
Fig. 1 Virtual network function scheduling scheme example
图1 虚拟网络功能调度方案示例
徐 冉 王文东 龚向阳 阙喜戎
(网络与交换技术国家重点实验室(北京邮电大学) 北京 100876) (ranxu@bupt.edu.cn)
摘 要 网络功能虚拟化(network function virtualization, NFV)旨在以软件的方式实现网络功能从而替代传统网络中的专有硬件设备.为了应对日益增长的资源密集型需求,面向软件的网络功能虚拟化带来了如虚拟网络功能的管理、低延迟的调度和虚拟网络资源分配等问题.虚拟网络功能调度问题本身为NP-hard,在虚拟网络功能资源调度延迟的特定问题上,为保证良好的用户体验,需要确保网络资源被合理地分配和协调以防止资源的过度供应和保持端到端低延迟.针对网络资源调度的延时问题建立了以最小化资源调度总体服务延迟为目标的整数线性规划模型.此外,为了满足网络动态性较高的特性,设计了一种基于贪婪的启发式算法,此算法首先构建辅助图,然后根据考虑到网络传播时延影响的不同业务链之间的时延影响分析来选择资源调度方案,并且对很多点处理功能采用了多路传输的方式.最终的实验结果表明:所提算法可以有效地指导模型的求解,在降低网络总体服务延时方面比之前相关研究有5%~15%的性能提升.
关键词 网络功能虚拟化;软件定义网络;服务链;资源调度;多路传输
现有的网络功能例如防火墙(FW)、入侵检测系统(IDS)、网络地址转换器(NAT)和负载平衡器(LB)等,通常部署在价格昂贵的专用硬件(Middlebox)上用以满足网络吞吐或者安全等方面的特殊需求.网络功能虚拟化(network function virtualization, NFV)的概念是由服务提供商组织提出,目的是在已有的商用设备上通过虚拟化技术以软件的方式实现特定网络功能(network functions, NFs),从而取代传统网络中的专用设备的方式 [1] ;而软件定义网络(software-defined networking, SDN)起源于校园网络,广泛应用与数据中心,SDN的特点是分离了传统网络格局的控制平面与转发平面,在这种架构下,网络具备较高的灵活性并且易于部署和管理 [2-3] .NFV和SDN作为未来网络创新的两个重要角色,都有着通过网络创新的方式以打破当前网络僵化与臃肿格局的目标.
NFV如今作为业界与学术界的热点,它支持NFs的快速创建、撤销或迁移,依托着虚拟技术降低了网络成本从而得以迅速发展.由于安全或者性能的需求,网络操作者往往要求数据流以特定的序列通过多个NFs(例如数据包需要经过防火墙,然后经过入侵检测系统,最后经过负载均衡器),即通常所称的服务链(service chaining) [4-5] .网络功能虚拟化的主要挑战之一是根据服务链规则执行所需服务时,实现快速和动态的网络功能资源分配,因此虚拟网络功能资源调度优化得到了研究者们的关注.
根据应用或者用户的需求不同,虚拟网络功能资源调度有着不同的优化目标,比如,对于电信服务商来说,他们的长远目标是实现最大化所接受服务请求的经济收益,这就要求网络功能虚拟化在分配与调度资源的时候提高对服务请求的接受率;但是对于提供语音IP网络服务商来说,一定程度的带宽和低延迟保证是首先需要考虑的,此外类似的优化目标包括容错能力、负载均衡和能源消耗 [6] 等.近些年来,由于互联网络和网络应用的发展,使得如今网络具有更大的带宽和存储容量,但是包括移动应用、在线交互或者交易等新业务模型的激增,对于业务延迟的需求越来越高.比如,包括监控系统、在线金融分析、算法交易等对实时性要求较高的应用场景 [7] ;包括高清晰度、低延迟视频流、远程手术触觉互联网、虚拟或增强现实等在内的应用场景 [8] .现有的一些延迟保证的研究实例包括:在5G系统中为了处理和传达用户的上下文信息,系统需要充分保证低的或者可预测的数据传输延迟来收集和共享上下文信息,并以及时和自动的方式执行服务 [9] ;“双十一”期间对网络延迟敏感的在线交易;移动端或者电脑端的在线游戏 [10] ;计算机辅助协同的设计与工程 [11] 和基于网络的电子学习 [12] 以及视频会议等.对于服务提供商来说为了给用户提供良好的服务体验就需要保证服务延迟在用户可接受范围内.
面临着基于延迟保证的业务激增的现状,在应对用户网络功能请求的时候,需要按照不同的服务链顺序在网络中多个功能节点处执行对应的请求功能,因为网络资源是有限的,这样以来就会带来不可忽视的服务延迟,而过高的服务延迟将会降低整体的网络性能和用户体验.对于网络中包含大量的服务延迟敏感型业务需求,NFV在资源部署中就需要考虑到服务延迟对系统性能的影响,合理的节点资源分配可以大大减少节点端的处理延迟,但由于在网络功能服务需要网络中特定序列的服务链,网络延迟同样成为实现网络功能服务中低延时高质量体验的主要障碍 [13] .因此在虚拟网络功能资源调度中存在的挑战包括:1)确定流路径,以正确的顺序遍历合适的处理节点,以满足给定服务链的需求;2)在通过现有的虚拟网络功能节点时考虑节点负载和其他动态特征.为实现有效的服务协调和管理,解决如何快速合理地分配和调度网络资源的问题,目前一些研究文献[14-16]等在功能节点处理延迟上取得了瞩目的成果,比如文献[14]考虑到虚拟网络功能的位置不确定情况下嵌入移动核心虚拟网络功能(VNF)的顺序,文献[15]提高了节点利用率并减少处理节点对请求的响应延迟.不同于之前的研究,本研究首先以降低资源调度中总体服务延迟作为目标,然后结合具体网络提供动态性较高的调度算法,其现实意义在于使得服务商能够满足更为严格的延迟约束服务,从而可以为更多的客户提供良好服务.
考虑到在软件定义的网络和网络功能虚拟化共存的背景下,NFV在创建服务方面更为动态灵活,通过SDN与NFV结合还可以轻易操纵网络流经过指定节点从而实现各种复杂的网络功能以及灵活的服务链规则 [17] .更为具体的解释即为:SDN控制器借助全网视图的优势可下发细粒度的规则到网络转发设备,网络转发设备根据规则执行对网络流的操作,通过这种方式运营商或者用户引导网络流按照正确的顺序经过NFs.因此在这项工作中,基于SDN与NFV结合的研究背景,我们将借助SDN与NFV的优势,同时考虑影响网络功能总体服务延时的多个因素,通过采用构建辅助图和多路技术等方式为用户选择NFV的有序序列和连接它们的数据传递路径,以最小化延迟来最大程度地保证整体服务质量,具体内容将在第2节和第3节中详细介绍.
为了解决虚拟网络功能资源调度的延迟问题,目前一些研究在网络功能节点端的资源调度方面取得了丰富的成果.其中文献[14]在延迟限定情况下对移动核心网络功能虚拟化映射问题做了研究,它考虑到虚拟网络功能的位置不确定情况下嵌入移动核心虚拟网络功能(VNF)的顺序,其延时限定包括处理、排队和传播引起的延迟.另外为提高节点利用率并减少处理节点对请求的响应延迟,文献[15]提出了基于服务优先级的加权服务链放置算法和基于组合优化的请求调度算法.文献[9]认为如今虚拟网络功能通常分布式地部署在网络边缘,在5G系统中,动态的服务需要在分布式和虚拟化的资源设施中灵活地配置并完成异构服务,在他们的工作中通过组合优化选择虚拟网络功能节点从而达到最小化的网络与处理延迟.文献[18]通过整数线性规划模型有效地放置虚拟网络功能和部署服务功能链,研究内容包括虚拟功能节点数目,优化目标包括CPU和带宽资源消耗以及端到端延迟等.文献[19]考虑虚拟网络功能的传输和处理延迟,在这里作者探讨了动态虚拟链路带宽分配的好处,作者对到达的业务通过遗传算法的带宽分配的决策处理作为提高网络性能的有效手段.在文献[20]中,研究者们针对网络功能虚拟化服务商为用户提供动态灵活的虚拟网络功能服务中面临的服务流波动问题,作者采用主动预测流的方式最小化预测产生的错误,并且采用自适应的调整策略,降低虚拟网络功能的部署成本.文献[21]设计实现了NFV-RT系统,此系统的目的是:在云计算环境中满足服务链时间限定的前提下最大化所接受的服务链请求数目.文献[22]通过测量不同类型的虚拟网络功能间协作干扰,研究不同VNF因竞争资源对性能产生的影响,并根据测量结果给出了更加有效的VNF放置方法,对于虚拟网络功能的研究和应用有着显著的现实意义.此外,在虚拟网络功能负载均衡对性能的影响方面,文献[23]首次提出主要控制荷载(dominant load)的概念作为衡量节点负载的标准,研究中提出的解决NFV中多资源负载均衡问题的优化算法比传统的标准算法更加快捷和高效.
但是,这些调度方法没有考虑到如下问题:当网络存在多个相同功能点的时候,采用多点处理方式会进一步降低系统的总体服务延迟,但前提在多点处理的时候必须考虑到路径不对等带来的延迟差异,所以此问题需要结合具体拓扑讨论,之上的研究中也没有考虑到网络拓扑问题;另外,由于如今网络动态性较高,需要提供一种计算复杂度和运行时间较低的算法.本研究提出了一种提前构建辅助图,根据不同服务链间延时影响分析确定调度顺序而且采用多路传输的资源调度方案,最后设计了一种基于贪婪的启发式算法,以提高虚拟网络资源调度中保障时效性的能力.
在问题模型中,我们用 S 来表示网络服务集,模型中的| S |代表服务集 S 的数量,[1,| S |]表示1~| S |的整数集合,其他类似表示以此类推; s i 表示对应网络服务 i 的服务链,其中 i ∈[1,| S |].每条服务链 s i 对应着一系列需要按规定顺序经过的网络功能,在此用 F 表示网络功能 f j 的集合, f ij 表示网络服务 i 所对应的虚拟网络功能 f j ,( i ∈[1,| S |], j ∈[1,| F i |]).在研究中用 G =( N , E )来表示节点集为 N 、边集为 E 的网络.此外,不论处理网络功能虚拟化虚拟机是位于服务器还是交换机,在这里统一为物理机,因此都用网络节点 N 来表示.不同的虚拟机节点可能配备不同的虚拟网络功能,因此我们定义虚拟机集合 V ={ v 1, v 2,…, v v }中各虚拟机所配备的功能为虚拟网络功能 F ={ f 1 , f 2 ,…}的子集.比如,如果表示节点 v k 的网络功能为{ f 1 , f 5 , f 8 },意思就是在虚拟机 v k 上只能处理网络功能 f 1 , f 5 和 f 8 .
Fig. 1 Virtual network function scheduling scheme example
图1 虚拟网络功能调度方案示例
在我们的虚拟网络功能资源分配优化的研究中,使用延迟作为成本度量,因此在网络模型中需要包含节点部分延迟和节点之间通信的延迟.虽然之前有部分的研究,如文献[14-16,18]等,在NFV节点资源调度带来的处理时延上取得显著的成果,也有个别的工作考虑了NFV节点资源调度带来的传输时延问题 [24] .在本研究中同时考虑了网络时延和处理时延,所谓的网络时延就是在资源分配与调度时带来的传输时延和传播时延.传输时延主要由包的大小和链路的传输能力决定,如果把某虚拟链路传输速率表示为 b l 、某网络服务 s i 需要传输的数据包大小表示为 D i ,传输延迟就可以很容易通过 D i ÷ b l 算出.而传播时延就是在资源调度时对源点与目的节点的路径选择带来的延迟,具体的延迟是由对应的网络拓扑和传输方式决定.如果细分的话网络服务总体延迟还需要包含队列时延,队列时延主要由输出接口链路负载、调度策略以及队列模型(比如经典的M  M 1模型 [25] )和缓存区的大小 [19] 影响,关于队列已经有了很成熟的研究,不属于本研究的范畴.为了简化,本研究遵循文献[18,24]的设定,即服务链已知情况下,每个虚拟节点最多只能同时处理一种网络功能并且在转发完一条服务流之后才能转发下一条网络服务流.
M 1模型 [25] )和缓存区的大小 [19] 影响,关于队列已经有了很成熟的研究,不属于本研究的范畴.为了简化,本研究遵循文献[18,24]的设定,即服务链已知情况下,每个虚拟节点最多只能同时处理一种网络功能并且在转发完一条服务流之后才能转发下一条网络服务流.
虚拟网络功能的调度与路由问题的约束有2个方面:1)维持提供服务的服务链顺序;2)以最小的代价找到从源到目的地的路径,在此项研究中的代价将由延迟来表示.具体来说,给定网络服务集,每项服务是由特定的序列构成,在网络资源限定的条件之下构建模型,根据规则序列为所有的用户流选择总体服务时间最短的网络功能实例和传输路径,通过最小化延迟来保证网络的整体服务质量.为了更好地描述问题,在此以图1所示的方式表示在虚拟网络功能调度中不同的调度方案对最终服务延迟的影响.在图1中,存在VM1,VM2,VM3三个不同的虚拟机,椭圆表示每个虚拟机所配置的网络功能,另外还有3种网络功能服务链,每种服务链对应不同的网络功能.
在图1(a)中,表示时间轴的箭头下方为一种网络功能资源调度方案,此方案中首先由VM1的服务链1中的 f 1 ,紧接着是服务链2中的 f 2 ,然后经过4 t 的传输时间服务链1接受VM2的 f 5 功能处理,在此期间服务链2必须等待至时间4 t 才能得到所需服务,其他服务以此类推,最终完成所有服务总体所耗费时间为11 t (由图2(a)中的VM3-1得到).但是如果采用箭头上方所示的另外一种方案,也就是在VM1处理完 f 1 和 f 2 时,调度的时候首先选择传输服务链2中 f 2 至VM3,最终可以得到总体所需服务时间为10.5 t (由图2(a)中的VM2得到),由此可知通过控制器对网络功能资源合理调度就能减少网络的总体服务时延.另外网络中还存在的常见情形就是在网络中具备多个相同功能的服务节点(比如有多个代理服务器的情况),或者下一个服务功能点同时受到多个上游功能节点制约(比如文献[17]中的防火墙与监听器并行处理对应着下个序列的负载均衡器).如图1(b)所示, f 7 同时受到 f 6 与 f 3 制约,VM1与VM2同时具备网络服务功能 f 6 ,通过计算选择VM1与VM2同时处理服务链3中所需的网络功能 f 6 ,即使存在传输时延,但通过VM2-1与VM2-2的服务结束时间对比可得,总体服务时延由10.5 t 降为10.1 t ,采用上面的调度方式,网络的服务延迟会降低,进而提升用户的体验.
表1表示的是每个服务链所需网络功能的服务时间,我们用时间片 t 来表示,除了服务链1的 f 1 → f 5 虚拟传输时延为4 t 以及服务链2的 f 2 → f 4 和服务链3的 f 6 → f 7 的传输时延为2 t 之外,其他的网络功能跳转切换虚拟机的传输时延均为 t ,比如在服务链2中,VM1处理网络功能 f 1 之后跳转到VM2处理网络功能 f 4 ,所需传输时延为时间 t .以上虽然是为了在图例中清晰表述而做出的设定,但在实际情况中这些都是可以由控制器计算得出.
Table 1 Required Service Time Value
表1 所需服务时间值

直观上来说,如果存在一个合理的网络功能调度方案使得对用户的服务延迟最小,在网络传播的时候选择,把延迟作为权重,选择最短路径算法(比如Dijkstra),用户就能得到总体最小延迟.但是如上所述,当网络中存在多个相同功能的网络功能节点时,不对等的路径就会带来额外的延迟.在此我们使用图2所示的例子来解释这些问题,其中实线的箭头表示从源 s 到目的地 d 的路径,虚线代表路径节点的其他可用链接下一跳.比如图2中选择源点 s 到目的地 d 的一条路径为{ s → u → w → y → d },其中 y 为用户所需服务节点.但是网络中若存在与 y 节点功能相同的另外节点 x ,如果因为链路负载或者多路传输减少服务延迟等原因使 x 作为网络功能服务节点,就会存在途径 x 的另一条路径 x .比如现在与网络功能虚拟化相关的部分研究成果文献[18]和文献[24],作者根据自己的研究目标提到在实现过程中可以考虑采用多路传输的方式.虽然多路传输的方式可以一定程度降低网络的总体服务延迟,但是如果路径 x 与路径 y 延迟不等就有可能带来额外延迟,所以在虚拟网络资源调度时,如果存在多路传输的情况,需要把传播延迟也要考虑其中.
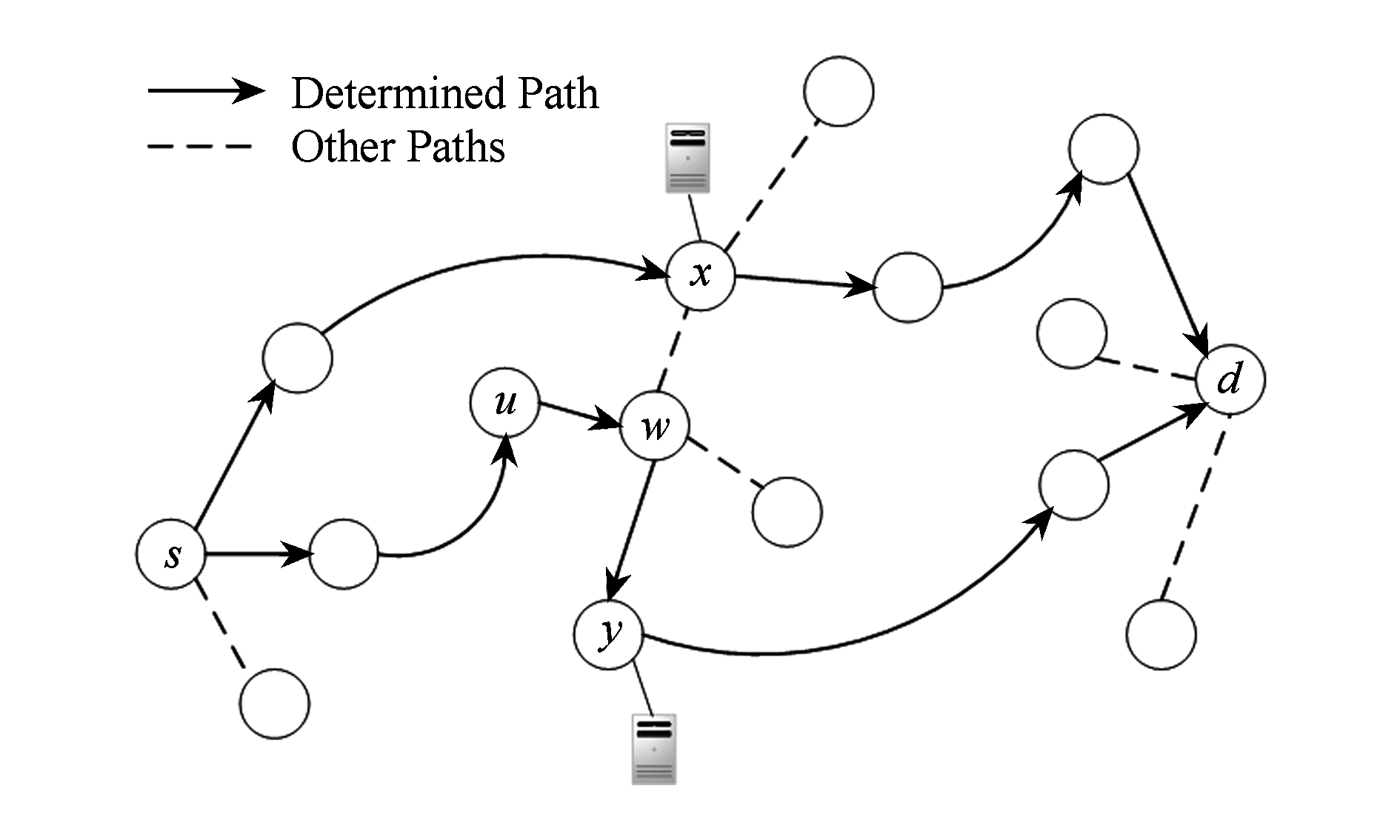
Fig. 2 Multipath transmission example
图2 多路传输示例
对每条网络服务请求 s i ,我们定义二进制变量 x ijk =1为服务链 i 对应的第 j 项功能由虚拟节点 k 来处理,并且引入变量 ![]() 用
用 ![]() 表示有向边( u , v )属于 s i 源端到目的端所分配的路径之上.用
表示有向边( u , v )属于 s i 源端到目的端所分配的路径之上.用 ![]() 表示处理时延, l uv 为边( u , v )的传播时延.形式上,目标函数可以使用以下方式表示:
表示处理时延, l uv 为边( u , v )的传播时延.形式上,目标函数可以使用以下方式表示:
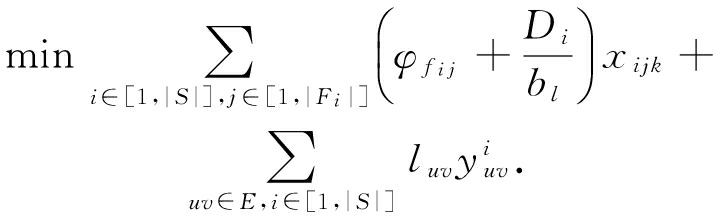
(1)
通过2.1和2.2节的描述,为保证网络服务在处理功能请求时所调度资源满足现有网络条件,限定条件由式(2)~(6)表示.值得注意的是,服务器硬件资源容量约束(CPU、内存等)、网络带宽约束等和延迟相关的其他约束都可以在计算处理延迟或者传输延迟的时候隐式地处理.在限定条件式(2)中, τ ij -1 表示第 j -1项功能节点开始转发服务流 s i 的时间, α ij 表示第 j 项功能处理的开始时间, ![]() 为具备 s i 的 f ij 功能的节点集,式(2)是为了保证服务链上的下一功能节点处理开始时间必须在上游节点传输与网络传播完成之后;条件式(3)是为了保证服务流 s i 在传输之前满足 j 项功能所需的处理时间;在源节点处,如果选择单路径,则输出链路的数量减去输入链路的数量应该等于1,限定条件式(4)表示服务流 s i 对应的源节点;式(5)表示为目的节点输出链路的数量与输入链路的数量关系;式(6)是为了保证所选择路径无环,其中定义
为具备 s i 的 f ij 功能的节点集,式(2)是为了保证服务链上的下一功能节点处理开始时间必须在上游节点传输与网络传播完成之后;条件式(3)是为了保证服务流 s i 在传输之前满足 j 项功能所需的处理时间;在源节点处,如果选择单路径,则输出链路的数量减去输入链路的数量应该等于1,限定条件式(4)表示服务流 s i 对应的源节点;式(5)表示为目的节点输出链路的数量与输入链路的数量关系;式(6)是为了保证所选择路径无环,其中定义 ![]() 为服务 s i 所选路径上的边对应的顺序编号,如果所选边不存在或者( u , v )不是所选路径上的边,则
为服务 s i 所选路径上的边对应的顺序编号,如果所选边不存在或者( u , v )不是所选路径上的边,则 ![]() 为所选路径节点集合 N p 的子集,2≤ h <| N p |, h 为整数.
为所选路径节点集合 N p 的子集,2≤ h <| N p |, h 为整数.
s.t. ![]()
(2)
∀ i ∈[1,| S |], ∀ j ∈[1,| F i |-1],
∀ 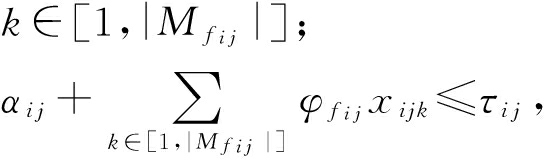
(3)
∀ i ∈[1,| S |], ∀ j ∈[1,| F i |]; ![]() ∀ i ∈[1,| S |];
∀ i ∈[1,| S |];
(4)
![]() ∀ i ∈[1,| S |];
∀ i ∈[1,| S |];
(5)
(6)
∀ i ∈[1,| S |],
∀ ![]()
事实上,在虚拟网络功能调度与路由问题中,想获得最佳的资源调度是一个组合难题.在基于延迟的虚拟网络资源调度问题中,需要考虑到给定的服务器或者其他硬件资源的限制,同时还要服从于虚拟网络功能的服务链顺序限定,必须为不同的网络服务找到对应的网络功能,并且根据已知的源与目的节点选取延迟最小的功能执行时隙和路径延迟,根据已有的研究结果可得出,此组合问题为NP难问题 [19,25-27] .由于网络功能资源调度问题的复杂度,实际中寻求最优结果的组合在计算复杂度和应用时间上是不现实的,本研究中我们选择采用启发式贪婪算法作为算法设计的基础思想.
一般来说,贪婪算法的基本思想是迭代选择每一步的最佳解决方案,这样有可能使得最终结果陷入局部最优,但是比起禁忌搜索和遗传算法等启发式算法来说贪婪算法的好处是运算时间较短,较为适合用户请求动态性比较高的网络场景.我们算法设计主要想法是首先将网络转换为分步骤处理的辅助图,然后通过保证延迟的多路径传输算法解决虚拟网络功能资源分配的延迟问题.如图3所示,目标是找到原点到 D 的最短延迟路径,首先我们先构造与图3类似的辅助图层,其中实线代表遵循服务顺序的最短路径,虚线代表其他路径或者其他功能节点路径.比如图3中VM1与VM2同时具备网络功能 f n ,VM3配置的网络功能为 f n -1 ,则服务链 s 2 ( f n → f n -1 )所对应的辅助图即为 S 2 → S 3 → S 10 → D 和 S 2 → S 7 → S 10 → D ,辅助图边上的权重由网络传播延迟计算可以得出.通过构建辅助图层的方式,加上节点的处理延迟和传输延迟以及等限定,问题就可以转化为在多个服务流共存的情况下找到总体延迟最短的路径.
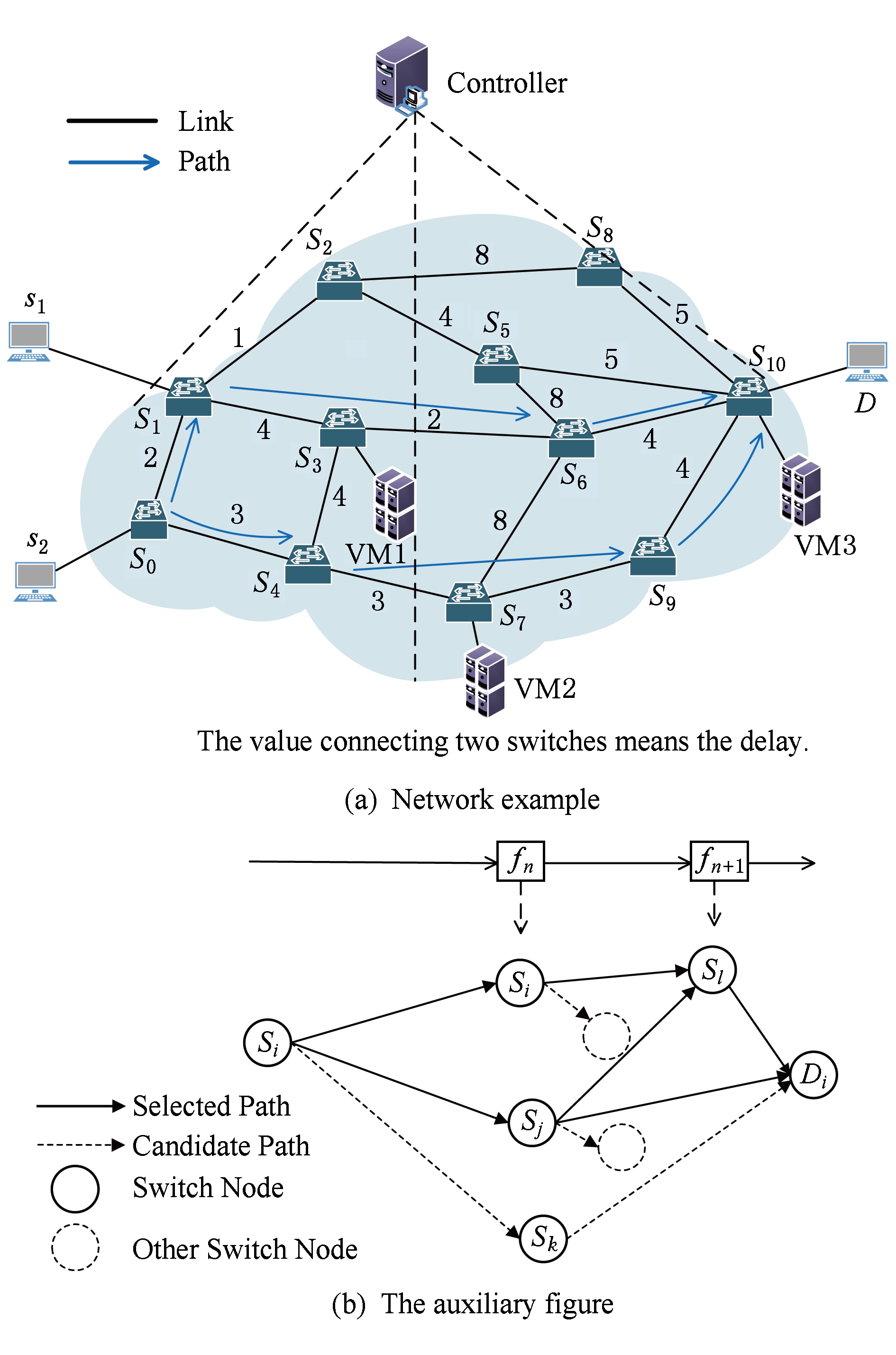
Fig. 3 Network example and auxiliary figure example
图3 网络示例与辅助图示例
算法1 . 延时感知的资源调度算法(AGM).
输入:网络图 G =( N , E )、网络服务请求集 S 、网络功能节点集合 ![]() 即为服务 s i 网络功能 f ij 对应的功能节点 k ;
即为服务 s i 网络功能 f ij 对应的功能节点 k ;
输出:可行的调度方案,其中包括 ![]() ∀ i ∈[1,| S |],∀ j ∈[1,| F i |-1],∀
∀ i ∈[1,| S |],∀ j ∈[1,| F i |-1],∀ ![]()
步骤1. 预处理生成辅助图形.根据请求服务集 S 中循环获取服务 s i 及其对应的服务功能 f ij 集合,并根据 f ij 对应的功能节点集 M f ij 由Dijkstra算法寻找最短路径生成 s i 的辅助图.
步骤2. 根据构建的辅助图,循环计算出各功能节点所需处理的服务链时延之和,按照递减排序为 M r .
步骤3. 如果首次循环找出其中辅助图上游节点为源节点的所有 M r 项,非首次循环选取 ![]() 的 M r 第1项,判断上游节点是否是已经分配节点或者源节点,否则选取下一项 M r ,从中找出所需时延之和最小的 s i 项和第2小的 s j 项.
的 M r 第1项,判断上游节点是否是已经分配节点或者源节点,否则选取下一项 M r ,从中找出所需时延之和最小的 s i 项和第2小的 s j 项.
步骤4. 对比 s i 和 s j ,如果上游节点存在多路传输的情况,选取该项,跳转到步骤5;否则对 s i 和 s j 项做交叉对比处理时延和传输时延的差值,选取绝对值最小的服务项,若下游节点存在多个可选功能节点对网络服务功能流进分解,跳转到步骤5.
步骤5. 多路传输处理,若存在多个可选功能节点,根据服务延时和路径时延计算比例函数,然后根据比例函数 θ j 分别进行传输, θ j 由下式算出:
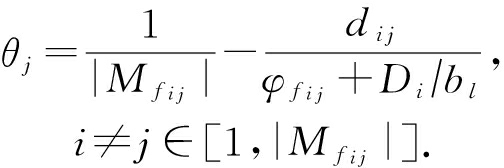
步骤6. 修改 ![]() 和 M r 中的项并记录对应的
和 M r 中的项并记录对应的 ![]() 跳转至步骤2直至循环结束.
跳转至步骤2直至循环结束.
鉴于本研究的目标是最小化服务延迟与节点之间通信的延迟,我们的算法循环原则是从资源冲突最大的功能节点中优先选取对其他服务延时影响最小和能多点同时处理的服务链.算法中 d ij 代表选定服务项 s i 所在路径与备选点之间的路径延迟差值,其中比例函数 θ j 可以由用户根据实际情况定义,比如下游节点负载,在这里采用和文献[24]类似的想法,但是目标是采用路径总体延迟等价的比例因子.因为Dijkstra算法的时间复杂度为 O ( n 2 ),其中 n 代表的是网络图中的节点个数,考虑在 l 条边的图中有 k 条服务链请求中,每条服务最多包含 m ( m ≤ n )个功能节点,则求每个节点到目的节点的路径需要的时间花费为 O ( k ×( l + m log m )),因此算法的复杂度为 O ( n 2 + k ×( l + m log m )).
在本节中,我们对本研究中虚拟网络功能调度和资源分配方法在延迟方面的性能进行了数值评估,通过与资源调度中的先来先服务方案对比得到延时性能提升比例,证明本研究方案的可行性和优越性.
在实验中我们使用与文献[18]和文献[20]相同的处理延时和传输延时设定,首先设定每个功能的处理时间随机选择区间为10~20 ms,对应的传输时延从5~20 ms中随机选择,并且保证每个网络功能至少配置在一个VM节点中.
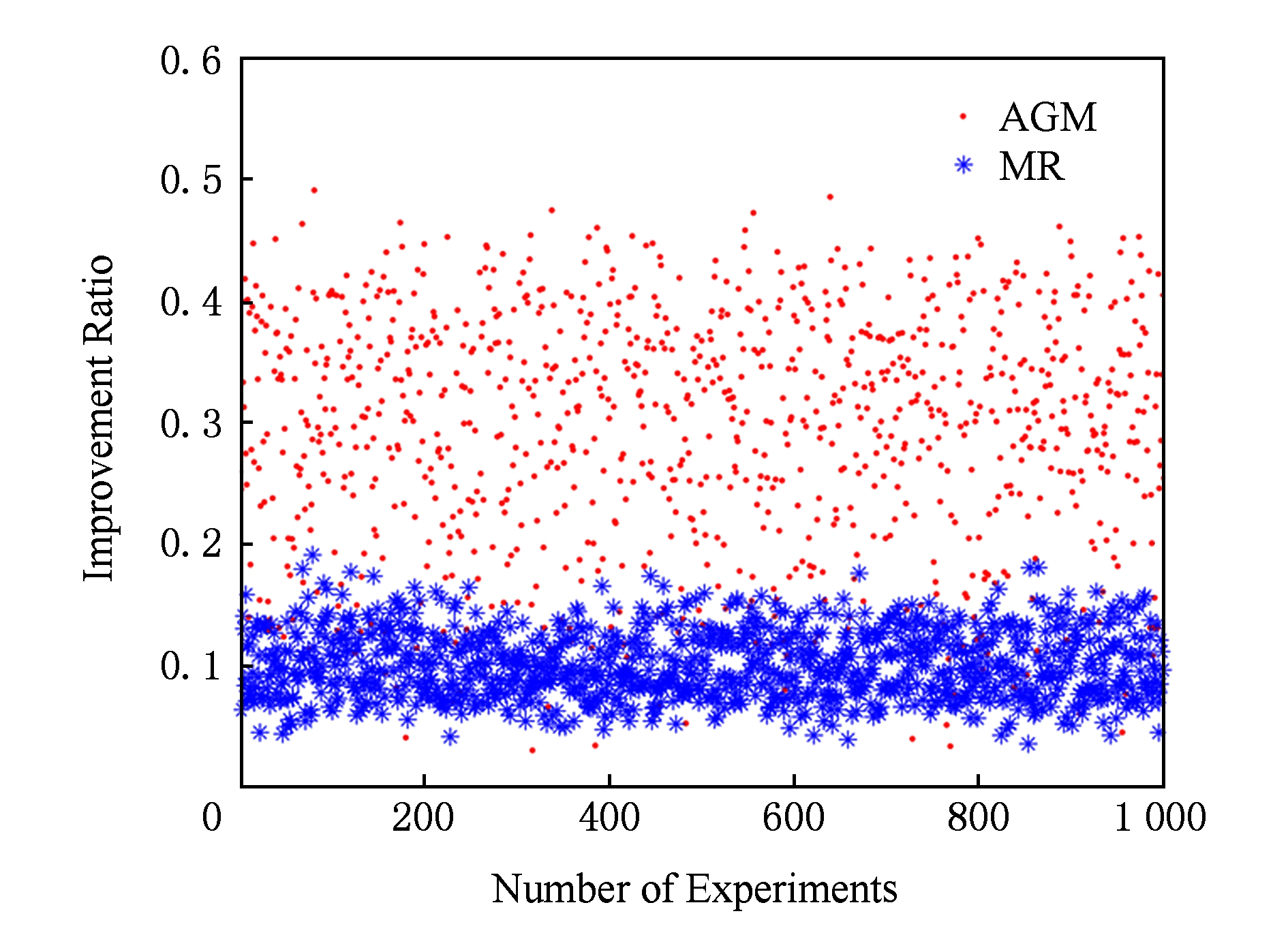
Fig. 4 Performance increase ratio of scheduling in simulated network topology
图4 模拟的网络拓扑中调度方案性能提升比例
在第1个实验案例中,采用了图3的例子对研究方案性能进行分析,在图3的3个VM节点中一共随机设定了5种网络功能,并且保证有2个节点存在相同的网络功能;然后进行了1 000次的循环实验,每次实验中都随机生成40条服务链请求并随机选择具备重复功能的节点;最后得到图4所示结果.图4中圆点代表我们的调度方案与随机的先来先服务调度方案在延时性能的提升比值(用AGM表示),可以看出在这些实验室中性能比例提升大部分都落在0.2~0.4的区间内,也就是20%~40%;星号点代表采用多路传输来同时处理相同网络功能在延时性能提升方面所占的比例(用MR表示),观察得出提升比率在5%~15%的区间.另外在文献[20]中提到,在资源调度中,对于一个5个节点的小型网络(对应的遗传算法运行时间为0.45 s),解决这个问题的最优解运行时间高达1 000 s,而我们的算法平均执行时间为0.16 s;而在具有2个网络服务的10个节点网络中,模型运行时获得最佳解决方案是按小时进行的.综上可以看出,我们基于贪婪的算法设计能更好地适应于网络的动态性需求.
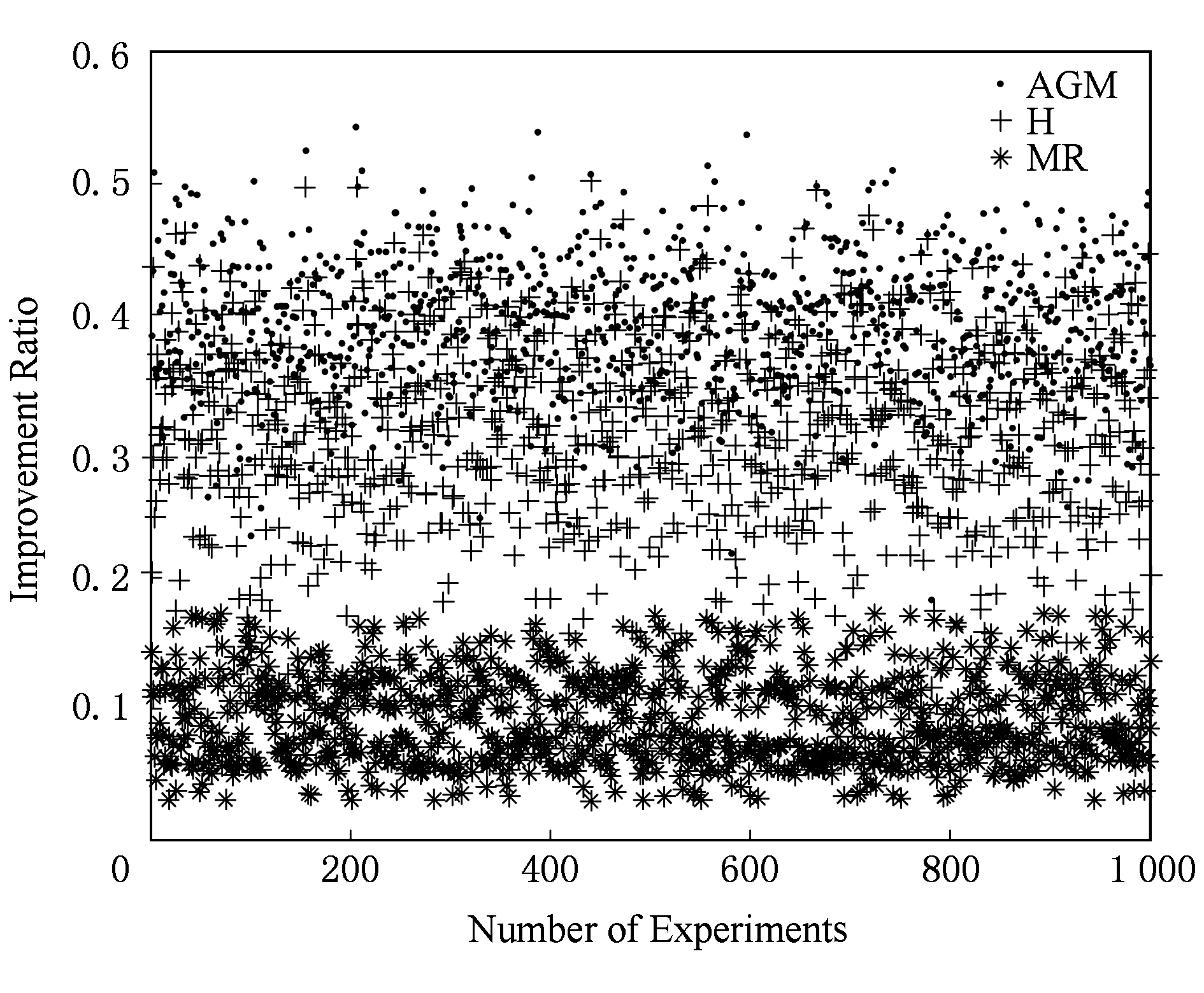
Fig. 5 Performance increase ratio of scheduling in real network topology
图5 真实网络拓扑中调度方案性能提升比例
在图5所示的第2个实验案例中,采用了文献[28]中具备88个节点和161条链接的真实拓扑,网络传播时延也来自于真实数据.在1 000次实验中,每次随机生成160~200条服务链请求,随机生成的6个VM节点配备了10种网络功能,其中3~5个功能节点配置有相同的网络功能.在本案例中增加了对文献[16]H算法的对比实验,H算法即:对于每个VNF链,首先将资源要求最高的VNF放在剩余资源容量最大的节点中处理,然后尝试将该服务链的其他VNF放置在尽可能多的同一个节点上,因为默认每个节点处理能力相同,在此选择剩余资源容量最大的节点为需要等待服务时间最小的节点.通过观察实验结果,可以发现其中多路传输的多点处理方式性能提升空间大部分在5%~17%之间,总体提升比例大部分在0.33~0.45之间,比起H算法仍有10%左右的性能提升.不足为奇的是,随着拓扑节点和请求的增加,我们可以获得更好的性能(例如:较多比例的提升空间).这是因为有了更多的可调度服务链和功能处理节点,使得选择变得更加灵活,从而导致服务延迟更短.另外在图6的100次实验中采用了文献[19]中的带宽方案,设定每个功能节点传输延迟选择 ![]() 或
或 ![]() 对应着方案中{1,4}Mbps的带宽设定.在图6中,底部的带星号的曲线表示不考虑网络传播延时的总调度延时(用NDS表示);顶部的虚线代表文献[19]中的方案(用DBS表示),即对于每个服务链如果功能节点中负载较大,则选择传输延迟为
对应着方案中{1,4}Mbps的带宽设定.在图6中,底部的带星号的曲线表示不考虑网络传播延时的总调度延时(用NDS表示);顶部的虚线代表文献[19]中的方案(用DBS表示),即对于每个服务链如果功能节点中负载较大,则选择传输延迟为 ![]() 的带宽分配方案,反之选择
的带宽分配方案,反之选择 ![]() 功能节点之间的路径选择采用最短路径;中间的直线表示考虑网络传播延时如果存在多点处理则采用多路传输的方案(用DMS表示).从图6中首先可以看出网络的传播延时对总体服务延时有着较大影响,然后即使采用了文献[19]中的带宽优化方案并且路径最短路径,我们的方案仍能体现出更好的性能提升效果.
功能节点之间的路径选择采用最短路径;中间的直线表示考虑网络传播延时如果存在多点处理则采用多路传输的方案(用DMS表示).从图6中首先可以看出网络的传播延时对总体服务延时有着较大影响,然后即使采用了文献[19]中的带宽优化方案并且路径最短路径,我们的方案仍能体现出更好的性能提升效果.
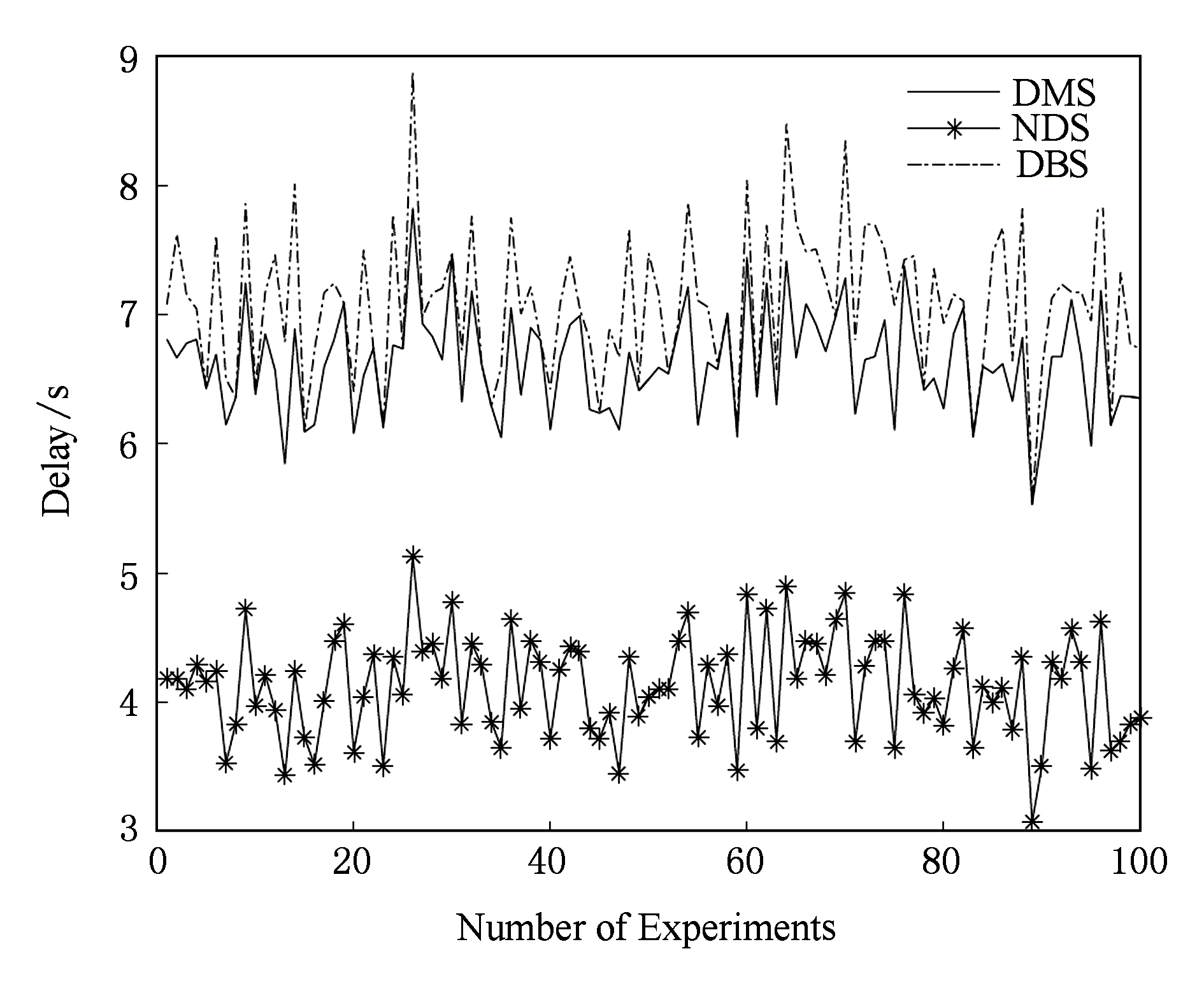
Fig. 6 Delay comparison for different schedules
图6 不同调度方案延时对比
本文针对网络功能虚拟化资源分配与调度过程中任务的调度顺序和传输方式影响网络总体服务延时的问题,本研究根据对服务链之间调度造成的延迟影响转移到其他能够降低该延迟的服务链顺序和多个处理节点之上的思路,提出创建辅助图与多点处理的策略,然后借助辅助图的简洁性设计了满足网络动态需求的启发式算法,实现对虚拟网络资源的合理调度并采用了多路传输方式进一步减少资源调度对总体服务延迟的影响.最后,通过模拟实验结果显示,本研究能够有效提高虚拟化网络功能时效性的能力,减少虚拟网络功能服务系统的总体服务延迟.
参考文献
[1]Guerzoni R. Network functions virtualization: An introduction, benefits, enablers, challenges and call for action, introductory white paper[C]  Darmstadt. SDN and OpenFlow World Congress, 2012 [2017-11-01]. https: portal.etsi.org nfv nfv_white_paper.pdf
Darmstadt. SDN and OpenFlow World Congress, 2012 [2017-11-01]. https: portal.etsi.org nfv nfv_white_paper.pdf
[2]Kreutz D, Ramos F M V, Verissimo P E, et al. Software-defined networking: A comprehensive survey[J]. Proceedings of the IEEE, 2015, 103(1): 14-76
[3]Yu Tao, Bi Jun, Wu Jianping. Research on the future virtualization of the Internet[J]. Journal of Computer Research and Development, 2015, 52 (9): 2069-2082 (in Chinese)(余涛, 毕军, 吴建平. 未来互联网虚拟化研究[J]. 计算机研究与发展, 2015, 52(9): 2069-2082)
[4]Bremler-Barr A, Harchol Y, Hay D. OpenBox: A software-defined framework for developing, deploying, and managing network functions[C] Proc of the 2016 ACM SIGCOMM Conf (SIGCOMM’16). New York: ACM, 2016: 511-524
[5]Qazi Z A, Tu C C, Chiang L, et al. SIMPLE-fying middlebox policy enforcement using SDN[J]. ACM SIGCOMM Computer Communication Review, 2013, 43(4): 27-38
[6]Herrera J G, Botero J F. Resource allocation in NFV: A comprehensive survey[J]. IEEE Trans on Network and Service Management, 2016, 13(3): 518-532
[7]Cui Xingcan, Yu Xiaohui, Liu Yang, et al. A survey of distributed stream processing technology[J]. Journal of Computer Research and Development, 2015, 52(2): 318-332 (in Chinese)(崔星灿, 禹晓辉, 刘洋, 等. 分布式流处理技术综述[J]. 计算机研究与发展, 2015, 52(2): 318-332)
[8]Cziva R, Pezaros D P. On the latency benefits of edge NFV[C] Proc of the Symp on Architectures for Networking and Communications Systems. Piscataway, NJ: IEEE, 2017: 105-106
[9]Martini B, Paganelli F, Cappanera P, et al. Latency-aware composition of virtual functions in 5G[C] Proc of the 1st IEEE Conf on Network Softwarization (NetSoft 2015).Piscataway, NJ: IEEE, 2015: 1-6
[10]Claypool M, Claypool K. Latency can kill: Precision and deadline in online games[C] Proc of the 1st Annual ACM SIGMM Conf on Multimedia Systems (MMSys’10). New York: ACM, 2010: 215-222
[11]Agustina, Liu Fei, Xia S, et al. CoMaya: Incorporating advanced collaboration capabilities into 3D digital media design tools[C] Proc of the 2008 ACM Conf on Computer Supported Cooperative Work. New York: ACM, 2008: 5-8
[12]Ahmad L, Boukerche A, Al Hamidi A, et al. Web-based e-learning in 3D large scale distributed interactive simulations using HLA RTI [C] Proc of the 2008 IEEE Int Symp on Parallel and Distribution Processing. Piscataway, NJ: IEEE, 2008: 1-4
[13]Zheng Hanying, Tang Xueyan. Analysis of server provisioning for distributed interactive applications[J]. IEEE Trans on Computers, 2015, 64(10): 2752-2766
[14]Baumgartner A, Reddy V S, Bauschert T. Combined virtual mobile core network function placement and topology optimization with latency bounds[C] Proc of the 4th European Workshop on Software Defined Networks (EWSDN). Piscataway, NJ: IEEE, 2015: 97-102
[15]Zhang Qixia, Xiao Yikai, Liu Fangming, et al. Joint optimization of chain placement and request scheduling for network function virtualization[C] Proc of the 37th IEEE Int Conf on Distributed Computing Systems (ICDCS 2017). Piscataway, NJ: IEEE, 2017: 731-741
[16]Xia Ming, Shirazipour M, Zhang Ying, et al. Network function placement for NFV chaining in packet optical datacenters[J]. Journal of Lightwave Technology, 2015, 33(8): 1565-1570
[17]Sun Chen, Bi Jun, Zheng Zhilong, et al. NFP: Enabling network function parallelism in NFV[C] Proc of the Conf of the ACM Special Interest Group on Data Communication. New York: ACM, 2017: 43-56
[18]Luizelli M C, Bays L R, Buriol L S, et al. Piecing together the NFV provisioning puzzle: Efficient placement and chaining of virtual network functions[C] Proc of 2015 IFIP IEEE Int Symp on Integrated Network Management. Piscataway, NJ: IEEE, 2015: 98-106
[19]Qu Long, Assi C, Shaban K. Delay-aware scheduling and resource optimization with network function virtualization[J]. IEEE Trans on Communications, 2016, 64(9): 3746-3758
[20]Fei Xincai, Liu Fangming, Xu Hong, et al. Adaptive VNF scaling and flow routing with proactive demand prediction [C] Proc of IEEE Int Conf on Computer Communications (INFOCOM 2018). Piscataway, NJ: IEEE, 2018 [2018-01-20]. http: grid.hust.edu.cn fmliu vnf-scaling-infocom18.pdf
[21]Li Yang, Phan L T X, Loo B T. Network functions virtualization with soft real-time guarantees[C] Proc of the 35th Annual IEEE Int Conf on Computer Communications. Piscataway, NJ: IEEE, 2016: 1-9
[22]Zeng Chaobing, Liu Fangming, Chen Shutong, et al. Demystifying the performance interference of co-located virtual network functions [C] Proc of IEEE Int Conf on Computer Communications (INFOCOM 2018). Piscataway, NJ: IEEE, 2018 [2018-01-20]. http: grid.hust.edu.cn fmliu vnf-interference-infocom18.pdf
[23]Wang Tao, Xu Hong, Liu Fangming. Multi-resource load balancing for virtual network functions[C] Proc of the 37th IEEE Int Conf on Distributed Computing Systems (ICDCS 2017). Piscataway, NJ: IEEE, 2017: 1322-1332
[24]Huang Huawei, Guo Song, Wu Jinsong, et al. Joint middlebox selection and routing for software-defined networking[C] Proc of 2016 IEEE Int Conf on Communications (ICC). Piscataway, NJ: IEEE, 2016: 1-6
[25]Mijumbi R, Serrat J, Gorricho J L, et al. Design and evaluation of algorithms for mapping and scheduling of virtual network functions[C] Proc of the 1st IEEE Conf on Network Softwarization (NetSoft 2015). Piscataway, NJ: IEEE, 2015: 1-9
[26]Riera J F, Escalona E, Batalle J, et al. Virtual network function scheduling: Concept and challenges[C] Proc of the 2014 Int Conf on Smart Communications in Network Technologies (SaCoNeT). Piscataway, NJ: IEEE, 2014: 1-5
[27]Nakibly G, Cohen R, Katzir L. Optimizing data plane resources for multipath flows[J]. IEEE ACM Trans on Networking, 2015, 23(1): 138-147
[28]Mahajan R, Spring N, Wetherall D, et al. Inferring link weights using end-to-end measurements[C] Proc of the 2nd ACM SIGCOMM Workshop on Internet Measurement. New York: ACM, 2002: 231-236

Xu Ran , born in 1988. PhD candidate at the State Key Laboratory of Networking and Switching Technology, Beijing University of Posts and Telecommunications, Beijing, China. His main research interests include software-defined networking and network function virtualization.



Xu Ran, Wang Wendong, Gong Xiangyang, and Que Xirong
( State Key Laboratory of Networking and Switching Technology ( Beijing University of Posts and Telecommunications ), Beijing 100876)
Abstract Network function virtualization (NFV) aims to implement software-enable network functions so as to replace proprietary hardware devices in traditional networks. In response to the growing need for intensive resource, the software-oriented network functions bring issues such as the management of virtual network functions, low-latency scheduling, and efficient allocation of virtual network resources. The virtual network function scheduling problem itself is NP-hard. In order to ensure a good user experience on the specific issues of scheduling delays for virtual network function resources, it is necessary to ensure that network resources are reasonably allocated to prevent over-provisioning of resources and to maintain low end-to-end latency. In this paper,we formulate the problem as an integer linear programming model. In addition, to meet the characteristics of high dynamic network, we design a heuristic algorithm based on greedy. This algorithm firstly constructs the auxiliary graph, and then selects the node resources according to the analysis of the delay impact among different service chains, which considers the influence of network propagation delay and adopts multi-path transmission scheme for the multipoint processing function. The final experimental results show that our algorithm can effectively solve the model and reduce the overall network service latency by 5% to 15% compared with the previous research.
Key words network function virtualization (NFV); software defined networking (SDN); service chain; resource scheduling; multipath transmission
Wang Wendong , born in 1963.
Received his BSc and MEn degrees from Beijing University of Posts and Telecommunications (BUPT), Beijing, China in 1985 and 1991, respectively. Full professor at BUPT. His main research interests include the next-generation network architecture, IP QoS and mobile Internet.
Gong Xiangyang , born in 1970.
Received his BSc and MEn degrees from Xi’an Jiaotong University(XJTU), Xi’an, China in 1992 and 1995, respectively, and his PhD degree in communication and information system in 2011 from Beijing University of Posts and Telecommunications (BUPT), Beijing, China. Full professor at BUPT. His main research interests include IP QoS, video communications, the next-generation network architecture, and mobile Internet (xygong@bupt.edu.cn).
Que Xirong , born in 1972.
Received her BEn and MEn degrees from Beijing University of Posts and Telecommunications (BUPT), Beijing, China in 1993 and 1998, respectively. Associate professor at BUPT. Her main research interests include the next-generation network architecture, IP QoS and mobile Internet (rongqx@bupt.edu.cn).
收稿日期: 2017-12-04;
修回日期: 2018-02-28
基金项目: 国家“八六三”高技术研究发展计划基金项目(2015AA016101);国家自然科学基金项目(61370197)
This work was supported by the National High Technology Researoh and Development Program of China (863 Program) (2015AA016101) and the the National Natural Science Foundation of China (61370197).
通信作者: 王文东(wdwang@bupt.edu.cn)
中图法分类号 TP391