 www.qatarliving.com
www.qatarliving.com 齐 乐 张 宇 刘 挺
(哈尔滨工业大学社会计算与信息检索研究中心 哈尔滨 150001) (lqi@ir.hit.edu.cn)
摘 要 判断问题相似是社区问答(community question answer, CQA)中很重要的一个研究方向.社区问答中的问题通常由主题和描述构成.由于社区问答的开放性,用户的提问长短不一,而问题中会包含大量干扰模型判断问题是否相似的背景信息.为了减少上述问题对计算问题相似度的影响,模型将关键词及问题主题视为问题的关键信息,并使用这些信息计算问题相似度.首先,在基于文本间相似及相异信息的CNN模型的基础上引入了关键词抽取技术.同时,为了更好地利用问题主题的信息,模型融合了问题主题相似度的特征.模型在SemEval2017评测的问题相似任务中进行了实验,其平均精度均值(mean average precision, MAP )达到了49.65%,超过了评测中的最佳结果.
关键词 问题相似;社区问答;关键词;问题主题;卷积神经网络
① http: www.qatarliving.com
社区问答系统(community question answering, CQA)以其灵活的用户交互特性能够满足人们获取和分享知识的需求,成为广受用户喜爱的只是知识共享平台 [1] .与其他社会媒体相比,CQA提供了一种特有的交互方式.首先,提问者将其信息需求以问题的方式提交给系统,并等待其他用户给出答案.回答者根据其个人兴趣、知识水平,选择适当的未解决问题来回答,以分享自己的知识 [1] .
在社区问答中,问题相似度计算有着很重要的意义.针对用户提出新的查询,我们可以通过判断问题相似,在历史纪录中检索与之相似的已解决问题,并将这些问题的答案推荐给用户,从而避免用户的重复提问,也方便用户更快速地获取问题答案 [1] .
社区问答中的问题通常包括2个部分:1)问题的主题或标题;2)问题的详细描述.这2部分对于判断问题相似都有很重要的作用.然而,用户的提问长短不一,而且由于需求和背景不同,问题描述中可能包含大量对判断问题相似无意义的背景信息.举个例子,对于相似问题 S 和 T (来源于QatarLiving ① ),如表1所示,两者句子长度相差悬殊,而且问题 T 中包含大量背景信息.在小规模的语料中,由于训练语料不足,若将全部文本作为神经网络的输入会引入大量噪声,而神经网络无法很好地去除这些噪声,因此会干扰对两者相似程度的判断.同时,问题主题是问题全部信息的高度概括,相似问题往往拥有相似的主题,主题不同但问题相似的概率很低,表1中的示例也证明了这一点.因此问题主题也是判断问题相似的重要依据.
Table 1 A Pair of Similar Questions in QatarLiving
表1 QatarLiving中的相似问题

针对上述问题,本文将关键词和问题主题视为问题的关键信息,利用这些信息辅助神经网络模型判断问题相似,提出了一种基于关键词和问题主题的相似度计算模型(convolutional neural network based on keywords and topic, KT-CNN).该模型在文本间相似及相异信息的卷积神经网络(convolu-tional neural network, CNN)模型 [2] 基础上引入了关键词抽取技术并融入了问题主题间的相似度作为特征.
在国内外均有大量研究人员进行社区问答中计算问题相似度方面的研究.部分研究人员使用基于翻译模型的方法判断问题相似或检索相关问题.Jeon等人 [3] 利用答案间语义的相似程度来估计基于翻译的问题检索模型的概率;Lee等人 [4] 基于经验将非主题词以及无关词汇去掉,构造了一个紧凑的翻译模型.除了词汇级别的翻译模型外;Zhou等人 [5] 提出了一种短语级别的翻译模型以提取更多的语境信息.基于翻译模型的可以在一定程度上解决文本相异但语义相近的问题,但其无法获取问题的结构信息、词共现信息以及语料中的词分布信息,而且会被翻译模型本身的误差所限制.
除了基于翻译模型的方法外,还有人利用基于主题模型的方法.Duan等人 [6] 使用基于最小描述长度(minimum description length, MDL)的树模型来识别问题主题和焦点,再通过问题主题和焦点来搜索相似问题;Zhang等人 [7] 认为问题和答案包括相同的主题,提出了一个基于主题的语言模型.该方法不仅对词项而且对主题进行了匹配;熊大平等人 [8] 则提出了基于潜在狄利克雷分布(latent Dirichlet allocation, LDA)的算法,该算法利用问句的统计信息、语义信息和主题信息来计算问句相似度.这一类方法主要利用问题主题的信息,其基本思想是主题相似的问题一定相似.其利用主题在语义层次上表示问题,但可能忽略文本中的一些细节问题.
于此同时,基于神经网络的方法也很流行.dos Santos等人 [9] 提出了一种将词袋模型同传统CNN模型相结合的神经网络模型,其效果要优于传统词频-逆文档频率(term frequency-inverse document frequency, TF-IDF)模型和基于长文本的CNN模型;Lei等人 [10] 为了解决关键信息隐藏在大量细节中的问题,提出了一种循环卷积网络将问题映射到语义表示.基于神经网络的模型从文本中自动抽取特征,可以更好地利用文本的语义信息,深层次地考虑文本间的相似性.
与这些模型相比,我们的模型利用了问题的关键词及主题信息,对问题的细节及全局信息进行了建模,能更好地表示问题.
我们提出的模型包括关键词抽取、基于关键词相似及相异信息的问句建模、计算主题相似度、问题相似度计算4个模块.对于输入的问题 S 和 T ,我们进行操作:1)进行一系列的预处理操作,再通过关键词抽取模块抽取 S 和 T 的关键词序列 Key S 和 Key T ;2)利用 Key S 和 Key T 间相似及相异信息对问题 S 和 T 建模得到 S 和 T 的特征向量 F S 和 F T ;3)对问题 S 和 T 的主题 Topic S 和 Topic T 计算相似度 Sim topic ;4)基于 S 和 T 的特征向量 F S 和 F T 以及问题主题间的相似度 Sim topic 计算问题 S 和 T 的相似度 Sim q .模型的结构如图1所示:
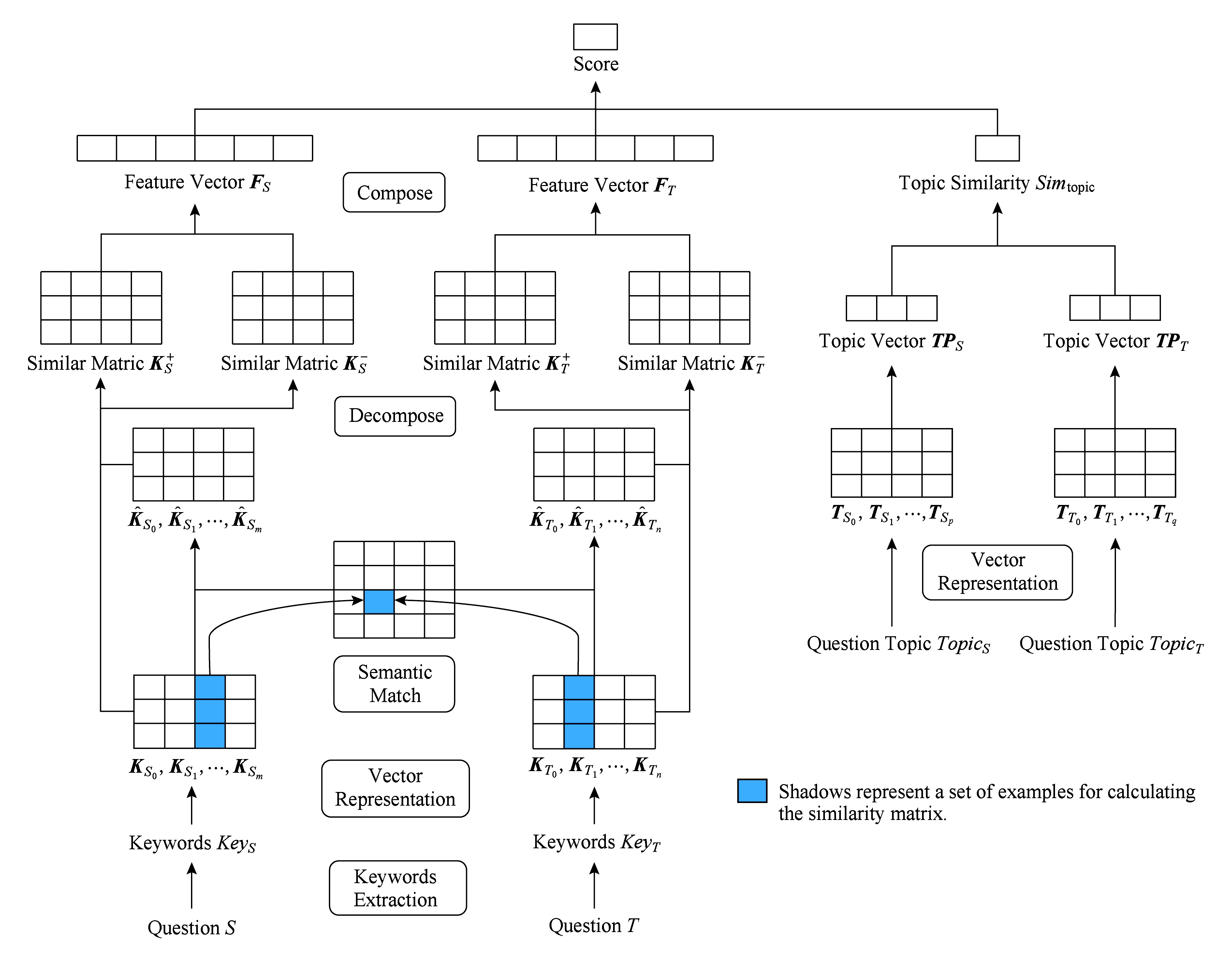
Fig. 1 Model architecture
图1 模型结构
我们对问题 S 和 T 的主题及描述抽取关键词 Key S 和 Key T .由于问题的主题及描述可能包含多个句子,因此我们对问题的每个子句都抽取关键词.我们将其子句的关键词按照得分进行排序,然后再按照子句出现的顺序对所有的关键词进行排序,得到问题的关键词序列.
对于每个子句,我们使用了一种无监督的基于依存排序的关键词提取算法.该算法由王煦祥 [11] 提出,我们在该算法的基础上进行了一些改进.对于给定的问句,该算法利用统计信息、词向量信息以及词语间的依存句法信息,通过构建依存关系图来计算词语之间的关联强度,利用TextRank算法 [12] 迭代计算出词语的重要度得分.
算法流程如图2所示,主要步骤包括构建无向有全图、图排序以及选取关键词.
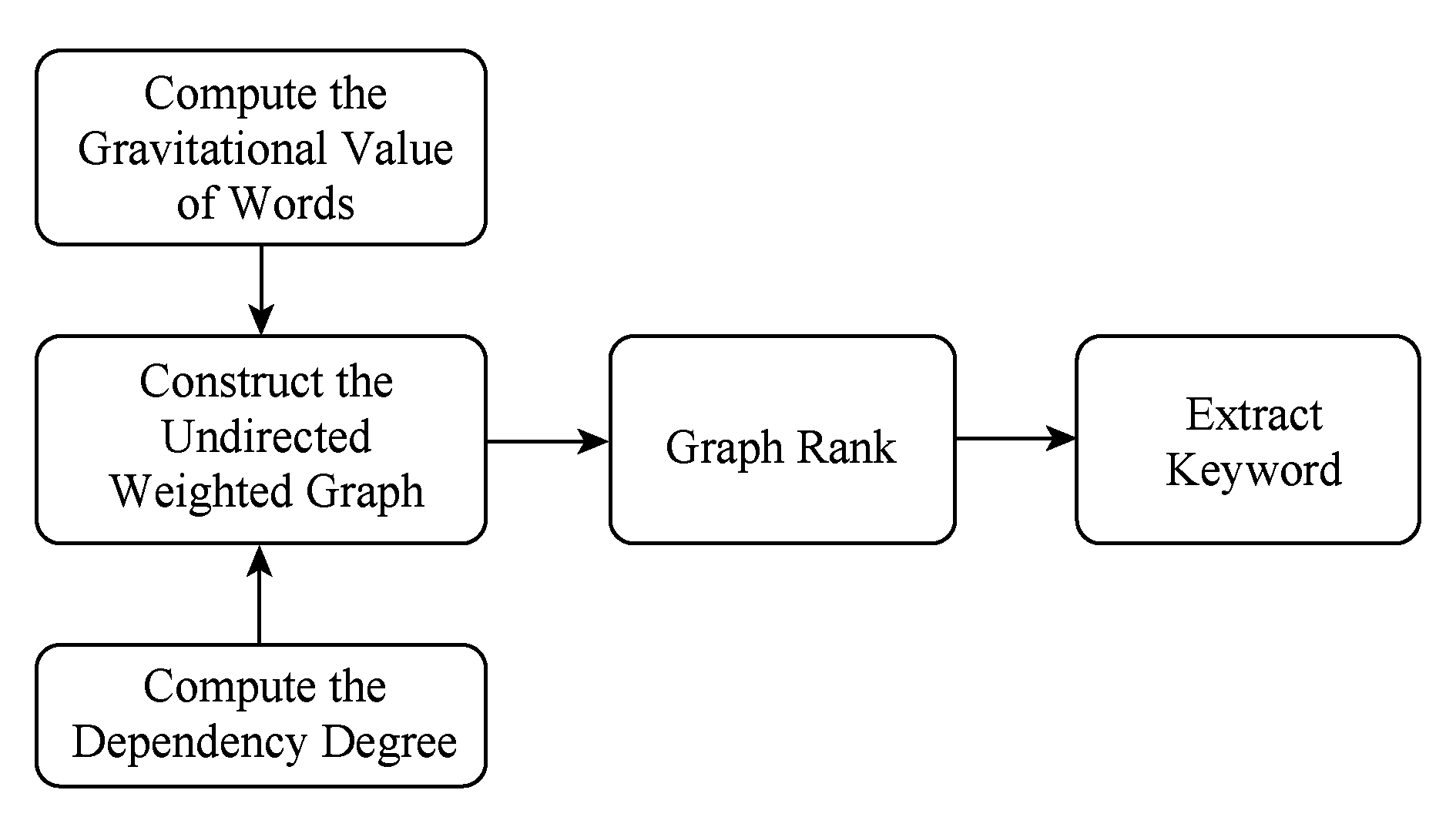
Fig. 2 The flow chart of keywords extraction
图2 关键词提取流程图
首先,我们根据句子的依存句法分析结果对所有非停用词构造无向图.依存句法分析的结果为树结构,只要去掉根节点并忽略弧的指向便可以得到无向的依存关系图 G =( V , E ), V = w 1 , w 2 ,…, w n , E = e 1 , e 2 ,…, e m ,其中 w i 表示词语, e j 表示2个词语之间的无向关系.
接着,我们利用词语之间的引力值以及依存关联度计算求得边的权重.
词引力值得概念由Wang等人 [13] 提出.作者认为2个词之间的语义相似度无法准确衡量词语的重要程度,只有当2个词中至少有一个在文本中出现的频率很高,才能证明2个词很重要.其受到万有引力定律的启发,将词频看作质量,将2个词的词向量间的欧氏距离视为距离,根据万有引力公式来计算2个词之间的引力.然而在社区问答的环境中,仅利用词频来衡量文本中某个词的重要程度太过片面,因此我们引入了IDF值,将词频替换为TF-IDF值,从而考虑到更全局性的信息.于是我们得到了新的词引力值公式.文本词语 w i 和 w j 的引力:
![]()
(1)
其中, tfidf ( w )是词 w 的TF-IDF值, d 是词 w i 和 w j 的词向量之间的欧氏距离.
依存关联度的概念由张伟男等人 [14] 提出.无向的依存关系图保证了问句中的任意2个词之间都有一条依存路径,而依存路径的长短反映了依存关系的强弱.因此,该算法根据依存路径的长度,计算依存关联度:
![]()
(2)
其中, len ( w i , w j )表示词语 w i 和 w j 之间的依存路径长度, b 是超参数.
综上,2个词语之间的关联度,即边的权重值是2个词的引力与依存关联度的乘积:
weight ( w i , w j )= Dep ( w i , w j )× f grav ( w i , w j ).
(3)
最后,我们使用有权重TextRank算法进行图排序.在无向图 G =( V , E )中, V 是顶点的集合, E 是边的集合,顶点 w i 的得分由式(4)计算得出,其中 weight ( w i , w j )由式(3)计算得出, C w i 是与顶点 w i 有边连接的顶点集合, η 为阻尼系数.我们选取得分最高的 t 个词语作为句子的关键词:
WS ( w i )=1- η + 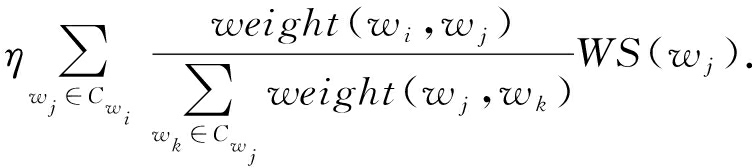
(4)
由于文本间相似信息和相异信息对判断2段文本是否相似均有重要的作用,因此我们使用了一种基于文本间相似及相异信息的CNN模型 [2] 对问题的关键词序列进行建模,并在原模型的基础上进行了改进.
假设存在问题 S 和 T ,1)将其关键词序列 Key S ( Key T )中的每一个关键词 Key S i ( Key T j )都转化为向量表示 K S =( K S 0 , K S 1 ,… K S i , K S i +1 ,…, K S m )( K T =( K T 0 , K T 1 ,…, K T j , K T j +1 ,…, K T n )).以问题 S 为例.2)用问题 T 的关键词序列 Key T 计算 Key S i 的语义匹配向量 ![]() 即用 Key T 中的部分关键词表示 Key S i .3)基于语义匹配向量
即用 Key T 中的部分关键词表示 Key S i .3)基于语义匹配向量 ![]() 对 K S i 进行分解,得到 Key S i 与 Key T 间相似向量
对 K S i 进行分解,得到 Key S i 与 Key T 间相似向量 ![]() 以及相异向量
以及相异向量 ![]() 对 Key S 中每一个词都进行上述操作,便将 K S 分解成同 K T 间的相似矩阵
对 Key S 中每一个词都进行上述操作,便将 K S 分解成同 K T 间的相似矩阵 ![]() 和相异矩阵
和相异矩阵 ![]() 用
用 ![]() 和
和 ![]() 进行合并得到问题 S 的特征向量 F S .
进行合并得到问题 S 的特征向量 F S .
2.2.1 词向量表示
我们使用基于Pennington等人 [15] 提出的GloVe模型预训练的词向量来表示关键词.对于关键词序列 Key S 和 Key T ,我们将其表示为矩阵:
K S =( K S 0 , K S 1 ,…, K S i , K S i +1 ,…, K S m )
( K T =( K T 0 , K T 1 ,…, K T j , K T j +1 ,…, K T n )),
其中, K S i 和 K T j 是关键词的 d 维词向量, m 和 n 是 K S 和 K T 中包含的关键词数量.
2.2.2 语义匹配
为了判断关键词序列 Key S 和 Key T 间的相似度,我们需要检查一个关键词序列中的关键词在语义上能否被另一个关键词序列中的某些关键词覆盖.在我们的模型中,我们通过组合 K T 中部分词向量来计算 K S 中的每个关键词 K S i 的语义匹配向量 ![]() 同理,我们也可以获得
同理,我们也可以获得 ![]()
为了计算语义匹配向量,我们先计算 K S 和 K T 的相似矩阵 A m × n .原论文使用余弦相似度计算词汇间的相似程度,我们将其替换为皮尔森相关系数,即 A m × n 中的每个元素 a i , j 是 K S i 和 K T j 的皮尔森相关系数,相对于余弦相似度,皮尔森相关系数考虑了对均值的修正操作,对向量进行了去中心化:
a i , j = Pearson ( K S i , K T j ),
(5)
![]()
(6)
其中, ![]() 和
和 ![]() 是 X 和 Y 的均值, s X 和 s Y 是 X 和 Y 的标准差.
是 X 和 Y 的均值, s X 和 s Y 是 X 和 Y 的标准差.
通过 A m × n 我们可以找到 K T 中同 K S i 最相关的词汇 K T k ,我们用 K T k 及其上下文的词向量的加权平均 ![]() 来表示 K S i .其中,权值为相应向量与 K S i 的相似度.因此利用 A m × n 可以定义计算语义匹配向量的函数 f match :
来表示 K S i .其中,权值为相应向量与 K S i 的相似度.因此利用 A m × n 可以定义计算语义匹配向量的函数 f match :
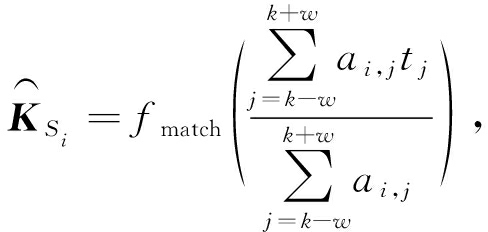
(7)
其中, ![]() 是以 k 为中心的窗口大小.
是以 k 为中心的窗口大小.
2.2.3 矩阵分解
在语义匹配模块之后,我们得到了语义匹配向量 ![]() 和
和 ![]() 以 K S i 为例,我们认为
以 K S i 为例,我们认为 ![]() 是 K T 对于 K S i 的语义覆盖.然而,
是 K T 对于 K S i 的语义覆盖.然而, ![]() 和 K S i 在语义上一定有所不同,因此我们要将两者相同部分以及相异部分提取出来.
和 K S i 在语义上一定有所不同,因此我们要将两者相同部分以及相异部分提取出来.
为此,我们选择了一种线性分解的方式.若 ![]() 和 K S i 语义越相似,则越大比例的 K S i 被分解到相似向量
和 K S i 语义越相似,则越大比例的 K S i 被分解到相似向量 ![]() 与原论文的余弦相似度不同,我们使用
与原论文的余弦相似度不同,我们使用 ![]() 和 K S i 的皮尔森相关系数 α 作为线性分解的权值.接着,我们根据 α 对 K S i 进行分解:
和 K S i 的皮尔森相关系数 α 作为线性分解的权值.接着,我们根据 α 对 K S i 进行分解:
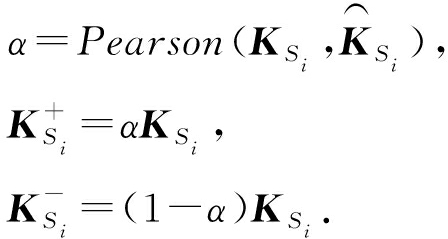
(8)
2.2.4 矩阵合并
通过对 K S 和 K T 分解,我们得到相似矩阵 ![]() 和相异矩阵
和相异矩阵 ![]() 这一步的目标是利用这些信息对问题 S 和 T 进行建模.由于相似矩阵和相异矩阵间有很深的联系,因此我们使用双通道的CNN模型对
这一步的目标是利用这些信息对问题 S 和 T 进行建模.由于相似矩阵和相异矩阵间有很深的联系,因此我们使用双通道的CNN模型对 ![]() 和
和 ![]() 进行建模,得到问题 S ( T )的特征向量 F S ( F T ).
进行建模,得到问题 S ( T )的特征向量 F S ( F T ).
以问题 S 为例,CNN模型包括2个连续的层:卷积层和最大池层.我们在卷积层设置了1组过滤器{ filter 0 , filter 1 } ,分别应用在相似通道和相异通道上来生成1组特征.每个过滤器的规模是 d × h , d 是词向量的维数, h 是窗口的大小,其过程为
c o , i = f ( w 0 * ![]() *
* ![]()
(9)
其中,操作 A * B 将 B 中所有元素按 A 中相应的权重加权求和; ![]() 和
和 ![]() 分别表示将
分别表示将 ![]() 和
和 ![]() 是偏移项, f 是非线性函数(我们使用tanh函数).
是偏移项, f 是非线性函数(我们使用tanh函数).
通过卷积层我们得到1组特征 c o =( c o ,0 , c o ,1 ,…, c o , l )特征的数量 l 取决于过滤器的规模以及输入关键词序列的长度.为了解决特征数量不固定的问题,我们对 c o 进行最大池化的操作.我们选取 c o 中最大的值作为输出,即 c o ,max =max c o .因此,经过池化操作后,每组过滤器生成1个特征.最后特征向量的维数将取决于过滤器的数量.
由于提取的关键词无法保证完全正确,基于关键词的CNN模型会不可避免地遗漏一些信息.而主题信息是判断问题相似的重要依据,因此我们利用主题间相似度来辅助模型进行判断.对于问题 S 的主题 Topic S ,我们用词向量表示 Topic S 中的每个词汇,即 T S =( T S 0 , T S 1 ,…, T S p ).我们将 Topic S 中所有词的词向量求和作为 Topic S 的向量表示: ![]() 同理,我们也得到了 Topic T 的向量表示 TP T .我们用皮尔森相关系数来表示两者的相似度:
同理,我们也得到了 Topic T 的向量表示 TP T .我们用皮尔森相关系数来表示两者的相似度:
Sim topic = Pearson ( TP S , TP T ).
(10)
我们依靠基于关键词间相似及相异特征的CNN模型生成的问题 S 和 T 的特征向量 F S 和 F T 以及问题主题间的相似度 Sim topic 计算问题 S 和 T 的相似度.我们使用一个线性模型将所有的特征加权相加,其中 w 0 , w 1 , w 2 是相应的权重, b sig 是偏移项,最后我们用sigmoid函数将计算结果限制在[0,1]的区间内:
Sim q =sigmoid( w 0 * F S + w 1 * F T +
w 2 × Sim topic + b sig ).
(11)
为了证明我们提出模型的有效性,我们在SemEval2017 [16] 的评测语料上进行了实验.SemEval2017的任务3子任务B [16] 的主题是社区问答中问题相似度计算.给定一个新提出的问题和10个由搜索引擎确定的相关问题,我们要依据问题间的相似度对相关问题进行重排序.该任务对相关问题设置了3个标签,分别为:PerfectMatch,Relevant,Irrelevant.我们认为标记为PerfectMatch和Relevant的是正例(不区分PerfectMatch和Relevant),标记为Irrelevant的是负例.对每一组问题的10个相关问题,我们使用模型得出的相似度对其进行重排序,并计算其平均精度,最后计算所有问题的平均精度均值(mean average precision, MAP )值作为系统的评价指标. MAP 是反映系统在全部相似问题上性能的单值指标.系统检索出来的相似问题越靠前, MAP 就可能越高.因此我们需要将标记为正例的问题排在标记为负例问题的前面.
SemEval2017的评测语料来自于QatarLiving,训练集包括270个问题,每个问题包括10个相关问题,共2 700个问题对.开发集包括50个问题,共500个问题对.测试集包括80个问题,共800个问题对.表2展示了1组训练数据的样例,每个问题包含问题主题和问题内容.虽然该任务是一个排序任务,但我们仍然按照分类任务对我们的模型进行训练并得到了很好的结果.
Table 2 The Sample of Training Data
表2 训练数据样例

在SemEval的语料中,由于用户书写不规范,语料中包含大量的错误.在实验前,我们对其中一些错误进行了处理.表3列出了一些错误示例以及我们处理后的结果.用户会将一些单词中的某些字符重复书写多次以表达感情,但这对我们处理问题造成了很大的干扰,因此我们将包含多余字符的词汇进行还原.而有些用户习惯用分号来分割句子,这会导致我们分句错误,因此我们将分号替换为句号.而且重复标点可能造成分词错误或句法分析错误,因此我们也将重复的标点去掉.与此同时,我们还将所有的字母全部变为小写以便后续处理.
在关键词抽取模块,我们使用nltk [17] 对语料进行分句,用Stanford的Universal Dependencies [18] 对语料进行依存句法分析.我们将问题的主题和描述分别看作一篇文档去计算每个词的IDF值,DF值则是根据该词在句子中出现的次数来计算.我们根据Floyd距离计算词汇间的依存路径长度,并设置计算语义关联度中的超参数 b =1.4.我们对问题的主题和描述分句并抽取关键词,每个句子抽取其句子长度 ![]() 的关键词,将关键词按照句子出现的顺序进行排序,其中问题主题的关键词排在问题描述的前面.
的关键词,将关键词按照句子出现的顺序进行排序,其中问题主题的关键词排在问题描述的前面.
Table 3 Error Example
表3 错误示例

在CNN模型中,我们设置计算语义匹配向量的窗口 w =3,卷积层中过滤器的尺寸为300×3,卷积层过滤器的个数为500.我们使用对数似然函数作为损失函数,使用SGD算法对模型进行优化,同时设置学习率为0.005.
在实验中,我们使用了2种不同的词向量.在关键词抽取模块以及CNN模块中,我们使用斯坦福大学GloVe模型 [15] 预训练的300维的词向量.该词向量没有在QatarLiving的语料上进行训练,更具有通用性,可以在一定程度上防止过拟合.而在基于问题主题的相似度计算模块中,我们使用了在QatarLiving语料上进行预训练的200维词向量 [19] .该词向量更具有领域的特殊性,因此更适合用于直接计算相似度.
首先,我们进行一组实验证明关键词提取和主题间相似度是有意义的.我们先后去掉基于主题信息的特征和关键词提取模块进行实验,接着我们将这2个模块全部去掉进行实验.实验结果如表4所示:
Table 4 Model Comparison Experiment
表4 模型对比实验

实验证明,基于关键词的模型要优于基于全部内容的模型.我们从3方面分析原因:
1) 由于不同问题包含的词汇量不同,可能差异很大.这导致将全文作为神经网络的输入时,两者所蕴含的信息量相差悬殊,不利于网络学习.而抽取关键词则将两者词汇量上的差距缩小,所蕴含的信息量的差距也同时缩小,这有利于神经网络学习到有意义的特征.
2) 由于用户的背景不同,所提出问题的背景信息有很大差别,这些背景信息会干扰模型判断问题相似.抽取关键词可以将干扰信息减少,帮助模型判断问题相似.
3) 理论上,CNN模型可以通过多轮学习自动过滤无用信息,但要达到上述目标需要大量的语料.而由于语料不足,神经网络模型无法很好地从过长的问题中抽取特征,将全文作为模型的输入很有可能造成过拟合,而将关键词作为模型的输入则减轻了这一问题.
实验也证明了问题主题相似度的特征可以辅助模型判断问题相似度.我们认为,用关键词序列代替全部文本作为神经网络的输入不可避免地会造成一些信息的流失,关键词提取本身也会造成级联错误.于是我们可以人为添加一些对判断问题相似度有帮助的特征辅助模型进行判断.而大量的研究表明问题主题可以帮助我们判断问题相似,因此我们选择了问题主题相似度作为辅助判断的依据.
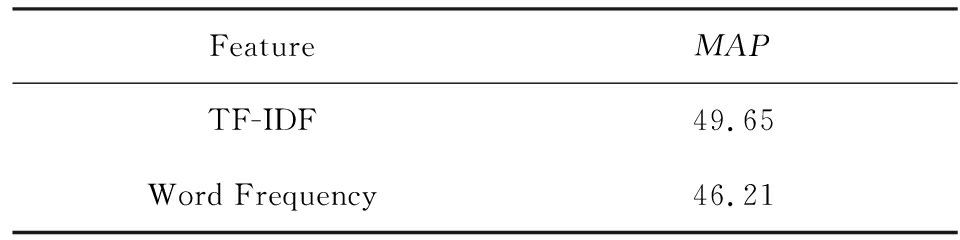
我们用实验证明关键词提取模块中,使用TFIDF而非词频来判断词的重要程度是更优的选择.实验表明引入全局信息有助于表示词的重要程度.结果如表5所示:
Table 5 Comparison of the Feature Used in Computing the Gravitational Value of Words
表5 词引力值使用特征对比实验
同时,我们的模型中多次计算向量间的相似度.因此我们设计了一组实验来证明在我们的模型中皮尔森相关系数要优于余弦相似度,皮尔森相似度可以更好地表示向量之间的相关程度.我们在语义匹配和矩阵分解以及主题相似度计算模块中分别尝试了余弦相似度以及皮尔森相关系数,实验结果如表6所示:
Table 6 Comparison of Cosine Similarity and Pearson ’ s Correlation Coefficient
表6 余弦相似度与皮尔森相关系数对比实验

从表6可知,除了当主题相似度计算模块使用余弦相似度时,在CNN模型中使用皮尔森相关系数的结果略差于余弦相似度且差距不大外,其他任何情况中皮尔森相关系数均优于余弦相似度.因此可以认为在我们的模型中,皮尔森相关系数要优于余弦相似度.
最后,将我们提出的模型同SemEval2017的评测结果进行比较,实验结果如表7所示:
Table 7 The Experimental Results in SemEval2017
表7 SemEval2017评测语料实验结果

表7中名称均为参加评测的队伍名称,我们选择了评测中排名前3的模型进行比较.KeLP [20] 系统基于SVM(support vector machine),使用具有问题间关系链接的句法树内核以及一些文本间的相似性度量计算问题间相似度.Simbow [21] 系统在余弦相似度中融入了关系度量,其使用多种关系度量计算余弦相似度,最后使用逻辑回归模型计算问题相似度.LearningToQuestion [22] 系统用神经网络模型生成特征再使用SVM或逻辑回归模型计算问题相似度.从表7中我们可以看出,我们的模型要优于评测中最好的模型,更远远优于基于IR(information retrieval)的基础模型.但是,我们的模型仍有一些不足:1)由于关键词提取技术的准确度不够,我们无法保证是否有关键信息遗漏;2)以关键词序列作为神经网络的输入破坏了问题的结构,我们无法利用问题结构上的信息来判断问题相似性;3)我们使用用户提供的问题主题间的相似度作为辅助判断的依据,但用户提供的主题可能太过简略,无法帮助甚至会阻碍我们判断问题相似.
我们提出了一种基于关键词间相似及相异信息的CNN模型去计算社区问答中问题相似度.同时,我们将问题主题间的相似度特征融入到模型中,以辅助模型进行判断.我们在SemEval2017的评测语料上进行了实验,并超过了现有的结果.下一步我们将尝试更多不同的关键词抽取算法以及不同的神经网络模型.同时,我们还会尝试在模型中融入主题模型来替代问题主题相似度.
参考文献
[1]Zhang Zhongfeng, Li Qiudan. Studies on community question answering—A survey[J]. Computer Science, 2010, 37(11):19-23 (in Chinese)(张中峰, 李秋丹. 社区问答系统研究综述[J]. 计算机科学, 2010, 37(11): 19-23)
[2]Wang Zhiguo, Mi Haitao, Ittycheriah A. Sentence similarity learning by lexical decomposition and composition[C] Proc of the 26th Int Conf on Computational Linguistics. Stroudsburg, PA: ACL, 2016: 1340-1349
[3]Jeon J, Croft W B, Lee J H. Finding similar questions in large question and answer archives[C] Proc of the 14th ACM Int Conf on Information and Knowledge Management. New York: ACM, 2005: 84-90
[4]Lee J T, Kim S B, Song Y I, et al. Bridging lexical gaps between queries and questions on large online Q&A collections with compact translation models[C] Proc of the 2008 Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2008: 410-418
[5]Zhou Guangyou, Cai Li, Zhao Jun, et al. Phrase-based translation model for question retrieval in community question answer archives[C] Proc of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies -Volume 1. Stroudsburg, PA: ACL, 2011: 653-662
[6]Duan Huizhong, Cao Yunbo, Lin C Y, et al. Searching questions by identifying question topic and question focus[C] Proc of the 46th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2008: 156-164
[7]Zhang Kai, Wu Wei, Wu Haocheng, et al. Question retrieval with high quality answers in community question answering[C] Proc of the 23rd ACM Int Conf on Conf on Information and Knowledge Management. New York: ACM, 2014: 371-380
[8]Xiong Daping, Wang Jian, Lin Hongfei. An LDA-based approach to finding similar questions for community question answer[J]. Journal of Chinese Information Processing, 2012, 26 (5): 40-45 (in Chinese)(熊大平, 王健, 林鸿飞. 一种基于LDA的社区问答问句相似度计算方法[J]. 中文信息学报, 2012, 26(5): 40-45)
[9]dos Santos C N, Barbosa L, Bogdanova D, et al. Learning hybrid representations to retrieve semantically equivalent questions[C] Proc of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th Int Joint Conf on Natural Language Processing (Short Papers). Stroudsburg, PA: ACL, 2015: 694-699
[10]Lei Tao, Joshi H, Barzilay R, et al. Semi-supervised question retrieval with gated convolutions[C] Proc of the 15th Annual Conf of the North American Chapter of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2016: 1279-1289
[11]Wang Xuxiang. Research on question keywords extraction techniques for question answering[D]. Harbin: Harbin Institute of Technology, 2016 (in Chinese)(王煦祥. 面向问答的问句关键词提取技术研究[D]. 哈尔滨: 哈尔滨工业大学, 2016)
[12]Mihalcea R, Tarau P. TextRank: Bringing order into texts[C] Proc of the 2004 Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2004, (4): 404-411
[13]Wang Rui, Liu Wei, McDonald C. Corpus-independent generic keyphrase extraction using word embedding vectors[C OL] Proc of Software Engineering Research Conf. 2014 [2017-10-27]. https: www.semanticscholar.org paper Corpus-independent-Generic-Keyphrase-Extraction-Us-Wang-Liu bd3794 c777af5ba363abae5708050ea78ecc97e2
[14]Zhang Weinan, Ming Zhaoyan, Zhang Yu, et al. The use of dependency relation graph to enhance the term weighting in question retrieval[C] Proc of the 24th Int Conf on Computational Linguistics. Stroudsburg, PA: ACL, 2012: 3105-3120
[15]Pennington J, Socher R, Manning C. Glove: Global vectors for word representation[C] Proc of the 2014 Conf on Empirical Methods in Natural Language Processing (EMNLP). Stroudsburg, PA: ACL, 2014: 1532-1543
[16]Nakov P, Hoogeveen D, Arquez L M, et al. SemEval-2017 Task 3: Community question answering[C] Proc of the 11th Int Workshop on Semantic Evaluations (SemEval-2017). Stroudsburg, PA: ACL, 2017: 27-48
[17]Bird S. NLTK: The natural language toolkit[C] Proc of the 21st Int Conf on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2006: 69-72
[18]De Marneffe M C, Dozat T, Silveira N, et al. Universal Stanford dependencies: A cross-linguistic typology[C] Proc of the 9th Int Conf on Language Resources and Evaluation (LREC’14). Paris: European Language Resources Association, 2014: 4585-4592
[19]Mihaylov T, Nakov P. SemanticZ at SemEval-2016 Task 3: Ranking relevant answers in community question answering using semantic similarity based on fine-tuned word embeddings[C] Proc of the 10th Int Workshop on Semantic Evaluations (SemEval-2016). Stroudsburg, PA: ACL, 2016: 879-886
[20]Filice S, Martino G D S, Moschitti A. KeLP at SemEval-2017 Task 3: Learning pairwise patterns in community question answering[C] Proc of the 11th Int Workshop on Semantic Evaluations (SemEval-2017). Stroudsburg, PA: ACL, 2017: 326-333
[21]Charlet D, Damnati G. SimBow at SemEval-2017 task 3: Soft-cosine semantic similarity between questions for community question answering[C] Proc of the 11th Int Workshop on Semantic Evaluations (SemEval-2017). Stroudsburg, PA: ACL, 2017: 315-319
[22]Goyal N. LearningToQuestion at SemEval 2017 task 3: Ranking similar questions by learning to rank using rich features[C] Proc of the 11th Int Workshop on Semantic Evaluations (SemEval-2017). Stroudsburg, PA: ACL, 2017: 310-314
Qi Le, Zhang Yu, and Liu Ting
( Research Center for Social Computing and Information Retrieval , Harbin Institute of Technology , Harbin 150001)
Abstract Question similarity calculation is a major task in community question answering (CQA). It is helpful to retrieve relevant question-answer pairs from QA community by leveraging the similarity among queries. Questions in CQA are usually composed of topics and descriptions, which are both important in the task of question similarity calculation. In addition, due to the openness of the CQA, the length of questions is different. Meanwhile, background information of the questions will interfere with the judgment on question similarity. In order to reduce the influence of the irrelevant content and the various length of questions, the keywords are extracted from the descriptions of questions. Then, the keywords are fed to the CNN-based model to extract the similar and dissimilar information between texts. At the same time, in order to make better use of the information about the question topic, the model also combines the feature from the similarity between them. In summary, the model treats the keywords and topics as the key information about the questions, and uses the information to calculate similarity between them. The model is experimented on the question similarity task of the SemEval2017. The mean average precision ( MAP ) reaches 49.65%, which exceeds the best result in the evaluation.
Key words question similarity; community question answering (CQA); keywords; question topic; convolutional neural network (CNN)
中图法分类号 TP391; TP18
This work was supported by the National Basic Research Program of China (973 Program) (2014CB340503) and the National Natural Science Foundation of China (61472105, 61502120).
修回日期: 2017-11-16
基金项目 : 国家“九七三”重点基础研究发展计划基金项目(2014CB340503);国家自然科学基金项目(61472105,61502120)

收稿日期 : 2017-07-04;
Qi Le , born in 1994. PhD candidate. His main research interests include question answering.

Zhang Yu , born in 1972. PhD, professor, MS supervisor. His main research interests include question answering and personalized information retrieval (zhangyu@ir.hit.edu.cn).

Liu Ting , born in 1972. PhD, professor, PhD supervisor. His main research interests include social computing, information retrieval and natural language processing (tliu@ir.hit.edu.cn)