

- 中国精品科技期刊
- CCF推荐A类中文期刊
- 计算领域高质量科技期刊T1类
| Citation: |
Wang Duo, Liu Jinglei, Yan Mingyu, Teng Yihan, Han Dengke, Ye Xiaochun, Fan Dongrui. Acceleration Methods for Processor Microarchitecture Design Space Exploration: A Survey[J]. Journal of Computer Research and Development, 2025, 62(1): 22-57. DOI: 10.7544/issn1000-1239.202330348

|
 Wang Duo: born in 1995. PhD. Student member of CCF. His main research interests include processor design space exploration and computer architecture
Wang Duo: born in 1995. PhD. Student member of CCF. His main research interests include processor design space exploration and computer architecture
 Liu Jinglei: born in 1982. Master, senior engineer. His main research interests include computility network and computer architecture
Liu Jinglei: born in 1982. Master, senior engineer. His main research interests include computility network and computer architecture
 Yan Mingyu: born in 1990. PhD, associate professor. Member of CCF. His main research interest includes graph based hardware accelerator and dataflow architecture
Yan Mingyu: born in 1990. PhD, associate professor. Member of CCF. His main research interest includes graph based hardware accelerator and dataflow architecture
 Teng Yihan: born in 2000. Master. His main research interests include graph-based hardware accelerator and high-throughput computer architecture
Teng Yihan: born in 2000. Master. His main research interests include graph-based hardware accelerator and high-throughput computer architecture
 Han Dengke: born in 1998. Master candidate. His main research interest includes graph-based hardware accelerator and high-throughput computer architecture
Han Dengke: born in 1998. Master candidate. His main research interest includes graph-based hardware accelerator and high-throughput computer architecture
 Ye Xiaochun: born in 1981. PhD, professor. Member of CCF. His main research interests include software simulation, algorithm paralleling and optimizing, and architecture for high performance computer
Ye Xiaochun: born in 1981. PhD, professor. Member of CCF. His main research interests include software simulation, algorithm paralleling and optimizing, and architecture for high performance computer
 Fan Dongrui: born in 1979. PhD, professor. Distinguished member of CCF. His main research interests include manycore processor design, high throughput processor design, and low power microarchitecture
Fan Dongrui: born in 1979. PhD, professor. Distinguished member of CCF. His main research interests include manycore processor design, high throughput processor design, and low power microarchitecture
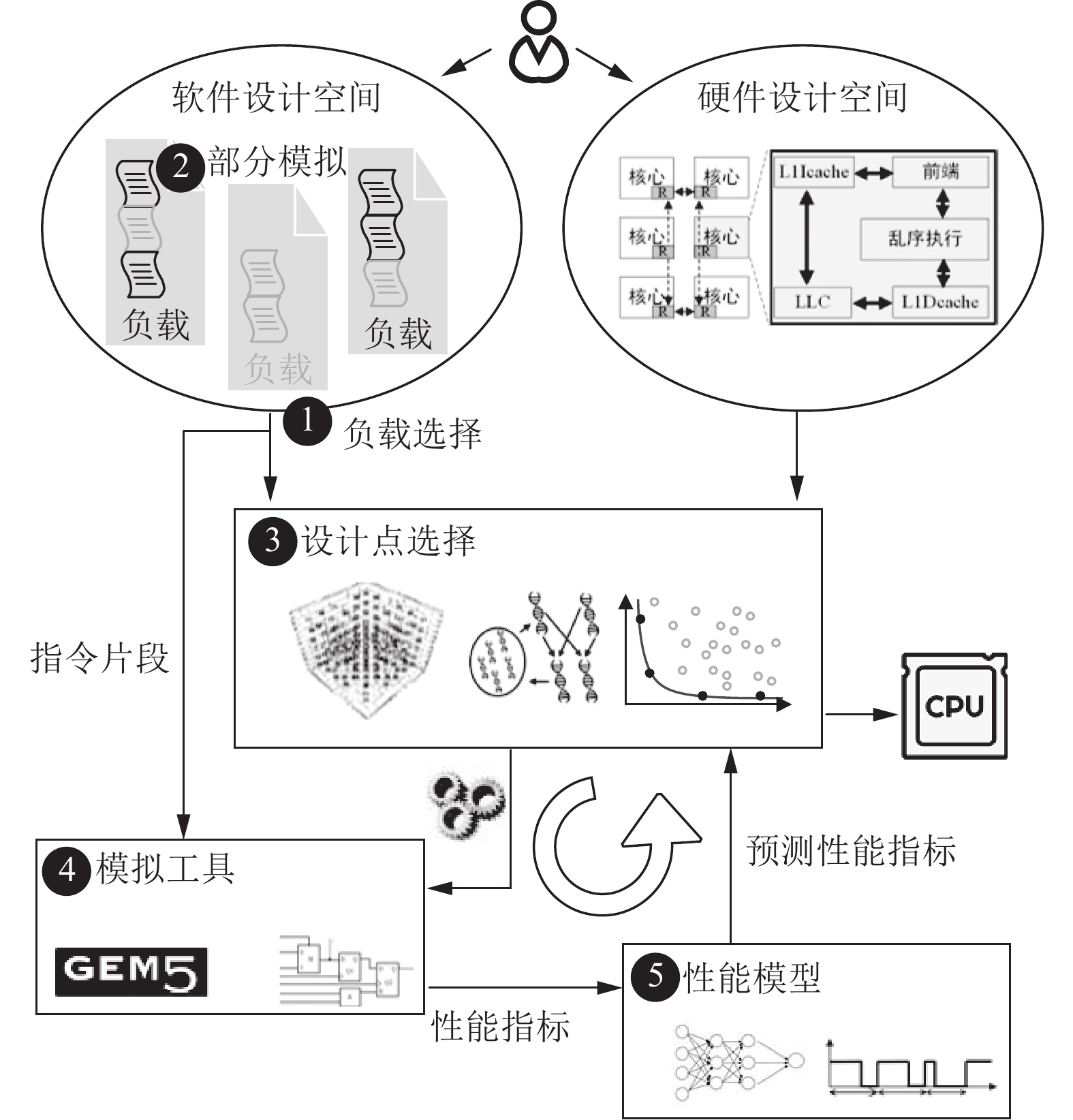
Central processing unit is the most important computing infrastructure nowadays. To maximize the profit, architects design the processor microarchitecture by trading-off multiple objectives including performance, power, and area. However, because of the tremendous instructions of workloads running on the processors, the evaluation of individual microarchitecture design point costs minutes to hours. Furthermore, the design space of the microarchitecture is huge, which results that the exploration of comprehensive design space is unrealistic. Therefore, many machine-learning-assisted design space exploration acceleration methods are proposed to reduce the size of evaluated design space or accelerate the evaluation of a design point. However, a comprehensive survey summarizing and systematically classifying recent acceleration methods is missing. This survey paper systematically summarizes and classifies the five kinds of acceleration methods for the design space exploration of the processor microarchitecture, including the workload selection of software design space, the partial simulation of workload instructions, the design point selection, the simulation tools, and the performance models. This paper systematically compares the similarities and differences between papers in the acceleration methods, and covers the complete exploration process from the software workload selection to the hardware microarchitecture design. Finally, the research direction is summarized, and the future development trend is discussed.
| [1] |
Azizi O, Mahesri A, Lee B C, et al. Energy-performance tradeoffs in processor architecture and circuit design: A marginal cost analysis[C]//Proc of the 27th Annual Int Symp on Computer Architecture. New York: ACM, 2010: 26–36
|
| [2] |
Lee B C, Brooks D M. Illustrative design space studies with microarchitectural regression models[C]//Proc of the 13th Int Conf on High-Performance Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2007: 340–351
|
| [3] |
Ipek E, McKee S A, Caruana R, et al. Efficiently exploring architectural design spaces via predictive modeling[C]//Proc of the 12th Int Conf on Architectural Support for Programming Languages and Operating Systems. New York: ACM, 2006: 195–206
|
| [4] |
Lee B C, Brooks D M. Accurate and efficient regression modeling for microarchitectural performance and power prediction[C]//Proc of the 12th Int Conf on Architectural Support for Programming Languages and Operating Systems. New York: ACM, 2006: 185–194
|
| [5] |
Lee B C, Collins J D, Wang Hong, et al. CPR: Composable performance regression for scalable multiprocessor models[C]//Proc of the 41st Annual IEEE/ACM Int Symp on Microarchitecture. Piscataway, NJ: IEEE, 2008: 270–281
|
| [6] |
Li Dandan, Yao Shuzhen, Wang Senzhang, et al. Cross-program design space exploration by ensemble transfer learning[C]//Proc of the 36th IEEE/ACM Int Conf on Computer-Aided Design. Piscataway, NJ: IEEE, 2017: 201–208
|
| [7] |
Li Dandan, Wang Senzhang, Yao Shuzhen, et al. Efficient design space exploration by knowledge transfer[C]//Proc of the 11th IEEE/ACM/IFIP Int Conf on Hardware/Software Codesign and System Synthesis. New York: ACM, 2016: 12: 1−12: 10
|
| [8] |
Wu Weidan, Lee B C. Inferred models for dynamic and sparse hardware-software spaces[C]//Proc of the 45th Annual IEEE/ACM Int Symp on Microarchitecture. Los Alamitos, CA: IEEE Computer Society, 2012: 413–424
|
| [9] |
Wang Yu, Lee V, Wei G Y, et al. Predicting new workload or CPU performance by analyzing public datasets[J]. ACM Transactions on Architecture and Code Optimization, 2019, 15(4): 53: 1−53: 21
|
| [10] |
Dubach C, Jones T M, O’Boyle M F P. An empirical architecture-centric approach to microarchitectural design space exploration[J]. IEEE Transactions on Computers, 2011, 60(10): 1445−1458 doi: 10.1109/TC.2010.280
|
| [11] |
Dubach C, Jones T M, O’Boyle M F P. Microarchitectural design space exploration using an architecture-centric approach[C]//Proc of the 40th Annual IEEE/ACM Int Symp on Microarchitecture. Los Alamitos, CA: IEEE Computer Society, 2007: 262–271
|
| [12] |
Eeckhout L, De Bosschere K. Speeding up architectural simulations for high-performance processors[J]. Simulation, 2004, 80(9): 451−468 doi: 10.1177/0037549704044326
|
| [13] |
Wang Hongwei, Shi Jinglin, Zhu Ziyuan. An expected hypervolume improvement algorithm for architectural exploration of embedded processors[C]//Proc of the 53rd Annual Design Automation Conf. New York: ACM, 2016: 161: 1−161: 6
|
| [14] |
Bai Chen, Sun Qi, Zhai Jianwang, et al. BOOM-Explorer: RISC-V BOOM microarchitecture design space exploration framework[C/OL]//Proc of the 40th IEEE/ACM Int Conf on Computer Aided Design. Piscataway, NJ: IEEE, 2021[2023-12-17]. https://ieeexplore.ieee.org/document/9643455
|
| [15] |
Yi J J, Lilja D J, Hawkins D M. A statistically rigorous approach for improving simulation methodology[C]//Proc of the 9th Int Symp on High-Performance Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2003: 281–291
|
| [16] |
Monchiero M, Canal R, González A. Power/performance/thermal design-space exploration for multicore architectures[J]. IEEE Transactions on Parallel and Distributed Systems, 2008, 19(5): 666−681 doi: 10.1109/TPDS.2007.70756
|
| [17] |
包云岗,常轶松,韩银和,等. 处理器芯片敏捷设计方法:问题与挑战[J]. 计算机研究与发展,2021,58(6):1131−1145 doi: 10.7544/issn1000-1239.2021.20210232
Bao Yungang, Chang Yisong, Han Yinhe, et al. Agile design of processor chips: Issues and challenges[J]. Journal of Computer Research and Development, 2021, 58(6): 1131−1145 (in Chinese) doi: 10.7544/issn1000-1239.2021.20210232
|
| [18] |
Standard Performance Evaluation Corporation. SPEC CPU2017[EB/OL]. (2012-12-06)[2023-12-01]. https://www.spec.org/cpu2017
|
| [19] |
Yi J J, Lilja D J. Simulation of computer architectures: Simulators, benchmarks, methodologies, and recommendations[J]. IEEE Transactions on Computers, 2006, 55(3): 268−280 doi: 10.1109/TC.2006.44
|
| [20] |
Guo Qi, Chen Tianshi, Chen Yunji, et al. Accelerating architectural simulation via statistical techniques: A survey[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2016, 35(3): 433−446 doi: 10.1109/TCAD.2015.2481796
|
| [21] |
O’Neal K, Brisk P. Predictive modeling for CPU, GPU, and FPGA performance and power consumption: A survey[C]//Proc of the 2018 IEEE Computer Society Annual Symp on VLSI. Los Alamitos, CA: IEEE Computer Society, 2018: 763–768
|
| [22] |
Chen Tianshi, Guo Qi, Tang Ke, et al. ArchRanker: A ranking approach to design space exploration[C]//Proc of the 41st Int Symp on Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2014: 85–96
|
| [23] |
Ding Yi, Mishra N, Hoffmann H. Generative and multi-phase learning for computer systems optimization[C]//Proc of the 46th Int Symp on Computer Architecture. New York: ACM, 2019: 39–52
|
| [24] |
Panerati J, Beltrame G. A comparative evaluation of multi-objective exploration algorithms for high-level design[J]. ACM Transactions on Design Automation of Electronic Systems, 2014, 19(2): 15: 1–15: 22
|
| [25] |
Palermo G, Silvano C, Zaccaria V. ReSPIR: A response surface-based pareto iterative refinement for application-specific design space exploration[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2009, 28(12): 1816−1829 doi: 10.1109/TCAD.2009.2028681
|
| [26] |
Mariani G, Palermo G, Zaccaria V, et al. DeSpErate++: An enhanced design space exploration framework using predictive simulation scheduling[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2015, 34(2): 293−306 doi: 10.1109/TCAD.2014.2379634
|
| [27] |
Cammarota R, Beni L A, Nicolau A, et al. Effective evaluation of multi-core based systems[C]//Proc of the 12th Int Symp on Parallel and Distributed Computing. Piscataway, NJ: IEEE, 2013: 19–25
|
| [28] |
KleinOsowski A J, Lilja D J. MinneSPEC: A new spec benchmark workload for simulation-based computer architecture research[J]. IEEE Computer Architecture Letters, 2002, 1(1): 7−10 doi: 10.1109/L-CA.2002.8
|
| [29] |
Eeckhout L, Vandierendonck H, De Bosschere K. Workload design: Selecting representative program-input pairs[C]//Proc of the 11th Int Conf on Parallel Architectures and Compilation Techniques. Los Alamitos, CA: IEEE Computer Society, 2002: 83–94
|
| [30] |
Breughe M, Eeckhout L. Selecting representative benchmark inputs for exploring microprocessor design spaces[J]. ACM Transactions on Architecture and Code Optimization, 2013, 10(4): 37: 1−37: 24
|
| [31] |
Joshi A, Phansalkar A, Eeckhout L, et al. Measuring benchmark similarity using inherent program characteristics[J]. IEEE Transactions on Computers, 2006, 55(6): 769−782 doi: 10.1109/TC.2006.85
|
| [32] |
Vandeputte F, Eeckhout L. Phase complexity surfaces: Characterizing time-varying program behavior[C]//Proc of the 3rd High Performance Embedded Architectures and Compilers. Berlin: Springer, 2008: 320–334
|
| [33] |
Zhan Hongping, Lin Weiwei, Mao Feiqiao, et al. BenchSubset: A framework for selecting benchmark subsets based on consensus clustering[J]. International Journal of Intelligent Systems, 2022, 37(8): 5248−5271 doi: 10.1002/int.22791
|
| [34] |
Sheidaeian H, Fatemi O. Toward a general framework for jointly processor-workload empirical modeling[J]. The Journal of Supercomputing, 2021, 77(6): 5319−5353 doi: 10.1007/s11227-020-03475-9
|
| [35] |
Phansalkar A, Joshi A, John L K. Analysis of redundancy and application balance in the SPEC CPU2006 benchmark suite[C]//Proc of the 34th Int Symp on Computer Architecture. New York: ACM, 2007: 412–423
|
| [36] |
Limaye A, Adegbija T. A workload characterization of the SPEC CPU2017 benchmark suite[C]//Proc of the 2018 IEEE Int Symp on Performance Analysis of Systems and Software. Los Alamitos, CA: IEEE Computer Society, 2018: 149–158
|
| [37] |
Panda R, Song Shuang, Dean J, et al. Wait of a decade: Did SPEC CPU 2017 broaden the performance horizon[C]//Proc of the 23rd IEEE Int Symp on High Performance Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2018: 271–282
|
| [38] |
Liu Qingrui, Wu Xiaolong, Kittinger L, et al. BenchPrime: Effective building of a hybrid benchmark suite[J]. ACM Transactions in Embedded Computing Systems, 2017, 16(5): 179: 1−179: 22
|
| [39] |
Wunderlich R E, Wenisch T F, Falsafi B, et al. SMARTS: Accelerating microarchitecture simulation via rigorous statistical sampling[C]//Proc of the 30th Annual Int Symp on Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2003: 84–95
|
| [40] |
Hassani S, Southern G, Renau J. LiveSim: Going live with microarchitecture simulation[C]//Proc of the 22nd IEEE Int Symp on High Performance Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2016: 606–617
|
| [41] |
Hamerly G, Perelman E, Lau J, et al. SimPoint 3.0: Faster and more flexible program phase analysis[J/OL]. Journal of Instruction-Level Parallelism, 2005[2023-12-18]. http://www.jilp.org/vol7/v7paper14.pdf
|
| [42] |
Sherwood T, Perelman E, Hamerly G, et al. Discovering and exploiting program phases[J]. IEEE Micro, 2003, 23(6): 84−93 doi: 10.1109/MM.2003.1261391
|
| [43] |
Shen Xipeng, Zhong Yutao, Ding Chen. Locality phase prediction[C]//Proc of the 11th Int Conf on Architectural Support for Programming Languages and Operating Systems. New York: ACM, 2004: 165–176
|
| [44] |
Ardestani E K, Renau J. ESESC: A fast multicore simulator using time-based sampling[C]//Proc of the 19th Int Symp on High Performance Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2013: 448–459
|
| [45] |
Jiang Chuntao, Yu Zhibin, Jin Hai, et al. PCantorSim: Accelerating parallel architecture simulation through fractal-based sampling[J]. ACM Transactions on Architecture and Code Optimization, 2013, 10(4): 49: 1–49: 24
|
| [46] |
Sabu A, Patil H, Heirman W, et al. LoopPoint: Checkpoint-driven sampled simulation for multi-threaded applications[C]//Proc of the 28th Int Symp on High-Performance Computer Architecture. Piscataway, NJ: IEEE, 2022: 604–618
|
| [47] |
Carlson T E, Heirman W, Van Craeynest K, et al. BarrierPoint: Sampled simulation of multi-threaded applications[C]//Proc of the 2014 IEEE Int Symp on Performance Analysis of Systems and Software. Los Alamitos, CA: IEEE Computer Society, 2014: 2–12
|
| [48] |
Grass T, Carlson T E, Rico A, et al. Sampled simulation of task-based programs[J]. IEEE Transactions on Computers, 2019, 68(2): 255−269 doi: 10.1109/TC.2018.2860012
|
| [49] |
Wenisch T F, Wunderlich R E, Ferdman M, et al. SimFlex: Statistical sampling of computer system simulation[J]. IEEE Micro, 2006, 26(4): 18−31 doi: 10.1109/MM.2006.79
|
| [50] |
Xu Yinan, Yu Zihao, Tang Dan, et al. Towards developing high performance RISC-V processors using agile methodology[C]//Proc of the 55th IEEE/ACM Int Symp on Microarchitecture. Piscataway, NJ: IEEE, 2022: 1178–1199
|
| [51] |
Bryan P D, Rosier M C, Conte T M. Reverse state reconstruction for sampled microarchitectural simulation[C]//Proc of the 2007 IEEE Int Symp on Performance Analysis of Systems & Software. Los Alamitos, CA: IEEE Computer Society, 2007: 190–199
|
| [52] |
Nussbaum S, Smith J E. Modeling superscalar processors via statistical simulation[C]//Proc of the 10th Int Conf on Parallel Architectures and Compilation Techniques. Los Alamitos, CA: IEEE Computer Society, 2001: 15–24
|
| [53] |
Eeckhout L, Nussbaum S, Smith J E, et al. Statistical simulation: Adding efficiency to the computer designer’s toolbox[J]. IEEE Micro, 2003, 23(5): 26−38 doi: 10.1109/MM.2003.1240210
|
| [54] |
Oskin M, Chong F T, Farrens M. HLS: Combining statistical and symbolic simulation to guide microprocessor designs[C]//Proc of the 27th Int Symp on Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2000: 71–82
|
| [55] |
Bell R H, John L K. Improved automatic testcase synthesis for performance model validation[C]//Proc of the 19th Annual Int Conf on Supercomputing. New York: ACM, 2000: 111–120
|
| [56] |
Genbrugge D, Eeckhout L. Statistical simulation of chip multiprocessors running multi-program workloads[C]//Proc of the 25th Int Conf on Computer Design. Piscataway, NJ: IEEE, 2007: 464–471
|
| [57] |
Genbrugge D, Eeckhout L. Chip multiprocessor design space exploration through statistical simulation[J]. IEEE Transactions on Computers, 2009, 58(12): 1668−1681 doi: 10.1109/TC.2009.77
|
| [58] |
Hughes C, Li T. Accelerating multi-core processor design space evaluation using automatic multi-threaded workload synthesis[C]//Proc of the 4th Int Symp on Workload Characterization. Los Alamitos, CA: IEEE Computer Society, 2008: 163–172
|
| [59] |
Balakrishnan G, Solihin Y. WEST: Cloning data cache behavior using stochastic traces[C]//Proc of the 18th IEEE Int Symp on High-Performance Comp Architecture. Los Alamitos, CA: IEEE Computer Society, 2012: 1–12
|
| [60] |
Awad A, Solihin Y. STM: Cloning the spatial and temporal memory access behavior[C]//Proc of the 20th IEEE Int Symp on High Performance Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2014: 237–247
|
| [61] |
Wang Yipeng, Awad A, Solihin Y. Clone morphing: Creating new workload behavior from existing applications[C]//Proc of the 2017 IEEE Int Symp on Performance Analysis of Systems and Software. Los Alamitos, CA: IEEE Computer Society, 2017: 97–108
|
| [62] |
Wang Yipeng, Balakrishnan G, Solihin Y. MeToo: Stochastic modeling of memory traffic timing behavior[C]//Proc of the 24th Int Conf on Parallel Architecture and Compilation. Los Alamitos, CA: IEEE Computer Society, 2015: 457–467
|
| [63] |
Hekstra G J, La Hei G D, Bingley P, et al. TriMedia CPU64 design space exploration[C]//Proc of the 17th IEEE Int Conf on Computer Design: VLSI in Computers and Processors. Los Alamitos, CA: IEEE Computer Society, 1999: 599–606
|
| [64] |
Fornaciari W, Sciuto D, Silvano C, et al. A design framework to efficiently explore energy-delay tradeoffs[C]//Proc of the 9th Int Symp on Hardware/Software Codesign. New York: ACM, 2001: 260–265
|
| [65] |
Fornaciari W, Sciuto D, Silvano C, et al. A sensitivity-based design space exploration methodology for embedded systems[J]. Design Automation for Embedded Systems, 2002, 7(1): 7−33
|
| [66] |
Sheldon D, Kumar R, Lysecky R, et al. Application-specific customization of parameterized FPGA soft-core processors[C]//Proc of the 25th IEEE/ACM Int Conf on Computer-Aided Design. New York: ACM, 2006: 261–268
|
| [67] |
Li Dandan, Yao Shuzhen, Liu Yuhang, et al. Efficient design space exploration via statistical sampling and AdaBoost learning[C]//Proc of the 53rd Annual Design Automation Conf. New York: ACM, 2016: 142: 1−142: 6
|
| [68] |
Wang Hongwei, Zhu Ziyuan, Shi Jinglin, et al. An accurate acosso metamodeling technique for processor architecture design space exploration[C]//Proc of the 20th Asia and South Pacific Design Automation Conf. Piscataway, NJ: IEEE, 2015: 689–694
|
| [69] |
Mariani G, Palermo G, Zaccaria V, et al. Design-space exploration and runtime resource management for multicores[J]. ACM Transactions on Embedded Computing Systems, 2013, 13(2): 20: 1−20: 27
|
| [70] |
Jahr R, Calborean H, Vintan L, et al. Boosting design space explorations with existing or automatically learned knowledge[C]//Proc of the 15th Measurement, Modelling, and Evaluation of Computing Systems and Dependability and Fault Tolerance. Berlin: Springer, 2012: 221–235
|
| [71] |
Palesi M, Givargis T. Multi-objective design space exploration using genetic algorithms[C]//Proc of the 10th Int Symp on Hardware/Software Codesign. New York: ACM, 2002: 67–72
|
| [72] |
Eyerman S, Eeckhout L, De Bosschere K. Efficient design space exploration of high performance embedded out-of-order processors[C]//Proc of the 9th Design, Automation & Test in Europe Conf and Exhibition. Piscataway, NJ: IEEE, 2006: 351−356
|
| [73] |
Ascia G, Catania V, Di Nuovo A G, et al. Efficient design space exploration for application specific systems-on-a-chip[J]. Journal of Systems Architecture, 2007, 53(10): 733−750 doi: 10.1016/j.sysarc.2007.01.004
|
| [74] |
Mariani G, Palermo G, Silvano C, et al. Multi-processor system-on-chip design space exploration based on multi-level modeling techniques[C]//Proc of the 9th Int Conf on Embedded Computer Systems: Architectures, Modeling and Simulation. Piscataway, NJ: IEEE, 2009: 118–124
|
| [75] |
Mariani G, Palermo G, Zaccaria V, et al. OSCAR: An optimization methodology exploiting spatial correlation in multicore design spaces[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2012, 31(5): 740−753 doi: 10.1109/TCAD.2011.2177457
|
| [76] |
Burger D, Austin T M. The SimpleScalar tool set, version 2.0[J]. ACM SIGARCH Computer Architecture News, 1997, 25(3): 13−25 doi: 10.1145/268806.268810
|
| [77] |
Renau J, Fraguela B, Tuck J, et al. SESC simulator[EB/OL]. 2005[2023-12-01]. http://sesc.sourceforge.net
|
| [78] |
Binkert N, Beckmann B, Black G, et al. The gem5 simulator[J]. ACM SIGARCH Computer Architecture News, 2011, 39(2): 1−7 doi: 10.1145/2024716.2024718
|
| [79] |
Chiou D, Sunwoo D, Kim J, et al. FPGA-accelerated simulation technologies (FAST): Fast, full-system, cycle-accurate simulators[C]//Proc of the 40th Annual IEEE/ACM Int Symp on Microarchitecture. Los Alamitos, CA: IEEE Computer Society, 2007: 249–261
|
| [80] |
Chung E S, Nurvitadhi E, Hoe J C, et al. A complexity-effective architecture for accelerating full-system multiprocessor simulations using FPGAs[C]//Proc of the 16th Int ACM/SIGDA Symp on Field Programmable Gate Arrays. New York: ACM, 2008: 77–86
|
| [81] |
Chung E S, Papamichael M K, Nurvitadhi E, et al. ProtoFlex: Towards scalable, full-system multiprocessor simulations using FPGAs[J]. ACM Transactions on Reconfigurable Technology and Systems, 2009, 2(2): 15: 1–15: 32
|
| [82] |
Tan Zhangxi, Waterman A, Avizienis R, et al. RAMP Gold: An FPGA-based architecture simulator for multiprocessors[C]//Proc of the 47th Design Automation Conf. New York: ACM, 2010: 463–468
|
| [83] |
Pellauer M, Adler M, Kinsy M, et al. HAsim: FPGA-based high-detail multicore simulation using time-division multiplexing[C]//Proc of the 17th Int Symp on High Performance Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2011: 406–417
|
| [84] |
Karandikar S, Mao H, Kim D, et al. FireSim: FPGA-accelerated cycle-exact scale-out system simulation in the public cloud[C]//Proc of the 45th Annual Int Symp on Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2018: 29–42
|
| [85] |
Balkind J, McKeown M, Fu Yaosheng, et al. OpenPiton: An open source manycore research framework[C]//Proc of the 21st Int Conf on Architectural Support for Programming Languages and Operating Systems. New York: ACM, 2016: 217–232
|
| [86] |
Wang Shenghong, Possignolo R T, Skinner H B, et al. LiveHD: A productive live hardware development flow[J]. IEEE Micro, 2020, 40(4): 67−75 doi: 10.1109/MM.2020.2996508
|
| [87] |
Petrisko D, Gilani F, Wyse M, et al. BlackParrot: An agile open-source RISC-V multicore for accelerator socs[J]. IEEE Micro, 2020, 40(4): 93−102 doi: 10.1109/MM.2020.2996145
|
| [88] |
Zhang Sizhuo, Wright A, Bourgeat T, et al. Composable building blocks to open up processor design[C]//Proc of the 51st Annual IEEE/ACM Int Symp on Microarchitecture. Los Alamitos, CA: IEEE Computer Society, 2018: 68–81
|
| [89] |
Amid A, Biancolin D, Gonzalez A, et al. Chipyard: Integrated design, simulation, and implementation framework for custom socs[J]. IEEE Micro, 2020, 40(4): 10−21 doi: 10.1109/MM.2020.2996616
|
| [90] |
Joseph P J, Vaswani K, Thazhuthaveetil M J. Construction and use of linear regression models for processor performance analysis[C]//Proc of the 12th Int Symp on High-Performance Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2006: 99–108
|
| [91] |
Agarwal N, Jain T, Zahran M. Performance prediction for multi-threaded applications[C]//Proc of the 2nd Int Workshop on AI-assisted Design for Architecture. New York: ACM, 2019: 71−76
|
| [92] |
Joseph P J, Vaswani K, Thazhuthaveetil M J. A predictive performance model for superscalar processors[C]//Proc of the 39th Annual IEEE/ACM Int Symp on Microarchitecture. Los Alamitos, CA: IEEE Computer Society, 2006: 161–170
|
| [93] |
Cho C B, Zhang Wangyuan, Li Tao. Informed microarchitecture design space exploration using workload dynamics[C]//Proc of the 40th Annual IEEE/ACM Int Symp on Microarchitecture. Los Alamitos, CA: IEEE Computer Society, 2007: 274–285
|
| [94] |
Ould-Ahmed-Vall E, Woodlee J, Yount C, et al. Using model trees for computer architecture performance analysis of software applications[C]//Proc of the 2007 IEEE Int Symp on Performance Analysis of Systems and Software. Los Alamitos, CA: IEEE Computer Society, 2007: 116–125
|
| [95] |
Powell A, Savvas-Bouganis C, Cheung P Y K. High-level power and performance estimation of FPGA-based soft processors and its application to design space exploration[J]. Journal of Systems Architecture, 2013, 59(10): 1144−1156 doi: 10.1016/j.sysarc.2013.08.003
|
| [96] |
Mankodi A, Bhatt A, Chaudhury B. Predicting physical computer systems performance and power from simulation systems using machine learning model[J]. Computing, 2022, 105(5): 1−19
|
| [97] |
Li Dandan, Yao Shuzhen, Wang Ying. Processor design space exploration via statistical sampling and semi-supervised ensemble learning[J]. IEEE Access, 2018, 6: 25495−25505 doi: 10.1109/ACCESS.2018.2831079
|
| [98] |
Guo Qi, Chen Tianshi, Chen Yunji, et al. Effective and efficient microprocessor design space exploration using unlabeled design configurations[C]//Proc of the 22nd Int Joint Conf on Artificial Intelligence. Palo Alto, CA: AAAI, 2011: 1671–1677
|
| [99] |
Hoste K, Phansalkar A, Eeckhout L, et al. Performance prediction based on inherent program similarity[C]//Proc of the 15th Int Conf on Parallel Architectures and Compilation Techniques. New York: ACM, 2006: 114–122
|
| [100] |
Guo Qi, Chen Tianshi, Chen Yunji, et al. Microarchitectural design space exploration made fast[J]. Microprocessors and Microsystems, 2013, 37(1): 41−51 doi: 10.1016/j.micpro.2012.07.006
|
| [101] |
Ahmadinejad H, Fatemi O. Moving towards grey-box predictive models at micro-architecture level by investigating inherent program characteristics[J]. IET Computers Digital Techniques, 2018, 12(2): 53−61 doi: 10.1049/iet-cdt.2016.0148
|
| [102] |
Taha T M, Wills S. An instruction throughput model of superscalar processors[J]. IEEE Transactions on Computers, IEEE, 2008, 57(3): 389−403 doi: 10.1109/TC.2007.70817
|
| [103] |
Xu Chi, Chen Xi, Dick R P, et al. Cache contention and application performance prediction for multi-core systems[C]//Proc of the 2010 IEEE Int Symp on Performance Analysis of Systems & Software. Los Alamitos, CA: IEEE Computer Society, 2010: 76–86
|
| [104] |
Eyerman S, Eeckhout L, Karkhanis T, et al. A mechanistic performance model for superscalar out-of-order processors[J]. ACM Transactions on Computer Systems, 2009, 27(2): 3: 1–3: 37
|
| [105] |
Breughe M B, Eyerman S, Eeckhout L. Mechanistic analytical modeling of superscalar in-order processor performance[J]. ACM Transactions on Architecture and Code Optimization, 2015, 11(4): 50: 1–50: 26
|
| [106] |
Carlson T E, Heirman W, Eeckhout L. Sniper: Exploring the level of abstraction for scalable and accurate parallel multi-core simulation[C]//Proc of the 2011 Conf on High Performance Computing Networking, Storage and Analysis. New York: ACM, 2011: 52: 1−52: 12
|
| [107] |
Wang Lei, Tang Yuxing, Deng Yu, et al. A scalable and fast microprocessor design space exploration methodology[C]//Proc of the 9th Int Symp on Embedded Multicore/Many-core Systems-on-Chip. Los Alamitos, CA: IEEE Computer Society, 2015: 33–40
|
| [108] |
Lee J, Jang H, Kim J. RpStacks: Fast and accurate processor design space exploration using representative stall-event stacks[C]//Proc of the 47th Annual IEEE/ACM Int Symp on Microarchitecture. Los Alamitos, CA: IEEE Computer Society, 2014: 255–267
|
| [109] |
Jang H, Jo J E, Lee J, et al. RpStacks-MT: A high-throughput design evaluation methodology for multi-core processors[C]//Proc of the 51st Annual IEEE/ACM Int Symp on Microarchitecture. Los Alamitos, CA: IEEE Computer Society, 2018: 586–599
|
| [110] |
Noonburg D B, Shen J P. A framework for statistical modeling of superscalar processor performance[C]//Proc of the 3rd Int Symp on High-Performance Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 1997: 298–309
|
| [111] |
Chen X E, Aamodt T M. A first-order fine-grained multithreaded throughput model[C]//Proc of the 15th Int Symp on High Performance Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2009: 329–340
|
| [112] |
Liang Y, Mitra T. An analytical approach for fast and accurate design space exploration of instruction caches[J]. ACM Transactions on Embedded Computing Systems, 2013, 13(3): 43: 1−43: 29
|
| [113] |
Hartstein A, Puzak T R. The optimum pipeline depth for a microprocessor[C]//Proc of the 29th Annual Int Symp on Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2002: 7–13
|
| [114] |
Chen X E, Aamodt T M. Hybrid analytical modeling of pending cache hits, data prefetching, and mshrs[J]. ACM Transactions on Architecture and Code Optimization, 2011, 8(3): 59−70
|
| [115] |
Li L, Pandey S, Flynn T, et al. SimNet: Accurate and high-performance computer architecture simulation using deep learning[C]//Proc of the 2022 ACM SIGMETRICS/IFIP Performance Joint Int Conf on Measurement and Modeling of Computer Systems. New York: ACM, 2022: 67–68
|
| [116] |
Panda R, John L K. Proxy benchmarks for emerging big-data workloads[C]//Proc of the 26th Int Conf on Parallel Architectures and Compilation Techniques. Los Alamitos, CA: IEEE Computer Society, 2017: 105–116
|
| [117] |
Kang S, Kumar R. Magellan: A search and machine learning-based framework for fast multi-core design space exploration and optimization[C]//Proc of the 2008 Design, Automation and Test in Europe. New York: ACM, 2008: 1432–1437
|
| [118] |
Guo Qi, Chen Tianshi, Zhou Zhihua, et al. Robust design space modeling[J]. ACM Transactions on Design Automation of Electronic Systems, 2015, 20(2): 18: 1–18: 22
|
| [119] |
张乾龙,侯锐,杨思博,等. 体系结构模拟器在处理器设计过程中的作用[J]. 计算机研究与发展,2019,56(12):2702−2719 doi: 10.7544/issn1000-1239.2019.20190044
Zhang Qianlong, Hou Rui, Yang Sibo, et al. The role of architecture simulators in the process of CPU design[J]. Journal of Computer Research and Development, 2019, 56(12): 2702−2719 (in Chinese) doi: 10.7544/issn1000-1239.2019.20190044
|
| [120] |
Hoste K, Eeckhout L. Microarchitecture-independent workload characterization[J]. IEEE Micro, 2007, 27(3): 63−72 doi: 10.1109/MM.2007.56
|
| [121] |
Jin Zhanpeng, Cheng A C. Evolutionary benchmark subsetting[J]. IEEE Micro, 2008, 28(6): 20−36 doi: 10.1109/MM.2008.87
|
| [122] |
Jin Zhanpeng, Cheng A C. SubsetTrio: An evolutionary, geometric, and statistical benchmark subsetting framework[J]. ACM Transactions on Modeling and Computer Simulation, 2011, 21(3): 21: 1–21: 23
|
| [123] |
Jin Zhanpeng, Cheng A C. Improve simulation efficiency using statistical benchmark subsetting: An implantbench case study[C]//Proc of the 45th Annual Design Automation Conf. New York: ACM, 2008: 970–973
|
| [124] |
Lee C, Potkonjak M, Mangione-Smith W H. MediaBench: A tool for evaluating and synthesizing multimedia and communications systems[C]//Proc of the 30th Annual Int Symp on Microarchitecture. Los Alamitos, CA: IEEE Computer Society, 1997: 330–335
|
| [125] |
Guthaus M R, Ringenberg J S, Ernst D, et al. MiBench: A free, commercially representative embedded benchmark suite[C]//Proc of the 4th Annual IEEE Int Workshop on Workload Characterization. Piscataway, NJ: IEEE, 2001: 3–14
|
| [126] |
Standard Performance Evaluation Corporation. SPEC CPU2000[EB/OL]. (2007-06-07)[2023-12-01]. https://www.spec.org/cpu2000
|
| [127] |
Standard Performance Evaluation Corporation. SPEC CPU2006[EB/OL]. (2023-01-06)[2023-12-01]. https://www.spec.org/cpu2006
|
| [128] |
Bienia C, Kumar S, Singh J P, et al. The parsec benchmark suite: Characterization and architectural implications[C]//Proc of the 17th Int Conf on Parallel Architectures and Compilation Techniques. New York: ACM, 2008: 72–81
|
| [129] |
Woo S C, Ohara M, Torrie E, et al. The splash−2 programs: Characterization and methodological considerations[C]//Proc of the 22nd Annual Int Symp on Computer architecture. New York: ACM, 1995: 24–36
|
| [130] |
Chandra D, Guo Fei, Kim S, et al. Predicting inter-thread cache contention on a chip multi-processor architecture[C]//Proc of the 11th Int Symp on High-Performance Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2005: 340–351
|
| [131] |
Hsu W C, Chen H, Yew P C, et al. On the predictability of program behavior using different input data sets[C]//Proc of the 6th Annual Workshop on Interaction between Compilers and Computer Architectures. Los Alamitos, CA: IEEE Computer Society, 2002: 45–53
|
| [132] |
Hoste K, Eeckhout L. Comparing benchmarks using key microarchitecture-independent characteristics[C]//Proc of the 2nd IEEE Int Symp on Workload Characterization. Los Alamitos, CA: IEEE Computer Society, 2006: 83–92
|
| [133] |
Yi J J, Sendag R, Eeckhout L, et al. Evaluating benchmark subsetting approaches[C]//Proc of the 2nd IEEE Int Symp on Workload Characterization. Los Alamitos, CA: IEEE Computer Society, 2006: 93–104
|
| [134] |
Conte T M, Hirsch M A, Menezes K N. Reducing state loss for effective trace sampling of superscalar processors[C]//Proc of the 14th Int Conf on Computer Design. Los Alamitos, CA: IEEE Computer Society, 1996: 468–477
|
| [135] |
Patil H, Cohn R, Charney M, et al. Pinpointing representative portions of large Intel® Itanium® programs with dynamic instrumentation[C]//Proc of the 37th Int Symp on Microarchitecture. Los Alamitos, CA: IEEE Computer Society, 2004: 81–92
|
| [136] |
Nair A A, John L K. Simulation points for SPEC CPU 2006[C]//Proc of the 26th Int Conf on Computer Design. Los Alamitos, CA: IEEE Computer Society, 2008: 397–403
|
| [137] |
Lau J, Perelman E, Calder B. Selecting software phase markers with code structure analysis[C]//Proc of the 4th Int Symp on Code Generation and Optimization. Los Alamitos, CA: IEEE Computer Society, 2006: 135–146
|
| [138] |
Lahiri K, Kunnoth S. Fast IPC estimation for performance projections using proxy suites and decision trees[C]//Proc of the 2017 IEEE Int Symp on Performance Analysis of Systems and Software. Los Alamitos, CA: IEEE Computer Society, 2017: 77–86
|
| [139] |
Carlson T E, Heirman W, Eeckhout L. Sampled simulation of multi-threaded applications[C]//Proc of the 2013 IEEE Int Symp on Performance Analysis of Systems and Software. Los Alamitos, CA: IEEE Computer Society, 2013: 2–12
|
| [140] |
Patil H, Pereira C, Stallcup M, et al. PinPlay: A framework for deterministic replay and reproducible analysis of parallel programs[C]//Proc of the 8th Annual IEEE/ACM Int Symp on Code Generation and Optimization. New York: ACM, 2010: 2–11
|
| [141] |
Patil H, Isaev A, Heirman W, et al. ELFies: Executable region checkpoints for performance analysis and simulation[C]//Proc of the 19th IEEE/ACM Int Symp on Code Generation and Optimization. Piscataway, NJ: IEEE, 2021: 126–136
|
| [142] |
Wenisch T F, Wunderlich R E, Falsafi B, et al. TurboSMARTS: Accurate microarchitecture simulation sampling in minutes[J]. ACM SIGMETRICS Performance Evaluation Review, 2005, 33(1): 408−409 doi: 10.1145/1071690.1064278
|
| [143] |
Khan T M, Pérez D G, Temam O. Transparent sampling[C]//Proc of the 10th Int Conf on Embedded Computer Systems: Architectures, Modeling and Simulation. Piscataway, NJ: IEEE, 2010: 28–36
|
| [144] |
Eeckhout L, Luo Yue, De Bosschere K, et al. BLRL: Accurate and efficient warmup for sampled processor simulation[J]. The Computer Journal, 2005, 48(4): 451−459 doi: 10.1093/comjnl/bxh103
|
| [145] |
Haskins J W, Skadron K. Accelerated warmup for sampled microarchitecture simulation[J]. ACM Transactions on Architecture and Code Optimization, 2005, 2(1): 78−108 doi: 10.1145/1061267.1061272
|
| [146] |
Van Ertvelde L, Hellebaut F, Eeckhout L. Accurate and efficient cache warmup for sampled processor simulation through NSL–BLRL[J]. The Computer Journal, 2008, 51(2): 192−206
|
| [147] |
Jiang Chuntao, Yu Zhibin, Jin Hai, et al. Shorter on-line warmup for sampled simulation of multi-threaded applications[C]//Proc of the 44th Int Conf on Parallel Processing. Los Alamitos, CA: IEEE Computer Society, 2015: 350–359
|
| [148] |
Bell R, Eeckhout L, John L, et al. Deconstructing and improving statistical simulation in HLS[C]//Proc of the 2004 Workshop on Duplicating, Deconstructing and Debunking held in Conjunction with the 31st Annual Int Symp on Computer Architecture. New York: ACM, 2004: 2−12
|
| [149] |
Joshi A, Yi J J, Bell R H, et al. Evaluating the efficacy of statistical simulation for design space exploration[C]//Proc of the 2006 IEEE Int Symp on Performance Analysis of Systems and Software. Los Alamitos, CA: IEEE Computer Society, 2006: 70–79
|
| [150] |
Eeckhout L, Bell R H, Stougie B, et al. Control flow modeling in statistical simulation for accurate and efficient processor design studies[C]//Proc of the 31st Annual Int Symp on Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2004: 350–361
|
| [151] |
Bell R H, Bhatia R R, John L K, et al. Automatic testcase synthesis and performance model validation for high performance PowerPC processors[C]//Proc of the 2006 IEEE Int Symp on Performance Analysis of Systems and Software. Los Alamitos, CA: IEEE Computer Society, 2006: 154–165
|
| [152] |
Lee H R, Sánchez D. Datamime: Generating representative benchmarks by automatically synthesizing datasets[C]//Proc of the 55th IEEE/ACM Int Symp on Microarchitecture. Piscataway, NJ: IEEE, 2022: 1144–1159
|
| [153] |
Joshi A, Eeckhout L, Bell R H, et al. Performance cloning: A technique for disseminating proprietary applications as benchmarks[C]//Proc of the 2nd IEEE Int Symp on Workload Characterization. Los Alamitos, CA: IEEE Computer Society, 2006: 105–115
|
| [154] |
Joshi A M, Eeckhout L, John L K, et al. Automated microprocessor stressmark generation[C]//Proc of the 14th Int Symp on High Performance Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2008: 229–239
|
| [155] |
Joshi A, Eeckhout L, Bell R H, et al. Distilling the essence of proprietary workloads into miniature benchmarks[J]. ACM Transactions on Architecture and Code Optimization, 2008, 5(2): 10: 1–10: 33
|
| [156] |
Ganesan K, John L K. Automatic generation of miniaturized synthetic proxies for target applications to efficiently design multicore processors[J]. IEEE Transactions on Computers, 2014, 63(4): 833−846 doi: 10.1109/TC.2013.36
|
| [157] |
Deniz E, Sen A, Kahne B, et al. MINIME: Pattern-aware multicore benchmark synthesizer[J]. IEEE Transactions on Computers, 2015, 64(8): 2239−2252 doi: 10.1109/TC.2014.2349522
|
| [158] |
Lee K, Evans S, Cho S. Accurately approximating superscalar processor performance from traces[C]//Proc of the 2009 IEEE Int Symp on Performance Analysis of Systems and Software. Los Alamitos, CA: IEEE Computer Society, 2009: 238–248
|
| [159] |
Lee K, Cho S. In-N-Out: Reproducing out-of-order superscalar processor behavior from reduced in-order traces[C]//Proc of the 19th Annual Int Symp on Modelling, Analysis, and Simulation of Computer and Telecommunication Systems. Los Alamitos, CA: IEEE Computer Society, 2011: 126–135
|
| [160] |
Lee K, Cho S. Accurately modeling superscalar processor performance with reduced trace[J]. Journal of Parallel and Distributed Computing, 2013, 73(4): 509−521 doi: 10.1016/j.jpdc.2012.12.002
|
| [161] |
Ganesan K, Jo J, John L K. Synthesizing memory-level parallelism aware miniature clones for SPEC CPU2006 and ImplantBench workloads[C]//Proc of the 2010 IEEE Int Symp on Performance Analysis of Systems & Software. Los Alamitos, CA: IEEE Computer Society, 2010: 33–44
|
| [162] |
Panda R, Zheng Xinnian, John L K. Accurate address streams for LLC and beyond (SLAB): A methodology to enable system exploration[C]//Proc of the 2017 IEEE Int Symp on Performance Analysis of Systems and Software. Los Alamitos, CA: IEEE Computer Society, 2017: 87–96
|
| [163] |
Van Biesbrouck M, Sherwood T, Calder B. A co-phase matrix to guide simultaneous multithreading simulation[C]//Proc of the 2004 IEEE Int Symp on Performance Analysis of Systems and Software. Los Alamitos, CA: IEEE Computer Society, 2004: 45–56
|
| [164] |
Yi J J, Kodakara S V, Sendag R, et al. Characterizing and comparing prevailing simulation techniques[C]//Proc of the 11th Int Symp on High-Performance Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2005: 266–277
|
| [165] |
Tairum Cruz M, Bischoff S, Rusitoru R. Shifting the barrier: Extending the boundaries of the barrierpoint methodology[C]//Proc of the 2018 IEEE Int Symp on Performance Analysis of Systems and Software. Los Alamitos, CA: IEEE Computer Society, 2018: 120–122
|
| [166] |
Bell R H, John L K. Efficient power analysis using synthetic testcases[C]//Proc of the 1st IEEE Int Symp Workload Characterization. Piscataway, NJ: IEEE, 2005: 110–118
|
| [167] |
Penry D A, Fay D, Hodgdon D, et al. Exploiting parallelism and structure to accelerate the simulation of chip multi-processors[C]//Proc of the 12th Int Symp on High-Performance Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2006: 29–40
|
| [168] |
Mariani G, Palermo G, Zaccaria V, et al. DeSpErate: Speeding-up design space exploration by using predictive simulation scheduling[C/OL]//Proc of the 17th Design, Automation & Test in Europe Conf & Exhibition. Piscataway, NJ: IEEE, 2014[2023-12-18]. https://ieeexplore.ieee.org/document/6800432?arnumber=6800432
|
| [169] |
Li Bin, Peng Lu, Ramadass B. Accurate and efficient processor performance prediction via regression tree based modeling[J]. Journal of Systems Architecture, 2009, 55(10): 457−467
|
| [170] |
Pang Jiufeng, Li Xiafeng, Xie Jinsong, et al. Microarchitectural design space exploration via support vector machine[J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2010, 46(1): 55−63
|
| [171] |
Cook H, Skadron K. Predictive design space exploration using genetically programmed response surfaces[C]//Proc of the 45th Annual Design Automation Conf. New York: ACM, 2008: 960–965
|
| [172] |
Zhai Jianwang, Bai Chen, Zhu Binwu, et al. McPAT-Calib: A microarchitecture power modeling framework for modern CPUs[C/OL]//Proc of the 40th IEEE/ACM Int Conf on Computer Aided Design. Piscataway, NJ: IEEE, 2021[2023-12-18]. https://ieeexplore.ieee.org/document/9643508
|
| [173] |
Zhai Jianwang, Bai Chen, Zhu Binwu, et al. McPAT-calib: A RISC-V boom microarchitecture power modeling framework[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2023, 42(1): 243−256 doi: 10.1109/TCAD.2022.3169464
|
| [174] |
Givargis T, Vahid F, Henkel J. System-level exploration for Pareto-optimal configurations in parameterized systems-on-a-chip[C]//Proc of the 20th IEEE/ACM Int Conf on Computer Aided Design. Los Alamitos, CA: IEEE Computer Society, 2001: 25–30
|
| [175] |
Yazdani R, Sheidaeian H, Salehi M E. A fast design space exploration for VLIW architectures[C]//Proc of the 22nd Iranian Conf on Electrical Engineering. Piscataway, NJ: IEEE, 2014: 856–861
|
| [176] |
Kansakar P, Munir A. A design space exploration methodology for parameter optimization in multicore processors[J]. IEEE Transactions on Parallel and Distributed Systems, 2018, 29(1): 2−15 doi: 10.1109/TPDS.2017.2745580
|
| [177] |
Ascia G, Catania V, Di Nuovo A G, et al. Performance evaluation of efficient multi-objective evolutionary algorithms for design space exploration of embedded computer systems[J]. Applied Soft Computing, 2011, 11(1): 382−398 doi: 10.1016/j.asoc.2009.11.029
|
| [178] |
Mariani G, Palermo G, Silvano C, et al. An efficient design space exploration methodology for multi-cluster VLIW architectures based on artificial neural networks[C]//Proc of the 16th IFIP/IEEE Int Conf on Very Large Scale Integration. Piscataway, NJ: IEEE, 2008: 13−15
|
| [179] |
Zaccaria V, Palermo G, Castro F, et al. MULTICUBE Explorer: An open source framework for design space exploration of chip multi-processors[C]//Proc of the 23rd Int Conf on Architecture of Computing Systems. Hannover, Germany: VDE Verlag, 2010: 325–331
|
| [180] |
Mariani G, Brankovic A, Palermo G, et al. A correlation-based design space exploration methodology for multi-processor systems-on-chip[C]//Proc of the 47th Design Automation Conf. New York: ACM, 2010: 120–125
|
| [181] |
Wang Duo, Yan Mingyu, Liu Xin, et al. A high-accurate multi-objective exploration framework for design space of CPU[C/OL]//Proc of the 60th ACM/IEEE Design Automation Conf. Piscataway, NJ: IEEE, 2023[2023-12-18]. https://ieeexplore.ieee.org/document/10247790
|
| [182] |
Wang Duo, Yan Mingyu, Teng Yihan, et al. A high-accurate multi-objective ensemble exploration framework for design space of CPU microarchitecture[C]//Proc of the 33rd Great Lakes Symp on VLSI 2023. New York: ACM, 2023: 379–383
|
| [183] |
Beltrame G, Fossati L, Sciuto D. Decision-theoretic design space exploration of multiprocessor platforms[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2010, 29(7): 1083−1095
|
| [184] |
Beltrame G, Nicolescu G. A multi-objective decision-theoretic exploration algorithm for platform-based design[C]//Proc of the 14th Design, Automation & Test in Europe Conf & Exhibition. Piscataway, NJ: IEEE, 2011: 1192−1195
|
| [185] |
Sheldon D, Vahid F, Lonardi S. Soft-core processor customization using the design of experiments paradigm[C]//Proc of the 10th Design, Automation & Test in Europe Conf & Exhibition. Piscataway, NJ: IEEE, 2007: 821−826
|
| [186] |
Mariani G, Palermo G, Silvano C, et al. Meta-model assisted optimization for design space exploration of multi-processor systems-on-chip[C]//Proc of the 12th Euromicro Conf on Digital System Design, Architectures, Methods and Tools. Los Alamitos, CA: IEEE Computer Society, 2009: 383–389
|
| [187] |
Palermo G, Silvano C, Zaccaria V. Multi-objective design space exploration of embedded systems[J]. Journal of Embedded Computing, 2005, 1(3): 305−316
|
| [188] |
Wu Nan, Xie Yuan, Hao Cong. IronMan: GNN-assisted design space exploration in high-level synthesis via reinforcement learning[C]//Proc of the 31st Great Lakes Symp on VLSI. New York: ACM, 2021: 39–44
|
| [189] |
Wu Nan, Xie Yuan, Hao Cong. IronMan-Pro: Multiobjective design space exploration in HLS via reinforcement learning and graph neural network-based modeling[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2023, 42(3): 900−913 doi: 10.1109/TCAD.2022.3185540
|
| [190] |
Kao S C, Jeong G, Krishna T. ConfuciuX: Autonomous hardware resource assignment for DNN accelerators using reinforcement learning[C]//Proc of the 53rd Annual IEEE/ACM Int Symp on Microarchitecture. Piscataway, NJ: IEEE, 2020: 622–636
|
| [191] |
Feng Lang, Liu Wenjian, Guo Chuliang, et al. GANDSE: Generative adversarial network based design space exploration for neural network accelerator design[J]. ACM Transactions on Design Automation of Electronic Systems, 2023, 28(3): 35: 1−35: 20
|
| [192] |
Akram A, Sawalha L. A survey of computer architecture simulation techniques and tools[J]. IEEE Access, 2019, 7: 78120−78145 doi: 10.1109/ACCESS.2019.2917698
|
| [193] |
Manjikian N. Multiprocessor enhancements of the simplescalar tool set[J]. SIGARCH Computer Architecture News, 2001, 29(1): 8−15 doi: 10.1145/373574.373578
|
| [194] |
Qureshi Y M, Simon W A, Zapater M, et al. Gem5-X: A many-core heterogeneous simulation platform for architectural exploration and optimization[J]. ACM Transactions on Architecture and Code Optimization, 2021, 18(4): 44: 1–44: 27
|
| [195] |
Carlson T E, Heirman W, Eyerman S, et al. An evaluation of high-level mechanistic core models[J]. ACM Transactions on Architecture and Code Optimization, 2014, 11(3): 28: 1–28: 25
|
| [196] |
Tan Zhangxi, Waterman A, Cook H, et al. A case for fame: FPGA architecture model execution[C]//Proc of the 37th Annual Int Symp on Computer Architecture. New York: ACM, 2010: 290–301
|
| [197] |
Lee Y, Waterman A, Cook H, et al. An agile approach to building RISC-V microprocessors[J]. IEEE Micro, 2016, 36(2): 8−20 doi: 10.1109/MM.2016.11
|
| [198] |
Di Biagio A, Davis M. llvm-mca: A static performance analysis tool[EB/OL]. (2018−03−01)[2023-12-01]. https://lists.llvm.org/pipermail/llvm-dev/2018-March/121490.html
|
| [199] |
Mendis C, Renda A, Amarasinghe D S, et al. Ithemal: Accurate, portable and fast basic block throughput estimation using deep neural networks[C]//Proc of the 36th Int Conf on Machine Learning. New York: PMLR, 2019: 4505–4515
|
| [200] |
Blocklove J, Garg S, Karri R, et al. Chip-Chat: Challenges and opportunities in conversational hardware design[C/OL]//Proc of the 5th ACM/IEEE Workshop on Machine Learning for CAD. Piscataway, NJ: IEEE, 2023[2023-12-18]. https://ieeexplore.ieee.org/document/10299874
|
| [201] |
Chang Kaiyan, Wang Ying, Ren Haimeng, et al. ChipGPT: How far are we from natural language hardware design[J]. arXiv preprint, arXiv: 2305.14019, 2023
|
| [202] |
Lu Yao, Liu Shang, Zhang Qijun, et al. RTLLM: An open-source benchmark for design RTL generation with large language model[J]. arXiv preprint, arXiv: 2308.05345, 2023
|
| [203] |
Balkind J, Chang Tingjung, Jackson P J, et al. OpenPiton at 5: A nexus for open and agile hardware design[J]. IEEE Micro, 2020, 40(4): 22−31 doi: 10.1109/MM.2020.2997706
|
| [204] |
Bachrach J, Vo H, Richards B, et al. Chisel: Constructing hardware in a scala embedded language[C]//Proc of the 49th Annual Design Automation Conf. New York: ACM, 2012: 1216–1225
|
| [205] |
Patel H D, Shukla S K. Tackling an abstraction gap: Co-simulating SystemC DE with Bluespec ESL[C]//Proc the of 10th Design, Automation & Test in Europe Conf & Exhibition. Piscataway, NJ: IEEE, 2007: 279−284
|
| [206] |
Bourgeat T, Pit-Claudel C, Chlipala A, et al. The essence of Bluespec: A core language for rule-based hardware design[C]//Proc of the 41st ACM SIGPLAN Conf on Programming Language Design and Implementation. New York: ACM, 2020: 243–257
|
| [207] |
Käyrä M, Hämäläinen T D. A survey on system-on-a-chip design using Chisel HW construction language[C/OL]//Proc of the 47th Annual Conf of the IEEE Industrial Electronics Society. Piscataway, NJ: IEEE, 2021[2023-12-18]. https://ieeexplore.ieee.org/document/9589614
|
| [208] |
王凯帆,徐易难,余子濠,等. 香山开源高性能RISC-v处理器设计与实现[J]. 计算机研究与发展,2023,60(3):476−493 doi: 10.7544/issn1000-1239.202221036
Wang Kaifan, Xu Yinan, Yu Zihao, et al. XiangShan open-source high performance RISC-V processor design and implementation[J]. Journal of Computer Research and Development, 2023, 60(3): 476−493(in Chinese) doi: 10.7544/issn1000-1239.202221036
|
| [209] |
Lee B C, Brooks D M, Supinski B R de, et al. Methods of inference and learning for performance modeling of parallel applications[C]//Proc of the 12th ACM SIGPLAN Sympon Principles and Practice of Parallel Programming. New York: ACM, 2007: 249–258
|
| [210] |
Hallschmid P, Saleh R. Fast design space exploration using local regression modeling with application to ASIPs[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2008, 27(3): 508−515 doi: 10.1109/TCAD.2008.915532
|
| [211] |
Zhang Changshu, Ravindran A, Datta K, et al. A machine learning approach to modeling power and performance of chip multiprocessors[C]//Proc of the 29th Int Conf on Computer Design. Los Alamitos, CA: IEEE Computer Society, 2011: 45–50
|
| [212] |
Beg A, Prasad P W C, Singh A K, et al. A neural model for processor-throughput using hardware parameters and software’s dynamic behavior[C]//Proc of the 12th Int Conf on Intelligent Systems Design and Applications. Piscataway, NJ: IEEE, 2012: 821–825
|
| [213] |
Paone E, Vahabi N, Zaccaria V, et al. Improving simulation speed and accuracy for many-core embedded platforms with ensemble models[C]//Proc of the 16th Design, Automation & Test in Europe Conf & Exhibition. Piscataway, NJ: IEEE, 2013: 671–676
|
| [214] |
Castillo P A, Mora A M, Guervós J J M, et al. Architecture performance prediction using evolutionary artificial neural networks[C]//Proc of the Applications of Evolutionary Computing. Berlin: Springer, 2008: 175–183
|
| [215] |
Khan S, Xekalakis P, Cavazos J, et al. Using predictive modeling for cross-program design space exploration in multicore systems[C]//Proc of the 16th Int Conf on Parallel Architecture and Compilation Techniques. Los Alamitos, CA: IEEE Computer Society, 2007: 327–338
|
| [216] |
Dubach C, Jones T M, O’Boyle M F P. Rapid early-stage microarchitecture design using predictive models[C]//Proc of the 27th Int Conf on Computer Design. Los Alamitos, CA: IEEE Computer Society, 2009: 297–304
|
| [217] |
Özisikyilmaz B, Memik G, Choudhary A N. Machine learning models to predict performance of computer system design alternatives[C]//Proc of the 37th Int Conf on Parallel Processing. Los Alamitos, CA: IEEE Computer Society, 2008: 495–502
|
| [218] |
Özisikyilmaz B, Memik G, Choudhary A N. Efficient system design space exploration using machine learning techniques[C]//Proc of the 45th Design Automation Conf. New York: ACM, 2008: 966–969
|
| [219] |
Ghosh A, Givargis T. Cache optimization for embedded processor cores: An analytical approach[J]. ACM Transactions on Design Automation of Electronic Systems, 2004, 9(4): 419−440 doi: 10.1145/1027084.1027086
|
| [220] |
Li Sheng, Chen Ke, Ahn J H, et al. CACTI-p: Architecture-level modeling for SRAM-based structures with advanced leakage reduction techniques[C]//Proc of the 30th Int Conf on Computer-Aided Design. Los Alamitos, CA: IEEE Computer Society, 2011: 694–701
|
| [221] |
Li Sheng, Ahn J H, Strong R D, et al. McPAT: An integrated power, area, and timing modeling framework for multicore and manycore architectures[C]//Proc of the 42nd Annual IEEE/ACM Int Symp on Microarchitecture. New York: ACM, 2009: 469–480
|
| [222] |
Karkhanis T S, Smith J E. A first-order superscalar processor model[C]//Proc of the 31st Annual Int Symp on Computer Architecture. Piscataway, NJ: IEEE, 2004: 338–349
|
| [223] |
Genbrugge D, Eyerman S, Eeckhout L. Interval simulation: Raising the level of abstraction in architectural simulation[C/OL]//Proc of the 16th Int Symp on High-Performance Computer Architecture. Piscataway, NJ: IEEE, 2010[2023-12-18]. https://ieeexplore.ieee.org/document/5416636
|
| [224] |
Breughe M, Eyerman S, Eeckhout L. A mechanistic performance model for superscalar in-order processors[C]//Proc of the 2012 IEEE Int Symp on Performance Analysis of Systems & Software. Los Alamitos, CA: IEEE Computer Society, 2012: 14–24
|
| [225] |
Van den Steen S, Eyerman S, De Pestel S, et al. Analytical processor performance and power modeling using micro-architecture independent characteristics[J]. IEEE Transactions on Computers, 2016, 65(12): 3537−3551
|
| [226] |
De Pestel S, Van den Steen S, Akram S, et al. RPPM: Rapid performance prediction of multithreaded workloads on multicore processors[C]//Proc of the 2019 IEEE Int Symp on Performance Analysis of Systems and Software. Piscataway, NJ: IEEE, 2019: 257–267
|
| [227] |
Jongerius R, Mariani G, Anghel A, et al. Analytic processor model for fast design-space exploration[C]//Proc of the 33rd IEEE Int Conf on Computer Design. Los Alamitos, CA: IEEE Computer Society, 2015: 411–414
|
| [228] |
Jongerius R, Anghel A, Dittmann G, et al. Analytic multi-core processor model for fast design-space exploration[J]. IEEE Transactions on Computers, 2018, 67(6): 755−770 doi: 10.1109/TC.2017.2780239
|
| [229] |
Kwon J, Carloni L P. Transfer learning for design-space exploration with high-level synthesis[C]//Proc of the 2nd ACM/IEEE Workshop on Machine Learning for CAD. New York: ACM, 2020: 163–168
|
| [230] |
Zhang Zheng, Chen Tinghuan, Huang Jiaxin, et al. A fast parameter tuning framework via transfer learning and multi-objective Bayesian optimization[C]//Proc of the 59th ACM/IEEE Design Automation Conf. New York: ACM, 2022: 133–138
|
| [231] |
Zhang Keyi, Asgar Z, Horowitz M. Bringing source-level debugging frameworks to hardware generators[C]//Proc of the 59th ACM/IEEE Design Automation Conf. New York: ACM, 2022: 1171–1176
|
| [232] |
Xiao Qingcheng, Zheng Size, Wu Bingzhe, et al. HASCO: Towards agile hardware and software co-design for tensor computation[C]//Proc of the 48th Annual Int Symp on Computer Architecture. Piscataway, NJ: IEEE, 2021: 1055–1068
|
| [233] |
Esmaeilzadeh H, Ghodrati S, Kahng A B, et al. Physically accurate learning-based performance prediction of hardware-accelerated ML algorithms[C]//Proc of the 4th ACM/IEEE Workshop on Machine Learning for CAD. New York: ACM, 2022: 119–126
|
| [234] |
Sun Qi, Chen Tinghuan, Liu Siting, et al. Correlated multi-objective multi-fidelity optimization for HLS directives design[C]//Proc of the 24th Design, Automation & Test in Europe Conf & Exhibition. Piscataway, NJ: IEEE, 2021: 46–51
|
| [235] |
Wu Y N, Tsai P A, Parashar A, et al. Sparseloop: An analytical approach to sparse tensor accelerator modeling[C]//Proc of the 55th IEEE/ACM Int Symp on Microarchitecture. Piscataway, NJ: IEEE, 2022: 1377–1395
|
| [236] |
Huang Qijing, Kang M, Dinh G, et al. CoSA: Scheduling by constrained optimization for spatial accelerators[C]//Proc of the 48th Annual Int Symp on Computer Architecture. Piscataway, NJ: IEEE, 2021: 554–566
|
| [237] |
Mei Linyan, Houshmand P, Jain V, et al. ZigZag: Enlarging joint architecture-mapping design space exploration for DNN accelerators[J]. IEEE Transactions on Computers, 2021, 70(8): 1160−1174 doi: 10.1109/TC.2021.3059962
|
| [1] | Tai Jianwei, Yang Shuangning, Wang Jiajia, Li Yakai, Liu Qixu, Jia Xiaoqi. Survey of Adversarial Attacks and Defenses for Large Language Models[J]. Journal of Computer Research and Development, 2025, 62(3): 563-588. DOI: 10.7544/issn1000-1239.202440630 |
| [2] | Jiang Yi, Yang Yong, Yin Jiali, Liu Xiaolei, Li Jiliang, Wang Wei, Tian Youliang, Wu Yingcai, Ji Shouling. A Survey on Security and Privacy Risks in Large Language Models[J]. Journal of Computer Research and Development. DOI: 10.7544/issn1000-1239.202440265 |
| [3] | 面向大语言模型安全部署的可信评估体系[J]. Journal of Computer Research and Development. DOI: 10.7544/issn1000-1239.202440566 |
| [4] | Chen Xuanting, Ye Junjie, Zu Can, Xu Nuo, Gui Tao, Zhang Qi. Robustness of GPT Large Language Models on Natural Language Processing Tasks[J]. Journal of Computer Research and Development, 2024, 61(5): 1128-1142. DOI: 10.7544/issn1000-1239.202330801 |
| [5] | Shu Wentao, Li Ruixiao, Sun Tianxiang, Huang Xuanjing, Qiu Xipeng. Large Language Models: Principles, Implementation, and Progress[J]. Journal of Computer Research and Development, 2024, 61(2): 351-361. DOI: 10.7544/issn1000-1239.202330303 |
| [6] | Yang Yi, Li Ying, Chen Kai. Vulnerability Detection Methods Based on Natural Language Processing[J]. Journal of Computer Research and Development, 2022, 59(12): 2649-2666. DOI: 10.7544/issn1000-1239.20210627 |
| [7] | Zheng Haibin, Chen Jinyin, Zhang Yan, Zhang Xuhong, Ge Chunpeng, Liu Zhe, Ouyang Yike, Ji Shouling. Survey of Adversarial Attack, Defense and Robustness Analysis for Natural Language Processing[J]. Journal of Computer Research and Development, 2021, 58(8): 1727-1750. DOI: 10.7544/issn1000-1239.2021.20210304 |
| [8] | Bao Yang, Yang Zhibin, Yang Yongqiang, Xie Jian, Zhou Yong, Yue Tao, Huang Zhiqiu, Guo Peng. An Automated Approach to Generate SysML Models from Restricted Natural Language Requirements in Chinese[J]. Journal of Computer Research and Development, 2021, 58(4): 706-730. DOI: 10.7544/issn1000-1239.2021.20200757 |
| [9] | Huang Kezhen, Lian Yifeng, Feng Dengguo, Zhang Haixia, Liu Yuling, Ma Xiangliang. Cyber Security Threat Intelligence Sharing Model Based on Blockchain[J]. Journal of Computer Research and Development, 2020, 57(4): 836-846. DOI: 10.7544/issn1000-1239.2020.20190404 |
| [10] | Zhang Yuqing, Dong Ying, Liu Caiyun, Lei Kenan, Sun Hongyu. Situation, Trends and Prospects of Deep Learning Applied to Cyberspace Security[J]. Journal of Computer Research and Development, 2018, 55(6): 1117-1142. DOI: 10.7544/issn1000-1239.2018.20170649 |
| 1. |
袁辉. 新质生产力理论指导下支付中心信息系统建设思路. 互联网周刊. 2025(05): 42-45 .

| |
| 2. |
李文秀. 人工智能助力高校图书馆阅读推广的路径探索. 科技视界. 2024(33): 76-80 .
|

微信订阅号
(实时资讯)

微信服务号
(同步网站)

微信视频号
(视频分享)

CCF
(扫码入会)
Copyright © Editorial Department of Computer Research and Development
Supported by: Beijing Renhe Information Technology Co.,
Ltd. 
 DownLoad:
DownLoad: