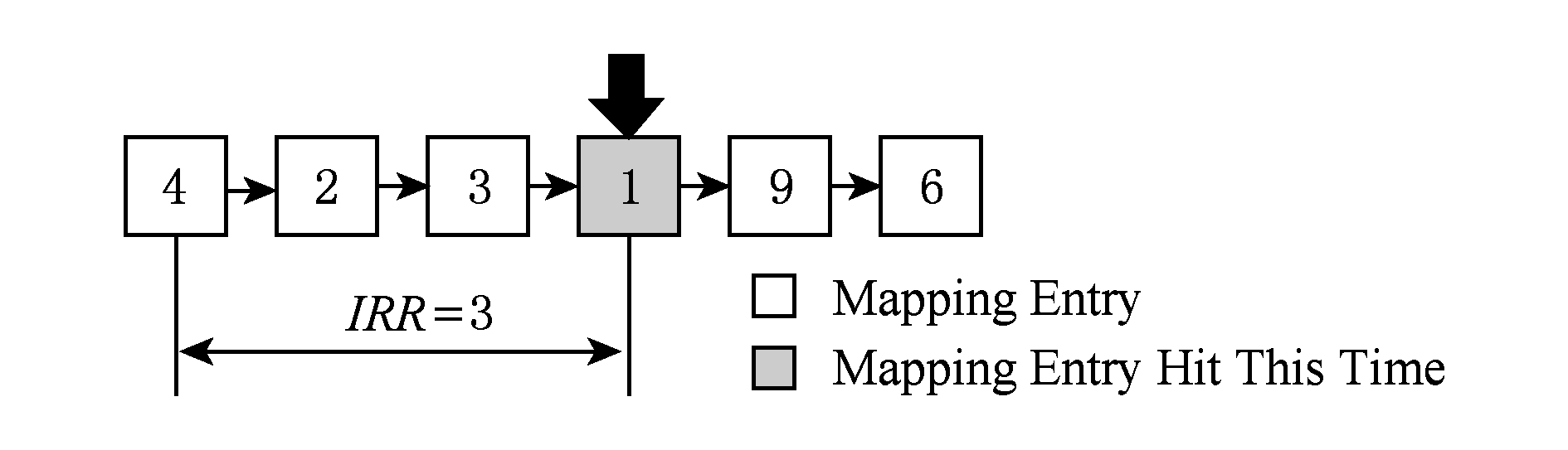
Fig. 1 Translation entry’s IRR in cache mapping table
图1 缓存映射表中被命中映射项的重用距离
周权彪 张兴军 梁宁静 霍文洁 董小社
(西安交通大学计算机科学与技术系 西安 710049) (zhouquanbiao1991@163.com)
在当前计算机应用向数据密集型转变的大趋势下,现代计算机系统对外存IO性能的要求不断提高.磁盘作为传统外存设备,虽然容量大、成本低,但是由于固有机械部件的限制,其IO性能无法满足当下快速交互型应用的需求.闪存作为一种无机械结构存储介质,性能远优于磁盘,具有随机存取速度快、能耗低、抗震能力好等优点,是外存介质的理想选择.随着闪存技术的不断成熟,闪存被广泛应用于消费电子和企业级计算机系统中,以大容量缓存或外存的形式存在 [1] .
闪存采用浮栅型场效应管作为数据储存单元,通过场效应管内浮置栅极存储的电荷量多少表示不同的数据.这种不同于磁盘的数据存储方式,使得闪存具有其独特的读写性质,包括“按页读写”、“按块擦除”和“写前先擦除” [2] ,其含义分别是:1)“按页读写”是指对闪存的读写操作必须以物理页为单位进行;2)“按块擦除”是指闪存擦除操作必须以物理块为单位进行;3)“写前先擦除”(erase-before-write)是指1个闪存单元在经过1次写入操作后,必须对该闪存单元进行1次擦除操作后,才能够写入新数据.
由于这3个性质的限制,对闪存的数据更新操作必须采取“异地更新”(out-of-place update) [3] 的方式完成.“异地更新”是指在闪存中,对某一逻辑地址的写入操作,不能直接将新的数据内容覆盖写到原有逻辑地址对应的物理地址上,而必须将新数据内容写入一个新的空闲物理地址,然后通过修改逻辑地址和物理地址映射信息的方式,使逻辑地址指向新的物理地址,并将原物理地址的数据无效化,从而达到更新数据的目的.
由于闪存拥有这些独特的性质和操作,在闪存存储系统中,为了屏蔽闪存与传统磁盘不一样的读写特性,需要一个专用软件层来对闪存进行管理和优化,这就是闪存转换层(flash translation layer,FTL) [4] .闪存转换层作为闪存系统中的核心软件管理层,在整个闪存软件栈中起到屏蔽闪存底层存取细节,向上层文件系统提供存取接口的作用.通过闪存转换层,闪存固态盘被封装成像磁盘一样的块设备,上层文件系统不需要修改,即可像读写磁盘一样,正常地读写闪存固态盘.闪存转换层具有一些重要的功能,如地址映射、垃圾回收、磨损均衡、坏块管理、读写数据缓存、闪存数据纠错和数据加密等 [4] .
闪存转换层地址映射方法的优劣极大影响到闪存的性能和寿命.DFTL(demand-based FTL) [5] 是经典的地址映射方法,它把较大的全局映射表放在闪存中,只将常用的映射项放在缓存中,根据映射项访问的近期性作为缓存替换的依据.
DFTL同样存在一些问题.首先,DFTL采用最近最少使用(least recently used, LRU)替换算法充分尊重了时间局部性原理,但忽略了负载的空间局部性特点,使得在负载访问的地址空间发生变化时会发生频繁的缓存失效,导致缓存命中率的下降.
此外,在发生缓存失效时,如果被换出的映射项是脏映射项,即若该映射项曾被修改,那么必须将该脏映射项写回闪存,以保证元数据映射信息的一致性.而脏映射项的频繁换出,会带来对闪存的频繁写操作,为闪存的性能和寿命带来额外负担.
另一方面,DFTL无法优化闪存中存在的由于垃圾回收导致的写放大(write amplification) [6] 问题.写放大问题指对闪存系统实际写入的数据量大于文件系统请求写入的数据量.闪存的垃圾回收过程是造成写放大问题的主要因素之一.在垃圾回收过程中,若被回收物理块内有未被覆写的有效数据页,则必须进行有效页迁移操作,每个有效页需要至少1次读操作和1次写操作来完成迁移过程.此外,有效页的迁移还会导致其对应的逻辑地址和物理地址映射信息发生改变,从而引起额外的元数据读写操作.被回收物理块内的有效页越多,则需要迁移的有效页也越多,对闪存性能和寿命带来的负面影响也更大.
针对上述问题,本文研究采用基于缓存映射项重用距离的地址映射方法IRR-FTL(inter-reference recency-based FTL),优化闪存地址映射过程.本文的贡献主要在:1)通过设置独立的映射页缓存槽,充分利用负载的空间局部性,提高缓存映射表的命中率.2)通过基于缓存映射项重用距离的负载自适应写缓存映射表冷热分区方法,将写缓存映射表分为热写缓存映射表和冷写缓存映射表,并对冷写缓存映射表采取非脏映射项优先换出和脏映射项最大化批量更新的策略,减少映射页写回次数.3)针对闪存垃圾回收中存在的写放大问题,实现基于缓存映射项重用距离的冷热数据分离存储,提高垃圾回收效率.
闪存转换层的地址映射过程是指SSD系统将上层文件系统请求的逻辑地址,通过地址映射表转换为下层闪存物理地址的过程.闪存转换层的地址映射策略 [4] ,可以根据地址映射粒度的大小,大致分为3种,即页级地址映射策略 [5,7-10] 、块级地址映射策略 [4] 和基于日志块的混合地址映射策略 [11-13] .
在页级地址映射策略中,每一个逻辑页地址可以映射到任意一个物理页地址.因此在页级地址映射表中,需要记录每一个逻辑页和对应物理页的映射关系.这种映射方式灵活高效、优化空间大、性能较好,但由于映射粒度较小,导致映射表条目较多,因此需要维护一个较大的页级地址映射表.但由于目前固态盘容量越来越大,而在固态盘中往往采用存取速度极快、单位存储成本较高的RAM,因此一般完整的页级地址映射表无法全部装入RAM中,因此纯页级映射策略在实际中应用较少.
在块级地址映射策略中,每一个逻辑块可以映射到任意一个物理块上,块内的数据页则需要严格按照逻辑地址的块内偏移量进行排列 [4] .相比于页级地址映射策略,块级地址映射策略的映射粒度大,所以块级地址映射表较小,占用的RAM空间较少.但是,为了维护块内数据页的偏移量,块级地址映射策略在进行垃圾回收过程中,需要进行数据块合并操作,这种合并操作往往涉及到大量数据页的拷贝和移动,对闪存的性能影响较大.因此,相对于页级地址映射策略而言,块级地址映射策略是以牺牲映射灵活性和性能为代价,换取空间开销的减少.
在基于日志块的混合地址映射策略中,闪存分为数据块区(data block area)和日志块区(log block area).其中数据块区采用块级地址映射策略,而日志块区采用页级地址映射策略,日志块区仅占闪存总容量的3% [13] .通过日志块暂时接纳写入的无序数据,当日志块区满时,再使用合并操作(merge operation),将日志块与对应的数据块进行合并.由于日志块采用性能较好的页级地址映射策略,因此可以较好地吸收随机写入的数据.但是由于在日志块与数据块的合并过程中,有较大几率发生开销较大的“全合并”(full merge)操作,因此基于日志块的混合地址映射策略同样会出现闪存性能下降的现象.典型的基于日志块的混合地址映射策略包括BAST [11] ,FAST [12] ,SuperBlock [13] .
为了解决基于日志块的混合地址映射策略中合并操作带来的额外读写开销问题,2009年Gupta等人 [5] 提出了基于需求的闪存转换层地址映射方法DFTL.DFTL采用页级地址映射策略,无需数据块合并操作,它将占用空间较大的全局页级地址映射表以映射页的形式存放在容量较大的闪存中,在容量较小而速度较快的RAM中设置缓存映射表,根据负载需求,动态地将最近最常使用的映射信息换入缓存映射表中,实现性能和RAM空间开销的平衡.此外,DFTL还在RAM中设置全局映射目录(global translation directory, GTD)记录映射页在闪存中的物理位置.DFTL采用逻辑页级的LRU算法保证缓存映射表的命中率,减少由于缓存失效造成的元数据换入换出操作;通过批量更新和推迟拷贝技术,减少由于元数据更新而造成的闪存映射页写回操作,提高闪存IO性能.但DFTL未充分利用负载的空间局部性特点提高缓存命中率.缓存中脏映射项的频繁换出也会带来额外映射页操作开销.此外,DFTL也未能对闪存垃圾回收过程中存在的有效页迁移开销进行优化.
此后,针对DFTL存在的问题,国内外有许多基于DFTL的研究被提出 [7-10, 14-17] .LazyFTL [7] 通过设置更新数据区和冷数据区分离冷热数据,并通过设置更新映射表推迟映射信息的更新操作;通过设置标志位,选择更新开销最小的映射信息进行更新,减少映射页额外操作.OAT [8] 则将缓存映射信息的粒度从映射项增大到映射页,以提高命中率;同时,为了解决DFTL的垃圾回收过程中涉及过多映射页的问题,通过将映射页对应的数据页聚集到同一物理块内,减少垃圾回收过程中的映射页操作.TPFTL [9] 则充分挖掘负载的空间局部性,根据缓存中映射项特征,动态调整预取的映射项数量,提高缓存命中率.CPFTL [10] 将映射表划分为冷映射表和热映射表,对冷映射表采用页聚簇的方法,减少由于映射项换出而导致的额外映射页操作.与文献[7-10]不同,本文通过独立的映射页缓存槽挖掘负载的空间局部性,提高缓存命中率.此外,通过缓存映射项重用距离,实现负载自适应的写缓存映射表冷热分区方法,优先换出冷写缓存映射表中已被更新的非脏映射项,并且采用脏映射项最大化批量更新策略,减少由于缓存失效造成的映射页操作开销.
另一方面,在闪存中冷热数据分离存储对减少垃圾回收开销、提高垃圾回收效率有重要作用 [3] .通过将热度相近的页面存储在同一物理块中,使得同一物理块内的页面更有可能在相近的时间段内被更新,从而减少在垃圾回收过程时进行的有效页迁移次数,提高垃圾回收效率.有诸多文献是通过闪存冷热数据分离存储 [14-17] ,减少垃圾回收过程中的有效页迁移开销,提高闪存性能.
LAST [14] 采用不同的地址映射策略管理随机请求和连续请求,同时通过冷热数据分离,减少垃圾回收开销.HFTL [15] 则基于多Hash框架,先识别冷热逻辑块,再进一步判断热逻辑块内部的逻辑页冷热性质,找出被频繁更新的逻辑页,实现冷热数据分离.文献[16]采用多层布隆过滤器的方法分离冷热数据,不仅考虑了数据存取频率,还考虑了数据使用的近期性,采用滑动窗口的方式捕捉细粒度的数据近期性信息,实现闪存冷热数据分离.不同于上述基于数据存取频率判别数据冷热性质的方法,本文将数据访问的重用距离作为判断冷热数据的标准,相比数据访问频率,数据访问重用距离对数据的冷热变化更敏感.而对于闪存而言,数据页的写入重用距离即是数据页被无效化的时间间隔,因此也更适合作为闪存冷热数据分离标准.
ASA-FTL [17] 将逻辑页写入间隔作为冷热数据分离的依据,记录每一个逻辑页面的写入间隔大小,并采用抽样聚类的方式将页面分组存储,实现冷热数据分离.与之类似,本文同样将页面写入间隔,即数据页写入重用距离作为判断冷热性质的依据,但是相比ASA-FTL,IRR-FTL不需要记录所有页面的重用距离,而是通过分离出在当前负载中热度较高的缓存映射项,从而识别出当前热度较高的数据页,从而在节省空间开销的同时降低记录和计算页面重用距离的复杂性.
针对写缓存映射表,本文提出一种基于缓存映射项重用距离的写缓存映射表冷热分区方法.不同于采用访问频率作为分离标准,本方法将缓存映射表中的写缓存映射项分为重用距离较短的热映射项和重用距离较长的冷映射项,并根据冷热重用距离阈值将写缓存映射表分为热写缓存映射表和冷写缓存映射表.同时,该方法能够根据负载局部性情况动态调节冷热分区的相对大小,实现负载自适应.
一般而言,对数据对象的热度有2种评价方法:1)根据数据对象在一定时间间隔内的访问次数即访问频率来判断页面热度 [13] .访问频率越高的页面,则其热度越高;相反,若某页面在一个较长时间间隔内访问次数较少,则证明其热度较低.2)数据对象热度评价方法,则是根据数据对象2次访问之间的时间间隔 [18] ,即重用距离进行判断.若数据对象2次访问之间的时间间隔较短,则该数据对象更有可能是热度较高的数据对象.
基于数据对象访问频率的冷热数据判别方法是判断冷热数据最直接的方法.但是,由于现实中的工作负载处于不断变化的过程之中,在前一个时间段内访问次数较多的热数据可能会因为负载变化而冷却成为访问较少的冷数据,但此时热数据可能会由于前一个时间段较高的访问次数,而需要经过较长的时间后才会被冷却.相比之下,数据对象2次访问的时间间隔,即重用距离,对负载的变化则更为敏感.当新数据对象的访问时间间隔短于热数据最后一次访问时间点距离当前时间点的时间间隔时,新数据对象即可取代原来的热数据对象,成为新的热数据.在本文中,数据对象是指缓存映射项,重用距离特指对特定逻辑页地址的2次写入操作之间的时间间隔.
对闪存而言,某一逻辑页面的2次写入操作之间的时间间隔,代表了该页面在第1次写入闪存后,其数据页在闪存中作为有效数据页存在直至被无效化的时间间隔.若该时间间隔越短,则该页面热度越高,同时也意味着该页面被无效化越快,在垃圾回收时更有可能不需要进行额外的有效页迁移操作.因此,相对于使用页面访问频率作为冷热数据判断标准,页面的写入时间间隔,即重用距离,更适合作为闪存数据冷热分离的判断依据.
映射项重用距离(inter-reference recency, IRR ) [18] ,此处特指写入重用距离,是指对某一映射项的2次写入之间,间隔地被其他写入请求访问的不同的映射项数量.例如对于写入访问序列:{1,2,3,2,4,1,4}、映射项1的2次访问之间,间隔了3个不同的逻辑页映射项2,3,4,因此映射项1的重用距离是3.同理,映射项4的重用距离是1.
采用映射项重用距离作为区分冷热元数据的标准,是因为相对于映射项访问频率而言,重用距离对映射项热度的变化更敏感.此外,映射项的重用距离也隐含了映射项对应的数据页在闪存中被无效化的写入间隔.如果一个映射项的重用距离为5,则意味着在经过5次写入操作之后,该映射项对应的数据页被无效化.因此,重用距离更适合用于闪存冷热数据分离.
本文在缓存映射表中使用LRU链表来计算缓存映射项的重用距离.在某时刻,在缓存映射表的LRU链表中,某命中的映射项的重用距离,可以表征为:该映射项被命中时,其结点所在位置距离链表首部的距离.如图1所示,若此时映射项1被命中,则映射项1的重用距离为该映射项距离链表首部的距离,此时是3.
Fig. 1 Translation entry’s IRR in cache mapping table
图1 缓存映射表中被命中映射项的重用距离
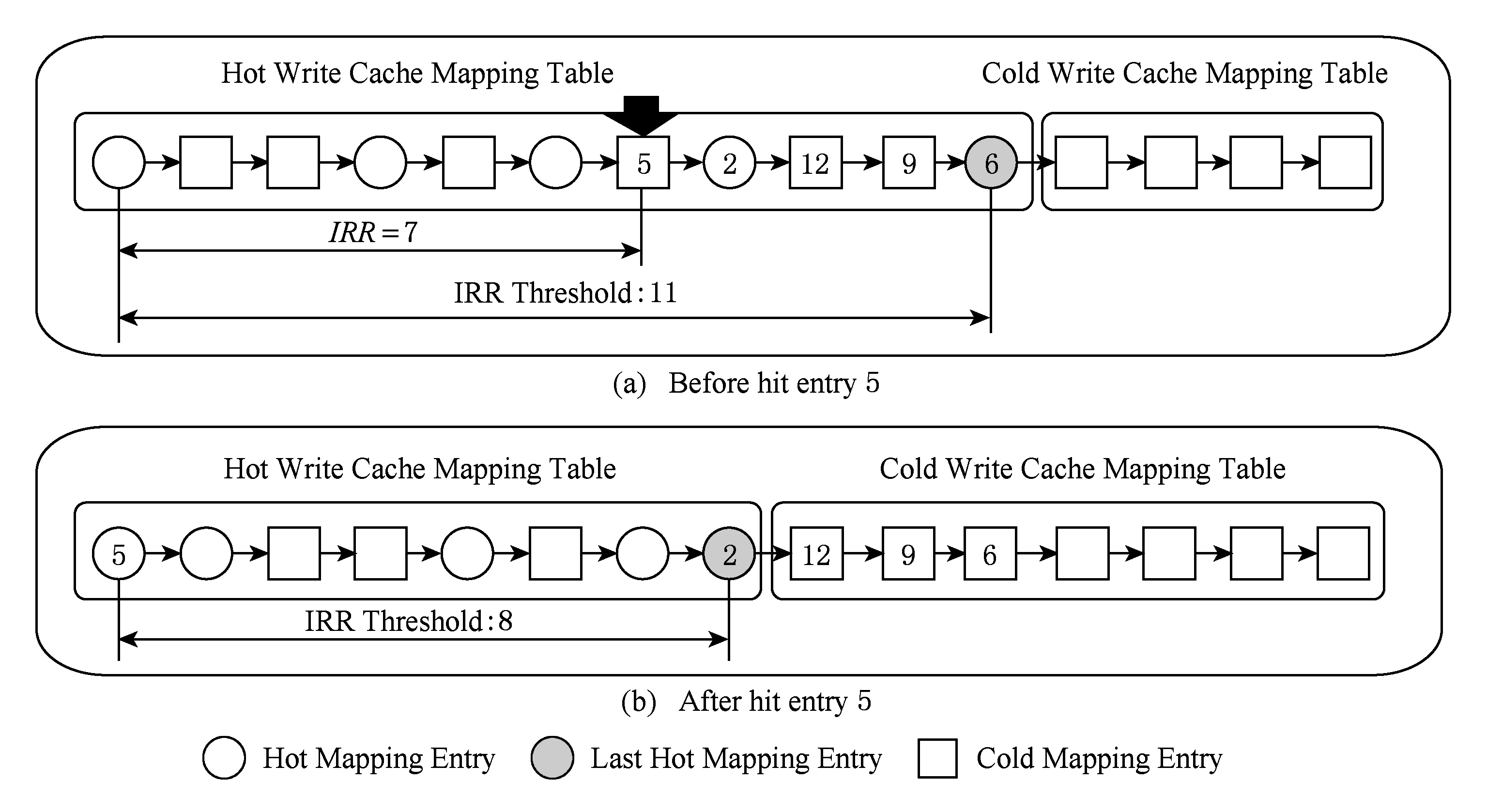
Fig. 2 The workload adaptive hot/cold cache mapping area based on IRR
图2 基于重用距离的负载自适应写缓存映射表冷热分区
同时,我们定义某时刻映射项的潜在重用距离为:当前时刻,该映射项结点距离链表首部的距离.若当前时刻,该映射项被命中,则该映射项潜在重用距离等于重用距离.某一时刻某一映射项的潜在重用距离,表征在当前时刻该映射项可能达到的最短重用距离,该映射项下一次命中时的重用距离大于或等于潜在重用距离,若该时刻该映射项命中,则等号成立.
在基于缓存映射项重用距离的缓存映射表中,将映射项根据上一次命中时重用距离的大小分为冷缓存映射项和热缓存映射项.缓存映射项链表同样遵循LRU规则,每次命中的映射项,无论是冷缓存映射项或是热缓存映射项,都会被移动到链表首部.而在缓存中,冷热重用距离阈值即为链表中最后一个热映射项的潜在重用距离.
冷热映射项之间的转换规则可以定义为:当某一冷映射项命中时,若该冷映射项的重用距离比最后一个热映射项的潜在重用距离更短,即若该冷映射项比最后一个热映射项更靠近链表首部,则该冷映射项可以取代最后一个热映射项成为热映射项.这是因为,在某时刻,若某冷映射项命中时,其位置在最后一个热映射项之前,则该命中的冷映射项当前的重用距离必定比最后一个热映射项未来命中时的重用距离更短.因此,该冷映射项可以代替原来的最后一个热映射项转变为热映射项,而最后一个热映射项作为潜在重用距离最长的热映射项,将被转换为冷映射项.
举例分析,有如图2(a)所示的LRU链表,当冷映射项5被命中时,此时映射项5的重用距离为7,而最后一个热映射项6的潜在重用距离为11,意味着热映射项6在未来命中时的重用距离大于等于11,比冷映射项5的重用距离更长,因此冷映射项5可以取代热映射项6成为新的热映射项,而热映射项6则被冷却为冷映射项.
如图2所示,本文基于缓存映射项的重用距离,以最后一个热映射项为界,将写缓存映射表分为热写缓存映射表(hot write cache mapping table, HW - CMT )和冷写缓存映射表(cold write cache mapping table, CW - CMT ).潜在重用距离小于冷热重用距离阈值的映射项在 HW - CMT 中,潜在重用距离大于冷热重用距离阈值的映射项在 CW - CMT 中.
HW - CMT 中存放的是最后一个热映射项之前的映射项,即所有的热映射项和一部分最近发生写入操作的冷映射项.由于该部分冷映射项最近曾被访问,如果再次命中,则由于其重用距离比最后一个热映射项的潜在重用距离更短,因此可以代替最后一个热映射项,转换为新的热映射项,并被放到 HW - CMT 链表首部.
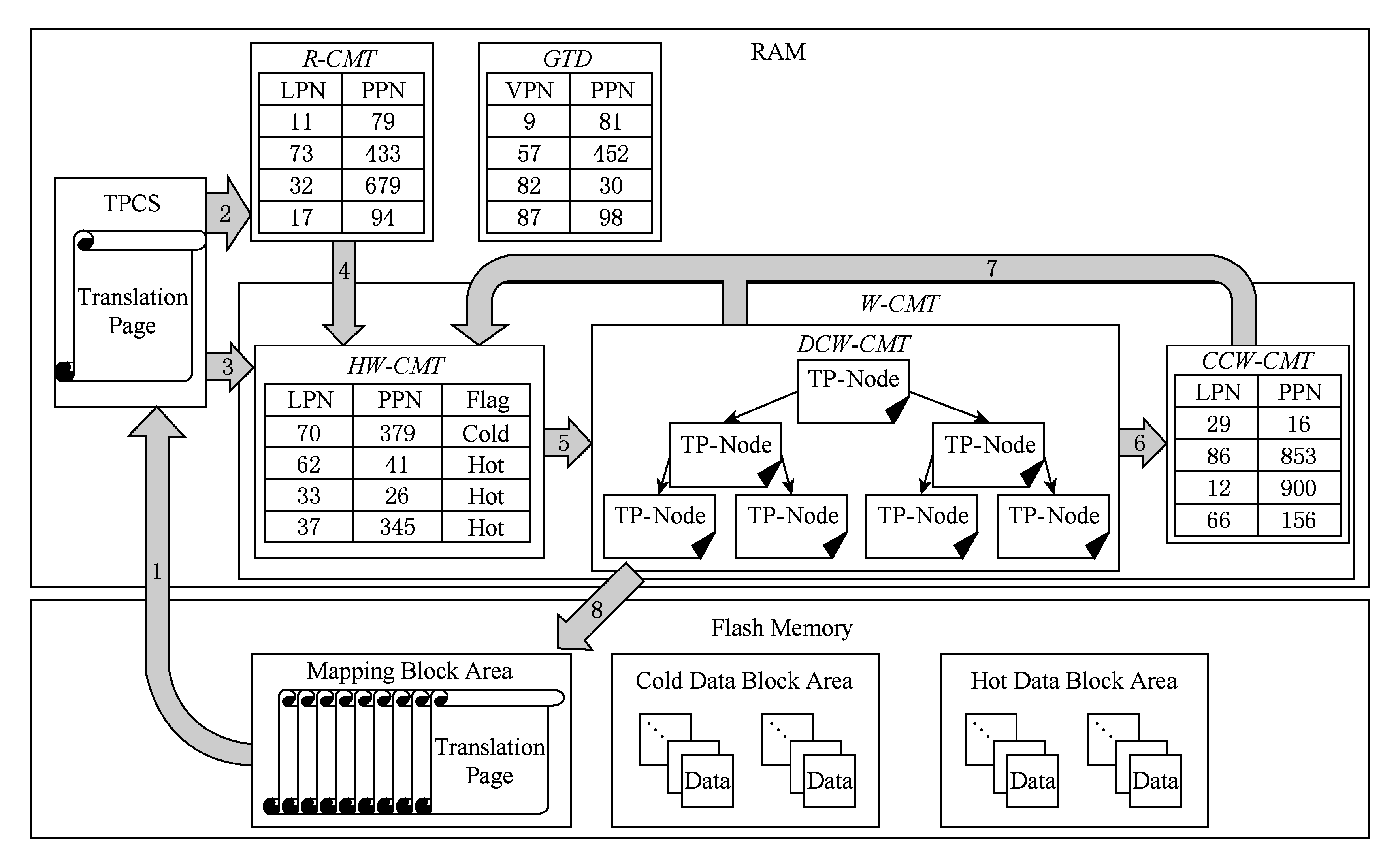
Fig. 3 The overall framework of IRR-FTL
图3 IRR-FTL整体框架
CW - CMT 中存放的是最后一个热映射项之后的冷映射项. CW - CMT 中的冷映射项即使再次命中,因为其当前命中的重用距离大于最后一个热映射的潜在重用距离,所以无法转换为热映射项,而是以冷映射项的形式再次插入 HW - CMT 链表首部,给予其在 HW - CMT 被命中而转换为热映射项的机会.当写缓存发生失效且写缓存已满时,系统会从 CW - CMT 中采用特定策略选择映射项进行换出操作.
当 HW - CMT 中的最后一个热映射项被转换为冷映射项或最后一个热映射项因被命中而被移动到 HW - CMT 队首时,会进行“剪枝”操作,即将 HW - CMT 链表尾部所有的非热映射项移动到 CW - CMT 中,保证了冷热写缓存映射表分区原则,即 HW - CMT 链表的最后一个映射项是热映射项.如图2(a)所示,当冷映射项5因命中而转变为热映射项时,最后一个热映射项6将转化为冷映射项.此时,由于 HW - CMT 最后一个映射项不是热映射项,因此发生“剪枝”操作,如图2(b)所示,冷映射项12,9,6将落入 CW - CMT 中.而最后一个热映射项变为映射项2,冷热重用距离阈值将变为8.
如图2所示,在本方法中, HW - CMT 和 CW - CMT 的总大小是固定的.但是,它们的相对大小是不断变化的. HW - CMT 和 CW - CMT 的相对大小由最后一个热映射项的潜在重用距离决定的.若最后一个热映射项距离链表首部越远,则 HW - CMT 越大、 CW - CMT 越小.当冷热映射项的比例一定时,若负载的局部性越强,则最后一个热映射项越靠近链表首部, HW - CMT 越小, CW - CMT 越大;相同负载环境下,若热映射项比例越小,则最后一个热映射项距离链表首部更近, HW - CMT 越小, CW - CMT 越大.
因此,为了保证 CW - CMT 不为空,需要维持 CW - CMT 的长度处于一个合理的区间内.当 CW - CMT 小于该区间时,系统会通过减少热映射项数量的方式,使最后一个热映射项位置靠前,使得更多的映射项落入 CW - CMT 中;当 CW - CMT 大于该区间时,系统会通过增大热映射项数量的方式,使最后一个热映射项位置靠后,从而使更多映射项被保留在 HW - CMT 中.
本文基于页级地址映射策略,提出一种基于缓存映射项重用距离的闪存转换层地址映射方法IRR-FTL.图3展示了IRR-FTL系统整体框架.
IRR-FTL通过设置独立的映射页缓存槽,充分利用负载的空间局部性,提高缓存命中率;通过读写缓存映射表分离,避免读请求对计算写入重用距离造成影响;通过基于缓存映射项重用距离的负载自适应写缓存映射冷热分区方法,分离出重用距离较长的热映射项和重用距离较短的冷映射项,并将其对应数据写入不同的闪存区域,实现冷热数据分离;此外,将冷写缓存映射表分为非脏缓存映射区和脏缓存映射区,通过非脏映射项优先换出和脏映射项最大化批量更新的方式,减少映射信息写回开销,提高闪存性能.
IRR-FTL将闪存分为冷数据区(cold data block area)、热数据区(hot data block area)和映射块区(mapping block area),分别存储冷用户数据、热用户数据和全局映射表.全局映射表以映射页的形式存储在闪存的映射块区中.在RAM中,使用全局转换目录(global translation directory, GTD )记录映射页在闪存中的物理位置.系统分别设置读缓存映射表(read cache mapping table, R - CMT )和写缓存映射表(write cache mapping table, W - CMT ).通过分离读写缓存映射表,避免读请求对写请求重用距离计算造成的影响.同时,为了适应负载变化,系统会根据前一段时间负载的读写比例,动态调整 R - CMT 和 W - CMT 的相对大小.
W - CMT 中存放的是被写请求访问过的映射项.根据第2节中论述的基于缓存映射项重用距离的负载自适应写缓存映射表冷热分区方法, W - CMT 被分为 HW - CMT 和 CW - CMT .而 CW - CMT 又被进一步分为冷脏写缓存映射表和冷非脏写缓存映射表.冷脏写缓存映射表(dirty cold write cache mapping table, DCW - CMT )存放冷映射项中未同步写回闪存的脏映射项,该部分映射项的换出需要进行映射页写回操作;冷非脏写缓存映射表(clean cold write cache mapping table, CCW - CMT )存放冷映射项中已被写回闪存的非脏映射项,由于该部分映射项已经被写回闪存,所以可以直接丢弃,而不需要换出开销.
下面分别介绍IRR-FTL的关键数据结构.
1) 映射页缓存槽TPCS
本文在RAM中设置大小为1个映射页的映射页缓存槽(translation page cache slot, TPCS),用以缓存每次读入的映射页(如图3中箭头1所示).每个映射页包含了一定逻辑地址范围内的映射项信息,有利于吸收连续的和较大的读写请求,充分挖掘负载的空间局部性.同时,为了保证元数据的一致性,当某映射项被读或写时,该映射项会被从TPCS移动到 R - CMT 或 W - CMT 中(如图3中箭头2和箭头3所示).在地址转换过程中,将会先检索读写缓存映射表中是否有目标映射项,若找不到则才会检索TPCS.当发生缓存失效时,TPCS内原有的映射信息将被丢弃,然后再将需求的映射页换入TPCS.
2) 读缓存映射表 R - CMT
读缓存映射表(read cache mapping table, R - CMT )中存放的是只被读请求访问过的映射项,以LRU方式组织.由于闪存读操作并不会改变映射信息,因此,读缓存映射表的换出操作没有映射项写回开销.当读请求导致缓存失效且 R - CMT 满时,将以LRU方式换出 R - CMT 的最后一个映射项.但是,当 R - CMT 中的映射项被写请求命中时,由于映射项将被写请求修改,因此需要将该映射项移动到 HW - CMT 中(如图3中箭头4所示).
3) 热写缓存映射表 HW - CMT
HW - CMT 以LRU链表的方式组织,链表中的每一个结点是一个映射项,并使用flag标记每个映射项的冷热性质,任何被命中的映射项都会被移动到 HW - CMT 的链表首部.同时,由于本文第3节阐明的原因, HW - CMT 链表必须保证链表的末尾是一个热映射项,否则将进行 HW - CMT “剪枝”操作(pruning),即 HW - CMT 末尾的冷映射项将被移动到 DCW - CMT 中(如图3中箭头5所示).有2种情况会触发 HW - CMT “剪枝”操作:1)当 HW - CMT 中最后一个热映射项被命中时,由于该映射项会被移动到首部,因此此时最后一个映射项可能不是热映射项;2)当 HW - CMT 中的冷映射项被命中时,会发生冷热映射项的转换,被命中的冷映射项会被转换为热映射项,此时,尾部的最后一个热映射项将被转换成冷映射项.
4) 冷脏写缓存映射表 DCW - CMT
DCW - CMT 被分为若干个映射页结点项(translation page node, TP-Node),每个TP-Node内的脏映射项属于同一个映射页,从 HW - CMT 中淘汰的冷脏映射项,会根据其所属的映射页号,放在其映射页对应的TP-Node中.如果未找到,则会为其新建一个TP-Node.TP-Node内的脏映射项按照该脏映射项进入 DCW - CMT 的时间顺序排列.全部TP-Node以大顶堆的形式组织,大顶堆按照每个TP-Node内的脏映射项数量为关键字进行排序,脏映射项数目最多的TP-Node会被放在大顶堆顶部.在需要进行脏映射项写回时,将选择顶部的TP-Node进行批量写回(如图3中箭头8所示).通过这种方法,我们可以快速找到并优先写回拥有脏映射项最多的映射页,最大化写回闪存的映射项数量,从而降低脏映射项写回而带来的元数据更新代价.此外,根据负载的空间局部性原理,若某个TP-Node内冷映射项较多,也意味着该TP-Node映射页所代表的逻辑地址范围的热度出现下降,优先写回该映射页,符合负载的空间局部性原理的要求.被批量更新后的脏映射项会变成非脏映射项并被移动至 CCW - CMT 中(如图3中箭头6所示).若 DCW - CMT 内的映射项被写请求命中,会被以冷映射项的形式移至 HW - CMT 首部(如图3中箭头7所示),以便计算其近期的重用距离,给予其变成热映射项的机会.
5) 冷非脏缓存映射表 CCW - CMT
CCW - CMT 存放的均是从 DCW - CMT 中被批量更新的映射项.在写缓存映射表满,需要进行换出时,优先选择 CCW - CMT 中的映射项换出,避免频繁的脏映射项换出导致额外映射页操作.若 CCW - CMT 内的映射项被写请求命中,基于第3节的原因,会被以冷映射项的形式移至 HW - CMT 首部(如图3中箭头7所示),给予其变成热映射项的机会,并由于写操作再次成为脏映射项.
通过写缓存映射表冷热分区方法可以有效区分重用距离较长的冷映射项和重用距离较短的热映射项.由于元数据映射信息的频繁使用,意味着其所对应的逻辑地址具有较高热度,因此分离冷热映射项对于分离写入冷热数据有重要意义.另一方面,重用距离较短的热映射项能够产生更多的无效页,因此将重用距离相近的逻辑数据放在同一物理区域,使得同一物理块内的数据页有更大概率在垃圾回收前被无效化,从而有效减少在闪存垃圾回收过程中需要进行的有效页迁移次数.因此,对于 HW - CMT 内映射项对应逻辑地址的写入操作,其数据将会被写入到闪存的热数据块区中;对于 CCW - CMT , DCW - CMT 或 R - CMT 内映射项对应的逻辑地址的写入操作,将会被写入到闪存的冷数据块区中;由于垃圾回收时被回收块内的有效页相对于被无效页来说是相对热度较低的数据页,因此被回收块内的有效页也将迁移至冷数据块区.
算法1展示了IRR-FTL的地址转换过程.输入是请求的逻辑页地址和请求类型,经过地址转换过程后,请求被完成并且结束地址转换过程.
算法1 . IRR-FTL算法.
/* LPN :请求的逻辑页号、 Request_type :请求的操作类型*/
输入: LPN , Request_Type .
① if (请求类型是读请求)
② if ( LPN 在 R - CMT 或 W - CMT 中命中)
③ 在缓存找到对应物理地址并返回;
④ else if ( LPN 不在TPCS中)
⑤ 从闪存中将目标映射页装入TPCS;
⑥ end if
⑦ if ( R - CMT 已满)
/*此时目标映射项在TPCS中,需要将目标映射项放入 R - CMT */
⑧ 根据LRU规则淘汰 R - CMT 的映射项;
⑨ end if
⑩ 从TPCS将目标映射项装入 R - CMT ;
 返回目标映射项中的物理地址;
返回目标映射项中的物理地址;
 else if (请求类型是写请求)
else if (请求类型是写请求)
 if ( LPN 在 HW - CMT 中命中)
if ( LPN 在 HW - CMT 中命中)
 if (命中映射项是冷映射项)
if (命中映射项是冷映射项)
 命中的冷映射项转换为热映射项;
命中的冷映射项转换为热映射项;
 HW - CMT 中最后一个热映射项转换为冷映射项;
HW - CMT 中最后一个热映射项转换为冷映射项;
 end if
end if
 更新entry的age;
更新entry的age;
 调用算法3; /*保证 HW - CMT 链表尾部最后一个映射项为热映射项*/
调用算法3; /*保证 HW - CMT 链表尾部最后一个映射项为热映射项*/
 将对应数据写到热数据区;
将对应数据写到热数据区;
 else if ( LPN 在 DCW - CMT 或 CCW - CMT 中命中)
else if ( LPN 在 DCW - CMT 或 CCW - CMT 中命中)
 将命中的映射项移动到 HW - CMT 中;
将命中的映射项移动到 HW - CMT 中;
 将对应数据写到冷数据区;
将对应数据写到冷数据区;
 el se if ( LPN 不在 R - CMT 或TPCS中)
el se if ( LPN 不在 R - CMT 或TPCS中)
/*写请求的逻辑地址触发缓存失效*/
 从闪存中将对应映射页载入TPCS;
从闪存中将对应映射页载入TPCS;
 end if
end if
 if ( W - CMT 已满)
if ( W - CMT 已满)
 调用算法2;
调用算法2;
 end if
end if
 将TPCS的映射项装入写缓存;
将TPCS的映射项装入写缓存;
 将对应数据写到冷数据区;
将对应数据写到冷数据区;
 end if
end if
算法1伪代码行②~ 展示了读请求的处理过程.对于读请求,依次检索 R - CMT , W - CMT ,TPCS.如果 R - CMT 命中,则将该映射项移动到 R - CMT 首部.若在 W - CMT 命中,则仅仅使用其映射信息完成地址转换,不对缓存做任何修改.若在缓存中未发现目标映射项,则最后检查TPCS.若在TPCS中命中,则将命中的目标映射项移动到 R - CMT 中.否则,触发读缓存失效过程,丢弃原TPCS内的映射页,并根据全局转换目录将目标映射页换入TPCS,将TPCS内被读到的映射项放入 R - CMT 中.当 R - CMT 满时,以LRU的方式换出 R - CMT 的最后一个映射项,由于 R - CMT 中的映射项均未被修改,因此换出操作不需要进行闪存写回.
算法1伪代码行 ~ 展示了写请求的处理过程.对于写操作,依次检索 HW - CMT , DCW - CMT , CCW - CMT , R - CMT , TPCS .若目标映射项在 HW - CMT 中,且命中映射项为热映射项,则将该热映射项移动到 HW - CMT 首部.如该映射项是最后一个热映射项,则还需执行“剪枝”操作,保证链表尾部是一个热映射项(如算法3所示);若目标映射项在 HW - CMT 中,且命中映射项为冷映射项,则执行冷热映射项转换过程,将命中的冷映射项转换为热映射项,并移动至 HW - CMT 首部,同时,将最后一个热映射项转换为冷映射项并执行“剪枝”操作;若目标映射项在 R - CMT 中,则将该映射项以冷映射项的形式移至 HW - CMT ,将数据写入到冷数据区,并修改映射关系.若读写缓存均未命中,则检查TPCS.如果需求的映射项在TPCS内,则将对应映射项移动到 HW - CMT 中;否则,发生写缓存失效,根据GTD,从闪存中找到对应映射页放入TPCS中,将TPCS内命中的映射项放入 HW - CMT 中.
算法2展示了当写缓存映射表满时,如何选择换出的映射项.当写缓存映射表满,需要换出映射项时会首先检查 CCW - CMT ,由于非脏映射项的换出不需要执行闪存写回操作,因此优先换出非脏映射项,能够有效减少映射页写回操作次数;如果 CCW - CMT 为空,则会选择 DCW - CMT 顶部的结点,对该结点对应的脏映射项链表进行批量更新,由于该结点内的映射项最多,因此写回更新代价相对较小.之后,将该链表插入 CCW - CMT 中,再换出最后一个映射项.
算法2 . W-CMT_swap_out算法.
/*写缓存映射项换出算法*/
① if ( CCW - CMT ≠∅)
/*优先从 CCW - CMT 中换出非脏映射项*/
② 按照LRU规则淘汰 CCW - CMT 中的映射项;
③ el se
/*若 CCW - CMT ≠∅,则按照最大化批量更新策略,更新 DCW - CMT 大顶堆顶部的映射页结点*/
④ 将 DCW - CMT 堆顶的TP_node中的映射项批量写回闪存;
⑤ 更新GTD;
⑥ 将更新后的clean entries从 DCW - CMT 移动到 CCW - CMT ;
⑦ 换出 CCW - CMT 中最后一个映射项;
⑧ end if
算法3 . Pruning_HW - CMT 剪枝算法.
/* HW - CMT 剪枝算法*/
① while( HW - CMT 链表最后一个映射项不是冷映射项时)
② 将 HW - CMT 链表尾部所有的冷映射项移动到 DCW - CMT ;
③ end while
本文实验使用被广泛运用在科研领域的开源闪存模拟器Flashsim [19] ,我们在Flashsim上分别实现了基于缓存映射项重用距离的闪存转换层地址映射算法IRR-FTL和DFTL算法,并将两者进行比较.本文衡量系统有效性的主要指标包括系统响应时间、块擦除次数、缓存命中率、映射页的写回次数、垃圾收集过程中拷贝的有效页数量.
表1列出了本实验中对闪存模拟器Flashsim的参数设置.考虑到标准负载数据集写入数据总量的大小,本实验模拟的SSD大小为2 GB,着重考查IRR-FTL对闪存垃圾回收性能的提高.
Table 1 Flash Memory Configuration
表1 实验闪存配置参数
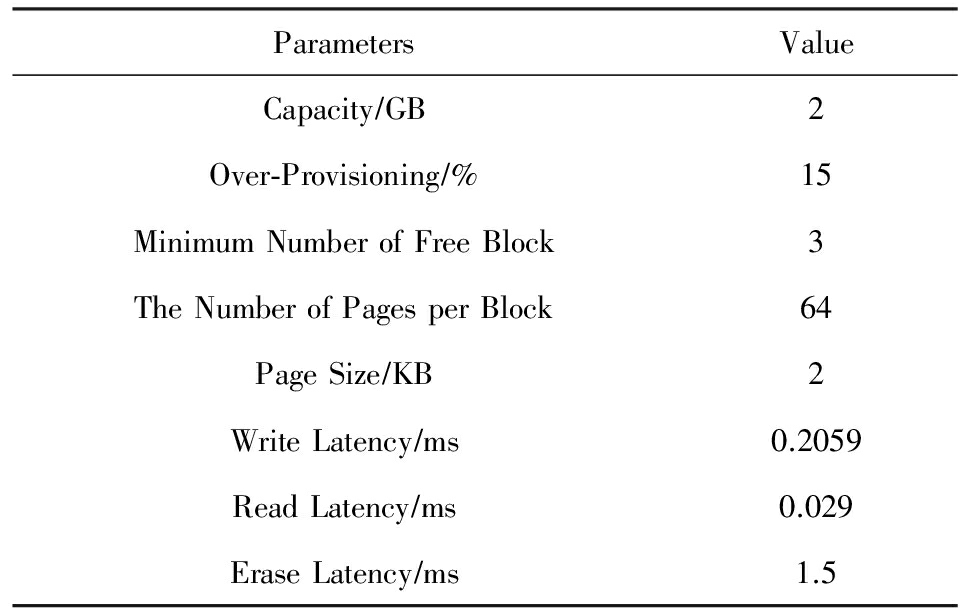
表2列出了各个标准负载数据集的特点.本文分别使用多个具有不同特点的标准负载数据集进行实验,以便能够客观评价本方法的有效性和普适性.
Table 2 Characteristics of Traces
表2 标准数据集特征
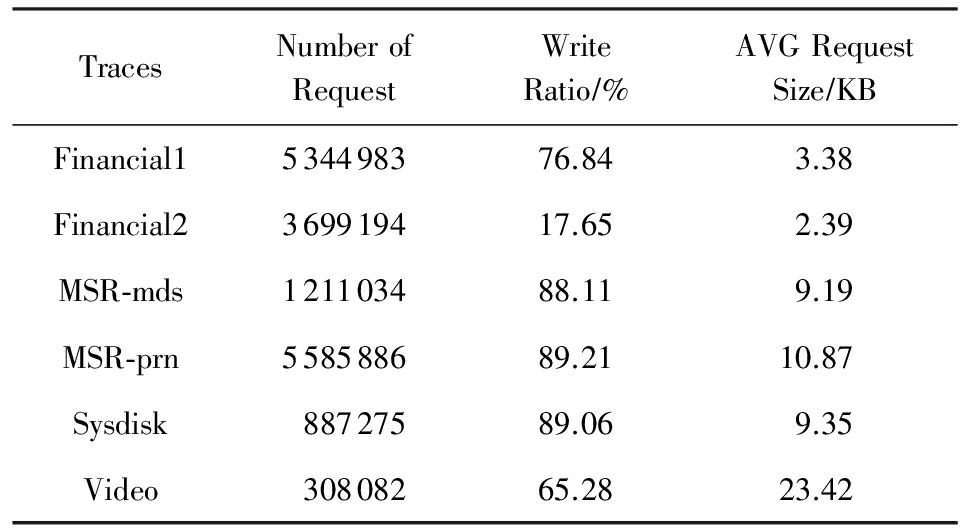
实验采用的标准负载数据集包括Financial1 [20] ,Financial2 [20] ,MSR-mds [21] ,MSR-prn [21] ,Sysdisk,Video.其中,Financial1和Financial2来自于SPC的金融型OLTP应用标准负载数据集.Financial1的特点是请求中写操作比例较高,但是写请求大小比较小;Financial2的特点是写操作比例较低,请求的平均长度较小.MSR-mds和MSR-prn来自于微软的企业级服务器数据集,特点是请求中写操作比例较高,而且请求平均长度较大,连续写入较多.数据集Sysdisk和Video是通过DiskMon工具,在本地计算机上收集的负载数据集.其中,Sysdisk是日常办公的负载集,Video是网络视频负载集.
基于第3节的叙述,在本实验中,通过动态调整热数据项数量的方式,确保 HW - CMT 和冷写缓存映射表的比例在1∶0.1到1∶0.5之间.
实验结果如图4~8所示,下面将逐一分析各个指标的实验结果.
图4是不同负载下DFTL和IRR-FTL的缓存命中率比较.闪存缓存命中率直接影响闪存性能和寿命,若频繁发生缓存失效,则需要进行更多的全局映射表读操作和缓存映射项换出操作,而脏映射项的换出,又会导致闪存写回操作,对闪存性能和寿命带来负面影响.可以看到IRR-FTL相对于DFTL在不同负载下,缓存命中率均有较大提高.特别是在负载的平均请求大小较大的情况下,命中率表现更好.缓存命中率平均提高达29.1%.缓存命中率的提高主要得益于映射页缓存槽和基于缓存映射项重用距离的冷热写缓存映射表,有效地吸收了连续读写请求,同时优先换出冷映射项,延长热映射项在缓存中保留的时间.
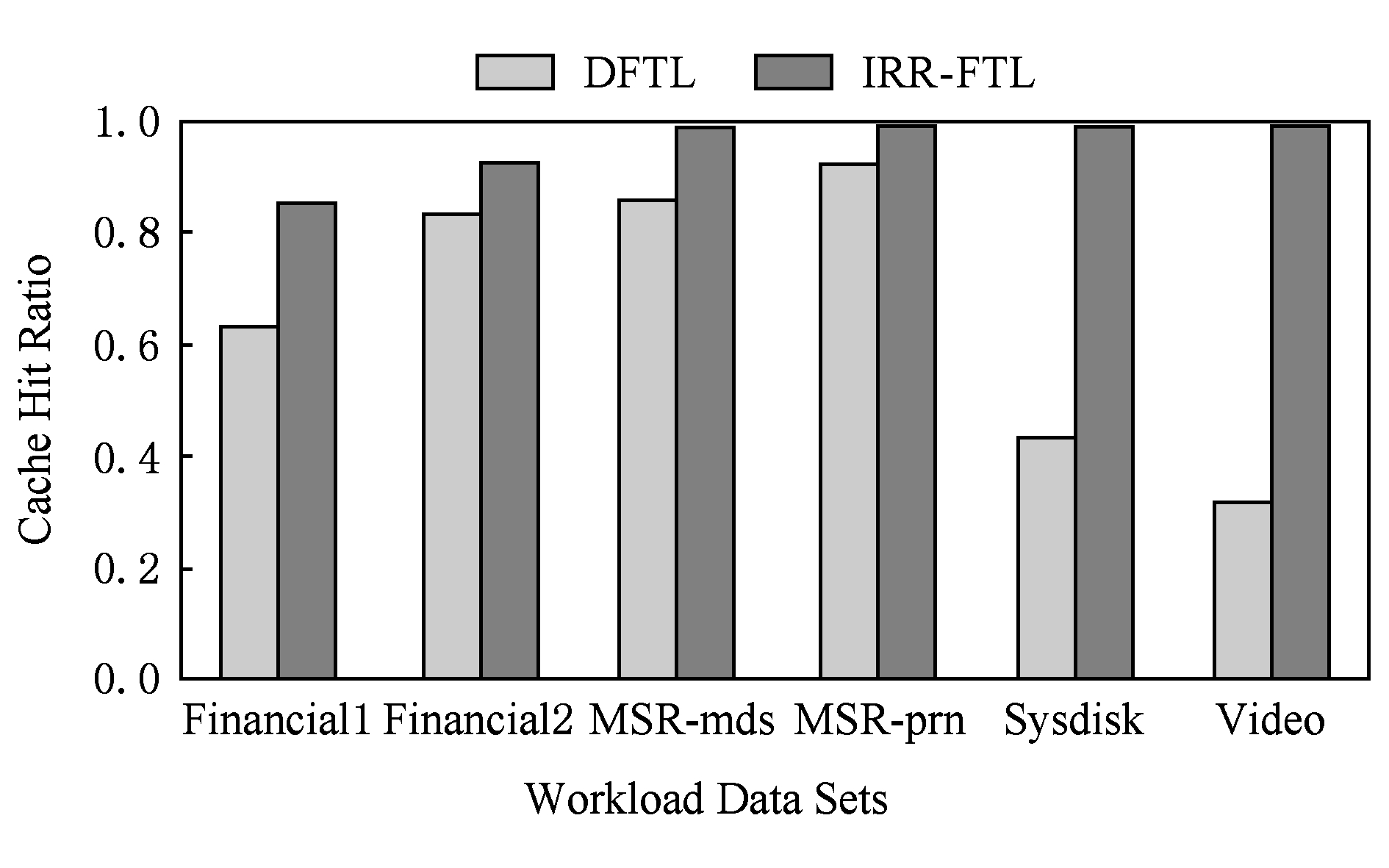
Fig. 4 Cache hit ratio under different workloads
图4 不同负载下的缓存命中率
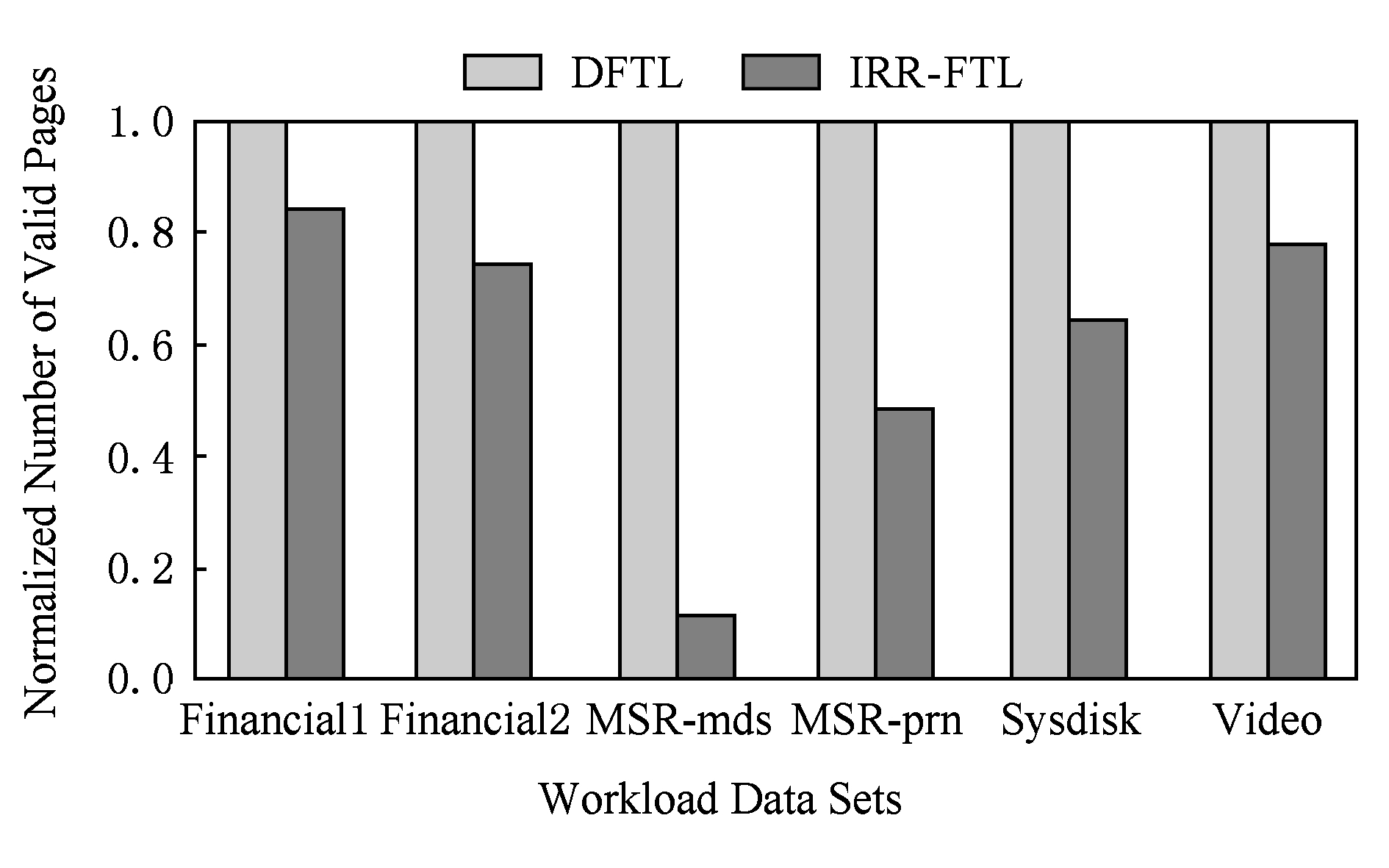
Fig. 5 Number of valid pages under different workloads
图5 不同负载下的有效页拷贝次数
垃圾收集过程中有效页拷贝是闪存额外读写的重要来源,在垃圾收集过程中被回收块内的每一个有效页都会引发1次闪存读和闪存写操作,还会引起由于有效页迁移而导致的映射关系的改变.因此,减少垃圾收集过程中有效页拷贝次数对优化闪存数据写放大和元数据写放大有重要意义.图5是不同负载下DFTL和IRR-FTL的垃圾收集过程中有效页拷贝次数的比较,纵坐标表示的是归一化的垃圾收集过程中有效页拷贝次数.可以看到,IRR-FTL有效地减少了垃圾收集过程中有效页拷贝次数,平均降低了39.9%的有效页拷贝次数.特别在MSR-mds负载上,由于MSR-mds负载的逻辑地址冷热性质较为清晰,因此冷热数据分离效果更好,有效页拷贝次数下降了88.5%.
由于脏映射项换出而导致的闪存映射页操作是元数据写放大的重要来源.图6是在不同负载下DFTL和IRR-FTL由于脏映射项换出而导致的闪存映射页写回操作数量,纵坐标是归一化的闪存写回次数.可以看到,在不同负载环境下,IRR-FTL比DFTL平均减少了70.8%的额外闪存写回次数.特别在MSR-prn,Sysdisk,Video等平均请求较大的负载场景下,IRR-FTL减少了80%以上的映射项写回操作.能够取得上述优良的效果,得益于冷写缓存映射表的非脏映射项优先换出策略和脏映射项最大化批量更新策略,实验证明这都能够有效减少由于脏映射项换出而导致的闪存写回操作,同时减少对缓存命中率的影响.
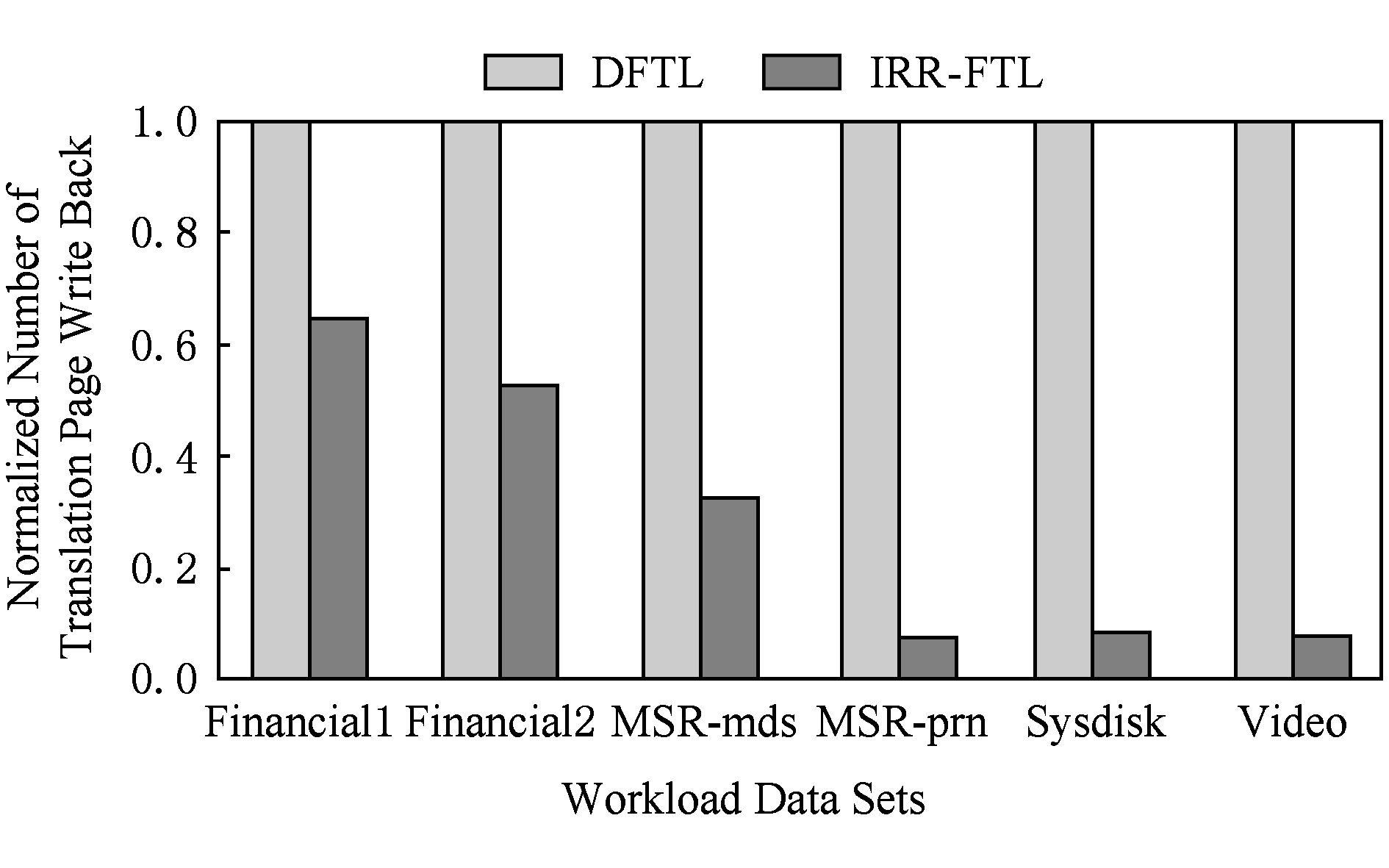
Fig. 6 Number of translation page write back
图6 不同负载下的映射页写回次数
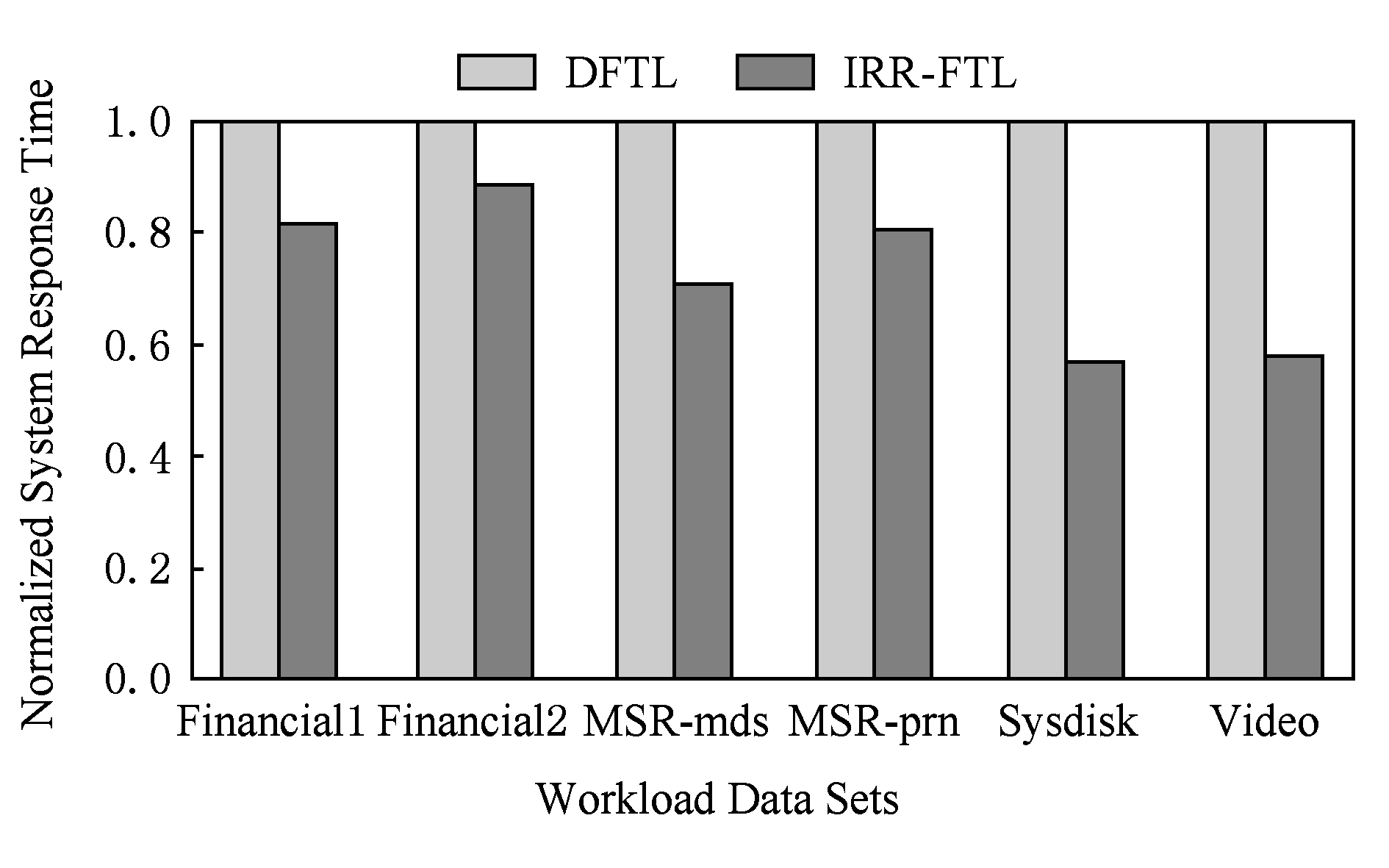
Fig. 7 Average response time under different workloads
图7 不同负载下的系统响应时间
系统平均响应时间是衡量闪存性能的重要指标.图7展示了各个不同负载下IRR-FTL和DFTL的系统平均响应时间的对比,其中纵坐标表示归一化的系统平均响应时间.可以看出,得益于在缓存命中率、垃圾回收效率、元数据写放大等指标上的优异表现,IRR-FTL较DFTL系统平均响应时间降低了27.3%.
块擦除次数是衡量闪存寿命的重要指标.图8展示了各个不同负载下,IRR-FTL和DFTL的块擦除次数的对比,其中,纵坐标是归一化的块擦除次数.可以看到,由于在垃圾回收时迁移有效页数量的减少和元数据映射项写回次数的减少,从而尽可能的减少闪存中发生的不必要的数据迁移和元数据同步.相应的在擦除次数上,IRR-FTL较DFTL平均降低了约10.7%,有效地减少了闪存内部发生的额外写入次数,提高了闪存寿命.
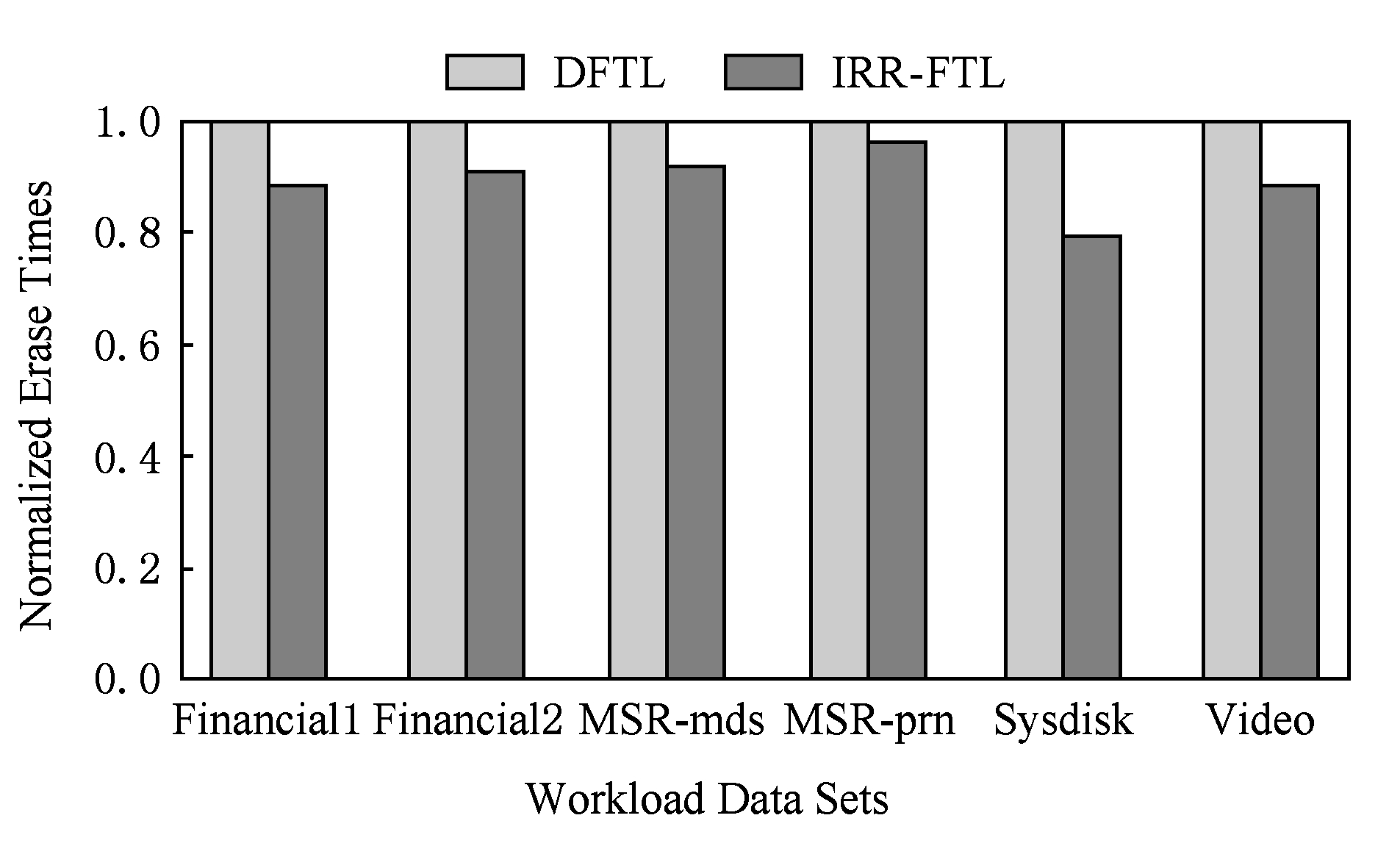
Fig. 8 Erase times under different workloads
图8 不同负载下的块擦除次数
在IRR-FTL中,空间开销主要来源于每一个映射项会增加1个冷热标志位,这个标志位仅占用1 b空间.按每个映射项8 B计算,每个映射项增加1 b大小,则需要额外空间占原大小的1.5%.此外, DCW - CMT 中的大顶堆中每个结点都有一个映射项数量计数器,而大顶堆中的结点数随着负载的变化而动态分配与释放,因此占用空间大小并不确定.但是,根据负载的空间局部性原理可以推断负载某时间段内访问涉及的TP-Node数量有限,同时以TP-Node映射页为单位的批量更新策略也可以有效更新和控制 DCW - CMT 中的TP-Node.
本文提出一种基于缓存映射项重用距离的闪存转换层地址映射方法IRR-FTL.针对DFTL中存在的对负载的空间局部性利用不强、频繁映射页写回和垃圾回收导致的写放大等问题,通过设置独立映射页缓存槽,充分挖掘负载的空间局部性.通过基于缓存映射项重用距离的负载自适应写缓存映射表冷热分区方法,将写缓存映射表分为热写缓存映射表和冷写缓存映射表,并将不同区域内映射项对应的冷热数据分别写入闪存不同区域,实现冷热数据分离,减少数据写放大;同时对于冷写缓存映射表,采取脏映射项最大化批量更新和非脏映射项优先换出策略,减少元数据写放大.在实验部分,本文通过多个不同负载类型数据集,验证IRR-FTL的有效性,结果证明IRR-FTL较DFTL缓存命中率提高29.1%,同时减少了39.9%的由于垃圾回收造成的额外读写操作和70.8%的映射页写回操作,使得整体系统响应时间降低了27.3%,擦除次数降低了10.7%.
参考文献
[1]Lu Youyou, Shu Jiwu. Survey on flash-based storage systems[J]. Journal of Computer Research and Development, 2013, 50(1): 49-59 (in Chinese)
(陆游游, 舒继武. 闪存存储系统综述[J]. 计算机研究与发展, 2013, 50(1): 49-59)
[2]Chen Feng, Koufaty D A, Zhang Xiaodong. Understanding intrinsic characteristics and system implications of flash memory based solid state drives[C] //Proc of the 35th ACM SIGMETRICS Int Conf on Measurement and Modeling of Computer Systems. New York: ACM, 2009: 181-192
[3]Agrawal N, Prabhakaran V, Wobber T, et al. Design tradeoffs for SSD performance[C] //Proc of the 19th USENIX Annual Technical Conference(ATC). Berkeley, CA: USENIX Association, 2008: 57-70
[4]Ma Dongzhe, Feng Jianhua, Li Guoliang. A survey of address translation technologies for flash memories[J]. ACM Computing Surveys, 2014, 46(3): 238-276
[5]Gupta A, Kim Y, Urgaonkar B. DFTL: A flash translation layer employing demand-based selective caching of page-level address mappings[C] //Proc of the 14th Int Conf on Architectural Support for Programming Languages and Operating Systems. New York: ACM, 2009: 229-240
[6]Grupp L M, Davis J D, Swanson S. The bleak future of NAND flash memory[C] //Proc of the 10th USENIX Conf on File and Storage Technologies. Berkeley, CA: USENIX Association, 2012: 17-24
[7]Ma Dongzhe, Feng Jianhua, Li Guoliang. LazyFTL: A page-level flash translation layer optimized for nand flash memory[C] //Proc of the 30th ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2011: 1-12
[8]Zhang Qi, Wang Linzhang, Zhang Tian, et al. Optimized address translation method for flash memory[J]. Journal of Software, 2014, 25(2): 314-325 (in Chinese)
(张琦, 王林章, 张天, 等. 一种优化的闪存地址映射方法[J]. 软件学报, 2014, 25(2): 314-325)
[9]Zhou You, Wu Fei, Huang Ping, et al. An efficient page-level FTL to optimize address translation in flash memory[C] //Proc of the 10th European Conf on Computer Systems. New York: ACM, 2015: 227-242
[10]Yao Yingbiao, Du Chenjie, Wang Fakuan. A clustered page-level flash translation layer algorithm based on classification strategy[J]. Journal of Computer Research and Development, 2017, 54(1): 142-153 (in Chinese)
(姚英彪, 杜晨杰, 王发宽. 一种基于分类策略的聚簇页级闪存转换层算法[J]. 计算机研究与发展, 2017, 54(1): 142-153)
[11]Kim J, Kim J M, Noh S H. A space-efficient flash translation layer for compactflash systems[J]. IEEE Trans on Consumer Electronics, 2002, 48(2): 366-375
[12]Lee S W, Park D J, Chung T S. A log buffer-based flash translation layer using fully-associative sector translation[J]. ACM Trans on Embedded Computing Systems, 2007, 6(3): 70-96
[13]Jung D, Kang J U, Jo H, et al. Superblock FTL: A superblock-based flash translation layer with a hybrid address translation scheme[J]. ACM Trans on Embedded Computing Systems, 2010, 9(4): 658-673
[14]Lee S, Shin D, Kim Y J, et al. LAST: Locality-aware sector translation for NAND flash memory-based storage systems[J]. ACM SIGOPS Operating Systems Review, 2008, 42(6): 36-42
[15]Lee H S, Yun H S, Lee D H. HFTL: Hybrid flash translation layer based on hot data identification for flash memory[J]. IEEE Trans on Consumer Electronics, 2009, 55(4): 2005-2011
[16]Park D, Du D. Hot data identification for flash-based storage systems using multiple bloom filters[C] //Proc of the 27th IEEE Symp on Mass Storage Systems and Technologies (MSST). Los Alamitos, CA: IEEE Computer Society, 2011: 1-11
[17]Xie Wei, Chen Yong, Roth P. ASA-FTL: An adaptive separation aware flash translation layer for solid state drives[J]. Parallel Computing, 2016, 61: 3-17
[18]Jiang Song, Zhang Xiaodong. LIRS: An efficient low inter-reference recency set replacement policy to improve buffer cache performance[C] //Proc of the 28th ACM SIGMETRICS Int Conf on Measurement and Modeling of Computer Systems. New York: ACM, 2002: 31-42
[19]Kim Y, Tauras B, Gupta A, et al. Flashsim: A simulator for NAND flash-based solid-state drives[C] //Proc of the 1st Int Conf on Advances in System Simulation. Los Alamitos, CA: IEEE Computer Society, 2009: 125-131
[20]Liberate M, Shenoy P. OLTP trace from umass trace repository[EB/OL]. [2016-12-19]. http://traces.cs.umass.edu/index.php/Storage
[21]Microsoft. MSR cambridge traces[EB/OL]. [2016-12-19]. http://iotta.snia.org/traces/388
Zhou Quanbiao, Zhang Xingjun, Liang Ningjing, Huo Wenjie, and Dong Xiaoshe
( Department of Computer Science and Technology , Xi ’ an Jiaotong University , Xi ’ an 710049)
Abstract Demand-based flash translation layer(DFTL), which is a classical FTL address mapping method, solves the contradiction between large amounts of mapping information and limited cache capacity by only caching address mappings least recently used and leaving global mappings in flash memory. However, DFTL does not take full advantage of the spatial locality of workloads. When the cache is invalidated, dirty mapping entries will be swapped out frequently, causing lots of write operations of mapping pages. In addition, DFTL can’t address the problem of write amplification caused by valid page migration operations during garbage collection. In this paper, we propose a novel FTL address mapping method named IRR-FTL, which is based on inter-reference recency (IRR) of mapping entries. Firstly, IRR-FTL makes the most of the spatial locality of workloads by setting cache slots for translation pages. Secondly, IRR-FTL can make workloads adaptively write cache mapping table partitions based on IRR of mapping entries, which can reduce write operations of translation pages. Finally, IRR-FTL achieves hot and cold data separation, which can improve garbage collection efficiency. Compared with DFTL, our experimental results with a variety of workloads show that IRR-FTL can increase cache hit rate, average response time and erase counts by 29.1%, 27.3% and 10.7%, respectively.
Key words NAND flash memory; flash translation layer (FTL); address translation; inter-reference recency; data separation
摘 要 经典的闪存转换层(flash translation layer, FTL)地址映射方法DFTL(demand-based FTL)将全局映射信息放在闪存中,仅缓存最近最常使用的映射信息,解决了页级映射策略中映射信息较大和缓存容量有限的矛盾.但是,DFTL没有充分利用负载的空间局部性特点提高缓存命中率;在缓存失效时频繁的脏映射项换出也会导致大量的映射页写操作;此外,它未能优化垃圾回收过程中有效页迁移导致的写放大问题.针对上述不足,提出一种基于缓存映射项重用距离的地址映射方法IRR-FTL(inter-reference recency-based FTL),通过设置映射页缓存槽,充分挖掘负载空间局部性;基于缓存映射项重用距离实现负载自适应的写缓存映射表冷热分区,并分别采取不同的管理策略,减少映射页写操作;此外,实现基于重用距离的冷热数据分离存储,提高垃圾回收效率.通过采用多种负载对该方法进行验证实验,实验结果表明IRR-FTL相比DFTL缓存命中率提高29.1%,平均响应时间降低了27.3%,擦除次数降低了10.7%.
关键词 NAND闪存;闪存转换层;地址转换;重用距离;数据分离
中图法分类号 TP333
收稿日期 :2017-04-11;
修回日期: 2017-10-25
基金项目 :国家重点研发计划项目(2016YFB1000303)
This work was supported by the National Key Research and Development Program of China (2016YFB1000303).
通信作者 :张兴军(xjzhang@xjtu.edu.cn)
DOI: 10.7544/issn1000-1239.2018.20170254

Zhou Quanbiao , born in 1991. Master. His main research interests include flash translation layer, and hot cold data separation.

Zhang Xingjun , born in 1969. PhD, professor, PhD supervisor. Member of CCF. His main research interests include wireless network, and big data storage system.

Liang Ningjing , born in 1989. PhD candidate. Her main research interests include distributed storage system, non-volatile storage, and erasure coding.

Huo Wenjie , born in 1993. Master candidate. Her main research interests include flash translation layer, and internal parallelism.

Dong Xiaoshe , born in 1963. PhD, professor, PhD supervisor. Member of CCF. His main research interests include high performance computer system, storage system, and cloud computing.