 *更新矩阵 G 和 m *
*更新矩阵 G 和 m * 綦小龙 1,2 高 阳 1 王 皓 1 宋 蓓 1 周春蕾 3 张友卫 3
1 (南京大学计算机科学与技术系 南京 210046) 2 (伊犁师范学院电子与信息工程学院 新疆伊宁 835000) 3 (江苏方天电力技术有限公司 南京 211102) (qxl_0712@sina.com)
摘 要 针对基于约束的方法存在的序依赖、高阶检验等问题,提出了一种通过互信息排序的贝叶斯网络结构学习方法,该方法包括度量信息矩阵学习和“偷懒”启发式策略2部分.其中度量信息矩阵刻画了变量间的依赖程度而且暗含了程度强弱的比较,有效地解决了检验过程中由于变量序导致的误判问题;“偷懒”启发式策略在度量信息矩阵的指导下有选择地将变量加入到条件集中,有效地降低了高阶检验而且减少了检验次数.从理论上证明了新方法的可靠性,从实验上展示了在不丢失学习结构质量的条件下,新方法的搜索比其他搜索过程显著快而且易扩展到样本量小且稀疏的数据集上.
关键词 贝叶斯网络结构;互信息;条件独立性检验;变量序;假阳性节点;假阴性节点
贝叶斯网络是个有向无圈图,图中节点表示随机变量,节点间的弧表示变量之间的直接依赖关系.每个节点都拥有一个概率分布,根节点所附的是它的边缘分布,而非根节点所附的是条件概率分布 [1] .
近几十年来,从数据中自动学习贝叶斯网络结构受到研究者的普遍关注 [2-7] .一般来说,目前有2类结构学习方式 [2,8] :1)基于约束的结构学习.该方法根据整体Markov性,使用统计假设检验对数据中的条件依赖和条件独立性关系进行检验,找到对依赖和独立关系最好解释的某个结构 [9-10] .2)基于优化的结构学习.该方式定义了测量模型对观测数据拟合程度的评分函数,如贝叶斯评分和最小描述长度(minimum description length, MDL)评分 [2] .结构学习的任务是找到一个最大化该评分函数的结构.这2种方法有各自的优缺点:基于约束的方式是有效的,但是它对个体独立性检验中的失败敏感 [8-9] ;基于优化的方法每次都考虑整个网络,因此对于个体错误并不敏感,但是搜索的结构空间包含超指数个结构.一般来说,该问题是NP-hard问题 [8,11] .
针对上述2种方法的主要挑战,学者们做了大量的研究.对于基于搜索-评分的学习方法,根据寻找到的解是全局最优还是局部最优提出了精确学习方式和近似学习方式:精确方式 [3,6,12-13] 的解是全局最优,但是由于其指数级的时空复杂性,这些方法只适合于数据集规模小的领域;而近似方式 [14-19] 的解虽是局部最优,但是易于扩展到大规模数据上.
基于约束的贝叶斯网络结构学习一直以来不论是方法的研究 [5,20-24] 还是应用 [25-28] 都受到了学者们的广泛关注.然而,高阶独立性检验、指数级的检验次数、变量序的影响依然制约着现有算法的性能.为此,本文针对基于约束算法存在的部分问题,提出了一种基于度量信息矩阵的“偷懒”启发式策略方法.新方法不仅与现有算法在时间和精度性能上是可比的,而且易于处理大规模的稀疏网络.
经典的基于约束的方法通常包含2个步骤:1)结构的骨骼识别;2)边定向.其中对于边定向一般有2类策略:一类是评分-搜索策略 [22] ,这种策略也被称之为混合策略;另一类是识别DAG的Markov等价类策略 [5,20-24] ,这类策略首先定向 υ -结构,再进一步对其他边定向.
在这里,我们关注结构骨骼的识别,即通过一系列条件独立性检验确定潜在DAG结构是否存在边.常用的条件独立性检验方法有统计假设检验或互信息、条件互信息等 [10] .
根据采用的不同条件独立性检验策略,我们将基于约束的学习方式大致分为基于启发式策略学习 [21-22] 和基于PC(Peter-Clark)算法策略学习 [5,20-24] 两类.下面,我们分别对这2类方法中具有代表性的方法进行概述.
基于启发式的策略通过设置某种启发式函数来实现减少检验次数的目的或减少假阴性节点的目的,主要包括以下2种.
1) 文献[21]给出了一种三阶段依赖分析算法TPDA.该算法在Monotone DAG-faithful假定下,通过逐渐缩小条件集规模的启发式策略来减少独立性检验次数.虽然该算法的条件独立性测试次数是 O ( n 4 ),但是Monotone DAG-faithful假定和DAG-faithful假定是不相容的 [2] .
2) 文献[22]中的MMHC(max-min hill-climbing)虽然采用了一种可纳的启发式策略,但是也产生了大量的假阳性节点.为了减少假阳性节点,该方法对目标变量的CPC(candidate parents and children)中所有元素执行条件独立性检验,该检验次数是CPC规模的指数级.
除了基于启发式策略的学习方法外,也有很多学者通过改进经典的PC算法来进行结构学习.他们设计边排序方法 [23] 或序独立方法 [24] 来解决PC算法中变量序对潜在结构的影响.然而,这类方法虽然在一定程度上缓解了假阴节点问题,却无法很好地解决假阳性节点问题或检验次数指数级问题.
首先,介绍众所周知的PC算法 [20] .该算法也被广泛应用于解决实际问题,尤其在生物信息学 [25-27] 、关系型数据的因果模型挖掘 [28] 等领域.PC算法从一个由节点构成的完全无向图开始,随着条件集规模的增长,检验每一个变量对.主要特点是条件集随着完全无向图呈动态变化,这样避免了高阶独立性检测.但是为了防止假阳性节点的产生,在相同条件集规模下,除非变量的邻居集合的某个子集使得变量对独立,否则,还要考虑另一变量的邻居集合的子集情况.这样一来,条件独立性检验次数显著增加.另外,检验过程对变量顺序非常敏感,严重影响了PC算法的性能 [25] .
文献[23]提出了使用BDe(Bayesian Dirichlet extension)评分函数测量每条边的强度并根据强度执行条件独立性检验的方法.因为存在没有进行独立性检测变量对(边),算法不能保证添加到最终图的变量对就是正确的决策.
文献[24]设计了一种序独立的PC-Stable算法,即条件独立性检验不会受到变量序的影响.该算法和PC算法的本质区别在于对相同条件集规模下的变量对执行条件独立性检验后,暂不更新无向图;而是当条件集规模增加后,再相应地更新无向图.相比之下,虽然减少了假阳性节点,却需要执行更多的条件独立性测试而且易于遭遇高阶独立性检验,效率比PC算法低.
为了提高其执行效率,文献[5]基于PC-Stable算法提出了一种多核并行化的处理方式.根据无向图的变化规律,将变量的邻接边分配到不同的处理器上,由于遵循了PC-Stable算法更新无向图的策略,所以在并行化计算条件独立性时,没有额外的通信开销.虽然极大地提升了PC-Stable算法效率,但是假阴性点依然没有得到好的解决.
上述方法的共同点是盲目地对到来的变量对立刻执行条件独立性检测,并没有考虑合适的时机;此外,由于条件集的选择也是盲目的,只要是变量邻居就有可能成为条件集元素,也会导致学习错误.
因此,本文提出了可度量的贝叶斯网络结构学习方法,创新点如下:1)提出了一种无需任何先验知识仅从样本中为每个变量自动地学习相应的变量序的方法,该方法称之为度量信息矩阵学习;2)根据度量信息矩阵提出了一种用于条件独立性检验的可靠启发式策略.该策略在度量信息矩阵的指导下,不仅能够合理地选择执行条件独立性检验的变量对,而且能合理地为其选择条件集.
数据中表现出来的变量间的依赖性包括直接依赖和间接依赖,我们期望在贝叶斯网络中评分最高的变量对就是直接依赖的变量对.测量变量对依赖强度的方法有互信息、偏相关性 [29] .
虽然全局最佳网络的学习是NP-hard问题,但是我们可以寻找一个近似最佳的网络.为此,选择高依赖关系的变量对( X , Y )并用这些边作为创建网络的启发式是合理的.因此,我们提出了一种可度量的贝叶斯网络结构学习方法,简称为BNS vo -learning.该方法与以往方法的本质区别在于不是盲目地执行条件独立性检测,而是根据度量信息利用“偷懒”启发式策略有序进行.该方法主要包含度量信息矩阵学习和“偷懒”启发式策略2部分.
度量信息矩阵学习过程从给定的数据中使用互信息度量了所有变量之间依赖程度.根据该依赖程度,它为每个变量分配了一个变量序.我们把这些变量序组成的矩阵称之为度量信息矩阵 m n × n .
度量信息矩阵刻画了变量间依赖程度的强弱,我们认为这是一种粗粒度上的刻画.原因是它并没有进一步刻画这种依赖程度是直接依赖还是间接依赖.此外,在实验观察中,我们发现互信息强的变量对在真实的网络结构中并不存在边,反而互信息相对弱的变量对在真实的网络中存在边.为了高效地获得潜在结构中真实的边,我们设计了一种“偷懒”启发式策略.根据度量信息矩阵,对变量序中任意一对变量执行条件独立性检验时,任意阶条件独立性断言都不依赖于序中前面的变量,除非该变量与行变量不独立.
算法具体描述如下:首先初始化了2个由节点构成的无向图矩阵 m n × n 和 G n × n .其中, m n × n 是由变量序构成的度量信息矩阵.该矩阵中的每一行暗含了与行变量对应的变量的检验顺序.其中 m ( i , j )= k 指示了矩阵的第 i 行、第 j 列元素变量 k 与变量 i 的依赖强度排在第 j 个位置.矩阵 m n × n 是动态变化,条件集的规模以及独立性计算由它决定.矩阵 G n × n 刻画了最终每个变量的邻居集合,它随着度量信息矩阵变化.初始化时, i = j , G ( i , j )=0,否则 G ( i , j )=1.在这里,0表示变量对之间没有边,1表示有边.
算法根据度量信息首先选择依赖程度最弱的变量对( i , m ( i , j ))执行条件独立性检测 Ind ( i , m ( i , j )| S ), S ⊆ V\ { i , m ( i , j )},如果 Ind ( i , m ( i , j )| S )=1,则设置 G ( i , m ( i , j ))=0同时设置 m ( i , j )=0;如果矩阵 m 中有0元素出现,那么后续变量的条件独立性检验的条件集就不再考虑该元素.即当处理变量对( i , m ( i , j + k ))时,如果∃ j ∈[1, j + k -1]满足 m ( i , j )=0,则 S ⊆ V\ { i , m ( i , j ), m ( i , j + k )},否则 S ⊆ V\ { i , m ( i , j + k )}.
算法1 . 基于变量序的贝网结构学习算法BNS vo -learning.
输入:数据集 data ;
输出:BNS结构 G .
① 初始化矩阵 G n × n ;
② 根据互信息学习信息度量矩阵 m n × n ;
③ for对矩阵 m 中的元素执行独立性检验
④ 初始化条件集规模: order ←0;
⑤ 获取当前的条件集 S ;
⑥ while | S |< order
⑦ 执行条件独立性检验;
⑧ if条件独立性检验
⑨ G ( i , m ( i , j ))←0; *更新矩阵 G 和 m *
⑩ m ( i , j )←0;
 Sepset ( i , m ( i , j ))← S ;
Sepset ( i , m ( i , j ))← S ;
 break;
break;
 else
else
 order ← order +1;
order ← order +1;
 end if
end if
 end while
end while
 end for
end for
 return G ;
return G ;
 根据图 G ,定向V-structure;
根据图 G ,定向V-structure;
 根据图 G ,定向其他边.
根据图 G ,定向其他边.
BNS vo -learning算法根据度量信息矩阵执行条件独立性检验时,实际上采用了一种“偷懒”启发式的检验策略.下面分析该算法的一些重要性质.
在给出这些性质之前,先介绍需用到的信息论知识: H ( X )指示了一个离散随机变量 X 的熵; H ( X | Y )指示了2个随机变量 X 和 Y 之间的条件熵; I ( X ; Y )指示了2个随机变量 X 和 Y 之间的互信息.
定理1 . 对任意2个随机变量 X 和 Y ,有:
1) I ( X ; Y )≥0;
2) H ( X | Y )≤ H ( X ).
上面两式当且仅当 X 和 Y 相互独立时等号成立 [1] .
定理2 . 对任意3个离散随机变量 X , Y 和 Z 有:
1) I ( X ; Y | Z )≥0;
2) H ( X | Y , Z )≤ H ( X | Z ).
上面两式当且仅当 X 和 Y 相互独立时等号成立 [1] .
定理3 . BNS vo -learning算法中,当 I ( X ; Y )> I ( X ; Z ),给定 Z 时, X 和 Y 不满足条件独立性.
证明. 充分条件,反证法.假定 I ( X ; Y | Z )=0成立.
由定理2可得:
H ( X | Y , Z )= H ( X | Z ),
由 I ( X ; Y )= H ( X )- H ( X | Y )可得:
H ( X | Z )= H ( X )- I ( X ; Z ).
由 H ( X | Z , Y )= H ( X )- I ( X ; Z , Y )可得:
H ( X )- I ( X ; Z )= H ( X )- I ( X ; Z , Y ).
由 I ( X ; Z )= I ( X ; Z , Y )可得:
I ( X ; Z )> I ( X ; Y ).
与已知 I ( X ; Y )> I ( X ; Z )相矛盾,充分条件得证.
必要条件:
由 I ( X ; Y | Z )= H ( X | Z )- H ( X | Z , Y ),
且 H ( X | Z )= H ( X )- I ( X , Z )可得:
I ( X ; Y | Z )= H ( X )- I ( X ; Z )- H ( X | Z , Y ),
由 H ( X | Z , Y )≤ H ( X | Y )
且 H ( X )- I ( X ; Z )- H ( X | Z , Y )≥
H ( X )- I ( X ; Z )- H ( X )+ I ( X ; Y )可得:
H ( X )- I ( X ; Z )- H ( X | Z , Y )≥
I ( X ; Y )- I ( X ; Z ).
由 I ( X ; Y )> I ( X ; Z )可得:
H ( X )- I ( X ; Z )- H ( X | Z , Y )>0,
可得: I ( X : Y | Z )>0.
证毕.
定理3证明了在一阶条件独立性检验过程中,互信息强的变量对是否独立一定不依赖于互信息弱的变量.为此,BNS vo -learning算法对任意一变量对执行一阶条件独立性检验时,没有考虑变量序中前面的变量作为其条件集.
为了进一步说明BNS vo -learning算法的有效性,我们给出定理4和推论1.
定理4 . BNS vo -learning算法中,当 I ( X ; Y )> I ( X ; Z ), I ( X ; Y )> I ( X ; W )且 I ( X ; Z | Φ )=0或 I ( X ; W | Φ )=0时,给定 Z , X 和 Y 不满足条件独立性.
证明.
由 I ( X ; Y )> I ( X ; Z ),
I ( X ; Y )> I ( X ; W ),
I ( X ; Z | Φ )=0可得:
I ( X ; Z , W )< I ( X ; Y ).
由定理3可知,定理4成立.
证毕.
定理4说明了边缘独立的变量对和互信息弱的变量组合得到高阶的条件集不能影响互信息强的变量对的条件独立性断言.为此,在检验过程中算法不考虑这样的条件集.
推论1 . 当 I ( X ; Y )< I ( X ; Z , W )时,如果 I ( X ; Z , W )= I ( X ; W ),那么 X 和 Y 独立只与 W 有关.
直观上来说,该启发式策略遵循:如果互信息强的变量组合的条件集不能使得变量对独立,那么含有强度弱的变量的条件集也不能使得变量对独立.形式化说明如下:
假定 I ( X ; W )< I ( X ; Y )< I ( X ; Z )< I ( X ; H )是变量 X 所对应的变量序.若 I ( X ; Y | Z , H )>0,那么 I ( X ; Y | Z , W )>0或者 I ( X ; Y | W , H )>0.尤其当条件集的规模较大时,弱的变量提供的信息会更少.
在做条件独立性断言的决策时,我们期望2种情况出现:① I ( X ; Y | Φ )=0,这意味着无论2个随机变量 X 和 Y 在矩阵 m n × n 中的顺序如何,二者满足边缘独立.②对于变量 X 而言, S ⊆ V\ { X , Y },∃ I ( X ; Y )< I ( X ; S ),使得 I ( X ; Y | S )=0;对于随机变量 Y 而言,∃ I ( X ; Y )< I ( Y ; S ),使得 I ( X ; Y | S )=0,意味着算法对于二者的独立性判断是一致的,那么 I ( X ; Y | S )=0一定成立;反之,对于随机变量 Y 而言,∃ I ( X ; Y )< I ( Y ; S ),使得 I ( X ; Y | S )=0,则独立性断言不一致,算法利用了不一致性来减少假阴性边出现的概率.
定义1 . 不一致性断言.随机变量 X 和 Y 分别执行完条件独立性检验后,存在 X ∈ adj ( Y ), Y ∉ adj ( X ),我们称随机变量 X 和 Y 之间的条件独立性断言为不一致性断言.
我们不期望不一致性断言的出现.因为我们很难对该类断言做出合理的决策.如果选择独立性成立,那么可能造成假阴性边,否则造成假阳性边.事实上,选择不成立是可靠的.最糟糕的情况就是执行条件独立性检测后,变量 X 的邻居集合没有任何变化,简单地说,花了大量的时间做了无用功,但是这至少保证了没有假阴性边,保证了存在找到最佳的贝叶斯网络结构的可能性.
定理5 . BNS vo -learning算法是可纳的.
算法采用的启发式策略避免了由高阶独立性检验造成的假阴性节点.另外,对任意变量对( X , Y )执行条件独立性检验时,如果独立,则对 X 的邻居集合修订 adj ( X )= adj ( X ) \Y ;变量 Y 的邻居集合 adj ( Y )保持不变.换句话说,对于变量 Y 而言,它和 X 是否条件独立只与 Y 和其对应的变量序有关.这样防止由变量 X 的误判对变量 Y 的影响.
为了进一步减少时间代价,算法在保证质量的前提下,对BNS vo -learning算法做了进一步的改进,当 m ( i , j )=0,对于变量 m ( i , j )而言,在变量 i 的索引 i index 满足 i index < n 2,设置 G ( m ( i , j ), i )=0,同时也置 m ( m ( i , j ), i index )=0.
这样做的想法很直观,对于变量 X 而言,如果变量对( X , Y )条件独立性成立,那么对于变量 Y 而言,如果变量 X 之后仍有许多互信息强的变量,那么( X , Y )条件独立性成立的概率很大.
算法2 . 改进后的学习算法IBNS vo -learning.
输入:数据集 data ;
输出:更新后的 m .
① for矩阵 m 中第 m ( i , j )行的每一个元素
② if变量 i 在第 m ( i , j )行中的索引为 i index
③ if索引小于变量数的1 2
④ m ( m ( i , j ), i index )←0;
⑤ G ( m ( i , j ), i )←0;
⑥ end if
⑦ end if
⑧ end for
⑨ return m .
改进后算法的实现,只需将IBNS vo -learning算法的行①~⑨嵌入在BNS vo -learning算法的行⑩~ 之间即可.
为了说明BNS vo -learning算法的性能,我们从贝叶斯网络知识库(the Bayesian network repository, BNR) [30] 中选择了5个不同规模的网络.同时也使用了拼贴技术 [31] 生成了一个适中规模网络Insurance 1和大网络Insurance 2.表1展示了7个网络中的节点数、弧数、最大父节点数和最大状态数.
Table 1 Bayesian Networks Used in the Evaluation Study
表1 在评估研究中使用的贝叶斯网络
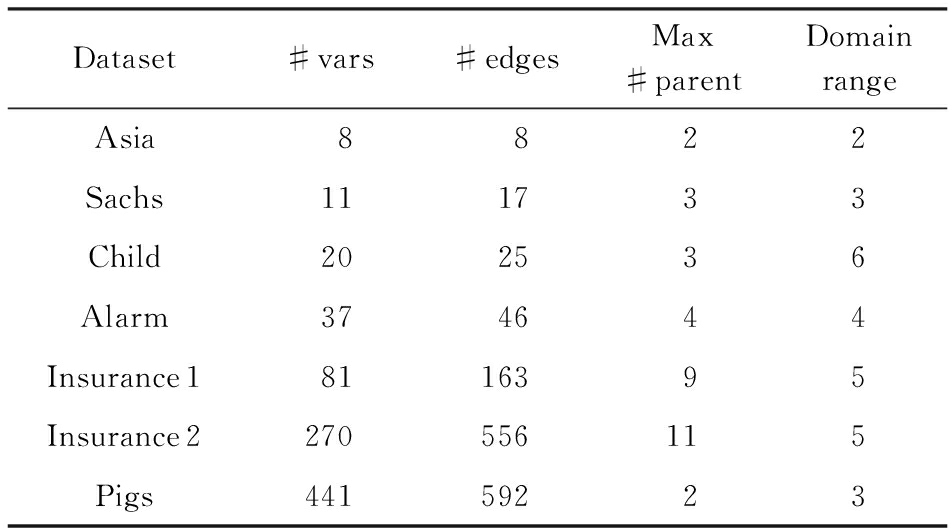
为了说明算法的可靠性,我们从以下4个方面来验证算法:1)变量的状态数少,属性数少,样本量10 000时(Asia-8,Sachs-11); 2)变量的状态数多,属性数适中,样本量10 000时(Alarm-37,Child-20);3)变量状态数多,属性数多,样本量5 000时(Insurance1,Insurance2);4)变量的状态数少,属性数多,样本量5 000时(Pigs-441).
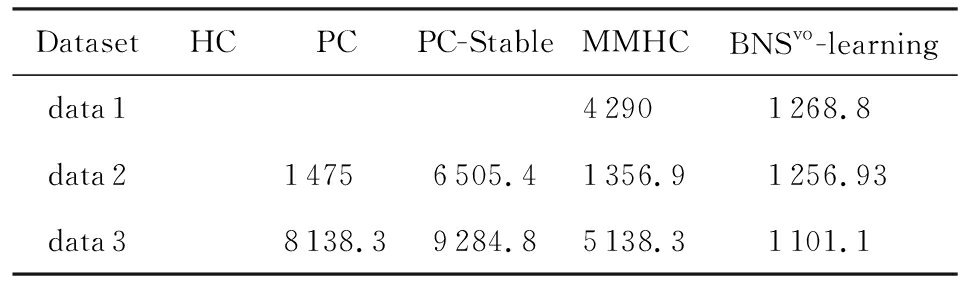
我们采用了边评分的评价方法来验证算法的精度性能即计算缺失边数(Missing)、多余边数(Additional)以及反向边数(Reverse).Edge Type越低表明算法的性能越好.表2给出了学习结构的边评分结果,其中,HC(Hill-Climbing)是指经典的基于评分方式的近似结构学习算法 [1] .
Table 2 Results Comparison of Our Method with Classic Algorithms
表2 和经典算法的对比实验结果
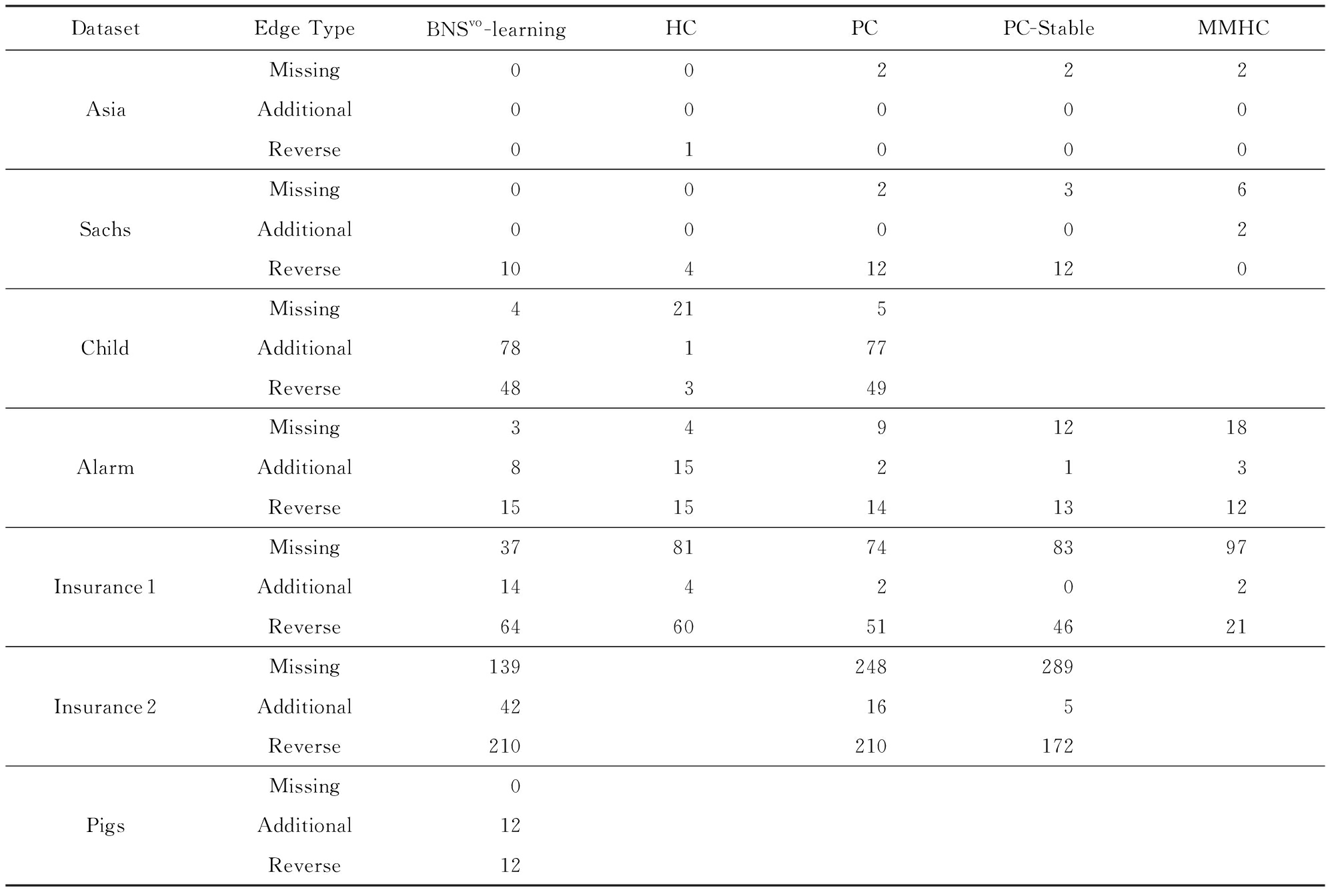
表2中的空白项表示由于内存不足或时间代价过高没有得到最终解.对于HC算法,在实验中发现,当数据维数超过200时,就警示“内存不足”.其原因是:当前结构的候选邻居接近 n 2 ,每一个候选邻居都是一个 n × n 的矩阵,故需要 n 4 的存储空间.对于PC和PC-Stable以及MMHC算法,时间代价过高.究其原因:随着数据维数的增加以及变量对的非独立性关系的成立,导致条件集规模迅速增大,从而使得独立性检测次数的指数级增长速度很快.
然而,本文提出的BNS vo -learning算法不仅不会遭遇到上述其他算法内存不足或时间代价高的情况,而且通过和真实结构的对比,除了Child数据外,解的质量优于对比算法.这不仅表现在简单的数据集Asia和Sachs上,而且对于高维稀疏的数据集Pigs依然出色.
为了说明BNS vo -learning算法在有限样本条件下的可靠性,我们分别在属性数是370,样本量是500,1 000,5 000的Alarm数据集 [31] 上进行了验证.由表3可以看出,在处理样本量小、属性数多的数据集时,BNS vo -learning算法依然表现良好.
Table 3 Results Comparison of Our Method with Constraint - Based Algorithms
表3 与经典基于约束的算法的对比实验结果
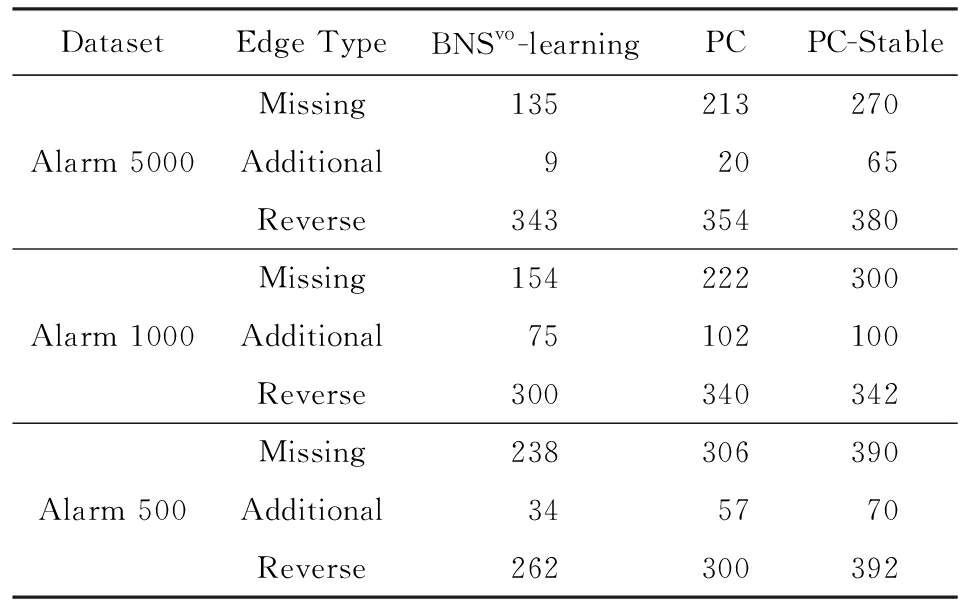
本文提出的BNS vo -learning算法不仅在网络的结构质量上有保障,而且在时间的需求上也合理.下面我们分别从实验和理论进行验证和说明.表4给出了和经典算法在时间需求上的对比实验.
Table 4 Performance Comparison of Algorithms in Time Cost
表4 算法在时间代价上的性能比较 s
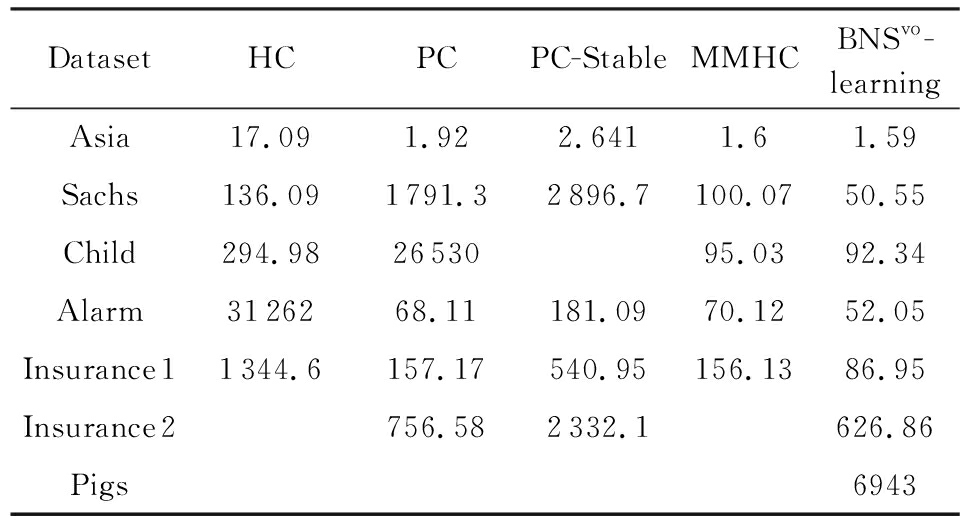
从表4中可以看出,所提算法BNS vo -learning在时间性能上显著优于经典的算法,尤其在处理高维稀疏数据集Pigs时,该算法能在6 943 s中求解,而对比算法在以天为单位的时间内得不到解.其原因在之前的精度性能实验中已作了分析,这里不再赘述.
算法的时间复杂度主要由图 G 的最大度界定, k 是任何节点的最大度, n 是节点数.在最坏的情况下,BNS vo -learning算法执行的条件独立性检验次数是 ![]() 这是一个放松的界.它假定了对于 n 和 k 而言,在最坏的情况下,不存在规模小于 k 的条件集使得变量对条件独立性成立.
这是一个放松的界.它假定了对于 n 和 k 而言,在最坏的情况下,不存在规模小于 k 的条件集使得变量对条件独立性成立.
事实上,大多互信息弱的变量对在 i < k 时,条件独立性成立.所以条件独立性检测平均次数是非常小的.通常情况下算法的时间复杂度为 ![]() 这里 M 指示了条件独立性成立的变量个数.
这里 M 指示了条件独立性成立的变量个数.
我们分别选取了不同规模的数据集,从时间代价层面展示了2种算法的性能,如表5所示.从表5中可以看出,随着数据集属性数的增多,改进后的算法明显优于BNS vo -learning算法.
IBNS vo -learning算法时间代价小的主要原因有2点:1)当设置 m ( m ( i , j ), i index )=0,算法没有再对变量对( m ( i , j ), i )执行条件独立性检测.具体而言,假设对于变量 m ( i , j )而言,还有 w 个待检变量,那么最坏的情况可能要执行2 w 次条件独立性检测.2)变量 m ( i , j )对应的其他变量的条件独立性检测次数减少.如果没有置0,最坏的情况下,条件独立性检测次数是2 w +1 ;置0,最坏的情况下是2 w .
Table 5 Performance Comparison of Algorithms in Time Cost
表5 算法在时间代价上的性能比较 s
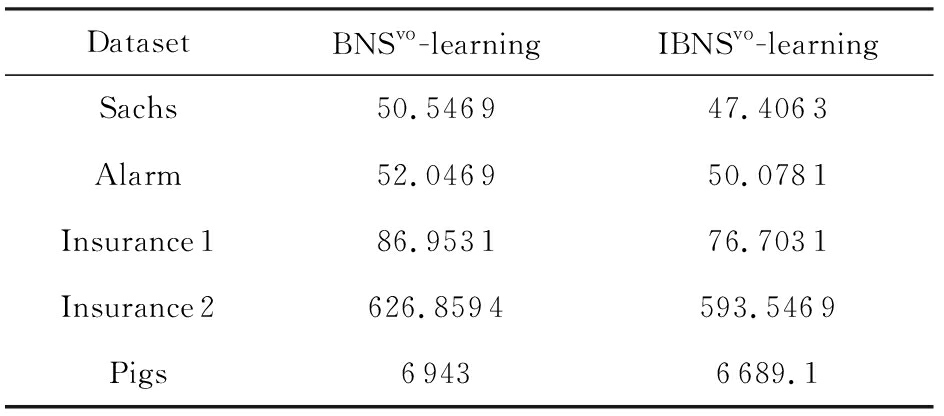
为了评估所提出算法在实际应用中的效果,我们用真实的数据集进行了实验.该数据集来源于供热机组3个月全工况监测数据.其中数据维数为50,每个月的样本量分别为43 200,44 640,44 641条,变量的最大状态数是10.由于没有真实的网络结构,我们仅在时间代价性能上做了对比实验.表6给出了在真实的电力数据集上关于需求时间的对比实验.
Table 6 Performance Comparison of Algorithms in Time Cost
表6 算法在时间代价上的性能比较 s
从表6可以看出,当数据维数适中、样本量较大时,所提算法依然能够在合理的时间内求解,这表明BNS vo -learning算法能够很好地扩展到大样本量的数据集上.此外,经典的爬山算法表现得相对很差,主要原因是样本量过大使得评分函数需要的计算时间加长.
本文的贡献如下:1)首次尝试提出使用变量间互信息来刻画变量序的度量信息矩阵,以实现条件独立性检验不是盲目地选择变量对,而是依赖于度量信息矩阵提供的信息有选择地进行;2)基于度量信息矩阵提议了一种合理的“偷懒”启发式策略,有效地避免高阶独立性,减少检验次数,保证了检验可靠性.我们从理论上证明算法的有效性,从实验上验证了算法的高效性和可靠性.但是由于在定向阶段我们采用了与PC算法类似的方式,这种方式对个体定向错误敏感,尤其是 υ -结构的定向,后期将探讨采用评分-搜索的策略解决定向问题;另外,对于数据集Child,本文所提算法虽然在时间性能和Missing上优于对比算法,但会导致过多的Additional和Reverse.跟踪实验发现,Additional主要是由于当样本数小于自由度时(相关概念读者可查阅文献[20])经典的算法和所提算法都采用了选择依赖的方法,后期我们将针对该问题进行研究.
参考文献
[1]Zhang Lianwen, Guo Haipeng. Introduction to Bayesian Networks[M]. Beijing: Science Press, 2006: 24-35 (in Chinese)
(张连文, 郭海鹏. 贝叶斯网引论[M]. 北京: 科学出版社, 2006: 24-35)
[2]Daly R, Shen Qiang, Aitken S. Learning Bayesian networks: Approaches and issues[J]. Knowledge Engineering Review, 2011, 26(2): 99-157
[3]Berg J, Järvisalo M, Malone B. Learning optimal bounded treewidth Bayesian networks via maximum satisfiability[C]  Proc of the 17th Artificial Intelligence and Statistics. Cambridge, MA: MIT Press, 2014: 86-95
Proc of the 17th Artificial Intelligence and Statistics. Cambridge, MA: MIT Press, 2014: 86-95
[4]Scanagatta M, de Campos C P, Corani G, et al. Learning Bayesian networks with thousands of variables[C] Proc of Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, 2015: 1864-1872
[5]Duy L T, Tao Hoang, Li Jiuyong, et al. A fast PC algorithm for high dimensional causal discovery with multi-core PCs[J]. IEEE ACM Trans on Computational Biology & Bioinformatics, 2015, 13(9): 1-13
[6]Bartlett M, Cussens J. Integer linear programming for the Bayesian network structure learning problem[J]. Artificial Intelligence, 2015, 244(1): 258-271
[7]Scanagatta M, Corani G, de Campos C P, et al. Learning treewidth-bounded Bayesian networks with thousands of variables[C] Proc of Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, 2016: 1462-1470
[8]Friedman N, Nachman I, Peér D. Learning Bayesian network structure from massive datasets: The sparse candidate algorithm[C] Proc of the 15th Conf on Uncertainty in Artificial Intelligence. San Francisco, CA: Morgan Kaufmann, 1999: 206-215
[9]Koller D, Friedman N. Probabilistic Graphical Models: Principles and Techniques[M]. Cambridge, MA: MIT Press, 2009
[10]Guo Min, Shi Hongbo, Ji Suqin. Survey of sparse structure learning of Bayesian networks[J]. Pattern Recognition and Artificial Intelligence, 2016, 29(10): 907-923 (in Chinese)
(郭珉, 石洪波, 冀素琴. 贝叶斯网络结构稀疏学习研究进展[J]. 模式识别与人工智能, 2016, 29(10): 907-923)
[11]Chickering D M. Learning Bayesian Networks is NP-Complete[M]. Berlin: Springer, 1996: 121-130
[12]Silander T, Myllyma P. A simple approach for finding the globally optimal Bayesian network structure[C] Proc of the 22nd Annual Conf on Uncertainty in Artificial Intelligence. Canberra, Australia: AUAI Press, 2006: 445-452
[13]Yuan Changhe, Malone B. Learning optimal Bayesian networks: A shortest path perspective[J]. Journal of Artificial Intelligence Research, 2013, 48(1): 23-65
[14]Chickering D M. Optimal structure identification with greedy search[J]. Journal of Machine Learning Research, 2002, 3(11): 507-554
[15]Kabli R, Herrmann F, McCall J. A chain-model genetic algorithm for Bayesian network structure learning[C] Proc of the 9th Annual Conf on Genetic and Evolutionary Computation. New York: ACM, 2007: 1264-1271
[16]Wu Yanghui, Mccall J, Corne D. Two novel ant colony optimization approaches for Bayesian network structure learning[C] Proc of the 2010 World Congress on Computational Intelligence. Piscataway, NJ: IEEE, 2010: 4473-4479
[17]Teyssier M, Koller D. Ordering-based search: A simple and effective algorithm for learning Bayesian networks[C] Proc of the 21st Annual Conf on Uncertainty in Artificial Intelligence. Canberra, Australia: AUAI Press, 2005: 548-549
[18]Chickering D M, Meek C. Selective greedy equivalence search: Finding optimal Bayesian networks using a polynomial number of score evaluations[C] Proc of the 31st Annual Conf on Uncertainty in Artificial Intelligence. Canberra, Australia: AUAI Press, 2015: 211-219
[19]Urcia W P, Mauá D. Better initialization heuristics for order-based Bayesian network structure learning[J]. Journal of Information and Data Management, 2017, 7(2): 181-195
[20]Spirtes P, Glymour C N, Scheines R. Causation, Prediction, and Search[M]. Cambridge, MA: MIT Press, 2000: 84-95
[21]Cheng Jie, Greiner R, Kelly J, et al. Learning belief networks from data: An information theory based approach[J]. Artificial Intelligence, 1997, 137(1 2): 43-90
[22]Tsamardinos I, Brown L E, Aliferis C F. The max-min hill-climbing Bayesian network structure learning algorithm[J]. Machine Learning, 2006, 65(1): 31-78
[23]Cano A, Gómez-Olmedo M, Moral S. A score based ranking of the edges for the PC algorithm[C] Proc of the 4th European Workshop on Probabilistic Graphical Models. San Francisco, CA: Morgan Kaufmann, 2008: 41-48
[24]Colombo D, Maathuis M H. Order-independent constraint-based causal structure learning[J]. Journal of Machine Learning Research, 2014, 15(1): 3741-3782
[25]Zhang Xiujun, Zhao Xingming, He Kun, et al. Inferring gene regulatory networks from gene expression data by path consistency algorithm based on conditional mutual information[J]. Bioinformatics, 2012, 28(1): 98-104
[26]Zhang Junpeng, Le Thucduy, Liu Lin, et al. Inferring condition-specific miRNA activity from matched miRNA and mRNA expression data[J]. Bioinformatics, 2014, 30(21): 3070-3077
[27]Zhang Junpeng, Le Thucduy, Liu Lin, et al. Identifying direct miRNA-mRNA causal regulatory relationships in heterogeneous data[J]. Journal of Biomedical Informatics, 2014, 52(C): 438-447
[28]Lee S, Honavar V. On learning causal models from relational data[C] Proc of the 30th AAAI Conf on Artificial Intelligence. Menlo Park, CA: AAAI, 2016: 3263-3270
[29]Chow Chao, Liu Chao. Approximating discrete probability distributions with dependence trees[J]. IEEE Trans on Information Theory, 1968, 14(3): 462-467
[30]Marco S. bnlearn-an R package for Bayesian network learning and inference[OL]. Berlin: Springer, 2013 [2017-09-06]. http: www.bnlearn.com bnrepository
[31]Tsamardinos I, Statnikov A R, Brown L E, et al. Generating realistic large Bayesian networks by Tiling[C] Proc of the 19th Int Florida Artificial Intelligence Research Society Conf. Menlo Park, CA: AAAI, 2006: 592-597

Qi Xiaolong , born in 1981. PhD candidate and lecturer. His main research interests include probabilistic graphical models, machine learning.

Gao Yang , born in 1972. PhD, professor, PhD supervisor. Committee member of CCF. His main research interests include reinforcement learning, agent theory (belief revision) and multi-agent systems, intelligent system, image process and video surveillance.

Wang Hao , born in 1983. PhD, assistant researcher. His main research interests include rank-aware query processing, reco-mmender systems, reinforcement learning & transfer learning (wanghao@nju.edu.cn).

Song Bei , born in 1994. Master candidate. Her main research interests include industrial big data analysis, probabilistic graph model (songbei07@gmail.com).

Zhou Chunlei , born in 1973. Engineer. Her main research interests include informationization of energy conservation and emission reduction in power industry and industrial big data mining (13913918185@163.com).

Zhang Youwei , born in 1986. Engineer. His main research interests include informationization of energy conservation and emission reduction in power industry and industrial big data mining (15905166639@163.com).
Qi Xiaolong 1,2 , Gao Yang 1 , Wang Hao 1 , Song Bei 1 , Zhou Chunlei 3 , and Zhang Youwei 3
1 ( Department of Computer Science and Technology , Nanjing University , Nanjing 210046) 2 ( Department of Electronics and Information Engineering , Yili Normal University , Yining , Xinjiang 835000) 3 ( Jiangsu Frontier Electric Technology Co . Ltd ., Nanjing 211102)
Abstract In this paper, a Bayesian network structure learning method via variable ordering based on mutual information (BNS vo -learning) is presented, which includes two components: the metric information matrix learning and the “lazy” heuristic strategy. The matrix of measurement information characterizes the degree of dependency among variables and implies the degree of strength comparison, which effectively solves the problem of misjudgment due to order of variables in the independence test process. Under the guidance of metric information matrix, the “lazy” heuristic strategy selectively adds variables to the condition set in order to effectively reduce high-order tests and reduce the number of tests. We theoretically prove the reliability of the new method and experimentally demonstrate that the new method searches significantly faster than other search processes. And BNS vo -learning is easily extended to small and sparse data sets without losing the quality of the learning structure.
Key words Bayesian network structure; mutual information; conditional independence test; variable order; false positive node; false negative node
中图法分类号 TP181
通信作者 : 高阳(gaoy@nju.edu.cn)
基金项目 : 国家自然科学基金项目(61432008,61503178)
This work was supported by the National Natural Science Foundation of China (61432008, 61503178).
收稿日期 : 2018-03-28;
修回日期: 2018-05-31
DOI: 10.7544/issn1000-1239.2018.20180197