时文华1,2倪永婧3,4张雄伟1邹 霞1孙 蒙1闵 刚5
1(陆军工程大学指挥信息系统学院 南京 210007)2(空军航空大学飞行训练基地 辽宁阜新 123100)3(燕山大学信息科学与工程学院 河北秦皇岛 066004)4(河北科技大学信息科学与工程学院 石家庄 050018)5(国防科技大学信息通信学院 西安 710106) (whshi0919@163.com)
摘要针对基于非负矩阵分解(non-negative matrix factorization, NMF)的语音增强方法在低信噪比部分和无结构特征的清音部分会引入失真这一问题,利用语音信号在时频域呈现的稀疏特性和深度神经网络在语音增强应用中表现出的谱重构特性,提出了一种联合稀疏非负矩阵分解和深度神经网络的单通道语音增强方法.首先对带噪语音的幅度谱进行非负矩阵分解得到与语音字典和噪声字典相对应的稀疏编码矩阵,其中语音字典和噪声字典通过对纯净语音和噪声进行训练预先得到,以维纳滤波方法恢复出语音成分的主要结构;然后利用深度神经网络在语音增强中表现出的时频保持特性,通过深层网络学习经维纳滤波分离出的语音的对数幅度谱和理想纯净语音对数幅度谱之间的非线性映射函数,进而恢复出语音结构的缺失成分.实验结果表明:所提方法可以有效抑制噪声且较好地恢复出语音成分,在语音感知质量和对数谱失真性能评价指标上均优于基线方法.
关键词深度神经网络;字典学习;非负矩阵分解;语音增强;稀疏约束
语音增强旨在抑制或分离噪声,尽可能地从被噪声污染的语音信号中不失真地恢复出目标语音,改善语音的感知质量和可懂度,或作为前端提高识别准确率,在语音通信系统、听觉辅助设备和自动语音识别系统中得到了广泛的应用,是语音信号和信息处理领域的重要研究课题.过去的几十年里,众多语音增强方法相继提出,极大地推动了语音增强技术的发展.但在实际场景中,特别是在单通道、非平稳噪声环境下,由于缺乏多通道场景下的时空域参考信息且难以对语音在时频域上的结构化信息进行有效建模和利用[1],单通道语音增强仍是一个非常具有挑战性的课题.
根据是否需要语音和噪声的先验信息,现有的语音增强方法可以分为有监督和无监督两大类.经典的无监督增强方法包括谱减法、维纳滤波法和基于统计模型的方法等[2],这类方法一般是基于语音和噪声不相关且频谱系数服从高斯分布的假设,增强性能依赖于话音活动检测或噪声功率谱估计的准确性.这类方法在平稳噪声环境下一般能够取得较好的噪声抑制效果,然而在非平稳噪声或低信噪比环境下,由于对噪声的实时追踪和准确估计将变得较为困难,将会严重影响这类方法的增强性能.有监督语音增强方法作为数据驱动的方法,代表性的有基于字典的方法[3-6]和基于神经网络的方法[7-11].这类方法直接从数据出发,通过训练的方法得到语音和噪声的模型,或是利用先验信息学习带噪语音到纯净语音之间的非线性映射.由于无需对语音和噪声的分布做各种假设,有监督增强方法在低信噪比或非平稳噪声环境下往往能获得比传统无监督方法更好的增强效果.
非负矩阵分解(non-negative matrix factorization, NMF)是字典学习中一种典型方法,利用非负的字典矩阵(也称作基矩阵)和编码矩阵(也称作时变增益矩阵或激活系数矩阵)的乘积实现对整体非负矩阵的逼近,由于符合人类对客观事物从局部到整体的认知过程,且分解结果具有物理可解释性,被广泛应用于目标识别、声信号检测、语音增强和声源分离等领域[12].利用NMF的声源分离存在的一个问题是由于各个声源的基向量不是正交的,当不同声源的基向量存在混叠时,即目标声源有可能被其他声源的基向量和编码向量表示时,会出现无法正确分离出各个声源的现象(这个问题也存在于语噪分离问题中).文献[5]采用对基向量进行区分性训练,文献[6]利用深度神经网络(deep neural network, DNN)学习从输入非负矩阵表示到编码矩阵的非线性映射来解决这一问题.另一方面, 对于语音增强问题,基于NMF的语音增强方法虽然对噪声抑制效果明显,但是在低信噪比情况下和无明显结构特征的清音部分,增强后的语音存在频谱结构成分缺失的问题,这将在去除噪声的同时不可避免地引入语音失真.
深度学习方法通过模拟人类大脑对事物逐层抽象的认知过程,挖掘潜在的高层特征,受到了学术界和产业界的广泛关注[13].语音信号的产生是一个典型的复杂非线性问题,深度学习技术的发展,极大促进了语音识别、语音合成等语音信号处理技术的发展[1].在语音增强领域,文献[8]利用DNN建立带噪语音的对数能量谱到纯净语音的对数能量谱之间的非线性映射函数,采用全局均衡方差方法来解决经DNN增强后语音频谱出现的过平滑问题.实验结果表明,在大规模训练数据集下,该方法对训练集中不包含的噪声和真实场景下的非平稳噪声都有着较好的抑制能力.文献[9]利用DNN估计计算听觉场景分析(computational auditory scene analysis, CASA)中的理想二值掩蔽,该方法可以有效提高带噪语音的可懂度.此外,深度循环神经网络(deep recurrent neural network, DRNN)、长短时记忆网络(long short-term memory, LSTM)利用循环连接或者存储和门结构单元对语音信号的长短时序相关性进行建模,使得语噪分离的性能进一步提升[7].文献[10]把在计算机视觉、图像处理领域得到成功应用的生成对抗网络(generative adversarial network, GAN)运用到了语音增强领域, 取得了一定效果.文献[11]提出一种利用增强学习(reinforcement learning, RL)对DNN进行自优化(self-optimization)的语音增强方法.用反映人类听觉打分的定量指标作为网络的奖赏反馈(reward)训练网络.主、客观测试表明该方法在有限的样本数据下的有效性.
考虑到语音信号在时频域的稀疏特性和深度神经网络在语音增强应用中表现出的频谱保持特性,本文提出了一种联合稀疏非负矩阵分解(sparse non-negative matrix factorization, SNMF)和深度神经网络的单通道语音增强方法.首先对带噪语音的幅度谱进行非负矩阵分解得到和语音字典、噪声字典对应的稀疏编码矩阵,以维纳滤波方式恢复语音成分的主要结构,通过深度神经网络学习分离语音的对数幅度谱和理想纯净语音对数幅度谱之间的非线性映射,恢复出语音结构的缺失成分.实验结果表明所提方法可以有效抑制噪声且较好地保留语音成分,在感知质量和对数谱失真性能评价指标上,均优于基线方法.
非负矩阵分解是利用非负的字典矩阵D∈![]()
![]() 和编码矩阵C∈
和编码矩阵C∈![]()
![]() 的乘积实现对整体非负矩阵V∈
的乘积实现对整体非负矩阵V∈![]()
![]() 的逼近,即:
的逼近,即:
(1)
式(1)通常通过式(2)的最小化问题来求解:
mind(V|DC) s.t.Df,k≥0,Ck,n≥0,
(2)
其中,d表示刻画分解矩阵与原始矩阵逼近程度的距离度量,常用的度量有欧氏距离(Euclidean distance)、KL散度(Kullback-Leibler, KL divergence)和板仓散度(Itakura-Saito, IS divergence), 度量函数的选取会影响分解的效果.
对于语音信号,浊音段的时域波形具有相似性,呈现出的准周期特性表征了语音信号在时域的冗余度.短时功率谱具有共振峰结构,且能量大部分集中在低频部分,表征了语音信号在频域的冗余性.语音信号在时频域的冗余性使得用稀疏表示方法所得到的模型变得简单高效,特别是使得模型在应对噪声方面更加鲁棒[14-15].而基于KL散度的目标函数对低能量观测值较为敏感,在目标分离任务中,KL散度往往能取得较好的效果[16].通过对编码矩阵C施加稀疏约束(sparse constraint),在KL散度距离度量下,式(2)可以表示为求解一个带稀疏约束最小化问题[17]:
![]()
(3)
其中,λ是控制编码矩阵C稀疏度的参数,λ取值越大代表编码矩阵越稀疏.距离度量dKL(·|·)的表达式为
(4)
在KL散度距离度量下,式(3)可以采用梯度下降方法,利用乘性迭代的方式求解[18]:
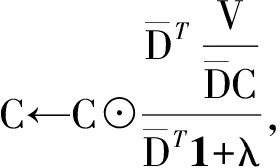
(5)

(6)
其中,![]() 表示字典矩阵D的按列归一化,除法表示矩阵中元素按位相除,符号⊙表示对应元素之间的按位相乘,1表示元素全为1的矩阵.
表示字典矩阵D的按列归一化,除法表示矩阵中元素按位相除,符号⊙表示对应元素之间的按位相乘,1表示元素全为1的矩阵.
在线性模型下,带噪语音信号y(t)可以由纯净语音s(t)及与语音信号不相关的加性噪声n(t)之和表示,且对应的短时傅里叶变换幅度谱满足:
Y=S+N.
(7)
将NMF方法用于语音增强时,首先通过对纯净语音和噪声数据进行训练预先得到语音和噪声的频谱基向量DSpeech和DNoise作为先验信息,而后将两者的基向量组合成联合基字典[DSpeechDNoise].通常选取带噪语音的幅度谱或是能量谱作为整体非负矩阵表示.利用SNMF方法将带噪语音信号的非负矩阵表示分解为联合基字典和稀疏编码矩阵(由语音和噪声的编码向量组成)的乘积:
Y≈DC=(DSpeechDNoise)(CSpeech;CNoise).
(8)
采用维纳滤波或时频掩蔽方法重构出估计语音![]() 的幅度谱或功率谱[4]:
的幅度谱或功率谱[4]:
![]()
(9)
基于SNMF的语音增强方法对噪声有较好的抑制能力,但观察经维纳滤波后的语谱图可以发现,在去除噪声的同时语音频谱也受到了破坏,增强后的语谱图中存在块状的缺失、频谱成分的缺失,会造成语音的谐波成分破坏,不可避免地引入语音的失真.为了更好地提高增强后语音的感知质量和语音的可懂度,考虑到基于DNN的语音增强方法具有有效的频谱重构特性,本文采用DNN网络对经SNMF方法增强后的语音进行后处理.首先带噪语音经SNMF方法处理后,可以使语音中的噪声成分得到了抑制;其次,经过处理后的语音作为DNN的输入可能降低网络训练的复杂度.本文提出了的语音增强方法流程图,如图1所示:
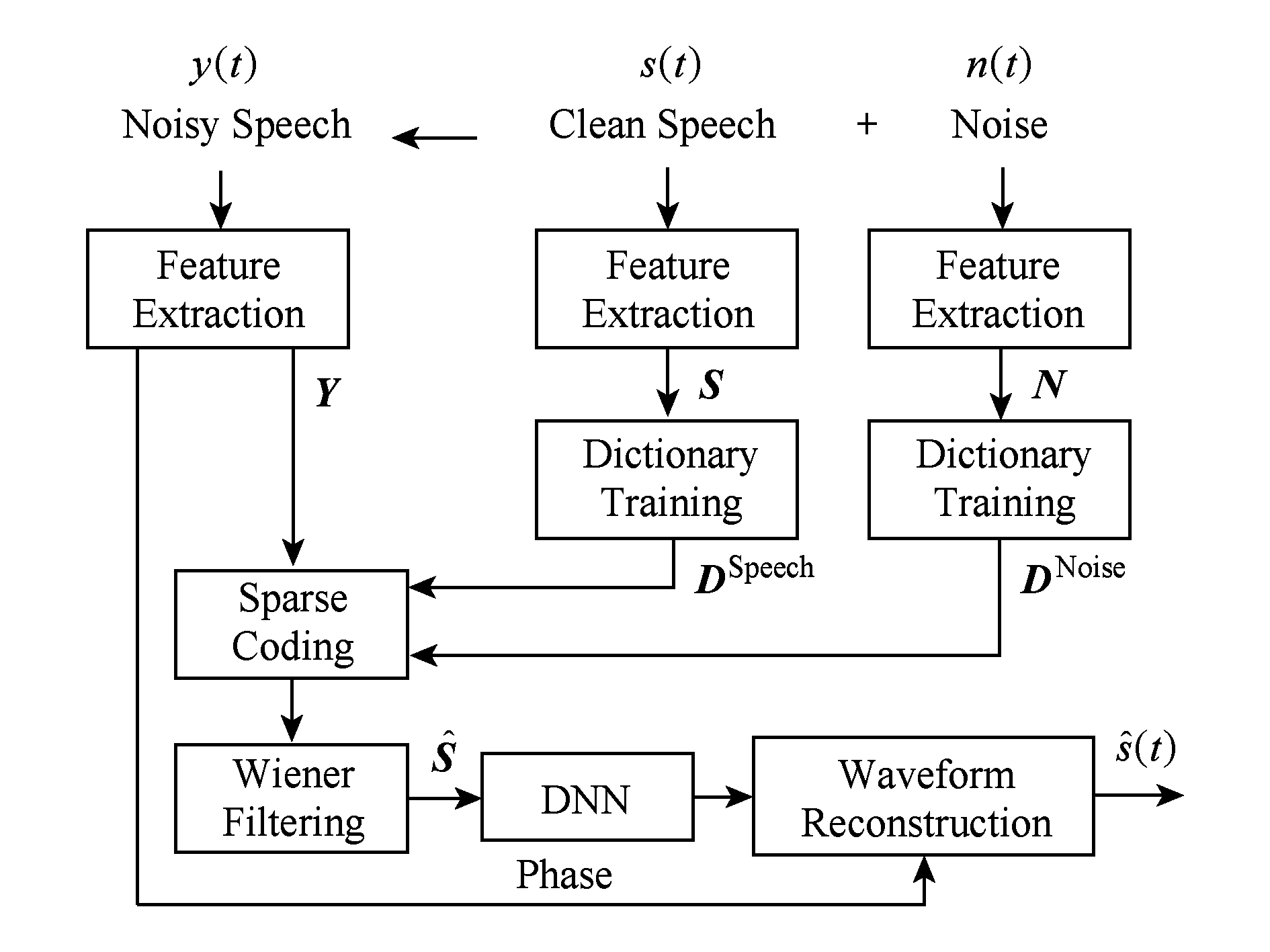
Fig. 1 A block diagram of the proposed method
图1 本文所提方法流程图
DNN是由输入层、多个隐藏层和输出层组成的神经网络.一个隐藏层数量为L的全连接前向DNN的输入、输出表达式为
y=φL+1(WL+1(φL(WL(…φ1(W1x))))),
(10)
其中,x表示网络的输入;y表示网络的输出;Wl表示网络从l-1层到第l层的参数矩阵;φl(·)表示网络第l-1层到第l层的激活函数,常用的激活函数有Sigmoid函数、双曲正切函数和修正线性函数等.
基于DNN的语音增强模型训练的常用方法是:提取带噪语音的声学特征作为网络的输入,常用的输入声学特征有:(对数)幅度谱、(对数)能量谱和各种声学特征的组合等.利用纯净语音的声学特征(或纯净语音与带噪语音的掩蔽特征)作为标签数据,采用反向传播方法(back propagation, BP),使用深层网络以有监督的方式挖掘语音数据中的结构信息,学习含噪语音特征和纯净语音特征之间的非线性映射关系.本文中我们采用经过NMF方法处理后的语音信号的对数幅度谱![]() 和目标干净语音信号的对数幅度谱X分别作为DNN的输入特征和训练目标.一方面对网络输入采用对数压缩可以减少DNN网络训练的数据的动态范围;另一方面,对数域的最小均方误差(minimum mean square error, MMSE)准则更符合人类的听觉系统特性[19].
和目标干净语音信号的对数幅度谱X分别作为DNN的输入特征和训练目标.一方面对网络输入采用对数压缩可以减少DNN网络训练的数据的动态范围;另一方面,对数域的最小均方误差(minimum mean square error, MMSE)准则更符合人类的听觉系统特性[19].
为了充分利用语音数据的上下文信息,由当前帧n及其相邻的K帧的对数幅度谱组合成一个高维联合特征向量![]() 作为DNN的输入,和当前帧n对应的纯净语音的对数幅度谱特征作为DNN的输出.定义网络的目标函数为
作为DNN的输入,和当前帧n对应的纯净语音的对数幅度谱特征作为DNN的输出.定义网络的目标函数为
![]()
(11)
其中,W和b分别为整个网络的权重矩阵和偏置矩阵,N为批处理的大小,JMSE代表基于最小均方误差准侧的网络输出和目标之间的损失函数.利用带动量的随机梯度下降方法通过反向传播损失函数更新网络的权重和偏置参数:
![]()
(12)
其中,1≤l≤L+1;λ表示学习率;ω为动量因子参数,用于加快模型的收敛速度,以减少在局部极值点附近的振荡.
在增强阶段则是使用维纳滤波方法得到经NMF方法处理后的语音幅度谱,该幅度谱特征归一化联合相邻帧的幅度谱特征作为训练好的DNN模型的输入,网络的输出即为增强语音的对数幅度谱.基于语音对相位信息不敏感的特性,联合带噪语音的相位信息即可通过逆短时傅里叶变换重构出时域的语音信号.
在本实验中,纯净语音选自IEEE语句[20],噪声信号取自于NOISEX-92标准噪声库[21].IEEE语句由720句男性说话人组成;NOISEX-92噪声库是由15种真实场景噪声组成,主要包含多种军事环境噪声和一些常见的环境噪声,以非平稳噪声为主,每种噪声长度在4 min左右.
为了增加数据的多样性、避免过拟合现象,每种噪声被分为前、后2段分别用于训练和测试[8].在训练阶段,从IEEE语句库中随机选取200句纯净语音,分别以-9 dB,-6 dB,-3 dB,0 dB,3 dB, 6 dB,9 dB这7种信噪比与NOISEX-92噪声库中的4种噪声的前半段的任意部分随机混合.这4种噪声分别是:F16双座舱内噪声、Factory工厂噪声、HF Channel高频噪声、White高斯白噪声,这样共生成5 600句带噪语音作为训练数据集.选取训练集的10%作为验证集,每个epoch后,在验证集上测试网络性能,选择在验证集表现最好的网络参数作为网络训练的最终模型.在测试阶段,从IEEE语句库中选取另外20句纯净语音并分别与训练阶段用的4类噪声的后半段按照 -5 dB,0 dB,5 dB,10 dB 混合,共生成320句带噪语音作为测试语句.
本文选取感知语音质量(perceptual evaluation of speech quality, PESQ)[22]和对数谱距离(log-spectral distance, LSD)[23]作为指标评价所提方法的性能.PESQ打分侧重于评估处理语音的总体质量,其得分位于区间[-0.5 4.5]之间,是广泛使用的客观评价方法.LSD指标衡量纯净语音和增强语音之间的短时功率谱差异,越小的值表示增强后语音的谱失真越小.
本文选取2种方法作为基线方法:基于DNN的自回归语音增强方法[8](简记为DNN)和基于卷积非负矩阵分解的(convolutive non-negative matrix factorization, CNMF)有监督语音增强方法[24].2种方法和本文所提方法使用相同的训练和测试数据.在DNN自回归方法中,网络输入为归一化的带噪语音的对数幅度谱,输出为纯净语音的对数幅度谱.基于CNMF的语音增强方法利用二维时频字典表征语音信号的时频结构特征,可以动态地描述语音和噪声的信息.语音字典和噪声字典通过预先训练得到.语音字典基依经验设为100,噪声字典基设为60.字典训练特征选择用Hamming窗计算的512维幅度谱,窗长为32 ms,帧移为8 ms.在SNMF方法中,稀疏约束λ取值依经验设为0.1.在CNMF方法中,时频原子的大小选为8.在本文所提方法中,经维纳滤波后的输出联合相邻2帧(即K=2)的对数幅度谱特征组成一个长度为5帧的长特征向量作为DNN网络的输入,网络的输出目标为当前帧对应的纯净语音的对数幅度谱.网络的输入层为257×5个节点,输出层为257个节点,隐藏层数设为3,每层的节点数为2 048个,dropout取值为0.2,批处理大小选为1024.300个epoch后,网络参数不再更新,选择在验证集上表现最好的网络参数作为训练结果.在实验中,我们选取修正线性激活函数[25]作为隐藏层的激活函数,该激活函数与Sigmoid函数和双曲正切函数相比更加符合神经元的激励原理,而且其输出具有稀疏性.研究表明,当网络训练采用修正线性单元(rectified linear unit, ReLU)[25]时,在大规模训练数据集下无需对网络进行无监督的预训练也能取得较好的效果[9].由于输出目标是纯净语音的对数幅度谱,故在DNN网络的输出层选择线性激活函数.
为了说明方法的有效性以及更好地体现出噪声抑制和语音频谱信息保留的细节信息,图2给出了一段噪声类型为Factory、输入信噪比为0 dB的带噪语音经不同有监督方法增强后的语谱图.由图2可以看出,基于NMF的增强方法对噪声的抑制水平要高于CNMF和DNN方法,但是增强后的语音在低频部分语音的频谱成分和纯净语音相比存在频谱结构缺失的现象.经过DNN方法能够较好地恢复出被噪声污染的语音成分和语音频谱结构,但是存在着较多的冗余噪声,我们认为主要原因是基于MMSE的损失函数对各个频带的权重相等,然而对语音信号,在低频成分的能量要远高于高频成分,所以经过DNN方法增强后的语音特别是在高频部分会存在噪声冗余.由图2可以看出,本文所提方法在抑制噪声成分的同时能够较好地恢复出语音的频谱结构.

Fig. 2 Spectrograms of an utterance
图2 语音语谱图
表1和表2分别给出了在不同信噪比下,被4种噪声污染的语音经过不同降噪方法处理后的PESQ和LSD指标结果.由表1和表2可以看出,除了在-5 dB HF Channel条件下,本文所提方法的PESQ和LSD得分要略低于DNN基线方法,在其他噪声和信噪比情况下,本文所提方法在2种评价指标上都要高于其他4种方法.从表2中可以看出,在F16噪声类型下,基于NMF或CNMF的方法在低信噪比时较DNN的方法在性能上效果相差不大,而在White噪声下性能要低于基于DNN的方法和本文所提方法.我们认为主要是F16双座舱内的噪声(比如说设备引擎等)具有较强的结构性,这种类型的噪声用字典中少量的原子组合就可以表示,所以基于NMF的增强方法对这类结构化噪声的建模能力较好,而White噪声不具备明显的谱结构信息,因此,基于NMF和CNMF的增强方法在此类噪声类型上的语音失真要高于其他类型的噪声.
Table1PESQScoreofDifferentEnhancementMethods
表1不同增强方法和噪声下的PESQ得分

Table2LSDScoreofDifferentEnhancementMethods
表2不同增强方法和噪声下的LSD值

在实验中训练集和测试集所选取的噪声类型相同,但测试集和训练集用的是语音库中不同的语句,按不同信噪比添加同一种类型噪声的不同部分,旨在避免过拟合,测试所提方法对不匹配类型的泛化性能.实验结果验证了本文所提方法在不匹配情况下,在平稳和非平稳噪声环境下的有效性.由于噪声字典仅在4种噪声类型下获得,因此在完全不匹配数据集(完全不匹配一般是指在训练阶段没有见过的噪声类型、没有训练过的信噪比和未曾出现过的说话人)上的性能没有做进一步的实验.事实上,在完全不匹配数据集上的泛化性能是基于字典或是基于DNN等有监督语音增强方法要面临的一个问题.这一问题一方面可以通过增加在字典训练或是网络训练中的样本数量,即增加训练集中样本的多样性来解决.在文献[8]中,通过选取104种噪声类型、625 h的语料进行训练,验证了基于DNN的自回归语音增强方法在完全不匹配数据集上也具有良好的去噪效果.文献[26]通过对训练集中数据添加抖动的方法来增加数据多样性以提高方法性能.另一方面可以通过半监督或者自适应字典学习的方法,即从样本和数据中在线学习字典的方法增加方法的自适应性,这也是我们下一步研究的一个方向.
针对基于非负矩阵分解的语音增强方法在低信噪比部分和无结构特征的清音部分会引入失真这一问题,充分利用语音信号在时频域的稀疏特性和深度神经网络在语音增强应用中表现出的谱重构特性,本文提出一种联合稀疏非负矩阵分解和深度神经网络的单通道语音增强方法.实验结果表明:本文所提方法在有效抑制噪声的同时能较好地恢复语音的频谱结构,特别是在非平稳噪声环境下,也具有较为理想的增强效果.
参考文献
[1] Dai Lirong, Zhang Shiliang. Deep speech signal and information processing: Research progress and prospect[J]. Data Acquisition & Processing, 2014, 36(2): 171-179 (in Chinese)
(戴礼荣, 张仕良. 深度语音信号与信息处理:研究进展与展望[J]. 数据采集与处理, 2014, 36 (2): 171-179)
[2]Loizou P C. Speech Enhancement: Theory and Practice[M]. Boca Raton, FL: CRC Press, 2007
[3]Kim M, Smaragdis P. Mixtures of local dictionaries for unsupervised speech enhancement[J]. IEEE Signal Processing Letters, 2015, 22(3): 293-297
[4]Mohammadiha N, Smaragdis P, Leijon A. Supervised and unsupervised speech enhancement using nonnegative matrix factorization[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2013, 21(10): 2140-2151
[5]Chung H, Plourde E, Champagne B. Single channel enhancement of convolutive noisy speech based on a discrimi-native NMF algorithm[C] //Proc of the 42nd IEEE Int Conf on Acoustics, Speech, and Signal Processing. Piscataway, NJ: IEEE, 2017: 2302-2306
[6]Vu T T, Bigot B, Chng E S. Combining non-negative matrix factorization and deep neural networks for speech enhance-ment and automatic speech recognition[C] //Proc of the 41st IEEE Int Conf on Acoustics, Speech, and Signal Processing. Piscataway, NJ: IEEE, 2016: 499-503
[7]Liu Wenju, Nie Shuai, Liang Shan, et al. Deep learning based speech separation technology and its developments[J]. Acta Automatica Sinica, 2016, 42(6): 819-833 (in Chinese)
(刘文举, 聂帅, 梁山, 等. 基于深度学习语音分离技术的研究现状与进展[J]. 自动化学报, 2016, 42(6): 819-833)
[8]Xu Yong, Du Jun, Dai Lirong, et al. A regression approach to speech enhancement based on deep neural networks[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(1): 7-19
[9]Wang Yuxuan, Narayanan A, Wang Deliang. On training targets for supervised speech separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014, 22(12): 1849-1858
[10]Michelsanti D, Tan Zhenghua. Conditional generative adversarial networks for speech enhancement and noise robust speaker verification[C] // Proc of the 18th Annual Conf of the Int Speech Communication Association. Grenoble, France: ISCA, 2017: 2008-2012
[11]Koizumi Y, Niwa K, Hioka Y, et al. DNN-based source enhancement self-optimized by reinforcement learning using sound quality measurements[C] //Proc of the 42nd IEEE Int Conf on Acoustics, Speech, and Signal Processing. Piscataway, NJ: IEEE, 2017: 81-85
[12]Li Le, Zhang Yujin. A survey on algorithms of non-negative matrix factorization [J], Acta Electronica Sinica, 2008, 36(4): 737-743 (in Chinese)
(李乐, 章毓晋. 非负矩阵分解算法综述[J]. 电子学报, 2008, 36(4): 737-743)
[13]Yu Kai, Jia Lei, Chen Yuqiang, et al. Deep learning: Yesterday, today, and tomorrow[J]. Journal of Computer Research and Development, 2013, 50(9): 1799-1804 (in Chinese)
(余凯, 贾磊, 陈雨强, 等. 深度学习的昨天、今天和明天[J]. 计算机研究与发展, 2013, 50(9): 1799-1804)
[14]Sun Meng, Li Yinan, Gemmeke J F, et al. Speech enhancement under low SNR conditions via noise estimation using sparse and low-rank NMF with Kullback-Leibler divergence[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(7): 1233-1242
[15]Giacobello D, Christensen M, Murthi M, et al. Retrieving sparse patterns using a compressed sensing framework: Applications to speech coding based on sparse linear prediction[J]. IEEE Signal Processing Letters, 2010, 17(1): 103-106
[16]Weninger F, Schuller B.Optimization and parallelization of monaural source separation algorithms in the open blissart toolkit[J]. Journal of Signal Processing Systems, 2012, 69(3): 267-277
[17]Eggert J, Korner E. Sparse coding and NMF[C] //Proc of Int Joint Conf on Neural Networks. Piscataway, NJ: IEEE, 2004: 2529-2533
[18]Schmidt M N, Olsson R K. Single-channel speech separation using sparse non-negative matrix factorization[C] // Proc of the 7th Annual Conf of the Int Speech Communication Association. Grenoble, France: ISCA, 2006: 2614-2617
[19]Xie Fei, Compernolle D V. A family of MLP based nonlinear spectral estimators for noise reduction[C] //Proc of the 19th IEEE Int Conf on Acoustics, Speech, and Signal Processing. Piscataway, NJ: IEEE, 1994: 53-56
[20]Rothauser E H, Chapman W D, Guttman N, et al. IEEE recommended practice for speech quality measurements[J]. IEEE Transactions on Audio and Electroacoustics, 2003, 17(3): 225-246
[21]Varga A, Steeneken H J M. Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems[J]. Speech Communication, 1993, 12(3): 247-251
[22]Rix A, Beerends J, Hollier M P, et al. Perceptual evalulation of speech quality (PESQ): An objective method for end-to-end speech quality assessment of narrowband telephone networks and speech codecs[C] //Proc of the 26th IEEE Int Conf on Acoustics, Speech, and Signal Processing. Piscataway, NJ: IEEE, 2001: 749-752
[23]Du Jun, Huo Qiang. A speech enhancement approach using piecewise linear approximation of an explicit model of environment distortions[C] //Proc of the 33rd IEEE Int Conf on Acoustics, Speech, and Signal Processing. Piscataway, NJ: IEEE, 2008: 4721-4724
[24]Smaragdis P. Convolutive speech bases and their application to supervised speech separation[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2007, 15(1): 1-12
[25]Andrew L M, Awni Y H, Andrew Y N. Rectifier nonlinearities improve neural network acoustic models[C] //Proc of the 30th Int Conf on Machine Learning (JMLR W&CP). Brookline, MA: Microtome Publishing, 2013: 315-323
[26]Chen Jitong, Wang Deliang. Noise perturbation for supervised speech separation[J]. Speech Communication, 2015, 78: 1-10
Shi Wenhua1,2, Ni Yongjing3,4, Zhang Xiongwei1, Zou Xia1, Sun Meng1, and Min Gang5
1(CollegeofCommandInformationSystem,TheArmyEngineeringUniversityofPLA,Nanjing210007)2(FlightTrainingBase,AirForceAviationUniversity,Fuxin,Liaoning123100)3(InstituteofInformationScienceandEngineering,YanshanUniversity,Qinhuangdao,Hebei066004)4(InstituteofInformationScienceandEngineering,HebeiUniversityofScienceandTechnology,Shijiazhuang050018)5(CollegeofInformationandCommunication,NationalUniversityofDefenseTechnology,Xi’an710106)
AbstractIn this paper, a monaural speech enhancement method combining deep neural network (DNN) with sparse non-negative matrix factorization (SNMF) is proposed. This method takes advantage of the sparse characteristic of speech signal in time-frequency (T-F) domain and the spectral preservation characteristic of DNN presented in speech enhancement, aiming to resolve the distortion problem introduced by low SNR situation and unvoiced components without structure characteristics in conventional non-negative matrix factorization (NMF) method. Firstly, the magnitude spectrogram matrix of noisy speech is decomposed by NMF with sparse constraint to obtain the corresponding coding matrix coefficients of speech and noise dictionary. The speech and noise dictionary are pre-trained independently. Then Wiener filtering method is used to get the separated speech and noise. DNN is employed to model the non-linear function which maps the log magnitude spectrum of the separated speech from Wiener filter to the target clean speech. Evaluations are conducted on the IEEE dataset, both stationary and non-stationary types of noise are selected to demonstrate the effectiveness of the proposed method. The experimental results show that the proposed method could effectively suppress the noise and preserve the speech component from the corrupted speech signal. It has better performance than the baseline methods in terms of perceptual quality and log-spectral distortion.
Keywordsdeep neural network (DNN); dictionary learning; non-negative matrix factorization; speech enhancement; sparse constraints
中图法分类号TP391.4; TN912.3
通信作者:张雄伟(xwzhang9898@163.com)
基金项目:国家自然科学基金项目(61402519,61471394);江苏省自然科学基金项目(BK20140071,BK20140074);陕西省自然科学基金项目(2017JQ6033)This work was supported by the National Natural Science Foundation of China (61402519, 61471394), the Natural Science Foundation of Jiangsu Province of China (BK20140071, BK20140074), and the Natural Science Foundation of Shaanxi Province of China (2017JQ6033).
修回日期:2018-03-05
收稿日期:2017-08-11;

ShiWenhua, born in 1982. PhD candidate. Her main research interests include image processing and speech enhancement.

NiYongjing, born in 1981. PhD canditate. Her main research interests include signal and information processing.

ZhangXiongwei, born in 1965. PhD, professor, PhD supervisor. His main research interests include multimedia infor-mation processing, digital communication and computational intelligence.

ZouXia, born in 1979. PhD, associate professor. His main research interests include speech enhancement and speech coding.

SunMeng, born in 1984. PhD, assistant professor. His main research interests include speech processing, machine learning and sequential pattern recognition.

MinGang, born in 1983. PhD, assistant professor. His main research interests include speech enhancement and speech coding.