
Fig. 1 The overall framework of our method
图1 多目标显著性检测方法的总体框架图
梁大川 1 李 静 1 刘 赛 2 李东民 1
1 (南京航空航天大学计算机科学与技术学院 南京 211106) 2 (南瑞集团有限公司(国网电力科学研究院有限公司) 南京 210003) (dacliang@nuaa.edu.cn)
显著性检测是目前计算机视觉领域的热点研究方向之一,经过近10年的发展,已经成功应用于图像压缩 [1] 、目标跟踪 [2] 、场景分类 [3] 、图像分割 [4] 等多种计算机视觉任务.
目前,显著性目标检测方法大多只针对2个以下目标且背景较为单一的情况,但实际应用中要面临更为复杂的情况,现有显著性检测方法往往无法满足实际需求,本文针对包含多个显著目标且背景较为复杂的图像,提出了一种基于全连接图与稀疏主成分分析的显著性目标检测方法.本文利用对像素信息变化较为敏感的测地线距离 [5] 计算方式快速获取图像中所有显著性目标的大致位置,将其作为目标先验知识以提取预选显著目标区域.在不同的分割尺度上利用SLIC(simple linear iterative clustering)超像素分割算法 [6] 进行超像素划分并构造全连接图,然后利用基于图的显著模型GBVS [7] 获取超像素级初始显著图.而现有超像素分割算法都存在一定的局限性,即超像素区域不可能完全按照目标轮廓划分,GBVS显著图中显著目标的超像素中可能包含背景区域,或缺失部分显著区域.因此,基于超像素得到的显著图一般不够准确.此外,由于超像素是分块的,显著性目标的不同超像素区域的显著值也可能不一致.为了解决上述问题,本文结合目标先验知识来获取不同尺度下GBVS显著图的预选显著目标区域,并利用预选目标区域与背景区域的相似性对预选目标区域进行优化,使预选目标区域尽可能地只包含显著目标区域.在预选显著目标区域的基础上,通过提取相应位置上像素点的颜色、空间、紧密度等特征构造像素特征矩阵.然后,通过截断幂稀疏主成分分析 [8] 提取像素矩阵的稀疏主成分特征并计算显著性,从而得到更加精确且显著值一致性更好的像素级显著图.由于不考虑背景区域仅利用目标先验知识获取预选显著目标区域,并针对预选显著目标区域进行后续像素特征的提取和显著性计算,因此,本文方法可以在较大程度降低计算复杂度提高检测效率的同时,得到更加精确的显著性检测结果.
显著性检测的本质是模拟人类视觉系统建立的视觉注意模型(visual attention model) [9] .首个视觉注意模型—KU模型是由Koch和Ullman [10] 在显著图(saliency map)概念基础上构建而成,为视觉注意建模研究的发展奠定了良好的基础.
文献[11]在KU视觉注意模型的基础上,提出了经典的Itti显著性检测方法.针对多尺度图像,根据人眼视觉特性通过底层特征的中心-周围对比度得到相应的显著图,通过显著图融合获取最终显著结果.该模型已成为现有算法的一个标准模型;文献[12]采用混合高斯模型将颜色相似的像素聚为区域,综合考虑各区域的颜色对比度和空间分布,以概率模型计算显著图.该方法有效地引入紧密度特征,通过对图像全局属性进行建模,能够较好地检测出整个目标,但计算复杂度较高;文献[13]根据图像边界区域大多是背景的假设,采用流形排序方法对前景信息进行加强得到最终的显著图;文献[14]以稀疏表示原理为基础,将原始图像进行多尺度分割,并以图像边界超像素作为背景样本集,对每个超像素进行稠密和稀疏重构,进而通过多尺度重构残差得到最终的显著图;文献[15]使用稀疏直方图简化图像颜色表示,采用基于图的分割方法将图像划分为多个区域,根据空间位置距离加权的颜色对比度之和计算图像区域的显著性;文献[16] 采用自底向上的注意力机制,对图像进行Haar小波分解,在垂直方向进行侧投影和多层阈值分割,得到针对自然图像中建筑物的显著图;文献[5]提出一种基于最小障碍距离转换的快速显著目标检测算法——MBS,该算法以行像素为单位进行计算,无需进行区域分割.该方法以像素为单位进行显著性计算,得到的显著图具有较好的一致性,但过于依赖边界连通性,对位于边界或较小的多目标检测效果不太理想.
近几年,一些基于图论的显著性检测方法也取得较大进展.文献[7]在Itti模型之上在显著图生成的过程引入Markov链,将生物视觉原理与数学计算结合,用数学计算求其平衡分布而得到显著图;文献[17]利用全连通 K -正则图的随机游走性质,获取显著性节点和背景节点,结合两种节点提取显著性区域得到显著图;文献[18]根据吸收Markov链模型计算节点显著性,以节点吸收时间作为全局相似性度量提取显著性目标;文献[19]按照正规随机游走排序,通过基于超像素预估前景与背景的显著性计算像素显著性值;文献[20]以超像素为节点构造无向图,提取相应区域的颜色、对比度和纹理特征,并通过背景先验进行显著图优化;文献[21]提出了一种基于抽象全连图模型的时空显著性检测方法,以视频帧的像素点作为节点,以时空特征距离为边来构造全连接图,将显著性问题转化为求解全连接图中具有最少节点的抽象全连接图优化问题;文献[22]提出了一种基于稠密子图的显著性检测算法,采用随机行走的Markov链获取显著图,然后通过稠密 K 子图增强图像显著性区域,得到最终的显著图.
上述方法大多是以超像素为基本单位进行显著性计算,不可避免地会因为超像素分割的局限性而影响检测结果的准确性.而且以超像素为单位的显著性计算虽然能提高检测速度,但会出现显著图中同一目标不同区域的显著值不一致的情况.本文采用与文献[17,22]相似的方法,通过构造以超像素为节点的全连接图,计算节点初始显著性值,并提取与图论相关的紧密度等特征,在此基础上结合目标先验知识提取和优化预选显著目标区域.利用基于像素的显著性计算优势,通过提取预选目标区域内像素的稀疏主成分特征,计算像素的显著性来进行一步细化基于图的显著性结果,得到更加准确的显著图.
本节对提出的多目标显著性检测方法进行详细介绍,其总体架构如图1所示.对给定的输入图像 I ,在多个尺度上采用SLIC超像素分割算法将输入图像分割成多个超像素块,通过快速检测算法MBS得到目标先验图 M GD ,获取显著目标的粗略位置和显著性值.与此同时,根据基于图的显著性模型GBVS得到超像素级的初始显著图 M GBVS .根据二值化的目标先验图 M GDB ,提取 M GBVS 中相应位置的初始显著区域构成超像素集 Supselect .计算 Supselect 中超像素与背景超像素的相似性,对预选显著性区域进行优化.通过提取优化后的超像素集 Supselect 中所有像素的空间、颜色、亮度、紧密度、节点度等特征构造样本矩阵.然后,采用稀疏主成分分析(sparse principal component analysis, sPCA)算法提取矩阵的主要特征,并计算显著性值.最后将多个尺度的显著图 M ( s ) 进行融合得到最终显著图 M final .
Fig. 1 The overall framework of our method
图1 多目标显著性检测方法的总体框架图
为了更好地获取待测图像的结构信息,保留显著图的目标边界,利用SLIC超像素分割算法将原始图像分割成多个分布均匀且紧凑的超像素块.
文献[2]证明2种颜色空间Lab和RGB结合可以有效提高显著性检测的准确性.因此,本文采用Lab和RGB两种颜色空间来表示像素图像块的特征.
首先,将RGB图像转换为Lab格式,然后在3个尺度空间上(1,1/2,1/4)用SLIC将图像分割多个超像素,每超像素可表示为包含的像素点的平均颜色特征和空间位置坐标的特征向量 Sp i =( x , y , R , G , B , L , a , b ).
在每个尺度上提取亮度( L )、颜色( R , G , B , a , b )、紧密度(compactness)特征.大部分显著目标往往具有紧密的区域和良好的边界,紧密度可以保证背景区域中相对稀疏的区域具有较低的显著性值.按照文献[23]中的方法来计算紧密度:
![]()
(1)
其中, σ i , x 和 σ i , y 是区域 Sp i 中像素度坐标 x 和 y 的标准偏差, α 是经验值, W 与 H 分别表示图像的宽度与高度.由式(1)可得到超像素区域 Sp i 的某一特征的紧密度.
(2)
其中, i 表示超像区域 Sp i , k 表示 Sp i 不同的特征,分别对应5种颜色 R , G , B , a , b 和亮度特征 L .式(2)求取最终的紧密度,计算基于图的GBVS显著图.
2.2.1 GBVS显著图
在超像素分割基础上,以超像素为节点、不同区域的空间距离和特征距离为边来构造图 G image ,连接节点 i 和 j 的边的权值是由特征距离 w f ( i , j ),空间距离 w s ( i , j )和紧密度权重 w c ( i , j )按照基本模型GBVS [6] 联合得到.
节点 i 和 j 之间空间距离可表示为
(3)
其中, I i , k 和 I j , k 分别表示 i 和 j 的特征 k 的值.
节点 i 和 j 之间空间距离可表示为
![]()
(4)
其中, x i 和 y i 表示节点 i (或超像素 Sp i )的重心或坐标平均值. D 是图像的对角线长度.
节点 i 和 j 之间的紧密度权重:
![]()
(5)
其中, C i 和 C j 分别表示超像素 Sp i 和 Sp i 的紧密度.
节点 i 和 j 之间最终的边权重:
w combine ( i , j )= w f ( i , j )× w s ( i , j )× w c ( i , j ).
(6)
在图 G image 基础上,可以得到 N × N 转换矩阵 TP ,其中 N 是图 G image 中节点的数量.元素 TP ( i , j )正比于图的边权值 w combine ( i , j ),表示从节点 i 随机转移到节点 j 的概率.节点的度可用所有与之相连边的权重和来表示.
根据转换矩阵 TP 按随机行走的方式形成Markov链 [24] .Markov链的均衡分布 π 满足条件: π = TP · π .对任意节点 i , P i = π ( i ),其中 π ( i )是平稳分布 π 的第 i 个元素,表示在平稳条件下随机行走在节点 i 停留的概率. P max 和 P min 分别表示所有节点中 π 的最大值和最小值.节点 i 的显著性可通过
![]()
(7)
计算,由式(7)得到的基于图的显著图 M GBVS ,不仅能够有效增强目标区域的显著值,而且还能抑制背景区域的显著值.
2.2.2 目标先验图
为了获取显著目标的大致空间分布,使用MBS算法中基于测地线距离的对比算法GD [5] 对输入图像进行快速显著性计算,可得到显著区域中心较为模糊的目标先验图 M GD ,获取目标先验知识,粗略判断显著目标的空间分布及显著性.
为了便于确定显著区域的位置,本节采用一种自适应的阈值策略对 M GD 进行二值化处理,将 M GD 的值划分为 K 个通道,计算阈值 T :
![]()
(8)
![]() / area ( I )< ε ,
/ area ( I )< ε ,
其中, p ( k )表示信道 k 上的像素数量且 k ∈[1, K ], area ( I )表示图像 I 的像素个数. ε 是在范围[0.65,0.95]范围内的经验值.条件 ![]()
 area ( I )< ε 可有效防止 T 取值过大,从而保证在显著目标在图像中占据大部分空间的情况下,显著像素不会被二值化为0,从而得到二值化后的目标先验图 M GDB .
area ( I )< ε 可有效防止 T 取值过大,从而保证在显著目标在图像中占据大部分空间的情况下,显著像素不会被二值化为0,从而得到二值化后的目标先验图 M GDB .
2.2.3 显著性区域提取与优化
根据二值化的目标先验图 M GDB 选取 M GBVS 中相应位置的超像素区域构成预选显著性超像素集 ![]() 是预选超像素个数, M < N .假设 N i 为超像素 Sp i 中像素总数, n 是二值图 M GDB 对应区域中值为1的像素个数,则应满足条件 n N >0.5.
是预选超像素个数, M < N .假设 N i 为超像素 Sp i 中像素总数, n 是二值图 M GDB 对应区域中值为1的像素个数,则应满足条件 n N >0.5.
由于MBS算法的局限性,超像素集 Supselect 中可能包含一些背景区域或缺失部分显著性区域.通过预选显著性超像素与背景区域的相似性或相异性,删除 Supselect 中可能的背景区域和添加背景区域中可能缺失的显著区域,对 Supselect 进行优化.
首先,通过颜色、亮度、空间、紧密度等特征的欧氏距离构造超像素之间的相异矩阵 DifMatrix ,表示超像素之间的相似性或相异性. DifMatrix 是一个 N 阶对称矩阵, N 是超像素个数.对于任意 Sp i ∈ Supselect ,计算 Sp i 的相邻显著区域的平均相异度:
(9)
其中, Sp j ∈ Supselect 且 i ≠ j , N 表示当前 Supselect 中的超像素个数. Dif ( Sp i , Sp j )表示相异矩阵 DifMatrix 在( i , j )上的元素值.
同样地,计算 Sp i 与其相邻的背景区域的平均相异度:
(10)
其中, Sp l ∉ Supselect ,且 Sp i 与 Sp l 相邻, N ′表示背景区域中与 Sp i 相邻的超像素个数.如果 MavDif ( Sp i )< MavDif ( Sp i )′,表明 Sp i 与相邻的背景区域的相似度更高,则将 Sp i 从 Supselect 中删除.
同样,对于任意 Sp h ∉ Supselect ,可计算 Sp h 与相邻背景区域中的平均相异度 MavDif ( Sp h )′,及 Sp h 与相邻预选显著区域的平均相异度 MavDif ( Sp h ).如果满足条件 MavDif ( Sp h )′> MavDif ( Sp h ),则说明与其他背景区域相比, Sp h 与相邻显著区域的相似度更高,则将 Sp h 加到 Supselect 中.
通过不断更新预选显著性超像素集 Supselect ,直到 Supselect 中超像素数量不再变化为止,预选显著区域的优化过程结束.
通过对输入的原始图像进行显著性区域提取和特征提取后,使用截断幂方法在抽取的底层特征上进行稀疏主成分分析,提取稀疏主特征.
2.3.1 截断幂稀疏主成分分析
给定像素矩阵 A ∈ ![]() n × p , n 为像素个数, p 为特征个数,对矩阵 A 进行正则化并计算协方差矩阵 Σ = A T A ,则稀疏主成分分析的求解为
n × p , n 为像素个数, p 为特征个数,对矩阵 A 进行正则化并计算协方差矩阵 Σ = A T A ,则稀疏主成分分析的求解为
![]()
(11)
其中, x * 是所求的稀疏负载因子, Σ 为协方差矩阵,负载因子的稀疏程度由参数 k ( k >0)决定, ![]() 为0-范数,表示向量中非零个数的总和.
为0-范数,表示向量中非零个数的总和.
稀疏主成分的模型求解是一个非凸优化问题,求解方法可以大致分为阈值压缩、近似回归、正定规划、局部优化和幂收缩 [25] .综合考虑求解主成分的可解释能力、负载因子的稀疏度和算法的运行时间等因素,本文选用截断幂方法 [26] 对图像特征矩阵进行稀疏主特征提取.截断幂方法结合了幂迭代和矩阵收缩求解稀疏主成分,算法1描述了截断幂方法的计算流程 [27] .在每次迭代过程中,应用幂方法求解主成分负载因子,然后根据定义的截断算子对其进行稀疏化处理:
![]()
(12)
其中, x 为负载因子向量, F 为截断下标集合,用来表示每个系数向量的非零位置,且 ![]() 当一个主成分的迭代求解结束后,对
当一个主成分的迭代求解结束后,对 ![]() 单位化即可得到稀疏主成分对应的负载因子.
单位化即可得到稀疏主成分对应的负载因子.
Σ ′=( I p × q - x * x T ) Σ ( I p × q - x * x T ).
(13)
在所有的主成分确定之后,根据式(13)对协方差矩阵进行收缩操作 [28] 以保证提取的主成分具有主次之分,即所有主成分的方差是呈下降趋势.
算法1 . 截断幂sPCA算法.
输入:数据集矩阵 A ∈ ![]() n × p ,包含 n 个样本, p 个属性, m 个主成分,协方差矩阵 Σ ∈
n × p ,包含 n 个样本, p 个属性, m 个主成分,协方差矩阵 Σ ∈ ![]() p × p ,负载因子的基数向量 k ∈{ k 1 , k 2 ,…, k m };
p × p ,负载因子的基数向量 k ∈{ k 1 , k 2 ,…, k m };
输出:负载因子向量 x =( x 1 , x 2 ,…, x m ).
for i =1: m
初始化负载因子向量 ![]() 迭代次数 t =1;
迭代次数 t =1;
do {
1) 使用幂迭代法计算
2) 根据 ![]() 向量中的具体值按从大到小的顺序提取前 k 个下标组成集合
向量中的具体值按从大到小的顺序提取前 k 个下标组成集合 ![]()
3) 使用截断算子 ![]() 对
对 ![]() 进行截断稀疏;
进行截断稀疏;
4) 正则化负载因子向量 ![]()
![]() 迭代次数 t = t +1.
迭代次数 t = t +1.
}while(直到收敛);
协方差矩阵进行收缩;
Σ =( I - x i x i T ) Σ ( I - x i x i T ), I ∈ ![]() p × p
p × p
end for
2.3.2 基于截断幂的稀疏特征提取
将2.2.3节提取到的显著目标区域 Supselect 中的所有像素按行排列构成数据矩阵 A n × p ,并按照文献[8]中的步骤来确定参数:
1) 将数据矩阵 A 标准化,计算特征点间的协方差矩阵 Σ ;
2) 使用主成分分析方法计算协方差矩阵的特征值 λ 并按降序完成排序,求出满足条件 ![]() 的最小 k 值就是主成分的个数;
的最小 k 值就是主成分的个数;
3) 使用局部迭代搜索的方法来确定每个主成分的非零个数.首先,给定一个方差阈值 δ ,则对于第 i 个主成分的方差范围可表示为( pev i - δ , pev i + δ ), pev i 是第 i 个主成分的方差,可近似地计算出每个主成分的非零个数的下限 ψ 和上限 φ .在[ ψ , φ ]内进行局部搜素,当满足│ pev ( t )- pev │< ζ i ,则可确定最佳非零个数.
经过上述3个步骤,可以确定所需的2个稀疏处理参数.然后,使用基于截断幂方法的稀疏主成分分析方法对提取的图像块底层特征矩阵进行稀疏降维并获取求解出的稀疏负载因子 X .最终,所要提取的稀疏特征为
F = A × X , F ∈ ![]() n × m .
n × m .
(14)
2.4.1 显著性计算
通过提取到的稀疏主成分特征 F ,按照与式(7)类似的方法来计算像素的显著性值:
![]()
(15)
其中, P i 是 F 的第 i 个像素, P max 和 P min 分别是 F 中的最大值和最小值.由式(5)计算所有显著性像素的显著值,而不包含在数据矩阵 A 中图像的像素的显著值设为0,从而得到当前尺度下的显著图 M s .
2.4.2 显著图融合
按照上述过程可得到所有尺度的显著图,并通过显著图融合得到最终的显著图.目前,常用的显著图或特征融合方法有线性融合 [29] 、基于像素的点乘融合 [30] 、条件随机场融合 [31] 等,通过实验对比发现线性融合方法可以很好地满足本文方法的需要.
![]()
(16)
根据式(16)进行显著图融合计算.其中, s 表示尺度, ![]() 是 F -范数.从而得到最终的显著图 M final .
是 F -范数.从而得到最终的显著图 M final .
为了验证本文方法的有效性,分别在目前比较通用的多目标数据集SED2 [32] 和HKU-IS [29] 上进行了实验,并与一些经典算法进行比较分析.
通过对比显著图的准确率 P (precision)-召回率 R (recall)曲线、准确率-召回率- F -measure值柱状图(以下分别简称 P - R 曲线、 F -measure柱状图)与平均绝对误差(mean absolute error, MAE )柱状图来评价显著性检测的性能.
针对显著性模型产生的显著图用阈值进行分割,其中阈值的取值范围为0~255.由此可以得到256个平均的准确率与召回率,以横轴为召回率、纵轴为准确率,将这些点平滑地连接起来,产生准确率-召回率 P - R 曲线.
与准确率-召回率曲线不同,在绘制准确率-召回率- F -measure值柱状图时,使用每幅图像的自适应阈值 T 对图像进行分割 [33] :
(17)
其中,参数 W 与 H 分别表示图像的宽度与高度.对每个数据集中的显著图,计算他们的平均准确率与召回率. F -measure值用于综合评价准确率与召回率,为了强调准确率的重要性,设置 β 2 =0.3 [33] ,并根据
![]()
(18)
计算平均的 F -measure值.
平均绝对误差是通过对比显著图与人工分割图的差异来评价显著性模型 [15] .根据
![]()
(19)
计算每个输入图像的 MAE 值,利用 MAE 值绘制柱状图.
数据集SED2是目前比较常用的多目标数据集,它包含了100张图像和相应的人工标注图,每张图像中都包含了2个显著目标.HKU_IS包含4 447张由作者整理挑选的图像,每张图像中至少包含了1个显著目标,并且目标与背景的颜色信息比较复杂,同时提供了人工标注的真实图.本文是主要针对多目标图像的显著性检测方法,从HKU_IS中选择具有2个以上目标的1 000张图片进行实验.
在2个数据集中随机选取100张图像,使用文献[8]中的方法确定稀疏化参数,主成份个数为3时,非零个数确定为9;经验值 α , ε 分别设置为10和0.75;在3个尺度上超像素分割的数量 N 分别取值为200,150和100.
为验证本文提出的多目标显著性检测方法的性能,在2个数据集上同近几年比较经典的10种算法进行对比,包括FT09 [34] ,GC13 [12] ,DSR13 [14] ,GM13 [13] ,MC13 [18] ,HS13 [33] ,PISA13 [35] ,HC15 [15] ,MBS15 [5] ,SBG16 [20] .所有显著性检测模型获取的显著图都被标准化到[0,255].
图2显示了本文方法与10种对比算法在数据集SED2上的显著图对比情况.从左至右依次是:原始输入图像 INPUT ,对比算法DSR,FT,GC,GM,HC,HS,MBS,MC,PISA,SBG的显著图,以及本文方法OUR和人工标注的真值图 GT .通过对比可以看出,OUR算法对位于图像边缘的目标(如图2中行⑤、行⑧)的检测效果明显优于对比算法.本文方法结合了超像素与像素2种显著性计算方法,在初始的超像素级显著图的基础上,进行一步计算像素的显著值,从而可以保留显著目标的更多细节,如图2中行②、行⑥、行⑦图像中的小目标区域.图3和图4是算法在复杂多目标数据集HKU_IS上的显著图对比情况.与图2相比,图3中图像的背景和显著目标都具有相对复杂的颜色信息,通过显著图的对比效果可以看出本文方法OUR在图像的背景(如图4的行①和行②)及目标信息(如图3中行③和行⑥)较为复杂的情况下的检测效果同样明显.

Fig. 2 The saliency maps on the SED2 dataset
图2 算法在数据集SED2上的多的视觉显著图

Fig. 3 The saliency maps on the HKU_IS dataset
图3 算法在数据集HKU_IS上的视觉显著图

Fig. 4 The multi-object saliency maps on the HKU_IS dataset
图4 算法在数据集HKU_IS上的多目标视觉显著图
与图2和图3相比,图4中的图像都包含3个以上的显著目标.本文方法通过对像素颜色变化较为敏感的方法获取目标先验知识,可以有效获取多个目标的空间信息,保证了多目标检测的有效性.从与其他算法的显著图对比可以看出本文方法在多目标的检测效果上具有较为明显的优势.
为了更加直观地比较本文方法与其他算法的效果,本文根据不同的评价标准,在2个数据集上进行了对比实验.
图5和图6是根据准确率-召回率和准确率-召回率- F -measure值评价标准分别在数据集SED2和HKU_IS上得到的 P - R 曲线图和 F -measure值柱状图.通过图5对比分析可以看出本文方法在 P - R 曲线及 F -measure值柱状图上与DSR和PISA算法相当,优于SBG,HC,HS等算法.而本文提出的算法更适合于复杂的多目标情况.而从图6的 P - R 曲线与 F -measure值柱状图上可以看出,本文方法在复杂多目标数据集HKU_IS上的 P - R 曲线与 F -measure值柱状图与其他的算法相比都具有相对明显的优势.本文方法与DSR,PISA都取得较好的 P - R 曲线,在 F -measure值上,本文方法分别比DSR与PISA算法高出6.7%,5.3%.在 P - R 曲线和 F -measure值上相对与其他对比算法的优势更加明显.这是由于本文的目标先验知识是通过颜色信息变化来获取多个显著性目标的空间信息,而在SED2数据集中的图像的显著性目标或背景信息较为简单,目标先验知识并没有起到太大的作用,但本文方法仍然可以达到与DSR和PISA算法相当的效果.相反对于图像信息相对复杂的数据集HKU_IS,图像颜色信息更加丰富,一般的算法都是基于图像中心来进行空间加权的,而本文方法通过目标先验知识可以获取多个目标的空间分布,并以目标中心进行空间加权,从而检测效果更加精确.这也充分体现了本文方法在图像信息复杂的多目标场景中的优越性,如显著性目标位于图像边缘、多个显著性目标、显著性目标包含多个对比度明显的区域等.
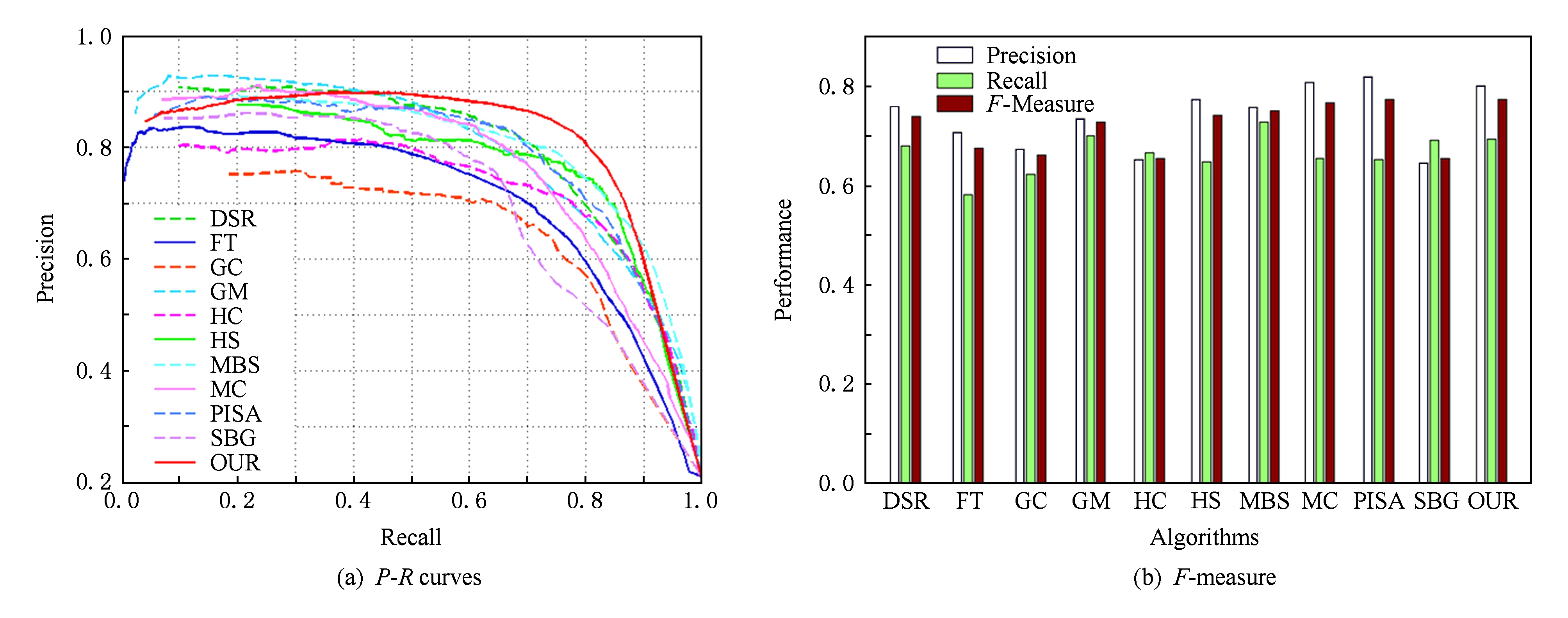
Fig. 5 The P-R curves and F-measure histograms respectively on the SED2 dataset
图5 算法在数据集SED2上的P-R曲线和F-measure柱状图
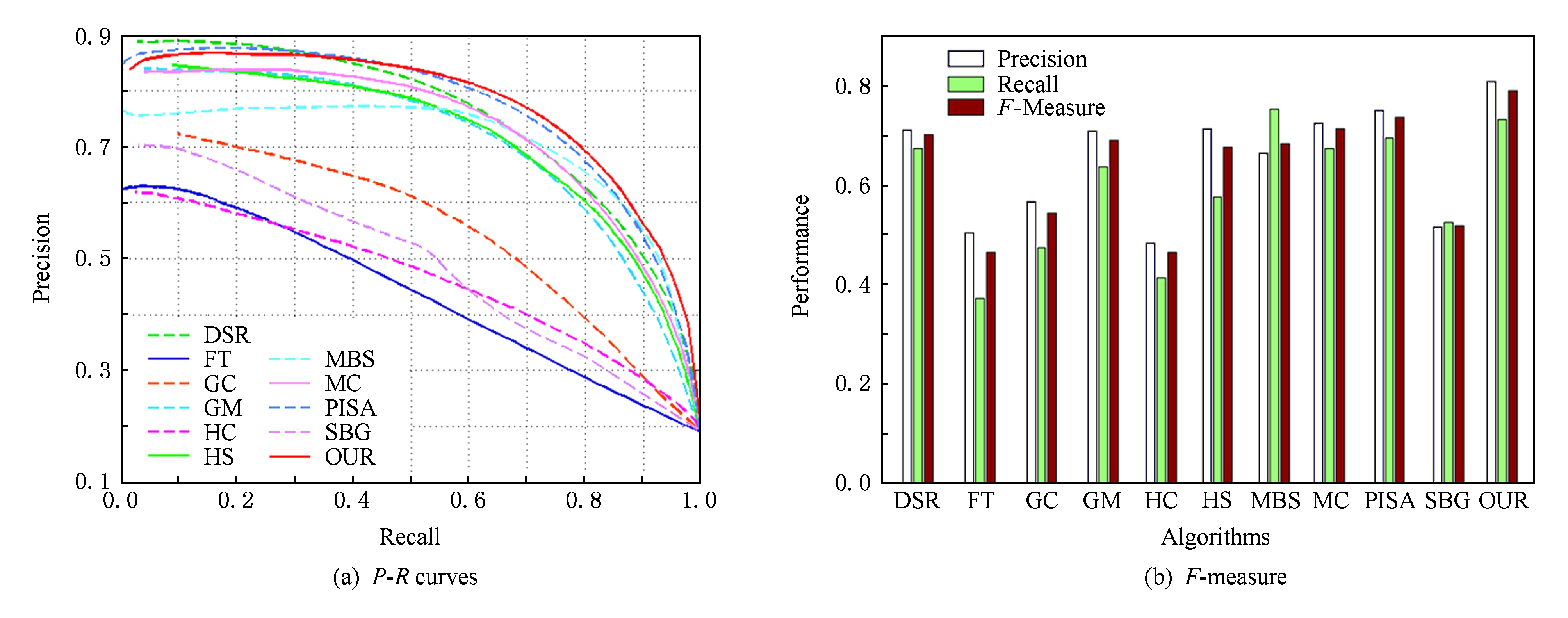
Fig. 6 The P-R curves and F-measure histograms respectively on the HKU_IS dataset
图6 算法在数据集HKU_IS上的P-R曲线和F-measure柱状图
由于本文方法中预选显著性目标区域的提取优化和显著值计算主要基于颜色特征,导致图像中显著目标与背景区域颜色相似性较高时区域优化效果较差,因而影响最终的检测效果,如图7所示:

Fig. 7 The failure case of our method
图7 本文方法检测失败案例
图8是根据平均绝对误差这一评价标准得到的 MAE 柱状图.对于SED2数据集,本文方法 MAE =0.1396,仅次于 MAE =0.1384的算法DSR,与MBS,PISA算法相当.在数据集HKU_IS上,所有算法的平均绝对误差 MAE 值都有所上升,OUR算法 MAE =0.1422,DSR与PISA的 MAE 值分别为0.1485,0.1479,与其他对比算法相比优势更加明显.这与上面的 P - R 曲线与 F -measure值柱状图的分析结果相一致.
本文方法利用目标先验知识获取预选目标区域,可以很大程度地减少计算量.为了验证本文方法在简化计算方面的作用,实验在2个数据集上随机选取100幅图像进行检测,然后计算每幅图的平均检测时间,对比结果如表1所示.实验借助MATLAB工具在Intel Core TM i3-3220处理器,4 GB内存的硬件环境下进行.其中,超像素分割的时间不计入处理时间.本文OUR算法每幅图像平均检测时间为0.073 s.
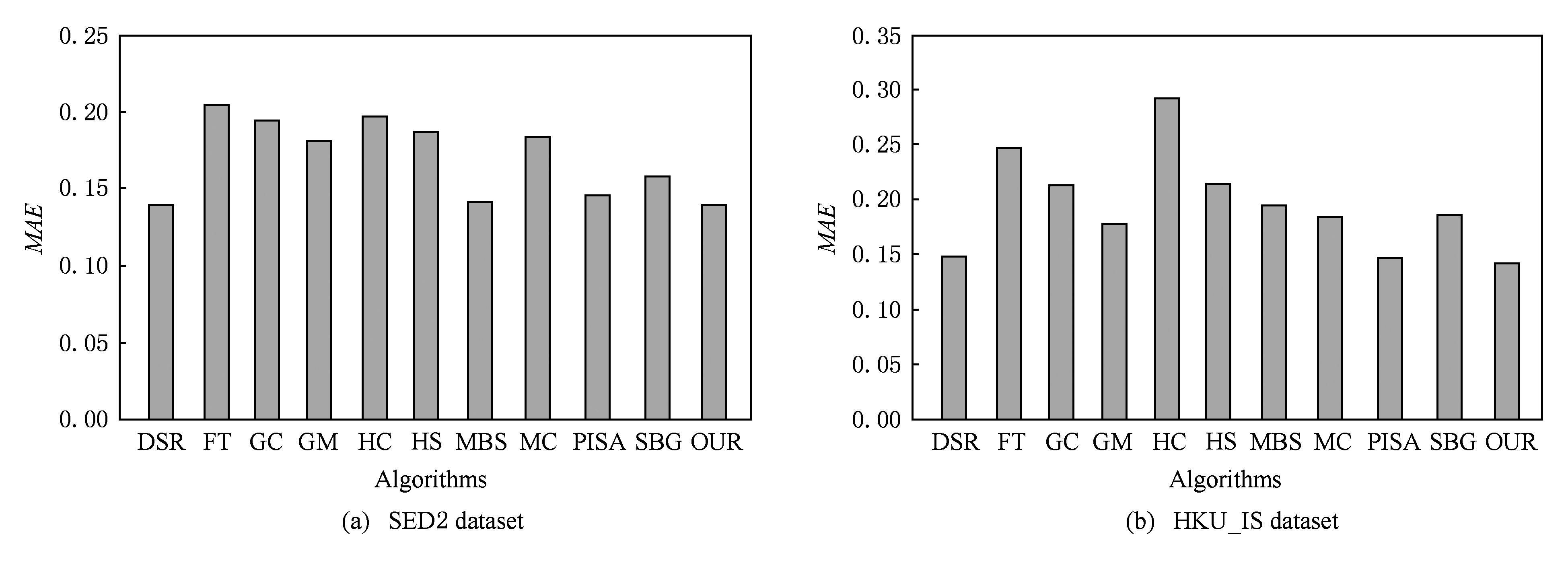
Fig. 8 The MAE histograms respectively on the SED2 and HKU_IS dataset
图8 算法在数据集SED2和HKU_IS上的MAE柱状图
Table 1 The Average Detection Time of 100 Images
表1 100张图片的平均检测时间对比表

本文提出了一种基于全连接图和稀疏主成分分析的多目标检测方法,并在2个多目标数据集上与经典显著性检测算法进行了性能对比分析,结果表明本文方法对于显著性目标位于边界、目标信息复杂、包含多个目标等情况,都可以得到较为精确的检测结果.结合超像素与像素显著性计算的优势,可在显著性检测过程中简化计算提高效率的同时提高检测的准确性.但对于显著目标与背景区域的颜色对比度较低的情况,本文方法往往不能很好地检测出完整的显著目标.针对存在的不足,下一步研究的主要目标是通过引入深度特征来提高自然场景中复杂图像显著性检测的鲁棒性.
参考文献
[1]Zünd F, Pritch Y, Sorkine-Hornung A, et al. Content-aware compression using saliency-driven image retargeting[C] //Proc of the 2013 IEEE Int Conf on Image Processing. Piscataway, NJ: IEEE, 2013: 1845-1849
[2]Borji A, Itti L. State-of-the-art in visual attention modeling[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2013, 35(1): 185-207
[3]Qi Mengshi, Wang Yunhong. DEEP-CSSR: Scene classification using category-specific salient region with deep features[C] //Proc of the 2016 IEEE Int Conf on Image Processing. Piscataway, NJ: IEEE, 2016: 1047-1051
[4]Shui Linlin. Aptive image segmentation based on saliency detection[J]. International Journal on Smart Sensing & Intelligent Systems, 2015, 8(1): 408-428
[5]Zhang Jianming, Sclaroff S, Lin Zhe, et al. Minimum barrier salient object detection at 80 fps[C] //Proc of the 2015 IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2015: 1404-1412
[6] Achanta R, Shaji A, Smith K, et al. SLIC superpixels compared to state-of-the-art superpixel methods[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2012, 34(11): 2274-2282
[7]Harel J, Koch C, Perona P. Graph-Based Visual Saliency[C] //Proc of Int Conf on Neural Information Processing Systems. Cambridge: MIT Press, 2006: 545-552
[8]Shen Ningmin, Li Jing, Zhou Peiyun, et al. BSFCoS: Block and sparse principal component analysis based fast co-saliency detection method[J]. International Journal of Pattern Recognition & Artificial Intelligence, 2015, 30(1): 1655003
[9]Osberger W M. Visual attention model: US, Patent 6.670.963[P]. 2003-12-30
[10]Koch C, Ullman S. Shifts in Selective Visual Attention: Towards the Underlying Neural Circuitry[M]. Berlin: Springer, 1987: 115-141
[11]Itti L, Koch C, Niebur E. A model of saliency-based visual attention for rapid scene analysis[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 1998, 20(11): 1254-1259
[12]Cheng Mingming, Warrell J, Lin Wenyan, et al. Efficient salient region detection with soft image abstraction[C] //Proc of the 2013 IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2013: 1529-1536
[13]Yang Chuan, Zhang Lihe, Lu Huchuan, et al. Saliency Detection via Graph-Based Manifold Ranking[C] //Proc of the 2013 IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2013: 3166-3173
[14]Li Xiaohui, Lu Huchuan, Zhang Lihe, et al. Saliency detection via dense and sparse reconstruction[C] //Proc of the 2013 IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2013: 2976-2983
[15]Cheng Mingming, Mitra N J, Huang Xiaolei, et al. Global contrast based salient region detection[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2015, 37(3): 569-582
[16]Qu Yanyun, Zheng Nanning, Li Cuihua, et al. Salient building detection based on SVM[J]. Journal of Computer Research and Development, 2007, 44(1): 141-147
[17]Gopalakrishnan V, Hu Yiqun, Rajan D. Random walks on graphs for salient object detection in images[J]. IEEE Trans on Image Processing, 2010, 19(12): 3232-3242
[18]Jiang Bowen, Zhang Lihe, Lu Huchuan, et al. Saliency detection via absorbing markov chain[C] //Proc of the 2013 IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2013: 1665-1672
[19]Li Changyang, Yuan Yuchen, Cai Weidong, et al. Robust saliency detection via regularized random walks ranking[C] //Proc of the IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015: 2710-2717
[20]Wang Qiaosong, Zheng Wen, Piramuthu R. GraB: Visual saliency via novel graph model and background priors[C] //Proc of the IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 535-543
[21]Karimi A H, Shafiee M J, Scharfenberger C, et al. Spatio-temporal saliency detection using abstracted fully-connected graphical models[C] //Proc of the Int Conf on Image Proc. Piscataway, NJ: IEEE, 2016: 694-698
[22]Chakraborty S, Mitra P. A dense subgraph based algorithm for compact salient image region detection [J]. Computer Vision and Image Understanding, 2016, 145(C): 1-14
[23]Kim J S, Sim J Y, Kim C S. Multiscale saliency detection using random walk with restart[J]. IEEE Trans on Circuits and Systems for Video Technology, 2014, 24(2): 198-210
[24]Norris J R. Markov Chains[M]. London: Cambridge University Press, 1998
[25]Hu Zhenfang, Pan Gang, Wang Yueming, et al. Sparse principal component analysis via rotation and truncation[J]. IEEE Trans on Neural Networks & Learning Systems, 2015, 27(4): 875-890
[26]Yuan Xiaotong, Zhang Tong. Truncated power method for sparse eigenvalue problems[J]. Journal of Machine Learning Research, 2011, 14(1): 899-925
[27]Saad Y. Numerical Methods for Large Eigenvalue Problems[M]. Manchester: Manchester University Press, 1992
[28]Mackey L. Deflation methods for sparse PCA[C] //Proc of the 21st Int Conf on Neural Information Processing Systems. New York: Curran Associates Inc., 2008: 1017-1024
[29]Li Guanbin, Yu Yizhou. Visual saliency based on multiscale deep features[C] //Proc of the 2015 IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015: 5455-5463
[30]Fu Huazhu, Cao Xiaochun, Tu Zhuowen. Cluster-based co-saliency detection[J]. IEEE Trans on Image Processing, 2013, 22(10): 3766-3778
[31]Mai Long, Niu Yuzhen, Liu Feng. Saliency aggregation: A data-driven approach[C] //Proc of the IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2013: 1131-1138
[32]Borji A, Sihite D N, Itti L. Salient object detection: A benchmark[G] //Computer Vision—ECCV 2012. Berlin: Springer, 2012: 414-429
[33]Yan Qiong, Liu Xu, Shi Jianping, et al. Hierarchical saliency detection[C] //Proc of the IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2013: 1155-1162
[34]Achanta R, Hemami S, Estrada F, et al. Frequency-tuned salient region detection[C] //Proc of the IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2009: 1597-1604
[35]Shi Keyang, Wang Keze, Lu Jiangbo, et al. Pisa: Pixelwise image saliency by aggregating complementary appearance contrast measures with spatial priors[C] //Proc of the 2013 IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2013: 2115-2122
Liang Dachuan 1 , Li Jing 1 , Liu Sai 2 , and Li Dongmin 1
1 ( College of Computer Science and Technology , Nanjing University of Aeronautics and Astronautics , Nanjing 211106) 2 ( NARI Group Corporation ( State Grid Electric Power Research Institute ), Nanjing 210003)
Abstract In order to detect multiple salient objects from the image with cluttered background, a new multi-object salient detection method based on fully connected graph and sparse principal component analysis is proposed. Firstly, a rapid coarse detection method with different scales is adopted to obtain the object prior with the location of candidate objects and the pixel level saliency map. Meanwhile, we construct a fully connected graph based on the superpixel segmentation to obtain the superpixel-level saliency map. The salient regions are extracted from the superpixel-level binarized salient object prior map and a sparse principal component analysis method is used to gain the main features vector from the pixel matrix composed of the pixels in the optimized salient regions and obtain the salient map of corresponding scale. Finally, the final salient map is fused with the multi-scale saliency maps. Our method takes the advantage of pixel and superpixel method, it can not only simplify the calculation but also improve the detection precision of the salient objects in the image. Quantitative experiments on two public datasets SED2 and HKU_IS demonstrate that out method can detect multiple salient objects from complex images and outperforms other state-of-the-art methods.
Key words saliency detection; fully connected graph; sparse principal component analysis; object prior; superpixel segmentation
摘 要 针对具有多个显著目标且背景较为复杂的图像,提出了一种基于全连接图和稀疏主成分分析(sparse principal component analysis, sPCA)的显著性检测方法.首先,在不同的尺度空间上利用目标先验知识快速获取包含预选显著目标的空间位置信息,同时,在超像素分割的基础上构造全连接图,并计算超像素级的显著图.然后,利用目标先验知识提取并优化超像素显著图的显著性区域,采用稀疏主成分分析提取优化后的显著性像素点的主要特征,获取相应尺度的显著图.最后,将多个尺度下的显著图进行融合得到最终的显著图.该方法充分利用了超像素与像素显著性计算的优势,在提高检测速度的同时获得更高的检测精度.在公开的多目标数据集SED2和HKU_IS上进行实验验证,结果表明:该方法能够有效检测出复杂背景下的多个显著目标.
关键词 显著性检测;全连接图;稀疏主成分分析;目标先验;超像素分割
中图法分类号 TP391
收稿日期 :2016-09-05;
修回日期: 2017-05-02
基金项目 :国家电网公司科技项目
This work was supported by the Science and Technology Project of State Grid Corporation of China.
通信作者 :李静(lijing@nuaa.edu.cn)
DOI: 10.7544/issn1000-1239.2018.20160681

Liang Dachuan , born in 1985. Master. His main research interests include image processing and software verification.

Li Jing , born in 1976. PhD, associate professor in Nanjing University of Aeronautics and Astronautics. Her main research interests include computer vision, software verification and data mining.

Liu Sai , born in 1988. Master. Researcher at NARI Group Corporation (State Grid Electric Power Research Institute). His main research interests include image processing and cloud computing.

Li Dongmin , born in 1992. Master candidate at Nanjing University of Aeronautics and Astronautics. His main research interests include image processing and software verification.