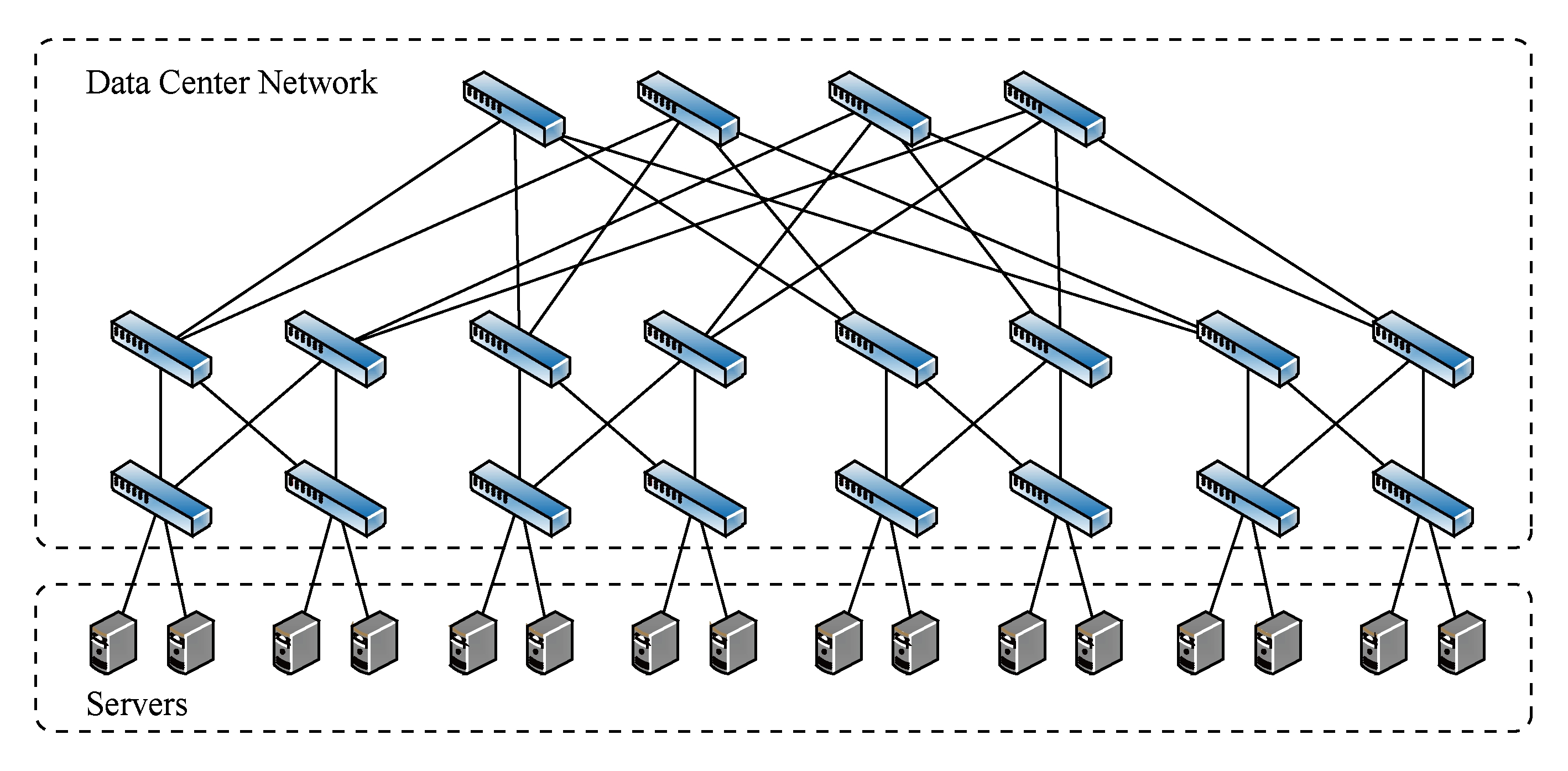
Fig.1 The illustrative fat-tree architecture of datacenter networking
图1 胖树结构数据中心网络示意图
胡智尧 李东升 李紫阳
(并行与分布处理国家重点实验室(国防科技大学) 长沙 410073) (国防科技大学计算机学院 长沙 410073) (huzhiyao14@nudt.edu.cn)
摘要数据中心网络流调度技术对数据中心网络的性能具有重要影响.它是指对数据中心应用产生的网络数据流,通过控制和调度这些网络流在数据中心网络中的传输链路、传输优先级、传输速率等,以优化网络流量的传输(包括减少数据流平均完成时间、降低加权的平均完成时间、降低数据流尾部完成时间、最大化满足有传输时限的数据流、提高网络资源利用率等),最终实现优化用户体验的目的.首先,对数据中心网络流调度问题及其面临的挑战进行简单介绍.流调度的关键挑战在于设计低开销、高效率的调度算法,以及在终端电脑或者网络交换机上实现调度算法.然后,从独立数据流调度方法和网络流组的调度方法进行综述.这2类流调度技术的区别在于应用的环境(如Web搜索和大数据分析)不同.最后,对未来流调度技术的发展方向进行展望,并且提出多个尚未解决、但仍值得研究的问题.
关键词数据中心;独立数据流调度;数据流调度;分布式计算;网络流组调度
数据中心的多样化应用对数据中心网络的高带宽和低延时等性能提出了很高的要求.为优化数据流的传输,数据中心网络流调度技术应运而生,其优化目标涉及很多方面,包括减少数据流平均完成时间、降低数据流尾部完成时间、降低加权的平均完成时间、最大化满足有传输时限的数据流、实现负载均衡、提高网络资源利用率等,最终达到优化用户体验的目的.流调度技术有多种实现手段,主要是通过合理安排数据流的传输优先级来分配有限的带宽资源.应用流调度技术可以有效改进数据中心的网络流量传输,因而在学术界和工业界引发了广泛关注.
数据中心网络的流调度对于优化用户体验也有着重要意义.谷歌、微软、阿里巴巴等大型企业都建设了数据中心.在这些商用数据中心内,用户的体验和网络数据流的时延紧密相关.不合理的数据流传输可能会造成链路拥塞,导致用户数据流的响应时延增加,对数据中心运行效率及业务效益产生重要影响.研究[1]表明,每20 ms的网络延时就会造成网页加载时间延长7%~15%;而亚马逊发现,如果网络延时增加0.1 s,会使得它们的业务减少1%;谷歌发现单次搜索响应时间每增加0.5 s就会减少20%的流量.由此可见,数据中心网络的流调度对于优化用户体验有着重要意义.
近年来,研究者们结合数据流的特征,对高效、低时延的数据中心网络流调度技术开展了很多研究工作.根据数据流的粒度,可以把数据中心的数据流分为单独的数据流和一组有相互关系的网络流组(即coflow[2]).不同的数据流存在差异,比如数据流的大小满足长尾分布[3].因此,在数据传输的时候,应当结合具体的数据流特征,有区别地调度数据流.同时,数据中心网络流调度技术的实现不仅要求设计一个合理的调度规则(以最短完成平均时间为目标或者兼顾公平性),还需要在网络设备(如交换机、路由器)和端系统上实现相应的流控制技术手段(如队列优先级管理、速率限制).此外,调度的过程是和数据流产生的过程同时进行的,这使得数据中心网络流调度技术在缺少先验知识的条件下变得更加复杂和难以实现.
图1展示了一种典型的胖树结构的数据中心网络拓扑.一个数据中心往往由多个集群组成,集群通过集群间路由器连接.而集群内部则有多个机架,一个机架内的服务器全部连接到一个机架交换机上.机架间的通信是通过二层交换机和二层聚合交换机来完成的.
Fig.1 The illustrative fat-tree architecture of datacenter networking
图1 胖树结构数据中心网络示意图
数据中心是集网络通信、存储、高性能计算于一体的计算设施,可为用户提供了种类多样的存储、计算以及网络服务,为云计算、大数据分析、网络搜索、电子商务等应用提供支持.以谷歌为例,该公司已经在全球范围内建造了15个大规模数据中心[4].这些数据中心提供各种各样的信息服务,创造着巨大的经济和社会效益.近年来,随着互联网和云计算应用的快速发展,数据中心服务的用户越来越多、通过网络传输的数据量越来越大,且用户对服务质量的要求也越来越高,数据中心内的带宽需求每12~15个月就会增长1倍[5].因此,强劲的应用需求驱动数据中心网络技术继续向前发展.数据中心运行着大量应用,这些应用每时每刻都通过网络传输大量的数据流.这些数据流之间竞争着带宽资源,并可能产生网络拥塞.如何高效地调度这些网络数据流,使得数据流的平均完成时间最短,是数据中心网络流调度技术需要解决的主要问题.
一条数据流是指发送端和接收端之间跨过网络传输的一个应用数据单元[6].在数据流的传输过程中存在着3种角色,即发送端、接收端和传输数据流的内部互联网络.在调度数据流时,现有研究工作通常采用HOSE模型[7]来对网络进行建模,实际上是对内部网络进行理想化假设,假定该网络能够提供全二分带宽和无阻塞传输.数据中心网络逻辑视图如图2所示,逻辑上在发送端和接收端之间相连的网络是一个巨大的交换机.这个抽象网络的入口是发送端的网卡,出口是最后一跳机架交换机.数据流由入口(即发送端网卡)进入网卡,经过中间网络传输,到达其对应的出口(即最后一跳机架交换机的端口).对网络内部的理想化假设使得我们可以不失一般性地简化数据中心网络流调度问题的描述.在该模型下,无阻塞交换机的输入端口处有多条数据流等待转发给不同输出端口的主机.为了表述方便,这些流可以通过在网络入口的虚拟输出队列来表示.如图2所示,输入端口1处有3个并列的数据包转发队列,每个队列是发给不同的输出端口。队列里不同颜色的区域代表不同的数据流。

Fig.2 The abstraction of datacenter networking for flow scheduling
图2 在流调度情况下的数据中心网络抽象
数据中心网络流调度问题近年来受到了来自学术界和工业界的广泛关注,相关研究成果在SIGCOMM,NSDI,CoNEXT和INFOCOM等知名网络学术会议上不断涌现.纵观这些流传输调度相关的研究工作,按照数据流的粒度,可将数据中心网络流调度研究分为面向独立数据流的调度方法和面向网络流组(即coflow)的调度方法.
为了优化数据中心的数据流传输,近年来国内外学者致力于从2个主要方面来研究流调度技术.具体来说,数据中心网络中流量的突发性很容易导致局部链路的负载不均衡,如果不能在较短时间内改变此情况最终会演变为链路拥塞.此问题并不能单纯地依靠增加链路带宽和数据中心交换网络规模来解决.该研究领域的数据流调度技术可以根据链路的负载情况来调度数据流,从而避免链路发生拥塞.具体是把一条完整的数据流拆分为多个小流,在小流的粒度上进行路由,使用其他没有被拥塞的链路来分担负载这些小流,从而避免拥塞.也就是说,该调度技术的目标是在数据流级别实现负载均衡.通过相关研究发现,数据流级别的传输速率控制比数据包级别的控制更加稳定,对于随时可能会出现新数据流的网络环境来说按照数据流划分的方法能更高效地实现分配网络资源.
数据中心里所产生的网络流量服从长尾分布.据统计,少于10%的任务产生了超过98%的流量,而大部分(超过90%)任务产生的是很小的流,一般是由网络搜索、社交网络、在线游戏等用户交互式应用产生的.由于这些任务直接与用户交互,所以小任务数据流的传输时间显著地影响着用户的体验.在线业务会产生单独的数据流,如网络搜索、社交网络和电子商务等网络服务.其流量一般比较小,而且对时延比较敏感.同时,由于一个任务通常会产生数个并发的数据流,使得数据中心的网络流量在秒级粒度上具有很强的突发性.当有多个任务同时运行时,在网络里传输的数据流会在交换机里排队,造成很长的延时,甚至是丢包.排队问题会严重地影响小任务数据流的传输.专门针对小任务设计的网络传输优化具有很强的现实意义.然而,传统传输协议无法保证单个数据报文的传输延时,无法满足网络搜索、电子商务等在线应用对延时的苛刻要求;其次,对于数据中心独特的网络环境存在TCP Incast[8]和Micro burst[9]等问题,传统协议无法妥善解决;最后,传统协议无法支持数据中心对不同类别业务的数据流有区别的调度,如交换机的分级队列等.解决这些问题是面向完成时间优化的独立数据流调度方法的研究内容.
而在数据中心的分布式计算平台上运行的数据挖掘、机器学习等应用会在多个节点上产生中间数据,只有汇总完中间数据才能完成整个分布式作业.对于分布式计算作业,其计算的数据量特别大,无论是读取输入数据集、传输中间数据还是输出最终结果都会通过网络传输大量的数据.这一类数据并行应用不仅需要较高的网络带宽,而且因其传输数据量大、耗时长,还会对处于同一网络下的其他应用造成影响.面向作业逻辑感知的网络流组的调度技术的优化目标是减少作业的平均完成时间.然而,一个作业执行的过程中会产生多条并发传输的数据流.这些数据流被称为网络流组.从应用层面来看,仅仅优化流组中某条数据流并不能缩短作业的完成时间;更复杂的是,流组中的数据流之间存在依赖关系,使得上述2种调度方法都不再适用.面向网络流组的调度方法可以有效感知到作业逻辑,从而掌握数据流的依赖关系,通过调度数据流传输来缩短作业的完成时间.
数据中心网络流调度机制需要结合数据流的优先级、网络链路的负载情况来有区别地传输数据流.因此,数据中心网络的大多数调度机制需要通过修改应用,以便获取准确的数据流大小等信息,然后采用相应的调度策略确定优先级.然而,修改应用获取数据流信息的方法在3个方面存在难点:1)修改用户应用带来巨大的工程上的工作量;2)有些应用的用户不支持对闭源软件或者公有云修改;3)对于那些采用边计算边传输的应用,在数据流传输完成之前无法准确获取数据流大小信息.这3个困难使得从应用获取信息的数据中心网络流调度机制难以在实际生产系统中得到应用.另一方面,传统协议和硬件不能很好地支持数据中心网络流调度技术,面临来自调度机制设计与实现的挑战.数据中心网络流调度相关研究里面有的需要设计新的传输协议;有的需要在数据中心网络交换机上实现不支持的功能[10];而有的则需要增加额外的设备,如集中式的仲裁器[11].事实上,数据中心的网络交换设备是常见的交换机,其内部的优先级队列数目十分有限,这使得数据中心网络很难支持依靠众多优先级队列的复杂流调度机制.
在部署数据流调度系统方面也会遇到难点,为数据中心网络流调度技术带来一定开销.这种开销对于那些数据量巨大的任务来讲是微不足道的,然而却对延时敏感型任务的性能有着巨大的影响.如何设计低开销的数据中心网络流调度技术是当前研究现状下的难点问题.降低调度开销的主要挑战为:1)如何降低获取数据流信息的开销.这些信息往往隐藏在应用层里,很难被网络层所感知到.最直观的方法是修改用户应用,将数据流信息汇报给一个中心式调度器.然而,修改用户应用和中心式调度器对于延时敏感型的任务来说会产生大量开销,是不可取的.2)如何降低调度策略的实施开销.调度策略的实施开销包括2个方面:①把调度策略实施到具体的每一条数据流上的开销,包括调度信息的收集、调度策略的计算以及消息的传递等环节;②将调度机制部署到系统中的开销,包括是否需要修改应用和系统、现有交换机能否支持数据中心网络流调度技术的功能等方面.
数据中心网络内部的数据流具有很强的应用驱动性,这导致了多条数据流之间往往有很复杂的逻辑关系.尤其是对于分布式计算任务的数据流会存在栅栏效应,即一个任务的开始时间取决于多个数据流中传输最慢的那条数据流,这使得调度过程需要考虑应用层面的逻辑.面向作业逻辑感知的网络流组技术通常将一个作业内的某阶段的并行任务所触发的一组并行数据流看作是一个coflow,并在作业内部依据coflow间的依赖关系进行调度.因为分布式计算作业内部包含了多个计算阶段,调度方法不仅需要考虑到一个任务内部的逻辑,还需要考虑整个作业的逻辑.在一个任务内部,当所有中间数据的数据流完成传输后,这个任务的下一阶段才能开始.也就是说,按照传统的最少剩余时间优先的策略,不仅无视多个coflow之间的先后调度顺序,而且对于一个coflow也仅仅集中优化其内部某单个数据流.这对提高一个任务的完成时间来说没有太大的好处.因此,对于独立数据流的传统调度方法不能适用于coflow调度.这促使研究者们设计一种专门针对这类具有内在逻辑的网络流组调度方法.
同时,整个作业的逻辑是由多个阶段按照依赖关系组成的,各个阶段间的执行逻辑通常表示为有向无环图(directed acyclic graph,DAG).设计最优的DAG调度策略是NP难[12]的,体现在2个方面:1)任务间存在着复杂的相互依赖关系,忽视这些依赖关系导致调度结果与作业的实际需求间出现偏差;2)作业的执行是一个动态的过程,作业执行的状态变化导致其最优调度策略也会变化,忽视作业实际运行状态的调度可能会使作业性能下降.然而,在数据中心内部,来自应用的作业逻辑是无法体现在数据流的传输过程中的,这使得很难从众多的数据流当中识别出coflow.同时,如何兼顾coflow的传输性能和公平性、如何在数据中心网络内部设施上实现coflow的调度器等问题,也是网络流组调度方法的主要研究难点.
当用户需要下载一个网站页面、传输一个文件、提交一个搜索请求时,他们并不关心网络的带宽、网络的有效利用率或者数据报文的往返延时等具体网络指标,用户想让数据传输尽快完成,即数据流完成时间尽可能短.传统流调度方法会在单瓶颈的情况下优先传输最短剩余时间的数据流,小流分配更高的优先级或更大的带宽.最近提出的数据中心网络流调度工作,通过近似最小剩余时间优先(shortest remaining processing time first,SRPT)的策略来最小化网络流平均传输时间[13].
根据调度机制实现方式,从是否使用仲裁器、自适应终端、可控优先级的网络设备3个方面把面向完成时间优化的独立数据流的流调度方法分为3类:基于仲裁的流调度机制、基于网络内优先级的流调度机制和基于自适应终端的流调度机制.表1总结了相关流调度工作.下面按照技术实现的手段来具体分析各项流调度技术.
Table1TheComparisononSingle-flowFlowSchedulingMethodforOptimizingCompleteTime
表1面向完成时间优化的独立数据流调度策略对比
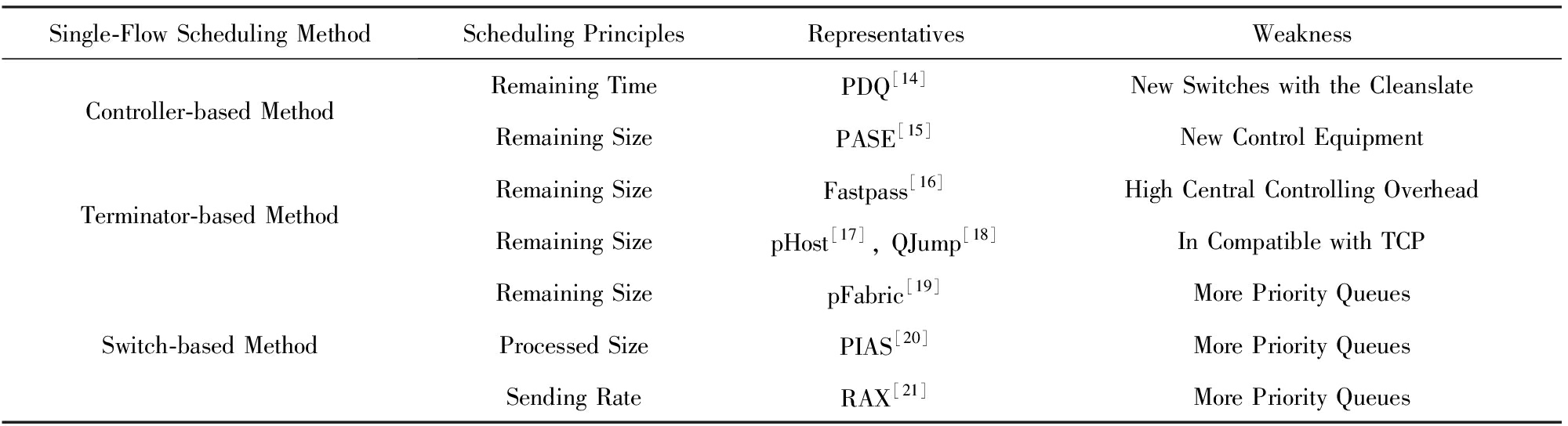
基于仲裁的流调度机制采用仲裁器来显式地控制网络内数据流的传输速率,达到减少数据流完成时间或满足截止时限的目的.PDQ[14]采用最小作业优先的启发式策略,最早提出以抢占的方式来进行流调度,以牺牲公平性为代价换来效率的提升、数据流平均完成时间的减少.PDQ将带宽优先分配给剩余时间小的数据流,而剩余时间较长的流会被抢占.在PDQ内,数据流的传输带宽由其交换机来控制,交换机需要完成数据流信息的统计、流调度仲裁等职能.因此,PDQ的交换机设计是复杂且无状态的,其技术难以在实际生产系统中得到应用.PASE[15]应用网络内仲裁、优先级以及自适应终端等技术,但其调度顺序是由仲裁器计算得出的.PASE在调度数据流时采用最小剩余大小优先的启发式策略,并依据流传输速率来分配带宽.
第1类自适应终端协议同时兼顾公平性和传输性能.这些调度技术的实现通常需要实现为内核模块或直接修改内核.Fastpass[16]则提出使用完全中心式的调度器,该调度器负责计算数据包进入网络的时间和传输路径.
第2类自适应终端协议的调度目标是要么减少数据流的平均传输时间、要么满足更多具有截止时限的数据流.相关研究主要采用最小流先传或最早截止时间先传等启发式策略;它们的不同点在于这些启发式的实现方式不同,有的采用控制窗口大小的方式,而有的采用基于令牌的方式如pHost[17].基于令牌的流调度机制如QJump[18],在发送端和接收端之间为流传递令牌,获得令牌的流可以得到一个传输窗口,小流优先得到令牌以减少平均完成时间.
采用网络内优先级的调度机制利用网络内交换机等设备提供的优先级调度功能,在终端服务器上为每个数据报文标记相应的优先级,网络内的交换机识别这些标记并把这些报文放置在相应的优先级队列中去,优先级高的报文将被优先传输.pFabric[19]通过解耦优先级和速率控制来实现流调度,它证明了如果流调度技术只采用优先级队列,同样可以实现近似最优的流完成时间.pFabric采用流剩余大小作为数据报文的优先级,交换机严格地按照标记的优先级进行调度,从而实现近似最优的调度.然而pFabric存在2个主要问题:1)很难获取数据流的大小,在某些情况下甚至是不可能的;2)现有的交换机仅支持数据有限的优先级队列,无法支持pFabric所需要的优先级.
pFabric在决策数据流的优先级时,必须掌握关于数据流的先验知识,比如数据流的大小.在现实中,很难获取数据流信息.这是因为数据流的产生和传输是同时进行的,所以准确地预判数据流的剩余大小是很有挑战性的问题.研究者们提出了在未知数据流信息的情况下进行流调度的方法PIAS[20].PIAS提出可以在生产系统中立即部署的流调度机制,一方面是PIAS利用已发送数据量来进行调度,避免了修改应用;另一方面利用现有交换机技术所支持的优先级队列采用了多级反馈队列(multi-level feedback queue, MLFQ)调度算法.基于MLFQ算法的流调度原理如图3所示,服务器端将数据流已发送量与预设的阈值相比较,计算出它的优先级,然后将优先级标记在数据包的IP头部DSCP区域.当数据包到达交换机的输入端口时,交换机端识别数据包的优先级标记,然后将该数据包放入相应的优先级队列中,优先级队列内部先入先出(first-in-first-out, FIFO),然后严格按照高优先级优先的方式传输.
研究者们提出一个普通商用数据中心网络内数据生成速率感知的网络流传输调度协议RAX[21].RAX系统内核里挖掘出丰富的流信息,并且依据网络流大小和数据生成速率来计算网络流的剩余时间.RAX依据网络流的剩余时间来进行分类,然后实行SRPT策略来优先调度那些具有最小剩余完成时间的流.此外,网络流数据的生成速率有可能受限于硬盘、CPU和数据入口处带宽,而小于其向外发送的网络带宽[22].例如,机械硬盘和固态硬盘的吞吐率分别远远小于网络带宽.
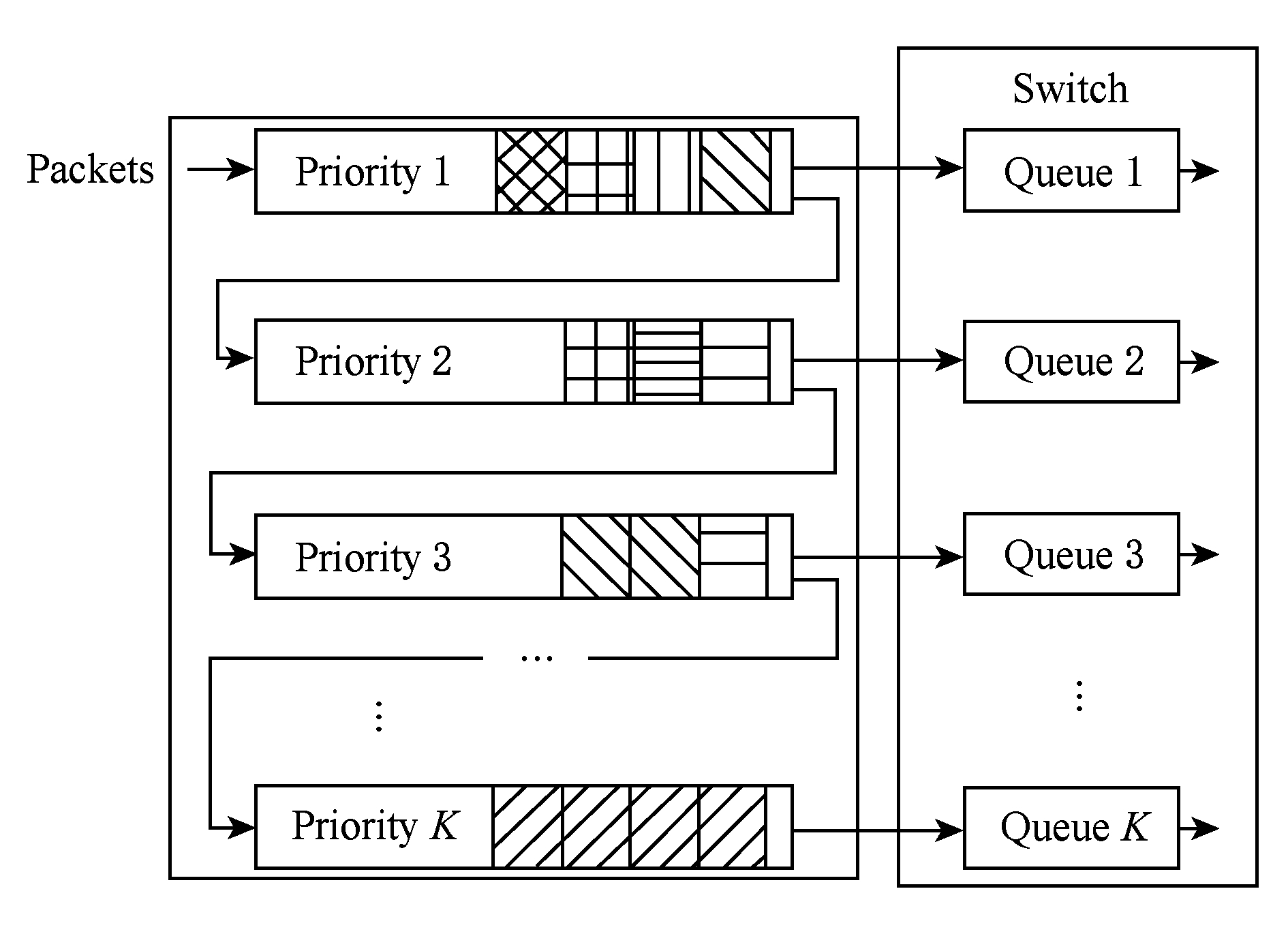
Fig.3 The illustrative architecture of MLFQ
图3 基于MLFQ算法的流调度基本原理[20]
数据中心的分布式计算任务需要执行复杂的运算逻辑,即不同的计算阶段和任务之间并不是相互独立的,而是存在着逻辑上的依赖关系.这种依赖关系决定了数据流之间的语义,即不同的数据流在从产生到结束的生命周期上存在着先后关系.传统流调度只关注独立数据流层面的指标(如流平均完成时间和满足截止时限等),不能有效解决此类关于作业逻辑的语义问题.实际上,一个正在运行的任务通常需要同时传输多条数据流,任务完成取决于最后一条流的完成时间,在独立数据流层面的优化并不能带来整体的性能提升.
一个任务的完成时间会从读取远程数据开始,到把结果数据发送给下一个任务才结束;通常一个任务读取远程数据,会涉及并发的多条数据流;只有当最后一条数据流完成传输,任务才能正常结束.因此,优化某一条单独的数据流并不能带来整个任务的性能提升.故而,任务感知的流调度机制将任务完成时间作为优化目标.图4分别展示了Hadoop[23]和Spark[24]的通信模式.可以看出,在不同计算阶段之间往往会产生多条数据流,而后续计算阶段的开始时间取决于其中最后一条流的完成时间.作业逻辑感知的流调度方法要求在端系统上结合应用层面的需要来决定传输数据流的先后顺序,从而实现流调度.学者们发现网络传输的时间占到了一个Hadoop作业完成时间的50%[25].在这些作业中,常见的网络通信(如广播和数据混洗)的性能并没有通过传统的流调度方法有所提升.传统的流调度方法仅集中于优化某条数据流的传输.从而出现了一种新的流调度方法,即作业完成时间作为流调度优化的目标,实现作业逻辑感知的调度方法.Orchestra[25]是这一类研究的第1个研究工作,它采用一种中心化网络传输控制器,可以同时优化一个作业内部的广播流量和数据混洗流量传输.对于广播流量,Orchestra采用一种Cornet协议,通过利用数据中心网络的层级网络拓扑来实现广播;对于数据混洗流量,采用带权重的混洗调度策略来提升一个作业内部的网络流的传输性能.此外,在不同作业之间的数据传输也可以得到优化.
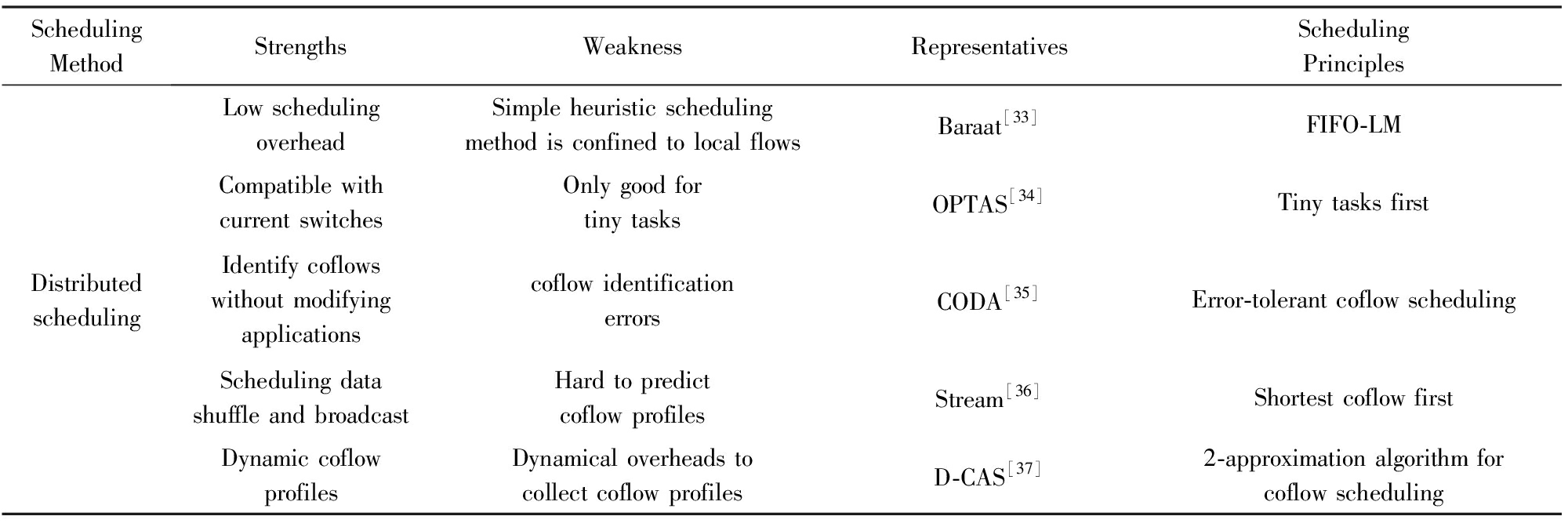
和以往的流调度方法不同,面向作业逻辑感知的网络流组的目标不是优化单独的数据流传输,而是减少任务的数据传输时间,即coflow的平均传输时间.根据作业逻辑,把一个任务并发的多条数据流看作是一个整体,称之为coflow.coflow的传输时间是从一个任务的第1条数据流开始发送到最后一条数据流被完全接收.通过引入coflow的概念来计算数据流的优先级,可以更好地提高coflow的平均传输时间、缩短作业的完成时间.表2中从中心式和分布式2类总结了主要的coflow调度机制的优点、缺点和有代表性的工作.
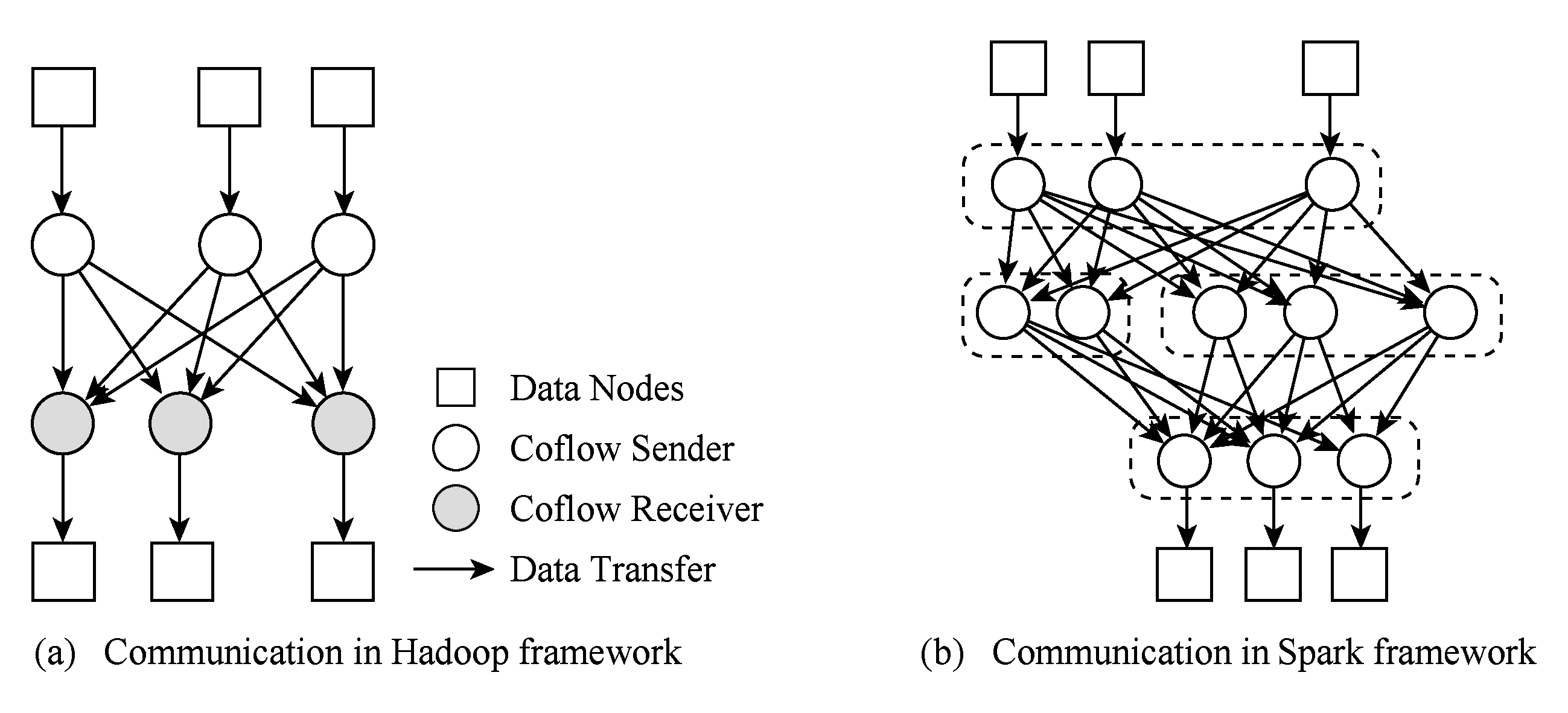
Fig.4 Communication mode of typical applications
图4 Hadoop[23]和Spark[24]通信模式
Table2ComparisononcoflowSchedulingMethod
表2网络流组调度技术

Table2(Continued)
调度coflow的首要问题是识别出数据流所属的coflow.正如coflow的定义,一个任务会产生多个中间数据;需要传输多个相应的数据流.这一组数据流构成了与这个任务对应的一个coflow.例如图4(a)所示的reduce任务会从多个map任务拉取数据,这些数据流属于同一个coflow,它们有共同的接收节点,却有不同的发送节点.如果要对单独的数据流实现作业逻辑感知的调度方法,就必须在这些数据流产生时,给它们打上唯一的标签来区别各自所属的coflow.然而,从图4上可以看出这些数据流是从不同节点发出的.这就表明,为了识别coflow,一个用于coflow ID分配、识别的集中控制节点必不可少.然后,网络设备在传输它们时才能根据这个标签来判断出其所属的coflow,再按照相应的优先级策略实现coflow调度.
不过,现有的分布式计算任务并没有考虑到coflow的识别问题.它们没有对属于一个coflow的一组数据流进行标记,其数据流传输仍然是单独的数据流.在数据传输的过程中,网络设备并不能从数据包中判别出作业逻辑关系.因此,为了实现针对coflow的作业逻辑感知的流调度方法,必须对单个数据流进行coflow识别.
为了识别数据流所属的coflow,必须改动现有的分布式计算框架,往其中增加应用程序接口来标记数据流.不过,要在共享的集群环境(如云环境)里增加应用程序接口,则需要改变分布式计算框架;对现有的分布式计算框架来说,是很难的.因此,在研究者们中提出一种不用更改分布式计算任务的方法——CODA[35].CODA用聚类的方法来对各个独立数据流进行分类,分出的每个coflow都是独立数据流的集合,并且CODA不需要修改应用.通过实验证明,错误分类的情况仅发生在很少的数据上,分错的数据会导致调度错误,降低平均完成时间.为了避免错误分类的数据流造成很不好的影响,作者结合使用不同优先级队列和最小数目优先的调度技巧,让少量错误识别的coflow被优先调度,从而实现一种对识别错误容忍的调度策略.
由于数据中心内众多任务会抢占网络资源,当多个任务并发时,coflow调度问题是NP难问题.因此,在短时间内计算最优解是不现实的.典型的coflow调度器如Varys和Aolo都采用最短作业优先的调度策略.
为了同时兼顾公平性和平均完成时间,一种公平性有效的调度器Coflex[27]被提出.Coflex通过采用2阶段的带宽分配策略来实现不同隔离粒度,保证了公平性.而在第2阶段的带宽分配过程,Coflex优先调度最小瓶颈带宽的coflow.除了上述的公平性和性能兼顾的研究,一个coflow的所有数据流也受网络设备优先级队列的影响.按照coflow的概念,一个coflow的数据流是不同的发送端节点到同一个接收端节点.而这些数据流会从不同节点出发,在网络里不同的交换设备上排队.因此,多条coflow数据流的传输过程是在网络里并发进行的.然而,过去的研究工作更关注应用层面上的coflow调度,很少研究在网络里多条coflow数据流的传输过程.为此,研究者们提出了把网络抽象成一个无阻塞交换机,并且设计出降低coflow传输延迟的调度方法[38].研究者们从作业执行的角度分析数据并行应用的网络传输模式,提出seflow[30]来表达作业层面的数据传输语需求.由于大多数分布式计算框架往往具有多层次的语义,一个seflow 不仅由所有coflow 组成,还包含了coflow 间的相互关系.研究者们设计一种最小化作业平均执行时间为目标的流调度算法,该算法依据作业运行状态动态地调整coflow 的优先级分配.
面向作业逻辑感知的网络流组的调度主要有中心式和分布式2种.中心式的coflow调度器需要有一个主控节点来负责处理调度信息,这个节点一般也是分布式计算框架Hadoop,Spark的主节点.
中心式coflow调度通常从整个集群内收集任务信息,然后来计算coflow的优先级.Varys是一种典型的中心式调度机制,它针对coflow调度问题提出了最少有效瓶颈优先的调度算法(smallest effective bottleneck first, SEBF).具体来说,它在为coflow分配优先级之前先计算每个coflow的SEBF值大小,然后按照该值排序,SEBF值小的coflow优先获得带宽资源.中心式的调度器Rapier[26]考虑coflow 的调度和路由,利用网络拓扑结构来优化coflow 传输.Aalo在流大小未知的情况下,基于coflow 已发送大小来决定数据流的优先级,进行中心式的任务感知流调度机制.除了上述的调度策略以外,Qiu等人[31]等提出一种优化coflow带权完成时间总和,能在较好的复杂性和近似比下实现coflow调度.OMCoflow[38]是一种可以实时解决多个coflow竞争带宽资源的调度算法,其优化目标是降低平均coflow完成时间;其中需要使用OneCoflow算法重新调度带宽资源.在文献[32]中,作者指出仅仅优化完成时间是不够的,还需要提高链路利用率,提出了Adia方法[32].它考虑到此前的coflow调度策略集中于完成时间的优化工作却忽视面向链路的调度问题,比如链路利用率.它采用一种双层的调度方案:对于一条链路内的数据流,Adia方法要考虑减少最晚完成数据流的时间;Adia方法还要优化跨链路的调度,以便提高吞吐量.最终使得平均完成时间和尾部数据流完成时间都得到减少.总的来看,中心式coflow调度器的优点在于可以依据全局的任务信息进行调度,避免局部最优解;其缺点在于信息收集、调度策略的计算和实施等环节带来的开销较大,因而对任务性能尤其是小任务的完成时间产生负面影响.
分布式的coflow调度机制以每个节点上的局部任务信息为基础,采用小任务优先传输等规则来决定任务的优先级.Baraat[33]是一种典型的分布式任务感知的流调度机制,它为每个任务分配一个独有的ID,统计各个任务传输的数据量,并采用FIFO-LM调度策略来避免大任务阻塞网络.Stream[36]是一种分布式、可快速部署的coflow调度器,它利用数据混洗过程中多对一、多对多的通信模式来协同调度coflow,从而优化平均完成时间.对于Varys和Barrat等调度器的不足,D-CAS[37]是一个采用近似比为2的分布式调度算法来实现coflow总完成时间最小的分布式调度器.OPTAS[34]是一个不需要修改用户应用和网络协议栈的、针对小任务的、轻量级的、能兼容现有交换机的调度系统,可以通过监控系统调用和发送端缓冲区占用情况来获取流信息.OPTAS通过设置2个阈值来利用从发送缓冲区中获得信息:一个是缓冲区大小的阈值,另一个是数据流大小的阈值.为避免大任务在网络中阻塞小任务,并通过调节TCP窗口大小和ACK延时时间来实现小任务的先到先服务的方式进行传输.分布式任务感知调度机制的优点在于其调度开销低、响应速度快;然而调度策略通常较为简单,依据局部任务信息所进行的调度通常难以实现全局优化.任务信息的获取是分布式的流调度机制中的重要环节.
在上述中心式和分布式的调度系统之外,coflow系统还存在其他实现方式和通用的问题,如依靠光电交换技术的coflow调度系统和空间维度问题.虽然用最短作业优先的方法来划分coflow的优先级,但是组成每一个coflow的数据流是在网络里分散传输的.具体来说,在最短作业优先的方法中,需要一个中心式的调度器负责把coflow放入到不同优先级的逻辑队列,以便coflow数据流被分到的逻辑队列有相同的优先级.而在具体某个交换设备的同一个优先级队列里,还是按照先到先服务的策略工作.因此,在各个分散于不同交换机的队列里并没有完全真实地按照coflow的优先级进行调度.这个问题被称为coflow的空间维度问题.Saath[29]采用最少竞争优先(least-contention-first)的方法来改进coflow的传统调度方法(即最短作业优先方法).同时,研究者们也提出面向光交换的数据中心网络coflow调度方案,可利用光电交换技术来加快网络数据流的传输,非常适合于传输稀疏的数据流.然而,coflow是非常密集的.为此,设计一种基于非抢占的方法SunFlow[28],比电路交换技术更降低了coflow的平均完成时间.
综上所述,数据中心流调度技术是一种近年来兴起的数据流调度方法.目前,在数据中心的各类应用里都存在数据流调度的问题.相对于依靠网络传输协议来控制数据流的传统调度方法,coflow调度技术还涉及到结合作业逻辑的调度机制.尽管这些新兴的调度策略在某种特定场景下表现出更好的性能,可是数据中心的流调度技术仍然会存在一些问题.如何设计可以被传统协议支持的流调度技术?如何在负载均衡中降低流调度技术的控制代价?如何在不修改用户应用的情况下更准确地获取数据流的先验信息?如何针对作业运算的DAG 设计流调度策略?如何结合数据流的特征来设计流调度策略?如何将流调度和传统的多播、数据流聚合[39]等工作结合起来?上述问题有待进一步探索.
参考文献
[1]Greenberg A, Hamilton J, Maltz D, et al.The cost of a cloud: Research problems in data center networks[J].SIGCOMM Computation Communication Review, 2008, 39(1): 6873
[2]Chowdhury M, Stoica I.Coflow: A networking abstraction for cluster applications[C]//Proc of ACM Workshop on Hot Topics in Networks.New York: ACM, 2012: 3136
[3]Chowdhury M, Zhong Yuan, Stoica I.Efficient coflow scheduling with varys[C]//Proc of ACM SIGCOMM 2014.New York: ACM, 2014: 443454
[4]Vahdat A, Al-Fares M, Loukissas A.A Scalable Commodity Data Center Network Architecture: USA, WO2010011221A1[P].2010-03-28
[5]Google.Google data center[EB/OL].[2018-06-22].https://www.google.com/about/datacenters/
[6]Singh A, Ong J, Agarwal A, et al.Jupiter rising: A decade of CLOS topologies and centralized control in Google’s datacenter network[C]//Proc of ACM SIGCOMM 2015.New York: ACM, 2015: 183197
[7]Ballani H, Costa P, Gkantsidis C, et al.Enabling end-host network functions[C]//Proc of ACM SIGCOMM 2015.New York: ACM, 2015: 493507
[8]Chen Yanpei, Griffith R, Liu Junda, et al.Understanding TCP incast throughput collapse in datacenter networks[C]//Proc of ACM Workshop on Research on Enterprise Networking.New York: ACM, 2009: 7382
[9]Kapoor R, Snoeren A, Voelker G, et al.Bullet trains: A study of NIC burst behavior at microsecond timescales[C]//Proc of ACM CoNEXT 2013.New York: ACM, 2013: 133138
[10]Alizadeh M, Yang Shuang, Sharif M, et al.pFabric: Minimal near-optimal datacenter transport[C]//Proc of ACM SIGCOMM 2013.New York: ACM, 2013: 435446
[11]Li Chen, Bai Wei, Chen Kai, et al.Scheduling mix-flows in commodity datacenters with Karuna[C]//Proc of ACM SIGCOMM 2016.New York: ACM, 2016: 491502
[12]Chowdhury M, Stoica I.Efficient coflow scheduling without prior knowledge[C]//Proc of ACM SIGCOMM 2015.New York: ACM, 2015: 393406
[13]Bansal N, Harchol M.Analysis of SRPT scheduling: Investigating unfairness[C]//Proc of ACM SIGMETRICS 2001.New York: ACM, 2001: 279290
[14]Munir A, Baig G, Irteza S, et al.Friends, not foes: Synthesizing existing transport strategies for data center networks[C]//Proc of ACM SIGCOMM 2014.New York: ACM, 2014: 491502
[15]Hong C, Caesar M, Godfrey P.Finishing flows quickly with preemptive scheduling[C]//Proc of ACM SIGCOMM 2012.New York: ACM, 2012: 127138
[16]Jonathan P, Amy O, Hari B, et al.Fastpass: A centralized “zero-queue” datacenter network[C]//Proc of ACM SIGCOMM 2014.New York: ACM, 2014: 307318
[17]Gao P, Narayan A, Kumar G, et al.pHost: Distributed near-optimal datacenter transport over commodity network fabric[C]//Proc of ACM CoNEXT 2015.New York: ACM, 2015: 112
[18]Grosvenor M, Schwarzkopf M, Gog I, et al.Queues don’t matter when you can JUMP them![C]//Proc of USENIX NSDI 2015.Berkalay, CA: USENIX Association, 2015: 114
[19]Alizadeh M, Yang Shuang, Sharif M, et al.pFabric: Minimal near-optimal datacenter transport[C]//Proc of ACM SIGCOMM 2013.New York: ACM, 2013: 435446
[20]Bai Wei, Chen Li, Chen Kai, et al.Information-agnostic flow scheduling for commodity data centers[C]//Proc of USENIX NSDI 2015.New York: ACM, 2015: 455468
[21]Li Ziyang, Bai Wei, Chen Kai, et al.Rate-aware flow scheduling for commodity data center networks[C]//Proc of IEEE INFOCOM 2017.Piscataway, NJ: IEEE, 2017: 2131
[22]Ongaro D, Rumble S, Stutsman R, et al.Fast crash recovery in RAMCloud[C]//Proc of ACM SOSP 2011.New York: ACM, 2011: 2941
[23]Bhandarkar M.MapReduce programming with apache Hadoop[C]//Proc of IEEE IPDPS 2010.Piscataway, NJ: IEEE, 2010: 2336
[24]Zaharia M, Chowdhury M, Franklin M, et al.Spark: Cluster computing with working sets[C]//Proc of USENIX HotCloud 2017.Berkalay, CA: USENIX Association, 2010: 1023
[25]Chowdhury M, Zaharia M, Ma J, et al.Managing data transfers in computer clusters with Orchestra[J].ACM SIGCOMM Computer Communication Review, 2011, 41(4): 98109
[26]Zhao Yangmin, Chen Kai, Bai Wei, et al.Rapier: Integrating routing and scheduling for coflow-aware data center networks[C]//Proc of IEEE INFOCOM 2015.Piscataway, NJ: IEEE, 2015: 424432
[27]Wang Wei, Ma Shiyao, Li Bo, et al.Coflex: Navigating the fairness-efficiency tradeoff for coflow scheduling[C]//Proc of IEEE Conf on Computer Communications.Piscataway, NJ: IEEE, 2017: 3645
[28]Huang X, Sun X, Ng T.Sunflow: Efficient optical circuit scheduling for coflows[C]//Proc of ACM CoNEXT 2016.New York: ACM, 2016: 297311
[29]Jajoo A, Gandhi R, Hu C, et al.Saath: Speeding up coflows by exploiting the spatial dimension[C]//Proc of ACM CoNEXT 2017.New York: ACM, 2017: 439450
[30]Li Ziyang, Zhang Yiming, Zhao Yunxiang, et al.Efficient semantic-aware coflow scheduling for data-parallel jobs[C]//Proc of IEEE INFOCOM 2016.Piscataway, NJ: IEEE, 2016: 154155
[31]Qiu Zhen, Stein C, Zhong Yuan.Minimizing the total weighted completion time of coflows in datacenter networks[C]//Proc of ACM SPAA 2015.New York: ACM, 2015: 294303
[32]Jiang Jingjie, Ma Shiyao, Li Bo, et al.Adia: Achieving high link utilization with coflow-aware scheduling in data center networks[J].IEEE Trans on Cloud Computing, 2016, 23(99): 2337
[33]Dogar F, Karagiannis T, Ballani H, et al.Decentralized task-aware scheduling for data center networks[C]//Proc of ACM SIGCOMM 2014.New York: ACM, 2014: 431442
[34]Li Ziyang, Zhang Yiming, Li Dongsheng, et al.OPTAS: Decentralized flow monitoring and scheduling for tiny tasks[C]//Proc of IEEE INFOCOM 2016.Piscataway, NJ: IEEE, 2016: 1322
[35]Zhang Hong, Chen Li, Yi Bairen, et al.CODA: Toward automatically identifying and scheduling coflows in the dark[C]//Proc of ACM SIGCOMM 2016.New York: ACM, 2016: 160173
[36]Susanto H, Jin Hao, Chen Kai.Stream: Decentralized opportunistic inter-coflow scheduling for datacenter networks[C]//Proc of IEEE INFOCOM 2016.Piscataway, NJ: IEEE, 2016: 2536
[37]Luo Shouxi, Yu Hongfang, Zhao Yangming, et al.Towards practical and near-optimal coflow scheduling for data center networks[J].IEEE Trans on Parallel & Distributed Systems, 2016, 27(11): 33663380
[38]Li Yupeng, Jiang H, Tan Haisheng, et al.Efficient online coflow routing and scheduling[C]//Proc of ACM SPAA 2016.New York: ACM, 2016: 161170
[39]Guo Deke, Luo Lailong, Li Yan, et al.Aggregating incast transfers in data centers[J].Journal of Computer Research and Development, 2016, 53(1): 5367 (in Chinese)(郭得科, 罗来龙, 李妍, 等.数据中心内Incast流量的网内聚合研究[J].计算机研究与发展, 2016, 53(1): 5367)
Hu Zhiyao, Li Dongsheng, and Li Ziyang
(ScienceandTechnologyonParallelandDistributedProcessingLaboratory(NationalUniversityofDefenseTechnology),Changsha410073) (CollegeofComputer,NationalUniversityofDefenseTechnology,Changsha410073)
AbstractFlow scheduling techniques impose an important impact on the performance of the data center.Flow scheduling techniques aim at optimizing the user experience by controlling and scheduling the transmission link, priority and transmission rate of data flows.Flow scheduling techniques can achieve various optimization objects such as reducing the average or weighted flow completion time, decreasing the delay of long-tail flows, optimizing the transmission of flows with deadline constraints, improving the utilization of the network link.In this paper, we mainly review the recent research involving flow scheduling techniques.First, we briefly introduce data center and flow scheduling problem and challenges.These challenges mainly lie in the means to implement flow scheduling on network devices or terminal hosts, and how to design low-overhead highly-efficient scheduling algorithms.Especially, the coflow scheduling problem is proved NP-Hard to solve.Then, we review the latest progress of flow scheduling techniques from two aspects, i.e., single-flow scheduling and coflow scheduling.The divergence between single-flow scheduling techniques and coflow scheduling techniques is the flow relationship under different applications like Web search and big data analytics.In the end of the paper, we outlook the future development direction and point out some unsolved problems involving flow scheduling.
Keywordsdata center; single-flow scheduling; flow scheduling; distributed computing; coflow scheduling
通信作者:李东升(dsl@nudt.edu.cn)
This work was supported by the National Natural Science Foundation of China for Excellent Young Scientists (61222205).
基金项目:国家自然科学基金优秀青年科学基金项目(61222205)
修回日期:2018--06--23
收稿日期:2018--03--06;
DOI:10.7544/issn1000-1239.2018.20180156
中图法分类号TP393

HuZhiyao, born in 1992.PhD candidate.His main research interests include distributed computing, data-parallel distri-buted framework and machine learning.

LiDongsheng, born in 1978.PhD, professor.Received his BSc degree and PhD degree in computer science from the College of Computer, National University of Defense Technology, Changsha, China, in 1999 and 2005, respectively.His main research interests include distributed computing, cloud computing and big Data.

LiZiyang, born in 1989.PhD.His main research interests include distributed computing, data-parallel distributed frame-work and machine learning.