

- 中国精品科技期刊
- CCF推荐A类中文期刊
- 计算领域高质量科技期刊T1类
| Citation: |
Zhu Minghang, Liu Xin, Yu Zhenning, Xu Xing, Zheng Shukai. Cross Face-Voice Matching Method via Bi-Pseudo Label Based Self-Supervised Learning[J]. Journal of Computer Research and Development, 2023, 60(11): 2638-2649. DOI: 10.7544/issn1000-1239.202220411

|
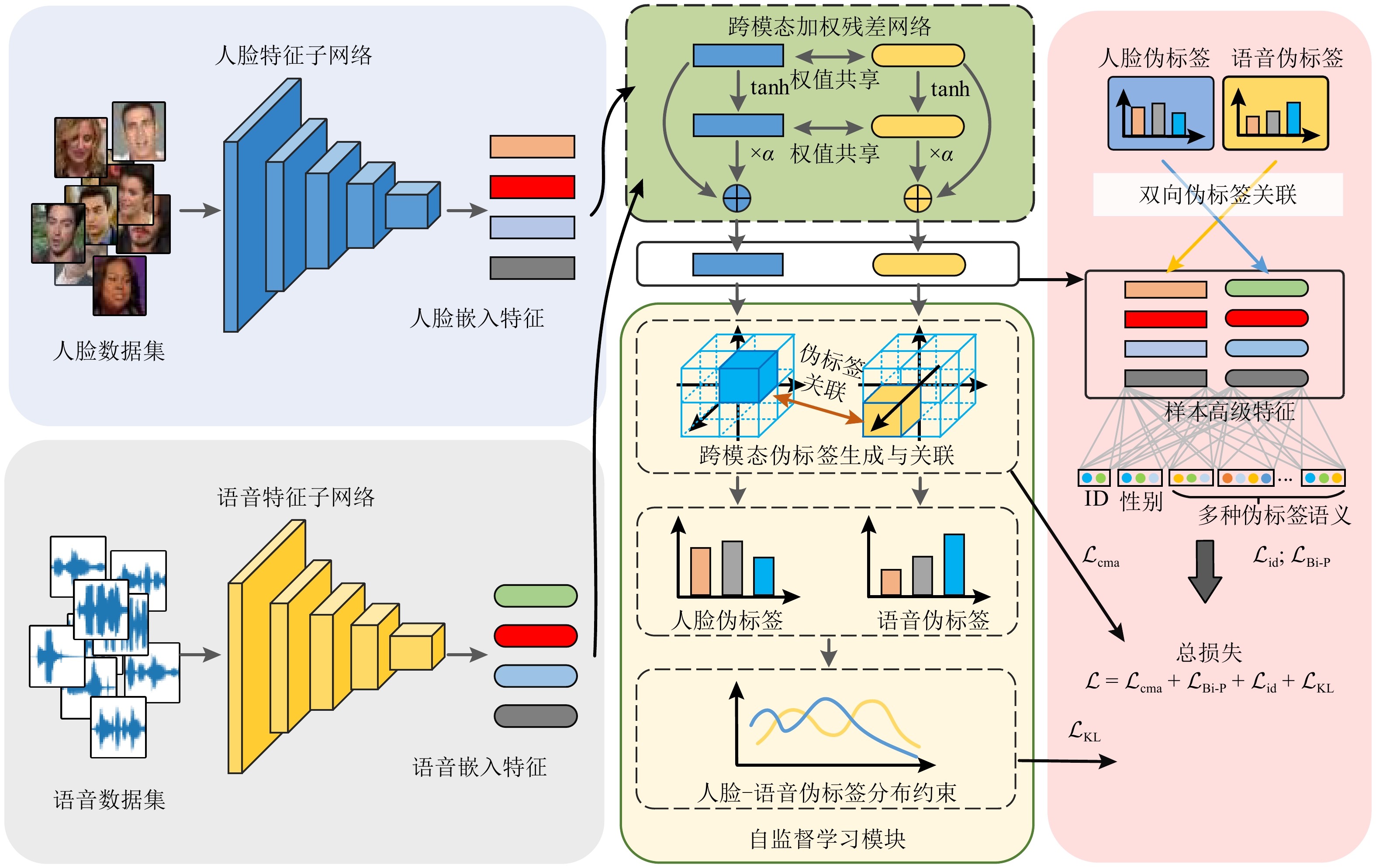
Neurocognitive science research shows that human brain often combines face information on cross-modal interaction analysis during the speech perception process. Nevertheless, existing cross-modal face-voice association methods still face the various challenges such as sensitivity to complex samples, lack of supervised information and insufficient semantic correlation, which mainly due to the lack of mining common semantic embeddings. To tackle these problems, we present an efficient cross-modal face-voice matching method from bi-pseudo label based self-supervised learning. First of all, we introduce a cross-modal weighted residual network to learn face-voice common embeddings, and then propose a novel self-supervised learning method for bi-pseudo label association, which learns the latent semantic supervision of one modality to supervise the feature learning of another modality. Accordingly, based on this interactive cross-modal self-supervised learning, the highly correlated face-voice associations can be well learned. Besides, in order to increase the discrimination of mining supervised information, we further construct two auxiliary losses to make the face-voice features of the same samples closer, while pushing the features of different samples to be far away. After a large number of experiments, the innovative method proposed in this paper has achieved a comprehensive improvement in the cross-modal face-voice matching task compared with the existing work.
| [1] |
McGurk H, MacDonald J. Hearing lips and seeing voices[J]. Nature, 1976, 264(5588): 746−748 doi: 10.1038/264746a0
|
| [2] |
Ellis A W. Neuro-cognitive processing of faces and voices[M]//Handbook of Research on Face Processing. Amsterdam : Elsevier, 1989: 207−215
|
| [3] |
Nawaz S, Janjua M K, Gallo I, et al. Deep latent space learning for cross-modal mapping of audio and visual signals[C/OL] //Proc of the 14th Int Conf on Digital Image Computing: Techniques and Applications. Piscataway, NJ: IEEE, 2019[2020-05-12]. https://ieeexplore.ieee.org/document/8945863
|
| [4] |
Liu Xin, Geng Jiajia, Ling Haibin, et al. Attention guided deep audio-face fusion for efficient speaker naming[J]. Pattern Recognition, 2019, 52(88): 557−568
|
| [5] |
Wen Yandong, Ismail M A, Liu Weiyang, et al. Disjoint mapping network for cross-modal matching of voices and faces[J]. arXiv preprint, arXiv: 1807.04836, 2018
|
| [6] |
张露,王华彬,陶亮,等. 基于分类距离分数的自适应多模态生物特征融合[J]. 计算机研究与发展,2018,55(1):151−162 doi: 10.7544/issn1000-1239.2018.20160675
Zhang Lu, Wang Huabin, Tao Liang, et al. Cross-media clustering by share and private information maximization[J]. Journal of Computer Research and Development, 2018, 55(1): 151−162 (in Chinese) doi: 10.7544/issn1000-1239.2018.20160675
|
| [7] |
Hermans A, Beyer L, Leibe B. In defense of the triplet loss for person re-identification[J]. arXiv preprint, arXiv: 1703.07737, 2017
|
| [8] |
Wells T, Baguley T, Sergeant M, et al. Perceptions of human attractiveness comprising face and voice cues[J]. Archives of Sexual Behavior, 2013, 42(5): 805−811 doi: 10.1007/s10508-012-0054-0
|
| [9] |
Nagrani A, Albanie S, Zisserman A. Seeing voices and hearing faces: Cross-modal biometric matching[C]// Proc of the 31st IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2018: 8427−8436
|
| [10] |
Nagrani A, Albanie S, Zisserman A. Learnable PINs: Cross-modal embeddings for person identity[C]// Proc of the 15th European Conf on Computer Vision. Berlin: Springer, 2018: 71−88
|
| [11] |
Horiguchi S, Kanda N, Nagamatsu K. Face-voice matching using cross-modal embeddings[C]// Proc of the 26th ACM Int Conf on Multimedia. New York: ACM, 2018: 1011−1019
|
| [12] |
Kim C, Shin H V, Oh T H, et al. On learning associations of faces and voices[C]//Proc of the 14th Asian Conf on Computer Vision. Berlin: Springer, 2018: 276−292
|
| [13] |
Wang Kaiye, He Ran, Wang Wei, et al. Learning coupled feature spaces for cross-modal matching[C]//Proc of the IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2013: 2088−2095
|
| [14] |
闫小强,叶阳东. 共享和私有信息最大化的跨媒体聚类[J]. 计算机研究与发展,2019,56(7):1370−1382 doi: 10.7544/issn1000-1239.2019.20180470
Yan Xiaoqiang, Ye Yangdong. Cross-media clustering by share and private information maximization[J]. Journal of Computer Research and Development, 2019, 56(7): 1370−1382 (in Chinese) doi: 10.7544/issn1000-1239.2019.20180470
|
| [15] |
Wang Rui, Liu Xin, Cheung Yiuming, et al. Learning discriminative joint embeddings for efficient face and voice association[C]//Proc of the 43rd Int ACM SIGIR Conf on Research and Development in Information Retrieval. New York: ACM, 2020: 1881−1884
|
| [16] |
Zhan Xiaohang, Xie Jiahao, Liu Ziwei, et al. Online deep clustering for unsupervised representation learning[C]//Proc of the 30th IEEE/CVF Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2020: 6688−6697
|
| [17] |
Zhen Liangli, Hu Peng, Wang Xu, et al. Deep supervised cross-modal retrieval[C]// Proc of the 32nd IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2019: 10394−10403
|
| [18] |
He Kaiming, Zhang Xiangyu, Ren Shaoqi, et al. Deep residual learning for image recognition[C]// Proc of the 29th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 770−778
|
| [19] |
Chung J S, Zisserman A. Out of time: Automated lip sync in the wild[C]// Proc of the 9th Asian Conf on Computer Vision. Berlin: Springer, 2016: 251−263
|
| [20] |
Kingma D P, Ba J. Adam: A method for stochastic optimization[J]. arXiv preprint, arXiv: 1412.6980, 2014
|
| [21] |
Nagrani A, Chung J S, Zisserman A. Voxceleb: A large-scale speaker identification dataset[J]. arXiv preprint, arXiv: 1706.08612, 2017
|
| [22] |
Parkhi O M, Vedaldi A, Zisserman A, et al. Deep face recognition[C]// Proc of the 26th Brithsh Machine Vision Conf. Durham, UK: BMVA, 2015: 1−12
|
| [23] |
Venkatesh G, Nurvitadhi E, Marr D. Accelerating deep convolutional networks using low-precision and sparsity[C]//Proc of the 42nd Int IEEE Conf on Acoustics, Speech and Signal Processing. Piscataway, NJ: IEEE, 2017: 2861−2865
|
| [24] |
Xiong Chuyuan, Zhang Deyuan, Liu Tao, et al. Voice-face cross-modal matching and retrieval: A benchmark [J]. arXiv preprint, arXiv: 1911.09338, 2019
|
| [25] |
Maaten L, Hinton G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008, 86(9): 2579−2605
|
| [1] | Li Zhongnian, Huangfu Zhiyu, Yang Kaijie, Ying Peng, Sun Tongfeng, Xu Xinzheng. Semi-supervised Open Vocabulary Multi-label Learning Based on Graph Prompting[J]. Journal of Computer Research and Development, 2025, 62(2): 432-442. DOI: 10.7544/issn1000-1239.202440123 |
| [2] | Song Xiaogang, Hu Haoyue, Ning Jingyu, Liang Li, Lu Xiaofeng, Hei Xinhong. Self-Supervised Monocular Depth Estimation Method for Joint Semantic Segmentation[J]. Journal of Computer Research and Development, 2024, 61(5): 1336-1347. DOI: 10.7544/issn1000-1239.202330485 |
| [3] | Xiao Mengnan, He Ruifang, Ma Jinsong. Event Detection Based on Hierarchical Latent Semantic-Driven Network[J]. Journal of Computer Research and Development, 2024, 61(1): 184-195. DOI: 10.7544/issn1000-1239.202220447 |
| [4] | Jiao Pengfei, Liu Huan, Lü Le, Gao Mengzhou, Zhang Jilin, Liu Dong. Globally Enhanced Heterogeneous Temporal Graph Neural Networks Based on Contrastive Learning[J]. Journal of Computer Research and Development, 2023, 60(8): 1808-1821. DOI: 10.7544/issn1000-1239.202330226 |
| [5] | Wang Ting, Wang Na, Cui Yunpeng, Li Huan. The Optimization Method of Wireless Network Attacks Detection Based on Semi-Supervised Learning[J]. Journal of Computer Research and Development, 2020, 57(4): 791-802. DOI: 10.7544/issn1000-1239.2020.20190880 |
| [6] | Liu Yufeng, Li Renfa. Graph Regularized Semi-Supervised Learning on Heterogeneous Information Networks[J]. Journal of Computer Research and Development, 2015, 52(3): 606-613. DOI: 10.7544/issn1000-1239.2015.20131147 |
| [7] | Hu Yan, Peng Qimin, Hu Xiaohui. A Personalized Web Service Recommendation Method Based on Latent Semantic Probabilistic Model[J]. Journal of Computer Research and Development, 2014, 51(8): 1781-1793. DOI: 10.7544/issn1000-1239.2014.20130024 |
| [8] | Chen Liwei, Feng Yansong, and Zhao Dongyan. Extracting Relations from the Web via Weakly Supervised Learning[J]. Journal of Computer Research and Development, 2013, 50(9): 1825-1835. |
| [9] | Gong Shu, Qu Youli, and Tian Shengfeng. Supervised Learning of an Automatic Noisy Semantic Unit Filter for Multi-Document Summarization[J]. Journal of Computer Research and Development, 2013, 50(4): 873-882. |
| [10] | Li Ming and Zhou Zhihua. Online Semi-Supervised Learning with Multi-Kernel Ensemble[J]. Journal of Computer Research and Development, 2008, 45(12): 2060-2068. |
| 1. |
李俊屿,卜凡亮,谭林,周禹辰,毛璟仪. 基于多模态共享网络的自监督语音-人脸跨模态关联学习方法. 科学技术与工程. 2024(07): 2804-2812 .

|

微信订阅号
(实时资讯)

微信服务号
(同步网站)

微信视频号
(视频分享)

CCF
(扫码入会)
Copyright © Editorial Department of Computer Research and Development
Supported by: Beijing Renhe Information Technology Co.,
Ltd. 
 DownLoad:
DownLoad: