杨卓群 2 金 芝 1,3
1 (高可信软件技术教育部重点实验室(北京大学) 北京 100871) 2 (中国科学院数学与系统科学研究院数学研究所 北京 100190) 3 (北京大学信息科学技术学院软件研究所 北京 100871) (zhuoqun.y@hotmail.com)
随着软件系统越来越深入地嵌入到人类社会和物理社会中,软件在运行时会与其他软硬件系统、物理设备和用户发生密切交互.来自交互环境和用户对软件期望的不确定性成为软件系统开发面临的挑战.
不确定性(uncertainty)指一种具有不完善或未知信息和知识的状况.在这一状况下,事物的当前状态、未来的某一结果或者多个结果都无法被确切地描述出来 [1] .它出现在部分可观测或者随机的环境中,并且由相关知识的缺失所导致.
不确定性存在于对未来事件的预测以及对事物的度量过程中 [2] .处理不确定性的方式有多种,比如:贝叶斯学派通过概率对事件的发生情况进行描述,以预测未来事件发生的可能性;模糊理论学派通过模糊逻辑对变量的度量结果进行描述,以处理度量过程中的误差 [3] .
软件系统所面对的不确定性包括交互环境的变化难以准确预测,及其需求随环境发生的改变无法预知 [4] .不确定性使软件系统变得复杂.为应对来自交互环境和需求的变化,软件需要做出相应调节以提供持续的服务.此调节过程实际上是一种自适应过程 [5] .为保证自适应软件系统能够根据运行时环境和需求的变化进行自主调节,需要构建自适应机制 [6] .
目前,关于自适应软件系统如何建模和决策以应对不确定性的研究有:1) 在应对环境不确定性方面,主要工作包括基于目标模型刻画环境对需求的影响 [7] 、通过追踪性刻画环境变化带来的需求变化 [8-10] ,基于组件结构的自适应决策 [11-12] 和基于概率计算的自适应决策 [13-15] ;2) 在应对需求变化方面,相关工作包括运行时的需求监控 [16] 、需求弹性建模 [17-18] 、环境和需求的推理关系建模 [19] 、不确定性需求的管理 [20-21] 及针对需求满足变化性的自适应决策 [22-24] .
当环境和需求均不确定时,在自适应过程中同时考虑两者变化及软件行为的调整非常必要.然而,现有工作缺乏对这一问题的综合考虑,有的仅关注如何建模环境和需求间的变化追踪关系,有的仅考虑如何在变化的环境下调整软件行为以满足固定需求.它们均不能处理环境和需求自身均有变化的自适应问题.
本文的主要关注点为如何通过自适应决策来应对环境和需求的不确定性.首先,环境的变化会引起软件质量需求的变化.在用户无法准确表达质量需求时,就无法精确建立环境对需求的影响关系.比如:“电量充足的情况下,用户希望能接收到更多的数据”,其中的“电量充足”和“更多的数据”都是无法准确衡量的.这些无法准确量化的表述,均适合通过模糊逻辑进行刻画.另外,环境和需求的变化也会导致无法准确描述它们和软件行为间的关系 [25] .其次,需求的不确定性会导致自适应决策目标的变化.决策目标固定时,软件系统可依据先验知识实现调节.然而在决策目标变化时,基于先验知识的调节过程可能会失效,因为先验知识无法覆盖不可预知的变化.这2点都对自适应决策过程带来很大的挑战.
为通过自适应决策应对不确定性,软件系统应当能够感知环境和需求变化,并根据这些变化对自身行为进行优化调节.从感知到调节的过程可通过控制方法实现 [26] ,尤其是采用反馈回路构建自适应机制 [27] .
本文提出一种基于模糊控制的自适应决策方法(fuzzy control based adaptation decision making, FADEM),通过控制机制和推理计算实现软件系统的在线优化决策,以应对运行时环境和需求的不确定性.主要工作包括3个方面:
1) 基于模糊逻辑建模并描述环境、需求和软件行为中的变化要素及要素间的影响关系;
2) 根据影响关系构建启发式推理规则,基于模糊推理过程实现量化的推理计算;
3) 基于前馈-反馈控制结构设计自适应机制与算法,并结合MAPE-K结构 [28] 设计软件自适应组件,用于实现自适应过程.
本节主要介绍一个移动端软件系统的研究案例,用于说明本文方法的可行性和有效性.
比特币(bitcoin) [29] 是近年来出现的一种电子货币,用作互联网上的交易媒介.与传统货币不同,比特币依存于一种丰富、广泛的互联网生态系统.比特币的计算核心是一个全局的、公共的日志.由于日志数据是通过节点逐个传递的,因此被形象的称为区块链.区块链记录了所有用户的比特币交易记录.
矿工(miner)是互联网中共同维护区块链的参与者,具有松散的、分布式的、去中心化的组织结构.矿工可以是服务提供商,也可以是自然人.他们在本地获取并处理其他用户的交易数据,将结果在区块链中传播.矿工处理交易数据的过程叫做采矿,采矿的工具称为比特币采矿机(bitcoin-miner),它可以用于PC端,也可以用于移动端.采矿模式概括为:矿工消耗本地的计算资源来维护区块链,同时会得到相应数量的比特币作为奖励.采矿机软件系统的业务功能需求为:
1) 用户需对个人账户进行管理;
2) 系统需收集并处理区块链中的交易记录;
3) 系统需将本地交易记录在网络中广播;
4) 用户需获得比特币作为采矿的奖励.
移动终端的采矿机系统会受到一系列计算资源的制约,如带宽、延迟、剩余电量和可用内存等.用户对系统还有质量需求(quality requirements).
1) QR1:用户希望系统的响应速度更快;
2) QR2:用户希望系统更加节能省电;
3) QR3:用户希望系统处理的交易数据更多.
软件开发问题就是要通过开发软件,使其与环境产生交互,以满足需求.软件( S )、软件系统的交互环境( E )及软件需求( R )之间存在关系 [30] :
E , S ![]() R .
R .
(1)
即软件应符合行为规约 S ,并通过和其交互环境 E 发生交互,使需求 R 得以满足.这里, R 不仅包含了功能需求还包括质量需求.
由于软件系统运行过程中存在不确定性,即 E 和 R 均会发生变化,这就要求 S 必须也能随之发生相应变化,以保证软件系统能满足需求(式(1)).其中,关于变化的影响分为2个方面:
1) 环境变化会引起需求变化.这体现为在不同的环境中,用户可能会对软件有不同的期望.我们目前仅关注质量需求变化的情况,即用户偏好的变化.这种偏好可通过用户对质量需求的预期满意度(desired satisfaction degree)来衡量.比如,对于比特币采矿机而言,终端电量较低时,用户对于节能需求的偏好会更强,即对此需求的预期满意度就会增高,反之则降低.此外,预期满意度也描述了用户对质量需求的接受程度,满意度高则表示用户对该需求的接受限制越高.当环境不确定时,质量需求的偏好也是不确定的.如何描述环境和质量需求,并建立两者间变化的关联是描述这一影响关系的关键点.
2) 环境和需求的变化会引起软件行为也随之发生变化,即软件根据环境和自身的变化,展现不同的行为,以保证当前需求的满足.质量需求的实际满足情况用其实际满意度(actual satisfaction degree)来衡量.这一方面的关键点是如何根据环境和质量需求来确定软件行为,即如何建立自适应机制,通过决策使质量需求的实际满意度能够达到预期满意度.
为刻画上述2个方面的影响,首先需要建立质量需求、环境和软件行为间的影响关系,即建立质量需求、环境和软件行为中那些变化要素间的影响关系.这就需要一种能建模和描述变化要素的方法.
其次,对于软件系统,量化求解往往无法采用精确的系统方程实现,而基于规则推理的方法能解决这一问题.比如,模糊推理可用于不确定性的量化计算.因此,在缺少系统方程的情况下,构建推理规则是支持决策求解的要点.
再次,软件在运行时需要不断感知环境和需求的变化,并基于这些变化对其行为进行决策,软件系统自身应构成封闭回路.故为实现自适应过程,还需提供一种将软件建模为回路的自适应机制.
针对此3点问题,FADEM方法:1)通过模糊逻辑建模并描述变化不确定的质量需求、环境和软件行为,并建立变化要素间的影响关系(第3节);2)基于变化要素间的影响关系,构建启发式推理规则,用于支持定量的推理计算(第4节);3)基于前馈-反馈控制结构,构建自适应机制,并通过具体算法和组件实现在线的自适应决策(第5节).
FADEM的框架可以通过图1表示:系统由业务逻辑层和自适应逻辑层2部分刻画,业务逻辑层包含软件的功能结构和交互环境,自适应逻辑层包含实现自适应决策所需要的自适应机制、算法和组件;系统建模过程从业务逻辑层抽象构建系统的需求模型、环境模型和配置模型,并进一步由用户和专家从模型中抽取出变化要素和要素间的影响关系;模糊控制器的构建包括2个部分:隶属函数根据变化要素的描述生成,推理规则根据影响关系的描述生成;模糊控制器构成了自适应逻辑层的求解单元.
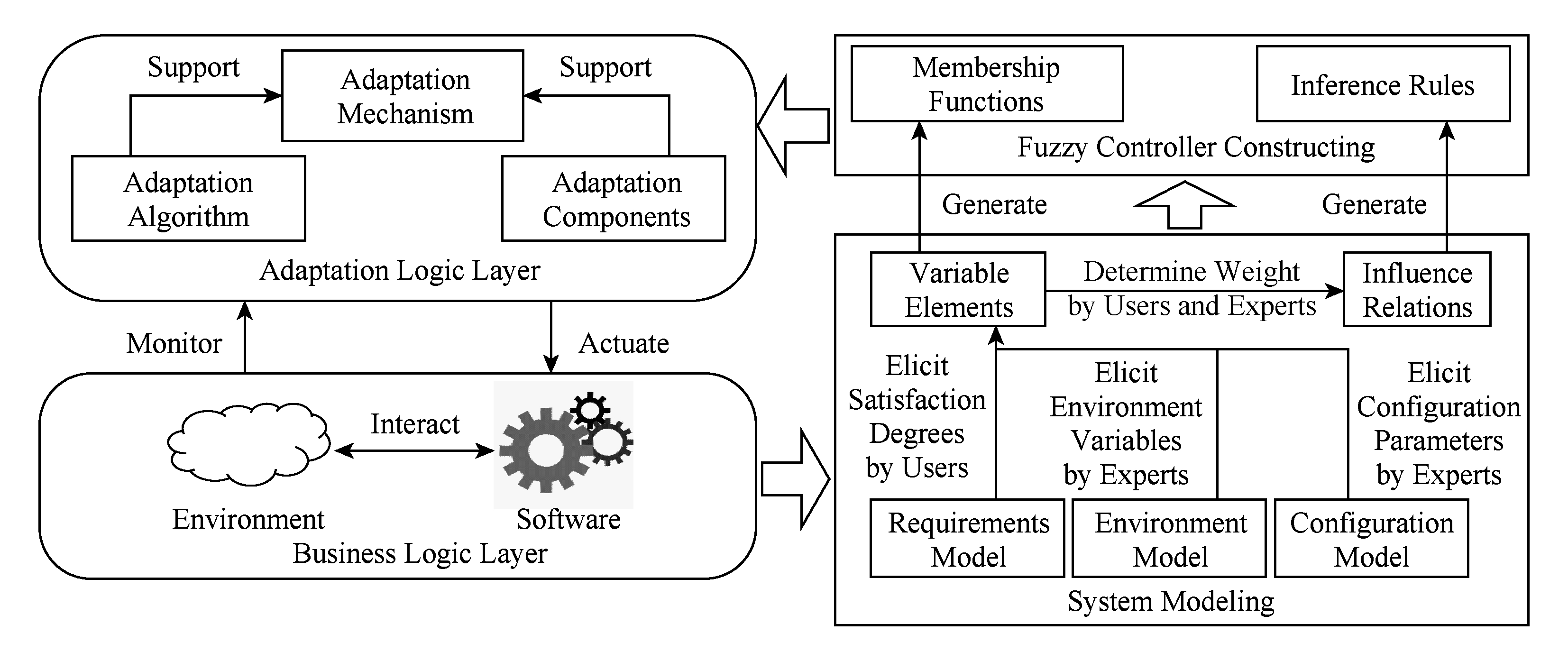
Fig. 1 Framework of FADEM
图1 FADEM的框架
为描述质量需求、环境和软件行为之间的关系,需要对系统进行建模.系统建模涉及3个方面:质量需求建模、环境建模和软件配置建模.本节首先介绍这3个方面的模型,然后进一步阐述质量需求、环境和软件行为间的关系.
为描述质量需求,首先应进行需求建模.目标模型是用于刻画软件需求的常用模型,建模元素分别为:目标描述软件的功能需求、任务描述实现目标所要执行的动作、软目标用于刻画质量需求、分解关系用于刻画目标间或目标与任务间的精化关系、贡献关系刻画任务对于软目标的支持.
为描述需求满足程度的弹性,Whittle等人 [18] 提出RELAX语言,对需求完成情况进行放松.其形式为在需求前加入模糊关键词,比如“尽可能满足 p ”,其中 p 为与需求相关的原子命题.然而,RELAX只考虑了需求满足情况的变化,并未关注需求本身是否会变化.因此不适用于处理需求自身变化的问题.
FADEM用于解决质量需求自身变化时的决策问题.质量需求的自身变化体现为其预期满意度的变化,而其实际满足情况则通过实际满意度来刻画.自适应决策目标为每个质量需求的预期满意度和实际满意度的差值尽可能接近于零.这种决策目标应在目标模型中的每个软目标上进行扩展,以刻画质量需求变化.
扩展过程首先通过目标建模,识别出软件所需满足的软目标集合 SG ={ sg 1 , sg 2 ,…, sg n }和软目标满意度集合 SD ={ sd 1 , sd 2 ,…, sd n }.满意度的取值为[0,1]上的实数.
为根据软目标满意度的变化进行决策,需要刻画满意度的变化性.软目标满意度描述为四元组
sd 
 v s d , dom s d , LV s d , MF s d
v s d , dom s d , LV s d , MF s d  .
.
1) v s d 是满意度的清晰值(crisp value);
2) dom s d 是满意度的定义域(domain),即[0,1];
![]() 指刻画该变量程度的语言变量 [31] 集合,如:{低,中,高};
指刻画该变量程度的语言变量 [31] 集合,如:{低,中,高};
![]() 指与 LV s d 相关的隶属函数(membership function)集合,隶属函数和语言变量是一一对应的.
指与 LV s d 相关的隶属函数(membership function)集合,隶属函数和语言变量是一一对应的.
软目标满意度的取值空间表示为笛卡儿积:
![]() ⊗ s d ∈ SD dom ( sd ).
⊗ s d ∈ SD dom ( sd ).
预期满意度和实际满意度是满意度的2种表现,其清晰值向量分别表示为 ![]() 和
和 ![]()
对于软目标 sg i ∈ SG ,其决策目标为实际满意度和预期满意度的偏差最小,即: ![]()
对于软件整体,其决策目标应权衡每个软目标,从而使整体满意度偏差达到最小,即:
![]()
![]()
(2)
其中, w i 是 sg i 的权重.
整体决策目标的含义是通过自适应决策使实际满意度更贴近预期满意度.从这一角度出发,考虑用户需求的变化性和需求预期满意度才具有意义.该决策目标既使软件的调节结果能更好地符合用户期望,又在满足需求的前提下,减小了系统开销.
以比特币采矿机为例,为能实现其业务需求,它应支持用户管理、交易数据收集、数据分析和报酬获取的功能.为更灵活地满足质量需求,采矿机应具有一定调整能力,比如,能对处理数据规模和时间进行设置.此外,由于软件所处的网络环境是多变的,它需要支持不同的交易数据广播方式,即广播到主区块或者广播到邻近节点.通过对采矿机软件目标建模,可得到图2所示的采矿机需求模型.其中,目标集合{ g 1 , g 2 ,…, g 15 }表示软件的功能需求,任务集合{ t 1 , t 2 ,…, t 8 }表示软件为实现目标所需要执行的任务.
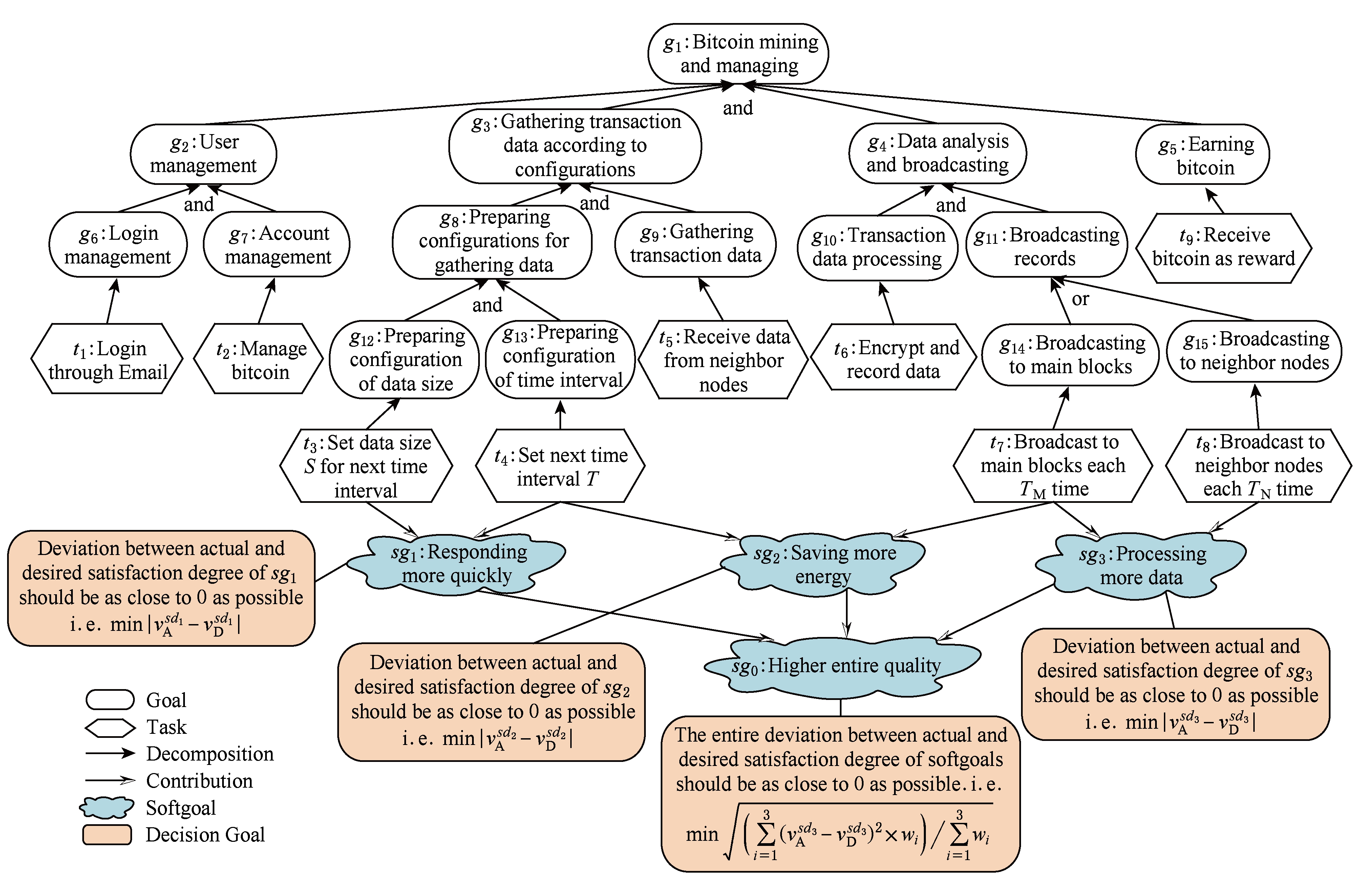
Fig. 2 Requirements model of bitcoin-miner
图2 比特币采矿机需求模型
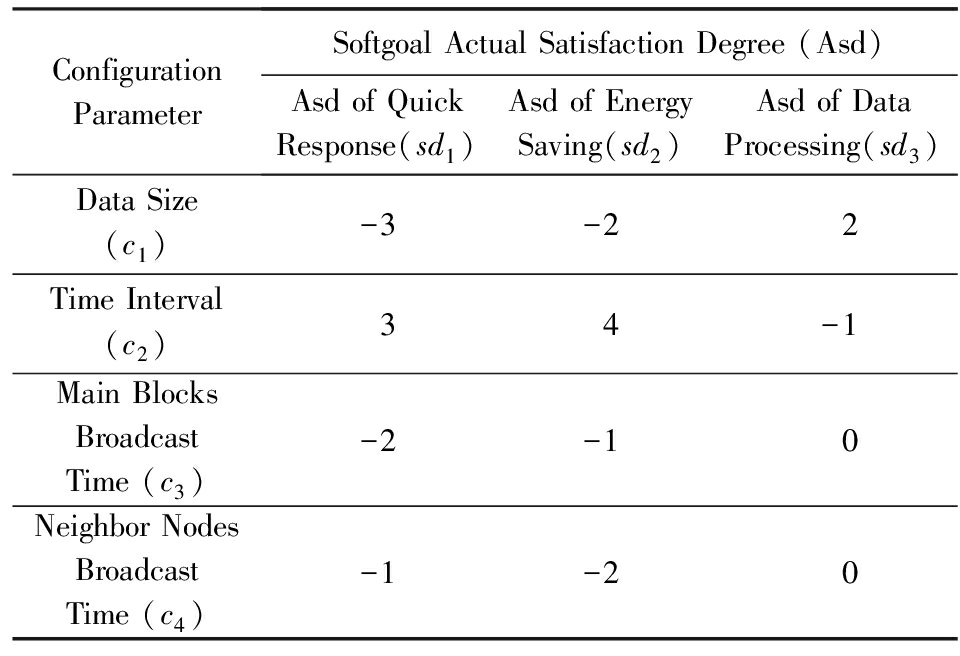
软目标 sg 1 , sg 2 , sg 3 分别建模采矿机质量需求QR1,QR2,QR3. sg 0 是在3个软目标之上的总体软目标.圆角矩形表示针对每个软目标扩展出的相应决策目标.
以 sg 1 的满意度 sd 1 为例,当用语言变量集合{低,中,高}对其进行刻画时,它描述为
v s d 1 ,[0,1],{低,中,高}, MF s d 1 .
满意度表达式中的隶属函数集合 MF s d 应通过用户对质量需求满足程度的评估来构建.构建隶属函数的过程就是确定隶属函数参数的过程.函数参数可采用问卷调研法(questionnaire survey)进行抽取.常见的隶属函数类型包括三角型隶属函数、梯形隶属函数和高斯型隶属函数等.对于不同类型的隶属函数,需要抽取的参数是不同的,但抽取步骤是一致的.注意,不同软目标满意度的隶属函数类型可以不同,并且针对不同的软目标满意度需设计不同的问卷.
以图2中 sg 1 的满意度和三角型隶属函数为例,该满意度隶属函数的抽取步骤如下:
1) 设计关于满意度的调研问题,如图3(a)所示,调研问题中应给定满意度取值范围;
2) 设计评估表格,如图3(b)所示.表格首行为描述满意程度的语言变量;表格首列为用户评估满意度属于某语言变量的边界(上界和下界);
3) 用户根据对质量需求的评估填写表格,如图3(b)所示中灰色部分,若认为无边界值则可设为缺省;
4) 根据每个语言变量对应的边界值确定隶属函数曲线的拐点,如图3(c)所示.不同语言变量对应的隶属函数构成的集合即为 MF s d 1 .
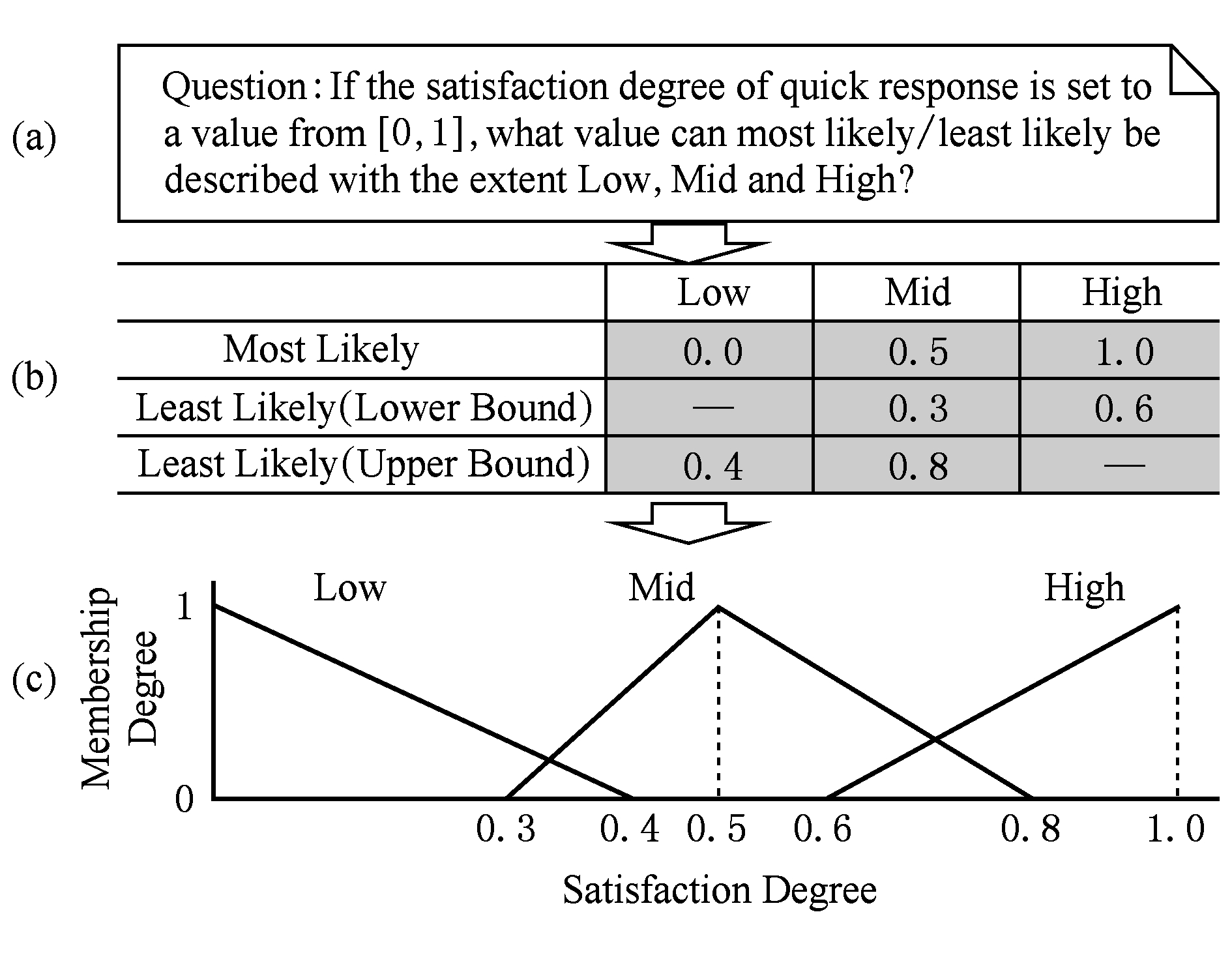
Fig. 3 Elicitation of functions for satisfaction degrees of quick response requirement
图3 快速响应需求的满意度隶属函数的抽取过程
环境变化由环境实体的变化所引起.从变化性的角度出发,软件运行所依赖的环境实体可分为2类,即固定的环境实体和变化的环境实体.对于变化的环境实体,又可根据变化类型进一步分为取值变化的环境实体和状态变化的环境实体.取值变化的环境实体的特点为其属性变量是连续变化的数值,而状态变化的环境实体的特点为其属性状态构成一个有限集.
环境建模就是要对软件运行所依赖的环境实体进行归类,将每个环境实体划分到固定的环境实体、取值变化的环境实体和状态变化的环境实体3类之一,进而对于变化的环境实体识别出它们的属性变量和属性状态.
根据识别出的属性变量和属性状态,可得到环境变量的集合为 E ={ e 1 , e 2 ,…, e n }.由于属性状态可看做是属性变量在离散域中的特例,属性变量和属性状态统一描述为四元组
e v e , dom e , LV e , MF e ,
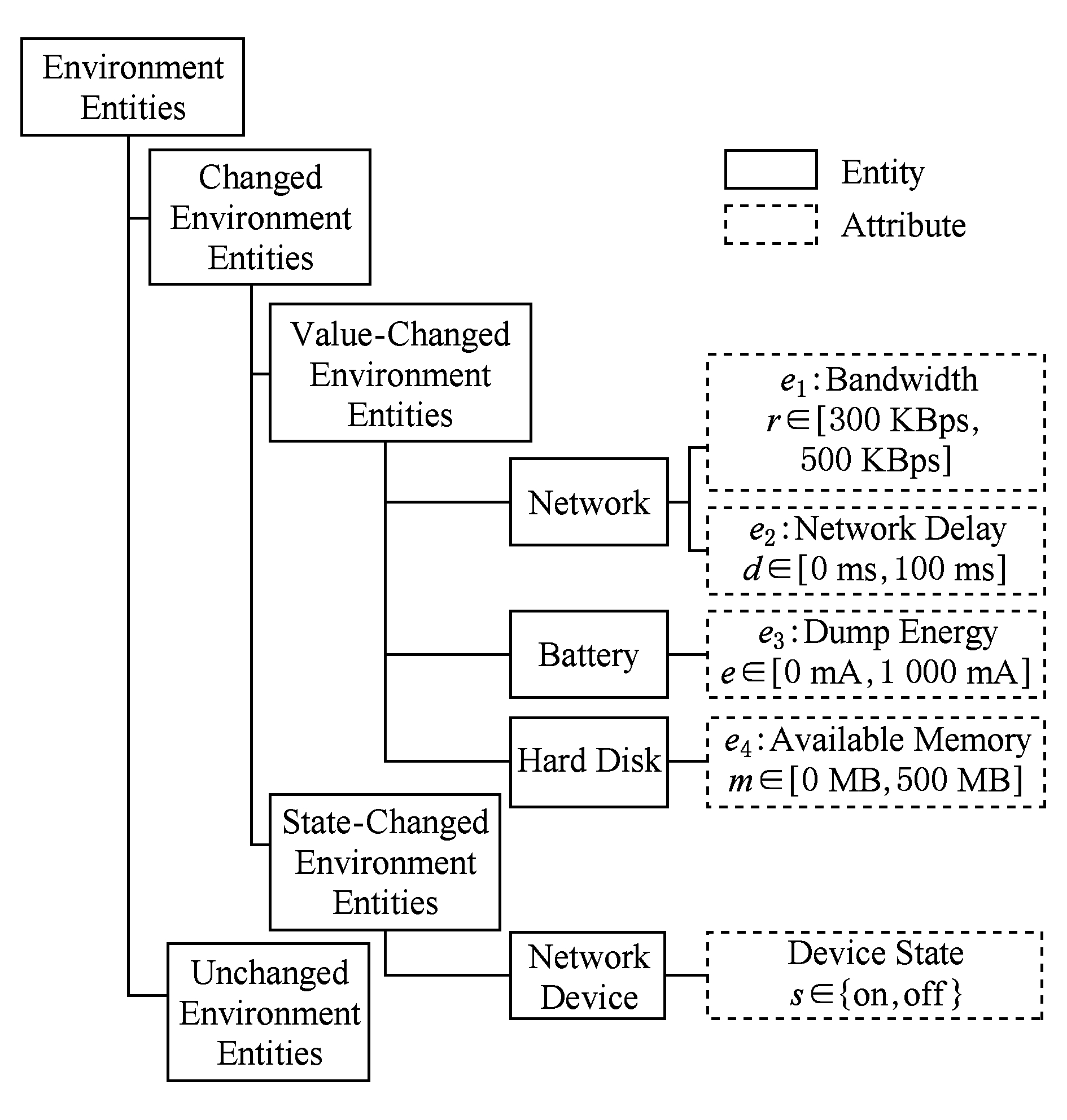
Fig. 4 Environment model of bitcoin-miner
图4 比特币采矿机环境模型
其中, v e 是环境变量的清晰值, dom e 是该变量的取值范围, LV e 是刻画该变量程度的语言变量集合, MF e 是隶属函数集合.
环境变量的取值空间定义为笛卡儿积
![]() ⊗ e ∈ E dom ( e ).
⊗ e ∈ E dom ( e ).
以比特币采矿机为例,由于软件运行依赖于互联网、能量和计算设备,因此网络、电池和硬盘均是影响软件的环境实体.相应地,带宽和网络延迟、剩余电量和可用内存是这些环境实体的属性.由于这些属性取值都无法通过一个有限集刻画,相应的实体都是取值变化类型的.由于软件运行还需要依赖设备捕获网络信号,故网络设备也是影响软件的环境实体.它的属性状态为设备的开或关.
以上建模结果可用图4表示,它描述了环境实体的分类及实体和属性的关系.其中环境变量 e 1 , e 2 , e 3 , e 4 的取值范围是一个区间,表达了它们的潜在变化.该区间可通过对环境变量的监测来确定.
以 e 3 为例,当环境变量取值用语言变量集合{低,中,高}刻画时,它描述为
v e 3 ,[0mA,1000mA],{低,中,高}, MF e 3 .
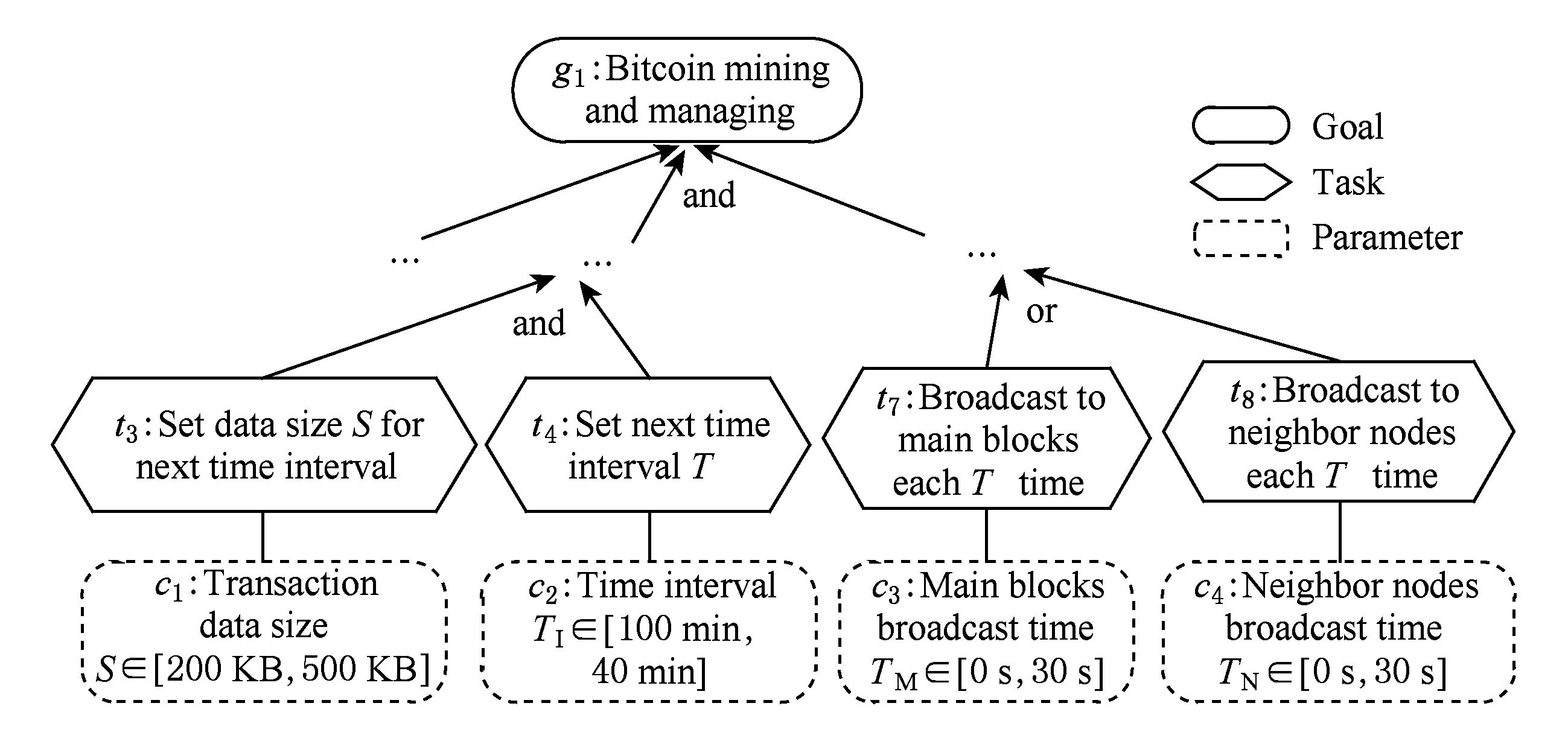
Fig. 6 Configuration model of bitcoin-miner
图6 比特币采矿机配置模型
环境变量隶属函数集合 MF e 可通过领域专家对环境变量的评估来构建.采用问卷法抽取环境变量隶属函数的步骤与抽取软目标满意度隶属函数的过程是一致的.以三角型隶属函数为例,图5展示了从问题到调研抽取出 MF e 3 的过程.
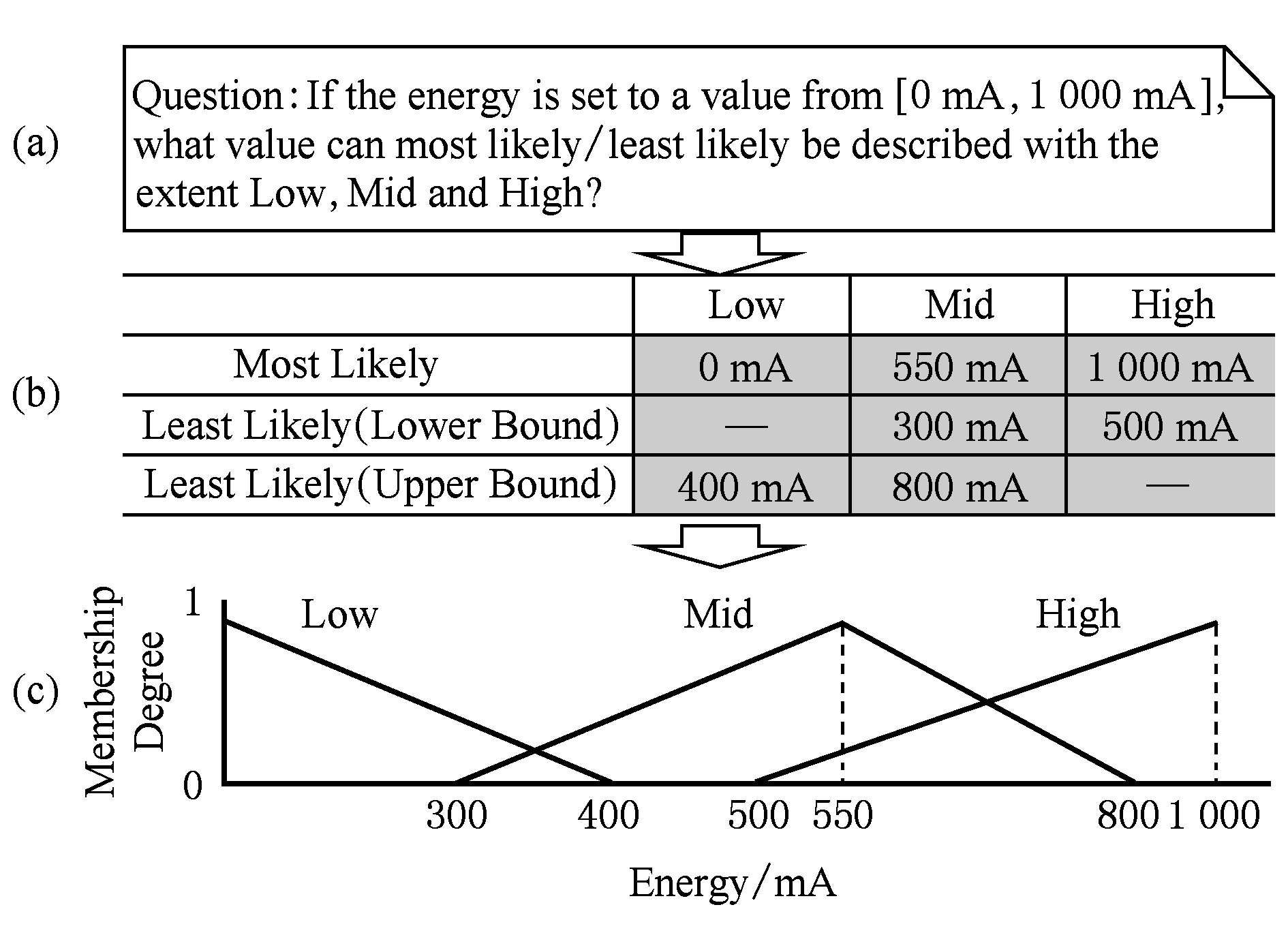
Fig. 5 Elicitation of functions for dump energy
图5 剩余电量隶属函数的抽取过程
软件行为的变化体现在其任务的动态调节中,包括任务参数的动态调节和任务结构的动态调节.
首先,可配置任务指在运行时需要通过自适应决策动态调整的任务,包括3种类型:参数可配置任务、结构可配置任务和混合配置任务.参数可配置任务指执行过程涉及参数(如时间、数据量等)动态调节的任务,这些需要动态调节的参数统称为配置参数;结构可配置任务指能够实现相同目标需求的多个任务;混合配置任务指该任务在结构可调节的基础上,还具有配置参数.
配置参数集合为 C ={ c 1 , c 2 ,…, c n }.参数描述为四元组:
c v c , dom c , LV c , MF c ,
其中, v c 是配置参数的清晰值, LV c 是表示参数大小的语言变量集, dom c 是参数的配置范围,隶属函数集合 MF c 可通过专家对软件行为评估来构建.
配置参数的取值空间表示为
![]() ⊗ c ∈ C dom ( c ),
⊗ c ∈ C dom ( c ),
其次,可配置任务为实现软件顶层目标提供不同行为选项.在软件自适应过程中,为保证软件的稳定性,应使调节的配置规模减至最小.最小配置集指能够实现软件顶层目标所需要的最少配置参数的集合.最小配置集用于刻画配置结构.在线自适应决策就是要确定选用哪个最小配置集并确定该最小配置集中所有配置参数的取值.
为识别软件的配置参数和可选的最小配置集,需对目标模型中的任务节点进行分析,抽取任务参数和结构选项,构建软件配置模型.软件配置模型体现了软件行为动态调节的特点.构建原则为:从需求模型中识别可配置任务,并抽取出这些任务所需要的配置参数;最后根据目标到任务的分解关系,将抽取出的配置参数划分为不同的最小配置集.
以采矿机软件为例,根据图2的需求模型, t 3 和 t 4 为参数可配置任务; t 7 和 t 8 为混合配置任务,因为 t 7 和 t 8 既包含配置参数,又为实现 g 11 提供不同任务选项.通过抽取可配置任务的参数,可得到图6所示的配置模型,它在目标模型的任务节点上添加了配置参数标签,即 c 1 , c 2 , c 3 , c 4 .
根据需求模型中目标到任务的分解关系,图6中的{ c 1 , c 2 , c 3 }和{ c 1 , c 2 , c 4 }被识别为2个最小配置集.
以 c 1 为例,当参数取值用语言变量集合{小,中,大}进行刻画时,它描述为
〈 v c 1 ,[200KB,500KB],{小,中,大}, MF c 1 .
配置参数隶属函数集合 MF c 可通过领域专家对软件行为的评估来构建.采用问卷法抽取隶属函数的步骤与抽取软目标满意度隶属函数的过程也一致.图7展示了抽取三角型隶属函数 MF c 1 的过程.
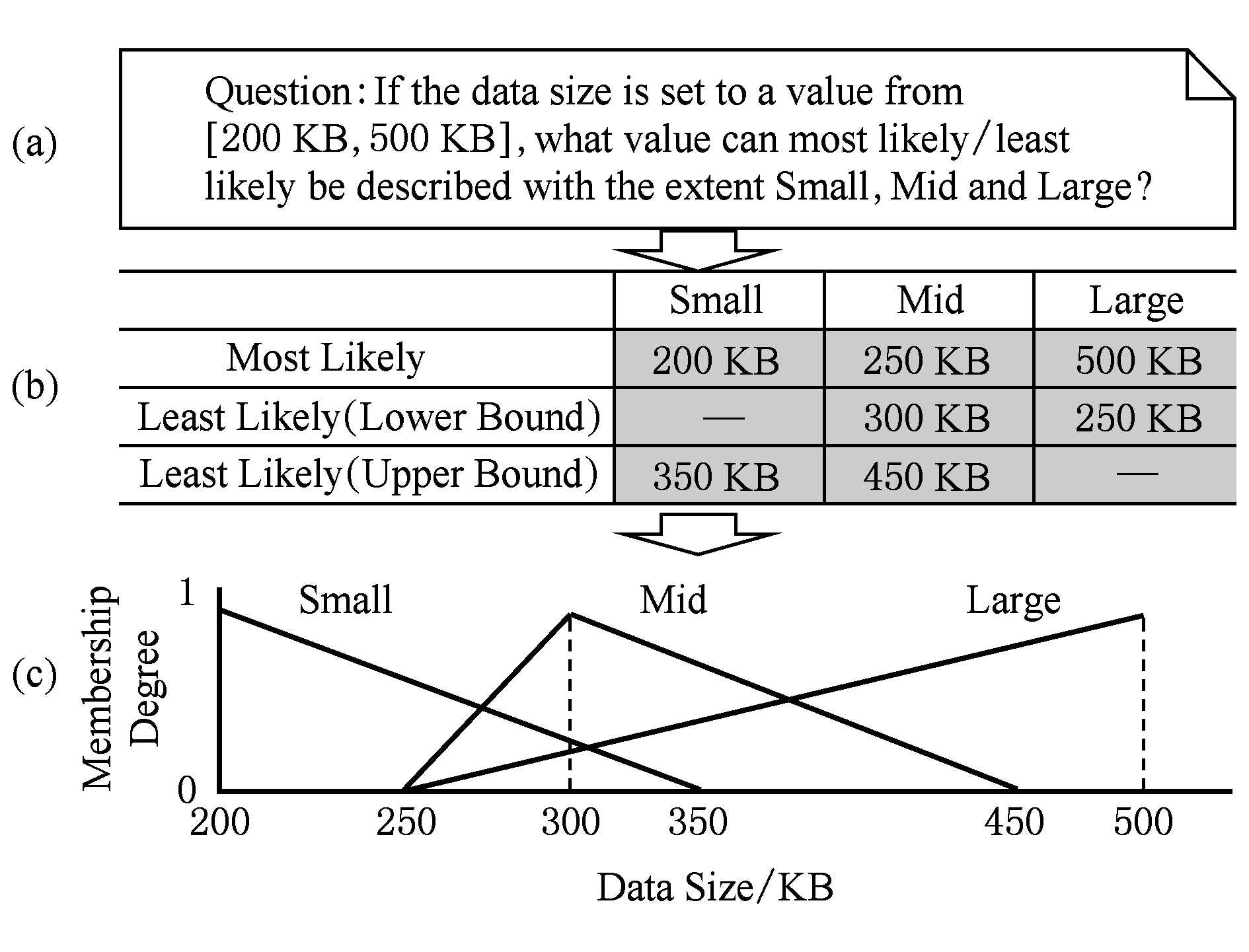
Fig. 7 Elicitation of functions for data size
图7 数据量隶属函数的抽取过程
为根据环境和质量需求的变化获得自适应决策,需要建立环境、质量需求和软件行为之间的量化关系.实际上,这就是要刻画环境变量、软目标满意度和配置参数之间的量化关系.
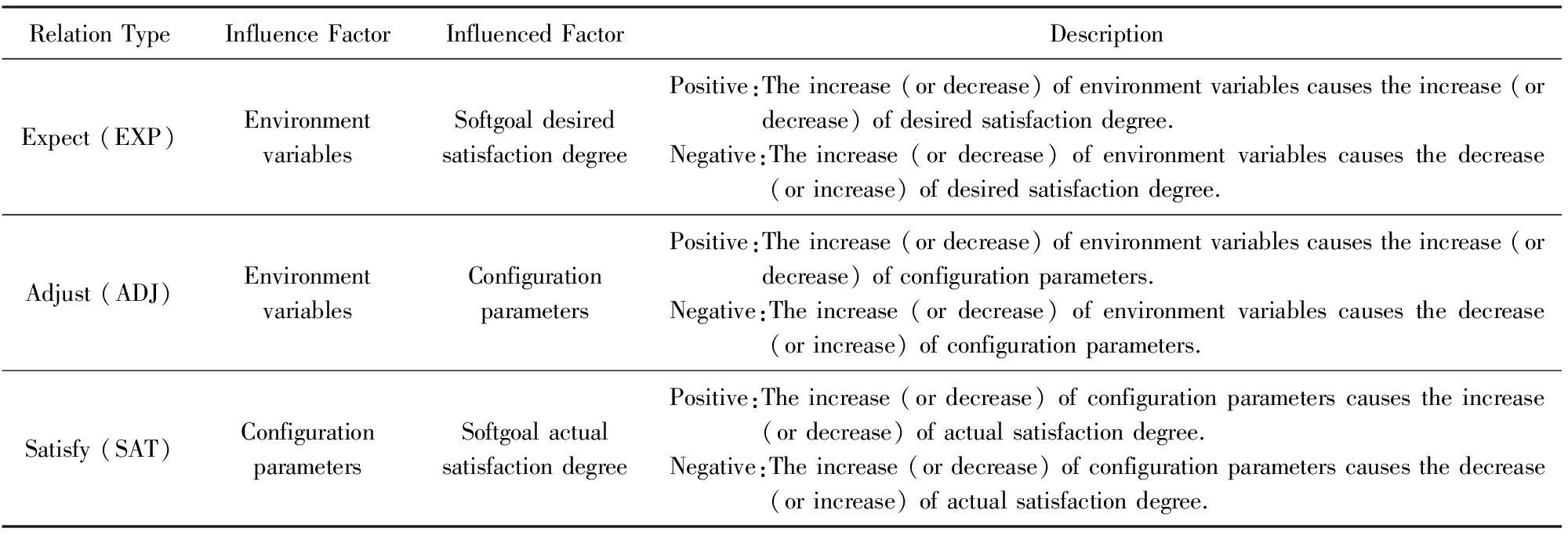
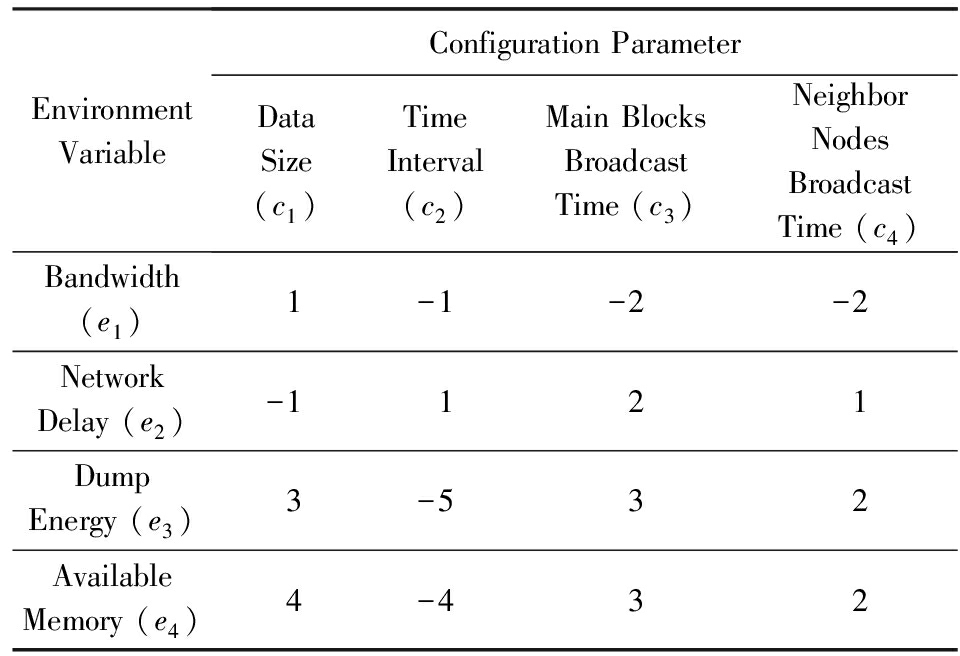
根据第2节中关于变化性影响关系的讨论,环境变量、软目标满意度和配置参数之间的影响关系主要体现在期望(expect)、调节(adjust)和满足(satisfy)3个方面,具体内容如表1所示.
其中,期望影响关系表示为三元组:
r EXP E , SD , W EXP ,
E 为环境变量集合, SD 为软目标满意度集合.该关系中 SD 表现为软目标预期满意度.权重矩阵 W EXP 由 E 中元素对 SD 中元素的影响权值组成.
期望影响关系的映射表示为
M EXP Space env → Space satDegree .
权重矩阵 W EXP 由领域专家和用户根据环境对质量需求的影响共同确定. W EXP 中的权值取自[- a , a ]上的实数,正值表示环境变量与软目标预期满意度之间正相关,负值表示负相关.权值的绝对值越大,表示环境变量的变化对软目标预期满意度的变化影响越大,两者关系越紧密.
Table 1 Influence Relations Between Environment Variables , Softgoal Satisfaction Degrees and Configuration Parameters
表1 环境变量 、 软目标满意度和配置参数间的影响关系
比如,以[-5,5]为权值区间,采矿机软件的 W EXP 如表2所示.其中,剩余电量对节能需求预期满意度的影响权值为-5,这表示剩余电量越低,用户对节能需求的预期满意度就会升高,意味着这种情景下用户对该需求更加关注.
调节影响关系表示为三元组:
r ADJ E , C , W ADJ ,
E 为环境变量集合, C 为配置参数集合,权重矩阵 W ADJ 由 E 中元素对 C 中元素的影响权值组成.
调节影响关系的映射表示为
M ADJ Space env → Space config .
权重矩阵 W ADJ 由领域专家根据环境对软件行为影响的先验知识确定. W ADJ 可支持软件基于领域知识,根据环境变量求解所需的配置参数. W ADJ 中的权值是取自[- a , a ]上的实数,正值表示环境变量与配置参数之间正相关,负值表示负相关.权值的绝对值越大,表示环境变量与配置参数间的关系越紧密.
Table 2 Weight Matrix of Expect - Relation
表2 期望影响关系的权重矩阵
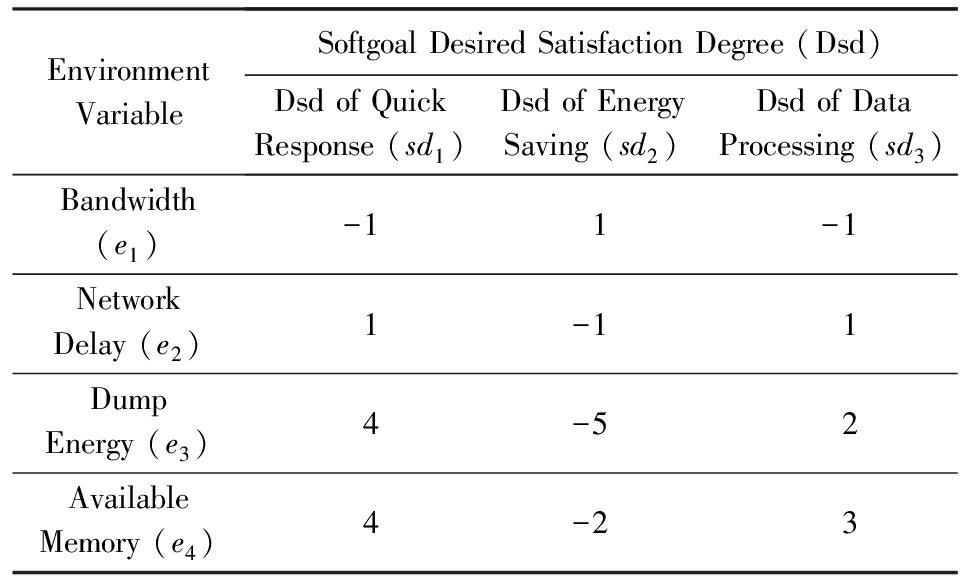
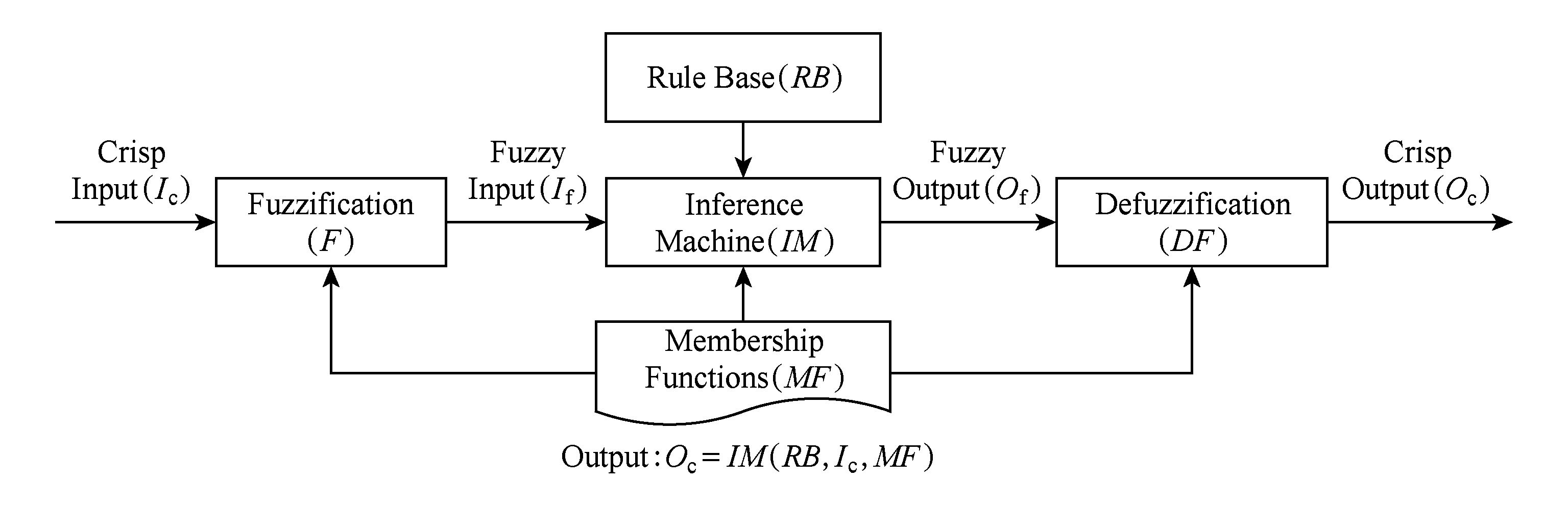
Fig. 8 Structure of fuzzy controller
图8 模糊控制器的结构
比如,采矿机系统的 W ADJ 描述如表3所示,其中,剩余电量对处理数据量的影响权值为3,表示剩余电量越高,处理的数据量就越大.这意味着电量充足的情况下,处理的事务数量会自主增多.
Table 3 Weight Matrix of Adjust - Relation
表3 调节影响关系的权重矩阵
满足影响关系表示为三元组:
r SAT C , SD , W SAT ,
C 为配置参数集合, SD 为软目标满意度集合.该关系中 SD 表现为软目标实际满意度.权重矩阵 W SAT 由 C 中元素对 SD 中元素的影响权值组成.
满足影响关系的映射表示为
M SAT Space config → Space satDegree .
权重矩阵 W SAT 由领域专家和用户根据软件行为对质量需求的影响共同确定. W SAT 中的权值也是取自[- a , a ]上的实数,正值表示配置参数与软目标实际满意度之间正相关,负值表示负相关.权值的绝对值越大,表示配置参数变化对软目标实际满意度变化的影响越大,两者关系越紧密.
比如,采矿机系统的 W SAT 如表4所示.其中,处理时间间隔对节能需求的影响权重为4,表示处理数据时间间隔越久,节能需求的实际满意度越高.
Table 4 Weight Matrix of Satisfy - Relation
表4 满足影响关系的权重矩阵
FADEM用于无法获得软件系统方程情况下的自适应优化决策,通过推理实现变量的计算.本节首先介绍模糊控制器,然后对推理规则进行描述,最后说明如何通过影响关系权重矩阵生成这些规则.
模糊控制 [32] 是以模糊集理论、模糊语言变量和模糊逻辑推理为基础的智能控制方法.它是从行为上模仿人的思维方式,对模糊现象进行识别和判断,并进行决策的一种智能控制方法.模糊控制器用于实现模糊推理,其结构如图8所示.
一个模糊控制器由4个组件构成:
1) 规则库记录了一系列启发式推理规则,由操作人员或者领域专家的知识编写而成;
2) 模糊化组件将来自传感器的实时信号通过隶属函数模糊化,这一过程将清晰值转变为模糊值,从而可利用推理规则进行比较和计算;
3) 推理机是模糊控制器的核心,利用推理规则对输入的模糊量进行推理,产生模糊值作为输出;
4) 解模糊化组件将输出的模糊值重新转化为清晰值,作为控制量加入到系统的执行器中.
此外,在模糊控制器中需要对输入和输出参量定义相应的隶属函数,用于支持模糊化过程、推理计算过程以及解模糊化过程.
为实现推理计算,除了需要抽取变量的隶属函数,还需要构造推理规则.为便于说明,此处将3.4节中的3种影响关系和映射分别抽象记为
r REL V 1 , V 2 , W REL ,
M REL ![]()
其中, V 1 和 V 2 表示2组变量, W REL 表示它们各分量之间的影响权重矩阵.对于映射M REL , V 1 和 V 2 变量间推理规则的基本形式为
rule i : IF v 11 is l ![]() ⊕…⊕ v m 1 is l
⊕…⊕ v m 1 is l ![]() ,
,
THEN v 12 is l ![]() ⊕…⊕ v n 2 is l
⊕…⊕ v n 2 is l ![]() .
.
其中, v ij ∈ V j , l ![]() ∈ lv v ij ,⊕={∧,∨}.
∈ lv v ij ,⊕={∧,∨}.
映射M REL 的推理规则集为 R REL =∪ rule i .根据第3.4节的影响关系, R REL 可泛化得到3类规则集,即 R EXP , R SAT , R ADJ .其中, R EXP 和 R SAT 与用户需求相关; R ADJ 与领域知识相关.注意,实现相同目标的不同配置参数是互斥的,所以 R ADJ 和 R SAT 应针对最小配置集进行构建.比如图6中的 c 3 和 c 4 ,它们是“或”关系,故不能出现在同一条推理规则中.
对于给定的 V 1 清晰值向量 ![]() 借助规则 R REL 求解 V 2 清晰值向量
借助规则 R REL 求解 V 2 清晰值向量 ![]() 的推理过程可表示为
的推理过程可表示为
其中, ![]() 是 V 1 的隶属函数集,
是 V 1 的隶属函数集, ![]() 是 V 2 的隶属函数集.与 R REL 的泛化结果相似,R REL 也可根据3类影响关系泛化出R EXP ,R ADJ ,R SAT .其中R EXP 用于根据环境变量求解软目标的预期满意度;R ADJ 用来根据环境变量推理求解配置参数;R SAT 用来根据配置参数求解软目标的实际满意度.
是 V 2 的隶属函数集.与 R REL 的泛化结果相似,R REL 也可根据3类影响关系泛化出R EXP ,R ADJ ,R SAT .其中R EXP 用于根据环境变量求解软目标的预期满意度;R ADJ 用来根据环境变量推理求解配置参数;R SAT 用来根据配置参数求解软目标的实际满意度.
在推理规则中,IF子句的表达式可通过逻辑运算转换为析取范式,并分割为不同的合取范式,从而保证每个规则的前件都是合取范式.对于THEN子句,由于同类变量之间是解耦的,所以THEN子句本身就是合取范式.故推理规则化简为
rule i :∧ i v i 1 is l ![]() →∧ j v j 2 is l
→∧ j v j 2 is l ![]() .
.
(3)
将式(3)中所有语言变量抽取出来构成一个 m + n 维语言变量向量
![]()
(4)
其中,前 m 维取自推理规则前件,后 n 维取自推理规则后件.
构造推理规则就是要确定式(4)的语言变量向量,即确定每条规则中IF子句的语言变量向量 ![]() 和THEN子句的语言变量向量
和THEN子句的语言变量向量 ![]() 记
记 ![]() 是所有 V 1 中各变量的语言变量排列组合得出的语言变量矩阵.下面给出根据
是所有 V 1 中各变量的语言变量排列组合得出的语言变量矩阵.下面给出根据 ![]() 和 V 1 中变量对应的 W REL ,生成与某个
和 V 1 中变量对应的 W REL ,生成与某个 ![]() 相关的
相关的 ![]() 的过程,如算法1所示.
的过程,如算法1所示.
算法1 . 推理后件的语言变量向量生成.
输入: ![]()
输出: ![]()
① ![]()
② ![]()
③ nv ′← nv × W REL ;
④ NM ′← NM × W REL ;
⑤ BM ←[ columnMax ( NM ′); columnMin ( NM ′)];
⑥ FOR 对 nv ′和 BM 的每列
⑦ 将 BM i 进行 n i 等分;
⑧ 比较 ![]() 和所有划分边界的大小;
和所有划分边界的大小;
⑨ 找到 ![]() 所属的区间 segment 0 ;
所属的区间 segment 0 ;
⑩ 将 segment 0 映射为 ![]()
 END FOR
END FOR
算法行①通过双射将 ![]() 按语言变量程度映射为数值向量 nv ;行②通过相同双射将矩阵
按语言变量程度映射为数值向量 nv ;行②通过相同双射将矩阵 ![]() 映射为数值矩阵 NM ;行③④通过与影响权值矩阵的乘法得到新的 nv ′和 NM ′;行⑤对 NM ′按列求最大和最小值,生成边界值矩阵 BM .行⑥~ 分别将边界值矩阵按列进行区间等分,每列分割区间的数目为 V 2 中对应变量的语言变量个数,分割区间连续且不相交;比较 nv ′各分量与对应列的区间边界值的大小,找到包含该值的区间;根据同列区间上界的大小,将找到的区间反向映射回语言变量,上界值越大的区间映射到描述程度越高的语言变量,并最终得到向量
映射为数值矩阵 NM ;行③④通过与影响权值矩阵的乘法得到新的 nv ′和 NM ′;行⑤对 NM ′按列求最大和最小值,生成边界值矩阵 BM .行⑥~ 分别将边界值矩阵按列进行区间等分,每列分割区间的数目为 V 2 中对应变量的语言变量个数,分割区间连续且不相交;比较 nv ′各分量与对应列的区间边界值的大小,找到包含该值的区间;根据同列区间上界的大小,将找到的区间反向映射回语言变量,上界值越大的区间映射到描述程度越高的语言变量,并最终得到向量 ![]() 通过对所有
通过对所有 ![]() 执行算法1,可得出规则集 R REL 中所有推理规则后件的语言变量向量.
执行算法1,可得出规则集 R REL 中所有推理规则后件的语言变量向量.
算法1对构建3类规则集 R EXP , R ADJ , R SAT 均适用.比如以采矿机软件的期望影响关系为例,令环境变量向量为(带宽,延迟,电量,内存)和满意度向量为(快速响应满意度,节能满意度,处理量大满意度),每个变量的语言变量值均取自集合{低,中,高},引入双射 f 将语言变量映射为数值,如 f (低)=1, f (中)=2, f (高)=3.当 lv E =(中,中,高,低)时,通过算法1可得出 lv SD =(中,低,低).此条规则的语言变量向量为(中,中,高,低,中,低,低),含义为:
如果带宽中等、且延迟中等、且电量高、且内存低,那么,快速响应的预期满意度为中,且节能的预期满意度为低,且处理量大的预期满意度为低.
在规则应用过程中,仍然引入双射 f ,将语言变量按程度映射为索引整数值,比如 f (低)=1, f (中)=2, f (高)=3.从而得到式(4)的数值向量:
( f ( l ![]() ), f ( l
), f ( l ![]() ),…, f ( l
),…, f ( l ![]() ),
),
f ( l ![]() ), f ( l
), f ( l ![]() ),…, f ( l
),…, f ( l ![]() )).
)).
推理时需要根据该数值向量匹配选择相应的隶属函数进行模糊化和解模糊化的计算,推理过程采用经典的模糊集推理算法 [33] 实现.
本节首先提出软件自适应过程所需具备的自适应机制和在线决策步骤,然后介绍用于支持该机制的自适应算法和组件结构.
软件面向不确定性的自适应决策是感知环境和质量需求变化、分析质量需求满意度并根据优化目标求解决策配置的综合过程.为实现这一过程,FADEM框架为软件系统提供了基于前馈-反馈结构的自适应机制,如图9所示.图9上半部分为该机制的框架;图9下半部分描述了各组成部分的实现方式.
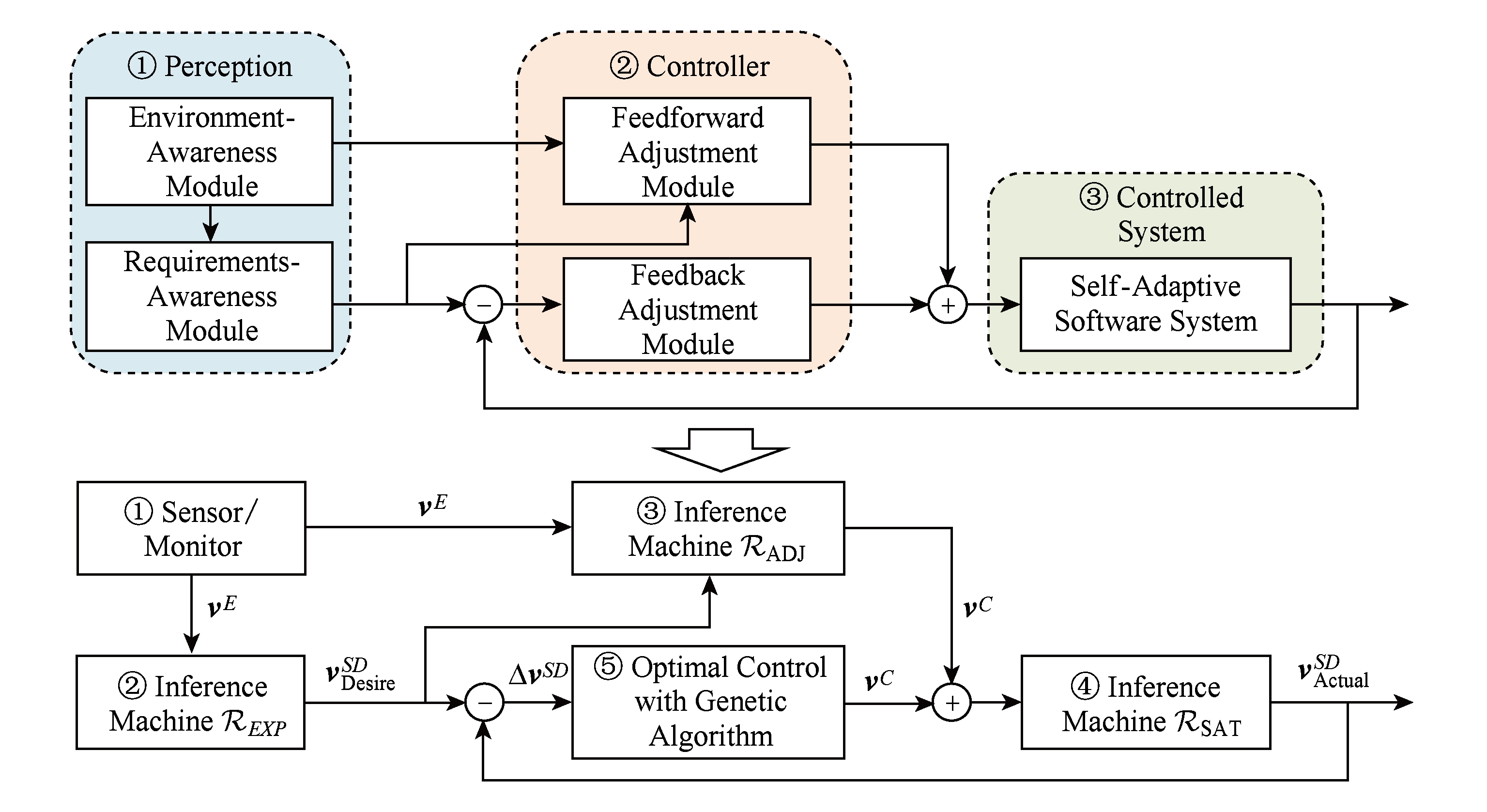
Fig. 9 Feedforward-feedback based adaptation mechanism
图9 基于前馈-反馈的自适应机制
自适应机制分为感知器、控制器和被控系统3个组成部分,其中:
1) 感知器由环境感知模块和需求感知模块构成,分别用于感知环境变量和质量需求预期满意度的变化;
2) 控制器由前馈调节模块和反馈调节模块构成,用于求解自适应决策;其中,前馈调节模块主要支持软件及时粗调节,根据环境变量求解配置参数,以消除环境变化对质量需求的影响;反馈控制模块主要用于根据质量需求满意度的偏差,通过全局寻优对配置参数进行细致校正;
3) 被控系统表示自适应软件系统,它接受获得的配置参数并进行在线部署.
基于此自适应机制的决策过程在运行时通过以下步骤实现,这些步骤与图9下半部分中的编号相对应.
1) 软件通过传感器或监测器测量环境变量;
2) 根据环境变量,求解质量需求预期满意度.
3) 当前配置下的质量需求满意度偏差符合给定阈值时,无需调整配置;否则,根据环境变量对配置参数进行前馈调节.
① github.com/ZhuoqunYang/FuzzyControlForSAS
v C =R ADJ ( R ADJ , v E , MF E ∪ MF C );
4) 求解前馈调节后的质量需求实际满意度.
5) 将实际满意度进行反馈,计算满意度偏差.若偏差符合给定阈值,则将该配置作为决策配置;否则,基于遗传算法对配置参数进行优化调节.此步骤的优化目标为
其中 ![]() 如式(2)所示.
如式(2)所示.
FADEM框架提供了支持决策过程的算法,包括前馈调节算法(算法2)、反馈调节算法(算法3)和综合自适应算法(算法4).算法中输入、输出和中间变量命名与图9下半部分中标注的传递参数相一致,并以最小配置集为执行单位.本文基于MATLAB给出了这些算法模块的具体实现,读者可参考GitHub链接 ① 进一步了解.
前馈调节算法用于实现基于先验知识的决策,根据环境变量获得新的配置参数.当软件功能目标有多种实现方式时,需对每个最小配置集分别执行算法2,并选择能够带来最小满意度偏差的配置集作为自适应决策结果.
算法2 . 前馈调节算法.
输入: v E , R SAT , R ADJ , MF E , MF SD , MF C ;
输出: ![]()
① v C ←R ADJ ( R ADJ , v E , MF E ∪ MF C );
② ![]()
③ ![]()
反馈算法用于实现基于优化目标的决策,通过遗传算法,迭代求解最优的配置参数.它是在自变量定义域内搜索全局最优解的算法.
遗传算法的求解过程为:将配置参数的取值范围作为自变量定义域,将配置参数编码为染色体;将初代染色体作为模糊控制器的输入,求解每一个染色体带来的需求满意度偏差,满意度偏差即为适应度;对适应度进行排序,并对染色体进行选择、交叉、重构和变异操作;将得到的新染色体作为下一轮的输入,并计算适应度;当满意度偏差收敛到阈值内时,得到最小偏差的染色体就对应着求得的配置参数.遗传算法的求解规模与种群数量、遗传迭代次数以及染色体的操作方式有关.由于本文将遗传算法与模糊控制相结合,适应度需要通过模糊控制过程进行计算,其求解规模又与模糊控制器的推理规则和隶属函数的规模有关.代码细节可参考GitHub链接中的相应文档.
当软件功能目标有多种实现方式时,需对每个最小配置集分别执行算法3,并选择能带来最小满意度偏差的配置集作为决策结果.
算法3 . 反馈调节算法.
输入: ![]()
输出: ![]()
① chrom ← createPopulation ( N , Space config );
② generation ←0;
③ FOR ALL chr ∈ chrom
④ ![]()
⑤ END FOR
⑥ WHILE generation < MAXgen
⑦ perform GA with new population;
⑧ ![]()
⑨ END WHILE
⑩ ![]()
综合自适应算法用于实现软件运行时整体的在线决策.首先,算法根据环境变化计算软目标预期满意度(行①)并根据当前配置计算实际满意度(行②);若当前满意度偏差达到阈值要求,则不需要调节配置(行③④);否则,调用算法2求解所需配置(行⑤);若算法2求得的配置参数使满意度偏差达到阈值要求,则该配置即为决策配置(行⑥⑦);否则,调用算法3求解最优配置参数(行⑧).
算法4 . 综合自适应算法.
输入: ![]()
输出: ![]()
① ![]()
② ![]()
③ ![]()
④ ![]()
⑤ ![]() 算法2
算法2
⑥ ![]()
⑦ ![]()
⑧ ![]() 算法3
算法3
⑨ END IF
⑩ END IF
FADEM框架从结构层提出自适应软件系统应具备的组件结构,如图10所示.该组件结构基于MAPE-K自主管理器 [28] 进行设计和搭建,不同组件用于实现自适应算法中的不同计算模块.这些组件在前述GitHub链接中均有对应实现代码.
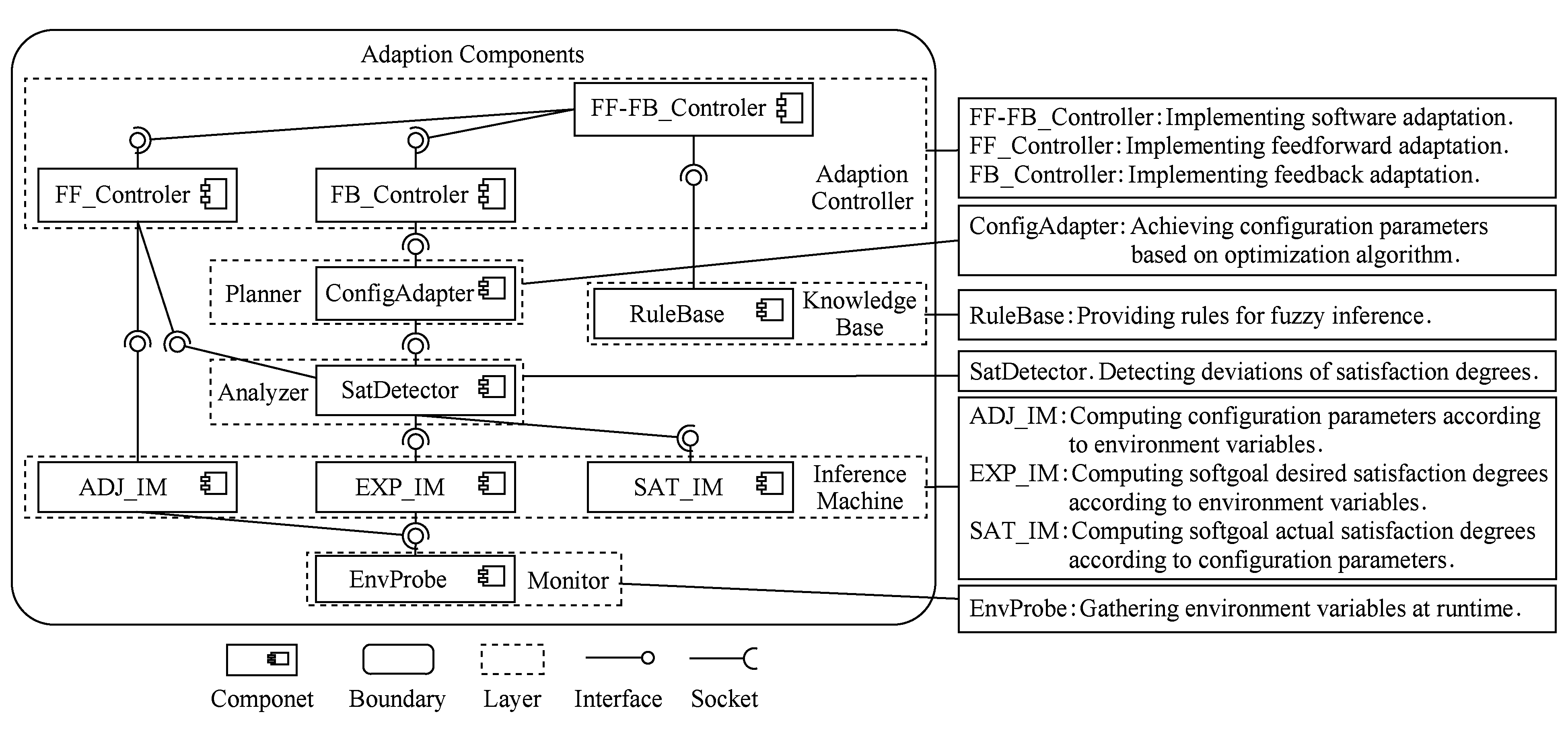
Fig. 10 Adaptation components of FADEM
图10 FADEM自适应组件结构
自适应组件分为6种类型:
1) 自适应控制器(adaptation controller)是自适应机制的控制核心,用于调度下层组件,同时也具有执行器(executor)的作用,将决策得到的配置进行部署;
2) 监测器(monitor)是软件和环境的接口,用探针采集相关的环境变量,并传递给上层模块;
3) 分析器(analyzer)用于诊断当前质量需求实际满意度是否达到其预期满意度;
4) 决策器(planner)用于求解最优配置参数;
5) 知识库(knowledge base)用于为自适应决策的推理计算过程提供启发式规则;
6) 推理机(inference machine)用于构建模糊推理系统并实现推理计算.
本节针对比特币采矿机的案例,通过仿真实验展示自适应机制和算法在面向环境和需求不确定性的优化决策问题中的有效性.具体实现过程和结果可参考前述GitHub中的MATLAB程序.
仿真实验环境为配置有AMDFX8350(3.8 GHz) 4核4线程CPU、4 GB内存和500 GB硬盘的Windows 7系统.采矿机案例的每个环境变量、软目标满意度和配置参数的语言变量集合均为{低,中,高};3种影响关系的权重分别取自表2~4.基于影响权重生成的243条推理规则所对应的数值向量请参考GitHub链接中的Excel文档.推理过程采用经典的模糊集的推理算法 [33] .满意度偏差的阈值集合为{0.002,0.004,0.006,0.008,0.01,0.02,0.04,0.06,0.08,0.1}.
遗传算法的参数设置为:种群大小为50,遗传迭代次数为100,种群代沟为0.9,交叉率0.9,变异率0.05.染色体选择方法为随机全局采样,交叉方法为单点交叉,适应度通过式(2)计算,其中软目标的权重均相同.为提高求解效率,遗传算法采用并行方式在4个资源池上共同完成.
为说明自适应机制在不同环境中的决策效果,实验仿真了3种动态变化的环境:
1) 可导型环境(derivable environment)中环境变量的变化规律服从连续可导函数.此类环境变量采用三角函数进行仿真,通过函数周期刻画环境变量间此消彼长的状况;
2) 准噪声型环境(quasi-noisy environment)中环境变量的变化趋势与可导型环境一致,但是具有微弱的噪声.此类环境变量采用在三角函数上加入高斯噪声进行仿真;
3) 噪声型环境(noisy environment)指变化完全不确定的环境,同时无规律可循.此类环境变量采用高斯噪声函数仿真.
环境变量在500个时间点的采样值如图11所示:
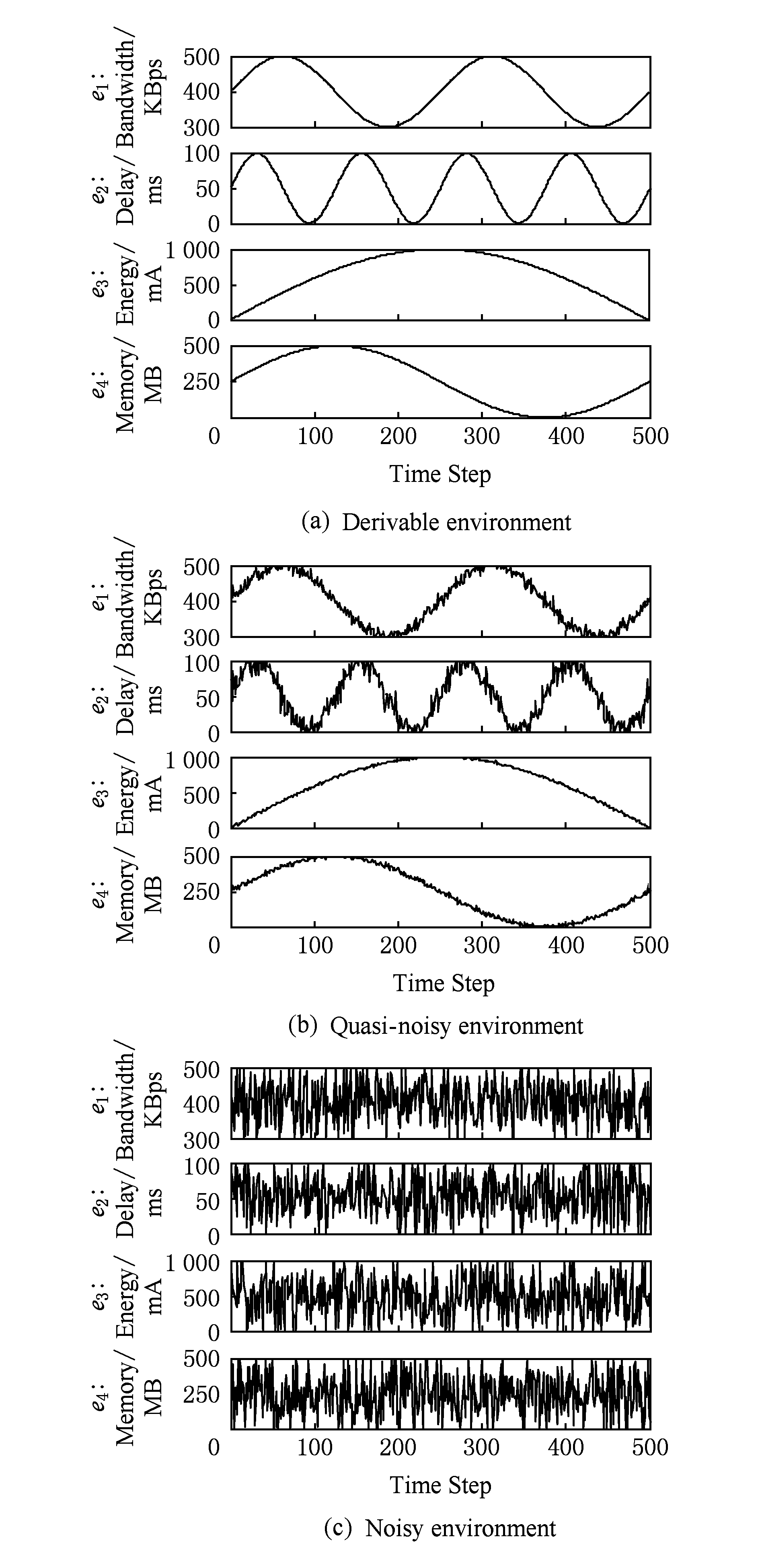
Fig. 11 Three types of environment variables
图11 3种类型的环境变量
在线自适应决策的结果主要包括4个方面:软目标预期满意度的变化结果、配置参数的决策结果、前馈和反馈调节的性能对比及满意度偏差的控制效果.
1) 软目标预期满意度的变化结果
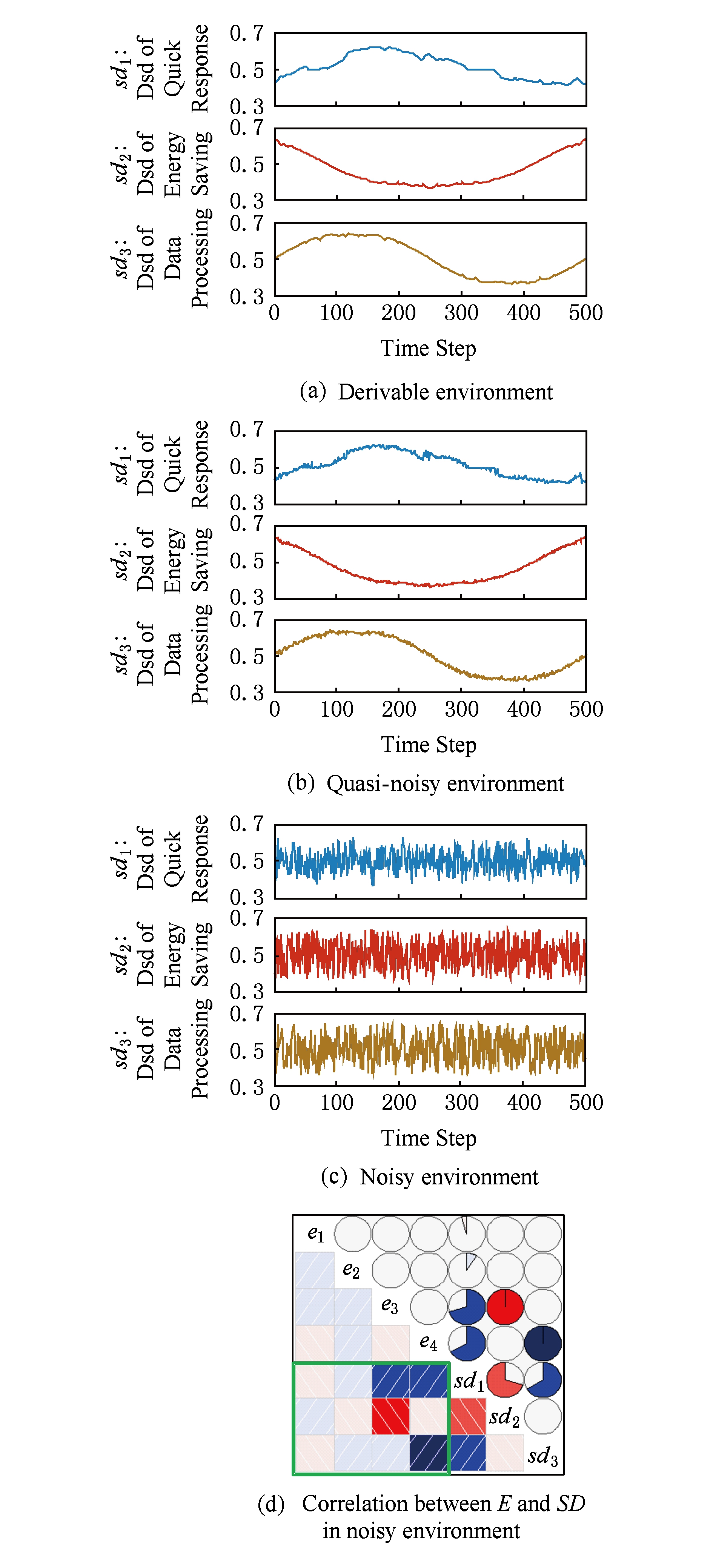
Fig. 12 Changes of softgoal desired satisfaction degrees and correlation with environment variables
图12 软目标预期满意度的变化和与环境变量的相关性
不同类型环境中软目标预期满意度的动态变化如图12(a)~(c)所示.通过与图11对照可知,软目标预期满意度和环境变量的相关性与表2中 W EXP 的权重取值是一致的.比如在可导型环境和准噪声型环境中,对比节能软目标预期满意度曲线和电量曲线,它们呈现负相关性.这与表2中两者对应的影响权值为-5是一致的.为便于观察噪声型环境变量与软目标预期满意度的相关性,此处采用R语言相关图表示它们的关系,如图12(d)所示.色块中的正斜率线条表示正相关,负斜率线条表示负相关;色块颜色越深,表示相关系数越大.左下角3×4方框内的色块与表2中的数值大小和符号均一致.
软目标预期满意度曲线刻画了质量需求自身变化的不确定性.预期满意度和环境变量的相关性表明,满意度的变化正确地反映出了用户偏好,即矩阵 W EXP .比如在时间点为100时,随着电量升高,节能需求的预期满意度呈下降趋势,而数据处理需求的预期满意度呈上升趋势,这说明用户此时对节能的偏好降低,而对处理数据的偏好升高.
2) 配置参数的决策结果
自适应机制在不同类型环境中求得的配置参数如图13(a)~(c)所示.为便于说明,将 c 3 (主区块广播时间)和 c 4 (邻居节点广播时间)的取值统一展示:第1行曲线中的正数表示广播到主区块,负数表示广播到邻居节点,绝对值表示广播时间.配置参数和软目标预期满意度间的相关性与表4中权重矩阵 W SAT 是一致的,说明软目标实际满意度与预期满意度有相同的变化趋势.图13(d)展示了噪声型环境中求得的配置参数和软目标预期满意度的相关性.左下角3×3方框所示的色块与表4中的权重符号和大小一致.
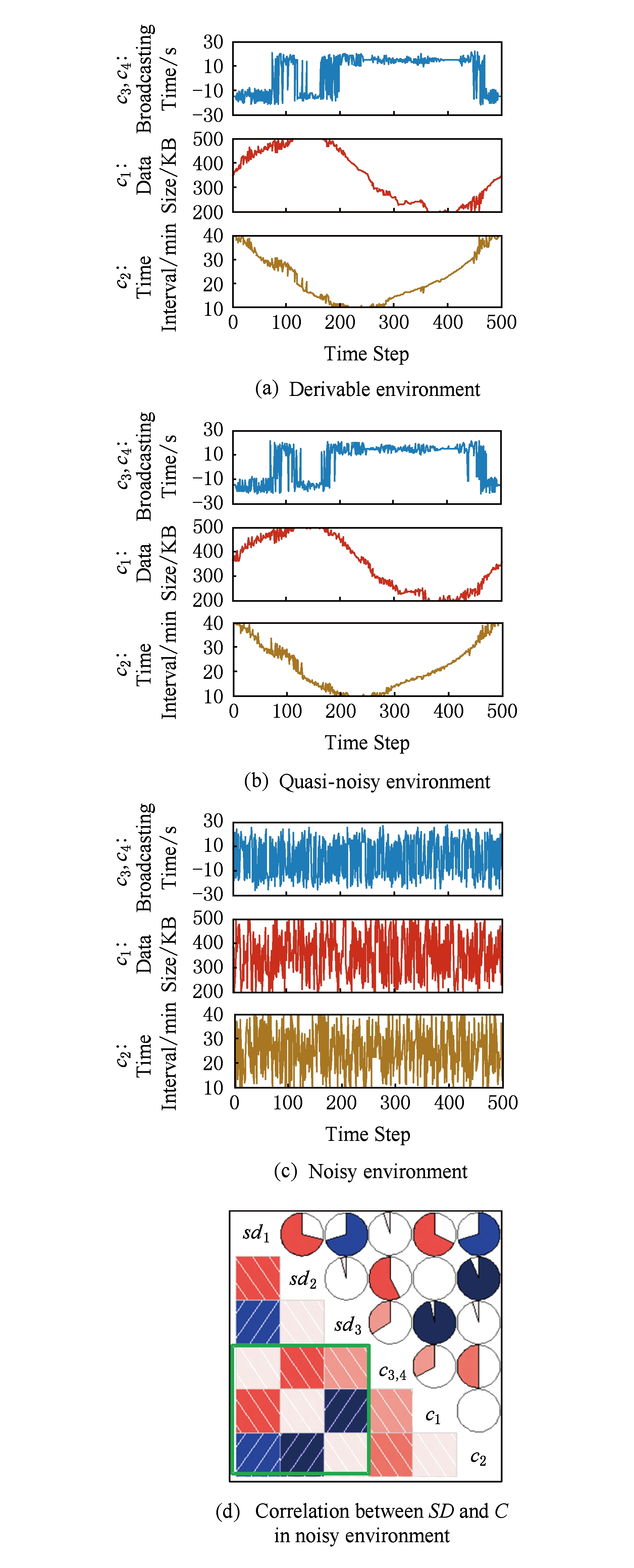
Fig. 13 Configuration parameters and correlation with desired satisfaction degrees
图13 配置参数及噪声型环境中配置参数与预期满意度的相关性
在微弱噪声的影响下,可导型环境中的配置参数和准噪声型环境中的配置参数偏差约为前者的5%.这一现象在 c 1 (数据规模)和 c 2 (时间间隔)上更加突出,这是由于它们与软目标间的影响权重更大.该结果说明,那些对软目标满意度影响较大的配置不会因环境和质量需求的微弱变化而发生大幅度调整.所以,在环境变化虽不确定但微弱的情况下,FADEM方法的自适应结果相对平稳.
3) 前馈和反馈调节的性能对比
图14(a)展示了不同满意度偏差阈值下,软件系统采用前馈调节和反馈调节结果作为决策配置的频率.阈值较小时,系统主要通过反馈算法来求解自适应决策;随着阈值增大,前馈调节的使用频率逐渐升高,反馈调节的作用逐渐淡化.
图14(b)对比了不同阈值下的决策用时.通过统计可得,前馈调节用时约为0.003 s,反馈调节用时约为0.64 s.注意,决策用时受本地计算资源(如CPU、缓存等)的影响,因此会有一定偏差.随着阈值增大,决策用时与前馈调节用时相同的情况逐渐增加.这从用时的角度说明软件采用前馈调节的情况增多.
结果表明:FADEM的自适应机制在决策过程中具有灵活性,可根据不同的约束条件,选择不同的调节方式:约束宽松时,采用前馈的粗调节提高决策速度;约束紧缩时,采用反馈的细调节提高决策精度.
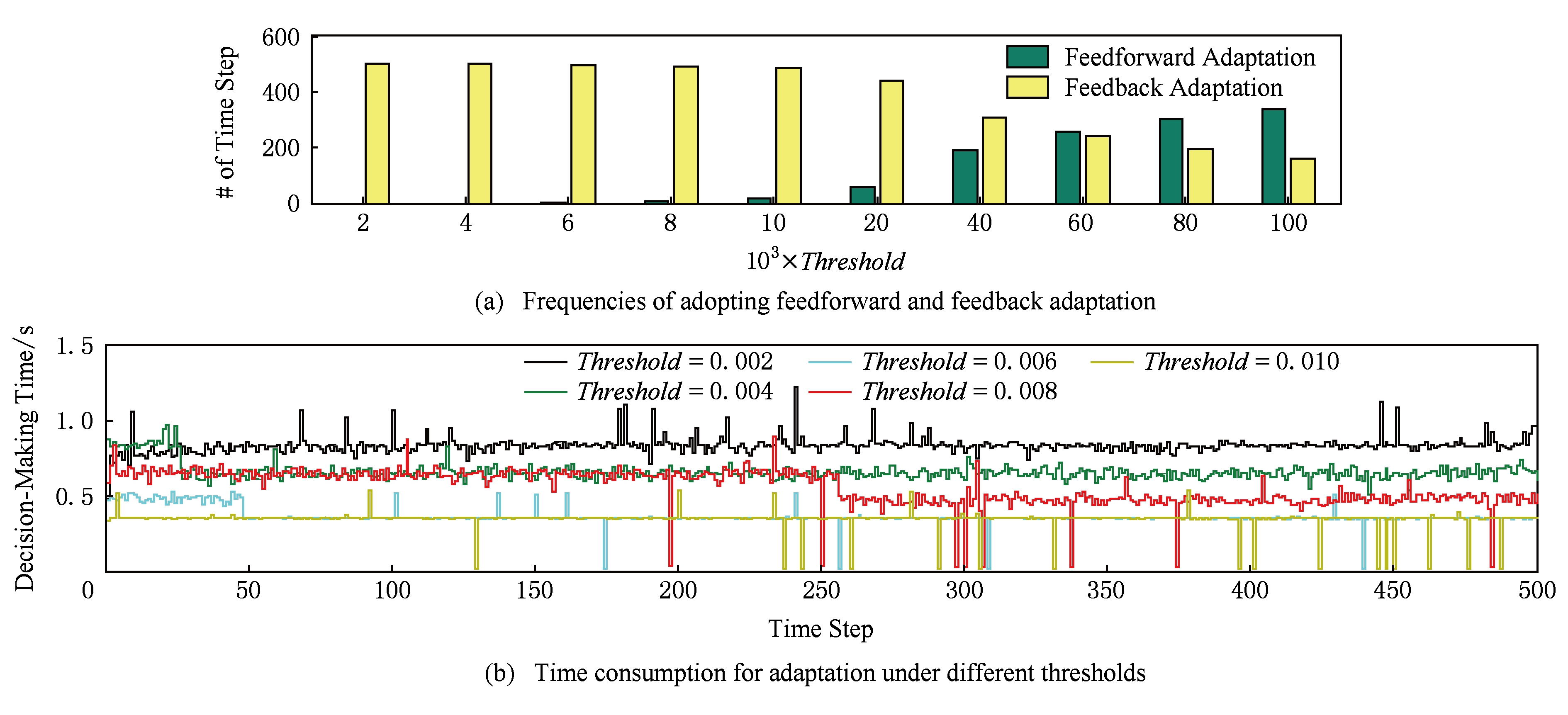
Fig. 14 Comparison between performances of feedforward and feedback adaptation
图14 前馈和反馈调节的性能对比
4) 满意度偏差的控制效果
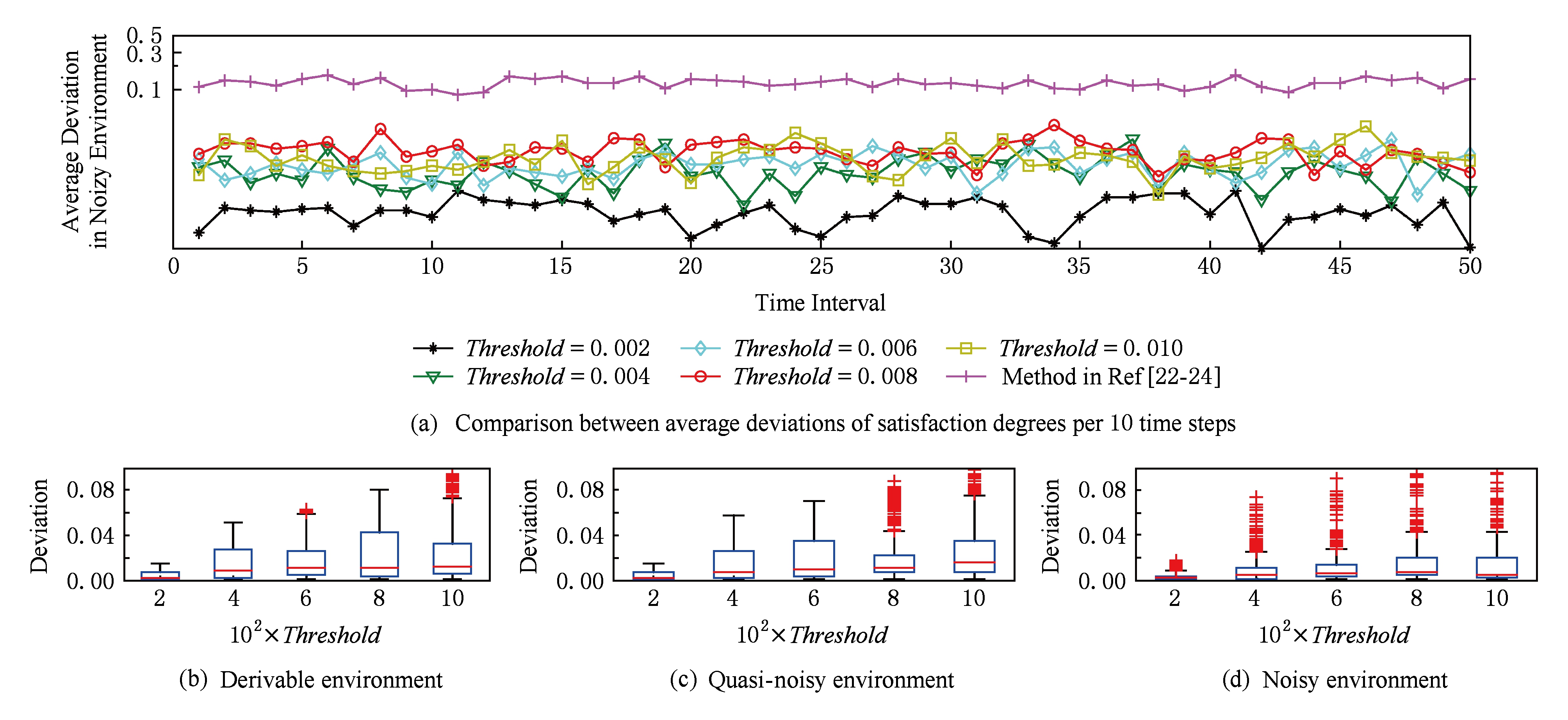
Fig. 15 Deviations of entire satisfaction degrees under different types of environment and thresholds
图15 不同类型环境和阈值下整体满意度偏差
图15(a)展示了自适应决策在不同阈值下带来的平均满意度偏差.FADEM方法通过优化决策算法将满意度偏差控制在给定阈值内.随着阈值的增大,偏差的控制效果会产生一定放松.对比文献[22-24]中单纯依据先验知识的自适应结果,FADEM具有更好的满意度偏差控制效果.因为FADEM采用反馈回路对配置参数进行优化决策,而文献[22-24]的方法没有控制机制支持,也就无法避免自适应决策产生的偏差.
图15(b)~(d)描述了自适应决策后,满意度偏差的统计结果.每个盒子表示500个时间点偏差值的分布.图15(b)~(d)表明:FADEM方法在可导型环境和准噪声型环境中的低阈值情况下的满意度偏差相对稳定,决策效果较好;而在高阈值情况下偏差较大,这是因为阈值增高时,软件系统采用前馈调节的频率升高,故系统调节结果的自由度更大.在噪声型环境中,满意度偏差的稳定性较差,这是由环境变量中大量的随机性引起的,但是偏差仍在可接受范围内.
1) 方法的可扩展性
本文以比特币采矿机案例对方法的可行性进行了分析说明.当软件更加复杂时,会涉及到其他种类的质量需求,比如关于用户负载的需求.且软件配置的数目会增多,交互环境也会变得复杂.采用本文方法解决复杂性问题的关键在于,识别和扩展那些对新的质量需求产生影响的关注点,包括软件配置和环境实体,并构建这些要素对需求的影响关系.比如,当引入用户负载的需求时,需要考虑对用户数进行监测,并对服务器等设备进行重配置.虽然软件配置和交互环境都会变得复杂,但配置内容和环境实体仍可按照本文的建模原则,划分为相应类别.因此,系统复杂性的增加会引起关注点的增加,但不会影响本文方法和流程的应用.
此外,本方法侧重软件需求建模和自适应策略的设计,主要考察需求、软件配置和环境间模型层面的关联.它不受限于软件运行的设备或硬件系统,也不受配置或代码模块具体能耗的影响.在需求阶段,为设计针对质量需求可满足性的自适应策略,需建模各类变化因素对需求的影响,而需求间的影响则应通过性能工程的测试评估进行确定.
2) 推理规则的构建
本文的推理规则是基于Mamdani模糊系统 [34] 的原理构造的,但是FADEM框架同样适用于基于T-S模糊系统 [35] 的推理过程,仅需要把推理规则中THEN子句中变成自变量的线性组合.T-S型推理规则为
rule i : IF v 11 is l ![]() ⊕…⊕ v m 1 is l
⊕…⊕ v m 1 is l ![]() ,
,
其中, a i 是实数线性系数.
这一规则可用于建立环境变量与配置参数的推理关系,其线性系数是未知的,需要通过运行时学习获得.由于 a i 取自实数域,这时遗传算法就不再适合作为学习算法,因为在自变量定义域已知情况下进行遗传编码,会使算法收敛效果更好.由于BP神经网络能学习和存储大量的输入-输出模式映射关系,而无需提前描述这种映射关系的数学方程,它比较适合用来学习T-S模糊系统推理规则的参数.此扩展也在前述的GitHub链接中给出了实例.
3) 参数评价与优化
隶属函数的构造有2种常见的方法,即基于专家的先验知识进行构造和基于学习的后验知识进行构造.由于在需求工程阶段缺乏系统运行时数据,以作为提取后验知识的基础,本文采用前者作为最初的构建方法.同时,在决策过程中采用遗传算法进行求解,避免了完全依赖先验知识.当系统运行后,FADEM可根据决策结果对隶属函数参数进行优化.参数优化问题可通过系统辨识过程来求解,具体可采用机器学习的方法.在本文提供的GitHub链接中,已经给出了2种修正隶属函数参数的方法,即通过遗传算法进行优化和通过神经网络进行优化,该问题将在后续工作中予以解决,不作为本文关注点.影响权值矩阵用于对不同变量间影响关系进行描述,它反映了概念和认知,这些数值也可根据用户对结果的评价进行调整.
4) 敏感性分析
质量需求预期满意度和配置参数的求解均通过基于隶属函数的模糊推理过程实现,故隶属函数参数会对计算结果的质量产生影响.因此,还需要对这类参数的敏感性进行分析.下面以表1中环境变量和质量需求预期满意度之间的期望关系为例,分析可导型环境中,环境变量隶属函数参数的变化对快速响应需求预期满意度求解结果的影响.
图16展示了环境变量隶属函数参数为初始值和参数变化范围在变量定义域5%~25%时,快速响应需求预期满意度结果.曲线表明,随着参数增大,满意度在多数时间点呈递减趋势,少数呈不规则变化.经计算,预期满意度的平均偏差分别为1.05%,1.89%,2.90%,3.89%,4.74%.这说明模糊推理的求解过程弱化了隶属函数参数变化带来的影响,使计算结果的敏感性降低.另一方面,在构造隶属函数时,可根据所需结果的质量对函数参数的准确性提出要求.比如,当可接受的预期满意度平均偏差在1.05%左右时,环境变量的隶属函数参数允许存在5%左右的浮动.
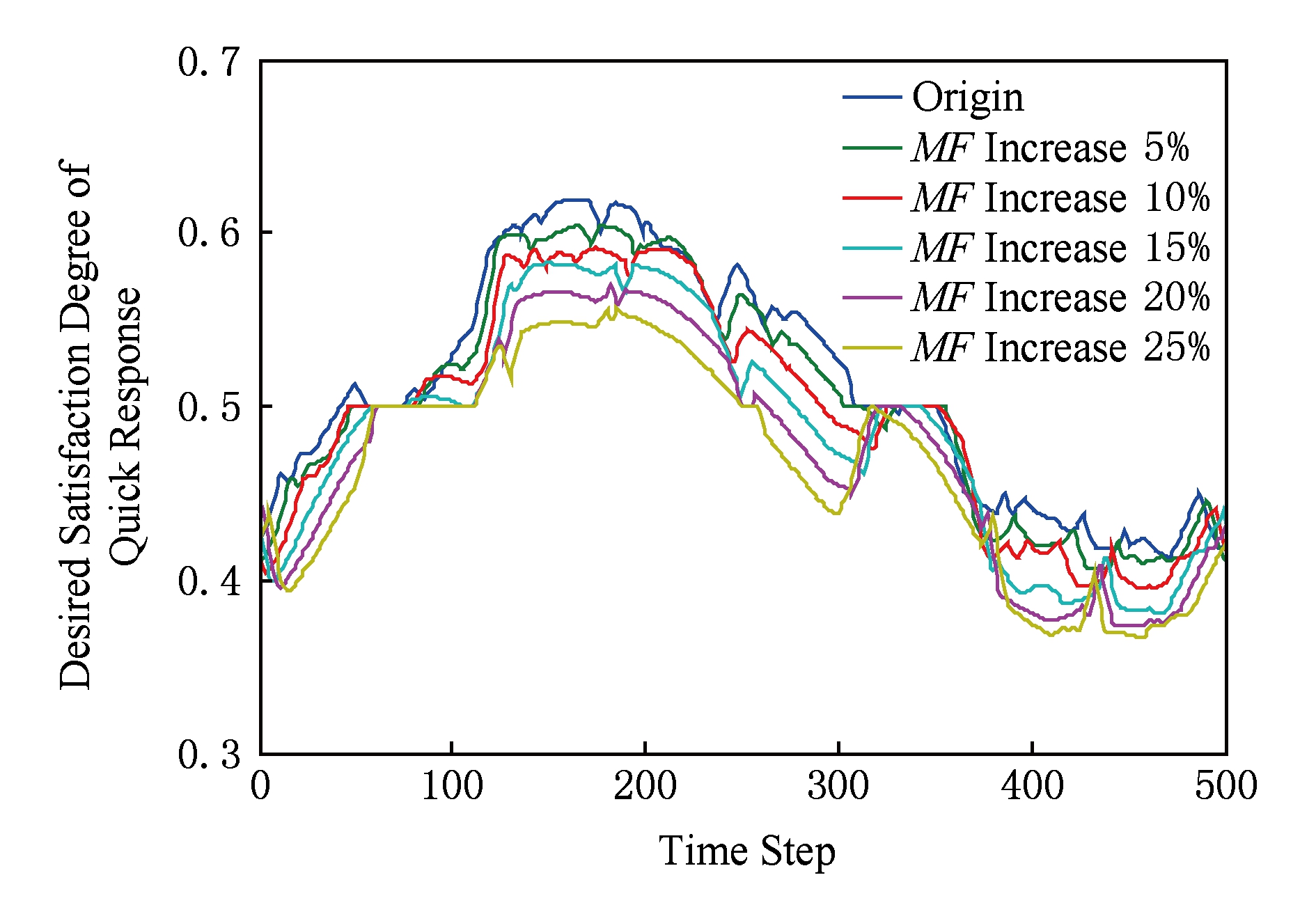
Fig. 16 Desired satisfaction degrees of quick response requirement under different membership function parameters
图16 不同隶属函数参数下的快速响应需求预期满意度
相关工作主要包括自适应系统如何通过建模和决策,以应对环境和需求的2种变化.
在面向环境变化的建模方面,Cheng等人 [7] 提出一种目标建模方法来构建动态适应系统的需求,描述环境不确定性对需求的影响,并通过RELAX [18] 规约语言来处理约束宽松的需求.该方法局限于描述需求不满足情况下的解决方案,没有关注运行时的自适应配置.Cheng [36] 最近将不确定性带来的挑战总结为基于模型的开发技术、自动需求确保技术和自适应决策技术3个方面.Bencomo等人 [8] 提出Claim模型,将环境对需求的影响作为需求变化的依据,并在模型层对软件行为作出解释.该模型还用于处理环境变化下的需求追踪问题 [9] .Ramirez等人 [10] 将RELAX和Claim融合,并对变化环境下的Claim模型的有效性给出说明,在需求模型的基础上显示化的描述出环境对松弛需求的影响,系统在不同环境中所满足需求也是不同的.但该模型用于记录有限的环境类别,当环境连续变化时,就不再适用了.
在面向环境变化的决策方面,现有工作主要采用方程计算的方式进行求解.Elkhodary等人 [11] 提出FUSION框架,通过特征重配置,消除环境变化对系统目标的影响.该方法支持环境不确定性下的配置调节,但是依赖于特征和决策目标间的数学关系,需要精确的领域知识为基础,应用条件较为严格.Esfahani等人 [12] 提出POISED框架,通过系统的全局优化配置来提高系统的质量属性.该方法评估了不确定性给质量属性带来的影响,分析不同配置在目标函数下的表现,以确定最优的解决方案.POISED有较好的普适性,但是它是一种基于架构的方法,与系统需求联系较弱,当有多组质量属性需要被提高时,该方法未能说明如何权衡不同质量属性.Lee等人 [13] 、Moreno等人 [14] 和Chen等人 [15] 分别采用概率方法针对特征模型、软件行为模型和目标需求模型求解自适应决策.这些工作主要关注软件行为不确定性对需求的影响.
在面向需求变化的建模方面,Sawyer等人 [16] 提出将自适应系统的需求作为运行时的实例予以监控,以支持系统自适应决策.该方法可用于自适应机制的设计,但未能支持决策求解.Baresi等人 [17] 提出FLAGS模型,在KAOS模型的基础上扩展自适应目标和自适应对策,通过将需求看做具有活性的运行时实例来触发自适应过程.该方法刻画了自适应需求和需求违背时的系统对策,同时提供良定的规约描述.但是其规约只用于对目标和调节策略的说明,未能支持在线的自动适应过程.Whittle等人 [18] 提出RELAX需求规约语言,它基于时态模糊逻辑描述松弛情况下的需求和环境.模糊化后的需求使系统具有灵活性,它也是一种用于规约的形式化方法,并未说明如何支持自适应调节过程.另外,RELAX放松了需求满足情况,但并未关注需求本身的变化性.Mendonca等人 [19] 提出根据上下文模型求解可靠性需求变化的框架,可靠性需求采用模糊逻辑进行量化,但没有关注自适应决策问题.此外,Chechik [20] 提出通过局部模型 [21] 建立需求模型间的追踪关系来管理需求不确定性.
在面向需求变化的决策方面,Pernici等人 [22-24] 从服务计算领域提出基于模糊推理实现服务自适应的方法.Web服务的性能参数变化引起服务质量的变化,服务质量变化是系统自适应调节的依据,调节过程基于领域知识实现.该类方法的切入点是软件行为变化对服务质量满足情况的影响,而不是对服务质量自身的影响.该种性能是软件行为的表现,因此变化并非来自交互环境,同时,该类方法的推理计算过程无法对自适应决策进行优化.另外,国内研究人员也对服务自身演化下的服务组合自适应方法进行了探讨 [37] .
与这些工作相比,本文在刻画环境和需求不确定性方面,侧重于通过建模过程抽取变化要素,采用模糊逻辑描述潜在的变化性,而不是枚举变化的可能性;同时将连续变量映射到离散域,以便于求解计算;在建模质量需求、环境和软件行为间的关系方面,本文根据用户偏好和领域知识抽取影响关系矩阵,进而生成推理规则.推理规则刻画出变量间的计算关系,摆脱了依赖精确系统数学模型的局限性.在实现自适应决策方面,本文将环境和需求不确定性纳入到统一的FADEM框架中,该框架支持从系统建模到规约描述,然后到推理规则生成,再到设计自适应机制、算法和组件结构的完整过程.该框架的优势在于,为软件工程师在需求工程阶段进行不确定性的表达、知识提取及模型算法的构建提供了理论依据和方法支持,并允许建模和计算过程具有一定的弹性.
本文提出一种在环境和需求不确定性下,自适应软件系统实现优化决策的框架.该框架通过需求建模、环境建模和软件配置建模,抽取出质量需求满意度、环境变量和配置参数,并通过模糊逻辑进行表示;描述各类变量间的影响关系,并根据影响权重矩阵构造模糊推理规则,以支持变量间的计算;基于前馈-反馈控制设计自适应机制及相应算法,并融合MAPE-K结构搭建自适应组件.
在自适应软件系统面向不确定性的在线决策研究方向上,本文具有4方面意义:
1) FADEM框架将环境和需求的不确定性同时纳入自适应机制的在线决策问题中,涉及到多种类型的环境变化(如取值变化型、状态变化型)和多种类型的自适应调节方式(如结构调节、参数调节);
2) 基于模糊逻辑的建模和描述方法具有通用性.形式化表达式通过变量范围刻画了变量潜在的不确定性,同时通过隶属函数将不确定的变量映射到离散的语言描述上;
3) 根据影响关系权值矩阵构建的推理规则,在不违背专家和用户认知的前提下,减轻了人工建立推理规则的复杂度.同时,构建的规则是考虑到所有影响因素后的综合结果;
4) 基于前馈-反馈结构建立的自适应机制,能与MAPE-K结构有机结合,以设计通用的自适应组件.在将软件建模为闭环系统的同时,还发挥了前馈控制和反馈控制的各自优势.
未来的研究工作中,我们主要关注2个方向:1)基于控制理论建立自适应机制是我们的关注点,尤其是软件系统辨识的问题,即如何找到更好的数学模型刻画软件系统的变化性,我们认为机器学习是解决软件系统辨识问题的有效途径;2)我们还关注模糊化需求的验证问题,并考虑如何通过需求放松和自适应机制给软件系统带来弹性.
参考文献
[1]Tversky A,Kahneman D. Judgment under uncertainty: Heuristics and biases[J]. Science, 1974, 185(1): 141-162
[2]Liu Baoding. Uncertainty Theory[M]. Berlin: Springer, 2007: 183-187
[3]Celikyilmaz A, Türksen I B. Modeling Uncertainty with Fuzzy Logic[M]. Berlin: Springer, 2011: 11-50
[4]Esfahani N, Malek S. Uncertainty in self-adaptive software systems[G] //LNCS 7475: Software Engineering for Self-Adaptive Systems Ⅱ. Berlin: Springer, 2013: 214-238
[5]Cheng B H C, Lemos R, Giese H, et al. Software engineering for self-adaptive systems: A research roadmap[G] //LNCS 5525: Software Engineering for Self-Adaptive Systems Ⅰ. Berlin: Springer, 2009: 1-26
[6]Yang Zhuoqun, Li Zhi, Jin Zhi, et al. A systematic literature review of requirements modeling and analysis for self-adaptive systems[C] //Proc of the 20th Int Working Conf on Requirements Engineering: Foundation for Software Quality. Berlin: Springer, 2014: 55-71
[7]Cheng B H C, Sawyer P, Benecomo N, et al. A goal-based modeling approach to develop requirements of an adaptive system with environmental uncertainty[C] //Proc of the 12th Int Conf on Model Driven Engineering Languages and Systems. New York: ACM, 2009: 468-483
[8]Bencomo N, Welsh K, Sawyer P, et al. Self-explanation in adaptive systems[C] //Proc of the 17th Int Conf on Engineering of Complex Computer Systems. Piscataway, NJ: IEEE, 2012: 157-166
[9]Welsh K, Sawyer P. Requirements tracing to support change in dynamically adaptive systems[C] //Proc of the 15th Int Working Conf on Requirements Engineering: Foundation for Software Quality. Berlin: Springer, 2009: 59-73
[10]Ramirez A J, Cheng B H C, Bencomo N, et al. RELAXing claims: Coping with uncertainty while evaluating assumptions at run time[C] //Proc of the 15th Int Conf on Model Driven Engineering Languages and Systems. New York: ACM, 2012: 53-69
[11]Elkhodary A, Esfahani N, Malek S. FUSION: A framework for engineering self-tuning self-adaptive software systems[C] //Proc of the 18th ACM SIGSOFT Int Symp on the Foundations of Software Engineering. New York: ACM, 2010: 7-16
[12]Esfahani N, Kouroshfar E, Malek S. Taming uncertainty in self-adaptive software[C] //Proc of the 19th ACM SIGSOFT Symp and the 13th European Conf on Foundations of Software Engineering. New York: ACM, 2011: 234-244
[13]Lee H C, Lee S W. Decision supporting approach under uncertainty for feature-oriented adaptive system[C] //Proc of the 39th Int Computer Software and Applications Conf. Piscataway, NJ: IEEE, 2015: 324-329
[14]Moreno G A, Mara J, Garlan D, et al. Proactive self-adaptation under uncertainty: A probabilistic model checking approach[C] //Proc of the 10th Joint Meeting of the European Software Engineering Conf and the ACM SIGSOFT Symp on the Foundations of Software Engineering. New York: ACM, 2015: 1-12
[15]Chen Bihuan, Peng Xin, Yu Yijun, et al. Uncertainty handling in goal-driven self-optimization - Limiting the negative effect on adaptation[J]. Journal of Systems & Software, 2014, 90(1): 114-127
[16]Sawyer P, Bencomo N, Whitle J. Requirements-aware systems: A research agenda for RE for self-adaptive systems[C] //Proc of the 18th IEEE Int Conf on Requirements Engineering. Piscataway, NJ: IEEE, 2010: 95-103
[17]Baresi L, Pasquale L, Spoletini P. Fuzzy goals for requirement-driven adaptation[C] //Proc of the 18th Int Conf on Requirements Engineering. Piscataway, NJ: IEEE, 2010: 125-134
[18]Whittle J, Sawyer P, Bencomo N, et al. RELAX: A language to address uncertainty in self-adaptive systems requirement[J]. Requirements Engineering, 2010, 15(2): 177-196
[19]Mendonca D F, Ali R, Rodrigues G N. Modelling and analysing contextual failures for dependability requirements[C] //Proc of the 9th Int Symp on Software Engineering for Adaptive and Self-Managing Systems. Piscataway, NJ: IEEE, 2014: 55-64
[20]Chechik M. Managing requirements uncertainty with partial models[J]. Requirements Engineering, 2013, 18(18): 107-128
[21] Famelis M, Salay R, Chechik M. Partial models: Towards modeling and reasoning with uncertainty[C] //Proc of the 34th Int Conf on Software Engineering. Piscataway, NJ: IEEE, 2012: 573-583
[22]Pernici B, Siadat S H. A fuzzy service adaptation based on QoS satisfaction[C] //Proc of the 23rd Int Conf on Advanced Information Systems Engineering. Berlin: Springer, 2011: 48-61
[23]Pernici B, Siadat S H, Benbernou S, et al. A penalty-based approach for QoS dissatisfaction using fuzzy rules[C] //Proc of the 9th Int Conf on Service-Oriented Computing. New York: ACM, 2011: 574-581
[24]Pernici B, Siadat S H. Selection of service adaptation strategies based on fuzzy logic[C] //Proc of the 7th IEEE World Congress on Services. Piscataway, NJ: IEEE, 2011: 99-106
[25]Souza V E S, Lapouchnian A, Mylopoulos J. System identification for adaptive software systems: A requirements engineering perspective[C] //Proc of the 30th Int Conf on Conceptual Modeling. Berlin: Springer, 2011: 346-361
[26]Patikirikorala T, Colman A, Han J, et al. A systematic survey on the design of self-adaptive software systems using control engineering approaches[C] //Proc of the 7th ICSE Workshop on Software Engineering for Adaptive and Self-Managing Systems. Piscataway, NJ: IEEE, 2012: 33-42
[27]Müller H, Villegas N. Runtime evolution of highly dynamic software[G] //Evolving Software Systems. Berlin: Springer, 2014: 229-264
[28]Kephart J O, Chess D M. The vision of autonomic computing[J]. Computer, 2003, 36(1): 41-50
[29]Nakamoto S. Bitcoin: A peer-to-peer electronic cash system[OL]. 2009[2016-09-16]. https://bitcoin.org/bitcoin.pdf
[30]Jackson M. The meaning of requirements[J]. Annals of Software Engineering, 1997, 3(1): 5-21
[31]Zadeh L A. The concept of a linguistic variable and its application to approximate reasoning-I[J]. Information Sciences, 1975, 8(3): 199-249
[32]Passino K M, Yurkovich S. Fuzzy Control[M]. Menlo Park, CA: Addison Wesley Longman, 1997: 137-144
[33]Zadeh L A. Fuzzy sets[J]. Information & Control, 1965, 8(3): 338-353
[34]Mamdani E H. Advances in the linguistic synthesis of fuzzy controllers[J]. International Journal of Man-Machine Studies, 1976, 8(6): 669-678
[35]Takagi T, Sugeno M. Fuzzy identification of systems and its applications to modeling and control[J]. IEEE Trans on System, 1985, 15(1): 387-403
[36]Cheng B H C. Addressing assurance for self-adaptive systems in the face of uncertainty[C] //Proc of the 13th Int Conf on Autonomic Computing. New York: ACM, 2016: 2
[37]Ren Lifang, Wang Wenjian, Xu Xing. Uncertainty-aware adaptive service composition in cloud computing[J]. Journal of Computer Research and Development, 2016, 53(12): 2867-2881 (in Chinese)
(任丽芳, 王文剑, 许行. 不确定感知的自适应云计算服务组合[J]. 计算机研究与发展, 2016, 53(12): 2867-2881)
Yang Zhuoqun 2 and Jin Zhi 1,3
1 ( Key Laboratory of High Confidence Software Technologies ( Peking University ), Ministry of Education , Beijing 100871) 2 ( Institute of Mathematics , Academy of Mathematics and Systems Science , Chinese Academy of Sciences , Beijing 100190) 3 ( Insitute of Software , School of Electronics Engineering and Computer Science , Peking University , Beijing 100871)
Abstract Software systems intensively interact with other software  hardware systems, devices and users. The operation environment of software becomes unstable and software requirements may also change. Due to the fact that it is hard to predict the environment and requirements at runtime, their changes become uncertain. For providing continuous service, software systems need to adjust themselves according to changes in the environment and themselves. Uncertainties bring great challenges to the adaptation process. Existing related efforts either target at modeling the effects on requirements caused by environmental changes, or focus on how to adjust software behaviors to satisfy fixed requirements under changing environment. With these approaches, it is difficult to deal with the variability and complexity in the adaptation process when requirements are uncertain. This paper proposes a fuzzy control based adaptation decision-making approach, to tackling environment and requirements uncertainties at runtime. It applies fuzzy logic to model and specify variables existing in the environment and software, and generates reasoning rules between variables; designs the adaptation mechanism based on the feedforward-feedback control structure and fuzzy controllers; implements decision-making through fuzzy inference and genetic algorithm. The adaptation results under different environment and constraints show that software can achieve the optimal decision with the adaptation mechanism and algorithms. The feasibility and effectiveness of the approach are illustrated through a mobile bitcoin-miner system.
hardware systems, devices and users. The operation environment of software becomes unstable and software requirements may also change. Due to the fact that it is hard to predict the environment and requirements at runtime, their changes become uncertain. For providing continuous service, software systems need to adjust themselves according to changes in the environment and themselves. Uncertainties bring great challenges to the adaptation process. Existing related efforts either target at modeling the effects on requirements caused by environmental changes, or focus on how to adjust software behaviors to satisfy fixed requirements under changing environment. With these approaches, it is difficult to deal with the variability and complexity in the adaptation process when requirements are uncertain. This paper proposes a fuzzy control based adaptation decision-making approach, to tackling environment and requirements uncertainties at runtime. It applies fuzzy logic to model and specify variables existing in the environment and software, and generates reasoning rules between variables; designs the adaptation mechanism based on the feedforward-feedback control structure and fuzzy controllers; implements decision-making through fuzzy inference and genetic algorithm. The adaptation results under different environment and constraints show that software can achieve the optimal decision with the adaptation mechanism and algorithms. The feasibility and effectiveness of the approach are illustrated through a mobile bitcoin-miner system.
Key words self-adaptive software system; uncertainty; requirements engineering; feedforward-feedback control; fuzzy logic; optimal decision-making
摘 要 软件系统在运行时会与其他软硬件系统、设备和用户发生密切交互.软件运行环境呈现出不稳定的特点,同时软件需求也可能会发生变化.由于难以准确预测和描述软件运行时的环境及需求,两者的变化具有不确定性.为提供持续服务,软件需要通过自适应能力,根据环境和自身的变化来调节其行为.不确定性给软件的自适应过程带来很大挑战.现有相关工作主要关注环境变化给需求带来的影响,以及环境变化时如何调节软件行为来满足固定的需求.这些方法难以处理需求不确定时自适应过程中的变化性和复杂性.针对该问题,提出一种基于模糊控制的自适应决策方法,以应对运行时环境与需求的不确定性.首先通过模糊逻辑建模与规约环境和软件中的变化要素,并构建要素间的推理规则;其次基于前馈-反馈控制结构和模糊控制器设计自适应机制;最后通过模糊推理和遗传算法实现决策求解.不同环境和约束下的自适应结果表明:软件能够通过自适应机制和算法求得优化决策.为验证方法的可行性和有效性,通过一个移动端比特币采矿机案例进行了评估.
关键词 自适应软件系统;不确定性;需求工程;前馈-反馈控制;模糊逻辑;优化决策
中图法分类号 TP311.5
收稿日期 :2016-12-27;
修回日期: 2017-04-27
基金项目 :国家“九七三”重点基础研究发展计划基金项目(2015CB352200);国家自然科学基金项目(61620106007)
This work was supported by the National Basic Research Program of China (973 Program) (2015CB352200) and the National Natural Science Foundation of China (61620106007).
通信作者 :金芝(zhijin@pku.edu.cn)
DOI: 10.7544/issn1000-1239.2018.20161039

Yang Zhuoqun , born in 1988. PhD. His main research interests include self-adaptive systems, intelligent algorithms, requirements engineering and control theory.

Jin Zhi , born in 1962. PhD, professor, PhD supervisor. Fellow member of CCF. Her main research interests include requir-ements engineering, knowledge engineering and artificial intelligence.