

- 中国精品科技期刊
- CCF推荐A类中文期刊
- 计算领域高质量科技期刊T1类
| Citation: |
Feng Yangyang, Wang Qing, Xie Minhui, Shu Jiwu. From BERT to ChatGPT: Challenges and Technical Development of Storage Systems for Large Model Training[J]. Journal of Computer Research and Development, 2024, 61(4): 809-823. DOI: 10.7544/issn1000-1239.202330554

|
 Feng Yangyang: born in 1998. PhD candidate. His main research interests include storage systems and machine learning systems
Feng Yangyang: born in 1998. PhD candidate. His main research interests include storage systems and machine learning systems
 Wang Qing: born in 1997. PhD. His main research interests include storage systems and memory systems
Wang Qing: born in 1997. PhD. His main research interests include storage systems and memory systems
 Xie Minhui: born in 1997. PhD candidate. Student member of CCF. His main research interests include storage systems and machine learning systems
Xie Minhui: born in 1997. PhD candidate. Student member of CCF. His main research interests include storage systems and machine learning systems
 Shu Jiwu: born in 1968. PhD, professor, PhD supervisor. Fellow of CCF. His main research interests include intelligent storage systems, non-volatile memory storage systems and technologies, storage security and reliability, and parallel and distributed computing
Shu Jiwu: born in 1968. PhD, professor, PhD supervisor. Fellow of CCF. His main research interests include intelligent storage systems, non-volatile memory storage systems and technologies, storage security and reliability, and parallel and distributed computing
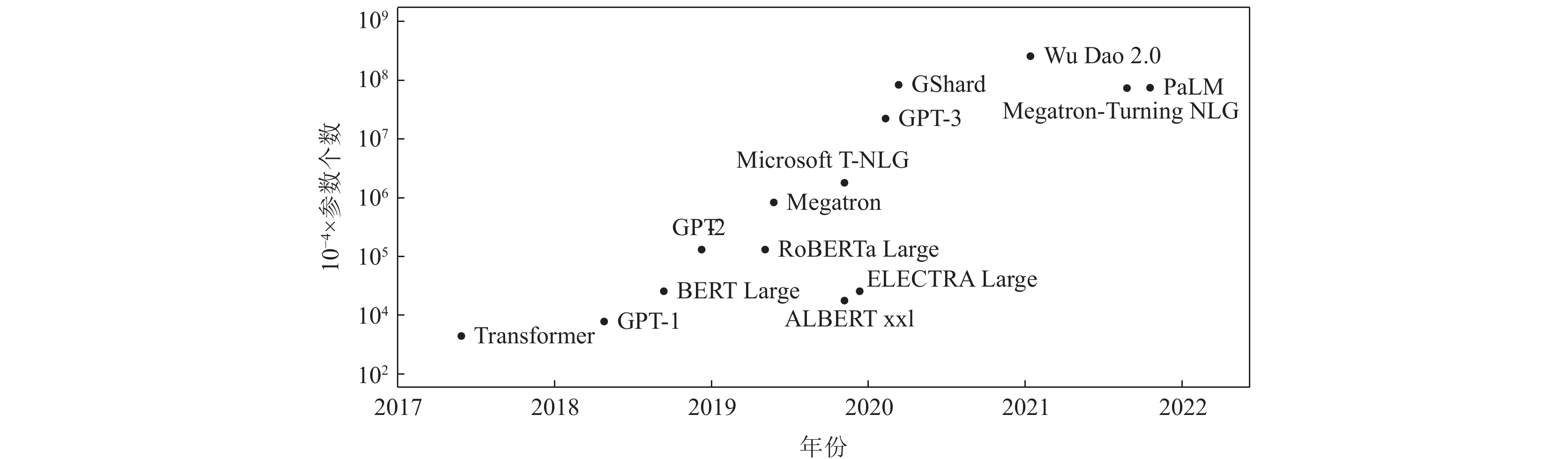
The large models represented by ChatGPT have attracted a lot of attention from industry and academia for their excellent performance on text generation and semantic understanding tasks. The number of large model parameters has increased tens of thousands of times in three years and is still growing, which brings new challenges to storage systems. First, we analyze the storage challenges of large model training, pointing out that large model training has unique computation patterns, storage access patterns, and data characteristics, which makes traditional storage techniques inefficient in handling large model training tasks. Then, we describe three types of storage acceleration techniques and two types of fault-tolerant techniques. The storage acceleration techniques for large model training include: 1) distributed storage technique based on large model computation patterns designs the partitioning, storage, and transferring strategies of model data in distributed clusters based on the partitioning of large model computation tasks and the dependencies between computation tasks; 2) heterogeneous storage access pattern-aware technique for large model training develops data prefetching and transferring strategies among heterogeneous devices with the predictability of storage access patterns in large model training; 3) large model data reduction technique reduces the data size in the model training process according to the characteristics of large model data. The storage fault-tolerant techniques for large model training include: 1) parameter checkpointing technique stores the large model parameters to persistent storage devices; 2) redundant computation technique computes the same version of parameters repeatedly in multiple GPUs. Finally, we give the summary and suggestions for future research.
| [1] |
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need [C/OL] //Proc of the 30th Conf on Neural Information Processing Systems. Cambridge, MA: MIT, 2017[2023-05-30].https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
|
| [2] |
Devlin J, Chang M, Lee K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding [J]. arXiv preprint, arXiv: 1810.04805, 2018
|
| [3] |
OpenAI. GPT-4 technical report [J]. arXiv preprint, arXiv: 2303.08774, 2023
|
| [4] |
Bae J, Lee J, Jin Y, et al. FlashNeuron: SSD-enabled large-batch training of very deep neural networks[C]//Proc of the 19th USENIX Conf on File and Storage Technologies. Berkeley, CA: USENIX Association, 2021: 387-401
|
| [5] |
Ruder S. An overview of gradient descent optimization algorithms[J]. arXiv preprint, arXiv: 1609.04747, 2016
|
| [6] |
Kingma D, Ba J. Adam: A method for stochastic optimization[J]. arXiv preprint, arXiv: 1412.6980, 2014
|
| [7] |
Thorpe J, Zhao Pengzhan, Eyolfson J, et al. Bamboo: Making preemptible instances resilient for affordable training of large DNNs[C]//Proc of the 20th USENIX Symp on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2023: 497-513
|
| [8] |
Zhang Susan, Roller S, Goyal N, et al. OPT: Open pre-trained transformer language models[J]. arXiv preprint, arXiv: 2205.01068, 2022
|
| [9] |
Jeon M, Venkataraman S, Phanishayee A, et al. Analysis of large-scale multi-tenant GPU clusters for DNN training workloads[C]// Proc of USENIX Annual Technical Conf. Berkeley, CA: USENIX Association, 2019: 947-960
|
| [10] |
Shvachko K, Kuang H, Radia S, et al. The Hadoop distributed file system[C/OL]//Proc of the 26th IEEE Symp on Mass Storage Systems and Technologies. Piscataway, NJ: IEEE, 2010[2023-05-21].https://www.computer.org/csdl/proceedings-article/msst/2010/05496972/12OmNwxlrhU
|
| [11] |
Zaharia M, Chowdhury M, Franklin M J, et al. Spark: Cluster computing with working sets[C/OL]//Proc of the 2nd USENIX Workshop on Hot Topics in Cloud Computing. Berkeley, CA: USENIX Association, 2010[2023-05-21].https://www.usenix.org/legacy/event/hotcloud10/tech/full_papers/Zaharia.pdf
|
| [12] |
Weil S, Brandt S, Miller E, et al. Ceph: A scalable, high-performance distributed file system[C]//Proc of the 7th Symp on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2006: 307−320
|
| [13] |
Rajbhandari S, Rasley J, Ruwase O, et al. ZeRO: Memory optimizations toward training trillion parameter models[C/OL]//Proc of the Int Conf for High Performance Computing, Networking, Storage and Analysis. Piscataway, NJ: IEEE, 2020[2023-05-21].https://dl.acm.org/doi/pdf/10.5555/3433701.3433727
|
| [14] |
Huang Yanping, Cheng Youlong, Bapna A, et al. GPipe: Efficient training of giant neural networks using pipeline parallelism[C/OL]// Proc of the 33rd Conf on Neural Information Processing Systems. Cambridge, MA: MIT, 2019[2023-05-30].https://proceedings.neurips.cc/paper_files/paper/2019/file/093f65e080a295f8076b1c5722a46aa2-Paper.pdf
|
| [15] |
Narayanan D, Harlap A, Phanishayee A, et al. PipeDream: Generalized pipeline parallelism for DNN training[C/OL]//Proc of the 27th ACM Symp on Operating Systems Principles. New York: ACM, 2019[2023-05-20].https://dl.acm.org/doi/pdf/10.1145/3341301.3359646
|
| [16] |
Jain A, Awan A, Aljuhani A, et al. GEMS: GPU-enabled memory-aware model-parallelism system for distributed DNN training[C/OL]// Proc of the Int Conf for High Performance Computing, Networking, Storage and Analysis. Piscataway, NJ: IEEE, 2020[2023-05-21].https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9355254
|
| [17] |
Narayanan D, Phanishayee A, Shi Kaiyu, et al. Memory-efficient pipeline-parallel DNN training[C]//Proc of the 38th Int Conf on Machine Learning Research. New York: PMLR, 2021: 7937−7947
|
| [18] |
Fan Shiqing, Rong Yi, Meng Chen, et al. DAPPLE: A pipelined data parallel approach for training large models[C]//Proc of the 26th ACM SIGPLAN Symp on Principles and Practice of Parallel Programming. New York: ACM, 2021: 431−445
|
| [19] |
Li Shigang, Hoefler T. Chimera: Efficiently training large-scale neural networks with bidirectional pipelines[C/OL]// Proc of the Int Conf for High Performance Computing, Networking, Storage and Analysis. Piscataway, NJ: IEEE, 2020[2023-05-21]. https://dl.acm.org/doi/abs/10.1145/3458817.3476145
|
| [20] |
Shoeybi M, Patwary M, Puri R, et al. Megatron-LM: Training multi-billion parameter language models using model parallelism[J]. arXiv preprint, arXiv: 1909.08053, 2019
|
| [21] |
Xu Qifan, You Yang. An efficient 2D method for training super-large deep learning models[C]//Proc of Int Symp on Parallel and Distributed Processing. Piscataway, NJ: IEEE, 2021: 222−232
|
| [22] |
Wang Boxiang, Xu Qifan, Bian Zhengda, et al. Tesseract: Parallelize the tensor parallelism efficiently[C/OL]//Proc of the 51st Int Conf on Parallel Processing. New York: ACM, 2022[2023-05-21]. https://dl.acm.org/doi/abs/10.1145/3545008.3545087
|
| [23] |
Bian Zhengda, Xu Qifan, Wang Boxiang, et al. Maximizing parallelism in distributed training for huge neural networks[J]. arXiv preprint, arXiv: 2105.14450, 2021
|
| [24] |
Narayanan D, Shoeybi M, Casper J, et al. Efficient large-scale language model training on GPU clusters using Megatron-LM[C/OL]// Proc of the Int Conf for High Performance Computing, Networking, Storage and Analysis. Piscataway, NJ: IEEE, 2021[2023-05-21].https://dl.acm.org/doi/abs/10.1145/3458817.3476209
|
| [25] |
Fang Jiarui, Zhu Zilin, Li Shenggui, et al. Parallel training of pre-trained models via chunk-based dynamic memory management[J]. IEEE Transactions on Parallel and Distributed Systems, 2022, 34(1): 304−315
|
| [26] |
Rhu M, Gimelshein N, Clemons J, et al. vDNN: Virtualized deep neural networks for scalable, memory-efficient neural network design[C/OL]//Proc of the 49th Annual IEEE/ACM Int Symp on Microarchitecture. Piscataway, NJ: IEEE, 2016[2023-05-21]. https://ieeexplore.ieee.org/abstract/document/7783721
|
| [27] |
Wang Linna, Ye Jinmian, Zhao Yiyang, et al. SuperNeurons: Dynamic GPU memory management for training deep neural networks[C]//Proc of the 23rd ACM SIGPLAN Symp on Principles and Practice of Parallel Programming. New York: ACM, 2018: 41−53
|
| [28] |
Huang C, Jin Gu, Li Jinyang. SwapAdvisor: Pushing deep learning beyond the GPU memory limit via smart swapping[C]//Proc of the 25th Int Conf on Architectural Support for Programming Languages and Operating Systems. New York: ACM, 2020: 1341−1355
|
| [29] |
Peng Xuan, Shi Xuanhua, Dai Hulin, et al. Capuchin: Tensor-based GPU memory management for deep learning[C]//Proc of the 25th Int Conf on Architectural Support for Programming Languages and Operating Systems. New York: ACM, 2020: 891−905
|
| [30] |
Ren Jie, Rajbhandari S, Aminabadi R Y, et al. ZeRO-Offload: Democratizing billion-scale model training[C]//Proc of USENIX Annual Technical Conf. Berkeley, CA: USENIX Association, 2021: 551−564
|
| [31] |
Li Youjie, Phanishayee A, Murray D, et al. Harmony: Overcoming the hurdles of GPU memory capacity to train massive DNN models on commodity servers[J]. arXiv preprint, arXiv: 2202.01306, 2022
|
| [32] |
Feng Yangyang, Xie Minhui, Tian Zijie, et al. Mobius: Fine tuning large-scale models on commodity GPU servers[C]//Proc of the 28th ACM Int Conf on Architectural Support for Programming Languages and Operating Systems. New York: ACM, 2023: 489−501
|
| [33] |
Rajbhandari S, Ruwase O, Rasley J, et al. ZeRO-Infinity: Breaking the GPU memory wall for extreme scale deep learning[C/OL]// Proc of the Int Conf for High Performance Computing, Networking, Storage and Analysis. Piscataway, NJ: IEEE, 2021[2023-05-21].https://dl.acm.org/doi/abs/10.1145/3458817.3476205
|
| [34] |
Buluç A, Fineman J T, Frigo M, et al. Parallel sparse matrix-vector and matrix-transpose-vector multiplication using compressed sparse blocks[C]//Proc of the 21st Annual Symp on Parallelism in Algorithms and Architectures. New York: ACM, 2009: 233−244
|
| [35] |
Scipy. scipy. sparse. coo_matrix[EB/OL]. 2023 [2023-06-29].https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.coo_matrix.html
|
| [36] |
Scipy. scipy. sparse. lil_matrix[EB/OL]. 2023 [2023-06-29].https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.lil_matrix.html
|
| [37] |
Fedus W, Zoph B, Shazeer N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity[J]. The Journal of Machine Learning Research, 2022, 23(1): 5232−5270
|
| [38] |
Chen Tianqi, Xu Bing, Zhang Chiyuan, et al. Training deep nets with sublinear memory cost[J]. arXiv preprint, arXiv: 1604.06174, 2016
|
| [39] |
Jain P, Jain A, Nrusimha A, et al. Checkmate: Breaking the memory wall with optimal tensor rematerialization[C/OL]// Proc of the 3rd Machine Learning and Systems. 2020[2023-05-20].https://proceedings.mlsys.org/paper_files/paper/2020/file/0b816ae8f06f8dd3543dc3d9ef196cab-Paper.pdf
|
| [40] |
Micikevicius P, Narang S, Alben J, et al. Mixed precision training[J]. arXiv preprint, arXiv: 1710.03740, 2017
|
| [41] |
Chen Jianfei, Zheng Lianmin, Yao Zhewei, et al. ActNN: Reducing training memory footprint via 2-bit activation compressed training[C]//Proc of the 38th Int Conf on Machine Learning Research. New York: PMLR, 2021: 1803−1813
|
| [42] |
Mohan J, Phanishayee A, Chidambaram V. CheckFreq: Frequent, fine-frained DNN checkpointing[C]//Proc of the 19th USENIX Conf on File and Storage Technologies. Berkeley, CA: USENIX Association, 2021: 203−216
|
| [43] |
NVIDIA. Megatron-LM [EB/OL]. 2023 [2023-06-01].https://github.com/NVIDIA/Megatron-LM
|
| [44] |
Microsoft. DeepSpeed [EB/OL]. 2023 [2023-06-10].https://github.com/microsoft/DeepSpeed
|
| [45] |
HPCAITech. Colossal-AI [EB/OL]. 2023 [2023-06-10].https://github.com/hpcaitech/ColossalAI
|
| [46] |
OneFlow Inc. OneFlow [EB/OL]. 2023 [2023-06-10].https://github.com/Oneflow-Inc/oneflow
|
| [1] | Li Kai, Zeng Kun, Rong Peitao, Chen Zhiqiang, Zhang Tian, Wang Yongwen. FireLink: An Evaluation Framework for Chiplet Design Space Exploration[J]. Journal of Computer Research and Development. DOI: 10.7544/issn1000-1239.202440082 |
| [2] | Lin Hanyue, Wu Jingya, Lu Wenyan, Zhong Langhui, Yan Guihai. Neptune: A Framework for Generic Network Processor Microarchitecture Modeling and Performance Simulation[J]. Journal of Computer Research and Development. DOI: 10.7544/issn1000-1239.202440084 |
| [3] | Zhang Qianlong, Hou Rui, Yang Sibo, Zhao Boyan, Zhang Lixin. The Role of Architecture Simulators in the Process of CPU Design[J]. Journal of Computer Research and Development, 2019, 56(12): 2702-2719. DOI: 10.7544/issn1000-1239.2019.20190044 |
| [4] | Liu He, Ji Yu, Han Jianhui, Zhang Youhui, Zheng Weimin. Training and Software Simulation for ReRAM-Based LSTM Neural Network Acceleration[J]. Journal of Computer Research and Development, 2019, 56(6): 1182-1191. DOI: 10.7544/issn1000-1239.2019.20190113 |
| [5] | Yang Meifang, Che Yonggang, Gao Xiang. Heterogeneous Parallel Optimization of an Engine Combustion Simulation Application with the OpenMP 4.0 Standard[J]. Journal of Computer Research and Development, 2018, 55(2): 400-408. DOI: 10.7544/issn1000-1239.2018.20160872 |
| [6] | Liu Yuchen, Wang Jia, Chen Yunji, Jiao Shuai. Survey on Computer System Simulator[J]. Journal of Computer Research and Development, 2015, 52(1): 3-15. DOI: 10.7544/issn1000-1239.2015.20140104 |
| [7] | Lü Huiwei, Cheng Yuan, Bai Lu, Chen Mingyu, Fan Dongrui, Sun Ninghui. Parallel Simulation of Many-Core Processor and Many-Core Clusters[J]. Journal of Computer Research and Development, 2013, 50(5): 1110-1117. |
| [8] | Jia Qunlin and Zhou Baijia. Earthquake Disaster Scenario Simulation Technology[J]. Journal of Computer Research and Development, 2010, 47(6): 1038-1043. |
| [9] | Mao Chengying, Lu Yansheng. Strategies of Regression Test Case Selection for Component-Based Software[J]. Journal of Computer Research and Development, 2006, 43(10): 1767-1774. |
| [10] | Wang Shihao, Wang Xinmin, Liu Mingye. Software Simulation for Hardware/Software Co-Verification[J]. Journal of Computer Research and Development, 2005, 42(3). |
| 1. |
马涛. 海量视讯资源加速分发技术研究. 数字通信世界. 2025(02): 51-54+57 .

| |
| 2. |
杨卫平. 新一代飞行器导航制导与控制技术发展趋势. 航空学报. 2024(05): 154-178 .
| |
| 3. |
陈杏仪,柯清建. 异构算力的应用与展望. 长江信息通信. 2023(11): 226-228 .
|

微信订阅号
(实时资讯)

微信服务号
(同步网站)

微信视频号
(视频分享)

CCF
(扫码入会)
Copyright © Editorial Department of Computer Research and Development
Supported by: Beijing Renhe Information Technology Co.,
Ltd. 
 DownLoad:
DownLoad: