

- 中国精品科技期刊
- CCF推荐A类中文期刊
- 计算领域高质量科技期刊T1类
| Citation: |
Ge Zhenxing, Xiang Shuai, Tian Pinzhuo, Gao Yang. Solving GuanDan Poker Games with Deep Reinforcement Learning[J]. Journal of Computer Research and Development, 2024, 61(1): 145-155. DOI: 10.7544/issn1000-1239.202220697

|
 Ge Zhenxing: born in 1998. PhD candidate. Student member of CCF. His main research interests include game theory, multi-agent systems, and reinforcement learning
Ge Zhenxing: born in 1998. PhD candidate. Student member of CCF. His main research interests include game theory, multi-agent systems, and reinforcement learning
 Xiang Shuai: born in 1997. Master candidate. Student member of CCF. His main research interests include game theory, reinforcement learning, and multi-agent systems
Xiang Shuai: born in 1997. Master candidate. Student member of CCF. His main research interests include game theory, reinforcement learning, and multi-agent systems
 Tian Pinzhuo: born in 1991. PhD, lecturer. His main research interests include machine learning, meta-learning, and transfer learning. (pinzhuo@shu.edu.cn)
Tian Pinzhuo: born in 1991. PhD, lecturer. His main research interests include machine learning, meta-learning, and transfer learning. (pinzhuo@shu.edu.cn)
 Gao Yang: born in 1972. PhD, professor, PhD supervisor. Committee member of CCF. His main research interests include reinforcement learning, multi-agent systems, computer vision, and big data analysis
Gao Yang: born in 1972. PhD, professor, PhD supervisor. Committee member of CCF. His main research interests include reinforcement learning, multi-agent systems, computer vision, and big data analysis
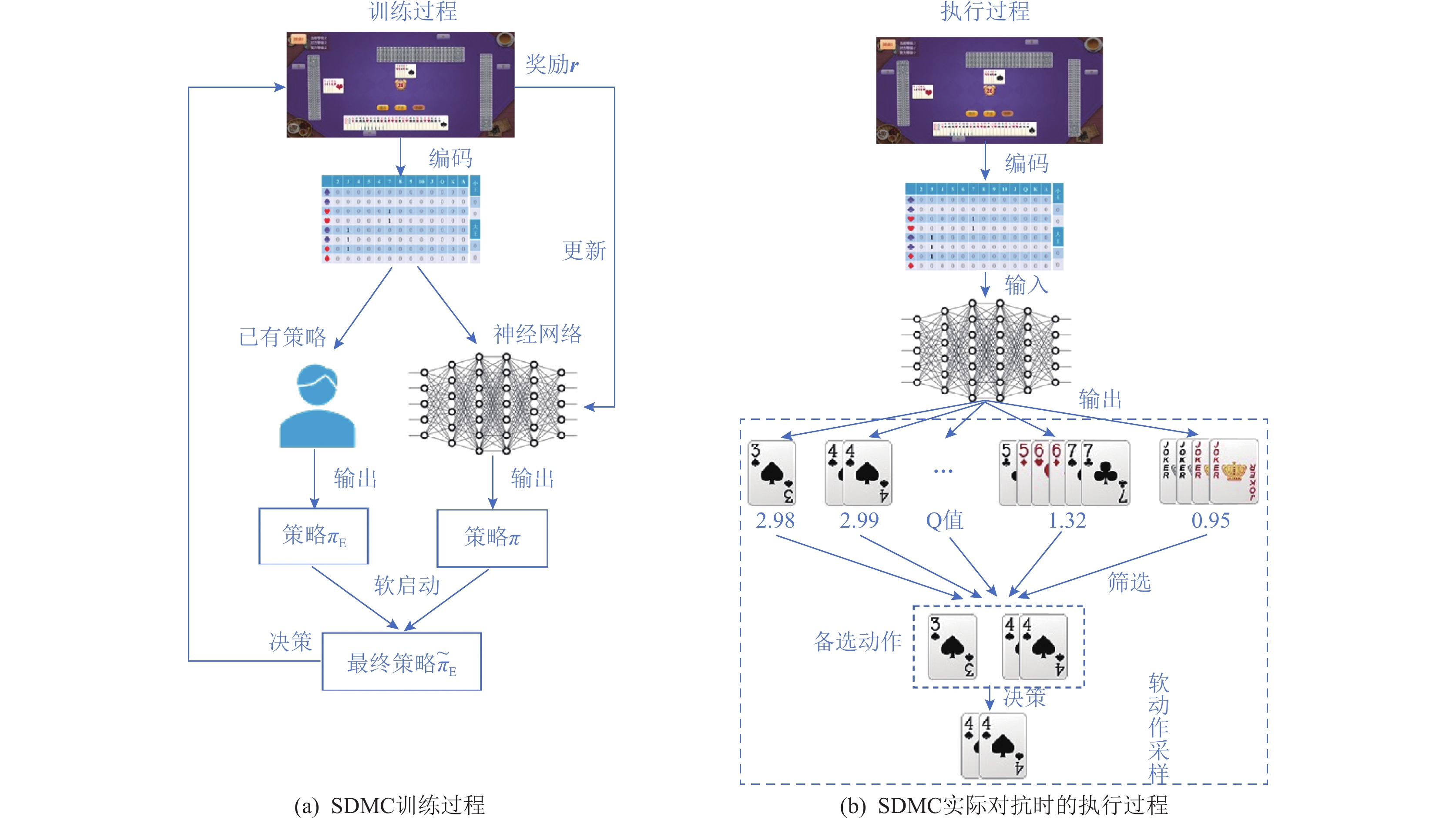
Decisions are often made in complex environment without exact information in many real-world occasions. Hence the capability of making proper decisions is expected for artificial intelligence agents. As abstractions of the real world, games provoke interests of researchers with the benefits of well-defined game structure and the facility to evaluate various algorithms. Among these games, GuanDan poker games are typical games with large action space and huge information set size, which exacerbates the problem and increases the difficulty to solve these games. In this work, we propose a novel soft deep Monte Carlo(SDMC) method to overcome the above-mentioned difficulties. By considering how the expert strategy acts in the training process, SDMC can better utilize the expert knowledge and accelerate the convergence of training process. Meanwhile, SDMC applies an action sample strategy in real time playing to confuse the opponents and prohibits the potentional exploitation of them, which could also lead to significant improvement of the performance against different agents. SDMC agent was the champion of the 2nd Chinese Artificial Intelligence Game Algorithm competition. Comprehensive experiments that evaluate the training time and final performance are conducted in this work, showing superior performance of SDMC against other agents such as the champion of 1st competition.
| [1] |
Silver D, Huang A, Maddison C J, et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016, 529(7587): 484−489 doi: 10.1038/nature16961
|
| [2] |
Silver D, Schrittwieser J, Simonyan K, et al. Mastering the game of Go without human knowledge[J]. Nature, 2017, 550(7676): 354−359 doi: 10.1038/nature24270
|
| [3] |
Brown N, Sandholm T. Superhuman AI for heads-up no-limit poker: Libratus beats top professionals[J]. Science, 2018, 359(6374): 418−424 doi: 10.1126/science.aao1733
|
| [4] |
Brown N, Sandholm T. Superhuman AI for multiplayer poker[J]. Science, 2019, 365(6456): 885−890 doi: 10.1126/science.aay2400
|
| [5] |
Li Junjie, Koyamada S, Ye Qiwei, et al. Suphx: Mastering mahjong with deep reinforcement learning[J]. arXiv preprint, arXiv: 2003. 13590, 2020
|
| [6] |
Vinyals O, Babuschkin I, Czarnecki W M, et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning[J]. Nature, 2019, 575(7782): 350−354 doi: 10.1038/s41586-019-1724-z
|
| [7] |
Berner C, Brockman G, Chan B, et al. Dota 2 with large scale deep reinforcement learning[J]. arXiv preprint, arXiv: 1912. 06680, 2019
|
| [8] |
Zha Daochen, Xie Jingru, Ma Wenye, et al. DouZero: Mastering DouDiZhu with self-play deep reinforcement learning [C] //Proc of the 38th Int Conf on Machine Learning. New York: ACM, 2021: 12333−12344
|
| [9] |
Zinkevich M, Johanson M, Bowling M, et al. Regret minimization in games with incomplete information [C] //Proc of the 21st Conf on Neural Information Processing Systems. Cambridge, MA: MIT, 2007: 1729−1736
|
| [10] |
Lanctot M, Waugh K, Zinkevich M, et al. Monte Carlo sampling for regret minimization in extensive games [C] //Proc of the 23rd Conf on Neural Information Processing Systems. Cambridge, MA: MIT, 2009: 1078−1086
|
| [11] |
Farina G, Kroer C, Sandholm T. Online convex optimization for sequential decision processes and extensive-form games [C] //Proc of the 33rd AAAI Conf on Artificial Intelligence. Palo Alto, CA: AAAI, 2019: 1917−1925
|
| [12] |
Johanson M, Bard N, Lanctot M, et al. Efficient Nash equilibrium approximation through Monte Carlo counterfactual regret minimization [C] //Proc of the 11th Int Conf on Autonomous Agents and Multiagent Systems. Berlin: Springer, 2012: 837−846
|
| [13] |
Burch N. Time and space: Why imperfect information games are hard [D]. Edmonton: University of Alberta, 2018
|
| [14] |
Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529−533 doi: 10.1038/nature14236
|
| [15] |
亓法欣,童向荣,于雷. 基于强化学习DQN的智能体信任增强[J]. 计算机研究与发展,2020,57(6):1227−1238
Qi Faxin, Tong Xiangrong, Yu Lei. Agent trust boost via reinforcement learning DQN[J]. Journal of Computer Research and Development, 2020, 57(6): 1227−1238 (in Chinese)
|
| [16] |
郑渤龙,明岭峰,胡琦,等. 基于深度强化学习的网约车动态路径规划[J]. 计算机研究与发展,2022,59(2):329−341
Zheng Bolong, Ming Lingfeng, Hu Qi, et al. Dynamic ride-hailing route planning based on deep reinforcement learning[J]. Journal of Computer Research and Development, 2022, 59(2): 329−341 (in Chinese)
|
| [17] |
Mnih V, Badia A P, Mirza M, et al. Asynchronous methods for deep reinforcement learning [C] //Proc of the 33rd Int Conf on Machine Learning. New York: ACM, 2016: 1928−1937
|
| [18] |
Küttler H, Nardelli N, Lavril T, et al. TorchBeast: A pytorch platform for distributed rl[J]. arXiv preprint, arXiv: 1910. 03552, 2019
|
| [19] |
Brown N, Sandholm T. Strategy-based warm starting for regret minimization in games [C] //Proc of the 30th AAAI Conf on Artificial Intelligence. Palo Alto, CA: AAAI, 2016: 432−438
|
| [20] |
Sandholm T. Abstraction for solving large incomplete-information games [C] //Proc of the 29th AAAI Conf on Artificial Intelligence. Palo Alto, CA: AAAI, 2015: 4127−4131
|
| [21] |
Bard N, Foerster J N, Chandar S, et al. The Hanabi Challenge: A new frontier for AI research[J]. Artificial Intelligence, 2020, 280: 103216 doi: 10.1016/j.artint.2019.103216
|
| [22] |
Foerster J, Song F, Hughes E, et al. Bayesian action decoder for deep multi-agent reinforcement learning [C] //Proc of the 36th Int Conf on Machine Learning. New York: ACM, 2019: 1942−1951
|
| [23] |
Hu Hengyuan, Foerster J. Simplified action decoder for deep multi-agent reinforcement learning[J]. arXiv preprint, arXiv: 1912. 02288, 2019
|
| [24] |
You Yang, Li Liangwei, Guo Baisong, et al. Combinatorial Q-learning for Dou Di Zhu [C] //Proc of the 16th AAAI Conf on Artificial Intelligence and Interactive Digital Entertainment. Palo Alto, CA: AAAI, 2020: 301−307
|
| [25] |
Jiang Qiqi, Li Kuangzheng, Du Boyao, et al. DeltaDou: Expert-level Doudizhu AI through self-play [C] //Proc of the 28th Int Joint Conf on Artificial Intelligence. San Francisco: Morgan Kaufmann, 2019: 1265−1271
|
| [26] |
Zahavy T, Haroush M, Merlis N, et al. Learn what not to learn: Action elimination with deep reinforcement learning [C] // Proc of the 32nd Conf on Neural Information Processing Systems. Cambridge, MA: MIT, 2018: 3566−3577
|
| [1] | Li Ke, Ma Sai, Dai Penglin, Ren Jing, Fan Pingzhi. Wireless Resource Allocation Algorithm Based on Multi-Objective Deep Reinforcement Learning for Vehicle-to-Vehicle Communications[J]. Journal of Computer Research and Development, 2024, 61(9): 2229-2245. DOI: 10.7544/issn1000-1239.202330895 |
| [2] | Liu Guoqing, Qian Yuhua, Zhang Yayu, Wang Jieting. Best Action Identification Algorithm in Monte Carlo Tree Search Based on Relative Entropy Confidence Interval with Given Budget[J]. Journal of Computer Research and Development, 2023, 60(8): 1780-1794. DOI: 10.7544/issn1000-1239.202330257 |
| [3] | Lu Haifeng, Gu Chunhua, Luo Fei, Ding Weichao, Yang Ting, Zheng Shuai. Research on Task Offloading Based on Deep Reinforcement Learning in Mobile Edge Computing[J]. Journal of Computer Research and Development, 2020, 57(7): 1539-1554. DOI: 10.7544/issn1000-1239.2020.20190291 |
| [4] | Wang Bo, Liu Jinglei. An Algorithm for Computing Core of Boolean Game[J]. Journal of Computer Research and Development, 2018, 55(8): 1735-1750. DOI: 10.7544/issn1000-1239.2018.20180360 |
| [5] | Guo Dongwei, Meng Xiangyan, Liu Miao, Hou Caifang. Naming Game on Multi-Community Network[J]. Journal of Computer Research and Development, 2015, 52(2): 487-498. DOI: 10.7544/issn1000-1239.2015.20131465 |
| [6] | Tian Youliang, Peng Chenggen, Ma Jianfeng, Jiang Qi, Zhu Jianming. Game-Theoretic Mechanism for Cryptographic Protocol[J]. Journal of Computer Research and Development, 2014, 51(2): 344-352. |
| [7] | Ma Xiao, Wang Xuan, and Wang Xiaolong. The Information Model for a Class of Imperfect Information Game[J]. Journal of Computer Research and Development, 2010, 47(12). |
| [8] | Ma Xin and Liang Yanchun. Study on GPGP-Cooperation-Mechanism-Based Multi-Agent Job Shop Scheduling Method[J]. Journal of Computer Research and Development, 2008, 45(3): 479-486. |
| [9] | Liu Wanwei, Wang Ji, and Chen Huowang. A Game-Based Axiomatization of μ-Calculus[J]. Journal of Computer Research and Development, 2007, 44(11): 1896-1902. |
| [10] | Liu Wanwei, Wang Ji, and Chen Huowang. A Game-Based Axiomatization of μ-Calculus[J]. Journal of Computer Research and Development, 2007, 44(11): 1896-1902. |
| 1. |
程和祥,王善江. 论真实概率游戏中的效果随机性——基于中国彩票业2008年开奖数据的考察. 贵州工程应用技术学院学报. 2025(01): 75-83 .

|

微信订阅号
(实时资讯)

微信服务号
(同步网站)

微信视频号
(视频分享)

CCF
(扫码入会)
Copyright © Editorial Department of Computer Research and Development
Supported by: Beijing Renhe Information Technology Co.,
Ltd. 
 DownLoad:
DownLoad: