


Private Protocol Reverse Engineering Based on Network Traffic: A Survey
-
摘要:
协议逆向技术是分析私有协议的重要途径,基于少量或零先验知识推断私有协议的约束与规范.在恶意应用监管、协议模糊测试、脆弱性检测、通信行为理解等方面均具有较高的实用价值.网络流量表征协议规范,承载协议固有特征,因此基于网络流量的私有协议逆向技术更适用于发现、分析并监管网络上的私有协议.在梳理现有的基于网络流量的私有协议逆向技术基础上,首先提出包括预推理、协议格式推断、语义分析以及协议状态机推理4步骤的基于网络流量的私有协议逆向技术框架,并阐述各个步骤的主要任务,提出面向研究方法本质的分类结构;其次,详细阐述各个私有协议逆向技术的方法流程,从适用协议类型、方法内核、推断算法等多个角度进行对比分析,提供现有基于网络流量的私有协议逆向技术系统概述;最后,归纳总结现有技术存在的问题以及主要影响因素,并对私有协议逆向技术的未来研究方向与应用场景进行展望.
Abstract:Protocol reverse engineering is an important way to analyze private protocols, which can infer the protocol constraints and specifications with little or no prior knowledge, so protocol reverse engineering has practical value in malware supervision, protocol fuzz testing and vulnerability detection, interaction behavior understanding and so on. Network traffic characterizes protocol specifications and bears the inherent characteristics of protocol, so that the private protocol reverse engineering based on network traffic is more suitable for discovering, analyzing and monitoring the private protocol on the network. In this paper, we provide a thorough review of the existing private protocol reverse engineering based on network traffic: Firstly, the architecture of private protocol reverse engineering based on network traffic is proposed, which includes four steps of pre-inference, protocol format inference, semantic analysis, and protocol state machine inference. The main research tasks of each step are also elaborated and a classification structure oriented to the core of the research method is proposed. Secondly, the method and process of each private protocol reverse engineering are described in detail, and a comparative analysis from multiple perspectives of applicable protocol type, technology kernel, and inference algorithms etc is made. A systematic overview of existing private protocol reverse engineering based on network traffic is conducted. Finally, the shortcomings of existing research and main influencing factors are summarized, and the future research direction and application scenarios of private protocol reverse engineering are prospected.
-
深度神经网络(deep neural network,DNN)模型规模变得越来越大,例如AlexNet[1]和VGG16[2]网络中分别包含6000万和1.38亿个参数,大规模的数据以及复杂的计算过程对硬件计算、存储资源的需求也随之加大,神经网络压缩技术能有效缓解对计算和存储的压力.量化是一种广泛使用的压缩技术,利用神经网络中数据的冗余性,将高精度浮点数据映射到使用更少位的低精度整型数据(INT8,INT4或者更低),以此降低神经网络推理的硬件开销.
为充分体现低精度神经网络的性能和能效优势,许多面向低精度神经网络的加速器被提出.DRQ架构[3]提出了一种基于区域的动态量化方法,该方法可以根据激活值中的敏感区域动态改变DNN模型的精度,并针对所提出的敏感区域算法设计了一种混合精度卷积阵列加速器.AQSS[4]基于随机计算方法实现了固定精度的7 b加速器结构,该加速器通过移位器代替乘加器,提高了加速器的性能.算法与硬件架构的配合使得此类加速器在模型准确率与性能等方面可以取得良好表现,但是此类架构与软件方法之间紧耦合且仅支持单一精度,使得很难适用于其他的量化算法和神经网络模型.
由于量化算法和神经网络模型的不同,一些架构通过支持多种精度运算来增加灵活性. OLAccel[5]基于4 b的乘加单元对权重和激活值进行低精度计算,同时考虑了少量高精度的离群值的存在,增加了一个额外的高精度乘加单元,用于离群值的计算. BitFusion[6]设计了精度可变的乘加单元,能够支持精度为2的任意指数的乘加运算.由于可以支持多精度数据的运算,相比于前一类加速器,此类加速器能支持更多的量化方法和低精度网络.但是,此类加速器采用细粒度的配置方式,给编译造成比较大的困难,并且对于计算部件的重构会带来额外的开销.另外,此类架构的时钟频率都受限于计算部件的设计.
数据流架构的执行方式与神经网络算法具有高度匹配性,并且在灵活性、性能之间具有良好权衡.Eyeriss[7]是一款典型的数据流神经网络加速器,通过减少数据移动、实现本地数据复用等方式最小化模型中数据移动距离,从而降低神经网络加速器的能耗. DPU[8]面向神经网络的稀疏性对数据流架构进行了优化,通过去掉与0相关的无效操作提升了数据流芯片的性能与能效.然而,现有数据流加速器没有面向低精度神经网络展开研究,而且都关注计算部件的设计,忽略了数据在片上存储和片外存储之间的传输问题.此外,传统数据流架构通过双缓冲机制掩盖数据传输的延迟,但是当部署低精度(INT8,INT4)神经网络时,传输带宽的利用率显著降低.这导致计算执行时间无法掩盖数据传输延迟,使得计算阵列完成此次计算之后不能马上开始下一次计算,需要等待数据传输完成,从而降低了数据流架构的性能和能效.
基于以上问题,本文面向低精度神经网络,对数据流架构进行了优化,设计了软硬件协同的低精度神经网络加速器DPU_Q.本文的贡献有4个方面:
1)为充分挖掘低精度卷积计算过程中的数据并行性,本文设计了灵活可重构的计算单元,根据指令的精度标志位动态重构数据通路,能高效灵活得支持多种低精度数据运算,并实现计算部件的高利用率和高峰值性能;
2)为支持低精度神经网络中复杂的访存模式,本文设计了Scatter引擎,能对低精度数据进行拼接、预处理,以满足高层次/片上存储对数据排列的格式要求,能有效应对复杂的访存模式并解决低精度数据传输带宽利用率低的问题;
3)为充分发挥数据流架构的性能优势,本文提出了一种数据流图映射算法,兼顾负载均衡的同时减少了访存和数据流图节点之间的数据传输带来的开销;
4)通过实验评估,相比于同精度的Titan Xp GPU,DPU_Q可以获得最高3.18倍的性能提升和4.49倍的能效提升.相比于同精度的Eyeriss加速器,DPU_Q可以最大获得6.05倍性能提升和1.6倍能效提升,相比于BitFusion加速器,可以最大获得1.52倍性能提升和1.13倍能效提升.
1. 相关研究
量化是一种神经网络压缩技术,通过将神经网络模型中的数据映射到使用更少位的数据域,减小神经网络存储规模、简化计算过程从而加快神经网络训练和推理的速度.量化的对象常为神经网络中的权值[9]、激活值[10]和反向传播中的梯度[11].常见的低精度有16 b,8 b,4 b.这些低精度神经网络经过量化、重训练过程之后,能够保证模型准确率损失在可接受的范围内,因此,面向低精度神经网络的量化算法和体系结构研究成为计算机领域的研究热点.表1展示了具有代表性的低精度神经网络加速器.
表 1 代表性低精度神经网络加速器Table 1. Representative Low-Precision Neural Network Accelerators为充分体现低精度神网络的性能和能效优势,许多面向低精度神经网络的加速器被提出[3-7].DRQ[3]架构根据激活值矩阵中敏感区域的特征,动态改变神经网络网络的精度,并且从硬件架构层面动态适配模型精度,设计了支持多种混合精度的卷积计算阵列.AQSS[7]架构则是基于随机计算的计算模式,设计了7 b精度的加速器微架构,并且使用移位器实现乘加计算,显著提升了计算性能和效率.然而,基于随机计算的架构需要额外的资源开销,例如随机数据生成、预处理等.以上述DRQ和AQSS为代表的、与软件算法紧耦合的架构的缺点是灵活性较差,很难适用于其他的量化算法、不同的神经网络模型以及模型精度.
由于量化算法和神经网络模型的不同,单一精度使加速器的灵活性受限,因此,一些架构通过支持多种精度运算来增加灵活性.OLAccel[5]基于4 b的乘加单元对权重和激活值进行低精度计算,同时考虑了少量高精度的离群值的情况.增加了一个高精度乘加单元,用于计算离群值,避免高精度与低精度计算单元的更新带来的一致性问题.BitFusion[6]引入了动态比特级融合/分解思想,是一种可变精度的比特级加速器,它由一组可组合的比特级乘加单元组成,动态融合以匹配单个DNN层的精度.该加速器的缺点在于细粒度的可重构运算部件使编程和算法移植变得困难,而且此类架构的时钟频率都受限于计算部件的设计.通过此类加速器的设计思想我们得到启发,低精度神经网络加速器的设计是需要同时支持低精度运算与部分高精度运算,一方面能在性能与模型准确率的权衡中获得最大收益,另一方面还可以支持更多的量化方法和网络模型,增加架构的灵活性.
数据流架构的执行方式与神经网络算法具有高度匹配性,并且在灵活性、粗粒度可重构性、性能之间具有良好权衡.Eyeriss[7]在整个模型中使用16 b的量化数据进行推理,并且通过减少某些数据移动、实现本地数据复用等方式最小化神经网络模型中数据移动距离,从而降低神经网络加速器的能耗,但Eyeriss由于精度较大,使其加速效果并不显著.DPU[8]面向稀疏神经网络对数据流处理器进行了优化.然而,现有数据流加速器没有面向低精度神经网络展开研究,更重要的,现有数据流架构侧重关注数据流计算单元和数据流图映射方面的研究,并未关注数据在片上存储和片外存储之间的传输.
2. 背 景
2.1 深度神经网络
DNN主要由多个卷积层组成,它们占据整个网络处理约85%的计算时间[12],这些卷积层执行高维的卷积计算.卷积层在输入特征图(input feature map,Ifmap)上应用卷积核(kernel)以生成输出特征图(output feature map,Ofmap).卷积层的输入数据由1组2维输入特征图组成,每个特征图称为1个通道,多个通道的输入组成1个输入图像,每个通道的特征值都与1个不同的2维滤波器(filter)进行卷积运算,通道上的每个点的卷积结果相加得到1个通道的输出特征图.卷积层的计算为
O[z][u][x][y]=C−1∑k=0S−1∑i=0R−1∑j=0I[z][k][Ux+i][Uy+j]×K[u][k][i][j],0≤z≤N,0≤u≤M,0≤x≤Q,0≤y≤P,P=H−R+UU,Q=W−S+UU, (1) 其中
{{\boldsymbol{O}} \in \mathbb{R}}^{N\times M\times P\times Q} ,{{\boldsymbol{I}} \in \mathbb{R}}^{N\times C\times H\times W} ,{{\boldsymbol{K}} \in \mathbb{R}}^{M\times C\times R\times S} 分别表示Ofmap,Ifmap,filter.2.2 低精度神经网络
低精度神经网络是经过量化操作之后得到的神经网络模型,量化能够减少神经网络模型中数据的精度,缩小神经网络的规模,简化计算来加速神经网络的训练或推理过程.
量化的过程可以描述为将网络中的参数分成不同的簇,同一簇中的参数共享相同的量化值,量化之后对参数进行编码,将量化后的参数转换为二进制编码来存储.常见的量化算法有线性映射、k-means聚类;常见的编码方式有固定长度的二进制编码和变长的霍夫曼编码.
表2展示了具有代表性的低精度神经网络及其数据精度.Q_CNN[13]是将卷积神经网络中的权值量化,对于图像识别应用能显著提升神经网络的性能并减少存储开销.EIA[14]将权值和激活值都量化成8 b定点数据,DFP[15]和LSQ[16]将网络中的权重和激活值等数据量化成多个不同的数据精度,而QIL[17]将权值和激活值量化成4 b数据.
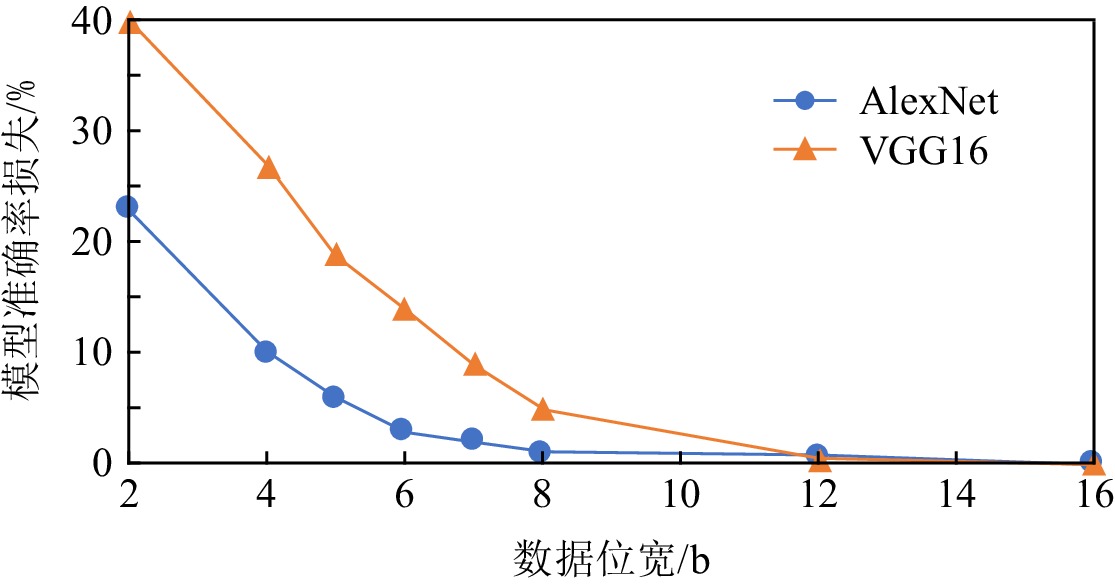
表 2 代表性低精度神经网络Table 2. Representative Low-Precision Neural Networks参考文献[18]中的方法,分别对AlexNet和 VGG16网络进行量化、微调,不同数据位宽与网络模型精度损失的关系如图1所示.对于VGG16网络,数据位宽少于8 b时,模型的准确率就会出现明显下降.而对于AlexNet网络,数据位宽至少为4 b时,可以保证模型的准确率.
![]() 图 1 神经网络模型准确率损失与数据位宽的关系Figure 1. Relationship between the accuracy loss of the neural network model and the quantization of bit-width
图 1 神经网络模型准确率损失与数据位宽的关系Figure 1. Relationship between the accuracy loss of the neural network model and the quantization of bit-width2.3 数据流架构
DPU[8]是一款典型的粗粒度数据流架构,采用数据流程序执行模型.计算机程序通过数据流图表示,数据流图由节点和连接节点的有向边构成.节点表示计算过程,节点之间的有向边表示数据依赖关系.计算节点是一个指令集合,各节点之间的调度与执行采用非抢占机制.借助于这种特殊的计算方式,DPU在功能灵活性方面与控制流驱动处理器相似,在能效上接近专用处理器芯片.
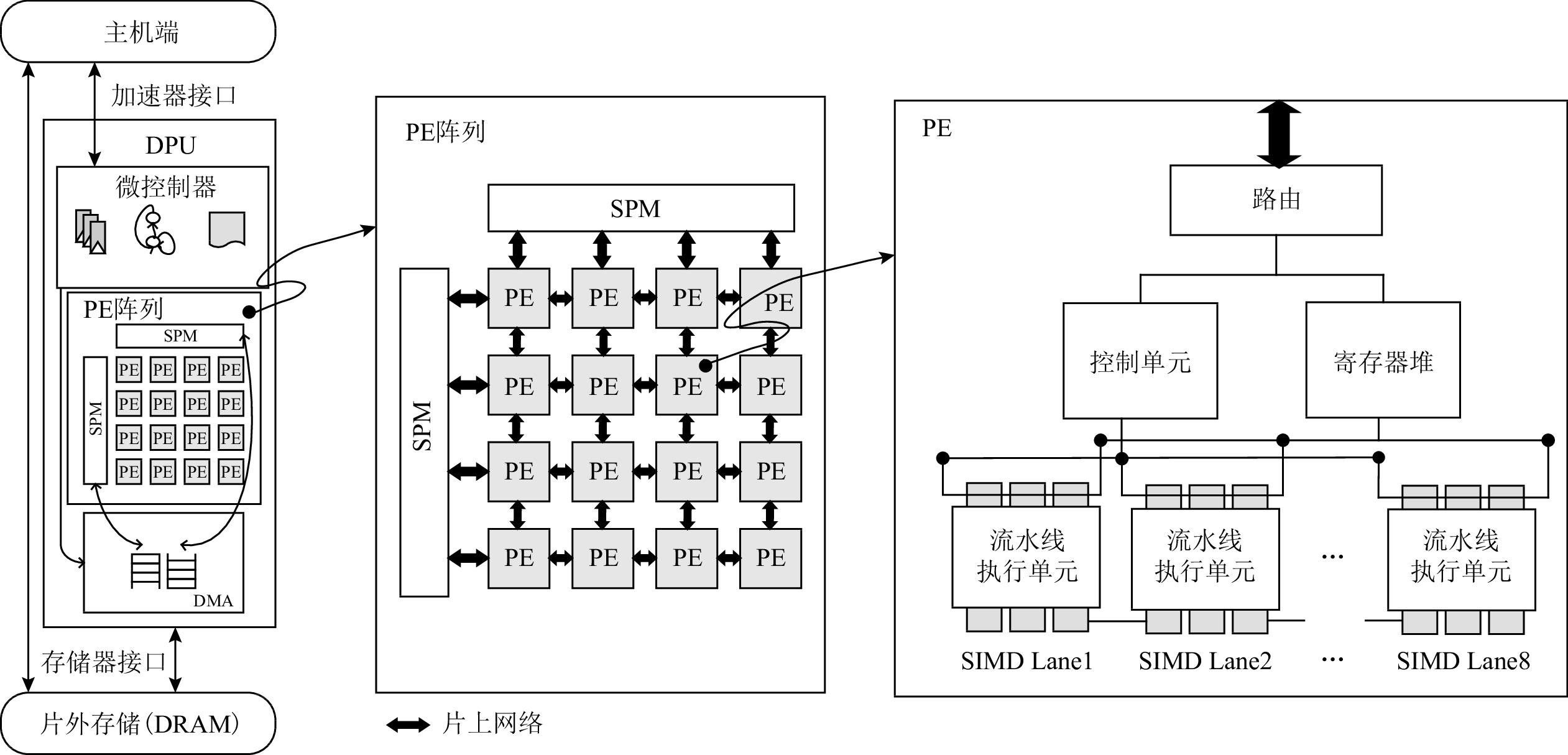
图2展示了DPU的整体架构,该架构由2维PE(process element)阵列、微控制器和DMA(direct memory access)组成.DPU作为协处理器,通过接口与主机端进行交互.由于DMA传输不占用计算资源且控制简单,所以,DPU使用DMA作为片上与片外存储之间数据传输的部件.
PE阵列由多个同构PE、片上网络和片上存储SPM(scratchpad memory)组成.片上存储SPM负责存储指令和数据,并由2块相同大小的SPM块组成,目的是通过双缓冲机制掩盖数据传输的延迟.片上网络将PE阵列组织为2维mesh拓扑结构,并负责在PE之间传输配置信息和数据.
在每个PE内部,由路由、控制单元、寄存器堆、流水线执行单元组成.为充分利用数据并行性,流水线执行单元使用单指令多数据(single instruction multiple data,SIMD)技术,进入流水线执行单元的矢量寄存器中都包含多个数据.为了提高PE计算部件的利用率,DPU采用解耦合的流水线设计,将访存、计算部件解耦合,访存部件采用传统5级流水,计算部件采用4级流水,减少了访存阶段.
微控制器负责控制PE阵列的执行,还负责与主机端进行通信.主机端向微控制器发送启动信号以及数据流图映射等配置信息,微控制器启动并配置DMA,DMA将片外存储中的数据加载至PE阵列的SPM中.微控制器配置并启动PE阵列,每个PE获得映射的数据流节点,根据节点中的指令,从SPM中加载数据,进入流水线单元执行.当PE阵列执行结束后,微控制器向主机端发送结束信息.DMA负责片上SPM中的结果传回片外存储.在此过程中,片上网络负责PE之间传递配置信息与数据.
3. 研究动机
3.1 计算单元精度不匹配
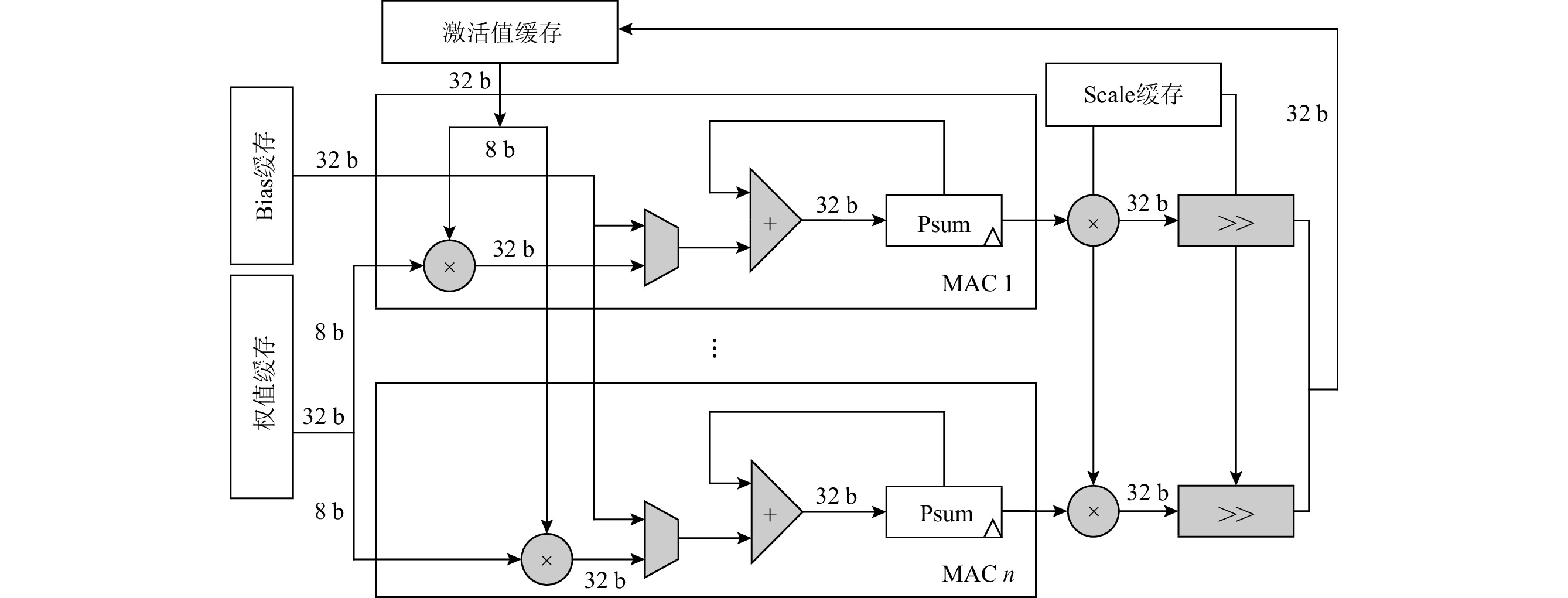
在传统数据流架构中,计算单元的数据通路宽度为32 b,与低精度神经网络中的数据宽度不匹配,不能充分利用低精度数据的性能、能耗优势.图3展示了数据流架构DPU中卷积运算的数据通路,数据通路中的数据位宽、计算部件、单个寄存器规模都是32 b,当计算低精度数据时,比如8 b数据,虽然能够完成计算,但在数据通路中传输、计算的数据的高24位全为0,造成计算资源的浪费.
3.2 访存模式复杂
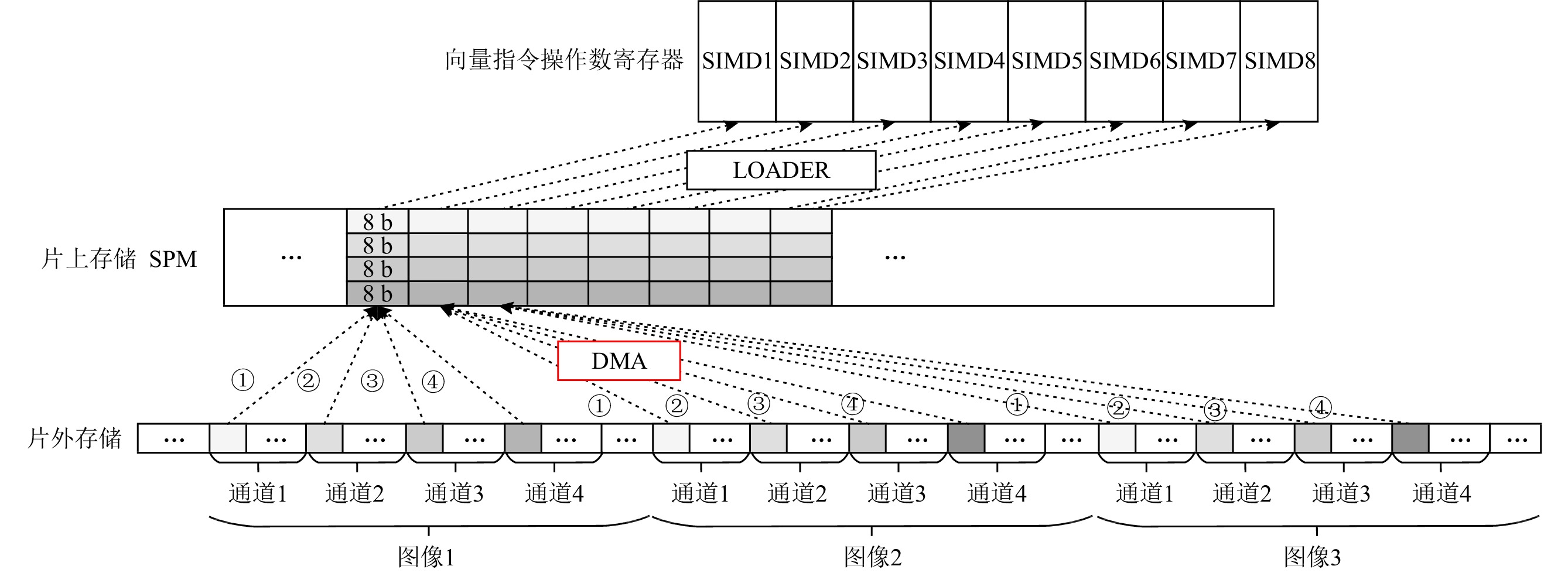
SIMD是一种利用数据并行性提升性能的技术.SIMD指令中的操作数都是一个向量,指令可以对向量中的每个操作数执行相同的操作和控制.SIMD的维度以8为例,即每条计算和访存指令同时对8个数据进行计算和读取/写回,每条Load指令就可以将8个分量从片上存储SPM加载到PE中的矢量寄存器中.在神经网络推理过程中,8个SIMD可以并行计算不同图像或者不同通道中相同位置的数据,但是这些数据需要在SPM中顺序排列.然而,在片外存储中,图像数据按照图像顺序依次排列存储在每张图像内部,不同通道的数据依次排列存储.所以在SPM中顺序排列的SIMD数据在片外存储中是地址离散、分散排列的,并非按照其在SPM中的顺序排列.面对片外存储中非连续数据的访问,DPU对DMA进行了优化,不同通道之间或者不同图像之间(SIMD之间的数据偏移)的地址偏移可以通过输入图像规模得到,所以根据访存首地址以及该偏移值,即可得到8个SIMD数据在片外存储的地址,DMA并行需要从片外存储中读取8个数据并依次写回SPM即可.
在低精度神经网络推理过程中,存储的访问模式变得更加复杂.图4以8 b精度为例,展示了数据在片上和片外存储中的排列格式.为了充分利用存储资源和数据并行性,SPM中每个存储单元存储同一图像中4个不同通道相同位置的数据,每个SIMD分量对4个通道数据进行卷积计算,而SIMD维度可以并行处理8个图像的数据,这样能充分挖掘数据的并行性,从而提升芯片的性能.但是,在每个图像中,相同位置不同通道的数据在片外存储中也并非连续存储,意味着在SPM中每个地址的32 b数据在片外存储中是分散排列的,因此,不同通道和不同图像之间数据在片外存储的偏移计算变得复杂.同时,使用优化后的DMA进行数据传输,每次只能并行读取8个SIMD的数据,即8个图像中单个通道的数据,所以对于8 b精度,DMA需要启动4次,才能完成1次计算所需的4个通道数据的传输.
3.3 传输带宽利用率降低
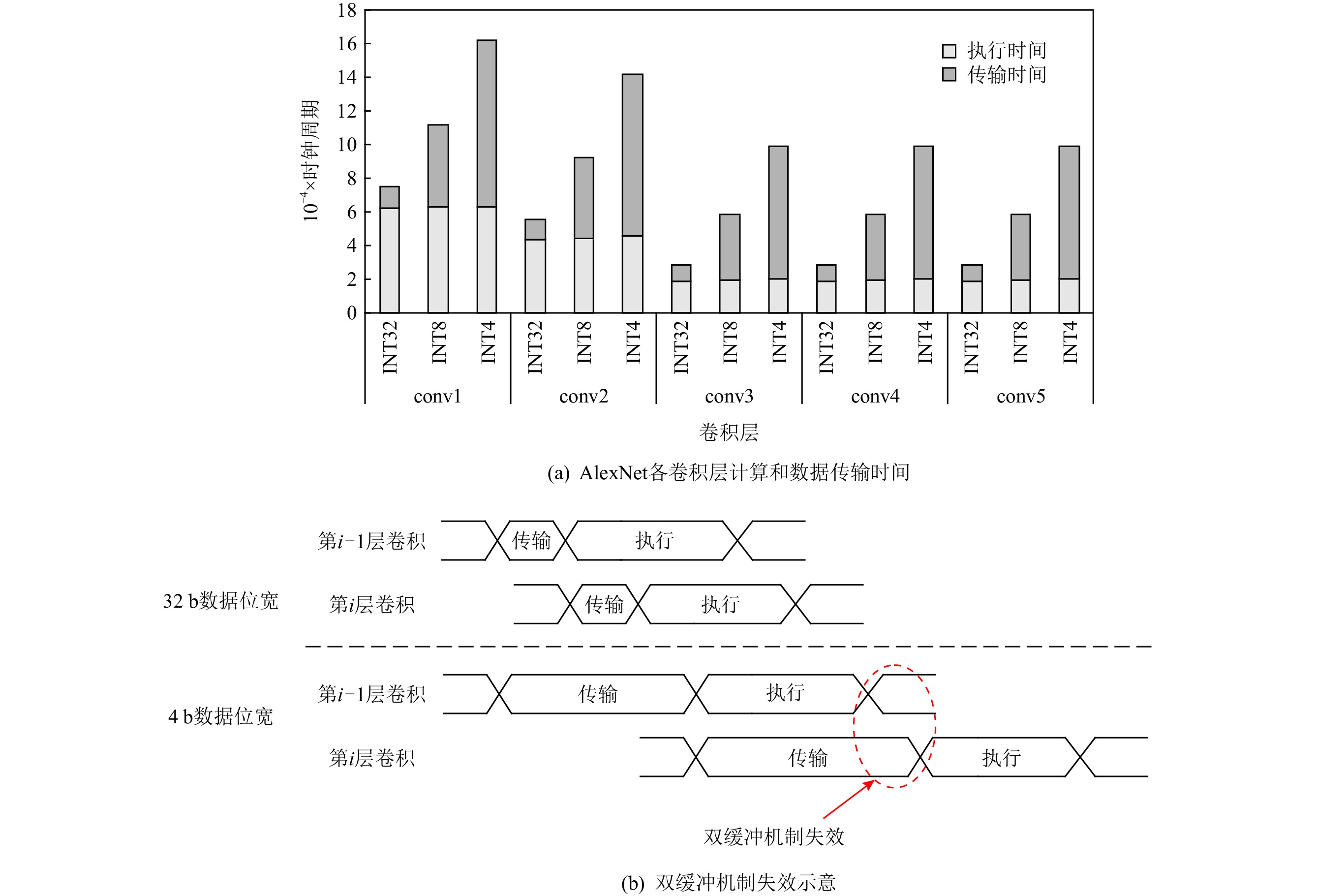
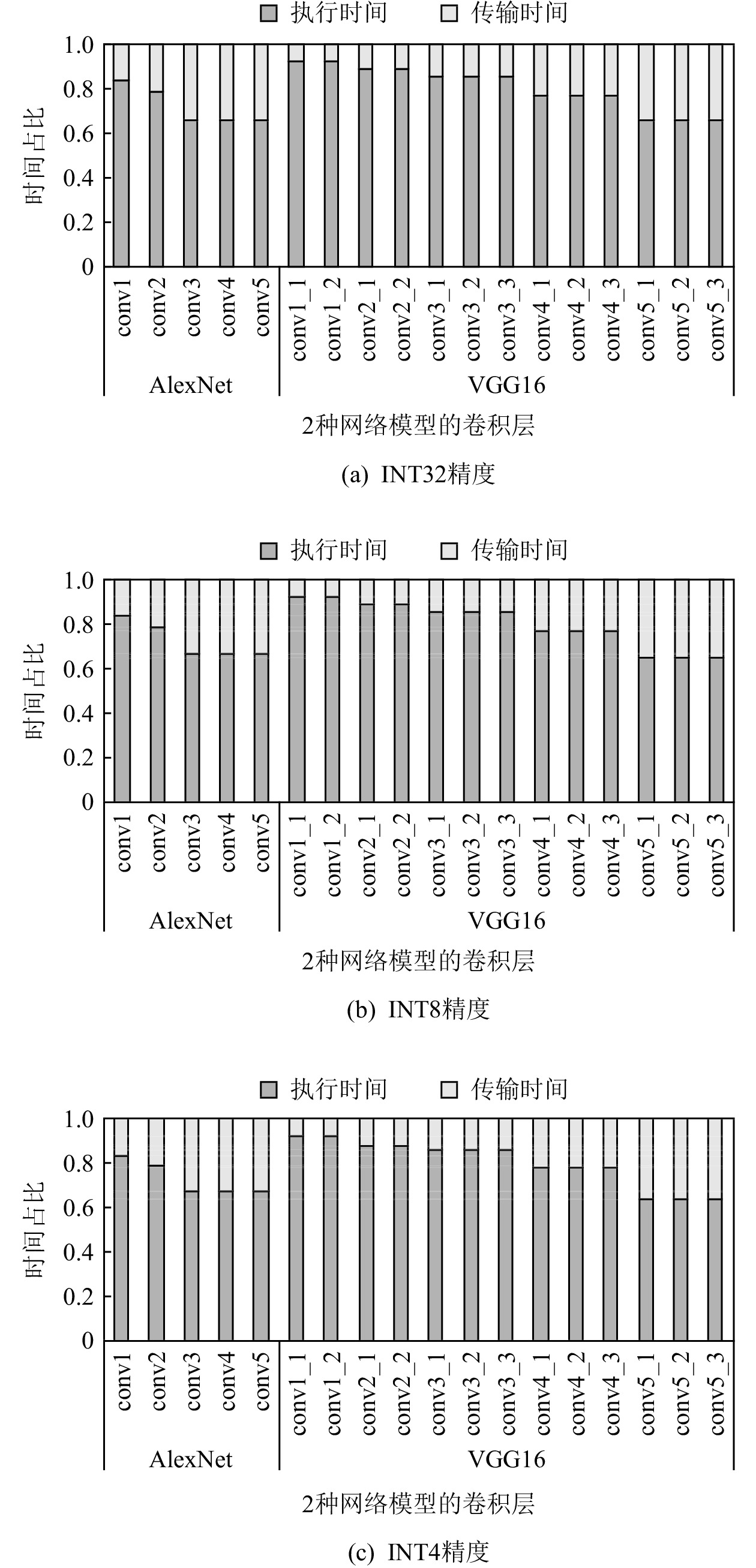
在数据流架构DPU中,DMA负责片上SPM与片外存储之间的数据搬运.与传统数据流架构一致,DPU的片上存储采用双缓冲机制,目的是用计算时间掩盖DMA的配置和数据传输时间.图5(a)展示了AlexNet网络5个卷积层进行1次DMA传输与1次计算的时间对比,对于32 b高精度数据,每一次启动DPU的执行时间远大于传输时间,传输时间完全可以通过双缓冲机制掩盖.然而,在数据流架构部署低精度神经网络时,基于3.2节的分析,需要多次启动DMA传输,导致数据传输时间变长,计算时间无法掩盖传输延迟,使得双缓冲机制失效.图5展示了AlexNet网络进行INT4和INT8的传输时间和执行时间.当精度为INT8时,conv3到conv5的数据传输时间超过了该层的执行时间,传输的平均带宽利用率仅为20.05%;当精度为INT4时,AlexNet每一层都无法通过双缓冲机制掩盖传输延迟,传输带宽的利用进一步降低.如图5(b)所示的是双缓存机制失效,可以看出,当第i−1层卷积运算结束后,第i层卷积的数据还未完成从片外存储到片上SPM的传输,导致第i层的计算无法在上一层结束之后立马开始,PE阵列需要长时间处于等待数据传输状态,双缓冲机制因此失去效果,使得计算单元的利用率下降,这会降低芯片的性能.
![]() 图 5 AlexNet网络不同精度的计算和传输开销Figure 5. Calculation and transmission overhead of different precisions in AlexNet
图 5 AlexNet网络不同精度的计算和传输开销Figure 5. Calculation and transmission overhead of different precisions in AlexNet4. DPU_Q架构
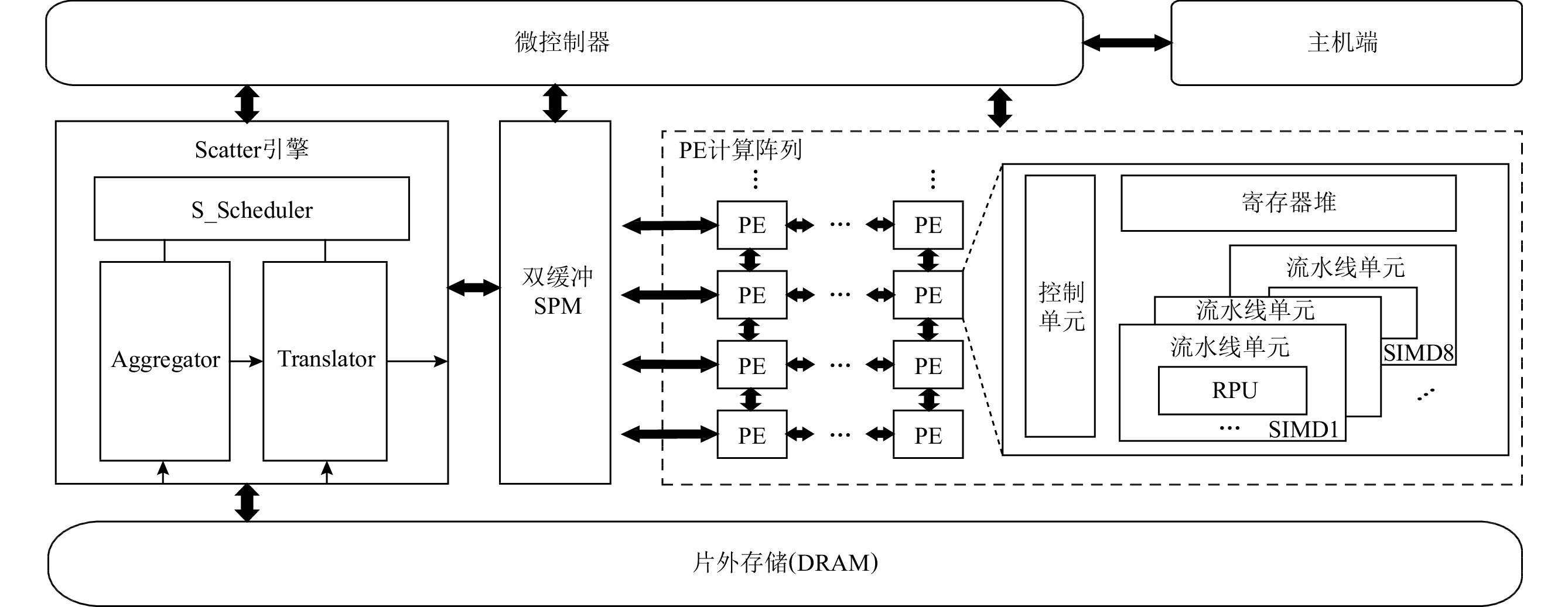
基于对低精度神经网络和数据流架构的分析,本文设计了面向低精度神经网络的数据流架构DPU_Q,总体架构如图6所示.DPU_Q核心部件包含微控制器、Scatter引擎、双缓冲SPM、PE计算阵列和片外存储.Scatter引擎负责片上SPM和片外存储之间的低精度数据访问和传输;PE阵列负责计算,其具有灵活可重构的低精度卷积计算部件RPU(reconfigurable process unit);双缓冲SPM既负责数据存储,又掩盖数据传输的延迟;微控制器负责控制各部分的功能.
与众多神经网络硬件加速器一样,DPU_Q是由PE阵列组成的空间架构(spatial architecture).PE之间通过片上网络进行互联,每个PE内包含本地存储和共享的片上存储,PE其内包含简单的计算单元.由于神经网络中的计算是相对简单且规则的操作,如张量的乘加运算,所以可以利用PE阵列的结构计算得到有效的处理.利用PE的本地和片上共享存储可以实现数据的时间复用,并且数据流程序执行模型提高了程序指令级并行性的同时,数据流图节点之间的数据传输实现数据的空间复用,从而减少存储访问.
DPU_Q架构的设计特点主要体现在3个方面:
1)在计算部件设计方面.以提升吞吐量和性能为目标,设计了灵活可重构的计算单元RPU,根据指令的精度标志位动态重构数据通路,能高效灵活地支持多种低精度数据运算,并且RPU内MAC簇可以进行通道维度并行,结合SIMD维度进行图像(batch)维度并行,以此充分挖掘低精度神经网络中的数据并行性.
2)在访存部件设计方面.以提升低精度数据传输带宽利用率为目标,设计了Scatter引擎,通过在数据传输过程中对数据进行重组、预处理,解决低精度数据访存模式复杂的问题.
3)在调度方面.以提高计算部件的利用率为目标,设计了兼顾负载均衡和数据重用的dR(data reuse)数据流图映射算法.
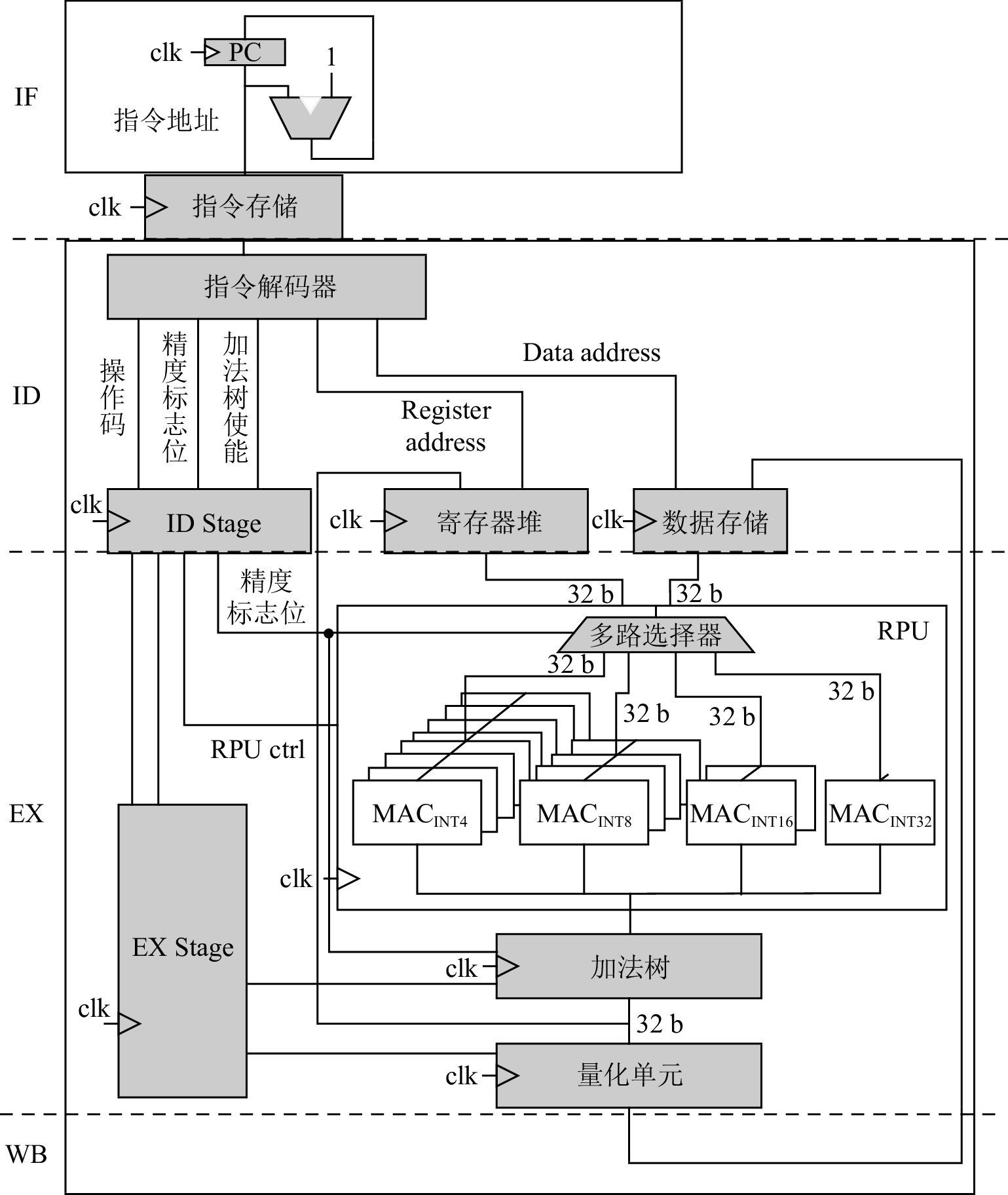
4.1 低精度卷积计算单元
图7展示了DPU_Q中低精度卷积计算单元的数据通路,该数据通路能够根据指令中的精度标志位动态选择可重构计算单元中的计算部件.该数据通路由4个流水线阶段组成.
第1阶段为取指(instruction fetch,IF).此阶段根据指令寄存器(program counter,PC)的值,从指令存储中获得指令.
第2阶段为译码(instruction decode,ID).指令译码器对指令进行译码,将指令码(opcode)、源/目的寄存器地址、精度标识位(precision flag)和加法树使能信号(adder tree enable)等信息分别发送到相应的状态寄存器和寄存器文件中.
第3阶段为指令执行(execution, EX).RPU根据精度标识位动态选择执行部件(MAC簇).然后,根据ID阶段解析的源寄存器地址获取源操作数,进行计算.加法树从流水线寄存器(EX stage)中获取使能信号,根据精度标识位将RPU计算的结果进行求和.另外,该阶段还包含了可选的量化部件,目的是为上层软件算法提供支持.
第4阶段为写回(write back, WB).在该阶段,计算结果被写回目的寄存器或者数据存储中.
在DPU_Q的实现中,精度标志位设计为2 b宽度,用于表示INT4,INT8,INT16,INT32这4种精度.对应地,RPU中包含了8个INT4的MAC簇、4个INT8的MAC簇、2个INT16的MAC簇以及1个INT32的MAC.RPU根据精度标志位选取MAC簇,并建立MAC簇与寄存器堆、加法树之间的线路链接.RPU和寄存器堆、加法树之间的线路连接宽度都为32 b,在RPU内部,不同精度的MAC簇的计算总的数据宽度也为32 b,目的是可以充分利用部件之间线路链接和寄存器文件.另一方面,结合卷积的算法特点,同一MAC簇的MAC可以并行计算同一图像不同通道的数据,充分利用低精度神经网络通道间的并行性.在DPU_Q中,向量SIMD不同维度用于不同图像之间的并行,单个SIMD内对相同图像的不同通道数据进行并行,以此进一步提高计算并行性和吞吐量.
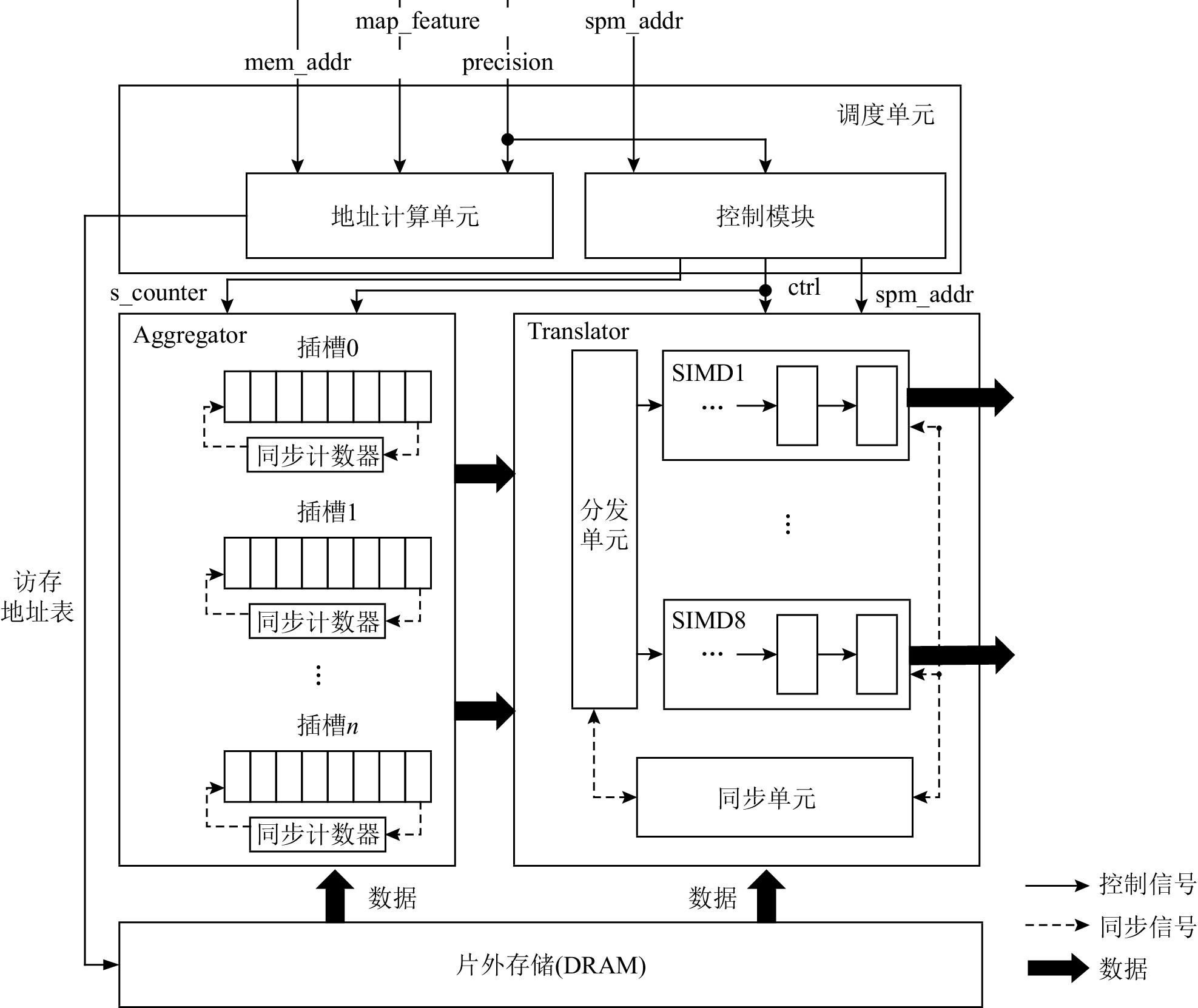
4.2 Scatter引擎
Scatter引擎主要包括调度单元、Aggregator和Translator这3部分,如图8所示.调度单元由地址计算单元和控制模块组成.调度单元一方面负责计算多个图像和通道数据在片外存储中的地址;另一方面负责控制Aggregator和Translator的执行.Aggregator完成低精度数据的拼接,由多个插槽和用于同步的计数器组成.Translator负责SIMD数据格式转换,由8个SIMD数据队列、分发单元和同步单元组成.
调度单元根据图像特征(map_feature)、访存地址(mem_addr)和精度(precision)可以得到参与计算的每张图像和每个通道的首地址.图像特征是个3元组(x_slice,y_slice,z_slice),分别表示图像的宽、高和通道规模.根据图像特征三元组和精度可得到每个图像在片外存储中的偏移,根据x_slice、y_slice和精度便可得到图像内每个通道的偏移,地址计算单元根据上述输入信息得到访存地址表,表中记录需要访问的片外存储地址.控制模块根据精度信息,首先生成Aggregator和Translator的控制信息.如果精度为32 b数据,Aggregator处于闲置状态,数据不会通过Aggregator,直接从片外存储进入Translator.如果是低精度数据,控制模块负责提供Aggregator同步所需的s_counter信号.最后,控制模块负责给Translator提供写地址信息spm_addr.
Aggregator负责同一张图像不同通道低精度数据的拼接,由多个插槽和同步计数器组成.Scatter引擎根据调度单元生成的访存地址表读取数据,每张图像中相同点不同通道的数据依次写进对应插槽中.每次在插槽中写入1个数据,对应的同步计数器值减1,插槽是一个32 b的存储单元,插槽的同步计数器归零意味着插槽中已经完成多个低精度通道数据的拼接,然后,Aggregator将该32 b数据单元传输至Translator.其中,同步计数器的初始值由调度单元生成s_counter信号提供.
Translator负责SIMD数据格式转换,由分发器、SIMD数据队列和同步单元组成.分发单元接受来自Aggregator或者片外存储的数据,将不同图像的数据送入不同的SIMD数据队列中,SIMD数据队列由先入先出(first in first out,FIFO)队列组成,同步单元使用bitmap进行同步操作,bitmap中纪录每个数据队列中队首数据是否就绪,一旦8个数据队列的队首数据就绪,则根据调度单元提供的spm_addr地址,将8个数据写入SPM对应地址中.
4.3 调 度
在数据流架构中,程序使用数据流图表示,数据流图(dataflow graph,DFG)记为GDFG,由一组节点(vertices)和连接节点的有向边(edge)组成,GDFG=(V,E).在粗粒度数据流架构中,数据流图每个节点由一段代码组成,代码段作为基本的调度和执行单元.
负载均衡有利于提升数据流架构的部件利用率从而保证数据流架构性能的发挥,而数据流图节点间的数据共享及复用能减少存储访问带来的开销,所以本文提出了兼顾负载均衡和数据复用的dR数据流图映射算法.具体的算法如算法1所示.
算法1. dR数据流图映射算法.
输入:特征矩阵规模IFmap、权值矩阵规模kernel、数据精度precision、计算阵列拓扑PEA、计算阵列规模PEvol、片上存储容量volume;
输出:数据流图GDFG=(V,E)、数据流图节点V与计算阵列拓扑PEA的映射关系map(V,PEA).
① d_volume←calculate(IFmap,kernel,precision);/*计算每层参与运算的数据量*/
② instance←calculate(d_volume,volume);/*由于某些神经网络每层数据规模较大,需要多次计算*/
③ vertices_work←calculate(d_volume,instance,PEvol); /*保证每个PE的负载均衡*/
④ generate(vertices_work,V); /*根据每个节点的工作负载,编译生成数据流图节点集合V */
⑤ reduce_MA(V,GDFG);/*遍历节点集合V,消除相同地址的访问指令,将具有相同访存指令的节点定义为节点之间的数据流动关系,实现数据复用*/
⑥ SD←BreadthFirstSort(GDFG);
⑦ for each node n in SD do
⑧ for each PE p in PEA do
⑨ curruentcost←Cost(n,p);
/*代价函数 */
⑩ if curruentcost < bestcost then
/*数据传输代价最小的映射 */
⑪ bestcost←curruentcost;
⑫ map(n,p);
⑬ endif
⑭ endfor
⑮ SD←SD
- {n};⑯ PEA←PEA
- {p};⑰ endfor
算法1首先根据特征矩阵、权值矩阵规模和精度计算神经网络每层参与运算的数据规模;然后根据片上存储的容量计算迭代次数,受限于片上存储容量,某些神经网络层需要多次迭代才能完成计算.由于每次迭代计算的数据规模可以提前计算得到,所以可以根据数据规模以及PE阵列的计算规模,为每个计算单元分配均衡数据量,达到负载均衡的目的.
根据每个PE的工作负载,编译器生成每个数据流图节点的指令,包括取数指令、计算指令等,生成了数据流图的节点集合V.在reduce_MA操作中,遍历节点集合V,如果节点之间包含了对相同地址的取数指令,意味着这些访存指令是冗余的,只保留一个节点内的访存指令,该节点作为访存节点,去除其他节点的该条访存指令.访存节点作为上游节点,其他节点作为该访存节点的下游节点,通过节点之间的数据流动代替冗余的访存操作,实现数据的复用.
算法的下一步是程序的数据流图GDFG到计算阵列PEA的映射.首先对数据流图进行宽度优先遍历,然后根据代价函数Cost评估每个数据流图节点与不同PE映射方法的代价,选取最小代价的方案进行映射.由于数据流图节点之间的依赖关系表示数据的流动,所以上下游节点应该尽可能映射到相邻的PE,这样一方面可以减少下游节点的等待时间,另一方面还可以减少对片上网络的压力.所以在算法1中将每个数据流图节点映射到与其所有上游节点欧氏距离之和最小的PE上.其中,代价函数如式(2)所示,式(2)计算待映射数据流图节点为n且映射到序号为p的PE时,节点n与其所有上游节点(已映射)的欧氏距离之和.
{{Cost}}(n\text{,}p)=\sum _{i\in father(n)}EuclideanDistance(i\text{,}p). (2) 5. 实验设置
5.1 实验平台
为验证第4节中所提方法的有效性以及评估DPU_Q处理低精度神经网络的能力,本文使用中科院计算所研发的大规模并行模拟框架SimICT[19]实现了时钟精确的模拟器,模拟器配置信息如表3所示.同时,实验中使用Verilog语言实现了对DPU_Q的RTL级仿真,并且利用Synopsys Design Compiler工具进行综合,使用Synopsys ICC编译器进行布局布线,使用Synopsys VCS进行验证设计.
表 3 DPU_Q的配置信息Table 3. Configuration Information of DPU_Q模块 配置信息 微控制器 ARM 核 PE 8×8, SIMD8, 1 GHz, 8 KB 指令缓存, 32KB数据缓存 片上网络 2维 mesh,1套访存网络,
1套控制网络,1套PE间通信网络片外存储 DDR3,1333MHz SPM/MB 6 在本实验中,微控制器用于执行控制程序,采用ARM架构处理器.DPU_Q由8×8的PE阵列组成, PE中配置了8 KB的指令缓存和32 KB的数据缓存.PE中数据通路的关键路径为DECODE_REG→MUX→MAC_REG,时延为0.8 ns,最高频率可以达到1.25 GHz.实验中PE时钟频率设置为1 GHz.PE之间通过2维的mesh网络连接,完成数据、控制信息在PE阵列的传输.SPM的大小配置为6 MB,用于保存数据和指令.
在启动阶段,主机端将DPU_Q所需要的指令和数据通过Scatter引擎从内存拷贝到SPM中,然后配置处理器阵列控制部件来启动加速器的执行.计算任务完成之后,结果数据通过Scatter从加速器的SPM中拷回片外存储当中.
5.2 测试程序
DPU_Q主要对低精度卷积运算进行优化加速,为评估性能,实验选取AlexNet,VGG16网络模型中的卷积层作为实验的测试程序,各层规模如表4所示.实验中使用文献[18]提出的方法对AlexNet,VGG16卷积层的激活值和参数进行量化,计算过程中保留全精度的部分和.使用基于LLVM平台设计的编译器,编译器将每个卷积层编译为数据流图并映射到PE阵列.
表 4 测试程序信息Table 4. Benchmark InformationCNN 模型 卷积层 特征矩阵规模
( H × W × C)卷积核规模
(R × S ×M)AlexNet conv1 227 × 227 × 3 11 × 11 × 96 conv2 31 × 31 × 96 5 × 5 × 256 conv3 15 × 15 × 256 3 × 3 × 384 conv4 15 × 15 × 384 3 × 3 × 384 conv5 15 × 15 × 384 3 × 3 × 256 VGG16 conv1_1 224 × 224 × 3 3 × 3 × 64 conv1_2 224 × 224 × 64 3 × 3 × 64 conv2_1 112 × 112 × 64 3 × 3 × 128 conv2_2 112 × 112 × 128 3 × 3 × 128 conv3_1 56 × 56 × 128 3 × 3 × 256 conv3_2 56 × 56 × 256 3 × 3 × 256 conv3_3 56 × 56 × 256 3 × 3 × 256 conv4_1 28 × 28 × 256 3 × 3 × 512 conv4_2 28 × 28 × 512 3 × 3 × 512 conv4_3 28 × 28 × 512 3 × 3 × 512 conv5_1 14 × 14 × 512 3 × 3 × 512 conv5_2 14 × 14 × 512 3 × 3 × 512 conv5_3 14 × 14 × 512 3 × 3 × 512 注:H,W,C分别表示特征矩阵的高、宽、通道;R,S,M分别表示卷积核的高、宽、通道. 5.3 对比平台
为评估DPU_Q性能,实验中选择GPU(NVIDIA Titan Xp)、低精度神经网络加速器Eyeriss和BitFusion作为对比平台.需要说明的是,由于cuDNN暂无法支持INT4,所以GPU平台仅使用cuDNN实现INT8神经网络;参考文献[4]中的方法,实现了INT8的Eyeriss加速器.实验中使用部件利用率评估映射算法的有效性,部件利用率计算为
部件利用率=\frac{应用性能}{理论峰值性能}\times 100\%. (3) 6. 结果分析
6.1 Scatter引擎收益
图9展示了DPU_Q在执行不同精度的AlexNet和VGG16网络时数据传输和执行的时间对比,其中传输时间指Scatter引擎进行数据传输的时间,执行时间指PE阵列计算时间.图9(a)中AlexNet和VGG16网络没有经过量化,对于每一层计算执行时间都超过该层数据在片上SPM和片外存储之间的传输延迟,DPU_Q可以通过双缓冲机制掩盖数据的传输延迟,对性能不会造成影响.
![]() 图 9 AlexNet和VGG16各层的数据传输和执行时间占比Figure 9. Data transmission and execution time proportion of each layer of AlexNet and VGG16
图 9 AlexNet和VGG16各层的数据传输和执行时间占比Figure 9. Data transmission and execution time proportion of each layer of AlexNet and VGG16图9(b)(c)分别为INT8和INT4精度下,DPU_Q部署AlexNet和VGG16网络时计算执行时间和传输时间的对比.得益于Scatter引擎,低精度数据的数据传输延迟不会超过计算部件的执行时间,双缓冲机制完全可以发挥作用.AlexNet和VGG16网络在不同精度下的传输带宽平均利用率为80.01%.
因此,实验证明了Scatter引擎可以有效解决低精度神经网络复杂的访存模式和带宽利用率降低的问题,解决了低精度神经网络执行过程中双缓冲机制面临失效的问题.
6.2 性能对比
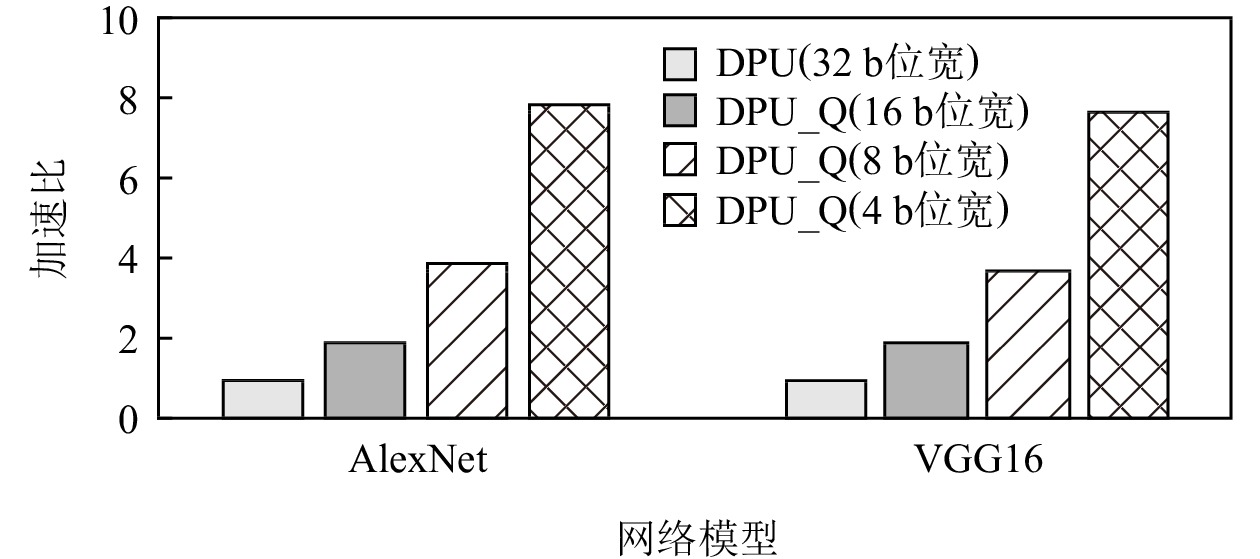
图10展示了不同精度下DPU_Q相对于DPU的性能提升.对于AlexNet和VGG16网络,INT4精度下,DPU_Q的性能达到了最佳,分别是DPU的7.9倍和7.7倍.当精度为INT8和INT16时,DPU_Q相对于DPU性能分别平均提升了3.80倍和1.89倍.DPU_Q的性能提升得益于RPU的设计,RPU可以根据精度动态重构数据通路,RPU内的MAC簇可以并行计算多个通道,这使得DPU_Q具有高吞吐量并以此获得性能的提升.当然,当精度缩小为1/n之后,性能并未达到理想的n倍加速,例如精度为8 b时的性能未到达32 b精度时的4倍,而是3.8倍.这是因为数据流架构的执行时间包括了配置初始化时间和计算时间,配置初始化的时间并未缩短.
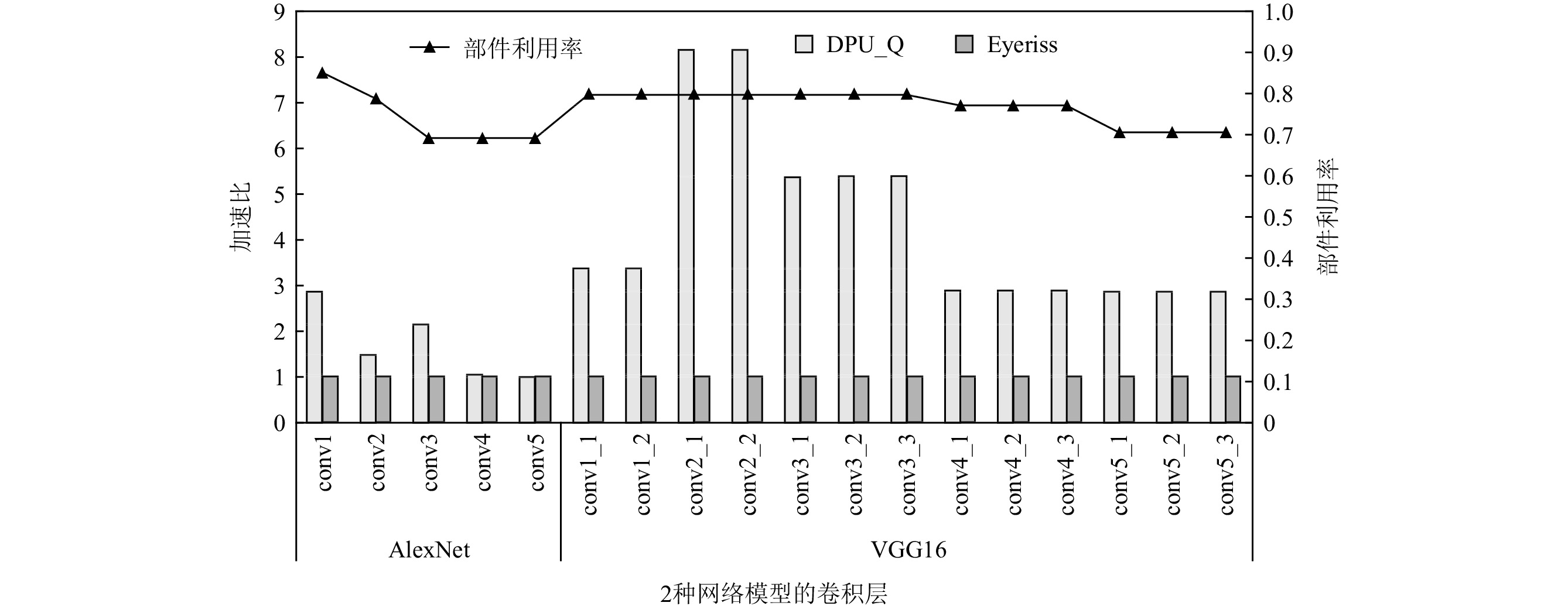
图11展示了以Eyeriss为基准,DPU_Q执行AlexNet和VGG16网络各层的加速比.DPU_Q执行各层的性能都优于Eyeriss.这是由于Eyeriss在进行神经网络部署时,仅考虑减少数据在片上的移动距离,减少数据搬运带来的功耗,并未挖掘神经网络计算中的并行性.对于AlexNet,加速比最高的是conv1,其加速比是2.85,这是因为第1层的权重矩阵规模较大、通道数较少,RPU中利用通道并行性以及SIMD间利用通道并行性的优势能显著减少数据的平均执行时间.另外得益于本文提出的映射算法能对数据进行充分复用,使得计算部件利用率提高,加速效果更明显.conv4和conv5的加速比较低,原因在于这2层的权重矩阵的规模很小,意味着可复用的数据占比减少,PE阵列的部件利用率下降,导致加速效果不明显.当执行VGG16时,conv2_1和conv2_2层的加速比较大,分别是8.155和8.157,这2层的通道数较少,DPU_Q加速效果明显的原因与第1层相似.执行AlexNet和VGG16网络时,DPU_Q计算平均部件利用率为76.02%.
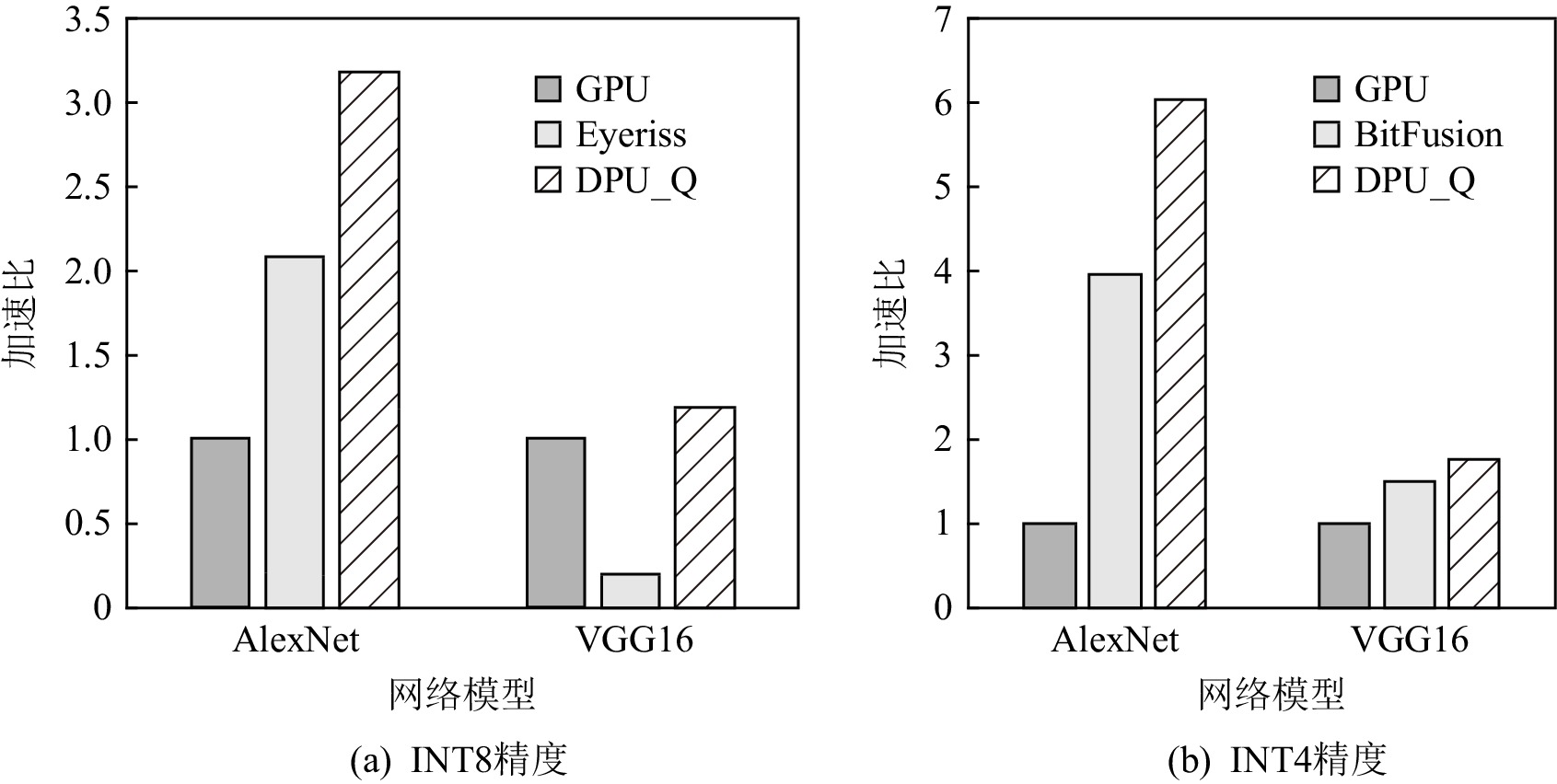
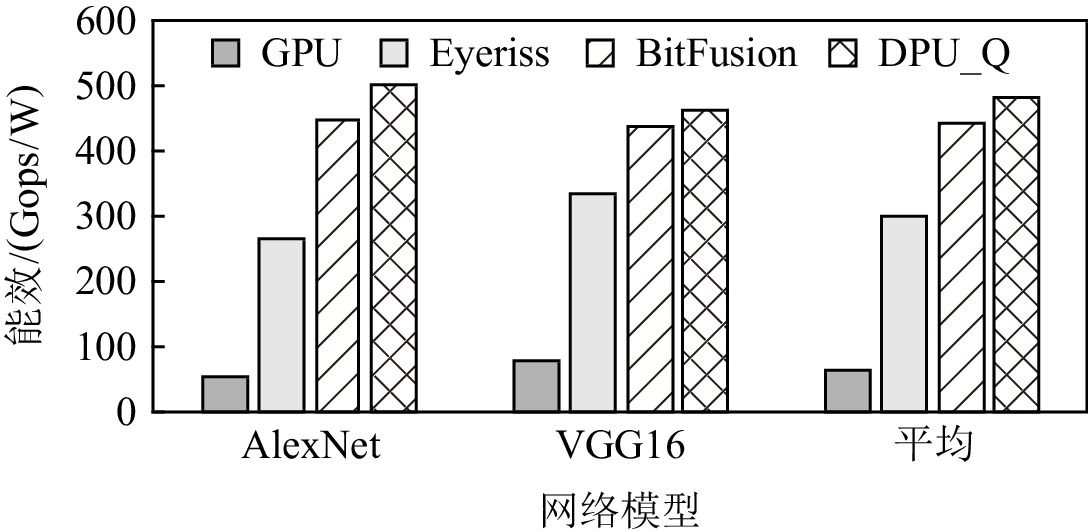
图12展示了DPU_Q,Eyeriss,BitFusion相对于GPU的性能对比,其中图12(a)是INT8精度的性能对比,图12(b)是INT4精度的性能对比.对于INT8精度,当部署AlexNet和VGG16网络时,DPU_Q相比于GPU可取得3.18和1.16的加速比,DPU_Q的性能是Eyeriss的1.52倍和6.05倍.当网络结构较为简单时,Eyeriss通过最小化数据传输距离作为优化目标以及细粒度的数据流执行方式能够取得较好的性能表现,但是当网络结构复杂时,较差的数据复用以及低并行性使得性能下降较为明显.
![]() 图 12 DPU_Q,BitFusion,Eyeriss相对于GPU的性能对比Figure 12. Performance comparison of DPU_Q,BitFusion,Eyeriss over GPU
图 12 DPU_Q,BitFusion,Eyeriss相对于GPU的性能对比Figure 12. Performance comparison of DPU_Q,BitFusion,Eyeriss over GPU对于INT4精度,当部署AlexNet和VGG16时,DPU_Q相对于加速器BitFusion可以取得1.52和1.17倍的性能提升.与BitFusion相比,DPU_Q能取得较好的性能表现,主要原因是由于BitFusion比特级的计算部件重构会导致计算的数据通路较长,计算周期增加.另外,得益于DPU_Q同时利用不同图像和不同通道维度的数据并行,实现了高吞吐量和性能的提升.
6.3 能效对比
图13展示了4种方案的能效对比,DPU_Q的能效都优于其他3种不同的平台.当部署AlexNet和VGG16网络时,DPU_Q的能效是GPU的4.49倍和3.34倍,造成GPU能效较低的主要原因是GPU的能耗非常高(计算资源平均部件利用率为41.35%).DPU_Q的能效是Eyeriss的1.6倍和1.38倍.虽然Eyeriss的性能表现不佳,但是由于其具有毫瓦级的功率,使得其在能效方面具有良好表现.DPU_Q的能效是BitFusion的1.13和1.05倍,DPU_Q在性能方面的提升得益于挖掘了多种并行性和映射算法,但是在计算单元以及传输Scatter引擎等特殊部件的设计也带来了额外能耗的开销.
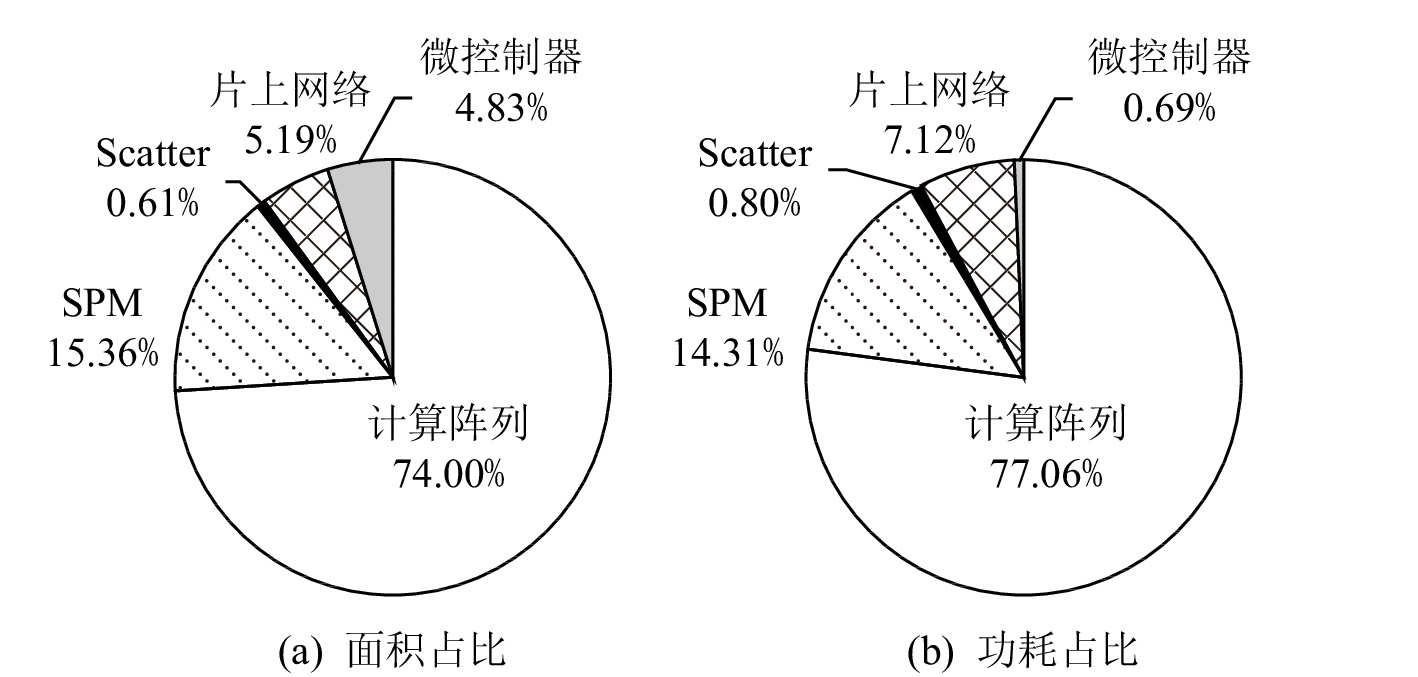
6.4 硬件开销
实验中使用Verilog语言实现了对DPU_Q的RTL级仿真,并且利用Synopsys Design Compiler工具以TSMC 12 nm工艺进行综合,使用Synopsys ICC编译器进行布局布线.DPU_Q的面积和功耗分布如图14所示,Scatter引擎所占面积比例为0.61%,功耗占比仅为0.80%.另外,DPU_Q的面积相对于DPU增加了17.6%,额定功耗增加33.59%,硬件增加的开销主要来源是PE内RPU多种不同精度的计算部件.
7. 总 结
本文结合低精度神经网络的计算需求,设计了灵活可重构的计算单元和Scatter引擎,并提出了负载均衡和数据复用的数据流图映射算法,设计了数据流加速器DPU_Q.相比于同精度的Titan Xp GPU,DPU_Q可以获得最高3.18倍的性能提升和4.49倍的能效提升.相比于同精度的Eyeriss加速器,DPU_Q可以最大获得6.05倍性能提升和1.6倍能效提升,相比于BitFusion加速器,可以最大获得1.52倍性能提升和1.13倍能效提升,表现出良好的性能和能效优势.本文仅针对卷积层进行了优化设计,由于神经网络中还包括其他类型的计算,未来会面向神经网络中其他类型的计算,进一步优化数据流架构.
作者贡献声明:范志华负责论文思路的提出、架构设计、实验和论文的撰写;吴欣欣负责论文思路讨论和架构设计讨论;李文明负责论文架构讨论和整体质量把控;曹华伟负责论文修改及实验指导;安学军负责论文整体思路的指导;叶笑春负责论文整体架构设计及修改;范东睿负责论文整体架构设计.
-
![]()
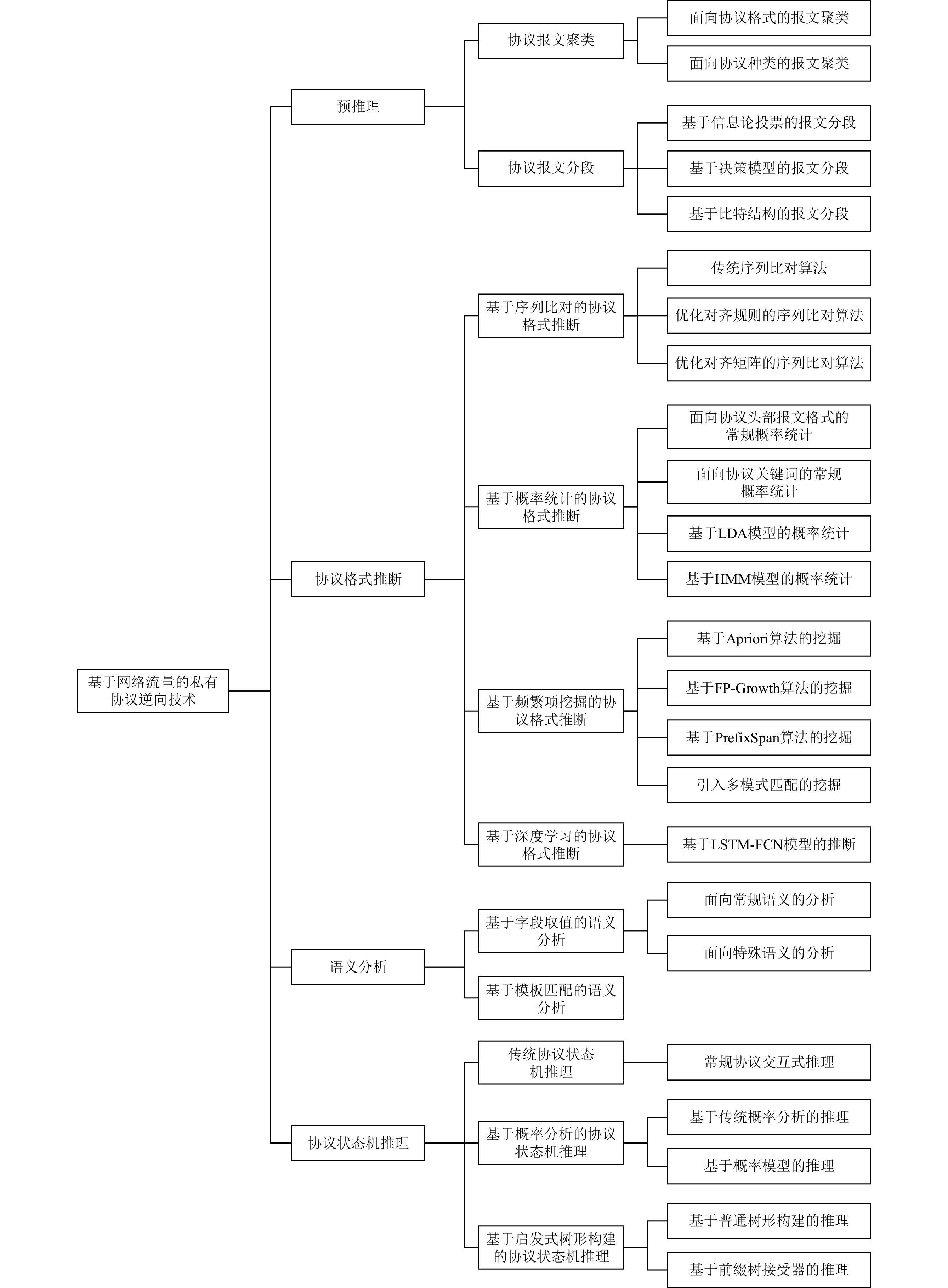
图 1 基于网络流量的私有协议逆向技术框架
Figure 1. Architecture of private protocol reverse engineering based on network traffic
![]()
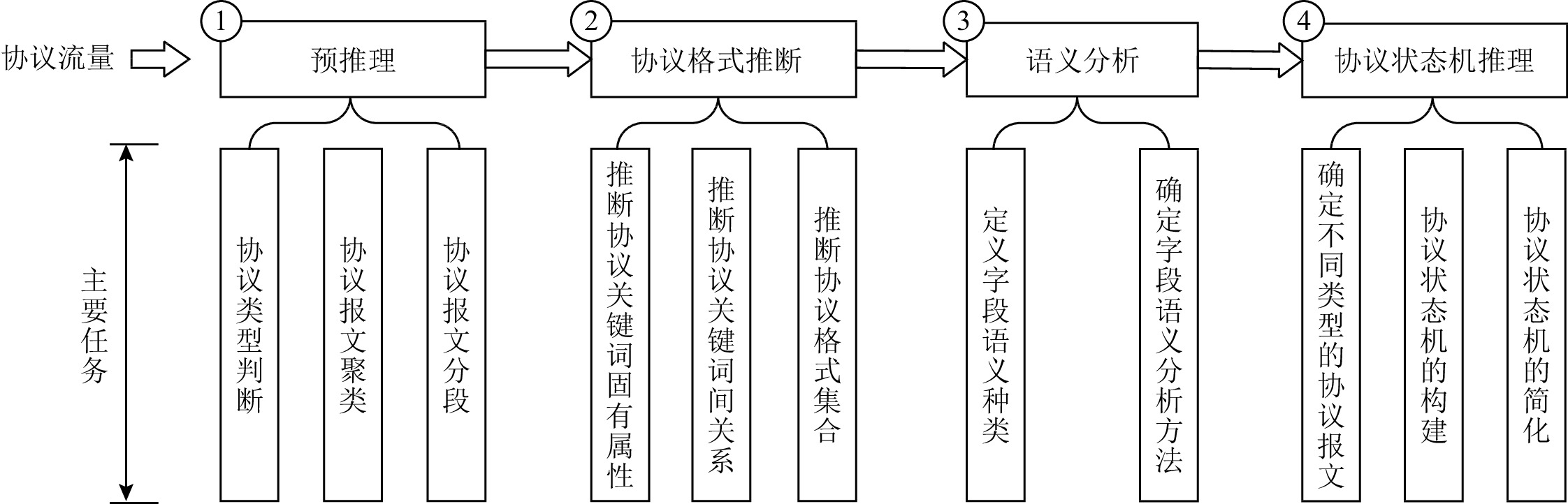
图 2 现有基于网络流量的私有协议逆向技术分类结构
Figure 2. Classification structure of private protocol reverse engineering based on network traffic
表 1 协议报文聚类方法概述
Table 1 Summary of Protocol Packets Clustering
面向目标 文献 协议类型 相似度计算方法 聚类算法 对比分析 面向协议格式的报文聚类 文献[25,35] 文本类 基于最长公共子序列 长度度量 凝聚层次聚类算法 计算简单,引入最长公共子序列相似度计算方法,但相似度计算并不能反映整个报文结构. 文献[36] 通用 基于语义信息的改进序列比对算法 基于语义信息的改进UPGMA算法 考虑协议报文的语义信息较为准确,但语义信息采集较为复杂,语义信息为自定义. 文献[37] 通用 基于字段概率分布信息度量 UPGMA算法 创新性利用概率模型生成的字段分布信息计算报文相似度. 文献[38] 文本类 基于ProWord产生的报文分段点度量 粗糙集划分算法 创新性引入粗糙集划分算法,但相似度计算过分依赖ProWord算法分段点. 面向协议种类的报文聚类 文献[40] 通用 基于TFD相似度的改进序列对比算法 参数指导的DBSCAN
聚类算法实现不同类型协议报文之间的聚类,但同一类型报文间相似度差距不大.同时仅考虑报文头部字节序列计算相似度存在一定的争议,并不合适.  下载: 导出CSV
下载: 导出CSV
表 2 协议报文分段方法概述
Table 2 Summary of Protocol Packets Segmentation
分段方法 文献 协议类型 方法基础 分段算法 对比分析 基于信息论投票的报文分段 文献[39] 通用 词内熵与词边界熵 基于信息熵的无监督专家投票算法 创新性引入无监督的专家投票算法,但计算时间复杂度较高,且针对二进制类协议效果不明显. 文献[41] 二进制类 字节信息熵与互信息 考虑字节间的互信息熵,结合字节间信息熵规律性,分段点选取更加合理.但针对二进制协效果不明显,且不同种类协议信息熵规律性易变,不能作为准则. 文献[42] 二进制类 字节信息熵 基于最近邻聚类算法决定分段点 考虑字节间的相似度,结合聚类算法,但计算时间复杂度较高,且产生的分段点可靠性不高. 基于决策模型的报文分段 文献[43] 通用 隐半马尔可夫模型 基于隐半马尔可夫模型的最大似然概率估计 创新性引入隐半马尔可夫模型,且对噪声有一定的容忍度,但频繁序列会对结果造成一定的影响. 文献[45] 二进制类 贝叶斯决策模型 基于序列比对算法的贝叶斯空位分段点决策估计 创新性引入贝叶斯决策估计,但其极度依赖于序列比对算法,部分分段点无法正确得到. 文献[46-47] 二进制类 时间序列突变点检测 基于时间序列多累积和的报文分段点检测算法 创新性引入时间序列突变点检测算法,但计算较为复杂,需要正序列、反序列2次检测. 基于比特结构的报文分段 文献[48] 二进制类 位一致性 基于多种位一致性值序列极大值点决定分段点 创新性引入位一致性,计算简单,但位一致性缺乏实际理论证明. 文献[49] 二进制类 位翻转频率 基于位翻转率极大值点决定分段点 只针对简单的二进制协议较为有效,更适合物联网协议分析.
下载: 导出CSV
表 3 协议格式推断方法概述
Table 3 Summary of Protocol Format Inference
推断方法 方法基础 文献 协议类型 推断算法 对比分析 基于序列
比对的协议
格式推断传统序列
比对算法文献[25,52,54] 通用 基于SW相似度的渐进式
NW序列比对算法创新性引入序列比对算法,但结果较为依赖对齐序列. 文献[53] 文本类 基于NW序列比对算法 只利用协议头部报文4个字节进行聚类,存在较多冗余,对齐结果并不准确. 文献[55] 文本类 基于PI方法的增量式近
实时协议格式推断算法其核心采用PI方法,推断基本协议格式,采用增量形式完善格式,但实时分析受网络环境限制,无法真正应用. 优化对齐
规则的序列
比对算法文献[57] 通用 基于字段类型的NW
序列比对算法基于字段的序列比对算法,对齐更加合理,但针对二进制类协议效果不明显. 文献[58] 通用 基于TF-IDF与位置信息的
DiAlign多序列比对算法对候选协议字段进行了初步筛选,去除冗余,优化后续序列比对算法. 优化对齐
矩阵的序列
比对算法文献[36] 通用 基于语义信息的NW
序列比对算法将语义信息用于改进推断结果的准确率,但需要人工参与语义信息的收集,需要较多的先验知识. 文献[60] 二进制类 基于Pair-HMM的NW
序列比对算法对序列比对算法的匹配规则进行创新,考虑概率对齐由概率给出得分情况,降低特殊字段造成的对齐影响. 文献[61] 二进制类 基于字段间不相似度的
Hirschberg对齐算法创新性考虑字段间的不相似度以适配序列比对算法,度量报文间的不相似度,从而推断协议格式. 基于概率
统计的协议
格式推断面向协议头部
报文格式的
常规概率统计文献[63] 通用 基于K-S统计检验的
格式推断算法提取协议关键词与协议头部报文格式,为状态机推断做准备. 文献[64] 二进制类 基于字节序列统计特征的
格式推断算法创新性提出以状态转移概率图形式描述协议格式,以字节序列作为状态. 面向协议
关键词的
常规概率统计文献[39] 通用 基于多维属性统一度量
排序的关键词提取算法度量关键词的多维属性,统一标准化排序,但部分属性对分数度量影响很大,即未平衡各个属性所占权重. 文献[65] 二进制类 基于报文分段点重定位的
协议关键词提取算法核心采用ProWord方法对报文进行分段,该方法对二进制协议效果不明显,但使用重定位对分段点再次确认,适用于较为简单的工控协议. 文献[46−47] 二进制类 基于最小描述长度与位置信
息的协议关键词提取算法创新性使用时间序列突变点检测算法对协议报文进行分段,并考虑位置信息提取协议关键词,但其较为依赖分段点的准确性,可能存在冗余. 文献[66] 通用 基于聚类效果直观度量的
协议关键词概率提取算法创新性对聚类效果建立直观度量模型,根据聚类效果筛选最优协议关键词,从而得到最佳的报文聚类簇,推断更准确的协议格式. 基于LDA模型
的概率统计文献[69] 通用 基于概率分布LDA模型的
格式推断算法创新性以LDA模型提取协议关键词,协议关键词筛选较为准确完整,错误冗余字段较少. 文献[70] 文本类 基于概率分布LDA模型的
FP-Growth频繁项挖掘算法结合频繁项挖掘算法推断协议格式,时间复杂度较高,且针对协议较为简单,分析结果得到的二进制字段无意义. 基于HMM
模型的
概率统计文献[71,74] 文本类 基于时间序列与状态分类
构建最小化HMM模型创新性引入HMM模型,针对文本类效果较为明显,但其仅提取协议头部报文格式,并不完整. 文献[72] 通用 基于最优化报文分段HsMM模型的协议格式推断 采用基于HsMM模型的报文分段算法,结合AP聚类算法对协议报文进行聚类,最终推断协议格式. 文献[73] 通用 基于统计信息与HsMM
模型的协议关键词提取算法在使用HsMM模型建模前,对候选协议字段初步筛选,去除冗余,构建的HsMM模型更加简洁. 基于频繁项
挖掘的协议
格式推断基于Apriori
算法的挖掘文献[78] 通用 基于多支持度与位置信息
的频繁项挖掘算法算法需要设置支持度较多,时间复杂度较高,但格式推断较为准确,推断的状态机不具有代表性. 文献[79] 文本类 基于信息熵与多支持度的
Apriori频繁项挖掘算法重点对文本类协议报文分隔符做了详细分类,以统计信息提取协议关键词. 文献[80−81] 通用 基于CSP算法的协议
格式推断将协议字段划分为4种类型,并填充协议格式,但该格式不具有代表性. 文献[82] 二进制类 基于多维度字段长度的
Apriori频繁项挖掘算法以多种字段长度为基础挖掘频繁项,尽量减少未分段或过分段的协议关键词,但算法时间复杂度较高. 基于FP-Growth算法
的挖掘文献[83] 通用 基于信息熵分段与位置信
息熵的频繁项挖掘算法核心采用ProWord方法对报文进行分段,在频繁项挖掘之前对候选协议字段进行过滤,但其无法挖掘到完整的协议格式. 文献[84] 文本类 基于频繁项挖掘的CFSM
算法与CFGM算法考虑挖掘协议关键词间的并列、顺序与层次关系,并使用树形结构予以表示. 基于
PrefixSpan
算法的挖掘文献[85] 二进制类 基于频繁项挖掘的加密
协议明文格式推断算法创新性提取加密协议明文格式,但基于位置偏移的协议关键词提取具有一定的局限性. 引入多模式匹配的挖掘 文献[87−88] 二进制类 基于AC多模式匹配的
FP-Growth频繁项挖掘算法针对无人机等简单二进制协议具有较高的可用性,无法适用文本协议. 文献[89] 二进制类 基于AC多模式匹配的
Apriori频繁项挖掘算法针对Apriori算法的时间复杂度大有改进,提高效率. 基于深度
学习的协议
格式推断基于LSTM-FCN模型
的推断文献[90] 二进制类 基于LSTM-FCN模型的
深度学习算法创新性将深度学习算法引入协议逆向,定义5种字段类型,需要大量已知公开协议关键词结合时序关系训练模型,协议格式即为字段的识别划分. 文献[92] 二进制类 定义6种字段类型,将协议报文分为多维度长度字段进行分类,针对未知协议格式推断具有一定可行性.
下载: 导出CSV
表 4 语义分析方法概述
Table 4 Summary of Semantic Analysis
分析
方法文献 环境参数相关语义 标识性语义 指示性语义 特殊语义 对比分析 端口 地址 时间戳 结点名 参数 计数器 ID 报文
类型长度 偏移量 偏移
指针校验码 字符串 常量 加密
字段枚举 功能
代码基于字段取值的语义分析 文献[56] ● ● ● ● ● 需要基于正确的报文分段,构建数值集合,对数值集合间关系予以描述. 文献[57] ● ● ● ● ● ● ● 文献[93−94] ● ● ● ● ● 文献[95] ● ● ● ● ● ● 对特殊语义字段具有针对性的检测方法. 文献[96] ● ● ● ● ● 文献[65] ● ● ● ● 文献[97] ● ● ● ● ● 基于模板匹配的语义分析 文献[25] ● 需要正确先验知识构建语义模板,模板具有较低的兼容性. 文献[62] ● ● ● ● 文献[98] ● ● ● ● ● ● 注:●表示该方法中提到的可推断字段语义种类.
下载: 导出CSV
表 5 协议状态机推理方法概述
Table 5 Summary of Protocol State Machine Inference
推理方法 文献 协议类型 协议状态标记方法 状态机构建方法 状态机简化方法 对比分析 传统协议状态机推理 文献[17] 二进制类 基于设定最大阈值
的协议交互式基于宏聚类、微聚类
2次聚类结果的相似
状态合并构建状态机方法较为简单,其采用全协议会话,生成状态机庞大,对化简造成负担. 文献[99] 二进制类 基于字节的VDV筛选状态相关字段进行报文类型划分 基于协议状态分裂
算法的协议交互式基于制定规则的协议
状态机化简定义状态分裂算法,与字节的方差分布变化,但其采用滑动窗口机制,造成的时间复杂度较高. 文献[35] 文本类 基于凝聚层次聚类的协议报文类型划分 协议交互式 基于报文流向与
状态唯一性的协议
状态机化简该方法推断仅仅是报文序列之间顺序模型,有违协议状态机原理,并不具有代表性. 基于概率分析的协议状态机推理 文献[63] 通用 基于PAM算法的协
议状态报文筛选基于有向图的
概率分析提出扩展的概率协议状态机,包含状态间的转换概率,但并未对协议状态机进行状态合并以化简. 文献[18,100] 通用 基于最近邻聚类的
协议报文类型划分基于马尔可夫
模型的概率分析Moore状态机
最小化算法引入马尔可夫模型,并以此生成协议状态机,状态转换附带概率信息,但协议状态机模型较为复杂,化简并不完善. 基于启发式树形构建的协议状态机推理 文献[53,101] 文本类 基于普通树形的
启发式构建基于状态等价
原则的树剪枝在构建协议状态机之前对协议会话进行过滤,删除循环报文,初步简化. 文献[102] 文本类 基于最近邻聚类的
协议报文类型划分基于状态兼容性
检测的状态合并引入状态兼容性原则,重点关注协议状态机的简化. 文献[103] 文本类 基于PTA的协议
报文类型划分基于PTA的启发式
树形构建基于报文类型间因果
关系的积极状态合并引入PTA区分报文类型与状态机构建,考虑报文类型间的因果关系更有助于状态合并. 文献[104] 通用 基于Apriori算法
与K-means算法的
协议报文类型划分K-tail状态合并算法 提出新型协议状态机,引入数据保护的概念,对协议状态机附加协议关键词间约束与协议报文间依赖等信息,使协议状态机更加完善,但同时造成推理的时间复杂度升高.
下载: 导出CSV
-
[1] 中国互联网络信息中心. 第48次中国互联网络发展状况统计报告[R/OL]. (2021-08-27) [2021-10-12]. http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/hlwtjbg/202108/P020210827326243065642.pdf China Internet Network Information Center. The 48th China statistical report on Internet development[R/OL]. (2021-08-27) [2021-10-12]. http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/hlwtjbg/202108/P020210827326243065642.pdf (in Chinese)
[2] Duchene J, Le Guernic C, Alata E, et al. State of the art of network protocol reverse engineering tools[J]. Journal of Computer Virology and Hacking Techniques, 2018, 14(1): 53−68 doi: 10.1007/s11416-016-0289-8
[3] Sija B D, Goo Y H, Shim K S, et al. A survey of automatic protocol reverse engineering approaches, methods, and tools on the inputs and outputs view[J]. Security and Communication Networks, 2018, 2018: 8370341 [4] Newsome J, Brumley D, Franklin J, et al. Replayer: Automatic protocol replay by binary analysis[C] //Proc of the 13th ACM Conf on Computer and Communications Security. New York: ACM, 2006: 311−321
[5] Caballero J, Yin Heng, Liang Zhenkai, et al. Polyglot: Automatic extraction of protocol message format using dynamic binary analysis[C] //Proc of the 14th ACM Conf on Computer and Communications Security. New York: ACM, 2007: 317−329
[6] Dupont P, Lambeau B, Dames C, et al. The QSM algorithm and its application to software behavior model induction[J]. Applied Artificial Intelligence, 2008, 22(1/2): 77−115
[7] Caballero J, Poosankam P, Kreibich C, et al. Dispatcher: Enabling active botnet infiltration using automatic protocol reverse-engineering[C] //Proc of the 16th ACM Conf on Computer and Communications Security. New York: ACM, 2009: 621−634
[8] Comparetti P M, Wondracek G, Kruegel C, et al. Prospex: Protocol specification extraction[C] //Proc of the 30th IEEE Symp on Security and Privacy. Piscataway, NJ: IEEE, 2009: 110−125
[9] Wang Zhi, Jiang Xuxian, Cui Weidong, et al. ReFormat: Automatic reverse engineering of encrypted messages[C] //Proc of the 14th European Symp on Research in Computer Security. Berlin: Springer, 2009: 200−215
[10] 应凌云,杨轶,冯登国,等. 恶意软件网络协议的语法和行为语义分析方法[J]. 软件学报,2011,22(7):1676−1689 doi: 10.3724/SP.J.1001.2011.03858 Ying Lingyun, Yang Yi, Feng Dengguo, et al. Syntax and behavior semantics analysis of network protocol of malware[J]. Journal of Software, 2011, 22(7): 1676−1689 (in Chinese) doi: 10.3724/SP.J.1001.2011.03858
[11] Caballero J, Song D. Automatic protocol reverse-engineering: Message format extraction and field semantics inference[J]. Computer Networks, 2013, 57(2): 451−474 [12] Zeng Junyuan, Lin Zhiqiang. Towards automatic inference of kernel object semantics from binary code[C] //Proc of the 18th Int Symp on Research in Attacks, Intrusions and Defenses. Berlin: Springer, 2015: 538−561
[13] 中国信息通信研究院, 工业互联网产业联盟. 2020年上半年工业互联网安全态势综述[EB/OL]. (2020-09-19) [2021-10-12]. http://www.caict.ac.cn/kxyj/qwfb/qwsj/202009/P020200919706881804206.pdf The China Academy of Information and Communications Technology, Alliance of Industrial Internet. The overview of industrial Internet security situation in the first half of 2020[EB/OL]. (2020-09-19) [2021-10-12]. http://www.caict.ac.cn/kxyj/qwfb/qwsj/202009/P020200919706881804206.pdf (in Chinese)
[14] IETF. RFC 8922: A Survey of the Interaction Between Security Protocols and Transport Services[S/OL]. (2019-10-04) [2021-10-12]. https://datatracker.ietf.org/doc/rfc8922/?include_text=1
[15] Kleber S, Maile L, Kargl F. Survey of protocol reverse engineering algorithms: Decomposition of tools for static traffic analysis[J]. IEEE Communication Surveys and Tutorials., 2019, 21(1): 526−561 doi: 10.1109/COMST.2018.2867544
[16] Cho C Y, Babic D, Shin E C R, et al. Inference and analysis of formal models of botnet command and control protocols[C] //Proc of the 17th ACM Conf on Computer and Communications Security. New York: ACM, 2010: 426−439
[17] Leita C, Mermoud K, Dacier M. ScriptGen: An automated script generation tool for honeyd[C] //Proc of the 21st Annual Computer Security Applications Conf. Piscataway, NJ: IEEE, 2005: 203−214
[18] Krueger T, Gascon H, Kramer N. Learning stateful models for network honeypots[C] //Proc of the 5th ACM Workshop on Security and Artificial Intelligence. New York: ACM, 2012: 37−48
[19] Gascon H, Wressnegger C, Yamaguchi F, et al. PULSAR: Stateful black-box fuzzing of proprietary network protocols[C] //Proc of the 11th Int Conf on Security and Privacy in Communication Networks. Berlin: Springer, 2015: 330−347
[20] Blumbergs B, Vaarandi R. Bbuzz: A bit-aware fuzzing framework for network protocol systematic reverse engineering and analysis[C] //Proc of the 36th IEEE Military Communications Conf. Piscataway, NJ: IEEE, 2017: 707−712
[21] Kim J, Choi H, Namkung H, et al. Enabling automatic protocol behavior analysis for android applications[C] //Proc of the 12th Int on Conf on Emerging Networking Experiments and Technologies. New York: ACM, 2016: 281−295
[22] Choi K, Son Y, Noh J, et al. Dissecting customized protocols: Automatic analysis for customized protocols based on IEEE 802.15.4[C] //Proc of the 9th ACM Conf on Security, Privacy in Wireless and Mobile Networks. New York: ACM, 2016: 183−193
[23] Stute M, Kreitschmann D, Hollick M. Reverse engineering and evaluating the apple wireless direct link protocol[J]. GetMobile Mobile Computer and Communications, 2019, 23(1): 30−33 doi: 10.1145/3351422.3351432
[24] Yang Zhi, Gou Xiantai, Jin Weidong, et al. Reverse engineering for UAV control protocol based on detection data[C] //Proc of the 2nd Int Conf on Multimedia and Image Processing. Piscataway, NJ: IEEE, 2017: 301−304
[25] Ji Ran, Wang Jian, Tang Chaojing, et al. Automatic reverse engineering of private flight control protocols of UAVs[J]. Security and Communication Networks, 2017, 2017: 1308045
[26] Wressnegger C, Kellner A, Rieck K. ZOE: Content-based anomaly detection for industrial control systems[C] //Proc of the 48th Annual IEEE/IFIP Int Conf on Dependable Systems and Networks. Piscataway, NJ: IEEE, 2018: 127−138
[27] Marin E, Singelee D, Yang Bohan, et al. On the feasibility of cryptography for a wireless insulin pump system[C] //Proc of the 6th ACM on Conf on Data and Application Security and Privacy. New York: ACM, 2016: 113−120
[28] Marin E, Singelee D, Yang Bohan, et al. Securing wireless neurostimulators[C] //Proc of the 8th ACM Conf on Data and Application Security and Privacy. New York: ACM, 2018: 287−298
[29] 潘吴斌,程光,郭晓军,等. 网络加密流量识别研究综述及展望[J]. 通信学报,2016,37(9):154−167 doi: 10.11959/j.issn.1000-436x.2016187 Pan Wubin, Cheng Guang, Guo Xiaojun, et al. Review and perspective on encrypted traffic identification research[J]. Journal on Communications, 2016, 37(9): 154−167 (in Chinese) doi: 10.11959/j.issn.1000-436x.2016187
[30] Fukunaga K, Narendra P M. A branch and bound algorithm for computing k-nearest neighbors[J]. IEEE Transactions on Computers, 1975, 24(7): 750−753
[31] Sokal R R, Michener C D. A statistical method of evaluating systematic relationships[J]. The University of Kansas Science Bulletin, 1958, 38(22): 1409−1438
[32] Kaufman L, Rousseeuw P J. Partitioning around medoids[M] //Finding Groups in Data: An Introduction to Cluster Analysis. Hoboken, NJ: John Wiley & Sons, 2005: 68−125
[33] Ester M, Kriegel H P, Sander J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise[C] //Proc of the 2nd Int Conf on Knowledge Discovery and Data Mining. Palo Alto, CA: AAAI, 1996: 226−231
[34] Frey B J, Dueck D. Clustering by passing messages between data points[J]. Science, 2007, 315(5814): 972−976 doi: 10.1126/science.1136800
[35] Shevertalov M, Mancoridis S. A reverse engineering tool for extracting protocols of networked applications[C] //Proc of the 14th Working Conf on Reverse Engineering. New York: ACM, 2007: 229−238
[36] Bossert G, Guihery F, Hiet G. Towards automated protocol reverse engineering using semantic information[C] //Proc of the 9th ACM Symp on Information, Computer and Communications Security. New York: ACM, 2014: 51−62
[37] Luo Xin, Chen Dan, Wang Yongjun, et al. A type-aware approach to message clustering for protocol reverse engineering[J]. Sensors, 2019, 19(3): 716−729 doi: 10.3390/s19030716
[38] Li Yihao, Hong Zheng, Feng Wenbo, et al. A message clustering method based on rough set theory[C] //Proc of the 4th Advanced Information Technology, Electronic and Automation Control Conf. Piscataway, NJ: IEEE, 2019: 1128−1133
[39] Zhang Zhuo, Zhang Zhibin, Lee P P C, et al. Toward unsupervised protocol feature word extraction[J]. IEEE Journal on Selected Areas in Communications, 2014, 32(10): 1894−1906 doi: 10.1109/JSAC.2014.2358857
[40] Sun Fanghui, Wang Shen, Zhang Chunrui, et al. Clustering of unknown protocol messages based on format comparison[J]. Computer Networks, 2020, 179: 107296
[41] Sun Fanghui, Wang Shen, Zhang Chunrui, et al. Unsupervised field segmentation of unknown protocol messages[J]. Computer Communications, 2019, 146: 121−130
[42] Jiang Dongxiao, Li Chenggang, Ma Lixin, et al. ABInfer: A novel field boundaries inference approach for protocol reverse engineering[C] //Proc of the 6th IEEE Int Conf on Big Data Security on Cloud (BigDataSecurity), IEEE Int Conf on High Performance and Smart Computing (HPSC), and IEEE Int Conf on Intelligent Data and Security (IDS). Piscataway, NJ: IEEE, 2020: 19−23
[43] 黎敏,余顺争. 抗噪的未知应用层协议报文格式最佳分段方法[J]. 软件学报,2013,24(3):604−617 Li Min, Yu Shunzheng. Noise-tolerant and optimal segmentation of message formats for unknown application-layer protocols[J]. Journal of Software, 2013, 24(3): 604−617 (in Chinese)
[44] Yu Shunzheng. Hidden semi-Markov models[J]. Artificial Intelligence, 2010, 174(2): 215−243 doi: 10.1016/j.artint.2009.11.011
[45] Tao Siyu, Yu Hongyi, Li Qing. Bit-oriented format extraction approach for automatic binary protocol reverse engineering[J]. IET Communications, 2016, 10(6): 709−716 doi: 10.1049/iet-com.2015.0797
[46] Cai Jun, Luo Jianzhen, Ruan Jianliang, et al. Toward fuzz test based on protocol reverse engineering[C] //Proc of the 13th Int Conf on Information Security Practice and Experience. Berlin: Springer, 2017: 892−897
[47] Luo Jianzhen, Shan Chun, Cai Jun, et al. IoT application-layer protocol vulnerability detection using reverse engineering[J]. Symmetry, 2018, 10(11): 561−574 doi: 10.3390/sym10110561
[48] Kleber S, Kopp H, Kargl F. NEMESYS: Network message syntax reverse engineering by analysis of the intrinsic structure of individual messages[C/OL] //Proc of the 12th USENIX Workshop on Offensive Technologies. Berkeley, CA: USENIX Association, 2018 [2021-10-12]. https://www.usenix.org/conference/woot18/presentation/kleber
[49] Marchetti M, Stabili D. READ: Reverse engineering of automotive data frames[J]. IEEE Transactions on Information Forensics and Security, 2019, 14(4): 1083−1097 doi: 10.1109/TIFS.2018.2870826
[50] Needleman S B, Wunsch C D. A general method applicable to the search for similarities in the amino acid sequence of two proteins[J]. Journal of Molecular Biology, 1970, 48(3): 443−453 doi: 10.1016/0022-2836(70)90057-4
[51] Smith T F, Waterman M S. Identification of common molecular subsequences[J]. Journal of Molecular Biology, 1981, 147(1): 195−197 doi: 10.1016/0022-2836(81)90087-5
[52] Beddoe M A. Network protocol analysis using bioinformatics algorithms[EB/OL]. 2004 [2021-10-12]. http://phreakocious.net/PI/PI.pdf
[53] Gorbunov S, Rosenbloom A. AutoFuzz: Automated network protocol fuzzing framework[J]. International Journal of Computer Science and Network Security, 2010, 10(8): 239−245
[54] Razo S I V, Anaya E A, Ambrosio P J E. Reverse engineering with bioinformatics algorithms over a sound android covert channel[C] //Proc of the 11th Int Conf on Malicious and Unwanted Software (MALWARE). Piscataway, NJ: IEEE, 2016: 3−9
[55] Zhang Xiaoming, Qiang Qian, Wang Weisheng, et al. IPFRA: An online protocol reverse analysis mechanism[C] //Proc of the 4th Int Conf on Cloud Computing and Security. Berlin: Springer, 2018: 324−333
[56] Cui Weidong, Paxson V, Weaver N, et al. Protocol-independent adaptive replay of application dialog[C/OL] //Proc of the 13th Network and Distributed System Security Symp(NDSS). Piscataway, NJ: IEEE, 2006 [2021-10-12]. https://www.ndss-symposium.org/ndss2006/protocol-independent-adaptive-replay-application-dialog
[57] Cui Weidong, Kannan J, Wang H J. Discoverer: Automatic protocol reverse engineering from network traces[C/OL] //Proc of the 16th USENIX Security Symp. Berkeley, CA: USENIX Association, 2007 [2021-10-12]. https://www.usenix.org/conference/16th-usenix-security-symposium/discoverer-automatic-protocol-reverse-engineering-network
[58] Esoul O, Walkinshaw N. Using segment-based alignment to extract packet structures from network traces[C] //Proc of the 2017 IEEE Int Conf on Software Quality, Reliability and Security. Piscataway, NJ: IEEE, 2017: 398−409 [59] Morgenstern B. DIALIGN 2: Improvement of the segment-to-segment approach to multiple sequence alignment[J]. Bioinformatics, 1999, 15(3): 211−218 doi: 10.1093/bioinformatics/15.3.211
[60] Meng Fanzhi, Zhang Chunrui, Wu Guo. Protocol reverse based on hierarchical clustering and probability alignment from network traces[C] //Proc of the 3rd IEEE Int Conf on Big Data Analysis. Piscataway, NJ: IEEE, 2018: 443−447
[61] Kleber S, Hejiden R W, Kargl F. Message type identification of binary network protocols using continuous segment similarity[C] //Proc of the 39th IEEE Conf on Computer Communications. Piscataway, NJ: IEEE, 2020: 2243−2252
[62] Kleber S, Kargl F. Poster: Network message field type recognition[C] //Proc of the 2019 ACM SIGSAC Conf on Computer and Communications Security. New York: ACM, 2019: 2581−2583
[63] Wang Yipeng, Zhang Zhibin, Yao Danfeng, et al. Inferring protocol state machine from network traces: A probabilistic approach[C] //Proc of the 9th Int Conf on Applied Cryptography and Network Security. New York: ACM, 2011: 1−18 [64] Wang Yipeng, Li Xingjian, Meng Jiao, et al. Biprominer: Automatic mining of binary protocol features[C] //Proc of the 12th Int Conf on Parallel and Distributed Computing, Applications and Technologies. Berlin: Springer, 2011: 179−184
[65] Wang Xiaowei, Lv Kezhi, Li Bo. IPART: An automatic protocol reverse engineering tool based on global voting expert for industrial protocols[J]. International Journal of Parallel, Emergent and Distributed Systems, 2020, 35(3): 376−395 doi: 10.1080/17445760.2019.1655740
[66] Ye Yapeng, Zhang Zhuo, Wang Fei, et al. NETPLIER: Probabilistic network protocol reverse engineering from message traces[C/OL] //Proc of the 28th Network and Distributed Systems Security Symp(NDSS). Piscataway, NJ: IEEE, 2021 [2021-10-12]. https://www.ndss-symposium.org/ndss-paper/netplier-probabilistic-network-protocol-reverse-engineering-from-message-traces/
[67] Blei D M, Yg A Y, Jordan M I. Latent Dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3: 993−1022 [68] Baum L E, Petrie T. Statistical inference for probabilistic functions of finite state Markov chains[J]. The Annals of Mathematical Statistics, 1966, 37(6): 1554−1563 doi: 10.1214/aoms/1177699147
[69] Wang Yipeng, Yun Xiaochun, Shafiq M Z, et al. A semantics aware approach to automated reverse engineering unknown protocols[C/OL] //Proc of the 20th IEEE Int Conf on Network Protocols. Piscataway, NJ: IEEE, 2012 [2021-10-12]. https://ieeexplore.ieee.org/document/6459963
[70] Li Haifeng, Shuai Bo, Wang Jian, et al. Protocol reverse engineering using LDA and association analysis[C] //Proc of the 11th Int Conf on Computational Intelligence and Security. New York: ACM, 2015: 312−316
[71] Whalen S, Bishop M, Crutchfield J P. Hidden Markov models for automated protocol learning[C] //Proc of the 6th Int ICST Conf on Security and Privacy in Communication Networks. Berlin: Springer, 2010: 415−428
[72] Cai Jun, Luo Jianzhen, Lei Fangyuan. Analyzing network protocols of application layer using hidden semi-Markov model[J]. Mathematical Problems in Engineering, 2016, 2016: 9161723
[73] Li Baichao, Yu Shunzheng. Keyword mining for private protocols tunneled over websocket[J]. IEEE Communications Letters, 2016, 20(7): 1337−1340
[74] He Yunhua, Shen Jialong, Xiao Ke, et al. A sparse protocol parsing method for IIoT protocols based on HMM hybrid model[C] //Proc of the 2020 IEEE Int Conf on Communications. Piscataway, NJ: IEEE, 2020: 1−6
[75] Agrawal R, Srikant R. Fast algorithms for mining association rules[C] //Proc of the 20th VLDB Conf. New York: ACM, 1994: 487−499
[76] Han Jiawei, Pei Jian, Yin Yiwen. Mining frequent patterns without candidate generation[C] //Proc of the 2000 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2000: 1−12 [77] Pei Jian, Han Jiawei, Mortazavi-Asl B, et al. Mining sequential patterns by pattern-growth: The PrefixSpan approach[J]. IEEE Transactions on Knowledge and Data Engineering, 2004, 16(11): 1424−1440 doi: 10.1109/TKDE.2004.77
[78] Luo Jianzhen, Yu Shunzheng. Position-based automatic reverse engineering of network protocols[J]. Journal of Network and Computer Application, 2013, 36(3): 1070−1077 doi: 10.1016/j.jnca.2013.01.013
[79] Lee M S, Goo Y H, Shim K S, et al. A method for extracting static fields in private protocol using entropy and statistical analysis[C/OL] //Proc of the 20th Asia-Pacific Network Operations and Management Symp. Piscataway, NJ: IEEE, 2019 [2021-10-12]. https://ieeexplore.ieee.org/document/8893038
[80] Shim K S, Goo Y H, Lee M S, et al. Inference of network unknown protocol structure using CSP(contiguous sequence pattern) algorithm based on tree structure[C/OL] //Proc of the 2018 IEEE/IFIP Network Operations and Management Symp. Piscataway, NJ: IEEE, 2018 [2021-10-12]. https://ieeexplore.ieee.org/document/8406311
[81] Goo Y H, Shim K S, Lee M S, et al. Protocol specification extraction based on contiguous sequential pattern algorithm[J]. IEEE Access, 2019, 7: 36057−36074
[82] 秦中元,陆凯,张群芳,等. 一种二进制私有协议字段格式划分方法[J]. 小型微型计算机系统,2019,40(11):2318−2323 doi: 10.3969/j.issn.1000-1220.2019.11.014 Qin Zhongyuan, Lu Kai, Zhang Qunfang, et al. Approach of field format extraction in binary private protocol[J]. Journal of Chinese Computer Systems, 2019, 40(11): 2318−2323 (in Chinese) doi: 10.3969/j.issn.1000-1220.2019.11.014
[83] Li Gaochao, Qiang Qian, Wang Zhonghua, et al. Protocol keywords extraction method based on frequent item-sets mining[C] //Proc of the 2018 Int Conf on Information Science and System. New York: ACM, 2018: 53−58 [84] Lin Peihong, Hong Zheng, Wu Lifa, et al. Protocol format extraction based on an improved CFSM algorithm[J]. China Communications, 2020, 17(11): 156−180 doi: 10.23919/JCC.2020.11.014
[85] 朱玉娜,韩继红,袁霖,等. SPFPA: 一种面向未知安全协议的格式解析方法[J]. 计算机研究与发展,2015,52(10):2200−2211 doi: 10.7544/issn1000-1239.2015.20150568 Zhu Yuna, Han Jihong, Yuan Lin, et al. SPFPA: A format parsing approach for unknown security protocols[J]. Journal of Computer Research and Development, 2015, 52(10): 2200−2211 (in Chinese) doi: 10.7544/issn1000-1239.2015.20150568
[86] Aho A V, Corasick M J. Efficient string matching: An aid to bibliographic search[J]. Communications of the ACM, 1975, 18(6): 333−340 doi: 10.1145/360825.360855
[87] Wang Yong, Zhang Nan, Wu Yanmei, et al. Protocol formats reverse engineering based on association rules in wireless environment[C] //Proc of the 12th IEEE Int Conf on Trust, Security and Privacy in Computing and Communications. Piscataway, NJ: IEEE, 2013: 134−141
[88] Ji Ran, Li Haifeng, Tang Chaojing. Extracting keywords of UAVs wireless communication protocols based on association rules learning[C] //Proc of the 12th Int Conf on Computational Intelligence and Security. Berlin: Springer, 2016: 309−313
[89] Hei Xinhong, Bai Binbin, Wang Yichuan, et al. Feature extraction optimization for bitstream communication protocol format reverse analysis[C] //Proc of the 18th IEEE Int Conf on Trust, Security and Privacy in Computing and Communications. Piscataway, NJ: IEEE, 2019: 662−669
[90] Zhao Rui, Liu Zhaohui. Analysis of private industrial control protocol format based on LSTM-FCN model[C] //Proc of the 2020 Int Conf on Aviation Safety and Information Technology. New York: ACM, 2020: 330−335 [91] Karim F, Majumdar S, Darabi H, et al. LSTM fully convolutional networks for time series classification[J]. IEEE Access, 2018, 6: 1662−1669
[92] Yang Chenglong, Fu Cao, Qian Yekui, et al. Deep learning-based reverse method of binary protocol[C] //Proc of the 1st Int Conf on Security and Privacy in Digital Economy. Berlin: Springer, 2020: 606−624
[93] Bermudez I, Tongaonkar A, Iliofotou M, et al. Automatic protocol field inference for deeper protocol understanding[C/OL] //Proc of the 14th IFIP Networking Conf. Piscataway, NJ: IEEE, 2015 [2021-10-12]. https://ieeexplore.ieee.org/document/7145307
[94] Bermudez I, Tongaonkar A, Iliofotou M, et al. Towards automatic protocol field inference[J]. Computer Communications, 2016, 84: 40−51
[95] De Carli L, Torres R, Modelo-Howard G, et al. Botnet protocol inference in the presence of encrypted traffic[C/OL] //Proc of the 36th IEEE Conf on Computer Communications. Piscataway, NJ: IEEE, 2017 [2021-10-12]. https://ieeexplore.ieee.org/document/8057064
[96] Ladi G, Buttyan L, Holczer T. Message format and field semantics inference for binary protocols using recorded network traffic[C/OL] //Proc of the 26th Int Conf on Software, Telecommunications and Computer Networks. Piscataway, NJ: IEEE, 2018 [2021-10-12]. https://ieeexplore.ieee.org/document/8555813
[97] 张蔚瑶,张磊,毛建瓴,等. 未知协议的逆向分析与自动化测试[J]. 计算机学报,2020,43(4):653−667 doi: 10.11897/SP.J.1016.2020.00653 Zhang Weiyao, Zhang Lei, Mao Jianling, et al. An automated method of unknown protocol fuzzing test[J]. Chinese Journal of Computers, 2020, 43(4): 653−667 (in Chinese) doi: 10.11897/SP.J.1016.2020.00653
[98] Wang Qun, Sun Zhonghua, Wang Zhangquan, et al. A practical format and semantic reverse analysis approach for industrial control protocols[J]. Security and Communication Networks, 2021, 2021: 6690988 [99] Trifilo A, Burschka S, Biersack E. Traffic to protocol reverse engineering[C/OL] //Proc of the 2009 IEEE Symp on Computational Intelligence in Security and Defense Applications. Piscataway, NJ: IEEE, 2009 [2021-10-12]. https://ieeexplore.ieee.org/document/5356565
[100] Krueger T, Kramer N, Rieck K. ASAP: Automatic semantics-aware analysis of network payloads [C] //Proc of Privacy and Security Issues in Data Mining and Machine Learning (Workshop of the 21st Int ECML/14th PKDD). Berlin: Springer, 2010: 50−63
[101] Hsu Y, Shu Guoqiang, Lee D. A model-based approach to security flaw detection of network protocol implementations[C] //Proc of the 16th IEEE Int Conf on Network Protocols. Piscataway, NJ: IEEE, 2008: 114−123
[102] Lee C, Bae J, Lee H. PRETT: Protocol reverse engineering using binary tokens and network traces[C] //Proc of the 33rd IFIP Int Conf on ICT Systems Security and Privacy Protection. Piscataway, NJ: IEEE, 2018: 141−155
[103] Antunes J, Neves N, Verissimo P. Reverse engineering of protocols from network traces[C] //Proc of the 18th Working Conf on Reverse Engineering. New York: ACM, 2011: 169−178
[104] Lin Yingdar, Lai Yukuen, Bui Quantien, et al. ReFSM: Reverse engineering from protocol packet traces to test generation by extended finite state machines[J]. Journal of Network and Computer Applications, 2020, 171: 102819
[105] Wang Yipeng, Yun Xiaochun, Zhang Yongzheng, et al. Rethinking robust and accurate application protocol identification[J]. Computer Networks, 2017, 129(P1): 64−78
[106] Liu Kaizheng, Yang Ming, Ling Zhen, et al. On manually reverse engineering communication protocols of Linux-based IoT systems[J]. IEEE Internet of Things Journal, 2021, 8(8): 6815−6827 doi: 10.1109/JIOT.2020.3036232
-
期刊类型引用(2)
1. 张凯,吕学强. 基于认知框架的多维融合作文拟人辞格自动识别方法. 数据分析与知识发现. 2025(02): 81-93 .  百度学术
百度学术
2. 陆靓倩,王中卿,周国栋. 结合多种语言学特征的中文隐式情感分类. 计算机科学. 2023(12): 255-261 . 百度学术
其他类型引用(3)








计量
- 文章访问数: 621
- HTML全文浏览量: 113
- PDF下载量: 262
- 被引次数: 5




