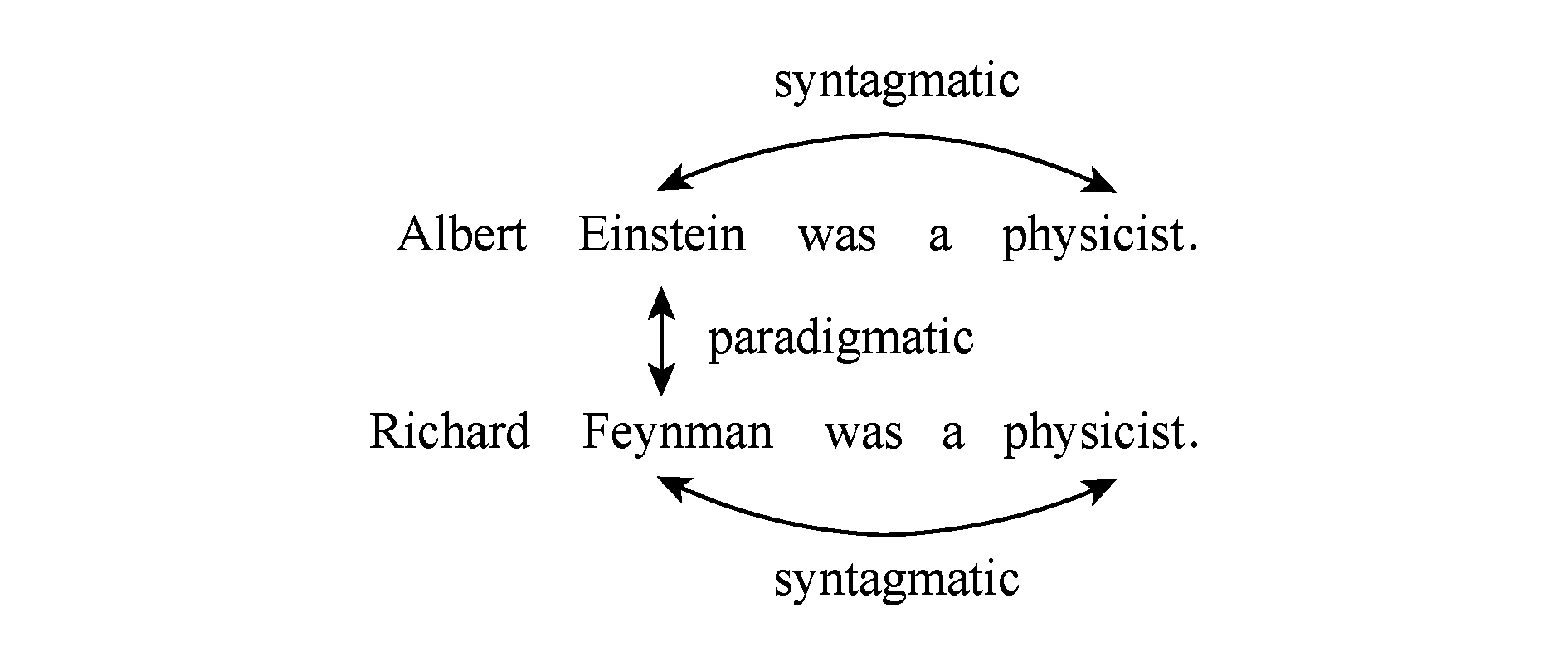
Fig.1 Example for syntagmatic and paradigmatic relations
图1 横向与纵向组合样例
郭嘉丰 范意兴
(中国科学院网络数据科学与技术重点实验室(中国科学院计算技术研究所) 北京 100190) (中国科学院计算技术研究所 北京 100190) (guojiafeng@ict.ac.cn)
摘要经过几十年的发展,信息检索技术获得了长足的进步和广泛的应用,但当前主流的搜索引擎系统距离真正智能的信息获取系统仍然有较大差距.智能信息获取系统能够对网络大数据的内容进行获取、阅读和理解,对关键语义信息实现存储和检索,并能够依据用户的信息需求进行推理、决策和信息生成.实现这样的系统,迫切需要在检索架构和检索模型上形成根本性的改变和理论突破.近年来,围绕智能信息获取的需求,利用深度学习检索框架展开了系统性研究,在数据表征、数据索引以及检索算法等方向上形成了一系列原创成果,在探索全新的深度学习检索架构上不断迈进.
关键词信息检索;深度学习;数据表征;相关匹配;数据索引
从大规模数据中帮助用户快速高效地获取所需的相关信息是信息检索研究的核心问题.近年来,尽管信息检索技术已经取得了长足的发展,特别地针对大规模网络数据的搜索引擎已经成为用户日常获取网络信息的主要手段,它离真正智能的信息获取系统仍有较大的差距,这主要体现在3个方面:
1) 为了支撑大规模数据的检索,基于关键词的倒排索引是当前搜索引擎的基础架构[1],关键词检索成为获取候选相关文档的基本手段,这极大地限制了对复杂的信息需求与网络信息语义匹配的能力;
2) 大部分搜索引擎将网页作为基本搜索对象,缺乏对其包含的数据内容的理解和加工,把真正的信息理解和获取难题仍然留给了用户;
3) 被搜索引擎广泛采用的机器学习排序模型[2],通常把相关性建模为人工定义特征的某种简单组合,缺乏对相关性的深入理解与建模、缺乏对信息获取复杂交互过程的支持.理想的搜索引擎,能够通过对网络空间大量数据内容的获取、阅读与理解,将其中所包含的关键语义信息建模与存储下来;当用户有信息需求时,用户可以用自然的描述方式阐述其信息需求,系统通过检索获得相关的支撑信息,并通过知识推理、相关决策与信息加工最终决定返回给用户的信息内容.我们将这样的搜索引擎称为“智能信息获取系统”,因为它不同于以往的搜索引擎仅把原始存在的网页/资源看作是天然的检索对象,而是认为网络数据包含的关键信息内容才是真正的获取对象,通过对细粒度信息内容的建模、索引、检索、决策、交互与生成,满足用户的信息需求.为了能够支撑这样的智能信息获取,我们亟需在检索架构、检索模型上产生根本性的改变和理论突破,包括:1)如何对网络数据包含的关键信息内容进行表征、存储与索引,以支撑大规模信息内容的高效语义检索(非关键词匹配);2)如何建模复杂的用户需求与信息的相关匹配关系,实现对相关性更深层更完备的推理、决策与生成.
近年来,深度学习技术在图像[3]、语音[4]、自然语言处理[5-6]等领域取得了显著的突破,已经开始延伸到信息检索领域,深度学习模型强大的表达能力和学习能力,可以为智能信息获取中数据语义信息表征、相关性推理决策以及复杂交互过程的建模提供良好的支撑.Google、微软等公司在该方向已经有了不少尝试[7],斯坦福大学的Manning教授在SIGIR 2016的大会主题报告上预言2017年将会是深度学习进军信息检索领域的一年,神经网络搜索的研讨会(NeuIR Workshop)也连续2年在SIGIR会议上成为最受关注的研讨会,由此可见无论工业界还是学术界对深度学习检索都十分关注.然而,目前已有的结果显示深度学习应用于检索并不是其他领域深度学习模型的简单移植,而是需要结合信息检索的固有特征、领域知识和独特模式来构建,并且对信息检索最基本的架构也会产生巨大的影响.
鉴于此,我们围绕智能信息获取的需求,利用深度学习检索框架展开了系统性研究,形成了一系列关于稠密数据索引和深度相关匹配的探索.随后,我们将从数据表征、数据索引和检索模型3个层面简要介绍我们在深度学习检索方面所取得的最新研究成果.
如何将语言文本表示成计算机可理解的表达形式,一直是自然语言理解任务中的重要问题.长久以来,最常用的单词表示方法一直是独热表示(one-hot representation),这种表示方法将单词表示成只有某一维非0的向量,且每个单词使用不同的维度.这种表示方法在实际应用中面临着稀疏以及组合爆炸的问题.近年来,伴随着深度学习研究的崛起,分布式表示,即将文本表示成低维实数向量,得到了广泛的研究,同时这些表示也被应用到自然语言处理的各类任务中并取得了显著性能提升.文本数据的表征研究主要集中在单词分布式表示研究以及句子的分布式表示研究,以下将对这2部分的工作进行详细的介绍.
分布式单词表示,又常被称作词向量或词嵌入,将单词表示为低维实数向量.这些向量,可以有多个维度取非零.最常见的形式则是所有维度都有值,也就是稠密向量.目前主流的学习单词的分布式表示的主流思路都是基于分布语义假设(distributional hypothesis)[8-9].它是整个自然语言处理领域最重要的假设之一,其假设处于相似上下文中的单词具有相似的含义.数十年来,研究人员基于此假设提出了大量的单词表示学习模型.这些模型大体上都是利用上下文的统计信息来表示一个单词,不同的只是不同模型使用了不同的方法,计算了不同的统计信息.而从分布语义假设的内容容易看出,“上下文”才是整个假设的基础.根据模型所建模的上下文的不同,现有的单词表示工作可以分为2类:
1) 横向组合模型,主要使用单词所处的文档(或句子)作为单词的上下文,认为2个单词如果经常在相同文本中共现,则这2个单词语义相似.对于图1示例,此类模型可以捕捉“Einstein”与“physicist”之间的语义关联.这类模型常用于信息检索领域,在这类场景下文档是一个关于单词上下文的自然选择,代表性工作包括隐式语义分析(latent semantic analysis)[10]和非负矩阵分解(non-negative matrix factorization)[11].
2) 纵向聚合模型,主要使用单词周围的单词作为上下文,认为如果2个单词其周围的单词总是相似的,则这2个单词语义相似.对于图1示例,此类模型可以捕捉“Einstein”与“physicist”之间的相似性,即使这2个单词并未在一句话中共现.这类模型主要建模了单词间的纵向聚合关系,在自然语言处理领域是一个非常常见的选择,代表性工作包括CBOW(continuous bag-of-words),SG(skip gram)[12-13]以及GloVe[14]等.
Fig.1 Example for syntagmatic and paradigmatic relations
图1 横向与纵向组合样例
然而,这2类工作都只建模了单词间的一种关系,丢失了单词的部分语义信息.如横向组合模型,虽然可以编码单词横向之间(如Einstein与physicist)的相似性,却无法捕捉纵向之间(如Einstein与Feynman)的相似,因为它们并没有共现.另一方面,纵向聚合模型虽然能得到单词纵向(如Einstein与Feynman)之间的相似性,却丢失了单词的横向关联(如Einstein与physicist).为克服这个问题,我们提出一种同时建模单词间的横向组合与纵向聚合关系的方法[15],具体地,本文不但利用单词所处的文本区域(如句子、文档)来学习单词的表示,同时也利用单词周围的单词(单词周围某个大小的窗口内的单词)来学习它的表示.如图2所示,在PDC模型中,不仅使用单词周围的上下文来预测它,还使用它所在的文档来预测它,前一个任务捕捉了单词间的纵向聚合关系,因为相似上下文意味着相似的网络输入,可以得到相似的输出向量;后一个任务则捕捉了单词间的横向组合关系,也就是单词间的共现信息.在HDC(hierarchical document context)模型中,首先使用单词所在的文档去预测当前单词,然后再使用此单词预测其周围的每一个单词.与PDC类似,文档预测单词部分建模了单词间的横向组合关系,而单词预测上下文部分则建模了单词间的纵向聚合关系.通过并行地或者层次化地建模这2种信息,本文提出了2个新型的学习单词表示的联合训练模型.本文在单词相似度以及单词类比这2个任务的多个数据集上对所提模型进行了实验评价.实验结果显示,本文所提模型在这2个任务上均显著好于现有只建模一种关系的模型.

Fig.2 PDC model and HDC model
图2 PDC模型和HDC模型框架图
单词的分布式表示在近些年取得了长足的发展,已成功用于文本处理的方方面面.在复杂的自然语言处理任务中,仅使用单词的语义表示并不足以直接完成这些任务.因此,句子的表示学习也成为近年来自然语言处理与机器学习另一个火热研究点.借助单词的分布式表示在文本处理领域取得显著突破,在单词表示上构建句子的分布式表示,逐渐成为句子表示领域的主流,目前也已在多个领域取得良好结果.
通过句子与单词间的共现信息利用统计学习方法来学习句子的表示,这种思路最早可以追溯到弗雷格于1892年提出的复合性原理(principle of compositionality),一句话的语义由其各组成部分的语义以及它们之间的组合方法所确定[16].这类方法大体上使用某种语义组合方式,组合单词的表示来得到句子的表示,常见的组合方法有简单求和[17-19]、按位乘法[20]、矩阵乘法[21]、张量乘法[22-23]等方式.然而,Gershman与Tenenbaum的最新工作表明,这些基于线性代数的组合方式并不能完全捕捉短语及句子的语义[24].同时,这些方法也存在另一些明显的缺陷:1)缺少健全的概率基础,使得它们具有很弱的可解释性;2)假设了文本间的相互独立,限制了对整体语料信息的利用.

Fig.3 Spherical paragraph model
图3 球面文档模型
为了解决上述问题,我们提出了一个基于词向量包(bag-of-word-embedding)的spherical paragraph model (SPM)模型[25],其通过建模整个语料库的生成来学习文本的表达.如图3所示,首先,每个文本先被表示成L2正则化词向量的词袋.通过正则化,词向量间的余弦相似度就等于词向量间的点积,因此所有的词向量都在一个单元超球面上.然后,我们假设生成过程为:首先从语料层的先验分布中采样一个文本向量,然后再从文本层的分布中采样文本包含的所有词向量.其中,von mises-fisher (vMF)分布能很好地建模单元球面上的数据,因此被用作语料层和文本层中的分布.和传统模型相比,我们的模型有3个特点:1)通过建模整个语料库的生成,SPM能很好地利用词语义,词-文本共现以及语料库信息;2)通过使用vMF分布,SPM能很好地捕捉词向量间的语义相似度;3)SPM具有很好的概率可解释性.基于单词的分布式表达,另一种构建文本片段表征的方法是使用fisher kernel (FK)框架.在传统的FK聚合方法中,词首先通过隐形语义索引(LSI)映射到欧几空间中;然后高斯混合模型(GMM)被应用作词向量的生成模型;最后,GMM的参数梯度被用作文本的表示.如今分布式表达(distributed representation)已经被证明比LSI具有更好的表现,因此我们希望将分布式表达很好地应用在FK框架中.然而,直接在分布式表达上使用FK框架是不合适的,因为传统方法中的GMM模型是被用来捕捉词向量间的欧氏距离,而分布式词向量之间的语义关系由余弦相似度测量更合适.因此,我们提出了一个基于分布式词向量的FK表达方法[26].如上所述,von mises-fisher (vMF)分布能很好地建模单元球面上的方向数据,并且能捕捉向量间的方向关系.因此,我们引入mixture of von mises-fisher distributions (moVMF)取代传统FK框架中的GMM,作为词向量的生成模型.我们在文本分类,文本聚类以及信息检索3个任务上,和已有的文本表达模型做了对比实验,实验结果证明了我们模型的有效性.
传统基于关键词的召回方法依靠倒排索引技术,能快速的召回包含每个关键词的文档,同时也面临经典的词失配(vocabulary mismatch)的问题,即同样含义的查询词用不同的文字表示,例如,当检索“计算机”时,包含“计算机”的文档可以很快被找到,然而包含“电脑”的文档却不能被检索出来.文本嵌入技术的提出使得每个文本可以有一个稠密向量表示,稠密向量的含义为大多数维度上都是有值的向量.含义相近的文本在向量空间中余弦距离较近,因此2个给定的文本的语义相似度可以通过文本向量来表示.将查询和文档表示成稠密向量,可以很好地在语义层面计算查询和文档的相关性.给定查询时,可以通过查询距离它最近的文档向量即可召回一些候选文档.基于稠密向量的召回虽然可以通过在语义层面匹配来解决词失配的问题,然而它也带来了一个关键问题:给定一个向量,如何快速在文档向量集合中找到与其语义相近的向量?这个问题的形式化定义为,给定检索数据集![]() ={x1,x2,…,xn}∈
={x1,x2,…,xn}∈![]() d,查询项q∈
d,查询项q∈![]() d,距离函数distance为欧氏距离或余弦距离,查询项的最近邻定义为
d,距离函数distance为欧氏距离或余弦距离,查询项的最近邻定义为![]() 常用的K-最近邻定义为离查询项最近的k个邻居.解决这个问题的方法大致可以分为2类,分别是面向稠密向量的索引方法以及基于Hash编码的索引方法.
常用的K-最近邻定义为离查询项最近的k个邻居.解决这个问题的方法大致可以分为2类,分别是面向稠密向量的索引方法以及基于Hash编码的索引方法.
直接面向稠密向量的索引方法在原始空间进行搜索,尝试减少距离计算来加速搜索.面向稠密向量的索引方式根据采用的数据结构的不同,可以分为两大类,分别是层次结构索引和近邻图索引.层次结构索引方法的主要思想是分层划分空间或数据,以范围从大到小.如图4所示,当给定一个查询时,从查询项在最后一层所在区域开始查找,排除掉大部分无关的向量来进行快速检索.早期的K-d树[27]通过分割空间和回溯查找尝试加速近邻查找,在向量维度较低时取得良好效果,但在维度较高时性能急剧下降,甚至退化到比线性搜索还慢.K-means树[28]是和k-d树类似的层次结构,不同的是,每一层采用K-means算法聚类来将数据分成2份或多份.然而,由于高维空间精确查找近邻问题太过于困难[29],基于k-d树和K-means树的随机版本[30]被提出,每次划分时采用随机选取的维度或者聚类中心来实现每一层的不确定划分,叶子结点也可以保存多个向量数据,检索时避免过多的回溯操作,同时可以采用多棵树构成森林同时查找来提升效果.近邻图索引则将每个向量连向一定数目的邻居,构成一张图,如图4(b)所示.基于近邻图索引的搜索算法的核心思想可以概括为邻居的邻居也有可能是邻居,通过在近邻图上采样一些点作为搜索起始点,不断扩展它们的邻居并保留离查询项更近的点作为下次扩展的起点,重复这个迭代过程直至无法扩展出更近的点.K-最近邻图(K-nearest-neighbor graph,K-NN)[31]关注在索引结构的构建上,将每个点连向离它最近的k个邻居.KGraph[32]采用k-NN图作为索引,同时提出了一种快速构建近似索引的最近邻下降算法.多样化近似图(diversified proximity graph)[33]提出采用双向图来提高图的连通性,同时提出选择的邻居应当在方向上多样性,并提出一种启发式算法来选择邻居,取得了不错的效果.小世界图(small world graph)[34]则提出构建的图应具有导航功能,在图上的搜索时可以实现跳跃功能,加速查找.
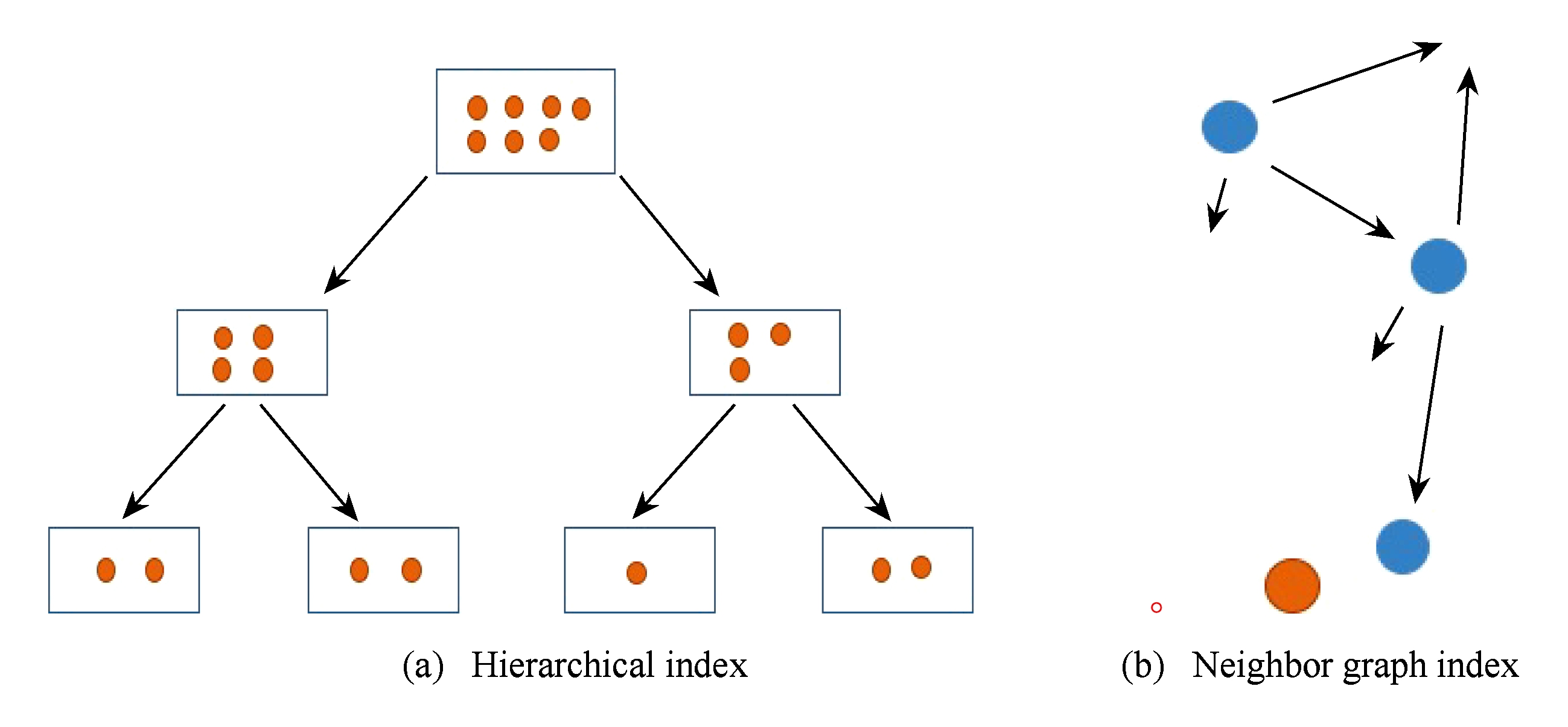
Fig.4 Different indexing methods
图4 不同的索引方法
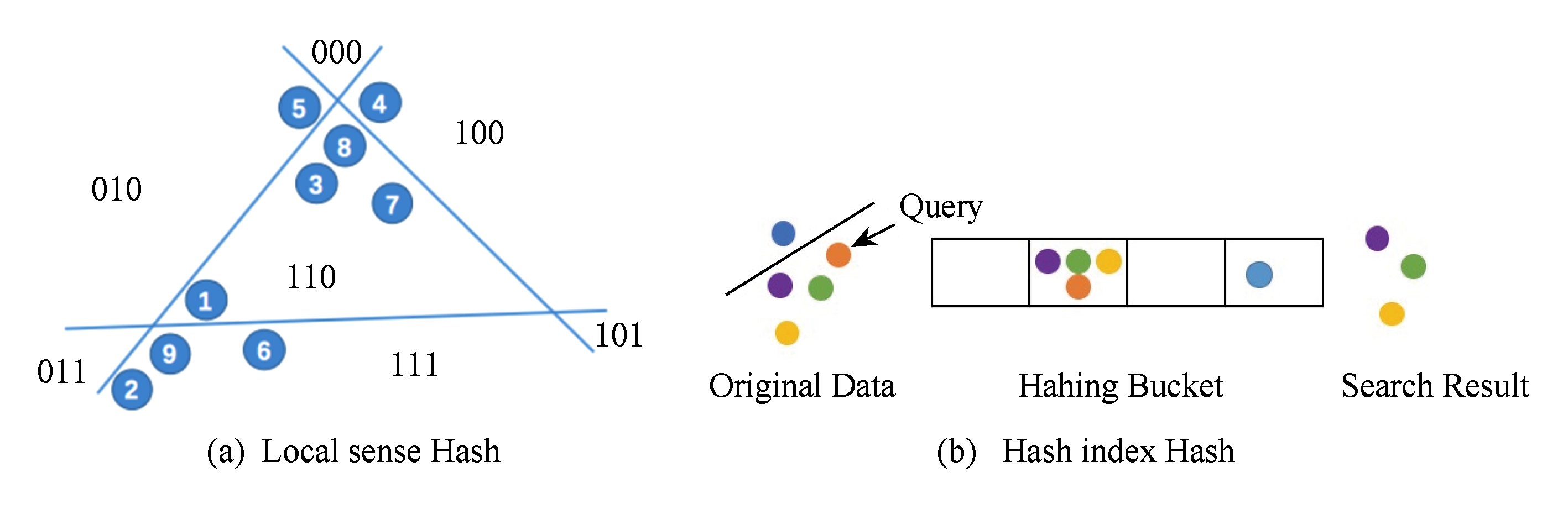
Fig.5 Hash indexing methods
图5 Hash索引算法
Hash索引则是寻求数据更简洁的表示,在编码空间尽可能保持原有空间的关系,主要通过减少计算带来加速搜索.由于表示简单,Hash索引同时具有存储代价小的特点,得到了广泛的应用.Hash相关的工作主要关注如何学习出更好的Hash编码,即采用更好的Hash函数,从而更好地保持原始空间的关系,根据是否考虑数据的分布可以分为局部敏感Hash和Hash学习两大类.局部敏感Hash(locality sensitive hashing,LSH)[35]是一类基于LSH家族定义,采用随机投影框架来将原始向量转为Hash编码进行近邻搜索方法的总称.如图5(a)所示,LSH家族是一类将相似的输入项比不相似的输入项以更高概率映射到相同Hash编码的函数家族.局部敏感Hash相关研究针对不同的距离或者相似性度量设计了不同的LSH家族,在不同距离度量空间下尽可能地保持原始向量之间的距离关系,如面向lp距离的p-稳定分布LSH[36]、面向余弦相似度的正负随机投影[37]等.Hash学习则试图根据原始向量空间中数据的分布学习出向量的Hash编码,更好地保持原始空间的关系,取得了比基于随机投影框架的局部敏感Hash更好的检索效果.Hash学习方法主要需要考虑5个方面的问题[38],即采用什么样的Hash函数、编码空间采用什么样的相似度、采用什么样的目标函数、采用什么样的优化技术.例如迭代量化(iterative quantization,ITQ)[39]通过主成分分析PCA将原始向量进行降维,根据向量中各元素的符号将其量化为比特.现有提出的Hash函数基于线性投影、核函数或者深度神经网络等,例如有线性Hash函数方法[40]和核函数Hash方法[41].除了二元Hash编码,量化采用多元编码[42-43],将原始向量划分为多个子空间,在多个子空间进行聚类,用聚类中心来替代子空间向量,所有子空间向量所属的聚类中心的拼接对原始向量进行估计.
现有的致力于分割数据或分割空间,希望能迅速排除掉大部分距离较远的向量,只对部分向量进行计算,以实现良好的检索性能.但是随着维度的增加,相邻块数目也以指数的速度增加.而近邻图结构不再分割空间,而是连接空间来构建索引[44],然而大部分k-最近邻图的方法中邻居是最近的顶点,因此缺乏探索能力,容易陷入局部最优.针对这一难题,我们提出了k-多样化最近邻图[45],并受信息检索中最著名的最大间隔多样性算法[46]的启发,提出了一种快速索引构建算法.我们希望图索引中每个顶点选择的邻居既尽可能靠近顶点,同时又尽可能在方向上多样化,这个目标和最大间隔多样化排序算法接近.受此启发,我们将k-多样化最近邻图的构建考虑成一个2阶段多样化排序过程:1)我们利用NN-Descent[47]算法为每个顶点获取邻居候选点;2)我们应用一个最大间隔多样化的算法对邻居候选点进行重排序,为每个顶点获取k个多样化的最近邻.通过这种方式,我们能平衡近邻图的准确率和多样性,因此同时具有良好的探索能力和利用能力.这个方法也提出了一种新的视角,将索引的构建过程视作信息检索中搜索结果多样化.具体来说,将每个顶点看作查询,邻居候选点看作文档,用最大间隔相关性准则来对邻居进行排序.
相关性建模一直是信息检索的核心问题,如何建模复杂的用户需求与信息的相关关系,实现对相关性更深层、更复杂的推理与决策成为了推进排序模型的原动力.近年来,深度学习的方法由于其强大的数据拟合能力,在各个领域取得了不同程度的进展,如计算机视觉中图片分类任务[48]、语音处理中语音识别任务[49]、自然语言处理中机器翻译任务[50]等.基于深度学习的相关性模型大致可以分为2类:1)利用神经表达改进排序模型,这类方法仍然以现有的相关性模型为主体框架,利用神经表达(neural representation)来改进其中的关键模块;2)端到端的神经网络排序模型,这是一种全新的方法体系,直接利用神经网络来建模查询与文档之间的相关性.
在利用神经表达改进相关性模型的工作中,主要是借助词向量在刻画单词语义关联上的优势来解决传统检索模型的不足.传统的方法基于独热的单词表示来表达查询和文档,面临着经典的语义失配的问题.例如给定查询“deep learning methods”,当一个相关的文档中大量出现“neural network algorithm”时,在独热表示下是无法刻画这些单词之间的语义关联,捕捉二者之间的相关性.一个最直接的方法就是使用上述的词向量来表示单词辅助文档与查询的相关性判断.基于此想法,研究人员提出了不同的利用词向量来改进现有相关性建模的方法[51-54],根据相关性判断中词向量使用方式不同,这些方法可以分为2类:全局匹配方法和局部匹配方法.
全局匹配方法使用查询或文档内部单词的词向量来构建查询和文档的整体向量表示,然后在向量空间中计算查询和文档的相关性.最直接的一个方法就是词向量加权法(average word embedding,AWE)[51],AWE采用线性组合词向量的方式来计算查询和文档的表达,然后通过余弦相似度来计算二者的相关性.进一步地,Clinchant等人[52]提出了一个非线性的组合词向量的方式来得到查询和文档的向量表示,他们基于fisher kernel(FK)框架,提出了一个新颖的fisher vector(FV)的文档表示方法.全局匹配的方法直接在查询和文档的向量表示空间中进行相关性度量,其性能依然和传统的相关性模型差别甚远[51],这主要是因为直接将文档中所有的单词向量组合得到文档的全局向量,包含了太多的噪音信息,难以精确刻画单词之间的细粒度匹配信号.然而,通过结合基于向量的全局匹配与传统的相关性模型,性能能够得到一定的提升.
局部匹配方法则直接利用词向量来计算查询和文档中单词之间的匹配相似度,然后整合局部单词的相似度值得到查询和文档整体的相关度.Mitra等人[53]指出在使用Word2Vec训练得到的词向量来增强查询和文档的相关性建模时,在查询语料中训练得到的词向量比在文档语料中得到的词向量效果更好,提出了一个对偶向量空间模型(dual embedding space model,DESM),通过为查询中的每一个单词计算其与文档整体的相似度,再融合不同的查询单词的匹配程度得到最终的相关性得分,DESM取得了比AVE更好的效果;Ganguly等人[54]基于语言模型提出了一个一般的语言模型(generalized language model, GLM)的方法,在原始的使用精确匹配语言模型的基础上引入了基于词向量的翻译模型.基于词向量的局部匹配组合得到查询-文档对的整体匹配的方法,总之,比基于全局的向量空间的匹配方法具有更好的性能.但是,由于在单词的相似度计算时,需要计算查询词和整个词表中所有单词的相似度,因此计算代价较大.
在借助分布式单词表示来增强查询和文档的相关性建模方面,我们在以往词袋模型的基础上,为每个单词关联其对应的词向量,得到词向量袋(bag-of-word-embedding, BoWE)假设表示.基于此,我们提出了一个基于词运输框架的相关性模型(non-linear word transportation,NWT),将查询与文档的相关性看成是一个从文档到查询的语义信息的运输过程,如图6所示,文档中的词看成是信息的“消费者”,查询中的词则是信息的“消费者”,从文档到查询运送的信息就是“商品”,最终文档向查询能运送的“商品”的总量就是文档与查询的相关程度.根据信息检索中相关性匹配的特性需求,我们为相关匹配中的词运输问题增加了3项假设:1)文档中的单词根据出现的频率有其确定的信息容量,且信息容量的设置需要满足不同文档类型的需要;而查询由于其模糊的信息需求,每个查询词的信息容量则不做限制,这样使得查询能够从文档中接收尽可能多的相关信号.因此,相关匹配的词运输是一个非对称的信息运输问题.2)从文档单词到查询单词“运送”的语义相关的词取得的信息增益定义为运输的“收益”,且精确匹配运输收益要显著优于语义匹配的运输收益.3)每个查询词的总收益应该满足边际效应递减的性质,也就是说,一个查询词上收益的增量会随着收益总量的增加而减少,以保证相关文档对于查询中不同层面信息需求的满足[55].最终,一个文档与查询的相关性匹配得分就由它能给查询提供的最大信息收益决定.NWT模型能有效地利用词向量来克服查询与文档之间的单词失配问题,显著提升相关性建模的性能,同时,NWT模型的设计极具灵活性,可以为不同模块设计合适的函数,从而得到不同的模型变种.
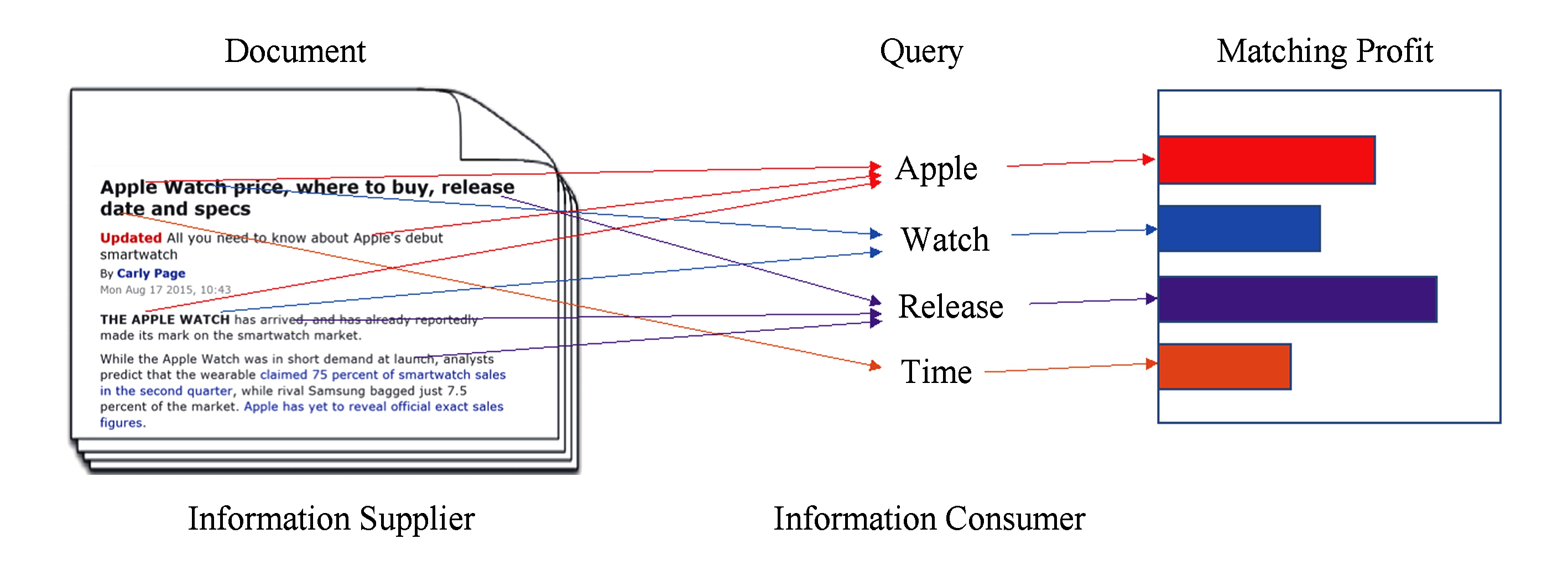
Fig.6 Non-linear word transportation model
图6 非线性的词运输模型
在利用深度学习方法直接建模查询与文档的相关性方法中,使用神经网络端到端的从原始的数据表示中学习二者的相关性特征用于最终的相关性的建模.伴随着深度学习方法的崛起,研究人员提出了大量的深度匹配模型,这些方法根据网络关注角度的不同,可以分为2类:关注表征的匹配模型和关注交互的匹配模型.
在关注表征的匹配模型中,其重点在于更好的学习文本的表征,因此这类模型通常是使用深度神经网络为文本(即查询或文档)构建复杂的表征,然后基于二者的表达进行简单的匹配.例如DSSM[56]将查询和文档中的词拆解成字母N-元组;然后使用全连接神经网络将查询和文档映射到同一个语义空间,得到二者的高层抽象的表征;最后通过简单的余弦相似度函数来刻画二者的语义相关性.另外,CDSSM[57]同样使用单词N-元组为基本的输入单元;然后使用卷积神经网络来学习查询和文档的高层的语义表征;最终在语义空间中,同样使用余弦相似度函数来计算二者的相关程度.另外,ARC-I[58]直接基于原始的单词,使用卷积神经网络来逐层抽象得到文本的稠密向量空间表征,最后通过全连接网络来建模2个表征的匹配.同样地,卷积神经张量网络(convolutional neural tensor network, CNTN)[59]使用卷积神经网络得到2个文本的表征,不同的是,交互函数使用的是张量匹配而不是全链接网络.Socher等人[60]提出了一个可扩展递归自编码器(unfolding recursive antoencoder, uRAE)模型,uRAE首先基于句法分析树使用递归自编码器为句子构建层次化的组合表达,然后通过不同层次的表达之间的匹配判断2个句子之间的语义关系.Yin等人[61]提出了一个MultiGranCNN模型,使用深度卷积神经网络学习层次化的句子表达,最后基于不同粒度的表达之间的交互得到最终的文本匹配得分.
在关注交互的匹配模型中,其重点在于建模文本内部基本单元的交互信号,因此这类模型通常是先构建2个文本(即查询与文档)中的单词交互,这里的交互函数可以是简单的异或函数、点积函数、或是余弦函数等,得到二者的交互矩阵;然后使用深度神经网络从交互矩阵中逐层抽象得到最终的匹配得分.大量的模型都属于这一类别,例如在DeepMatch[62]中,文本中的单词序列通过主题模型构建好单词的基本交互矩阵,然后使用深度前馈神经网络来得到最终匹配得分.在ARC-II[58]中,单词被映射到词向量,然后使用拼接函数得到单词之间的交互,然后使用深度卷积神经网络来捕捉信号之间的交互最终得到二者的匹配得分.MatchPyramid[63]首先基于词向量构建2个文本片段匹配矩阵或者张量M,M中的元素值为2个句子中对应单词的词向量的交互得分,在匹配矩阵的基础上使用卷积神经网络逐层抽象得到最终的匹配得分.和MatchPyramid类似,Match-SRNN[64]也是先构建匹配矩阵M,不同的是,Match-SRNN使用二维循环神经网络(2D-GRU)来捕捉2个文本片段中的递归的匹配模式.
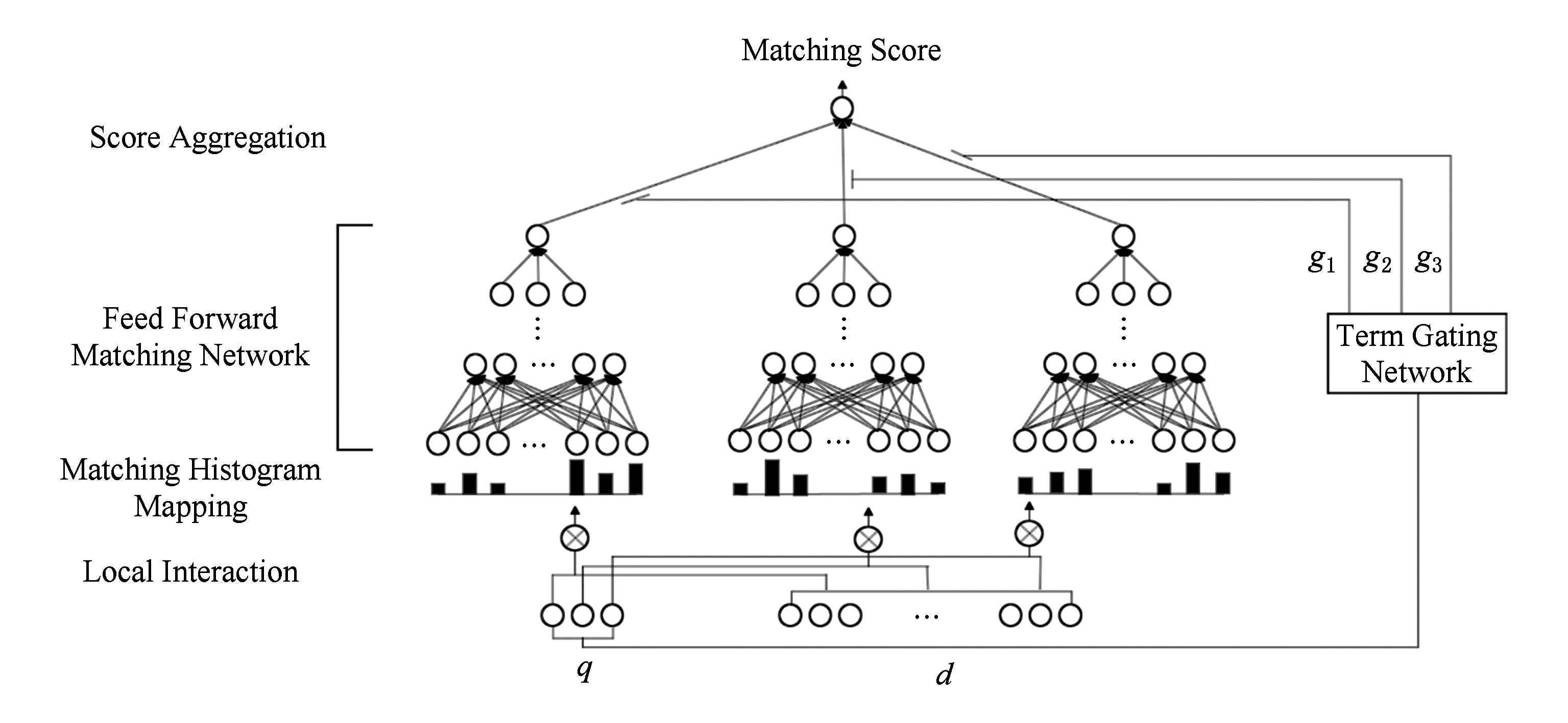
Fig.7 The deep relevance matching model
图7 深度相关性匹配模型
尽管大量深度匹配模型被剔除并用于文本的匹配,但是这些方法大都是面向2个同构的文本片段之间的匹配,例如复述问题中2个句子的匹配,即便是针对信息检索设计的模型DSSM和CDSSM,也是在点击日志的查询-标题对上取得较好的效果.然而,对于像短查询与长文档这类异构文本之间的相关性匹配,目前依然没有取得太大的进展.同时,当我们将这些深度匹配模型应用在检索中查询与文档的匹配时,发现其效果比传统的检索方法(如BM25和语言模型)更差.针对这个问题,我们对检索问题中的相关性建模进行了深入的分析,利用深度学习模型,从相关匹配、相关决策到相关感知,不断深入地建模相关关系,提出了一系列的相关性模型[65-68].
3.2.1 基于匹配的深度相关性模型
查询与内容的相关性判定问题可以被形式化成2个文本片段的匹配问题.以往的工作将信息检索中的相关性匹配问题与复述问题、自动问答和对话系统等任务同等对待,然而,我们认为信息检索中的相关性匹配与其他自然语言任务存在显著的差异.具体地,在传统的自然语言相关任务中,最核心的关注点是语义匹配,而在信息检索中重点关注的是相关性匹配.语义匹配与相关性匹配在建模时有各自完全不同的需求:对于语义匹配而言,相似度匹配信号、组合语义以及全局的匹配(例如主题匹配)是其最重要的3个特性;而对于相关性匹配、精确匹配信号、查询词的重要度以及多样的匹配需求(例如对于一个查询、一篇相关的文档可以是全局匹配也可以是局部部分匹配)是其最核心的要素.
针对上述提出的信息检索中相关性匹配的需求,我们提出了一个深度相关性匹配模型(deep relevance matching model)[66].具体地,我们的模型包括3个部分,如图7所示:1)匹配直方图映射网络.这个网络将查询与文档内容的匹配信号按信号强度分成不同的直方图,从而能直接区分精确匹配和相似度匹配的信号.2)前馈匹配网络.这个网络将上一个网络的输出作为输入,通过前馈网络来捕捉多样的不同层次的匹配需求;最后一个部分是词门控网络,这个网络对不同的查询词分配不同的重要度.3)融合起来就得到如图1所示的最终网络模型图.我们和多个基准模型在3个经典的相关性匹配任务上进行了比较,我们的模型比所有的基准模型效果都要显著地好.
3.2.2 基于决策的相关性模型DeepRank
之前的工作直接建模了用户信息需求与文本内容的相关匹配关系,但是进一步我们发现人们对相关性的判断是一个复杂的决策过程,仅仅考虑简单的匹配是不足够的.我们通过分析人工标注相关性标签的产生过程,形成对人们判断相关性的主要阶段的认识,进而提出了一个结合语义匹配信息、匹配信号的空间关系以及匹配信号的聚合方式,即端到端的相关性排序深度学习模型——DeepRank[67].DeepRank模型启发自人工标注相关文档的过程,主要分为3个模块:相关区域检测策略、局部相关性度量网络和全局相关性聚合网络,具体的模型结构图如图8所示:
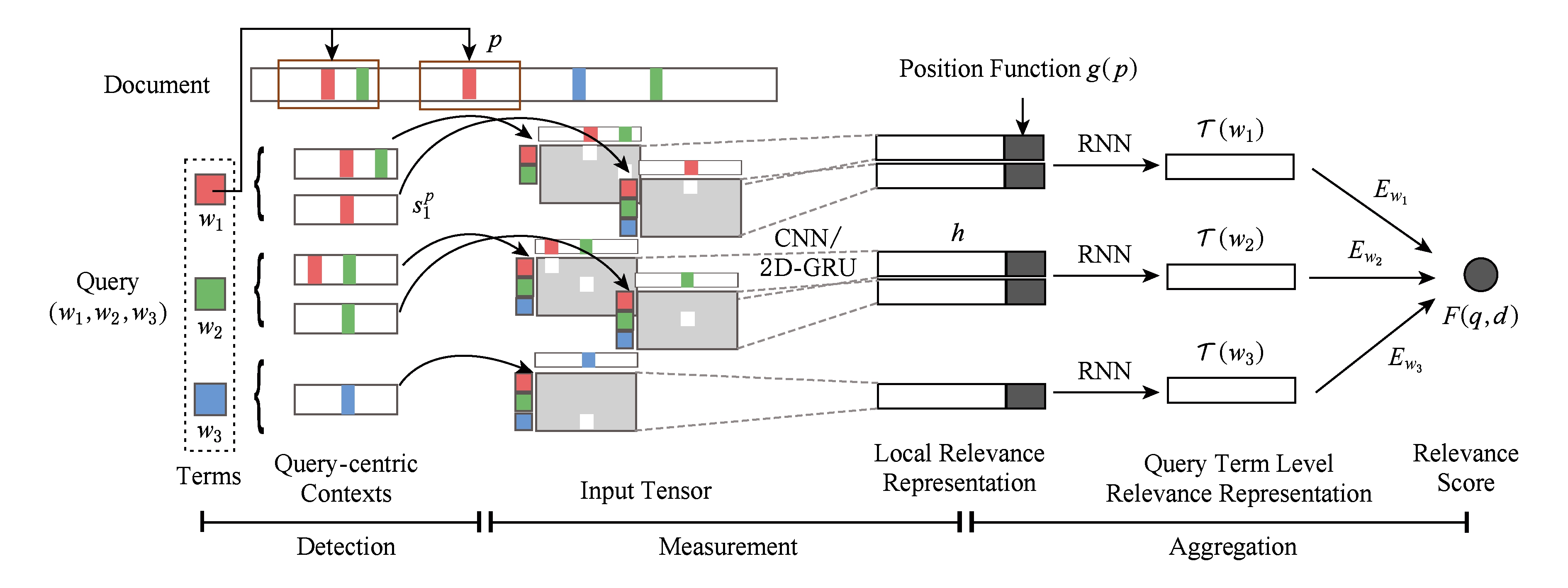
Fig.8 The DeepRank model
图8 深度排序模型
根据人工标注过程的理解与眼球跟踪实验的结论,我们发现人们在判断文档相关性的时候重点会关注关键词匹配为中心的一个窗口内的文本,所以我们定义相关区域为以查询项关键词为中心的一个文本片段.得到的文本片段数量相对于整个文档而言已经大大精简,不仅减少了计算量,也很好地过滤了长文档中的噪声影响.在这些得到的文档片段之上,我们采用深度文本匹配的模型MatchPyramid和MatchSRNN,建模查询项和文档片段之间的相关性,我们称为局部相关性度量.为了得到全局相关性的分数,需要经过2个步骤的局部相关性的聚合:1)在查询项关键词级别的聚合,聚合采用时序相关的循环神经网络,旨在建模不同片段出现的先后顺序和重要程度的累计;2)在全局的相关度聚合,聚合采用门控神经网络,旨在确定各个查询项关键词的重要度.最后我们提出的DeepRank与当前的基于特征构建的learning to rank方法进行了对比,发现仅仅用文本内容信息的DeepRank模型,已经能达到和超过利用了文档重要度等其他特征的learning to rank模型.
3.2.3 基于感知的相关性模型ViP
在这部分工作组中,我们进一步利用深度学习模型的强大能力来直接模拟人看网页内容、产生相关性判断的过程.具体地,我们直到传统的排序模型主要是基于学习排序(learning to rank, L2R)的思想来构建的,学习排序的方法需要对网页和查询对构建相关性的特征,目前现有的特征构建是先从网页中抽取出网页的正文内容,然后基于正文的内容和查询构建相关性的特征.然而,一个网页是一个精心设计的文档,其不仅包含重要的文本信息,同时,还包含了丰富的视觉信息.首先,给定一个网页,从该网页的快照信息中可以看到,一个高质量的网页往往具有良好的结构、清晰的布局;而一个低质量的垃圾网页,通常具有很多漂浮的广告,布局也比较凌乱.其次,在给定一个查询的情况下,一个整体相关的网页,查询词通常会均匀分布在网页正文的各个部分,而一个相关度比较低的网页、查询词可能会分布在网页中比较边缘的位置(例如广告区).
我们提出直接利用网页的视觉信息来进行相关性建模.具体地,给定一个网页,我们首先生成该网页的快照,网页的快照是从原始的网页内容渲染处理出来的一个图片.网页快照包含2种:1)查询无关的,这种快照就是原始的网页图片;2)查询相关的网页快照,这种快照是在原始网页快照的基础上,将查询中每个词在网页快照中高亮出来.基于网页的快照,我们提出了一个视觉感知模型(visual perception model)[68]来学习网页的视觉特征,如图9所示,该模型是模拟人们在网页上的视觉搜索行为而设计的,具体地,给定一个网页,人们浏览网页是呈现F型的浏览模式,具有从左到右、从上到下的一个顺序.基于此,我们将网页按行切成多个块,每个块具有和原始网页快照相同的宽度,块的高度则作为一个可调节的超参.针对每一个块,我们使用卷积神经网络来获取该块的特征;然后使用长短时记忆网络来对不同块的特征进行整合得到整个文档的视觉特征;最后,通过视觉感知模型学习到的特征可以和传统的文本相关的特征拼接起来输入到全连接的网络中,得到最终查询和网页的相关度.同时,针对该视觉感知模型,我们改进了原始倒排索引,用以支持快速的网页快照检索,具体地,我们在原始的倒排索引中,针对每一个文档id,我们不仅存储了原始的网页内容,同时也存储了网页的快照,除此以外,我们还存储了该倒排索引词在快照中出现的位置,可以在网页快照中快速地渲染查询词的信息.我们和多个基准模型在2个经典的相关性匹配的任务上进行了比较,实验效果得到了显著的提升.
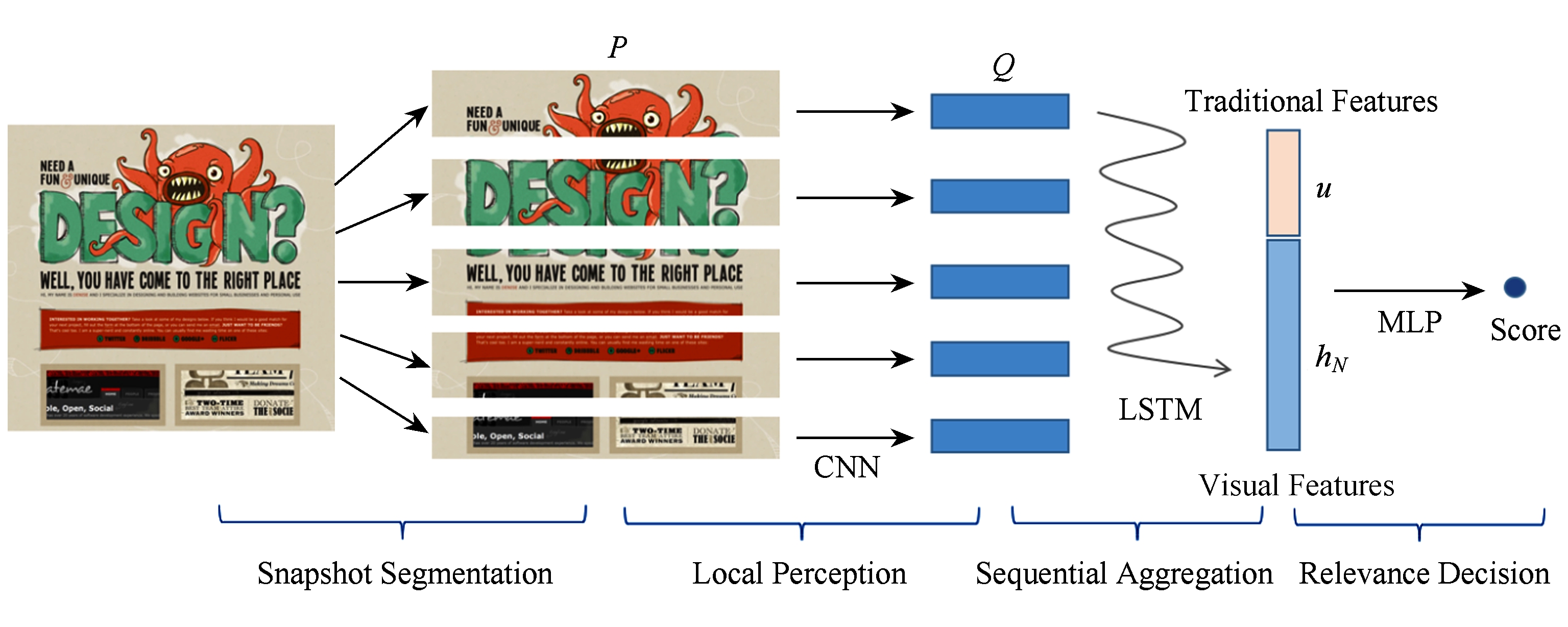
Fig.9 Visual perception model
图9 视觉感知模型
信息检索技术的研究已经有很长的历史,传统的检索框架已经进入到了相对成熟的阶段,但是随着数据规模、复杂程度的不断增大,人们对信息获取手段更加智能的期望也越来也强烈,这对已有的信息检索框架提出了全新的挑战,也为这个领域的技术革新提供了契机.我们有幸参与到这个历程中,并通过多年的研究取得了一些创新的理论成果.未来,对于信息内容、用户、检索过程、交互方式都有可能产生全新的定义,通过引入全新的机器学习技术(例如深度学习技术和强化学习技术),我们有可能带来搜索体系全新的变革,让信息检索变得更智能、更高效以及更无所不在.
参考文献
[1]Manning D, Prabhakar R, Hinrich S.Introduction to Infor-mation Retrieval[M].Cambridge, UK: Cambridge University Press, 2008
[2]Liu Tieyan.Learning to rank for information retrieval[J].Foundations and Trends in Information Retrieval, 2009, 3(3): 225331
[3]LeCun Y, Bengio Y.Convolutional networks for images, speech, and time series[J].The Handbook of Brain Theory and Neural Networks, 1998, 3361(10): 255258
[4]Hinton G, Deng Li, Yu Dong, et al.Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups[J].Signal Processing Magazine, 2012, 29(6): 8297
[5]Socher R, Huang E, Pennin J, et al.Dynamic pooling and unfolding recursive autoencoders for paraphrase detection[C]//Proc of the 25th Advances in Neural Information Processing Systems, Cambridge, MA: MIT Press, 2011: 801809
[6]Lu Z, Li H.A deep architecture for matching short texts[C]//Proc of the 27th NIPS.Cambridge, MA: MIT Press, 2013: 13671375
[7]Huang P, He Xiaodong, Gao Jianfeng, et al.Learning deep structured semantic models for Web search using clickthrough data[C]//Proc of the 22nd ACM Int Conf on Information and Knowledge Management.New York: ACM, 2013: 23332338
[8]Harris Z.Distributional structure[J].Word, 1954, 10(23): 146162
[9]Firth J.A synopsis of linguistic theory 1930-55[J].Studies in Linguistic Analysis (Special Volume of the Philological Society), 1957, 1952(59): 132
[10]Deerwester S, Dumais S, Furnas G, et al.Indexing by latent semantic analysis[J].Journal of the American Society for Information Science, 1990, 41(6): 391407
[11]Lee D, Seung H.Learning the parts of objects by non-negative matrix factorization[J].Nature, 1999, 6755(401): 788791
[12]Mikolov T, Chen K, Corrado G, et al.Efficient estimation of word representations in vector space[C]//Proc of the 1st Int Conf on Learning Representations.2013
[13]Mikolov T, Sutskever I, Chen Kai, et al.Distributed representations of words and phrases and their compositionality[C]//Proc of the 27th Advances in Neural Information Processing Systems.Cambridge, MA: MIT Press, 2013: 31113119
[14]Pennington J, Socher R, Manning C.Glove: Global vectors for word representation[C]//Proc of the 19th Conf on Empirical Methods in Natural Language Processing.Stroudsburg, PA: ACL, 2014: 15321543
[15]Sun Fei, Guo Jiafeng, Lan Yanyan, et al.Learning word representations by jointly modeling syntagmatic and paradigmatic relations[C]//Proc of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th Int Joint Conf on Natural Language Processing.Stroudsburg, PA: ACL, 2015: 136145
[16]Gosehke T, Dirk K.Connectionist representation, semantic compositionality, and the instability of concept structure[J].Psychological Research, 1990, 52(2/3): 253270
[17]Landauer T, Dumais S.A solution to plato’s problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge[J].Psychological Review, 1997, 104(2): 211240
[18]Foltz P, Kintsch W, Landauer T.The measurement of textual coherence with latent semantic analysis[J].Discourse Processes, 1998, 25(2/3): 285307
[19]Williams E.Predication[J].Linguistic Inquiry, 1980, 11(1): 203238
[20]Mitchell J, Lapata M.Vector-based models of semantic composition[C]//Proc of the 46th Annual Meeting of the Association for Computational Linguistics.Stroudsburg, PA: ACL, 2008: 236244
[21]Socher R, Huval B, Manning C D, et al.Semantic compositionality through recursive matrix-vector spaces[C]//Proc of the 17th Joint Conf on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Stroudsburg, PA: ACL, 2012: 12011211
[22]Smolensky P.Tensor product variable binding and the representation of symbolic structures in connectionist systems[J].Artificial Intelligence, 1990, 46(1/2): 159216
[23]Fried D, Polajnar T, Clark S.Low-rank tensors for verbs in compositional distributional semantics[C]//Proc of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th Int Joint Conf on Natural Language Processing.Stroudsburg, PA: ACL, 2015: 731736
[24]Gershman S, Tenenbaum J.Phrase similarity in humans and machines[C]//Proc of the 37th Annual Conf of the Cognitive Science Society.Oxford, UK: Psychology Press, 2015
[25]Zhang Ruqing, Guo Jiafeng, Lan Yanyan, et al.Spherical paragraph model[C]//Proc of the 40th European Conf on IR Research.Berlin: Springer, 2018: 289302
[26]Zhang Ruqing, Guo Jiafeng, Lan Yanyan, et al.Aggregating neural word embeddings for document representation[C]//Proc of the 40th European Conf on IR Research.Berlin: Springer, 2018: 303315
[27]Bentley J.Multidimensional binary search trees used for associative searching[J].Communications of the ACM, 1975, 18(9): 509517
[28]Fukunaga K, Narendra P M.A branch and bound algorithm for computingk-nearest neighbors[J].IEEE Trans on Computers, 1975, 100(7): 750753
[29]Weber R, Schek H J, Blott S.A quantitative analysis and performance study for similarity-search methods in high-dimensional spaces[C]//Proc of the 24th Int Conf on Very Large Databases (VLDB).New York: ACM, 1998: 194205
[30]Silpa-Anan C, Hartley R.Optimised KD-trees for fast image descriptor matching[C]//Proc of the 18th IEEE Computer Society Conf on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE, 2008: 18
[31]Hajebi K, Abbasi-Yadkori Y, Shahbazi H, et al Fast approximate nearest-neighbor search with k-nearest neighbor graph[C]//Proc of the 22nd Int Joint Conf on Artificial Intelligence.Palo Alto, CA: AAAI, 2011: 1312
[32]Dong W, Moses C, Li K.Efficient k-nearest neighbor graph construction for generic similarity measures[C]//Proc of the 20th Int Conf on World Wide Web.New York: ACM, 2011: 577586
[33]Li Wen, Zhang Ying, Sun Yifang, et al.Approximate nearest neighbor search on high dimensional data-experiments, analyses, and improvement[OL].(2016-10-08) [2018-02-01].https://arxiv.org/abs/1610.02455
[34]Malkov Y, Ponomarenko A, Logvinov A, et al.Approxi-mate nearest neighbor algorithm based on navigable small world graphs[J].Information Systems, 2014, 45: 6168
[35]Indyk P, Motwani R.Approximate nearest neighbors: Towards removing the curse of dimensionality[C]//Proc of the 30th Annual ACM Symp on Theory of Computing.New York: ACM, 1998: 604613
[36]Datar M, Immorlica N, Indyk P, et al.Locality-sensitive hashing scheme based onp-stable distributions[C]//Proc of the 20th Annual Symp on Computational Geometry.New York: ACM, 2004: 253262
[37]Charikar M.Similarity estimation techniques from rounding algorithms[C]//Proc of the 35th Annual ACM Symp on Theory of Computing.New York: ACM, 2002: 380388
[38]Wang Jingdong, Zhang Ting, Sebe N, et al.A survey on learning to hash[J].IEEE Trans on Pattern Analysis and Machine Intelligence, 2018, 40(4): 769790
[39]Gong Yunchao, Lazebnik S.Iterative quantization: A procrustean approach to learning binary codes for large-scale image retrieval[J].IEEE Trans on Pattern Analysis and Machine Intelligence, 2013, 35(12): 29162929
[40]Strecha C, Bronstein A, Bronstein M, et al.Ldahash: Improved matching with smaller descriptors[J].IEEE Trans on Pattern Analysis and Machine Intelligence, 2012, 34(1): 6678
[41]He Junfeng, Liu Wei, Chang Shih-Fu, et al.Scalable similarity search with optimized kernel hashing[C]//Proc of the 16th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining.New York: ACM, 2010: 11291138
[42]Zhang Ting, Du Chao, Wang Jingdong, et al.Composite quantization for approximate nearest neighbor search[C]//Proc of the 31st Int Conf on Machine Learning.New York: ACM, 2014: 838846
[43]Jegou H, Douze M, Schmid C.Product quantization for nearest neighbor search[J].IEEE Trans on Pattern Analysis and Machine Intelligence, 2011, 33(1): 117128
[44]Wang Jingdong, Li Shipeng.Query-driven iterated neighbor-hood graph search for large scale indexing[C]//Proc of the 20th ACM Int Conf on Multimedia.New York: ACM, 2012: 179188
[45]Xiao Yan, Guo Jiafeng, Lan Yanyan, et al.Fast approximate nearest neighbor search viak-diverse nearest neighbor graph[C]//Proc of the 32nd AAAI Conf on Artificial Intelligence.Palo Alto, CA: AAAI, 2018: 81758176
[46]Carbonell J, Goldstein J.The use of mmr, diversity-based reranking for reordering documents and producing summaries[C]//Proc of the 21st Annual Int ACM SIGIR Conf on Research and Development in Information Retrieval.New York: ACM, 1998: 335336
[47]Dong W, Moses C, Li K.Efficient k-nearest neighbor graph construction for generic similarity measures[C]//Proc of the 20th Int Conf on World Wide Web.New York: ACM, 2011: 577586
[48]Krizhevsky A, Sutskever I, Hinton G E.Imagenet classification with deep convolutional neural networks[C]//Proc of the 26th Annual Conf on Neural Information Processing Systems.Cambridge, MA: MIT Press, 2012: 10971105
[49]Dahl G, Mohamed A, Hinton G E.Phone recognition with the mean-covariance restricted Boltzmann machine[C]//Proc of the 24th Annual Conf on Neural Information Processing Systems.Cambridge, MA: MIT Press, 2010: 469477
[50]Bahdanau D, Cho K, Bengio Y.Neural machine translation by jointly learning to align and translate[C]//Proc of the 3rd Int Conf on Learning Representations.2015
[51]Vuli![]() I, Moens M F.Monolingual and cross-lingual information retrieval models based on (bilingual) word embeddings[C]//Proc of the 38th Int ACM SIGIR Conf on Research and Development in Information Retrieval.New York: ACM, 2015: 363372
I, Moens M F.Monolingual and cross-lingual information retrieval models based on (bilingual) word embeddings[C]//Proc of the 38th Int ACM SIGIR Conf on Research and Development in Information Retrieval.New York: ACM, 2015: 363372
[52]Clinchant S, Perronnin F.Aggregating continuous word embeddings for information retrieval[C]//Proc of the 18th Workshop on Continuous Vector Space Models and Their Compositionality.Stroudsburg, PA: ACL, 2013: 100109
[53]Mitra B, Nalisnick E, Craswell N, et al.A dual embedding space model for document ranking[C]//Proc of the 25th Int Conf on World Wide Web.New York: ACM, 2016
[54]Ganguly D, Roy D, Mitra M, et al.Word embedding based generalized language model for information retrieval[C]//Proc of the 38th Int ACM SIGIR Conf on Research and Development in Information Retrieval.New York: ACM, 2015: 795798
[55]Robertson S E, Walker S.Some simple effective approximations to the 2-poisson model for probabilistic weighted retrieval[C]//Proc of the 17th Annual Int ACM SIGIR Conf on Research and Development in Information Retrieval.New York: ACM, 1994: 232241
[56]Huang J C, Frey B J.Structured ranking learning using cumulative distribution networks[C]//Proc of the 23rd Advances in Neural Information Processing Systems.Cambridge, MA: MIT Press, 2009: 697704
[57]Shen Yelong, He Xiaodong, Gao Jianfeng, et al.A latent semantic model with convolutional-pooling structure for information retrieval[C]//Proc of the 23rd ACM Int Conf on Information and Knowledge Management.New York: ACM, 2014: 101110
[58]Hu Baotian, Lu Zhengdong, Li Hang, et al.Convolutional neural network architectures for matching natural language sentences[C]//Proc of the 28th Advances in Neural Information Processing Systems.Cambridge, MA: MIT Press, 2014: 20422050
[59]Qiu Xipeng, Huang Xuanjing.Convolutional Neural Tensor Network Architecture for Community-Based Question Answering[C]//Proc of the 24th Int Joint Conf on Artificial Intelligence.Menlo Park, CA: AAAI, 2015: 13051311
[60]Socher R, Huang E H, Pennin J, et al.Dynamic pooling and unfolding recursive autoencoders for paraphrase detection[C]//Proc of the 25th Advances in Neural Information Processing Systems.Cambridge, MA: MIT Press, 2011: 801809
[61]Yin Wenpeng, Schütze H.Multigrancnn: An architecture for general matching of text chunks on multiple levels of granularity[C/OL]//Proc of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th Int Joint Conf on Natural Language Processing.2015 [2018-02-01].http://www.aclweb.org/anthology/P15-1007
[62]Lu Zhengdong, Li Hang.A deep architecture for matching short texts[C]//Proc of the 27th Advances in Neural Information Processing Systems.Cambridge, MA: MIT Press, 2013: 13671375
[63]Pang Liang, Lan Yanyan, Guo Jiafeng, et al.Text matching as image recognition[C]//Proc of the 30th AAAI Conf on Artificial Intelligence.Palo Alto, CA: AAAI, 2016: 27932799
[64]Wan Shengxian, Lan Yanyan, Xu Jun, et al.Match-SRNN: Modeling the recursive matching structure with spatial RNN[C]//Proc of the 25th Int Joint Conf on Artificial Intelligence.Palo Alto, CA: AAAI, 2016: 29222928
[65]Guo Jiafeng, Fan Yixing, Ai Qingyao, et al.Semantic matching by non-linear word transportation for information retrieval[C]//Proc of the 25th ACM Int Conf on Information and Knowledge Management.New York: ACM, 2016: 701710
[66]uo Jiafeng, Fan Yixing, Ai Qingyao, et al.A deep relevance matching model for ad-hoc retrieval[C]//Proc of the 25th ACM Int Conf on Information and Knowledge Management.New York: ACM, 2016: 5564
[67]Pang Liang, Lan Yanyan, Guo Jiafeng, et al.Deeprank: A new deep architecture for relevance ranking in information retrieval[C]//Proc of the 26th ACM Conf on Information and Knowledge Management.New York: ACM, 2017: 257266
[68]Fan Yixing, Guo Jiafeng, Lan Yanyan, et al.Learning visual features from snapshots for Web search[C]//Proc of the 26th ACM Int Conf on Information and Knowledge Management.New York: ACM, 2017: 247256
Guo Jiafeng and Fan Yixing
(CASKeyLaboratoryofNetworkDataScience&Technology(InstituteofComputingTechnology,ChineseAcademyofSciences),Beijing100190) (InstituteofComputingTechnology,ChineseAcademyofSciences,Beijing100190)
AbstractAfter decades of research, information retrieval technology has been significantly advanced and widely applied in our daily life.However, there is still a huge gap between modern search engines and true intelligent information accessing systems.In our opinion, an intelligent information accessing system should be able to crawl, read and understand the content of the big Web data, index and search the key semantic information, and reason, decide and generate the right results based on users’ information need.To develop such kind of systems, we need theoretical breakthrough on the search architecture and models.In recent years, to address the intelligent information accessing problem, we have conducted systematical research on neural information retrieval framework.We have achieved a few of original contributions on text representation, data indexing and relevance matching.However, there is still a long way in this direction and we will continue our exploration on neural information retrieval in the future.
Keywordsinformation retrieval; deep learning; data representation; relevance matching; data indexing
This work was supported by the National Natural Science Foundation of China for Excellent Young Scientists (61722211).
基金项目:国家自然科学基金优秀青年科学基金项目(61722211)
修回日期:2018--07--13
收稿日期:2018--02--25;
DOI:10.7544/issn1000-1239.2018.20180133
中图法分类号TP391

GuoJiafeng, born in 1980.PhD and professor.He has won the Best Paper Award in CIKM (2011), Best Student Paper Award in SIGIR (2012) and Best Full Paper Runner-up Award in ACM CIKM (2017).His main research interests include Web search and data mining.

FanYixing, born in 1990.PhD and assistant professor.He has won the Best Full Paper Runner-up Award in CIKM (2017).He has also led an open source project MatchZoo.His main research interests include information retrieval, question answering, and text generation.