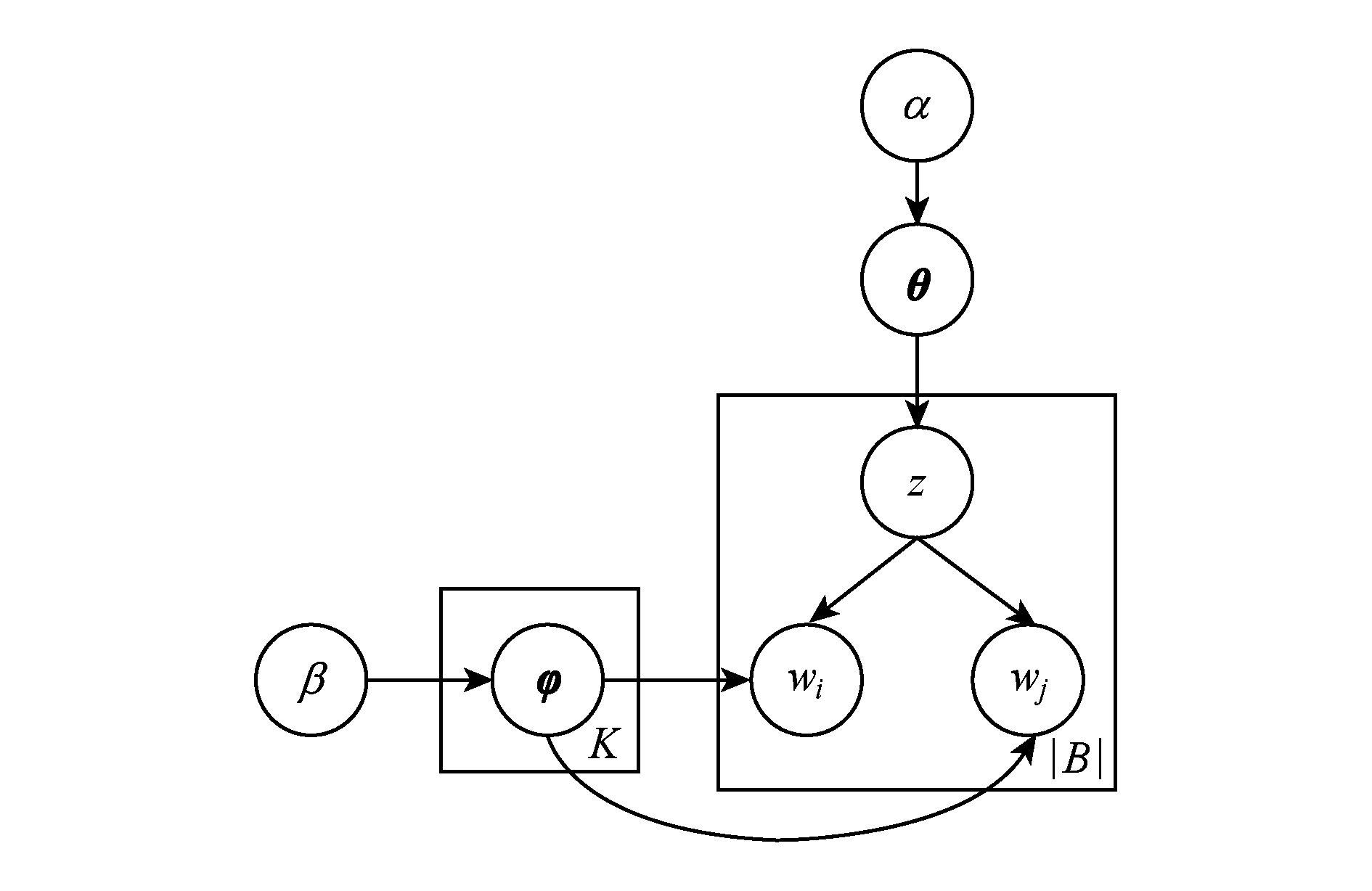
Fig. 1 BTM graphical model
图1 BTM图模型
梁吉业 乔 洁 曹付元 刘晓琳
(山西大学计算机与信息技术学院 太原 030006) (计算智能与中文信息处理教育部重点实验室(山西大学) 太原 030006) (ljy@sxu.edu.cn)
摘 要 短文本的分布式表示已经成为文本数据挖掘的一项重要任务.然而,直接应用分布式表示模型Paragraph Vector尚有不足,其根本原因是其在训练过程中并没有利用到语料库级别的信息,从而不能有效改善短文本中语境信息不足的情况.鉴于此,提出了一种面向短文本分析的分布式表示模型——词对主题句向量模型(biterm topic paragraph vector, BTPV),该模型通过将词对主题模型(biterm topic model, BTM)得出的主题信息融入Paragraph Vector中,不仅使得模型训练过程中利用到了全局语料库的信息,而且还利用BTM显性的主题表示完善了Paragraph Vector隐性的空间向量.实验采用爬取到的热门新闻评论作为数据集,并选用 K -Means聚类算法对各模型的短文本表示效果进行比较.实验结果表明,基于BTPV模型的分布式表示较常见的分布式向量化模型word2vec和Paragraph Vector来说能取得更好的短文本聚类效果,从而显现出该模型面向短文本分析的优势.
关键词 分布式表示;短文本;文本分析;句向量;词对主题模型
随着Web 2.0的普及,大众的角色逐渐由信息的接收者转变为信息的传递者和创造者.特别是随着微博、微信等自媒体的兴起,短文本广泛出现在网络上并且增长速度极快.短文本表示对于短文本分析任务,如信息检索、舆情分析、推荐系统等都是至关重要的.但是,不同于传统的长文本,短文本由于缺乏丰富的上下文语义信息,使得基于短文本的表示面临极大的挑战.
短文本的向量化表示,常用以下4种方法:
1) 基于向量空间模型(vector space model, VSM) [1] 的文本表示方法.VSM将每个文本表示为向量空间中的一个向量,向量空间中的每一维对应语料库中每一个不同的词,每个维度的值就是对应的词在文本中的权重.但由于短文本评论的语料库较大,每个短文本评论的长度又较短,所以如果使用该模型,短文本表示将面临高维灾难,且VSM仅考虑单个词作为特征,忽略了词与词之间的语义特征.
2) 基于频繁词集的的文本表示方法.Zhang等人提出了MC(maximum capturing)算法 [2] ,该算法将每个文本表示为以频繁词集作为特征项的向量,再利用文本间共有的频繁词集个数度量向量之间的相似性,进而对文本进行聚类.该方法在一定程度上缓解了VSM模型存在的高维问题,但同VSM模型一样,该模型也属于词袋(bag of words, BOW)模型 [3] ,忽略了词序信息,导致包含相同词的不同文本可能具有相同的表示.
3) 基于主题模型的的文本表示方法.以上2种方法中词的语义表示是原始的、面向字符串的,如一意多词“番茄”和“西红柿”用这些方法来区分是困难的,因为它们虽然表示同一个意思,但字符串完全不同.Blei等人于2003年提出了LDA(latent Dirichlet allocation)主题模型 [4] ,该模型被广泛使用到文本主题建模中,但是该模型更适用于长文本,在短文本上效果不太理想,且该模型的重点是对文本中的主题进行建模,不能对文本中的词进行鲁棒的表示.Hong等人 [5] 提出将含有同样词语的短消息进行聚合,从而将短文本聚合成伪长文本,然后用传统的主题模型进行训练,但是这种聚合对文本集有很大的依赖性.Phan等人 [6] 提出利用外部资源来丰富短文本的表达,从而学习其中隐含的主题,但是该方法对外部资源的有效性要求很高,所以没有普遍适用性.Yan等人于2013年提出了一种同时适用于短文本和长文本的词对主题模型 (biterm topic model, BTM) [7] ,通过对语料库中的所有词对进行建模,得出每个文本的主题分布和各个主题下的词分布.此类基于主题模型的方法,其重点是对文档的主题进行建模,而不是对文本中的词进行语义表示 [8] ,进而在一些词义消歧、机器翻译、词性标注等需要词表示的任务中显得无力从心.
4) 基于神经网络模型的分布式表示方法.这类方法使用Hinton在1986年提出的分布式表示 [9] 的思想,将文本表示为稠密、低维、连续的向量.Bengio等人在2003年提出神经网络语言模型(neutral net-work language model, NNLM) [10] 模型,将几个词向量的拼接输入神经网络,并且尝试利用Softmax算法去预测接下来的词.当模型训练完成后,词向量被映射到了一个向量空间,并且在这个向量空间中,具有相似语义的词会有相似的向量表示,但该模型输出层中的节点数等于输入语料的单词数,当训练大规模语料时,运算复杂度高,模型训练缓慢.Mikolov等人于2013年提出word2vec模型,包括CBOW(continuous bag of words)和skip-gram模型 [11] ,模型使用Hierarchical Softmax算法加速训练,当训练完成后,拥有相似语义的单词会被映射到向量空间里相近的位置上,并且发现词向量之间的距离差距也包含着一定语义信息.为了把模型从词层面扩展到句子层面,在词向量的基础上,Le等人于2014年提出了Paragraph Vector模型 [12] ,可将变长文本训练成固定维度的段落向量.
在以上4种文本表示方法中,基于神经网络模型的分布式表示方法近年来得到了人们的广泛关注 [13] ,特别是Paragraph Vector模型,该模型克服了传统词袋模型的2个缺点,不仅保留了词向量包含的语义信息,而且考虑了词序,保留了 n -gram模型的信息.但其在训练过程中只用到了文档级别的信息,因而在面向短文本分析时,还未能有效改善短文本中语境信息不足的情况.
本文提出了一种面向短文本分析的分布式表示模型——词对主题句向量模型(biterm topic para-graph vector, BTPV),该模型将BTM得出的全局主题信息融入Paragraph Vector模型中,使得该模型既能在模型训练过程中利用到整个语料库的信息,又能保持Paragraph Vector模型的优势.又由于聚类是文本分析任务中常用的方法之一 [14] ,本文选取 K -Means聚类算法对模型的表示效果进行验证.
本节对本文中使用的词对主题模型BTM和句向量表示模型Paragraph Vector的相关概念进行回顾.
BTM主题模型是Yan等人于2013年针对短文本提出的主题模型,该模型通过词对共现模式来加强主题模型的学习,利用整个语料库的丰富信息来推断主题,不仅缓解了LDA处理短文本的数据稀疏问题,而且满足了一条短文本可以包含多个主题的现实要求.图1为BTM的概率图模型.
Fig. 1 BTM graphical model
图1 BTM图模型
如图1所示, α , β 为狄利克雷超参数; θ 为词对-主题概率分布; φ 为主题-词概率分布; K 为主题个数参数,一般根据语料库选取; z 为词对对应的主题变量; w i , w j 为2个词语构成的词对;| B |为语料库中词对的总数.BTM生成过程如下:
1) 采样每一个主题下的主题-词分布 φ k ~ Dir ( β );
2) 采样整个语料库的词对-主题分布 θ ~ Dir ( α );
3) 对词对集合 B 里的每一个词对 b =( w i , w j );
① 采样得到主题 z ~ Multi ( θ );
② 采样得到词对 w i , w j ~ Multi ( φ z ).
在BTM模型中,隐含变量 θ 和 φ 计算为
![]()
(1)
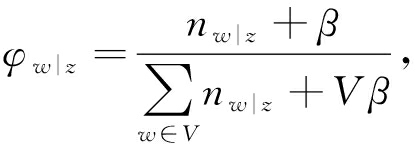
(2)
文档下的主题分布计算为
![]()
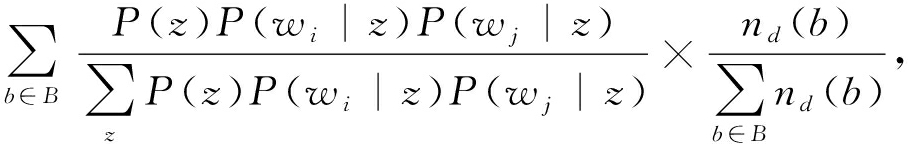
(3)
其中 n z 表示词对被分配到主题 z 的次数, n w | z 表示词 w 被分配主题 z 的次数, V 是短文本集中不同词的词数, n d ( b )是文档 d 中词对 b 出现的次数.具体可参考文献[7].
随着word2vec模型CBOW和skip-gram的广泛使用,研究者们试图把模型扩展至句子级层面,最简单的方法就是使用文本中所有词向量的加权平均,但是这种方法属于BOW模型,丢失了词序信息.Le等人提出的Paragraph Vector模型在保留原来词向量语义信息的基础上又考虑了词序,同时也具有很好的泛化能力.
Paragraph Vector模型中的PV-DM(paragraph vector-distributed memory)模型通过上下文和段落向量来预测中心词,如图2所示,其中每个文本被映射成一个指定维度的向量,具体表示为矩阵 D 中的一列,每一个词也被映射成一个指定维度的向量,具体表示为矩阵 W 中的一列,然后将段落向量和词向量进行相加或拼接来预测上下文的中心词,可以将段落向量看作是上下文的另一个词,用来记忆当前上下文中遗忘的文本信息,其中上下文是用一个固定长度的滑动窗口在一个文本中不断采样得到的.
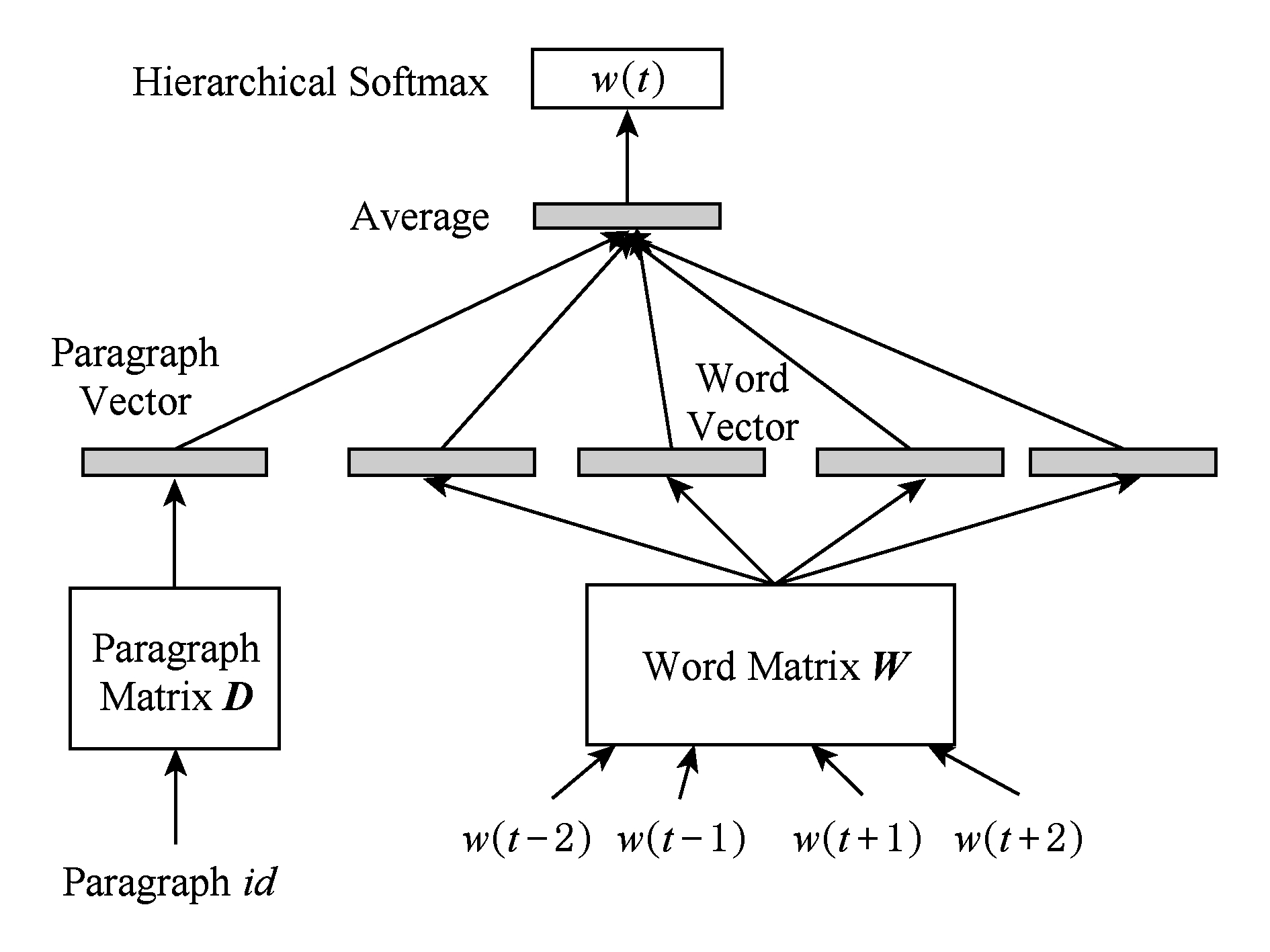
Fig. 2 The diagram of PV-DM
图2 PV-DM图示
模型使用随机梯度上升方法进行训练,在整个训练过程中,段落向量被该文本中的所有上下文窗口共同拥有,不跨越该文本.训练完成后,段落向量就可以被用来作为文本的特征表示,并且该特征表示可直接用于机器学习算法中,例如逻辑斯蒂回归、支持向量机或者 K -Means聚类.
Paragraph Vector模型中还包括PV-DBOW(paragraph vector-distributed bags of words)模型,不同于PV-DM通过段落向量和词向量来预测中心词,PV-DBOW只通过段落向量来预测该文本中随机采样的词.
由于Paragraph Vector模型只运用了文档级别的信息,无法对整个语料库的信息加以利用,并且Paragraph Vector模型是一种隐性语义表示模型 [15] ,它将一个短文本表示为一个隐性语义空间上的向量,该向量每一维度所代表的含义人们无法解释;在BTM中,由于是对整个语料库中的词对进行建模,利用了整个语料库的信息来训练词对的主题,并且BTM是一种半显性语义表示模型,它将短文本表示为一个半显性语义空间上的向量,向量的每一维度是一个主题,该主题又是一组词的分布.所以提出一种面向短文本的分布式表示模型BTPV,将BTM主题分布的全局半显性信息和Paragraph Vector的局部隐性信息相融合来训练句向量,使得在模型训练时既能利用整个语料库的信息,也能用BTM半显性的语义空间完善Paragraph Vector的隐性语义空间.对应于Paragraph Vector,该模型也有2种实现方法BTPV-DM和BTPV-DBOW.
BTPV-DM模型如图3所示,该模型在输入层将每个文本映射成一个指定维度的向量,具体表示为矩阵 D 中的一列,每一个词也被映射成一个指定维度的向量,具体表示为矩阵 W 中的一列,并由矩阵 M 和该文本的主题分布 θ i d 相乘得出该文本的主题向量,之后在连接层进行上述段落向量、词向量和主题向量的平均,用以预测上下文的中心词,可以将主题向量看作是上下文的另一个词,用来记忆当前上下文中遗忘的主题信息,显然加上主题向量后,模型包含的文本主题信息更加丰富.
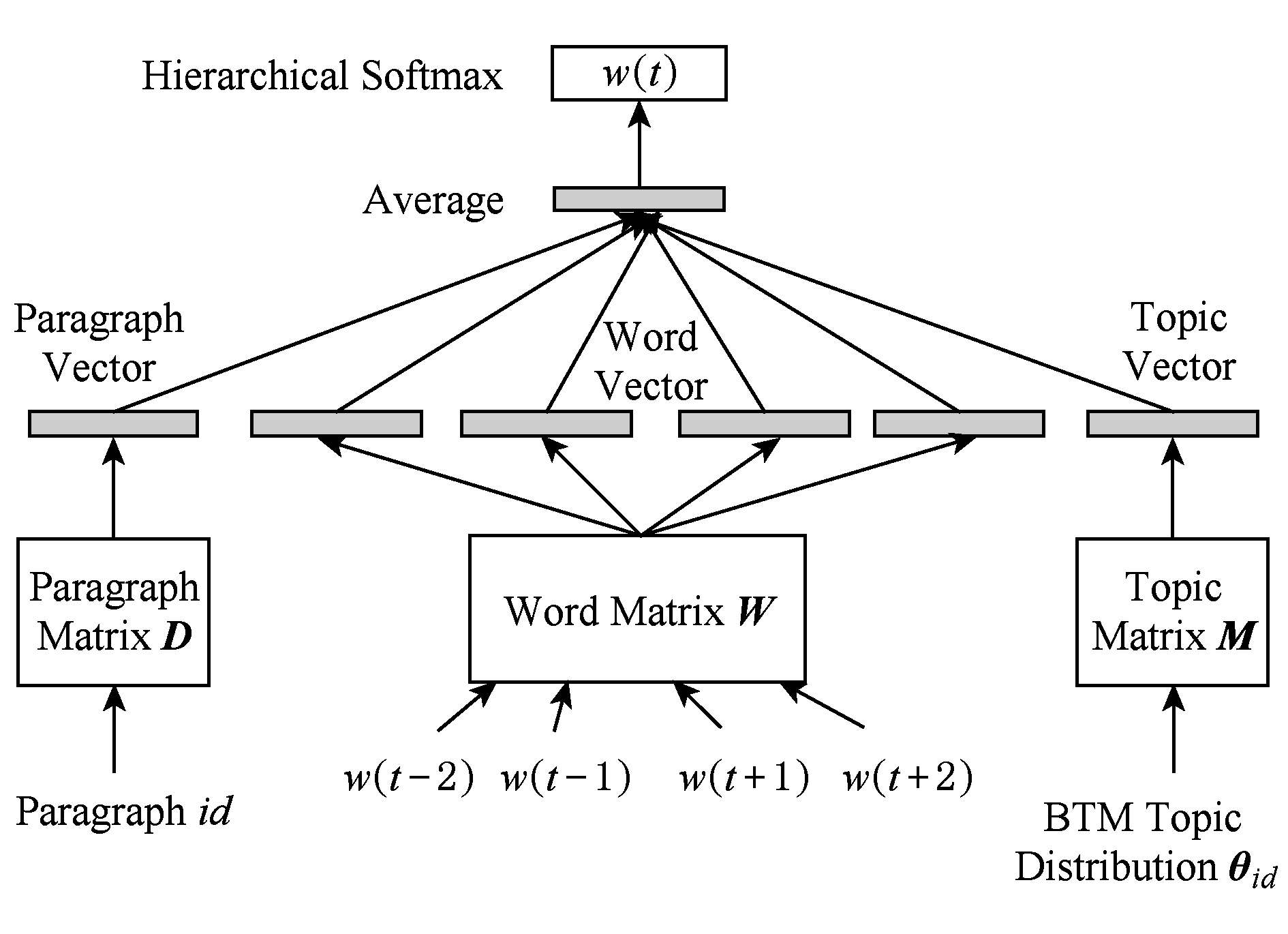
Fig. 3 The diagram of BTPV-DM
图3 BTPV-DM图示
BTPV-DM模型用随机梯度上升算法进行参数训练,并在训练模型时选择了Hierarchical Softmax的方法来提高模型的训练效率,降低计算复杂度.过程中需要的符号总结如表1:
Table 1 Notations and Explanations
表1 符号及意义

由最大似然估计,BTPV-DM模型的目标函数为
(4)
其中 ρ w = M · θ w ,目的是将BTM得出词 w 所在文本的主题分布 θ w 映射为与 ![]() 相同维度的向量,其中 θ w 是 K ×1维,
相同维度的向量,其中 θ w 是 K ×1维, ![]() 是 T ×1维,矩阵 M 是 T × K 维.将求和项中的每一项记为 L w 则:
是 T ×1维,矩阵 M 是 T × K 维.将求和项中的每一项记为 L w 则:
![]()
(5)
在连接层进行词向量、句向量、主题向量的相加并求均值,可知:
(6)
利用哈夫曼树对语料库中所有的词语进行编码,由Hierarchical Softmax和式(6)得:
L w =log P ( w | x w , ω )= ![]()
(7)
哈夫曼树中每一个非叶节点处是一个Softmax分类器,可得:
![]()
![]()
![]()
(8)
将求和项中的每一项记为 ![]() 则:
则:
![]()
(9)
对各参数求偏导数可得:
![]()
(10)
![]()
(11)
![]()
(12)
由以上BTPV-DM模型求解过程可得算法1.
算法1 . BTPV-DM算法.
输入:短文本语料库 DOC ={ d 1 , d 2 ,…, d n }、学习率 ε ,窗口大小 p 、循环次数 iter ;
输出:语料库中每个短文本的句向量.
Step1. 利用BTM主题模型得出语料库 DOC 中每个短文本的主题分布 θ i ,其中 i ∈[1, n ];
Step2. 对于语料库 DOC 中的每一个短文本 d i ,随机初始化句向量 η 、 词向量 v 、主题矩阵 M 、Hierarchical Softmax参数集合 ω ;
Step3. 对于短文本 d i 中的每一个词 w ,由式(6)计算出 x w ,并初始化误差 e = 0 , e M = 0 ;
Step4. 对词 w 所在哈夫曼树的每一层 j ∈[1, h w ],由式(10)~(12),计算向量梯度 e 
![]() 更新参数
更新参数 ![]()
![]() 计算矩阵梯度
计算矩阵梯度 ![]()
Step5. 对于词 w 上下文中包含在以 p 为大小的窗口内的每一个词 ![]() 更新词向量
更新词向量 ![]()
![]()
Step6. 更新 d i 的句向量 η η + e ;
Step7. 更新主题矩阵 M M + e M ;
Step8. 返回Step3,训练下一个词;
Step9. 返回Step2,训练下一个短文本;
Step10. 迭代 iter 次后,输出每个短文本的句向量.
BTPV-DBOW模型如图4所示,该模型忽略上下文信息,在输入层将每个文本映射成一个指定维度的向量,具体表示为矩阵 D 中的一列,并由矩阵 M 和该文本的主题分布 θ i d 相乘得出该文本的主题向量,之后在连接层进行上述2个向量段落向量和主题向量的平均,用以预测文本中随机采样的词,同样加上主题向量后,该模型记忆的主题信息会更准确、更丰富.
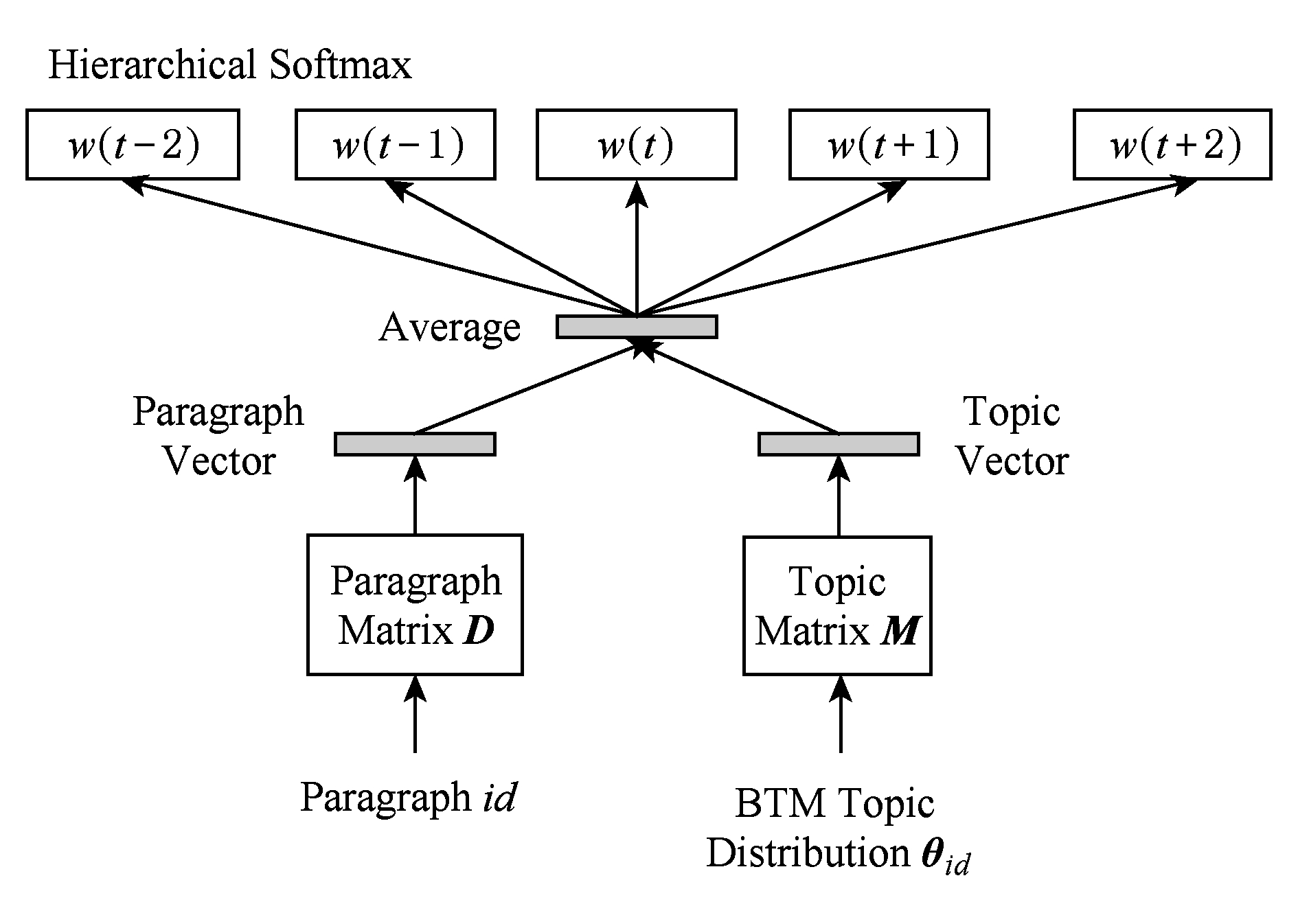
Fig. 4 The diagram of BTPV-DBOW
图4 BTPV-DBOW图示
BTPV-DBOW模型忽略上下文信息,由最大似然估计,模型的目标函数为
(13)
不同于BTPV-DM,在连接层仅将主题向量和句向量相加求均值:
![]()
(14)
同样利用哈夫曼树对语料库中所有的词语进行编码,由Hierarchical Softmax和式(14)得:
![]()
(15)
对参数求偏导数得:
![]()
(16)
![]()
(17)
![]()
(18)
BTPV-DBOW模型同样采用随机梯度上升算法进行参数训练,也在训练模型时选择了Hierarchical Softmax的方法来提高模型的训练效率,降低计算复杂度,模型求解过程由算法2所示.
算法2 . BTPV-DBOW算法.
输入:短文本语料库 DOC ={ d 1 , d 2 ,…, d n }、学习率 ε 、窗口大小 p 、循环次数 iter ;
输出:语料库中每个短文本的句向量.
Step1. 利用BTM主题模型得出语料库 DOC 中每个短文本的主题分布 θ i ,其中 i ∈[1, n ];
Step2. 对于语料库 DOC 中的每一个短文本 d i ,随机初始化句向量 η 、主题矩阵 M 、Hierarchical Softmax参数集合 ω ;
Step3. 对于短文本 d i 中的每一个词 w ,由式(14)计算出 x w ,并初始化误差 e = 0 , e M = 0 ;
Step4. 对于词 w 上下文中包含在以 p 为大小的窗口内的每一个词 ![]()
Step5. 对于 ![]() 所在哈夫曼树的每一层
所在哈夫曼树的每一层 ![]() 由式(16)~(18),计算向量梯度 e
由式(16)~(18),计算向量梯度 e ![]() 更新参数
更新参数 ![]()
![]() 计算主题矩阵梯度 e M
计算主题矩阵梯度 e M ![]()
Step6. 更新 d i 的句向量 η η + e ;
Step7. 更新主题矩阵 M M + e M ;
Step8. 返回Step3,训练下一个词;
Step9. 返回Step2,训练下一个短文本;
Step10. 迭代 iter 次后,输出每个短文本的句向量.
在现实任务中,由于要处理的数据量通常是非常大的,所以模型的计算复杂度对于算法的实现也很关键.表2列出了常见分布式表示模型的计算复杂度以及本文新提出的BTPV模型的计算复杂度.其中 p 表示训练过程中滑动窗口的大小, q 表示采样词语的个数, T 表示词向量和句向量的维度, V 表示整个语料库词表中词的个数.
Table 2 Computational Complexity of Each Model
表2 各模型的计算复杂度
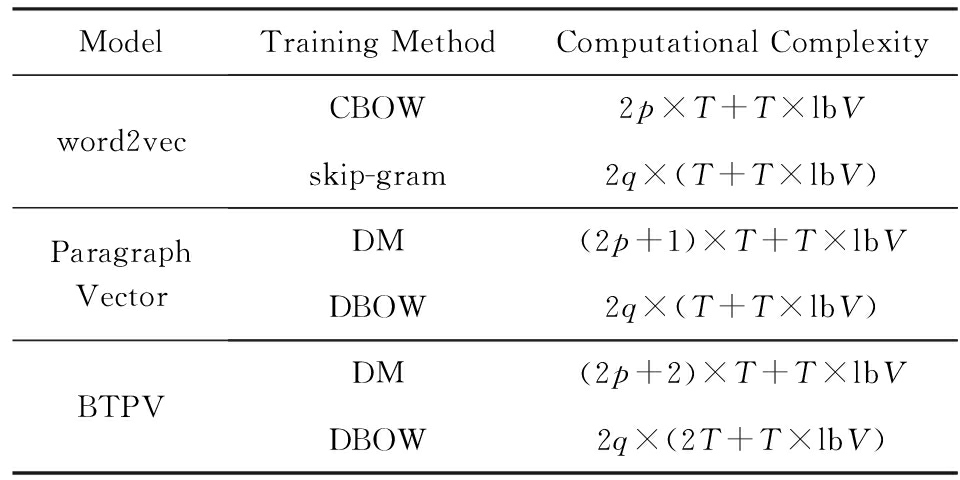
由表2可以看出,上述3种表示模型在2种训练方法下计算复杂度本质上是相同的.
本文通过Python的requests库抓取数据,通过指定3个参数:新闻评论页面的URL、评论的初始 id 以及评论的爬取数目,返回json字符串数据,采用Python的json包解析提取到的评论字符串数据并保存为文本文件.本文实验所采用的数据集均为热门新闻下的评论数据,如表3所示:
Table 3 News Review Dataset
表3 新闻评论数据

由于本文实验所采用的数据集均为热门新闻下的无标签数据,所以本文采用类内紧密性(compact-ness, CP )、类间间隔性(separation, SP )、分类适确性指标(Davies-Bouldin index, DBI ) [16] 这3种聚类内部评价指标对BTPV模型处理后的短文本聚类效果进行评价.
![]()
(19)
(20)
(21)
其中 K 为类个数, CP 计算每一个样本点 x 到聚类中心 μ i 的平均距离, SP 计算各聚类中心两两之间平均距离, DBI 计算任意两类别的 CP 指标之和除以两聚类中心距离的最大值.
数据采集后,对每个新闻数据集选用jieba进行分词,然后进行去标点、去停用词、去单字词等预处理过程.之后将预处理后的语料库通过BTM主题模型进行主题建模,设定BTM模型的超参数 α =50/ K , β =0.01 [7] ,主观选取主题个数参数 K ,最终得到每一个短文本的主题分布.
将本文提出的BTPV模型与word2vec模型、Paragraph Vector模型进行比较,实验主要对比在各个分布式模型表示下聚类结果的 CP , SP , DBI 指标.设定窗口大小 p =5,迭代次数为 iter =20,为方便维度设定,在连接层进行求均值操作,对向量维度 T 在主观范围内进行选取.
实验选用 K -Means聚类算法 [17] 验证模型的有效性, K -Means属于平面划分方法,该算法理论可靠且速度快、易实现,对数据依赖度低,而且还适用于文本、图像特征等多种数据的聚类分析,因而在文本聚类中得到广泛的应用.但在 K -Means算法里初始聚类中心的选取是随机的,每次都会造成不同的聚类结果,本文选择牺牲一些时间复杂度,采用 K -Means++算法 [18] 初始化聚类中心,使初始聚类中心之间的距离尽可能地远,避免上述问题.另外,根据实际经验,假定 K -Means聚类簇数等于BTM主题个数参数 K .
CP 越小意味着类内聚类距离越近,但该指标缺乏对类间效果的考虑. SP 越大意味类间聚类距离越远,但该指标缺乏对类内效果的考虑. DBI 综合考虑了类内紧密性和类间间隔性, DBI 指数越小,证明聚类划分的结果较好,所以在实验结果中我们着重分析 DBI 指标.
根据3.3节实验方案进行实验,得到对比结果如表4.以第1条新闻“恒大净利大增负债率大降探因”的95 826条评论为例,从表4的 DBI 指数可以看出:
Table 4 K - Means Clustering Result Based on Different Short Texts Representation Models
表4 基于不同短文本表示模型上的 K - Means聚类效果
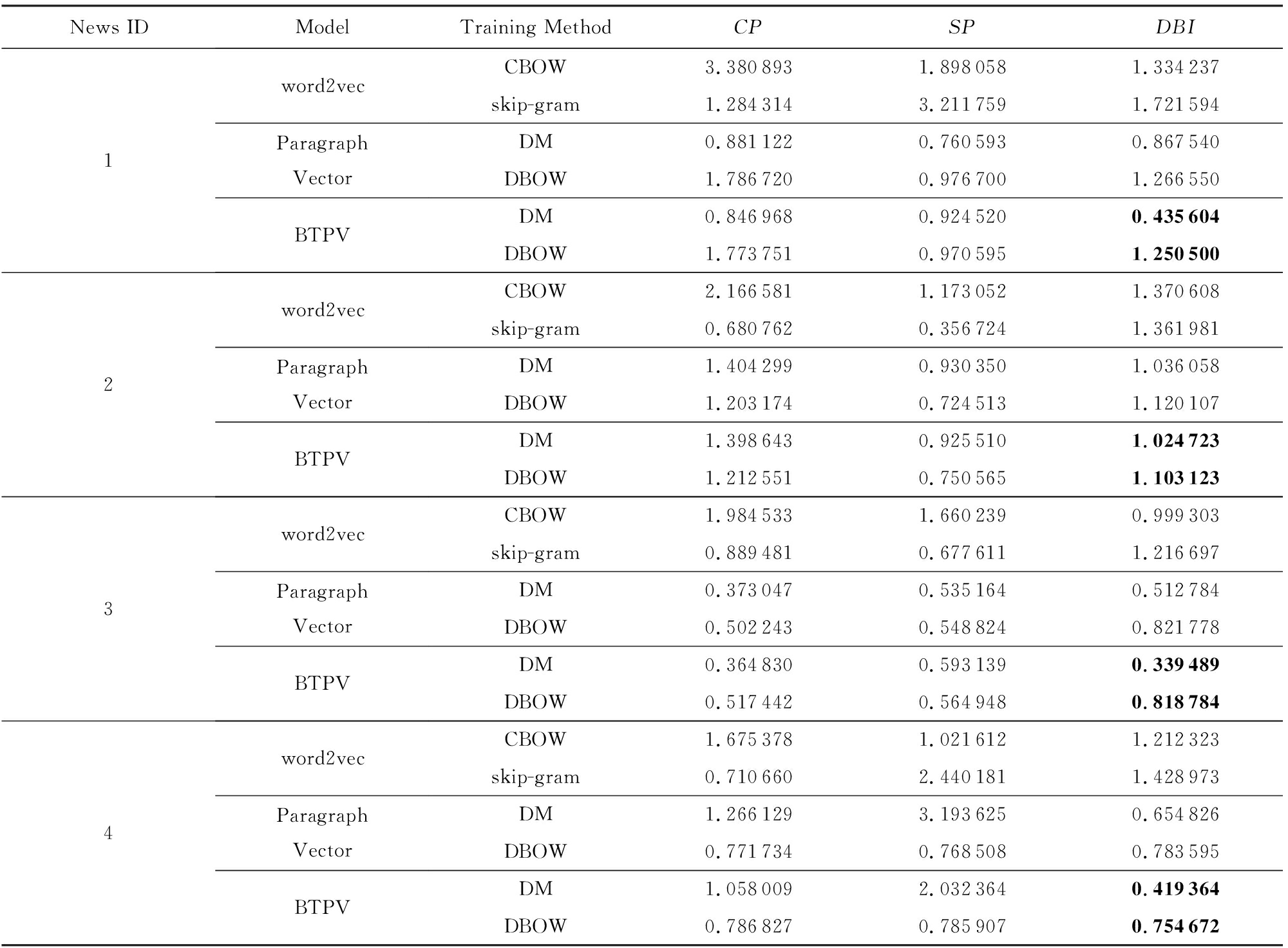
1) 基于Paragraph Vector和BTPV模型表示的聚类效果明显优于word2vec的聚类效果,这是由于word2vec直接将句子中词的词向量相加或求平均作为句子的向量化表示,没有考虑词之间的先后顺序,丢失了一部分语义信息.
2) 在Paragraph Vector和BTPV模型中,DM方法训练出的结果比用DBOW方法训练出来的结果要好.这与文献[12]的结果相同.
3) 无论是DM还是DBOW训练方法,基于BTPV模型表示的聚类效果明显优于Paragraph Vector的聚类效果.这是由于BTPV模型中融入了BTM的主题信息,使得在模型训练时既能利用整个语料库的信息,也能用BTM半显性的语义空间完善Paragraph Vector的隐性语义空间.
可以观察出基于Paragraph Vector和BTPV模型表示的 SP 指标小于基于word2vec表示的值,因为 SP 指标没有考虑类内效果.同理, CP 指标没有考虑类间效果,所以我们更加看重同时考虑类内紧密性和类间间隔性的 DBI 指标.
本文对各数据集进行了参数分析实验,以第1个数据集“恒大净利大增负债率大降探因”为例,在假定BTM主题个数参数 K 等于 K -Means聚类簇数的情形下,在[3,7]范围内,以1为步长选取参数 K ,在[100,200]范围内,以20为步长选取句向量维度 T 进行实验,聚类结果如下:
Table 5 The Effect of K and T on CP
表5 K 和 T 对 CP 的影响
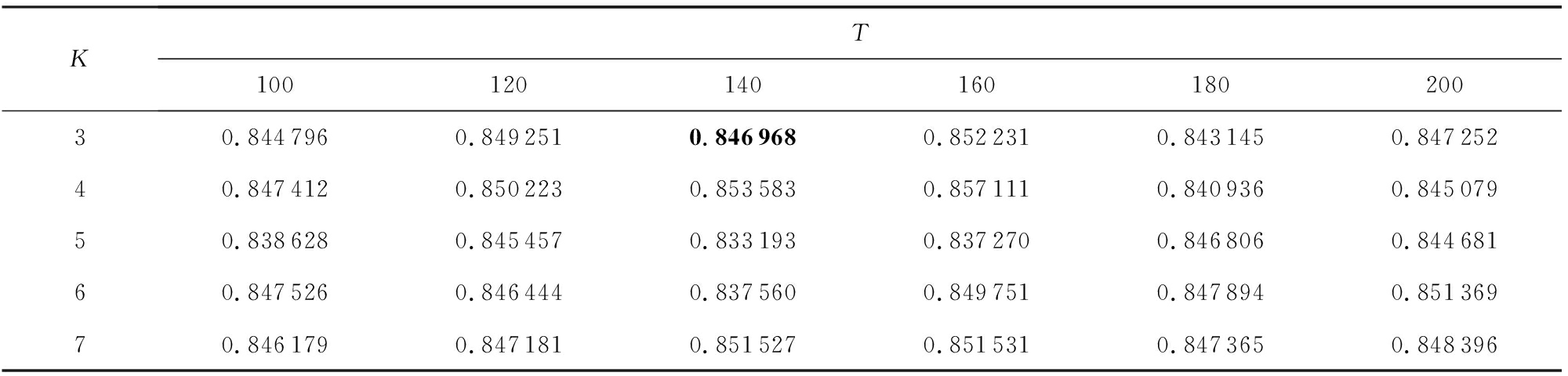
Table 6 The Effect of K and T on SP
表6 K 和 T 对 SP 的影响
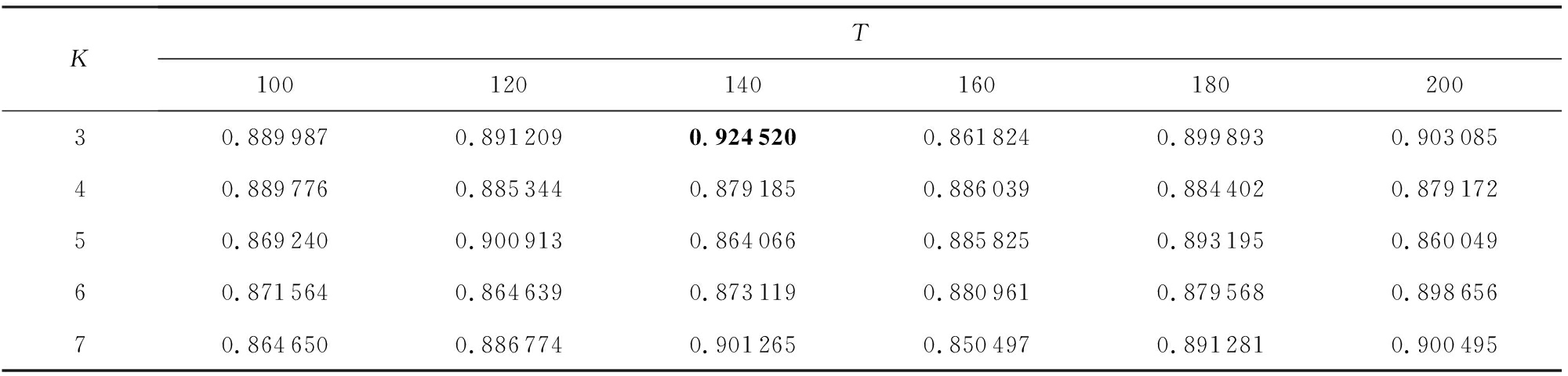
Table 7 The Effect of K and T on DBI
表7 K 和 T 对 DBI 的影响
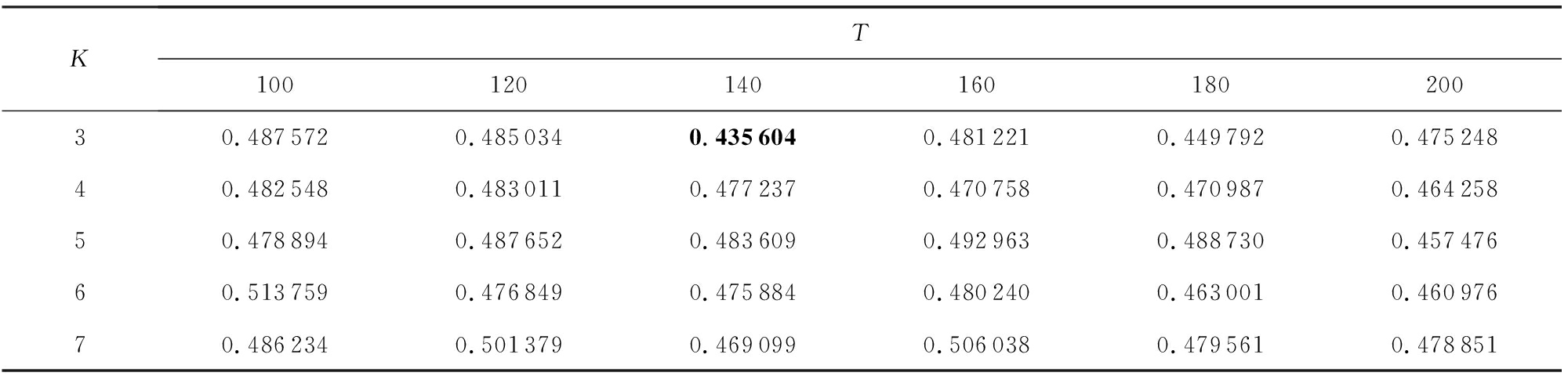
由表5~7中的实验数据可以看出, K =3, T =140时聚类 DBI 指标最小,即同时满足类内紧密性 CP 较小且类间间隔性 SP 较大,因此,可以认为第1个数据集“恒大净利大增负债率大降探因”在 K =3, T =140时基于BTPV模型表示的聚类效果最好.
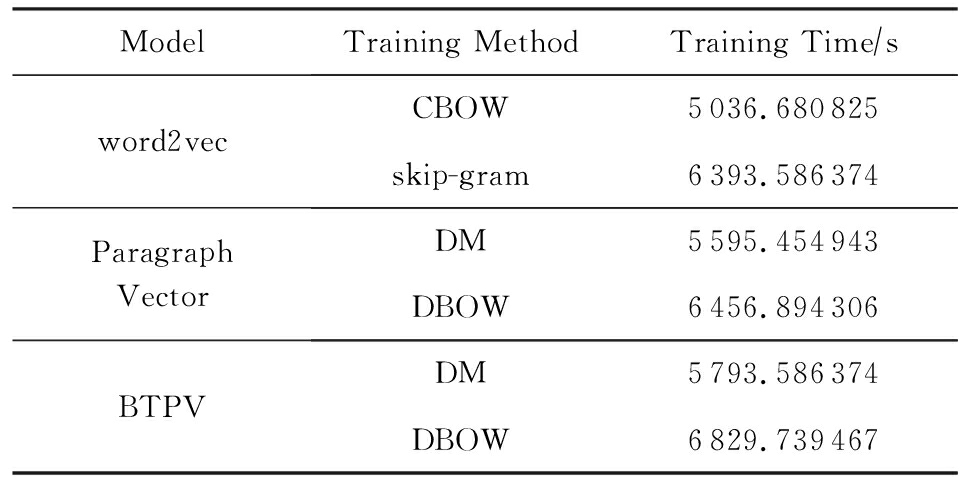
我们以新闻“恒大净利大增负债率大降探因”的95 826条评论为例来对各模型的训练效率进行比较.各个模型的训练次数均为20次,结果如表8所示.
由表8可以看出,BTPV模型和Paragraph Vector以及word2vec的耗时相差不多,BTPV模型耗时略多,主要是由于模型训练过程中融入了BTM主题信息.但是从聚类结果来看,BTPV模型的聚类结果明显优于Paragraph Vector和word2vec,这表明了BTPV模型处理海量文本的有效性.BTPV模型的高效性和有效性,反映出该模型的价值和应用前景.
Table 8 Training Time of Each Model
表8 各模型的训练时间
以第1个数据集为例,根据BTPV-DM模型建模时,设置 K =3,向量维度 T =140,经过 K -Means聚类后得到3个类,用Python的wordcloud库绘制词云,用jieba.analyse提取关键字分别显示这3个类中的关键字如图5所示.可以直观地看出,网民的观点主要围绕在宏观市场、企业规模、实力增长3个方面.
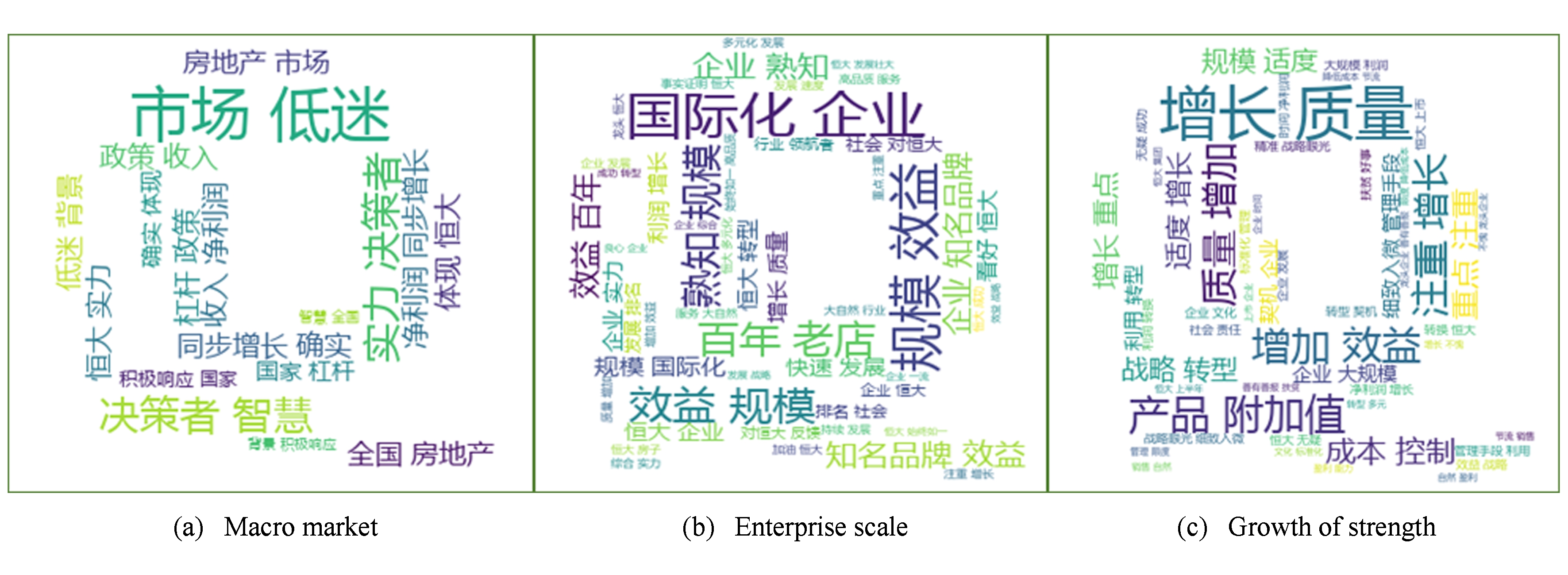
Fig. 5 Wordcloud display of clustering results
图5 聚类结果词云展示
本文提出一种面向短文本分析的分布式表示模型BTPV,通过将BTM的主题信息融入Paragraph Vector,使得在模型训练时既能利用整个语料库的信息,也能用BTM半显性的语义空间完善Paragraph Vector的隐性语义空间,从而比较全面地获取到短文本中的语义信息.基于该模型表示的聚类效果也明显优于传统分布式向量化模型的聚类效果.然而,本文仅验证了基于BTPV模型的聚类效果,该模型在其他应用方面的优势将是未来重点研究方向.
参考文献
[1]Lu Yuchang, Lu Mingyu, Li Fan, et al. Analysis and construction of word weighing function in VSM[J]. Journal of Computer Research and Development, 2002, 39(10): 1205-1210 (in Chinese)
(陆玉昌, 鲁明羽, 李凡, 等. 向量空间法中单词权重函数的分析与构造[J]. 计算机研究与发展, 2002, 39(10): 1205-1210)
[2]Zhang Wen, Yoshida T, Tang Xijin, et al. Text clustering using frequent itemsets[J]. Knowledge-Based Systems, 2010, 23(5): 379-388
[3]Harris Z S. Distributional structure[J]. Word, 1954, 10(13): 146-162
[4]Blei D M, Ng A Y, Jordan M I. Latent Dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3(1): 993-1022
[5]Hong Liangjie, Brian D. Empirical study of topic modeling in Twitter[C]  Proc of the 1st Workshop on Social Media. New York: ACM, 2010: 80-88
Proc of the 1st Workshop on Social Media. New York: ACM, 2010: 80-88
[6]Phan X H, Nguyen L M, Horiguchi S. Learning to classify short and sparse text & Web with hidden topics from large-scale data collections[C] Proc of the 17th Int Conf on World Wide Web. New York: ACM, 2008: 91-100
[7]Yan Xiaohui, Guo Jiafeng, Lan Yanyan, et al. A biterm topic model for short text[C] Proc of the 22nd Int Conf on World Wide Web. New York: ACM, 2013: 1445-1456
[8]Maas A L, Daly R E, Pham P T, et al. Learning word vectors for sentiment analysis[C] Proc of Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2011: 142-150
[9]Hinton G E. Learning distributed representations of concepts[C] Proc of the 8th Annual Conf of the Cognitive Science Society. Mahwah, NJ: Erlbaum, 1986: 1-12
[10]Bengio Y, Schwenk H, Senécal J S, et al. Neural probabilistic language models[J]. Journal of Machine Learning Research, 2003, 3(6): 1137-1155
[11]Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their composi-tionality[C] Proc of the 2013 Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, 2013: 3111-3119
[12]Le Q V, Mikolov T. Distributed representations of sentences and documents[C] Proc of the 31st Int Conf on Machine Learning. New York: ACM, 2014: 873-882
[13]He Yanxiang, Sun Songtao, Niu Feifei, et al. A deep learning model enhanced with emotion semantics for microblog sentiment analysis[J]. Chinese Journal of Computers, 2017, 40(4): 773-790 (in Chinese)
(何炎祥, 孙松涛, 牛菲菲, 等. 用于微博情感分析的一种情感语义增强的深度学习模型[J]. 计算机学报, 2017, 40(4): 773-790)
[14]Peng Zeying, Yu Xiaoming, Xu Hongbo, et al. Incomplete clustering for large scale short texts[J]. Journal of Chinese Information Processing, 2011, 25(1): 54-59 (in Chinese)
(彭泽映, 俞晓明, 许洪波, 等. 大规模短文本的不完全聚类[J]. 中文信息学报, 2011, 25(1): 54-59)
[15]Wang Zhongyuan, Cheng Jianpeng, Wang Haixun, et al. Short text understanding: A survey[J]. Journal of Computer Research and Development, 2016, 53(2): 262-269 (in Chinese)
(王仲远, 程健鹏, 王海勋, 等. 短文本理解研究[J]. 计算机研究与发展, 2016, 53(2): 262-269)
[16]Davies D L, Bouldin D W. A cluster separation measure[J]. IEEE Trans on Pattern Analysis & Machine Intelligence, 1979, 1(2): 224-227
[17]Hartigan J A, Wong M A. Algorithm AS 136: A K -Means clustering algorithm[J]. Journal of the Royal Statistical Society, 1979, 28(1): 100-108
[18]Arthur D, Vassilvitskii S. K -Means++: The advantages of careful seeding[C] Proc of the 18th Annual ACM-SIAM Symp on Discrete algorithms. Philadelphia, PA: SIAM, 2007: 1027-1035

Liang Jiye , born in 1962. Professor and PhD supervisor. Distinguished member of CCF. His main research interests include granular computing, data mining and machine learning.

Qiao Jie , born in 1994. Master candidate. Student member of CCF. Her main research interests include data mining and machine learning.

Cao Fuyuan , born in 1974. Professor and PhD supervisor. Member of CCF. His main research interests include data mining and machine learning.

Liu Xiaolin , born in 1990. PhD candidate. Student member of CCF. Her main research interests include data mining and machine learning.
Liang Jiye, Qiao Jie, Cao Fuyuan, and Liu Xiaolin
( School of Computer and Information Technology , Shanxi University , Taiyuan 030006) ( Key Laboratory of Computational Intelligence and Chinese Information Processing ( Shanxi University ), Ministry of Education , Taiyuan 030006)
Abstract The distributed representation of short texts has become an important task in text mining. However, the direct application of the traditional Paragraph Vector may not be suitable, and the fundamental reason is that it does not make use of the information of corpus in training process, so it can not effectively improve the situation of insufficient contextual information in short texts. In view of this, in this paper we propose a novel distributed representation model for short texts called BTPV (biterm topic paragraph vector). BTPV adds the topic information of BTM (biterm topic model) to the Paragraph Vector model. This method not only uses the global information of corpus, but also perfects the implicit vector of Paragraph Vector with the explicit topic information of BTM. At last, we crawl popular news comments from the Internet as experimental data sets, using K -Means clustering algorithm to compare the models’ representation performance. Experimental results have shown that the BTPV model can get better clustering results compared with the common distributed representation models such as word2vec and Paragraph Vector, which indicates the advantage of the proposed model for short text analysis.
Key words distributed representation; short text; document analysis; paragraph vector; biterm topic model (BTM)
中图法分类号 TP391
This work was supported by the National Natural Science Foundation of China (U1435212, 61432011, 61573229) and the Key Scientific and Technological Project of Shanxi Province (MQ2014-09).
基金项目 : 国家自然科学基金项目(U1435212,61432011,61573229);山西省重点科技攻关项目(MQ2014-09)
收稿日期 : 2018-04-02;
修回日期: 2018-06-12
DOI: 10.7544/issn1000-1239.2018.20180233