


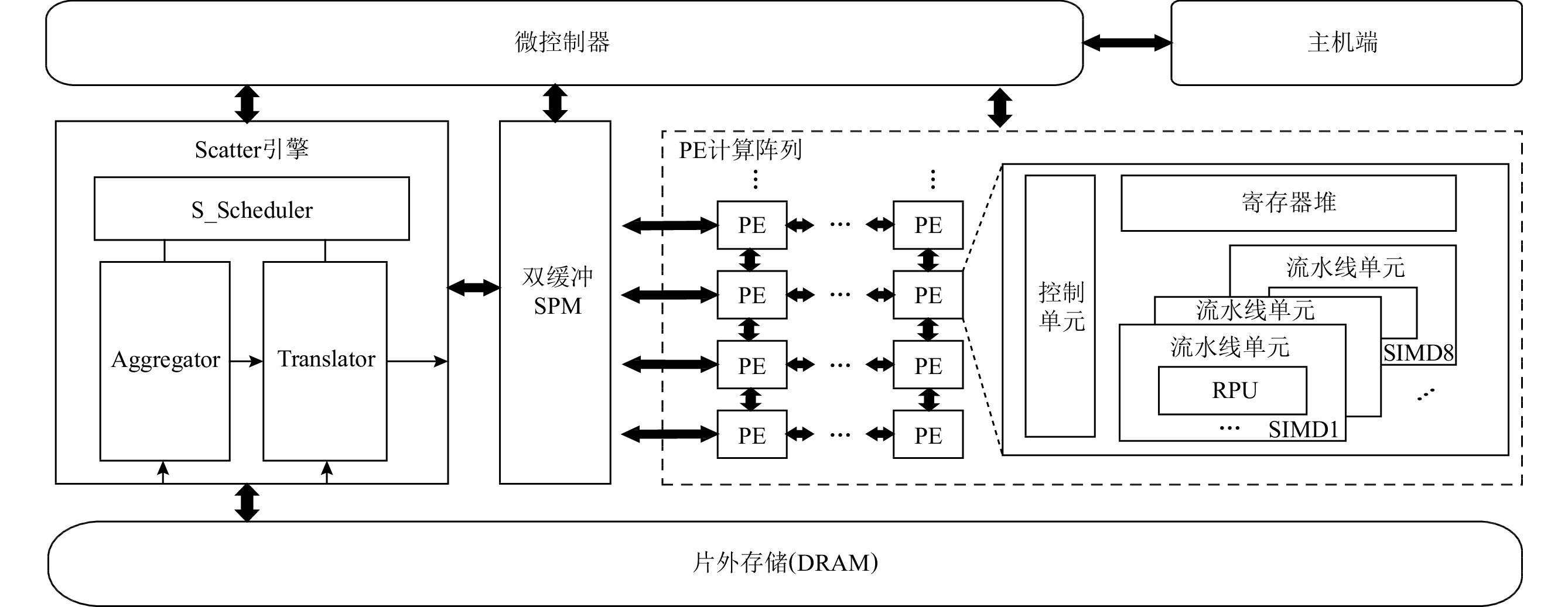
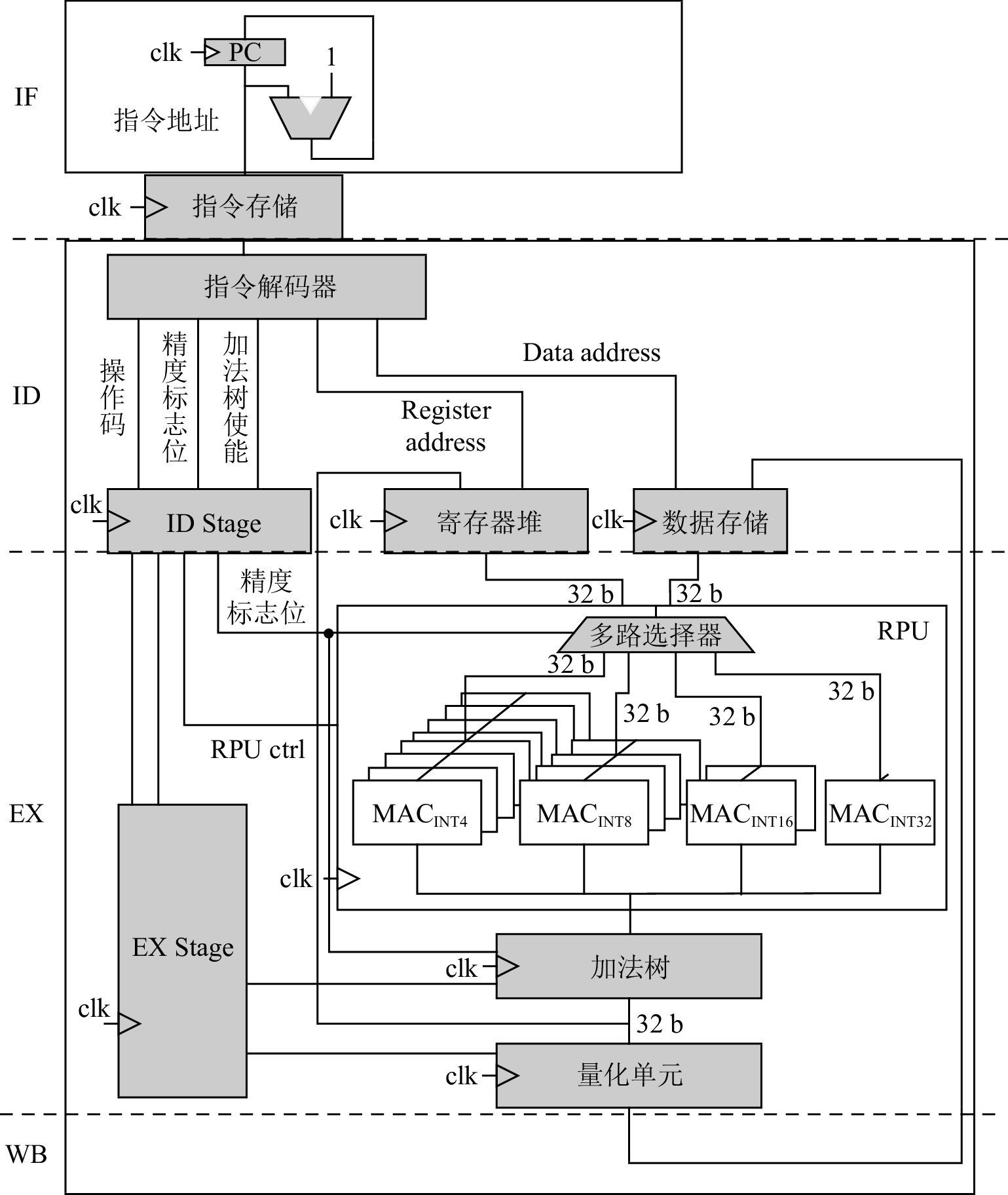
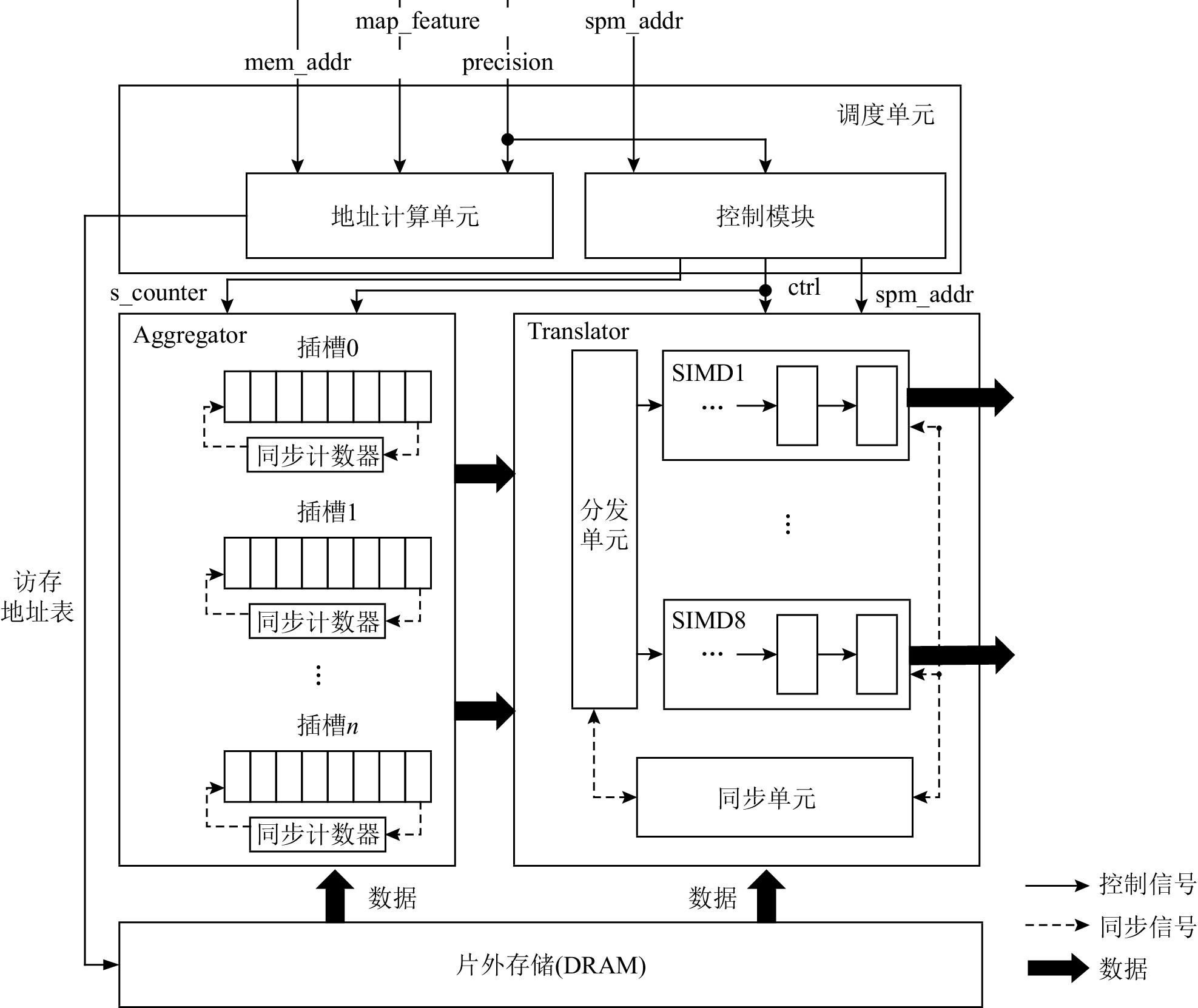
Dataflow Architecture Optimization for Low-Precision Neural Networks
-
摘要:
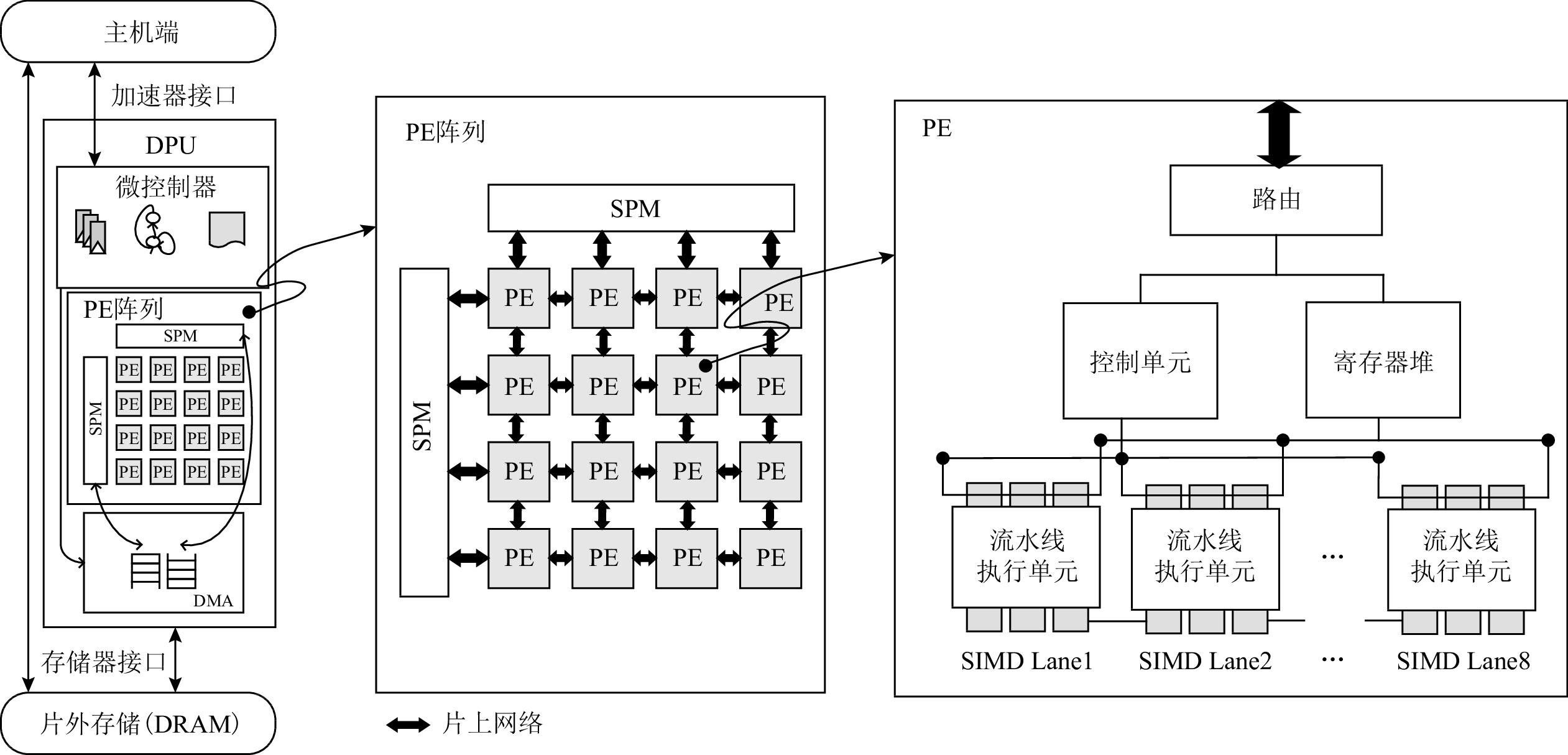
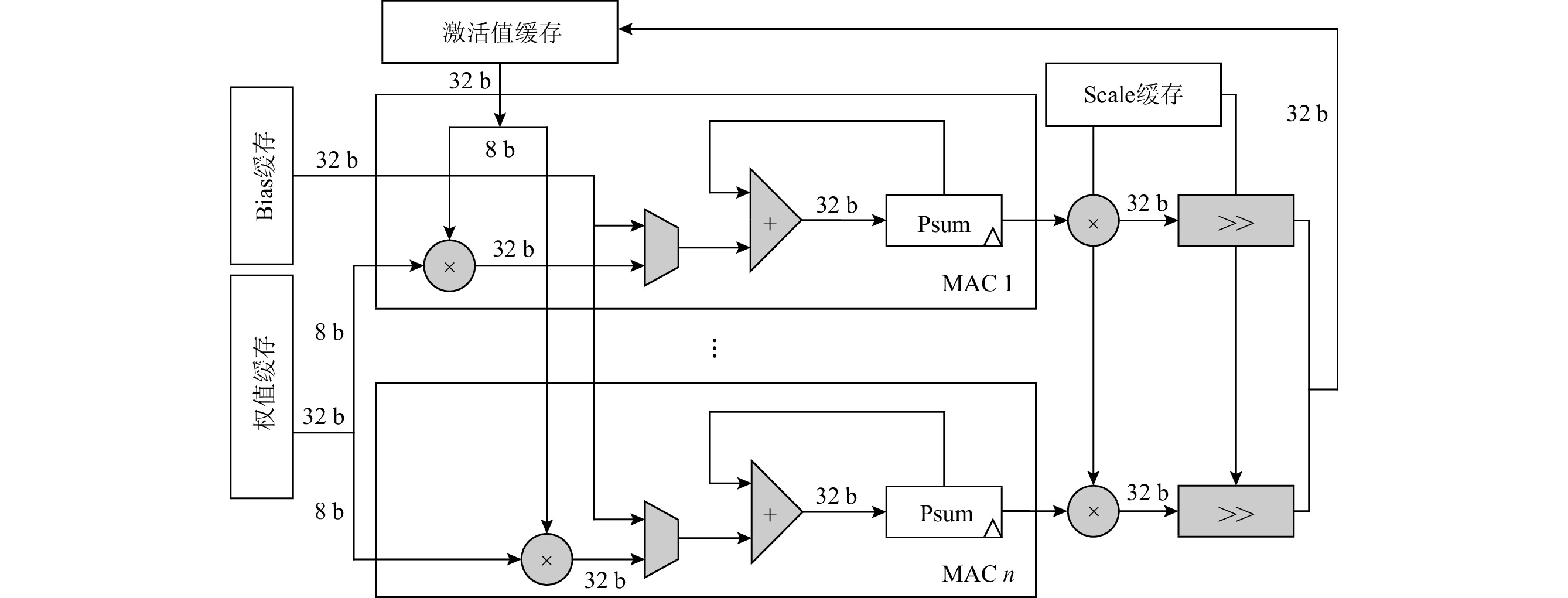
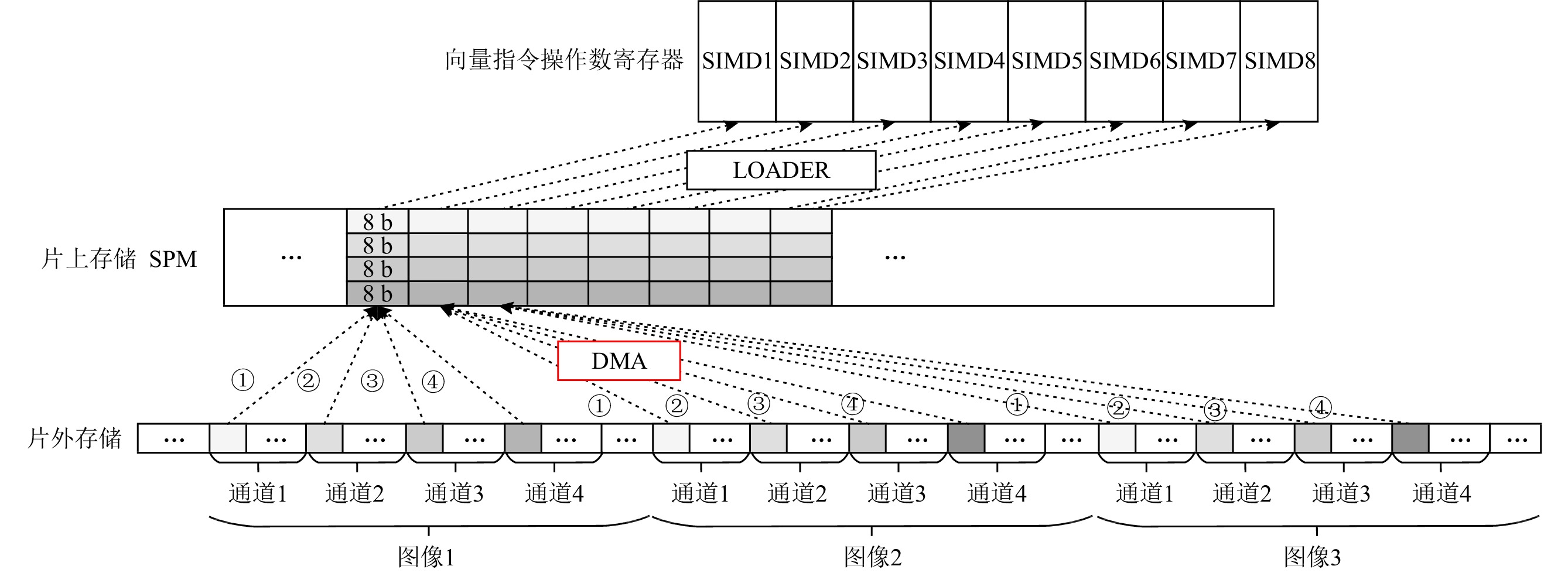
数据流架构的执行方式与神经网络算法具有高度匹配性,能充分挖掘数据的并行性. 然而,随着神经网络向更低精度的发展,数据流架构的研究并未面向低精度神经网络展开,在传统数据流架构部署低精度(INT8,INT4或者更低)神经网络时,会面临3个问题:1)传统数据流架构的计算部件数据通路与低精度数据不匹配,无法体现低精度神经网络的性能和能效优势;2)向量化并行计算的低精度数据在片上存储中要求顺序排列,然而它在片外存储层次中是分散排列的,使得数据的加载和写回操作变得复杂,传统数据流架构的访存部件无法高效支持这种复杂的访存模式;3)传统数据流架构中使用双缓冲机制掩盖数据的传输延迟,但是,当传输低精度数据时,传输带宽的利用率显著降低,导致计算延迟无法掩盖数据传输延迟,双缓冲机制面临失效风险,进而影响数据流架构的性能和能效.为解决这3个问题,设计了面向低精度神经网络的数据流加速器DPU_Q.首先,设计了灵活可重构的计算单元,根据指令的精度标志位动态重构数据通路,一方面能高效灵活地支持多种低精度数据运算,另一方面能进一步提高计算并行性和吞吐量. 另外,为解决低精度神经网络复杂的访存模式,设计了Scatter引擎,该引擎将在低层次或者片外存储中地址空间离散分布的低精度数据进行拼接、预处理,以满足高层次或者片上存储对数据排列的格式要求.同时,Scatter引擎能有效解决传输低精度数据时带宽利用率低的问题,解决了双缓冲机制失效的问题.最后,从软件方面提出了基于数据流执行模式的低精度神经网络映射算法,兼顾负载均衡的同时能对权重、激活值数据进行充分复用,减少了访存和数据流图节点间的数据传输开销.实验表明,相比于同精度的GPU(Titan Xp)、数据流架构(Eyeriss)和低精度神经网络加速器(BitFusion),DPU_Q分别获得3. 18倍、6.05倍、1.52倍的性能提升和4.49倍、1.6倍、1.13倍的能效提升.
Abstract:The execution model of the dataflow architecture is similar to the execution of neural network algorithm, which can exploit more parallelism. However, with the development of low-precision neural networks, the research on dataflow architecture has not been developed for low-precision neural networks. When low-precision (INT8, INT4 or lower) neural networks are deployed in traditional dataflow architectures, they will face the following three challenges: 1) The data path of the traditional dataflow architecture does not match the low-precision data, which cannot reflect the performance and energy efficiency advantages of the low-precision neural networks. 2) Vectorized low-precision data are required to be arranged in order in the on-chip memory, but these data are arranged in a scattered manner in the off-chip memory hierarchy, which makes data loading and writing back operations more complicated. The memory access components of the traditional dataflow architecture cannot support this complex memory access mode efficiently. 3) In traditional dataflow architecture, the double buffering mechanism is used to conceal the transmission delay. However, when low-precision data are transmitted, the utilization of the transmission bandwidth is significantly reduced, resulting in calculation delays that cannot cover the data transmission delay, and the double buffering mechanism faces the risk of failure, thereby affecting the performance and energy efficiency of the dataflow architecture. In order to solve the above problems, we optimize the dataflow architecture and design a low-precision neural networks accelerator named DPU_Q. First of all, a flexible and reconfigurable computing unit is designed, which dynamically reconstructs the data path according to the precision flag of the instruction. On the one hand, it can efficiently and flexibly support a variety of low-precision operations. On the other hand, the performance and throughput of the architecture can be further improved in this way. In addition, in order to solve the complex memory access mode of low-precision data, we design Scatter engine, which can splice and preprocess the low-precision data discretely distributed in the off-chip/low-level memory hierarchy to meet the format requirements of the on-chip/high-level memory hierarchy for data arrangement. At the same time, Scatter engine can effectively solve the problem of reduced bandwidth utilization when transmitting low-precision data. The transmission delay will not increase significantly, so it can be completely covered by the double buffer mechanism. Finally, a low-precision neural network scheduling method is proposed, which can fully reuse weights, activation values, reducing memory access overhead. Experiments show that compared with the same precision GPU (Titan Xp), state-of-the-art dataflow architecture (Eyeriss) and state-of-the-art low-precision neural network accelerator (BitFusion), DPU_Q achieves 3.18
× , 6.05× , and 1.52× of performance improvement and 4.49× , 1.6× , and 1.13× of energy efficiency improvement, respectively. -
-
![]()
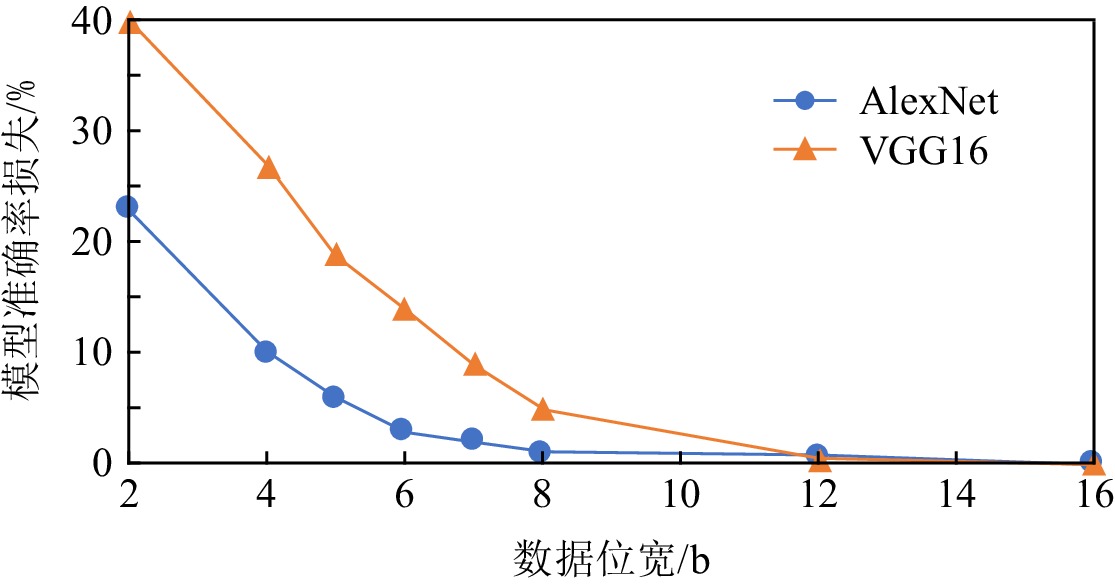
图 1 神经网络模型准确率损失与数据位宽的关系
Figure 1. Relationship between the accuracy loss of the neural network model and the quantization of bit-width
![]()
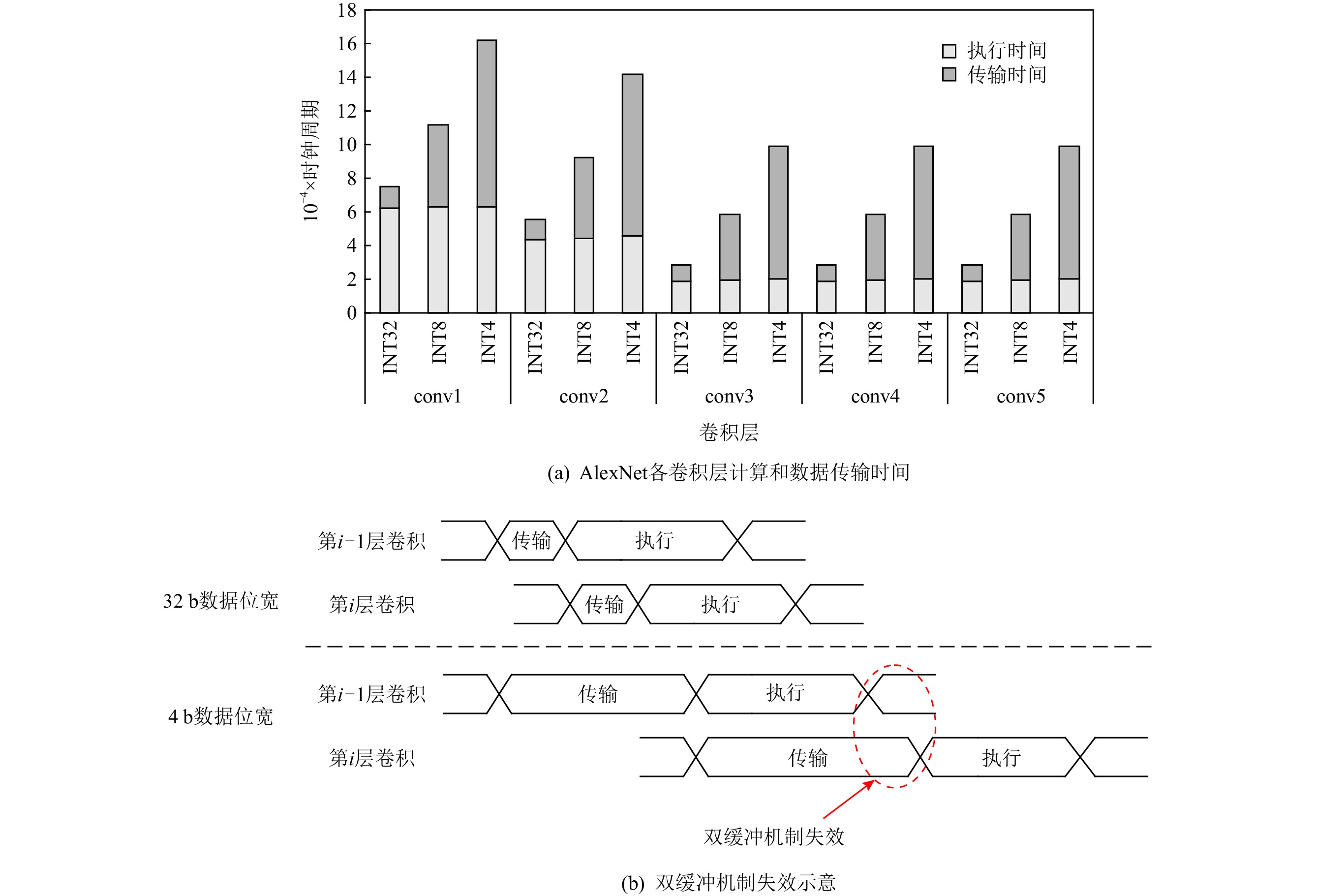
图 5 AlexNet网络不同精度的计算和传输开销
Figure 5. Calculation and transmission overhead of different precisions in AlexNet
![]()
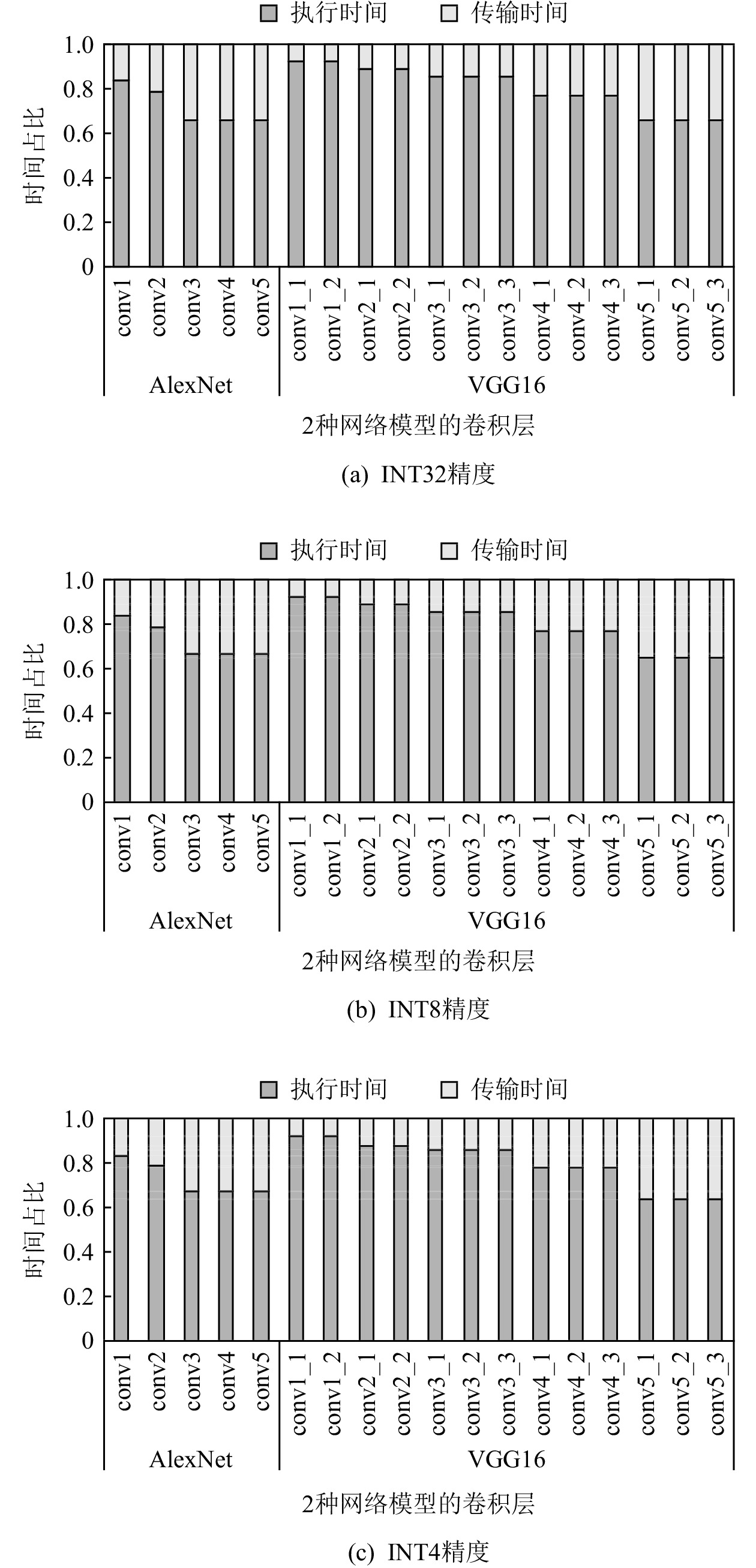
图 9 AlexNet和VGG16各层的数据传输和执行时间占比
Figure 9. Data transmission and execution time proportion of each layer of AlexNet and VGG16
![]()
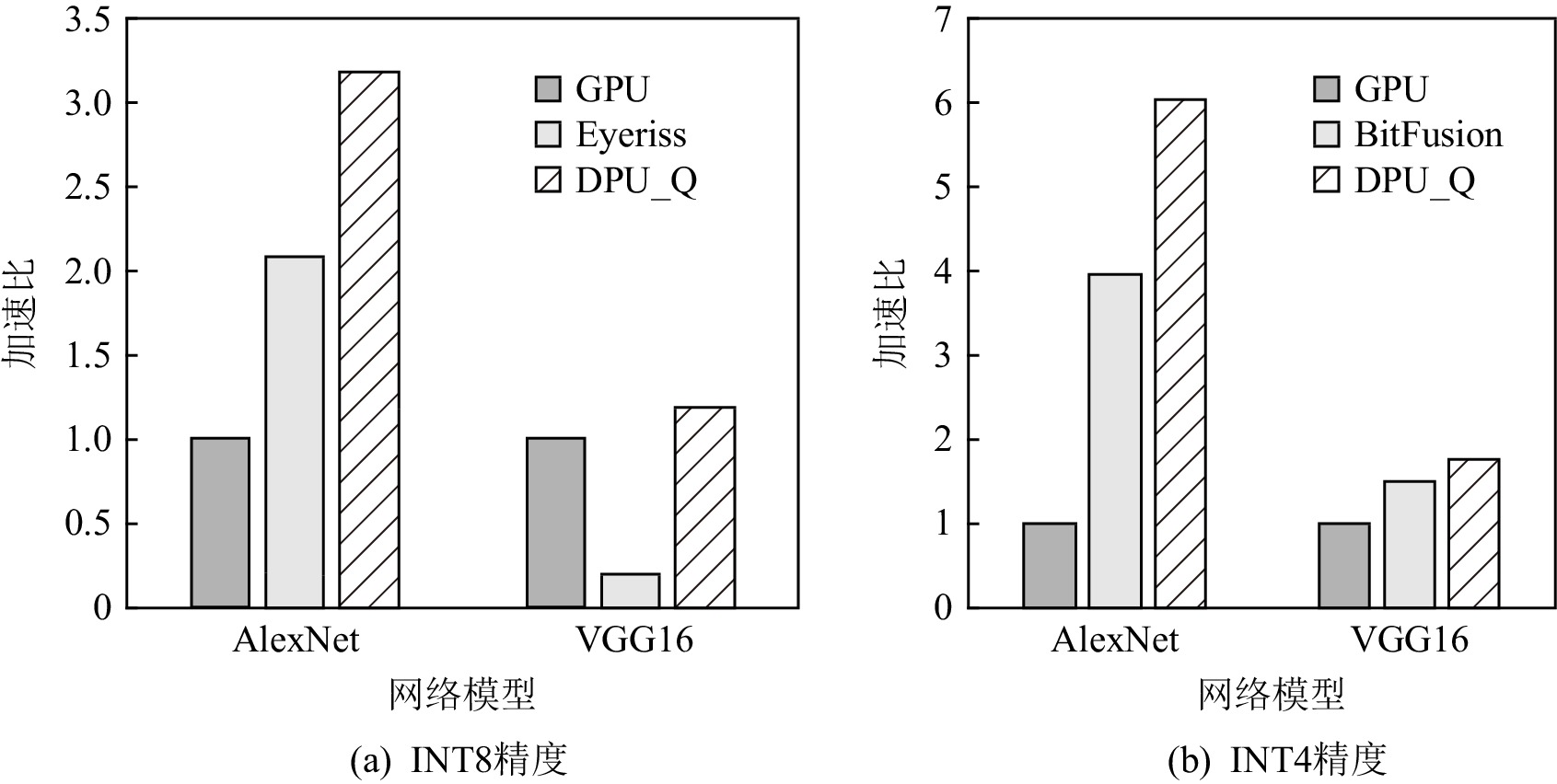
图 12 DPU_Q,BitFusion,Eyeriss相对于GPU的性能对比
Figure 12. Performance comparison of DPU_Q,BitFusion,Eyeriss over GPU
表 2 代表性低精度神经网络
Table 2 Representative Low-Precision Neural Networks
 下载: 导出CSV
下载: 导出CSV
表 3 DPU_Q的配置信息
Table 3 Configuration Information of DPU_Q
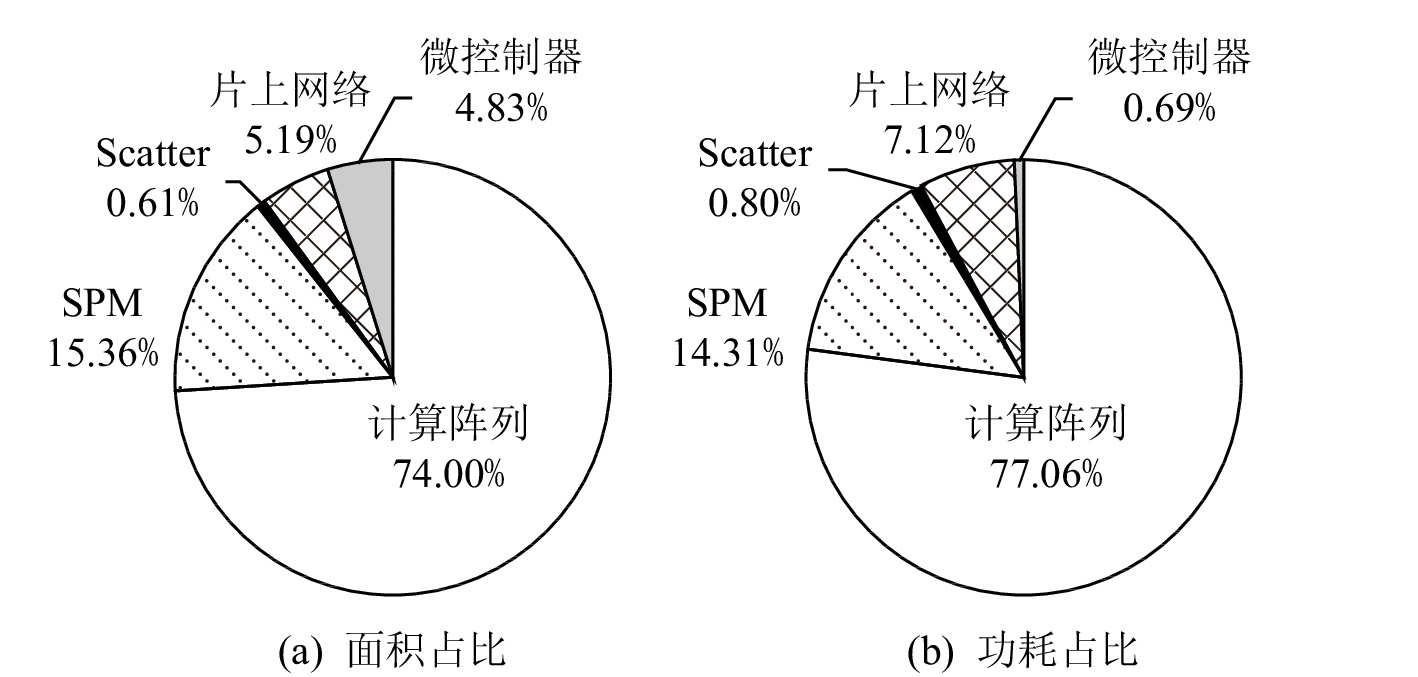
模块 配置信息 微控制器 ARM 核 PE 8×8, SIMD8, 1 GHz, 8 KB 指令缓存, 32KB数据缓存 片上网络 2维 mesh,1套访存网络,
1套控制网络,1套PE间通信网络片外存储 DDR3,1333MHz SPM/MB 6
下载: 导出CSV
表 4 测试程序信息
Table 4 Benchmark Information
CNN 模型 卷积层 特征矩阵规模
( H × W × C)卷积核规模
(R × S ×M)AlexNet conv1 227 × 227 × 3 11 × 11 × 96 conv2 31 × 31 × 96 5 × 5 × 256 conv3 15 × 15 × 256 3 × 3 × 384 conv4 15 × 15 × 384 3 × 3 × 384 conv5 15 × 15 × 384 3 × 3 × 256 VGG16 conv1_1 224 × 224 × 3 3 × 3 × 64 conv1_2 224 × 224 × 64 3 × 3 × 64 conv2_1 112 × 112 × 64 3 × 3 × 128 conv2_2 112 × 112 × 128 3 × 3 × 128 conv3_1 56 × 56 × 128 3 × 3 × 256 conv3_2 56 × 56 × 256 3 × 3 × 256 conv3_3 56 × 56 × 256 3 × 3 × 256 conv4_1 28 × 28 × 256 3 × 3 × 512 conv4_2 28 × 28 × 512 3 × 3 × 512 conv4_3 28 × 28 × 512 3 × 3 × 512 conv5_1 14 × 14 × 512 3 × 3 × 512 conv5_2 14 × 14 × 512 3 × 3 × 512 conv5_3 14 × 14 × 512 3 × 3 × 512 注:H,W,C分别表示特征矩阵的高、宽、通道;R,S,M分别表示卷积核的高、宽、通道.
下载: 导出CSV
-
[1] Krizhevsky A, Sutskever I, Hinton G. Imagenet classification with deep convolutional neural networks[C] //Proc of the 25th Int Conf on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2012: 1097−1105
[2] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint, arXiv: 1409.1556, 2014
[3] Song Zhuoran, Fu Bangqi, Wu Feiyang, et al. DRQ: Dynamic region-based quantization for deep neural network acceleration[C] //Proc of the 47th Annual Int Symp on Computer Architecture. Piscataway, NJ: IEEE, 2020: 1010−1021
[4] Ueki T, Keisuke I, Matsubara T, et al. AQSS: Accelerator of quantization neural networks with stochastic approach[C] //Proc of the 6th Int Symp on Computing and Networking Workshops. Piscataway, NJ: IEEE, 2018: 138−144
[5] Park E, Kim D, Yoo S. Energy-efficient neural network accelerator based on outlier-aware low-precision computation[C] //Proc of the 45th Annual Int Symp on Computer Architecture. Piscataway, NJ: IEEE, 2018: 688−698
[6] Sharma H, Park J, Suda N, et al. BitFusion: Bit-level dynamically composable architecture for accelerating deep neural network[C] //Proc of the 45th Annual Int Symp on Computer Architecture. Piscataway, NJ: IEEE, 2018: 764−775
[7] Chen Yu-Hsin, Krishna T, Emer J, et al. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks[J]. IEEE Journal of Solid-State Circuits, 2017, 52(1): 127−138 doi: 10.1109/JSSC.2016.2616357
[8] Wu Xinxin, Fan Zhihua, Liu Tianyu, et al. LRP: Predictive output activation based on SVD approach for CNNs acceleration[C] //Proc of the 25th Design, Automation & Test in Europe. Piscataway, NJ: IEEE, 2022: 837−842
[9] Courbariaux M, Bengio Y, David J. BinaryConnect: Training deep neural networks with binary weights during propagations[C] //Proc of the 28th Int Conf on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2015: 3123−3131
[10] Zhang Donqing, Yang Jiaolong, Ye Dongqiangzi, et al. LQ-Nets: Learned quantization for highly accurate and compact deep neural networks[C] //Proc of the 15th European Conf on Computer Vision. Berlin: Springer, 2018: 365−382
[11] Wang Naigang, Choi J, Brand D, et al. Training deep neural networks with 8-bit floating point numbers[C] //Proc of the 31st Int Conf on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2018: 7685−7694
[12] Chen Tianshi, Du Zidong, Sun Ninghui, et al. DianNao: A small-footprint high-throughput accelerator for ubiquitous machine-learning[C] //Proc of the 19th Int Conf on Architectural Support for Programming Languages and Operating Systems. New York: ACM, 2014: 269−284
[13] Wu Jiaxiang, Leng Cong, Wang Yonghang, et al. Quantized convolutional neural networks for mobile devices[C] //Proc of the 29th Int Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 4820−4828
[14] Park E, Yoo S, Vajda P. Value-aware quantization for training and inference of neural networks[C] //Proc of the 15th European Conf on Computer Vision. Berlin: Springer, 2018: 608−624
[15] Deng Lei, Li Guoqi, Han Song, et al. Model compression and hardware acceleration for neural networks: A comprehensive survey[J]. Proceedings of IEEE, 2020, 108(4): 485−532 doi: 10.1109/JPROC.2020.2976475
[16] Jung S, Son C, Lee S, et al. Learning to quantize deep networks by optimizing quantization intervals with task loss[C] //Proc of the 31st Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2019: 4350−4359
[17] Szegedy C, Liu Wei, Jia Yangqing, et al. Going deeper with convolutions[C] //Proc of the 27th Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015: 1−9
[18] Han Song, Mao Huizi, Dally J. Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman coding[J]. arXiv preprint, arXiv: 1510.00149v2, 2015
[19] Ye Xiaochun, Fan Dongrui, Sun Ninghui, et al. SimICT: A fast and flexible framework for performance and power evaluation of large-scale architecture[C] //Proc of the 18th Int Symp on Low Power Electronics and Design (ISLPED). Piscataway, NJ: IEEE, 2013: 273−278

计量
- 文章访问数: 331
- HTML全文浏览量: 35
- PDF下载量: 233




