柳培忠1,3汪鸿翔1骆炎民2杜永兆1
1(华侨大学工学院 福建泉州 362021)2(华侨大学计算机科学与技术学院 福建厦门 361021)3(华侨大学现代应用统计与大数据研究中心 福建厦门 361021)
摘要基于卷积神经网络提取抽象特征缺乏时空信息的问题,结合时空上下文模型作为卷积神经网络的各阶滤波器,提出一种在线卷积神经网络的视觉跟踪算法.首先对初始目标进行归一化处理并提取目标置信图,跟踪过程中结合时空信息更新得到时空上下文模型,第1层使用更新后的模型对输入进行卷积,并对卷积结果进行滑动窗口取片,第2层再使用时空模型分别对取片结果进行卷积,提取目标简单抽象特征,然后叠加简单层的卷积结果得到目标的深层次表达,最后结合粒子滤波跟踪框架实现目标跟踪.实验表明:结合时空上下文模型的在线卷积网络结构提取的深度抽象特征,保留相关时空信息,提高复杂背景下的跟踪效率.
关键词视觉跟踪;时空上下文;卷积神经网络;粒子滤波;在线更新
视觉跟踪是计算机视觉领域的一个研究热点,在人机交互、运动分析、智能驾驶、视频监控等领域有着广泛应用.针对背景干扰、低分辨率、目标遮挡和光照变化等复杂场景时,如何实现更鲁棒性的跟踪仍是目前的研究热点.
传统的视觉跟踪算法分为2类:判别式跟踪和生成式跟踪[1-3].判别式模型将跟踪问题建模为一个二元分类问题,用以区分前景和背景,采用机器学习训练分类器,用训练好的分类器寻找最优区域.生成式模型是不考虑背景信息直接为目标进行建模的算法,在当前帧对目标进行建模,预测位置下一帧与模型匹配最大的区域.传统的视觉目标跟踪算法主要使用视频图像序列中的像素值为主要特征进行建模,当跟踪过程中出现复杂场景时,浅层的像素级特征效果不好[1-3].
近年来,判别类方法主要有相关滤波类方法和深度学习类方法.相关滤波算法通过学习一个判别式分类器,用于估计搜索窗口中目标的最大响应以实现跟踪.深度学习方法诸如卷积神经网络(con-volutional neural network, CNN)、深度信念网络(deep belief network, DBN)能够挖掘出数据的深度抽象特征,反映数据更深层的本质.目前卷积神经网络是应用最多的方法,主要有2类:1)应用已经训练好的CNN模型提取目标特征,再结合传统的目标跟踪方法实现跟踪,深度学习方法采用CNN提取的特征具有很强的语义信息,但是缺乏时空信息;2)应用已知的跟踪目标样本对CNN模型进行在线微调,将最终训练结果用于跟踪,但是由于跟踪过程中只能提供第1帧的目标样本,面临训练样本缺少问题,因此在线微调的新模型容易出现过拟合.
本文结合时空上下文模型(spatio-temporal con-text model, STM)与卷积神经网络,采用简化后的浅层卷积神经网络提取目标抽象特征,时空上下文模型提取目标的时间与空间信息,浅层卷积神经网络提取目标深度抽象信息,判断目标的背景与前景,对目标进行精确定位.
目前大多跟踪算法采用检测跟踪(tracking by detection)框架[4-10].Kalal等人[5]提出的单目标长时间TLD(tracking learning detection)跟踪算法,综合了目标的跟踪检测及在线学习,将跟踪和检测通过在线学习机制结合起来,能够很好应对目标局部遮挡等场景.Ji等人[6]应用第1帧和最近几帧的特征构成字典,应用 L1最小二乘化准则将候选粒子投影到字典,确定前景背景.Zhang等人[9]提出一种基于图割理论的Mean Shift尺度自适应算法,克服缩放10%核带宽的经典尺度适应方法的带宽趋于缩小问题,针对尺度变化问题具有较好的实用性和鲁棒性.Hu等人[10]针对单目标特征描述不完整的问题,提出一种基于多特征联合稀疏表示的跟踪算法,结合粒子滤波充分考虑粒子间的依赖性并且实现了局部块的稀疏性,提高跟踪精度.
最近几年基于相关滤波(correlation filter, CF)的跟踪框架由于速度快,效果好吸引了众多研究者的目光[11-18].Bolme等人[11]第1个将相关滤波方法引入视觉跟踪领域,应用灰度特征表达目标,最小化二次方差去学习一个MOSSE(minimum output sum of squared error filter)滤波器,最大响应位置即跟踪过程中目标所在的位置,优势在于算法速度快. Henriques等人[12]提出的高效核函数CSK(circulant structure of tracking with kernels)跟踪算法应用循环位移矩阵进行稠密性采样,并结合快速傅里叶变换进行分类器训练,仅仅采用灰度特征使算法鲁棒性不足.Danelljan等人[13]在CSK灰度特征的基础上联合颜色属性描述目标,并进行降维处理去除冗余信息,对背景杂乱、光照变化和运动模糊表现出很好的跟踪结果,但快速运动、尺度变化和低分辨率等场景下跟踪效果不佳.核相关滤波(kernel correlation filter, KCF)算法[14]同样在CSK基础上由单通道特征拓展到多通道方向梯度直方图(histogram of oriented gradient, HOG)特征与高斯核结合,训练所得分类器对检测目标具有更强的解释力,跟踪效果取得显著提升.基于MOSSE算法加入尺度特性的判别尺度空间跟踪DSST(discriminative scale space tracking)算法[15]设计2个相对独立的相关滤波器定义为位置滤波器和尺度滤波器实现目标跟踪和尺度变换,选择不同的特征种类和特征计算方式来训练和测试,实现了快速且准确的跟踪效果.Zhang等人[16]应用贝叶斯框架对目标和其局部上下文区域进行建模,得到目标和其周围区域的统计相关性.对光照变化、尺度变化、遮挡、背景杂乱的场景有较好的效果,但对刚性形变、出视角和低分辨率的视频效果不佳.
CNN特征由于其包括大量深度抽象信息被广泛应用到视觉跟踪领域,相比传统浅层像素特征,应用深度抽象特征能够获得明显的性能提升.但卷积神经网络在目标跟踪领域面临训练样本缺失与算法运算量大实时性低等重要问题[19-24].Wang等人[19]第1次将深度网络运用于单目标跟踪,首先提出“离线预训练+在线微调”思路的深度学习跟踪算法(deep learning tracker, DLT),有效解决跟踪中训练样本不足的问题;Nam等人[20]提出的树结构CNN(tree structure convolutional neural network, TCNN)算法核心在于使用树状CNN结构,每个阶段都训练出新的CNN,即每个CNN学习到的特征是目标在不同阶段的特征,最后结果由多个CNN加权求和得到,可以减少模型飘移;Wang等人[21]使用序贯集成学习方法在线训练CNN,采用2个神经网络结合的方式,预训练的CNN的输出作为在线更新的CNN的输入,进行特征提取;文献[22]结合人脑视觉处理系统,简化了卷积网络结构,使用目标区域中随机提取的归一化图像块作为卷积神经网络的滤波器,从而实现了不用训练卷积神经网络的快速特征提取;Ma等人[23]将KCF算法中使用的HOG特征替换为深度卷积特征,使用预训练好的网络当中的3个卷积层的输出,从3个层当中提取的特征分别经过相关滤波器学习得到不同的模板,然后对所得到的3个置信图进行加权融合得到最终的目标位置;文献[24]设计一个针对跟踪的网络结构,用跟踪数据集作为训练样本,加入在线微调和尺度更新模块提高跟踪精度,但采用测试集训练网络模型存在过拟合.
目前CNN研究的演化方法总结为4种:1)更深的网络;2)增强卷积模块功能以及上述2种思路的融合;3)从分类到检测;4)增加新的功能模块.
卷积神经网络在目标跟踪方面的研究基本考虑更深的网络和增强卷积模块功能,而基于图像帧与帧之间的时空信息研究不多.本文采用一个在线卷积神经网络结构,融合目标的时空上下文信息共同提取目标的深度抽象特征,并且无需依赖数据集进行离线辅助训练.实验证明,本文提取的特征不仅保留CNN特征深度语义信息,也含有目标相应的时空信息,在位置预测、时空信息保留方面与传统卷积网络相比具有更多优势,可以取得更加鲁棒准确的跟踪效果.
本文结合文献[16]给出的时空信息(spatio-temporal context, STC)设计的时空上下文模型STM作为卷积神经网络中的各阶滤波器,在第1帧中,计算出目标置信图用来更新时空模型.假设x∈![]() 2为某一位置,o为需要跟踪的目标,定义目标所在位置x的置信值:
2为某一位置,o为需要跟踪的目标,定义目标所在位置x的置信值:
map(x)=P(x|o)=![]()
(1)
其中,Xc={c(z)=(I(z),z)|z∈Ωc(x*)}为上下文特征集合,x*为目标位置,I(z)为点z灰度特征,p(x|c(z),o)表示目标与局部上下文的空间关系,条件概率表示:p(x|c(z),o)=hsc(x-z),hsc(x-z) 定义目标位置x与其局部上下文位置z之间的空间关系.p(c(z)|o)表示局部上下文中各位置的先验概率,建模为
所以,式(1)可以转换为
![]()
![]()
hsc(x)⊗(I(x)ωσ(x-x*)),
(2)
c(z)与目标邻域内点z到目标位置x*的相对距离有关,转换到频域进行计算,得空间上下文模型hsc(x):
![]()
(3)
每帧根据当前目标状态计算当前帧的空间上下文hsc(x),并更新时空上下文模型![]()
![]()
(4)
本文区别于传统的卷积神经网络加深卷积网络结构的研究方法,应用卷积网络设计一个2层的目标表示结构,结合跟踪过程中目标的上下文信息,实时更新卷积网络的滤波器,提取目标深度抽象特征.特征提取结构如图1所示.
简单层特征,第t+1帧对输入图像It+1应用第t帧更新的时空上下文模型![]() 进行卷积:
进行卷积:
![]() ⊗It+1.
⊗It+1.
(5)
对得到的结果St+1归一化到n×n大小,利用w×w大小的滑动窗口进行采样,得到长度为L的图像块组X,然后从L=(n-w+1)×(n-w+1)个图片块中聚类出d个图像块,再应用第t帧更新的时空上下文模型![]() 进行第2层卷积,对输入图像I对应的响应为
进行第2层卷积,对输入图像I对应的响应为
![]()
(6)
得到d个简单层特征,记作:Fx={F1,F2,…,Fd}⊂X.
复杂层特征,为了加强对目标的特征表达,本文将d个简单层特征进行堆叠,构成一个3维张量来表示目标的复杂层特征,记作F∈![]() (n-w+1)×(n-w+1)×d.
(n-w+1)×(n-w+1)×d.
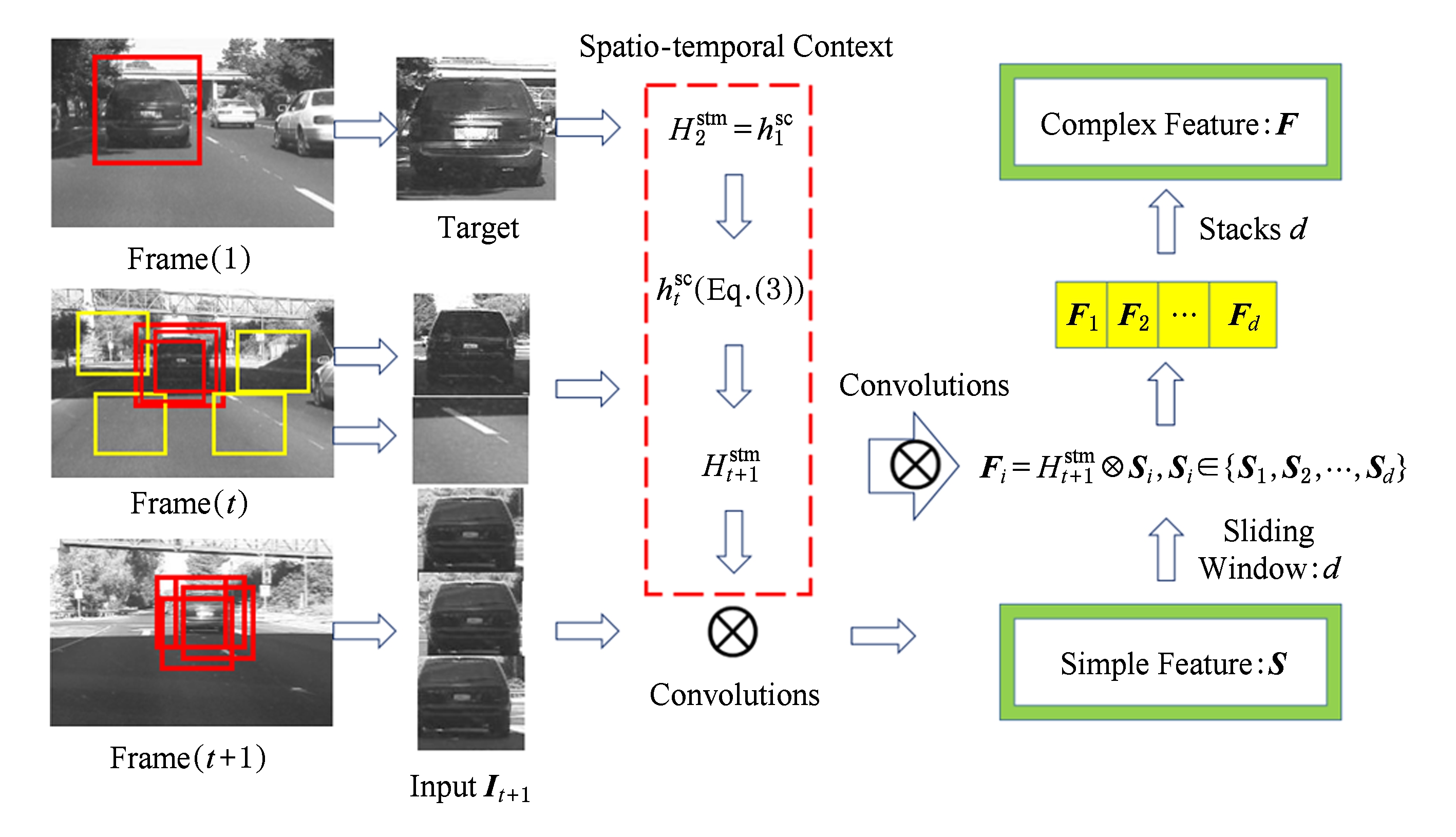
Fig. 1 Convolution feature extraction structure
图1 卷积特征提取结构
这种特征具有平移不变特性,由于图像归一化后,使得特征对目标的尺度具有鲁棒性,且复杂层特征保留不同尺度目标的局部几何信息.为了增加对目标表观特征的鲁棒性采用了稀疏表达的方式表示特征:
![]()
(7)
得到对特征张量F的稀疏表达![]() 采用soft-shrinking解得唯一解:
采用soft-shrinking解得唯一解:
![]()
(8)
其中ρ为vec(F)的中位数。得到目标的最终特征表达,构建特征模板,结合粒子滤波实现跟踪.
本文基于粒子滤波框架,设第t帧时观测序列为O1:t={o1,o2,…,ot},则跟踪主要是求出后验概率p的最大值,根据贝叶斯理论,可知:
p(St|O1:t)∝p(O1:t|St)![]()
(9)
其中St=![]() ,其中xt,yt为目标的位置,st为尺度参数.p(St|St-1)为运动模型,用于根据第t-1帧的位置预测第t帧的位置,假设目标状态参数是相互独立的,可用3个高斯分布来描述,从而运动模型即为布朗运动,于是:
,其中xt,yt为目标的位置,st为尺度参数.p(St|St-1)为运动模型,用于根据第t-1帧的位置预测第t帧的位置,假设目标状态参数是相互独立的,可用3个高斯分布来描述,从而运动模型即为布朗运动,于是:
p(St|St-1)=N(St|St-1,Σ),
(10)
其中,Σ=diag(σx,σy,σt)为对角协方差矩阵,p(St|O1:t)为观测模型,用于评估观测序列O1:t与目标的相似性.
观测模型通过测量样本与目标之间的相似度来计算:
![]()
(11)
于是,整个跟踪过程就是求最大响应:
![]()
(12)
2.2节给出了结合时空上下文模型的卷积神经网络特征提取结构,获取目标的深度抽象信息,基于这种卷积特征,结合粒子滤波,提出本文跟踪算法如图2所示:
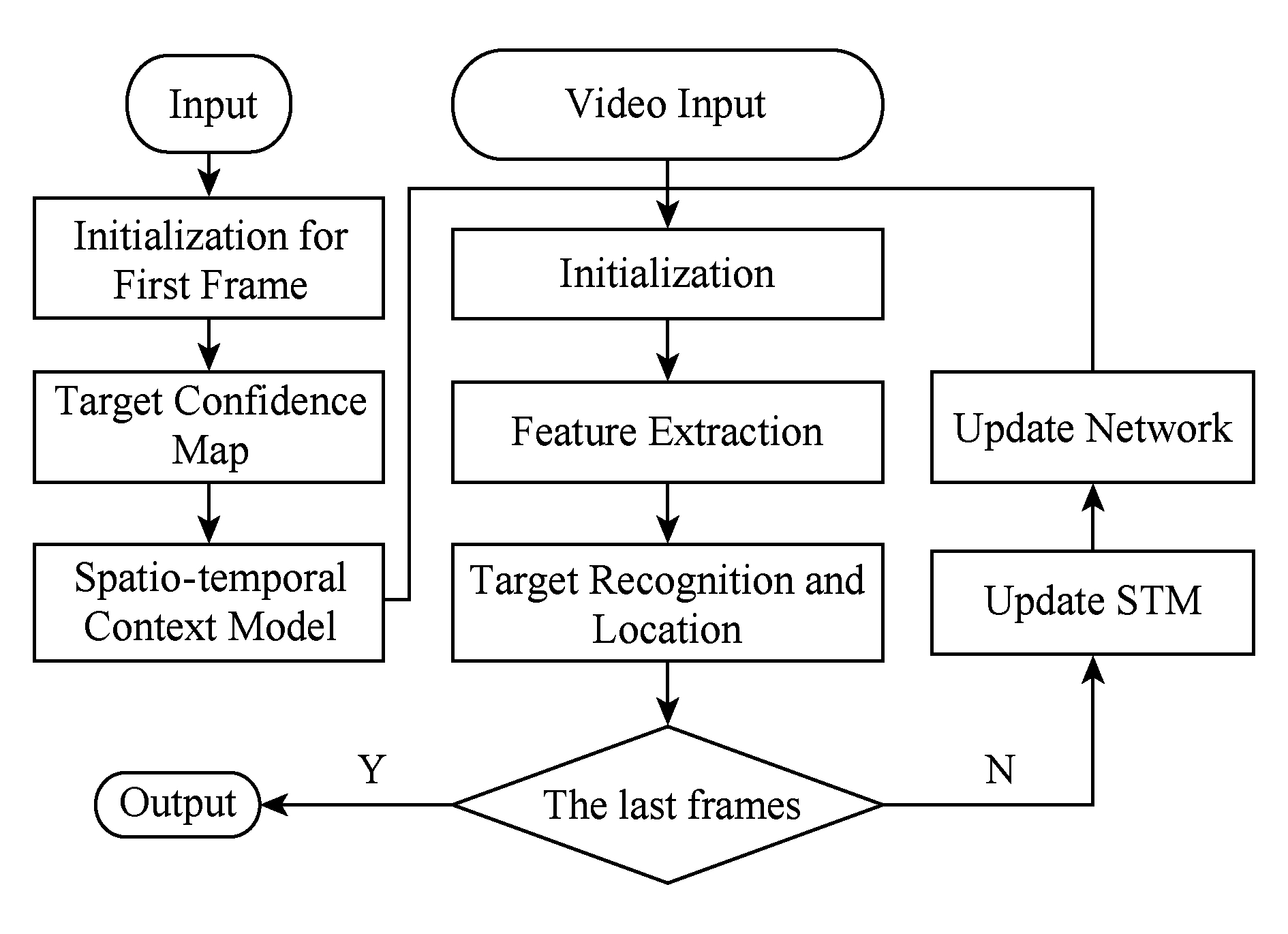
Fig. 2 Tracking flow chart
图2 跟踪算法流程图

Fig. 3 Examples of the tracking results on video sequences
图3 视频序列跟踪结果实例
主要有5个步骤:
1) 初始化.归一化、粒子滤波、网络规模、样本容量等参数设置.
2) 置信图计算.应用第1帧的目标,根据式(1)计算出初始目标置信图,用作后续更新上下文模型.
3) 特征提取.根据上文的提出的卷积网络结构,利用式(5)~(7)提取出各候选样本的深层抽象特征.
4) 粒子滤波.归一化后生成规定尺寸大小的候选图片样本集,按照式(9)~(12)的粒子滤波算法,进行目标识别与定位.
5) 网络更新.根据式(2)(4)给出的上下文模型计算公式,在跟踪过程中实时更新上下文模型,用作卷积神经网络中的滤波器.
本文应用MATLAB2014a编程环境,PC配置为Inter Core i3-3220,3.3 GHz,8 GB内存,根据文献[3]在CVPR2013中给出的Database OTB2013中提供的测试视频序列对算法进行仿真分析,2015年文献[25]对测试集进一步进行了扩充.本文按照目前较为流行的定性与定量分析相结合,对算法进行分析验证,其中本文仿真参数设置为:滤波器数100,归一化尺寸32×32,滑动窗口尺寸6×6,学习因子设置为0.95,粒子滤波器的目标状态的标准偏差设置如下:σx=4,σy=4,σt=0.01,使用N= 300个粒子.
限于论文篇幅,本文仅给出5组代表性的跟踪实验结果,对比算法分别为:MIL(multiple instance learning tracker)[4], TLD[5], L1[6],CT(compressive tracking)[7], CSK[12],KCF[14],CNT(convolutional networks tracker)[22], Ours.如图3所示,先后给出了Car4,Football,Jogging2,Matrix ,Walking2部分测试视频的跟踪结果.Car4伴随有光照变化和尺度变化,在第180帧目标发生强烈光照变化,很多算法出现漂移,第240帧继续发生光照变化,CSK,L1,CT,TLD,MIL等算法均跟踪失败,剩下CNT,KCF与本文算法正确跟踪目标,后续伴随相应尺度变化,本文算法在跟踪准确算法中尺度变化是最准确的.Football序列目标奔跑伴随着相应的形变与旋转,第100帧时目标进入队伍中出现大量相似目标的背景干扰,大部分算法都能很好区分进行准确跟踪,第290帧时目标发生激励碰撞,并产生遮挡与相应剧烈变化,此后只有本文算法能够持续准确跟踪.Jogging2序列,目标在第50帧发生完全遮挡,TLD算法应用持续跟踪检测模块重新定位到跟踪目标,但尺度变化上出现一定误差,本文算法结合时空上下文提取的深度抽象特征,能够有效地针对遮挡,鲁棒较好.Matrix序列存在相应光照变化,尺度变化,局部遮挡,目标快速运动并伴随相应形变,大部分算法未能表现出准确的跟踪效果,本文算法因为采用卷积神经网络对快速运动目标跟踪存在计算缺陷,同样是跟踪不准确,本文算法的误差能够做到相对较小.Walking2序列实在低分辨场景下的监控视频,第180帧与350帧目标先后被遮挡,在运动过程中伴随相应形变与尺度变化,可见本文算法在所有算法中取得最准确的效果.
根据文献[3]在CVPR2013中给出的Database OTB2013综合评价方法,如图4所示,本文主要使用距离精度图(precision plots)和跟踪成功率图(success plots)的一次通过成功率OPE(one-pass evaluation, OPE)对算法进行评估,并给出背景干扰(background clutters)、光照变化(illumination variation)、低分辨率(low resolution)和遮挡(occlu-sion)四种场景的具体数据,如图5所示.本文比较算法有MIL[4],TLD[5],CT[7],Struck[8],CSK[12],CN(adaptive color tracker)[13],KCF[14],DSST[15],STC[16],SRDCF (spatially regularized correlation filters tracker)[17],DeepSRDCF (convolutional features for correlation filter tracker)[18],CNT[22],Ours.
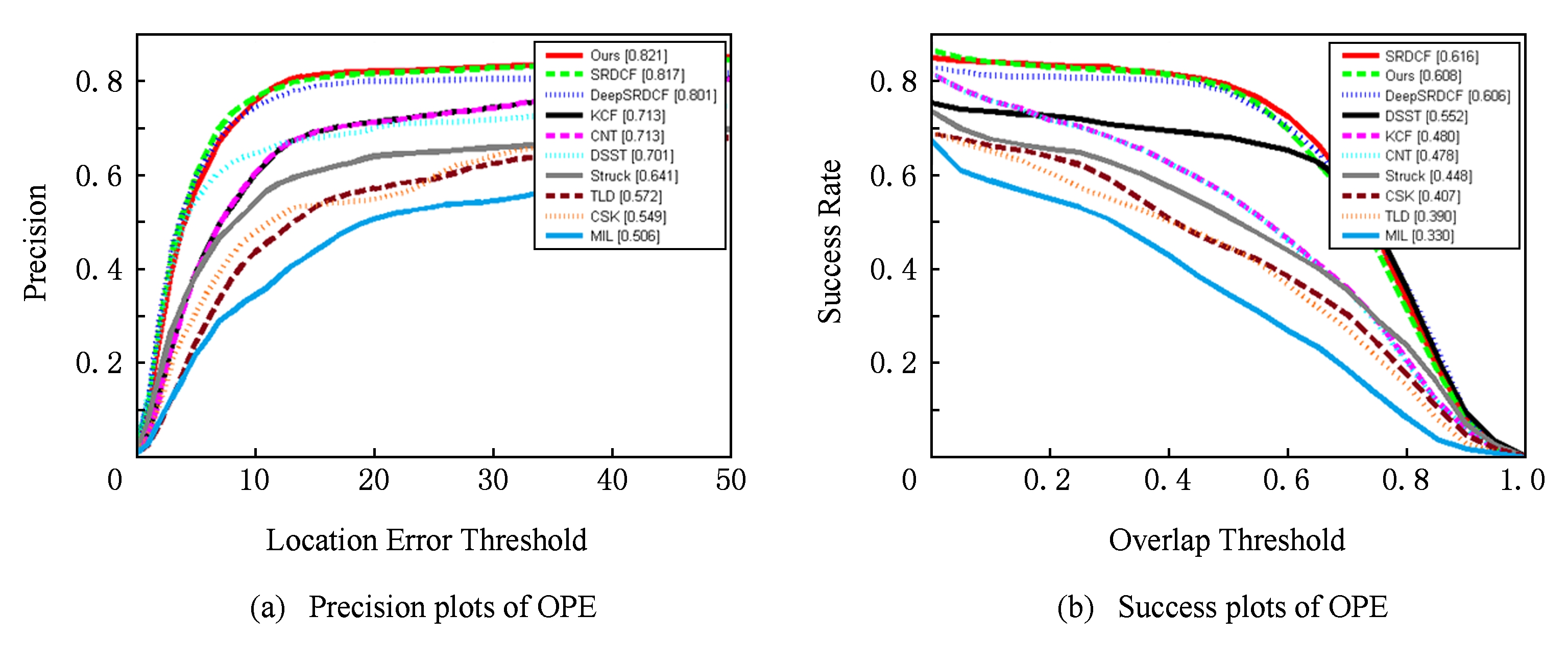
Fig. 4 Precision plots and success plots of OPE
图4 OPE精度图与成功率图

Fig. 5 Precision plots and success plots of OPE
图5 OPE精度图与成功率图
分析实验数据可知,本文算法结合时空上下文模型提取的深度抽象特征,可以很好地应对背景干扰,面对光照变化与低分辨率场景时,本文算法与文献[18]DeepSRDCF提取的深度特征,相对于传统特征,能够更好地表达目标的深度抽象信息,可以更好地应对复杂场景的跟踪问题;本文提取的特征能够保留CNN特征深度语义信息和目标相应的时空信息,在应对遮挡时可以利用时空信息更好地确定被遮挡目标的位置,减少漂移现象.实验证明,本文提取的特征不仅保留CNN特征深度语义信息,也含有目标相应的时空信息,在位置预测、时空信息保留方面与传统卷积网络和传统特征相比具有更多优势,在面对背景干扰、光照变化、低分辨率和遮挡等复杂场景时,可以取得更加鲁棒准确的跟踪效果.
为了测试算法性能,给出了部分序列的中心位置误差与距离精度的具体数据.中心位置误差(center location error,CLE)表示目标的中心位置与标准中心位置的欧氏距离的误差,表达式为ε=
![]() 是图片序列的帧数,Ci为目标中心位置,Cri为标准中心位置;距离精度(distance precision,DP)表示中心误差小于一个给定阈值的帧的相对数量,表达式为
是图片序列的帧数,Ci为目标中心位置,Cri为标准中心位置;距离精度(distance precision,DP)表示中心误差小于一个给定阈值的帧的相对数量,表达式为![]() 为CLE小于某个固定阈值(实验中均选为20像素)的图片序列帧数.表1给出了算法的平均中心位置误差和距离精度的对比数据(黑体数字代表最优性能).为保证数据真实性,本文所示数据均为5次实验后取平均值.
为CLE小于某个固定阈值(实验中均选为20像素)的图片序列帧数.表1给出了算法的平均中心位置误差和距离精度的对比数据(黑体数字代表最优性能).为保证数据真实性,本文所示数据均为5次实验后取平均值.
Table1CenterLocationError(Pixels)&DistancePrecision
表1位置中心误差CLE(像素点) &距离精度DP
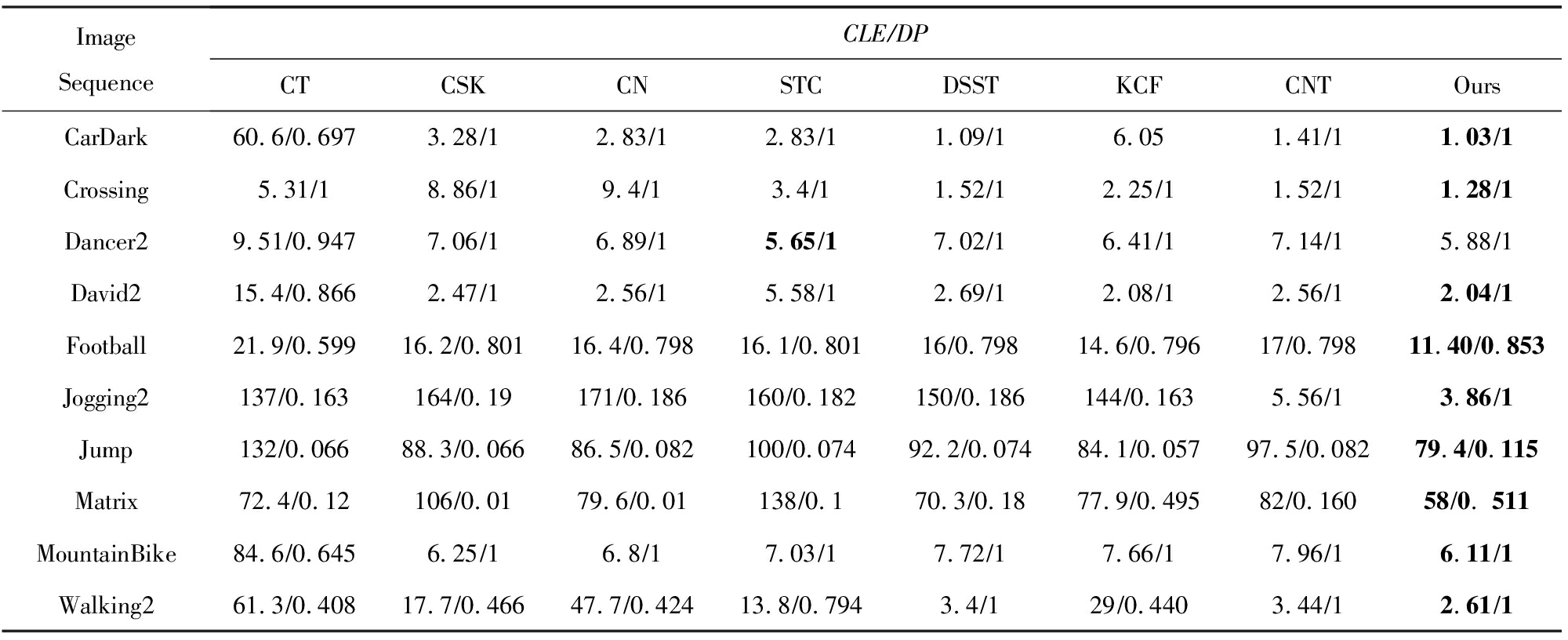
ImageSequenceCLE∕DPCTCSKCNSTCDSSTKCFCNTOursCarDark60.6∕0.6973.28∕12.83∕12.83∕11.09∕16.051.41∕11.03∕1Crossing5.31∕18.86∕19.4∕13.4∕11.52∕12.25∕11.52∕11.28∕1Dancer29.51∕0.9477.06∕16.89∕15.65∕17.02∕16.41∕17.14∕15.88∕1David215.4∕0.8662.47∕12.56∕15.58∕12.69∕12.08∕12.56∕12.04∕1Football21.9∕0.59916.2∕0.80116.4∕0.79816.1∕0.80116∕0.79814.6∕0.79617∕0.79811.40∕0.853Jogging2137∕0.163164∕0.19171∕0.186160∕0.182150∕0.186144∕0.1635.56∕13.86∕1Jump132∕0.06688.3∕0.06686.5∕0.082100∕0.07492.2∕0.07484.1∕0.05797.5∕0.08279.4∕0.115Matrix72.4∕0.12106∕0.0179.6∕0.01138∕0.170.3∕0.1877.9∕0.49582∕0.16058∕0. 511MountainBike84.6∕0.6456.25∕16.8∕17.03∕17.72∕17.66∕17.96∕16.11∕1Walking261.3∕0.40817.7∕0.46647.7∕0.42413.8∕0.7943.4∕129∕0.4403.44∕12.61∕1
针对视觉跟踪中运动目标鲁棒性跟踪问题,本文结合时空上下文信息和卷积神经网络,提出一种无需训练的在线卷积网络提取深度特征的视觉跟踪算法.首先对初始目标进行预处理并提取目标置信图,跟踪过程中结合时间信息与空间信息更新得到时空上下文模型,作为卷积网络结构中的各阶滤波器,用来提取目标简单抽象特征;然后叠加简单层的卷积结果得到目标的深层次表达;最后结合粒子滤波跟踪框架实现跟踪.实验表明,本文简化后的卷积网络结构,结合时空上下文模型提取的深度抽象特征,不仅能够保留深度抽象特性的抽象语义信息,也保留有目标相应的时空下上文信息,能够提高复杂背景下的跟踪效率.本文采用的卷积神经网络,因为计算复杂的原因,本文算法实时性不高,速度仅达到3~5 fps,在应对快速运动目标时效果不好,另外时空上下文模型对于目标出界丢失上下文,没有很好的补偿措施,不能很好地应对出界目标的跟踪,这是后续需要改进的地方.
参考文献
[1]Huang Kaiqi, Chen Xiaotang, Kang Yunfeng, et al. Intelligent visual surveillance: A review[J]. Chinese Journal of Computers, 2015, 38(6): 1093-1118 (in Chinese)(黄凯奇, 陈晓棠, 康运锋, 等. 智能视频监控技术综述 [J].计算机学报, 2015, 38(6): 1093-1118)
[2]Zhang Huanlong, Hu Shiqiang, Yang Guosheng. Video object tracking based on appearance models learning[J]. Journal of Computer Research and Development, 2015, 52(1): 177-190 (in Chinese)(张焕龙, 胡士强, 杨国胜. 基于外观模型学习的视频目标跟踪方法综述[J]. 计算机研究与发展, 2015, 52(1): 177-190)
[3]Wu Yi, Lim J, Yang Minghsuan. Online object tracking: A benchmark[C] //Proc of IEEE Conf on Computer Vision and Pattern Recognition. Los Alamitos, CA: IEEE Computer Society, 2013: 2411-2418
[4]Babenko B, Yang Minghsuan, Belongie S. Robust object tracking with online multiple instance learning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(8): 1619-32
[5]Kalal Z, Mikolajczyk K, Matas J.Tracking-learning-detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(7): 1409-1422
[6]Ji Hui, Ling Haibin, Wu Yi, et al. Real time robust L1 tracker using accelerated proximal gradient approach[C] //Proc of IEEE Conf on Computer Vision and Pattern Recognition. Los Alamitos, CA: IEEE Computer Society, 2012: 1830-1837
[7]Zhang Kaihua, Zhang Lei, Yang Minghsuan. Real-time compressive tracking[C] //Proc of the 12th European Conf on Computer Vision. Berlin: Springer, 2012: 864-877
[8]Hare S, Golodetz S, Saffari A, et al. Struck: Structured output tracking with kernels[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(10): 2096-2109
[9]Zhang Fengjun, Zhao Ling, An Guocheng, et al. Mean shift tracking algorithm with scale adaptation[J]. Journal of Computer Research and Development, 2014, 51(1): 215-224 (in Chinese)(张凤军, 赵岭, 安国成, 等. 一种尺度自适应的Mean Shift跟踪算法[J]. 计算机研究与发展, 2014, 51(1): 215-224)
[10]Hu Zhaohua, Yuan Xiaotong, Li Jun, et al. Robust fragments-based tracking with multi-feature joint kernel sparse representation[J]. Journal of Computer Research and Development, 2015, 52(7): 1692-1704 (in Chinese)(胡昭华, 袁晓彤, 李俊, 等. 基于目标分块多特征核稀疏表示的视觉跟踪[J]. 计算机研究与发展, 2015, 52(7): 1692-1704)
[11]Bolme D S, Beveridge J R, Draper B A, et al. Visual object tracking using adaptive correlation filters[C] //Proc of IEEE Conf on Computer Vision and Pattern Recognition. Los Alamitos, CA: IEEE Computer Society, 2010: 2544-2550
[12]Henriques J F, Caseiro R, Martins P, et al. Exploiting the circulant structure of tracking-by-detection with kernels[C] //Proc of the 12th European Conf on Computer Vision. Berlin: Springer, 2012: 702-715
[13]Danelljan M, Khan F S, Felsberg M, et al. Adaptive color attributes for real-time visual tracking[C] //Proc of IEEE Conf on Computer Vision and Pattern Recognition. Los Alamitos, CA: IEEE Computer Society, 2014: 1090-1097
[14]Henriques J F, Rui C, Martins P, et al. High-speed tracking with kernelized correlation filters[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(3): 583-596
[15]Danelljan M, Häger G, Khan F, et al. Accurate scale estimation for robust visual tracking[C/OL] //Proc of the 25th British Machine Vision Conf. 2014 [2017-05-01]. http://www.cvl.isy.liu.se/research/objrec/visualtracking/scalvistrack/ScaleTracking_BMVC14.pdf
[16]Zhang Kaihua, Zhang Lei, Liu Qingshan, et al. Fast visual tracking via dense spatio-temporal context learning[C] //Proc of the 13th European Conf on Computer Vision. Berlin: Springer, 2014: 127-141
[17]Danelljan M, Häger G, Khan F S, et al. Learning spatially regularized correlation filters for visual tracking[C] //Proc of the 15th Int Conf on Computer Vision. Los Alamitos, CA: IEEE Computer Society, 2015: 4310-4318
[18]Danelljan M, Häger G, Khan F S, et al. Convolutional features for correlation filter based visual tracking[C] //Proc of Int Conf on Computer Vision Workshop. Los Alamitos, CA: IEEE Computer Society, 2016: 621-629
[19]Wang Naiyan, Yeung D Y. Learning a deep compact image representation for visual tracking[C] //Proc of Int Conf on Neural Information Processing Systems. Los Alamitos, CA: IEEE Computer Society, 2013: 809-817
[20]Nam H, Baek M, Han B. Modeling and propagating CNNSs in a tree structure for visual tracking[OL]. 2016 [2017-06-01]. https: //arxiv.org/abs/1608.07242
[21]Wang Lijun, Ouyang Wanli, Wang Xiaogang, et al. STCT: Sequentially training convolutional networks for visual tracking[C] //Proc of IEEE Conf on Computer Vision and Pattern Recognition. Los Alamitos, CA: IEEE Computer Society, 2016: 1373-1381
[22]Zhang Kaihua, Liu Qingshan, Wu Yi, et al. Robust visual tracking via convolutional networks without training[J]. IEEE Transactions on Image Processing, 2016, 25(4): 1779-1792
[23]Ma Chao, Huang Jiabin, Yang Xiaokang, et al. Hierarchical convolutional features for visual tracking[C] //Proc of the 15th Int Conf on Computer Vision. Los Alamitos, CA: IEEE Computer Society, 2015: 3074-3082
[24]Nam H, Han B. Learning multi-domain convolutional neural networks for visual tracking[C] //Proc of IEEE Conf on Computer Vision and Pattern Recognition. Los Alamitos, CA: IEEE Computer Society, 2016: 4293-4302
[25]Wu Yi, Lim J, Yang Minghsuan. Object tracking benchmark[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1834-1848
Liu Peizhong1,3, Wang Hongxiang1, Luo Yanmin2, and Du Yongzhao1
1(CollegeofEngineering,HuaqiaoUniversity,Quanzhou,Fujian362021)2(CollegeofComputerScienceandTechnology,HuaqiaoUniversity,Xiamen,Fujian361021)3(ResearchCenterforAppliedStatisticsandBigData,HuaqiaoUniversity,Xiamen,Fujian361021)
AbstractDeep networks have been successfully applied to visual tracking by learning a generic representation offline from numerous training images. However, the features of the convolutional neural network abstraction algorithm are lack of spatio-temporal context information and the offline training is time-consuming. To tackle the above issues, an online convolution network tracking via spatio-temporal context is proposed, adopting the spatio-temporal context as the every order filter in convolutional neural network. Firstly, the initial target is normalized and the target confidence map is extracted. In the process of tracking, the spatio-temporal information is updated to obtain the spatio-temporal context model. The first layer utilizes the updated model to convolve the input and performs sliding window on the convolution result. The second layer convolves the fetch results by spatio-temporal model respectively, extracts the simple target abstract features, and then the convolution result of the simple layer is superposed to the deep level target expression. Finally, the target tracking is realized by the particle filter tracking framework. Our convolutional networks have a lightweight structure and perform favorably against several state-of-the-art methods on OTB-2013 and OTB-2015. As documented in the experimental results, the deep abstract feature extracted by online convolution network structure combining with spatio-temporal context model, can preserve related spatio-temporal information and then the tracking efficiency under complex background is improved.
Keywordsvisual tracking; spatio-temporal context; convolutional neural network; particle filter; online update
This work was supported by the National Natural Science Foundation of China (61203242, 61605048), the Natural Science Foundation of Fujian Province of China (2016J01300, 2015J01256), and the Graduate Innovation and Practice Foundation of Huaqiao University (1511422004).
通信作者:骆炎民(lym@hqu.edu.cn)
基金项目:国家自然科学基金项目(61203242,61605048);福建省自然科学基金项目(2016J01300,2015J01256);华侨大学研究生科研创新能力培育计划资助项目(1511422004)
修回日期:2018-03-05
收稿日期:2017-05-16;
中图法分类号TP391
(pzliu@hqu.edu.cn)

LiuPeizhong, born in 1976. Received his PhD degree from Xiamen University. Associate professor. His main research interests include multi-dimensional space biomimetic informatics, visual media retrieval, network model, information security.

WangHongxiang, born in 1992. Master from Huaqiao University. His main research interests include deep learning and visual tracking (kakadadudu@163.com).

LuoYanming, born in 1975. Received his PhD degree from Xiamen University. Associate professor. His main research interests include artificial intelligence, machine learning, image processing, data mining and artificial immune learning algorithm.

DuYongzhao, born in 1985. Received his PhD degree from Sichuan University in 2014. Associate professor. His main research interests include optical imaging measurement and photo-electric image processing (yongzhaodu@126.com).