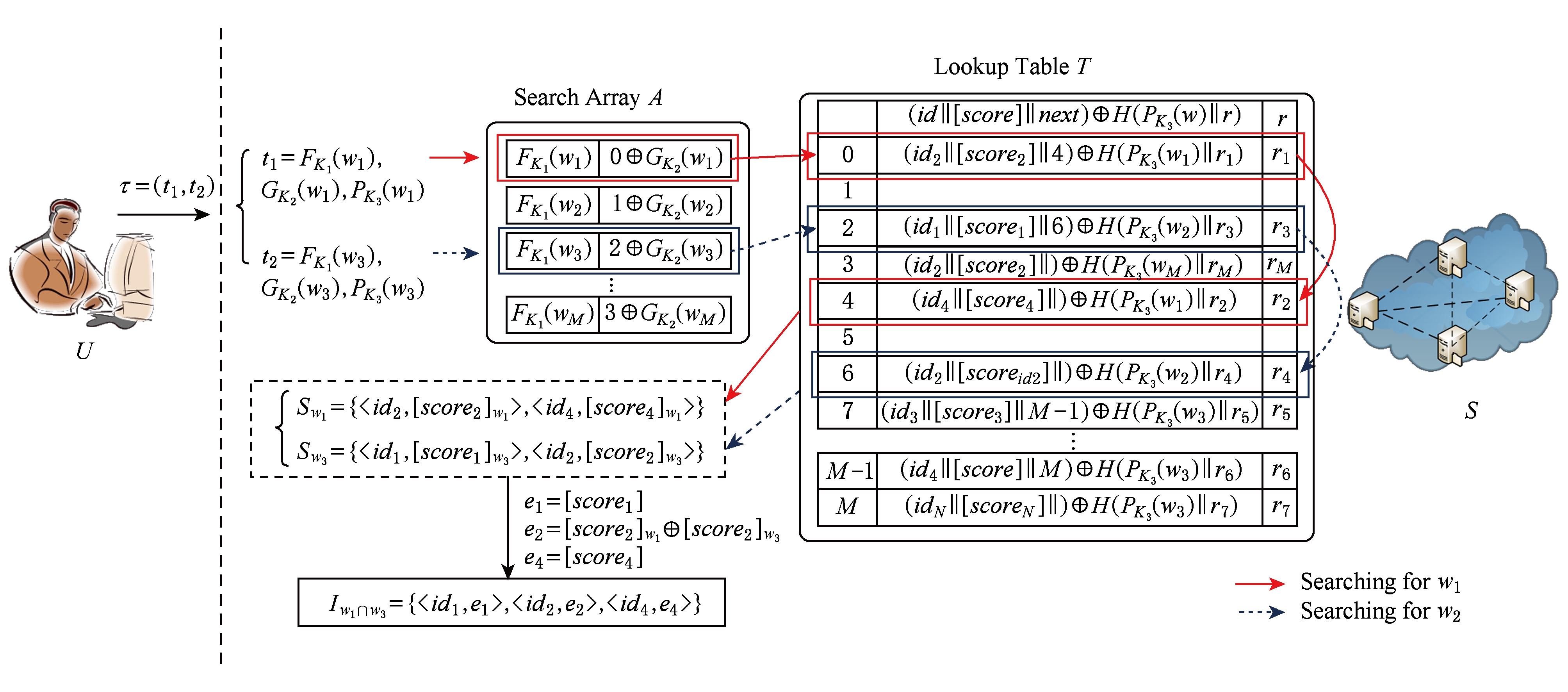
Fig. 3 Searching procedure
图3 搜索过程
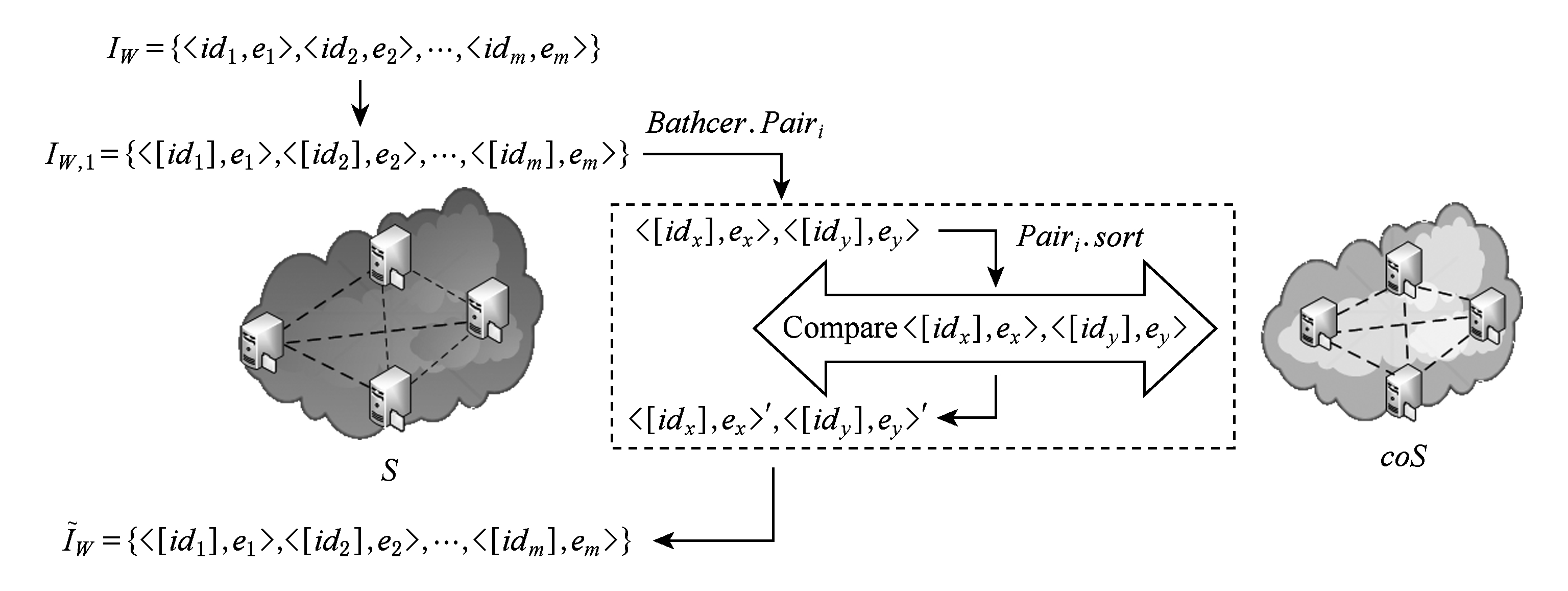
Fig. 4 Collaborated comparison procedure
图4 协同排序过程
进行O((lbm)2)轮Bathcer排序之后,最终服务器S得到根据权值排序并重加密的搜索结果![]() [id1],e1,[id2],e2,…,[idm],em},满足:P.DecSKP(e1)≤P.DecSKP(e2)≤…≤P.DecSKP(em),并将
[id1],e1,[id2],e2,…,[idm],em},满足:P.DecSKP(e1)≤P.DecSKP(e2)≤…≤P.DecSKP(em),并将![]() 返回给用户,用户利用Paillier解密密钥SK将
返回给用户,用户利用Paillier解密密钥SK将![]() 中的权值密文(e1,e2,…,em)解密,得到文件标示符(id1,id2,…,idm),并请求服务器返回相应的文件密文(c1,c2,…,cm),通过解密算法得到文件明文f1,f2,…,fm.
中的权值密文(e1,e2,…,em)解密,得到文件标示符(id1,id2,…,idm),并请求服务器返回相应的文件密文(c1,c2,…,cm),通过解密算法得到文件明文f1,f2,…,fm.
本节详细介绍MES-RR的算法与协议.在运行之前应该首先选择确定所使用的公共参数,包括内容:
选择选择伪随机函数:F{0,1}k×{0,1}*→{0,1}k、G:{0,1}k×{0,1}*→{0,1}*和P:{0,1}k×{0,1}*→{0,1}k;选择Hash函数:H{0,1}*→{0,1}*;选择Paillier同态加密方法P=(P.Gen,P.Enc,P.Dec)以及GM加密方法GM=(GM.Gen,GM.Enc,GM.Dec).
3.3.1 密钥生成算法
KeyGen(1k)→(SK,PK)由用户U执行,生成用户密钥以及加密算法公私钥.主要步骤如下:
1) 调用P.Gen(1k)生成Paillier加密算法的公私钥(PKP,SKp);
2) 调用GM.Gen(1k)生成GM加密算法的公私钥(PKGM,SKGM);
3) 随机选择3个长度为k位的数值K1,K2,K3;
4) 用户U将生成的密钥在本地进行存储,将(PKP,PKGM)发布给云存储服务器S,并将(PKP,SKP,PKGM,SKGM)发送给协同服务器coS.
3.3.2 初始化算法
Setup(K,PK,F)→(γ,C)由用户U执行,用于生成安全索引结构并对要上传的数据进行加密.创建有足够空间的查找表T以及一个有足够空间的搜索数组A.
1) 构建倒排索引δ
从文件集F中提取关键字集合W,对于每个关键字wi∈W:
① 对于每个关键字wi∈W计算其在每个文件中的的TF-IDF相关度权值;
② 创建一个长度为N的数组Fwi,将wi在文件r中权值插入数组Fwi中的位置d中.如果权值为0则表示这个关键字不存在文件d中.每个关键字后面都存在一组包含该关键字的文件集合;
③ 所有关键字的数组组成倒排索引δ,δ中列的个数为M(W中关键字的个数)行数为N(F中文件的个数).
2) 构建安全索引γ
创建有足够空间的查找表T以及一个有足够空间的搜索数组A.对于每个关键字w∈W:
① 将δ中每一个相关度权值映射到一个空间为Zn的整数值scorei之中,其中i为对应的文件fi标识,并将其用Paillier加密算法进行加密(明文空间为Zn),生成密文[scorei]←P.EncPKP(scorei);
② 创建一个有#w个节点的链表Lw=(N1,N2,…,N#w),节点的结构定义为Ni=(idi,[scorei],addr(Ni+1)⊕H(PK3(w),ri),ri),其中[scorei]是w在fi中的权值密文,ri为一个随机的k位比特串,addrs(N#w+1)=addrs(N0)=0log #A.将链表中的节点存储在搜索数组A的随机位置;
③ 通过以下方式将链表Lw的头节点的地址储存在查找表T中:T[FK1(w)]=addr(N1)⊕GK2(w).
算法输出γ=(A,T)为加密索引,C=(c1,c2,…,c#F)为密文集合.
3.3.3 搜索令牌生成算法
SrchToken(K,W)→τ由用户执行,用于用户在搜索时生成搜索令牌.主要步骤如下:
1) 输入对称密钥K和待搜索关键字集合W,对于每一个待搜索关键字wi∈W,计算ti=(FK1(wi),GK2(wi),PK3(wi));
2) 输出搜索令牌τ=(t1,t2,…,tn).
3.3.4 搜索算法
Search(γ,C,τ)→IW由服务器S执行,用于实现搜索.对与搜索令牌中每一个ti∈τ,依次按以下步骤:
1) 计算α=T[t1]⊕t2=T[FK1(w)]⊕GK2(w),找到关键字链表Lw的头结点N1的坐标,其中α代表N1在A中的坐标值;
2) 查找节点N1=A[α1],使用t3解密该节点,例如N1⟹(l1,r1),计算id1,[score1],addr(N2)=l1⊕H(τ3,r1);
对于j≥2,重复2)中过程,直至αj+1为0.
3) 将得到的结果记为Si={id1,[score1],id2,[score2],…,idm,[scorem]};
4) 针对集合关键字布尔搜索模式,处理每个关键字令牌对应的搜索结果集合Si:
对于集合中每个文件标示符idi,对其权值密文进行相加,得到最终的权值![]() 因此交集为IW={id1,e1,id2,e2,…,idm,em}=S1∩S2∩…∩Sn,并集为IW={id1,e1,id2,e2,…,idm,em}=S1∪S2∪…∪Sn.
因此交集为IW={id1,e1,id2,e2,…,idm,em}=S1∩S2∩…∩Sn,并集为IW={id1,e1,id2,e2,…,idm,em}=S1∪S2∪…∪Sn.
3.3.5 排序协议
![]() 是一个服务器S和协同服务器coS之间运行的交互式协议,用于对搜索结果进行排序.主要步骤如下:
是一个服务器S和协同服务器coS之间运行的交互式协议,用于对搜索结果进行排序.主要步骤如下:
1) 服务器将IW中的每个文件标示符idi进行加密,得到[idi]←P.EncPKP(idi);
2) 生成IW,1={[id1],e1,[id2],e2,…,[idm],em};
3) 服务器S与协同服务器coS利用Batcher排序网络对IW,1中的ei进行两两比较并排序,具体来说,对于每个层级i(总层级为(lbm)2,且1≤i≤(lbm)2-1)顺序执行以下步骤:
① 标记IW,1的pairsi为([idx],ex,[idy],ey):
Ⅰ.S计算[z][2l]·[ex]·[ey]-1modn2(l>k);
Ⅱ. 选择r∈(0,1)l+k,并计算r′rmod 2l,计算并发送[d][z]·[r] modn2,给代理服务器coS;
Ⅲ.coS运行P.Dec算法解密[d]→d,并计算d′dmod 2l;
Ⅳ. 利用DGK协议,S与coS联合计算GM密文‖λ‖,满足λ=1⟺d′≤r′;
Ⅴ.coS用GM加密方案加密dl并发送‖dl‖给S;
Ⅵ.S加密rl并计算‖v‖=‖dl‖×‖rl‖×‖λ‖;
Ⅶ.S与coS运行比特重加密协议与密文选择协议[23],得到有序的pairsi:([idx],ex′,[idy],ey′);
Ⅷ.S将得到的重加密之后的有序([idx],ex′,[idy],ey′)存入Bathcer排序网络中层级i+1的序列IW,i+1对应位置.
② 将IW,1在层级i的下一组元素继续执行步骤(1),直到IW,1完成层级i的比较.
4) 在log(m)2次层级排序结束后,S得到根据权值排序之后的结果的重加密序列![]() [id1],e1,[id2],e2,…,[idm],em},满足:P.DecSKP(e1)≤P.DecSKP(e2)≤…≤P.DecSKP(em);
[id1],e1,[id2],e2,…,[idm],em},满足:P.DecSKP(e1)≤P.DecSKP(e2)≤…≤P.DecSKP(em);
5) 服务器将![]() 返回给用户.
返回给用户.
3.3.6 解密算法
![]() 由用户U执行,用于对接收到的搜索结果进行解密.
由用户U执行,用于对接收到的搜索结果进行解密.
用户U利用密钥PKP和搜索结果![]() [id1],eid1,[id2],eid2,…,[idm],eidm},对序列中的文件标识符idi,运行P.DECPKP([idi])算法,解密输出按相关度排序的文件标示符序列id1,id2,…,idm.
[id1],eid1,[id2],eid2,…,[idm],eidm},对序列中的文件标识符idi,运行P.DECPKP([idi])算法,解密输出按相关度排序的文件标示符序列id1,id2,…,idm.
本节首先对本文提出的MSE-RR方案的安全性进行概述,然后对其所具有的安全性进行详细的数学证明.
在接下来的内容中,首先分析在方案的执行过程中有哪些信息泄露给了用户,然后给出泄露函数的形式化定义.
1) 初始化.定义安全索引γ=(T,A)和密文集合C,在初始化阶段,服务器S可以获知数组A的大小、T中的集合[id(w)]w∈W和每个文件[|f|]f∈F的长度.将这些信息记为L1,即:L1=(#A,[id(w)]w∈W,[|f|]f∈F).
2) 搜索.在多项式次搜索操作中,方案向服务器S泄露了搜索令牌中关键字w∈W的标识id(w),每个关键字标识id(w)和包含关键字w的文件标识之间的关联,以及用户的搜索历史.具体来说,设Q为nq次多关键字搜索的搜索令牌集合Q={q1,q2,…,qnq},lmax表示在集合Q中长度最长的搜索令牌,nq次搜索之后的搜索历史可表示为一个二进制四阶的矩阵Qnq×nq×lmax×lmax.将这些信息记为L2,即:
L2=([id(f)]f∈Fw,id(w),Qnq×nq×lmax×lmax)w∈W.
3) 排序.在对每次搜索结果进行排序的过程中,需要S与coS进行交互,coS能够学习到的知识包括和S运行两方安全密文比较协议中的泄露的消息![]() 以及需要排序的文件的个数m.其中将这些信息记为L3,即:
以及需要排序的文件的个数m.其中将这些信息记为L3,即:
现在利用定理来证明方案在泄漏函数(L1,L2,L3)存在的情况下,在随机语言模式下具有IND-CKA2安全性.
定理1. 若Paillier,GM加密方案是CPA安全的,F,G和P为伪随机函数,并且DGK协议在随机模型下可证明安全,则本文所提出的方案在随机预言模型下针对自适应敌手AS与AcoS攻击是安全的,即满足IND-CKA2安全性.
证明. 在随机语言模型下构造2个模拟器Sim1和Sim2,能够在仅获得泄露函数中包括的内容中的情况下,在理想游戏中通过模拟敌手AS与AcoS的行为生成相应的模拟值来与用户U进行交互.安全目标是这些模拟值应该和真实游戏中的相对应的值具有不可区分性.
给定泄漏函数L1的信息,模拟器Sim1可以学习到数组A的大小、T中的集合[id(w)]w∈W和每个文件[|f|]f∈F的长度.随后,它可以使用随机值来构建这些结构,并输出作为模拟值![]() 伪随机函数的伪随机性及离散对数假设保证了模拟值
伪随机函数的伪随机性及离散对数假设保证了模拟值![]() 与真实值(A,T,F)是无法区分的.即
与真实值(A,T,F)是无法区分的.即
给定泄漏函数L2的信息,Sim1可以学习到搜索令牌中关键字w∈W的标识id(w),每个关键字标识id(w)和包含关键字w的文件标识之间的关联,以及用户的搜索历史.用户U能够挑选不同个数关键字组成的集合并且用任意搜索请求qi向系统发起质询.设Q为nq次多关键字搜索的搜索令牌集合Q={q1,q2,…,qnq},lmax表示在集合Q中长度最长的搜索令牌,nq次搜索之后的搜索历史可表示为一个二进制四阶的矩阵Qnq×nq×lmax×lmax.为了响应质询,Sim1需要使用L2来构建模拟搜索令牌,使其与真实令牌是无法区分的.Sim1需要跟踪这些质询之间的依赖关系,来保证各个令牌之间的一致性.通过定义额外的辅助结构iA和iT来记录L2所揭示的依赖关系[3],与此同时![]() 数据依然保持随机.这使得Sim1能够像真实AS一样应答用户的质询,不同的是其使用的是模拟值,即
数据依然保持随机.这使得Sim1能够像真实AS一样应答用户的质询,不同的是其使用的是模拟值,即
给定泄漏函数L3的信息,Sim2能够学习到两方安全密文比较协议中的泄露的消息![]() 以及需要排序的文件的个数m.由于AS与AcoS的交互为多次密文比较协议组成的(logm)2层Bathcer排序网络,所以通过证明Sim1和Sim2能够通过泄漏函数来模拟密文比较协议中的AS与AcoS,进而模拟(logm)2层Bathcer排序网络.
以及需要排序的文件的个数m.由于AS与AcoS的交互为多次密文比较协议组成的(logm)2层Bathcer排序网络,所以通过证明Sim1和Sim2能够通过泄漏函数来模拟密文比较协议中的AS与AcoS,进而模拟(logm)2层Bathcer排序网络.
在进行每次密文比较协议时,AS的view可表示为viewAs=(ex,ey,l,PKQR,PKP,r;‖λ‖,[zl]).给定(ex,ey,l,PKQR,PKP),我们能够构建出一个能够模拟AS的Sim1:
1) 选择![]()
2) 选择随机数![]() 生成2个GM方案的密文
生成2个GM方案的密文![]()
3) 输出![]()
对于viewAs和![]() 从一个均匀分布(0,2λ+l)∩Z中提取,而
从一个均匀分布(0,2λ+l)∩Z中提取,而![]() 为Paillier的二重密文,具有随机性.所以
为Paillier的二重密文,具有随机性.所以![]() 除此之外,r和
除此之外,r和![]() 的都是从同一个均匀分布中提取,基于GM方案的语义安全性,我们能得出结论:AS的view和Sim1的view具有计算不可区分性.
的都是从同一个均匀分布中提取,基于GM方案的语义安全性,我们能得出结论:AS的view和Sim1的view具有计算不可区分性.
同理,AcoS的view可表示为viewAcoS=(SKGM,SKP,‖z‖,‖λ‖),其中SKGM是GM方案的私钥,SKP是Paillier加密方案的私钥.
给定(SKGM,SKP,‖z‖,[λ]),我们能够构建出一个能够模拟AcoS的Sim2:
1) 随机选择一个随机数![]() 计算
计算![]() 的GM方案的密文
的GM方案的密文![]() 用于表示P.DecSKP(ex)≤P.DecSKP(ey);
用于表示P.DecSKP(ex)≤P.DecSKP(ey);
2) 随机选择![]()
3) 利用Paillier方案将![]() 加密,生成密文
加密,生成密文![]()
4) 输出![]()
可以得出![]()
在真实试验中,z=x+r,其中x是一个l位长的整数并且r是一个l+λ比特长的整数,所以![]() 的分布和z具有不可区分性.我们能够直接得出
的分布和z具有不可区分性.我们能够直接得出![]() 并且,因为
并且,因为![]() 和z的分布独立于t,所以
和z的分布独立于t,所以![]()
除此之外,由于![]() 所以
所以![]() 由于DGK协议为随机语言模型下具有语义安全性,所以:
由于DGK协议为随机语言模型下具有语义安全性,所以:
Outpu![]() (SKGM,SKP,‖λ‖,[z])≈
(SKGM,SKP,‖λ‖,[z])≈![]()
![]()
由于Sim1和Sim2能够从泄漏函数L3中获取需要排序的文件的个数m,所以Sim1和Sim2能够模拟每次密文比较协议中的AS与AcoS,进而模拟(logm)2层Bathcer排序网络.所以,给定泄漏函数L3的信息,Sim1和Sim2能够像真实AS与AcoS一样应答用户的质询,不同的是其使用的是模拟值.
综上所述,对于敌手AS,存在一个多项式时间的模拟器Sim1满足2个分布式计算不可区分性:
对于敌手AcoS,存在一个多项式时间的模拟器Sim2满足2个分布式计算不可区分性:
因此,本文MES-RR方案在随机预言模型下针对自适应选择关键字攻击是安全的,即满足IND-CKA2安全性.
证毕.
本节将MES-RR方案与现有具有代表性的支持排序的多关键字密文搜索方案[15-16,20]进行了比较.在本文中评估的指标有以下6种:同态技术、搜索结果的准确性(Accuracy)、排序机制(Rank Method)、用户生成搜索令牌的时间复杂度ComU,服务器生成最终搜索结果的时间复杂度ComS以及安全性等.表1中IPS(inner scalar product)表示内积相似性,N指的是文件个数,M指的是文件集合中关键字的个数,指的是搜索关键字个数,CKA-1和 CKA-2分别指指选择关键字安全性和自适应性选择密文攻击安全.时间复杂度均为渐进的.
Table1SchemesComparison
表1性能对比

搜索结果准确性方面,由于文献[15]中的方案仅仅基于内积相似性来计算每个文件中匹配到的关键字的数量,以此来计算文件权值并对文件进行排序.然而,因为这种方法失去了关键词对于文件的重要性这一信息,所以结果具有一定的误报率.文献[20]中的方案基于位置敏感Hash函数来聚类相似文件.然而,LSH适用于相似性搜索但是同样不能提供精确排序.本方案利用TF-IDF加权规则来计算关键字文件相关度权值,实现对于关键字的精确排序.
安全性方面,文献[15]利用了启发式方法来隐藏搜索模式和访问模式,所以安全性不在比较范围之内.文献[16]基于全同态加密构建搜索索引,安全性较高,方案假设一个单独的服务器仅仅执行搜索功能,并不能对结果进行排序,服务器找到需要的密文文件以及权值,将其全部返回给用户,用户在本地基于TF-IDF进行对搜索结果排序.文献[20]中引入2个不共谋服务器模型,但是服务器之间的交互过程中,其中一个服务器能够访问每一个搜索结果的明文,这对于用户的数据安全以及搜索模式和访问模式造成了极大的威胁,存在信息泄露的隐患,安全性较弱.本方案基于同态加密算法对相关度权值进行加密,使得服务器无需解密即可对权值密文进行计算,从而在不获取额外信息的前提下对搜索结果进行排序.除此之外,本文方案中协同服务器仅仅在排序过程中起到了协助作用,在交互过程中得到的全部是密文,并不会得到任何有关搜索模式和用户真实数据相关的信息,安全性方面较高.
效率方面,文献[15]的搜索阶段中时间复杂度为O(M2),搜索令牌的大小O(M),与文件集合关键字个数呈线性关系.为了响应查询请求,服务器需要进行O(NM2)次计算,其中N是文件集中文件个数.文献[16]中为了实现排序,频率信息由全同态加密方法进行加密,导致服务期计算代价为O(qN+M2),效率较其他方案相比较差,且方案不支持动态更新.文献[20]中的协同服务器中存储复杂度是与文件集呈线性关系,存储代价稍高.本方案中搜索过程中需要2个服务器进行两方安全交互计算,导致服务器的搜索复杂度为O(N(lbN)2),略高于其他方案,但是本方案中用户生成长度为q的搜索令牌仅仅需要常数级O(q)的时间复杂度,与集合中文件数量和关键字数量无关,与其他方案相比客户端计算代价较低.在如今分布式云存储环境下,如何降低客户端存储与计算代价为首要考虑问题,所以本方案在效率更适用于实际云存储部署需求.
本文对多关键字密文搜索和搜索结果排序方法展开研究,提出一种双服务器模型下支持相关度排序的多关键字密文搜索方案,在能够保证高效地实现多关键字密文搜索的同时,实现对于搜索结果的排序.方案基于TF/IDF加权技术以及Paillier同态加密算法,构建关键字相关度安全索引,优化计算代价并降低了存储复杂度;方案设计双服务器模型,引入安全可信的协同服务器处理机制来构造安全排序协议,在不向协同服务器泄露搜索模式与访问模式的前提下,实现对于搜索结果的高效排序.在安全性方面,本文在诚实与好奇的威胁场景下,构建方案的安全模型,并对该方案的安全性进行严格分析,结果表明在结果表明在有限泄漏函数存在的情况下,方案能够在随机语言模型下具有语义安全性.性能分析表明,与以往的支持搜索结果排序的多关键字密文搜索方案相比,本方案大大降低了存储代价和访问交互次数,适用于实际的云存储环境.未来工作包括对提出的方案部署进真实云环境进行部署试验并在服务器交互次数和计算代价方面进行进一步提高.
参考文献
[1]Yousef E, Bharath K S, Wei J. Securek-nearest neighbor query over encrypted data in outsourced environments[C] //Proc of the 30th IEEE Int Conf on Data Engineering. Piscataway, NJ: IEEE, 2014: 664-675
[2]Raphael B, Raluca A P, Stephen T, et al. Machine learning classification over encrypted data[C/OL] //Proc of 2015 Network and Distributed System Security (NDSS) Symp. Reston, VA: The Internet Society, 2015[2018-06-10]. http://www.internetsociety.org/doc/machine-learning-classific-ation-over-encrypted-data
[3]Liu An, Zheng Kai, Li Lu, et al. Efficient secure similarity computation on encrypted trajectory data[C] //Proc of the 31st IEEE Int Conf on Data Engineering. Piscataway, NJ: IEEE, 2015: 66-77
[4]Song D, Wagner D, Perrig A. Practical techniques for searches on encrypted data[C] //Proc of 2000 IEEE Symp on Security and Privacy (S&P 2000). Piscataway, NJ: IEEE, 2000: 44-55
[5]Curtmola R, Garay J, Kamara S, et al. Searchable symmetric encryption: Improved definitions and efficient constructions[C] //Proc of the 13th ACM Conf on Computer and Communications Security. New York: ACM, 2006: 79-88
[6]Kamara S, Papamanthou C, Roeder T. Dynamic searchable symmetric encryption[C] //Proc of 2012 ACM Conf on Computer and Communications Security. New York: ACM, 2011: 965-976
[7]Boneh D, Di C G, Ostrovsky R, et al. Public key encryption with keyword search[G] //LNCS 3027: Proc of Int Conf on the Theory and Applications of Cryptographic Techniques. Berlin: Springer, 2004: 506-522
[8]Golle P, Staddon J, Waters B. Secure conjunctive keyword search over encrypted data[G] //LNCS 3089: Proc of Int Conf on Applied Cryptography and Network Security. Berlin: Springer, 2004: 31-45
[9]Cash D, Jarecki S, Jutla C, et al. Highly-scalable searchable symmetric encryption with support for boolean queries[G] //LNCS 8042: Proc of Advances in Cryptology-CRYPTO 2013. Berlin: Springer, 2013: 353-373
[10]Cash D, Jaeger J, Jarecki S, et al. Dynamic searchable encryption in very-large databases: Data structures and implementation[C] //Proc of 2014 Network and Distributed System Security (NDSS) Symp. Reston, VA: The Internet Society, 2014: 23-26
[11]Wang Kaixuan, Li Yuxi, Zhou Fucai, et al. Multi-keyword fuzzy search over encrypted data[J]. Journal of Computer Research and Development, 2017, 54(2): 348-360 (in Chinese)(王恺璇, 李宇溪, 周福才, 等. 面向多关键字的模糊密文搜索方法[J]. 计算机研究与发展, 2017, 54(2): 348-360)
[12]Swaminathan A, Mao Y, Su G M, et al. Confidentiality-preserving rank-ordered search[C] //Proc of the 2007 ACM Workshop on Storage Security and Survivability. New York: ACM, 2007: 7-12
[13]Zerr S, Olmedilla D, Nejdl W, et al. Zerber+r: Top-kretrieval from a confidential index[C] //Proc of the 12th Int Conf on Extending Database Technology: Advances in Database Technology. New York: ACM, 2009: 439-449
[14]Wang Cong, Cao Ning, Ren Kui, et al. Enabling secure and efficient ranked keyword search over outsourced cloud data[J]. IEEE Trans on Parallel and Distributed Systems, 2012, 23(8): 1467-1479
[15]Cao Ning, Wang Cong, Li Ming, et al. Privacy-preserving multi-keyword ranked search over encrypted cloud data[J]. IEEE Trans on Parallel and Distributed Systems, 2014, 25(1), 222-233
[16]Strizhov M, Ray I. Multi-keyword similarity search over encrypted cloud data[G] //IFIPAICT 428: Proc of IFIP Int Information Security Conf. Berlin: Springer, 2014: 52-65
[17]Sun Wenhai, Wang Bing, Cao Ning, et al. Verifiable privacy-preserving multi-keyword text search in the cloud supporting similarity-based ranking[J]. IEEE Trans on Parallel and Distributed Systems, 2014, 25(11): 3025-3035
[18]Zhang Wei, Xiao Sheng, Lin Yaping, et al. Secure ranked multi-keyword search for multiple data owners in cloud computing[C] //Proc of the 44th Annual IEEE/IFIP Int Conf on Dependable Systems and Networks. Piscataway, NJ: IEEE, 2014: 276-286
[19]Fu Zhangjie, Sun Xingming, Liu Qi, et al. Achieving efficient cloud search services: Multi-keyword ranked search over encrypted cloud data supporting parallel computing[J]. IEICE Trans on Communications, 2015, 98(1): 190-200
[20]Orencik C, Kantarcioglu M, Savas E. A practical and secure multi-keyword search method over encrypted cloud data[C] //Proc of 2013 6th Int Conf on Cloud Computing. Piscataway, NJ: IEEE, 2013: 390-397
[21]Xia Zhihua, Wang Xinhui, Sun Xingming, et al. A secure and dynamic multi-keyword ranked search scheme over encrypted cloud data[J]. IEEE Trans on Parallel and Distributed Systems, 2016, 27(2): 340-352
[22]Song Wei, Wang Bing, Wang Qian, et al. A privacy-preserved full-text retrieval algorithm over encrypted data for cloud storage applications[J]. Journal of Parallel and Distributed Computing, 2017, 99: 14-27
[23]Shen Peisong, Chen Chi, Zhu Xiaojie. Privacy-preserving relevance ranking scheme and its application in multi-keyword searchable encryption[C] //Proc of the 13th Int Conf on Security and Privacy in Communication Systems. Berlin: Springer, 2018: 128-146
[24]Paillier P. Public-key cryptosystems based on composite degree residuosity classes[G] //LNCS 1592: Proc of Int Conf on the Theory and Applications of Cryptographic Techniques. Berlin: Springer, 1999: 223-238
[25]Goldwasser S, Micali S. Probabilistic encryption[J]. Journal of Computer and System Sciences, 1984, 28(2): 270-299
[26]Lipmaa H. An oblivious transfer protocol with log-squared communication[G] //LNCS 3650: Proc of Int Conf on Information Security. Berlin: Springer, 2005: 314-328
[27]Wikipedie: tf-idf[EB/OL]. [2018-07-02]. https://en.wikipedia.org/wiki/Tf%E2%80%93idf
[28]Veugen T. Comparing encrypted data[EB/OL]. [2018-06-10]. https://www.researchgate.net/publication/266527434_COMPARING_ENCRYPTED_DATA, 2011[2015-04-29]
[29]Damgard I, Geisler M, Kroigard M. Homomorphic encryption and secure comparison[J]. International Journal of Applied Cryptography, 2008, 1(1): 22-31
[30]Baldimtsi F, Ohrimenko O. Sorting and searching behind the curtain[G] //LNCS 8975: Proc of Int Conf on Financial Cryptography and Data Security. Berlin: Springer, 2015: 127-146
Li Yuxi, Zhou Fucai, Xu Jian, and Xu Zifeng
(CollegeofSoftware,NortheasternUniversity,Shenyang110819)
AbstractFocusing on the problem of confidentiality and availability of user data in cloud storage environment, we study the encrypted search method with multi-keyword. Aiming at the practical demand, we propose a multi-keyword encrypted search scheme with relevance ranking (MES-RR) in dual-server model, which can not only achieve secure multi-keyword encrypted search, but also ensure efficient search result sorting. We construct a relevance-based keyword index with the tools of TF-IDF weighting scheme and Paillier homomorphic cryptosystems, which not only obtains optimize computational complexity but also reduces storage complexity. We design a dual-server model architecture to perform the collaborated mechanism. Based on that, we design a secure sorting protocol between the two collaborated servers to sort the encrypted search results, which outputs private ranking result to user. In terms of security, we design the security model of MES-RR under honest but curious threat scenario, and give formal security analysis. The result shows that MES-RR can resist adaptive chosen keyword attacks under the random oracle model (IND-CKA2). The performance analysis shows that compared with the previous multi-keyword encrypted search scheme that supports result sorting, MES-RR reduces the storage cost and interactions, and is applicable to the cloud storage environment in the real world.
Keywordsencrypted search; relevance ranking; dual-server; homomorphic cryptosystems; adaptive chosen keyword attack
通信作者:周福才(fczhou@mail.neu.edu.cn)
This work was supported by the National Natural Science Foundation of China (61772127, 61472184), the Major National Science and Technology Program (2013ZX03002006), the Liaoning Province Science and Technology Projects (2013217004), and the Fundamental Research Funds for the Central Universities ( N151704002).
基金项目:国家自然科学基金项目(61772127,61472184);国家科技重大专项基金项目(2013ZX03002006);辽宁省科技攻关项目(2013217004);中央高校基本科研业务费专项资金项目(N151704002)
修回日期:2018-08-13
收稿日期:2018-06-10;
中图法分类号TP391
(eliyuxi@gmail.com)

LiYuxi, born in 1990. PhD candidate. Her main research interests include secure cloud storage.

ZhouFucai, born in 1964. PhD, professor and PhD supervisor. Senior member of CCF. His main research interests include cryptography and network security, trusted computing, and critical technology in electronic commerence.

XuJian, born in 1978. PhD, associate professor. His main research interests include secure computing.

XuZifeng, born in 1990. PhD candidate. His main research interests include secure cloud storage.