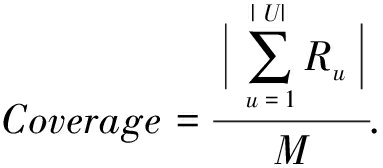基于主题序列模式的旅游产品推荐引擎
朱桂祥 1 曹 杰 1,2
1 (南京理工大学计算机科学与工程学院 南京 210094) 2 (南京财经大学江苏省电子商务重点实验室 南京 210003) (zgx881205@gmail.com)
近年来,推荐系统领域的研究工作发展迅猛,各种各样的推荐系统亦随之在电子商务、社交网站、电子旅游、互联网广告等大量领域得到了广泛应用,并展示出优越的效果与前景 [1-3] .其中,随着越来越多的在线旅游网站的兴起(如Expedia,Travelzoo、途牛等)能刻画用户旅游兴趣偏好的在线数据越来越丰富,使得旅游产品推荐成为推荐系统研究领域的热门议题之一 [4-6] .
目前,针对传统商品的推荐已有许多成熟的推荐算法得到广泛应用,如协同过滤算法 [7] 、基于内容的推荐算法 [8] 和混合型推荐算法 [9] 等.然而大量已有研究表明 [4-6,10-12] :旅游产品推荐与电影、商品等传统推荐有显著差异.1)用户通常不会频繁或大量购买旅游产品,这导致“用户-产品”关联矩阵极为稀疏;2)旅游产品描述信息维度多样复杂,微小的参数变化会导致完全不同的旅游产品,如景点参观线路和日程、酒店和交通工具选择等因素的变化,然而这类有内在关联的不同旅游产品却指向用户共同的兴趣偏好;3)用户往往不会长期关注旅游产品,即在电子旅游网站上留下访问记录,而往往是有了旅游目标和安排之后,才开始浏览旅游产品,这导致在线旅游数据中存在大量冷启动用户.因此,针对传统商品的推荐算法很难直接应用到旅游推荐领域.
基于上述原因,本文首先从旅游数据的特征入手,对旅游数据的稀疏性和冷启动问题进行了深入的分析,并从日志会话的相似性角度进行了论证,以启发研究基于主题序列模式的旅游产品推荐引擎.具体而言,本文首先提出了面向旅游产品的推荐引擎(sequential recommendation engine for travel products, SECT),该引擎通过用户实时点击流可以捕捉用户的兴趣偏好,并实时产生旅游产品推荐列表.其次,本文分别从旅游页面的主题挖掘、访问序列的模式挖掘和模式库的存储、匹配计算等方面对SECT的原理进行了详细的说明.为了提升在线匹配计算的效率,本文设计一种新的多叉树数据结构PSC-tree用于存储历史模式库,并与在线计算模块无缝衔接.最后,本文选取了常用的基准推荐算法,在真实的旅游数据集上进行了实验对比,并从多个评价指标上对实验结果进行分析.实验结果表明:SECT推荐引擎不但性能上比传统推荐算法更有优势,更值得注意的是SECT在对冷启动用户和长尾物品推荐方面也具有显著的优势.
1 相关工作
本节主要回顾一些与本文相关的研究工作,这些工作主要围绕旅游推荐和基于序列模式的推荐展开.
1) 旅游推荐.从应用场景角度看,旅游推荐大致包含2类:①兴趣点或路径推荐;②旅游产品或套餐推荐.第1类应用场景吸引了大部分研究者的目光,试图融合移动终端数据与地理信息数据为用户推荐兴趣点(points of interest, POI) [13-15] 或为旅游者动态推荐旅游路径 [16-18] .如文献[15]从用户大量的GPS轨迹数据中挖掘兴趣点和旅行线路序列,通过协同过滤方法为用户推荐景点和线路;文献[18]从社交网络中的旅游图片信息抽取用户的特征并根据旅游地标和路径信息挖掘出频繁模式,最终构建贝叶斯学习模型对用户线路进行个性化推荐;面向第2类应用场景的研究则相对偏少,已有研究 [4-5,12] 针对旅游数据稀疏性强等特点,大多先从异构数据中提取描述旅游产品的多维度特征,如从文本中提取的隐含主题、景点与地域的关系、时间与价格的关系等,以期加强用户和产品之间的关联,从而设计出一些新颖的协同过滤或基于内容的推荐方法.比如Liu等人 [4-5] 的系列研究尝试从STA Travel * STA Travel, URL: http://www.statravel.com/
旅游套餐描述文本中挖掘潜在主题,结合季节和价格等因素提出混合协同过滤推荐方法,该类方法有效地解决了协同过滤推荐在极其稀疏的旅游数据中应用的问题.
2) 基于时间序列的推荐.本文的研究立足于第2类应用场景,试图从用户点击旅游网站页面留下的日志数据出发挖掘用户行为模式,从而根据用户实时点击流推荐旅游产品.因此,与本文研究相关的另一系列研究工作是基于时间序列或轨迹数据的推荐系统.文献[19-20]基于出租车GPS轨迹数据的挖掘推荐最近载客点及避拥堵行驶路径;文献[21]通过挖掘播放列表预测用户喜欢的音乐标签;文献[22]则研究了时间序列数据中的事件预测问题;文献[23]提出了一种排序学习模型,它通过融合潜在因子和行为序列的效用函数来提升购买预测的精度.由于时间序列数据的复杂性及应用问题的多样性,基于时间序列数据的推荐问题仍然呈现出开放性 [24-25] ;同时,从日志数据角度切入研究旅游产品推荐问题虽然已经有一定的研究成果,但是此类工作 [11,26-27] 的日志数据大多是基于用户分享的地理位置标签或者发表的游记,该类日志数据类型单一,可以用于刻化旅游产品的特征比较少,也很难精确地表征用户的兴趣偏好;如文献[11]从游记文本中抽取地理信息并构建了一个“Location-Topic”主题模型进行景点或者旅游目的地推荐.
总的来说,以上已有的相关推荐技术在某种程度上解决了旅游推荐问题.但是这类推荐技术只适应于数据结构相对简单的旅游数据或者依赖于地理信息数据,且很难全面地捕捉用户的实时兴趣偏好.而本文使用的数据为旅游企业真实的Web服务器日志,该日志蕴含了丰富的旅游产品相关信息和大量的用户行为的点击记录,通过构建推荐引擎能够根据用户实时的点击流精确地捕捉用户即时的兴趣并对站内旅游产品进行个性化推荐.
2 数据描述
2 . 1 数据来源与规模
本文所使用的旅游产品数据集来自于途牛旅游网 * http://www.tuniu.com/
,包含用户访问Web服务器日志和用户订单记录.每条服务器日志记录表示为一个五元组:由  User_ID , Page_ID , Page_Name , Time , Session_ID
User_ID , Page_ID , Page_Name , Time , Session_ID  字段构成.其中 User_ID 用于跟踪用户,为用户匿名标识,由浏览器Cookie生成; Page_ID 和 Page_Name 分别表示途牛页面标识及相应代表页面的语义文本描述; Time 为用户访问时间; Session_ID 用于标识该条记录所属的用户会话.用户订单记录则由 User_ID , Item_ID , Time 构成,其中 User_ID 代表下单的用户; Item_ID 为用户购买的旅游产品标识; Time 代表为用户下单时间.
字段构成.其中 User_ID 用于跟踪用户,为用户匿名标识,由浏览器Cookie生成; Page_ID 和 Page_Name 分别表示途牛页面标识及相应代表页面的语义文本描述; Time 为用户访问时间; Session_ID 用于标识该条记录所属的用户会话.用户订单记录则由 User_ID , Item_ID , Time 构成,其中 User_ID 代表下单的用户; Item_ID 为用户购买的旅游产品标识; Time 代表为用户下单时间.
旅游产品数据集的时间跨度为2个月(即2013年7-8月).本文实验以7月份用户访问日志为训练集,用于挖掘用户兴趣偏好;8月份订单记录及其所属会话为测试集,用于验证推荐引擎的效果.我们对训练数据做了必要的预处理,包括:1)删除了大量重复出现的首页;2)删除了会员登录后访问留下的重定向登录页面.表1展示了预处理后训练集的规模,其中# Session ,# Record ,# User ,# Page 分别表示会话、记录、用户和页面的数量,# L 表示会话平均长度.页面包含产品页面和非产品页面,产品页面又进一步细分为出境签证、旅游线路及景点门票,这些产品不仅能体现出用户的兴趣偏好,同时也是推荐的目标对象.与其不同的是,非产品页面包含分类页面和攻略页面2类,分类页面是包含用户选定的旅游目的地或旅游主题的所有产品页面的汇总,例如西藏旅游、欧洲旅游、名山胜水、游乐园、海边海岛等;攻略页面介绍了目的地的旅游景点、线路、美食、住宿、地图、游记等.这2类页面的主题有助于推荐引擎刻画用户的兴趣偏好.表2展示了训练集页面的分类及规模,其中# Visa ,# Route ,# Ticket ,# Category ,# Guide 分别代表出境签证、旅游线路、景点门票、分类和攻略页面的数量.可以看出,非产品页面数量甚至超过了产品页面数量,这意味着基于“用户-项目”矩阵的传统产品推荐方法将不能利用非产品页面中蕴含的丰富信息.
Table 1 Statistic of the Training Set
表1 训练集日志数据特征

#Session#Record#User#Page#L11785266434934022781195.64
Table 2 Category and Sizes of Web Pages
表2 页面分类及规模
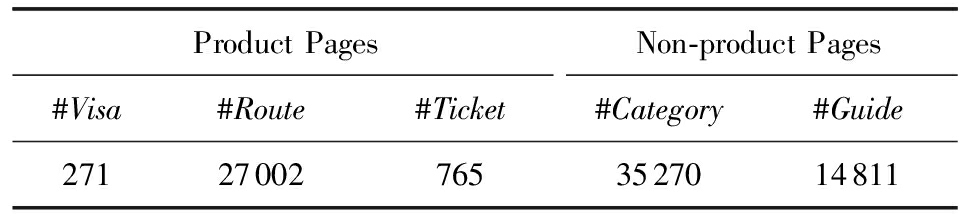
ProductPagesNon⁃productPages#Visa#Route#Ticket#Category#Guide271270027653527014811
2 . 2 数据特点
本节通过分析旅游数据集的特点,以阐明提出本文方法的动机.
特点1 .“用户-项目”购买矩阵极度稀疏.
表3描述了测试集中订单数据的基本特征,其中# Order ,# User ,# Item 分别代表订单、用户、项目数量, Density 代表密度.如果构建“用户-项目”购买矩阵使用协同过滤算法 [28] 进行推荐,矩阵中非零值比例仅为0.0155%,而常用的MovieLens100K * http://grouplens.org/datasets/movielens/100k/
“用户-项目”评分矩阵的密度为6.3%.我们再观察用户购买旅游产品的次数分布,如图1所示,有27 551(94.8%)的用户仅购买1种旅游产品,仅有0.07%的用户购买了5种以上的旅游产品.因此,传统协同过滤算法难以直接运行于“用户-项目”购买矩阵.
Table 3 Statistic of Purchase Record in Test Data
表3 测试集订单数据特征

#Order#User#ItemDensity∕%329552905767990.0155
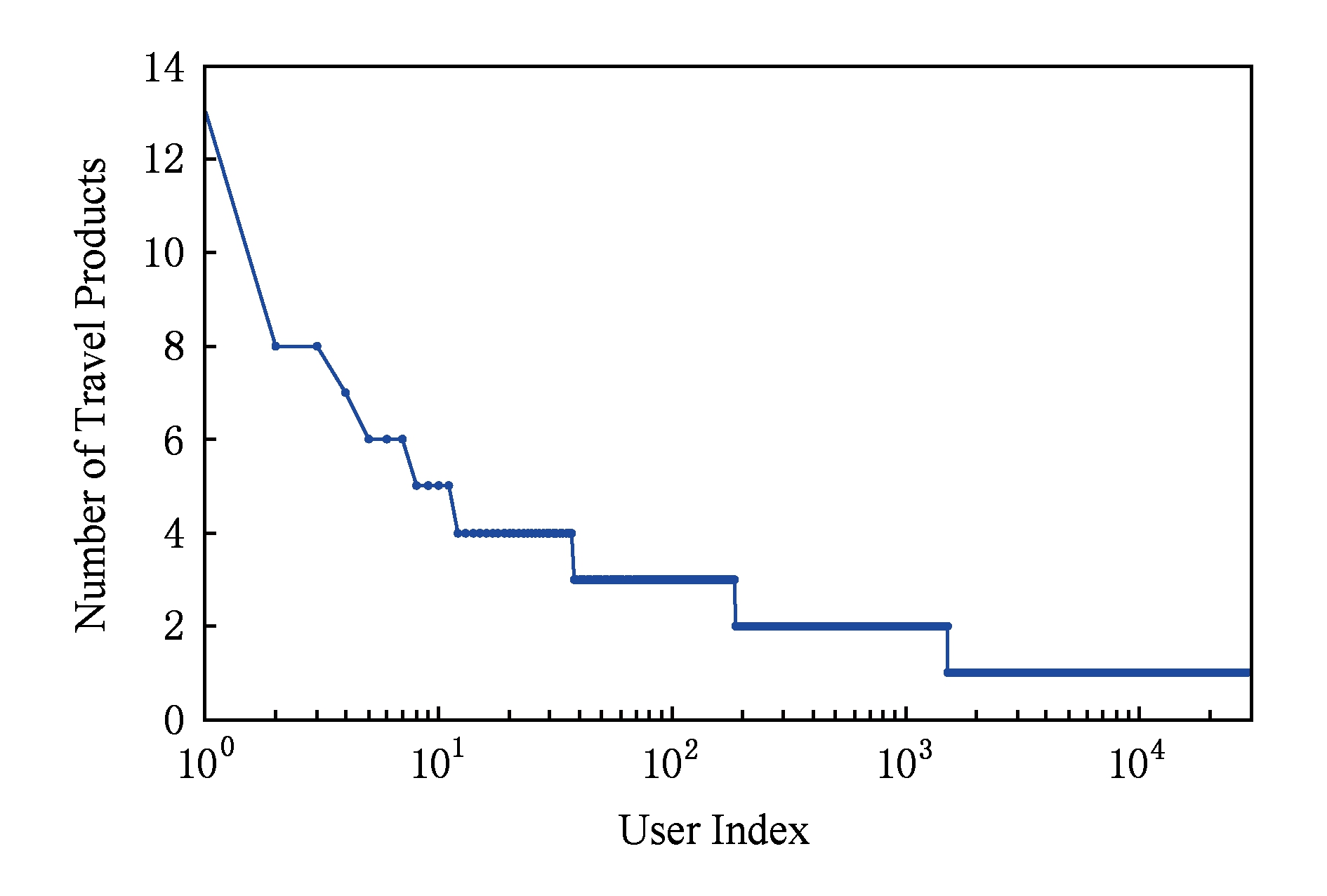
Fig. 1 The distribution of user-item purchasing matrix
图1 用户购买旅游产品次数分布
特点2 . 冷启动用户比例极高.
在测试集的订单数据中,有20 990个用户为冷启动用户,比例达到63.7%,即存在大量用户在训练数据中没有任何访问记录.当然,部分冷启动用户可能使用不同终端访问网站,利用Cookie标识用户容易引起冷启动用户比例偏高.图2展示了剩余的8 067个用户在训练集中的访问网页数量,可以看出,接近半数的用户在上个月访问网页数量不足10个.因此,冷启动用户比例高是基于日志数据推荐所面临的挑战性问题之一,即如果构造“用户-项目”访问频率矩阵同样面临数据稀疏性问题,传统协同过滤算法仍然难以奏效.
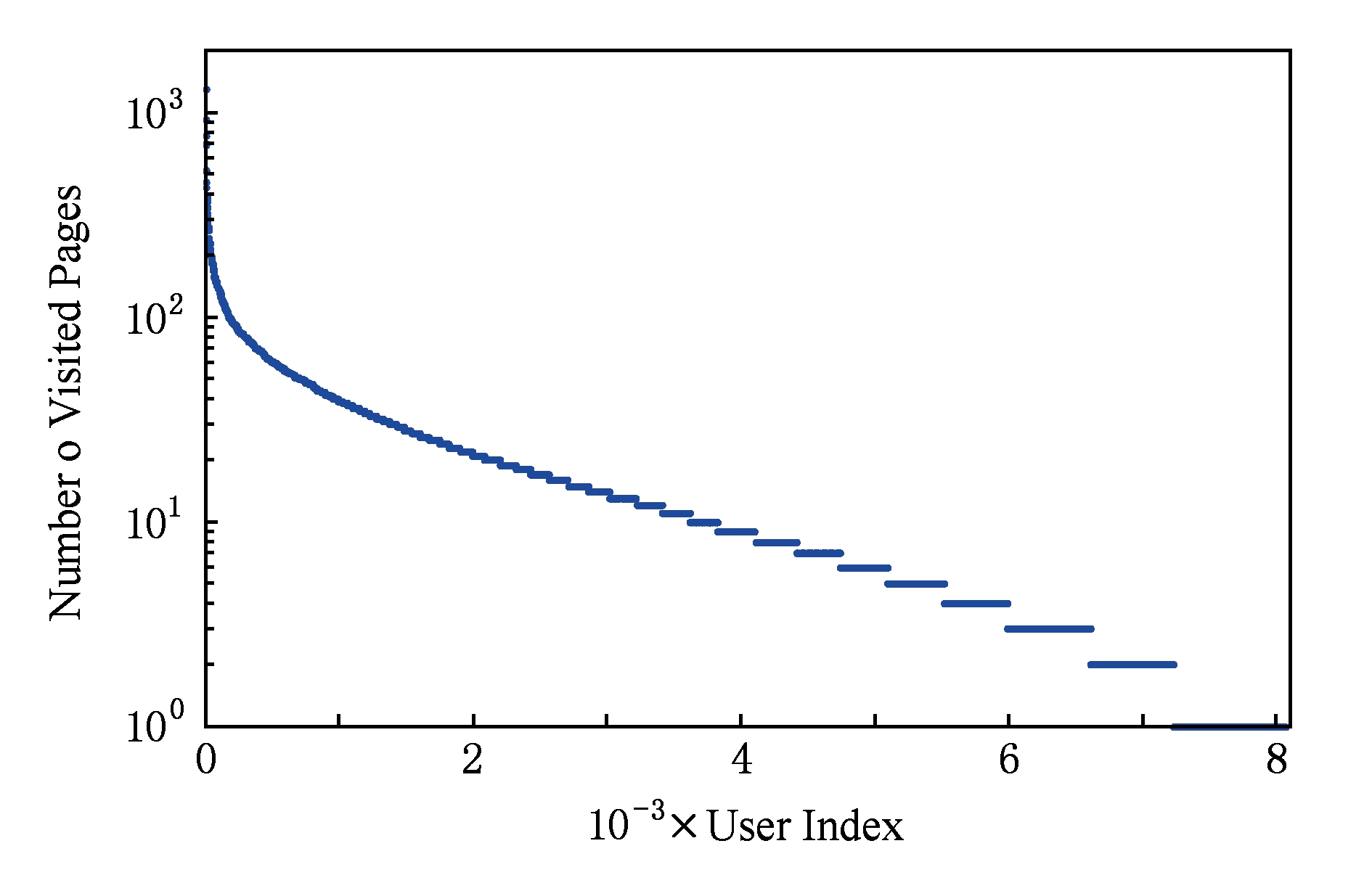
Fig. 2 The distribution of user-item visiting matrix
图2 用户浏览页面的数量分布
特点3 . 购买同种产品的会话相似性高.
从测试集的订单数据中,我们首先提取被购买超过10次的热门旅游产品688个,再抽取不同用户购买每个产品的访问会话22 584条,该会话包含下订单操作.动态时间规划(dynamic time warping, DTW)定义了序列之间的最佳对齐匹配关系,支持不同长度时间序列的相似性度量 [29] ,被广泛用于衡量时间序列的相似性.我们计算购买同种产品会话的DTW距离(标记为Intra-Sessions),为便于比较,我们再计算每个会话与其他所有会话的DTW距离(标记为Inter-Sessions),图3展示了上述2种情况的DTW距离分布.
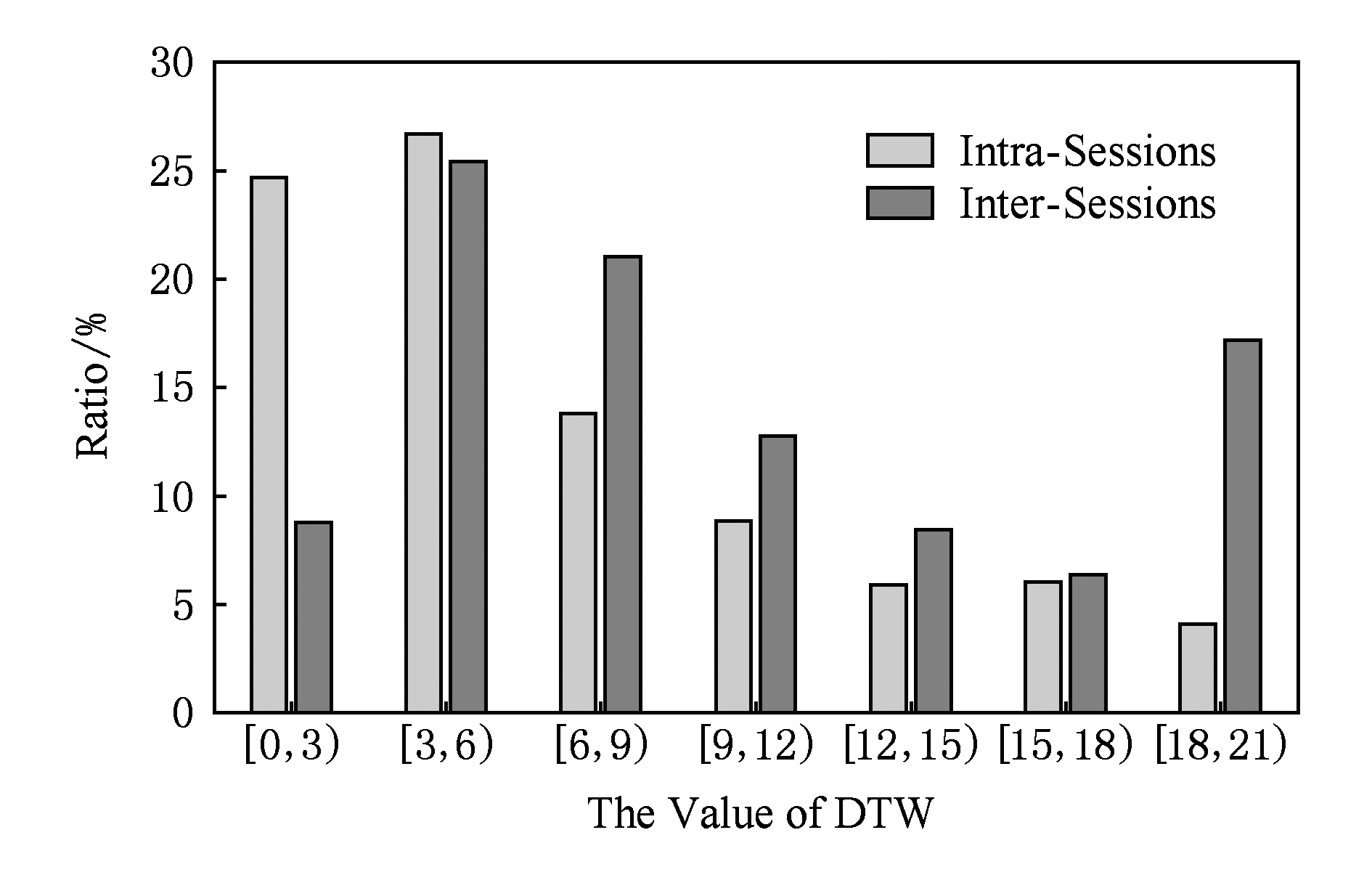
Fig. 3 The DTW distribution among sessions purchasing the same product
图3 购买同种产品的会话DTW距离分布
从图3可以看出,在最小DTW区间[0,3)上,Intra-Sessions比例远远高于基准线,而在较大的DTW距离区间上(如[6,9),[9,12),[12,15),[18,21]),Intra-Sessions比例却低于基准线.因此,尽管用户兴趣迥异,购买同个旅游产品的访问序列(即会话)却有较高的相似性,这启发着本文利用频繁序列模式作为推荐引擎的计算依据.
3 推荐引擎总体框架
本节简要介绍SECT推荐引擎的总体框架,如图4所示,主要分为离线批处理和在线计算两大模块,其功能简述:
1) 离线批处理.①从页面语义文本描述中挖掘主题,将相似度高的线路产品映射到同一泛化主题,以期扩大匹配范围,技术细节将在4.1节中介绍;②将经主题泛化后会话集合看作时间序列事务数据集,从中挖掘序列频繁模式,形成点击模式库,并为每个模式寻找相关联的候选产品,技术方案将在4.2节中阐述.
2) 在线计算.该模块的任务主要是根据用户最新的访问会话,基于由离线批处理所产生的模式库进行匹配计算和推荐分值计算,最终依据推荐分值的排序,产生一个Top- k 的推荐列表,技术细节将在4.3节中予以介绍.
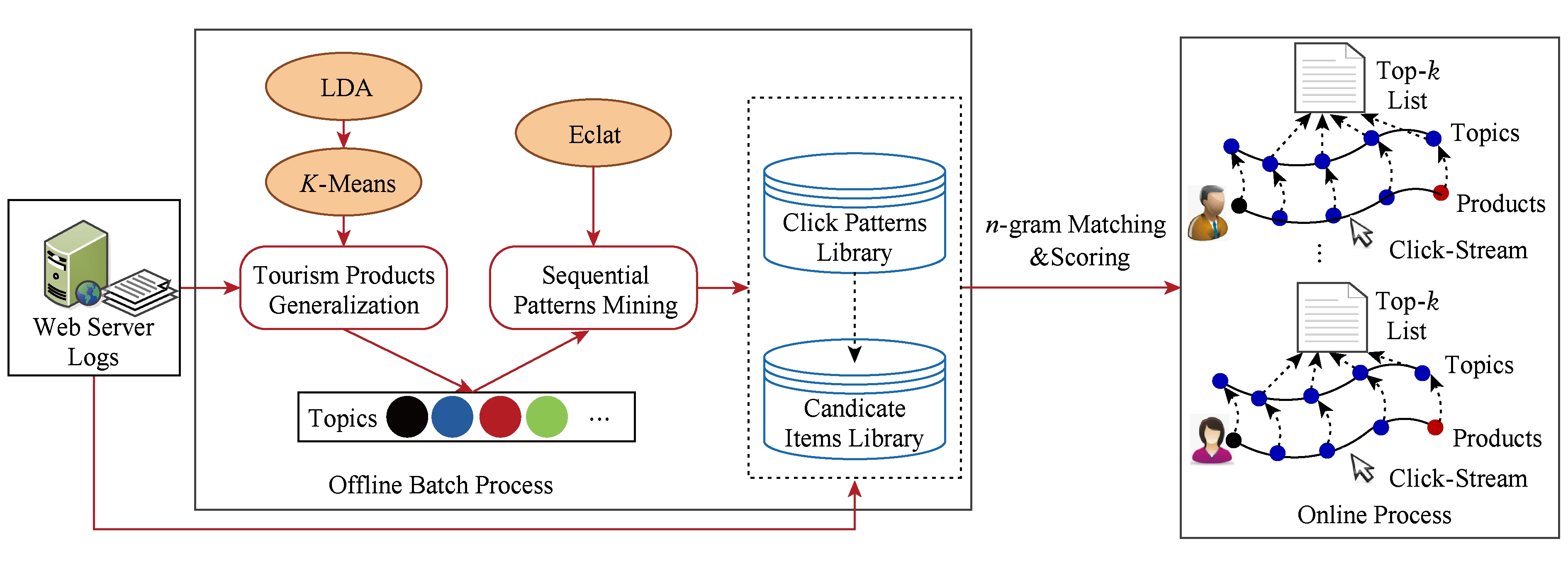
Fig. 4 The framework of SECT engine
图4 SECT推荐引擎总体框架
SECT推荐引擎具有较好的可扩展性,离线批处理在空闲时间周期性执行,承担计算繁重的主题挖掘与序列频繁模式挖掘任务;而在线计算模块则负责轻量级的匹配和分值计算任务.
4 基于主题序列模式的推荐方法
4 . 1 页面主题泛化
页面主题泛化试图将内容相似的不同页面投影到同一个主题,进而将主题相同的访问序列合并成一个主题序列.图5给出了一个说明性例子,从 Page_ID 上看,2个用户访问序列差异甚大.但是,从页面描述文本上看,2个访问序列均反映出用户计划去北京旅游的兴趣偏好.此外,访问序列中的分类页面和攻略页面也同样反映出用户的兴趣偏好.
旅游线路页面的文本描述信息复杂多样化,且具有显著的领域特色.抽取主题本质上是文本聚类问题,通常,最朴素直观的思路是将文本形成词袋模型,然后通过不同的聚类算法进行文本聚类操作,从而实现主题抽取.但是这种方法对数据噪音比较敏感,在实际应用中文本聚类难以获得良好效果,因此我们提出用主题模型(latent Dirichlet allocation, LDA) [30] 模型降维并过滤噪音,再通过 K -Means [31] 进行文本聚类实现主题抽取.首先,对线路页面文本信息进行分词、去停用词等预处理操作得到文本向量矩阵.其次,借助LDA模型对所有文本向量矩阵进行主题建模,并采用Gibbs抽样法对建模后的文本向量矩阵进行求解,得到线路页面的隐含主题概率分布矩阵,进而将该矩阵作为 K -Means的输入.最终聚类后的每个类簇分别代表线路页面的不同主题.
与线路页面不同的是签证和门票页面的文本描述信息为明确的结构化数据,其中签证页面包含签证国家和签证类型,门票页面包含景点名称和景点所在地,我们分别依据签证国家和景点所在地对签证和门票页面进行主题泛化.在分类页面和攻略页面中,考虑到这些页面的文本描述特点,我们直接依据旅游目的地或者旅游主题对这2类页面进行主题泛化.
设 I ={ i 1 , i 2 ,…, i M }为训练集中所有的页面集合,Т={ t 1 , t 2 ,…, t K }为所有页面泛化后的主题集合,页面主题泛化可以抽象为函数:
φ ( i p )→ t k ,
(1)
其中,1≤ p ≤ M ,1≤ k ≤ K , M 表示页面的数量,设 K 为页面泛化的主题数量, t k 表示为页面 i p 经泛化后的主题.
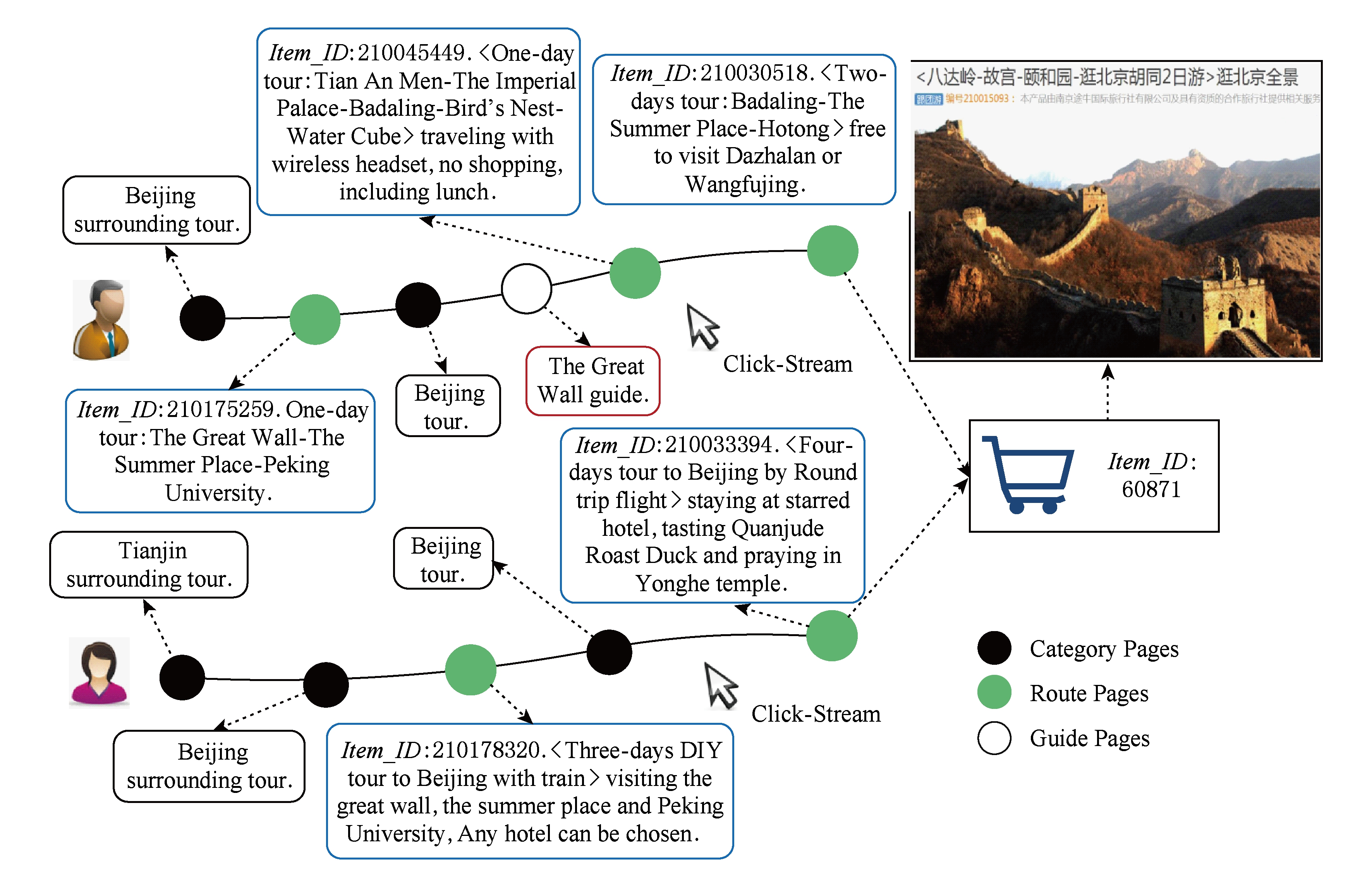
Fig. 5 An example of two different sessions which can reflect the same preferences to travel around Beijing
图5 体现出北京旅游偏好的2个不同会话的举例
4 . 2 序列模式挖掘及存储结构
由2.2节中旅游数据特点可知,购买同个旅游产品的访问序列具有较高的相似性,而且用户当前的兴趣偏好能够通过访问序列的页面主题来刻画.因此,挖掘用户访问主题序列的模式对于刻画用户兴趣偏好显得尤为重要.每一个主题模式代表不同用户访问旅游页面的兴趣偏好.
定义1 . 主题访问序列事务集.主题访问序列事务集由训练集中所有主题访问序列组成,记为 D ={ D 1 , D 2 ,…, D U },1≤ u ≤ U .其中, U 为用户数量, D u 表示由连续访问页面组成的访问序列 X u 通过式(1)泛化后得到的主题访问序列.因此, X u 包含的项集都是 I 的子集, D u 包含的项集都是 T 的子集.
定义2 . 主题频繁时序模式.令 P 为主题时序模式,模式 P 的支持度计数与支持度分别表示成 σ ( P )和 supp ( P ),设 min_supp 为最小支持度阈值,若 σ ( P )≥ min_supp ,则称 P 为主题频繁时序模式.
本文采用Eclat (equivalence class transformation)算法 [32] 对主题序列模式进行挖掘.Eclat算法是采用垂直数据表示的频繁项集挖掘方法,在序列模式挖掘中应用广泛.将主题访问序列事务集 D 作为Eclat的输入,设置 min_supp ,通过运行Eclat程序得到挖掘出的主题频繁时序模式项集,记为 P ={ P 1 , P 2 ,…, P S },其中 S 为模式的数量.
在基于关联规则的推荐算法里候选项目取之于关联规则右边的项目 [33] ,即候选项目被频繁模式所包含.由于每个频繁模式里的项目都是频繁的,这极大地限制了候选项集的质量和多样性.为了解决这个难题,我们抽取了每个频繁模式在原始会话中紧跟着的旅游产品页面作为候选项集,方法如算法1所示,其中模式 P s (1≤ s ≤ S )对应的候选集记为 C Ps ,每个模式对应的候选集都是 I 的子集.最终所有模式对应的候选集记为 C ={ C P 1 , C P 2 ,…, C Ps }.
算法1 . SECT产品候选集提取算法.
输入:模式项集 P 、主题序列事务集合 D ;
输出:产品候选集 C .
① for s =1 to S do
② for each D u ∈ D do
③ if P s in D u then
④ 返回 P s 在主题访问序列 D u 中的末尾位置 l 并从访问序列 X u 中提取第 l +1个访问页面 i t ;
⑤ if i t 为产品页面then
⑥ C Ps ← C Ps ∪{ i t };
⑦ end if
⑧ end if
⑨ end for
⑩ C ← C ∪ C Ps ;
 end for
end for
 return产品候选集 C .
return产品候选集 C .
测试集中用户的主题序列与模式库中模式项集的匹配对于推荐引擎的效率而言是极大的挑战,通常一种蛮力的做法是将主题序列与模式库中的模式一一匹配,但是考虑到模式库中模式的数量,这种做法不但影响推荐引擎的效率,而且还增加推荐引擎的运行负担.为了使SECT推荐引擎能够根据用户访问会话快速匹配到模式库中的主题模式,我们提出了一个多叉树数据结构PSC-tree (pattern support candidate-tree)用于存储历史模式库,并与匹配计算模块无缝衔接.
定义3 . PSC-tree.PSC-tree是一个多叉树:
1) 包含一个名为 Root 的根节点,其余节点为 Root 节点的孩子节点;
2) 每个节点都有2个域,第1个域存储模式的支持度计数,第2个域存储产品候选集;
3) 从PSC-tree第2层的每个节点开始,每一个遍历到孩子节点的路径分别代表对应的主题序列模式.
图6展示了PSC-tree的构造示例:1)将主题频繁时序模式项集中的模式按照页面标识进行排序,形成如图6(a)中的列表;2)初始的PSC-tree只有一个根节点,按照以下方法依据图6(a)中的模式列表依次构造孩子节点:①读取第1个主题频繁时序模式 T 1 , T 2 ,构造节点 T 1 和 T 2 ,增加路径 Root → T 1 → T 2 ,支持度计数 σ ( T 1 , T 2 )=20存储在节点 T 2 的第1个域中,推荐候选集 C T 1 , T 2 ={ i 3 , i 5 , i 6 }存储在第2个域中;②第2个模式 T 1 , T 2 , T 3 与第1个模式具有公共的前缀 T 1 , T 2 ,因此,节点 T 3 增加在路径 Root → T 1 → T 2 的终点,节点 T 3 的2个域也存储对应的信息;3)以上过程直到每一个模式映射到PSC-tree中的其中一条路径为止.按照图6(a)中的模式项集,构造PSC-tree的最终结果如图6(b)所示.
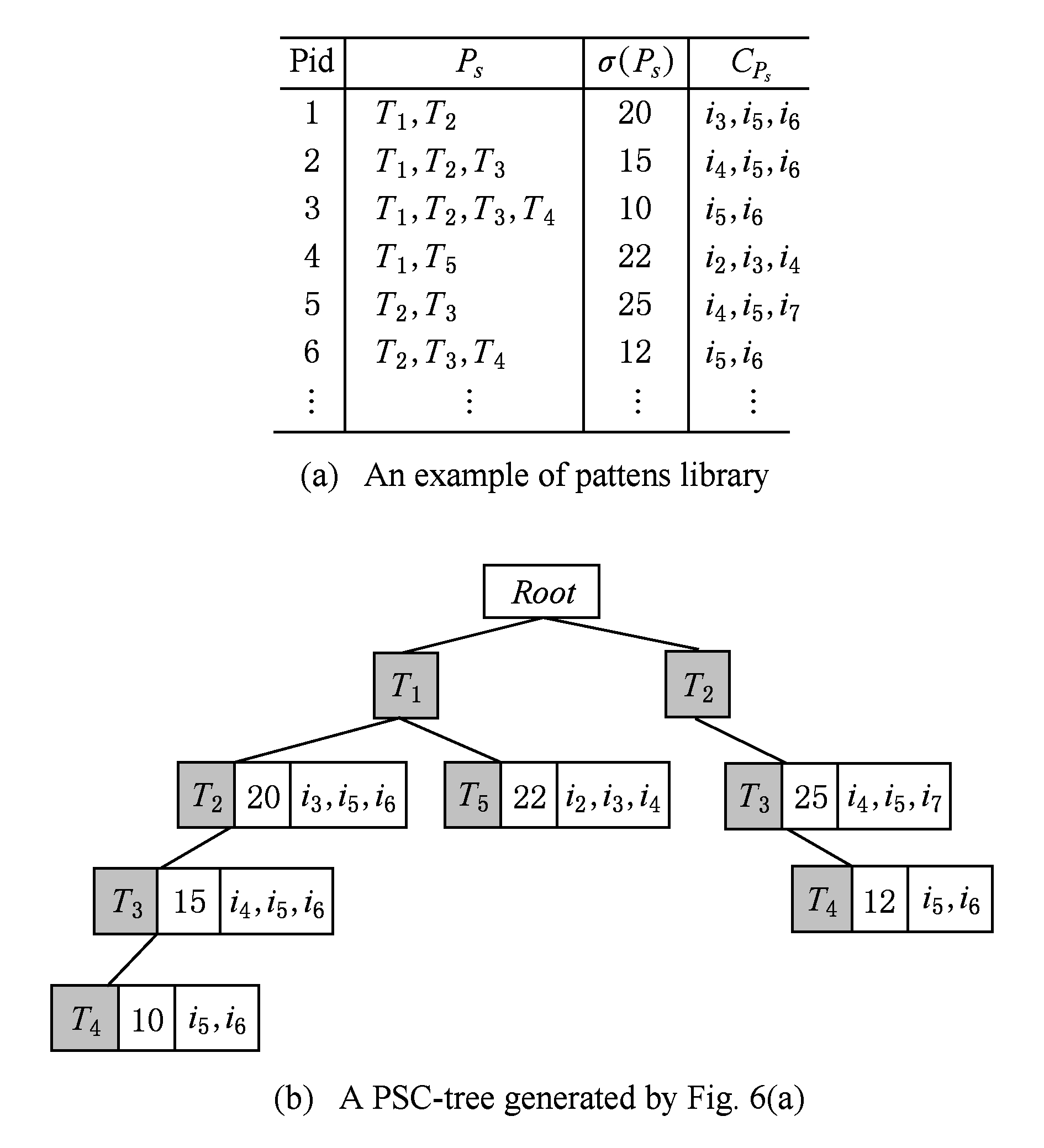
Fig. 6 An illustration of PSC-tree
图6 PSC-tree的示例说明
4 . 3 基于 n - gram模型的推荐计算
不失一般性,设用户 u 的实时页面访问会话为: X u = i 1 , i 2 ,…, i p , i p 为最晚访问的页面.初始设待推荐的目标产品为 i t ,我们将会话 X u 中每个产品映射到对应的主题,即 X u = T 1 , T 2 ,…, T p , T q = φ ( i q ),1≤ q ≤ p .为了更简明地表示,我们将 T 1 , T 2 ,…, T p 标记为 Tp 1 .我们用条件概率 Pr ( i t | Tp 1 )表示给定会话 X u 时,用户 u 对产品 i t 的偏好程度,即: Pr ( i t | Tp 1 )越大表明用户 u 购买该目标产品的概率越高.理论上, Pr ( i t | Tp 1 )由 X u 的所有子序列所决定:
(2)
由于求解式(2)需要穷举 p 个子序列,即每个子序列需要与模式库中所有频繁序列模式进行匹配,计算复杂性极高.因此,已有文献[34-35]提出 n -gram模型对式(2)进行近似求解.我们假设 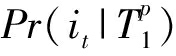 只与前面 n -1个访问页面相关,称为Markov n -gram独立性假设,即:
只与前面 n -1个访问页面相关,称为Markov n -gram独立性假设,即:
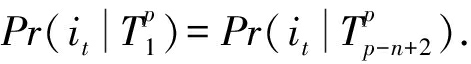
(3)
在Markov n -gram独立性假设之下,求解式(3)可以简化为
① http://mahout.apache.org/
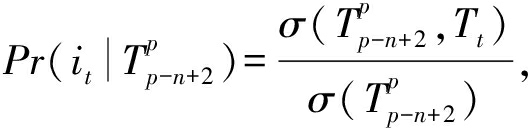
(4)
此处, T t = φ ( i t ),对于给定的频繁模式集合, σ (·)为序列或者模式的支持度计数.但是,式(4)仅适用于 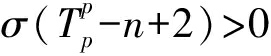 的情况,即 X u 的最近 n -1项子序列被历史模式所包含.当
的情况,即 X u 的最近 n -1项子序列被历史模式所包含.当 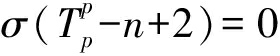 时,我们去掉最早的访问页面 i p - n +2 ,用 n -2项子序列替代原来的 n -1项子序列 [36] .由于序列长度的减小,
时,我们去掉最早的访问页面 i p - n +2 ,用 n -2项子序列替代原来的 n -1项子序列 [36] .由于序列长度的减小, 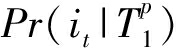 随之衰减,表征对目标产品推荐置信度的下降.我们选择文献[37]总结的回退类平滑技术back-off models来刻画条件概率的衰减,因此,式(4)可以总结为
随之衰减,表征对目标产品推荐置信度的下降.我们选择文献[37]总结的回退类平滑技术back-off models来刻画条件概率的衰减,因此,式(4)可以总结为
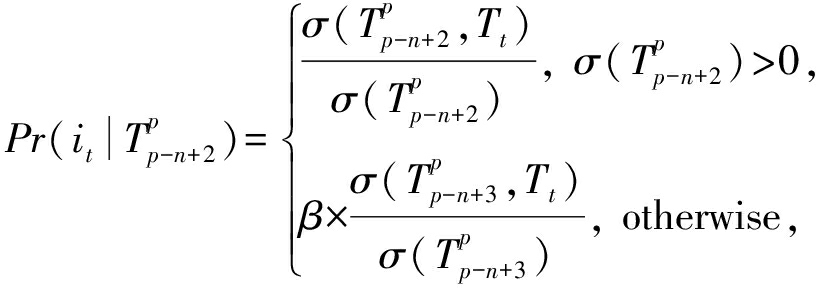
(5)
其中, β 为惩罚因子,衡量的是平滑处理后的 n -2项子序列和处理前 n -1项序列之间的条件概率衰减,可计算为
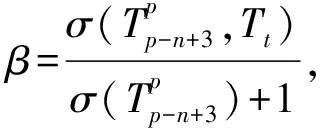
(6)
式(6)迭代进行,直到 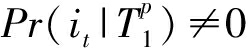 为止.假设待匹配的主题访问序列为 T 1 , T 2 ,…, T p ,采用深度优先的策略在PSC-tree中寻找路径 Root → T 1 → T 2 →…→ T p ,如果存在此路径,可以获得模式的支持度计数和对应的产品候选集.以图6(b)进行举例,如果待匹配的主题访问序列为 T 1 , T 2 , T 3 ,那么能够在PSC-tree中成功搜索到路径 Root → T 1 → T 2 → T 3 ,并从路径的终点 T 3 中提取模式 T 1 , T 2 , T 3 的支持度计数15和产品候选集{ i 4 , i 5 , i 6 }.
为止.假设待匹配的主题访问序列为 T 1 , T 2 ,…, T p ,采用深度优先的策略在PSC-tree中寻找路径 Root → T 1 → T 2 →…→ T p ,如果存在此路径,可以获得模式的支持度计数和对应的产品候选集.以图6(b)进行举例,如果待匹配的主题访问序列为 T 1 , T 2 , T 3 ,那么能够在PSC-tree中成功搜索到路径 Root → T 1 → T 2 → T 3 ,并从路径的终点 T 3 中提取模式 T 1 , T 2 , T 3 的支持度计数15和产品候选集{ i 4 , i 5 , i 6 }.
算法2展示了基于主题序列模式的推荐算法.对于给定的用户 u 的实时会话 X u ,首先将其映射为主题序列,我们再重复执行以上的back-off models流程直到生成一个推荐分值集合 R 为止.对于任意一个给定的目标产品 i t ,其对应的分值集合记为 R ( i t ),我们将目标产品分值集合按照降序排列,最终取分值最高的 k 个产品作为推荐列表,记为Top- k .
算法2 . 基于 n -gram的推荐算法.
输入:当前访问序列 i 1 , i 2 ,…, i p ;
输出:推荐列表Top- k .
① 将序列映射为主题序列 T 1 , T 2 ,…, T p ;
② for j = p - n +2 to p do
③ 在PSC-tree中寻找路径 Root → T j →…→ T p ,从路径终点 T p 读取 σ ( P s )和 C Ps ;  * P s =
* P s = 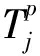 *
*
④ if ( σ ( P s )>0) then
⑤ for each i t ∈ C Ps do
⑥ T t = φ ( i t ),沿着路径 Root → T j →…→
T p 的终点 T p 寻找其孩子节点 T t 并读取 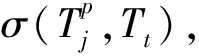 计算式(5)求得 R ( i t );
计算式(5)求得 R ( i t );
⑦ R ← R ∪ R ( i t );
⑧ end for
⑨ break;
⑩ end if
end for
将推荐分值集合 R 降序排列;
 return Top- k 列表. *取 R 中Top- k 个项目*
return Top- k 列表. *取 R 中Top- k 个项目*
5 实验结果和分析
本节展示在实际旅游数据集(如第2节所述)上的实验结果及比较分析.
5 . 1 实验设置
1) 基准推荐算法.我们选择4种最常见的推荐算法作为比较对象:
① 基于用户的协同过滤算法(user-based coll-aborative filtering, UCF) [38] ,选择余弦为相似度度量,近邻用户数量设为10.
② 基于矩阵分解模型的协同过滤(singular value decomposition, SVD) [39] ,潜变量维度设为100.UCF和SVD均借助开源项目Mahout ① 实现,同时,由于2.2节的研究已经表明旅游数据中“用户-项目”购买矩阵极度稀疏,因此我们构造“用户-项目”访问频率矩阵作为协同过滤的输入,矩阵中的元素表示用户点击线路页面的次数.
③ 流行推荐算法Popular,按照购买次数直接排序,取最热门的Top- k 种产品作为推荐列表;
④ 基于关联规则挖掘的推荐算法(max confi-dence algorithm, MCA) [33] ,从训练数据中挖掘频繁项集,以置信度作为推荐分值计算依据.SECT和MCA中的 min_supp 均默认设置为15,主题数量 K 均设为80.由于训练集中会话平均长度为5.64,因此当测试集中会话长度大于6时,推荐算法中 n 取5,否则 n 即为会话长度.
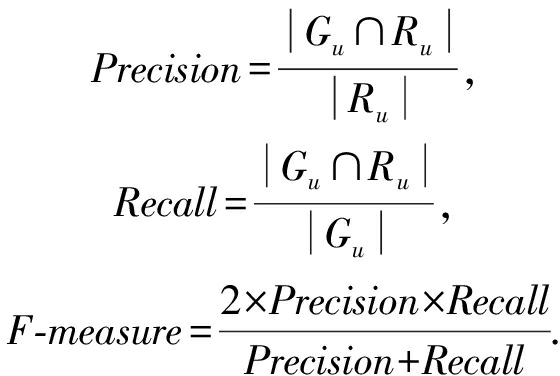
2) 评价指标.我们选择3类指标从不同角度衡量推荐引擎的性能,其中, F - measure 是体现推荐引擎准确率的综合指标 [40] , Coverage 是反映推荐列表多样性的指标 [41] , NDCG @ k (normalized discounted cumulative gain)则用于衡量推荐列表的排序优劣 [42] .具体地,假设为用户 u 推荐生成的Top- k 列表记为 R u , R u ( j )代表为用户 u 产生的推荐列表在位置 j 上的产品,测试集中用户 u 真正购买的产品列表为 G u ,上述3种评价指标的计算方法如下:
① F - measure 是准确率( Precision )和召回率( Recall )的调和平均值,值越高则表明推荐系统的精度越好.
(7)
② Coverage 指的是推荐结果里的物品占全部物品的比例,比例越高代表推荐系统推荐的产品覆盖范围越广.
(8)
③ NDCG @ k 是一个考虑推荐项目次序的指标,该指标衡量了推荐项目的排名,值越高代表排序推荐效果越好:
(9)
NDCG @ k 计算的是位置 j 从1到 k 总的 NDCG 值; Rel 是一个指示函数,计算的是推荐项目出现在位置 j 的增益,在本文中,如果列表中位置为 j 的推荐产品为用户下单的产品,则 Rel 的值为1,否则为0; IDCG 为规格化因子,代表最理想情况下的 DCG 值 [43] ,在本文中,最理想的 DCG 情况为用户实际下单产品在推荐列表中排名第一,即 IDCG =1.
5 . 2 总体性能比较分析
图7分别展示了SECT和另外4种基准算法在3类评价指标上的对比结果, x 轴为Top- k 推荐列表长度,分别设为3,5,10,20.总体上看,SECT推荐引擎在不同指标上均明显优于其他基准推荐算法,其中Popular流行推荐效果最差,这说明用户在购买旅游产品时具有明显的个性化偏好,排行榜式的推荐难以取得良好效果.
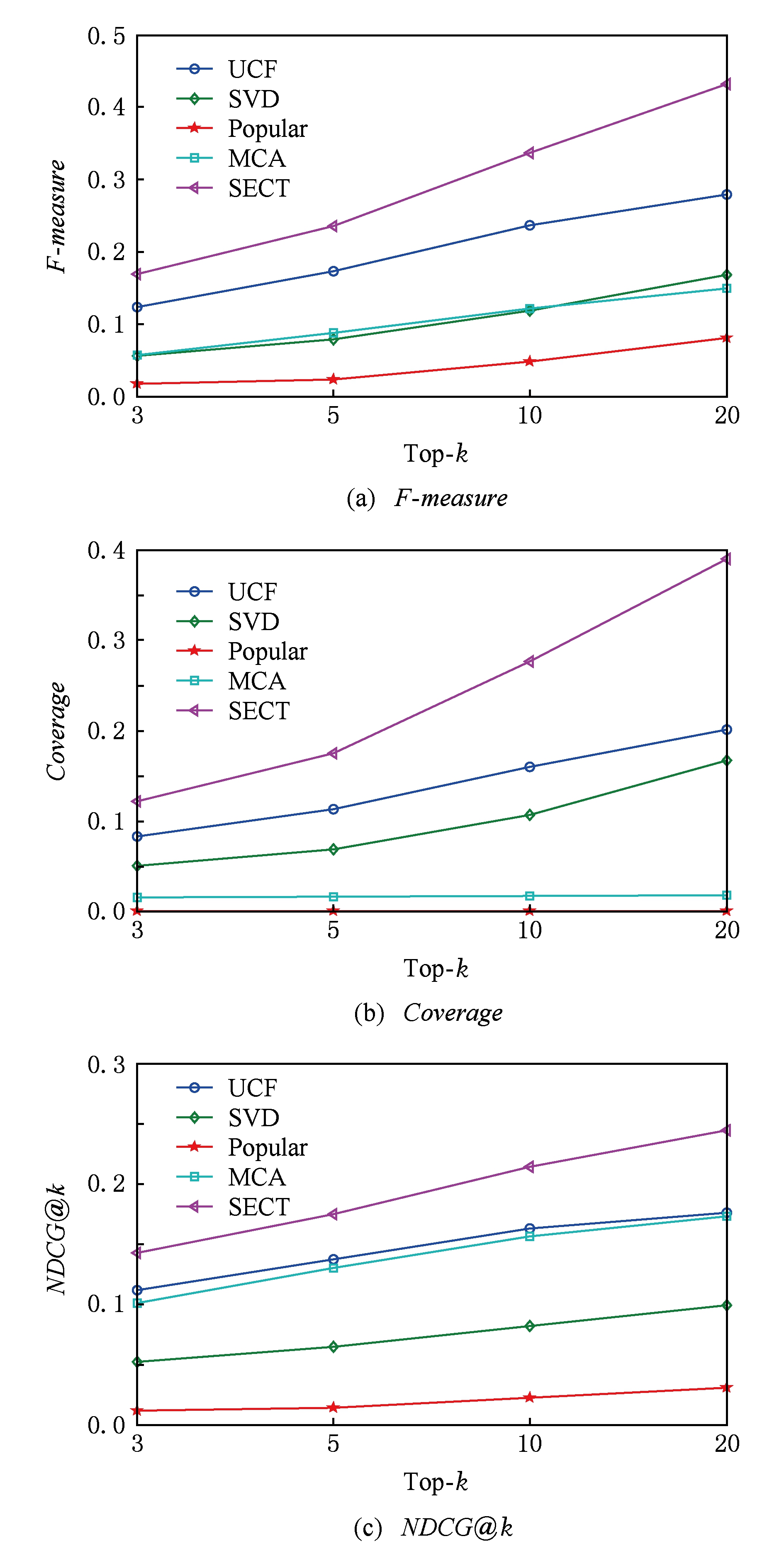
Fig. 7 Performance comparison on different evaluation metrics
图7 在不同评价指标上的比较
从图7(a)可以看出,当 k 值分别取10和20时,SECT的 F - measure 超过30%,比排名第2的UCF算法高出至少10%.从平均意义上,SECT每推荐10种旅游产品将会带来3次的实际购买.
从图7(b)可以看出,SECT在 Coverage 指标上的性能最好,且随着 k 的增大,优势变得更加显著,当 k =20时, Coverage 达到40%,这表明SECT推荐结果能覆盖更多的产品;UCF和SVD通过“用户-项目”访问频率矩阵能够找到的相似用户的数量比较少,因此,推荐的产品覆盖范围有限;Popular针对所有用户都是推荐同样的流行产品,因此, Coverage 值最低,接近于0.
从图7(c)可以看出,SECT的推荐列表排序效果最好,UCF其次,MCA仅次于UCF,当 k 值逐渐增大到20,MCA和UCF的推荐产品的排序性能接近.当 k 值分别取10和20时,SECT要比UCF和MCA高出至少5%,比SVD高出至少10%.这充分说明SECT推荐的正确的产品位置比较靠前,排序性能较好.
5 . 3 冷启动用户推荐效果
旅游数据冷启动问题是影响旅游推荐的一个难题.正如2.2节中所提及,本文旅游数据集中的冷启动用户比例较高,测试集中冷启动用户数量达到20 090.因此,针对冷启动用户的推荐性能评估显得尤为重要.我们选择了5.2节中推荐效果相对不错的UCF和SVD作为基准算法,考察针对冷启动用户的推荐性能.
图8展示了SECT与基准算法在产生推荐的冷启动用户比例方面的对比,可以看出SECT能够为93.1%的冷启动用户产生推荐列表.从平均意义来看,每10个冷启动用户就有9个能够被SECT产生推荐.而SVD要比SECT要低10.9%.此外,UCF产生推荐的冷启动用户比例最低,仅为67.7%.
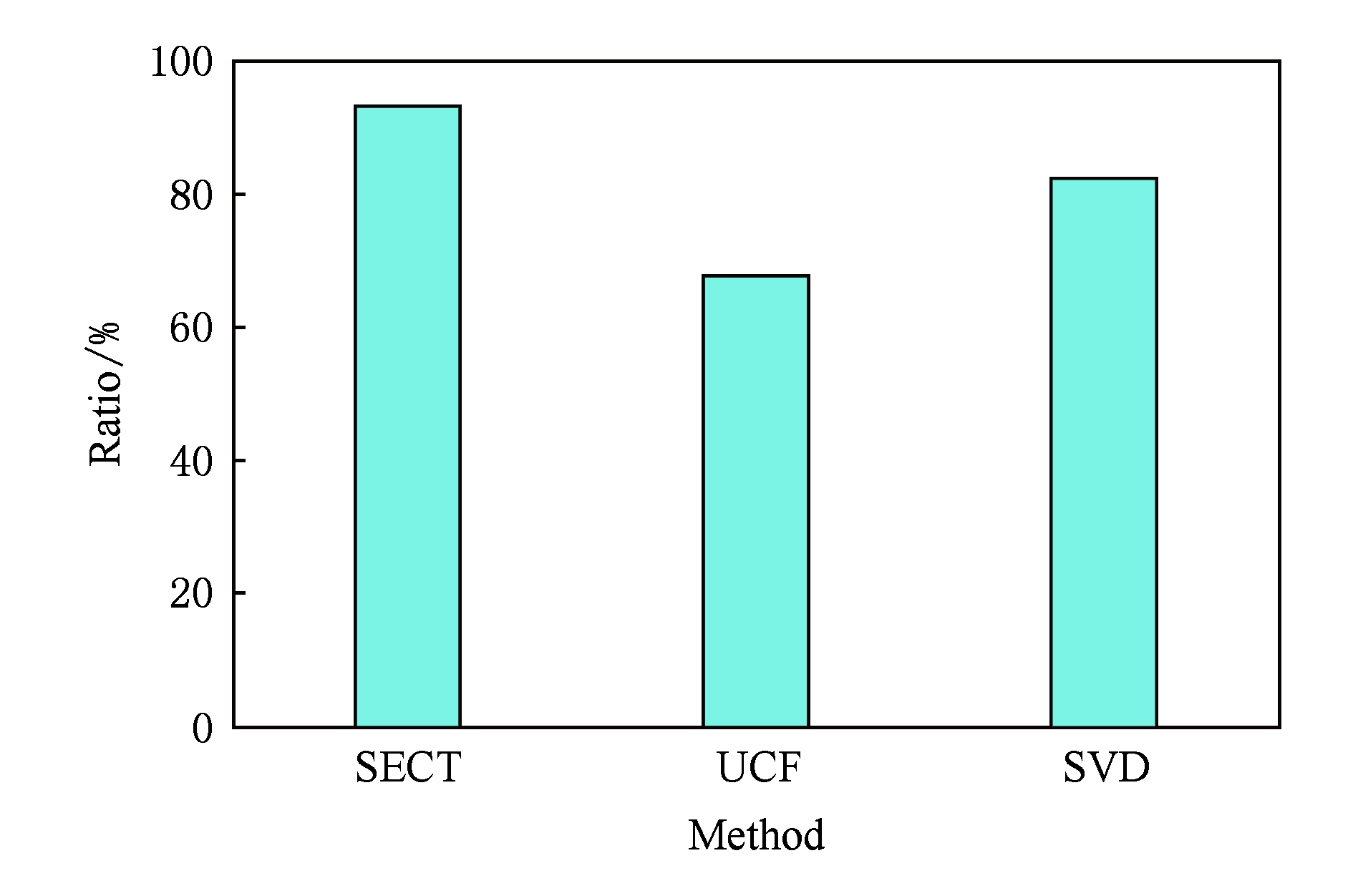
Fig. 8 Cold-start users with successful recommendations
图8 产生推荐的冷启动用户
图9展示了SECT与基准算法针对冷启动用户推荐准确率的对比,可以看出SECT性能最出色.当 k 值分别取3和5时,UCF与SECT在推荐准确率方面接近,而随着 k 值增加,SECT的优势越来越显著.当 k =20时,准确推荐的冷启动用户占产生推荐的冷启动用户的比例高达44.3%,分别比UCF和SVD的胜出5%和32%.尽管UCF在产生推荐的冷启动用户的性能方面要差于SVD,但是在冷启动用户推荐准确率方面要更胜一筹.
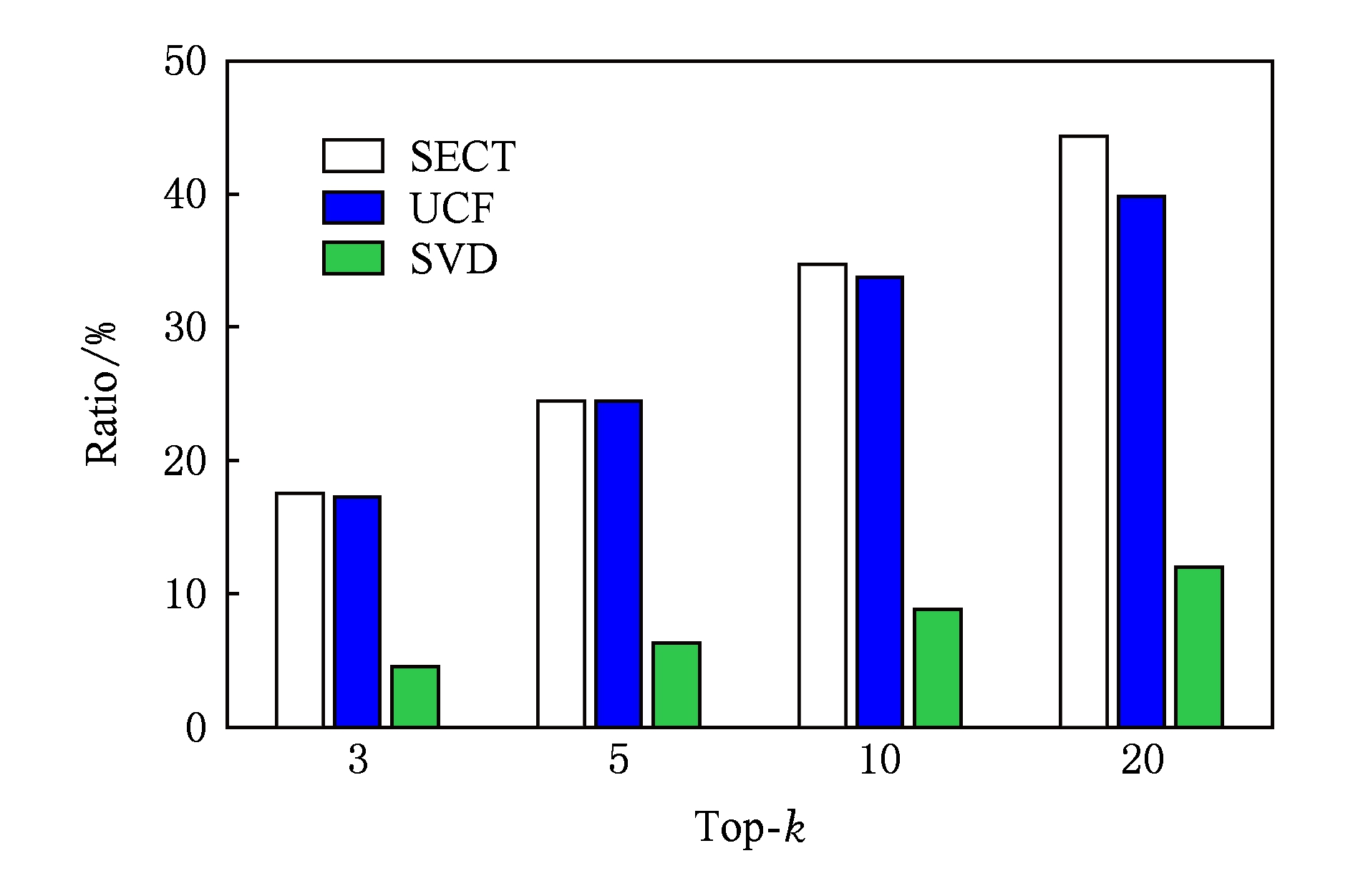
Fig. 9 Cold-start users with accurate recommendations
图9 准确推荐的冷启动用户
表4进一步将SECT对测试集中冷启动用户和全局用户的推荐结果进行了对比,可以看出冷启动用户的会话并没有降低SECT的推荐性能,与全局用户上的推荐性能基本一致.因此,相比于协同过滤算法,SECT在解决冷启动问题上优势显著.
Table 4 Performance Comparison among Cold - start Users and Global Users in Terms of F - measure Results
表4 冷启动用户和全局用户在 F - measure 上的比较
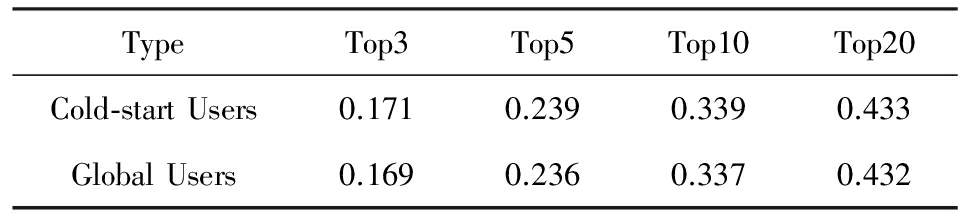
TypeTop3Top5Top10Top20Cold⁃startUsers0.1710.2390.3390.433GlobalUsers0.1690.2360.3370.432
从以上实验分析可知,相比于传统推荐算法,SECT推荐引擎不但性能具有明显优势,而且针对冷启动用户的推荐率和准确率方面也提高显著.这是由于SECT根据用户实时会话从主题泛化的层面捕捉用户兴趣,且不受冷启动问题的困扰,而UCF和SVD借助的“用户-项目”访问频率矩阵比较稀疏,因此,在冷启动用户的方面表现都不如SECT.
5 . 4 长尾物品的推荐
众所周知,对于推荐系统而言推荐流行的商品较为容易也微不足道,而推荐长尾物品增加了推荐商品的新颖性,同时也是一个挑战 [44] .
图10展示了训练集中所有产品的访问频率分布,可以看出长尾现象尤其显著.具体而言,训练集中所有产品的平均访问频率为17,此外,低于平均访问频率的产品比例高达80.7%,这意味着大多数的访问集中于少数的流行产品.我们同样选择UCF和SVD作为基准算法来考察SECT挖掘长尾物品的能力.
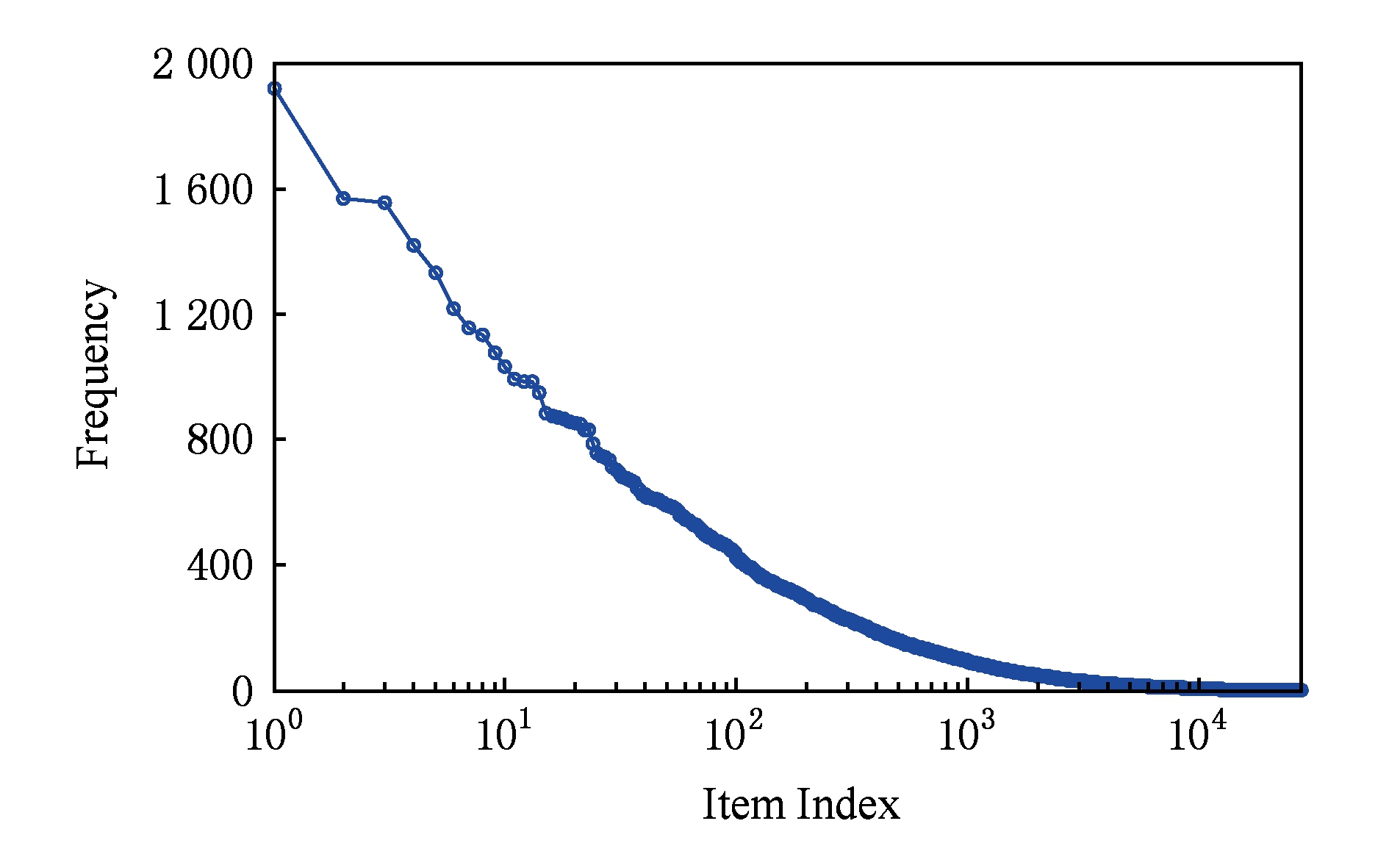
Fig. 10 Visiting distribution over items in the training set
图10 训练集中产品的访问频率分布
图11展示了3种算法在旅游数据集上推荐产品的平均流行度(即产品在训练集中的访问频率).总体来看,SECT推荐的产品的流行度要低于UCF和SVD,其中UCF最高,SVD其次.当 k 分别取值3和5时,SECT和SVD接近,而UCF的流行度明显偏高.相比于UCF和SVD,随着 k 的不断增大SECT推荐的产品的流行度下降趋势更加显著,当 k =20时,SECT的流行度为221,而UCF和SVD分别高达319和278.
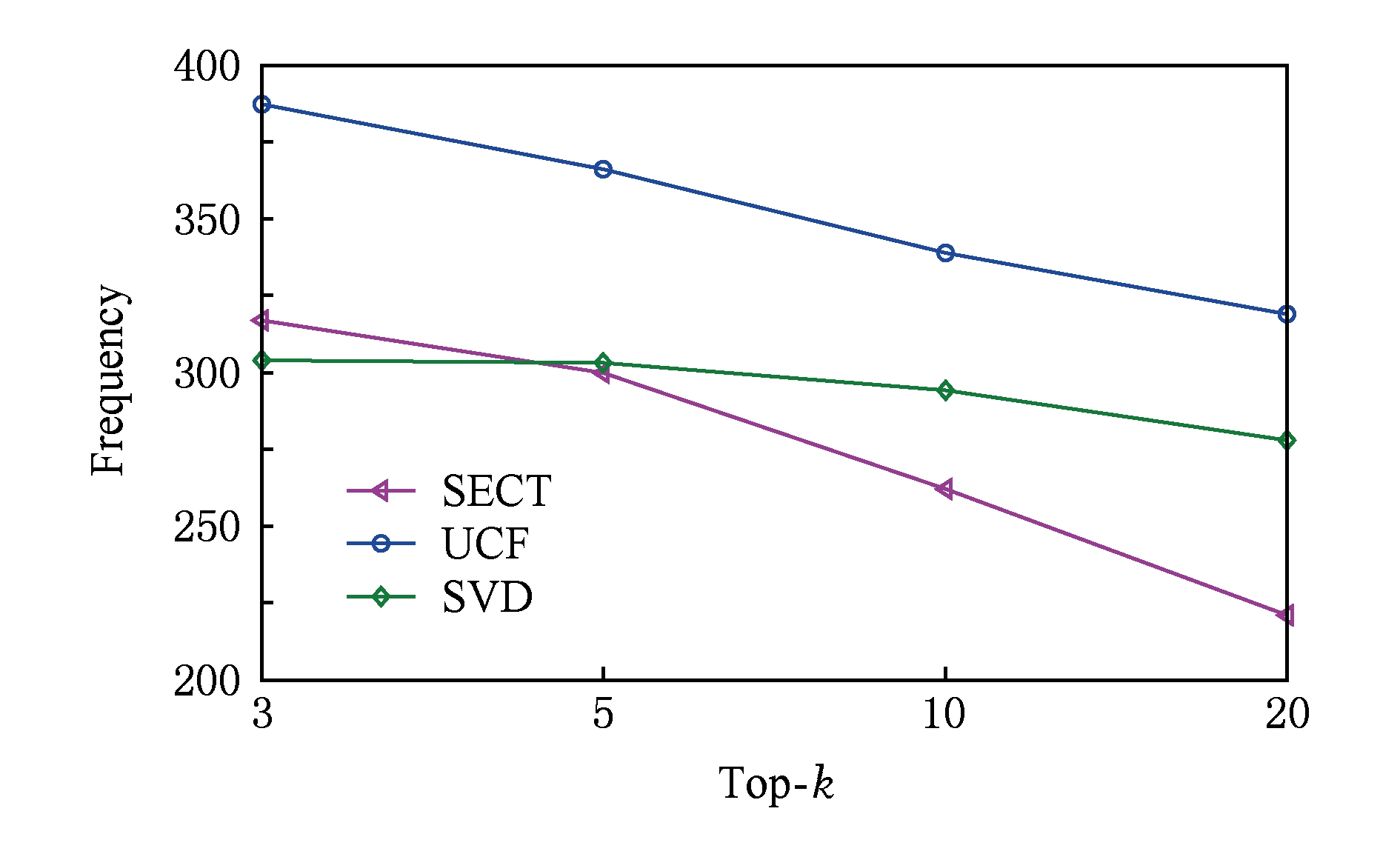
Fig. 11 Average frequency of recommended items
图11 推荐商品的平均流行度
我们将训练集中所有物品根据访问频率进行倒序排序,分别将排在前60%,70%,80%,90%的产品标记为长尾物品.图12分别展示了SECT与基准算法在Top-20推荐列表中准确推荐的长尾产品的比例.从图12可以看出,在长尾产品阈值从0.6~0.9之间SECT性能要优于UCF和SVD,且随着阈值增加,SECT优势越来越显著.当阈值设为0.9时,SECT推荐准确的长尾产品比例为22.8%,分别比UCF和SVD的性能高出9%和12%.因此,相比于传统的协同过滤算法,SECT的推荐列表更具有新颖性,能够准确推荐更多的长尾物品,这得益于SECT能够从历史会话中挖掘出很多有趣的模式.
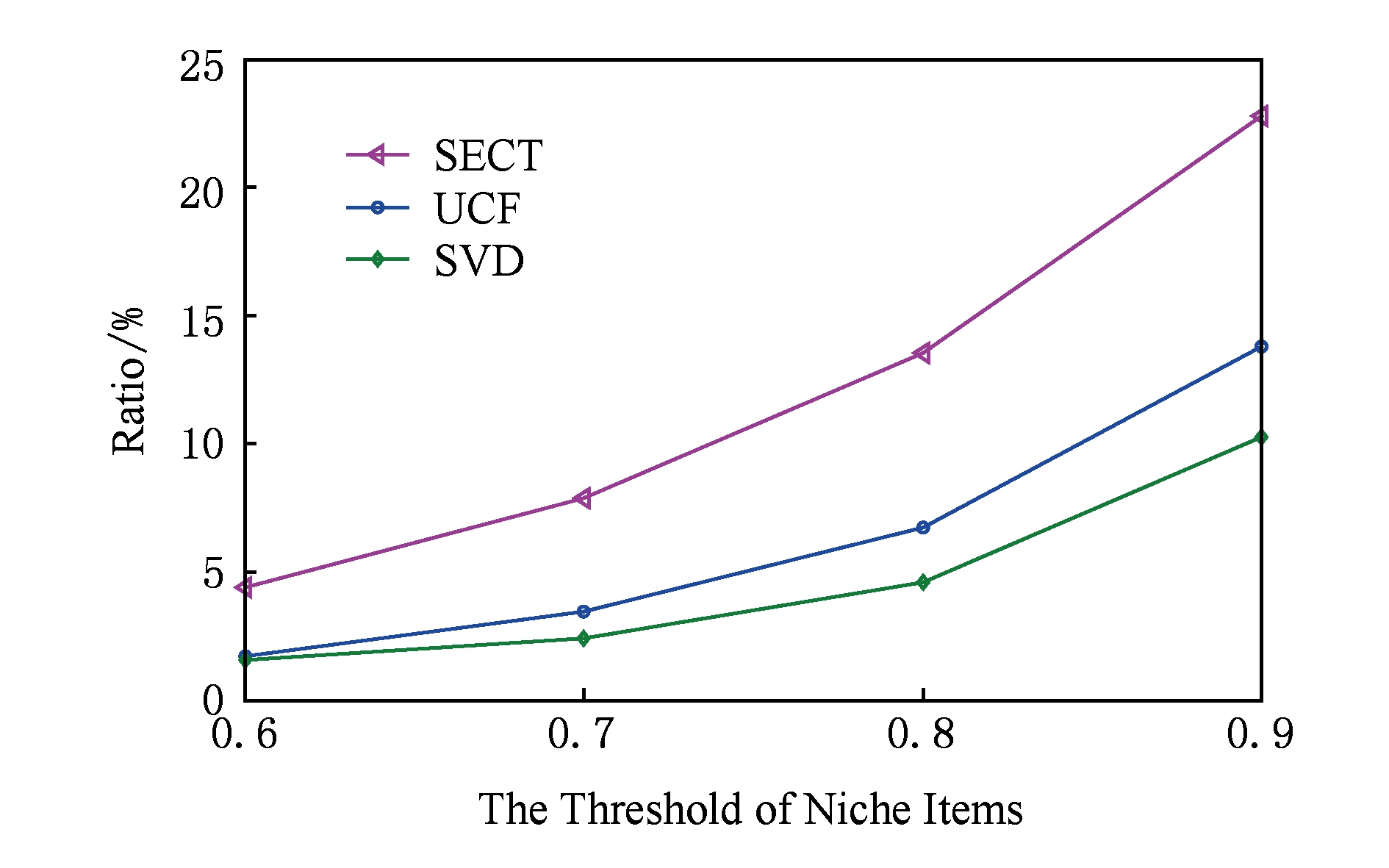
Fig. 12 Niche items with accurate recommendations
图12 准确推荐的长尾产品
6 总 结
本文研究了基于主题序列模式的旅游产品推荐问题.首先,本文提出了SECT推荐引擎,离线批处理阶段,SECT利用已有的LDA和 K -Means算法从页面语义描述文本中挖掘旅游主题,并通过ECLAT算法对在线旅游网站点击日志进行挖掘产生频繁序列模式,最后依据本文提出的算法从模式库和日志会话中产生候选产品集;在线计算阶段,提出了基于Markov n -gram的推荐算法,依据用户实时点击流进行模式匹配和推荐产品的分值计算,最终产生旅游产品推荐列表.同时,设计了一种新的多叉树数据结构PSC-tree以存储模式库并提升在线匹配计算的效率.为了验证SECT的优势,本文在真实旅游数据集上进行了实验,实验结果表明:SECT推荐引擎不但在性能上比传统推荐算法更有优势,而且能有效提升冷启动用户和长尾物品的推荐率和准确率.
参考文献
[1]Guo Hongyi, Liu Gongshen, Su Bo, et al. Collaborative filtering recommendation algorithms combining community structure and interest clusters[J]. Journal of Computer Research and Development, 2016, 53(8): 1664-1672 (in Chinese)
(郭弘毅, 刘功申, 苏波, 等. 融合社区结构和兴趣聚类的协同过滤推荐算法[J]. 计算机研究与发展, 2016, 53(8): 1664-1672)
[2]Ge Yong, Xiong Hui, Tuzhilin A, et al. An energy-efficient mobile recommender system[C] //Proc of the 16th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2010: 899-908
[3]Adomavicius G, Tuzhilin A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions[J]. IEEE Trans on Knowledge and Data Engineering, 2005, 17(6): 734-749
[4]Liu Qi, Ge Yong, Li Zhongmou, et al. Personalized travel package recommendation[C] //Proc of the 11th Int Conf on Data Mining. Los Alamitos, CA: IEEE Computer Society, 2011: 407-416
[5]Liu Qi, Chen Enhong, Xiong Hui, et al. A cocktail approach for travel package recommendation[J]. IEEE Trans on Knowledge and Data Engineering, 2014, 26(2): 278-293
[6]Ge Yong, Liu Qi, Xiong Hui, et al. Cost-aware travel tour recommendation[C] //Proc of the 17th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2011: 983-991
[7]Ge Yong, Xiong Hui, Tuzhilin A, et al. Collaborative filtering with collective training[C] //Proc of the 5th ACM Int Conf on Recommender Systems. New York: ACM, 2011: 281-284
[8]Pazzani M J, Billsus D. Content-Based Recommendation Systems[M]. Berlin: Springer, 2007: 325-341
[9]Burke R. Hybrid Web Recommender Systems[M]. Berlin: Springer, 2007: 377-408
[10]Jannach D, Zanker M, Fuchs M. Constraint-based recommendation in tourism: A multiperspective case study[J]. Information Technology & Tourism, 2009, 11(2): 139-155
[11]Hao Qiang, Cai Rui, Wang Changhu, et al. Equip tourists with knowledge mined from travelogues[C] //Proc of the 19th Int Conf on World Wide Web. New York: ACM, 2010: 401-410
[12]Tan Chang, Liu Qi, Chen Enhong, et al. Object-oriented travel package recommendation[J].ACM Trans on Intelligent Systems and Technology, 2014, 5(3): 43:1-43:26
[13]Baltrunas L, Ludwig B, Peer S, et al. Context-aware places of interest recommendations for mobile users[C] //Proc of the 14th Int Conf of Design, User Experience, and Usability. Berlin: Springer, 2011: 531-540
[14]Gavalas D, Konstantopoulos C, Mastakas K, et al. Mobile recommender systems in tourism[J]. Journal of Network and Computer Applications, 2014, 39: 319-333
[15]Zheng Yu, Xie Xing. Learning travel recommendations from user-generated GPS traces[J]. ACM Trans on Intelligent Systems and Technology, 2011, 2(1): 9:1-9:29
[16]Cao Xin, Cong Gao, Jensen C S. Mining significant semantic locations from GPS data[J]. Proceedings of the VLDB Endowment, 2010, 3(1): 1009-1020
[17]Drosatos G, Efraimidis P S, Arampatzis A, et al. Pythia: A privacy-enhanced personalized contextual suggestion system for tourism[C] //Proc of the 39th Annual Int Conf Computers, Software & Applications. Los Alamitos, CA: IEEE Computer Society, 2015: 822-827
[18]Cheng Anjung, Chen Yanying, Huang Yenta, et al. Personalized travel recommendation by mining people attributes from community-contributed photos[C] //Proc of the 19th ACM Int Conf on Multimedia. New York: ACM, 2011: 83-92
[19]Ge Yong, Liu Chuanren, Xiong Hui, et al. A taxi business intelligence system[C] //Proc of the 17th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2011: 735-738
[20]Yuan Jing, Zheng Yu, Zhang Chengyang, et al. T-drive: Driving directions based on taxi trajectories[C] //Proc of the 18th SIGSPATIAL Int Conf on Advances in Geographic Information Systems. New York: ACM, 2010: 99-108
[21]Hariri N, Mobasher B, Burke R. Context-aware music recommendation based on latenttopic sequential patterns[C] //Proc of the 6th ACM Conf on Recommender Systems. New York: ACM, 2012: 131-138
[22]Letham B, Rudin C, Madigan D. Sequential event prediction[J]. Machine Learning, 2013, 93(2): 357-380
[23]Zeng Xianyu, Liu Qi, Zhao Hongke, et at. Online consumptions prediction via modeling user behaviors and choices[J]. Journal of Computer Research and Development, 2016, 53(8): 1673-1683 (in Chinese)
(曾宪宇, 刘淇, 赵洪科, 等. 用户在线购买预测: 一种基于用户操作序列和选择模型的方法[J]. 计算机研究与发展, 2016, 53(8): 1673-1683)
[24]Chen Wei, Niu Zhendong, Zhao Xiangyu, et al. A hybrid recommendation algorithm adapted in e-learning environments[J]. World Wide Web, 2014, 17(2): 271-284
[25]Wright A P, Wright A T, McCoy A B, et al. The use of sequential pattern mining to predict next prescribed medications[J]. Journal of Biomedical Informatics, 2015, 53(C): 73-80
[26]Kennedy L S, Naaman M. Generating diverse and representative image search results for landmarks[C] //Proc of the 17th Int Conf on World Wide Web. New York: ACM, 2008: 297-306
[27]Mei Qiaozhu, Liu Chao, Su Hang, et al. A probabilistic approach to spatiotemporal theme pattern mining on weblogs[C] //Proc of the 15th Int Conf on World Wide Web. New York: ACM, 2006: 533-542
[28]Schafer J B, Frankowski D, Herlocker J, et al. Collaborative Filtering Recommender Systems[M]. Berlin: Springer, 2007: 291-324
[29]Fu A W C, Keogh E, Lau L Y, et al. Scaling and time warping in time series querying[J]. The VLDB Journal, 2008, 17(4): 899-921
[30]Blei D M, Ng A Y, Jordan M I. Latent Dirichlet allocation[J]. Journal of machine Learning research, 2003, 3(Jan): 993-1022
[31]Kanungo T, Mount D M, Netanyahu N S, et al. An efficient k -means clustering algorithm: Analysis and implementation[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2002, 24(7): 881-892
[32]Zaki M J. Scalable algorithms for association mining[J]. IEEE Trans on Knowledge & Data Engineering, 2000, 12(3): 372-390
[33]Rudin C, Letham B, et al. Sequential event prediction with association rules[C] //Proc of the 24th Annual Conf on Learning Theory. New York: ACM, 2011: 615-63
[34]Peng Fuchun, Schuurmans D, Wang Shaojun. Augmenting naive bayes classifiers with statistical language models[J]. Information Retrieval, 2004, 7(3): 317-345
[35]Fakhraei S, Foulds J, Shashanka M, et al. Collective spammer detection in evolving multi-relational social networks[C] //Proc of the 21st ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2015: 1769-1778
[36]Ney H, Essen U, Kneser R. On structuring probabilistic dependences in stochastic language modelling[J]. Computer Speech & Language, 1994, 8(1): 1-38
[37]Chen S F, Goodman J. An empirical study of smoothing techniques for language modeling[C] //Proc of the 34th Annual Meeting on Association for Computational Linguistics. New York: ACM, 1996: 310-318
[38]Resnick P, Iacovou N, Suchak M, et al. GroupLens: An open architecture for collaborative filtering of netnews[C] //Proc of the 1994 ACM Conf on Computer Supported Cooperative Work. New York: ACM, 1994: 175-186
[39]Koren Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model[C] //Proc of the 14th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2008: 426-434
[40]Powers D M. Evaluation: From precision, recall and F -measure to ROC, informedness, markedness and correlation[J]. Journal of Machine Learning Technologies, 2011, 2(1): 37-63
[41]Ge Mouzhi, Delgado-Battenfeld C, Jannach D. Beyond accuracy: Evaluating recommender systems by coverage and serendipity[C] //Proc of the 4th ACM Conf on Recommender Systems. New York: ACM, 2010: 257-260
[42]Järvelin K, Kekäläinen J. IR evaluation methods for retrieving highly relevant documents[C] //Proc of the 23rd Annual Int ACM SIGIR Conf on Research and Development in Information Retrieval. New York: ACM, 2000: 41-48
[43]Hu Meiqun, Lim Eepeng, Sun Aixin, et al. Measuring article quality in Wikipedia: Models and evaluation[C] //Proc of the 16th ACM Conf on Information and Knowledge Management. New York: ACM, 2007: 243-252
[44]Yin Hongzhi, Cui Bin, Li Jing, et al. Challenging the long tail recommendation[J]. Proceedings of the VLDB Endowment, 2012, 5(9): 896-907
A Recommendation Engine for Travel Products Based on Topic Sequential Patterns
Zhu Guixiang 1 and Cao Jie 1,2
1 ( College of Computer Science and Engineering , Nanjing University of Science and Technology , Nanjing 210094) 2 ( Jiangsu Provincial Key Laboratory of E - Business , Nanjing University of Finance and Economics , Nanjing 210003)
Abstract Travel products recommendation has become one of emerging issues in the realm of recommendation systems. The widely-used collaborative filtering algorithms are usually difficult to be used for recommending travel products due to a number of reasons, including: 1) the content of travel products is very complex, 2) the user-item matrix is extremely sparse, and 3) the cold-start users are widely existing. To tackle these issues, we try to exploit Web server logs for generating recommenda-tion, and present a novel recommendation engine (SECT for short) for travel products based on topic sequential patterns. In detail, we first extract topics from semantic description of every Web page. Then, we mine topic frequent sequential patterns and their target products to form click patterns library. At last, we propose a Markov n -gram model for matching the real-time click-stream of users with the click patterns library and thus computing recommendation scores. To enhance the efficiency of online computing, we design a new multi-branch tree data structures called PSC-tree to store the historical click patterns library and integrate with online computing module seamlessly. Experimental results on a real-world travel dataset demonstrate that the SECT prevails over the state-of-art baseline algorithms. In particular, SECT shows merits in improving both the coverage and accuracy for recommending products to cold-start users. Also, SECT is effective to recommend long tail items and outperform baseline algorithms.
Key words travel recommendation; frequent sequential pattern; cold-start users; Web server logs; recommender system
摘 要 旅游产品推荐是当前推荐系统研究领域中的新兴议题之一.由于旅游产品描述信息维度多样复杂、“用户-产品”关联矩阵极为稀疏且冷启动问题突出,已经在电子商务领域获得成功的协同过滤推荐往往难以直接被应用于旅游产品推荐.提出基于主题序列模式的旅游产品推荐引擎SECT,试图通过在线旅游网站点击日志的挖掘产生推荐.首先,从页面语义描述文本中挖掘主题,以在泛化层面捕捉用户行为模式;其次,从页面访问时间序列数据中挖掘频繁序列模式及其候选产品集,形成序列模式库;最后,提出Markov n -gram模型,完成用户实时点击流与模式库匹配计算.为了提升在线匹配计算的效率,设计一种新的多叉树数据结构PSC-tree用于存储历史模式库,并与在线计算模块无缝衔接.在真实旅游数据集上的实验结果表明:该推荐引擎比传统推荐算法具有更优越的性能,而且能有效提升冷启动用户的推荐率和准确率.此外,针对长尾物品的推荐,SECT也优于基准算法.
关键词 旅游产品推荐;频繁序列模式;冷启动用户;Web日志数据;推荐系统
中图法分类号 TP391
收稿日期 :2016-12-07;
修回日期: 2017-06-14
基金项目 :国家自然科学基金项目(91646204,71372188);国家电子商务信息处理联合研究中心项目(2013B01035);江苏省科技支撑计划工业项目(BE2014141);江苏省属高校自然科学研究重大项目(14KJA520001)
This work was supported by the National Natural Science Foundation of China (91646204, 71372188), the National Center for International Joint Research on E-Business Information Processing (2013B01035), the Industry Projects in Jiangsu S&T Pillar Program (BE2014141), and the Key Project of Natural Science Research in Jiangsu Provincial Colleges and Universities (14KJA520001).
通信作者 :曹杰(Jie.Cao@njue.edu.cn)
DOI: 10.7544/issn1000-1239.2018.20160926

Zhu Guixiang , born in 1989. PhD candidate. His main research interests include recommender system, social network analysis.

Cao Jie , born in 1969. PhD, professor, PhD supervisor. He is currently a Professor and the Dean of the School of Information Engineering, Nanjing University of Finance and Economics, Nanjing. His main research interests include cloud computing, business intelligence, and data mining.