 O技术的Memcached优化研究 O技术的Memcached优化研究
O技术的Memcached优化研究 O技术的Memcached优化研究 安仲奇 1 杜 昊 1,2 李 强 1 霍志刚 1 马 捷 1
1 (中国科学院计算技术研究所高性能计算机研究中心 北京 100190) 2 (中国科学院大学计算机与控制工程学院 北京 100049) (anzhongqi@ncic.ac.cn)
摘 要 内存对象缓存系统在通信方面受制于传统以太网的高延迟,在存储方面受限于服务器内可部署的内存规模,亟需融合新一代高性能I  O技术来提升性能、扩展容量.以广泛应用的Memcached为例,聚焦内存对象缓存系统的数据通路并基于高性能I O对其进行通信加速与存储扩展.首先,基于日益流行的高性能远程直接内存访问(remote direct memory access, RDMA)语义重新设计通信协议,并针对不同的Memcached操作及消息大小设计不同的策略,降低了通信延迟.其次,利用高性能NVMe SSD来扩展Memcached存储,采用日志结构管理内存与外存2级存储,并通过用户级驱动实现对SSD的直接访问,降低了软件开销.最终,实现了支持JVM环境的高性能缓存系统U2cache.U2cache通过旁路操作系统内核和JVM运行时与内存拷贝、RDMA通信、SSD访问交叠流水的方法,显著降低了数据访问开销.实验结果表明,U2cache通信延迟接近RDMA底层硬件性能;对大消息而言,相较无优化版本,性能提高超过20%;访问SSD中的数据时,相比通过内核I O软件栈的方式,访问延迟最高降低了31%.
O技术来提升性能、扩展容量.以广泛应用的Memcached为例,聚焦内存对象缓存系统的数据通路并基于高性能I O对其进行通信加速与存储扩展.首先,基于日益流行的高性能远程直接内存访问(remote direct memory access, RDMA)语义重新设计通信协议,并针对不同的Memcached操作及消息大小设计不同的策略,降低了通信延迟.其次,利用高性能NVMe SSD来扩展Memcached存储,采用日志结构管理内存与外存2级存储,并通过用户级驱动实现对SSD的直接访问,降低了软件开销.最终,实现了支持JVM环境的高性能缓存系统U2cache.U2cache通过旁路操作系统内核和JVM运行时与内存拷贝、RDMA通信、SSD访问交叠流水的方法,显著降低了数据访问开销.实验结果表明,U2cache通信延迟接近RDMA底层硬件性能;对大消息而言,相较无优化版本,性能提高超过20%;访问SSD中的数据时,相比通过内核I O软件栈的方式,访问延迟最高降低了31%.
关键词 Memcached;远程直接内存访问;NVMe固态硬盘;Java虚拟机;用户级I O
内存对象缓存系统是互联网服务架构的重要组成部分,对服务性能及体验有着至关重要的影响.随着互联网的飞速发展,为应对用户量与数据量的爆炸式增长,互联网服务架构普遍采用内存对象缓存系统来降低请求响应延迟、提高服务吞吐率.在典型的互联网服务系统中,由于传统数据库提供的结构化查询机制开销较大,难以承载大量的访问请求.利用内存对象缓存系统缓冲查询结果,在以读操作为主的场景中,能够将大量昂贵的数据库查询转换为简单高效的内存键值访问,从而降低访问延迟、改善用户体验.Memcached [1] 是应用最为广泛的内存对象缓存系统之一,已于诸多互联网服务中大规模部署,其使用者中不乏Facebook [2] 、Twitter [3] 、阿里巴巴 [4] 等知名互联网服务提供商.
目前的内存对象缓存系统,在通信方面受制于传统以太网的高延迟,在存储方面受限于服务器内可部署的内存规模,其性能与容量难以应对未来海量数据下用户体验的挑战.一方面,互联网服务的竞争在很大程度上是用户体验的竞争,在单网页数据量快速增加的背景下,为了保持良好的用户体验,内存对象缓存系统必须提升响应速度,否则将给互联网服务商带来严重的损失.相关统计结果表明,网页加载时间超过2 s,3 s,8 s以后,分别会有47%,57%,99%的用户选择离开.网页加载时间每增加1 s,就会造成网站流量转化率下降7%,页面访问量下降11%,以及用户好评率下降16% [5] .另一方面,由于互联网数据总量的快速攀升,内存对象缓存系统在存储空间方面的不足将更加凸显.据思科系统公司估计,从2014—2019年,全球互联网流量的年均增长率为23% [6] .随着互联网服务系统处理的数据规模越来越大,内存对象缓存系统所需缓存的数据量必然水涨船高.在数据爆炸的时代,现有内存对象缓存系统受服务器内存容量限制的弊端将愈发明显.
内存对象缓存系统融合高性能I O技术具有广泛的应用价值.高性能I O设备的性价比正逐步提高,具备推广普及的条件.在高性能网络领域,InfiniBand网卡和万兆以太网卡价格逐步走低,与千兆以太网卡的单位性能价格已经没有量级的差距.基于数据中心桥域、融合增强以太网等无损链路,远程直接内存访问(remote direct memory access, RDMA)通信得到了RoCE(RDMA over converged Ethernet) [7] 等的商用技术的支持.在高性能存储领域,固态盘(solid state drive, SSD)单位性能价格已显著领先传统机械磁盘;而随着三层单元(triple level cell, TLC)闪存以及3D NAND闪存技术 [8] 的应用与普及,其单位容量价格也将逐步接近机械磁盘.与传统易失性内存相比,SSD在成本与能耗方面具备明显优势;面向PCIe SSD的接口规范NVMe(NVM express) [9] 释放了SSD的性能潜力,大幅拉近了2级存储与系统主存之间的性能鸿沟;而新型存储介质(比如PCM,RRAM,3D XPoint [10] 等)将进一步提高SSD的性能、容量与耐久度.随着高性能I O技术的不断发展成熟及生产规模的扩大,未来高性能I O的性价比将对商用数据中心产生巨大的吸引力.
虽然新型高性能I O大都支持传统软件接口(BSD sockets,POSIX I O等),但由于锁竞争、数据拷贝、上下文切换等的软件开销,传统机制往往无法发挥出高性能I O的最佳性能.在数据中心环境中,企业应用更多的采用受控运行时系统(如Java语言)以确保程序执行的鲁棒性与安全性,但厚厚的软件栈引入了即时编译、垃圾回收、冗余处理等的开销,进一步掩盖了高性能I O的性能优势.故而,底层硬件与上层应用之间的中间件亟需优化.
本文以Memcached为例,聚焦数据通路,研究基于高性能I O的内存对象缓存系统的通信加速和存储扩展问题.本文的主要贡献有3个方面:
1) 提出了一种基于RDMA语义的Memcached通信协议,支持应用广泛的Java客户端并面向Java虚拟机(Java virtual machine,JVM)内存管理机制进行了优化.
2) 设计了一种基于NVMe SSD的Memcached服务端存储扩展机制,采用日志结构管理内存与外存2级存储,并通过用户级驱动实现对SSD的直接数据访问以最大限度地降低软件开销.
3) 实现了高效缓存系统U2cache,通过改造、优化Memcached数据通路,旁路操作系统内核与Java虚拟机运行时,数据访问与传输均于用户态本地环境中完成,并针对不同的数据访问场景设计了不同的优化策略.相比标准版的Memcached,U2cache能够显著降低通信延迟并高效扩展存储容量.
U2cache缓存系统基于高性能网络与存储硬件,采取直通式数据I O的架构.图1给出了U2cache内部架构与传统Memcached的比较.U2cache服务端与Java客户端之间采用高性能RDMA通信取代传统的BSD sockets机制,基于RDMA语义重新设计了Java感知的通信协议,并针对不同操作及消息大小采取不同的优化策略,大幅降低了Memcached操作延迟.服务端使用高性能NVMe SSD作为内存的扩展,采用2级日志式数据管理结构以提高存储效率;同时于用户空间直接访问SSD,旁路操作系统并进一步降低软件开销.通过I O与通信的联合优化,U2cache能够显著改善高性能并提高容量.其他方面,U2cache则是沿用了Memcached原有的架构与机制,包括客户端一致性Hash算法、slab内存管理机制、LRU(least recently used)淘汰算法等 [7] .
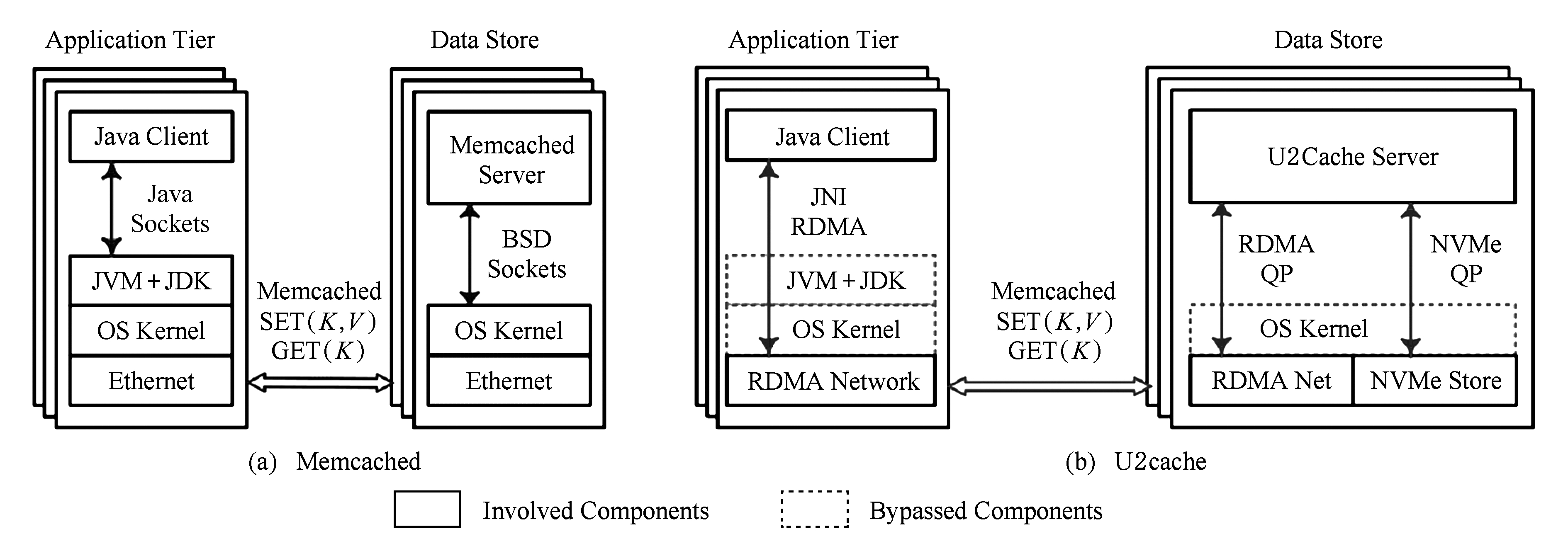
Fig. 1 Comparison of the internal architectures of Memcached and U2cache
图1 Memcached与U2cache架构比较
现有开源Memcached实现大都基于传统的BSD sockets接口以及TCP IP协议栈.在传统网络机制下,操作系统复用对网络的访问;用户程序进行网络通信时,数据需在用户空间与内核空间之间拷贝,并进行用户态与内核态的上下文切换,加之TCP IP协议栈的处理需占用较多的处理器资源,导致传统通信方式下软件开销较大.相较而言,RDMA由网卡直接读写数据而无额外的数据拷贝,InfiniBand网络传输层亦由硬件实现而无需软件处理;用户程序通过“虚接口”(即queue pair)直接访问网络硬件,操作系统仅参与通信连接的初始化与建立,不干涉数据传输.
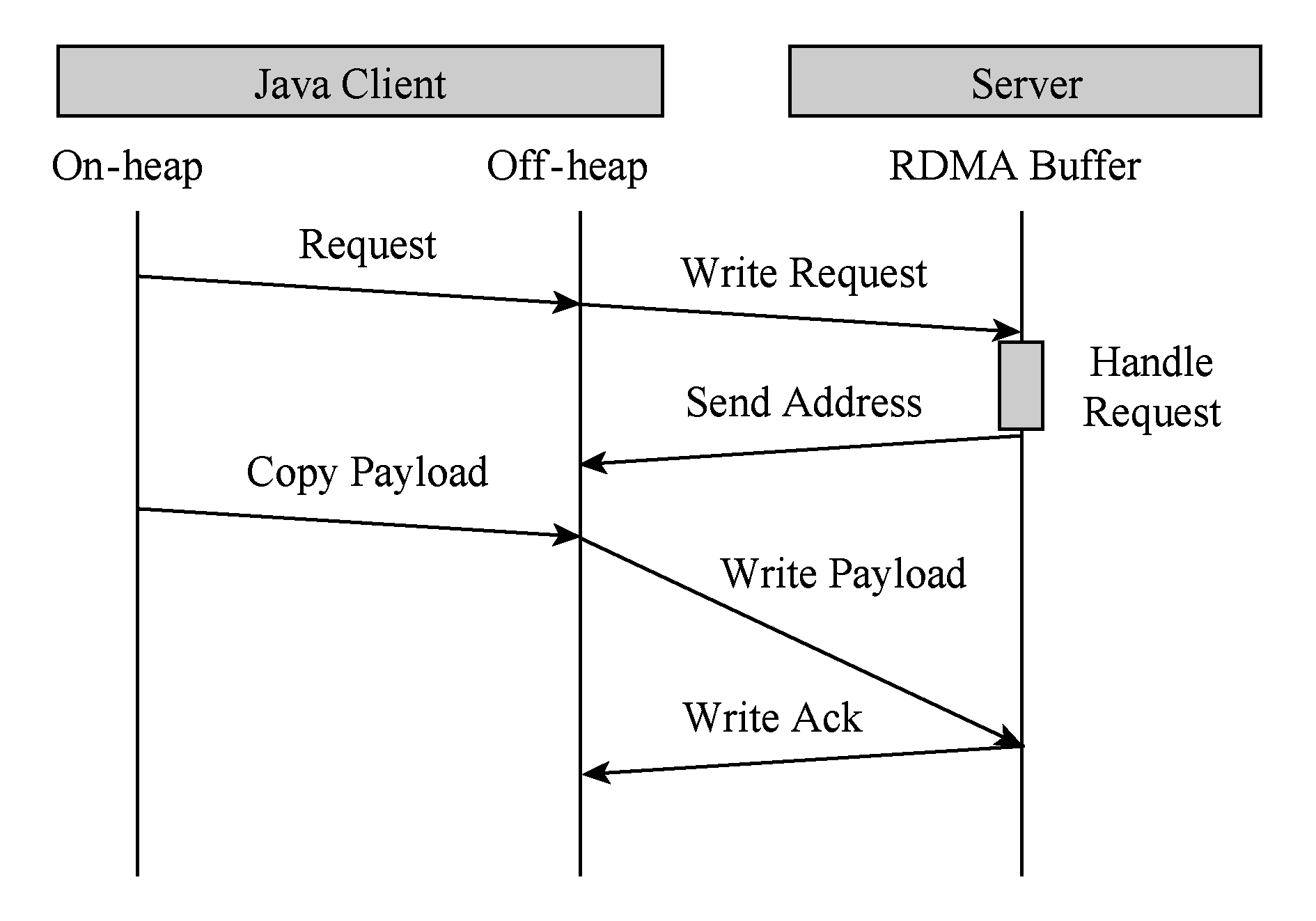
Fig. 2 Rendevzous-based SET protocol
图2 基于rendevzous协议的SET操作
U2cache基于RDMA提供的直接内存读写语义,重新设计了服务端与客户端之间的通信协议,并使用底层InfiniBand Verbs API [11] 实现.基于RDMA的数据通信根据消息大小采取了不同的优化策略.在U2cache中,服务端与客户端之间的通信过程不只是单向的数据载荷的传输,还包括附加消息头、状态标识等的控制信息的传输.MPI(message passing interface)是高性能计算领域消息通信的事实标准,本文借鉴基于RDMA的MPI实现方法 [12] 并结合Memcached操作的特点,将SET小消息传输采取有拷贝的eager协议 [13] 进行通信,而SET大消息操作则采用无拷贝的rendevzous协议 [13] ,如图2所示.受限于JVM内存访问的限制,GET操作采取类似eager的有拷贝传输方式,如图3所示.为获得最佳延迟,数据载荷的传输均采用基于可靠连接的RDMA Write操作;部分控制信息的传输则采用了SEND RECV原语.
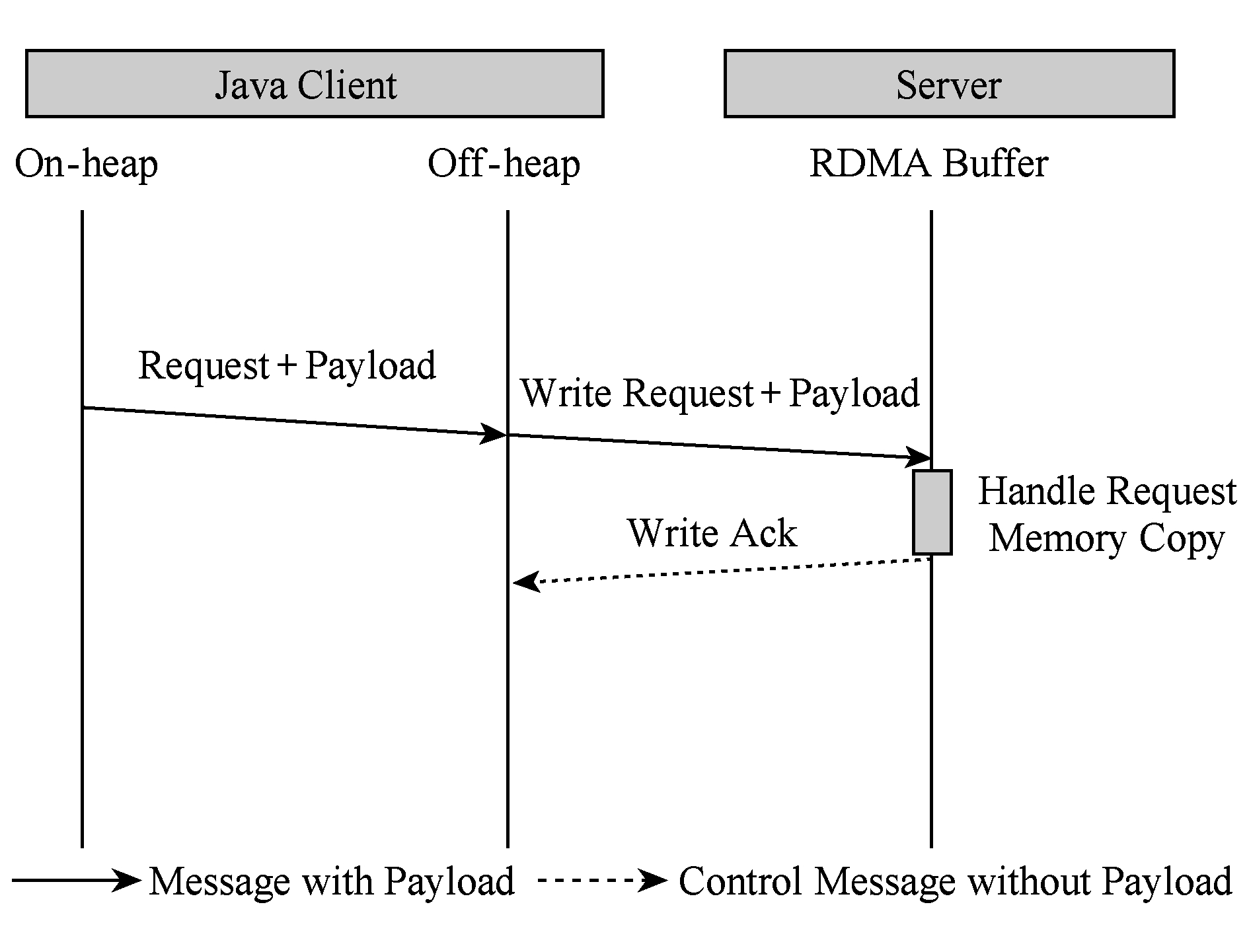
Fig. 3 Eager-like GET protocol
图3 有拷贝的类eager协议的GET操作
U2cache选取了应用更为广泛的Memcached Java客户端进行改造与优化.Java本身是一种受限的运行时环境,Java字节码于JVM中执行以提供可控性与安全性,但引入了额外的软件开销.JVM堆采取了垃圾回收的内存管理机制,堆内(on-heap)内存无法直接参与RDMA通信,目前主流的JDK实现亦未提供对RDMA网络的支持.
U2cache设计开发了高性能的Java RDMA通信库 [14] ,通过Java本地接口(Java native interface, JNI) [15] 接口实现旁路JVM以直接访问InfiniBand Verbs API;另外,Java的直接字节缓冲位于堆外(off-heap),可由操作系统锁定(pin)并注册,进而实现RDMA通信.但是,绝大多数情况下,Java代码并不使用堆外内存;将数据需拷贝至堆内或反序列化为堆内的对象更加适用Java的应用场景.因而,考虑JVM堆内内存与堆外内存之间的数据拷贝开销更具实际意义.相比RDMA网络的性能,堆内-堆外数据传输开销不可忽略.U2cache针对不同的操作类型和不同的消息大小,通过服务端与客户端的协作以及内存拷贝与RDMA通信的交叠流水化,最大限度地掩藏数据拷贝的开销,大幅降低了JVM环境下Memcached操作的通信延迟.
与传统硬盘机械运动及磁极翻转的机制不同,SSD本质是由高速闪存颗粒组成的阵列,其并行度高、访问延迟低.基于PCIe的高性能SSD接口规范NVMe采用了与RDMA类似的队列机制接口 [16] ,与传统SATA SAS接口相比,其协议栈大幅简化,进而释放了SSD架构与NVM介质的性能潜力,缩短了2级存储与内存之间的性能差距.
U2cache基于NVMe SSD对Memcached的存储空间进行了扩展.U2cache沿用了Memcached的slab内存管理机制,内存与SSD均被视作slab对象存储.具体来说,slab分为内存slab与磁盘slab,分别由先进先出的日志维护.在内存存储用尽时,内存slab队列的队头数据被写入SSD以得到可用slab;当SSD容量用尽时,磁盘slab队列的队头数据将被驱逐.slab的大小取为MB的整数倍,这样可将随机写于内存中聚合,再以顺序写的方式写入SSD,避免了大量小数据随机写对SSD性能与寿命的影响.U2cache于内存中维护全部的数据索引,SSD中仅存储数据;这样在缓存未命中时不会访问SSD、命中时最多只发生1次I O访问.U2cache采用了只追加的写方式,SSD中的数据不会被原地更新,故存储的slab没有固定的地址;另外,删除slab时仅删除索引而不删除数据,SSD中没有被索引的slab对象将在容量写满时被自动回收,进一步避免了随机写.
虽然NVMe SSD性能取得了大幅提升,但目前仍与内存有一定的性能差距.在软件方面,开销主要来自传统操作系统的存储软件栈.以Linux内核为例,访问SSD的最短路径是:用户进程发起I O读写系统调用将上下文切换至内核态,经由块I O层队列调度与设备驱动后到达设备.如若涉及文件系统,则需首先经过更上层的虚拟文件系统(virtual file system, VFS)层,将引入更多的软件处理开销甚至额外的数据拷贝.过厚的存储软件栈限制了NVMe SSD性能的发挥,难以获得最佳的延迟表现.Linux的块I O层自3.13版本开始引入了多队列机制 [17] ,利用多核处理器来获取最佳性能.但对较少核心数量的情况,由于中断处理等的开销,为获得更好的性能,需要更高主频的处理器.
为进一步降低软件开销,U2cache借助了由Intel公司开源的SPDK(storage performance development kit) [18] 所提供的NVMe用户级驱动来实现对SSD的直接访问.SPDK支持标准NVMe设备,使用前需将设备从内核驱动“解绑”,然后将设备的PCI地址空间映射至用户进程空间,此后设备即由用户级驱动“接管”,内核不再干涉.SPDK采用轮询模式取代中断机制来处理设备的完成事件,并通过设定处理器核亲和度绑定、使用物理连续的大页内存等的方法来进一步屏蔽性能干扰.这样,通过旁路操作系统内核并采用轮询模式,避免了系统调用、中断处理等的上下文切换所带来的延迟开销.在此种机制下,较低主频的单一处理器即可获得设备的最佳性能.
另外,U2cache还通过SSD访问与RDMA通信交叠流水化、数据分散化写以充分利用SSD多通道等的优化,进一步掩盖了延迟.
当传输小消息时,RDMA通信与U2cache服务端处理的占据总延迟的绝大比例,且二者必须顺序执行,缺少进一步优化的空间.
当传输大消息时,Memcached的SET与GET操作均存在并行优化的空间.以写缓存SET操作为例,其具体流程如图2所示,延迟主要包括:握手延迟、堆外与堆内之间数据拷贝延迟、RDMA通信延迟、发送状态延迟.如图4所示,虽然RDMA通信延迟所占比重依旧最大,但随着消息变大,堆外与堆内之间的内存拷贝延迟越来越显著,而且握手过程始终会带来约3 μs的延迟.在不影响程序正确性的前提下,可尽可能让数据拷贝与握手操作以及数据传输交叠并行执行以降低整体延迟.
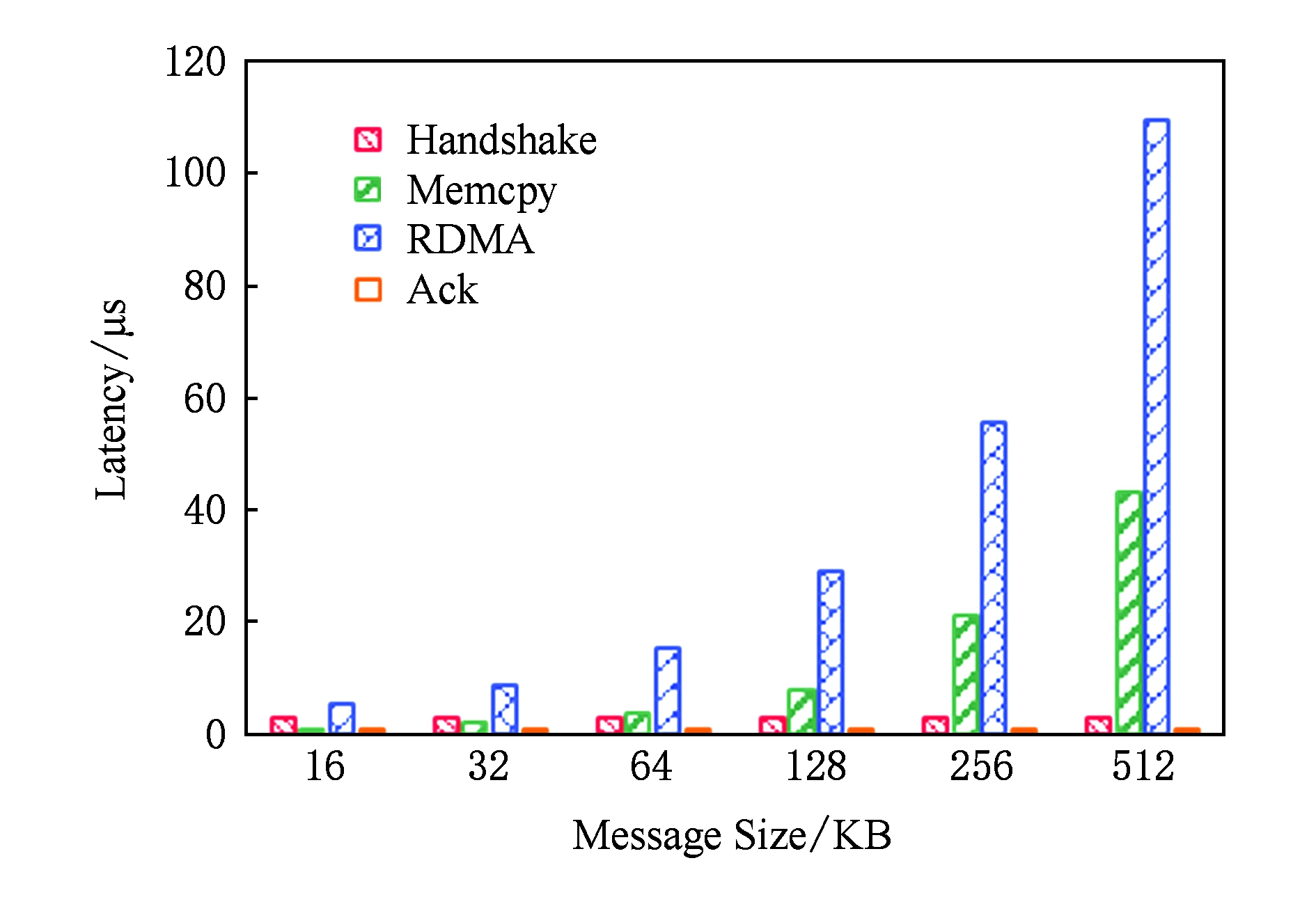
Fig. 4 Latency of each stage in the SET operation
图4 SET操作中各阶段延迟
2.1.1 数据分片流水
针对大消息传输,本文提出了数据分片后内存拷贝与RDMA通信并行流水的优化方法.之所以能够进行较好的交叠优化,主要是由于RDMA数据传输完全由硬件设备完成,CPU被旁路,RDMA通信与内存数据拷贝可以同时进行.另外,对相同大小的数据而言,RDMA通信延迟高于内存拷贝延迟,故每次拷贝能够在RDMA通信结束前完成.经过内存拷贝与RDMA通信交叠优化后的SET与GET过程分别如图5和图6所示:
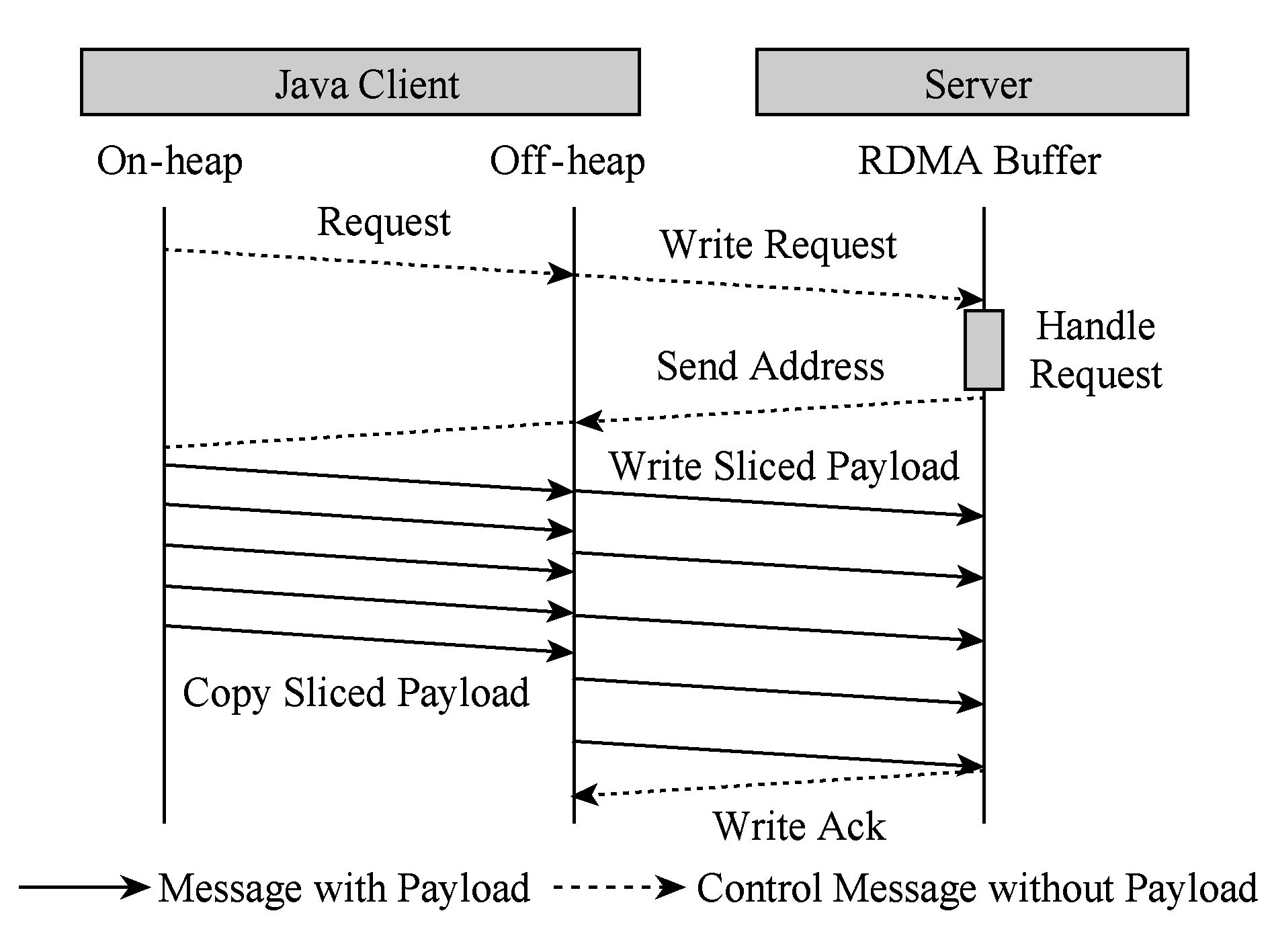
Fig. 5 Overlapping of Memcpy and RDMA transfer in SET
图5 SET操作中内存拷贝与RDMA通信交叠
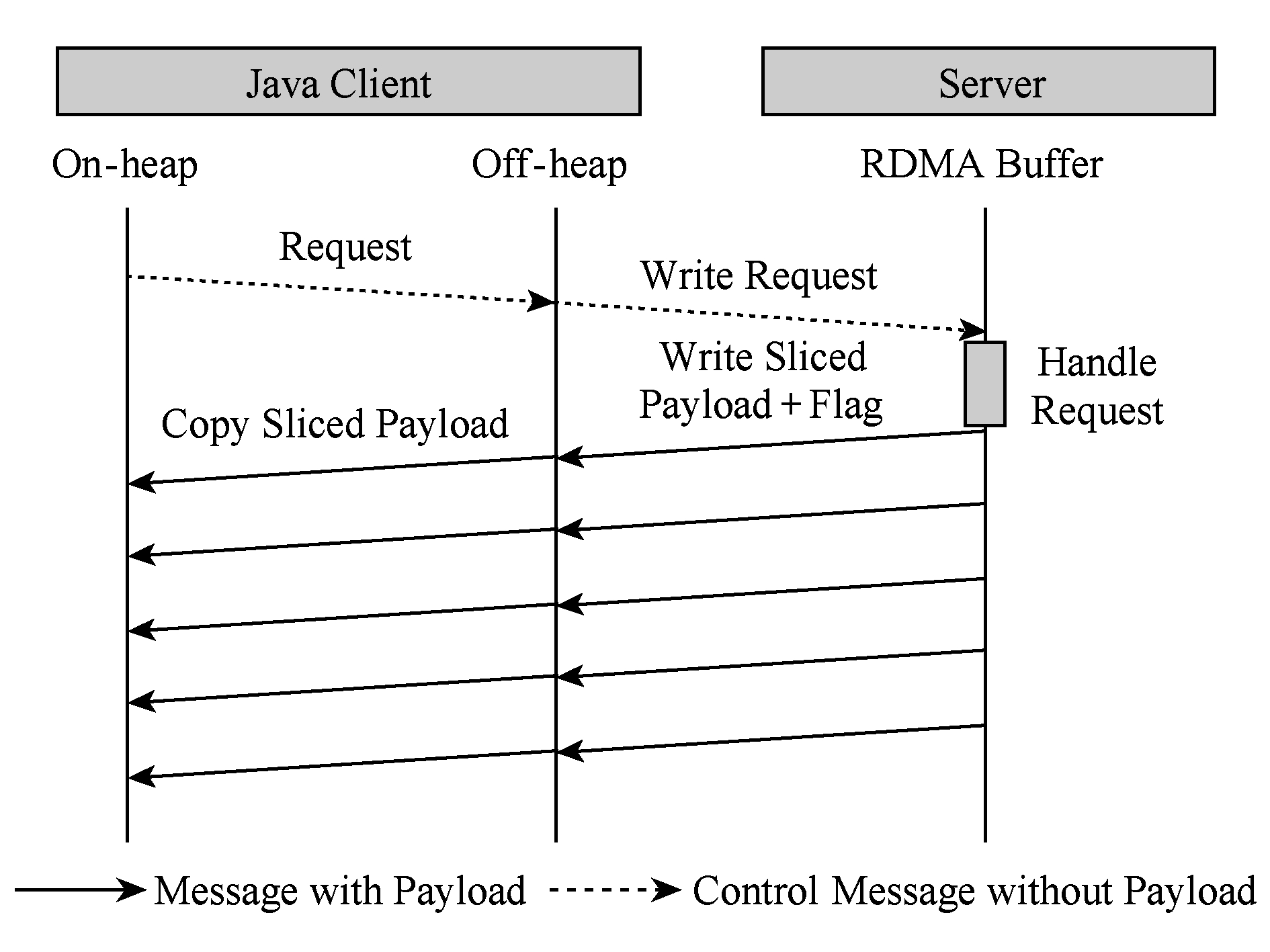
Fig. 6 Overlapping of Memcpy and RDMA transfer in GET
图6 GET操作中内存拷贝与RDMA通信交叠
在SET操作中,分片后的数据载荷由堆内逐个拷贝至堆外;每片拷贝结束后立即发起相应的RDMA传输,然后继续下段分片的拷贝.GET流程采取了类似的分片流水方法,不同的是每段分片的RDMA通信结束后服务端立即发送相应标识位,以供客户端同步通信与拷贝;这也意味着GET命令引入了额外的网络通信,限制了延迟掩藏的效果.
2.1.2 RME通信协议
针对大消息SET操作,为进一步掩藏3 μs的握手延迟,本文提出了一种新的通信协议——RME(rendezvous mixed with eager)协议.RME通信协议规定:1)客户端向服务端发送请求后,不等待握手响应立即开始向服务端预设缓冲区按分片流水的方式发送数据;2)服务端收到请求并解析后返回数据存放地址;3)客户端在收到地址回复后,首先通知服务端已发送的数据大小,然后将剩余数据继续以分片流水的方式发送到新地址;4)服务端在获知已接收的数据大小后,将该部分数据拷贝到新地址.采用RME通信协议后的SET操作流程如图7所示.这样,通过服务端与客户端之间的协作,最大限度地降低大消息的SET延迟.
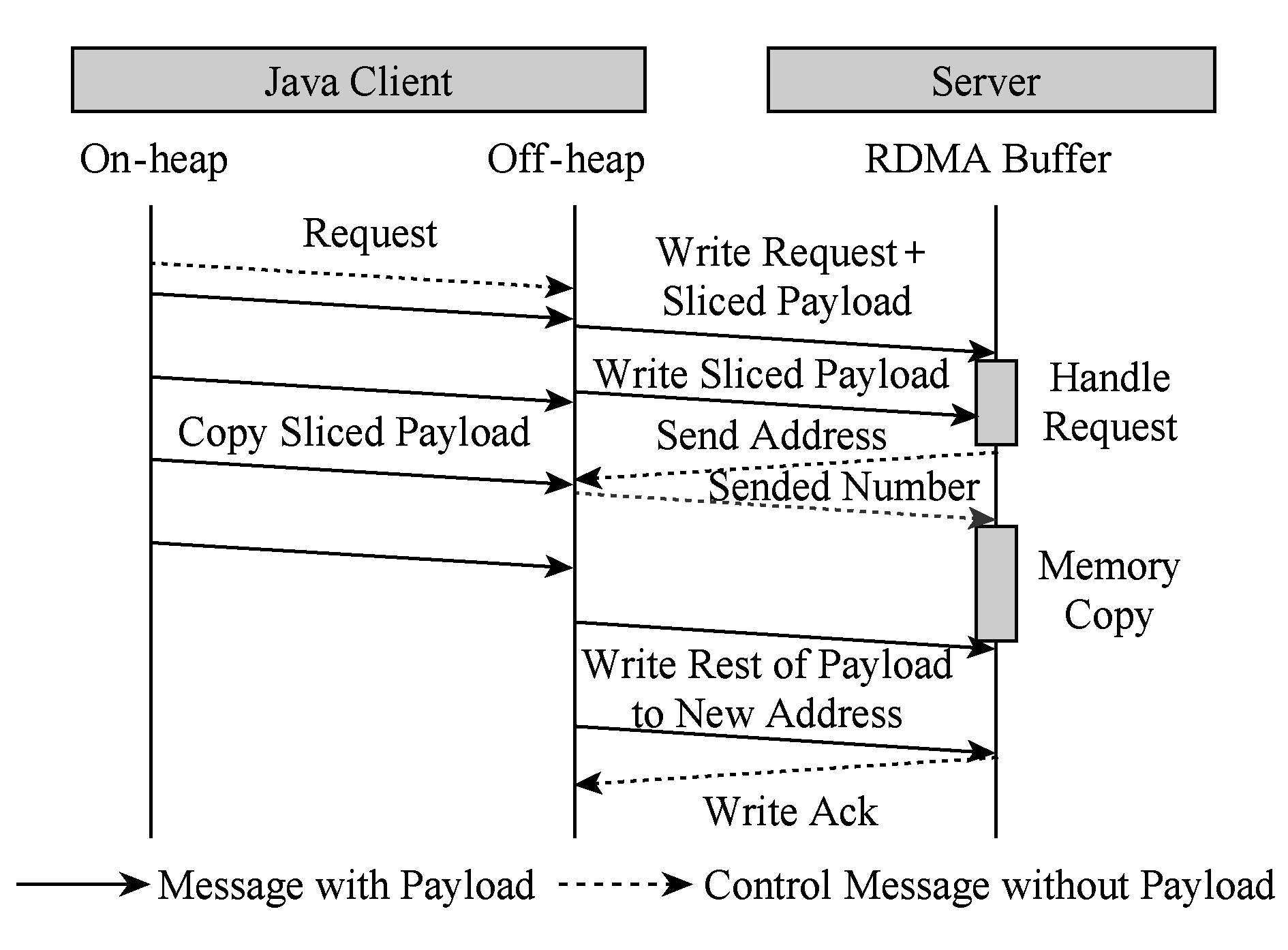
Fig. 7 RME-based SET protocol
图7 采用RME协议的SET操作过程
 O与通信联合优化
O与通信联合优化 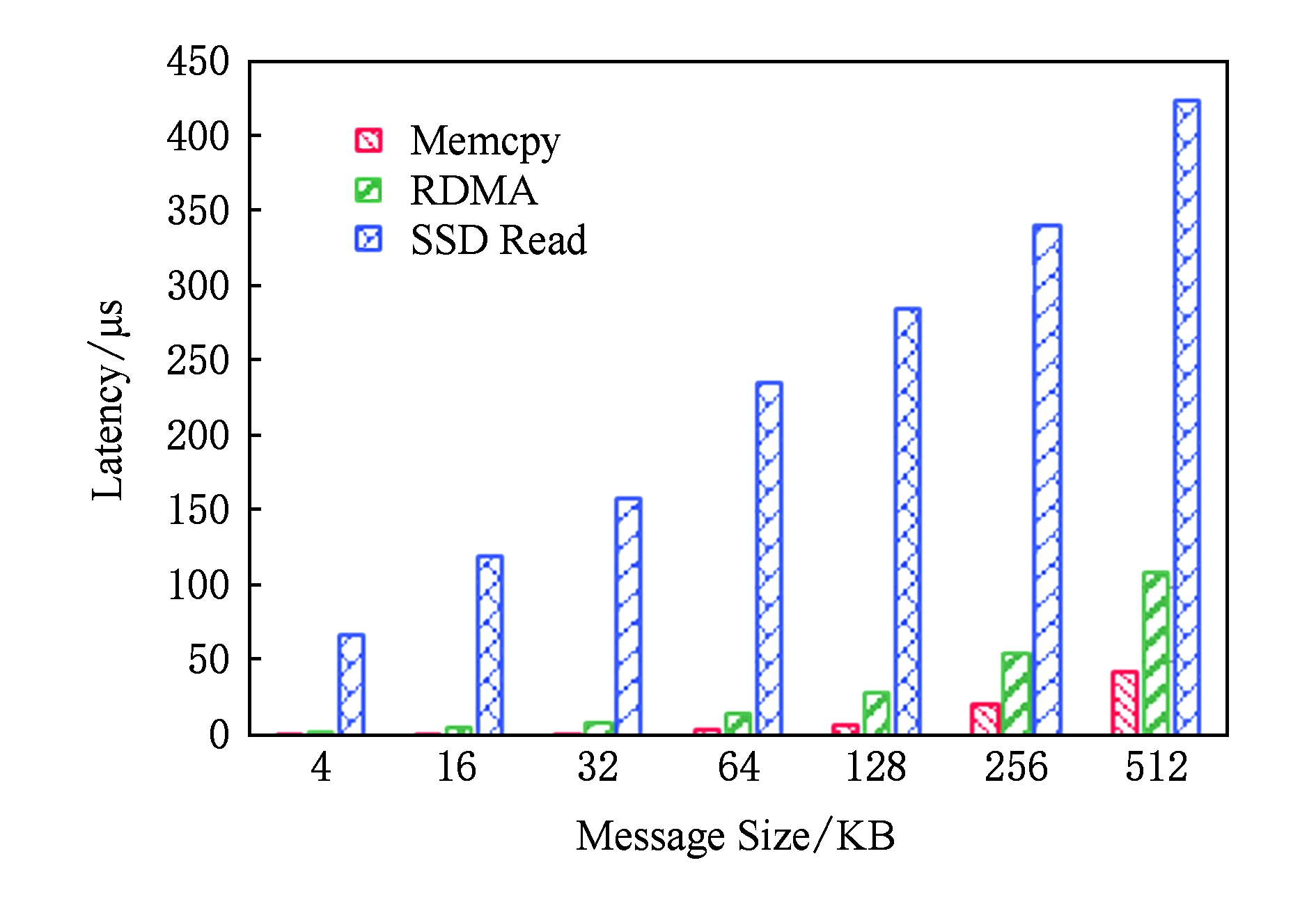
Fig. 8 Latency of each stage in SSD GET operation
图8 SSD GET操作中各阶段延迟
在传输大消息的GET操作中,SSD读操作与RDMA通信存在并行流水优化的空间.对于SSD中的数据,服务端需要先将数据从SSD读到内存,再进行RDMA通信.另外,客户端每接收到服务器发送来的数据分片,就会将数据从RDMA缓冲区拷贝到JVM堆内存上.SSD读操作、RDMA通信和内存拷贝这3个阶段占据了GET操作的绝大部分延迟.实验测得各类操作延迟如图8所示:当消息较小时,SSD读延迟远远大于RDMA通信延迟和拷贝延迟;随着消息变大,受益于SSD的多通道机制,SSD读延迟增长缓慢,而RDMA通信延迟和拷贝延迟快速增加,在总延迟中占比扩大.
当发送位于SSD数据区的较大数据时,GET操作采用SSD读操作与RDMA通信并行流水方法,其流程如图9所示.服务端将数据分片后按序将从SSD读取至内存的RDMA缓冲区中;每次SSD读操作完成后立即发起RDMA传输,并随之传输相应标记位;客户端每接收到1段数据分片,就将该部分数据拷贝到JVM堆内存上;该过程一直持续到客户端完成最后1段数据分片的拷贝.
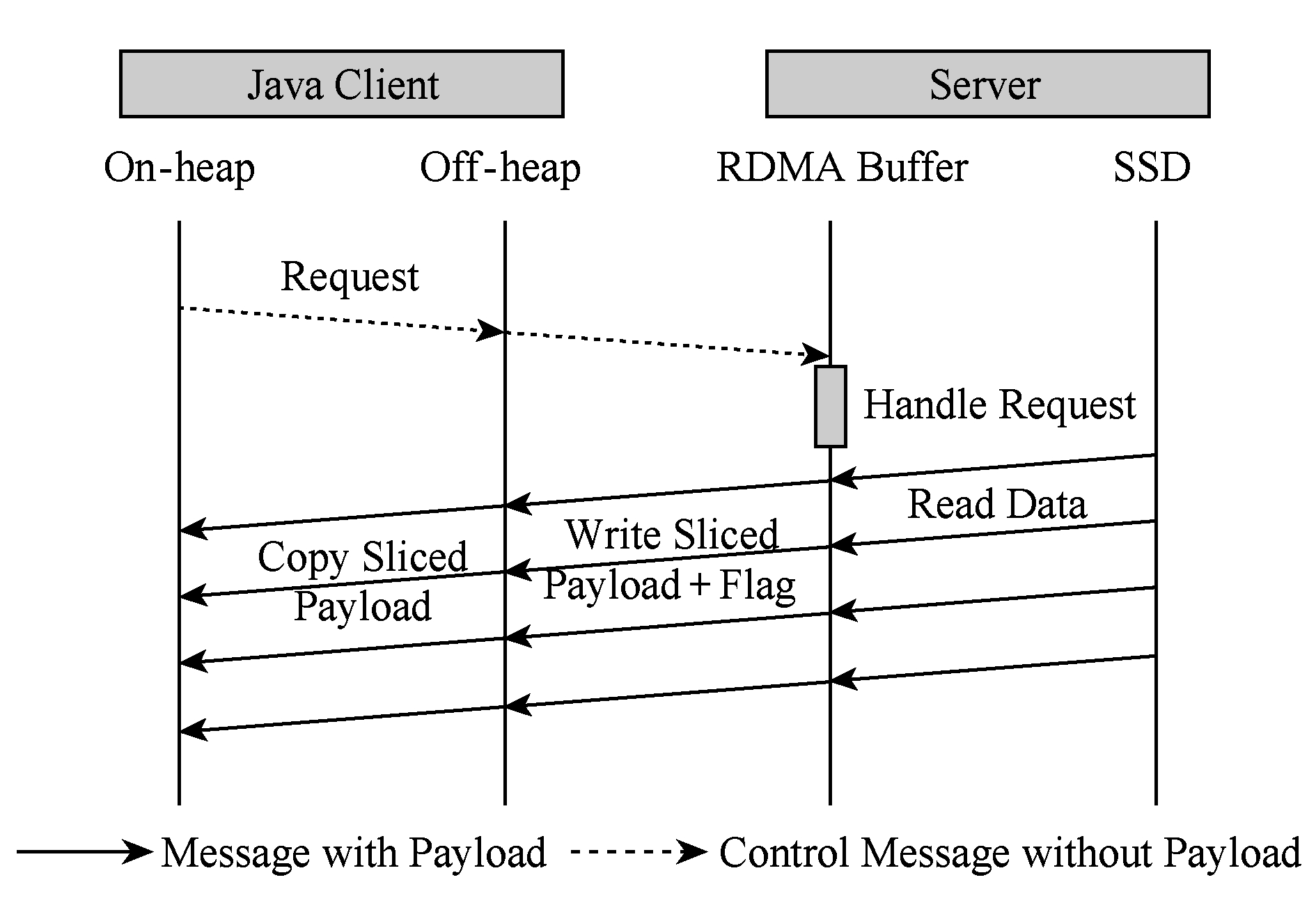
Fig. 9 Overlapping SSD read and RDMA communication in SSD GET operation
图9 SSD GET操作中SSD读与RDMA通信交叠
本节对U2cache缓存系统进行性能评测与分析.测试平台选取3台物理服务器节点,每个节点配有双路Intel Sandy-Bridge Xeon E5-2650处理器,主频为2.00 GHz,每颗处理器具备8个核心,20 MB最外层缓存.每节点配有32 GB DDR3内存.RDMA网络采用了InfiniBand FDR网络,每节点配有Mellanox MT27500 56 Gbps网卡.NVMe SSD选用了Intel P3700 SSD,容量为400 GB.操作系统为CentOS 6.7,内核版本为2.6.32-573,JVM版本为1.7.0_79.选取其中1个节点部署U2cache服务端,另外2个节点部署U2cache客户端.本文将U2cache缓存系统和俄亥俄州立大学实现的基于RDMA优化的Memcached系统(下文以OSU-Memcached或OSU-MC代指)于相同平台进行了测试对比,具体版本为0.9.4.OSU-MC基于高度优化的MVAPICH UCR重写,其是高性能通信系统的代表.
当消息小于1 KB,SET操作延迟不超过5 μs.如图10所示,在传输大消息时,SET操作采用RME通信协议时延迟最低.这是由于:首先,RME通信协议是在内存拷贝与RDMA通信并行流水方法的基础上实现的,能够隐藏数据拷贝的延迟;其次,RME通信协议还隐藏了SET操作发起时客户端与服务端的握手延迟.如图10所示,在传输的数据长度分别为64 KB,128 KB,256 KB,512 KB时,相对于采用未流水化的RDMA通信方式,SET操作采用内存拷贝与RDMA通信并行流水优化后的延迟分别降低4%,13%,22%,26%,而采用RME协议后的延迟分别降低7%,18%,26%,28%.如图11所示,当消息长度不超过4 KB时,U2cache和OSU-Memcached的SET操作延迟相当;当消息长度超过16 KB时,U2cache比OSU-Memcached的SET操作的延迟要低,这主要得益于U2cache采用的RME协议隐藏了握手延迟.SET操作数据接收方为U2cache服务端,不受JVM限制,数据通路终点无额外路径开销,故而可获得与完全本地化的OSU-Memcached相当的性能.
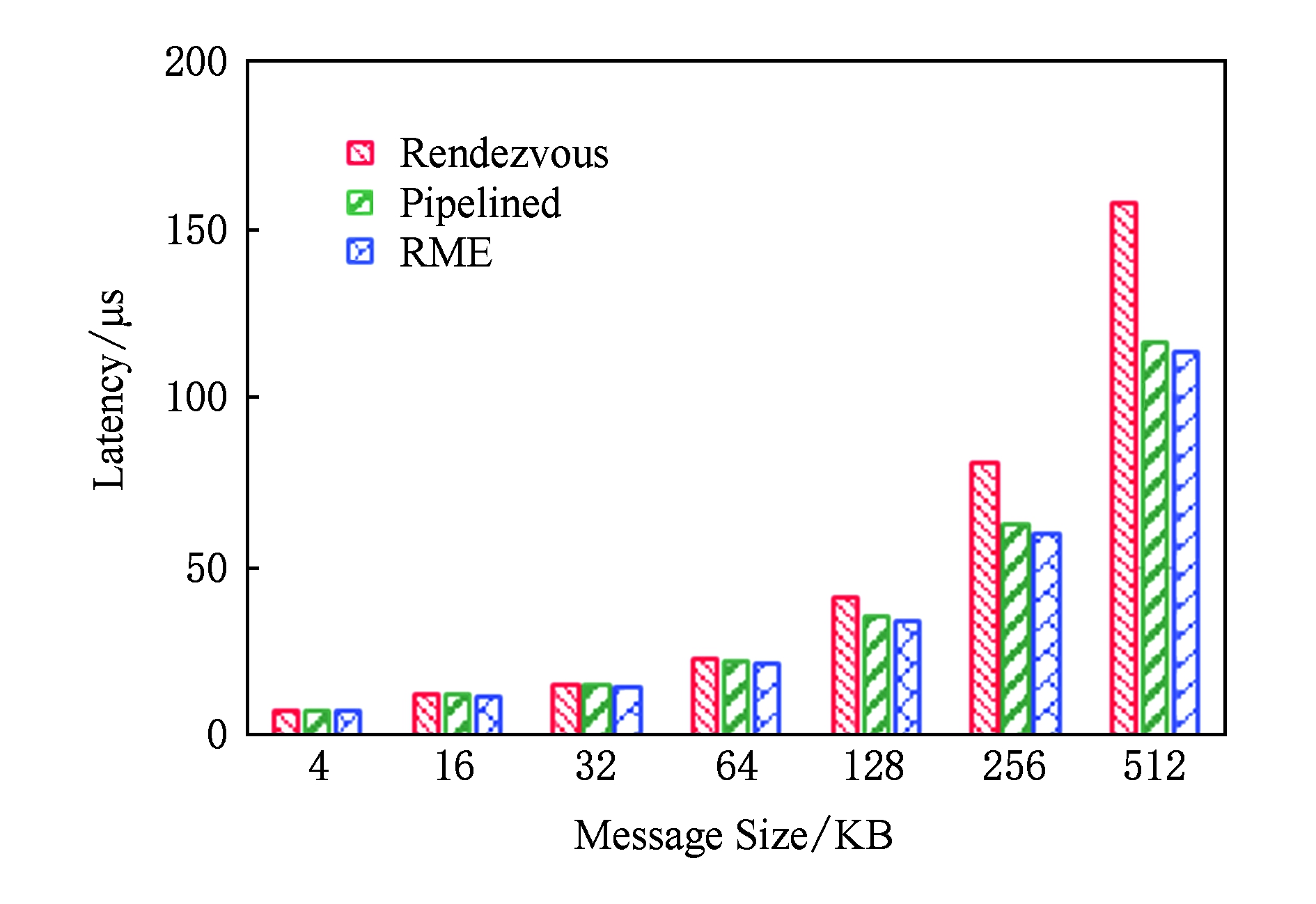
Fig. 10 Comparison of latency of SET operations
图10 SET操作延迟对比
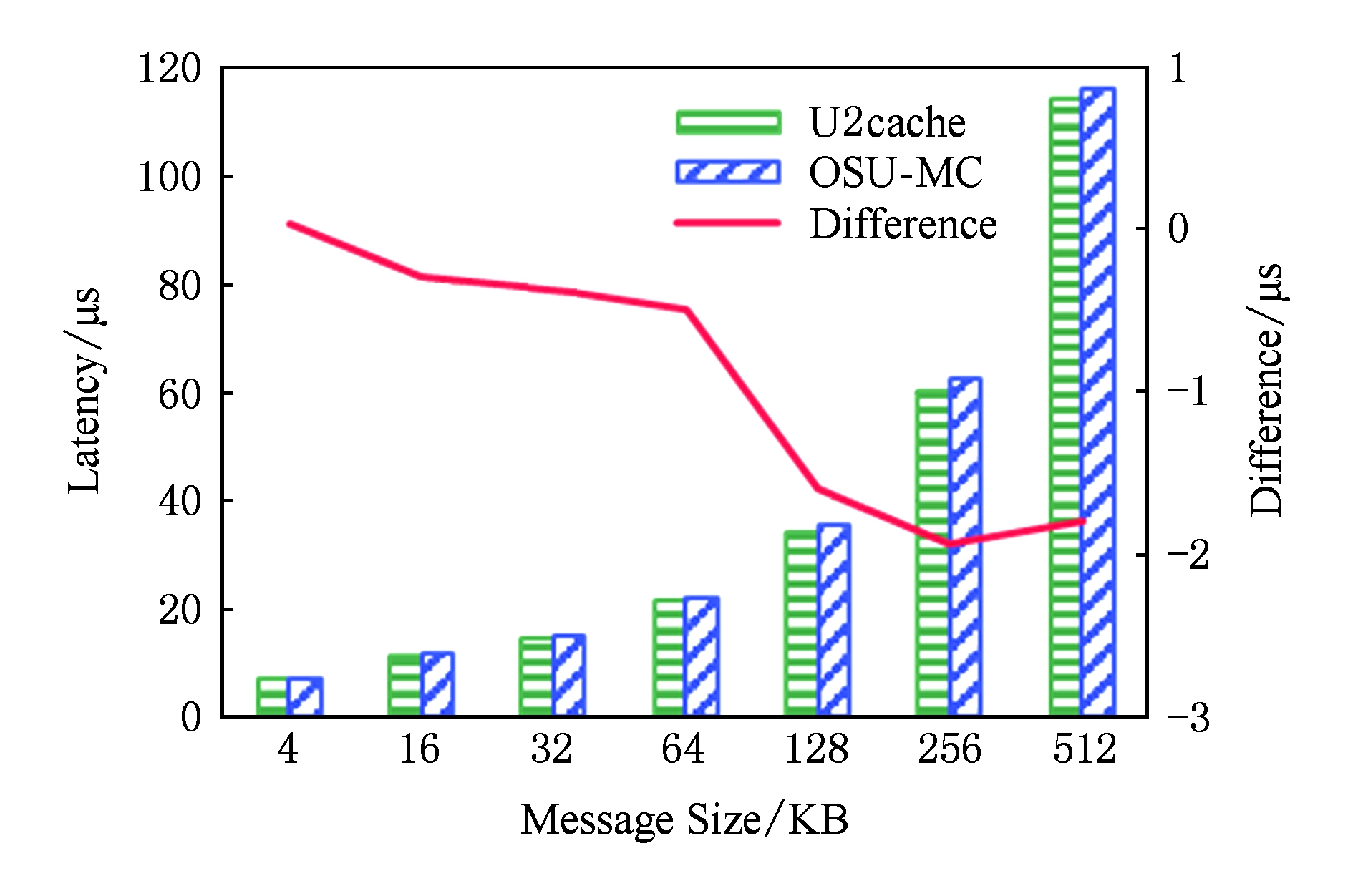
Fig. 11 Comparison of U2cache and OSU-Memcached on SET
图11 U2cache与OSU-Memcached SET延迟比较
低于1 KB的小消息GET操作延迟不超过6 μs.在传输大消息时,GET操作实现了内存拷贝与RDMA通信并行流水优化.如图12所示,当传输的数据长度分别为64 KB,128 KB,256 KB,512 KB时,相对于未经优化的方式,GET操作采用内存拷贝与RDMA通信交叠优化后的延迟分别降低13%,17%,24%,27%.不过,受JVM数据拷贝开销的影响,GET延迟始终高于OSU-Memcached.如图13所示,在消息长度低于4 KB以及大于256 KB时,U2cache与OSU-Memcached的GET延迟差距稍大,但差距最大不超过2 μs.对小消息而言,开销主要源自请求命令序列化与数据向堆内的拷贝;对大消息而言,开销主要是堆内与堆外之间的数据拷贝.当消息大小为16 KB,32 KB,64 KB,128 KB时,并行流水的优化拉近了性能差距;但随着消息大小的继续增长,性能差距再次被拉大,这是由于伴随每个消息分片而传输的控制信息造成的通信开销累加.
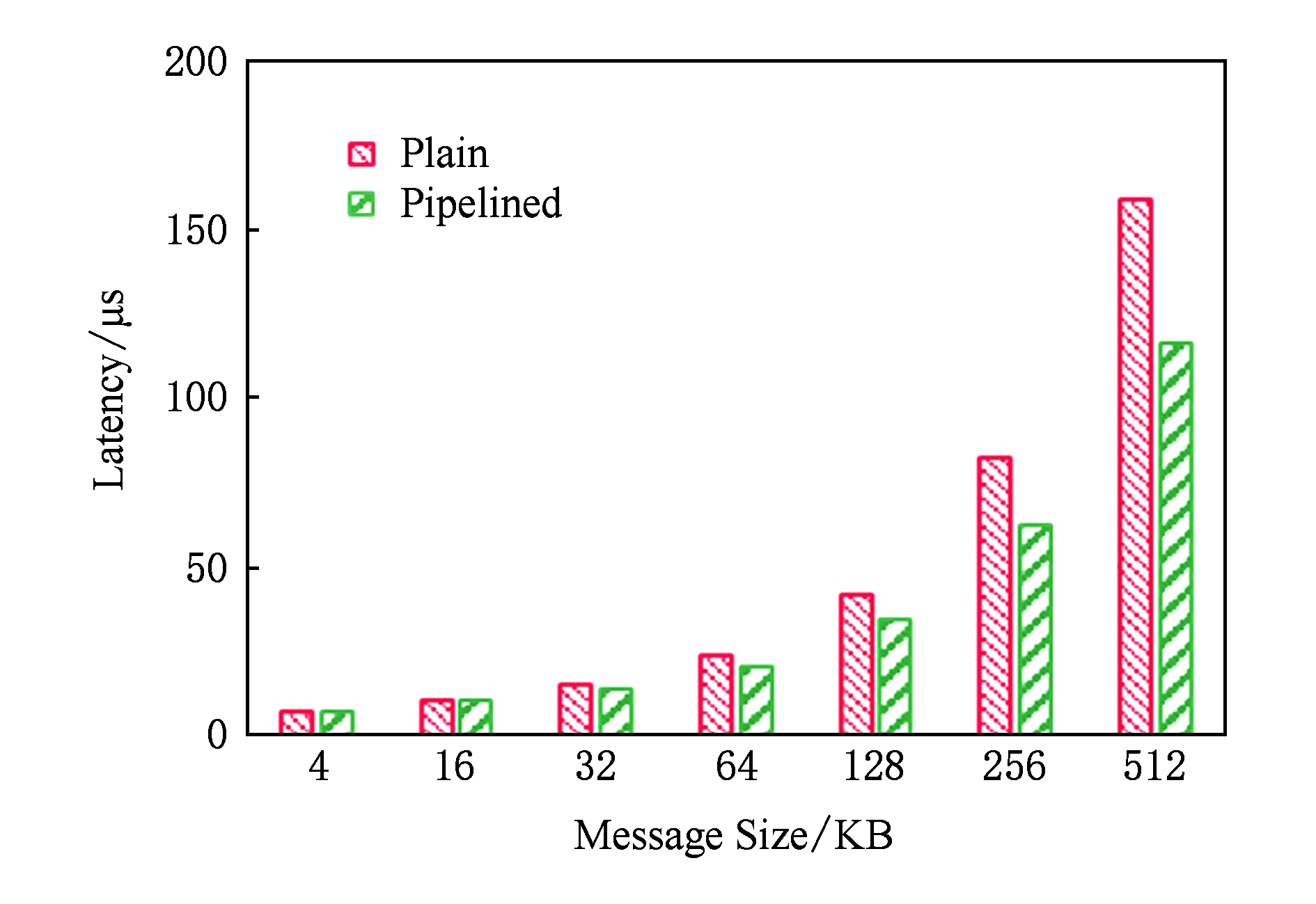
Fig. 12 Comparison of latency of GET operations
图12 GET操作延迟对比
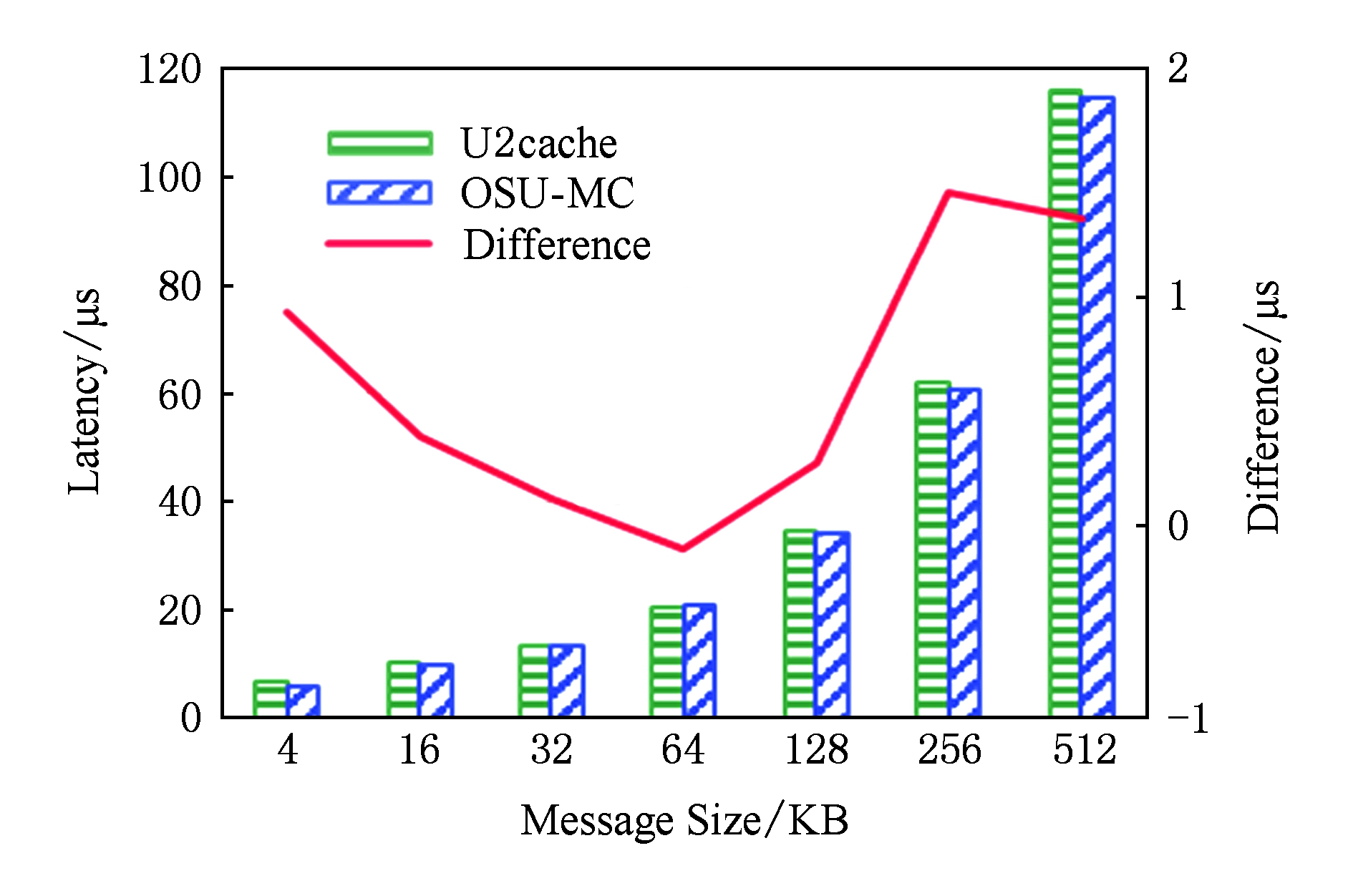
Fig. 13 Comparison of U2cache and OSU-Memcached on GET
图13 U2cache与OSU-Memcached GET延迟比较
由于对SSD的批量写入并非位于性能关键通路,本节主要分析涉及SSD的GET延迟.本文提出的基于用户级NVMe访问的存储扩展方法能够显著降低GET操作的延迟.图14和图15分别给出了小消息与大消息的GET延迟对比,可以发现不同消息长度对应的GET延迟的降幅有明显区别.当数据长度在16 KB以内时,相对于采用内核I O栈访问SSD的方式,优化后的GET操作延迟减少了10 μs左右.随着数据长度的增加,其延迟降幅从21%逐渐减小到12%,这同样受益于用户级驱动直接访问SSD的延迟优势.当数据长度为32 KB和64 KB时,受益于SSD数据分散化,GET操作的延迟降幅有所扩大,分别达到了19%和31%.当数据长度超过128 KB后,相比采用内核I O栈访问SSD的方式,优化后的GET操作的延迟绝对值减小了30~70 μs,延迟降幅在7%~15%之间,这主要受益于SSD读操作与RDMA通信并行流水优化隐藏了部分RDMA通信的延迟.
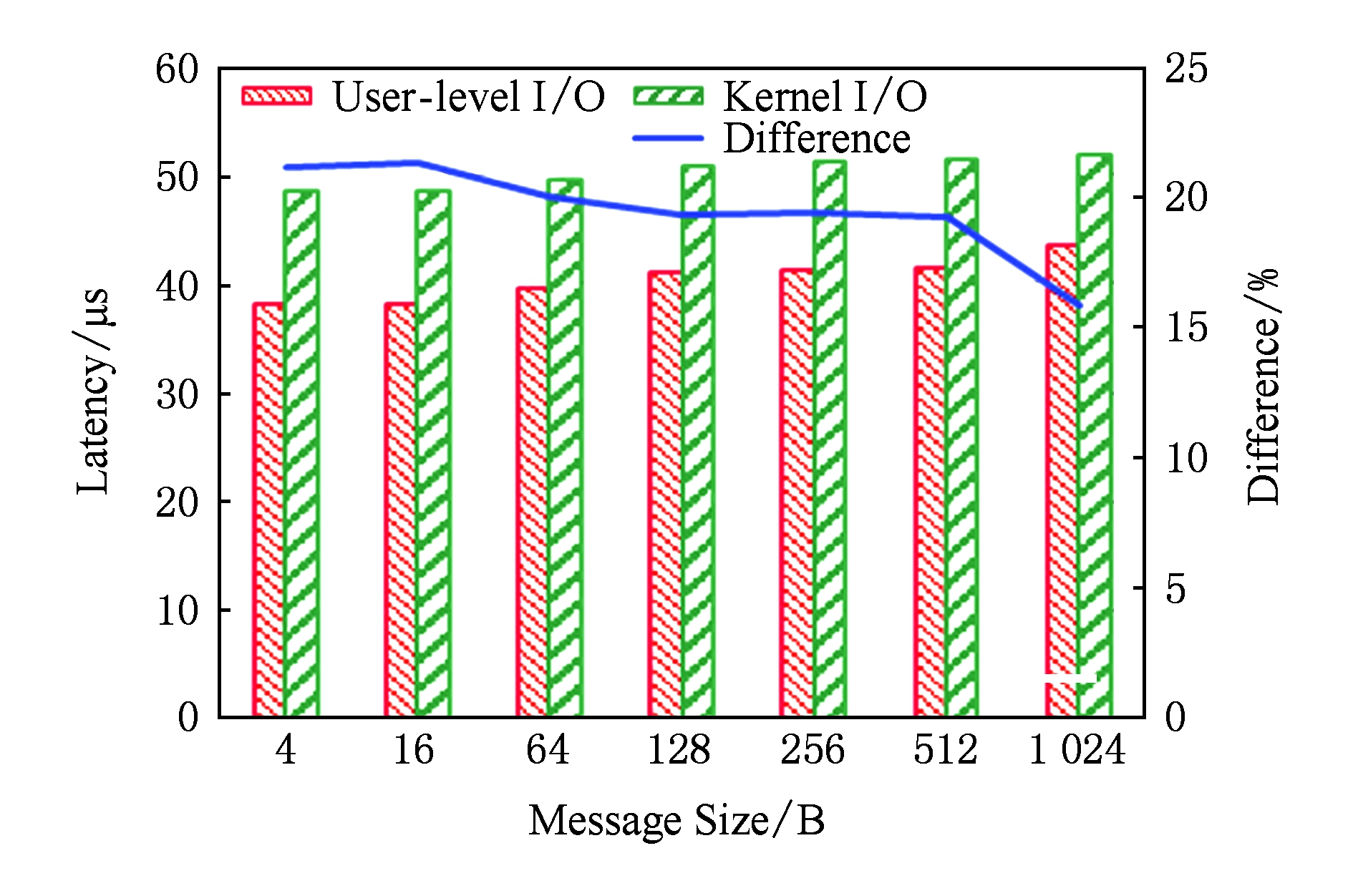
Fig. 14 Comparison of latency of GET on small messages
图14 小消息GET操作延迟对比
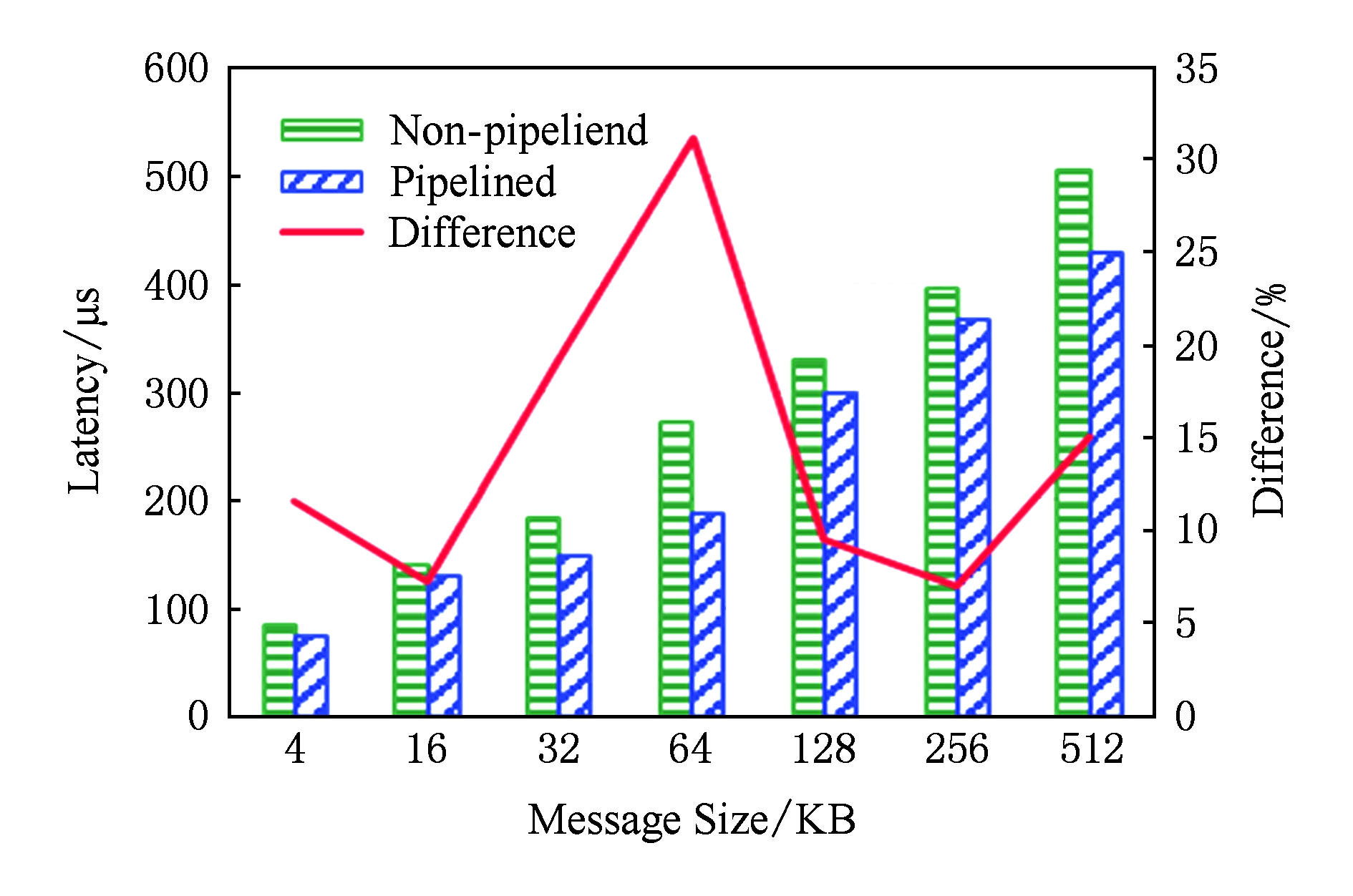
Fig. 15 Comparison of latency of GET on large messages
图15 大消息GET操作延迟对比
本节同时启用2个客户端,分别对服务端处理SET请求和GET请求的吞吐率进行了测试.当消息长度为4 KB时,服务端SET和GET请求处理的吞吐率分别为23万次 s和20万次 s.
为了测试U2cache缓存系统在实际应用中的表现,本节还采用不同的缓存系统搭建了页面内容完全相同的2个网站系统,并采用压力测试工具ab [19] 进行测试.2组对比系统均采用了相同的Tomcat,Servlet,MySQL的部署方案,不同之处是系统1采用了标准Memcached缓存,系统2采用了本文提出的U2cache高性能缓存系统.其中Tomcat和U2cache之间采用InfiniBand FDR网络通信,其余组件间均采用千兆以太网进行通信.在压力测试中,ab会发起1 000次网页请求,每个页面请求会产生200次查询操作,而每次查询的数据量为20 B,这样数据总量约为4 MB.测试结果如图16所示,结果表明U2cache能够大幅降低Web服务的响应时间.
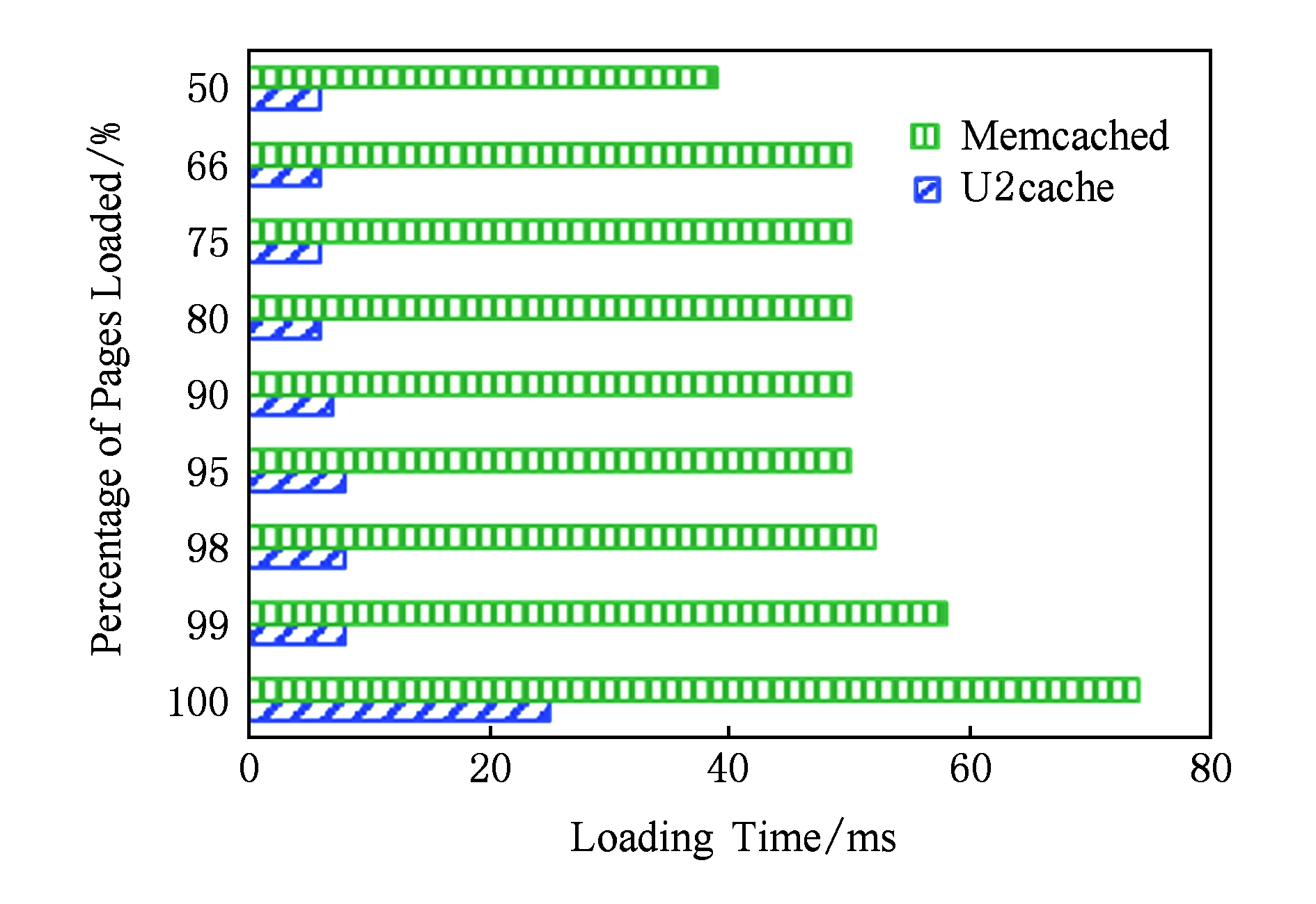
Fig. 16 Distribution of average page loading time
图16 平均网页加载时间分布
相比传统以太网络,RDMA网络具备低延迟的优势,且内存读写语义与Memcached的键值存储方式相契合,国内外已经有一些采用RDMA技术加速Memcached通信的研究.
Jose等人 [20] 提出了基于RDMA over InfiniBand来加速Memcached通信的方案,该工作基于UCR(unified communication runtime)通信系统.该方案在传输小消息时采用有拷贝的通信方法,而传输大消息时采用无拷贝的通信方法,权衡了内存拷贝开销和RDMA通信延迟的相对比重,从而降低了整体操作延迟.该工作取得了非常理想的加速效果,在QDR网络下,与IPoIB相比,SET操作延迟改进3~6倍,GET操作延迟改进4~7倍.但是,该工作基于纯本地环境,并未涉及诸如JVM等的高延迟语言运行时.
Stuedi等人 [21] 面向普通数据中心,提出了基于RDMA over Ethernet来加速Memcached的GET操作的方法.该方案由客户端维护数据在服务端的存放地址信息,通过单边RDMA Read操作直接从服务端获取数据.如若客户端没有相应的地址信息,则通过sockets向服务端发起请求,服务端再通过RDMA Write将数据传输至客户端.该方法客户端逻辑实现复杂,并引入了服务端与客户端数据索引一致性的问题.
Kalia等人 [22] 设计了高效利用RDMA技术的内存键值系统Herd.Herd仅使用RDMA Write与RDMA Send原语,放弃使用延迟更高的RDMA Read操作.考虑到RDMA网络链路层采用了无损的流控机制,Herd大胆使用了不可靠传输及降低额外开销,而由应用层负责重传.客户端通过基于不可靠连接的RDMA Write操作将请求写至服务端,服务端轮询检查请求并处理,服务端轮询检查请求并处理,完成后通过基于不可靠数据报的RDMA Send操作回复客户端.
选择一种性价比更高的存储设备作为内存的备用存储,成为扩展内存对象缓存系统存储空间的关键.在众多存储设备中,SSD的性能与内存更加接近,单位价格低于内存,并且技术正在走向成熟.目前,国内外已经有一些基于SSD扩展Memcached存储容量的研究.
将闪存存储设备作为Swap分区可以轻易实现对内存的扩展,但是会面临许多问题.Ko等人 [23] 对Linux Swap策略进行了改进,保留了Linux系统日志结构 [24] 的Swap-Out方法,同时将Swap-In过程改为按块对齐的机制.该方案的不足之处在于系统的整体性能与闪存设备的基础性能差距仍然较大.
相较于SSD作为系统Swap分区的方案,Ouyang等人 [25] 提出了一种在Memcached内部集成SSD的方法.该方法采取slab的方式管理SSD,并且采用聚合写的办法来减少SSD写放大.通过这种内部集成定制的方法,Memcached获得了较为理想的SSD读写性能.该方法在系统软件层面仍需通过内核I O栈,无法获取最佳延迟表现.
本文以Memcached为例,从通信加速和存储扩展2个角度研究内存对象缓存系统的数据通路优化问题,实现了高效缓存系统U2cache.U2cache采用了日益流行的高性能RDMA通信技术,服务端针对不同的缓存操作类型及消息大小设计了不同的通信策略,客户端则重点面向应用更加广泛的Java客户端,并针对JVM内存管理机制,通过服务端与客户端的协作以及内存拷贝与RDMA通信交叠的技巧,掩盖了多数JVM开销,保证了整体的低延迟响应.实验结果表明,U2cache通信延迟接近RDMA底层通信性能,并且针对大消息,相较无优化版本,其性能提升比例超过20%;在引入JVM的情况下,部分测试结果与俄亥俄州立大学Panda教授团队的RDMA优化后的高性能Memcached相当.在存储方面,U2cache采用高性能读友好的NVMe SSD设备来解决服务器节点内存容量不足的问题,设计实现了基于SSD的Memcached存储扩展机制,并通过轮询式的用户级NVMe驱动直接访问设备,大幅降低了软件开销.实验结果表明,当服务端访问SSD中4 KB大小以下的数据时,相比传统的内核存储栈,U2cache的读延迟降低了10%以上;对大消息而言,通过数据分片并行流水的优化,性能提升最高超过30%.
基于本文的研究成果,下一步工作继续基于高性能I O技术优化诸如Redis等的键值存储系统,推广基于RDMA和NVMe SSD的全用户态直通式数据通路架构,进一步提升效率、降低成本.
参考文献
[1]Memcached Organization. Memcached—A distributed memory object caching system[EB  OL]. 2016 [2016-07-31]. http: memcached.org
OL]. 2016 [2016-07-31]. http: memcached.org
[2]Nishtala R, Fugal H, Grimm S, et al. Scaling memcache at Facebook[C] Proc of the 10th USENIX Symp on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2013: 385-398
[3]Twitter Inc. Twemcache[EB OL]. 2016 [2016-07-31]. https: engineering.twitter.com opensource projects twemcache
[4]Cen Wenchu. memcache-client-forjava[EB OL]. (2009-07-30) [2016-07-31]. https: code.google.com archive p memcache-client-forjava
[5]Tiwari P. Infographic: The cost of your website and mobile App’s poor performance in 2015[EB OL]. (2015-10-22) [2016-07-31]. http: blog.smartbear.com web-monitoring cost-of-your-website-and-mobile-apps-poor-performance-in-2015
[6]Cisco Systems Inc. Cisco visual networking index: Forecast and methodology[EB OL]. 2015 [2016-07-31]. http: www.cisco.com c en us solutions collateral service-provider ip-ngn-ip-next-generation-network white_paper_c11-481360.html
[7]Cohen D, Talpey T, Kanevsky A, et al. Remote direct memory access over the converged enhanced Ethernet fabric: Evaluating the options[C] Proc of the 17th IEEE Symp on High Performance Interconnects. Piscataway, NJ: IEEE, 2009: 123-130
[8]Micron Technology Inc. 3D NAND[EB OL]. 2016 [2016-07-31]. https: www.micron.com about emerging-technologies 3d-xpoint-technology
[9]Xu Qiumin, Siyamwala H, Ghosh M, et al. Performance analysis of NVMe SSDs and their implication on real world databases[C] Proc of the 8th ACM Int Systems and Storage Conf. New York: ACM, 2015: No.6
[10]Micron Technology Inc. 3D XPoint technology[EB OL]. [2016-07-31]. https: www.micron.com about emerging-technologies 3d-xpoint-technology
[11]Grun P. Introduction to Infiniband for end users[EB OL]. 2010 [2016-07-31]. https: www.mellanox.com pdf whitepapers Intro_to_IB_for_End_Users.pdf
[12]Li Qiang, Sun Ninghui, Huo Zhigang, et al. T-NBC: Transparent non-blocking MPI collective operations[J]. Chinese Journal of Computers, 2011, 34(11): 2052-2063 (in Chinese)(李强, 孙凝晖, 霍志刚, 等. T-NBC: 透明的MPI非阻塞集合操作[J]. 计算机学报, 2011, 34(11): 2052-2063)
[13]Liu Jiuxing, Wu Jiesheng, Kini S, et al. High performance RDMA-based MPI implementation over InfiniBand[C] Proc of the 17th Annual Int Conf on Supercomputing. New York: ACM, 2003: 295-304
[14]An Zhongqi. Jni-verbs: Access the RDMA verbs API via JNI from Java[EB OL]. (2015-08-12) [2016-07-31]. https: github.com qzan9 jni-verbs
[15]Oracle Corporation. Java native interface[EB OL]. 2014 [2016-07-31]. http: docs.oracle.com javase 7 docs technotes guides jni
[16]Walker D H. A comparison of NVMe and AHCI[R]. Beaverton, OR: The Serial ATA International Organization, 2012
[17]Bjørling M, Axboe J, Nellans D, et al. Linux block IO: Introducing multi-queue SSD access on multi-core systems[C] Proc of the 6th Int Systems and Storage Conf. New York: ACM, 2013: No.22
[18]Jonathan S. Introduction to the storage performance development kit (SPDK)[EB OL]. 2016 [2016-07-31]. https: software.intel.com en-us articles introduction-to-the-storage-performance-development-kit-spdk
[19]The Apache Software Foundation. ab-Apache HTTP server benchmarking tool[EB OL]. 2016 [2016-07-31]. http: httpd.apache.org docs current programs ab.html
[20]Jose J, Subramoni H, Luo Miao, et al. Memcached design on high performance RDMA capable interconnects[C] Proc of the 2011 Int Conf on Parallel Processing. Piscataway, NJ: IEEE, 2011: 743-752
[21]Stuedi P, Trivedi A, Metzler B. Wimpy nodes with 10GbE: Leveraging one-sided operations in RDMA over Ethernet to boost Memcached[C] Proc of the 2012 USENIX Annual Technical Conf. Berkeley, CA: USENIX Association, 2012: 31-31
[22]Kalia A, Kaminsky M, Andersen D G. Using RDMA efficiently for key-value services[C] Proc of the 2014 ACM Conf on SIGCOMM. New York: ACM, 2014: 295-306
[23]Ko S, Jun S, Ryu Y, et al. A new Linux swap system for flash memory storage devices[C] Proc of Int Conf on Computational Sciences and ITS Applications. Piscataway, NJ: IEEE, 2008: 151-156
[24]Rosenblum M, Ousterhout J K. The design and implementation of a log-structured file system[J]. ACM Trans on Computer Systems, 1992, 10(1): 26-52
[25]Ouyang X, Islam N S, Rajachandrasekar R, et al. SSD-assisted hybrid memory to accelerate Memcached over high performance networks[C] Proc of the 41st Int Conf on Parallel Processing. Piscataway, NJ: IEEE, 2012: 470-479

An Zhongqi , born in 1987. Recieved his master degree in computer science and technology from China University of Petroleum (East China) in 2013. Engineer. His main research interests include high-performance OS R and middleware.

Du Hao , born in 1990. MSc candidate. His main research interests include computer architecture and high performance comm-unication (duhao@ncic.ac.cn).


Huo Zhigang , born in 1978. PhD, associate professor. His main research interests include fault tolerance in HPC (zghuo@ncic.ac.cn).

Ma Jie , born in 1975. PhD, professor. His main research interest is high performance communication (majie@ict.ac.cn).
O Technology An Zhongqi 1 , Du Hao 1,2 , Li Qiang 1 , Huo Zhigang 1 , and Ma Jie 1
1 ( High Performance Computer Research Center , Institute of Computing Technology , Chinese Academy of Sciences , Beijing 100190) 2 ( School of Computer and Control Engineering , University of Chinese Academy of Sciences , Beijing 100049)
Abstract Existing in-memory object caching systems are bottlenecked by the latency overhead of traditional Ethernet and the limited DRAM amount within the servers. Modern high-performance I O technologies such as RDMA and NVMe provide a promising solution to address such challenges. In this paper, we focus on the data plane efficiency of in-memory object caching systems and undertake a study on the widely deployed Memcached for fast message transfer and cost-effective storage extension based on high-performance I O. First, the communication protocol is re-designed on RDMA semantics, and different strategies are applied according to the Memcached operation type and message payload size for optimal overall latency. Second, Memcached is altered to incorporate the NVMe SSDs to expand storage capacity. A circular log structure is adopted to manage the two-level hierarchy of DRAM and SSD. The SSD is directly accessed from the user-space to reduce software overhead. Finally, a JVM-enabled caching system named U2cache is presented. U2cache significantly improves the performance by bypassing both the OS kernel and the JVM runtime. The latency is further hidden through pipelining and overlapping of memory copy, RDMA transfer and SSD access. Benchmarking results indicate that U2cache achieves near-optimal performance of the underlying RDMA interconnect. Performance is further improved by 20% with careful optimization for transferring large messages. For accessing data located in SSD, the latency is reduced by up to 31% compared with the kernel-based I O.
Key words Memcached; remote direct memory access (RDMA); NVMe SSD; Java virtual machine (JVM); user-level I O
Li Qiang , born in 1983.
Received his PhD degree in computer architecture from the Institute of Computing Technology, Chinese Academy of Sciences in 2012. Associate professor. His main research interests include high performance communication and cloud computing (liqiang@ncic.ac.cn).
收稿日期: 2016-11-21
修回日期: 2017-08-09
基金项目: 国家重点研发计划项目(2016YFB0200204,2016YFB0200300);国家自然科学基金青年科学基金项目(61402444,61502454)
This work was supported by the National Key Research and Development Program of China (2016YFB0200204, 2016YFB0200300) and the National Natural Science Foundation of China for Young Scientists (61402444,61502454).
中图法分类号 TP316