


Cache Side-Channel Attacks and Defenses
-
摘要:
近年来,随着信息技术的发展,信息系统中的缓存侧信道攻击层出不穷.从最早利用缓存计时分析推测密钥的想法提出至今,缓存侧信道攻击已经历了10余年的发展和演进.研究中梳理了信息系统中缓存侧信道攻击风险,并对缓存侧信道攻击的攻击场景、实现层次、攻击目标和攻击原理进行了总结.系统分析了针对缓存侧信道攻击的防御技术,从缓存侧信道攻击防御的不同阶段出发,分析了攻击检测和防御实施2部分研究工作,并基于不同防御原理对防御方法进行分类和分析.最后,总结并讨论了互联网生态体系下缓存侧信道攻击与防御的研究热点,指出缓存侧信道攻击与防御未来的研究方向,为想要在这一领域开始研究工作的研究者提供参考.
Abstract:In recent years, with the development of information technology, cache side-channel attack threats in information system has a rapid growth. It has taken more than 10 years for cache side channel attacks to evolve and develop since cache-timing analysis was proposed to speculate encryption keys. In this survey, we comb the cache side-channel attack threats in the information system by analyzing the vulnerabilities in the design characteristics of software and hardware. Then we summarize the attacks from attack scene, cache levels, attack targets and principles. Further more, we compare the attack conditions, advantages and disadvantages of 7 typical cache side-channel attacks in order to better understand their principles and applications. We also make a systematic analysis of the defense technology against cache side channel attack from detection stage and prevention stage, classify and analyze the defence technology based on different defense principles. Finally, we summarize the work of this paper, discuss the research hotspots and the development trend of cache side-channel attack and defense under the Internet ecosystem, and point out the future research direction of cache side-channel attack and defense, so as to provide reference for researchers who want to start research in this field.
-
SGX允许应用程序初始化一个Enclave,Enclave是一块硬件隔离的可信内存区域,可以为应用程序的敏感部分提供硬件增强的机密性和完整性保护,实现不同程序间的隔离运行。文献主要来自dblp数据库,此外还有部分其他在线资源。在实践中,T表通常是提前算出然后作为一个常量数组编码在密码算法软件的实现代码中。这样,就可将繁琐的运算过程变成对于计算机而言简单高效的查表和按位运算。
-
![]()
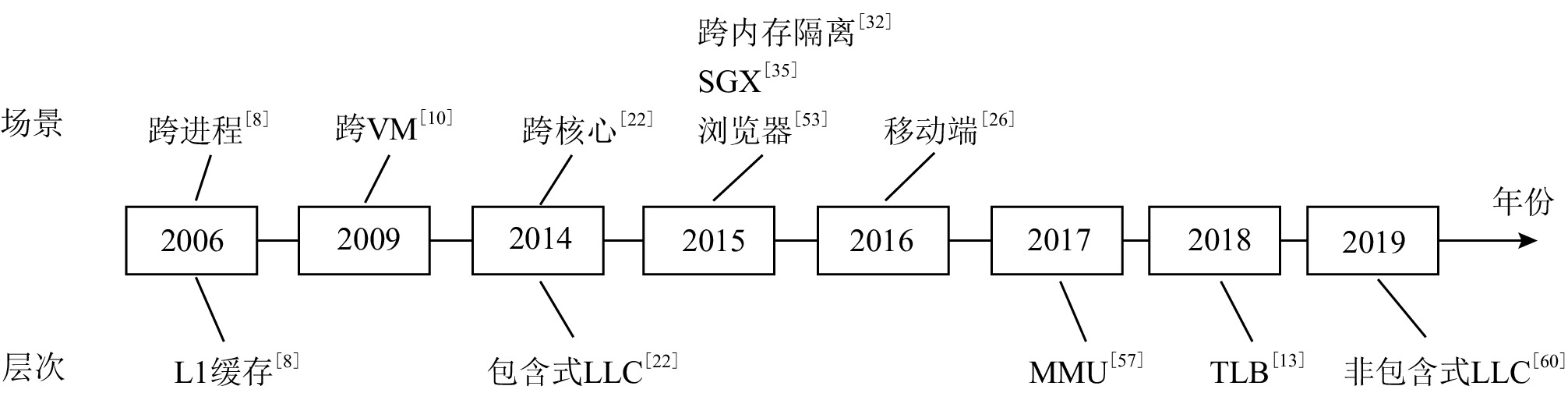
图 3 缓存侧信道攻击场景和层次的发展
Figure 3. The development of scenarios and levels of cache side-channel attacks
![]()
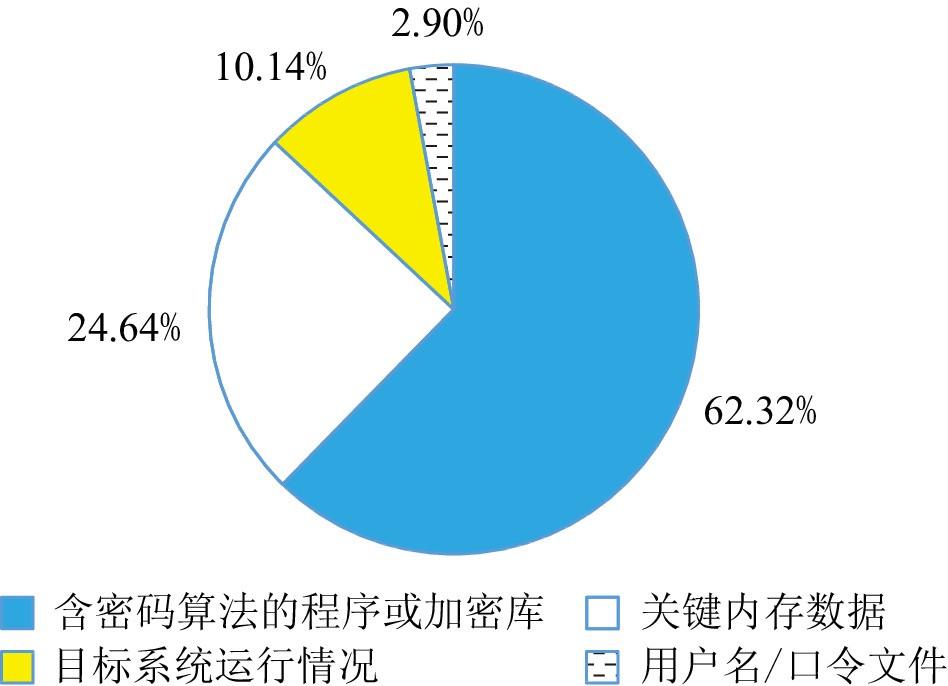
图 4 缓存侧信道攻击目标统计分析
Figure 4. Statistical analysis of targets of cache side-channel attacks
表 1 不同缓存侧信道攻击技术的综合比较
Table 1 Comprehensive Comparison of Cache Side-Channel Attacks
攻击方法 出现年份 攻击条件 优点 缺点 Evict-Time 2006 攻击者和目标运行在同一处理器,实现查表操作的加密算法攻击.攻击进程可以触发目标进程执行加密操作,并对目标进程加密操作时间进行测量.攻击为已知明文攻击,且通过先验测试获取目标进程T表或者S盒加载缓存空间 只需要测试加密操作整体时间 不适用于实际攻击场景,需要多次测试 Prime-Probe 2006 攻击进程需要精确把握“等待”间隔,才能准确监测目标进程缓存变化;攻击进程需要事先测好缓存命中的阈值,以便精确判断 细粒度的监测,可以基于缓存组粒度来监测 需提前对缓存状态进行建模,噪声较多,需要多次测试获取缓存状态 Flush-Reload 2014 攻击进程和目标进程共享内存,且支持clflush指令.需要提前对程序地址空间进行分析(反汇编等),获取目标函数地址 细粒度的监测,可以进行函数粒度的监控,干扰较少 需要在共享内存的前提下攻击,攻击条件较为苛刻 Evict-Reload 2015 属于Flush-Reload攻击变种,在限制clflush指令的场景中可以利用Evict-Reload方法实现攻击,需要了解缓存映射和替换策略 与Flush-Reload攻击相比,不受clflush指令的限制 需要在共享内存的前提下攻击,攻击条件较为苛刻 Flush-Flush 2016 属于Flush-Reload攻击变种,攻击进程和目标进程共享内存,需支持clflush指令 与Flush-Reload相比,具有更快速和更隐蔽的特点.细粒度的监测,可以进行函数粒度的监控,干扰较少 需要在共享内存的前提下攻击,攻击条件较为苛刻 Prime-Abort 2017 基于Intel TSX的非计时攻击,攻击者需要将要监控的内存空间利用TSX机制保护起来,当目标监控的缓存集中有缓存换出,触发Abort事件发生 不受高精度计数器的限制,在不具有计时分析条件的场景下也可以实现攻击,不依赖中断保持攻击者进程与目标进程同步 依赖于硬件TSX机制 Reload-Refresh 2020 需要知道处理器的缓存替换策略和要监控的目标地址在缓存中的位置,能够构造出该目标地址的驱逐集,并且攻击者和受害者在同一处理器上运行 不需要强制驱逐受害者缓存数据,攻击隐蔽性强 需要在共享内存和明确缓存替换策略的前提下攻击,攻击条件较为苛刻  下载: 导出CSV
下载: 导出CSV
-
[1] Kocher P C. Timing attacks on implementations of Diffie-Hellman, RSA, DSS, and other systems[C] //Proc of the 16th Annual Int Cryptology Conf on Advances in Cryptology. Berlin: Springer, 1996: 104−113
[2] Zhang Yinqian. Cache side channels: State of the art and research opportunities[C] //Proc of the 24th ACM SIGSAC Conf on Computer and Communications Security. New York: ACM, 2017: 2617−2619
[3] Acıiçmez O, Schindler W, Koç Ç K. Cache based remote timing attack on the AES[C] //Proc of the 7th Cryptographers’ Track at the RSA Conf on Topics in Cryptology. Berlin: Springer, 2007: 271−286
[4] Bernstein D J. Cache-timing attacks on AES[EB/OL]. [2021-05-27]. http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=01774A09A6B2A49EC3AAB74B4EC8705B?doi=10.1.1.67.1622&rep=rep1&type=pdf
[5] Weiß M, Heinz B, Stumpf F. A cache timing attack on AES in virtualization environments[C] //Proc of the 16th Int Conf on Financial Cryptography and Data Security. Berlin: Springer, 2012: 314−328
[6] Aciiçmez O, Koç Ç K. Trace-driven cache attacks on AES[C] //Proc of the 8th Int Conf on Information & Communications Security. Berlin: Springer, 2006: 112−121
[7] Zhang Yinqian, Juels A, Reiter M K, et al. Cross-VM side channels and their use to extract private keys[C] //Proc of the 19th ACM Conf on Computer and Communications Security. New York: ACM, 2012: 305−316
[8] Osvik D A, Shamir A, Tromer E. Cache attacks and countermeasures: The case of AES[C] //Proc of the 6th Topics in Cryptology—the Cryptographers’ Track at the RSA Conf. Berlin: Springer, 2006: 1−20
[9] Percival C. Cache missing for fun and profit[C/OL]. [2021-05-27]. http://css.csail.mit.edu/6.858/2014/readings/ht-cache.pdf
[10] Ristenpart T, Tromer E, Shacham H, et al. Hey, you, get off of my cloud: Exploring information leakage in third-party compute clouds[C] //Proc of the 16th ACM Conf on Computer and Communications Security. New York: ACM, 2009: 199−212
[11] Gullasch D, Bangerter E, Krenn S. Cache games: Bringing access-based cache attacks on AES to practice[C] //Proc of the 32nd IEEE Symp on Security and Privacy. Piscataway, NJ: IEEE, 2011: 490−505
[12] Bryant R E, O'Hallaron D R. Computer Systems: A Programmer’s Perspective[M]. 2nd ed. New York: Addison-Wesley Educational Publishers Inc, 2010
[13] Gras B, Razavi K, Bos H, et al. Translation leak-aside buffer defeating cache side-channel protections with TLB attacks[C] //Proc of the 27th USENIX Security Symp. Berkeley, CA: USENIX Association, 2018: 955−972
[14] Disselkoen C, Kohlbrenner D, Porter L. Prime+abort: A timer-free high-precision L3 cache attack using Intel TSX[C] //Proc of the 26th USENIX Security Symp. Berkeley, CA: USENIX Association, 2017: 51−67
[15] Lipp M, l Schwarz M, Gruss D, et al. Meltdown: Reading kernel memory from user space[C] //Proc of the 27th USENIX Security Symp. Berkeley, CA: USENIX Association, 2018: 973−990
[16] Paul K, Daniel G, Daniel G, et al. Spectre attacks: Exploiting speculative execution[J]. arXiv preprint, arXiv: 1801.01203, 2018
[17] Lenovo. Reading privileged memory with a side-channel[EB/OL]. [2021-05-27]. https://support.lenovo.com/us/en/solutions/ps500151-reading-privileged-memory-with-a-side-channel
[18] Intel. Speculative store bypass[EB/OL]. [2021-05-27]. https://www.intel.com/content/www/us/en/developer/articles/technical/software-security-guidance/advisory-guidance/speculative-store-bypass.html
[19] Intel. Q3 2018 speculative execution side channel update[EB/OL]. [2021-05-27]. https://www.intel.com/content/www/us/en/security-center/advisory/intel-sa-00161.html
[20] Kiriansky V, Waldspurger C. Speculative buffer overflows: Attacks and defenses[J]. arXiv preprint, arXiv: 1807.03757, 2018
[21] Koruyeh E M, Khasawneh K N, Song Chengyu, et al. Spectre returns! Speculation attacks using the return stack buffer[C/OL]. [2021-05-27]. https://www.usenix.org/system/files/conference/woot18/woot18-paper-koruyeh.pdf
[22] Yarom Y, Falkner K. FLUSH+RELOAD: A high resolution, low noise, L3 cache side-channel attack[C] //Proc of the 23rd USENIX Security Symp. Berkeley, CA: USENIX Association, 2014: 719–732
[23] Page D. Theoretical use of cache memory as a cryptanalytic side-channel[J/OL]. [2021-05-25]. http://eprint.iacr.org/2002/169
[24] Kelsey J, Schneier B, Wagner D, et al. Side channel cryptanalysis of product ciphers[C] //Proc of the 5th European Symp on Research in Computer Security. Berlin: Springer, 1998: 97–110
[25] Irazoqui G, Eisenbarth T, Sunar B. Cross processor cache attacks[C] //Proc of the 11th ACM on Asia Conf on Computer and Communications Security. New York: ACM, 2016: 353–364
[26] Lipp M, Gruss D, Spreitzer R, et al. ARMageddon: Last-level cache attacks on mobile devices[C] //Proc of the 25th USENIX Security Symp. Berkeley, CA: USENIX Association, 2016: 549–564
[27] Intel. Intel software guard extensions[EB/OL]. [2021-05-27].https://software.intel.com/content/www/cn/zh/develop/topics/software-guard-extensions.html
[28] Brasser F, Müller U, Dmitrienko A, et al. Software grand exposure: SGX cache attacks are practical[C/OL]. [2021-05-25]. https://arxiv.org/abs/1702.07521
[29] Schwarz M, Weiser S, Gruss D, et al. Malware guard extension: Using SGX to conceal cache attacks[C] //Proc of the 13th Int Conf on Detection of Intrusions and Malware, and Vulnerability Assessment. Berlin: Springer, 2017: 3–24
[30] Hähnel M, Cui Weidong, Peinado M. High-resolution side channels for untrusted operating systems[C] //Proc of the 26th USENIX Annual Technical Conf. Berkeley, CA: USENIX Association, 2017: 299–312
[31] Moghimi A, Irazoqui G, Eisenbarth T. CacheZoom: How SGX amplifies the power of cache attacks[C] //Proc of the 19th Int Conf on Cryptographic Hardware and Embedded Systems. Berlin: Springer, 2017: 69–90
[32] Xu Yuanzhong, Cui Weidong, Peinado M. Controlled-channel attacks: Deterministic side channels for untrusted operating systems[C] //Proc of the 36th IEEE Symp on Security and Privacy. Piscataway, NJ: IEEE, 2015: 640–656
[33] Bulck J V, Weichbrodt N, Kapitza R, et al. Telling your secrets without page faults: Stealthy page table-based attacks on enclaved execution[C] //Proc of the 26th USENIX Security Symp. Berkeley, CA: USENIX Association, 2017: 1041–1056
[34] Lee S, Shih MW, Gera P, et al. Inferring fine-grained control flow inside SGX enclaves with branch shadowing[C] //Proc of the 26th USENIX Security Symp. Berkeley, CA: USENIX Association, 2017: 556–574
[35] Pessl P, Gruss D, Maurice C, et al. DRAMA: Exploiting DRAM addressing for cross-CPU attacks[C] //Proc of the 24th USENIX Security Symp. Berkeley, CA: USENIX Association, 2015: 564–581
[36] Wang Wenhao, Chen Guoxing, Pan Xiaorui, et al. Leaky cauldron on the dark land: Understanding memory side-channel hazards in SGX[C] //Proc of the 24th ACM SIGSAC Conf on Computer and Communications Security. New York: ACM, 2017: 2421–2434
[37] Schaik S V, Milburn A, Österlund S, et al. RIDL: Rogue in-flight data load[C] //Proc of the 40th IEEE Symp on Security and Privacy. Piscataway, NJ: IEEE, 2019: 88–105
[38] Schwarz M, Lipp M, Moghimi D, et al. ZombieLoad: Cross-privilege-boundary data sampling[C] //Proc of the 26th ACM SIGSAC Conf on Computer and Communications Security. New York: ACM, 2019: 753–768
[39] Schaik S V, Minkin M, Kwong A, et al. CacheOut: Leaking data on Intel CPUs via cache evictions[EB/OL]. [2021-10-05]. https://cacheoutattack.com/files/CacheOut.pdf
[40] Schaik S V, Kwong A, Genkin D, et al. SGAxe: How SGX fails in practice[EB/OL]. [2021-10-05]. https://cacheoutattack.com/files/SGAxe.pdf
[41] Bulck J V, Minkin Ma, Weisse O, et al. Foreshadow: Extracting the keys to the Intel SGX kingdom with transient out-of-order execution[C] //Proc of the 27th USENIX Security Symp. Berkeley, CA: USENIX Association, 2018: 991–1008
[42] Chen Guoxing, Chen Sanchuan, Xiao Yuan, et al. SgxPectre: Stealing Intel secrets from SGX enclaves via speculative execution[C] //Proc of the 4th IEEE European Symp on Security and Privacy. Piscataway, NJ: IEEE, 2019: 142–157
[43] Aciiçmez O. Yet another micro architectural attack: Exploiting I-Cache[C] //Proc of the 1st ACM Workshop on Computer Security Architecture. New York: ACM, 2007: 11–18
[44] Aciicmez O, Schindler W. A major vulnerability in RSA implementations due to microarchitectural analysis threat[J/OL]. [2021-05-27]. http://eprint.iacr.org/2007/336
[45] Acıiçmez O, Brumley B B, Grabher P. New results on instruction cache attacks[C] //Proc of the 12th Int Conf on Cryptographic Hardware and Embedded Systems. Berlin: Springer, 2010: 110–124
[46] Neve M, Seifert J P. Advances on access-driven cache attacks on AES[C] //Proc of the 13th Int Workshop on Selected Areas in Cryptography. Berlin: Springer, 2006: 147–162
[47] Benger N, Pol J, Smart N P, et al. “Ooh aah. . . Just a little bit”: A small amount of side channel can go a long way[C] //Proc of the 16th Int Workshop on Cryptographic Hardware and Embedded Systems. Berlin: Springer, 2014: 75–92
[48] Yarom Y, Benger N. Recovering OpenSSL ECDSA nonces using the FLUSH+RELOAD cache side-channel attack[J/OL]. [2021-05-27]. https://eprint.iacr.org/2014/140.pdf
[49] Zhang Yinqian, Juels A, Reiter M K, et al. Cross-tenant side-channel attacks in PaaS clouds[C] //Proc of the 21st ACM SIGSAC Conf on Computer and Communications Security. New York: ACM, 2014: 990–1003
[50] Inci M S, Gulmezoglu B, Irazoqui Go, et al. Seriously, get off my cloud! Cross-VM RSA key recovery in a public cloud[J/OL]. [2021-05-27]. https://eprint.iacr.org/2015/898
[51] Apecechea G I, Eisenbarth T, Sunar B. S$A: A shared cache attack that works across cores and defies VM sandboxing and its application to AES[C] //Proc of the 36th IEEE Symp on Security and Privacy. Piscataway, NJ: IEEE 2015: 591–604
[52] Zhang Xiaokuan, Xiao Yuan, Zhang Yinqian. Return-oriented Flush-Reload side channels on ARM and their implications for Android devices[C] //Proc of the 23rd ACM SIGSAC Conf on Computer and Communications Security. New York: ACM, 2016: 858–870
[53] Oren Y, Kemerlis V P, Sethumadhavan S, et al. The spy in the sandbox: Practical cache attacks in JavaScript and their implications[C] //Proc of the 22nd ACM SIGSAC Conf on Computer and Communications Security. New York: ACM, 2015: 1406–1418
[54] Liu Fangfei, Yarom Y, Ge Qian, et al. Last-level cache side-channel attacks are practical[C] //Proc of the 36th IEEE Symp on Security and Privacy. Piscataway, NJ: IEEE, 2015: 605–622
[55] Gruss D, Spreitzer R, Mangard S. Cache template attacks: Automating attacks on inclusive last-level caches[C] //Proc of the 24th USENIX Security Symp. Berkeley, CA: USENIX Association, 2015: 897–912
[56] Kayaalp M, Abu-Ghazaleh N, Ponomarev D. A high-resolution side-channel attack on last-level cache[C/OL]. [2021-05-25]. https://dl.acm.org/doi/10.1145/2897937.2897962
[57] Gras B, Razavi K, Bosman E, et al. ASLR on the line: Practical cache attacks on the MMU[C/OL]. [2021-05-26]. https://www.ndss-symposium.org/wp-content/uploads/2017/09/ndss2017_09-1_Gras_paper.pdf
[58] Schaik S V, Giuffrida C, Bos H, et al. Malicious management unit: Why stopping cache attacks in software is harder than you think[C] //Proc of the 27th USENIX Security Symp. Berkeley, CA: USENIX Association, 2018: 937–954
[59] Canella C, Genkin D, Giner L, et al. Fallout: Leaking data on meltdown-resistant CPUs[C] //Proc of the 26th ACM SIGSAC Conf on Computer and Communications Security. New York: ACM, 2019: 769–784
[60] Yan Mengjia, Sprabery R, Gopireddy B, et al. Attack directories, not caches: Side channel attacks in a non-inclusive world[C] //Proc of the 40th IEEE Symp on Security and Privacy. Piscataway, NJ: IEEE, 2019: 888–904
[61] Zhou Yongbin , Feng Dengguo. Side-channel attacks: Ten years after its publication and the impacts on cryptographic module security testing[J/OL]. [2021-05-27]. https://eprint.iacr.org/2005/388.pdf
[62] Irazoqui G, Inci M S, Eisenbarth T, et al. Wait a minute! A fast, cross-VM attack on AES[C] //Proc of the 17th Int Workshop on Recent Advances in Intrusion Detection. Berlin: Springer, 2014: 299–319
[63] Tromer E, Osvik D A, Shamir A. Efficient cache attacks on AES and countermeasures[J]. Journal of Cryptology, 2010, 23(1): 37−71 doi: 10.1007/s00145-009-9049-y
[64] Tóth R, Faigl Z, Szalay M, et al. An advanced timing attack scheme on RSA[C] //Proc of the 13th Int Telecommunications Network Strategy and Planning Symp. Piscataway, NJ: IEEE, 2008: 1–24
[65] Hund R, Willems Ca, Holz T. Practical timing side channel attacks against kernel space ASLR[C] //Proc of the 34th IEEE Symp on Security and Privacy. Piscataway, NJ: IEEE, 2013: 191–205
[66] Evtyushkin D, Ponomarev D, Abu-Ghazaleh N. Jump over ASLR: Attacking branch predictors to bypass ASLR[C] //Proc of the 49th IEEE/ACM Int Symp on Microarchitecture. Piscataway, NJ: IEEE, 2016: 40:1–40:13
[67] Irazoqui G, Inci M S, Eisenbarth T, et al. Know thy neighbor: Crypto library detection in cloud[J]. Proceedings on Privacy Enhancing Technologies, 2015, 2015(1): 25−40 doi: 10.1515/popets-2015-0003
[68] Shusterman A, Kang L, Haskal Y, et al. Robust website fingerprinting through the cache occupancy channel[C] //Proc of the 28th USENIX Security Symp. Berkeley, CA: USENIX Association, 2019: 639–656
[69] Gruss D, Clémentine M, Wagner K, et al. Flush+Flush: A fast and stealthy cache attack[C] //Proc of the 13th Int Conf on Detection of Intrusions and Malware, and Vulnerability Assessment. Berlin: Springer, 2016: 279–299
[70] Intel. Intel development manual[EP/OL]. [2021-05-27]. https://software.intel.com/en-us/download/intel-64-and-ia-32-architectures-sdm-combined-volumes-1-2a-2b-2c-2d-3a-3b-3c-3d-and-4
[71] Briongos S, Malagón P, Moya J M, et al. RELOAD+REFRESH: Abusing cache replacement policies to perform stealthy cache attacks[C] //Proc of the 29th USENIX Security Symp. Berkeley, CA: USENIX Association, 2020: 1966–1984
[72] Zhang Yinqian, Juels A, Oprea A, et al. HomeAlone: Co-residency detection in the cloud via side-channel analysis[C] //Proc of the 32nd IEEE Symp on Security and Privacy. Piscataway, NJ: IEEE, 2011: 313–328
[73] Demme J, Maycock M, Schmitz J, et al. On the feasibility of online malware detection with performance counters[C] //Proc of the 40th Annual Int Symp on Computer Architecture. New York: ACM, 2013: 559–570
[74] Chiappetta M, Savas E, Yilmaz C. Real time detection of cache-based side-channel attacks using hardware performance counters[J]. Applied Soft Computing, 2016, 49(C): 1162−1174
[75] Zhang Tianwei, Zhang Yinqian, Lee R B. CloudRadar: A real-time side-channel attack detection system in clouds[C] //Proc of the 19th Int Symp on Research in Attacks, Intrusions, and Defenses. Berlin: Springer, 2016: 118–140
[76] Chen Jie, Venkataramani G. CC-Hunter: Uncovering covert timing channels on shared processor hardware[C] //Proc of the 47th Annual IEEE/ACM Int Symp on Microarchitecture. Piscataway, NJ: IEEE, 2014: 216–228
[77] Guo Shengjian, Chen Yueqi, Li Peng, et al. SpecuSym: Speculative symbolic execution for cache timing leak detection[C] //Proc of the 42nd ACM/IEEE Int Conf on Software Engineering. New York: ACM, 2020: 1235–1247
[78] Kim H, Hahn C, Hur J. Real-time detection of cache side-channel attack using non-cache hardware events[C] //Proc of the 35th Int Conf on Information Networking. Piscataway, NJ: IEEE. 2021: 28–31
[79] Chen Guoxing, Wang Wenhao, Chen Tianyu, et al. Racing in hyperspace: Closing hyper-threading side channels on SGX with contrived data races[C] //Proc of the 39th IEEE Symp on Security and Privacy. Piscataway, NJ: IEEE, 2018: 178–194
[80] Chen Sanchuan, Liu Fangfei, Mi Zeyu, et al. Leveraging hardware transactional memory for cache side-channel defenses[C] //Proc of the 13th on Asia Conf on Computer and Communications Security. New York: ACM, 2018: 601–608
[81] Chen Sanchuan, Zhang Xiaokuan, Reiter M K, et al. Detecting privileged side-channel attacks in shielded execution with Déjà Vu[C] //Proc of the 12th Asia Conf on Computer and Communications Security. New York: ACM, 2017: 7–18
[82] Shih M W, Lee S, Kim T, et al. T-SGX: Eradicating controlled-channel attacks against enclave programs[C/OL]. [2021-05-27]. https://www.ndss-symposium.org/wp-content/uploads/2017/09/ndss2017_07-2_Shih_paper.pdf
[83] Page D. Partitioned cache architecture as a aide-channel defence mechanism[J/OL]. [2021-05-27]. https://eprint.iacr.org/2005/280
[84] Wang Zhenghong, Lee R B. New cache designs for thwarting software cache-based side channel attacks[C] //Proc of the 34th Annual Int Symp on Computer Architecture. Piscataway, NJ: IEEE, 2007: 494–505
[85] Kong Jingfei, Aciiçmez O, Seifert J, et al. Hardware-software integrated approaches to defend against software cache-based side channel attacks[C] //Proc of the 15th Int Conf on High Performance Computer Architecture. Piscataway, NJ: IEEE, 2009: 393–404
[86] Zhou Ziqiao, Reiter M K, Zhang Yinqian. A software approach to defeating side channels in last-level caches[C] //Proc of the 23rd ACM SIGSAC Conf on Computer and Communications Security. New York: ACM, 2016: 871–882
[87] Liu Fangfei, Ge Qian, Yarom Y, et al. CATalyst: Defeating last-level cache side channel attacks in cloud computing[C]//Proc of the 22nd IEEE Int Symp on High Performance Computer Architecture. Piscataway, NJ: IEEE, 2016: 406–418
[88] Yan Mengjia, Gopireddy B, Shull T, et al. Secure hierarchy-aware cache replacement policy (SHARP): Defending against cache-based side channel attacks[C] //Proc of the 44th Annual Int Symp on Computer Architecture. New York: ACM, 2017: 347–360
[89] Werner M, Unterluggauer T, Giner L, et al. SCATTERCACHE: Thwarting cache attacks via cache set randomization[C] //Proc of the 28th USENIX Security Symp. Berkeley, CA: USENIX Association, 2019: 675–692
[90] Raj H, Nathuji R, Singh A, et al. Resource management for isolation enhanced cloud services[C] //Proc of the 1st ACM Workshop on Cloud Computing Security. New York: ACM, 2009: 77–84
[91] Shi Jicheng, Song Xiang, Chen Haibo, et al. Limiting cache-based side channel in multi-tenant cloud using dynamic page coloring[C] //Proc of the 41st IEEE/IFIP Int Conf on Dependable Systems and Networks Workshops. Piscataway, NJ: IEEE, 2011: 194–199
[92] Kim T, Peinado M, Mainar-Ruiz G. STEALTHMEM: System-level protection against cache-based side channel attacks in the cloud[C] //Proc of the 21st USENIX Security Symp. Berkeley, CA: USENIX Association, 2012: 189–204
[93] Liu Fangfei, Lee R B. Random fill cache architecture[C] //Proc of the 47th Annual IEEE/ACM Int Symp on Microarchitecture. Piscataway, NJ: IEEE, 2014: 203–215
[94] Crane S, Homescu A, Brunthaler S, et al. Thwarting cache side-channel attacks through dynamic software diversity[C/OL]. [2021-05-27]. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.714.3408&rep=rep1&type=pdf
[95] Rane A, Lin C, Tiwari M. Raccoon: Closing digital side-channels through obfuscated execution[C] //Proc of the 24th USENIX Security Symp. Berkeley, CA: USENIX Association, 2015: 431–446
[96] Vattikonda B C, Das S, Shacham H. Eliminating fine grained timers in Xen[C] //Proc of the 3rd ACM Cloud Computing Security Workshop. New York: ACM, 2011: 41–46
[97] Martin R, Demme J, Sethumadhavan S. TimeWarp: Rethinking timekeeping and performance monitoring mechanisms to mitigate side-channel attacks[C] //Proc of the 39th Int Symp on Computer Architecture. Piscataway, NJ: IEEE, 2012: 118–129
[98] Andrysco M, Kohlbrenner D, Mowery K, et al. On subnormal floating point and abnormal timing[C] //Proc of the 36th IEEE Symp on Security and Privacy. Piscataway, NJ: IEEE, 2015: 623–639
[99] Doychev G, Köpf B, Mauborgne L, et al. CacheAudit: A tool for the static analysis of cache side channels[J]. ACM Transactions on Information & System Security, 2015, 18(1): 4:1−4:32
[100] Wang Shuai, Bao Yuyan, Liu Xiao, et al. Identifying cache-based side channels through secret-augmented abstract interpretation[C] //Proc of the 28th USENIX Security Symp. Berkeley, CA: USENIX Association, 2019: 657–674
[101] Hassan S U, Gridin I, Delgado-Lozano I M, et al. Déjà vu: Side-channel analysis of Mozilla’s NSS[C] //Proc of the 27th ACM SIGSAC Conf on Computer and Communications Security. New York: ACM, 2020: 1887–1902
[102] Gras B, Giuffrida C, Kurth M, et al. ABSynthe: Automatic blackbox side-channel synthesis on commodity microarchitectures[C/OL]. [2021-05-28]. https://www.ndss-symposium.org/wp-content/uploads/2020/02/23018-paper.pdf
[103] Andrea M, Neugschwandtner M, Sorniotti A, et al. Speculator: A tool to analyze speculative execution attacks and mitigations[C] //Proc of the 35th Annual Computer Security Applications Conf. New York: ACM, 2019: 747–761
[104] Yu Jiyong, Hsiung L, Hajj M E, et al. Data oblivious ISA extensions for side channel-resistant and high performance computing[C/OL]. [2021-05-28]. https://www.ndss-symposium.org/wp-content/uploads/2019/02/ndss2019_05B-4_Yu_paper.pdf
[105] Koruyeh E M, Shirazi S, Khasawneh K N, et al. SpecCFI: Mitigating spectre attacks using CFI informed speculation[C] //Proc of the 41st IEEE Symp on Security and Privacy. Piscataway, NJ: IEEE, 2020: 39–53
[106] Gruss D, Lettner J, Schuster F, et al. Strong and efficient cache side- channel protection using hardware transactional memory[C] //Proc of the 26th USENIX Security Symp. Berkeley, CA: USENIX Association, 2017: 217–233
[107] Weiser S, Mayr L, Schwarz M, et al. SGXJail: Defeating enclave malware via confinement[C] //Proc of the 22nd Int Symp on Research in Attacks, Intrusions, and Defenses. Berkeley, CA: USENIX Association, 2019: 353–366
[108] Ahmad A, Joe B, Xiao Yuan, et al. OBFUSCURO: A commodity obfuscation engine on Intel SGX[C/OL]. [2021-05-27]. https://www.ndss-symposium.org/wp-content/uploads/2019/02/ndss2019_10-1_Ahmad_paper.pdf
[109] Weichbrodt N, Aublin PL, Kapitza R. SGX-perf: A performance analysis tool for Intel SGX enclaves[C] //Proc of the 19th Int Middleware Conf. New York: ACM, 2018: 201–213
[110] Green M, Rodrigues-Lima L, Zankl A, et al. AutoLock: Why cache attacks on ARM are harder than you think[C] //Proc of the 26th USENIX Security Symp. Berkeley, CA: USENIX Association, 2017: 1075–1091
[111] Intel. 6th Gen Intel Core X-Series Processor Family Datasheet[EP/OL]. [2021-05-26]. https://www.intel.com/content/www/us/en/products/processors/core/6thgen-x-series-datasheet-vol-1.html
-
期刊类型引用(7)
1. 王忠勇,孟杰,王玮,巩克现,刘宏华. 基于特征再挑选的网络未知流量检测算法. 计算机工程与设计. 2025(01): 60-66 .  百度学术
百度学术
2. 董姝岐,黄辑贤,粘镇泓,井靖. 字段语义推断模型的二进制协议语义推理方法. 信息工程大学学报. 2025(02): 238-244 . 百度学术
3. 安晓明,王忠勇,翟慧鹏,巩克现,王玮,孙鹏. 基于深度学习的二进制变种协议字段划分方法. 计算机工程与设计. 2024(04): 982-988 . 百度学术
4. 童瑞谦,胡夏南,刘优然,秦研,张宁,王强. 基于自动化私有协议识别的挖矿流量检测. 北京航空航天大学学报. 2024(07): 2304-2313 . 百度学术
5. 刘奇旭,肖聚鑫,谭耀康,王承淳,黄昊,张方娇,尹捷,刘玉岭. 工业互联网流量分析技术综述. 通信学报. 2024(08): 221-237 . 百度学术
6. 肖盛忠,毛永强,吴晓丹,赵舒敏. 工业控制系统私有协议解析方法研究. 中国宽带. 2024(02): 70-72 . 百度学术
7. 郑红兵,王焕伟,赵琪,董姝岐,井靖. 基于Tamarin的MQTT协议安全性分析方法. 计算机应用研究. 2023(10): 3132-3137+3143 . 百度学术
其他类型引用(6)
计量
- 文章访问数: 378
- HTML全文浏览量: 35
- PDF下载量: 169
- 被引次数: 13




