


A Time and Relation-Aware Graph Collaborative Filtering for Cross-Domain Sequential Recommendation
-
摘要:
跨域序列推荐旨在从给定的某用户在不同领域中的历史交互序列中挖掘其偏好,预测其在多个领域中最可能与之交互的下一个项目,以缓解数据稀疏对用户意图捕捉和预测的影响. 受协同过滤思想启发,提出一种基于时间和关系感知的图协同过滤跨域序列推荐(time and relation-aware graph collaborative filtering for cross-domain sequential recommendation, TRaGCF)算法,充分挖掘用户高阶行为模式同时利用跨域用户行为模式双向迁移,解决序列推荐中的数据稀疏问题. 首先,为获得用户行为序列中项目间复杂的时序依赖关系,提出时间感知图注意力(time-aware graph attention, Ta-GAT)学习项目的域间序列级表示;其次,通过域内用户-项目交互二部图挖掘用户的行为偏好,提出关系感知图注意力(relation-aware graph attention, Ra-GAT)学习项目协同表示和用户协同偏好表示,为用户偏好特征的跨域迁移提供基础;最后为同步提高2个领域中的推荐效果,提出用户偏好特征双向迁移模块(user preference feature bi-directional transfer module, PBT),实现迁移用户域间共有偏好,保留用户域内特有偏好. 在Amazon Movie-Book和Food-Kitchen数据集上验证了算法的正确性和有效性. 实验结果表明,在跨域序列推荐场景下考虑项目间深层复杂的关联关系对挖掘用户意图十分必要;实验还验证了在跨域迁移用户偏好过程中保留域内用户特有偏好对全面用户画像的重要性.
-
关键词:
- 跨域序列推荐 /
- 图协同过滤 /
- 时间感知图注意力机制 /
- 关系感知注意力机制 /
- 数据稀疏
Abstract:Cross-domain sequential recommendation aims to mine a given user’s preferences from the historical interaction sequences in different domains and to predict the next item that the user is most likely to interact with among multiple domains, further to mitigate the impact of data sparsity on the capture and prediction for users’ intents. Inspired by the idea of collaborative filtering, a time and relation-aware graph collaborative filtering for cross-domain sequential recommendation (TRaGCF) algorithm is proposed to solve the problem of data sparsity by uncovering users’ high-order behavior patterns as well as utilizing the characteristics of bi-directional migration of user behavior patterns across domains. Firstly, we propose a time-aware graph attention (Ta-GAT) mechanism to obtain the cross-domain sequence-level item representation. Then, a user-item interaction bipartite graph in the domain is used to mine users’ preferences, and a relation-aware graph attention (Ta-GAT) mechanism is proposed to learn item collaborative representation and user collaborative representation, which creates the foundation for cross-domain transfer of user preferences. Finally, to simultaneously improve the recommendation results in both domains, a user preference feature bi-directional transfer module (PBT) is proposed, transferring shared user preferences across domains and retaining specific preferences within one domain. The accuracy and effectiveness of our model are validated by two experimental datasets, Amazon Movie-Book and Food-Kitchen. The experimental results have demonstrated the necessity of considering intricate correlations between items in a cross-domain sequential recommendation scenario for mining users’ intents, and the results also prove the importance of preserving users’ specific preferences in creating a comprehensive user portrait when transferring users’ preferences across domains.
-
当预期的系统观测和真实的系统观测不一致时,这时系统就存在故障,需要对故障进行诊断.基于模型诊断(model-based diagnosis, MBD)[1]是根据系统的描述利用基于推理的方法解释系统观测不一致的过程.几十年来,MBD问题已经广泛应用于的各个领域,包括调试关系规范[2]、诊断系统调试[3]、电子表格调试[4]和软件故障定位[5]等领域.
文章的主要贡献包括3个方面:
1) 提出利用观测的扇入过滤边和扇出过滤边对边进行过滤的约简方法.这2种边都是冗余的,因为它们的值在进行诊断求解过程中是必须进行传播的值.
2) 提出利用观测的过滤节点来进行过滤的约简方法.对于基于观察的过滤节点而言,它所有的扇入和扇出都是固定的,即它的扇入和扇出之间不存在冲突.
3) 在ISCAS85和ITC99基准测试实例上的实验结果表明,提出的方法可以有效缩减MBD问题编码时生成的子句规模,进而降低最大可满足性问题(maximum satisfiability, MaxSAT)求解诊断问题的难度,有效地提高了诊断求解效率.
1. 相关工作
近几十年来,越来越多的研究者投入到MBD问题的研究中,提出了许多求解算法,其中包括单个观测的MBD算法[6-11]和多观测的MBD算法[12-15].目前用于解决单个观测下的MBD问题算法为:随机搜索算法[6,16]、基于编译的算法[7],基于广度优先搜索的算法[8]、基于可满足性问题(satisfiability,SAT)的算法[9-10]、基于冲突导向的算法[11]等[17-21].在这些算法中,基于广度优先搜索的算法及其改进算法利用了树结构.此类算法检查树的每个节点是否表示最小诊断解,这类方法是完备的.显然,只要有足够的时间,这类方法可以得到所有的诊断解.然而,这类方法是相当耗时的,它们在解决大型现实实例问题时是不太现实的.随着计算机处理器的快速发展,一些并行化技术也被用于MBD求解问题中,Jannach等人[8]通过并行地构造碰集树(hitting set-tree, HS-Tree)返回所有诊断.基于编译的方法通过利用给定的系统层次结构和DNF编码的方式[7]计算候选解的方法也显示出它们的优势.SAFARI算法[6]证明了在MBD问题上随机搜索算法的有效性.SAFARI随机删除一个组件,然后判断候选解是否仍然是一个诊断,直到没有组件可以删除.显然,SAFARI不能保证返回的诊断解是极小势诊断.近年来,随着SAT及MaxSAT求解器性能的大幅提升,使得基于SAT的诊断方法引起了广泛的关注.Feldman等人[6]提出将诊断的电路编码成MaxSAT问题,该方法比SAFARI运行时间更长.相比之下,Metodi等人[20]提出的SATbD考虑电路的直接统治者,并找出所有极小势诊断.2015年,Marques-Silva等人[22]提出一种面向统治者的编码(dominator oriented encoding, DOE)方法,通过过滤掉一些节点和一些边的方法将MBD编码为MaxSAT.作为一种先进的编码方法,DOE利用了系统的结构属性,有效地缩减了MBD问题编码后子句集的规模.虽然DOE保证返回基数最小的诊断,但它没有考虑与观察有关的多余带权重的合取范式(weighted conjunctive normal form, WCNF).本文提出一种面向观察的编码(observation-oriented encoding, OOE)方法,该方法在将MBD编码到Max SAT时能有效减少子句集规模.此外,本文在调用相同的MaxSAT求解器情况下,将OOE方法与基础编码(basic encoding, BE)和DOE进行了比较.实验结果表明,OOE方法有效提高了MBD问题的求解效率.
2. 基于模型的诊断问题
本节主要介绍MBD问题的相关定义及概念.
2.1 基本定义
诊断问题可以被定义为一个三元组
⟨ SD,Comps,Obs⟩ ,其中,SD表示诊断问题的系统描述,Comps代表组件的集合,Obs代表一个观测.假定所有组件的状态是正常的情况下,当系统的模型描述和观测出现不一致时,我们称存在一个诊断问题.也就是:SD∧Obs∧{¬AB(c)|c∈Comps}⊨⊥, (1) 其中,AB(c)=1代表组件c是故障的,相反,AB(c)=0代表组件c是正常的.下面我们给出诊断的定义.
定义1. 诊断[1].给定一个诊断问题D=
⟨ SD,Comps,Obs⟩ .一个诊断被定义为一组组件∆的集合,其中 ∆⋤ Comps,当SD∧Obs∧{AB(c)|c∈Δ}∧ \left\{\neg AB\left(c\right)\right|c\in Comps-\Delta \}\nvDash\perp . 其中
\Delta 是一个极小子集诊断当且仅当不存在当前诊断的一个子集{\Delta' }{\text{⋤}}\Delta 是一个诊断.诊断解的长度称为诊断的势,\Delta 是一个极小势诊断当且仅当不存在另外一个诊断解{\Delta '} 满足∣\Delta ∣>∣\Delta ' ∣.2.2 将诊断问题编码为MaxSAT
许多MBD问题在求解时先被编码为MaxSAT问题[14-15,22],下面本文介绍编码过程.当一个MBD问题被编码为一系列WCNF子句集时,诊断系统中的组件和电路线分别用变量表示,它们的值用文字表示.下面我们分别表示有2个输入的与非门(nand2)、与门(and2)、与或门(nor2)、或门(or2)的公式:
{F}_{\mathrm{n}\mathrm{a}\mathrm{n}\mathrm{d}2\_c}\triangleq Clauses({o}_{\mathrm{n}\mathrm{a}\mathrm{n}\mathrm{d}2\_c}\leftrightarrow \neg ({i}_{\mathrm{n}\mathrm{a}\mathrm{n}\mathrm{d}2\_c1}\wedge {i}_{\mathrm{n}\mathrm{a}\mathrm{n}\mathrm{d}2\_c2}\left)\right) , {F}_{\mathrm{a}\mathrm{n}\mathrm{d}2\_c}\triangleq Clauses({o}_{\mathrm{a}\mathrm{n}\mathrm{d}2\_c}\leftrightarrow ({i}_{\mathrm{a}\mathrm{n}\mathrm{d}2\_c1}\wedge {i}_{\mathrm{a}\mathrm{n}\mathrm{d}2\_c2}\left)\right) , {F}_{\mathrm{n}\mathrm{o}\mathrm{r}2\_c}\triangleq Clauses({o}_{\mathrm{n}\mathrm{o}\mathrm{r}2\_c}\leftrightarrow \neg ({i}_{\mathrm{n}\mathrm{o}\mathrm{r}2\_c1}\vee {i}_{\mathrm{n}\mathrm{o}\mathrm{r}2\_c2}\left)\right) , {F}_{\mathrm{o}\mathrm{r}2\_c}\triangleq Clauses({o}_{\mathrm{o}\mathrm{r}2\_c}\leftrightarrow ({i}_{\mathrm{o}\mathrm{r}2\_c1}\vee {i}_{\mathrm{o}\mathrm{r}2\_c2}\left)\right) . 例如,对于一个NAND组件c而言,
{i}_{\mathrm{nand}\_c1} 和{i}_{\mathrm{nand}\_c2} 分别代表组件c的输入,{o}_{\mathrm{n}\mathrm{a}\mathrm{n}\mathrm{d}\_c} 是组件c的输出.由一组组件组成的系统SD的表示公式为SD\triangleq \mathop \wedge\limits_{c\in Comps}\left(AB\right(c)\vee {F}_{\mathrm{nand}\mathrm{a}\mathrm{n}\mathrm{d}\_c}) , 此处,代表组件c的编码.在一个观测中,观测可以表示为
Obs\triangleq v .v 和一个电路的逻辑值相关,当v=1 代表电路逻辑值为正,当v=0 代表电路逻辑值为负.WCNF中的子句cl的权重用ω(cl)表示,我们分别设置SD,Comps,Obs相关的子句为:
1) 对于SD和Comps中的子句被设置为硬子句,
\mathrm{\omega }\left(cl\right):=num\left(Obs\right)+1 ,其中num\left(Obs\right) 代表观测的数量;2) Obs中的子句被设置为软子句,
\omega \left(cl\right):=1 .在基于SAT的方法中,MBD问题被编码为一组子句,然后通过迭代调用SAT或MaxSAT求解器来计算诊断.通过添加阻塞子句可以避免相同的诊断解被多次计算.利用诊断系统的结构属性是一种可行的方法,这种方法在许多基于SAT的诊断算法中得到了应用[23-24].相应地,诊断中的统治节点和顶层诊断(top-level diagnosis,TLD)也是重要的概念.
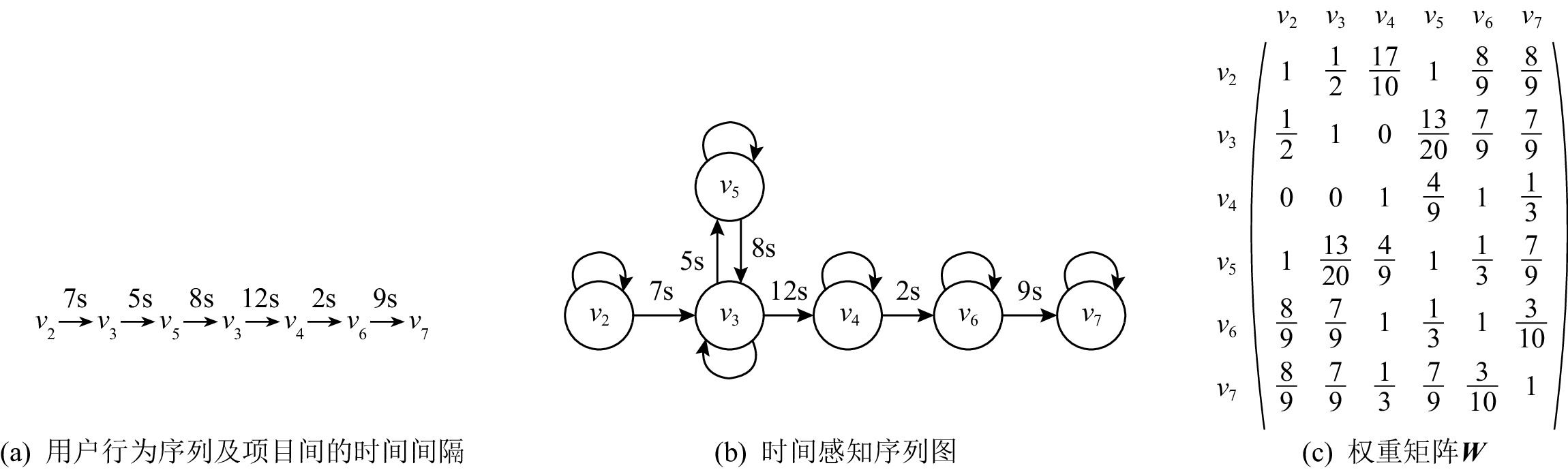
定义2. 统治节点[20].给定一个组件G1和G2,如果从G1到电路的输出的所有路径都包含G2,则称G2是G1的统治节点.换句话说,G1是被G2统治的节点.
定义3. 顶层诊断解[20].称
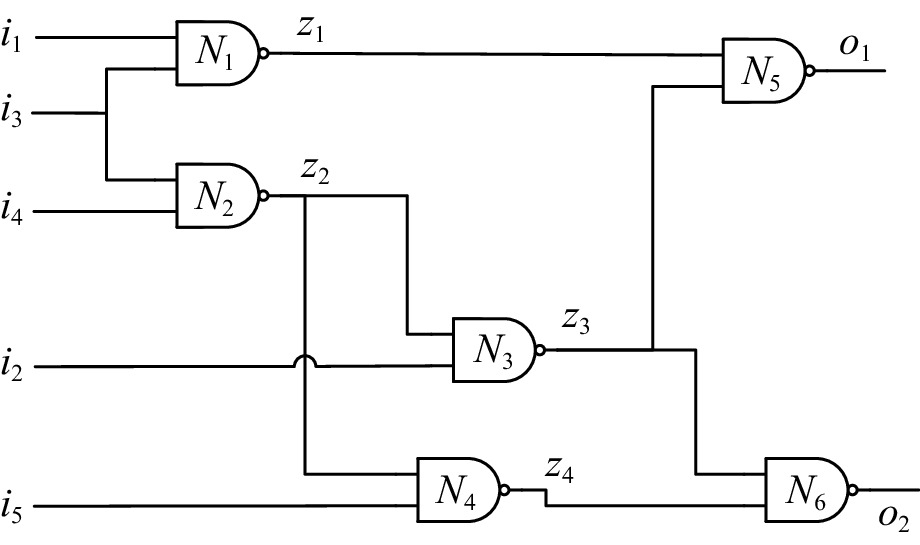
\Delta 为一个顶层诊断解,如果它是一个极小势诊断且不包含任何统治组件.以图1为例,由于N1到达系统输出的路径是唯一的,且包括N5,所以N1被N5统治.假定有观测i1= i2= i3= i5= o1= o2=1, i4=0, N6是一个TLD,因为N6不被任何组件统治.通过将统治组件编码到硬子句中 (即申明这些组件是健康的),就可以计算TLD.
3. 求解基于模型的诊断问题的DOE方法
为了简化MBD到MaxSAT的编码过程,缩减被编码的“门”生成的子句规模.DOE方法利用“门控制关系”,同时计算TLD.除此之外,一些曾在DOE方法中被提出的概念如阻塞连接及骨干组件,将在本节定义中给出解释.
定义4. 骨架节点(backbone node, B-Node)[22].我们称一个组件为骨架节点当且仅当其是一个被统治的组件且它的扇出对于任何一个TLD有固定的值.
考虑图1中组件N1,N1被N5统治,当给定一个观测时,N1的所有输入是固定的,也就是说,i1和i3有固定的值,当求解一个TLD时,N1的扇出就有固定的值,所以N1是一个B-Node.
定义5. 阻塞边(blocked edge,B-Edge)[22].我们称组件的一个扇入边E是一个阻塞边,如果边的值不会对该组件的扇出起作用.
考虑图1中的N2,当给定一个观测Obs={i4=0},N2的输出被确定为1,无论i3的值是什么,因此i3边是一个阻塞边.
定义6. 过滤节点[22].我们称组件B为一个过滤节点,如果它的所有扇出边都是过滤边.
定义7. 过滤边[22].我们称边E为一个过滤边,如果它是一个B-Node或者它的扇出组件是一个过滤节点.
由于N1是一个被统治组件,给定一个观测Obs={i1=1},当z1的值 (z1=0) 被传播后,z3的值将不会对N5的输出起作用.也就是说,N5的输出值是固定的.因此,
\langle N3,N5\rangle 是一个B-Edge,因此,\langle N3,N5\rangle 是一个过滤边.假定\langle N3,N6\rangle 也是一个过滤边,这时N3的所有输入边都是过滤边,那么组件N3是一个过滤节点.具体的DOE方法如算法1所示:算法1. 编码MBD到MaxSAT的DOE方法[22].
输入:SD,Comps,Obs;
输出:编译后的模型.
① repeat
② Dominators
\leftarrow 所有统治节点;③ BackboneComps
\leftarrow 所有骨架组件;④ BlockedConnections
\leftarrow 所有阻塞连接;⑤ if 到达最大迭代次数 then
⑥ break;
⑦ end if
⑧ until NoMoreChanges;
⑨
M\leftarrow 产生MaxSAT模型.4. OOE方法
文献[22]中的实验表明了DOE方法在求解MBD问题上的有效性.在本节中,我们将介绍OOE方法及该方法中为了改进基于MaxSAT的MBD编译过程用到的其他过滤节点和过滤边的概念.
定义8. 基于观测的扇入过滤边.我们称边E为一个基于观测的扇入过滤边,如果它是一个系统的输入或者它是一个统治组件的一个固定输出边.
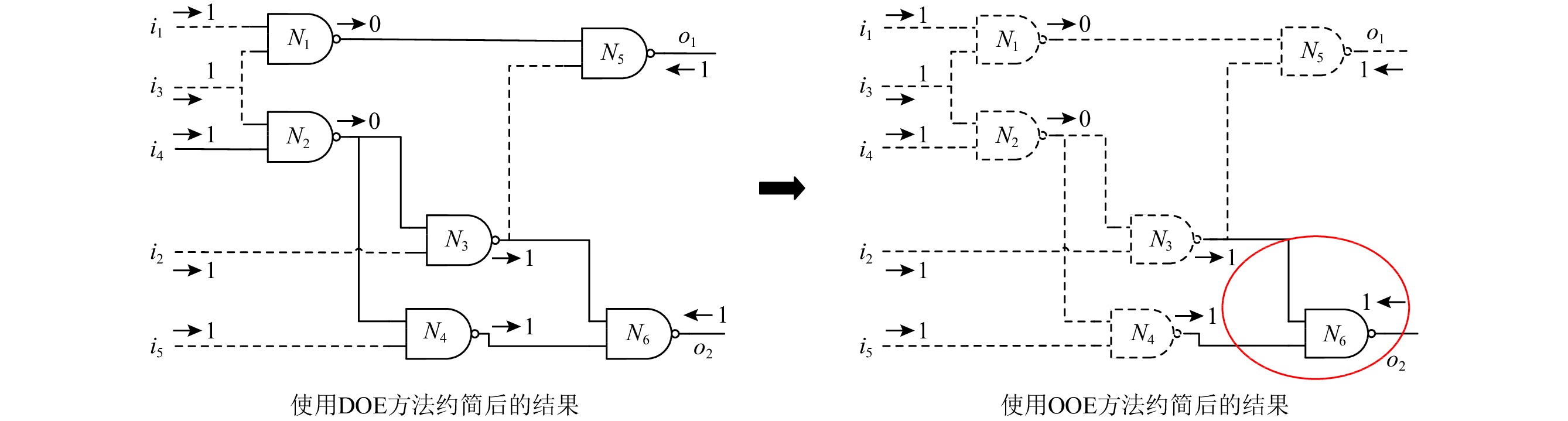
此处继续讨论观测Obs = {i1 = 1, i2 = 1, i3 = 1, i4 = 1, i5 = 1, o1 = 1, o2 = 1},在第1次迭代中,i1, i2, i3, i4, i5是基于观测的扇入过滤边.在DOE方法过滤了一些节点和边之后,因为N1,N4,N3,N2依次成为统治节点之后,
\langle N1,N5\rangle ,\langle N3,N6\rangle ,\langle N2,N4\rangle ,\langle N4,N6\rangle 变成了基于观察的扇入过滤边.定义9. 基于观测的扇出过滤边.我们称边E为一个基于观测的扇出过滤边,如果它是一个系统的输出.
给定观测Obs={ i1 = 1, i2 = 1, i3 = 1, i4 = 1, i5 = 1, o1 = 1, o2 = 1},o1和o2 均为基于观测的扇出过滤边.
定义10. 基于观测的过滤边.我们称边E为一个基于观测的过滤边,如果它是一个基于观测的扇出过滤边或者它是一个基于观测的扇入过滤边.
初始状态下,系统的输入输出是固定的.因此,任何基于观测的边缘边都是固定的.
定义11. 基于观察的过滤节点.我们称一个组件B为基于观察的过滤节点,如果该组件的扇入和扇出都是固定的,并且扇出值与扇入值在逻辑上一致,或者该组件是一个B-Node.
给定一个观测Obs= { i1 = 1, i2 = 1, i3 = 1, i4 = 1, i5 = 1, o1 = 1, o2 = 1},在DOE编译过程中,因为N1,N2,N3,N4都是B-Node,所以它们都是基于观测的过滤节点.此外,N5也是一个基于观测的过滤节点因为它有一个输入值为0,这与它的输出值1是一致的.
在OOE方法中,被统治的组件编码为硬子句,这种设置与DOE方法中的设置是相同的.
在OOE编译方法的预处理过程中,不仅过滤边和过滤节点不被编码为WCNF,而且基于观测的过滤边和基于观测的过滤节点也不被编码为WCNF.
命题1. 假定ζ为使用DOE方法求解出的一个TLD,那么使用OOE方法可以求解出一个和ζ具有相同势的TLD,ζ ’.
考虑观测Obs = { i1 = 1, i2 = 1, i3 = 1, i4 = 1, i5 = 1, o1 = 1, o2 = 1},我们详细解释DOE方法和OOE方法在进行编码时的约简子句的细节.在第1次迭代中,被统治节点为{N1, N4}.N1被N5统治,N4被N6统治.之后N1的输出值0被传播, N5的输出值是固定的,所以
\langle N3,N5\rangle 是一个B-Edge.在第2次迭代时,因为过滤边\langle N3,N5\rangle ,所以N3被N6统治.随后, N2由N6统治.除此之外,i2,i5被过滤,成为过滤边.这就是所有的DOE方法的约简过程及贡献.剩余的组件{N5, N6}以及边\langle N1,N5\rangle ,\langle N3,N6\rangle ,\langle N4,N6\rangle 均在DOE方法中没有被考虑到.在OOE方法中,为了考虑将更多的节点和边进行约简,基于观测的过滤边和基于观测的过滤节点被提出用于减少生成的WCNF子句的数量.算法2概述了OOE方法的伪代码.
算法2. 编码MBD到MaxSAT的OOE方法.
输入:SD,Comps,Obs;
输出:编译后的WCNF子句.
① repeat
② Dominators
\leftarrow 所有统治节点;③ BackboneComps
\leftarrow 所有骨架组件;④ BlockedConnections
\leftarrow 所有阻塞连接;⑤ if 到达最大迭代次数 then
⑥ break;
⑦ end if
⑧ until NoMoreChanges;
⑨ edgeStack
\leftarrow 所有基于观测的过滤边;⑩ nodeStack
\leftarrow 所有基于观测的过滤节点;⑪ while edgeStack ≠ NULL do
⑫ e
\leftarrow edgeStack中的栈顶元素;⑬ Propagation(e);
⑭ node
\leftarrow nodeStack中的栈顶元素;⑮ Propagation(node);
⑯ if 获得一个新的基于观测的过滤 then
⑰ edgeStack
\leftarrow Push\left(E\right) ;⑱ end if
⑲ if 获得一个新的基于观测的过滤节点
node then
⑳ nodeStack
\leftarrow Push\left(node\right); ㉑ end if
㉒ end while
算法2一直迭代至没有发现新的基于观测的过滤边和过滤节点.其中,算法2的行①~⑧和文献[22]中提出的DOE方法的预处理部分相同,经过DOE预处理后,初步地,我们找到基于观测的过滤边和基于观测的过滤节点.算法2在行⑨~⑩分别将初步得到的基于观测的过滤边和基于观测的过滤节点压入栈中.在行⑪~㉒,算法2找出所有的基于观测的过滤边和基于观测的过滤节点,旨在减少生成的WCNF子句的数量.在行⑬和行⑮中,函数Propagation是一种单元传播技术用于传播行⑫和行⑭中的e和node变量的赋值.
给定观测Obs = { i1 = 1, i2 = 1, i3 = 1, i4 = 1, i5 = 1, o1 = 1, o2 = 1},图2分别为算法1和算法2的编译结果.在图2中,虚线表示过滤边(如图2(a)的
\langle N3, N5\rangle )或基于观测的过滤边(如图2(b)的\langle N1, N5\rangle ).同样地,虚线点表示的组件代表过滤节点或基于观测的过滤节点(如图2(a)的N1).过滤边、过滤节点、基于观测的过滤边和基于观测的过滤节点均将不会被编译成WCNF子句.如图2所示,仅有实线表示的元件和电路线被编码为WCNF子句,虚线表示的元件和电路线不被编码为WCNF子句.在这个例子中,在OOE方法之后,只有1个组件和3条电路线最终被编码为WCNF子句,图2(b)中用椭圆表示.5. 实验结果
在本节中,我们将在MBD中提出的预处理方法与目前最好的预处理方法DOE[22]及不用预处理过程的编码方法BE进行了对比.在编码为MaxSAT问题后求解诊断问题时,我们选择了一种MaxSAT求解器——UwrMaxSAT[19]进行求解, UwrMaxSAT在2020年MaxSAT评估中的加权组中表现最好.实验分别在ISCAS85和ITC99这2组测试实例上执行,这2组测试实例均在文献[22]中使用.其中,第1组测试实例包含9998个测试用例,第2个测试实例包含7822个测试用例.本文提出的OOE方法用C++实现并使用G++编译.我们的实验是在Ubuntu 16.04 Linux和Intel Xeon E5-1607@3.00 GHz, 16 GB RAM上进行.
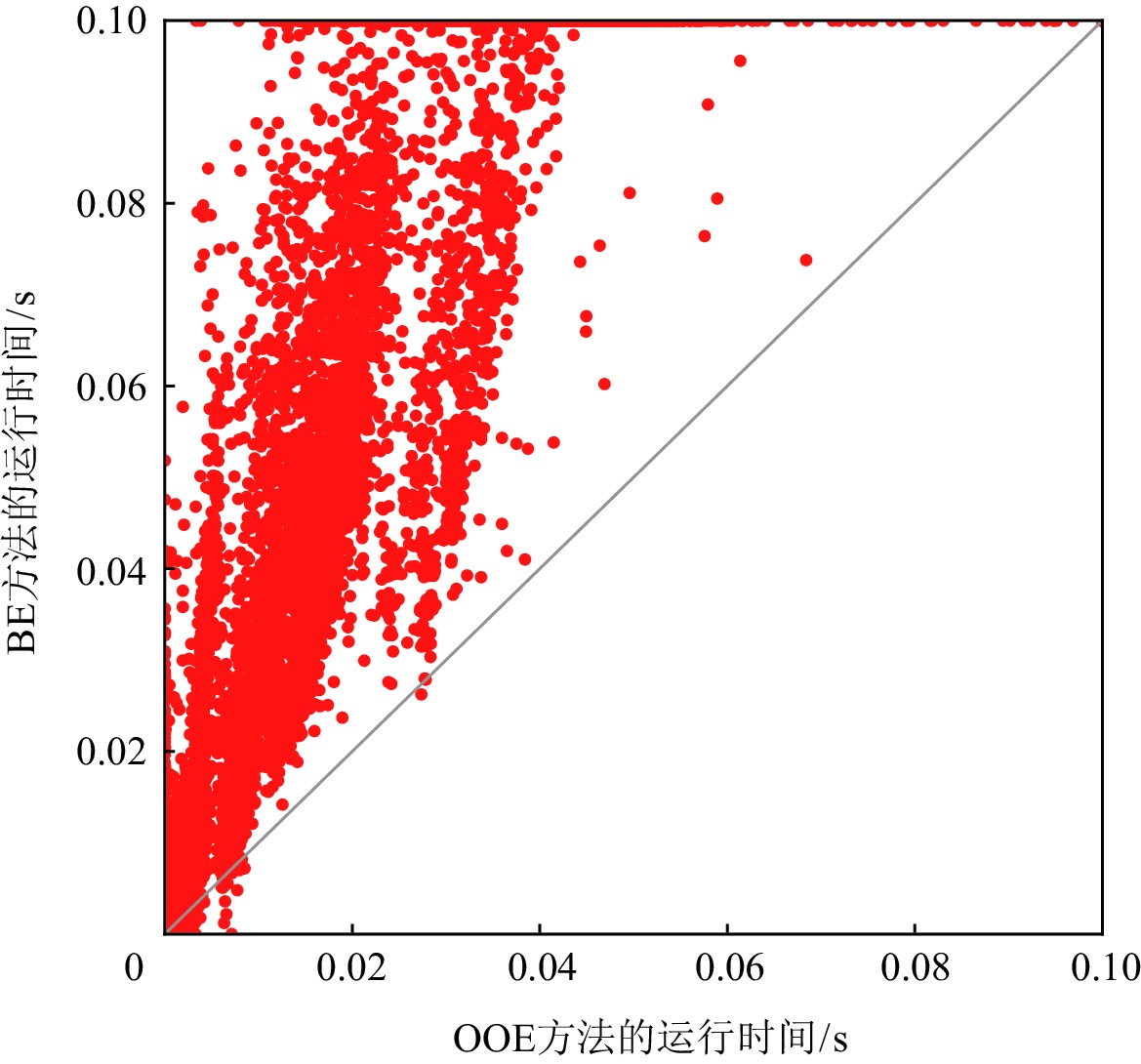
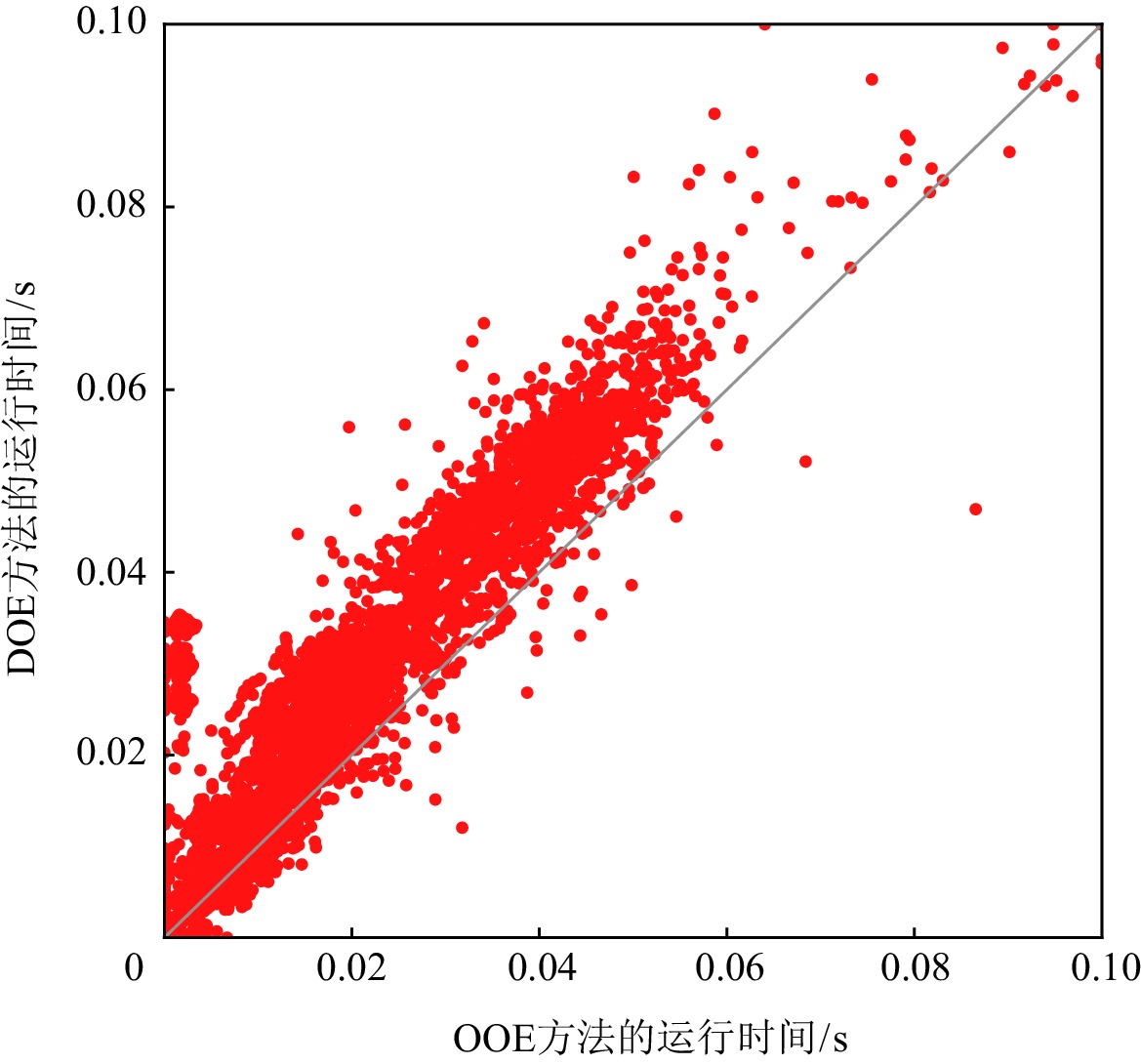
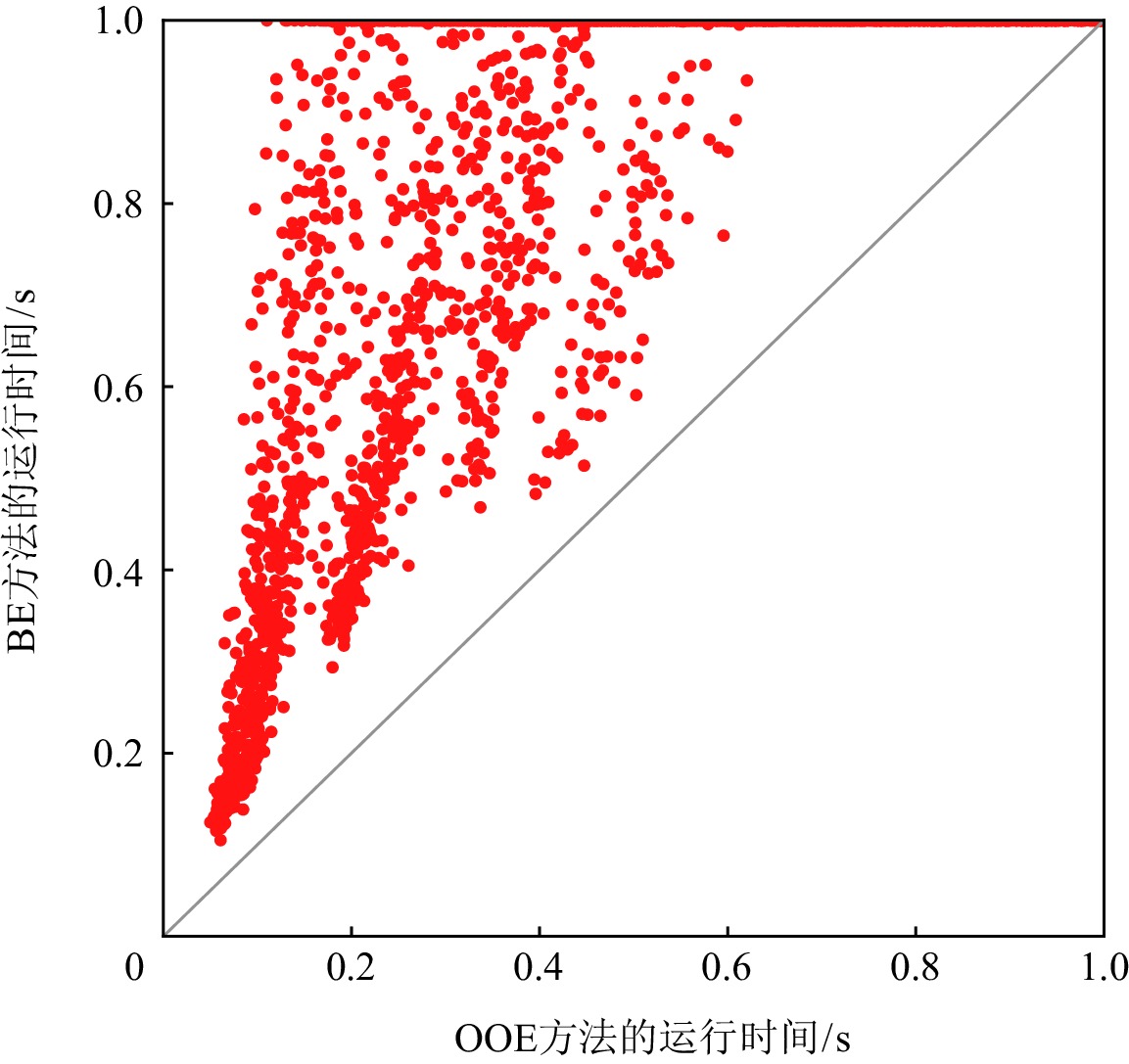
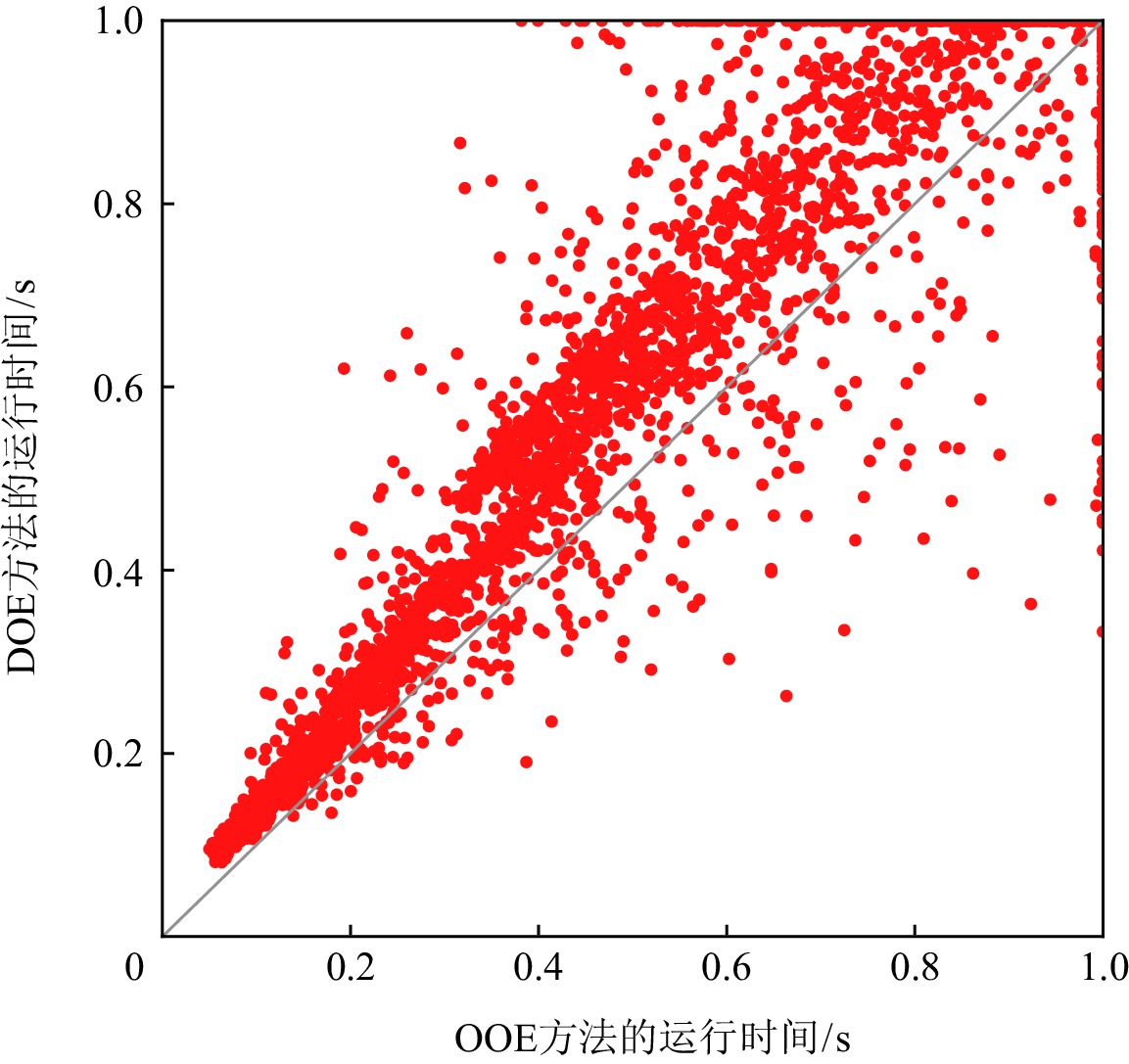
图3和图4分别给出OOE方法与BE方法和DOE方法在求解ISCAS85实例时,MaxSAT求解器求得一个诊断解的运行时间.在实验中,我们设置MaxSAT求解的时间上限为0.1 s.如图3和图4所示,对于大多数测试实例,OOE和DOE方法可以在0.1 s内通过MaxSAT求解器返回诊断结果.用BE方法求解时,有1431个测试实例不能在时间限制内得到一个诊断解;但是对于OOE和DOE方法,只有350个实例不能在0.1 s内得到一个诊断解.此外,如图4中所示,对于大多数测试实例,OOE方法要明显优于DOE方法.
![]() 图 3 BE和OOE方法在ISCAS85实例上的运行时间比较Figure 3. Comparison of the run time of BE and OOE approaches on ISCAS85 benchmark
图 3 BE和OOE方法在ISCAS85实例上的运行时间比较Figure 3. Comparison of the run time of BE and OOE approaches on ISCAS85 benchmark![]() 图 4 DOE和OOE方法在ISCAS85实例上的运行时间比较Figure 4. Comparison of the run time of DOE and OOE approaches on ISCAS85 benchmark
图 4 DOE和OOE方法在ISCAS85实例上的运行时间比较Figure 4. Comparison of the run time of DOE and OOE approaches on ISCAS85 benchmark图5和图6分别显示了在ITC99实例上OOE方法与BE及DOE方法在求解诊断问题时MaxSAT求解器运行时间方面的比较.我们设置MaxSAT求解器的时间限制为1 s.坐标轴上的点表示在给定时间内无法求解的一些测试实例.使用OOE,DOE,BE方法不能得到一个解的测试实例的个数分别为4939,5197,6669.在求解实例个数上OOE方法明显优于BE和DOE方法,除此之外,在大多数情况下,相比于BE和DOE方法,使用OOE方法能在更短的时间内得到一个诊断解.
![]() 图 5 BE和OOE方法在ITC99实例上的运行时间比较Figure 5. The run time of BE and OOE approaches on ITC99 benchmark
图 5 BE和OOE方法在ITC99实例上的运行时间比较Figure 5. The run time of BE and OOE approaches on ITC99 benchmark![]() 图 6 DOE和OOE方法在ITC99实例上的运行时间比较Figure 6. The run time of DOE and OOE approaches on ITC99 benchmark
图 6 DOE和OOE方法在ITC99实例上的运行时间比较Figure 6. The run time of DOE and OOE approaches on ITC99 benchmark在ITC99 实例和ISCAS85实例上的详细实验结果分别如表1和表2所示:
表 1 在ITC99实例上的求解结果Table 1. Solved Results for ITC99 Benchmark电路名称 观测个数 所用时间比竞争
对手短的实例个数所用时间比竞争
对手短的实例个数OOE BE OOE DOE[22] b14 919 433 164 569 2 b15 995 663 188 819 2 b17 1000 946 54 1000 0 b18 1000 884 46 917 2 b19 1000 823 56 833 42 b20 997 596 222 782 0 b21 919 636 166 780 0 b22 992 722 223 932 0 在2组表中,我们分别列出了4组数据.第1列显示电路名称,第2列显示测试实例的数量.第3~6列显示OOE方法求解诊断时所用时间比竞争对手短的实例个数.从表1和表2可以看出,对每一个电路进行诊断问题求解时,OOE方法都是可行的,且求解结果显示,相比于DOE及 BE方法,OOE方法都有明显的优势.特别是在c880电路上,OOE方法在所有1182个测试实例中的实验结果均优于BE方法,有97.8%的实例的实验结果优于DOE方法.
表 2 在ISCAS85 实例上的求解结果Table 2. Solved Results for ISCAS85 Benchmark电路名称 观测个数 所用时间比竞争
对手短的实例个数所用时间比竞争
对手短的实例个数OOE BE OOE DOE[22] c17 63 48 14 56 7 c432 301 280 17 278 23 c499 835 734 96 760 71 c880 1182 1182 0 1157 20 c1355 836 719 113 832 4 c1908 864 664 182 834 12 c2670 1162 1128 34 1158 4 c3540 756 705 51 756 0 c5315 2038 2028 10 2038 0 c6288 404 246 158 398 6 c7552 1557 1536 21 1557 0 6. 总 结
目前,很多基于SAT的MBD方法把MaxSAT编码作为分析MBD问题的一个基本步骤.本文在面向支配者编码的方法研究基础之上,提出一种OOE的面向观测的编码方法,显著减少了MBD编码后子句的数量,进而降低了MaxSAT求解诊断的难度,提高了求解诊断的效率.本文提出了2种方法用于提高OOE的效率.首先,根据诊断系统的输入观测和输出观测对过滤边进行约简.其次,利用基于观测的过滤节点,在编码时对一些组件进行约简,进而不被编码到MBD问题的子句中.实验结果表明,通过找到更多的基于观测的过滤节点和基于观测的过滤边,能有效减少编码后子句集规模,进而提高基于MaxSAT计算诊断解的效率.OOE方法在ISCAS85系统和ITC99系统的基准测试实例上求解诊断是高效的.在未来的研究中,将探索多观测下OOE方法的扩展算法.
作者贡献声明:周慧思负责文章主体撰写和修订,文献资料的分析、整理及文章写作;欧阳丹彤负责确定综述选题,指导和督促完成相关文献资料的收集整理;田新亮负责文献资料的收集以及部分图表数据的绘制;张立明负责提出文章修改意见, 指导文章写作.
-
表 1 预处理之后的数据集统计分析
Table 1 The Statistics of the Datasets After Preprocessing
数据集 项目总数 测试集
项目数训练集
项目数验证集
项目数平均序
列长度Movie-Book 36845/63937 34732 19861 9274 11.98 Food-Kitchen 29207/34886 25766 17280 7650 9.91 注:Movie-Book的项目总数36845/63937表示在Movie域中项目总数为36845,Book域中的项目总数为63937;Food-Kitchen同理.  下载: 导出CSV
下载: 导出CSV
表 2 在Amazon Movie-Book上的实验结果
Table 2 Experimental Results on Amazon Movie-Book
% 算法 Movie域 Book域 k=5 k=10 k=20 k=5 k=10 k=20 Recall MRR Recall MRR Recall MRR Recall MRR Recall MRR Recall MRR POP 0.18 0.07 0.29 0.11 0.58 0.13 0.20 0.11 0.44 0.14 0.75 0.16 Item-KNN 2.11 1.05 3.84 1.27 6.99 1.48 2.87 1.34 5.10 1.64 9.69 1.95 GRU4REC 13.69 12.79 14.11 12.70 14.43 12.88 14.64 13.79 15.02 13.82 15.34 13.95 NARM 14.20 13.80 14.53 13.85 14.80 13.96 15.57 15.25 15.66 15.26 15.78 15.27 STAMP 13.66 12.44 14.58 12.56 15.68 12.63 11.82 11.52 12.00 11.56 12.20 11.57 SR-GNN 12.66 11.77 14.18 13.54 14.87 13.88 15.43 15.12 15.61 15.14 15.77 15.15 CoNet 2.89 1.43 5.20 1.73 9.24 2.01 2.13 1.17 3.54 1.36 5.77 1.51 CDIE-C 9.56 7.31 10.45 8.96 12.18 9.45 9.30 7.18 10.11 7.25 11.29 7.49 CDHRM 13.05 12.60 13.97 12.55 14.12 12.74 14.89 13.91 15.33 14.27 15.50 14.32 π-Net 14.88 14.49 15.10 14.52 15.37 14.54 15.94 15.75 16.02 15.77 16.09 15.77 MIFN 15.13 14.84 16.34 15.07 16.56 15.38 16.57 16.05 16.66 16.16 16.73 16.23 TRaGCF 15.85 15.21 17.15 15.32 17.31 15.45 16.37 16.12 16.94 16.38 17.16 16.69
下载: 导出CSV
表 3 在Amazon Food-Kitchen上的实验结果
Table 3 Experimental Results on Amazon Food-Kitchen
% 算法 Food域 Kitchen域 k=5 k=10 k=20 k=5 k=10 k=20 Recall MRR Recall MRR Recall MRR Recall MRR Recall MRR Recall MRR POP 0.83 0.40 1.50 0.49 2.15 0.56 0.39 0.22 0.70 0.25 1.47 0.27 Item-KNN 3.28 1.55 6.70 1.98 12.47 2.43 2.61 1.13 4.77 1.44 11.08 1.90 GRU4REC 9.46 8.10 10.38 8.23 11.26 8.29 8.70 8.36 8.93 8.39 9.25 8.41 NARM 10.34 9.43 11.86 9.54 12.23 9.62 8.69 8.41 8.91 8.44 9.21 8.46 STAMP 10.22 9.29 10.91 9.38 11.81 9.44 8.81 8.52 9.05 8.55 9.28 8.57 SR-GNN 10.68 9.31 11.02 9.49 11.67 9.60 9.12 8.31 9.36 8.62 9.57 8.92 CoNet 5.07 3.38 7.07 3.64 9.73 3.82 5.09 3.30 7.03 3.55 9.47 3.71 CDIE-C 7.98 6.44 9.36 7.12 10.75 7.79 8.57 8.34 8.95 8.39 9.38 8.45 CDHRM 9.56 8.21 10.40 9.66 11.49 9.35 8.62 8.41 9.07 8.43 9.41 8.50 π-Net 10.59 9.56 10.46 9.67 12.54 9.75 8.89 8.57 9.12 8.60 9.52 8.89 MIFN 11.20 9.91 12.25 10.16 13.27 10.25 9.72 9.18 10.01 9.21 10.33 9.23 TRaGCF 11.79 10.17 12.86 10.59 13.96 11.32 10.24 9.75 11.29 9.89 11.60 9.94
下载: 导出CSV
表 4 TRaGCF各功能模块贡献对比结果
Table 4 Comparison Results of the Contributions of Different Modules of TRaGCF
% 算法 Food 域 Kitchen域 Recall@20 MRR@20 Recall@20 MRR@20 TRaGCF-SBM 12.87 10.95 10.88 9.03 TRaGCF-CBM 13.42 11.03 11.41 9.79 TRaGCF 13.96 11.32 11.60 9.94
下载: 导出CSV
-
[1] Fang Hui, Guo Guibing, Zhang Danning, et al. Deep learning-based sequential recommender systems: Concepts, algorithms, and evaluations[C] //Proc of the 19th Int Conf on Web Engineering. Berlin: Springer, 2019: 574−577
[2] Wang Shoujin, Hu Liang, Wang Yan, et al. Sequential recommender systems: Challenges, progress and prospects[C] //Proc of the 28th Int Joint Conf Artificial Intelligence. San Francisco, CA: Morgan Kaufmann, 2019: 6332−6338
[3] Rendle S, Freudenthaler C, Schmidt-Thieme L. Factorizing personalized Markov chains for next-basket recommendation[C] //Proc of the 19th Int Conf on World Wide Web. New York: ACM, 2010: 811−820
[4] Quadrana M, Karatzoglou A, Hidasi B, et al. Personalizing session-based recommendations with hierarchical recurrent neural networks[C] //Proc of the 11th ACM Conf on Recommender Systems. New York: ACM, 2017: 130−137
[5] Tang Jiaxi, Wang Ke. Personalized top-n sequential recommendation via convolutional sequence embedding[C] //Proc of the 11th ACM Int Conf on Web Search and Data Mining. New York: ACM, 2018: 565−573
[6] Wu Shu, Tang Yuyuan, Zhu Yanqiao, et al. Session-based recommendation with graph neural networks[C] //Proc of the 33rd AAAI Conf on Artificial Intelligence. Palo Alto, CA : AAAI, 2019: 346−353
[7] Li Xiaohan, Zhang Mengqi, Wu Shu, et al. Dynamic graph collaborative filtering[C] //Proc of the 20th IEEE Int Conf on Data Mining (ICDM). Piscataway, NJ: IEEE, 2020: 322−331
[8] Guo Yupu, Ling Yanxiang, Chen Honghui. A time-aware graph neural network for session-based recommendation[J]. IEEE Access, 2020, 8: 167371−167382
[9] Qiu Ruihong, Li Jingjing, Huang Zi, et al. Rethinking the item order in session-based recommendation with graph neural networks[C] //Proc of the 28th ACM Int Conf on Information and Knowledge Management. New York: ACM, 2019: 579−588
[10] 王俊,李石君,杨莎,等. 一种新的用于跨领域推荐的迁移学习模型[J]. 计算机学报,2017,40(10):2367−2380 doi: 10.11897/SP.J.1016.2017.02367 Wang Jun, Li Shijun, Yang Sha, et al. A new transfer learning model for cross-domain recommendation[J]. Chinese Joural of Computers, 2017, 40(10): 2367−2380 (in Chinese) doi: 10.11897/SP.J.1016.2017.02367
[11] Ma Muyuan, Ren Pengjie, Lin Yujie, et al. π-Net: A parallel information-sharing network for shared-account cross-domain sequential recommendations[C] //Proc of the 42nd Int ACM SIGIR Conf on Research and Development in Information Retrieval. New York: ACM, 2019: 685−694
[12] 郭磊,李秋菊,刘方爱,等. 基于自注意力网络的共享账户跨域序列推荐[J]. 计算机研究与发展,2021,58(11):2524−2537 doi: 10.7544/issn1000-1239.2021.20200564 Guo Lei, Li Qiuju, Liu Fang’ai, et al. Shared-account cross-domain sequential recommendation with self-attention network[J]. Journal of Computer Research and Development, 2021, 58(11): 2524−2537 (in Chinese) doi: 10.7544/issn1000-1239.2021.20200564
[13] Ma Muyuan, Ren Pengjie, Chen Zhumin, et al. Mixed information flow for cross-domain sequential recommendations[J]. arXiv preprint, arXiv: 2012.00485, 2020
[14] Yang Guang, Hong Xiaoguang, Peng Zhaohui, et al. Long short-term memory with sequence completion for cross-domain sequential recommendation[C] //Proc of the 4th Asia-Pacific Web (APWeb) and Web-Age Information Management (WAIM) Joint Int Conf on Web and Big Data. Berlin: Springer, 2020: 378−393
[15] Wang Yaqin, Guo Caili, Chu Yunfei, et al. A cross-domain hierarchical recurrent model for personalized session-based recommendations[J]. Neurocomputing, 2020, 380(2): 271−284
[16] Yuan Fajie, He Xiangnan, Karatzoglou A, et al. Parameter-efficient transfer from sequential behaviors for user modeling and recommendation[C] //Proc of the 43rd Int ACM SIGIR Conf on Research and Development in Information Retrieval. New York: ACM, 2020: 1469−1478
[17] Kim D, Kim S, Zhao Handong, et al. Domain switch-aware holistic recurrent neural network for modeling multi-domain user behavior[C] //Proc of the 12th ACM Int Conf on Web Search and Data Mining. New York: ACM, 2019: 663−671
[18] Wu Zonghan, Pan Shirui, Chen Fengwen, et al. A comprehensive survey on graph neural networks[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020, 31(1): 4−24 doi: 10.1109/TNNLS.2019.2899262
[19] Yu Juliang, Yin Hongzhi, Li Jundong, et al. Enhance social recommendation with adversarial graph convolutional networks[J]. arXiv preprint, arXiv: 2024.02340, 2020
[20] Wang Wen, Zhang Wei, Liu Shukai, et al. Beyond clicks: Modeling multi-relational item graph for session-based target behavior prediction[C] //Proc of the 29th Web Conf 2020. New York: ACM, 2020: 3056−3062
[21] Chen Tianwen, Wong R C-W. Handling information loss of graph neural networks for session-based recommendation[C] //Proc of the 26th ACM SIGKDD Int Conf on Knowledge Discovery & Data Mining. New York: ACM, 2020: 1172−1180
[22] Xu Chengfeng, Zhao Pengpeng, Liu Yanchi, et al. Graph contextualized self-attention network for session-based recommendation[C] //Proc of the 28th Int Joint Conf on Artificial Intelligence. San Francisco, CA: Morgan Kaufmann, 2019: 3940−3946
[23] Cui Zhihua, Xu Xianghua, Fei Xue, et al. Personalized recommendation system based on collaborative filtering for IoT scenarios[J]. IEEE Transactions on Services Computing, 2020, 13(4): 685−695 doi: 10.1109/TSC.2020.2964552
[24] Wang Ziyang, Wei Wei, Cong Gao, et al. Global context enhanced graph neural networks for session-based recommendation[C] //Proc of the 43rd Int ACM SIGIR Conf on Research and Development in Information Retrieval. New York: ACM, 2020: 169−178
[25] Ma Chen, Ma Liheng, Zhang Yingxue, et al. Memory augmented graph neural networks for sequential recommendation[C] //Proc of the 34th AAAI Conf on Artificial Intelligence. Palo Alto, CA: AAAI, 2020, 34(3): 5045−5052
[26] Sarwar B, Karypis G, Konstan J, et al. Item-based collaborative filtering recommendation algorithms[C] //Proc of the 10th Int Conf on World Wide Web. New York: ACM, 2001: 285−295
[27] Wu Yuexin, Liu Hanxiao, Yang Yiming. Graph convolutional matrix completion for bipartite edge prediction[C] //Proc of the 10th Int Joint Conf on Knowledge Discovery, Knowledge Engineering and Knowledge Management. Berlin: Springer, 2018: 49−58
[28] Wang Xiang, He Xiangnan, Wang Meng, et al. Neural graph collaborative filtering[C] //Pro of the 42nd Int ACM SIGIR Conf on Research and Development in Information Retrieval. New York: ACM, 2019: 165−174
[29] Chen Lei, Wu Le, Hong Richang, et al. Revisiting graph based collaborative filtering: A linear residual graph convolutional network approach[C] //Proc of the 34th AAAI Conf on Artificial Intelligence. Palo Alto, CA: AAAI, 2020: 27−34
[30] He Xiangnan, Deng Kuan, Wang Xiang, et al. LightGCN: Simplifying and powering graph convolution network for recommendation[C] //Proc of the 43rd Int ACM SIGIR Conf on Research and Development in Information Retrieval. New York: ACM, 2020: 639−648
[31] Sun Jianing, Zhang Yingxue, Ma Chen, et al. Multi-graph convolution collaborative filtering[C] //Proc of the 19th IEEE Int Conf on Data Mining (ICDM). Piscataway, NJ: IEEE, 2019: 1306−1311
[32] Schlichtkrull M, Kipf T N, Bloem P, et al. Modeling relational data with graph convolutional networks[C] //Proc of the 18th European Semantic Web Conf. Berlin: Springer, 2018: 593−607
[33] Reddy S R S, Nalluri S, Kuniseti S, et al. Content-based movie recommendation system using genre correlation[M] //Smart Intelligent Computing and Applications. Berlin: Springer, 2019: 391−397
[34] Hidasi B, Karatzoglou A, Baltrunas L, et al. Session-based recommendations with recurrent neural networks[J]. arXiv preprint, arXiv: 1511.06939, 2017
[35] Li Jing, Ren Pengjie, Chen Zhumin, et al. Neural attentive session-based recommendation[C] //Proc of the 26th ACM on Conf on Information and Knowledge Management. New York: ACM, 2017: 1419−1428
[36] Liu Qiao, Zeng Yifu, Mokhosi R, et al. STAMP: Short-term attention/memory priority model for session-based recommendation[C] //Proc of the 24th ACM SIGKDD Int Conf on Knowledge Discovery & Data Mining. New York: ACM, 2018: 1831−1839
[37] Hu Guangneng, Zhang Yu, Yang Qiang. CoNet: Collaborative cross networks for cross-domain recommendation[C] //Proc of the 27th ACM Int Conf on Information and Knowledge Management. New York: ACM, 2018: 667−676
[38] Wang Yaqing, Feng Chunyan, Guo Caili, et al. Solving the sparsity problem in recommendations via cross-domain item embedding based on co-clustering[C] //Proc of the 12th ACM Int Conf on Web Search and Data Mining. New York: ACM, 2019: 717−725
-
期刊类型引用(2)
1. 史宏志 ,赵健 ,赵雅倩 ,李茹杨 ,魏辉 ,胡克坤 ,温东超 ,金良 . 大模型时代的混合专家系统优化综述. 计算机研究与发展. 2025(05): 1164-1189 .  本站查看
本站查看
2. 谢星丽,谢跃雷. 基于差分星座轨迹图的多任务802.11b/g信号识别方法. 电讯技术. 2023(11): 1771-1778 . 百度学术
其他类型引用(0)









































































计量
- 文章访问数: 316
- HTML全文浏览量: 53
- PDF下载量: 181
- 被引次数: 2




