


Knowledge-Enhanced Graph Encoding Method for Metaphor Detection in Text
-
摘要:
隐喻识别是自然语言处理中语义理解的重要任务之一,目标为识别某一概念在使用时是否借用了其他概念的属性和特点. 由于单纯的神经网络方法受到数据集规模和标注稀疏性问题的制约,近年来,隐喻识别研究者开始探索如何利用其他任务中的知识和粗粒度句法知识结合神经网络模型,获得更有效的特征向量进行文本序列编码和建模.然而,现有方法忽略了词义项知识和细粒度句法知识,造成了外部知识利用率低的问题,难以建模复杂语境.针对上述问题,提出一种基于知识增强的图编码方法(knowledge-enhanced graph encoding method,KEG)来进行文本中的隐喻识别. 该方法分为3个部分:在文本编码层,利用词义项知识训练语义向量,与预训练模型产生的上下文向量结合,增强语义表示;在图网络层,利用细粒度句法知识构建信息图,进而计算细粒度上下文,结合图循环神经网络进行迭代式状态传递,获得表示词的节点向量和表示句子的全局向量,实现对复杂语境的高效建模;在解码层,按照序列标注架构,采用条件随机场对序列标签进行解码.实验结果表明,该方法的性能在4个国际公开数据集上均获得有效提升.
Abstract:Metaphor recognition is one of the essential tasks of semantic understanding in natural language processing, aiming to identify whether one concept is viewed in terms of the properties and characteristics of the other. Since pure neural network methods are restricted by the scale of datasets and the sparsity of human annotations, recent researchers working on metaphor recognition explore how to combine the knowledge in other tasks and coarse-grained syntactic knowledge with neural network models, obtaining more effective feature vectors for sequence coding and modeling in text. However, the existing methods ignore the word sense knowledge and fine-grained syntactic knowledge, resulting in the problem of low utilization of external knowledge and the difficulty to model complex context. Aiming at the above issues, a knowledge-enhanced graph encoding method (KEG) for metaphor detection in text is proposed. This method consists of three parts. In the encoding layer, the sense vector is trained using the word sense knowledge, combined with the context vector generated by the pre-training model to enhance the semantic representation. In the graph layer, the information graph is constructed using fine-grained syntactic knowledge, and then the fine-grained context is calculated. The layer is combined with the graph recurrent neural network, whose state transition is carried out iteratively to obtain the node vector and the global vector representing the word and the sentence, respectively, to realize the efficient modeling of the complex context. In the decoding layer, conditional random fields are used to decode the sequence tags following the sequence labeling architecture. Experimental results show that this method effectively improves the performance on four international public datasets.
-
隐喻(metaphor)是一种在自然语言中广泛存在的语言现象.当借用某一概念的属性和特点来看待和使用另一个概念时,隐喻现象就发生了[1].文本隐喻识别(metaphor detection)作为自然语言处理(natural language processing,NLP)中的一个重要语义理解任务,获得越来越多研究者的广泛关注.其目标是:从文本中识别出表现为隐喻的词汇.表1给出了4条包含隐喻词汇的文本样例,其中粗体显示的单词“went(出现)”“kill(终止)”“invested(投入)”“forged(建立)”表示隐喻现象,在句子中体现出了该单词原本所不具有的语义.
表 1 包含隐喻词汇的文本样例Table 1. Examples of Sentences with Metaphor Words编号 文本样例 1 It went to his head rather. 2 How to kill a process? 3 I invested myself fully in this relationship. 4 They forged contacts with those left behind in Germany. 注:黑体单词表示隐喻现象. 隐喻识别方法的发展大致分为3个阶段:
1)早期隐喻识别研究处于特征向量构建阶段.传统隐喻识别方法采用人工编制的特征抽取器,将输入文本转化为特征向量,包括上下文特征[2]、词性特征[3]、属性特征[4]、语音视觉特征[5]等,对在特定上下文中出现的词或短语进行隐喻现象的识别.
2)随着深度学习在自然语言处理中的流行,隐喻识别的研究进入朴素序列建模阶段.该阶段的方法[6-8]一般利用文本表示学习替代人工编制的特征抽取器,将每个词转化为词向量,使用卷积神经网络(convolution neural network,CNN)、循环神经网络(recurrent neural network,RNN)等基础算法搭建编码器,对输入的文本进行序列编码和建模,进而利用全连接网络实现分类.
3)在外部知识融合阶段,研究者发现单纯的神经网络方法受到数据集规模和标注稀疏性问题的制约,由此衍生出探索外部知识结合神经网络模型寻求突破的方法.有研究者探索了基于预训练引入其他任务知识的方式[9-10]和结合粗粒度句法知识的方法[11].
然而,现有的隐喻识别深度学习模型对词法和句法知识的利用不充分,主要体现为2个局限性:
1)忽略了词级别的义项知识.一词多义现象在自然语言处理中是常见的现象和难点.隐喻现象的判定就与词义有关,若一个词在上下文中所表现的含义不为它本义,那么这种现象很可能就是隐喻.现有的隐喻识别深度学习方法没有显式地利用词义项知识,在建模过程中会对区分词义产生困难,从而产生对更大标注数据规模的需求.
2)忽略了细粒度句法知识.句法分析中的关系具有设定完备的标签和方向性,它们是句法知识中的重要组成部分,可以帮助在文本建模时的信息传递.但是,现有的隐喻识别方法舍弃了句法分析中关系的标签和方向性,仅仅利用了粗类别的句法知识,使得模型难以对复杂语境进行建模.
针对2个局限,本文提出基于知识增强的图编码方法(knowledge-enhanced graph encoding method,KEG)来进行文本中的隐喻识别.该方法首先利用预训练语言模型为输入文本构建上下文向量,利用词义项知识训练得到语义向量,拼接形成文本语义表示;然后,根据细粒度句法知识构建信息图,利用图循环神经网络建模输入文本序列,通过边感注意力机制和边绑定权重进行细粒度上下文计算,迭代进行信息传递,得到代表词信息的节点向量和代表句子信息的全局向量;最后,利用条件随机场进行序列建模,计算和解码最佳输出标签序列,实现隐喻识别.
本文将所提出的KEG模型在4个国际公开数据集VUA-VERB[12],VUA-ALLPOS[12],TroFi[13],MOH-X[5]上分别与3类先进的隐喻识别方法进行了对比.实验结果表明,KEG模型在这4个数据集上的F1值和准确率均获得提升,在图编码方法中结合词义项知识和细粒度句法知识对隐喻识别的性能有明显增强.
本文的主要贡献分为3个方面:
1)提出融合细粒度句法信息的图编码方法,提出边感注意力机制和边绑定权重在图神经网络中进行细粒度上下文计算,并利用句子级别细粒度句法知识构建信息图实现信息传递,进而实现了对复杂语境的高效建模.
2)利用词义项知识学习词义向量,并利用注意力机制将词义向量和上下文向量结合,增强文本的语义表示,降低对一词多义现象建模的困难,以此获得融合了语境信息和词义信息的文本表示.
3)相比于先进的隐喻识别方法,本文提出的KEG模型在国际公开数据集VUA-VERB,VUA-ALLPOS,TroFi,MOH-X上均获得提升.
1. 相关工作
本节将从隐喻识别方法和数据集构建这2个方面介绍相关工作.
1.1 隐喻识别方法
早期的隐喻识别方法主要是基于特征向量的方法,依赖人工设计的特征提取器,将文本转化为特征向量,进而针对在特定上下文中的单个词或短语,实现隐喻识别.例如,Dunn[14]设计了文本特征,以回归任务的设定实现句子级隐喻识别.Jang等人[2]提出了一种显式利用对话中的全局上下文来检测隐喻的方法.Klebanov等人[3]利用语义分类来做动词的隐喻分类,从正交的一元语法(1-gram)特征开始,尝试了各种定义动词语义类的方法(语法的、基于资源的、分布的),并测量了这些类对一篇文章中的所有动词分类为隐喻或非隐喻的有效性.Bulat等人[4]提出了第1种基于属性规范的隐喻识别方法.Shutova等人[5]提出了第1种同时从语言和视觉数据中提取知识的隐喻识别方法.Gutiérrez等人[15]探讨文本隐喻的上下文构成在组合分布语义模型框架中的特殊性,并提出了一种将隐喻特征作为向量空间中的线性变换来学习的方法.但是受制于设计特征提取器的复杂性和涵盖面的不完全性,该类方法难以迁移到新数据集上.
随着深度学习在自然语言处理中的飞速发展和广泛应用,隐喻识别的方法逐步转向利用文本表示学习来代替人工设计的特征向量的方法.此外,序列建模的方式也在隐喻识别中逐步流行.本文称该阶段的隐喻识别方法为朴素序列建模的方法.例如,Rei等人[8]提出一种词对级别的隐喻识别方法,提出了第1个用于捕获隐喻含义组合的神经网络架构,并在MOH数据集[16]和TSV数据集[17]上进行测试.Gao等人[7]提出利用双向长短期记忆网络(long short-term memory,LSTM)做序列标注,并结合注意力机制实现词级别分类的文本隐喻识别方法.Mao等人[6]提出结合2种语言学理论的神经网络模型,针对SPV理论[18]设计了基于上下文和目标词的多头窗口注意力机制,针对MIP理论[19]设计了基于词本意和语境含义的表示结合方法.虽然深度学习的方法可以避免大量的手工特征,但是朴素序列建模的方法忽略了在自然语言处理领域中长期积累并被广泛证明有效的各类知识.
近年来,结合知识的方法在隐喻识别中取得了更好的性能.这类方法主要可以分为2种类型:1)通过引入其他任务中的知识来辅助隐喻识别.例如,Chen等人[9]提出利用2个数据集相互微调BERT模型[20],并利用习语检测任务(idiom detection)的标注数据对BERT模型进一步微调.Su等人[10]提出利用孪生Transformer编码器[21]编码文本,并在阅读理解任务的框架下利用预训练的RoBERTa初始化模型权重[22],同时为每一个词级别分类设计查询文本和上下文文本,进而实现隐喻识别.这类方法在ACL2020会议的隐喻识别评测任务[23]中取得了靠前的排名.2)结合粗粒度句法知识的方法.例如,Rohanian等人[11]提出使用多词表达式(multiword experssion,MWE)结构信息结合省略类别的句法信息,利用图卷积神经网络[24]进行编码,从而实现隐喻识别.该类方法没有考虑到词级别义项知识在隐喻识别中的潜力,也忽略了句法信息中的细粒度信息对复杂语境建模的有效性.本文将从这2种类型入手,利用知识增强的图编码方法实现文本隐喻识别.
1.2 数据集构建
数据集构建在隐喻识别中是一个重要的研究方向,分为单语数据集构建和多语数据集构建2个方面.
在单语数据集方面,Steen等人[25]构建了VUAMC数据集,具有万级的标注实例,被用于NAACL2018会议[12]和ACL2020会议[23]的隐喻识别评测任务中.Birke等人[13] 基于《华尔街日报》的新闻内容构建了TroFi语料库.Mohammad等人[16]针对动词构建了一个句子级别的隐喻识别标注语料库MOH,Shutova等人[5]在此基础上针对“动词–主语”和“动词–宾语”对进一步标注了MOH-X数据集.Klebanov等人[26]利用240篇非英语母语作者完成的文章作为语料,标注了TOEFL隐喻识别语料库,被用于ACL2020会议[23]的隐喻识别评测任务中.
在多语隐喻识别标注方面,Tsvetkov等人[17]针对“主语–谓语–宾语”三元组构建了一个句子级别的隐喻识别标注的语料库,包含英语训练集和英语、俄语、西班牙语、波斯语测试集.Levin等人[27]在这4个语种上,针对多种词对级别,构建了隐喻识别标注语料库CCM,包括“主语–动词”“动词–宾语”“动词–副词”“名词–形容词”“名词–名词”“名词–复合词”等类型.之后Mohler等人[28]构建了英语、俄语、西班牙语、波斯语的多种词对级别的隐喻识别标注语料库LCC,包括动词、名词、多词表达式、形容词、副词之间的词对.
此外,还有研究者针对隐喻现象中的属性构建了数据集.例如,Parde等人[29] 在VUAMC语料库之上,针对有句法关系的词对,标注了规模较大的隐喻重要性(metaphor novelty)语料库.Tredici等人[30]探讨了隐喻性与动词分布特征之间的关系,引入语料库衍生指标POM,标注了某个动词所在的任何表达式的隐喻性上限.
为了与各类先进的隐喻识别方法进行对比,本文采用了被广泛用于实验对比的VUAMC数据集、TroFi数据集和MOH-X数据集进行实验.
2. 本文方法
在本节中,我们主要介绍基于知识增强的图编码方法在文本隐喻识别中的应用,将带标签的有向句法信息融入图神经网络中,并提出KEG模型.
2.1 基本定义
本文提出基于知识增强的文本隐喻识别图编码方法.本文用
S={s1,s2,…,sn} 表示长度为n 个词的句子.文本隐喻识别任务是为句子S 中的每一个词si 计算一个0-1标签yi ,表示该词是否为隐喻.2.2 总体框架
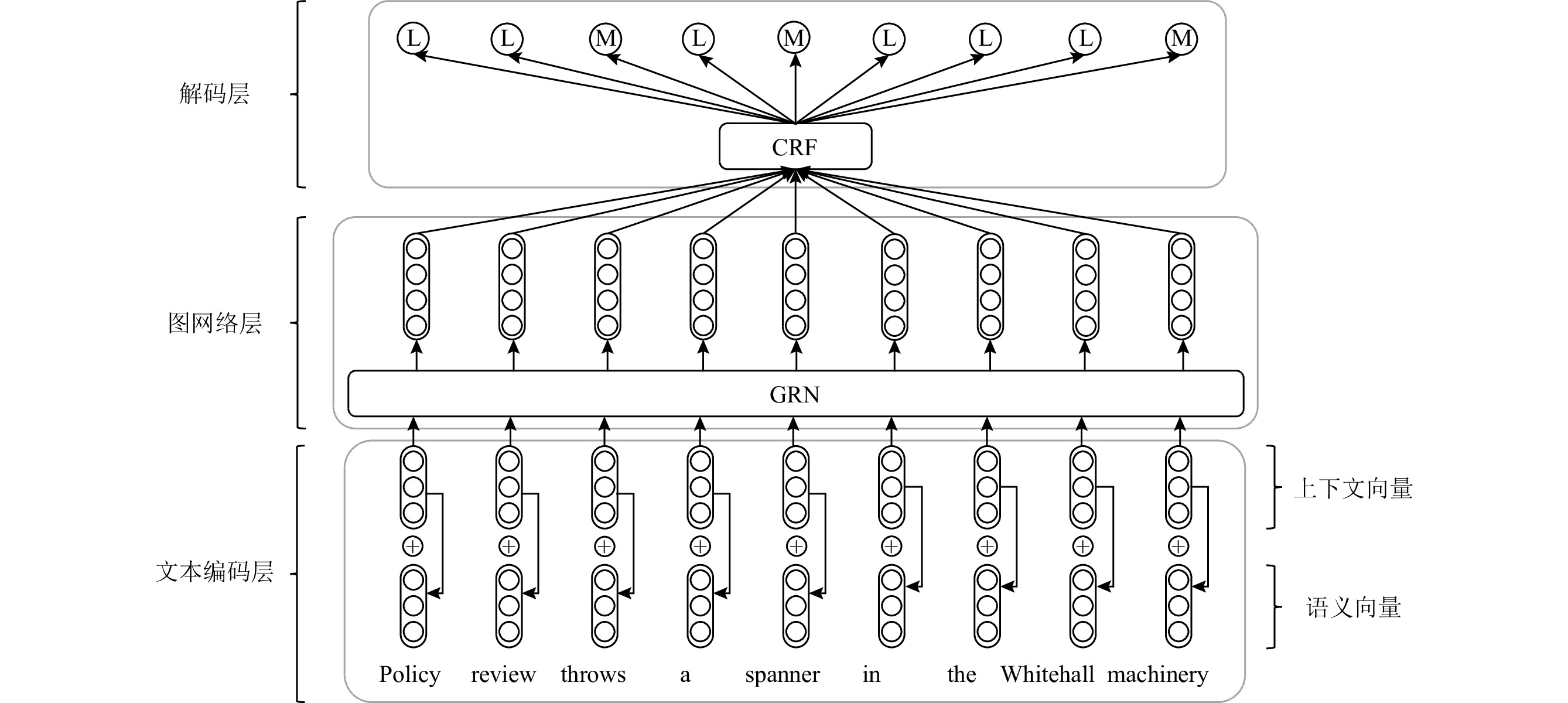
图1所示为KEG模型整体网络结构,主要分为3个部分:1)文本编码层;2)图网络层;3)解码层.对于一个句子
S={s1,s2,…,sn} ,首先在文本编码层中结合知识转换为上下文向量序列{E^{\text{c}}} = \{ {\boldsymbol{e}}_1^{\text{c}},{\boldsymbol{e}}_2^{\text{c}},…,{\boldsymbol{e}}_n^{\text{c}}\} 和语义向量序列{E^{\text{s}}} = \{ {\boldsymbol{e}}_1^{\text{s}},{\boldsymbol{e}}_2^{\text{s}},…,{\boldsymbol{e}}_n^{\text{s}}\} ,进而将两者进行拼接得到词表示序列E = \{ {{\boldsymbol{e}}_1},{{\boldsymbol{e}}_2},…,{{\boldsymbol{e}}_n}\} ;接着构建句子S 对应的信息图{G_S} ,利用图网络层结合图信息进行编码,得到图编码向量序列Q = \{ {{\boldsymbol{q}}_1},{{\boldsymbol{q}}_2},…,{{\boldsymbol{q}}_n}\} ;最后利用解码层对图编码向量序列进行解码,获取各个单词对应的预测标签Y = \{ {y_1},{y_2},…,{y_n}\} ,其中{y_i} \in \{ {\text{L,M}}\} ,{\text{L}} 表示不存在隐喻(literal),{\text{M}} 表示隐喻(metaphorical).2.3 文本编码层
本文采用的语义表示分为上下文向量和语义向量2个部分.
2.3.1 上下文向量构建
预训练语言模型在自然语言处理任务中十分广泛,取得了良好的成绩和明显的效果.本文采用BERT模型[20]计算上下文向量.BERT模型是一个预训练编码器,由多层Transformer编码层[21]堆叠而成.具体地,对于一个句子
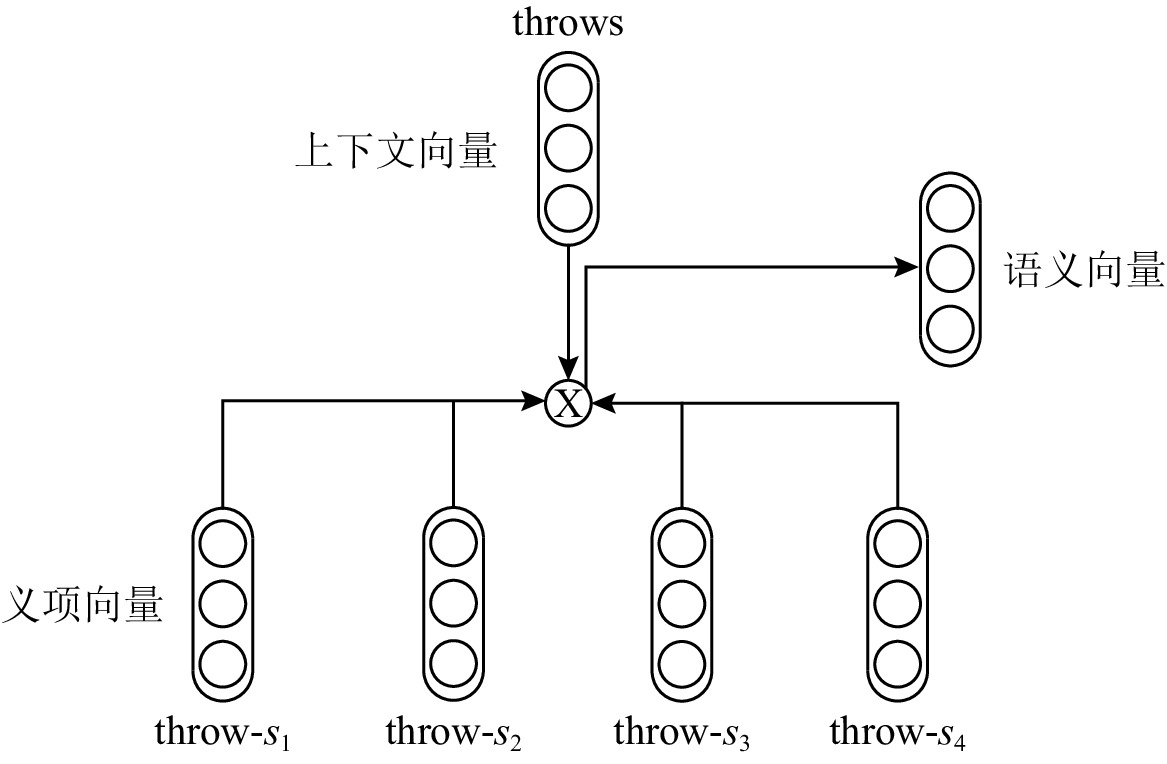
S = \{ {s_1},{s_2},…,{s_n}\} ,首先进行词块(word piece)划分;然后将词块序列输入BERT模型,获得最后一层Transformer编码层的输出向量序列作为词块上下文向量序列;最后取每个词的第1个词块上下文向量作为该词的上下文向量,从而形成句子S 的上下文向量序列{E^{\text{c}}} = \{ {\boldsymbol{e}}_1^{\text{c}},{\boldsymbol{e}}_2^{\text{c}},…,{\boldsymbol{e}}_n^{\text{c}}\} .2.3.2 语义向量构建
语义向量构建如图2所示.虽然上下文向量中蕴含了语境信息,但是缺少语义知识.本文利用语义知识对上下文向量进行增强,即利用WordNet中每个词的义项标注信息训练义项向量.本文继承Chen等人[31]的方法,首先利用skip-gram算法[32]训练词向量,使用WordNet中每个义项的自然语言释义文本中词向量的平均值作为义项向量的初始值;然后利用义项初始值设计了词义消歧(word dense disambiguation,WSD)模块,用其在Wikipedia语料库上产生词义消歧结果;最后修改skip-gram的目标函数,从而重新训练词向量和义项向量.获得预训练的义项向量之后,对句子
S 中的每一个词{s_i} 通过词根(lemma)匹配查找所有可能的义项,然后使用注意力机制根据上下文向量{\boldsymbol{e}}_i^{\text{c}} 计算语义向量{\boldsymbol{e}}_i^{\text{s}} ,具体的计算公式为{\alpha _{ij}} = {softmax} _{j = 1}^n\bigg(\frac{{{\boldsymbol{e}}_i^{\text{c}}{{\boldsymbol{W}}^{\text{c}}}{{\boldsymbol{s}}_{ij}}}}{{\sqrt {{\ell_{{{\boldsymbol{e}}^{\text{c}}}}}} }}\bigg), (1) {\boldsymbol{e}}_i^{\text{c}} = \sum\limits_{j = 1}^n {{\alpha _{ij}}} {{\boldsymbol{s}}_{ij}}, (2) 其中,
{{\boldsymbol{W}}^{{\rm{c}}}} 为模型参数,{\ell_{{{\boldsymbol{e}}^{{\rm{c}}}}}} 为上下文向量\boldsymbol e_i^{{\rm{c}}} 的维度,\alpha_{ij} 为义项向量的权重.最后将上下文向量
{\boldsymbol{e}}_i^{\text{c}} 和语义向量{\boldsymbol{e}}_i^{\text{s}} 拼接得到句子S 中的每一个词{s_i} 对应的词表示{{\boldsymbol{e}}_i} :{{\boldsymbol{e}}_i} = \left[ {{\boldsymbol{e}}_i^{\text{s}} \oplus {\boldsymbol{e}}_i^{\text{c}}} \right], (3) 其中
\left[ \oplus \right] 为向量拼接操作.2.4 图网络层
图神经网络作为编码器在许多自然语言处理中有着很大的应用价值.其在自然语言处理领域的经典应用[11,33-34]中通常使用依存分析(dependency parsing)工具,将句子转化成依存树,以词作为节点,使用粗粒度句法知识(coarse-grained syntactic knowledge)构建信息图,进而指导图神经网络的信息传递.
由于堆叠图神经网络会导致模型参数增加,从而增加过拟合的风险,本文扩展图循环神经网络[35-36]作为图网络层的编码器.一个图循环神经网络以一个图的邻接矩阵、词表示
{\boldsymbol{e}} 、初始时刻的节点向量{{\boldsymbol{h}}^0} 和全局向量{{\boldsymbol{g}}^0} 作为输入,利用多层之间参数共享的特性,经过K 次迭代式状态传递,输出最终时刻的节点向量{{\boldsymbol{h}}^K} 和全局向量{{\boldsymbol{g}}^K} .同时,针对目前图神经网络方法在自然语言处理应用中仅仅利用到粗粒度句法知识的局限,本文提出将细粒度句法知识(fine-grained syntactic knowledge)与图循环神经网络(graph recurrent neural network)相结合的方法,首先利用边感注意力机制(edge-aware attention mechanism)和边绑定权重(edge-tied weight)进行细粒度上下文计算,接着利用图循环神经网络结合细粒度信息进行
K 次状态传递.下面,本文将从图构建、细粒度上下文计算和状态传递3个方面介绍图网络层.2.4.1 图构建
首先为句子
S = \{ {s_1},{s_2},…,{s_n}\} 构造一个信息图{G_S} .其中,节点为句子S 中的词,边为词之间的关系.本文继承图神经网络在自然语言处理中的经典应用方法[11,33-34],利用句子S 的依存树{T_S} 作为信息图{G_S} 的基本结构,并在图中每个节点上增加了自环{\text{[self]}} .但是与传统构图方法不同的是,本文一方面保留了依存树{T_S} 中边的方向信息;另一方面在图中加入了代表文本序列顺序的边{\text{[seq]}} ,从而将序列建模信息与句法信息相结合.信息图{G_S} 的邻接矩阵中从节点i 到节点j 的有向边< i \to j >lt; i \to j >$ 类型{a_{ij}} 为:{a_{ij}} = \left\{ {\begin{aligned} &{{T_S}(i,j),}\;\;\;\;\;{ < i \to j > \in {T_S},} \\ & {{\text{[seq],}}}\;\;\;\;\;\;\;\;{(j \equiv i + 1){\text{ }} \wedge (< i \to j > \notin {T_S}),} \\ & {{\text{[self],}}}\;\;\;\;\;\;\;\;{i \equiv j,} \\ & {{\text{null,}}}\;\;\;\;\;\;\;\;\;\;{{\text{其他,}}} \end{aligned}} \right. (4) 其中
{\text{null}} 表示有向边< i \to j > 不存在.2.4.2 细粒度上下文计算
本节提出利用边感注意力机制和边绑定权重进行细粒度上下文计算,其中结合的细粒度句法知识包括有向信息和句法类别信息.具体地,本节将为句子
S 中的词{s_i} 构造时刻t 的传入上下文向量\mathord{\buildrel{\lower3pt\hbox{$\scriptscriptstyle\leftarrow$}} \over {\boldsymbol{m}}} {}_i^t 和传出上下文向量\vec {\boldsymbol{m}}_i^t .首先利用基于双线性(bilinear)的边感注意力机制分别计算传入和传出边的权重
\mathord{\buildrel{\lower3pt\hbox{$\scriptscriptstyle\leftarrow$}} \over {\boldsymbol{m}}} {}_i^t 和{\vec {\boldsymbol{w}}_{ij}} .{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\leftarrow}$}}{{\boldsymbol{w}}} _{ij}} = \mathop {{{softmax}}}\limits_{j \in \{ j|{a_{ji}} \ne {\text{null}}\} } \left(\frac{{{\boldsymbol{h}}{{_i^{t - 1}}^{^{\text{T}}}}{\boldsymbol{W}}_{type(j,i)}^{{\text{in}}}{\boldsymbol{h}}_j^{t - 1}}}{{\sqrt {{\ell_{\boldsymbol{h}}}} }}\right), (5) {\vec {\boldsymbol{w}}_{ij}} = \mathop {{{softmax}}}\limits_{j \in \{ j|{a_{ij}} \ne {\text{null}}\} } \left(\frac{{{\boldsymbol{h}}{{_i^{t - 1}}^{^{\text{T}}}}{\boldsymbol{W}}_{type(i,j)}^{{\text{out}}}{\boldsymbol{h}}_j^{t - 1}}}{{\sqrt {{\ell_{\boldsymbol{h}}}} }}\right), (6) 其中,
{{\boldsymbol{W}}^{{\text{in}}}} 和{{\boldsymbol{W}}^{{\text{out}}}} 为模型参数,{\ell_{\boldsymbol{h}}} 为节点向量{{\boldsymbol{h}}^{t - 1}} 的维度,type(i,j) 表示信息图{G_S} 中有向边< i \to j > 类型,{\text{T}} 表示向量和矩阵的转置操作.接着,时刻
t 的传入和传出上下文向量\mathord{\buildrel{\lower3pt\hbox{$\scriptscriptstyle\leftarrow$}} \over {\boldsymbol{m}}} {}_i^t 和\vec {\boldsymbol{m}}_i^t 被表示为时刻t - 1 的节点向量{{\boldsymbol{h}}^{t - 1}} 与有向边类别权重{\boldsymbol{k}} 的带权和.具体计算公式为\mathord{\buildrel{\lower3pt\hbox{$\scriptscriptstyle\leftarrow$}} \over {\boldsymbol{m}}} {}_i^t = \sum \limits_{j \in \{ j|{a_{ji}} \ne {\text{null}}\} } {\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\leftarrow}$}}{{\boldsymbol{w}}} _{ij}}[{\boldsymbol{h}}_j^{t - 1} \oplus {{\boldsymbol{k}}_{type(j,i)}}], (7) \vec {\boldsymbol{m}}_i^t = \mathop \sum \limits_{j \in \{ j|{a_{ij}} \ne {\text{null}}\} } {\vec {\boldsymbol{w}} _{ij}}[{\boldsymbol{h}}_j^{t - 1} \oplus {{\boldsymbol{k}}_{type(i,j)}}], (8) 其中初始节点向量
{{\boldsymbol{h}}^0} 被初始化为零向量0.2.4.3 状态传递
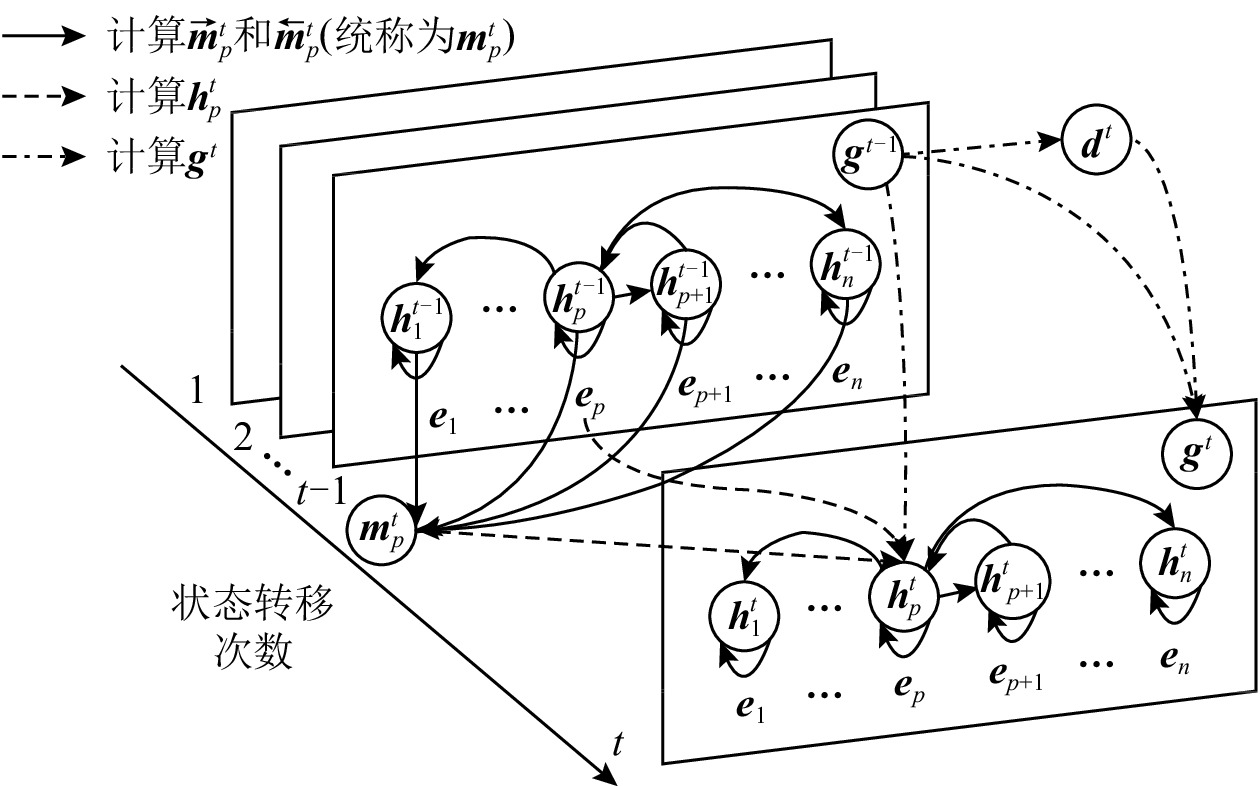
本文扩展经典的图循环神经网络[35-36],结合细粒度上下文进行状态传递.本文以时刻
t - 1 到时刻t 为例进行说明.本文提出的图网络层分别采用2个门控循环单元[37](gated recurrent unit,GRU)作为节点向量{{\boldsymbol{h}}^t} 和全局向量{{\boldsymbol{g}}^t} 的更新框架.图3为图循环神经网络的状态传递示例图.为了更新句子
S 中词{s_i} 所对应的的节点向量{\boldsymbol{h}}_i^t ,首先将拼接词表示{{\boldsymbol{e}}_i} 、细粒度上下文向量\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\leftarrow}$}}{{\boldsymbol{m}}}{}_i^t 和\vec {\boldsymbol{m}}_i^t 、时刻t - 1 的全局向量{{\boldsymbol{g}}^{t - 1}} 得到含有更新信息的向量{\boldsymbol{c}}_i^t ,然后分别计算重置门{\boldsymbol{r}}_i^t 和更新门{\boldsymbol{z}}_i^t 的状态,最后计算时刻t 的节点向量{\boldsymbol{h}}_i^t .具体更新过程为:{\boldsymbol{c}}_i^t = [{{\boldsymbol{e}}_i} \oplus \vec {\boldsymbol{m}}_i^t \oplus \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\leftarrow}$}}{{\boldsymbol{m}}}{ }_i^t \oplus {{\boldsymbol{g}}^{t - 1}}], (9) {\boldsymbol{r}}_i^t = sigmoid({{\boldsymbol{W}}^r}{\boldsymbol{c}}_i^t + {{\boldsymbol{U}}^r}{\boldsymbol{h}}_i^{t - 1}), (10) {\boldsymbol{z}}_i^t = sigmoid({{\boldsymbol{W}}^{\boldsymbol{z}}}{\boldsymbol{c}}_i^t + {{\boldsymbol{U}}^{\boldsymbol{z}}}{\boldsymbol{h}}_i^{t - 1}), (11) {\boldsymbol{\mu}} _i^t = {\text{tanh}}({{\boldsymbol{W}}^{\boldsymbol{\mu}} }{\boldsymbol{c}}_i^t + {{\boldsymbol{U}}^{\boldsymbol{\mu}} }({\boldsymbol{r}}_i^t \odot {\boldsymbol{h}}_i^{t - 1})), (12) {\boldsymbol{h}}_i^t = (1 - {\boldsymbol{z}}_i^t) \odot {\boldsymbol{h}}_i^{t - 1} + {\boldsymbol{z}}_i^t \odot {\boldsymbol{\mu}} _i^t, (13) 其中
{{\boldsymbol{W}}^{\boldsymbol r}} ,{{\boldsymbol{U}}^{\boldsymbol r}} ,{{\boldsymbol{W}}^{\boldsymbol{z}}} ,{{\boldsymbol{U}}^{\boldsymbol{z}}} ,{{\boldsymbol{W}}^{\boldsymbol{\mu}} } ,{{\boldsymbol{U}}^{\boldsymbol{\mu}} } 为模型参数,\odot 为向量和矩阵的元素积(element-wise product)操作,初始全局向量{{\boldsymbol{g}}^0} 也被初始化为零向量0.相似地,本文为了更新句子
S 对应的全局向量{{\boldsymbol{g}}^t} ,首先将节点向量{\boldsymbol{h}}_i^t 求平均得到全局更新信息向量{{\boldsymbol{d}}^t} ,然后分别计算重置门{\bar {\boldsymbol{r}}^t} 和更新门{\bar {\boldsymbol{z}}^t} 的状态,最后计算时刻t 的全局向量{{\boldsymbol{g}}^t} .具体更新过程为:{{\boldsymbol{d}}^t} = \frac{1}{n}\mathop \sum \limits_{i = 1}^n {\boldsymbol{h}}_i^t, (14) {\bar {\boldsymbol{r}}^t} = sigmoid({{\boldsymbol{W}}^{\bar r}}{{\boldsymbol{d}}^t} + {{\boldsymbol{U}}^{\bar r}}{{\boldsymbol{g}}^{t - 1}}), (15) {\bar {\boldsymbol{z}}^t} = sigmoid({{\boldsymbol{W}}^{\bar {\boldsymbol{z}}}}{{\boldsymbol{d}}^t} + {{\boldsymbol{U}}^{\bar {\boldsymbol{z}}}}{{\boldsymbol{g}}^{t - 1}}), (16) {\bar {\boldsymbol{\mu}} ^t} = {\text{tanh}}({{\boldsymbol{W}}^{\bar {\boldsymbol{\mu}} }}{{\boldsymbol{c}}^t} + {{\boldsymbol{U}}^{\bar {\boldsymbol{\mu}} }}({\bar {\boldsymbol{r}}^t} \odot {{\boldsymbol{g}}^{t - 1}})), (17) {{\boldsymbol{g}}^t} = (1 - {\bar {\boldsymbol{z}}^t}) \odot {{\boldsymbol{g}}^{t - 1}} + {\bar {\boldsymbol{z}}^t} \odot {\bar {\boldsymbol{\mu}} ^t}. (18) 最终,经过
K 次状态传递,图网络层输出最终的节点向量{{\boldsymbol{h}}^K} 和全局向量{{\boldsymbol{g}}^K} .2.5 解码层
由于任务目标是对句子
S 中每一个词进行二分类判断是否隐喻,最终本方法产生一个标签序列\hat z = \{ {\hat z_1},{\hat z_2},…,{\hat z_n}\} ,本文采用条件随机场(condition random field,CRF)[38]作为解码层.首先采用前馈网络将图网络层输出的每个词所对应的最终节点向量
{\boldsymbol{h}}_i^K 转化为输出分值向量{\hat {\boldsymbol{y}}_i} .解码层中对一个标签序列\hat z 的评分为{\hat {\boldsymbol{y}}_i} = sigmoid({{\boldsymbol{W}}^y}{\boldsymbol{h}}_i^K), (19) s(S,\hat z) = \sum\limits_{i = 1}^n {{{\hat {\boldsymbol{y}}}_{i,{{\hat z}_i}}}} + \sum\limits_{i = 1}^{n + 1} {{{\boldsymbol{A}}_{{{\hat z}_{i - 1}},{{\hat z}_i}}}} , (20) 其中
{{\boldsymbol{W}}^{\boldsymbol y}} 和{\boldsymbol{A}} 为模型参数.为了描述得更具一般性和简洁性,本文在序列\hat z 的首尾加入了表示标签序列开始和终结的特殊标志{\text{[start]}} 和{\text{[end]}} 作为{\hat z_0} 和{\hat z_{n + 1}} .在训练阶段,目标为最大化标准答案中标签序列
\hat z 的对数似然,具体为\ln p(\hat z|S) = s(S,\hat z) - \ln \sum\limits_{z' \in Z} {{{\boldsymbol{e}}^{s(S,z')}}} , (21) 其中
Z 为包含所有可能的标签序列的集合.在测试阶段和验证阶段,通过维特比算法(Viterbi algorithm)对输出标签序列进行解码.3. 实验与分析
3.1 数据集
实验中使用的数据集包括NAACL2018评测任务中使用的VUA-VERB和VUA-ALLPOS数据集[12]、TroFi数据集[13]和MOH-X数据集[5].数据统计信息如表2所示,包括数据集中单词(token)总数、数据集中句子总数、标注为隐喻的数量、标注为隐喻的数量占所有标注结果中的百分比、平均每个句子中的单词数.在实验中按照相关工作[6-7,9-12,23]对VUA-VERB和VUA-ALLPOS数据集进行训练集、开发集、测试集划分,并在TroFi和MOH-X数据集上进行10折交叉验证.
表 2 数据集统计信息Table 2. Statistics of Datasets数据集 单词总数 句子总数 隐喻总数 隐喻占比/% 平均单词数 VUA-VERB 239847 16189 6554 28.36 14.82 VUA-ALLPOS 239847 16189 15026 15.85 14.82 TroFi 105949 3737 1627 43.54 28.35 MOH-X 5178 647 315 48.68 8.00 VUA-VERB和VUA-ALLPOS数据集[12]分别源于依照MIP规则[19]对句子为单位所标注的VUAMC阿姆斯特丹隐喻语料库[25],具有超过2000个被标注为隐喻的不同词汇.NAACL2018会议的隐喻识别评测任务[12]首次基于VUAMC语料库设置了VERB和ALLPOS这2个赛道,并分别形成了VUA-VERB和VUA-ALLPOS数据集,并被沿用于ACL2020会议的隐喻识别评测任务[23]中.
TroFi数据集[13]是由包含1987—1989年《华尔街日报》新闻内容的第1版WSJ语料库[39]中的句子组成,标注人员针对每个句子中的动词进行了隐喻标注.TroFi数据集只有50个被标注为隐喻的不同词汇,且其中句子的平均长度是本文所采用的数据集中最长的.
MOH-X数据集[5]来源于MOH数据集[16],其中的句子来自WordNet中义项的例句.在该数据集中,标注人员针对每个句子中的“动词–主语”对和“动词–宾语”对进行了隐喻标注,得到了214个不同的词汇.MOH-X数据集中句子的平均长度是本文所采用的数据集中最短的.
3.2 实验设置及超参数
本文所提出的模型在实验中所使用的超参数均由在VUA-VERB的测试集上针对F1值的格搜索(grid search)得出,具体数值如表3所示.
表 3 本文实验中使用的超参数Table 3. Hyper-Parameters Used in Our Experiment超参数 取值 {{\boldsymbol{e}}^{\rm{c}}}的向量维度 1024 {{\boldsymbol{e}}^{\rm{s}}}的向量维度 200 {\boldsymbol{k}}的向量维度 256 {\boldsymbol{m}},{\boldsymbol{h}},{\boldsymbol{g}}的向量维度 512 状态传递次数K 3 批大小(batch size) 16 BERT模型dropout率 0.5 模型其他部分dropout率 0.4 BERT模型学习率 1E−5 模型其他部分学习率 1E−3 BERT模型{L_2}权重衰减 1E−5 模型其他部分{L_2}权重衰减 1E−3 Warmup迭代轮次 5 最大迭代轮次 50 梯度裁剪 4.0 模型采用BERT-Large的权值初始化上下文向量构建模块,并在训练时采用学习率热身(warm-up)方法,即总共训练50个回合(epoch),在前5个回合中,模型各部分的学习率从0开始线性增长至最大值,并在之后的回合中线性衰减至0.本文采用AdamW算法[40]对参数进行优化.在后续的实验中,为了保证公平起见,根据开发集上的评测结果选择一组F1值最高的模型参数,然后在测试集上评测使用了这组参数的模型并记录各项指标.为了减少模型中随机种子对结果的影响,后续实验结果表格中的值为3次运行结果的平均值.
3.3 评价指标
与相关工作[6-7,9-12,23]相同,本文采用精确率(precision,
P )、召回率(recall,R )、F1值和准确率(accuracy,Acc )作为实验的评价指标.对测试集中的每一个标注结果,本文提出的模型会对其进行二分类,产生一个预测结果.将标注结果与预测结果一致,且为隐喻的词数量记为
TP ,不为隐喻的词数量记为TN ;标注结果与预测结果不一致,且预测结果为隐喻的词数量记为FP ,不为隐喻的词数量记为FN .则精确率P 、召回率R 、F1值、准确率Acc 分别计算得到:P = \frac{{TP}}{{TP + FP}} \times 100\% , (22) R = \frac{{TP}}{{TP + FN}} \times 100\% , (23) {F1} = \frac{{2P \times R}}{{P + R}} \times 100\% = \frac{{2TP}}{{2TP + FP + FN}} \times 100\% , (24) Acc = \frac{{TP + TN}}{{TP + TN + FP + FN}} \times 100\% . (25) 3.4 KEG与SOTA方法比较
为了验证本文提出的KEG模型的有效性,本文设置3组对比模型,包含了3类SOTA方法.
第1组是朴素序列建模的方法,其中的模型均未采用词级别义项知识或句子级别细粒度句法知识,具体模型为:
1)RNN_ELMo[7]将GloVe向量[41]和ELMo向量[42]拼接作为词级别特征,使用双向LSTM进行编码,对输出的隐状态采用softmax分类器进行序列分类.
2)RNN_BERT[20]依照RNN_ELMo的序列分类框架,将BERT-Large模型后4层输出向量作为特征.
3)RNN_HG[6] 在RNN_ELMo模型的基础上,在利用双向LSTM对词级别特征进行编码之后,将双向LSTM输出的隐状态与GloVe向量拼接,然后采用softmax分类器进行序列分类.
4)RNN_MHCA[6]在RNN_ELMo模型的基础上强化了softmax分类器的输入,利用多头注意力机制为双向LSTM输出的隐状态计算了上下文向量,并将它们拼接后输入softmax分类器.
第2组是采用其他任务的知识来辅助增强隐喻识别的方法,具体模型为:
1)Go Figure![9]是在ACL2020会议的隐喻识别评测任务[23]中VUA榜单排名第2的模型,采用基于微调预训练BERT模型的多任务架构,将习语识别作为辅助任务,引入其他修辞语言(figurative language)识别任务的知识,通过学习到更具一般性的BERT参数增强隐喻识别的效果.
2)DeepMet-S[10]是一个基于RoBERTa[22]的阅读理解(reading comprehension)式隐喻识别模型,其多模型集成(ensemble)的结果在ACL2020会议的隐喻识别评测任务[23]中VUA榜单排名第1.DeepMet-S将需要被识别的句子作为上下文,为句中每一个需要进行隐喻识别的词建立了问题提示(prompt),利用其他任务的知识进行隐喻识别.
第3组是结合粗粒度句法知识的方法,具体为:
1)GCN_BERT[11]首先利用预训练BERT模型对词进行编码,然后利用粗类别依存分析结果结合注意力机制为句子构建了仅含无类别边的信息图,并采用图卷积神经网络[24]进行编码.
2)MWE[11]在GCN_BERT的基础上,利用额外的图卷积神经网络[24]编码了属于粗类别句法知识的多词表达式结构信息,并与原网络的编码进行拼接.
表4展示了本文提出的KEG模型与上述3组SOTA模型的对比结果.
表 4 KEG与SOTA方法对比的实验结果Table 4. Experimental Results of KEG and SOTA Methods% 组别 对比模型 VUA-VERB VUA-ALLPOS TroFi MOH-X P R F1 Acc P R F1 Acc P R F1 Acc P R F1 Acc 第1组 RNN_ELMo[7] 68.2 71.3 69.7 81.4 71.6 73.6 72.6 93.1 70.7 71.6 71.1 74.6 79.1 73.5 75.6 77.2 RNN_BERT[20] 66.7 71.5 69.0 80.7 71.5 71.9 71.7 92.9 70.3 67.1 68.7 73.4 75.1 81.8 78.2 78.1 RNN_HG[6] 69.3 72.3 70.8 82.1 71.8 76.3 74.0 93.6 67.4 77.8 72.2 74.9 79.7 79.8 79.8 79.7 RNN_MHCA[6] 66.3 75.2 70.5 81.8 73.0 75.7 74.3 93.8 68.6 76.8 72.4 75.2 77.5 83.1 80.0 79.8 第2组 Go Figure![9] 73.2 82.3 77.5 72.1 74.8 73.4 DeepMet-S[10] 76.2 78.3 77.2 86.2 73.8 73.2 73.5 90.5 第3组 GCN_BERT[11] 72.3 70.5 70.7 72.0 79.8 79.4 79.3 79.4 MWE[11] 73.8 71.8 72.8 73.5 80.0 80.4 80.2 80.5 本文 KEG 80.5 77.4 78.9 86.7 74.6 76.5 75.5 92.8 75.6 77.8 76.7 76.2 82.1 81.6 81.8 81.6 在第1组对比实验中,与朴素序列建模方法进行比较,KEG模型在4个数据集上均取得了更高的F1值,在除VUA-ALLPOS数据集之外也取得了更高的准确率.相比于RNN_HG和RNN_MHCA,在F1值方面分别提升了8.1,1.2,4.3,1.8个百分点.这体现了知识增强的图编码方法相对朴素序列建模方法有助于提升隐喻识别的性能.朴素序列建模方法仅依靠词向量将文本转化为输入向量,双向LSTM进行序列建模,会出现长距离依赖关系难以捕获的问题.而KEG不仅丰富了输入向量,也利用句法知识和信息图能更直接捕获到文本中的依赖关系,是朴素序列建模方法不具备的优势.
在第2组对比实验中,还比较了采用其他任务知识来增强隐喻识别的方法.从实验结果来看,第2组中结合知识的方法在VUA-VERB上明显优于第1组中的朴素序列建模方法.此外,相比结合习语识别进行多任务建模的Go Figure!模型,KEG在VUA-VERB和VUA-ALLPOS上的F1值分别提升了1.4和2.1个百分点.相比于阅读理解架构的DeepMet-S,KEG在VUA-VERB和VUA-ALLPOS上的F1值分别提升了1.7和2.0个百分点.这表明结合知识是可以有效提升隐喻识别的性能,而且本文提出的KEG引入词级别和句子级别2方面的知识在VUA-VERB和VUA-ALLPOS数据集上可以取得更优的效果.
在第3组对比实验中,比较了结合粗粒度句法知识的方法.KEG在TroFi和MOH-X上均取得了更优的F1值和准确率.MWE的各项指标均高于GCN_BERT.相比于MWE模型,KEG分别在F1值方面提升了3.9和1.6个百分点,在准确率方面提升了2.7和1.1个百分点.MWE和GCN_BERT均基于堆叠的图卷积神经网络进行隐喻识别,仅利用句法分析中的无向关系构建信息图,还舍弃了细粒度的类别信息.本文提出的KEG扩展了图循环神经网络架构进行图编码,利用循环迭代的方式达到堆叠图卷积神经网络的目的,包含更少的参数,降低了过拟合的风险.此外,KEG可以建模细粒度的句法知识,对信息的利用率更高.KEG还利用词级别义项知识丰富了输入向量,是MWE所不具备的优势.
综上可见,本文提出的KEG模型优于对比的3类SOTA方法,本文提出的词级别义项知识和细粒度句法知识应用于隐喻识别任务具有一定的优越性.
3.5 状态传递次数K对比分析
状态传递次数
K 是本文提出的KEG模型中的一个重要超参数.为了验证状态传递次数对实验结果的影响,在3.4节的实验基础上,本节设置不同的状态传递次数K 值,得到不同的实验结果,如表5所示:表 5 对比不同状态传递次数的实验结果Table 5. Experimental Results With Different State Transition Times% 状态传递次数K VUA-VERB VUA-ALLPOS TroFi MOH-X P R F1 Acc P R F1 Acc P R F1 Acc P R F1 Acc 1 67.3 72.6 69.8 82.5 71.8 73.3 72.5 91.7 72.6 70.4 71.5 74.6 77.8 79.8 78.8 78.1 2 74.6 75.7 75.1 84.2 73.3 75.7 74.5 92.4 74.1 75.6 74.8 75.3 81.3 80.5 80.9 80.8 3 80.5 77.4 78.9 86.7 74.6 76.5 75.5 92.8 75.6 77.8 76.7 76.2 82.1 81.6 81.8 81.6 4 80.9 77.1 79.0 86.2 75.1 76.0 75.5 92.8 75.8 77.5 76.6 76.3 82.1 81.8 81.9 81.2 5 80.8 77.2 78.9 86.6 74.8 76.1 75.4 93.1 76.1 77.8 76.9 75.3 81.4 82.1 81.7 81.6 实验结果表明,当状态传递次数K从1增大到3时,在4个数据集上的F1值和准确率均有所提升,其中F1值提升了9.1,3.0,5.2,3.0个百分点,准确率提升了4.2,1.1,1.6,3.5个百分点.增大状态传递次数K可以使模型学习到句子中距离更长的依赖关系,这证明了在一定范围内增加状态传递次数有利于提升模型的性能.当状态传递次数K从3增大到5时,在4个数据集上的F1值和准确率并没有观察到明显提升.而且增大状态传递次数K会导致模型运行所需时间变长.所以,实验中的状态传递次数K并不是越大越好.由于在4个数据集上,状态传递次数K = 3时取得了较优的F1值和准确率,并且在K > 3时评价指标均无明显提升.考虑到模型运行时间,本文在所有数据集上统一选择了状态传递次数K = 3时的实验结果作为KEG性能的对比和分析.
3.6 上下文向量对比分析
本文提出的KEG方法中构建了上下文向量.为了验证上下文向量对实验结果的影响,本文在KEG的基础上分别使用word2vec[32](记为KEG-word2vec),GloVe[41](记为KEG-GloVe),ELMo[42](记为KEG-ELMo)算法训练的词向量替换上下文向量,与使用BERT构建上下文向量的KEG进行对比,实验结果如表6所示.
表 6 词向量和上下文向量构建方法的实验结果Table 6. Experimental Results of Constructing Word Vectors and Context Vectors% 对比模型 VUA-VERB VUA-ALLPOS TroFi MOH-X P R F1 Acc P R F1 Acc P R F1 Acc P R F1 Acc KEG-word2vec 74.2 73.2 73.7 82.3 73.5 74.7 74.1 90.6 74.1 73.5 73.8 74.4 78.5 76.6 77.5 78.6 KEG-GloVe 74.6 73.2 73.9 82.6 73.6 74.7 74.1 90.8 74.0 73.8 73.9 74.2 78.4 76.8 77.6 79.1 KEG-ELMo 76.4 75.5 75.9 84.8 74.2 76.1 75.1 91.7 74.6 75.8 75.2 75.6 80.4 80.3 80.3 80.7 KEG 80.5 77.4 78.9 86.7 74.6 76.5 75.5 92.8 75.6 77.8 76.7 76.2 82.1 81.6 81.8 81.6 根据实验结果,使用BERT构建上下文向量的KEG相对于使用word2vec训练词向量的方法,在4个数据集上均有性能提升,F1值提升了5.2,1.4,2.9,4.3个百分点,准确率提升了4.4,2.2,1.8,3.0个百分点.原因在于,KEG-word2vec通过静态查表的方式将每个词转化为对应的词向量,同一个词在不同上下文中产生的词向量相同;而KEG则利用BERT中的编码器动态地根据上下文的内容实时计算一个向量表示,具有更强的编码能力.
对比KEG-word2vec和KEG-GloVe可以发现,这2个模型在4个数据集上的性能相差不多,F1值和准确率的差距均不超过0.5个百分点.经过分析,这2个模型相似,都采用了静态查表转化词向量的方式,产生相同维度的词向量,并在训练过程中对词向量进行微调.
若将BERT方法替换为ELMo方法构建上下文向量,在4个数据集上的性能有所下降,F1值下降了3.0,0.4,1.5,1.5个百分点,准确率下降了1.9,1.1,0.6,0.9个百分点.KEG与KEG-ELMo相比,使用的编码器参数更多,产生的上下文向量维度更大,进而有利于对上下文建模.
3.7 词级别义项知识对比分析
为了验证词级别义项知识对实验结果的影响,本文在KEG的基础上去掉利用词级别义项知识构造的语义向量(记为KEG-NOS),实验结果与KEG进行对比,如表7所示:
表 7 KEG有无词级别义项知识的实验结果Table 7. Experimental Results of KEG With and Without Lexicon Word Sense Knowledge% 对比模型 VUA-VERB VUA-ALLPOS TroFi MOH-X P R F1 Acc P R F1 Acc P R F1 Acc P R F1 Acc KEG-NOS 68.2 72.9 70.5 82.7 72.6 73.1 72.8 92.1 73.2 71.5 72.3 75.4 79.4 78.2 78.8 78.8 KEG 80.5 77.4 78.9 86.7 74.6 76.5 75.5 92.8 75.6 77.8 76.7 76.2 82.1 81.6 81.8 81.6 从表7分析可知,在KEG基础上去掉利用词级别义项知识构造的语义向量,在4个数据集上都出现了性能下降,其中F1值下降了8.4,2.7,4.4,3.0个百分点,准确率下降了4.0,0.7,0.8,2.8个百分点.由此可见,引入词级别义项知识有助于隐喻识别.其原因在于,词级别义项知识归纳了每个词常用的几种义项,并通过训练词义向量的方式,将常用的义项编码成向量.进而通过注意力机制在当前上下文环境下对各义项进行加权,利用义项知识对上下文表示进行补充,具备更强的语境表现力,从而有助于隐喻识别的性能提升.
3.8 细粒度句法知识对比分析
本文提出的KEG方法中为了指导图神经网络的信息传递,引入了细粒度句法知识来构建信息图.为了验证细粒度句法知识对实验结果的影响,本文设置了2组对比实验:在第1组中,在KEG的基础上,采用图神经网络经典应用[11,33-34]中利用粗粒度句法知识的方法构建信息图(记为KEG-CSK);在第2组中,采用无向完全图(undirected completed graph)作为信息图(记为KEG-UCG),实验结果对比如表8所示.
表 8 KEG有无细粒度句法知识的实验结果Table 8. Experimental Results of KEG With and Without Fine-Grained Syntactic Knowledge% 对比模型 VUA-VERB VUA-ALLPOS TroFi MOH-X P R F1 Acc P R F1 Acc P R F1 Acc P R F1 Acc KEG-UCG 67.5 71.1 69.3 80.6 70.3 71.3 70.8 89.4 72.5 70.1 71.3 74.0 77.5 76.9 77.2 77.1 KEG-CSK 71.2 70.7 70.9 81.3 72.0 71.4 71.7 90.2 73.1 70.7 71.9 74.7 78.2 78.3 78.2 78.3 KEG 80.5 77.4 78.9 86.7 74.6 76.5 75.5 92.8 75.6 77.8 76.7 76.2 82.1 81.6 81.8 81.6 由表8可见,对比KEG-CSK与KEG,利用粗粒度句法知识的方法构建信息图会在4个数据集上造成性能下降,其中F1值下降了8.0,3.8,4.8,3.6个百分点,准确率下降了5.4,2.6,1.5,3.3个百分点.通过分析,相对于KEG-CSK,本文提出的KEG中利用细粒度句法知识涵盖了更为细致的信息,即有向边和细粒度的边类型标签,并且通过KEG中的边感注意力机制和边绑定权重实现了在每次状态传递中有向边贡献的计算,进而从出、入2个视角分别计算了上下文表示向量,具有更强的语境建模能力,有助于提升隐喻识别性能.
另一方面,通过对比KEG-CSK和KEG-UCG可以发现,利用句法知识构建信息图比直接利用完全图作为信息图时的性能更好,F1值提升了1.6,0.9,0.6,1.0个百分点,准确率提升了0.7,0.8,0.7,1.2个百分点.经过分析,利用完全图作为信息图时,由于没有考虑到不同边的贡献可能不同,经过多次状态传递之后,各点的节点向量会趋于相似,丧失了其表示的独立性.利用粗粒度句法信息构建信息图以先验知识指导的形式对完全图进行剪枝,删除了在状态转移中作用小的边,保护了节点向量的独立性,进而产生了更好的性能.这证明了计算信息图中边贡献的必要性和融入句法知识对性能提升的有效性.
3.9 解码方式对比分析
本文提出的KEG方法中采用了条件随机场作为解码层.为了验证解码方式对实验结果的影响,本文按照文献[7]中提出的位置分类架构,在KEG的基础上,将一个序列的解码拆分成多次给定位置的预测(KEG-C).具体地,在单次给定位置的预测中,首先在模型的文本编码层加入位置向量,并在解码时采用注意力机制,针对给定位置计算了所有词的最终节点向量的加权和,进而利用类似式(19)的方式计算输出分值进行训练和测试.本节中将预测给定位置的KEG-C与序列解码的KEG进行对比,对比实验结果如表9所示:
表 9 2种解码方式的实验结果Table 9. Experimental Results of Two Decoding Methods% 对比模型 VUA-VERB VUA-ALLPOS TroFi MOH-X P R F1 Acc P R F1 Acc P R F1 Acc P R F1 Acc KEG-C 79.5 77.3 78.4 86.5 74.2 75.6 74.9 92.2 75.8 76.3 76.0 75.9 82.0 81.2 81.6 81.5 KEG 80.5 77.4 78.9 86.7 74.6 76.5 75.5 92.8 75.6 77.8 76.7 76.2 82.1 81.6 81.8 81.6 从表9可以看出,利用序列解码的KEG比预测给定位置的KEG-C在4个数据集上的性能方面稍显优势,F1值提升了0.5,0.6,0.7,0.2个百分点,准确率提升了0.2,0.6,0.3,0.1个百分点.经过分析,在训练时,KEG利用序列解码的方式将序列标签作为整体进行优化,将多个位置的标签监督信号聚合之后进行梯度下降;而KEG-C中的预测给定位置的方式在优化过程中显得较为分散,所以可能需要更长的训练时间才能达到与KEG相似的性能.但是由于使用的数据集规模相同,仅仅延长训练时间可能会增大模型过拟合的风险.因此,在这种情况下,采用序列解码的方式有助于模型学习到更健壮的监督信号,从而有助于隐喻识别.
4. 结 论
本文提出一种基于知识增强的文本隐喻识别图编码方法.该方法包含3个部分,分别是文本编码层、图网络层和解码层.在文本编码层,利用了预训练语言模型计算输入文本的上下文向量,与通过skip-gram和词义消歧共同训练得到的词义向量进行拼接,融合了词义项知识,增强了语义表示.在图网络层,相比于传统图神经网络建模文本的方法,构造了引入细粒度句法知识的信息图,并设计了边感注意力机制和边绑定权重计算细粒度上下文;结合图循环神经网络进行迭代式状态传递,并通过多层之间参数共享的特性,降低了模型参数,降低了过拟合的风险,有助于有效建模复杂语境.在解码层,利用了条件随机场对序列标签进行计算.实验证明,本文提出的方法在4个国际公开数据集上性能均有提升.
作者贡献声明:黄河燕指导并修改论文;刘啸提出了算法思路和实验方案,完成实验并撰写论文;刘茜提出算法和方案指导意见并修改论文.
-
表 1 包含隐喻词汇的文本样例
Table 1 Examples of Sentences with Metaphor Words
编号 文本样例 1 It went to his head rather. 2 How to kill a process? 3 I invested myself fully in this relationship. 4 They forged contacts with those left behind in Germany. 注:黑体单词表示隐喻现象.  下载: 导出CSV
下载: 导出CSV
表 2 数据集统计信息
Table 2 Statistics of Datasets
数据集 单词总数 句子总数 隐喻总数 隐喻占比/% 平均单词数 VUA-VERB 239847 16189 6554 28.36 14.82 VUA-ALLPOS 239847 16189 15026 15.85 14.82 TroFi 105949 3737 1627 43.54 28.35 MOH-X 5178 647 315 48.68 8.00
下载: 导出CSV
表 3 本文实验中使用的超参数
Table 3 Hyper-Parameters Used in Our Experiment
超参数 取值 {{\boldsymbol{e}}^{\rm{c}}}的向量维度 1024 {{\boldsymbol{e}}^{\rm{s}}}的向量维度 200 {\boldsymbol{k}}的向量维度 256 {\boldsymbol{m}},{\boldsymbol{h}},{\boldsymbol{g}}的向量维度 512 状态传递次数K 3 批大小(batch size) 16 BERT模型dropout率 0.5 模型其他部分dropout率 0.4 BERT模型学习率 1E−5 模型其他部分学习率 1E−3 BERT模型{L_2}权重衰减 1E−5 模型其他部分{L_2}权重衰减 1E−3 Warmup迭代轮次 5 最大迭代轮次 50 梯度裁剪 4.0
下载: 导出CSV
表 4 KEG与SOTA方法对比的实验结果
Table 4 Experimental Results of KEG and SOTA Methods
% 组别 对比模型 VUA-VERB VUA-ALLPOS TroFi MOH-X P R F1 Acc P R F1 Acc P R F1 Acc P R F1 Acc 第1组 RNN_ELMo[7] 68.2 71.3 69.7 81.4 71.6 73.6 72.6 93.1 70.7 71.6 71.1 74.6 79.1 73.5 75.6 77.2 RNN_BERT[20] 66.7 71.5 69.0 80.7 71.5 71.9 71.7 92.9 70.3 67.1 68.7 73.4 75.1 81.8 78.2 78.1 RNN_HG[6] 69.3 72.3 70.8 82.1 71.8 76.3 74.0 93.6 67.4 77.8 72.2 74.9 79.7 79.8 79.8 79.7 RNN_MHCA[6] 66.3 75.2 70.5 81.8 73.0 75.7 74.3 93.8 68.6 76.8 72.4 75.2 77.5 83.1 80.0 79.8 第2组 Go Figure![9] 73.2 82.3 77.5 72.1 74.8 73.4 DeepMet-S[10] 76.2 78.3 77.2 86.2 73.8 73.2 73.5 90.5 第3组 GCN_BERT[11] 72.3 70.5 70.7 72.0 79.8 79.4 79.3 79.4 MWE[11] 73.8 71.8 72.8 73.5 80.0 80.4 80.2 80.5 本文 KEG 80.5 77.4 78.9 86.7 74.6 76.5 75.5 92.8 75.6 77.8 76.7 76.2 82.1 81.6 81.8 81.6
下载: 导出CSV
表 5 对比不同状态传递次数的实验结果
Table 5 Experimental Results With Different State Transition Times
% 状态传递次数K VUA-VERB VUA-ALLPOS TroFi MOH-X P R F1 Acc P R F1 Acc P R F1 Acc P R F1 Acc 1 67.3 72.6 69.8 82.5 71.8 73.3 72.5 91.7 72.6 70.4 71.5 74.6 77.8 79.8 78.8 78.1 2 74.6 75.7 75.1 84.2 73.3 75.7 74.5 92.4 74.1 75.6 74.8 75.3 81.3 80.5 80.9 80.8 3 80.5 77.4 78.9 86.7 74.6 76.5 75.5 92.8 75.6 77.8 76.7 76.2 82.1 81.6 81.8 81.6 4 80.9 77.1 79.0 86.2 75.1 76.0 75.5 92.8 75.8 77.5 76.6 76.3 82.1 81.8 81.9 81.2 5 80.8 77.2 78.9 86.6 74.8 76.1 75.4 93.1 76.1 77.8 76.9 75.3 81.4 82.1 81.7 81.6
下载: 导出CSV
表 6 词向量和上下文向量构建方法的实验结果
Table 6 Experimental Results of Constructing Word Vectors and Context Vectors
% 对比模型 VUA-VERB VUA-ALLPOS TroFi MOH-X P R F1 Acc P R F1 Acc P R F1 Acc P R F1 Acc KEG-word2vec 74.2 73.2 73.7 82.3 73.5 74.7 74.1 90.6 74.1 73.5 73.8 74.4 78.5 76.6 77.5 78.6 KEG-GloVe 74.6 73.2 73.9 82.6 73.6 74.7 74.1 90.8 74.0 73.8 73.9 74.2 78.4 76.8 77.6 79.1 KEG-ELMo 76.4 75.5 75.9 84.8 74.2 76.1 75.1 91.7 74.6 75.8 75.2 75.6 80.4 80.3 80.3 80.7 KEG 80.5 77.4 78.9 86.7 74.6 76.5 75.5 92.8 75.6 77.8 76.7 76.2 82.1 81.6 81.8 81.6
下载: 导出CSV
表 7 KEG有无词级别义项知识的实验结果
Table 7 Experimental Results of KEG With and Without Lexicon Word Sense Knowledge
% 对比模型 VUA-VERB VUA-ALLPOS TroFi MOH-X P R F1 Acc P R F1 Acc P R F1 Acc P R F1 Acc KEG-NOS 68.2 72.9 70.5 82.7 72.6 73.1 72.8 92.1 73.2 71.5 72.3 75.4 79.4 78.2 78.8 78.8 KEG 80.5 77.4 78.9 86.7 74.6 76.5 75.5 92.8 75.6 77.8 76.7 76.2 82.1 81.6 81.8 81.6
下载: 导出CSV
表 8 KEG有无细粒度句法知识的实验结果
Table 8 Experimental Results of KEG With and Without Fine-Grained Syntactic Knowledge
% 对比模型 VUA-VERB VUA-ALLPOS TroFi MOH-X P R F1 Acc P R F1 Acc P R F1 Acc P R F1 Acc KEG-UCG 67.5 71.1 69.3 80.6 70.3 71.3 70.8 89.4 72.5 70.1 71.3 74.0 77.5 76.9 77.2 77.1 KEG-CSK 71.2 70.7 70.9 81.3 72.0 71.4 71.7 90.2 73.1 70.7 71.9 74.7 78.2 78.3 78.2 78.3 KEG 80.5 77.4 78.9 86.7 74.6 76.5 75.5 92.8 75.6 77.8 76.7 76.2 82.1 81.6 81.8 81.6
下载: 导出CSV
表 9 2种解码方式的实验结果
Table 9 Experimental Results of Two Decoding Methods
% 对比模型 VUA-VERB VUA-ALLPOS TroFi MOH-X P R F1 Acc P R F1 Acc P R F1 Acc P R F1 Acc KEG-C 79.5 77.3 78.4 86.5 74.2 75.6 74.9 92.2 75.8 76.3 76.0 75.9 82.0 81.2 81.6 81.5 KEG 80.5 77.4 78.9 86.7 74.6 76.5 75.5 92.8 75.6 77.8 76.7 76.2 82.1 81.6 81.8 81.6
下载: 导出CSV
-
[1] Shutova E. Models of metaphor in NLP[C] //Proc of the 48th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2010: 688−697 [2] Jang H, Moon S, Jo Y, et al. Metaphor detection in discourse[C] //Proc of the 16th Annual Meeting of the Special Interest Group on Discourse and Dialogue. Stroudsburg, PA: ACL, 2015: 384−392
[3] Klebanov B, Leong C, Gutiérrez E, et al. Semantic classifications for detection of verb metaphors[C] //Proc of the 54th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2016: 101−106
[4] Bulat L, Clark S, Shutova E. Modelling metaphor with attribute-based semantics[C] //Proc of the 15th Conf of the European Chapter of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2017: 523−528
[5] Shutova E, Kiela D, Maillard J. Black holes and white rabbits: Metaphor identification with visual features[C] //Proc of the 2016 Conf of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2016: 160−170 [6] Mao Rui, Lin Chenghua, Guerin F. End-to-end sequential metaphor identification inspired by linguistic theories[C] //Proc of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2019: 3888−3898
[7] Gao Ge, Choi E, Choi Y, et al. Neural metaphor detection in context[C] //Proc of the 2018 Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2018: 607−613 [8] Rei M, Bulat L, Kiela D, et al. Grasping the finer point: A supervised similarity network for metaphor detection[C] //Proc of the 2017 Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2017: 1537−1546 [9] Chen Xianyang, Leong C, Flor M, et al. Go Figure! Multi-task transformer-based architecture for metaphor detection using idioms: ETS team in 2020 metaphor shared task[C] //Proc of the 2nd Workshop on Figurative Language Processing, Fig-Lang@ACL 2020. Stroudsburg, PA: ACL, 2020: 235−243 [10] Su Chuandong, Fukumoto F, Huang Xiaoxi, et al. DeepMet: A reading comprehension paradigm for token-level metaphor detection[C] //Proc of the 2nd Workshop on Figurative Language Processing, Fig-Lang@ACL 2020. Stroudsburg, PA: ACL, 2020: 30−39
[11] Rohanian O, Rei M, Taslimipoor S, et al. Verbal multiword expressions for identification of metaphor[C] //Proc of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2020: 2890−2895
[12] Leong C, Klebanov B, Shutova E. A report on the 2018 VUA metaphor detection shared task[C] //Proc of the 1st Workshop on Figurative Language Processing, Fig-Lang@NAACL-HLT 2018. Stroudsburg, PA: ACL, 2018: 56−66
[13] Birke J, Sarkar A. A clustering approach for nearly unsupervised recognition of nonliteral language[C] //Proc of the 11th Conf of the European Chapter of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2017: 523−528
[14] Dunn J. Measuring metaphoricity[C] //Proc of the 52nd Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2014: 745−751
[15] Gutiérrez E, Shutova E, Marghetis T, et al. Literal and metaphorical senses in compositional distributional semantic models[C] //Proc of the 54th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2016: 183−193
[16] Mohammad S, Shutova E, Turney P. Metaphor as a medium for emotion: An empirical study[C] //Proc of the 5th Joint Conf on Lexical and Computational Semantics, *SEM@ACL 2016. Stroudsburg, PA: ACL, 2016: 23−33
[17] Tsvetkov Y, Boytsov L, Gershman A, et al. Metaphor detection with cross-lingual model transfer[C] //Proc of the 52nd Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2014: 248−258
[18] Wilks Y. A preferential, pattern-seeking, semantics for natural language inference[J]. Artificial Intelligence, 1975, 6(1): 53−74 doi: 10.1016/0004-3702(75)90016-8
[19] Pragglejaz Group. MIP: A method for identifying metaphorically used words in discourse[J]. Metaphor and Symbol, 2007, 22(1): 1−39 doi: 10.1080/10926480709336752
[20] Devlin J, Chang M, Lee K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[C] //Proc of the 2019 Conf of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2019: 4171−4186 [21] Vaswani A, Shazzer N, Parmar N, et al. Attention is all you need[C] //Proc of the Advances in Neural Information Processing Systems 30: Annual Conf on Neural Information Processing Systems 2017. San Diego, CA: NIPS, 2017: 5998−6008 [22] Liu Yinhan, Ott M, Goyal N, et al. RoBERTa: A robustly optimized BERT pretraining approach [J]. arXiv preprint, arXiv: 1907.11692, 2019
[23] Leong C, Klebanov B, Hamill C, et al. A report on the 2020 VUA and TOEFL metaphor detection shared task[C] //Proc of the 2nd Workshop on Figurative Language Processing, Fig-Lang@ACL 2020. Stroudsburg, PA: ACL, 2020: 18−29
[24] Kipf T, Welling M. Semi-supervised classification with graph convolutional networks[C/OL] //Proc of the 5th Int Conf on Learning Representations. La Jolla, CA: ICLR, 2017 [2018-05-20]. https://openreview.net/pdf?id=SJU4ayYgl
[25] Steen G, Dorst A, Herrmann J, et al. A method for linguistic metaphor identification: From MIP to MIPVU[M] //Converging Evidence in Language and Communication Research, Volume 14. Amsterdam: John Benjamins Publishing Company, 2010: 25−42
[26] Klebanov B, Leong C, Flor M. A corpus of non-native written english annotated for metaphor[C] //Proc of the 2018 Conf of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2018: 86−91 [27] Levin L, Mitamura T, MacWhinney B, et al. Resources for the detection of conventionalized metaphors in four languages[C] //Proc of the 9th Int Conf on Language Resources and Evaluation. Paris: LREC, 2014: 498−501
[28] Mohler M, Brunson M, Rink B, et al. Introducing the LCC metaphor datasets[C] //Proc of the 10th Int Conf on Language Resources and Evaluation. Paris: LREC, 2016: 4221−4227
[29] Parde N, Nielsen R. A corpus of metaphor novelty scores for syntactically-related word pairs[C] //Proc of the 11th Int Conf on Language Resources and Evaluation. Paris: LREC, 2018: 1535−1540
[30] Tredici M, Bel N. Assessing the potential of metaphoricity of verbs using corpus data[C] //Proc of the 10th Int Conf on Language Resources and Evaluation. Paris: LREC, 2016: 4573−4577
[31] Chen Xinxiong, Liu Zhiyuan, Sun Maosong. A unified model for word sense representation and disambiguation[C] //Proc of the 2014 Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2014: 1025−1035 [32] Mikolov T, Sutskever I, Chen Kai, et al. Distributed representations of words and phrases and their compositionality[C] //Proc of the Advances in Neural Information Processing Systems 26: Annual Conf on Neural Information Processing Systems 2013. San Diego, CA: NIPS, 2013: 3111−3119 [33] Marcheggiani D, Titov I. Encoding sentences with graph convolutional networks for semantic role labeling[C] //Proc of the 2017 Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2017: 1506−1515 [34] Liu Xiao, Luo Zhunchen, Huang Heyan. Jointly multiple events extraction via attention-based graph information aggregation[C] //Proc of the 2018 Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2018: 1247−1256 [35] Zhang Yue, Liu Qi, Song Linfeng. Sentence-state LSTM for text representation[C] //Proc of the 56th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2018: 317−327
[36] Song Linfeng, Zhang Yue, Wang Zhiguo, et al. A graph-to-sequence model for AMR-to-text generation[C] //Proc of the 56th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2018: 1616−1626
[37] Cho K, Merrienboer B, Gülçehre Ç, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[C] //Proc of the 2014 Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2014: 1724−1734 [38] Lafferty J, McCallum A, Pereira F. Conditional random fields: Probabilistic models for segmenting and labeling sequence data[C] //Proc of the 18th Int Conf on Machine Learning. San Diego, CA: ICML, 2001: 282−289
[39] Linguistic Data Consortium. BLLIP 1987-89 WSJ Corpus Release 1[DB/OL]. [2020-12-28]. https://catalog.ldc.upenn.edu/LDC2000T43
[40] Loshchilov I, Hutter F. Decoupled weight decay regularization[C/OL] //Proc of the 7th Int Conf on Learning Representations. La Jolla, CA: ICLR, 2019 [2020-01-10]. https://openreview.net/pdf?id=Bkg6RiCqY7
[41] Pennington J, Socher R, Manning C. GloVe: Global vectors for word representation[C] //Proc of the 2014 Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2014: 1532−1543 [42] Peters M, Neumann M, Iyyer M, et al. Deep contextualized word representations[C] //Proc of the 2018 Conf of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2018: 2227−2237 -
期刊类型引用(2)
1. 张凯,吕学强. 基于认知框架的多维融合作文拟人辞格自动识别方法. 数据分析与知识发现. 2025(02): 81-93 .  百度学术
百度学术
2. 陆靓倩,王中卿,周国栋. 结合多种语言学特征的中文隐式情感分类. 计算机科学. 2023(12): 255-261 . 百度学术
其他类型引用(3)





































































































































































计量
- 文章访问数: 271
- HTML全文浏览量: 33
- PDF下载量: 125
- 被引次数: 5




